Kapitel 4. Text-Klassifizierung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Organisieren ist das, was du tust, bevor du etwas tust,
damit nicht alles durcheinander ist, wenn du es tust.A.A. Milne
Alle von uns checken jeden Tag ihre E-Mails, vielleicht sogar mehrmals. Eine nützliche Funktion der meisten E-Mail-Anbieter ist die Möglichkeit, Spam-E-Mails automatisch von normalen E-Mails zu trennen. Dies ist ein Anwendungsfall einer beliebten NLP-Aufgabe, die als Textklassifizierung bekannt ist und um die es in diesem Kapitel geht. Bei der Textklassifizierung geht es darum, einem bestimmten Text eine oder mehrere Kategorien aus einer größeren Menge möglicher Kategorien zuzuordnen. Im Beispiel des E-Mail-Spam-Erkenners gibt es zwei Kategorien - Spam und Nicht-Spam - und jede eingehende E-Mail wird einer dieser Kategorien zugeordnet. Die Aufgabe, Texte anhand bestimmter Eigenschaften zu kategorisieren, findet in vielen verschiedenen Bereichen Anwendung, z. B. in den sozialen Medien, im E-Commerce, im Gesundheitswesen, im Recht und im Marketing, um nur einige zu nennen. Auch wenn sich der Zweck und die Anwendung der Textklassifizierung von Bereich zu Bereich unterscheiden können, bleibt das zugrunde liegende abstrakte Problem dasselbe. Diese Unveränderlichkeit des Kernproblems und seine Anwendungen in unzähligen Bereichen machen die Textklassifizierung zur mit Abstand am häufigsten verwendeten NLP-Aufgabe in der Industrie und zur am meisten erforschten in der Wissenschaft. In diesem Kapitel erörtern wir den Nutzen der Textklassifikation und wie wir Textklassifikatoren für unsere Anwendungsfälle erstellen. Außerdem geben wir einige praktische Tipps für reale Szenarien.
Beim maschinellen Lernen ist die Klassifizierung das Problem, einen Datenpunkt in eine oder mehrere bekannte Klassen zu kategorisieren. Die Daten können in verschiedenen Formaten vorliegen, z. B. als Text, Sprache, Bild oder numerisch. Die Textklassifizierung ist ein spezieller Fall des Klassifizierungsproblems, bei dem es sich bei den Eingabedaten um Text handelt und das Ziel darin besteht, den Text in einen oder mehrere Bereiche (eine sogenannte Klasse) aus einer Reihe von vordefinierten Bereichen (Klassen) einzuordnen. Der "Text" kann eine beliebige Länge haben: ein Zeichen, ein Wort, ein Satz, ein Absatz oder ein ganzes Dokument. Nehmen wir an, wir wollen alle Kundenrezensionen für ein Produkt in drei Kategorien einteilen: positiv, negativ und neutral. Die Herausforderung bei der Textklassifizierung besteht darin, diese Einteilung aus einer Sammlung von Beispielen für jede dieser Kategorien zu "lernen" und die Kategorien für neue, noch nicht gesehene Produkte und neue Kundenrezensionen vorherzusagen. Diese Kategorisierung muss aber nicht immer zu einer einzigen Kategorie führen, sondern es kann eine beliebige Anzahl von Kategorien geben. Um das zu verstehen, werfen wir einen kurzen Blick auf die Taxonomie der Textklassifizierung.
Jeder überwachte Klassifizierungsansatz, einschließlich der Textklassifizierung, kann anhand der Anzahl der beteiligten Kategorien in drei Typen unterschieden werden: binäre, Multiklassen- und Multilabel-Klassifizierung. Wenn die Anzahl der Klassen zwei beträgt, spricht man von einer binären Klassifizierung. Beträgt die Anzahl der Klassen mehr als zwei, spricht man von einer Multiklassenklassifizierung. Die Einstufung einer E-Mail als Spam oder Nicht-Spam ist also ein Beispiel für eine binäre Klassifizierung. Die Einstufung der Stimmung einer Kundenrezension als negativ, neutral oder positiv ist ein Beispiel für eine Mehrklassen-Klassifizierung. Sowohl bei der binären als auch bei der Multiklassen-Klassifizierung gehört jedes Dokument zu genau einer Klasse aus C, wobei C die Menge aller möglichen Klassen ist. Bei der Multilabel-Klassifizierung kann ein Dokument mit einem oder mehreren Labels/Klassen versehen werden. Ein Nachrichtenartikel über ein Fußballspiel kann zum Beispiel gleichzeitig zu mehr als einer Kategorie gehören, wie "Sport" und "Fußball", während ein anderer Nachrichtenartikel über die US-Wahlen die Labels "Politik", "USA" und "Wahlen" haben kann. Jedes Dokument hat also Labels, die eine Teilmenge von C sind. Jeder Artikel kann keiner Klasse, genau einer Klasse, mehreren Klassen oder allen Klassen angehören. Manchmal kann die Anzahl der Labels in der Menge C sehr groß sein (bekannt als "extreme Klassifizierung"). In anderen Szenarien haben wir vielleicht ein hierarchisches Klassifizierungssystem, das dazu führt, dass jeder Text auf verschiedenen Ebenen der Hierarchie unterschiedliche Bezeichnungen erhält. In diesem Kapitel konzentrieren wir uns nur auf die binäre und die Mehrklassen-Klassifikation, da dies die häufigsten Anwendungsfälle der Textklassifikation in der Industrie sind.
Textklassifizierung wird manchmal auch als Themenklassifizierung, Textkategorisierung oder Dokumentenkategorisierung bezeichnet. Im weiteren Verlauf dieses Buches werden wir uns auf den Begriff "Textklassifizierung" beschränken. Beachte, dass sich die Themenklassifizierung von der Themenerkennung unterscheidet, die sich auf das Problem der Aufdeckung oder Extraktion von "Themen" aus Texten bezieht und mit der wir uns in Kapitel 7 beschäftigen werden.
In diesem Kapitel werden wir uns die Textklassifizierung genauer ansehen und Textklassifikatoren mit verschiedenen Ansätzen erstellen. Unser Ziel ist es, einen Überblick über einige der am häufigsten verwendeten Techniken zu geben und praktische Ratschläge zum Umgang mit verschiedenen Szenarien und Entscheidungen zu geben, die beim Aufbau von Textklassifizierungssystemen in der Praxis getroffen werden müssen. Wir beginnen mit einer Einführung in einige gängige Anwendungen der Textklassifizierung, erörtern dann, wie eine NLP-Pipeline für die Textklassifizierung aussieht und veranschaulichen die Verwendung dieser Pipeline zum Trainieren und Testen von Textklassifizierern mit verschiedenen Ansätzen, von traditionellen Methoden bis hin zum neuesten Stand der Technik. Anschließend werden wir uns mit dem Problem der Sammlung von Trainingsdaten und den verschiedenen Methoden zur Bewältigung dieses Problems befassen. Am Ende des Kapitels fassen wir zusammen, was wir in all diesen Abschnitten gelernt haben, und geben einige praktische Ratschläge und eine Fallstudie.
Beachte, dass wir uns in diesem Kapitel nur mit dem Training und der Auswertung der Textklassifikatoren befassen werden. Fragen, die mit dem Einsatz von NLP-Systemen im Allgemeinen und der Qualitätssicherung zusammenhängen, werden in Kapitel 11 behandelt.
Anwendungen
Die Klassifizierung von Texten ist in einer Reihe von Anwendungsszenarien von Interesse, von der Identifizierung des Autors eines unbekannten Textes in den 1800er Jahren bis hin zu den Bemühungen des USPS in den 1960er Jahren, eine optische Zeichenerkennung für Adressen und Postleitzahlen durchzuführen [1]. In den 1990er Jahren begannen Forscher, ML-Algorithmen zur Textklassifizierung für große Datensätze erfolgreich anzuwenden. Die E-Mail-Filterung, im Volksmund als "Spam-Klassifizierung" bekannt, ist eines der ersten Beispiele für automatische Textklassifizierung, die unser Leben bis heute beeinflusst. Von der manuellen Analyse von Textdokumenten bis hin zu rein statistischen, computergestützten Ansätzen und hochmodernen tiefen neuronalen Netzen haben wir bei der Textklassifizierung einen langen Weg zurückgelegt. Bevor wir uns mit den verschiedenen Ansätzen zur Textklassifizierung beschäftigen, wollen wir kurz auf einige beliebte Anwendungen eingehen. Diese Beispiele werden dir auch dabei helfen, Probleme zu identifizieren, die mit Textklassifizierungsmethoden in deinem Unternehmen gelöst werden können.
- Klassifizierung und Organisation des Inhalts
Damit ist die Aufgabe gemeint, große Mengen von Textdaten zu klassifizieren/zu verschlagworten. Dies wiederum wird für Anwendungsfälle wie die Organisation von Inhalten, Suchmaschinen und Empfehlungssysteme genutzt, um nur einige zu nennen. Beispiele für solche Daten sind Nachrichten-Websites, Blogs, Online-Bücherregale, Produktrezensionen, Tweets usw.; die Verschlagwortung von Produktbeschreibungen auf einer E-Commerce-Website, die Weiterleitung von Kundendienstanfragen in einem Unternehmen an das zuständige Support-Team und die Einteilung von E-Mails in persönliche, soziale und Werbe-E-Mails in Google Mail sind alles Beispiele für die Verwendung von Textklassifizierung zur Klassifizierung und Organisation von Inhalten.
- Kundenbetreuung
Kunden nutzen häufig soziale Medien, um ihre Meinung über Produkte oder Dienstleistungen und ihre Erfahrungen damit zu äußern. Die Textklassifizierung wird häufig verwendet, um die Tweets zu identifizieren, auf die Marken reagieren müssen (d. h. die, die eine Reaktion erfordern), und die, die keine Reaktion erfordern (d. h. das Rauschen) [2, 3]. Betrachten wir zur Veranschaulichung die drei Tweets über die Marke Macy's in Abbildung 4-1.
Obwohl alle drei Tweets die Marke Macy's explizit erwähnen, erfordert nur der erste eine Antwort des Macy's-Kundendienstes.
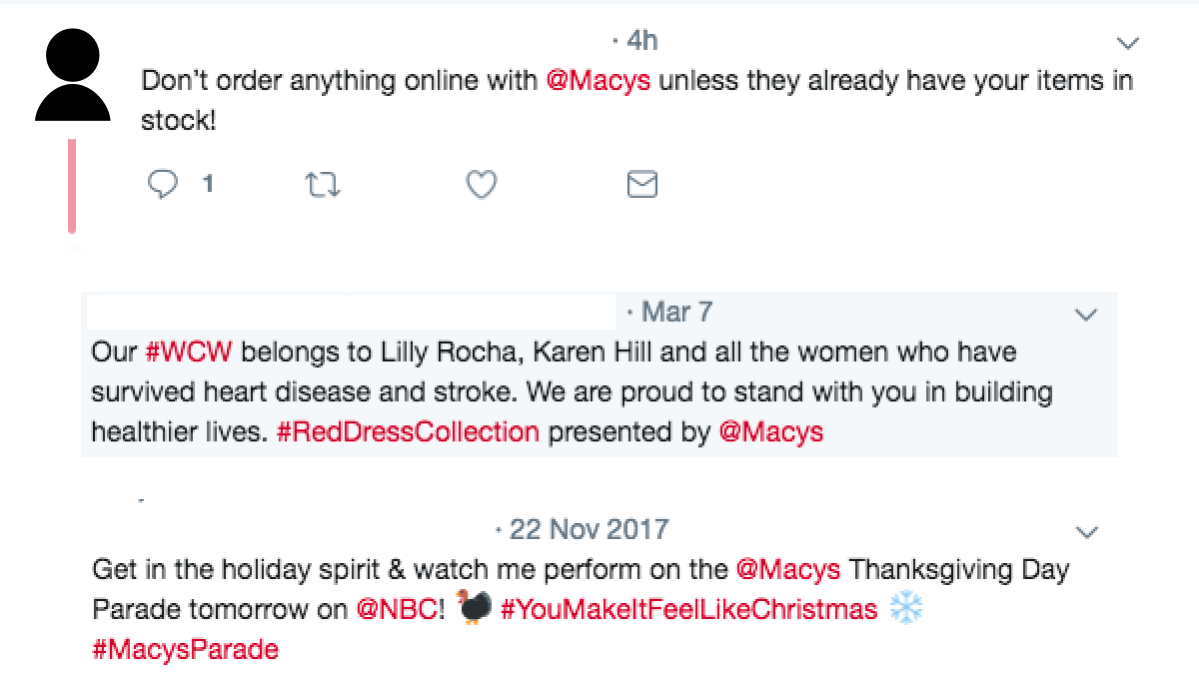
Abbildung 4-1. Tweets, die sich an Marken wenden: einer ist verwertbar, die anderen beiden sind nur Lärm
- E-Commerce
Kunden hinterlassen Bewertungen für eine Reihe von Produkten auf E-Commerce-Websites wie Amazon, eBay, etc. Ein Beispiel für die Anwendung der Textklassifizierung in einem solchen Szenario ist das Verstehen und Analysieren der Kundenwahrnehmung eines Produkts oder einer Dienstleistung auf der Grundlage ihrer Kommentare. Dies ist allgemein als "Stimmungsanalyse" bekannt. Sie wird von Marken auf der ganzen Welt eingesetzt, um besser zu verstehen, ob sie sich ihren Kunden annähern oder von ihnen entfernen. Anstatt das Kundenfeedback einfach nur als positiv, negativ oder neutral zu kategorisieren, hat sich die Stimmungsanalyse zu einem anspruchsvolleren Paradigma entwickelt: der "aspektbasierten Stimmungsanalyse. Um dies zu verstehen, betrachte die in Abbildung 4-2 dargestellte Kundenbewertung eines Restaurants.
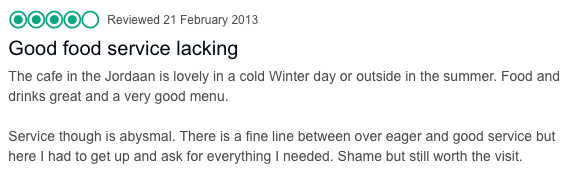
Abbildung 4-2. Eine Überprüfung, die einige Aspekte lobt und wenige kritisiert
Würdest du die Bewertung in Abbildung 4-2 als negativ, positiv oder neutral bezeichnen? Es ist schwierig, diese Frage zu beantworten - das Essen war großartig, aber der Service war schlecht. Praktiker und Marken, die mit Stimmungsanalysen arbeiten, haben erkannt, dass viele Produkte oder Dienstleistungen mehrere Facetten haben. Um die allgemeine Stimmung zu verstehen, ist es wichtig, jede einzelne Facette zu kennen. Die Textklassifizierung spielt eine wichtige Rolle bei der Durchführung einer solchen feinkörnigen Analyse des Kundenfeedbacks. Wir werden diese spezielle Anwendung in Kapitel 9 im Detail besprechen.
- Andere Anwendungen
Abgesehen von den oben genannten Bereichen wird die Textklassifizierung auch in zahlreichen anderen Anwendungen in verschiedenen Domänen eingesetzt:
-
Die Textklassifizierung wird in der Spracherkennung verwendet, um z. B. die Sprache neuer Tweets oder Posts zu identifizieren. Google Translate hat zum Beispiel eine automatische Spracherkennung.
-
Ein weiterer beliebter Anwendungsfall für die Textklassifizierung ist die Autorenzuordnung, d. h. die Identifizierung der unbekannten Autoren von Texten aus einem Pool von Autoren, die in vielen Bereichen von der forensischen Analyse bis zur Literaturwissenschaft eingesetzt wird.
-
Die Textklassifizierung wurde in der jüngeren Vergangenheit für die Einstufung von Beiträgen in einem Online-Unterstützungsforum für psychosoziale Dienste verwendet [4]. In der NLP-Community werden jährlich Wettbewerbe (z. B. clpsych.org) zur Lösung solcher Textklassifikationsprobleme aus der klinischen Forschung durchgeführt.
-
In der jüngeren Vergangenheit wurde auch die Textklassifizierung eingesetzt, um Fake News von echten Nachrichten zu unterscheiden.
-
Wir hoffen aber, dass du damit genug Hintergrundwissen hast, um Probleme bei der Textklassifizierung in deinen Arbeitsprojekten zu erkennen, wenn du auf sie stößt. Sehen wir uns nun an, wie man solche Textklassifizierungsmodelle erstellt.
Eine Pipeline für den Aufbau von Textklassifizierungssystemen
In Kapitel 2 haben wir einige der gängigen NLP-Pipelines besprochen. Die Textklassifizierungs-Pipeline teilt einige ihrer Schritte mit den Pipelines, die wir in diesem Kapitel kennengelernt haben.
Beim Aufbau eines Textklassifizierungssystems werden normalerweise folgende Schritte durchgeführt:
-
Sammle oder erstelle einen beschrifteten Datensatz, der für die Aufgabe geeignet ist.
-
Teile den Datensatz in zwei (Training und Test) oder drei Teile auf: Trainings-, Validierungs- (d.h. Entwicklungs-) und Testdatensätze und entscheide dann über die Bewertungsmetrik(en).
-
Wandle Rohtext in Merkmalsvektoren um.
-
Trainiere einen Klassifikator mit den Merkmalsvektoren und den entsprechenden Bezeichnungen aus der Trainingsmenge.
-
Verwende die Bewertungsmetrik(en) aus Schritt 2, um die Leistung des Modells in der Testmenge zu bewerten.
-
Setze das Modell für den realen Anwendungsfall ein und überwache seine Leistung.
Abbildung 4-3 zeigt diese typischen Schritte beim Aufbau eines Textklassifikationssystems.
