Capítulo 4. Bloques de construcción para la enseñanza automática
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
A mi hijo de ocho años, Christien, le encanta jugar con bloques LEGO. Puede jugar durante horas construyendo coches, aviones y paisajes. Disfruto construyendo cosas con él. A veces, cuando estamos construyendo, necesitamos justo la pieza adecuada para completar una sección. Así que buscamos en grandes cubos la pieza adecuada. Cuando encontramos un bloque que cumple la función adecuada, toda la estructura quedamuy bien.
Lo mismo ocurre con los cerebros de IA. La toma de decisiones autónoma que funciona en la vida real no surge mágicamente de un algoritmo monolítico: se construye a partir de bloques de aprendizaje automático, IA, optimización, teoría del control y sistemas expertos.
He aquí un ejemplo. Un grupo de investigadores de la UC Berkeley, bajo la dirección de Pieter Abbeel, enseñó a andar a un robot. Este robot, Cassie, se parece un poco a un pájaro sin torso (sólo con patas). El cerebro de IA que construyeron para controlar el robot encaja módulos de toma de decisiones de múltiples tipos diferentes y los orquesta de un modo que tiene sentido con lo que sabemos sobre el funcionamiento de la marcha. Combina matemáticas (teoría de control), manuales (sistemas expertos) y módulos de IA de aprendizaje automático para permitir un aprendizaje más rápido de una marcha más competente que cualquiera de esas técnicas de toma de decisiones por sí solas.
Puedes ver en la Figura 4-1 que este cerebro utiliza diferentes módulos para realizar diferentes funciones. Utiliza controladores PD para controlar las articulaciones. Como aprendiste en el Capítulo 2, los controladores PD son bastante buenos para controlar una única variable, como la posición de una articulación, basándose en la retroalimentación. La biblioteca de la marcha contiene experiencia almacenada sobre patrones de marcha satisfactorios (dentro de un minuto hablaré de lo que es exactamente una marcha). Este módulo es un sistema experto (recuerda los manuales del Capítulo 2) que permite consultar la experiencia codificada y almacenada. El módulo etiquetado como "Política" es un módulo DRL que selecciona el modelo de andar correcto y cómo ejecutarlo. Puedes leer los detalles de cómo funciona este cerebro en el documento de investigación del equipo de Cassie.
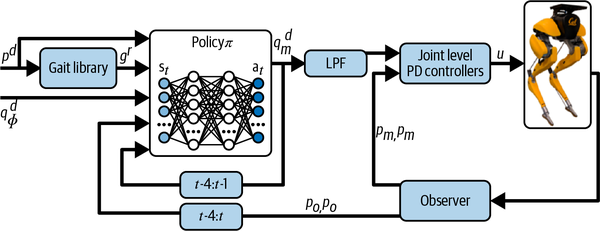
Figura 4-1. Diseño del cerebro de la IA que controla el robot andante Cassie.
Cada uno de estos módulos funciona a escalas de tiempo distintas y utiliza una tecnología de toma de decisiones diferente, pero ninguna de estas características explica por qué este cerebro tiene múltiples módulos. La razón de los diferentes módulos cerebrales es realizar las múltiples habilidades necesarias para caminar. Sin embargo, una forma rápida y fácil de determinar que se necesitan múltiples módulos es buscar decisiones que se produzcan en diferentes escalas temporales y asignarlas a habilidades. Por ejemplo, los controladores de la EP funcionan a una frecuencia muy alta (piensa en 10 decisiones por segundo) mientras mueven las articulaciones. Pero, ¿con qué rapidez cambia la posición del cuerpo durante la ejecución de la marcha? No tan rápido. Cuando caminamos, cambiamos de marcha cuando cambia la superficie o las condiciones para caminar, incluso con menos frecuencia que cuando nos ajustamos a una nueva posición del cuerpo para ejecutar la marcha.
La Tabla 4-1 resume las habilidades que el equipo de investigación enseñó explícitamente al cerebro mediante su diseño modular. La primera habilidad consiste en comprender qué es una marcha. Una marcha es un ciclo repetitivo de fases en un movimiento complejo de caminar. Los robots sencillos tienen marchas más simples, pero los bípedos con tobillos y dedos (como los humanos) utilizamos aproximadamente ocho fases de marcha cuando caminamos. Antes de que te dejes llevar pensando si la IA tiene una comprensión verdadera, similar a la humana, déjame explicarte lo que quiero decir. Sin este sistema experto de biblioteca de andares, la IA no entendería qué es un andar, cómo se relaciona un andar con caminar o cómo utilizar los andares para caminar. Pero este sistema experto define y almacena los andares que la IA utilizará para hacer andar al robot. Así que, de un modo primitivo, este cerebro sí que entiende los andares.
| Habilidad para caminar | Técnica utilizada para realizar la habilidad |
|---|---|
Comprender la marcha |
Sistema experto (menús) |
Selecciona y ejecuta la marcha |
Aprendizaje profundo por refuerzo |
Traducir la marcha al control articular |
Filtro paso bajo (matemático) |
Juntas de control |
Control PD (matemáticas) |
La segunda habilidad consiste en seleccionar qué marcha utilizar en cada momento y asegurarse de que la pose del robot obedece a la marcha. La pose de un robot es muy parecida a la pose humana: la forma del armazón del robot cuando sus articulaciones se colocan en posiciones específicas. ¡Éste es un trabajo para DRL! Puedes pensar en cada fase de la marcha(Figura 4-2) como una estrategia que debe utilizarse justo en el momento adecuado para completar la tarea con éxito. DRL es estupendo para aprender estrategias y adaptar el comportamiento a las condiciones cambiantes.
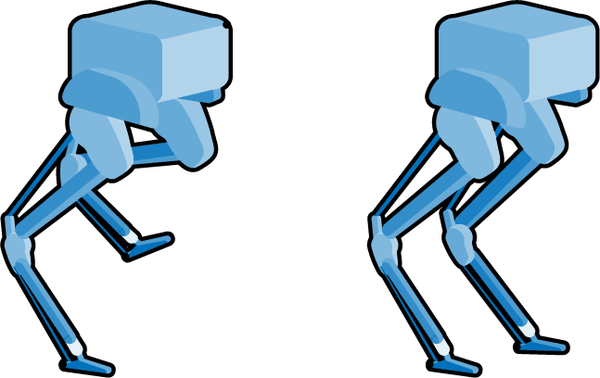
Figura 4-2. Ejemplos de posturas del robot relacionadas con la marcha.
A continuación, tenemos que traducir las posturas a un control de bajo nivel de las articulaciones. Esta tercera habilidad no es una habilidad de toma de decisiones. No realiza ninguna acción sobre el sistema. Es un traductor entre la pose y la orden de posición de la articulación que hay que dar al controlador de la PD. La tecnología que encaja perfectamente para realizar esta habilidad es un filtro de paso bajo. Utilizados a menudo en aplicaciones de audio, los filtros de paso bajo son excelentes para difuminar o suavizar las señales, de modo que las articulaciones se muevan suavemente entre las poses en lugar de dar tirones. Después de utilizar filtros de paso bajo para articular las articulaciones, por fin podemos utilizar nuestros probados y verdaderos controladores de EP para aplicar la retroalimentación y asegurarnos de que las articulaciones ejecutan los movimientos de la marcha con éxito. El diseño del cerebro capta las habilidades fundamentales necesarias para caminar y permite que el algoritmo de aprendizaje adquiera el comportamiento de caminar de forma estructurada con la práctica. La Figura 4-3 muestra el aspecto del diseño del cerebro traducido a nuestro lenguaje visual para cerebros.
Figura 4-3. Diagrama de diseño del cerebro del robot Cassie del equipo de Abbeel.
Caso práctico: Aprender a andar es difícil de evolucionar,más fácil de enseñar
Caminar sobre dos piernas es un movimiento complejo y difícil de describir y ejecutar. Los roboticistas han trabajado mucho en la ingeniería inversa de la marcha y en enseñar a caminar a los robots. La mayor parte de este trabajo utiliza matemáticas complejas para calcular las acciones de control y luego aplicarlas a cada articulación del robot. Un segundo enfoque aprovecha algoritmos de IA para aprender políticas de control o buscar la forma correcta de controlar cada articulación para caminar (esto incluye algoritmos de optimización como los algoritmos evolutivos y el DRL). Ninguno de estos enfoques permite que un humano enseñe ni siquiera los conocimientos más comprendidos sobre la marcha.
¿Ves el robot morado de aspecto gracioso de la Figura 4-4? Se trata de un gimnasio de entrenamiento para enseñar a la IA a andar sobre dos piernas. Este entorno simula un robot de dos piernas con cuatro articulaciones: dos articulaciones superiores que funcionan como las caderas humanas y dos articulaciones inferiores que funcionan como las rodillas humanas. Este robot no tiene tobillos ni pies.
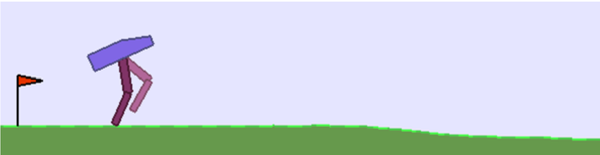
Figura 4-4. Robot andante simple y simulado de dos patas para que la IA practique su control.
Recuerda que, en DRL, el agente practica la tarea y recibe una recompensa en función de lo bien que la realice. La recompensa básica que viene con este entorno de gimnasio da puntos por cuánto avance, pero penaliza con 100 puntos si se cae (su casco morado toca el suelo). Un investigador de IA utiliza la imagen de la Figura 4-5 para describir cuatro estrategias de movimiento que los agentes aprenderán por sí solos con esta recompensa.
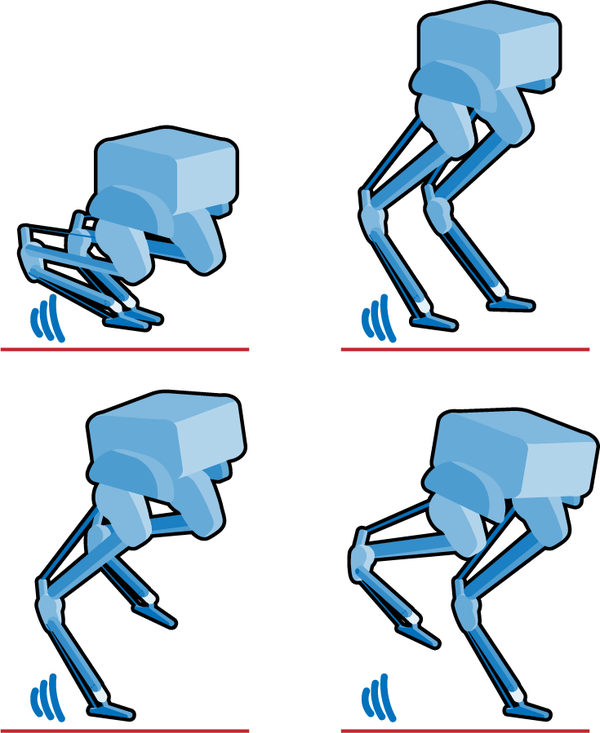
Figura 4-5. Cuatro estrategias de movimiento autoaprendidas que no se consideran caminar.
El equilibrio doble se parece a alguien que golpea rápidamente el suelo de puntillas. En el equilibrio de rodillas, la IA se arrodilla sobre una rodilla y, a continuación, utiliza la pierna delantera para estirarse y arrastrar el cuerpo hacia delante con un movimiento de zarpazo. La estrategia de equilibrio trasero coloca el peso del cuerpo sobre la pierna trasera y se desplaza hacia delante dando zarpazos con la pierna delantera. Es similar al equilibrio de rodillas, pero en posición de pie. A primera vista, se parece un poco a caminar, pero las piernas nunca se cruzan en el característico movimiento de tijera. Por último, el equilibrio frontal extiende y endurece la pata trasera y da un zarpazo hacia delante con la pata delantera. De nuevo, las patas nunca se cruzan.
Entonces, ¿por qué caminamos?
