Kapitel 1. NLP: Eine Fibel
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Eine Sprache besteht nicht nur aus Wörtern. Sie ist eine Kultur, eine Tradition,
eine Vereinigung einer Gemeinschaft,
eine ganze Geschichte, die eine Gemeinschaft ausmacht.
All das ist in einer Sprache verkörpert.Noam Chomsky
Stell dir eine hypothetische Person vor, John Doe. Er ist der CTO eines schnell wachsenden Technologieunternehmens. An einem arbeitsreichen Tag wacht John auf und führt dieses Gespräch mit seinem digitalen Assistenten:
John: "Wie ist das Wetter heute?"
Digitaler Assistent: "Es sind 37 Grad Celsius draußen und es regnet heute nicht."
John: "Wie sieht mein Zeitplan aus?"
Digitaler Assistent: "Du hast um 16 Uhr ein Strategiemeeting und um 17:30 Uhr eine Besprechung mit allen Beteiligten. Aufgrund der heutigen Verkehrssituation wird empfohlen, dass du um 8:15 Uhr ins Büro fährst ."
Während er sich anzieht, befragt John den Assistenten zu seiner Modewahl:
John: "Was soll ich heute anziehen?"
Digitaler Assistent: "Weiß scheint eine gute Wahl zu sein."
Vielleicht hast du schon einmal intelligente Assistenten wie Amazon Alexa, Google Home oder Apple Siri benutzt, um ähnliche Dinge zu tun. Wir sprechen mit diesen Assistenten nicht in einer Programmiersprache, sondern in unserer natürlichen Sprache - der Sprache, in der wir alle kommunizieren. Diese natürliche Sprache ist seit jeher das wichtigste Kommunikationsmittel zwischen Menschen. Aber Computer können nur binäre Daten verarbeiten, d.h. 0s und 1s. Wir können Sprachdaten zwar binär darstellen, aber wie bringen wir Maschinen dazu, die Sprache zu verstehen ? An dieser Stelle kommt die natürliche Sprachverarbeitung (NLP) ins Spiel. Es ist ein Teilgebiet der Informatik, das sich mit Methoden zur Analyse, Modellierung und zum Verständnis menschlicher Sprache beschäftigt. Hinter jeder intelligenten Anwendung, die mit menschlicher Sprache zu tun hat, steckt ein Stück NLP. In diesem Buch erklären wir, was NLP ist und wie man NLP nutzt, um intelligente Anwendungen zu entwickeln und zu skalieren. Da NLP-Probleme sehr offen sind, gibt es Dutzende von alternativen Ansätzen, die man zur Lösung eines bestimmten Problems wählen kann. Dieses Buch hilft dir, dich in diesem Labyrinth von Optionen zurechtzufinden und zeigt dir, wie du die beste Option für dein Problem auswählen kannst.
Dieses Kapitel soll einen kurzen Überblick darüber geben, was NLP ist, bevor wir uns eingehender mit der Implementierung NLP-basierter Lösungen für verschiedene Anwendungsszenarien beschäftigen. Wir beginnen mit einem Überblick über zahlreiche Anwendungen von NLP in realen Szenarien und behandeln dann die verschiedenen Aufgaben, die die Grundlage für den Aufbau verschiedener NLP-Anwendungen bilden. Darauf folgt ein Verständnis von Sprache aus der NLP-Perspektive und warum NLP so schwierig ist. Danach geben wir einen Überblick über Heuristiken, maschinelles Lernen und Deep Learning und stellen dann einige häufig verwendete Algorithmen im NLP vor. Danach werden wir eine NLP-Anwendung durchgehen. Zum Abschluss des Kapitels geben wir einen Überblick über die restlichen Themen des Buches. Abbildung 1-1 zeigt eine Vorschau auf die Gliederung der Kapitel in Bezug auf die verschiedenen NLP-Aufgaben und -Anwendungen.
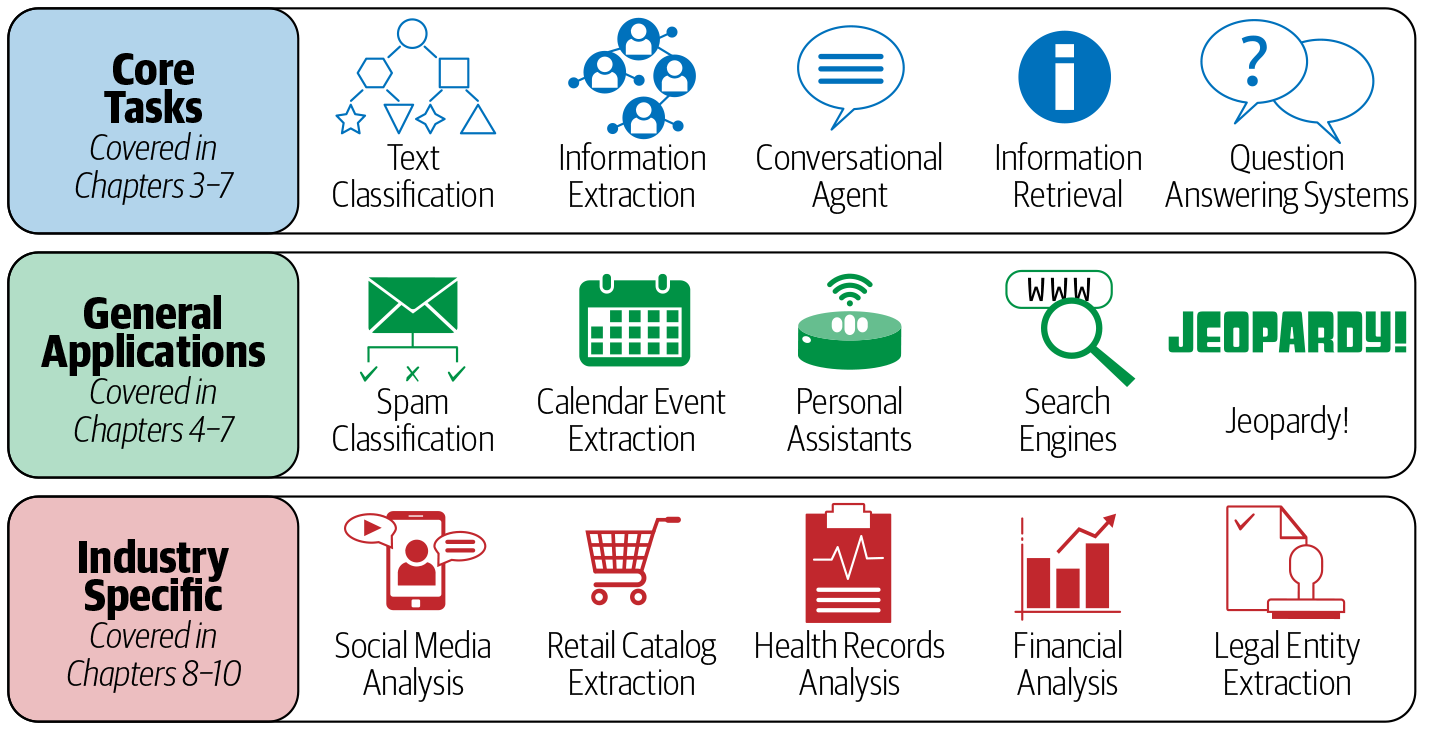
Werfen wir zunächst einen Blick auf einige beliebte Anwendungen, die du im Alltag benutzt und die eine Form von NLP als Hauptbestandteil haben.
NLP in der realen Welt
NLP ist eine wichtige Komponente in einer Vielzahl von Softwareanwendungen, die wir im täglichen Leben nutzen. In diesem Abschnitt stellen wir dir einige wichtige Anwendungen vor und werfen auch einen Blick auf einige häufige Aufgaben, die du in verschiedenen NLP-Anwendungen findest. Dieser Abschnitt untermauert die Anwendungen, die wir dir in Abbildung 1-1 gezeigt haben und die du im Laufe des Buches noch genauer kennenlernen wirst.
-
E-Mail-Plattformen wie Gmail, Outlook usw. nutzen NLP ausgiebig, um eine Reihe von Produktfunktionen bereitzustellen, wie z. B. die Klassifizierung von Spam, den priorisierten Posteingang, die Extraktion von Kalenderereignissen, die automatische Vervollständigung usw. Wir werden einige dieser Funktionen in den Kapiteln 4 und 5 ausführlich besprechen.
-
Sprachbasierte Assistenten wie Apple Siri, Google Assistant, Microsoft Cortana und Amazon Alexa verlassen sich auf eine Reihe von NLP-Techniken, um mit dem Nutzer zu interagieren, seine Befehle zu verstehen und entsprechend zu reagieren. Wir werden die wichtigsten Aspekte solcher Systeme in Kapitel 6 behandeln, in dem wir über Chatbots sprechen.
-
Moderne Suchmaschinen, wie z. B. Google und Bing, die den Eckpfeiler des heutigen Internets bilden, nutzen NLP in hohem Maße für verschiedene Teilaufgaben, wie z. B. das Verstehen von Anfragen, die Erweiterung von Anfragen, die Beantwortung von Fragen, das Abrufen von Informationen sowie das Ranking und die Gruppierung der Ergebnisse, um nur einige zu nennen. Wir werden einige dieser Teilaufgaben in Kapitel 7 besprechen.
-
Maschinelle Übersetzungsdienste wie Google Translate, Bing Microsoft Translator und Amazon Translate werden in der heutigen Welt zunehmend genutzt, um eine Vielzahl von Szenarien und geschäftlichen Anwendungsfällen zu lösen. Diese Dienste sind direkte Anwendungen von NLP. Auf die maschinelle Übersetzung gehen wir in Kapitel 7 ein.
-
Unternehmen aller Branchen analysieren ihre Social Media Feeds, um ein besseres und tieferes Verständnis für die Stimme ihrer Kunden zu bekommen. Wir werden dies in Kapitel 8 behandeln.
-
NLP wird häufig eingesetzt, um verschiedene Anwendungsfälle auf E-Commerce-Plattformen wie Amazon zu lösen. Diese reichen von der Extraktion relevanter Informationen aus Produktbeschreibungen bis hin zum Verständnis von Nutzerbewertungen. Kapitel 9 behandelt diese im Detail.
-
Die Fortschritte im NLP werden zur Lösung von Anwendungsfällen in Bereichen wie dem Gesundheitswesen, dem Finanzwesen und dem Recht eingesetzt. Kapitel 10 befasst sich mit diesen Bereichen.
-
Unternehmen wie Arria [1] arbeiten daran, NLP-Techniken zu nutzen, um automatisch Berichte für verschiedene Bereiche zu erstellen, von der Wettervorhersage bis zu Finanzdienstleistungen.
-
NLP bildet das Rückgrat von Tools zur Rechtschreib- und Grammatikkorrektur, wie Grammarly und die Rechtschreibprüfung in Microsoft Word und Google Docs.
-
Jeopardy! ist eine beliebte Quizshow im Fernsehen. In der Show werden den Teilnehmern Hinweise in Form von Antworten gegeben, und die Teilnehmer müssen ihre Antworten in Form von Fragen formulieren. IBM hat die KI Watson entwickelt, um sich mit den besten Spielern der Show zu messen. Watson gewann den ersten Preis mit einer Million Dollar, mehr als die Weltmeister. Die Watson-KI wurde mit NLP-Techniken entwickelt und ist eines der Beispiele für NLP-Bots, die einen weltweiten Wettbewerb gewinnen.
-
NLP wird in einer Reihe von Lern- und Bewertungstools und Technologien eingesetzt, z. B. bei der automatischen Bewertung in Prüfungen wie der Graduate Record Examination (GRE), bei der Plagiatserkennung (z. B. Turnitin), bei intelligenten Nachhilfesystemen und bei Sprachlern-Apps wie Duolingo.
-
NLP wird verwendet, um große Wissensdatenbanken zu erstellen, wie z.B. den Google Knowledge Graph, der in einer Reihe von Anwendungen wie der Suche und der Beantwortung von Fragen nützlich ist.
Diese Liste ist keineswegs erschöpfend. NLP wird zunehmend auch in anderen Bereichen eingesetzt ( ), und neue Anwendungen von NLP entstehen in diesem Moment. Unser Hauptaugenmerk liegt darauf, dich mit den Ideen vertraut zu machen, die hinter der Entwicklung dieser Anwendungen stehen. Dazu besprechen wir verschiedene Arten von NLP-Problemen und wie sie gelöst werden können. Um dir einen Überblick über das zu verschaffen, was du in diesem Buch lernen wirst, und um die Feinheiten zu verstehen, die bei der Entwicklung dieser NLP-Anwendungen eine Rolle spielen, werfen wir einen Blick auf einige wichtige NLP-Aufgaben, die die Grundlage für viele NLP-Anwendungen und Anwendungsfälle in der Industrie bilden .
NLP-Aufgaben
Es gibt eine Reihe grundlegender Aufgaben, die in verschiedenen NLP-Projekten häufig vorkommen. Da sich diese Aufgaben immer wiederholen und grundlegend sind, wurden sie ausgiebig untersucht. Wenn du sie gut beherrschst, bist du in der Lage, verschiedene NLP-Anwendungen für unterschiedliche Branchen zu entwickeln. (Einige dieser Aufgaben haben wir bereits in Abbildung 1-1 gesehen.) Stellen wir sie kurz vor:
- Sprachmodellierung
- Dies ist die Aufgabe, das nächste Wort in einem Satz auf der Grundlage der vorherigen Wörter vorherzusagen. Das Ziel dieser Aufgabe ist es, die Wahrscheinlichkeit zu erlernen, mit der eine Folge von Wörtern in einer bestimmten Sprache vorkommt. Die Sprachmodellierung ist nützlich, um Lösungen für eine Vielzahl von Problemen zu entwickeln, z. B. Spracherkennung, optische Zeichenerkennung, Handschrifterkennung, maschinelle Übersetzung und Rechtschreibkorrektur.
- Textklassifizierung
- Dies ist die Aufgabe, den Text auf der Grundlage seines Inhalts in eine bekannte Gruppe von Kategorien einzuordnen. Die Textklassifizierung ist bei weitem die beliebteste Aufgabe im NLP und wird in einer Vielzahl von Tools eingesetzt, von der Erkennung von E-Mail-Spam bis zur Stimmungsanalyse.
- Informationsextraktion
- Wie der Name schon sagt, geht es darum, relevante Informationen aus Text zu extrahieren, z. B. Kalendertermine aus E-Mails oder die Namen von Personen, die in einem Social-Media-Post erwähnt werden.
- Informationsabfrage
- Das ist die Aufgabe, aus einer großen Sammlung von Dokumenten diejenigen zu finden, die für eine Benutzeranfrage relevant sind. Anwendungen wie die Google-Suche sind bekannte Anwendungsfälle des Information Retrieval.