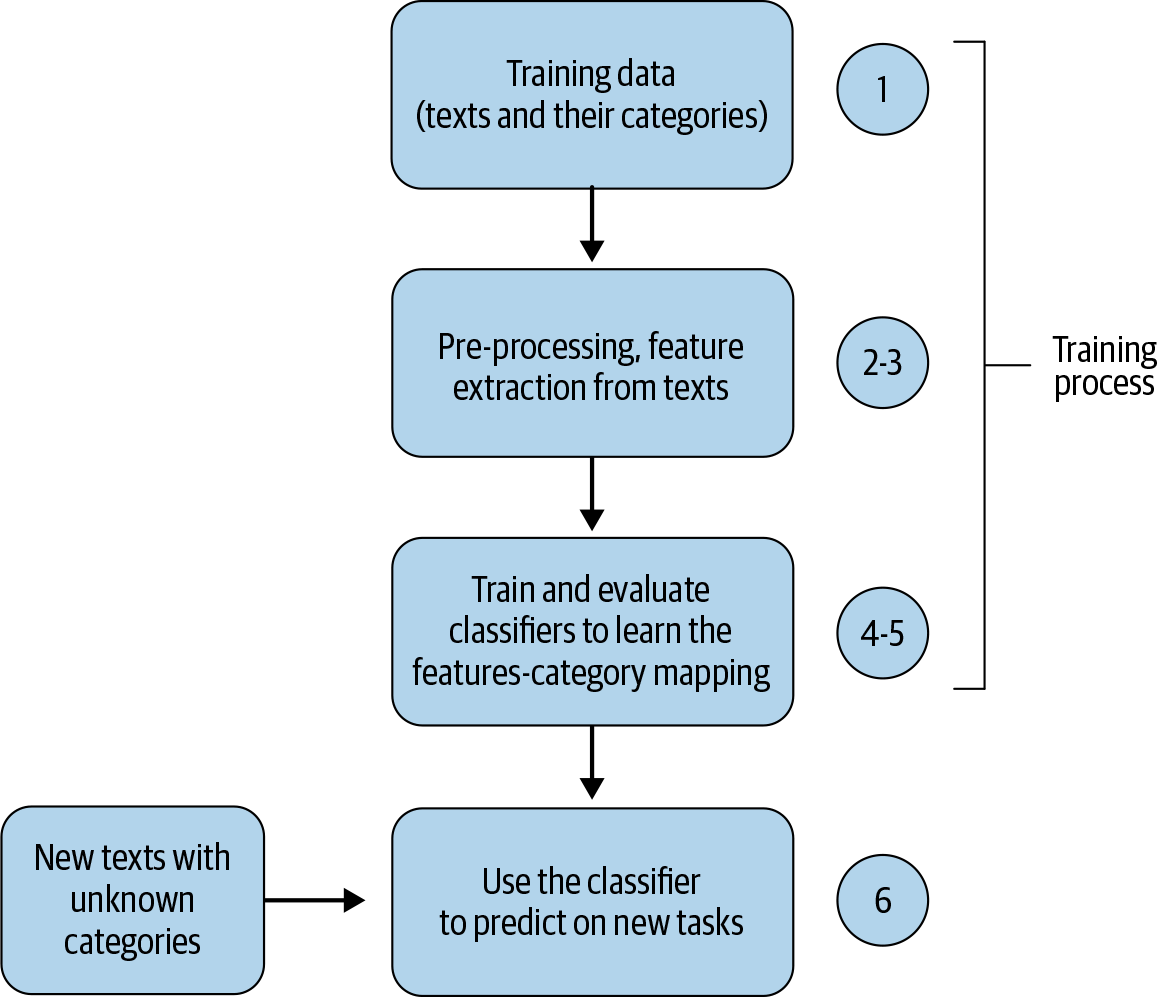
Abbildung 4-3. Flussdiagramm einer Pipeline zur Textklassifizierung
Die Schritte 3 bis 5 werden iteriert, um verschiedene Varianten von Merkmalen und Klassifizierungsalgorithmen und deren Parameter zu untersuchen und die Hyperparameter abzustimmen, bevor mit Schritt 6, dem Einsatz des optimalen Modells in der Produktion, fortgefahren wird.
Einige der einzelnen Schritte im Zusammenhang mit der Datenerhebung und -vorverarbeitung wurden bereits in früheren Kapiteln behandelt. So wurden zum Beispiel die Schritte 1 und 2 in Kapitel 2 ausführlich besprochen. Kapitel 3 konzentrierte sich ganz auf Schritt 3. In diesem Kapitel konzentrieren wir uns auf die Schritte 4 bis 5. Gegen Ende des Kapitels werden wir uns noch einmal mit Schritt 1 befassen, um spezielle Fragen der Textklassifizierung zu besprechen. Mit Schritt 6 befassen wir uns in Kapitel 11. Um die Schritte 4 bis 5 durchführen zu können (d. h. um die Leistung eines Modells zu bewerten oder mehrere Klassifikatoren zu vergleichen), brauchen wir die richtige(n) Bewertungsmaßstab(e). In Kapitel 2 wurden verschiedene allgemeine Maßstäbe für die Bewertung von NLP-Systemen vorgestellt. Für die Bewertung von Klassifizierern werden von den in Kapitel 2 vorgestellten Metriken vor allem die folgenden verwendet: Klassifizierungsgenauigkeit, Präzision, Recall, F1-Score und Fläche unter der ROC-Kurve. In diesem Kapitel werden wir einige dieser Kennzahlen verwenden, um unsere Modelle zu bewerten, und uns außerdem Konfusionsmatrizen ansehen, um die Leistung der Modelle im Detail zu verstehen.
Wenn Klassifizierungssysteme in der Praxis eingesetzt werden, werden außerdem Leistungskennzahlen (Key Performance Indicators, KPIs) für einen bestimmten Anwendungsfall verwendet, um die Auswirkungen und die Investitionsrendite (ROI) zu bewerten. Dies sind oft die Kennzahlen, die für die Unternehmen von Bedeutung sind. Wenn wir z. B. die Textklassifizierung nutzen, um Kundendienstanfragen automatisch weiterzuleiten, könnte ein möglicher KPI die Verkürzung der Wartezeit bis zur Beantwortung der Anfrage im Vergleich zur manuellen Weiterleitung sein. In diesem Kapitel konzentrieren wir uns auf die NLP-Evaluierungsmaßnahmen. In Teil III des Buches, in dem wir NLP-Anwendungsfälle in bestimmten Branchen besprechen, werden wir einige KPIs vorstellen, die in diesen Branchen häufig verwendet werden.
Bevor wir uns ansehen, wie man mit der eben besprochenen Pipeline Textklassifikatoren erstellt, werfen wir einen Blick auf die Szenarien, in denen diese Pipeline überhaupt nicht notwendig ist oder in denen es nicht möglich ist, sie zu verwenden.
Ein einfacher Klassifikator ohne die Pipeline zur Textklassifizierung
Wenn wir über die Textklassifizierungs-Pipeline sprechen, beziehen wir uns auf ein überwachtes maschinelles Lernszenario. Es ist jedoch auch möglich, einen einfachen Klassifikator ohne maschinelles Lernen und ohne diese Pipeline zu erstellen. Betrachten wir das folgende Problemszenario: Wir haben einen Korpus von Tweets, in dem jeder Tweet mit der entsprechenden Stimmung gekennzeichnet ist: negativ oder positiv. Ein Tweet mit der Aussage "Der neue James-Bond-Film ist großartig!" drückt eindeutig eine positive Stimmung aus, während ein Tweet mit der Aussage "Ich würde nie wieder in dieses Restaurant gehen, ein schrecklicher Ort" eine negative Stimmung ausdrückt. Wir wollen ein Klassifizierungssystem entwickeln, das die Stimmung eines ungesehenen Tweets nur anhand des Textes vorhersagen kann. Eine einfache Lösung könnte darin bestehen, Listen mit positiven und negativen Wörtern im Englischen zu erstellen, d. h. Wörter, die eine positive oder negative Stimmung haben. Wir vergleichen dann die Verwendung positiver und negativer Wörter im eingegebenen Tweet und treffen auf der Grundlage dieser Informationen eine Vorhersage. Weitere Verbesserungen dieses Ansatzes können darin bestehen, anspruchsvollere Wörterbücher mit dem Grad der positiven, negativen und neutralen Stimmung von Wörtern zu erstellen oder spezielle Heuristiken zu formulieren (z. B. die Verwendung bestimmter Smileys weist auf eine positive Stimmung hin) und diese für Vorhersagen zu nutzen. Dieser Ansatz wird als lexikonbasierte Stimmungsanalyse bezeichnet.
Dies beinhaltet natürlich kein "Lernen" der Textklassifizierung, d.h. es basiert auf einer Reihe von Heuristiken oder Regeln und speziell angefertigten Ressourcen wie Wörterbüchern mit Stimmungen. Auch wenn dieser Ansatz zu einfach erscheint, um für viele reale Szenarien gut geeignet zu sein, können wir damit schnell ein Minimum Viable Product (MVP) entwickeln. Vor allem aber kann dieses einfache Modell zu einem besseren Verständnis des Problems führen und uns eine einfache Grundlage für unsere Bewertungsmetrik und Geschwindigkeit liefern. Unserer Erfahrung nach ist es immer gut, mit solchen einfacheren Ansätzen zu beginnen, wenn wir ein neues NLP-Problem angehen, sofern möglich. Irgendwann brauchen wir jedoch ML-Methoden, die mehr Erkenntnisse aus großen Sammlungen von Textdaten ableiten können und besser sind als der Basisansatz.
Vorhandene APIs zur Textklassifizierung nutzen
Ein weiteres Szenario, in dem wir keinen Klassifikator "lernen" oder dieser Pipeline folgen müssen, ist, wenn unsere Aufgabe eher allgemeiner Natur ist, wie z. B. das Erkennen einer allgemeinen Kategorie eines Textes (z. B. ob es um Technik oder Musik geht). In solchen Fällen können wir bestehende APIs nutzen, wie z. B. Google Cloud Natural Language [5], die fertige Modelle zur Klassifizierung von Inhalten bereitstellen, mit denen fast 700 verschiedene Textkategorien erkannt werden können. Eine weitere beliebte Klassifizierungsaufgabe ist die Stimmungsanalyse. Alle großen Anbieter (z. B. Google, Microsoft und Amazon) bieten APIs zur Stimmungsanalyse [5, 6, 7] mit unterschiedlichen Bezahlstrukturen an. Wenn wir einen Sentiment-Klassifikator entwickeln sollen, müssen wir nicht unbedingt ein eigenes System entwickeln, wenn eine bestehende API unsere Anforderungen erfüllt.
Viele Klassifizierungsaufgaben könnten jedoch spezifisch für die geschäftlichen Anforderungen unserer Organisation sein. Im weiteren Verlauf dieses Kapitels befassen wir uns mit dem Szenario, einen eigenen Klassifikator zu erstellen, indem wir die oben beschriebene Pipeline betrachten.
Eine Pipeline, viele Klassifikatoren
Schauen wir uns nun die Erstellung von Textklassifikatoren an, indem wir die Schritte 3 bis 5 der Pipeline ändern und die übrigen Schritte konstant lassen. Ein guter Datensatz ist die Voraussetzung für die Nutzung der Pipeline. Wenn wir von einem "guten" Datensatz sprechen, meinen wir damit einen Datensatz, der die Daten repräsentiert, die wir in der Produktion wahrscheinlich sehen werden. In diesem Kapitel werden wir einige öffentlich verfügbare Datensätze für die Textklassifizierung verwenden. Eine große Auswahl an NLP-bezogenen Datensätzen, darunter auch solche für die Textklassifizierung, sind online aufgelistet [8]. Außerdem enthält Figure Eight [9] eine Sammlung von Crowdsourced-Datensätzen, von denen einige für die Textklassifizierung relevant sind. Das UCI Machine Learning Repository [10] enthält ebenfalls einige Datensätze zur Textklassifizierung. Google hat kürzlich ein spezielles Suchsystem für Datensätze zum maschinellen Lernen eingeführt [11]. Wir werden in diesem Kapitel mehrere Datensätze verwenden, anstatt uns auf einen zu beschränken, um datensatzspezifische Probleme zu veranschaulichen, auf die du stoßen könntest.
Unser Ziel in diesem Kapitel ist es, dir einen Überblick über die verschiedenen Ansätze zu geben. Es ist nicht bekannt, dass ein einzelner Ansatz bei allen Arten von Daten und allen Klassifizierungsproblemen universell gut funktioniert. In der Praxis experimentieren wir mit mehreren Ansätzen, bewerten sie und wählen schließlich einen Ansatz aus, den wir in der Praxis einsetzen.
Im weiteren Verlauf dieses Abschnitts verwenden wir den Datensatz "Economic News Article Tone and Relevance" aus Abbildung 8, um die Textklassifizierung zu demonstrieren. Er besteht aus 8.000 Nachrichtenartikeln, die mit der Angabe versehen sind, ob sie für die US-Wirtschaft relevant sind oder nicht (d. h. eine binäre Ja/Nein-Klassifizierung). Der Datensatz ist außerdem unausgewogen: ~1.500 relevante und ~6.500 nicht relevante Artikel, was die Herausforderung mit sich bringt, eine Voreingenommenheit gegenüber der Mehrheitskategorie (in diesem Fall nicht relevante Artikel) zu vermeiden. Bei diesem Datensatz ist es eindeutig schwieriger zu lernen, was ein relevanter Nachrichtenartikel ist, als zu lernen, was irrelevant ist. Wenn wir davon ausgehen, dass alles irrelevant ist, erreichen wir bereits eine Genauigkeit von 80 %!
Wir wollen nun untersuchen, wie eine BoW-Darstellung (eingeführt in Kapitel 3) mit diesem Datensatz verwendet werden kann, indem wir die zuvor in diesem Kapitel beschriebene Pipeline verwenden. Wir werden Klassifikatoren mit drei bekannten Algorithmen erstellen: Naive Bayes, logistische Regression und Support-Vektor-Maschinen. Das Notebook zu diesem Abschnitt(Ch4/OnePipeline_ManyClassifiers.ipynb) zeigt den schrittweisen Ablauf unserer Pipeline mit diesen drei Algorithmen. In diesem Abschnitt werden wir einige der wichtigsten Aspekte besprechen.
Naive Bayes Klassifikator
Naive Bayes ist ein probabilistischer Klassifikator, der das Bayes-Theorem verwendet, um Texte auf der Grundlage der Evidenz in den Trainingsdaten zu klassifizieren. Er schätzt die bedingte Wahrscheinlichkeit jedes Merkmals eines bestimmten Textes für jede Klasse auf der Grundlage des Auftretens des Merkmals in dieser Klasse und multipliziert die Wahrscheinlichkeiten aller Merkmale eines bestimmten Textes, um die endgültige Klassifizierungswahrscheinlichkeit für jede Klasse zu berechnen. Schließlich wird die Klasse mit der höchsten Wahrscheinlichkeit ausgewählt. Eine detaillierte Schritt-für-Schritt-Erklärung des Klassifikators würde den Rahmen dieses Buches sprengen. Wer sich jedoch für Naive Bayes interessiert und eine ausführliche Erklärung im Zusammenhang mit der Klassifizierung von Texten sucht, kann sich das Kapitel 4 von Jurafsky und Martin [12] ansehen. Obwohl er einfach ist, wird Naive Bayes häufig als Basisalgorithmus in Klassifizierungsexperimenten verwendet.
Gehen wir nun die wichtigsten Schritte einer Implementierung der oben beschriebenen Pipeline für unseren Datensatz durch. Dazu verwenden wir eine Naive Bayes-Implementierung in Scikit-Learn. Sobald der Datensatz geladen ist, teilen wir die Daten in Trainings- und Testdaten auf, wie im folgenden Codeschnipsel gezeigt:
#Step 1: train-test splitX=our_data.text#the column text contains textual data to extract features from.y=our_data.relevance#this is the column we are learning to predict.X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)#split X and y into training and testing sets. By default,itsplits75%#training and 25% test. random_state=1 for reproducibility.
Im nächsten Schritt werden die Texte vorverarbeitet und dann in Merkmalsvektoren umgewandelt. Es gibt viele verschiedene Möglichkeiten, die Vorverarbeitung vorzunehmen. Nehmen wir an, wir wollen Folgendes tun: Kleinschreibung und Entfernen von Satzzeichen, Ziffern und anderen benutzerdefinierten Zeichenfolgen sowie Stoppwörter. Der folgende Codeschnipsel zeigt diese Vorverarbeitung und die Umwandlung der Trainings- und Testdaten in Merkmalsvektoren mit CountVectorizer in scikit-learn, der Implementierung des BoW-Ansatzes, den wir in Kapitel 3 besprochen haben:
#Step 2-3: Pre-process and Vectorize train and test datavect=CountVectorizer(preprocessor=clean)#clean is a function we defined for pre-processing, seen in the notebook.X_train_dtm=vect.fit_transform(X_train)X_test_dtm=vect.transform(X_test)(X_train_dtm.shape,X_test_dtm.shape)
Wenn wir das im Notebook ausführen, werden wir sehen, dass wir einen Feature-Vektor mit über 45.000 Features erhalten haben! Jetzt haben wir die Daten in dem Format, das wir brauchen: Merkmalsvektoren. Der nächste Schritt besteht also darin, einen Klassifikator zu trainieren und auszuwerten. Der folgende Codeschnipsel zeigt, wie man einen Naive Bayes-Klassifikator mit den oben extrahierten Merkmalen trainiert und auswertet:
nb=MultinomialNB()#instantiate a Multinomial Naive Bayes classifiernb.fit(X_train_dtm,y_train)#train the modey_pred_class=nb.predict(X_test_dtm)#make class predictions for test data
Abbildung 4-4 zeigt die Konfusionsmatrix dieses Klassifikators mit Testdaten.