La marcha se define por una marcha pendular invertida en la que el cuerpo salta sobre la extremidad o extremidades rígidas a cada paso y en la que al menos una pierna permanece en contacto con el suelo en todo momento. Básicamente, esto significa que cuando caminas, saltas (como un saltador de pértiga) sobre la pierna plantada, levantas la pierna contraria y luego repites el proceso. Esto es un poco cómo caminamos, pero he aquí por qué: caminar es la forma más eficiente energéticamente para que los bípedos (animales con dos patas) se desplacen. No es la forma más rápida de desplazarse ni la más fácil, pero caminar consume la menor cantidad de energía por cada distancia que recorres.
Entonces, ¿te estoy diciendo que ninguna de las estrategias de movimiento anteriores cumple siquiera los criterios de la marcha? Exacto, ninguna de estas estrategias para desplazarse sobre dos piernas cumple la definición de caminar. Así pues, aunque estos agentes han aprendido a moverse sólo con la experiencia, no han aprendido a andar. Si los cerebros pueden aprender mediante la práctica y la búsqueda de recompensas, ¿por qué estos agentes no aprenden a andar? Resulta que el DRL se vuelve conservador cuando se le penaliza duramente, de forma muy parecida a como lo hacen los aprendices humanos. La IA recibe un castigo severo cuando se cae, pero una recompensa mucho menor para incentivarla a dar sus primeros pasos. En cambio, la IA tiene que hacer muchas cosas bien para obtener toda la recompensa de caminar, así que se conforma con cosas que son formas más seguras de obtener recompensas sin castigo. Estas cosas (que son más parecidas al gateo) permiten al cerebro obtener la recompensa de avanzar con mucho menos riesgo de caerse y sin tener queaprender a mantener el equilibrio.
El gimnasio de entrenamiento de IA viene con un controlador PID que está ajustado para realizar el movimiento de andar. El controlador camina con éxito, pero sólo lo hará a determinadas velocidades de marcha. El cálculo matemático proporciona una definición muy precisa de la acción que debe realizar en cada condición, pero da como resultado un movimiento mecánico espasmódico al andar. Cuando vi el ejemplo del control PID, me dio una idea. El controlador PID separa el movimiento en tres fases de marcha. Después de ver esto, utilicé mis dos primeros dedos (índice y corazón) como "piernas andantes" para identificar y nombrar las tres habilidades andantes que quería enseñar. Mi objetivo era ir más allá de las estrategias de movimiento surgidas únicamente del ensayo y error y de los movimientos rígidos de andar del controlador PID: quería enseñar a la IA a andar.
La Tabla 4-2 muestra cómo cada estrategia heurística especifica los movimientos articulares efectivos que componen la marcha al caminar.
| Fase de la marcha | Estrategia heurística (caderas) | Estrategia heurística (rodillas) |
|---|---|---|
Levanta la pierna basculante |
Flexiona la cadera oscilante (flexiona la pierna oscilante), extiende la cadera plantada |
Flexiona la rodilla oscilante, extiende la rodilla plantada (mantén recta la pierna plantada) |
Planta la pierna basculante |
Extender la cadera basculante, flexionar la cadera plantada/flexionar |
Extiende la rodilla basculante (flexiona y luego estira la pierna basculante) |
Estrategia frente a evolución
La conferencia de investigación sobre IA NeurIPS (Neural Information Processing Systems), antes NIPS, organizó en 2017 y 2018 , un concurso de aprendizaje por refuerzo en el que el reto consistía en entrenar a la IA para controlar un esqueleto humano y 18 músculos de la parte inferior del cuerpo para que corriera y caminara. En la Figura 4-6 se muestran un par de fotogramas congelados de la IA ganadora.
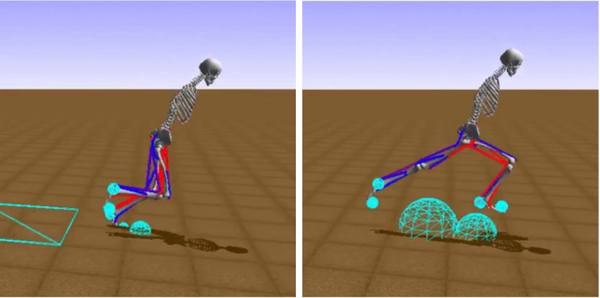
Figura 4-6. El participante ganador del concurso NIPS '17 ¡corre de verdad!
Diseñé y entrené la IA para esta competición. Era extremadamente frustrante ver a mi cerebro de IA hacer cosas como los movimientos que se muestran en la Figura 4-7, ninguno de los cuales se utiliza al andar, cuando (siendo yo mismo un andador bípedo), ya tenía bastantes conocimientos sobre el andar que quería enseñar.
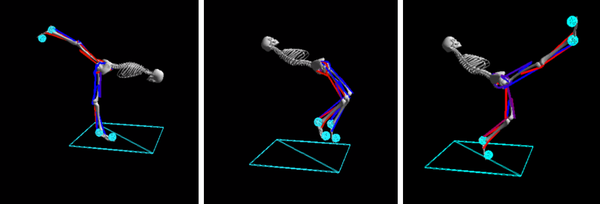
Figura 4-7. Mi esqueleto realizando tres movimientos que no se utilizan para andar: inclinarse hacia delante y extender una pierna hacia atrás (esto es yoga, no andar), saltar y caer hacia atrás, y dar una patada con una pierna hacia fuera (esto parece más un mal baile de can-can que andar).
Mis cerebros rindieron horriblemente en las tareas de la competición, pero lo que aprendí me ayudó a desarrollar las técnicas de diseño cerebral de este libro y a resolver un montón de problemas del mundo real. La Tabla 4-3 muestra algunos otros comportamientos que mi cerebro de IA pasó mucho tiempo explorando, y las cosas correspondientes que yo deseaba desesperadamente enseñarle en su lugar.
| No lo hagas | Razón | Haz esto en su lugar |
|---|---|---|
Lúpulo |
Al andar y correr, las dos piernas no funcionan al unísono. |
Mueve las piernas en movimiento de tijera. |
Caída hacia delante |
Caminar implica saltar sobre una pierna plantada. |
Balancea una pierna hacia delante y plántala. |
Ponte de pie sobre una pierna, mientras balanceas la otra |
Caminar requiere plantar la pierna que se balancea, para que puedas saltar sobre ella y avanzar. |
Balancea una pierna hacia delante y plántala. |
Incluso el ganador del concurso de 2017, NNAISENSE, siente mi dolor. Aquí está la advertencia que comparten en el sitio web con el código que utilizaron para crear la IA:
[Reproducir] los resultados utilizando este código es difícil por varias razones. En primer lugar, el proceso de aprendizaje (sobre todo en la Etapa I: Optimización de la Política Global) se realizó manualmente: se ejecutaron varias ejecuciones y se inspeccionaron visualmente para seleccionar la más prometedora para las etapas siguientes. En segundo lugar, se perdieron las semillas aleatorias originales. En tercer lugar, todo el proceso de aprendizaje requería importantes recursos informáticos (al menos un par de semanas de una máquina de 128 CPUs). Estás avisado.
Traducción: tuvimos que capturar el cerebro haciendo cosas correctamente como un rayo en una botella y coser los comportamientos, e incluso entonces se necesitaron cantidades extremas de práctica y potencia de cálculo.
Esto no es sorprendente, ya que los humanos tardaron aproximadamente 2 millones de años en aprender a caminar totalmente erguidos a través de la evolución. En "El origen de la estrategia", un artículo pionero sobre estrategia empresarial, el profesor de la Harvard Business School Bruce D. Henderson afirma que la estrategia crea una interrupción inteligente, creativa y planificada de la evolución incremental. En biología, la competencia impulsa a la selección natural a diferenciarse, pero de forma incremental y a un ritmo muy lento. Así es como la rana venenosa desarrolló una piel tóxica de colores brillantes para disuadir a los depredadores, y cómo el sapo de los arbustos de Roraima desarrolló el comportamiento de enroscarse y saltar desde los acantilados de las montañas, lo que le hace parecer una roca rodando cuesta abajo.
La estrategia interrumpe y desvía la evolución y sus largos periodos de deriva hacia el equilibrio. De forma muy parecida a las revoluciones científicas de las que hablamos en el Capítulo 1, la estrategia puntúa estos periodos. Stephen Jay Gould y Niles Eldredge describen un fenómeno muy similar en su artículo de 1977 "Equilibrios puntuados".1 Lo vemos en los negocios todo el tiempo. La cadena de alquiler de películas Blockbuster dominaba el mercado del entretenimiento doméstico permitiéndote buscar títulos en la tienda y pedir prestada tu selección por unos pocos dólares. Luego, Netflix se ofreció a enviarte la película directamente a casa y más tarde te permitió transmitirla directamente a tu televisor. No tienes que salir de casa, pero tampoco tienes acceso a todos los estrenos más recientes. Luego, Redbox ofreció un nuevo e interesante giro al alquiler de películas basado en la localización, cuando creó máquinas expendedoras en las que puedes autoservirte y alquilar los títulos que quieras. Los andares son estrategias que los humanos descubrieron a lo largo de millones de años. Podemos atajar el aprendizaje de la marcha introduciendo estas estrategias en el agente. En la siguiente sección, te mostraré cómo utilicé estrategias para arrancar el aprendizaje de mi cerebro de IA.
Enseñar a andar como tres habilidades
Así que decidí enseñar a mi cerebro las mismas tres habilidades que utilizaba el controlador PID en el ejemplo de referencia: las habilidades que validaba al pasar los dedos por una mesa.
Definir las competencias
Para enseñar cada una de estas tres habilidades, tuve que limitar la amplitud de movimiento de la cadera y la rodilla para cada habilidad (estrategia). Por ejemplo, no puedes levantar una pierna (haciendo equilibrio sobre la otra) a menos que mantengas rígida la pierna plantada. No puedes mantener rígida la pierna plantada a menos que extiendas la rodilla y flexiones la cadera. Aquí es donde ayuda probarlo caminando con los dedos sobre una superficie dura. Consulta la Tabla 4-4 para obtener información detallada sobre los intervalos de acciónque he utilizado.
| Fase de la marcha | Amplitud de movimiento (cadera) | Amplitud de movimiento (rodilla) |
|---|---|---|
Levanta la pierna |
Flexiona (cierra) la cadera basculante, flexiona y luego extiende (abre) la cadera plantada |
Flexiona (curva) la rodilla oscilante, extiende (endereza) la rodilla plantada |
Pata de planta |
Extiende (abre) la cadera basculante, flexiona y luego extiende la cadera plantada |
Extiende (endereza) la rodilla oscilante, extiende (endereza) la rodilla plantada |
Pata giratoria |
Flexiona (cierra) la cadera basculante, flexiona y luego extiende la cadera plantada |
Flexiona (curva) la rodilla oscilante, extiende (endereza) la rodilla plantada |
La Figura 4-8 ilustra el resultado de estos esfuerzos. Esto es lo que parece caminar. La IA cometió muchos errores y necesitó mucha práctica, ¡pero no perdió el tiempo haciendo cosas que no se parecen a caminar! Por cierto, este paso de definir las acciones que requiere cada habilidad es crucial. Lo cubro en detalle en el Capítulo 5, "Enseñar a tu cerebro de IA lo que debe hacer". Puedes encontrar el código completo para enseñar a este cerebro en un fork de GitHub de OpenAI Baselines.
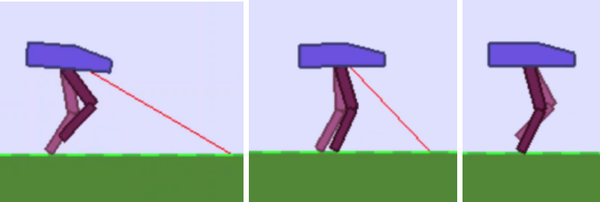
Figura 4-8. Mi cerebro de IA ejecutó las tres habilidades que le enseñé: levantar la pierna, plantar la pierna, balancear la pierna (opuesta).