- Konversationsagent
- Das ist die Aufgabe, Dialogsysteme zu entwickeln, die sich in menschlichen Sprachen unterhalten können. Alexa, Siri, etc. sind einige gängige Anwendungen dieser Aufgabe.
- Text-Zusammenfassung
- Diese Aufgabe zielt darauf ab, kurze Zusammenfassungen von längeren Dokumenten zu erstellen und dabei den Kerninhalt und die Gesamtbedeutung des Textes zu erhalten.
- Frage beantworten
- Das ist die Aufgabe, ein System zu bauen, das automatisch Fragen in natürlicher Sprache beantworten kann.
- Maschinelle Übersetzung
- Dies ist die Aufgabe, einen Text von einer Sprache in eine andere zu übersetzen. Tools wie Google Translate sind gängige Anwendungen für diese Aufgabe.
- Thema Modellierung
- Dies ist die Aufgabe, die thematische Struktur einer großen Sammlung von Dokumenten aufzudecken. Die Themenmodellierung ist ein gängiges Text-Mining-Tool und wird in einer Vielzahl von Bereichen eingesetzt, von der Literatur bis zur Bioinformatik.
Abbildung 1-2 zeigt eine Darstellung dieser Aufgaben nach ihrem relativen Schwierigkeitsgrad, was die Entwicklung umfassender Lösungen angeht.
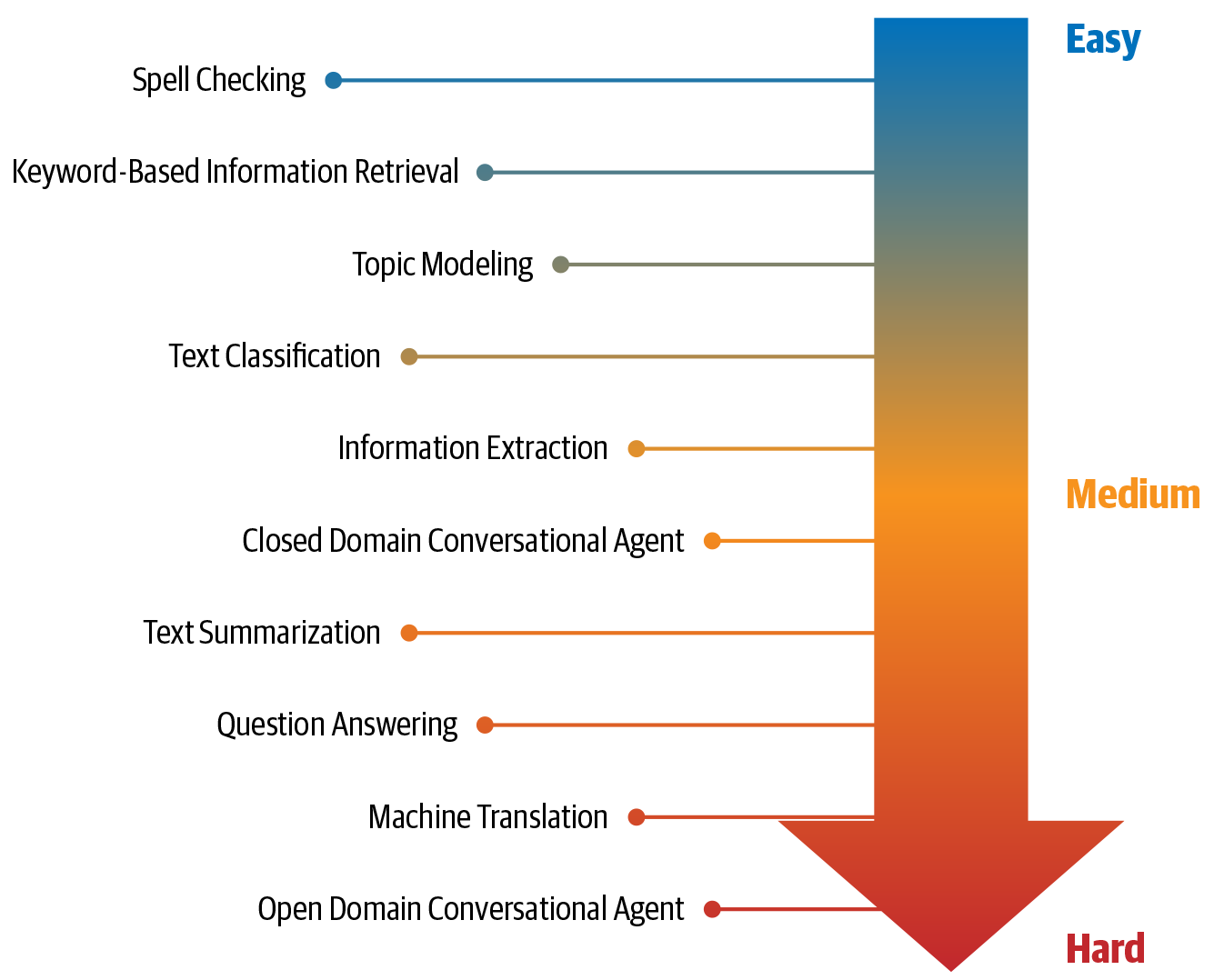
Abbildung 1-2. NLP-Aufgaben, geordnet nach ihrem relativen Schwierigkeitsgrad
In den restlichen Kapiteln dieses Buches werden wir die Herausforderungen dieser Aufgaben sehen und lernen, wie man Lösungen entwickelt, die für bestimmte Anwendungsfälle funktionieren (sogar für die in der Abbildung gezeigten schwierigen Aufgaben). Um das zu erreichen, ist es hilfreich, die Natur der menschlichen Sprache und die Herausforderungen bei der Automatisierung der Sprachverarbeitung zu verstehen. Die nächsten beiden Abschnitte geben einen grundlegenden Überblick.
Was ist Sprache?
Sprache ist ein strukturiertes Kommunikationssystem, das aus komplexen Kombinationen von Bestandteilen wie Zeichen, Wörtern, Sätzen usw. besteht. Linguistik ist die systematische Untersuchung von Sprache. Um NLP studieren zu können, ist es wichtig, einige Konzepte aus der Linguistik zu verstehen, wie Sprache strukturiert ist. In diesem Abschnitt stellen wir sie vor und erklären, wie sie mit einigen der oben genannten NLP-Aufgaben zusammenhängen.
Wir können uns vorstellen, dass die menschliche Sprache aus vier Hauptbausteinen besteht: Phoneme, Morpheme und Lexeme, Syntax und Kontext. NLP-Anwendungen benötigen Kenntnisse über die verschiedenen Ebenen dieser Bausteine, angefangen bei den Grundlauten der Sprache (Phoneme) bis hin zu Texten mit sinnvollen Ausdrücken (Kontext). Abbildung 1-3 zeigt diese Bausteine der Sprache, was sie beinhalten und einige NLP-Anwendungen, die wir bereits vorgestellt haben und die dieses Wissen benötigen. Einige der hier aufgeführten Begriffe, die in diesem Kapitel noch nicht vorgestellt wurden (z. B. Parsing, Worteinbettung usw.), werden später in den ersten drei Kapiteln eingeführt.
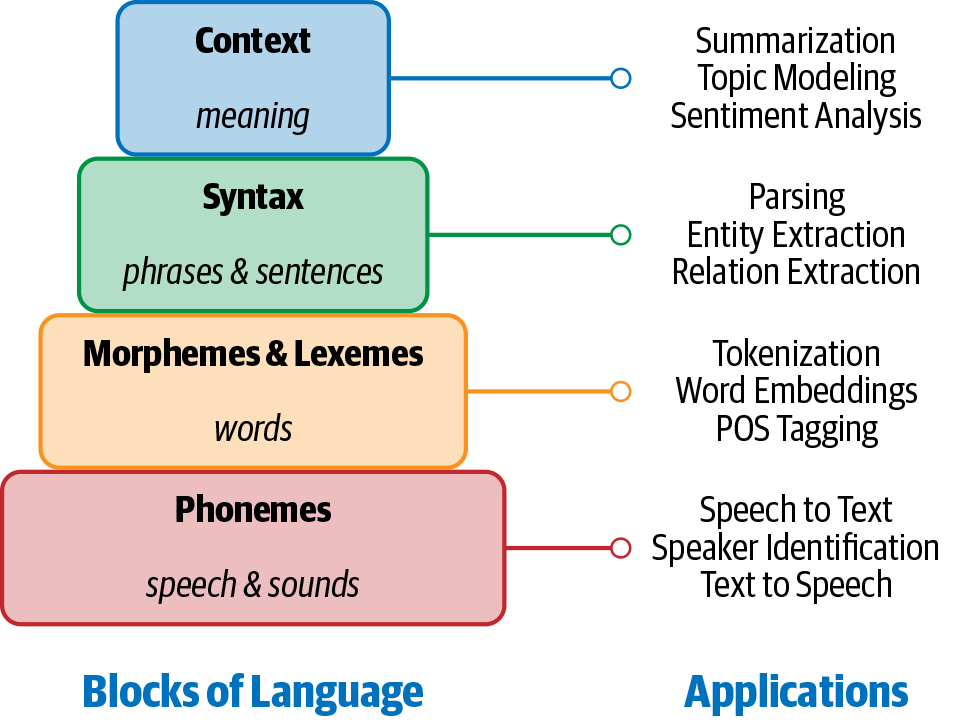
Abbildung 1-3. Bausteine der Sprache und ihre Anwendungen
Bausteine der Sprache
Zuerst wollen wir uns ansehen, was diese Sprachblöcke sind, um den Kontext für die Herausforderungen im NLP zu verdeutlichen.
Phoneme
Phoneme sind die kleinsten Lauteinheiten in einer Sprache. Sie haben für sich allein keine Bedeutung, können aber in Kombination mit anderen Phonemen Bedeutungen hervorrufen. Das Standard-Englisch hat zum Beispiel 44 Phoneme, die entweder einzelne Buchstaben oder eine Kombination von Buchstaben sind [2]. Abbildung 1-4 zeigt diese Phoneme zusammen mit Beispielwörtern. Phoneme sind besonders wichtig für Anwendungen, bei denen es um das Verstehen von Sprache geht, z. B. bei der Spracherkennung, der Umwandlung von Sprache in Text und der Umwandlung von Text in Sprache.
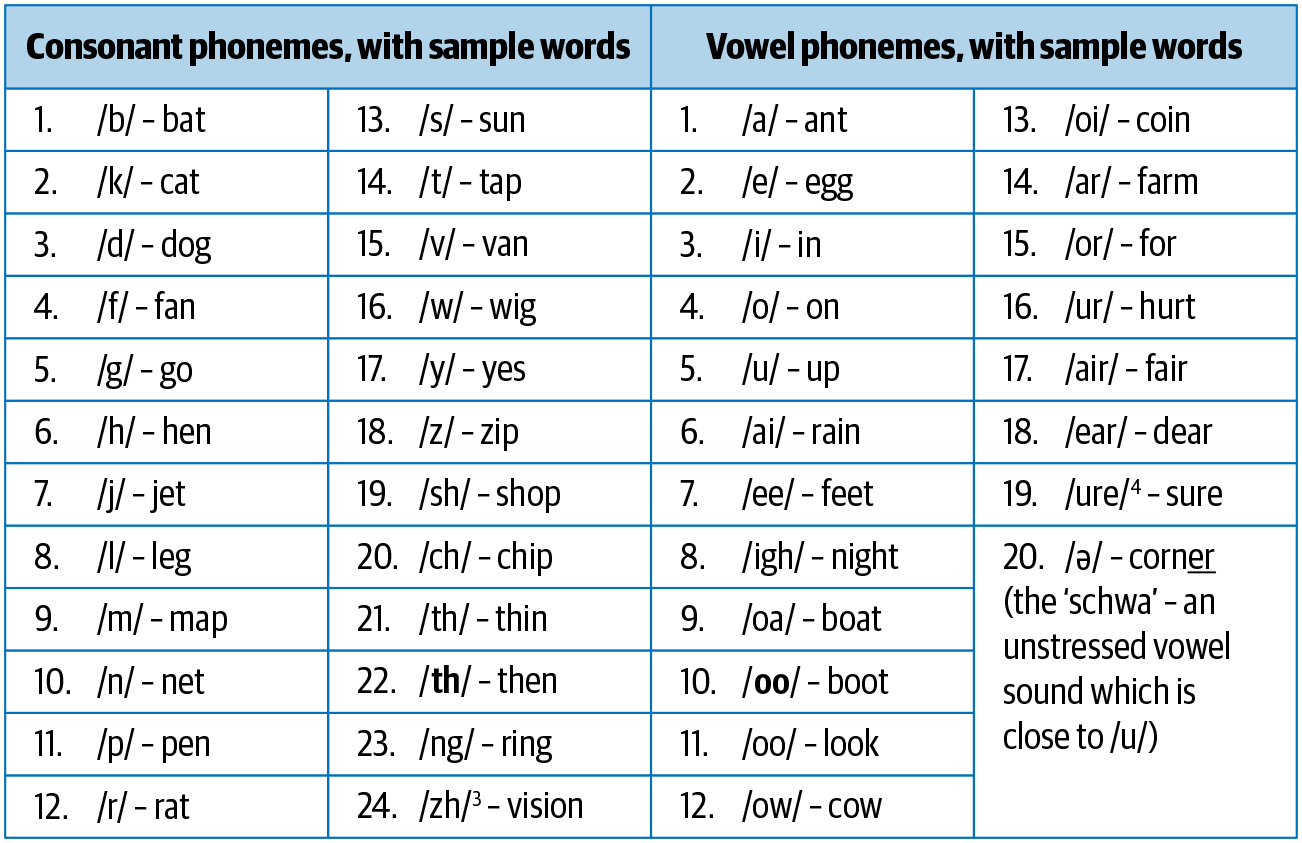
Abbildung 1-4. Phoneme und Beispiele
Morpheme und Lexeme
Ein Morphem ist die kleinste Einheit der Sprache, die eine Bedeutung hat. Es wird durch eine Kombination von Phonemen gebildet. Nicht alle Morpheme sind Wörter, aber alle Präfixe und Suffixe sind Morpheme. Im Wort "Multimedia" zum Beispiel ist "Multi-" kein Wort, sondern eine Vorsilbe, die die Bedeutung verändert, wenn sie mit "Medien" zusammengesetzt wird. "Multi-" ist ein Morphem. Abbildung 1-5 veranschaulicht einige Wörter und ihre Morpheme. Bei Wörtern wie "Katzen" und "unzerbrechlich" sind die Morpheme nur Bestandteile des ganzen Wortes, während es bei Wörtern wie "taumelnd" und "unzuverlässig" einige Unterschiede gibt, wenn man die Wörter in ihre Morpheme zerlegt.