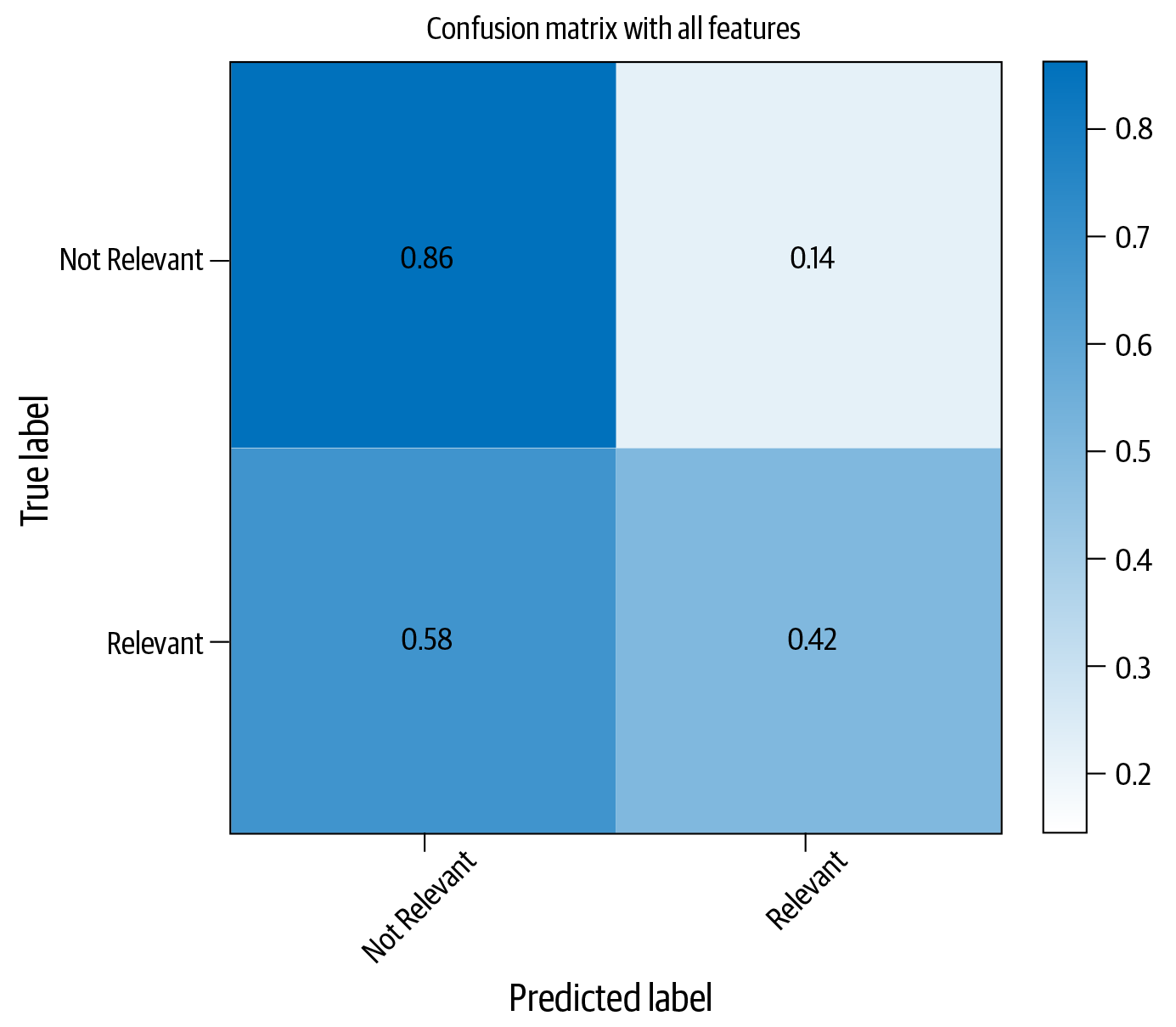
Abbildung 4-4. Konfusionsmatrix für Naive Bayes Klassifikator
Wie aus Abbildung 4-4 ersichtlich ist, schneidet der Klassifikator bei der Erkennung nicht relevanter Artikel recht gut ab und macht nur in 14 % der Fälle Fehler. Im Vergleich zur zweiten Kategorie, der Relevanz, schneidet er jedoch nicht so gut ab. Diese Kategorie wird nur in 42 % der Fälle richtig erkannt. Ein naheliegender Gedanke wäre, mehr Daten zu sammeln. Das ist richtig und oft der lohnendste Ansatz. Aber im Interesse der Abdeckung anderer Ansätze gehen wir davon aus, dass wir es nicht ändern oder zusätzliche Daten sammeln können. Diese Annahme ist nicht weit hergeholt - in der Industrie haben wir oft nicht den Luxus, mehr Daten zu sammeln; wir müssen mit dem arbeiten, was wir haben. Es gibt einige mögliche Gründe für diese Leistung und Möglichkeiten, diesen Klassifikator zu verbessern. Diese sind in Tabelle 4-1 zusammengefasst, und wir werden im weiteren Verlauf dieses Kapitels einige davon näher betrachten.
| Grund 1 | Da wir alle möglichen Merkmale extrahiert haben, haben wir einen großen, spärlichen Merkmalsvektor erhalten, bei dem die meisten Merkmale zu selten sind und als Rauschen enden. Eine spärliche Merkmalsmenge macht auch das Training schwierig. |
| Grund 2 | Es gibt nur sehr wenige Beispiele für relevante Artikel (~20%) im Vergleich zu den nicht relevanten Artikeln (~80%) im Datensatz. Dieses Klassenungleichgewicht führt dazu, dass der Lernprozess in Richtung der Kategorie der nicht relevanten Artikel verzerrt wird, da es nur sehr wenige Beispiele für "relevante" Artikel gibt. |
| Grund 3 | Vielleicht brauchen wir einen besseren Lernalgorithmus. |
| Grund 4 | Vielleicht brauchen wir einen besseren Mechanismus zur Vorverarbeitung und Merkmalsextraktion. |
| Grund 5 | Vielleicht sollten wir die Parameter und Hyperparameter des Klassifikators anpassen. |
Schauen wir uns an, wie wir unsere Klassifizierungsleistung verbessern können, indem wir einige der möglichen Gründe dafür angehen. Eine Möglichkeit, Grund 1 anzugehen, besteht darin, das Rauschen in den Merkmalsvektoren zu reduzieren. Der Ansatz im vorangegangenen Code-Beispiel hatte fast 40.000 Merkmale (Details findest du im Jupyter-Notebook). Eine große Anzahl von Merkmalen führt zu Sparsamkeit, d.h. die meisten Merkmale im Merkmalsvektor sind Null und nur wenige Werte sind ungleich Null. Dies wirkt sich wiederum auf die Lernfähigkeit des Algorithmus zur Textklassifizierung aus. Schauen wir uns an, was passiert, wenn wir die Anzahl der Merkmale auf 5.000 beschränken und den Trainings- und Bewertungsprozess wiederholen. Dazu müssen wir die CountVectorizer Instanziierung im Prozess ändern, wie im folgenden Codeschnipsel gezeigt, und alle Schritte wiederholen:
vect=CountVectorizer(preprocessor=clean,max_features=5000)#Step-1X_train_dtm=vect.fit_transform(X_train)#combined step 2 and 3X_test_dtm=vect.transform(X_test)nb=MultinomialNB()#instantiate a Multinomial Naive Bayes model%timenb.fit(X_train_dtm,y_train)#train the model(timing it with an IPython "magic command")y_pred_class=nb.predict(X_test_dtm)#make class predictions for X_test_dtm("Accuracy: ",metrics.accuracy_score(y_test,y_pred_class))
Abbildung 4-5 zeigt die neue Verwirrungsmatrix mit dieser Einstellung.
Während die durchschnittliche Leistung niedriger ist als zuvor, ist die korrekte Identifizierung relevanter Artikel um über 20 % gestiegen. An dieser Stelle könnte man sich fragen, ob das das ist, was wir wollen. Die Antwort auf diese Frage hängt von dem Problem ab, das wir zu lösen versuchen. Wenn es uns darum geht, bei der Identifizierung nicht relevanter Artikel einigermaßen gut abzuschneiden und bei der Identifizierung relevanter Artikel so gut wie möglich abzuschneiden oder bei beiden gleich gut abzuschneiden, könnten wir zu dem Schluss kommen, dass die Verringerung der Größe des Merkmalsvektors mit dem Naive Bayes-Klassifikator für diesen Datensatz sinnvoll war.
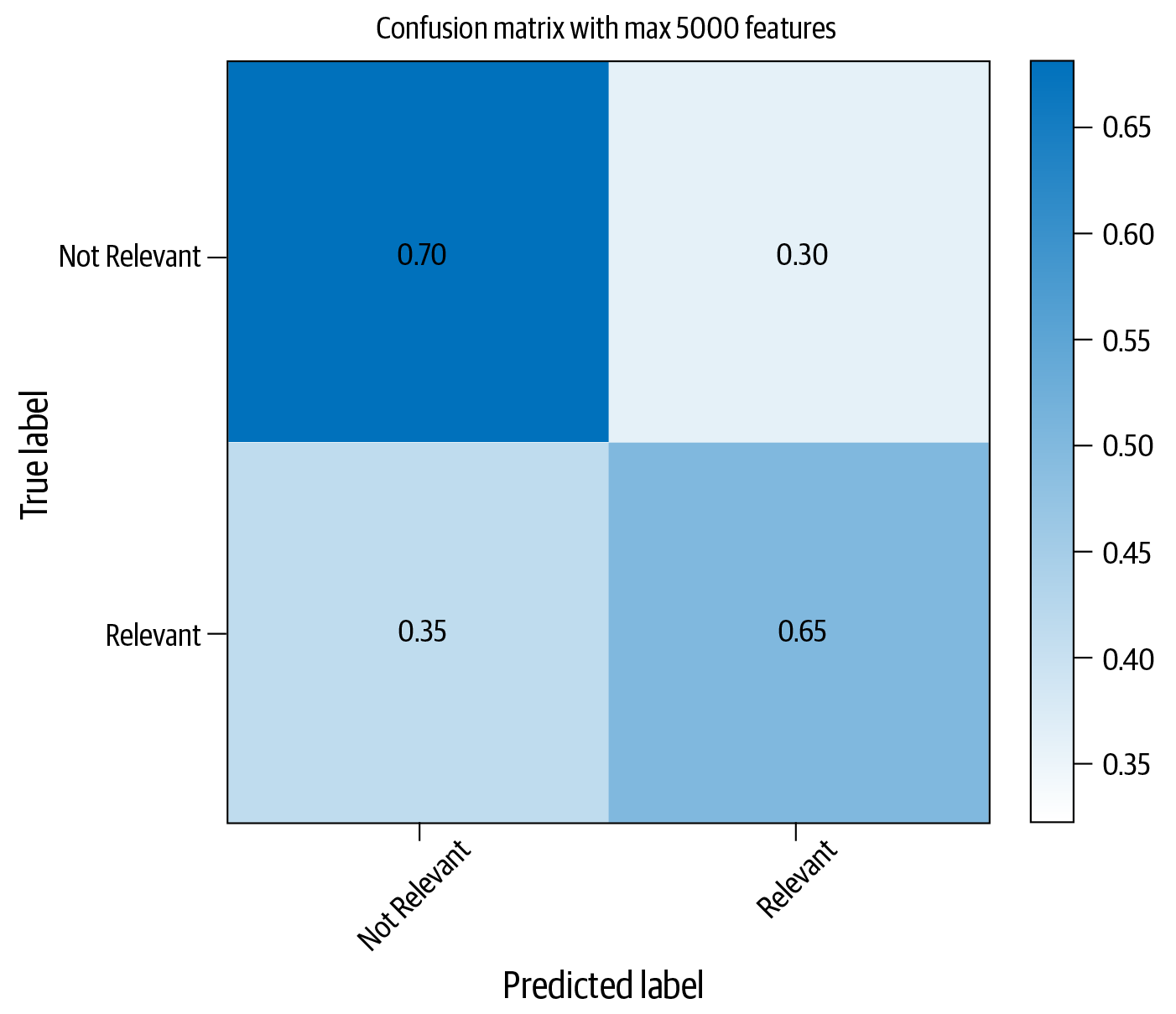
Abbildung 4-5. Verbesserte Klassifizierungsleistung mit Naive Bayes und Merkmalsauswahl
Tipp
Ziehe in Erwägung, die Anzahl der Merkmale zu reduzieren, wenn es zu viele sind, um die Spärlichkeit der Daten zu verringern.
Grund 2 auf unserer Liste war das Problem der Verzerrung der Daten zugunsten der Mehrheitsklasse. Es gibt verschiedene Möglichkeiten, dieses Problem zu lösen. Zwei typische Ansätze sind das Oversampling der Instanzen, die zu Minderheitsklassen gehören, oder das Undersampling der Mehrheitsklasse, um einen ausgewogenen Datensatz zu erstellen. Imbalanced-Learn [13] ist eine Python-Bibliothek, die einige der Sampling-Methoden nutzt, um dieses Problem zu lösen. Wir werden hier nicht auf die Details dieser Bibliothek eingehen, aber Klassifikatoren haben auch einen eingebauten Mechanismus, um solche unausgewogenen Datensätze zu behandeln. Im nächsten Unterkapitel werden wir sehen, wie man das mit einem anderen Klassifikator, der logistischen Regression, nutzen kann.
Tipp
Ein Ungleichgewicht zwischen den Klassen ist einer der häufigsten Gründe, warum ein Klassifikator nicht gut funktioniert. Wir müssen immer prüfen, ob dies bei unserer Aufgabe der Fall ist und dagegen vorgehen.
Um Grund 3 anzugehen, versuchen wir es mit anderen Algorithmen, angefangen mit der logistischen Regression.
Logistische Regression
Als wir den Naive Bayes-Klassifikator beschrieben haben, haben wir erwähnt, dass er die Wahrscheinlichkeit eines Textes für jede Klasse lernt und diejenige mit der höchsten Wahrscheinlichkeit auswählt. Ein solcher Klassifikator wird als generativer Klassifikator bezeichnet. Im Gegensatz dazu gibt es einen diskriminativen Klassifikator, der darauf abzielt, die Wahrscheinlichkeitsverteilung über alle Klassen zu lernen. Die logistische Regression ist ein Beispiel für einen diskriminativen Klassifikator und wird häufig für die Textklassifizierung, als Basis für die Forschung und als MVP in realen Industrieszenarien verwendet.
Im Gegensatz zu Naive Bayes, das Wahrscheinlichkeiten auf der Grundlage des Auftretens von Merkmalen in den Klassen schätzt, "lernt" die logistische Regression die Gewichte für einzelne Merkmale auf der Grundlage ihrer Wichtigkeit für eine Klassifizierungsentscheidung. Das Ziel der logistischen Regression ist es, eine lineare Trennung zwischen den Klassen in den Trainingsdaten zu lernen, um die Wahrscheinlichkeit der Daten zu maximieren. Dieses "Lernen" der Merkmalsgewichte und der Wahrscheinlichkeitsverteilung über alle Klassen erfolgt über eine Funktion, die "logistische" Funktion genannt wird, und (daher der Name) logistische Regression [14].
Nehmen wir den 5.000-dimensionalen Merkmalsvektor aus dem letzten Schritt des Naive-Bayes-Beispiels und trainieren wir einen logistischen Regressionsklassifikator anstelle von Naive Bayes. Der folgende Codeschnipsel zeigt, wie man die logistische Regression für diese Aufgabe verwendet:
fromsklearn.linear_modelimportLogisticRegressionlogreg=LogisticRegression(class_weight="balanced")logreg.fit(X_train_dtm,y_train)y_pred_class=logreg.predict(X_test_dtm)("Accuracy: ",metrics.accuracy_score(y_test,y_pred_class))
Das Ergebnis ist ein Klassifikator mit einer Genauigkeit von 73,7 %. Abbildung 4-6 zeigt die Konfusionsmatrix mit diesem Ansatz.
Die Instanziierung unseres Klassifikators für die logistische Regression hat ein Argument class_weight, das einen Wert “balanced” erhält. Damit wird der Klassifikator angewiesen, die Gewichte für die Klassen umgekehrt proportional zur Anzahl der Stichproben für diese Klasse zu erhöhen. Wir erwarten also eine bessere Leistung für die weniger stark vertretenen Klassen. Wir können mit diesem Code experimentieren, indem wir dieses Argument entfernen und den Klassifikator neu trainieren. Dabei werden wir feststellen, dass die untere rechte Zelle der Konfusionsmatrix um etwa 5 % sinkt. Allerdings scheint die logistische Regression bei diesem Datensatz eindeutig schlechter abzuschneiden als Naive Bayes.
Grund 3 auf unserer Liste war: "Vielleicht brauchen wir einen besseren Lernalgorithmus." Das wirft die Frage auf: "Was ist ein besserer Lernalgorithmus?" Eine allgemeine Faustregel bei der Arbeit mit ML-Ansätzen ist, dass es nicht den einen Algorithmus gibt, der für alle Datensätze gut lernt. Ein gängiger Ansatz ist es, mit verschiedenen Algorithmen zu experimentieren und sie zu vergleichen.