Establecer objetivos para cada habilidad
A continuación, establecí un objetivo y unos criterios de éxito para cada una de las tres habilidades. Hablaremos más sobre cómo establecer objetivos para tu cerebro de IA en el Capítulo 6. Cada fase de la marcha tiene objetivos distintos que facilitan la marcha.
| Fase de la marcha | Objetivo |
|---|---|
Levanta la pierna |
Empuja con suficiente velocidad para saltar por encima de la pierna plantada. |
Pata de planta |
Planta la pierna con suficiente impulso (fuerza en el momento del impacto) para soportar el peso del robot. |
Pata giratoria |
Esta es la fase de la marcha que genera la mayor parte del movimiento hacia delante. |
Puedes ver que cada una de estas fases de la marcha tiene objetivos radicalmente distintos. La primera fase de la marcha consiste en empujar y coger velocidad suficiente para saltar por encima de la otra pierna cuando la plantas. En la segunda fase, la velocidad no importa tanto. Los caminantes tienen éxito en la segunda fase cuando plantan la pierna con fuerza suficiente para soportar el peso del cuerpo. De lo contrario, el caminante se desplomará sobre el suelo. La fase final tiene otro objetivo primordial: el movimiento hacia delante. Esta fase es la gran impulsora de las tres marchas. Durante la primera y la segunda fase, el cuerpo no se mueve mucho hacia delante, aunque las fases tengan mucho éxito. ¿Ves cómo cada fase de la marcha realiza una habilidad funcional diferente con objetivos diferentes?
Organizar las competencias
A continuación, encajé estas habilidades en un diseño cerebral. El patrón de marcha para caminar circula las habilidades en una secuencia: levantar la pierna, plantar la pierna, balancear la pierna, levantar la pierna (contraria), plantar la pierna (contraria), balancear la pierna (contraria), etc. La figura 4-9 muestra el aspecto del diseño cerebral.
Este diseño cerebral separa el cerebro en las habilidades que aprenderá y orquesta cómo funcionarán juntas las habilidades aprendidas. Cada diseño cerebral es una IA en miniatura que practicará y aprenderá a realizar esa habilidad. Tres habilidades ejecutan las fases de la marcha y una habilidad cambia entre fases de la marcha. En la siguiente sección, defino y categorizo los bloques de construcción que ensamblarás en tus diseños cerebrales y proporciono un marco para organizar esas habilidades juntas.
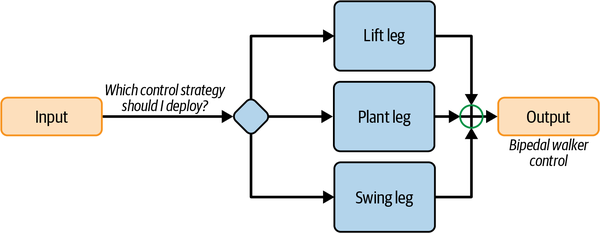
Figura 4-9. Un diagrama de diseño cerebral que enumera y orquesta las habilidades necesarias para realizar con éxito la tarea de caminar.
Los conceptos captan el conocimiento
Un concepto es una noción o una idea que comprende una unidad componible de conocimiento. Hay una serie de conceptos que quería que mi cerebro andante de IA aprendiera practicando las habilidades que le enseñé:
- Saldo
-
Quiero que el cerebro aprenda a evitar que el robot se caiga.
- Simetría
-
Quiero que el cerebro aprenda que los andares son movimientos aproximadamente simétricos.
- Oscilación
-
Quiero que el cerebro aprenda que las piernas que caminan oscilan en movimiento periódico.
Estos conceptos son difíciles de describir, pero como humanos dependemos de ellos para caminar correctamente. En el diseño de mi cerebro, mi plan de enseñanza se basa en enseñar explícitamente los movimientos de la marcha como habilidades y en que la IA aprenda los conceptos adicionales mediante la búsqueda de recompensas mientras practica. El cerebro de la IA no tendrá éxito de forma consistente a menos que aprenda el equilibrio, la simetría y la oscilación, aunque no haya enseñado explícitamente ninguno de estos conceptos.
Las habilidades son conceptos especializados
Las habilidades también son conceptos, pero son conceptos especializados que pasan a la acción para realizar tareas. Las habilidades son unidades de competencia para completar tareas con éxito. Son los bloques de construcción de tareas complejas. Si realizas la habilidad adecuada en el momento adecuado, tendrás éxito. Por ejemplo, la secuencia de habilidades en nuestra IA de andar es importante. Para caminar con éxito, tienes que levantar la pierna del robot, luego plantar la pierna del robot y luego balancear la pierna opuesta del robot. De lo contrario, el robot no se impulsará con suficiente velocidad (ése es el objetivo de la primera habilidad para caminar), no plantará la pierna con suficiente fuerza para soportar su peso (ése es el objetivo de la segunda habilidad para caminar), y no conseguirá un movimiento eficiente hacia delante al saltar sobre la pierna plantada (ése es el objetivo de la tercera habilidad para caminar).
Esto es cierto para todas las habilidades complejas, ya sea Pac-Man, la Venganza de Moctezuma, el ajedrez, el baloncesto o los muchos ejemplos industriales que proporciono en este libro. Permíteme que te ponga un ejemplo más. ¿Recuerdas el cerebro de IA que diseñé para controlar los sistemas de climatización del Campus de la Sede Central de Microsoft? La Figura 4-10 muestra algunos datos del control de la refrigeración de esos siete edificios.
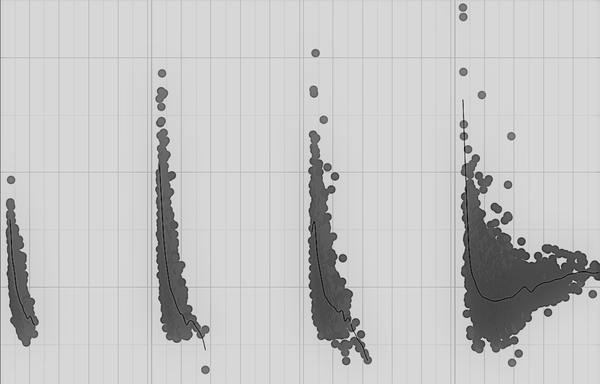
Figura 4-10. Gráfico de datos de las variables del sistema de enfriadoras HVAC que muestran las diferentes políticas de control necesarias para cada uno de los cuatro rangos de temperatura.
¿Puedes adivinar cuántas habilidades se necesitan para controlar bien este sistema?
Los datos nos dicen que el sistema se comporta de forma completamente distinta en cada uno de los cuatro regímenes de temperatura. Así pues, cuando los expertos nos dijeron que se necesitaban cuatro habilidades, simplemente estaban informando sobre cómo se comportaba el sistema según su experiencia. Este análisis exploratorio de datos nos dijo exactamente lo mismo.
Enseñamos estas habilidades explícitamente creando diferentes módulos en el cerebro que practicaban cada uno de estos distintos regímenes de temperatura por separado. El cerebro aprendió explorando cada uno de estos regímenes y construyendo correlaciones más matizadas entre las variables de entrada y las acciones de salida que las que podría establecer cualquier modelo matemático aislado.
Los cerebros se construyen a partir de habilidades
La mentalidad de la inteligencia algorítmica sugiere que los cerebros se construyen a partir de algoritmos. Si necesitas un cerebro nuevo para una tarea nueva, escribe un algoritmo nuevo. Pero la mentalidad de la inteligencia docente nos dice que los cerebros se construyen a partir de habilidades. Si necesitas un cerebro nuevo para realizar una tarea nueva, identifica y enseña habilidades. Independientemente del paradigma de aprendizaje que utilices para simular el aprendizaje, el cerebro necesitará adquirir habilidades para tener éxito. Entonces, ¿cómo construye y adquiere habilidades un cerebro de IA?
Construir habilidades
¿Has intentado alguna vez articular un concepto difícil de describir? He aquí algunos ejemplos: amor, justicia, belleza. Cada uno de estos conceptos son abstractos y se definen mejor dando muchos ejemplos y contraejemplos (las puestas de sol y las rosas y las sonrisas pueden ser bellas, pero una sonrisa sardónica no es bella, es perturbadora). El sociólogo Herbert Blumer describió este tipo de conceptos como conceptos sensibilizadores.2 Sensibilizar significa establecer una serie de parámetros que podemos utilizar para evaluar si el concepto es aplicable. Blumer definiría el amor, la justicia y la belleza como conceptos sensibilizadores.
Las habilidades que aprenderá tu cerebro se parecen mucho a los conceptos sensibilizadores. Aprendemos conceptos sensibilizadores recibiendo información sobre los parámetros que evalúan si el concepto es aplicable. Por ejemplo, un parámetro que muchos utilizan para evaluar la belleza es cómo te hace sentir algo cuando lo ves. Si te hace sentir feliz o triste, puede ser bello. Si te hace sentir miedo, enfado o asco, probablemente no sea bello. A continuación, descubrimos los límites en torno a estos conceptos comparando muchos ejemplos con los parámetros de sensibilización definidos para el concepto. Lo mismo ocurre con las habilidades que aprenderá tu cerebro.
Por ejemplo, la habilidad de un ataque eficaz de fútbol (americano) es difusa. Debes ser capaz de marcar contra defensas 3-4, 4-3, de jugador contra jugador y de zona (cobertura). Cada una de esas defensas son criterios sensibilizadores de la habilidad de un equipo para ejecutar el ataque de fútbol americano. Lo mismo ocurre con los procesos industriales y la automatización de fábricas. Uno de los aspectos más desafiantes de la gestión de procesos industriales es que hay múltiples objetivos, a menudo contrapuestos, y muchos más escenarios en los que tener éxito. Un objetivo en la fabricación es el rendimiento (cuánto produces), pero otro objetivo contrapuesto es la eficiencia. Puedo fabricar muchos productos, pero también puedo gastar mucha energía para hacerlo. Puedo fabricar productos de forma muy eficiente (mano de obra y energía), pero podría sacrificar la producción para conseguir esa eficiencia. Para esta habilidad de fabricación, tanto el rendimiento como la eficiencia son criterios de sensibilidad.
Las Reglas Expertas se Inflan en Habilidades
El proceso de aprendizaje de habilidades encaja bien en la prescripción de Blumer para aprender conceptos sensibilizadores: empieza con un conjunto de ejemplos y, a partir de ahí, añade ejemplos y contraejemplos.
Consejo
Puedes pensar en una regla experta como el punto de partida para aprender una habilidad.
Una regla proporciona un conjunto de ejemplos del mismo modo que la definición de una recta proporciona un conjunto de puntos. La forma y = mx + b (la ecuación de una recta) nos da un conjunto de puntos para la recta. Así, si a = 1 y b = 0, el conjunto de puntos de la recta será (0,0), (1,1), (2,2), etc. La regla proporciona ejemplos sólidos que son a la vez fieles al concepto y fáciles de entender para el principiante. Con la práctica y la experiencia, el principiante empieza a identificar las excepciones a la regla. Estas excepciones también son fieles al concepto y proporcionan una comprensión mucho más matizada del mismo.
Una regla es el punto de partida de una habilidad. Una habilidad se desarrolla identificando las excepciones a una regla y agregándolas en una descripción más completa y matizada del concepto. Este concepto se define mediante parámetros en dos dimensiones en la Figura 4-11, pero los conceptos pueden definirse mediante parámetros en cualquier número de dimensiones.
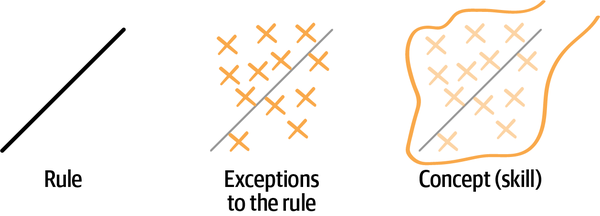
Figura 4-11. Una regla como punto de partida de una habilidad.