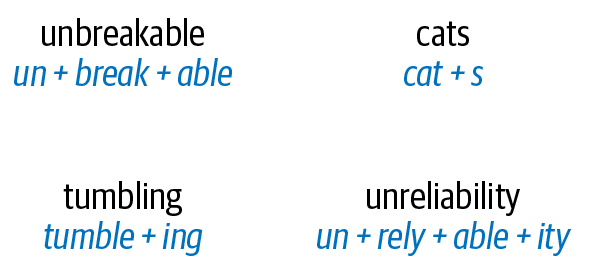
Abbildung 1-5. Beispiele für Morpheme
Lexeme sind die strukturellen Variationen von Morphemen, die durch ihre Bedeutung miteinander verbunden sind. Zum Beispiel gehören "laufen" und "laufen" zur gleichen Lexemform. Die morphologische Analyse, die die Struktur von Wörtern durch die Untersuchung ihrer Morpheme und Lexeme analysiert, ist ein grundlegender Baustein für viele NLP-Aufgaben, wie z. B. Tokenisierung, Stemming, Lernen von Worteinbettungen und Part-of-Speech-Tagging, die wir im nächsten Kapitel vorstellen.
Syntax
Syntax ist eine Reihe von Regeln, um grammatikalisch korrekte Sätze aus Wörtern und Phrasen in einer Sprache zu bilden. Die syntaktische Struktur wird in der Linguistik auf viele verschiedene Arten dargestellt. Ein gängiger Ansatz zur Darstellung von Sätzen ist ein Parse-Baum. Abbildung 1-6 zeigt ein Beispiel für einen Parse-Baum für zwei englische Sätze.
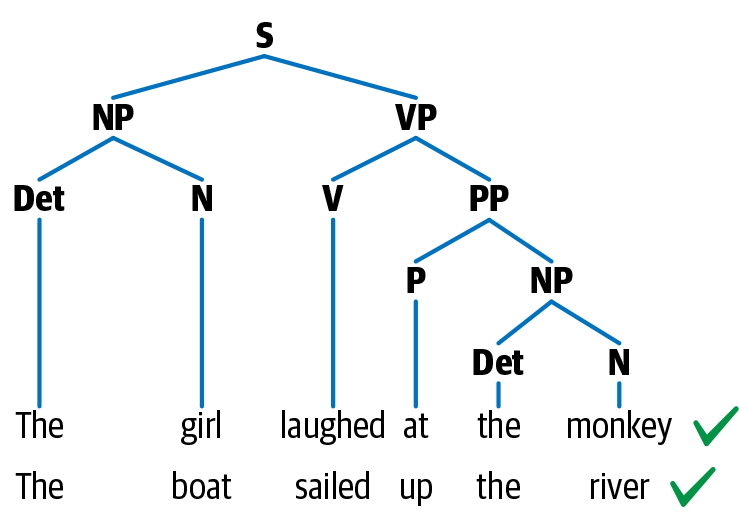
Abbildung 1-6. Syntaktische Struktur von zwei syntaktisch ähnlichen Sätzen
Dieser hat eine hierarchische Struktur der Sprache, mit Wörtern auf der untersten Ebene, gefolgt von Part-of-Speech-Tags, gefolgt von Phrasen und endend mit einem Satz auf der höchsten Ebene. In Abbildung 1-6 haben beide Sätze eine ähnliche Struktur und damit auch einen ähnlichen syntaktischen Parse-Baum. In dieser Darstellung steht N für Nomen, V für Verb und P für Präposition. Die Substantivphrase wird mit NP und die Verbphrase mit VP bezeichnet. Die beiden Substantivphrasen sind "Das Mädchen" und "Das Boot", während die beiden Verbphrasen "lachte über den Affen" und "segelte den Fluss hinauf" sind. Die syntaktische Struktur richtet sich nach einer Reihe von Grammatikregeln für die Sprache (z. B. besteht der Satz aus einer NP und einer VP), die wiederum einige der grundlegenden Aufgaben der Sprachverarbeitung, wie das Parsen, leiten. Parsing ist die NLP-Aufgabe, solche Bäume automatisch zu konstruieren. Entitätsextraktion und Beziehungsextraktion sind einige der NLP-Aufgaben, die auf diesem Wissen über das Parsen aufbauen und die wir in Kapitel 5 genauer besprechen werden. Beachte, dass die oben beschriebene Parse-Struktur spezifisch für das Englische ist. Die Syntax einer Sprache kann sich stark von der einer anderen Sprache unterscheiden, und die für diese Sprache erforderlichen Sprachverarbeitungsansätze ändern sich entsprechend.
Kontext
Kontext ist die Art und Weise, wie verschiedene Teile einer Sprache zusammenkommen, um eine bestimmte Bedeutung zu vermitteln. Zum Kontext gehören neben der wörtlichen Bedeutung von Wörtern und Sätzen auch langfristige Bezüge, Weltwissen und der gesunde Menschenverstand. Die Bedeutung eines Satzes kann sich je nach Kontext ändern, da Wörter und Sätze manchmal mehrere Bedeutungen haben können. Im Allgemeinen setzt sich der Kontext aus Semantik und Pragmatik zusammen. Semantik ist die direkte Bedeutung von Wörtern und Sätzen ohne externen Kontext. Die Pragmatik fügt das Weltwissen und den externen Kontext des Gesprächs hinzu, damit wir auf die implizite Bedeutung schließen können. Komplexe NLP-Aufgaben wie die Erkennung von Sarkasmus, Zusammenfassungen und Themenmodellierung sind einige der Aufgaben, die den Kontext stark nutzen.
Linguistik ist die Lehre von der Sprache und damit ein weites Feld für sich. Wir haben nur einige grundlegende Ideen vorgestellt, um die Rolle von linguistischem Wissen im NLP zu verdeutlichen. Verschiedene Aufgaben im NLP erfordern ein unterschiedliches Maß an Wissen über diese Bausteine der Sprache. Ein interessierter Leser kann sich in den Büchern von Emily Bender [3, 4] über die linguistischen Grundlagen für NLP weiterbilden. Nachdem wir nun eine Vorstellung davon haben, was die Bausteine von Sprache sind, wollen wir uns ansehen, warum Sprache für Computer schwer zu verstehen ist und was NLP zu einer Herausforderung macht.
Warum ist NLP eine Herausforderung?
Was macht NLP zu einem anspruchsvollen Problemfeld? Die Mehrdeutigkeit und Kreativität der menschlichen Sprache sind nur zwei der Merkmale, die NLP zu einem anspruchsvollen Arbeitsbereich machen. In diesem Abschnitt wird jedes Merkmal genauer untersucht, beginnend mit der Mehrdeutigkeit der Sprache.
Zweideutigkeit
Mehrdeutigkeit bedeutet Unsicherheit in der Bedeutung. Die meisten menschlichen Sprachen sind von Natur aus mehrdeutig. Betrachte den folgenden Satz: "Ich habe sie zur Ente gemacht." Dieser Satz hat mehrere Bedeutungen. Die erste ist: Ich habe eine Ente für sie gekocht. Die zweite Bedeutung ist: Ich habe sie dazu gebracht, sich zu bücken, um einem Gegenstand auszuweichen. (Es gibt auch noch andere mögliche Bedeutungen; wir überlassen es dem Leser, sich diese auszudenken.) Die Zweideutigkeit entsteht hier durch die Verwendung des Wortes "gemacht". Welche der beiden Bedeutungen zutrifft, hängt vom Kontext ab, in dem der Satz erscheint. Wenn der Satz in einer Geschichte über eine Mutter und ihr Kind vorkommt, dann trifft wahrscheinlich die erste Bedeutung zu. Wenn der Satz aber in einem Buch über Sport vorkommt, wird wahrscheinlich die zweite Bedeutung zutreffen. Das Beispiel, das wir gesehen haben, ist ein direkter Satz.
Wenn es um figurative Sprache- also um Redewendungen - geht, wird die Zweideutigkeit noch größer. Zum Beispiel: "Er ist so gut wie John Doe." Versuche zu antworten: "Wie gut ist er?" Die Antwort hängt davon ab, wie gut John Doe ist. Abbildung 1-7 zeigt einige Beispiele, die die Mehrdeutigkeit der Sprache verdeutlichen.
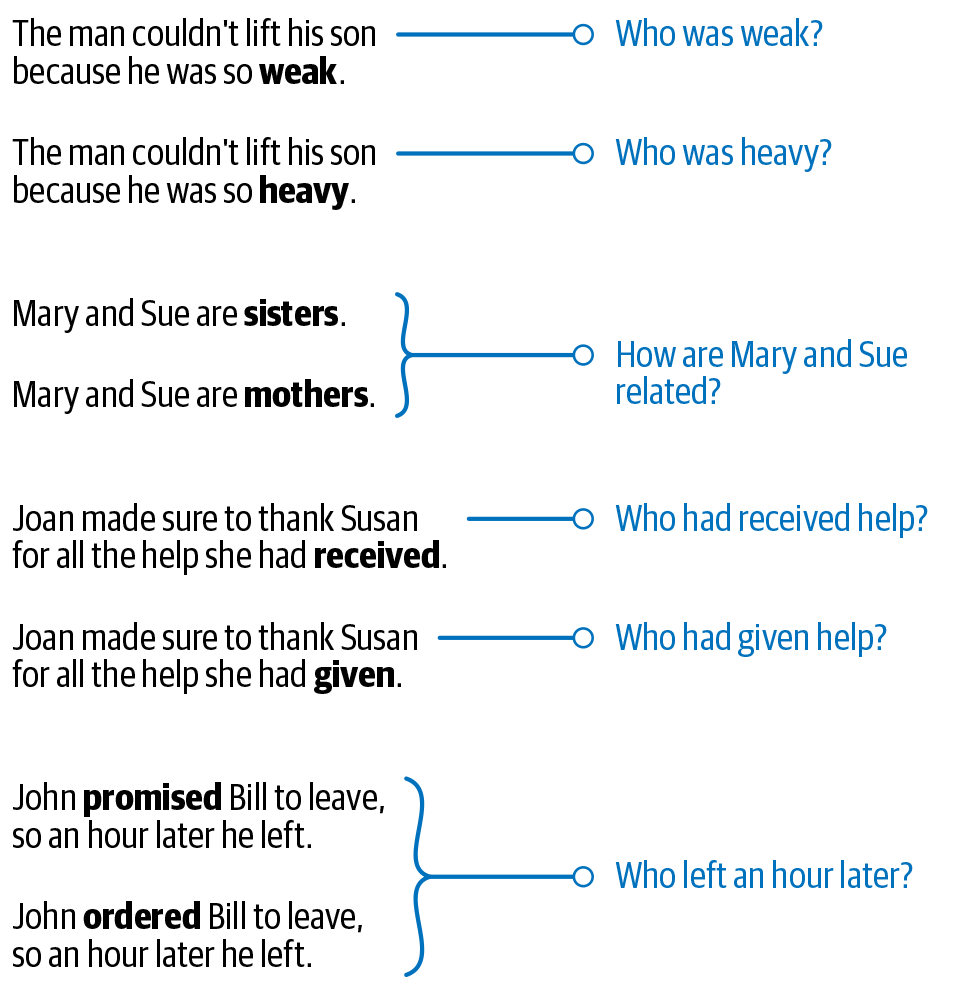
Abbildung 1-7. Beispiele für Mehrdeutigkeit in der Sprache aus der Winograd Schema Challenge
Die Beispiele stammen aus der Winograd Schema Challenge [5], benannt nach Professor Terry Winograd von der Stanford University. In diesem Schema gibt es Satzpaare, die sich nur durch ein paar Wörter unterscheiden, aber die Bedeutung der Sätze wird durch diese kleine Änderung oft umgedreht. Diese Beispiele können von einem Menschen leicht disambiguiert werden, sind aber mit den meisten NLP-Techniken nicht lösbar. Betrachte die Satzpaare in der Abbildung und die dazugehörigen Fragen. Wenn du ein wenig nachdenkst, solltest du erkennen können, wie sich die Antwort durch eine einzige Wortänderung ändert. Als weiteres Experiment kannst du ein Standard-NLP-System wie Google Translate nehmen und verschiedene Beispiele ausprobieren, um zu sehen, wie sich solche Mehrdeutigkeiten auf die Ausgabe des Systems auswirken (oder auch nicht).
Allgemeinwissen
Ein zentraler Aspekt jeder menschlichen Sprache ist das "Allgemeinwissen". Es ist die Menge aller Fakten, die den meisten Menschen bekannt sind. In einem Gespräch wird davon ausgegangen, dass diese Fakten bekannt sind, daher werden sie nicht explizit erwähnt, aber sie haben einen Einfluss auf die Bedeutung des Satzes. Betrachte zum Beispiel zwei Sätze: "Mann hat Hund gebissen" und "Hund hat Mann gebissen". Wir alle wissen, dass der erste Satz unwahrscheinlich ist, während der zweite sehr wohl möglich ist. Warum sagen wir das? Weil wir alle "wissen", dass es sehr unwahrscheinlich ist, dass ein Mensch einen Hund beißt. Außerdem sind Hunde dafür bekannt, dass sie Menschen beißen. Dieses Wissen ist erforderlich, damit wir sagen können, dass der erste Satz unwahrscheinlich ist, während der zweite Satz möglich ist. Beachte, dass dieses Allgemeinwissen in keinem der beiden Sätze erwähnt wurde. Der Mensch nutzt das Allgemeinwissen ständig, um Sprache zu verstehen und zu verarbeiten. Im obigen Beispiel sind sich die beiden Sätze syntaktisch sehr ähnlich, aber für einen Computer wäre es sehr schwierig, zwischen den beiden zu unterscheiden, da ihm das gemeinsame Wissen fehlt, das Menschen haben. Eine der größten Herausforderungen im NLP ist die Frage, wie man all die Dinge, die für Menschen alltägliches Wissen sind, in einem computergestützten Modell kodieren kann.
Kreativität
Sprache ist nicht nur regelgesteuert, sondern hat auch einen kreativen Aspekt. In jeder Sprache werden verschiedene Stile, Dialekte, Genres und Variationen verwendet. Gedichte sind ein gutes Beispiel für Kreativität in der Sprache. Maschinen dazu zu bringen, Kreativität zu verstehen, ist ein schwieriges Problem, nicht nur im NLP, sondern in der KI im Allgemeinen.