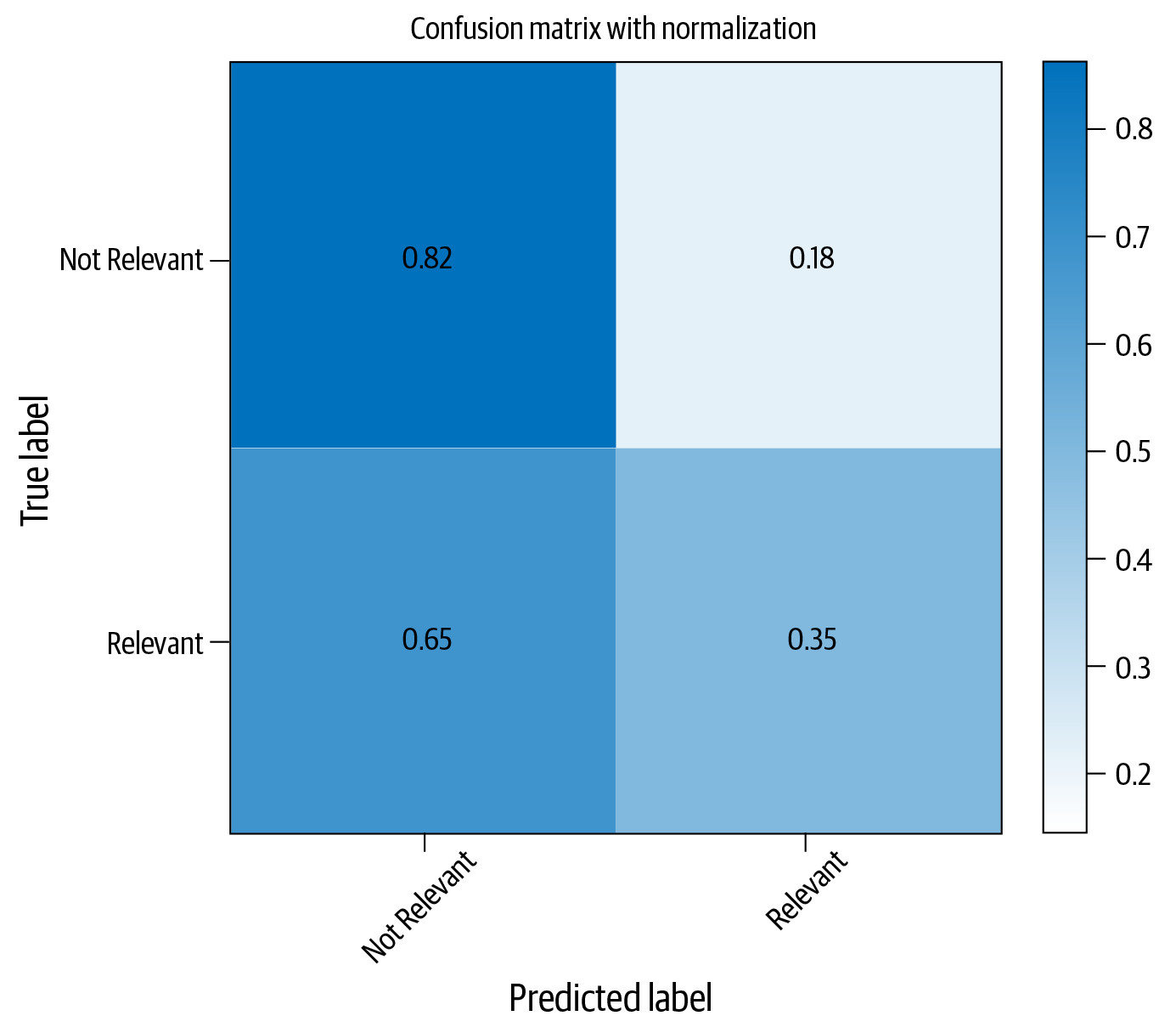
Abbildung 4-6. Klassifizierungsleistung mit logistischer Regression
Wir wollen sehen, ob uns diese Idee weiterhilft, indem wir die logistische Regression durch einen anderen bekannten Klassifizierungsalgorithmus ersetzen, der sich für verschiedene Textklassifizierungsaufgaben als nützlich erwiesen hat: die "Support Vector Machine".
Support-Vektor-Maschine
Wir haben die logistische Regression als einen diskriminierenden Klassifikator beschrieben, der die Gewichte für einzelne Merkmale lernt und eine Wahrscheinlichkeitsverteilung über die Klassen vorhersagt. Eine Support Vector Machine (SVM), die Anfang der 1960er Jahre erfunden wurde, ist ein diskriminatives Klassifizierungsverfahren wie die logistische Regression. Im Gegensatz zur logistischen Regression sucht sie jedoch nach einer optimalen Hyperebene in einem höherdimensionalen Raum, die die Klassen in den Daten mit einem möglichst großen Abstand voneinander trennen kann. Außerdem sind SVMs im Gegensatz zur logistischen Regression in der Lage, auch nicht-lineare Trennungen zwischen den Klassen zu lernen. Allerdings kann es auch länger dauern, sie zu trainieren.
SVMs gibt es in Sklearn in verschiedenen Varianten. Schauen wir uns an, wie eine von ihnen verwendet wird, indem wir alles andere gleich lassen und die maximale Anzahl der Merkmale auf 1.000 statt der 5.000 des vorherigen Beispiels ändern. Wir beschränken uns auf 1.000 Merkmale, um die Zeit zu berücksichtigen, die ein SVM-Algorithmus zum Trainieren braucht. Der folgende Codeschnipsel zeigt, wie das geht, und Abbildung 4-7 zeigt die resultierende Konfusionsmatrix:
fromsklearn.svmimportLinearSVCvect=CountVectorizer(preprocessor=clean,max_features=1000)#Step-1X_train_dtm=vect.fit_transform(X_train)#combined step 2 and 3X_test_dtm=vect.transform(X_test)classifier=LinearSVC(class_weight='balanced')#notice the “balanced” optionclassifier.fit(X_train_dtm,y_train)#fit the model with training datay_pred_class=classifier.predict(X_test_dtm)("Accuracy: ",metrics.accuracy_score(y_test,y_pred_class))
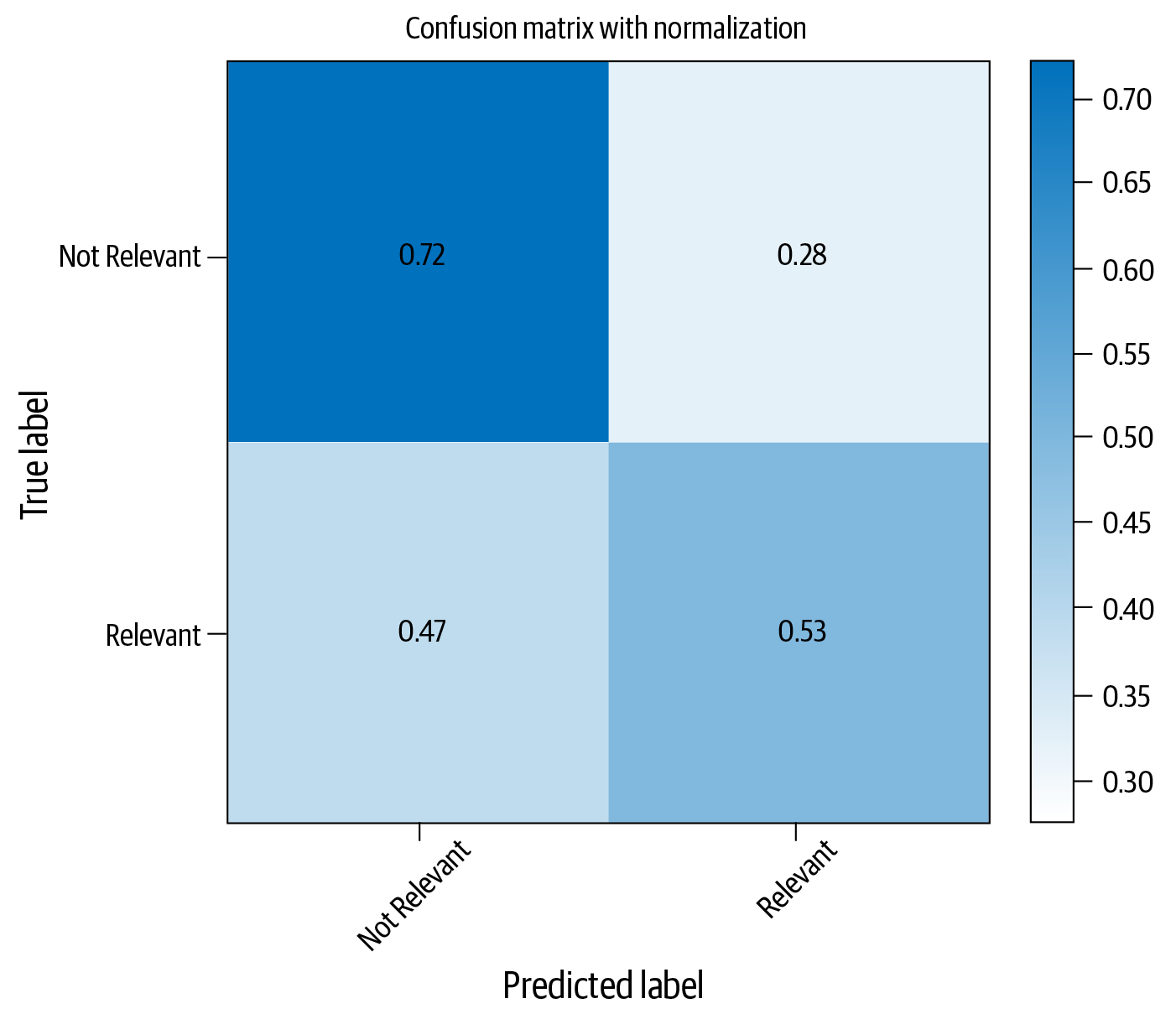
Abbildung 4-7. Konfusionsmatrix für die Klassifizierung mit SVM
Im Vergleich zur logistischen Regression scheinen SVMs bei der Kategorie "relevante Artikel" besser abzuschneiden, obwohl Naive Bayes mit dem kleineren Satz an Merkmalen in dieser kleinen Gruppe von Experimenten der beste Klassifikator für diesen Datensatz zu sein scheint.
Alle Beispiele in diesem Abschnitt zeigen, wie sich Änderungen in verschiedenen Schritten auf die Klassifizierungsleistung auswirken und wie die Ergebnisse zu interpretieren sind. Natürlich haben wir viele andere Möglichkeiten ausgeschlossen, z. B. die Erforschung anderer Algorithmen zur Textklassifizierung, die Änderung verschiedener Parameter der verschiedenen Klassifizierer, die Entwicklung besserer Vorverarbeitungsmethoden usw. Wir überlassen sie dem Leser als weitere Übungen, wobei das Notebook als Spielwiese dient. Bei einem realen Textklassifizierungsprojekt müssen wir mehrere Optionen wie diese ausprobieren, wobei wir mit dem einfachsten Ansatz in Bezug auf Modellierung, Einsatz und Skalierung beginnen und die Komplexität schrittweise erhöhen. Unser Ziel ist es schließlich, den Klassifikator zu entwickeln, der unseren geschäftlichen Anforderungen unter Berücksichtigung aller anderen Einschränkungen am besten gerecht wird.
Betrachten wir nun einen Teil des Grundes 4 in Tabelle 4-1: die bessere Darstellung von Merkmalen. Bislang haben wir in diesem Kapitel BoW-Features verwendet. Sehen wir uns nun an, wie wir andere Techniken der Merkmalsdarstellung, die wir in Kapitel 3 kennengelernt haben, für die Textklassifizierung nutzen können.
Neuronale Einbettungen bei der Textklassifizierung verwenden
In der zweiten Hälfte von Kapitel 3 haben wir Feature-Engineering-Techniken mit neuronalen Netzen besprochen, z. B. Worteinbettungen, Zeicheneinbettungen und Dokumenteneinbettungen. Der Vorteil von einbettungsbasierten Merkmalen ist, dass sie eine dichte, niedrigdimensionale Merkmalsrepräsentation erzeugen, anstatt der spärlichen, hochdimensionalen Struktur von BoW/TF-IDF und anderen Merkmalen. Es gibt verschiedene Möglichkeiten, auf neuronalen Einbettungen basierende Merkmale zu entwickeln und zu verwenden. In diesem Abschnitt sehen wir uns einige Möglichkeiten an, solche Einbettungsrepräsentationen für die Textklassifizierung zu nutzen .
Wort-Einbettungen
Wörter und n-Gramme werden schon seit langem hauptsächlich als Merkmale in der Textklassifikation verwendet. Es wurden verschiedene Methoden zur Vektorisierung von Wörtern vorgeschlagen, und wir haben im letzten Abschnitt eine solche Darstellung verwendet: CountVectorizer. In den letzten Jahren sind auf neuronalen Netzen basierende Architekturen für das "Lernen" von Wortrepräsentationen populär geworden, die als "Worteinbettungen" bezeichnet werden. Wir haben uns in Kapitel 3 mit den dahinter stehenden Intuitionen beschäftigt. Sehen wir uns nun an, wie man Worteinbettungen als Merkmale für die Textklassifizierung nutzen kann. Dazu verwenden wir den Sentiment-Labeled Sentences-Datensatz aus dem UCI-Repository, der aus 1.500 Sätzen mit positiver und 1.500 Sätzen mit negativer Bewertung von Amazon, Yelp und IMDB besteht. Alle Schritte sind im Notizbuch Ch4/Word2Vec_Example.ipynb beschrieben. Gehen wir die wichtigsten Schritte durch und erfahren wir, worin sich dieser Ansatz von den Verfahren im vorherigen Abschnitt unterscheidet.
Das Laden und Vorverarbeiten der Textdaten bleibt ein üblicher Schritt. Anstatt die Texte jedoch mit BoW-basierten Merkmalen zu vektorisieren, verwenden wir jetzt neuronale Einbettungsmodelle. Wie bereits erwähnt, verwenden wir ein vortrainiertes Einbettungsmodell. Word2vec ist ein beliebter Algorithmus, den wir in Kapitel 3 für das Training von Wort-Einbettungsmodellen besprochen haben. Im Internet gibt es mehrere vortrainierte Word2vec-Modelle, die mit großen Korpora trainiert wurden. Hier verwenden wir das Modell von Google [15]. Der folgende Codeschnipsel zeigt, wie man dieses Modell mit gensim in Python lädt:
data_path="/your/folder/path"path_to_model=os.path.join(data_path,'GoogleNews-vectors-negative300.bin')training_data_path=os.path.join(data_path,"sentiment_sentences.txt")#Load W2V model. This will take some time.w2v_model=KeyedVectors.load_word2vec_format(path_to_model,binary=True)('done loading Word2Vec')
Es handelt sich dabei um ein großes Modell, das als Wörterbuch betrachtet werden kann. Die Schlüssel sind die Wörter des Vokabulars und die Werte sind ihre gelernten Einbettungen. Wenn die Einbettung eines gesuchten Wortes im Wörterbuch vorhanden ist, wird es auch so wiedergegeben. Wie nutzen wir diese vorgelernte Einbettung, um Merkmale darzustellen? Wie wir in Kapitel 3 besprochen haben, gibt es mehrere Möglichkeiten, dies zu tun. Ein einfacher Ansatz besteht darin, die Einbettungen für einzelne Wörter im Text zu mitteln. Der folgende Codeschnipsel zeigt eine einfache Funktion, die dies ermöglicht:
# Creating a feature vector by averaging all embeddings for all sentencesdefembedding_feats(list_of_lists):DIMENSION=300zero_vector=np.zeros(DIMENSION)feats=[]fortokensinlist_of_lists:feat_for_this=np.zeros(DIMENSION)count_for_this=0fortokenintokens:iftokeninw2v_model:feat_for_this+=w2v_model[token]count_for_this+=1feats.append(feat_for_this/count_for_this)returnfeatstrain_vectors=embedding_feats(texts_processed)(len(train_vectors))
Beachte, dass die Einbettungen nur für die Wörter verwendet werden, die im Wörterbuch vorhanden sind. Die Wörter, für die keine Einbettungen vorhanden sind, werden ignoriert. Beachte auch, dass der obige Code einen einzigen Vektor mit DIMENSION(=300) Komponenten ergibt. Wir behandeln den resultierenden Einbettungsvektor als den Merkmalsvektor, der den gesamten Text repräsentiert. Wenn diese Merkmalsentwicklung abgeschlossen ist, ist der letzte Schritt ähnlich wie im vorherigen Abschnitt: Wir verwenden diese Merkmale und trainieren einen Klassifikator. Das überlassen wir dem Leser als Übung (den vollständigen Code findest du im Notebook).
Beim Training mit einem logistischen Regressionsklassifikator erreichten diese Merkmale eine Klassifizierungsgenauigkeit von 81 % in unserem Datensatz (weitere Einzelheiten findest du im Notebook). Wenn man bedenkt, dass wir nur ein bestehendes Worteinbettungsmodell verwendet und nur grundlegende Vorverarbeitungsschritte durchgeführt haben, ist dies ein großartiges Modell, das uns als Grundlage dient! In Kapitel 3 haben wir gesehen, dass es auch andere vortrainierte Einbettungsansätze gibt, wie z. B. GloVe, mit denen man für diesen Ansatz experimentieren kann. Gensim, das wir in diesem Beispiel verwendet haben, unterstützt bei Bedarf auch das Training eigener Worteinbettungen. Wenn wir an einer benutzerdefinierten Domäne arbeiten, deren Vokabular sich deutlich von dem der hier verwendeten vortrainierten Nachrichteneinbettungen unterscheidet, wäre es sinnvoll, unsere eigenen Einbettungen zu trainieren, um Merkmale zu extrahieren.
Um zu entscheiden, ob wir unsere eigenen Einbettungen trainieren oder bereits trainierte Einbettungen verwenden sollen, ist es eine gute Faustregel, die Vokabelüberschneidung zu berechnen. Wenn die Überschneidung zwischen dem Vokabular unserer benutzerdefinierten Domäne und dem der vortrainierten Worteinbettungen mehr als 80 % beträgt, liefern vortrainierte Worteinbettungen tendenziell gute Ergebnisse bei der Textklassifizierung.
Ein wichtiger Faktor, der beim Einsatz von Modellen mit einbettungsbasierten Merkmalsextraktionsansätzen berücksichtigt werden muss, ist, dass die gelernten oder vortrainierten Einbettungsmodelle gespeichert und in den Speicher geladen werden müssen, wenn diese Ansätze verwendet werden. Wenn das Modell selbst sehr umfangreich ist (z. B. benötigt das von uns verwendete Modell 3,6 GB), müssen wir dies bei unseren Einsatzanforderungen berücksichtigen.