La Tabla 4-6 muestra algunos ejemplos de conceptos de habilidad que pueden expresarse como una regla experta, pero también desarrollarse con más detalle descubriendo excepciones. La mayoría de estos ejemplos ya se han tratado en el libro; veremos momentáneamente el ejemplo de la planificación de la flota naval.
| Habilidad | Regla | Ejemplos de excepciones |
|---|---|---|
Pujar (como en el póquer Texas hold 'em) |
Juega sólo las manos "top 10", retira todo lo demás. |
A menos que tengas una pareja inferior y creas (normalmente por la puja) que nadie más tiene una mano top 10. |
Manipulación de equipajes (logística aeroportuaria) |
Utiliza la cinta transportadora para las maletas cuyo vuelo de conexión esté programado para dentro de 45 minutos o más. |
A menos que las predicciones indiquen que algunos vuelos se cancelarán por causas meteorológicas. En ese caso, utiliza la cinta transportadora para las maletas cuyo vuelo de conexión sea probable que se cancele, aunque esté previsto que salga dentro de 45 minutos. |
Puntuación en baloncesto |
Si estás cerca de la canasta, lanza una bandeja, no un salto. |
A menos que te defienda de cerca un defensor más grande. En ese caso, lanza un tiro en salto (considera un fadeaway). |
Trituradora de rocas |
Estrangula la trituradora para rocas grandes y duras, y regula la trituradora para rocas pequeñas y blandas. |
A menos que tengas una baja demanda de mineral por parte del cliente. En ese caso, produce el mineral necesario de la forma más eficiente posible, lo que puede incluir estrangular la trituradora para obtener rocas más pequeñas y blandas de lo que lo harías de otro modo. |
Planificación de flotas de juegos navales |
Utiliza un tanque (nave con blindaje y armamento sobredimensionados) para atraer y hundir a la flota enemiga. |
A menos que el enemigo tenga un gran enjambre de naves. En ese caso, utiliza varias naves medianas-grandes para dividir el enjambre, luego atrae y derrota a cada sección del enjambre. |
A medida que los humanos y la IA practican habilidades, identifican excepciones a la regla que proporcionan una imagen más precisa y matizada de cómo realizar la habilidad, del mismo modo que adquirimos una comprensión más matizada de lo que son el amor, la justicia o la belleza después de muchas experiencias y de ejemplos contraejemplos.
Echa un vistazo a los puntos de datos de la Figura 4-12. No sé qué concepto o habilidad representa esto, pero parece bastante matizado y complejo. Una forma de abordar esta habilidad es encontrar una única línea recta que parezca representar mejor este concepto. Esta técnica de ajustar una recta a un conjunto de puntos se denomina regresión lineal. La Figura 4-13 muestra una recta de regresión lineal trazada sobre los puntos de datos.
Este enfoque simplificador tiene sus ventajas. Estas representaciones simplificadas proporcionan réplicas portátiles del concepto que son fáciles de manipular y transferir. En el contexto del diseño de la IA autónoma, donde los conceptos son habilidades que la IA aprenderá, las representaciones simplificadas son reglas expertas. Los humanos simplifican los conceptos en reglas expertas por tres razones principales:
-
Las reglas de experto proporcionan un punto de partida para practicar habilidades.
-
Las reglas de los expertos son fáciles de entender y seguir para los principiantes.
-
Las reglas de los expertos son fáciles de comunicar para los profesores.
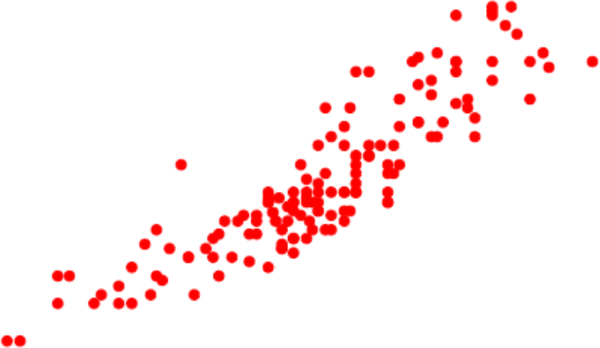
Figura 4-12. Conjunto de ejemplos que podrían representar un concepto. Quizá puedas aproximarte a este concepto con una línea recta, pero la realidad tiene muchos más matices que la línea recta.
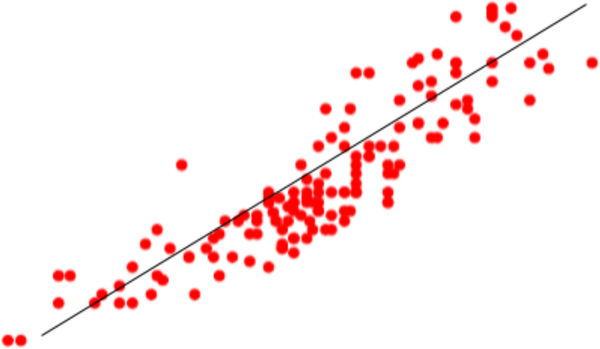
Figura 4-13. Una regresión lineal que describe este concepto complejo como una línea.
Esta idea de desinflar conceptos en reglas expertas simplificadas es la base de los sistemas expertos. Del mismo modo que el sellado al vacío de los alimentos los hace más transportables, desinflar los conceptos en reglas expertas los hace más fáciles de enseñar. Prometedor, pero ya hablé de los inconvenientes en el Capítulo 2. ¿Hay alguna forma de aprovechar las ventajas simplificadoras de las reglas expertas y seguir abarcando todos los matices del concepto?
Sí! En la siguiente sección, y luego con mucho más detalle en el Capítulo 7, te mostraré cómo utilizar reglas de experto como abreviaturas de los conceptos que te gustaría enseñar. Esto te permite definir qué destrezas son importantes que el alumno domine (en lugar de dejar que sea el alumno quien descubra tanto las destrezas como la forma de realizarlas) y permite que el alumno descubra formas únicas y creativas de realizar estas destrezas practicándolas.
Enseña reglas expertas y deja que el alumno infle los conceptos mediante la práctica
Un conjunto de reglas expertas define las habilidades en el cerebro de la IA, pero en lugar de escribir cientos de reglas expertas adicionales para capturar excepciones que describan los matices de cada habilidad, permitimos que algoritmos como DRL inflen la habilidad practicando: identificando y adaptándose a los matices. La estructura de las habilidades proporciona parte de la explicabilidad y previsibilidad de los sistemas expertos con la creatividad y flexibilidad de los agentes DRL. A menudo, los aprendices humanos también se benefician de ver unos cuantos ejemplos iniciales de cómo inflar un concepto; luego pueden llevarlo más lejos por sí mismos.
Volvamos al ejemplo de la trituradora giratoria. La estructura de las reglas expertas, que reflejan los dos modos de funcionamiento de la máquina, esboza tres habilidades que deben enseñarse y aprenderse. La primera habilidad es la estrategia de estrangular la trituradora cuando la mina produce rocas más grandes y duras. La segunda habilidad es la estrategia de regular la trituradora cuando la mina produce rocas más pequeñas y blandas. La tercera habilidad decide cuándo estrangular la trituradora y cuándo regularla. Este acto de utilizar la experiencia en la materia para definir estas tres habilidades es en sí mismo una enseñanza. Entonces, si entrenamos a cada uno de los tres agentes DRL por separado en una de las tres habilidades anteriores, el cerebro combinado no sólo dirá a los ingenieros qué próxima acción tomar para controlar la trituradora, sino también qué habilidad está utilizando en cada punto de decisión para tomar esa decisión. La figura 4-14 muestra cómo se pueden expresar las habilidades como reglas expertas (tanto para las personas como para la IA), y luego practicarlas para inflarlas completamente en una red neuronal basada en la retroalimentación sensibilizadora.
A medida que la IA aprende (en el caso de DRL, al menos), captura la política en una red neuronal. El profesor define las habilidades a aprender. El algoritmo de aprendizaje aprende cada habilidad. La enseñanza automática aprovecha lo que ya sabes sobre cómo realizar la habilidad para estructurar la IA. El aprendizaje automático construye la IA (en este caso, un conjunto de redes neuronales).
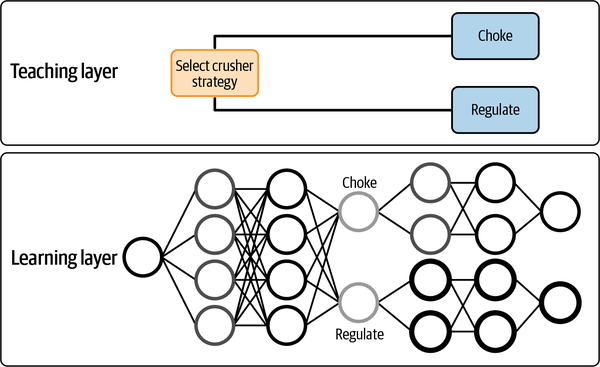
Figura 4-14. Diagrama de habilidades para controlar una trituradora minera.
Consejo
Como diseñador de cerebros, esfuérzate por expresar las habilidades conocidas en forma de reglas expertas. Luego, permite que la IA practique, domine e intercambie con otras habilidades.
A continuación, describiré los tres tipos diferentes de conceptos que utilizarás en tus diseños cerebrales. Los conceptos perceptivos ayudan al cerebro a comprender lo que está ocurriendo. Los conceptos directivos ayudan al cerebro a decidir qué hacer. Los conceptos selectivos asignan el trabajo de percepción y decisión a otros módulos cerebrales.
Conceptos perceptivos Discernir o reconocer
Reaccionar ante un entorno cambiante empieza por recopilar información sobre lo que ocurre en ese entorno. Las máquinas recopilan información con sensores mecánicos. Por ejemplo, un termómetro es un tipo de sensor que mide la temperatura y un barómetro es un tipo de sensor que mide la presión atmosférica. Las personas que diseñan fábricas y sistemas industriales no utilizan los mismos termómetros y barómetros que utilizamos en casa, pero son buenos ejemplos. También tenemos sensores en el cuerpo. Nuestros ojos son complejos sensores de luz, nuestros oídos son sofisticados sensores de audio (como micrófonos), etc. Consulta la entrada del blog de Ravi Teja, "¿Qué es un sensor? Diferentes tipos de sensores y sus aplicaciones" para obtener una lista y una descripción más completas de los sensores industriales.
Los sensores recogen la información, pero ésta debe procesarse y traducirse a un formato que pueda utilizarse para tomar decisiones. Por ejemplo, nuestros ojos son algo más que sensores que reciben luz. Los bastones y conos de nuestros ojos procesan la luz y la traducen en señales eléctricas que nuestro cerebro puede utilizar para tomar decisiones. Nuestros oídos realizan una función similar tras recibir un sonido. Las máquinas necesitan algo más que sensores para tomar decisiones.
Los conceptos perceptivos procesan la información que llega a través de los sensores y envían la información relevante a las partes del cerebro encargadas de tomar decisiones. Por ejemplo, el trastorno del procesamiento auditivo (TPA) es un trastorno del neurodesarrollo que afecta a la percepción del sonido en los seres humanos. Los oídos oyen bien, pero la dificultad para interpretar los sonidos oscurece la información. Hay cinco habilidades perceptivas comunes que se suelen utilizar en el diseño de IA autónoma.
Ver y oír
Bell Flight diseña y construye helicópteros y otros vehículos de despegue y aterrizaje vertical (VTOL). ¿Has visto alguna vez el V-22 Osprey? Parece un avión, pero cuando despega, inclina sus rotores hacia arriba y despega (en línea recta) como un helicóptero. Una vez en el aire, inclina los rotores hacia atrás y vuela como un avión. Existe una versión autónoma, el V-280 Valor, que vuela sin piloto. Bell también fabrica drones de transporte de mercancías y pasajeros.
Los drones autónomos y los helicópteros más grandes, como el V-280, utilizan sistemas de posicionamiento global (GPS) para calcular la posición y el control. Pero si el GPS está bloqueado por edificios, los sistemas autónomos deben volar y aterrizar con la vista, como harían los pilotos humanos. Los sistemas de cálculo como los que vuelan por GPS se basan en la teoría del control (matemáticas) y no pueden procesar la información visual de las transmisiones de vídeo y las imágenes de las cámaras.