Vielfalt der Sprachen
Für die meisten Sprachen der Welt gibt es keine direkte Zuordnung zwischen den Vokabularen zweier Sprachen. Das macht es schwierig, eine NLP-Lösung von einer Sprache in eine andere zu portieren. Eine Lösung, die in einer Sprache funktioniert, funktioniert möglicherweise in einer anderen Sprache überhaupt nicht. Das bedeutet, dass man entweder eine sprachenunabhängige Lösung entwickeln muss oder für jede Sprache eine eigene Lösung. Während die erste Lösung konzeptionell sehr schwierig ist, ist die zweite mühsam und zeitintensiv.
All diese Aspekte machen NLP zu einem herausfordernden - aber auch lohnenden - Arbeitsgebiet. Bevor wir uns ansehen, wie einige dieser Herausforderungen im NLP angegangen werden, sollten wir die gängigen Ansätze zur Lösung von NLP-Problemen kennen. Beginnen wir mit einem Überblick darüber, wie maschinelles Lernen und Deep Learning mit NLP zusammenhängen, bevor wir uns näher mit den verschiedenen Ansätzen für NLP beschäftigen.
Maschinelles Lernen, Deep Learning und NLP: Ein Überblick
Frei übersetzt ist künstliche Intelligenz (KI) ein Zweig der Informatik, der darauf abzielt, Systeme zu entwickeln, die Aufgaben ausführen können, die menschliche Intelligenz erfordern. Dies wird manchmal auch als "maschinelle Intelligenz" bezeichnet. Die Grundlagen der KI wurden in den 1950er Jahren auf einem Workshop am Dartmouth College [6] gelegt. Die ersten KI-Systeme bestanden hauptsächlich aus logischen, heuristischen und regelbasierten Systemen. Maschinelles Lernen (ML) ist ein Zweig der KI, der sich mit der Entwicklung von Algorithmen befasst, die auf der Grundlage einer großen Anzahl von Beispielen lernen können, Aufgaben automatisch auszuführen, ohne dass dafür von Hand ausgearbeitete Regeln erforderlich sind. Deep Learning (DL) bezieht sich auf den Zweig des maschinellen Lernens, der auf künstlichen neuronalen Netzwerkarchitekturen basiert. ML, DL und NLP sind Teilgebiete der KI, deren Beziehung zueinander in Abbildung 1-8 dargestellt ist.
Es gibt zwar einige Überschneidungen zwischen NLP, ML und DL, aber sie sind auch ganz unterschiedliche Forschungsbereiche, wie die Abbildung zeigt. Wie andere frühe Arbeiten in der KI basierten auch die frühen NLP-Anwendungen auf Regeln und Heuristiken. In den letzten Jahrzehnten wurde die Entwicklung von NLP-Anwendungen jedoch stark von Methoden der ML beeinflusst. In jüngster Zeit wird auch die DL häufig für die Entwicklung von NLP-Anwendungen genutzt. Daher wollen wir in diesem Abschnitt einen kurzen Überblick über ML und DL geben.
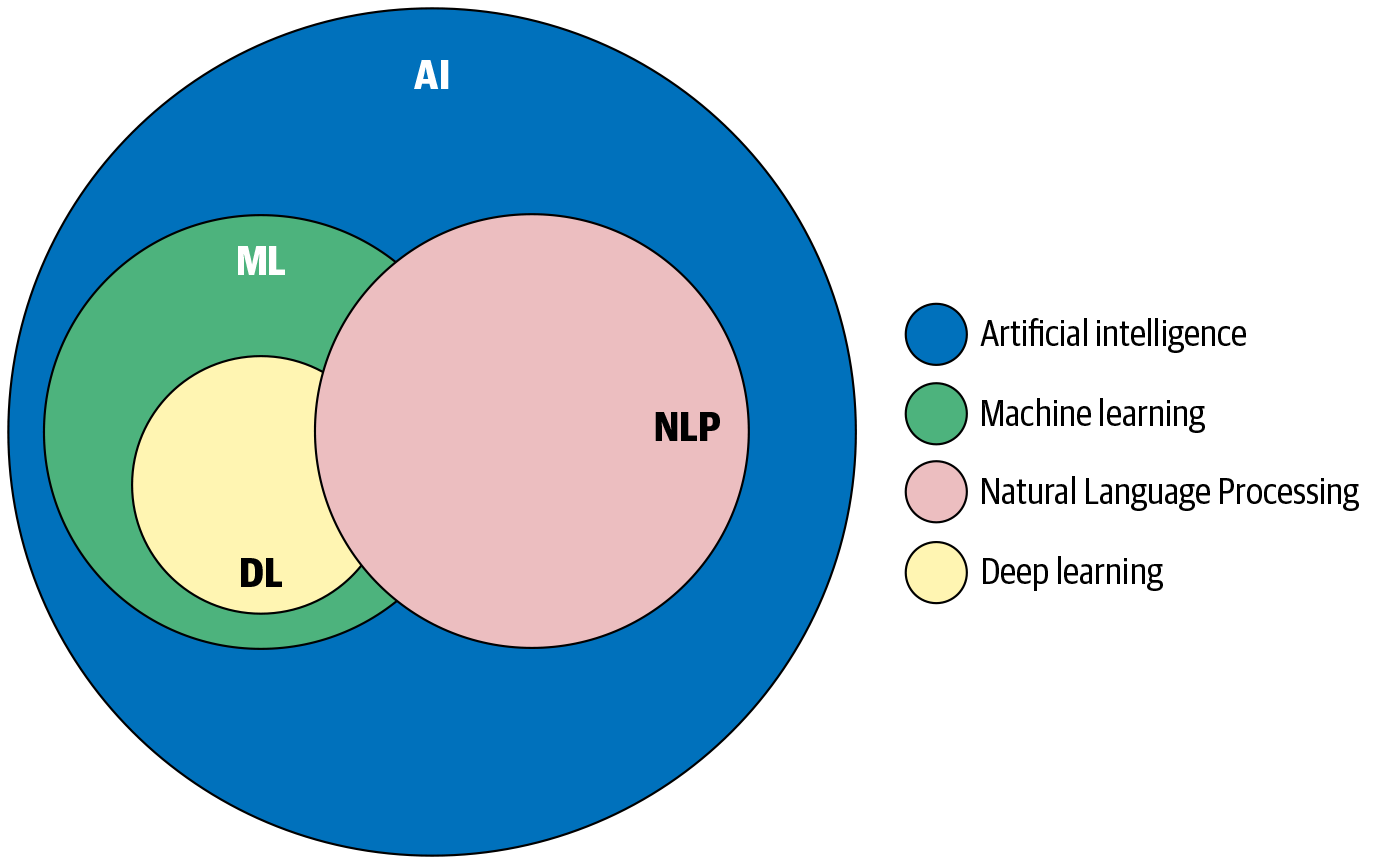
Abbildung 1-8. Wie NLP, ML und DL miteinander verbunden sind
Das Ziel von ML ist es, zu "lernen", Aufgaben auf der Grundlage von Beispielen (genannt "Trainingsdaten") ohne explizite Anweisungen auszuführen. Dies geschieht in der Regel durch die Erstellung einer numerischen Repräsentation (genannt "features") der Trainingsdaten und die Verwendung dieser Repräsentation, um die Muster in diesen Beispielen zu lernen. Algorithmen für maschinelles Lernen lassen sich in drei primäre Paradigmen einteilen: überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen. Beim überwachten Lernen besteht das Ziel darin, aus einer großen Anzahl von Beispielen in Form von Input-Output-Paaren die Zuordnungsfunktion von Input zu Output zu lernen. Die Input-Output-Paare werden als Trainingsdaten bezeichnet und die Outputs als labels oder ground truth. Ein Beispiel für ein überwachtes Lernproblem im Zusammenhang mit Sprache ist das Erlernen der Klassifizierung von E-Mail-Nachrichten als Spam oder Nicht-Spam anhand von Tausenden von Beispielen in beiden Kategorien. Dies ist ein häufiges Szenario in der NLP, und wir werden im Laufe des Buches, insbesondere in Kapitel 4, immer wieder Beispiele für überwachtes Lernen sehen.
Unüberwachtes Lernen bezieht sich auf eine Reihe von Methoden des maschinellen Lernens, die darauf abzielen, versteckte Muster in gegebenen Eingabedaten zu finden, ohne dass eine Referenzausgabe vorliegt. Im Gegensatz zum überwachten Lernen arbeitet das unüberwachte Lernen also mit großen Sammlungen von unmarkierten Daten. Im NLP besteht eine solche Aufgabe beispielsweise darin, latente Themen in einer großen Sammlung von Textdaten zu identifizieren, ohne diese Themen zu kennen. Dies wird als Themenmodellierung bezeichnet und in Kapitel 7 behandelt.
In realen NLP-Projekten gibt es häufig den Fall des halbüberwachten Lernens, bei dem wir einen kleinen beschrifteten Datensatz und einen großen unbeschrifteten Datensatz haben. Bei semi-supervised Techniken werden beide Datensätze verwendet, um die jeweilige Aufgabe zu lernen. Nicht zuletzt befasst sich das Reinforcement Learning mit Methoden zum Lernen von Aufgaben durch Versuch und Irrtum. Das Lernen findet in einer abgeschlossenen Umgebung statt und verbessert sich durch Feedback (Belohnung oder Bestrafung), das durch die Umgebung ermöglicht wird. Diese Form des Lernens ist im angewandten NLP (noch) nicht üblich. Sie ist eher in Anwendungen wie maschinellen Spielen wie Go oder Schach, bei der Entwicklung von autonomen Fahrzeugen und in der Robotik verbreitet.
Deep Learning bezieht sich auf den Bereich des maschinellen Lernens, der auf künstlichen neuronalen Netzwerken basiert. Die Ideen, die hinter neuronalen Netzen stehen, sind von den Neuronen im menschlichen Gehirn und deren Interaktion miteinander inspiriert. In den letzten zehn Jahren wurden auf Deep Learning basierende neuronale Architekturen erfolgreich eingesetzt, um die Leistung verschiedener intelligenter Anwendungen wie Bild- und Spracherkennung und maschinelle Übersetzung zu verbessern. Dies hat zu einer starken Verbreitung von Deep-Learning-Lösungen in der Industrie geführt, auch bei NLP-Anwendungen.
Im Laufe dieses Buches werden wir besprechen, wie all diese Ansätze für die Entwicklung verschiedener NLP-Anwendungen genutzt werden. Im Folgenden werden wir die verschiedenen Ansätze zur Lösung eines beliebigen NLP Problems diskutieren.
Ansätze zum NLP
Die verschiedenen Ansätze, die zur Lösung von NLP-Problemen verwendet werden, lassen sich im Allgemeinen in drei Kategorien einteilen: Heuristiken, maschinelles Lernen und Deep Learning. Dieser Abschnitt ist lediglich eine Einführung in die einzelnen Ansätze - mach dir keine Sorgen, wenn du die Konzepte noch nicht ganz verstehst, denn sie werden im weiteren Verlauf des Buches ausführlich behandelt. Beginnen wir mit dem NLP, das auf Heuristiken basiert: .
Heuristik-basiertes NLP
Ähnlich wie bei anderen frühen KI-Systemen basierten die ersten Versuche, NLP-Systeme zu entwickeln, auf der Erstellung von Regeln für die jeweilige Aufgabe. Dies setzte voraus, dass die Entwickler/innen über ein gewisses Fachwissen in dem Bereich verfügten, um Regeln zu formulieren, die in ein Programm integriert werden konnten. Solche Systeme benötigten auch Ressourcen wie Wörterbücher und Thesauri, die in der Regel über einen längeren Zeitraum hinweg zusammengestellt und digitalisiert wurden. Ein Beispiel für die Entwicklung von Regeln zur Lösung eines NLP-Problems unter Verwendung solcher Ressourcen ist die lexikonbasierte Stimmungsanalyse. Sie nutzt die Anzahl der positiven und negativen Wörter im Text, um die Stimmung des Textes zu ermitteln. Wir werden dies in Kapitel 4 kurz behandeln.
Neben Wörterbüchern und Thesauri wurden auch komplexere Wissensdatenbanken erstellt, um NLP im Allgemeinen und regelbasiertes NLP im Besonderen zu unterstützen. Ein Beispiel ist Wordnet [7], eine Datenbank mit Wörtern und den semantischen Beziehungen zwischen ihnen. Einige Beispiele für solche Beziehungen sind Synonyme, Hyponyme und Meronyme. Synonyme beziehen sich auf Wörter mit ähnlichen Bedeutungen. Hyponyme erfassen is-type-of-Beziehungen. Zum Beispiel sind Baseball, Sumo-Ringen und Tennis alles Hyponyme von Sport. Meronyme erfassen is-part-of-Beziehungen. Hände und Beine sind zum Beispiel Meronyme des Körpers. All diese Informationen sind nützlich, wenn es darum geht, regelbasierte Systeme für Sprache zu entwickeln. Abbildung 1-9 zeigt ein Beispiel für die Darstellung solcher Beziehungen zwischen Wörtern mit Wordnet.
![Wordnet graph for the word “sport” [_38]](/api/v2/epubs/9781098183899/files/assets/pnlp_0109.png)
Abbildung 1-9. Worthäufigkeitsdiagramm für das Wort "Sport" [8]
In jüngerer Zeit wurde das Weltwissen des gesunden Menschenverstands auch in Wissensdatenbanken wie Open Mind Common Sense [9] integriert, die ebenfalls solche regelbasierten Systeme unterstützen. Was wir bisher gesehen haben, sind vor allem lexikalische Ressourcen, die auf Informationen auf Wortebene basieren, aber regelbasierte Systeme gehen über Wörter hinaus und können auch andere Formen von Informationen einbeziehen. Einige von ihnen werden im Folgenden vorgestellt.
Reguläre Ausdrücke (regex) sind ein großartiges Werkzeug für die Textanalyse und den Aufbau regelbasierter Systeme. Eine Regex ist eine Gruppe von Zeichen oder ein Muster, das verwendet wird, um Teilzeichenfolgen in einem Text zu finden. Eine Regex wie '^([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$' wird zum Beispiel verwendet, um alle E-Mail-IDs in einem Textstück zu finden. Regexe sind eine großartige Möglichkeit, Domänenwissen in dein NLP-System einzubinden. Wenn wir zum Beispiel eine Kundenbeschwerde per Chat oder E-Mail erhalten, wollen wir ein System entwickeln, das automatisch das Produkt identifiziert, um das es in der Beschwerde geht. Es gibt eine Reihe von Produktcodes, die bestimmten Markennamen zugeordnet sind. Mit Hilfe von Regexen können wir diese leicht zuordnen.