Subword Embeddings und fastText
Bei Worteinbettungen geht es, wie der Name schon sagt, um Wortrepräsentationen. Wie wir bereits gesehen haben, scheinen sogar Standardeinbettungen bei Klassifizierungsaufgaben gut zu funktionieren. Wenn aber ein Wort in unserem Datensatz nicht im Vokabular des trainierten Modells enthalten ist, wie sollen wir dann eine Repräsentation für dieses Wort bekommen? Dieses Problem ist allgemein als "out of vocabulary" (OOV) bekannt. In unserem vorherigen Beispiel haben wir solche Wörter bei der Merkmalsextraktion einfach ignoriert. Gibt es einen besseren Weg?
Wir haben fastText-Einbettungen [16] in Kapitel 3 besprochen. Sie beruhen auf der Idee, Worteinbettungen mit Informationen auf Unterwortebene anzureichern. So wird die Einbettungsrepräsentation für jedes Wort als Summe der Repräsentationen der einzelnen Zeichen-N-Gramme dargestellt. Auch wenn dies im Vergleich zur Schätzung von Einbettungen auf Wortebene ein längerer Prozess zu sein scheint, hat er zwei Vorteile:
-
Dieser Ansatz kann mit Wörtern umgehen, die in den Trainingsdaten nicht vorkamen (OOV).
-
Die Implementierung ermöglicht ein extrem schnelles Lernen auch auf sehr großen Korpora.
FastText ist eine universelle Bibliothek zum Erlernen der Einbettungen, unterstützt aber auch die Klassifizierung von Texten, indem sie das Training und Testen des Klassifikators von Anfang bis Ende ermöglicht, d. h. wir müssen die Merkmalsextraktion nicht separat durchführen. Der verbleibende Teil dieses Unterabschnitts zeigt, wie man den fastText-Klassifikator [17] für die Textklassifizierung verwendet. Wir werden mit dem DBpedia-Datensatz [18] arbeiten. Es handelt sich um einen ausgewogenen Datensatz, der aus 14 Klassen besteht, mit 40.000 Trainings- und 5.000 Testbeispielen pro Klasse. Die Gesamtgröße des Datensatzes beträgt also 560.000 Trainings- und 70.000 Testdatenpunkte. Das ist natürlich ein viel größerer Datensatz als der, den wir bisher gesehen haben. Können wir mit fastText ein schnelles Trainingsmodell erstellen? Probieren wir es aus!
Die Trainings- und Testsätze werden als CSV-Dateien in diesem Datensatz bereitgestellt. Der erste Schritt besteht also darin, diese Dateien in deine Python-Umgebung einzulesen und den Text zu bereinigen, um überflüssige Zeichen zu entfernen, ähnlich wie bei den Vorverarbeitungsschritten für die anderen Klassifizierungsbeispiele, die wir bisher gesehen haben. Wenn das erledigt ist, ist die Verwendung von fastText ganz einfach. Der folgende Codeschnipsel zeigt ein einfaches fastText-Modell. Der schrittweise Prozess wird im zugehörigen Jupyter-Notizbuch(Ch4/FastText_Example.ipynb) beschrieben:
## Using fastText for feature extraction and trainingfromfasttextimportsupervised"""fastText expects and training file (csv), a model name as input arguments.label_prefix refers to the prefix before label string in the dataset.default is __label__. In our dataset, it is __class__.There are several other parameters which can be seen in:https://pypi.org/project/fasttext/"""model=supervised(train_file,'temp',label_prefix="__class__")results=model.test(test_file)(results.nexamples,results.precision,results.recall)
Wenn wir diesen Code im Notebook ausführen, werden wir feststellen, dass das Training trotz des riesigen Datensatzes und der Tatsache, dass wir dem Klassifikator den Rohtext und nicht den Merkmalsvektor gegeben haben, nur ein paar Sekunden dauert und wir fast 98 % Genauigkeit und Wiedererkennung erreichen! Als Übung kannst du versuchen, einen Klassifikator mit demselben Datensatz zu erstellen, aber entweder mit BoW- oder Word Embedding-Features und Algorithmen wie der logistischen Regression. Beachte, wie lange die einzelnen Schritte der Merkmalsextraktion und des Klassifizierungslernens dauern!
Wenn wir einen großen Datensatz haben und das Lernen mit den bisher beschriebenen Ansätzen undurchführbar erscheint, ist fastText eine gute Option, um eine solide Arbeitsgrundlage zu schaffen. Wie bei den Word2vec-Einbettungen gibt es bei fastText jedoch ein Problem zu beachten: Es verwendet vortrainierte n-Gramm-Einbettungen von Zeichen. Wenn wir also das trainierte Modell speichern, enthält es das gesamte Wörterbuch der n-Gramm-Einbettungen. Das führt zu einem unhandlichen Modell und kann zu technischen Problemen führen. Das Modell, das im obigen Codeschnipsel unter dem Namen "temp" gespeichert ist, hat beispielsweise eine Größe von fast 450 MB. Die fastText-Implementierung verfügt jedoch auch über Optionen, mit denen der Speicherbedarf der Klassifizierungsmodelle bei minimaler Verringerung der Klassifizierungsleistung reduziert werden kann [19]. Dies geschieht durch Vokabelbeschneidung und Kompressionsalgorithmen. Diese Möglichkeiten zu nutzen, könnte eine gute Option sein, wenn große Modellgrößen eine Einschränkung darstellen.
Tipp
fastText lässt sich extrem schnell trainieren und ist sehr nützlich, um starke Baselines zu erstellen. Der Nachteil ist die Modellgröße.
Wir hoffen, dass diese Diskussion einen guten Überblick über die Nützlichkeit von fastText für die Textklassifizierung gibt. Was wir hier gezeigt haben, ist ein Standard-Klassifizierungsmodell ohne Anpassung der Hyperparameter. In der fastText-Dokumentation findest du weitere Informationen zu den verschiedenen Optionen zur Anpassung deines Klassifizierers und zum Training von benutzerdefinierten Einbettungsrepräsentationen für einen gewünschten Datensatz. Beide Einbettungsrepräsentationen, die wir bisher gesehen haben, lernen eine Darstellung von Wörtern und Zeichen und fassen sie zu einer Textrepräsentation zusammen. Schauen wir uns an, wie man die Repräsentation für ein Dokument direkt mit dem Doc2vec-Ansatz lernt, den wir in Kapitel 3 besprochen haben.
Dokument-Einbettungen
Bei der Doc2vec Einbettung lernen wir eine direkte Darstellung für das gesamte Dokument (Satz/Absatz) und nicht für jedes einzelne Wort. Genauso wie wir Wort- und Zeicheneinbettungen als Merkmale für die Textklassifizierung verwendet haben, können wir auch Doc2vec als Mechanismus für die Merkmalsdarstellung nutzen. Da es keine vorgefertigten Modelle gibt, die mit der neuesten Version von Doc2vec [20] funktionieren, schauen wir uns an, wie wir unser eigenes Doc2vec-Modell erstellen und es für die Textklassifizierung verwenden können.
Wir verwenden einen Datensatz namens "Sentiment Analysis: Emotion in Text" von figure-eight.com [9], der 40.000 Tweets enthält, die mit 13 Labels für verschiedene Emotionen gekennzeichnet sind. Wir nehmen die drei häufigsten Labels in diesem Datensatz - neutral, besorgt, glücklich - und erstellen einen Textklassifikator, der neue Tweets in eine dieser drei Klassen einordnet. Das Notebook für diesen Unterabschnitt(Ch4/Doc2Vec_Example.ipynb) führt dich durch die Schritte zur Verwendung von Doc2vec für die Textklassifizierung und stellt den Datensatz zur Verfügung.
Nach dem Laden des Datensatzes und der Auswahl der drei häufigsten Labels ist ein wichtiger Schritt die Vorverarbeitung der Daten. Was ist hier anders als bei den vorherigen Beispielen? Warum können wir nicht einfach das gleiche Verfahren wie zuvor anwenden? Tweets unterscheiden sich in einigen Punkten von Nachrichtenartikeln oder anderen Texten, wie wir in Kapitel 2 bei der Vorverarbeitung von Texten kurz erläutert haben. Erstens sind sie sehr kurz. Zweitens funktionieren unsere herkömmlichen Tokenizer nicht gut mit Tweets, da sie Smileys, Hashtags, Twitter Handles usw. in mehrere Token aufteilen. Diese speziellen Anforderungen haben in der jüngeren Vergangenheit zu einer Vielzahl von Eingabenaufforderungen im Bereich NLP für Twitter geführt, die zu verschiedenen Vorverarbeitungsoptionen für Tweets führten. Eine dieser Lösungen ist TweetTokenizer , die in der NLTK [21] Bibliothek in Python implementiert ist. Wir werden in Kapitel 8 mehr über dieses Thema erfahren. Sehen wir uns im folgenden Codeschnipsel an, wie wir TweetTokenizer verwenden können:
tweeter=TweetTokenizer(strip_handles=True,preserve_case=False)mystopwords=set(stopwords.words("english"))#Function to pre-process and tokenize tweetsdefpreprocess_corpus(texts):defremove_stops_digits(tokens):#Nested function to remove stopwords and digitsreturn[tokenfortokenintokensiftokennotinmystopwordsandnottoken.isdigit()]return[remove_stops_digits(tweeter.tokenize(content))forcontentintexts]mydata=preprocess_corpus(df_subset['content'])mycats=df_subset['sentiment']
Der nächste Schritt in diesem Prozess ist das Trainieren eines Doc2vec-Modells, um die Darstellung von Tweets zu lernen. Im Idealfall eignet sich jeder große Datensatz von Tweets für diesen Schritt. Da wir aber keinen solchen fertigen Korpus haben, teilen wir unseren Datensatz in Training und Test auf und verwenden die Trainingsdaten zum Lernen der Doc2vec-Repräsentationen. Der erste Teil dieses Prozesses besteht darin, die Daten in ein Format zu konvertieren, das von der Doc2vec-Implementierung gelesen werden kann. Dies kann mit der Klasse TaggedDocument geschehen. Sie wird verwendet, um ein Dokument als eine Liste von Token darzustellen, gefolgt von einem "Tag", der in seiner einfachsten Form einfach der Dateiname oder die ID des Dokuments sein kann. Doc2vec selbst kann aber auch als Nearest Neighbor Classifier für Multiclass- und Multilabel-Klassifizierungsprobleme verwendet werden ( ). Wir überlassen es dem Leser, dies zu erforschen. Schauen wir uns nun an, wie man einen Doc2vec-Klassifikator für Tweets trainiert:
#Prepare training data in doc2vec format:d2vtrain=[TaggedDocument((d),tags=[str(i)])fori,dinenumerate(train_data)]#Train a doc2vec model to learn tweet representations. Use only training data!!model=Doc2Vec(vector_size=50,alpha=0.025,min_count=10,dm=1,epochs=100)model.build_vocab(d2vtrain)model.train(d2vtrain,total_examples=model.corpus_count,epochs=model.epochs)model.save("d2v.model")("Model Saved")
Für das Training von Doc2vec müssen mehrere Parameter ausgewählt werden, wie in der Modelldefinition im obigen Codeschnipsel zu sehen ist. vector_size bezieht sich auf die Dimensionalität der gelernten Einbettungen; alpha ist die Lernrate; min_count ist die Mindesthäufigkeit der Wörter, die im Vokabular verbleiben; dm steht für verteiltes Gedächtnis und ist einer der Repräsentationslerner, die in Doc2vec implementiert sind (der andere ist dbow oder verteilter Wortsack); und epochs ist die Anzahl der Trainingswiederholungen. Es gibt noch ein paar andere Parameter, die angepasst werden können. Es gibt zwar einige Richtlinien zur Auswahl optimaler Parameter für das Training von Doc2vec-Modellen [22], aber diese sind nicht vollständig validiert, und wir wissen nicht, ob die Richtlinien für Tweets funktionieren.
Der beste Weg, dieses Problem anzugehen, ist, eine Reihe von Werten für die für uns wichtigen zu untersuchen (z. B. dm versus dbow, Vektorgrößen, Lernrate) und mehrere Modelle zu vergleichen. Wie können wir diese Modelle vergleichen, da sie nur die Textrepräsentation lernen? Eine Möglichkeit besteht darin, die gelernten Repräsentationen in einer nachgelagerten Aufgabe zu verwenden - in diesem Fall die Textklassifizierung. Die Funktion infer_vector von Doc2vec kann verwendet werden, um die Vektordarstellung für einen gegebenen Text mit Hilfe eines vortrainierten Modells zu ermitteln. Da die Wahl der Hyperparameter eine gewisse Zufälligkeit mit sich bringt, unterscheiden sich die abgeleiteten Vektoren jedes Mal, wenn wir sie extrahieren. Um eine stabile Repräsentation zu erhalten, führen wir das Modell daher mehrmals durch (sogenannte Schritte) und fassen die Vektoren zusammen. Verwenden wir das gelernte Modell, um Merkmale für unsere Daten abzuleiten und einen logistischen Regressionsklassifikator zu trainieren:
#Infer the feature representation for training and test data using#the trained modelmodel=Doc2Vec.load("d2v.model")#Infer in multiple steps to get a stable representationtrain_vectors=[model.infer_vector(list_of_tokens,steps=50)forlist_of_tokensintrain_data]test_vectors=[model.infer_vector(list_of_tokens,steps=50)forlist_of_tokensintest_data]myclass=LogisticRegression(class_weight="balanced")#because classes are not balancedmyclass.fit(train_vectors,train_cats)preds=myclass.predict(test_vectors)(classification_report(test_cats,preds))
Die Leistung dieses Modells scheint ziemlich schlecht zu sein. Bei einem relativ großen Korpus mit nur drei Klassen erreichte es einen F1-Wert von 0,51. Für dieses schlechte Ergebnis gibt es mehrere Erklärungen. Erstens enthalten Tweets im Gegensatz zu vollständigen Nachrichtenartikeln oder sogar wohlgeformten Sätzen nur sehr wenige Daten pro Instanz. Außerdem verwenden die Menschen in ihren Tweets eine große Vielfalt an Rechtschreibung und Syntax. Es gibt eine Vielzahl von Emoticons in verschiedenen Formen. Unsere Merkmalsdarstellung sollte in der Lage sein, solche Aspekte zu erfassen. Während die Abstimmung der Algorithmen durch die Suche nach dem besten Modell in einem großen Parameterraum hilfreich sein kann, könnte eine Alternative darin bestehen, problemspezifische Merkmalsrepräsentationen zu erforschen, wie wir in Kapitel 3 besprochen haben. In Kapitel 8 werden wir sehen, wie man das für Tweets macht. Ein wichtiger Punkt, den du bei der Verwendung von Doc2vec beachten musst, ist derselbe wie bei fastText: Wenn wir Doc2vec für die Merkmalsrepräsentation verwenden müssen, müssen wir das Modell speichern, das die Repräsentation gelernt hat. Es ist zwar nicht so umfangreich wie fastText, aber auch nicht so schnell zu trainieren. Solche Kompromisse müssen wir abwägen und vergleichen, bevor wir uns für einen Einsatz entscheiden.
Bisher haben wir eine Reihe von Merkmalsrepräsentationen gesehen und wie sie bei der Textklassifizierung mit ML-Algorithmen eine Rolle spielen. Wenden wir uns nun einer Familie von Algorithmen zu, die in den letzten Jahren populär geworden ist und als "Deep Learning" bekannt ist.
Deep Learning für die Textklassifizierung
Wie in Kapitel 1 erläutert, ist Deep Learning eine Familie von Algorithmen für maschinelles Lernen, bei denen das Lernen durch verschiedene Arten von mehrschichtigen neuronalen Netzwerkarchitekturen erfolgt. In den letzten Jahren hat es bemerkenswerte Verbesserungen bei Standardaufgaben des maschinellen Lernens wie der Bildklassifizierung, der Spracherkennung und der maschinellen Übersetzung gezeigt. Das hat dazu geführt, dass ein großes Interesse daran besteht, Deep Learning für verschiedene Aufgaben einzusetzen, darunter auch für die Textklassifizierung. Bisher haben wir gesehen, wie man verschiedene Klassifizierer für maschinelles Lernen trainiert, indem man BoW und verschiedene Arten von Einbettungsrepräsentationen verwendet. Jetzt wollen wir uns ansehen, wie Deep Learning-Architekturen für die Textklassifizierung eingesetzt werden können.
Zwei der am häufigsten verwendeten neuronalen Netzwerkarchitekturen für die Textklassifizierung sind Faltungsneuronale Netze (CNNs) und rekurrente neuronale Netze (RNNs). LSTM-Netzwerke (Long Short Memory) sind eine beliebte Form von RNNs. Neuere Ansätze gehen auch von großen, vortrainierten Sprachmodellen aus und passen sie an die jeweilige Aufgabe an. In diesem Abschnitt lernen wir, wie man CNNs und LSTMs trainiert und wie man ein vortrainiertes Sprachmodell für die Textklassifizierung anhand des IMDB Sentiment-Klassifizierungsdatensatzes [23] abstimmt. Bitte beachte, dass eine ausführliche Diskussion über die Funktionsweise neuronaler Netzwerke den Rahmen dieses Buches sprengen würde. Interessierte Leser/innen können das Lehrbuch von Goodfellow et al. [24] für eine allgemeine theoretische Diskussion und Goldbergs Buch [25] für NLP-spezifische Anwendungen von neuronalen Netzwerkarchitekturen lesen. Das Buch von Jurafsky und Martin [12] bietet ebenfalls einen kurzen, aber prägnanten Überblick über verschiedene neuronale Netzwerkmethoden für NLP.