Así que Bell construyó una IA autónoma para aterrizar con la vista. Este cerebro tiene dos módulos: el primero es un módulo de aprendizaje automático que procesa los datos de la imagen y extrae características sobre la zona de aterrizaje. Imagina un modelo que pueda introducir una imagen de la zona de aterrizaje y obtener datos como las coordenadas del centro de la zona de aterrizaje, así como el cabeceo, la guiñada y el balanceo del dron en el espacio 3D. Éste es el concepto perceptivo y ayuda al cerebro a ver.
El segundo módulo es un módulo DRL que ha practicado el aterrizaje del dron en simulación muchas veces, en muchas zonas de aterrizaje diferentes, utilizando la información visual que le pasaba el primer módulo.
Predecir
Hacemos predicciones para ayudarnos a tomar decisiones todo el tiempo. Cuando decido en qué cola de la caja voy a esperar en el supermercado, miro el número de personas que hay en cada cola (longitud) y el número de artículos que llevan en sus carros, y hago una evaluación aproximada de la velocidad de cada cajero. No miro todos los carritos de todas las colas y no tengo forma de medir la velocidad real de cada cajero ni el número real de artículos que cada cliente de cada cola necesita para pasar por caja. Tomo muestras de datos de muchas variables que he observado antes, utilizo mi experiencia para predecir qué fila me hará pasar por caja más rápidamente, y luego actúo según esa percepción y elijo una fila.
Trabajé con una empresa de fabricación que quería predecir mejor cuánto durarían sus herramientas de corte. Las herramientas giratorias cortan metal para fabricar todo tipo de piezas diferentes que utilizamos a diario. Se desgastan y rompen en función de la velocidad a la que giran, la fricción que experimentan y cuánto las doblas en cada dirección. Si jubilas la herramienta demasiado pronto, habrás malgastado dinero, pero si la herramienta se rompe mientras cortas una pieza, puede que tengas que tirar la pieza en la que estabas trabajando, malgastando aún más dinero.
La Figura 4-15 muestra tres escenarios de desgaste de la pieza. En el escenario 1, la herramienta funciona a baja velocidad pero con alta carga durante la primera parte de su vida útil y a baja velocidad y alta carga durante la segunda parte de su vida útil. La herramienta experimenta una alta fricción durante toda su vida útil. Aunque esta herramienta funciona siempre a alta velocidad o con alta carga, tiene la vida útil más larga de las tres herramientas. La herramienta del escenario 2 falla más pronto cuando se la somete a velocidad y fricción muy altas, aunque comienza su vida con velocidad, carga y fricción bajas. La herramienta del escenario 3 comienza su vida a muy alta velocidad, y aunque luego se utilice a baja velocidad, carga y fricción, falla poco después de la transición. Este ejemplo no pretende modelar ningún escenario físico concreto, pero quiero demostrarte dos cosas: predecir el desgaste es difícil, y los escenarios determinan los patrones de desgaste.
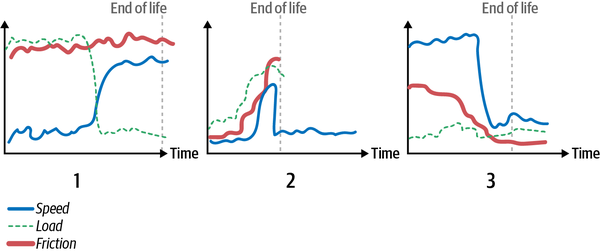
Figura 4-15. Tres piezas se desgastan de forma diferente y sobreviven durante periodos distintos en función de lo que experimentan a lo largo de su vida útil.
Las dos predicciones complejas más comunes que veo en la industria son las predicciones de desgaste como la anterior y las predicciones sobre cuánta demanda de mercado habrá para los productos. La demanda del mercado es compleja, estacional y depende de distintas variables para distintos productos. La demanda de algunos productos es muy estacional, por ejemplo las raquetas de nieve y la crema solar. El petróleo crudo contiene gasolina, gasóleo y combustible para aviones, por lo que las refinerías de petróleo funcionan de forma diferente para fabricar más o menos de cada uno en función de la demanda. Europa consume más gasóleo en invierno para calentar los hogares y más combustible de aviación durante la temporada de viajes de verano.
Detecta
¿Has jugado alguna vez al juego de la infancia "una de estas cosas no es como la otra"? En este juego, observas varios objetos (véase un ejemplo en la Figura 4-16 ) para determinar cuál de ellos es diferente (de alguna manera no coincide con el patrón). Cuando juegas a este juego, buscas anomalías.

Figura 4-16. Algunos de estos objetos se parecen, pero pertenecen a categorías diferentes.
Detectar anomalías es una importante habilidad de percepción que informa la toma de decisiones. Una empresa con la que trabajé quería utilizar la IA en ciberseguridad para detener ciberataques como el ataque de denegación de servicio distribuido (DDoS) de 2018, que utilizó más de 1.000 bots autónomos diferentes para interrumpir el sitio de repositorios de código GitHub durante más de 20 minutos. En un ataque DDoS, los hackers generan a propósito tráfico falso a un sitio web, tanto tráfico que el sitio web no puede funcionar. El primer paso para contrarrestar un ataque DDoS es detectarlo. Es difícil saber si un pico repentino de tráfico se debe a un aumento legítimo de la demanda de los clientes (lo que sería muy bueno) o al comienzo de un ataque DDoS (algo muy malo). Mi receta era que la IA tuviera un módulo que aprendiera a detectar anomalías en el tráfico web y las clasificara como un pico de tráfico o un ataque DDoS, y otro módulo que aceptara las conclusiones del primero y las transmitiera al módulo de toma de decisiones, que actúa para detener los ataques pero deja pasar el tráfico legítimo y valioso.
Clasifica
A veces ayuda clasificar las cosas en categorías antes de tomar una decisión. En el ejemplo anterior de la compra en el supermercado, además de predecir, clasifico las cosas que veo: colas lentas, colas rápidas, colas largas, colas cortas, carros de la compra llenos, carros de la compra vacíos, sin carro de la compra (sólo algunos artículos de mano) y carros de la compra abarrotados. Ya te haces una idea. Los técnicos de mantenimiento suelen hacer lo mismo después de desconectar una máquina para repararla. Clasifican la máquina en estados, y luego toman diferentes medidas para ponerla en línea en función del estado en que se encuentre. Es como lo que puedes hacer cuando mueves una bicicleta desde una posición fija. Si la bicicleta está cuesta abajo, no te preocupes por la marcha que lleves, simplemente empújala. Si la bicicleta está en terreno llano, cambia a una marcha inferior y luego empuja. Si la bicicleta está en una colina, levántate y pedalea. Necesitarás la fuerza extra para arrancar, independientemente de la marcha que lleves. Antes de tomar esta decisión, debes percibir la pendiente del camino por el que te diriges.
Filtrar
Hay una parte fascinante del proceso de fabricación del acero llamada coquización, en la que se introduce carbono en el hierro fundido en presencia de piedra caliza. Hay cientos de variables a tener en cuenta al controlar el alto horno donde se produce este proceso. Es difícil incluso para los expertos humanos que han acumulado décadas de experiencia en su intuición. Así que, en lugar de tener en cuenta todo el conjunto de variables en cada punto de decisión, los ingenieros idearon un índice que reúne una enorme cantidad de información en un solo número. Este número indica a los operarios la mayor parte de lo que necesitan saber para controlar bien el horno. Sí, se pierde mucha información al procesar los datos de este modo, pero para eso están los filtros: para mostrarte la información que necesitas ver mientras eliminas la que no te ayudará a decidir. Es probable que este índice se construyera y probara cuidadosamente antes de utilizarlo como información sobre hornos reales. Tú también deberías tener cuidado en cómo filtras los datos para tomar decisiones.
Conceptos directivos Decidir y actuar
Los conceptos directivos hacen que las cosas sucedan. Deciden y actúan. Tanto si la toma de decisiones es aprendida, programada o incluso aleatoria, estos conceptos toman las decisiones sobre lo que el sistema hará a continuación. En el Capítulo 5, "Enseñar a tu cerebro de IA lo que debe hacer", hablo con mucho detalle de cómo utilizar conceptos directivos en tus cerebros .
Conceptos Selectivos Supervisar y Asignar
Todo trabajo necesita un supervisor, ¿verdad? A menos que seas una hormiga, necesitas un supervisor que tenga una visión de alto nivel del trabajo y asigne tareas y trabajos a los miembros del equipo y a las cuadrillas. Cada cuadrilla sirve a un propósito distinto o necesita ser activada en situaciones diferentes según su especialidad o formación. Los conceptos selectivos son los supervisores del cerebro. Son conceptos directivos especializados. Su función es asignar las decisiones correctas al concepto adecuado. Una vez que un concepto directivo es llamado al servicio, toma la decisión por el cerebro.
La Figura 4-17 muestra un ejemplo de IA que controla la calefacción y la refrigeración en grandes edificios comerciales (como un edificio de oficinas). El sistema de climatización utiliza hielo para almacenar energía y agua para enfriar el aire del edificio. Los conductos pasan el aire a través del agua que lo enfría. La enfriadora utiliza energía para fabricar hielo durante las horas del día en que la energía es más barata. El hielo almacena la energía para enfriar el edificio sin utilizar energía cuando ésta es más cara. Para controlar la enfriadora, la pones en el modo adecuado (fabricar hielo, fundir hielo, pasar el agua directamente sin enfriar, etc.).
Lo más difícil de controlar la enfriadora es el hecho de que los edificios se comportan de forma diferente durante el día y durante la noche. Durante el día, el flujo de personas que entran y salen del edificio impulsa la demanda de refrigeración. Por la noche, cuando hay pocas personas en el edificio, las máquinas en funcionamiento requieren la mayor parte de la refrigeración. Estos escenarios diurno y nocturno son tan diferentes que tendrías que formar a un equipo diurno y otro nocturno distintos para controlar el edificio en momentos diferentes. A veces es fácil determinar cuándo enviar al personal diurno a casa y llamar al personal nocturno; otras veces no.
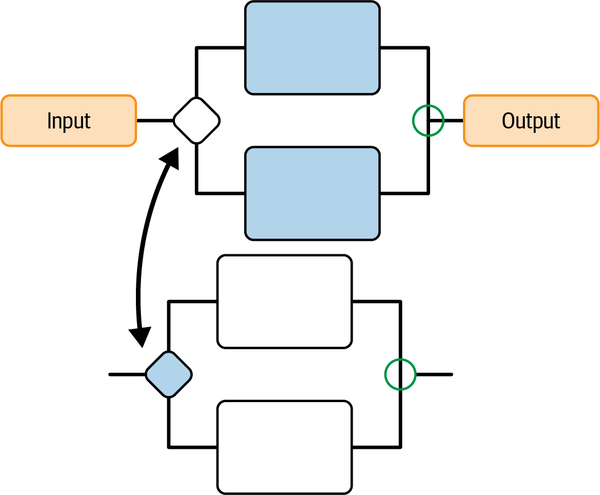
Figura 4-17. Cerebro de IA que controla enfriadores para calefacción y refrigeración de edificios. Un concepto se entrena en escenarios diurnos, otro en escenarios nocturnos; un concepto selectivo supervisor asigna el control al concepto diurno o al nocturno.
Aquí podemos distinguir dos tipos de conceptos: programados y aprendidos. Diseña conceptos programados en tu cerebro cuando esté claro qué concepto debe tomar la decisión. Utiliza conceptos aprendidos cuando sea difícil saber qué concepto debe ser llamado para tomar la decisión en un cerebro.
Conceptos programados
La regla general es que si alguien puede describir cómo asignar cada cuadrilla a la tarea correcta como un conjunto de reglas, entonces programa el selector. Para los edificios con empleados que en su mayoría vienen exactamente a las 9 de la mañana y se van exactamente a las 5 de la tarde, puedes programar el selector como hicimos nosotros. Éste es el aspecto del código del selector en Python:
iftime>=9andtime<=5:# It’s daytime, assign the day crewassign=day_conceptelse:# It’s nighttime, call in the night crewassign=night_concept
La programación es una enseñanza paso a paso en la que especificas cada decisión a tomar a lo largo del camino. Si estás seguro de que sabes y puedes expresar sencillamente las instrucciones para supervisar los conceptos en tu cerebro, diseña con un selector programado.