Regexe sind ein sehr beliebtes Paradigma für den Aufbau regelbasierter Systeme. NLP-Software wie StanfordCoreNLP enthält TokensRegex [10], ein Framework zur Definition regulärer Ausdrücke. Es wird verwendet, um Muster im Text zu erkennen und den übereinstimmenden Text zur Erstellung von Regeln zu verwenden. Regexes werden für deterministische Übereinstimmungenverwendet, d. h. entweder es ist eine Übereinstimmung oder nicht. Probabilistische Regexe sind ein Unterzweig, der diese Einschränkung ausgleicht, indem er eine Wahrscheinlichkeit für eine Übereinstimmung angibt. Interessierte Leser können sich Softwarebibliotheken wie pregex [11] ansehen. Letzter Zugriff am 15. Juni 2020.
Die kontextfreie Grammatik (CFG) ist eine Art von formaler Grammatik, die zur Modellierung natürlicher Sprachen verwendet wird. Erfunden wurde die CFG von Professor Noam Chomsky, einem renommierten Linguisten und Wissenschaftler. Mit CFGs lassen sich komplexere und hierarchische Informationen erfassen, die eine Regex nicht erfassen kann. Der Earley-Parser [12] ermöglicht das Parsen aller Arten von CFGs. Um komplexere Regeln zu modellieren, können Grammatiksprachen wie JAPE (Java Annotation Patterns Engine) verwendet werden [13]. JAPE verfügt über Funktionen sowohl von Regexen als auch von CFGs und kann für regelbasierte NLP-Systeme wie GATE (General Architecture for Text Engineering) [14] verwendet werden. GATE wird für die Erstellung von Textextraktionen für geschlossene und klar definierte Domänen verwendet, bei denen Genauigkeit und Vollständigkeit der Abdeckung wichtiger sind. JAPE und GATE wurden zum Beispiel verwendet, um Informationen über Herzschrittmacher-Implantationen aus klinischen Berichten zu extrahieren [15]. Abbildung 1-10 zeigt die GATE-Benutzeroberfläche zusammen mit mehreren im Text hervorgehobenen Informationstypen als Beispiel für ein regelbasiertes System.
Regeln und Heuristiken spielen auch heute noch im gesamten Lebenszyklus von NLP-Projekten eine Rolle. Einerseits sind sie eine großartige Möglichkeit, um erste Versionen von NLP-Systemen zu erstellen. Einfach ausgedrückt: Regeln und Heuristiken helfen dir, schnell die erste Version des Modells zu erstellen und ein besseres Verständnis für das Problem zu bekommen. Wir werden diesen Punkt in den Kapiteln 4 und 11 ausführlich behandeln. Regeln und Heuristiken können auch als Funktionen für NLP-Systeme, die auf maschinellem Lernen basieren, nützlich sein. Am anderen Ende des Spektrums des Projektlebenszyklus werden Regeln und Heuristiken verwendet, um die Lücken im System zu schließen. Jedes NLP-System, das mit statistischen, maschinellen Lern- oder Deep-Learning-Techniken entwickelt wird, macht Fehler. Manche Fehler können sehr teuer werden - zum Beispiel ein Gesundheitssystem, das alle Krankenakten eines Patienten durchsucht und fälschlicherweise entscheidet, einen wichtigen Test nicht zu empfehlen. Dieser Fehler könnte sogar ein Leben kosten. Regeln und Heuristiken sind eine gute Möglichkeit, solche Lücken in Produktionssystemen zu schließen. Wenden wir uns nun den Techniken des maschinellen Lernens zu, die für NLP verwendet werden.
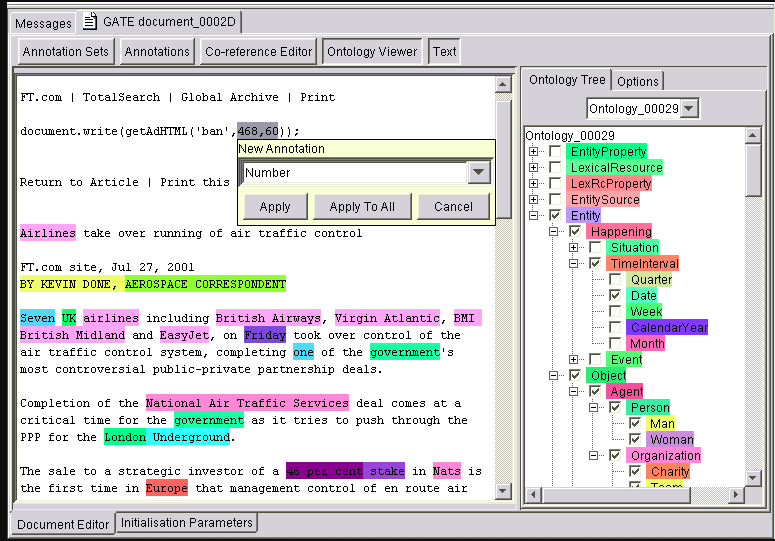
Abbildung 1-10. GATE-Werkzeug
Maschinelles Lernen für NLP
Techniken des maschinellen Lernens werden auf Textdaten genauso angewandt wie auf andere Arten von Daten, z. B. Bilder, Sprache und strukturierte Daten. Überwachte maschinelle Lerntechniken wie Klassifizierungs- und Regressionsmethoden werden häufig für verschiedene NLP-Aufgaben verwendet. Eine NLP-Klassifizierungsaufgabe wäre z. B. die Einordnung von Nachrichtenartikeln in eine Reihe von Themen wie Sport oder Politik. Regressionsverfahren, die eine numerische Vorhersage liefern, können dagegen verwendet werden, um den Kurs einer Aktie anhand der Diskussionen in den sozialen Medien über diese Aktie zu schätzen. Ebenso können unüberwachte Clustering-Algorithmen verwendet werden, um Textdokumente zusammenzufassen.
Jeder Ansatz des maschinellen Lernens für NLP, ob überwacht oder unbeaufsichtigt, besteht aus drei gemeinsamen Schritten: Extraktion von Merkmalen aus Text, Verwendung der Merkmalsrepräsentation zum Lernen eines Modells und Bewertung und Verbesserung des Modells. Mehr über Merkmalsrepräsentationen für Text erfahren wir in Kapitel 3 und über die Auswertung in Kapitel 2. Für den zweiten Schritt (Verwendung der Merkmalsrepräsentation zum Lernen eines Modells) werden wir nun kurz einige der in der NLP häufig verwendeten überwachten ML-Methoden vorstellen. Die Kenntnis dieser Methoden wird dir helfen, die in den späteren Kapiteln besprochenen Konzepte zu verstehen.
Naive Bayes
Naive Bayes ist ein klassischer Algorithmus für Klassifizierungsaufgaben [16], der sich hauptsächlich auf das Bayes'sche Theorem stützt (wie der Name schon sagt). Mithilfe des Bayes'schen Theorems wird die Wahrscheinlichkeit berechnet, mit der ein Klassenlabel beobachtet wird, wenn eine Reihe von Merkmalen für die Eingabedaten vorhanden ist. Ein Merkmal dieses Algorithmus ist, dass er davon ausgeht, dass jedes Merkmal unabhängig von allen anderen Merkmalen ist. Für das Beispiel der Nachrichtenklassifizierung, das weiter oben in diesem Kapitel erwähnt wurde, ist eine Möglichkeit, den Text numerisch darzustellen, die Anzahl der domänenspezifischen Wörter, wie z. B. sport- oder politikspezifische Wörter, die in dem Text vorkommen. Wir gehen davon aus, dass die Anzahl dieser Wörter nicht miteinander korreliert. Wenn diese Annahme zutrifft, können wir Naive Bayes verwenden, um Nachrichtenartikel zu klassifizieren. Obwohl dies in vielen Fällen eine starke Annahme ist, wird Naive Bayes häufig als Startalgorithmus für die Textklassifizierung verwendet. Das liegt vor allem daran, dass er einfach zu verstehen ist und sehr schnell trainiert und ausgeführt werden kann.
Support-Vektor-Maschine
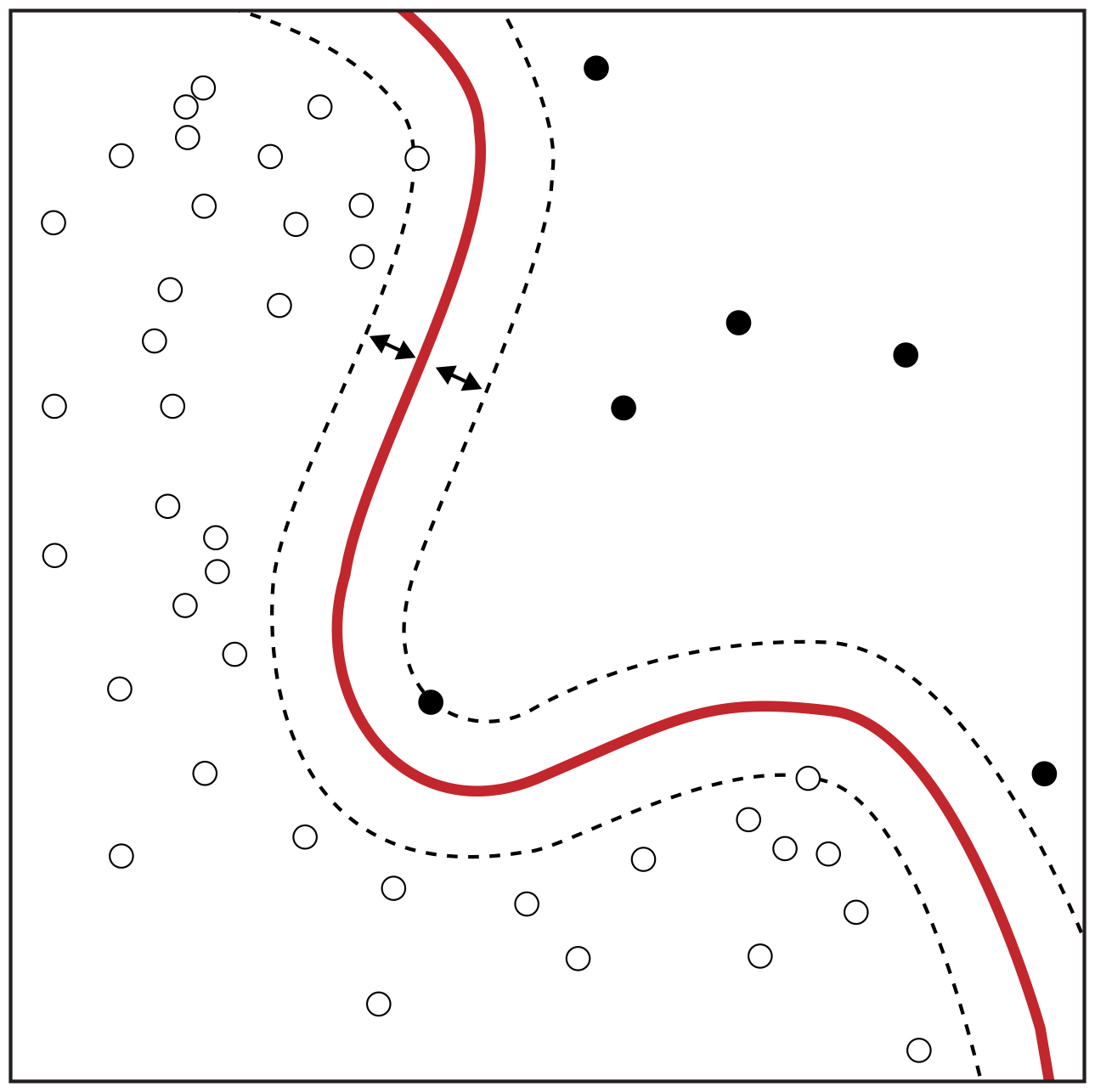
Die Support-Vektor-Maschine (SVM) ist ein weiterer beliebter Klassifizierungsalgorithmus [17]. Das Ziel eines jeden Klassifizierungsansatzes ist es, eine Entscheidungsgrenze zu lernen, die als Trennung zwischen verschiedenen Textkategorien dient (z. B. Politik und Sport in unserem Beispiel der Nachrichtenklassifizierung). Diese Entscheidungsgrenze kann linear oder nichtlinear sein (z. B. ein Kreis). Ein SVM kann sowohl eine lineare als auch eine nichtlineare Entscheidungsgrenze erlernen, um Datenpunkte, die zu verschiedenen Klassen gehören, zu trennen. Eine lineare Entscheidungsgrenze lernt, die Daten so darzustellen, dass die Klassenunterschiede deutlich werden. Ein anschauliches Beispiel für zweidimensionale Merkmalsdarstellungen findest du in Abbildung 1-11, in der die schwarzen und weißen Punkte zu verschiedenen Klassen gehören (z. B. Sport- und Politiknachrichten). Ein SVM lernt eine optimale Entscheidungsgrenze, so dass der Abstand zwischen den Punkten über die Klassen hinweg am größten ist. Die größte Stärke von SVMs ist ihre Robustheit gegenüber Schwankungen und Rauschen in den Daten. Ein großer Schwachpunkt ist die lange Trainingszeit und die mangelnde Skalierbarkeit bei großen Mengen an Trainingsdaten.
Bedingte Zufallsfelder
Das bedingte Zufallsfeld (CRF) ist ein weiterer Algorithmus, der für sequentielle Daten verwendet wird. Konzeptionell führt ein CRF im Wesentlichen eine Klassifizierungsaufgabe für jedes Element in der Sequenz durch [20]. Man stelle sich das gleiche Beispiel wie beim POS-Tagging vor, bei dem ein CRF Wort für Wort markieren kann, indem es sie einem der Parts of Speech aus dem Pool aller POS-Tags zuordnet. Da sie die sequentielle Eingabe und den Kontext der Tags berücksichtigt, ist sie aussagekräftiger als die üblichen Klassifizierungsmethoden und schneidet im Allgemeinen besser ab. CRFs übertreffen HMMs bei Aufgaben wie dem POS-Tagging, die auf der sequenziellen Natur der Sprache beruhen. Wir besprechen CRFs und ihre Varianten sowie Anwendungen in den Kapiteln 5, 6 und 9.
Dies sind einige der populären ML-Algorithmen, die häufig bei NLP-Aufgaben eingesetzt werden. Ein gewisses Verständnis dieser ML-Methoden hilft dabei, die verschiedenen Lösungen zu verstehen, die in diesem Buch besprochen werden. Außerdem ist es wichtig zu wissen, wann man welchen Algorithmus einsetzt, was wir in den nächsten Kapiteln besprechen werden. Um mehr über andere Schritte und weitere theoretische Details des maschinellen Lernprozesses zu erfahren, empfehlen wir das Lehrbuch Pattern Recognition and Machine Learning von Christopher Bishop [21]. Für eine eher angewandte Perspektive des maschinellen Lernens ist das Buch von Aurélien Géron [22] eine hervorragende Quelle. Werfen wir nun einen Blick auf Deep Learning-Ansätze im NLP.