Der erste Schritt zum Training eines ML- oder DL-Modells ist die Definition einer Merkmalsrepräsentation. Bei den bisher vorgestellten Ansätzen mit BoW- oder Embedding-Vektoren war dieser Schritt relativ einfach. Für neuronale Netze müssen wir die Eingangsvektoren jedoch weiter verarbeiten, wie wir in Kapitel 3 gesehen haben. Rekapitulieren wir kurz die Schritte, die nötig sind, um die Trainings- und Testdaten in ein Format umzuwandeln, das für die Eingabeschichten des neuronalen Netzes geeignet ist:
-
Tokenisiere die Texte und wandle sie in Wortindex-Vektoren um.
-
Fülle die Textsequenzen so auf, dass alle Textvektoren die gleiche Länge haben.
-
Bilde jeden Wortindex auf einen Einbettungsvektor ab. Dazu multiplizieren wir die Wortindex-Vektoren mit der Einbettungsmatrix. Die Einbettungsmatrix kann entweder mit vorher trainierten Einbettungen gefüllt werden oder sie kann für Einbettungen auf diesem Korpus trainiert werden.
-
Verwende die Ausgabe aus Schritt 3 als Eingabe für eine neuronale Netzwerkarchitektur.
Sobald dies erledigt ist, können wir mit der Spezifikation der neuronalen Netzwerkarchitekturen und dem Training der Klassifikatoren fortfahren. Das Jupyter-Notizbuch zu diesem Abschnitt(Ch4/DeepNN_Example.ipynb) führt dich durch den gesamten Prozess von der Textvorverarbeitung bis zum Training und der Auswertung des neuronalen Netzes. Wir verwenden Keras, eine Python-basierte DL-Bibliothek. Das folgende Codeschnipsel veranschaulicht die Schritte 1 und 2:
#Vectorize these text samples into a 2D integer tensor using Keras Tokenizer.#Tokenizer is fit on training data only, and that is used to tokenize both train#and test data.tokenizer=Tokenizer(num_words=MAX_NUM_WORDS)tokenizer.fit_on_texts(train_texts)train_sequences=tokenizer.texts_to_sequences(train_texts)test_sequences=tokenizer.texts_to_sequences(test_texts)word_index=tokenizer.word_index('Found%sunique tokens.'%len(word_index))#Converting this to sequences to be fed into neural network. Max seq. len is#1000 as set earlier. Initial padding of 0s, until vector is of#size MAX_SEQUENCE_LENGTHtrainvalid_data=pad_sequences(train_sequences,maxlen=MAX_SEQUENCE_LENGTH)test_data=pad_sequences(test_sequences,maxlen=MAX_SEQUENCE_LENGTH)trainvalid_labels=to_categorical(np.asarray(train_labels))test_labels=to_categorical(np.asarray(test_labels))
Schritt 3: Wenn wir vortrainierte Einbettungen verwenden wollen, um die Trainings- und Testdaten in eine Einbettungsmatrix umzuwandeln, wie wir es in den früheren Beispielen mit Word2vec und fastText getan haben, müssen wir sie herunterladen und verwenden, um unsere Daten in das Eingabeformat für die neuronalen Netze umzuwandeln. Der folgende Codeschnipsel zeigt ein Beispiel dafür, wie wir dies mit GloVe-Einbettungen tun, die in Kapitel 3 vorgestellt wurden. GloVe-Einbettungen gibt es in verschiedenen Dimensionalitäten, und wir haben hier 100 als Dimension gewählt. Der Wert der Dimensionalität ist ein Hyperparameter, und wir können auch mit anderen Dimensionen experimentieren:i
embeddings_index={}withopen(os.path.join(GLOVE_DIR,'glove.6B.100d.txt'))asf:forlineinf:values=line.split()word=values[0]coefs=np.asarray(values[1:],dtype='float32')embeddings_index[word]=coefsnum_words=min(MAX_NUM_WORDS,len(word_index))+1embedding_matrix=np.zeros((num_words,EMBEDDING_DIM))forword,iinword_index.items():ifi>MAX_NUM_WORDS:continueembedding_vector=embeddings_index.get(word)ifembedding_vectorisnotNone:embedding_matrix[i]=embedding_vector
Schritt 4: Jetzt sind wir bereit, DL-Modelle für die Textklassifizierung zu trainieren! DL-Architekturen bestehen aus einer Eingabeschicht, einer Ausgabeschicht und mehreren versteckten Schichten zwischen den beiden Schichten. Je nach Architektur werden unterschiedliche versteckte Schichten verwendet. Die Eingabeschicht für Texteingaben ist in der Regel eine Einbettungsschicht. Die Ausgabeschicht ist, insbesondere im Zusammenhang mit der Textklassifizierung, eine Softmax-Schicht mit kategorialer Ausgabe. Wenn wir die Eingabeschicht trainieren wollen, anstatt vorgefertigte Einbettungen zu verwenden, ist es am einfachsten, die Klasse Embedding in Keras aufzurufen und die Eingabe- und Ausgabedimensionen anzugeben. Da wir jedoch bereits trainierte Einbettungen verwenden wollen, sollten wir eine eigene Einbettungsschicht erstellen, die die gerade erstellte Einbettungsmatrix verwendet. Der folgende Codeschnipsel zeigt, wie das geht:
embedding_layer=Embedding(num_words,EMBEDDING_DIM,embeddings_initializer=Constant(embedding_matrix),input_length=MAX_SEQUENCE_LENGTH,trainable=False)("Preparing of embedding matrix is done")
Diese dient als Eingabeschicht für jedes neuronale Netz, das wir verwenden wollen (CNN oder LSTM). Da wir nun wissen, wie wir die Eingabe vorverarbeiten und eine Eingabeschicht definieren, können wir nun die restliche Architektur des neuronalen Netzes mit CNNs und LSTMs festlegen.
CNNs für die Textklassifizierung
Schauen wir uns nun an, wie man ein CNN-Modell für die Textklassifizierung definiert, trainiert und bewertet. CNNs bestehen in der Regel aus einer Reihe von Faltungsschichten und Pooling-Schichten als versteckte Schichten. Im Zusammenhang mit der Textklassifizierung kann man sich CNNs so vorstellen, dass sie die nützlichsten Bag-of-Words/N-Gram-Merkmale lernen, anstatt die gesamte Sammlung von Wörtern/N-Grammen als Merkmale zu nehmen, wie wir es zuvor in diesem Kapitel getan haben. Da unser Datensatz nur zwei Klassen hat - positiv und negativ - hat die Ausgabeschicht zwei Ausgänge mit der Aktivierungsfunktion Softmax. Wir definieren ein CNN mit drei Faltungs-Pooling-Schichten, indem wir die Modellklasse Sequential in Keras verwenden, die es uns ermöglicht, DL-Modelle als sequenziellen Stapel von Schichten - eine nach der anderen - zu definieren. Sobald die Schichten und ihre Aktivierungsfunktionen festgelegt sind, geht es darum, andere wichtige Parameter zu definieren, wie den Optimierer, die Verlustfunktion und die Bewertungsmetrik, um die Hyperparameter des Modells einzustellen. Ist dies alles erledigt, wird das Modell im nächsten Schritt trainiert und ausgewertet. Der folgende Codeschnipsel zeigt eine Möglichkeit, eine CNN-Architektur für diese Aufgabe mit der Python-Bibliothek Keras festzulegen und gibt die Ergebnisse mit dem IMDB-Datensatz für dieses Modell aus:
('Define a 1D CNN model.')cnnmodel=Sequential()cnnmodel.add(embedding_layer)cnnmodel.add(Conv1D(128,5,activation='relu'))cnnmodel.add(MaxPooling1D(5))cnnmodel.add(Conv1D(128,5,activation='relu'))cnnmodel.add(MaxPooling1D(5))cnnmodel.add(Conv1D(128,5,activation='relu'))cnnmodel.add(GlobalMaxPooling1D())cnnmodel.add(Dense(128,activation='relu'))cnnmodel.add(Dense(len(labels_index),activation='softmax'))cnnmodel.compile(loss='categorical_crossentropy',optimizer='rmsprop',metrics=['acc'])cnnmodel.fit(x_train,y_train,batch_size=128,epochs=1,validation_data=(x_val,y_val))score,acc=cnnmodel.evaluate(test_data,test_labels)('Test accuracy with CNN:',acc)
Wie du siehst, haben wir bei der Festlegung des Modells eine Menge Entscheidungen getroffen, z. B. Aktivierungsfunktionen, versteckte Schichten, Schichtgrößen, Verlustfunktion, Optimierer, Metriken, Epochen und Stapelgröße. Es gibt zwar einige allgemein empfohlene Optionen, aber es gibt keinen Konsens über eine Kombination, die für alle Datensätze und Probleme am besten geeignet ist. Ein guter Ansatz bei der Erstellung deiner Modelle ist es, mit verschiedenen Einstellungen (d.h. Hyperparametern) zu experimentieren. Vergiss nicht, dass all diese Entscheidungen mit gewissen Kosten verbunden sind. In der Praxis haben wir zum Beispiel die Anzahl der Epochen auf 10 oder mehr festgelegt. Dadurch erhöht sich aber auch die Zeit, die für das Training des Modells benötigt wird. Eine weitere Besonderheit ist, dass sich nur die Zeile cnnmodel.add(embedding_layer) ändert, wenn du eine Einbettungsschicht trainieren willst, anstatt bereits trainierte Einbettungen in diesem Modell zu verwenden. Stattdessen können wir eine neue Einbettungsschicht angeben, z. B. cnnmodel.add(Embedding(Param1, Param2)). Der folgende Codeschnipsel zeigt den Code und die Leistung des Modells für dasselbe:
("Defining and training a CNN model, training embedding layer on the flyinsteadofusingpre-trainedembeddings")cnnmodel=Sequential()cnnmodel.add(Embedding(MAX_NUM_WORDS,128))…...cnnmodel.fit(x_train,y_train,batch_size=128,epochs=1,validation_data=(x_val,y_val))score,acc=cnnmodel.evaluate(test_data,test_labels)('Test accuracy with CNN:',acc)
Wenn wir diesen Code im Notebook ausführen, werden wir feststellen, dass in diesem Fall das Training der Einbettungsschicht auf unserem eigenen Datensatz zu einer besseren Klassifizierung auf den Testdaten zu führen scheint. Wären die Trainingsdaten jedoch wesentlich kleiner, wäre es besser, sich an die vortrainierten Einbettungen zu halten oder die Techniken zur Domänenanpassung zu verwenden, die wir später in diesem Kapitel besprechen werden. Schauen wir uns an, wie man ähnliche Modelle mit einem LSTM trainieren kann.
LSTMs für die Textklassifizierung
Wie wir in Kapitel 1 kurz gesehen haben, haben sich LSTMs und andere Varianten von RNNs in den letzten Jahren zur bevorzugten Methode für die neuronale Sprachmodellierung entwickelt. Das liegt vor allem daran, dass Sprache von Natur aus sequenziell ist und RNNs darauf spezialisiert sind, mit sequenziellen Daten zu arbeiten. Das aktuelle Wort im Satz hängt von seinem Kontext ab - den Wörtern davor und danach. Wenn wir Texte mit CNNs modellieren, wird diese entscheidende Tatsache jedoch nicht berücksichtigt. RNNs arbeiten nach dem Prinzip, diesen Kontext beim Lernen der Sprachrepräsentation oder eines Sprachmodells zu nutzen. Daher sind sie dafür bekannt, dass sie gut für NLP-Aufgaben geeignet sind. Es gibt auch CNN-Varianten, die diesen Kontext berücksichtigen können, und der Vergleich zwischen CNNs und RNNs ist immer noch umstritten. In diesem Abschnitt sehen wir uns ein Beispiel für die Verwendung von RNNs zur Textklassifizierung an. Nachdem wir nun ein neuronales Netzwerk in Aktion gesehen haben, ist es relativ einfach, ein weiteres zu trainieren! Ersetze einfach die Faltung und das Pooling in den beiden vorherigen Codebeispielen durch ein LSTM. Der folgende Codeschnipsel zeigt, wie man ein LSTM-Modell mit demselben IMDB-Datensatz für die Textklassifizierung trainiert:
("Defining and training an LSTM model, training embedding layer on the fly")rnnmodel=Sequential()rnnmodel.add(Embedding(MAX_NUM_WORDS,128))rnnmodel.add(LSTM(128,dropout=0.2,recurrent_dropout=0.2))rnnmodel.add(Dense(2,activation='sigmoid'))rnnmodel.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])('Training the RNN')rnnmodel.fit(x_train,y_train,batch_size=32,epochs=1,validation_data=(x_val,y_val))score,acc=rnnmodel.evaluate(test_data,test_labels,batch_size=32)('Test accuracy with RNN:',acc)
Beachte, dass die Ausführung dieses Codes viel länger dauert als die des CNN-Beispiels. LSTMs sind zwar leistungsfähiger, wenn es darum geht, die sequentielle Natur von Text zu nutzen, aber sie sind im Vergleich zu CNNs sehr viel datenintensiver. Daher muss die relativ geringere Leistung des LSTM in einem Datensatz nicht unbedingt als Mangel des Modells selbst interpretiert werden. Es ist möglich, dass die uns zur Verfügung stehende Datenmenge nicht ausreicht, um das volle Potenzial eines LSTMs zu nutzen. Wie bei CNNs spielen mehrere Parameter und Hyperparameter eine wichtige Rolle für die Leistung des Modells, und es ist immer eine gute Praxis, mehrere Optionen zu untersuchen und verschiedene Modelle zu vergleichen, bevor man sich für ein Modell entscheidet.
Textklassifizierung mit großen, vortrainierten Sprachmodellen
In den letzten zwei Jahren gab es große Fortschritte bei der Verwendung von Textrepräsentationen, die auf neuronalen Netzen basieren, für NLP-Aufgaben. Einige davon haben wir in "Universelle Textrepräsentationen" besprochen . Diese Repräsentationen wurden in der jüngsten Vergangenheit erfolgreich für die Textklassifizierung eingesetzt, indem die vortrainierten Modelle an die jeweilige Aufgabe und den Datensatz angepasst wurden. BERT, das in Kapitel 3 erwähnt wurde, ist ein beliebtes Modell, das auf diese Weise für die Textklassifizierung verwendet wird. Schauen wir uns an, wie BERT für die Textklassifizierung verwendet wird, und zwar anhand des IMDB-Datensatzes, den wir weiter oben in diesem Abschnitt verwendet haben. Der vollständige Code befindet sich im entsprechenden Notizbuch(Ch4/BERT_Sentiment_Classification_IMDB.ipynb).
Wir verwenden ktrain, einen leichtgewichtigen Wrapper, um mit der TensorFlow-Bibliothek Keras vortrainierte DL-Modelle zu trainieren und zu verwenden. ktrain bietet einen unkomplizierten Prozess für alle Schritte, von der Beschaffung des Datensatzes und des vortrainierten BERT bis zur Feinabstimmung für die Klassifizierungsaufgabe. Im folgenden Codeschnipsel sehen wir uns an, wie wir den Datensatz zuerst laden:
dataset=tf.keras.utils.get_file(fname="aclImdb.tar.gz",origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",extract=True,)
Sobald der Datensatz geladen ist, wird im nächsten Schritt das BERT-Modell heruntergeladen und der Datensatz gemäß den Anforderungen von BERT vorverarbeitet. Der folgende Codeschnipsel zeigt, wie du das mit den Funktionen von ktrain machst:
(x_train,y_train),(x_test,y_test),preproc=text.texts_from_folder(IMDB_DATADIR,maxlen=500,preprocess_mode='bert',train_test_names=['train','test'],
Der nächste Schritt ist das Laden des vortrainierten BERT-Modells und dessen Feinabstimmung für diesen Datensatz. Hier ist das Codeschnipsel für diesen Schritt:
model=text.text_classifier('bert',(x_train,y_train),preproc=preproc)learner=ktrain.get_learner(model,train_data=(x_train,y_train),val_data=(x_test,y_test),batch_size=6)learner.fit_onecycle(2e-5,4)
Diese drei Codezeilen trainieren einen Textklassifikator mit dem von BERT trainierten Modell. Wie bei den anderen Beispielen, die wir bisher gesehen haben, müssten wir die Parameter anpassen und viel experimentieren, um das beste Modell zu finden. Das überlassen wir dem Leser als Übung.
In diesem Abschnitt haben wir die Idee vorgestellt, DL für die Textklassifizierung mit zwei neuronalen Netzwerkarchitekturen - CNN und LSTM - zu verwenden, und gezeigt, wie wir ein hochmodernes, vortrainiertes Sprachmodell (BERT) für einen bestimmten Datensatz und eine bestimmte Klassifizierungsaufgabe abstimmen können. Es gibt mehrere Varianten dieser Architekturen, und täglich werden von NLP-Forschern neue Modelle vorgeschlagen. Wir haben gesehen, wie man ein vortrainiertes Sprachmodell, BERT, verwendet. Es gibt noch weitere Modelle dieser Art, und dieser Bereich der NLP-Forschung entwickelt sich ständig weiter; der Stand der Technik ändert sich alle paar Monate (oder sogar Wochen!). Nach unserer Erfahrung als Praktiker in der Industrie werden jedoch bei verschiedenen NLP-Aufgaben, insbesondere bei der Textklassifizierung, immer noch häufig mehrere der oben beschriebenen Nicht-DL-Ansätze verwendet. Zwei Hauptgründe dafür sind der Mangel an großen Mengen aufgabenspezifischer Trainingsdaten, die für neuronale Netze erforderlich sind, und Probleme mit den Rechen- und Bereitstellungskosten.
Tipp
DL-basierte Textklassifikatoren sind oft nichts anderes als verdichtete Darstellungen der Daten, auf denen sie trainiert wurden. Diese Modelle sind oft nur so gut wie der Trainingsdatensatz. Die Auswahl des richtigen Datensatzes ist in solchen Fällen umso wichtiger.