Conceptos aprendidos
Pero cuando la decisión de qué cuadrilla asignar a una tarea es difusa, es mejor enseñar a un supervisor inteligente a asignar la cuadrilla correcta. Un selector aprendido es un módulo de aprendizaje por refuerzo que practica la asignación de tareas al concepto correcto en el momento adecuado. Experimenta recompensas y penalizaciones en función de si realiza la asignación correcta. Los selectores aprendidos funcionan realmente bien cuando la política sobre a qué concepto asignar las tareas es matizada y depende de muchos factores diferentes.
Así pues, un selector erudito es perfecto para supervisar el cerebro que controla los refrigeradores de un edificio en el que los empleados llegan y se van a horas muy distintas. Para decidir si asignar al personal diurno o al nocturno, el selector debe tener en cuenta muchos factores que afectan al momento en que la gente llega y se va. Por ejemplo, los martes y miércoles por la tarde los empleados tienden a quedarse más tarde para evitar el tráfico. Los jueves y viernes por la tarde, muchos empleados se van pronto para evitar el tráfico, o incluso antes los viernes antes de los fines de semana festivos.
El aprendizaje permite al cerebro explorar la mejor forma de supervisar los conceptos en un cerebro. Si no sabes cuál es la mejor manera de supervisar los conceptos en un cerebro en todas las circunstancias, o si lo sabes pero escribir las instrucciones te llevaría demasiado tiempo y esfuerzo, diseña con conceptos aprendidos. Uno de mis clientes me dijo que sabía que había dos estrategias para manejar su equipo, pero que sólo sabía utilizar bien una de las estrategias. Diseñé un selector aprendido en el cerebro. El concepto aprendido averigua cómo realizar la segunda estrategia, el selector aprendido averigua cuándo utilizar la segunda estrategia.
La distinción entre conceptos programados y aprendidos se aplica tanto a los conceptos directivos como a los selectores. Por ejemplo, puedes utilizar matemáticas, métodos o manuales para realizar habilidades de acción. Si realizar una habilidad (recuerda que las habilidades son conceptos que realizan una tarea específica) tiene matices y requiere identificar muchas excepciones a una regla en distintas circunstancias, aprende el concepto directivo.
Los cerebros están organizados por funciones y estrategias
Entonces, si los bloques de construcción de los cerebros son conceptos que realizan habilidades y subtareas, ¿cómo se organizan estas habilidades al diseñar un cerebro? Las secuencias y las jerarquías son los dos paradigmas principales para organizar las habilidades en los cerebros.
Volvamos a la analogía del mapa. Recuerda, un punto en un mapa representa un buen resultado en tu proceso al que llegarás si tomas buenas decisiones. Los diseños cerebrales son mapas mentales con puntos de referencia que te ayudan a explorar la masa terrestre. Ten cuidado de no confundir el mapa mental con la propia masa de tierra (terreno). Incluso con el mapa mental y los puntos de referencia, tendrás que practicar para llegar a los destinos objetivo desde diversos puntos de partida. El hecho de que hayas definido una habilidad que requiere una tarea, no significa que seas competente en ella. Sé que lanzar en salto es la mejor forma de anotar en baloncesto desde 18 pies de distancia, pero todavía no soy un gran lanzador en salto. Sigues necesitando practicar y tus cerebrostambién necesitarán practicar las habilidades queles enseñes.
Secuencias o Ejecución Paralela para Habilidades Funcionales
Los clientes me dicen a menudo que, para su tarea, es necesario realizar las habilidades en una secuencia determinada. Informan de que la experiencia y las pruebas sugieren (incluso exigen) que realicen las habilidades en un orden determinado. Ten en cuenta que no estoy hablando de una secuencia de pasos, sino de una secuencia de habilidades. Para estas tareas, si realizas las habilidades en la secuencia correcta, alcanzarás el objetivo. Si realizas las habilidades en la secuencia incorrecta, te perderás irremediablemente y nunca encontrarás la ubicación en el mapa que representa el éxito en la tarea.
La Figura 4-18 nos da un ejemplo perfecto. El paso de montaña proporciona un obstáculo que secuencia las habilidades. Una habilidad: abrirte camino a través de las montañas, desde varios puntos de partida en el lado izquierdo de la isla, debe completarse primero. Después de atravesar las montañas, se hace posible la segunda habilidad: alcanzar el objetivo. Esto me recuerda a los árboles tecnológicos del videojuego Civilization. Debes desarrollar la energía de vapor antes de inventar el tren locomotor. Esto también está relacionado con el concepto de zonas de desarrollo próximo de Vygotzky, que ya hemos tratado en el Capítulo 3. Descubrir la energía del vapor hace más probable que inventes la locomotora. Las habilidades están relacionadas.
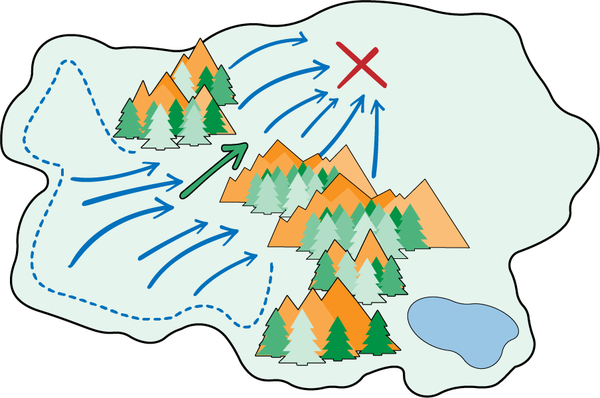
Figura 4-18. Un paisaje de decisión en el que deben ejecutarse dos habilidades en secuencia para alcanzar la meta. Atraviesa el paso de montaña y luego explora la llanura para llegar a la meta.
Hay un término matemático para las tareas con masas de tierra en el espacio de decisión que tienen este aspecto: se llaman estados embudo. Los estados embudo son cuellos de botella matemáticos como puertas que debes atravesar en un problema para llegar a los estados meta deseables (como las marcas X rojas en cada uno de nuestros diagramas de masas terrestres). Para navegar por este tipo de espacios, necesitas utilizar distintas habilidades en secuencia. Cada habilidad es una función que realiza la acción de navegación correcta en el momento adecuado. He aquí un ejemplo real.
Exploremos con más detalle la IA autónoma que construyeron los investigadores de Microsoft para enseñar a un robot a agarrar y apilar bloques de la sección Preocupaciones por las personas y los procesos del Capítulo 1. Los investigadores diseñaron un cerebro con cinco conceptos directivos para ejecutar habilidades y un selector aprendido para supervisar los conceptos:
- Llega a
-
Este movimiento extiende la mano hacia fuera del cuerpo.
- Muévete
-
Este movimiento barre el brazo hacia delante y hacia atrás y hacia arriba y hacia abajo.
- Oriente
-
Este movimiento puso la mano del robot en la posición correcta para agarrar el bloque.
- Agarra
-
Este movimiento aprieta los dedos para agarrar el bloque.
- Pila
-
Este movimiento recoge el bloque y lo coloca encima de otro bloque.
Cada habilidad es una función que utiliza articulaciones específicas para realizar una subtarea. Esto es importante porque limitar las acciones que realiza cada habilidad al realizar su función evita que el cerebro tenga que explorar muchos movimientos que no podrían cumplir el objetivo. Por ejemplo, orientar la mano alrededor de un bloque (poner la mano en posición para cogerlo) implica rotar la muñeca. Ahora, imagina que tu brazo está en la posición perfecta y todo lo que necesitas hacer es girar la muñeca para poner la mano en posición de coger el bloque, ¡pero das un tirón con el codo! Ahora tu mano está en una posición en la que no puedes agarrar el bloque, independientemente de cómo gires la muñeca.
La Figura 4-19 ilustra algunas de estas habilidades para nuestro ejemplo de robot que mueve bloques. La habilidad alcanzar extiende el brazo del robot activando el hombro, el codo y la muñeca. La habilidad mover mueve el brazo lateralmente hacia delante y hacia atrás y hacia arriba y hacia abajo activando sólo la articulación del hombro. La habilidad de agarre cierra la mano activando sólo los dedos.
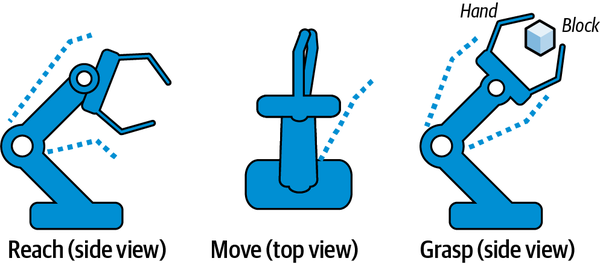
Figura 4-19. Tres habilidades para un brazo robótico.
| Habilidad | Acciones |
|---|---|
Llega a |
Codo, hombro, muñeca |
Muévete |
Hombro |
Oriente |
Muñeca |
Agarra |
Dedos |
Pila |
Hombro, dedos |
Pruébalo por ti mismo. Identifica un objeto a tu alcance que puedas agarrar. Extiende el brazo (moviendo sobre todo el codo, y también el hombro y la muñeca si es necesario), pero extiende sólo el brazo recto hacia fuera del cuerpo. Ahora utiliza sólo el hombro para mover lateralmente la mano hacia el objeto. Puede que en este punto seas capaz de agarrar el objeto, pero no lo hagas. ¡Estás muy cerca! Ahora mueve el brazo desde el codo. ¡Mira qué frustrante es! Tus movimientos de codo acaban de alejar tu mano del objeto que antes podías agarrar. Ahora imagina ver cómo tu cerebro de IA utiliza articulaciones que arruinan la secuencia de habilidad una y otra vez de 1.000 formas distintas, en lugar de girar la muñeca y agarrar después de que el brazo esté en posición. Esto es exactamente lo que te ocurrirá si permites que una IA practique una tarea sin enseñarle explícitamente las habilidades funcionales.
Las secuencias viven en el selector
¿Ves la secuencia? En el ejemplo anterior del brazo robótico, las habilidades deben realizarse en una secuencia. Imagina lo que ocurrirá si intentas agarrar el bloque y luego mueves la mano a la posición correcta, ¡o si intentas apilar el bloque antes de haberlo agarrado!
En primer lugar, antes de hablar de los distintos tipos de destrezas funcionales y de cómo representarlas, déjame decirte dónde viven. Las secuencias viven en los conceptos selectivos. Los conceptos selectivos que supervisan el cerebro y asignan qué habilidad realizar a continuación deben obedecer todas las reglas de secuencia que presento en esta sección. Para cada ejemplo, incluyo un diagrama de diseño cerebral que esboza la secuencia que debe obedecer el selector al realizar sus asignaciones (como se muestra en la Figura 4-20).
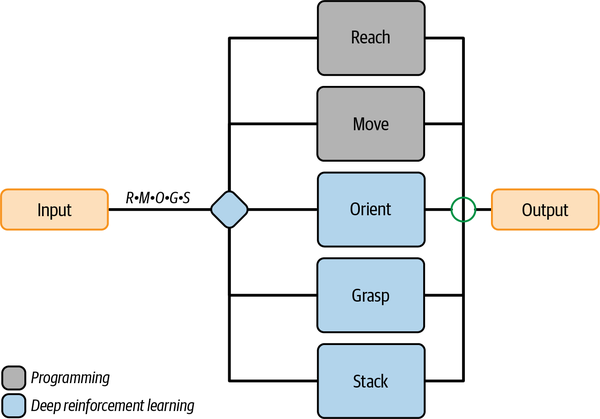
Figura 4-20. Diseño del cerebro para la tarea robótica de agarrar y apilar, con la definición de la secuencia viviendo en el selector.