Deep Learning für NLP
Wir haben uns kurz mit einigen beliebten Methoden des maschinellen Lernens befasst, die bei verschiedenen NLP-Aufgaben häufig eingesetzt werden. In den letzten Jahren hat der Einsatz neuronaler Netze bei der Verarbeitung komplexer, unstrukturierter Daten stark zugenommen. Sprache ist von Natur aus komplex und unstrukturiert. Deshalb brauchen wir Modelle mit einer besseren Repräsentation und Lernfähigkeit, um Sprachaufgaben zu verstehen und zu lösen. Hier sind einige beliebte tiefe neuronale Netzwerkarchitekturen, die zum Status quo im NLP geworden sind.
Rekurrente neuronale Netze
Wie wir bereits erwähnt haben, ist die Sprache von Natur aus sequentiell. In jeder Sprache fließt ein Satz von einer Richtung zur anderen (z. B. liest Englisch von links nach rechts). Daher kann ein Modell, das einen Eingabetext schrittweise von einem Ende zum anderen lesen kann, für das Sprachverständnis sehr nützlich sein. Rekurrente neuronale Netze (RNNs) wurden speziell dafür entwickelt, eine solche sequentielle Verarbeitung und das Lernen zu berücksichtigen. RNNs haben neuronale Einheiten, die in der Lage sind, sich an das zu erinnern, was sie bisher verarbeitet haben. Dieses Gedächtnis ist zeitlich begrenzt, und die Informationen werden gespeichert und mit jedem Zeitschritt aktualisiert, wenn das RNN das nächste Wort in der Eingabe liest. Abbildung 1-13 zeigt ein abgewickeltes RNN und wie es sich die Eingabe in verschiedenen Zeitschritten merkt.
![An unrolled recurrent neural network [_10]](/api/v2/epubs/9781098183899/files/assets/pnlp_0113.png)
Abbildung 1-13. Ein ausgerolltes rekurrentes neuronales Netz [23]
RNNs sind leistungsstark und eignen sich sehr gut für die Lösung einer Vielzahl von NLP-Aufgaben, wie z. B. Textklassifizierung, Named-Entity-Erkennung, maschinelle Übersetzung usw. Man kann RNNs auch verwenden, um Texte zu generieren, bei denen das Ziel darin besteht, den vorangegangenen Text zu lesen und das nächste Wort oder das nächste Zeichen vorherzusagen. Unter "The Unreasonable Effectiveness of Recurrent Neural Networks" [24] findest du eine ausführliche Diskussion über die Vielseitigkeit von RNNs und die Bandbreite der Anwendungen innerhalb und außerhalb des NLP, für die sie nützlich sind.
Langes Kurzzeitgedächtnis
Trotz ihrer Fähigkeit und Vielseitigkeit leiden RNNs unter dem Problem des Vergessens - sie können sich nicht an längere Zusammenhänge erinnern und bringen daher keine guten Leistungen, wenn der Eingabetext lang ist, was bei Texteingaben typischerweise der Fall ist. Netzwerke mit Langzeitgedächtnis (LSTMs), eine Art von RNN, wurden erfunden, um dieses Manko der RNNs zu mildern. LSTMs umgehen dieses Problem, indem sie den irrelevanten Kontext loslassen und sich nur an den Teil des Kontexts erinnern, der für die Lösung der jeweiligen Aufgabe benötigt wird. Das entlastet das Erinnern von sehr langen Zusammenhängen in einer Vektordarstellung. LSTMs haben RNNs in den meisten Anwendungen aufgrund dieser Lösung ersetzt. Gated recurrent units (GRUs) sind eine weitere Variante von RNNs, die vor allem bei der Spracherzeugung eingesetzt werden. (Der Artikel von Christopher Olah [23] behandelt die Familie der RNN-Modelle sehr detailliert.) Abbildung 1-14 veranschaulicht die Architektur einer einzelnen LSTM-Zelle. Wir werden in den Kapiteln 4, 5, 6 und 9 auf die spezifischen Einsatzmöglichkeiten von LSTMs in verschiedenen NLP-Anwendungen eingehen.
![Architecture of an LSTM cell [_10]](/api/v2/epubs/9781098183899/files/assets/pnlp_0114.png)
Abbildung 1-14. Architektur einer LSTM-Zelle [23]
Faltungsneuronale Netze
Convolutional Neural Networks (CNNs) sind sehr beliebt und werden häufig bei Computer-Vision-Aufgaben wie Bildklassifizierung, Videoerkennung usw. eingesetzt. CNNs haben sich auch im NLP-Bereich bewährt, insbesondere bei der Textklassifizierung. Man kann jedes Wort in einem Satz durch den entsprechenden Wortvektor ersetzen, und alle Vektoren haben die gleiche Größe(d) (siehe "Worteinbettungen" in Kapitel 3). Daher können sie übereinander gestapelt werden und bilden eine Matrix oder ein 2D-Array der Dimension n ✕ d, wobei n die Anzahl der Wörter im Satz und d die Größe der Wortvektoren ist. Diese Matrix kann nun ähnlich wie ein Bild behandelt werden und von einem CNN modelliert werden. Der Hauptvorteil von CNNs besteht darin, dass sie eine Gruppe von Wörtern mit Hilfe eines Kontextfensters zusammen betrachten können. Ein Beispiel: Wir führen eine Sentiment-Klassifizierung durch und erhalten einen Satz wie: "Dieser Film gefällt mir sehr gut!" Um diesem Satz einen Sinn zu geben, ist es besser, Wörter und verschiedene Gruppen von zusammenhängenden Wörtern zu betrachten. CNNs können aufgrund ihrer Architektur genau das tun. Darauf werden wir in späteren Kapiteln noch genauer eingehen. Abbildung 1-15 zeigt, wie ein CNN aus einem Textstück nützliche Phrasen extrahiert, um schließlich eine binäre Zahl zu erhalten, die die Stimmung des Satzes in einem bestimmten Textstück angibt.
Wie in der Abbildung zu sehen ist, verwendet CNN eine Sammlung von Faltungsschichten und Pooling-Schichten, um diese komprimierte Darstellung des Textes zu erreichen, die dann als Eingabe für eine voll verknüpfte Schicht verwendet wird, um einige NLP-Aufgaben wie die Textklassifizierung zu lernen. Weitere Einzelheiten über die Verwendung von CNNs für NLP finden sich in [25] und [26]. Wir behandeln sie auch in Kapitel 4.
![CNN model in action [_11]](/api/v2/epubs/9781098183899/files/assets/pnlp_0115.png)
Abbildung 1-15. CNN-Modell in Aktion [27]
Transformers
Transformers [28] sind der neueste Eintrag in der Liga der Deep-Learning-Modelle für NLP. Transformer-Modelle haben in den letzten zwei Jahren bei fast allen wichtigen NLP-Aufgaben den Stand der Technik erreicht. Sie modellieren den Textzusammenhang, aber nicht in einer sequenziellen Weise. Bei einem Wort in der Eingabe zieht es vor, alle Wörter in der Umgebung zu betrachten (bekannt als Self-Attention) und jedes Wort in Bezug auf seinen Kontext darzustellen. Zum Beispiel kann das Wort "Bank" je nach Kontext, in dem es vorkommt, unterschiedliche Bedeutungen haben. Wenn es in dem Kontext um Finanzen geht, dann bezeichnet "Bank" wahrscheinlich ein Finanzinstitut. Wenn der Kontext hingegen einen Fluss erwähnt, dann bezeichnet es wahrscheinlich ein Ufer des Flusses. Transformers können solche Kontexte modellieren und werden daher aufgrund ihrer höheren Repräsentationskapazität im Vergleich zu anderen tiefen Netzen häufig für NLP-Aufgaben eingesetzt.
In letzter Zeit wurden große Transformatoren für das Transferlernen mit kleineren nachgelagerten Aufgaben eingesetzt. Transferlernen ist eine Technik in der KI, bei der das bei der Lösung eines Problems gewonnene Wissen auf ein anderes, aber verwandtes Problem angewendet wird. Bei Transformatoren geht es darum, einen sehr großen Transformatormodus auf unbeaufsichtigte Weise zu trainieren (bekannt als Pre-Training g), um einen Teil eines Satzes anhand des restlichen Inhalts vorherzusagen, damit er die hochrangigen Nuancen der Sprache darin kodieren kann. Diese Modelle werden mit mehr als 40 GB Textdaten aus dem gesamten Internet trainiert. Ein Beispiel für einen großen Transformator ist BERT (Bidirectional Encoder Representations from Transformers) [29], das in Abbildung 1-16 dargestellt ist, mit umfangreichen Daten trainiert wurde und von Google zur Verfügung gestellt wird.
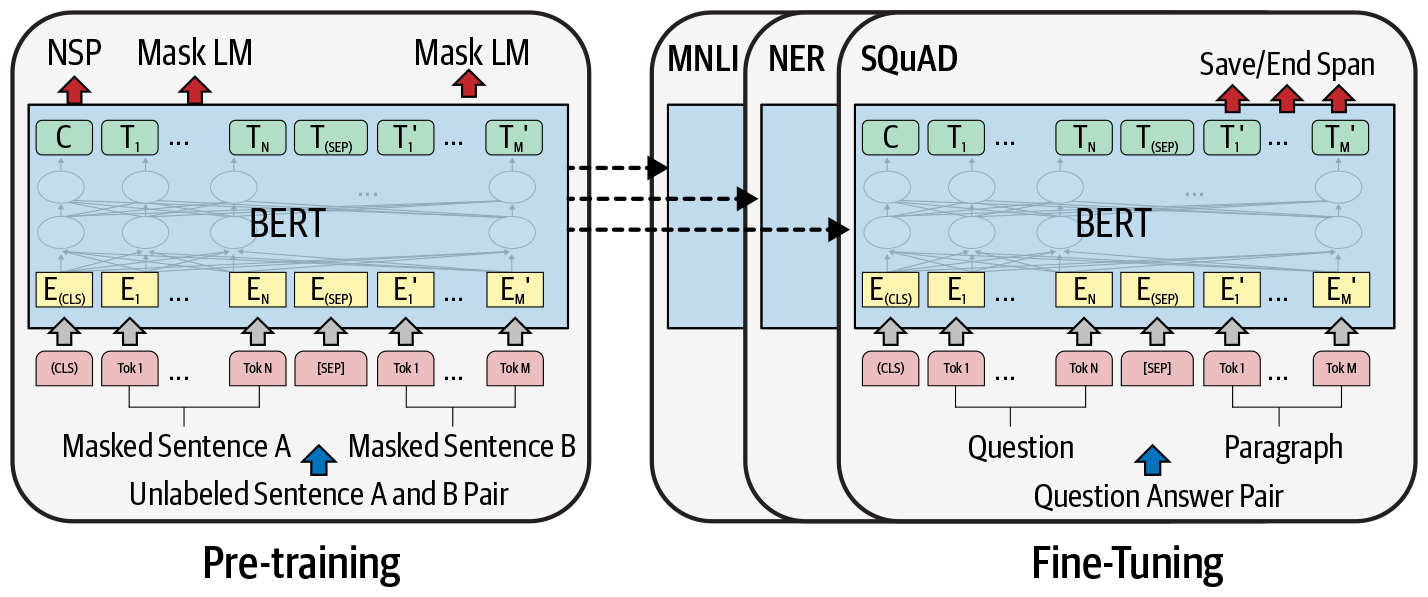
Abbildung 1-16. BERT-Architektur: vortrainiertes Modell und fein abgestimmte, aufgabenspezifische Modelle
Das vortrainierte Modell ist auf der linken Seite von Abbildung 1-16 zu sehen. Dieses Modell wird dann auf nachgelagerte NLP-Aufgaben wie Textklassifikation, Entity-Extraktion, Fragenbeantwortung usw. abgestimmt, wie in Abbildung 1-16 rechts dargestellt. Aufgrund der schieren Menge an vortrainiertem Wissen arbeitet BERT effizient bei der Übertragung des Wissens für nachgelagerte Aufgaben und erreicht bei vielen dieser Aufgaben den Stand der Technik. Im Laufe des Buches haben wir verschiedene Beispiele für den Einsatz von BERT für unterschiedliche Aufgaben behandelt. Abbildung 1-17 veranschaulicht die Funktionsweise eines Selbstbeobachtungsmechanismus, der ein wichtiger Bestandteil eines Transformators ist. Interessierte Leserinnen und Leser können unter [30] weitere Einzelheiten über Selbstbeobachtungsmechanismen und die Architektur von Transformatoren nachlesen. Wir behandeln BERT und seine Anwendungen in den Kapiteln 4, 6 und 10.
![Self-attention mechanism in a transformer [_3]](/api/v2/epubs/9781098183899/files/assets/pnlp_0117.png)
Abbildung 1-17. Selbstbehauptungsmechanismus in einem Transformator [30]
Autoencoder
Ein Autoencoder ist eine andere Art von Netzwerk, das hauptsächlich zum Lernen einer komprimierten Vektordarstellung der Eingabe verwendet wird. Wenn wir zum Beispiel einen Text durch einen Vektor darstellen wollen, wie können wir das am besten tun? Wir können eine Abbildungsfunktion vom Eingabetext zum Vektor lernen. Um diese Abbildungsfunktion nutzbar zu machen, "rekonstruieren" wir die Eingabe aus der Vektordarstellung zurück. Das ist eine Form des unüberwachten Lernens, da du dafür keine von Menschen kommentierten Labels brauchst. Nach dem Training sammeln wir die Vektordarstellung, die als Kodierung des Eingabetextes in Form eines dichten Vektors dient. Autoencoder werden in der Regel verwendet, um Merkmalsrepräsentationen zu erstellen, die für nachgelagerte Aufgaben benötigt werden. In Abbildung 1-18 ist die Architektur eines Autoencoders dargestellt.