Am Ende dieses Abschnitts wiederholen wir, was wir bereits bei der Textklassifizierungs-Pipeline erwähnt haben: In den meisten industriellen Umgebungen ist es immer sinnvoll, mit einem einfacheren, leicht zu implementierenden Ansatz als MVP zu beginnen und diesen schrittweise auszubauen, wobei die Kundenbedürfnisse und die Machbarkeit berücksichtigt werden.
Wir haben bisher verschiedene Ansätze zur Erstellung von Textklassifizierungsmodellen kennengelernt. Im Gegensatz zu heuristikbasierten Ansätzen, bei denen die Vorhersagen durch die Rückverfolgung der auf die Daten angewandten Regeln begründet werden können, werden ML-Modelle bei ihren Vorhersagen als Blackbox behandelt. In jüngster Zeit hat das Thema interpretierbare ML-Modelle jedoch an Bedeutung gewonnen, und es gibt inzwischen Programme, die die Vorhersagen eines ML-Modells "erklären" können. Werfen wir einen kurzen Blick auf ihre Anwendung bei der Textklassifizierung.
Modelle zur Textklassifizierung interpretieren
In den vorherigen Abschnitten haben wir gesehen, wie man Textklassifikatoren mit verschiedenen Ansätzen trainiert. In all diesen Beispielen haben wir die Vorhersagen des Klassifikators so übernommen, wie sie sind, ohne nach Erklärungen zu suchen. Die meisten realen Anwendungsfälle der Textklassifizierung sind ähnlich - wir nehmen die Ergebnisse des Klassifizierers einfach hin und hinterfragen seine Entscheidungen nicht. Beispiel Spam-Klassifizierung: In der Regel suchen wir nicht nach Erklärungen dafür, warum eine bestimmte E-Mail als Spam oder als normale E-Mail eingestuft wird. Es kann jedoch Szenarien geben, in denen solche Erklärungen notwendig sind.
Stellen wir uns ein Szenario vor, in dem wir einen Klassifikator entwickelt haben, der beleidigende Kommentare auf einer Diskussionsforum-Website identifiziert. Der Klassifikator identifiziert Kommentare, die anstößig/beleidigend sind, und übernimmt die Aufgabe eines menschlichen Moderators, indem er sie entweder löscht oder für die Nutzer unsichtbar macht. Wir wissen, dass Klassifizierer nicht perfekt sind und Fehler machen können. Was ist, wenn der/die Kommentator/in diese Moderationsentscheidung anzweifelt und um eine Erklärung bittet? In solchen Fällen kann eine Methode nützlich sein, die Klassifizierungsentscheidung zu "erklären", indem sie darauf hinweist, welches Merkmal die Eingabeaufforderung zu dieser Entscheidung ausgelöst hat. Eine solche Methode ist auch nützlich, um Einblicke in das Modell zu erhalten und zu erfahren, wie es sich bei realen Daten (anstelle von Trainings-/Testsätzen) verhält, was in Zukunft zu besseren, zuverlässigeren Modellen führen kann.
Mit dem Einsatz von ML-Modellen in realen Anwendungen wuchs das Interesse an der Interpretierbarkeit von Modellen. Jüngste Forschungsarbeiten [26, 27] haben zu brauchbaren Werkzeugen [28, 29] für die Interpretation von Modellvorhersagen (insbesondere für die Klassifizierung) geführt. Lime [28] ist ein solches Tool, das versucht, ein Blackbox-Klassifizierungsmodell zu interpretieren, indem es es mit einem linearen Modell lokal um eine bestimmte Trainingsinstanz herum approximiert. Der Vorteil dabei ist, dass ein solches lineares Modell als gewichtete Summe seiner Merkmale ausgedrückt wird und für Menschen leicht zu interpretieren ist. Wenn es zum Beispiel zwei Merkmale, f1 und f2, für eine gegebene Testinstanz eines binären Klassifizierers mit den Klassen A und B gibt, könnte ein lineares Modell von Lime für diese Instanz etwa -0,3 × f1 + 0,4 × f2 mit einer Vorhersage B sein. Das bedeutet, dass das Vorhandensein des Merkmals f1 diese Vorhersage negativ (um 0,3) beeinflusst und sie in Richtung A verschiebt. [26] erklärt dies genauer. Schauen wir uns nun an, wie Lime [28] verwendet werden kann, um die Vorhersagen eines Textklassifikators zu verstehen.
Klassifikatorvorhersagen mit Lime erklären
Nehmen wir ein Modell, das wir bereits zu Beginn dieses Kapitels erstellt haben, und sehen wir uns an, wie Lime uns bei der Interpretation seiner Vorhersagen helfen kann. Das folgende Codeschnipsel verwendet das logistische Regressionsmodell, das wir zuvor mit dem Datensatz "Economy News Article Tone and Relevance" erstellt haben, der einen bestimmten Nachrichtenartikel als relevant oder nicht relevant einstuft, und zeigt, wie wir Lime verwenden können (der vollständige Code ist im Notebook Ch4/LimeDemo.ipynb zu finden):
fromlimeimportlime_textfromlime.lime_textimportLimeTextExplainerfromsklearn.pipelineimportmake_pipeliney_pred_prob=classifier.predict_proba(X_test_dtm)[:,1]c=make_pipeline(vect,classifier)mystring=list(X_test)[221]#Take a string from test instance(c.predict_proba([mystring]))#Prediction is a "No" here, i.e., not relevantclass_names=["no","yes"]#not relevant, relevantexplainer=LimeTextExplainer(class_names=class_names)exp=explainer.explain_instance(mystring,c.predict_proba,num_features=6)exp.as_list()
Dieser Code zeigt sechs Merkmale, die bei dieser Vorhersage eine wichtige Rolle gespielt haben. Sie lauten wie folgt:
[('YORK', 0.23416984139912805),
('NEW', -0.22724581340890154),
('showing', -0.12532906927967377),
('AP', -0.08486610147834726),
('dropped', 0.07958281943957331),
('trend', 0.06567603359316518)]
Das Ergebnis des obigen Codes kann also als eine lineare Summe dieser sechs Merkmale betrachtet werden. Das heißt, wenn wir die Merkmale "NEU" und "Zeigen" entfernen, sollte sich die Vorhersage um 0,35 (die Summe der Gewichte dieser beiden Merkmale) in Richtung der entgegengesetzten Klasse, d. h. "relevant/Ja", bewegen. Lime hat auch Funktionen, um diese Vorhersagen zu visualisieren. Abbildung 4-8 zeigt eine Visualisierung der obigen Erklärung.
Wie in der Abbildung zu sehen ist, verschiebt das Vorhandensein von drei Wörtern - York, Trend und dropped - die Vorhersage in Richtung Ja, während die anderen drei Wörter die Vorhersage in Richtung Nein verschieben.
Wir hoffen, diese kurze Einführung hat dir eine Vorstellung davon gegeben, was du tun kannst, wenn du die Vorhersagen eines Klassifikators erklären musst. Wir haben auch ein Notizbuch(Ch4/Lime_RNN.ipynb), das die Vorhersagen eines LSTM-Modells mit Lime erklärt.
Abbildung 4-8. Visualisierung der Erklärung von Lime zur Vorhersage eines Klassifikators
Lernen mit keinen oder weniger Daten und Anpassung an neue Bereiche
In allen Beispielen, die wir bisher gesehen haben, hatten wir einen relativ großen Trainingsdatensatz für die Aufgabe zur Verfügung. In den meisten realen Situationen sind solche Datensätze jedoch nicht ohne Weiteres verfügbar. In anderen Fällen steht zwar ein kommentierter Datensatz zur Verfügung, aber er ist vielleicht nicht groß genug, um einen guten Klassifikator zu trainieren. Es kann auch vorkommen, dass wir einen großen Datensatz mit z. B. Kundenbeschwerden und -anfragen für eine Produktreihe haben, aber unseren Klassifikator an eine andere Produktreihe anpassen sollen, für die wir nur eine sehr kleine Datenmenge haben (d. h. wir passen ein bestehendes Modell an einen neuen Bereich an). In diesem Abschnitt geht es darum, wie wir gute Klassifizierungssysteme für solche Fälle entwickeln, in denen wir keine oder nur wenige Daten haben oder uns an neue Trainingsdaten anpassen müssen.
Keine Trainingsdaten
Nehmen wir an, wir sollen für unser E-Commerce-Unternehmen einen Klassifikator zur Unterscheidung von Kundenbeschwerden entwickeln. Der Klassifikator soll E-Mails mit Kundenbeschwerden automatisch in eine Reihe von Kategorien einordnen: Rechnungsstellung, Lieferung und andere. Wenn wir Glück haben, entdecken wir innerhalb des Unternehmens eine Quelle mit großen Mengen an kommentierten Daten für diese Aufgabe in Form einer historischen Datenbank mit Kundenanfragen und ihren Kategorien. Wenn es eine solche Datenbank nicht gibt, wo sollen wir dann anfangen, unseren Klassifikator zu erstellen ?
Der erste Schritt in einem solchen Szenario ist die Erstellung eines kommentierten Datensatzes, in dem die Kundenbeschwerden den oben genannten Kategorien zugeordnet werden. Eine Möglichkeit, dies zu tun, besteht darin, Kundendienstmitarbeiter dazu zu bringen, einige der Beschwerden manuell zu beschriften und diese als Trainingsdaten für unser ML-Modell zu verwenden. Ein anderer Ansatz ist das so genannte "Bootstrapping" oder die "schwache Überwachung". Es kann bestimmte Informationsmuster in verschiedenen Kategorien von Kundenanfragen geben. Bei rechnungsbezogenen Anfragen werden vielleicht Varianten des Wortes "Rechnung", Beträge in einer bestimmten Währung usw. erwähnt. Bei lieferungsbezogenen Anfragen geht es um den Versand, Verzögerungen usw. Wir können damit beginnen, einige solcher Muster zu sammeln und ihr Vorhandensein oder Fehlen in einer Kundenanfrage zu nutzen, um sie zu kennzeichnen. Von hier aus können wir einen Klassifikator erstellen, um eine größere Datensammlung zu annotieren. Snorkel [30], ein kürzlich von der Stanford University entwickeltes Softwaretool, ist nützlich, um schwache Überwachung für verschiedene Lernaufgaben, einschließlich Klassifizierung, einzusetzen. Snorkel wurde verwendet, um Textklassifizierungsmodelle mit schwacher Überwachung im industriellen Maßstab bei Google einzusetzen [31]. Es wurde gezeigt, dass mit schwacher Überwachung Klassifizierungsmodelle erstellt werden können, die in ihrer Qualität mit denen vergleichbar sind, die mit zehntausenden von handbeschrifteten Beispielen trainiert wurden! [32] zeigt ein Beispiel für die Verwendung von Snorkel zur Erstellung von Trainingsdaten für die Textklassifizierung mit einer großen Menge an nicht beschrifteten Daten.
In einigen anderen Szenarien, in denen die Sammlung von Daten in großem Umfang notwendig und möglich ist, kann Crowdsourcing als eine Option zur Kennzeichnung der Daten angesehen werden. Websites wie Amazon Mechanical Turk und Figure Eight bieten Plattformen zur Nutzung menschlicher Intelligenz, um hochwertige Trainingsdaten für ML-Aufgaben zu erstellen. Ein beliebtes Beispiel für die Nutzung der Weisheit der Masse zur Erstellung eines Klassifizierungsdatensatzes ist der "CAPTCHA-Test", mit dem Google abfragt, ob eine Reihe von Bildern ein bestimmtes Objekt enthält (z. B. "Wähle alle Bilder aus, die ein Straßenschild enthalten").
Weniger Trainingsdaten: Aktives Lernen und Bereichsanpassung
In Szenarien wie dem oben beschriebenen, in dem wir kleine Datenmengen mit Hilfe von menschlichen Anmerkungen oder Bootstrapping gesammelt haben, kann sich manchmal herausstellen, dass die Datenmenge zu gering ist, um ein gutes Klassifizierungsmodell zu erstellen. Es ist auch möglich, dass die meisten der gesammelten Anfragen zur Rechnungsstellung gehörten und nur sehr wenige zu den anderen Kategorien, was zu einem sehr unausgewogenen Datensatz führte. Es ist nicht immer machbar, die Agenten zu bitten, viele Stunden mit der manuellen Kommentierung zu verbringen. Was sollten wir in solchen Fällen tun?
Ein Ansatz, um solche Probleme zu lösen, ist das aktive Lernen, bei dem es vor allem darum geht, herauszufinden, welche Datenpunkte für die Verwendung als Trainingsdaten am wichtigsten sind. Es hilft bei der Beantwortung der folgenden Frage: Wenn wir 1.000 Datenpunkte hätten, aber nur 100 davon beschriftet bekommen könnten, welche 100 würden wir wählen? Das bedeutet, dass nicht alle Datenpunkte gleich sind, wenn es um Trainingsdaten geht. Einige Datenpunkte sind wichtiger als andere, wenn es darum geht, die Qualität des trainierten Klassifikators zu bestimmen. Aktives Lernen verwandelt dies in einen kontinuierlichen Prozess.
Die Verwendung von aktivem Lernen für das Training eines Klassifikators kann als schrittweiser Prozess beschrieben werden :
-
Trainiere den Klassifikator mit der verfügbaren Menge an Daten.
-
Beginne damit, den Klassifikator zu verwenden, um Vorhersagen für neue Daten zu treffen.
-
Die Datenpunkte, bei denen der Klassifikator sehr unsicher in seinen Vorhersagen ist, schickst du an menschliche Annotatoren, um sie richtig einzuordnen.
-
Nimm diese Datenpunkte in die bestehenden Trainingsdaten auf und trainiere das Modell neu.
Wiederhole die Schritte 1 bis 4, bis du eine zufriedenstellende Modellleistung erreicht hast.
Tools wie Prodigy [33] haben aktive Lernlösungen für die Textklassifizierung implementiert und unterstützen die effiziente Nutzung von aktivem Lernen, um schnell annotierte Daten und Textklassifizierungsmodelle zu erstellen. Der Grundgedanke des aktiven Lernens ist, dass die Datenpunkte, bei denen das Modell weniger sicher ist, am meisten zur Verbesserung der Qualität des Modells beitragen und deshalb nur diese Datenpunkte beschriftet werden.
Stell dir vor, dass wir für unseren Klassifikator für Kundenbeschwerden eine Menge historischer Daten für eine Reihe von Produkten haben. Nun sollen wir ihn aber so anpassen, dass er auch für eine Reihe neuerer Produkte funktioniert. Was ist in dieser Situation eine potenzielle Herausforderung? Typische Textklassifizierungsverfahren verlassen sich auf das Vokabular der Trainingsdaten. Daher sind sie von Natur aus auf die Art von Sprache ausgerichtet, die in den Trainingsdaten vorkommt. Wenn also die neuen Produkte sehr unterschiedlich sind (z. B. wenn das Modell für eine Reihe von Elektronikprodukten trainiert wurde und wir es für Beschwerden über Kosmetikprodukte verwenden), werden die vortrainierten Klassifikatoren, die auf anderen Quelldaten trainiert wurden, wahrscheinlich nicht gut abschneiden. Es ist aber auch nicht realistisch, für jedes Produkt oder jede Produktreihe ein neues Modell von Grund auf zu trainieren, da wir dann wieder mit dem Problem unzureichender Trainingsdaten konfrontiert werden. Die Domänenanpassung ist eine Methode, um solche Szenarien zu bewältigen; sie wird auch als Transferlernen bezeichnet. Dabei "übertragen" wir das Gelernte aus einem Bereich (Quelle) mit großen Datenmengen auf einen anderen Bereich (Ziel) mit weniger beschrifteten Daten, aber großen Mengen an unbeschrifteten Daten. Ein Beispiel für den Einsatz von BERT zur Textklassifizierung haben wir bereits weiter oben in diesem Kapitel gesehen.
Dieser Ansatz zur Domänenanpassung bei der Textklassifizierung lässt sich wie folgt zusammenfassen :
-
Beginne mit einem großen, vortrainierten Sprachmodell, das auf einem großen Datensatz der Ausgangsdomäne (z. B. Wikipedia-Daten) trainiert wurde.
-
Verfeinere dieses Modell mit den unbeschrifteten Daten der Zielsprache.
-
Trainiere einen Klassifikator auf den gelabelten Daten der Zieldomäne, indem du Merkmalsrepräsentationen aus dem feinabgestimmten Sprachmodell aus Schritt 2 extrahierst.
ULMFit [34] ist ein weiterer beliebter Ansatz zur Domänenanpassung für die Textklassifizierung. In Forschungsexperimenten wurde gezeigt, dass dieser Ansatz bei Textklassifizierungsaufgaben die gleiche Leistung erbringt wie das Training von Grund auf mit 10- bis 20-mal mehr Trainingsbeispielen und nur 100 gelabelten Beispielen. Wenn unbeschriftete Daten zur Feinabstimmung des vortrainierten Sprachmodells verwendet wurden, erreichte es bei denselben Textklassifizierungsaufgaben die gleiche Leistung wie bei der Verwendung von 50- bis 100-mal mehr beschrifteten Beispielen, die von Grund auf trainiert wurden. Transfer-Learning-Methoden sind derzeit ein aktives Forschungsgebiet im Bereich NLP. Ihre Anwendung für die Textklassifizierung hat noch keine dramatischen Verbesserungen bei Standarddatensätzen gezeigt und sie sind auch noch nicht die Standardlösung für alle Klassifizierungsszenarien in der Industrie. Wir können aber davon ausgehen, dass dieser Ansatz in naher Zukunft immer bessere Ergebnisse liefert.
Bisher haben wir eine Reihe von Textklassifizierungsmethoden kennengelernt und darüber gesprochen, wie man geeignete Trainingsdaten erhält und verschiedene Merkmalsdarstellungen für das Training der Klassifizierer verwendet. Wir haben auch kurz besprochen, wie man die Vorhersagen einiger Textklassifizierungsmodelle interpretiert. Jetzt wollen wir das bisher Gelernte anhand einer kleinen Fallstudie zur Erstellung eines Textklassifizierers für ein reales Szenario zusammenfassen.