Entonces, ¿cómo hacer que un selector obedezca a una secuencia mientras asigna tareas? Hay dos formas de conseguirlo. Los selectores programados pueden aceptar reglas de selección que impongan secuencias. Alternativamente, puedes imponer secuencias en selectores aprendidos utilizando el enmascaramiento de acciones. El enmascaramiento de acciones es una técnica que fija en cero laprobabilidad de acciones no deseadas en el algoritmo de aprendizaje. Ésta es la técnica que utilicé para imponer la secuencia de la marcha del cerebro andador bípedo.
Tomamos prestados algunos símbolos del lenguaje matemático de un campo llamado álgebra de tareas para describir las reglas sobre cómo se relacionan las habilidades entre sí. Estos símbolos, recogidos en la Tabla 4-9, representan los puntos de referencia que proporcionan pistas sobre la secuencia de habilidades. Cada una de las habilidades de la secuencia es una función. Cuando la función haya cumplido su función, pasa a la siguiente función de la secuencia.
| Operario | Nombre | Ejemplo | Descripción |
|---|---|---|---|
⊸ |
Secuenciación |
A ⊸ B |
La habilidad A debe completarse antes de que la habilidad B pueda ejecutarse. |
⊗ |
Elección exclusiva |
A ⊗ B |
Tanto la Habilidad A como la Habilidad B están activadas y pueden ejecutarse en cualquier orden, pero no al mismo tiempo. |
& |
Conjunción |
A Y B |
Tanto la habilidad A como la habilidad B están activadas. |
X[ ] |
Jerarquía |
X[A, B] |
La Habilidad X asigna la ejecución de la Habilidad A o la Habilidad B. La tarea asignada debe completarse (Habilidad A o B) antes de que la Habilidad X se considere realizada. |
Nota
Algunos lectores encontrarán este tipo de representación matemática refrescantemente precisa y otros la encontrarán intimidante. No te preocupes, te daré muchos ejemplos.
El álgebra de tareas para el ejemplo del brazo robótico anterior es R ⊸ M ⊸ O ⊸ G ⊸ S. Esto significa que el cerebro siempre alcanzará primero, luego se moverá, luego orientará la mano robótica alrededor del bloque, luego agarrará el bloque, luego apilará el bloque.
Secuencias de orden fijo
R ⊸ M ⊸ O ⊸ G ⊸ S es una secuencia de orden fijo. La secuencia no cambia, independientemente del punto de partida o de destino en la masa terrestre. A veces sabemos por qué esto es cierto (la física o la química nos lo dicen), pero a veces no tenemos la ciencia para explicarlo; sin embargo, sabemos que la secuencia es cierta porque la experiencia a lo largo del tiempo lo demuestra. En este caso, la secuencia de habilidades de orden fijo es eficaz, pero parece un poco demasiado rígida. Por ejemplo, puedo imaginar fácilmente muchas formas de mover el brazo primero, antes de alcanzar, o alternar entre alcanzar y mover el brazo para poner el brazo en posición de orientar la mano. Un diseño cerebral más flexible permite más opciones sobre cómo secuencia el cerebro las tareas de alcanzar y mover, por ejemplo:
R ⊗ M ⊸ (O ⊸ G ⊸ S)
R ⊗ M significa que puedes realizar la habilidad de alcanzar y mover tantas veces como quieras en cualquier orden, lo que supone un movimiento más natural. Entonces, una vez completados el alcance y el movimiento (la mano está en posición de agarrar el bloque tras el movimiento correcto de la muñeca), las habilidades de orientar, agarrar y apilar deben ejecutarse exactamente en ese orden, como se muestra en la Figura 4-21.
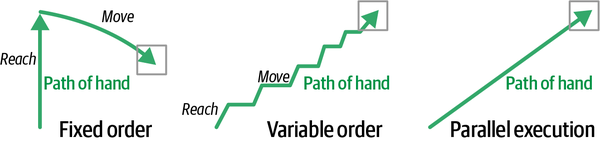
Figura 4-21. Trayectoria de la mano del robot moviéndose hacia el bloque para secuencias de tareas de orden fijo, secuencias de tareas de orden variable y ejecución paralela de las funciones alcanzar y mover
Ejecución paralela de las competencias funcionales
A veces las habilidades pueden ejecutarse independientemente pero en paralelo. El movimiento de la mano más suave y natural para alcanzar y mover probablemente resulte de la ejecución en paralelo. Mira un ejemplo en la Figura 4-21. Si primero alcanzas y luego mueves R ⊸ M, el movimiento parece muy mecánico. El robot alcanza toda la distancia y luego activa la habilidad de movimiento para barrer hacia el bloque. Una secuencia de orden variable R ⊗ M alterna entre alcanzar y moverse, lo que parece más suave pero sigue siendo un movimiento espasmódico. Activar alcanzar y moverse simultáneamente en cada paso de tiempo (R & M) conduce a la trayectoria más suave hacia el bloque. La habilidad alcanzar controla un conjunto de articulaciones y la habilidad mover controla otro conjunto de articulaciones, de modo que cada acción para controlar el brazo une las decisiones de las habilidades independientes alcanzar y mover. Creo que la definición original de la habilidad alcanzar (con el hombro, el codo y la muñeca) es un diseño cerebral mejor.
No todos los conjuntos de habilidades pueden ejecutarse con éxito en paralelo. Sólo podemos enseñar estas habilidades en paralelo (practicarlas por separado y luego combinarlas para ejecutarlas en paralelo) si cambiamos ligeramente las definiciones de las habilidades. Recuerda que la destreza de alcance utiliza el hombro, la muñeca y el codo, y que la destreza de desplazamiento sólo utiliza el hombro. Para enseñar y ejecutar estas habilidades en paralelo, cada una de ellas debe utilizar un conjunto de articulaciones mutuamente excluyentes. Esto significa que no se comparten articulaciones entre las habilidades. Por tanto, si cambiamos la habilidad de alcance para que sólo utilice el codo y la muñeca, podremos enseñar y ejecutar el alcance y el movimiento en paralelo.
Puede que mires las trayectorias resultantes hacia el bloque y te preguntes por qué deberíamos utilizar secuencias de orden fijo o de orden variable para las habilidades que aprenden esta tarea de agarrar y apilar. Ten en cuenta que el proyecto de investigación utilizó R ⊸ M de orden fijo con mucho éxito para completar las tareas y que el movimiento parece bastante suave a medida que este robot de siete articulaciones aprende y ejecuta las habilidades. Ésa es una de las grandes cosas del diseño cerebral: hay múltiples (quizá incluso muchos) diseños cerebrales válidos que proporcionan buenos puntos de referencia para que las IA autónomas adquieran habilidades que les permitan completar bien las tareas, igual que hay muchas estrategias de enseñanza que pueden guiar a los alumnos humanos para que aprendan con éxito el salto.
Secuencias de orden variable
Al igual que la secuencia de habilidades de alcanzar y moverse de R ⊗ M, otras secuencias de tareas pueden completarse en cualquier orden. En el juego de Nintendo Breath of the Wild del que he hablado antes, los cuatro primeros puzles pueden resolverse en cualquier orden, pero las habilidades posteriores deben realizarse en una secuencia. Necesitas un parapente para salir de la meseta (completando el primer "nivel" del juego). El álgebra de tareas para las habilidades iniciales en Breath of the Wild es:
(Gain Spirit Orb from Ja Baij Shrine ⊗ Gain Spirit Orb from Keh Namut Shrine ⊗ Gain Spirit Orb from Oman Au Shrine ⊗ Gain Spirit Orb from Owa Daim Shrine) ⊸ Climb Tower ⊸ Fly Glider
La Figura 4-22 muestra una masa de tierra que requiere que las habilidades se realicen en un orden variable. A veces tendrás que rodear primero el lago y luego atravesar el puerto de montaña para llegar al estado objetivo; otras veces tendrás que atravesar primero el puerto de montaña y luego rodear el lago. Realiza las tareas en cualquier orden que te ayude a tener éxito.
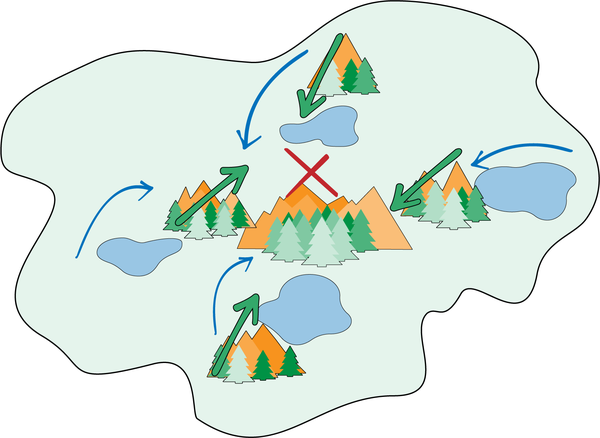
Figura 4-22. Landmass donde las funciones de exploración ("viajar por el puerto de montaña" y "viajar alrededor del lago") deben utilizarse en secuencias variables.
Desde cualquier punto de las afueras de la isla, tendrás que navegar alrededor de lagos y a través de puertos de montaña en secuencia, pero la secuencia variará dependiendo del punto desde el que empieces. El álgebra de tareas tiene este aspecto:
Travel through the mountain pass ⊗ Travel around the lake
Permíteme que te ponga otro ejemplo de robot real, esta vez con secuencias de orden variable. En este ejemplo, el cerebro está controlando al robot de dos brazos Baxter para que levante una mesa. Este cerebro también fue construido por investigadores de Microsoft. Pero aquí está el truco: el robot tiene que seguir las órdenes de un humano. La mayoría de nosotros lo hemos hecho alguna vez. Formamos equipo con otra persona para levantar una mesa: una persona dirige y la otra sigue.

Figura 4-23. Robot Baxter levantando una mesa en simulación. Hay una fuerza simulada e invisible que sustituye al humano al otro lado de la mesa. Baxter intenta aprender a levantar la mesa siguiendo las indicaciones de esta fuerza.
Dividimos la tarea y la enseñamos como dos habilidades separadas, que se muestran en la Tabla 4-10: levantar y nivelar.
| Habilidad | Objetivo |
|---|---|
Ascensor |
Desplaza el centro de masa de la mesa verticalmente hacia arriba. Si levantas sólo un extremo de la mesa, este objetivo no puede cumplirse. |
Nivel |
Devuelve el ángulo de la mesa a 0 grados (perfectamente nivelada). Sólo necesitas nivelar la mesa si está inclinada. |
Para las tareas de elevación y nivelación, existe claramente una secuencia, pero ésta es variable. Si la mesa no está nivelada, tienes que realizar la habilidad de nivelación antes de poder elevarla verticalmente con éxito. Pero si la mesa está nivelada, debes empezar a levantarla (no hay que nivelar). El álgebra de tareas para estas habilidades tiene este aspecto: Lift ⊗ Level. Las tareas deben realizarse en secuencia, pero la secuencia es variable. Una buena secuencia podría parecerse a (Lift ⊸ Lift ⊸ Level ⊸ Lift ⊸ Level ⊸ Lift), pero variará en función de cómo dirija el otro levantador. Ten en cuenta que estas habilidades no pueden enseñarse como ejecución paralela (se enseñan por separado y luego se combinan) porque no son completamente independientes.
Jerarquías para las estrategias
Las estrategias son diferentes de las funciones. Las funciones son habilidades que deben realizarse en alguna secuencia o ejecutarse en paralelo. Las estrategias son habilidades que se asignan a un escenario, no a una secuencia. Utiliza estrategias en paisajes que te obliguen a elegir las habilidades adecuadas para el escenario adecuado.
Echa un vistazo a la masa de tierra de la Figura 4-24. A diferencia de las habilidades de elevación y nivelación del ejemplo de elevación de la mesa, ambas estrategias son formas completamente válidas de atravesar la isla de izquierda a derecha. Pero una de las estrategias parece significativamente más atractiva según dónde empieces y dónde esté el objetivo. Si empiezas más cerca de la parte superior o inferior de la isla, rodear las masas de agua requerirá recorrer menos distancia. Si empiezas más cerca del centro de la isla (verticalmente), podrás alcanzar antes el objetivo viajando entre las masas de agua.