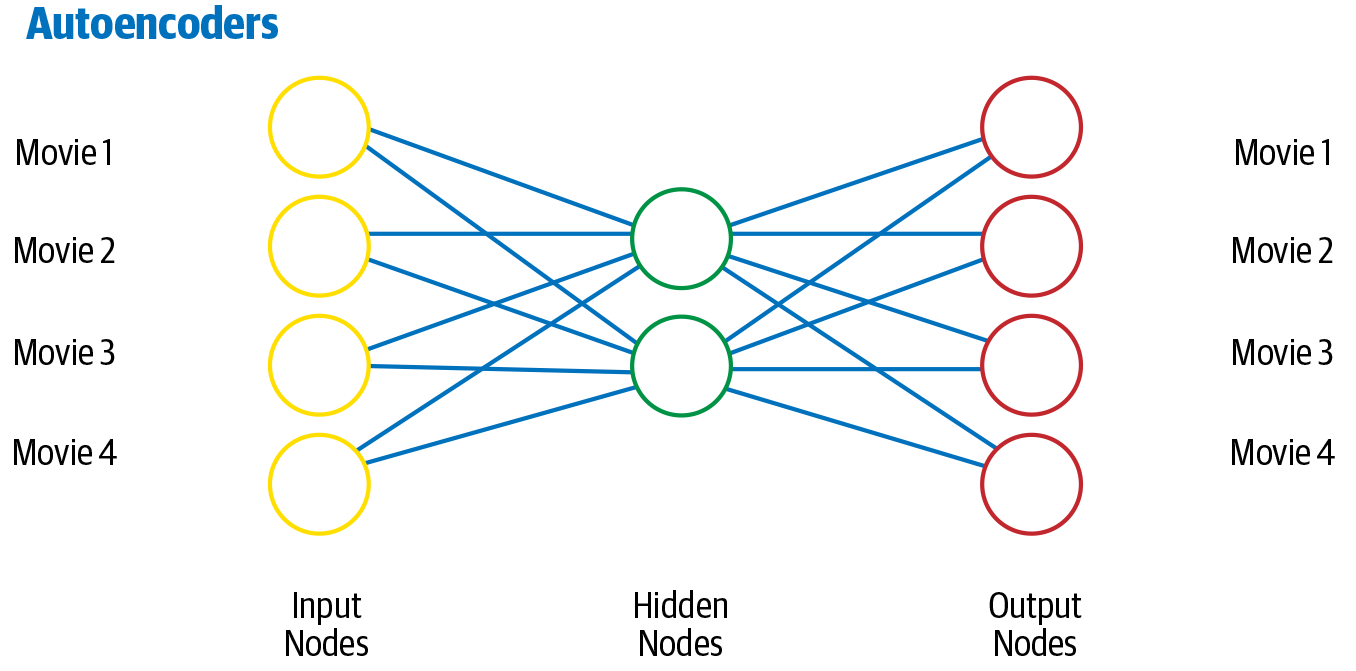
Abbildung 1-18. Architektur eines Autoencoders
Bei diesem Schema liefert die verborgene Schicht eine komprimierte Darstellung der Eingabedaten, die das Wesentliche erfasst, und die Ausgangsschicht (Decoder) rekonstruiert die Eingabedaten aus der komprimierten Darstellung. Die in Abbildung 1-18 gezeigte Architektur des Autocodierers kann zwar nicht mit den spezifischen Eigenschaften von sequentiellen Daten wie Text umgehen, aber Variationen von Autocodierern, wie z. B. LSTM-Autocodierer, können diese gut verarbeiten. Weitere Informationen zu Autocodierern findest du in [31].
Wir haben hier kurz einige der gängigen DL-Architekturen für NLP vorgestellt. Eine ausführlichere Studie über Deep Learning-Architekturen im Allgemeinen findest du unter [31] und speziell für NLP unter [25]. Wir hoffen, dass diese Einführung genug Hintergrundwissen vermittelt, um die Verwendung von DL im Rest des Buches zu verstehen.
Angesichts der jüngsten Errungenschaften von DL-Modellen könnte man meinen, dass DL die erste Wahl für den Aufbau von NLP-Systemen sein sollte. Für die meisten Anwendungsfälle in der Industrie ist das jedoch nicht der Fall. Sehen wir uns an, warum dies der Fall ist .
Warum Deep Learning noch nicht die Silberkugel für NLP ist
In den letzten Jahren hat DL erstaunliche Fortschritte im NLP gemacht. So haben LSTM- und CNN-basierte Modelle bei vielen Klassifizierungsaufgaben die Leistung von maschinellen Standardlernverfahren wie Naive Bayes und SVM übertroffen. Ebenso haben LSTMs bei Sequenzkennzeichnungsaufgaben wie der Entitätsextraktion besser abgeschnitten als CRF-Modelle. In letzter Zeit sind leistungsstarke Transformationsmodelle bei den meisten dieser NLP-Aufgaben, von der Klassifizierung bis zur Sequenzkennzeichnung, zum Stand der Technik geworden. Ein großer Trend besteht derzeit darin, große (in Bezug auf die Anzahl der Parameter) Transformer-Modelle zu nutzen, sie auf großen Datensätzen für allgemeine NLP-Aufgaben wie Sprachmodelle zu trainieren und sie dann an kleinere nachgelagerte Aufgaben anzupassen. Dieser Ansatz (bekannt als Transfer Learning) hat sich auch in anderen Bereichen wie Computer Vision und Sprache bewährt.
Trotz dieses großen Erfolgs ist DL immer noch nicht der Königsweg für alle NLP-Aufgaben, wenn es um industrielle Anwendungen geht. Einige der Hauptgründe dafür sind die folgenden:
- Überanpassung bei kleinen Datensätzen
- DL-Modelle haben in der Regel mehr Parameter als traditionelle ML-Modelle, was bedeutet, dass sie mehr Aussagekraft besitzen. Das bringt auch einen Fluch mit sich. Occams Rasiermesser [32] besagt, dass eine einfachere Lösung immer vorzuziehen ist, vorausgesetzt, alle anderen Bedingungen sind gleich. In der Entwicklungsphase stehen oft nicht genügend Trainingsdaten zur Verfügung, um ein komplexes Netz zu trainieren. In solchen Fällen sollte ein einfacheres Modell einem DL-Modell vorgezogen werden. DL-Modelle passen sich zu sehr an kleine Datensätze an und führen dann zu einer schlechten Generalisierungsfähigkeit, was wiederum zu einer schlechten Leistung in der Produktion führt.
- Few-Shot-Lernen und Generierung synthetischer Daten
- In Disziplinen wie dem Computersehen hat DL bedeutende Fortschritte gemacht: few-shot learning (d.h. Lernen aus sehr wenigen Trainingsbeispielen) [33] und bei Modellen, die Bilder von hoher Qualität erzeugen können [34]. Diese beiden Fortschritte haben das Training von DL-basierten Bildverarbeitungsmodellen mit kleinen Datenmengen möglich gemacht. Aus diesem Grund hat die DL eine viel breitere Akzeptanz für die Lösung von Problemen in der Industrie gefunden. Wir haben noch nicht gesehen, dass ähnliche DL-Techniken erfolgreich für NLP entwickelt wurden.
- Domänenanpassung
- Wenn wir ein großes DL-Modell verwenden, das auf Datensätzen aus einigen gängigen Domänen (z. B. Nachrichtenartikel) trainiert wurde, und das trainierte Modell auf eine neuere Domäne anwenden, die sich von den gängigen Domänen unterscheidet (z. B. Social-Media-Posts), kann dies zu einer schlechten Leistung führen. Dieser Verlust an Generalisierungsleistung zeigt, dass DL-Modelle nicht immer nützlich sind. Modelle, die für Internettexte und Produktbewertungen trainiert wurden, funktionieren beispielsweise nicht gut, wenn sie auf Bereiche wie Recht, soziale Medien oder das Gesundheitswesen angewendet werden, in denen sowohl die syntaktische als auch die semantische Struktur der Sprache spezifisch für den jeweiligen Bereich ist. Wir brauchen spezielle Modelle, um das Domänenwissen zu kodieren, z. B. einfache domänenspezifische, regelbasierte Modelle.
- Interpretierbare Modelle
- Abgesehen von einer effizienten Domänenanpassung ist die Kontrollierbarkeit und Interpretierbarkeit von DL-Modellen schwierig, da sie meist wie eine Blackbox funktionieren. Unternehmen verlangen oft interpretierbare Ergebnisse, die dem Kunden oder Endnutzer erklärt werden können. In solchen Fällen können traditionelle Techniken nützlicher sein. Ein Naive-Bayes-Modell für die Sentiment-Klassifizierung kann zum Beispiel die Auswirkung starker positiver und negativer Wörter auf die endgültige Vorhersage des Sentiments erklären. Bis heute ist es schwierig, solche Erkenntnisse aus einem LSTM-basierten Klassifizierungsmodell zu gewinnen. Dies steht im Gegensatz zu Computer Vision, wo DL-Modelle keine Blackboxen sind. In der Computer Vision gibt es zahlreiche Techniken [35], mit denen man herausfinden kann, warum ein Modell eine bestimmte Vorhersage trifft. Solche Ansätze sind im NLP nicht so weit verbreitet.
- Gesunder Menschenverstand und Weltwissen
- Auch wenn wir mit ML- und DL-Modellen bei Benchmark-Aufgaben im Bereich NLP gute Ergebnisse erzielt haben, bleibt Sprache für Wissenschaftler/innen ein großes Rätsel. Neben Syntax und Semantik umfasst Sprache auch das Wissen über die Welt um uns herum. Sprache zur Kommunikation beruht auf logischem Denken und gesundem Menschenverstand in Bezug auf Ereignisse in der Welt. Ein Beispiel: "Ich mag Pizza" bedeutet: "Ich fühle mich glücklich, wenn ich Pizza esse." Ein komplexeres Beispiel wäre: "Wenn John aus dem Schlafzimmer in den Garten geht, dann ist er nicht mehr im Schlafzimmer und befindet sich im Garten. Für uns Menschen mag das trivial erscheinen, aber eine Maschine muss in mehreren Schritten denken, um Ereignisse zu erkennen und ihre Folgen zu verstehen. Da dieses Weltwissen und der gesunde Menschenverstand der Sprache inhärent sind, ist es für jedes DL-Modell entscheidend, sie zu verstehen, um bei verschiedenen Sprachaufgaben gut abzuschneiden. Aktuelle DL-Modelle mögen bei Standard-Benchmarks gut abschneiden, sind aber nicht in der Lage, den gesunden Menschenverstand zu verstehen und logisch zu denken. Es gibt zwar Bestrebungen, Ereignisse des gesunden Menschenverstands und logische Regeln (wie z. B. das Wenn-dann-Schlussfolgern) zu erfassen, aber sie sind noch nicht gut in ML- oder DL-Modelle integriert.
- Kosten
- Die Entwicklung DL-basierter Lösungen für NLP-Aufgaben kann ziemlich teuer sein. Die Kosten, sowohl in Form von Geld als auch in Form von Zeit, sind auf mehrere Ursachen zurückzuführen. DL-Modelle sind als Datenfresser bekannt. Einen großen Datensatz zu sammeln und zu beschriften, kann sehr teuer sein. Aufgrund der Größe der DL-Modelle kann das Trainieren der Modelle, um die gewünschte Leistung zu erreichen, nicht nur die Entwicklungszyklen verlängern, sondern auch eine hohe Rechnung für die Spezialhardware (GPUs) nach sich ziehen. Auch die Bereitstellung und Pflege von DL-Modellen kann teuer sein, sowohl was die Hardwareanforderungen als auch den Aufwand angeht. Und nicht zuletzt können diese Modelle aufgrund ihrer Größe zu Latenzproblemen während der Inferenzzeit führen und sind daher in Fällen, in denen eine niedrige Latenzzeit erforderlich ist, nicht unbedingt sinnvoll. Zu dieser Liste kann man auch die technischen Schulden hinzufügen, die durch die Erstellung und Pflege eines umfangreichen Modells entstehen. Grob gesagt sind technische Schulden die Kosten für Nacharbeiten, die entstehen, wenn man einer schnellen Lieferung Vorrang vor guten Design- und Implementierungsentscheidungen gibt.
- Bereitstellung auf dem Gerät
- Für viele Anwendungsfälle muss die NLP-Lösung nicht in der Cloud, sondern auf einem eingebetteten Gerät eingesetzt werden, z. B. ein maschinelles Übersetzungssystem, das Touristen hilft, den übersetzten Text auch ohne Internet zu sprechen. In solchen Fällen muss die Lösung aufgrund der Einschränkungen des Geräts mit begrenztem Speicher und begrenzter Leistung arbeiten. Die meisten DL-Lösungen passen nicht zu diesen Einschränkungen. Es gibt zwar einige Ansätze in dieser Richtung [36, 37, 38], bei denen DL-Modelle auf Kanten-Geräten eingesetzt werden können, aber von generischen Lösungen sind wir noch weit entfernt.
Bei den meisten Projekten in der Industrie kommen einer oder mehrere der oben genannten Punkte zum Tragen. Das führt zu längeren Projektzyklen und höheren Kosten (Hardware, Arbeitskräfte), und dennoch ist die Leistung entweder vergleichbar oder manchmal sogar geringer als bei ML-Modellen. Dies führt zu einer schlechten Kapitalrendite und lässt das NLP-Projekt oft fehlschlagen.
Anhand dieser Diskussion wird deutlich, dass DL nicht immer die beste Lösung für alle industriellen NLP-Anwendungen ist. Daher beginnt dieses Buch mit grundlegenden Aspekten verschiedener NLP-Aufgaben und wie wir sie mit Techniken lösen können, die von regelbasierten Systemen bis hin zu DL-Modellen reichen. Wir legen den Schwerpunkt auf die Datenanforderungen und die Modellierungspipeline, nicht nur auf die technischen Details der einzelnen Modelle. Angesichts der rasanten Fortschritte in diesem Bereich gehen wir davon aus, dass es in Zukunft neue DL-Modelle geben wird, die den Stand der Technik vorantreiben, dass sich aber die Grundlagen der NLP-Aufgaben nicht wesentlich ändern werden. Deshalb werden wir uns mit den Grundlagen des NLP befassen und darauf aufbauen, um Modelle mit zunehmender Komplexität zu entwickeln, wo immer dies möglich ist, anstatt direkt an die Spitze der Entwicklung zu springen.
Wie Professor Zachary Lipton von der Carnegie Mellon University und Professor Jacob Steinhardt von der UC Berkeley [39] möchten auch wir davor warnen, viele wissenschaftliche Artikel, Forschungsarbeiten und Blogs über ML und NLP ohne Kontext und angemessene Schulung zu konsumieren. Wenn du eine große Menge an neuesten Arbeiten verfolgst, kann das zu Verwirrung und ungenauem Verständnis führen. Viele neuere DL-Modelle sind nicht interpretierbar genug, um die Quellen der empirischen Gewinne aufzuzeigen. Lipton und Steinhardt erkennen auch die mögliche Vermischung von Fachbegriffen und den falschen Sprachgebrauch in ML-bezogenen wissenschaftlichen Artikeln, die oft keinen klaren Weg zur Lösung des jeweiligen Problems aufzeigen. Deshalb beschreiben wir in diesem Buch verschiedene technische Konzepte bei der Anwendung von ML in NLP-Aufgaben sorgfältig anhand von Beispielen, Code und Tipps in den Kapiteln.
Bis jetzt haben wir einige grundlegende Konzepte zu Sprache, NLP, ML und DL behandelt. Bevor wir Kapitel 1 abschließen, schauen wir uns eine Fallstudie an, um ein besseres Verständnis für die verschiedenen Komponenten einer NLP Anwendung zu bekommen.