Fallstudie: Ticketing für Unternehmen
Betrachten wir ein reales Szenario und erfahren wir, wie wir einige der Konzepte, die wir in diesem Abschnitt besprochen haben, anwenden können. Stell dir vor, wir sollen ein Ticketingsystem für unser Unternehmen erstellen, das alle Tickets oder Probleme, mit denen die Mitarbeiter im Unternehmen konfrontiert sind, erfasst und sie entweder an interne oder externe Mitarbeiter weiterleitet. Abbildung 4-9 zeigt einen repräsentativen Screenshot eines solchen Systems; es handelt sich um ein unternehmensweites Ticketingsystem namens Spoke.
Abbildung 4-9. Ein unternehmensweites Ticketingsystem
Nehmen wir an, unser Unternehmen hat kürzlich einen medizinischen Berater eingestellt und arbeitet mit einem Krankenhaus zusammen. Unser System sollte also in der Lage sein, medizinische Probleme zu erkennen und sie an die zuständigen Personen und Teams weiterzuleiten. Aber obwohl wir einige Tickets aus der Vergangenheit haben, ist keines davon als gesundheitsbezogen gekennzeichnet. Wie sollen wir ein solches Klassifizierungssystem für Gesundheitsprobleme aufbauen, wenn wir diese Kennzeichnungen nicht haben?
Lass uns ein paar Optionen ausprobieren:
- Vorhandene APIs oder Bibliotheken verwenden
Eine Möglichkeit ist, mit einer öffentlichen API oder Bibliothek zu beginnen und ihre Klassen auf das abzubilden, was für uns relevant ist. Die bereits erwähnten Google-APIs können beispielsweise Inhalte in über 700 Kategorien einordnen. Es gibt 82 Kategorien, die mit medizinischen oder gesundheitlichen Themen zu tun haben. Dazu gehören Kategorien wie /Gesundheit/Gesundheitszustände/Schmerzmanagement, /Gesundheit/Medizinische Einrichtungen & Dienstleistungen/Arztpraxen, /Finanzen/Versicherungen/Krankenversicherungen usw.
Zwar sind nicht alle Kategorien für unser Unternehmen relevant, aber einige könnten es sein, und wir können sie entsprechend zuordnen. Nehmen wir zum Beispiel an, dass unser Unternehmen Drogenmissbrauch und Fettleibigkeit nicht als relevant für die medizinische Beratung ansieht. Dann können wir /Gesundheit/Substanzmissbrauch und /Gesundheit/Gesundheitszustände/Fettleibigkeit in dieser API ignorieren. Auch die Frage, ob Versicherungen Teil der Personalabteilung sein sollen oder nicht, kann mit diesen Kategorien geklärt werden.
- Öffentliche Datensätze verwenden
Wir können auch öffentliche Datensätze für unsere Zwecke verwenden. 20 Newsgroups zum Beispiel ist ein beliebter Datensatz zur Textklassifizierung, der auch Teil der sklearn-Bibliothek ist. Er enthält eine Reihe von Themen, darunter auch sci.med. Wir können damit auch einen einfachen Klassifikator trainieren, der alle anderen Themen in eine Kategorie und sci.med in eine andere einordnet.
- Schwache Aufsicht ausnutzen
Wir haben eine Historie der vergangenen Tickets, aber sie sind nicht beschriftet. Daher können wir mit den oben beschriebenen Ansätzen einen Datensatz daraus erstellen. Stell dir zum Beispiel eine Regel vor: "Wenn die letzte Anfrage Wörter wie Fieber, Durchfall, Kopfschmerzen oder Übelkeit enthält, ordne sie der Kategorie "Medizinischer Rat" zu. Diese Regel kann eine kleine Menge an Daten erzeugen, die wir als Ausgangspunkt für unseren Klassifikator verwenden können.
- Aktives Lernen
Mit Tools wie Prodigy können wir Datenerhebungsexperimente durchführen, bei denen wir jemanden, der am Kundendienst arbeitet, bitten, sich Ticketbeschreibungen anzusehen und sie mit einer voreingestellten Liste von Kategorien zu versehen. Abbildung 4-10 zeigt ein Beispiel für die Verwendung von Prodigy zu diesem Zweck.
Abbildung 4-10. Aktives Lernen mit Prodigy
- Lernen aus implizitem und explizitem Feedback
Während des gesamten Prozesses des Aufbaus, der Iteration und des Einsatzes dieser Lösung erhalten wir Feedback, das wir zur Verbesserung unseres Systems nutzen können. Explizites Feedback könnte sein, wenn der medizinische Berater oder das Krankenhaus ausdrücklich sagt, dass das Ticket nicht relevant war. Implizites Feedback könnte aus anderen abhängigen Variablen wie Ticket-Antwortzeiten und Ticket-Antwortraten abgeleitet werden. All diese Faktoren können wir berücksichtigen, um unser Modell mithilfe aktiver Lerntechniken zu verbessern.
Eine Beispielpipeline, die diese Ideen zusammenfasst, könnte so aussehen, wie in Abbildung 4-11 dargestellt. Wir beginnen ohne beschriftete Daten und verwenden entweder eine öffentliche API oder ein Modell, das mit einem öffentlichen Datensatz oder schwacher Überwachung erstellt wurde, als erstes Basismodell. Sobald wir dieses Modell in Betrieb nehmen, erhalten wir explizite und implizite Signale darüber, wo es funktioniert oder fehlschlägt. Wir nutzen diese Informationen, um unser Modell zu verfeinern und durch aktives Lernen die besten Instanzen auszuwählen, die beschriftet werden müssen. Im Laufe der Zeit, wenn wir mehr Daten sammeln, können wir immer ausgefeiltere und tiefere Modelle erstellen.
In diesem Abschnitt haben wir uns ein praktisches Szenario angesehen, bei dem wir nicht genügend Trainingsdaten haben, um unseren eigenen Textklassifikator für unser eigenes Problem zu erstellen. Wir haben mehrere mögliche Lösungen für dieses Problem diskutiert. Wir hoffen, dass dir das hilft, einige der Szenarien im Zusammenhang mit der Datenerfassung und -erstellung in deinen zukünftigen Projekten zur Textklassifizierung vorauszusehen und dich darauf vorzubereiten.
Praktische Ratschläge
Bisher haben wir eine Reihe verschiedener Methoden zur Erstellung von Textklassifikatoren und mögliche Probleme aufgezeigt, auf die du stoßen könntest. Wir möchten dieses Kapitel mit einigen praktischen Ratschlägen abschließen, die unsere Beobachtungen und Erfahrungen beim Aufbau von Textklassifizierungssystemen in der Industrie zusammenfassen. Die meisten dieser Ratschläge sind so allgemein gehalten, dass sie auch auf andere Themen in diesem Buch angewendet werden können.
- Starke Basiswerte schaffen
Ein weit verbreiteter Irrtum ist es, mit einem hochmodernen Algorithmus zu beginnen. Das gilt besonders in der aktuellen Ära des Deep Learning, in der jeden Tag neue Ansätze/Algorithmen auftauchen. Es ist jedoch immer gut, mit einfacheren Ansätzen zu beginnen und zunächst eine solide Basis zu schaffen. Das ist vor allem aus drei Gründen sinnvoll:
-
Sie hilft uns, die Problemstellung und die wichtigsten Herausforderungen besser zu verstehen.
-
Die Erstellung eines schnellen MVP hilft uns, erstes Feedback von Endnutzern und Stakeholdern zu bekommen.
-
Ein modernes Forschungsmodell bringt uns vielleicht nur eine geringfügige Verbesserung im Vergleich zum Ausgangsmodell, aber es kann mit einer großen Menge technischer Schulden einhergehen.
-
- Daten zum Gleichgewichtstraining
Bei der Klassifizierung ist es sehr wichtig, einen ausgewogenen Datensatz zu haben, in dem alle Kategorien gleich stark vertreten sind. Ein unausgewogener Datensatz kann sich negativ auf das Lernen des Algorithmus auswirken und zu einem verzerrten Klassifikator führen. Obwohl wir diesen Aspekt der Trainingsdaten nicht immer kontrollieren können, gibt es verschiedene Techniken, um ein Ungleichgewicht der Klassen in den Trainingsdaten zu beheben. Einige davon sind das Sammeln von mehr Daten, Resampling (Unterstichprobe aus Mehrheitsklassen oder Überstichprobe aus Minderheitsklassen) und Gewichtsausgleich.
- Kombiniere Modelle und Menschen in der Schleife
In praktischen Szenarien ist es sinnvoll, die Ergebnisse mehrerer Klassifizierungsmodelle mit handgefertigten Regeln von Fachexperten zu kombinieren, um die beste Leistung für das Unternehmen zu erzielen. In anderen Fällen ist es sinnvoll, die Entscheidung einem menschlichen Bewerter zu überlassen, wenn die Maschine sich bei ihrer Klassifizierungsentscheidung nicht sicher ist. Schließlich kann es auch Szenarien geben, in denen sich das gelernte Modell mit der Zeit und neueren Daten ändern muss. In Kapitel 11, das sich mit End-to-End-Systemen befasst, werden wir einige Lösungen für solche Szenarien diskutieren.
- Mach es möglich, mach es besser
Beim Aufbau eines Klassifizierungssystems geht es nicht nur um die Erstellung eines Modells. In den meisten industriellen Umgebungen macht die Erstellung eines Modells oft nur 5 bis 10 % des Gesamtprojekts aus. Der Rest besteht aus dem Sammeln von Daten, dem Aufbau von Datenpipelines, dem Einsatz, dem Testen, der Überwachung usw. Es ist immer gut, ein Modell schnell zu erstellen, es zum Aufbau eines Systems zu verwenden und dann mit Verbesserungsiterationen zu beginnen. Das hilft uns, schnell die größten Hindernisse und die Teile zu erkennen, an denen am meisten gearbeitet werden muss, und das ist oft nicht der Modellierungsteil.
- Nutze die Weisheit der Vielen
Jeder Algorithmus zur Textklassifizierung hat seine eigenen Stärken und Schwächen. Es gibt keinen einzigen Algorithmus, der immer gut funktioniert. Eine Möglichkeit, dies zu umgehen, ist das Ensembling: das Training mehrerer Klassifikatoren. Die Daten durchlaufen jeden Klassifikator und die erzeugten Vorhersagen werden kombiniert (z. B. durch Mehrheitsabstimmung), um zu einer endgültigen Klassenvorhersage zu gelangen. Interessierte Leser/innen können sich in der Arbeit von Dong et al. [35, 36] eingehend mit Ensemble-Methoden für die Klassifizierung von Texten befassen.
Einpacken
In diesem Kapitel haben wir gesehen, wie man das Problem der Textklassifizierung aus verschiedenen Blickwinkeln angeht. Wir haben besprochen, wie man ein Klassifizierungsproblem identifiziert, die verschiedenen Schritte in einer Textklassifizierungspipeline angeht, Daten sammelt, um relevante Datensätze zu erstellen, verschiedene Merkmalsdarstellungen verwendet und verschiedene Klassifizierungsalgorithmen trainiert. Wir hoffen, dass du jetzt gut gerüstet bist, um Textklassifizierungsprobleme für deinen Anwendungsfall und dein Szenario zu lösen und zu verstehen, wie du bestehende Lösungen nutzen, eigene Klassifizierer mit verschiedenen Methoden erstellen und die Hindernisse überwinden kannst, die sich dir dabei in den Weg stellen. Wir haben uns nur auf einen Aspekt des Aufbaus von Textklassifizierungssystemen in industriellen Anwendungen konzentriert: den Aufbau des Modells. Fragen, die mit dem durchgängigen Einsatz von NLP-Systemen zu tun haben, werden in Kapitel 11 behandelt. Im nächsten Kapitel werden wir einige der Ideen, die wir hier gelernt haben, nutzen, um ein verwandtes, aber anderes NLP-Problem anzugehen: die Informationsextraktion.
Fußnoten
i Es gibt noch andere solche vortrainierten Einbettungen. Unsere Wahl ist in diesem Fall willkürlich.
Referenzen
[1] United States Postal Service. Der Postdienst der Vereinigten Staaten: An American History, 57-60. ISBN: 978-0-96309-524-4. Letzter Zugriff am 15. Juni 2020.
[2] Gupta, Anuj, Saurabh Arora, Satyam Saxena, und Navaneethan Santhanam. "Rauschunterdrückung und Smart Ticketing für Social Media-basierte Kommunikationssysteme". US-Patentanmeldung 20190026653, eingereicht am 24. Januar 2019.
[3] Spasojevic, Nemanja und Adithya Rao. "Identifying Actionable Messages on Social Media". 2015 IEEE International Conference on Big Data: 2273-2281.
[4] CLPSYCH: Computergestützte Linguistik und klinische Psychologie Workshop. Shared Tasks 2019.
[5] Google Cloud. "Natürliche Sprache". Letzter Zugriff am 15. Juni 2020.
[6] Amazon Comprehend. Letzter Zugriff am 15. Juni 2020.
[7] Azure Cognitive Services. Letzter Zugriff am 15. Juni 2020.
[8] Iderhoff, Nicolas. nlp-datasets: Alphabetische Liste freier/öffentlicher Datensätze mit Textdaten zur Verwendung in der natürlichen Sprachverarbeitung (NLP), (GitHub Repo). Letzter Zugriff am 15. Juni 2020.
[9] Kaggle. "Sentiment Analysis: Emotion in Text". Letzter Zugriff am 15. Juni 2020.
[10] UC Irvine Machine Learning Repository. Eine Sammlung von Repositories für maschinelles Lernen. Letzter Zugriff am 15. Juni 2020.
[11] Google. "Datensatzsuche". Letzter Zugriff am 15. Juni 2020.
[12] Jurafsky, Dan und James H. Martin. Speech and Language Processing, Third Edition (Draft), 2018.
[13] Lemaître, Guillaume, Fernando Nogueira, und Christos K. Aridas. "Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning". The Journal of Machine Learning Research 18.1 (2017): 559-563.
[14] Eine detaillierte mathematische Beschreibung der logistischen Regression findest du in Kapitel 5 in [12].
[15] Google. Vorgeprüftes word2vec-Modell. Letzter Zugriff am 15. Juni 2020.
[16] Bojanowski, Piotr, Edouard Grave, Armand Joulin, und Tomas Mikolov. "Enriching Word Vectors with Subword Information". Transactions of the Association for Computational Linguistics 5 (2017): 135-146.
[17] Joulin, Armand, Edouard Grave, Piotr Bojanowski, und Tomas Mikolov. "Bag of Tricks for Efficient Text Classification".(2016).
[18] Ramesh, Sree Harsha. torchDatasets, (GitHub Repo). Letzter Zugriff am 15. Juni 2020.
[19] Joulin, Armand, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, und Tomas Mikolov. "Fasttext.zip: Komprimierung von Textklassifizierungsmodellen".(2016).
[20] Für ältere Doc2vec-Versionen gibt es einige vortrainierte Modelle, z. B. https://oreil. ly/kt0U0 (letzter Zugriff am 15. Juni 2020).
[21] Natural Language Toolkit. "NLTK 3.5 Dokumentation". Letzter Zugriff am 15. Juni 2020.
[22] Lau, Jey Han und Timothy Baldwin. "Eine empirische Bewertung von doc2vec mit praktischen Einblicken in die Erzeugung von Dokumenteneinbettungen".(2016).
[23] Stanford Artificial Intelligence Laboratory. "Large Movie Review Dataset". Letzter Zugriff am 15. Juni 2020.
[24] Goodfellow, Ian, Yoshua Bengio, und Aaron Courville. Deep Learning. Cambridge: MIT Press, 2016. ISBN: 978-0-26203-561-3
[25] Goldberg, Yoav. "Neural Network Methods for Natural Language Processing". Synthesis Lectures on Human Language Technologies 10.1 (2017): 1-309.
[26] Ribeiro, Marco Tulio, Sameer Singh, und Carlos Guestrin. "'Warum sollte ich dir vertrauen?' Erklärung der Vorhersagen eines Klassifikators". Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016): 1135-1144.
[27] Lundberg, Scott M. und Su-In Lee. "A Unified Approach to Interpreting Model Predictions" (Ein einheitlicher Ansatz zur Interpretation von Modellvorhersagen). Advances in Neural Information Processing Systems 30 (NIPS 2017): 4765-4774.
[28] Marco Tulio Correia Ribeiro. Lime: Erklären der Vorhersagen eines beliebigen Klassifizierers für maschinelles Lernen, (GitHub Repo). Letzter Zugriff am 15. Juni 2020.
[29] Lundberg, Scott. shap: A game theoretic approach to explain the output of any machine learning model, (GitHub repo).
[30] Snorkel. " Programmatische Erstellung und Verwaltung von Trainingsdaten". Letzter Zugriff am 15. Juni 2020.
[31] Bach, Stephen H., Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, Souvik Sen et al. "Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale".(2018).
[32] Snorkel. "Snorkel Intro Tutorial: Datenbeschriftung". Letzter Zugriff am 15. Juni 2020.
[33] Prodigy. Letzter Zugriff am 15. Juni 2020.
[34] Fast.ai. "Einführung der modernsten Textklassifizierung mit universellen Sprachmodellen". Letzter Zugriff am 15. Juni 2020.
[35] Dong, Yan-Shi und Ke-Song Han. "Ein Vergleich verschiedener Ensemble-Methoden zur Textkategorisierung". IEEE International Conference on Services Computing (2004): 419-422.
[36] Caruana, Rich, Alexandru Niculescu-Mizil, Geoff Crew, und Alex Ksikes. "Ensemble Selection from Libraries of Models". Proceedings of the Twenty-First International Conference on Machine Learning (2004): 18.
Get Praktische natürliche Sprachverarbeitung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