Ein NLP-Walkthrough: Konversations-Agenten
Sprachbasierte Konversationsagenten wie Amazon Alexa und Apple Siri gehören zu den allgegenwärtigsten Anwendungen von NLP und sind den meisten Menschen bereits bekannt. Abbildung 1-19 zeigt das typische Interaktionsmodell eines Konversationsagenten.
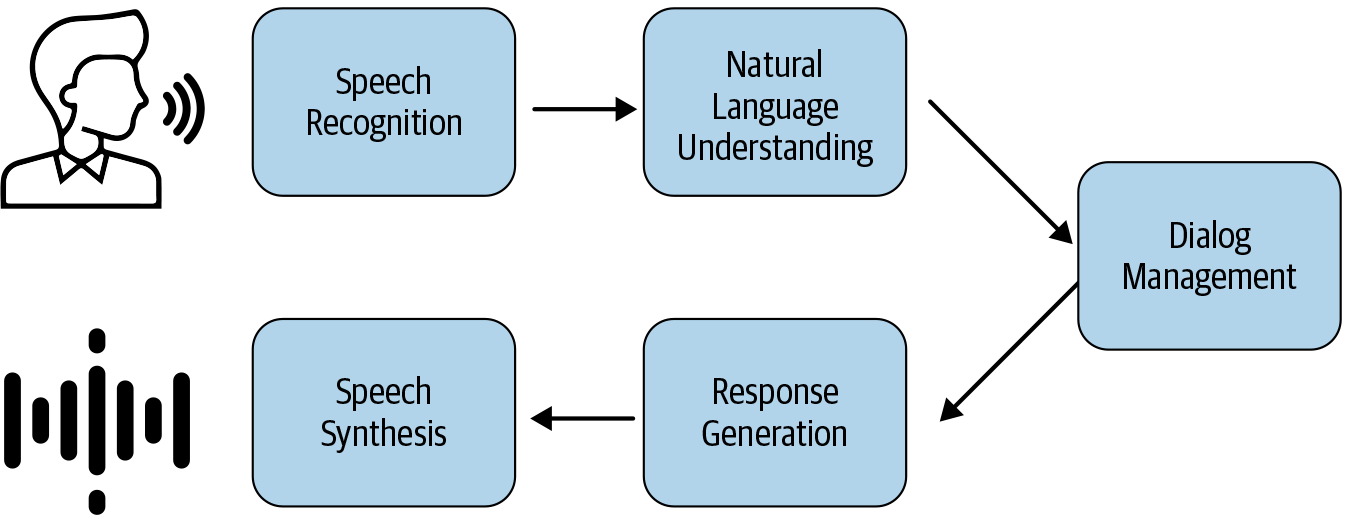
Hier gehen wir alle wichtigen NLP-Komponenten durch, die in diesem Flow verwendet werden:
Spracherkennung und Sprachsynthese: Dies sind die wichtigsten Komponenten eines sprachbasierten Gesprächsagenten. Bei der Spracherkennung werden Sprachsignale in ihre Phoneme umgewandelt, die dann als Wörter transkribiert werden. Bei der Sprachsynthese wird der umgekehrte Prozess durchgeführt, indem die Ergebnisse in gesprochene Sprache umgewandelt und dem Benutzer mitgeteilt werden. Beide Techniken haben sich in den letzten zehn Jahren erheblich weiterentwickelt, und wir empfehlen für die meisten Standardfälle die Verwendung von Cloud-APIs.
Natürliches Sprachverständnis: Dies ist die nächste Komponente in der Konversationsagenten-Pipeline, bei der die erhaltene (als Text transkribierte) Benutzerantwort mit einem System zum Verstehen natürlicher Sprache analysiert wird. Dies kann in viele kleine NLP-Teilaufgaben unterteilt werden, wie z. B.:
Sentiment-Analyse: Hier analysieren wir das Sentiment der Nutzerantwort. Dies wird in Kapitel 4 behandelt.
Named Entity Recognition: Hier identifizieren wir alle wichtigen Entitäten, die der Nutzer in seiner Antwort erwähnt hat. Dies wird in Kapitel 5 behandelt.
Koreferenzauflösung: Hier finden wir die Referenzen der extrahierten Entitäten aus dem Gesprächsverlauf heraus. Ein Nutzer könnte z. B. sagen: "Avengers Endgame war fantastisch" und sich später auf den Film beziehen, indem er sagt: "Die Spezialeffekte des Films waren toll." In diesem Fall würden wir eine Verknüpfung herstellen wollen, dass "Film" sich auf Avengers Endgame bezieht. Dies wird kurz in Kapitel 5 behandelt.
Dialogmanagement: Wenn wir die nützlichen Informationen aus der Antwort des Nutzers extrahiert haben, möchten wir vielleicht die Absicht des Nutzers verstehen, d. h., ob er eine sachliche Frage wie "Wie ist das Wetter heute? Wir können ein Textklassifizierungssystem verwenden, um die Antwort des Nutzers als eine der vordefinierten Absichten zu klassifizieren. So weiß der Konversationsagent, was er gefragt wird. Die Klassifizierung von Intentionen wird in den Kapiteln 4 und 6 behandelt. Während dieses Prozesses kann das System ein paar klärende Fragen stellen, um weitere Informationen vom Nutzer zu erhalten. Sobald wir die Absicht des Nutzers herausgefunden haben, wollen wir herausfinden, welche geeignete Aktion der Conversational Agent durchführen sollte, um die Anfrage des Nutzers zu erfüllen. Dies geschieht auf der Grundlage der Informationen und Absichten, die aus der Antwort des Nutzers hervorgehen. Beispiele für geeignete Aktionen sind das Generieren einer Antwort aus dem Internet, das Abspielen von Musik, das Dimmen der Beleuchtung oder das Stellen einer klärenden Frage. Wir werden dies in Kapitel 6 behandeln.
Antwortgenerierung: Schließlich generiert der Konversationsagent auf der Grundlage einer semantischen Interpretation der Absicht des Nutzers und zusätzlicher Eingaben aus dem Dialog mit dem Nutzer eine geeignete Aktion, die auszuführen ist. Wie bereits erwähnt, kann der Agent Informationen aus der Wissensdatenbank abrufen und Antworten anhand einer vordefinierten Vorlage generieren. Er könnte zum Beispiel antworten: "Jetzt wird die Symphonie Nr. 25 gespielt" oder "Das Licht wurde gedimmt". In bestimmten Szenarien kann er auch eine völlig neue Antwort generieren.
Wir hoffen, dass diese kurze Fallstudie einen Überblick darüber gegeben hat, wie die verschiedenen NLP-Komponenten, die wir in diesem Buch besprechen werden, zusammenkommen, um eine Anwendung zu erstellen: einen Konversationsagenten. Im weiteren Verlauf des Buches werden wir mehr Details zu diesen Komponenten erfahren und in Kapitel 6 speziell auf conversational agents eingehen.
Einpacken
In diesem Kapitel haben wir eine Reihe von NLP-Themen behandelt, von den allgemeinen Konturen dessen, was eine Sprache ist, bis hin zu einer konkreten Fallstudie über eine NLP-Anwendung in der realen Welt. Wir haben auch besprochen, wie NLP in der realen Welt angewendet wird, welche Herausforderungen und Aufgaben es gibt und welche Rolle ML und DL im NLP spielen. Dieses Kapitel sollte dir einen Grundstock an Wissen vermitteln, auf dem wir im Laufe des Buches aufbauen werden. In den nächsten beiden Kapiteln (Kapitel 2 und3) lernst du einige der grundlegenden Schritte kennen, die für die Entwicklung von NLP-Anwendungen notwendig sind. In den Kapiteln 4-7 geht es um die wichtigsten NLP-Aufgaben und um industrielle Anwendungsfälle, die damit gelöst werden können. In den Kapiteln 8-10 geht es darum, wie NLP in verschiedenen Branchen wie E-Commerce, Gesundheitswesen, Finanzen usw. eingesetzt wird. Kapitel 11 fasst alles zusammen und erklärt, was es braucht, um eine durchgängige NLP-Anwendung zu entwerfen, zu entwickeln, zu testen und zu implementieren. Mit diesem umfassenden Überblick können wir nun tiefer in die Welt des NLP eintauchen.
Fußnoten
Referenzen
[1] Arria.com. "NLG für deine Branche". Letzter Zugriff am 15. Juni 2020.
[2] UCL. Phonetische Symbole für Englisch. Letzter Zugriff am 15. Juni 2020.
[3] Bender, Emily M. "Linguistische Grundlagen für die Verarbeitung natürlicher Sprache: 100 Essentials From Morphology and Syntax". Synthesis Lectures on Human Language Technologies 6.3 (2013): 1-184.
[4] Bender, Emily M. und Alex Lascarides. "Linguistische Grundlagen für die Verarbeitung natürlicher Sprache II: 100 Essentials aus Semantik und Pragmatik". Synthesis Lectures on Human Language Technologies 12.3 (2019): 1-268.
[5] Levesque, Hector, Ernest Davis, und Leora Morgenstern. "The Winograd Schema Challenge". The Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning (2012).
[6] Wikipedia. "Dartmouth Workshop". Zuletzt geändert am 30. März 2020.
[7] Miller, George A. "WordNet: Eine lexikalische Datenbank für Englisch". Communications of the ACM 38.11 (1995): 39-41.
[8] Visual Thesaurus of English Collocations. "Visual Wordnet with D3.js". Letzter Zugriff am 15. Juni 2020.
[9] Singh, Push, Thomas Lin, Erik T. Mueller, Grace Lim, Travell Perkins, und Wan Li Zhu. "Open Mind Common Sense: Knowledge Acquisition from the General Public," Meersman R. und Tari Z. (Hrsg.), On the Move to Meaningful Internet Systems 2002: CoopIS, DOA, und ODBASE. OTM 2002. Vorlesungsberichte in Informatik, Band 2519. Berlin, Heidelberg: Springer.
[10] Die Stanford Natural Language Processing Group. Stanford TokensRegex, (Software). Letzter Zugriff am 15. Juni 2020.
[11] Hewitt, Luke. Probabilistische reguläre Ausdrücke, (GitHub Repo).
[12] Earley, Jay. "An Efficient Context-Free Parsing Algorithm". Communications of the ACM 13.2 (1970): 94-102.
[13] "Java Annotation Patterns Engine: Reguläre Ausdrücke über Annotationen". Developing Language Processing Components with GATE Version 9 (a User Guide), Kapitel 8. Letzter Zugriff am 15. Juni 2020.
[14] Allgemeine Architektur für Text Engineering (GATE). Letzter Zugriff am 15. Juni 2020.
[15] Rosier, Arnaud, Anita Burgun, und Philippe Mabo. "Mit regulären Ausdrücken Informationen über Herzschrittmacher-Implantationen aus klinischen Berichten extrahieren". AMIA Annual Symposium Proceedings v.2008 (2008): 81-85.
[16] Zhang, Haiyi und Di Li. "Naïve Bayes Text Classifier". 2007 IEEE International Conference on Granular Computing (GRC 2007): 708.
[17] Joachims, Thorsten. Learning to Classify Text Using Support Vector Machines, Vol. 668. New York: Springer Science & Business Media, 2002. ISBN: 978-1-4615-0907-3
[18] Baum, Leonard E. und Ted Petrie. "Statistische Inferenz für probabilistische Funktionen von endlichen Markov-Ketten". The Annals of Mathematical Statistics 37.6 (1966): 1554-1563.
[19] Jurafsky, Dan und James H. Martin. Speech and Language Processing, Third Edition (Draft), 2018.
[20] Settles, Burr. "Biomedical Named Entity Recognition Using Conditional Random Fields and Rich Feature Sets". Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP) (2004): 107-110.
[21] Bishop, Christopher M. Pattern Recognition and Machine Learning. New York: Springer, 2006. ISBN: 978-0-3873-1073-2
[22] Géron, Aurélien. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Boston: O'Reilly, 2019. ISBN: 978-1-492-03264-9
[23] Olah, Christopher. "LSTM-Netzwerke verstehen". 27. August 2015.
[24] Karpathy, Andrej. "Die unvernünftige Effektivität rekurrenter neuronaler Netze". 21. Mai 2015.
[25] Goldberg, Yoav. "Neural Network Methods for Natural Language Processing". Synthesis Lectures on Human Language Technologies 10.1 (2017): 1-309.
[26] Britz, Denny. "Convolutional Neural Networks für NLP verstehen". November 7, 2015.
[27] Le, Hoa T., Christophe Cerisara, und Alexandre Denis. "Do Convolutional Networks need to be Deep for Text Classification?" Workshops auf der Zweiunddreißigsten AAAI-Konferenz über Künstliche Intelligenz, 2018.
[28] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, und Illia Polosukhin. "Attention Is All You Need". Advances in Neural Information Processing Systems, 2017: 5998-6008.
[29] Devlin, Jacob, Ming-Wei Chang, Kenton Lee, und Kristina Toutanova. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding". October 11, 2018.
[30] Alammar, Jay. "Der illustrierte Transformator". 27. Juni 2018.
[31] Goodfellow, Ian, Yoshua Bengio, und Aaron Courville. Deep Learning. Cambridge: MIT Press, 2016. ISBN: 978-0-262-03561-3
[32] Varma, Nakul. COMS 4771: Einführung in maschinelles Lernen, Vorlesung 6, Folie 7. Letzter Zugriff am 15. Juni 2020.
[33] Wang, Yaqing, Quanming Yao, James Kwok, und Lionel M. Ni. "Generalizing from a Few Examples: A Survey on Few-Shot Learning",(2019).
[34] Wang, Zhengwei, Qi She, und Tomas E. Ward. "Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy",(2019).
[35] Olah, Chris, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, und Alexander Mordvintsev. "The Building Blocks of Interpretability" (Die Bausteine der Interpretierbarkeit). Distill 3.3 (März 2018): e10.
[36] Nan, Kaiming, Sicong Liu, Junzhao Du, und Hui Liu. "Deep Model Compression for Mobile Platforms: A Survey." Tsinghua Science and Technology 24.6 (2019): 677-693.
[37] TensorFlow. "Erste Schritte mit TensorFlow Lite". Zuletzt geändert am 21. März 2020.
[38] Ganesh, Prakhar, Yao Chen, Xin Lou, Mohammad Ali Khan, Yin Yang, Deming Chen, Marianne Winslett, Hassan Sajjad, und Preslav Nakov. "Komprimierung großer transformatorbasierter Modelle: A Case Study on BERT",(2020).
[39] Lipton, Zachary C. und Jacob Steinhardt. "Troubling Trends in Machine Learning Scholarship",(2018).
Get Praktische natürliche Sprachverarbeitung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