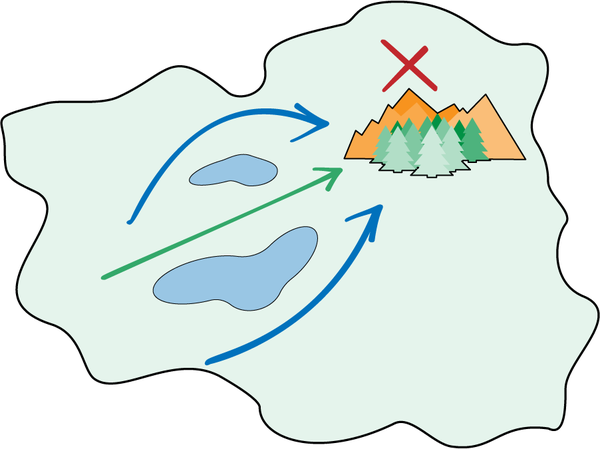
Figura 4-24. Esta masa de tierra te permite viajar de izquierda a derecha utilizando una de estas dos estrategias: pasar entre las dos masas de agua o rodearlas.
Así es como funcionan las estrategias. Tienes que leer correctamente la situación para elegir la estrategia adecuada. En su emblemática charla de 1985 "¿Pueden pensar las máquinas?", Richard Feynman cuenta la historia de cómo Douglas Lenat utilizó la estrategia para ganar una importante competición de juegos. En esta competición de wargames, los participantes diseñaron una flota naval de barcos en miniatura con distintas cantidades de blindaje y armamento. Las batallas navales simuladas tenían reglas que regulaban la maniobrabilidad, la capacidad de supervivencia y la potencia destructiva de una serie de naves, y los jugadores utilizaban una combinación de maniobras tácticas y azar (como hacen muchos juegos) para determinar el resultado del combate entre naves, declarándose vencedora la última armada que quedaba en pie.
Durante el mes de junio de 1981, se encomendó al programa EURISKO la tarea de explorar el diseño de flotas navales conformes a un conjunto de (varios centenares de) reglas y limitaciones, tal como se exponen en Traveller: La Escuadra del Trillón de Créditos. EURISKO diseñó una flota de barcos apta para participar en el torneo nacional de wargames Origins de 1981, celebrado en el Hotel Dunfey's, en San Mateo, California, durante el fin de semana del 4 de julio. El torneo de Traveller, dirigido por Game Designers Workshop (con sede en Normal, Illinois), era de eliminación simple, a seis rondas. La flota de EURISKO ganó dicho torneo, convirtiéndose así en el jugador de mayor rango de Estados Unidos (y también en almirante honorario de la armada Traveller). Esta victoria es aún más significativa por el hecho de que el creador del programa, el profesor Douglas Lenat, del Proyecto de Programación Heurística de la Universidad de Stanford, nunca había jugado a este juego, ni a ningún juego de batalla de miniaturas de este tipo.
El programa heurístico de Lenat (heurístico es sólo otro término para estrategia) ideó una estrategia para construir una nave gigantesca que contuviera todo el blindaje y las armas disponibles. Se trata de una estrategia muy utilizada en muchos videojuegos de batallas; los jugadores llamarían a esta nave un "tanque" (una gran unidad que puede tanto infligir como absorber una enorme cantidad de daño). Estas unidades suelen ser muy lentas, pero su potencia de fuego y su volumen de absorción de daños pueden ayudarlas a triunfar, como hizo la gigantesca nave de Lenat.
Descubrir estrategias
Pues bien, al año siguiente, se cambiaron las reglas del wargame para impedir que una sola nave enorme ganara la competición. Bien, se acabó el juego, ¿verdad? Pues no. Ese año, el participante de Lenat utilizó una armada de 100.000 naves diminutas para arrollar a la competencia y ganar por segundo año consecutivo. Cada barco causaba una cantidad ínfima de daño, pero eran tantos que se sumaron para conseguir la victoria. Los videojugadores también utilizan con frecuencia esta estrategia en los juegos de batalla. Lo llaman "enjambre".
No soy un jugador de videojuegos (sobre todo porque no los juego bien), pero solía disfrutar con un juego de estrategia llamado StarCraft II. En este juego, controlas un ejército espacial galáctico. Dependiendo de la raza del ejército espacial que controles (Terran, Protoss o Zerg), resultan atractivas distintas estrategias. Los Zerg son una raza "enjambre"; sus unidades militares son colectivamente más fuertes al formar parte de un grupo. Es fácil derrotar a una unidad Zerg individual, pero te verás abrumado por un enjambre. Así es como la mayoría de los jugadores Zerg ganan la partida.
La eficacia de las estrategias aumenta y disminuye con el tiempo
Este tipo de estrategias no sólo son útiles en los juegos. Las empresas también utilizan la estrategia del enjambre. Amazon se labró una reputación como gigante de las compras en línea, un megalito que vende de todo desde ropa interior hasta electrónica de alta gama desde su sitio web. Incluso compró la cadena de supermercados Whole Foods. Gana por escala y por controlar una cadena de suministro masiva y eficiente. El dominio global de Amazon recuerda al Imperio Galáctico de la serie de ciencia ficción La Guerra de las Galaxias: un enorme gobierno intergaláctico con ingentes recursos. Incluso construyeron un arma espacial del tamaño de un planeta: aparentemente imbatible.
Pues bien, llega Shopify (y la Alianza Rebelde). Shopify proporciona tecnología para que casi cualquiera pueda crear y mantener una tienda de comercio electrónico. DE ACUERDO. Ahora estamos impulsando un enjambre de pequeñas y ágiles tiendas de comercio electrónico; los Zerg del comercio electrónico, por así decirlo. He aquí otra cosa sobre los Zerg. El ecosistema Zerg crece en poder con el tiempo y es casi imbatible al final del juego. Tienes que vencerlos al principio de la partida para ganar. En un artículo titulado "Shopify: Una estrategia empresarial inspirada en StarCraft", Mike, un "ex inversor activista", ilumina estas mismas ideas y sugiere que, con el tiempo, la estrategia de Shopify ganará terreno a lade Amazon.
Las estrategias captan las compensaciones
Una nave frente a muchas, un tanque frente a un enjambre, pequeño y rápido frente a grande y lento: siempre hay una compensación. He aprendido algunas de mis lecciones más valiosas sobre las compensaciones estudiando el ajedrez. No soy un jugador experto, pero me fascina la estrategia del juego. Un libro en particular que me ha servido de fuente de inspiración es El libro completo de estrategia ajedrecística, de Jeremy Silman.
En sus libros, Silman, profesor y entrenador de maestros de ajedrez, evalúa las posiciones según los "desequilibrios", o diferencias, que existen en cada posición, y aboga por que los jugadores planifiquen su juego de acuerdo con ellos. Un buen plan, según Silman, es aquel que resalta los desequilibrios positivos de la posición. Está diciendo que las diferencias en los escenarios del tablero de ajedrez presentan oportunidades para que varias estrategias tengan más impacto en la partida que otras.
Pero ¡había tantas estrategias enumeradas en la enciclopedia! Necesitaba un patrón que me ayudara a organizar y dar sentido a tanta estrategia ajedrecística. En este contexto, una compensación es un patrón de organización de estrategias.
Empecemos por las fases de la partida de ajedrez: la apertura, el medio juego y el final. Cada una de estas fases tiene objetivos diferentes y, por tanto, estrategias diferentes que se ajustan a ellos. El objetivo de la apertura es sobrevivir. El objetivo del medio juego es ganar ventaja, y el objetivo del final es dar mate al rey del adversario.
Aún necesitaba otro esquema que me ayudara a organizar mejor toda la estrategia que veía en la enciclopedia. Otro libro de Silman, La mente del aficionado, me proporcionó el esquema de organización que buscaba. Era una compensación. Buscar estrategias que definan compensaciones para una tarea te ayudará a identificar patrones entre muchas estrategias y a diseñar cerebros que equilibren objetivos importantes. Hablaremos de cómo hacerlo en detalle en el Capítulo 6.
-
Una estrategia es extremadamente agresiva. Favorece la movilidad (la capacidad de mover piezas rápidamente) y, por tanto, favorece a los alfiles frente a los caballos. Los alfiles son muy móviles y pueden viajar por el tablero por la larga supercarretera diagonal (llamada fiancetto). Bobby Fischer favorecía esta estrategia.
-
La estrategia opuesta es fundamentalmente defensiva. Favorece el control del centro del tablero y construye edificios de piezas para bloquear y poseer el centro del tablero. Prefiere los caballos a los alfiles. Los caballos pueden moverse más fácilmente a través de las zonas centrales abarrotadas del tablero. Un grupo de maestros de ajedrez preferían tanto este estilo que desarrollaron el Gambito de Dama para atraer a un jugador a jugar la estrategia agresiva y ofensiva y castigar su arrogancia. El Gambito de Dama aceptó el reto. El Gambito de Dama rechazado ve el peligro y actúa para mitigar las ventajas de esta estrategia.
Como se muestra en la Figura 4-25, las estrategias suelen venir por parejas, pero ejecutar la estrategia suele requerir navegar eficazmente por las zonas entre los extremos.
Figura 4-25. Péndulo de la estrategia
La idea más importante es que no puedes jugar cualquier estrategia que quieras. El escenario del tablero (posición de tus piezas y de las piezas de tu oponente) te dice cuándo es más ventajoso utilizar cada estrategia. Hay estrategias en casi todos los puntos del continuo que ayudan a navegar desde casi cualquier tipo de posición del tablero.
He aquí un ejemplo de las carreras de caballos. La película Ride Like a Girl cuenta la historia de Michelle Payne, la primera mujer que gana la prestigiosa carrera de la Copa de Melbourne. Su padre le enseña a leer a los competidores durante una carrera para navegar eficazmente entre estrategias. La primera estrategia consiste en contener al caballo y permanecer con el pelotón. Su padre le explica entonces que cuando los caballos se cansan durante la carrera, el pelotón se separa y aparece una apertura clara pero temporal. Si esperas a que aparezca la abertura para hacer tu movimiento, te adelantarás a la manada. Si intentas moverte antes de que aparezca la abertura, no podrás separarte de la manada.
Los conceptos selectivos navegan por las jerarquías estratégicas
Las estrategias viven en jerarquías. El selector (recuerda que los selectores son supervisores) decide qué estrategia utilizar en cada situación, y la estrategia decide qué hacer. El álgebra de tareas para las jerarquías anteriores tiene este aspecto: Selector[Strategy 1, Strategy 2]. He aquí las representaciones del álgebra de tareas de cada uno de los ejemplos de estrategia que presenté anteriormente en el capítulo:
Select Navigation Strategy[Travel Between Lakes, Travel Around Lakes] Select Naval Fleet Strategy[One Huge Ship, 100000 Tiny Ships] Select Chess Strategy[Offensive, Defensive] Select Horse Racing Strategy[Hold Horse Back, Charge Ahead of Pack] Select Crusher Strategy[Choke, Regulate]
A medida que diseñes cerebros, tendrás que identificar jerarquías de estrategias y secuencias de habilidades funcionales para poder aplicar patrones de diseño de IA que enseñen habilidades de forma eficaz (es decir, que guíen al algoritmo de aprendizaje para que adquiera las habilidades necesarias para tener éxito). Al igual que un profesor o entrenador experto, debes preocuparte mucho más de proporcionar puntos de referencia para guiar la exploración que de averiguar cómo prescribir cada acción (realizar la tarea tú mismo). En el próximo capítulo, describiré cómo escuchar descripciones detalladas de tareas y procesos en busca de pistas que iluminen qué bloques de construcción debes utilizar para diseñar un cerebro que pueda aprender esa tarea. Si practicas, podrás identificar rápida y fácilmente secuencias y jerarquías y esbozar diseños cerebrales eficaces. A continuación, te proporcionaré un lenguaje visual para expresar diseños cerebrales y un ejemplo que combina muchos de los bloques de construcción que hemos introducido en este capítulo.
Lenguaje visual del diseño cerebral
Colaborarás con muchas partes interesadas durante y después del proceso de diseño del cerebro, por lo que ayuda tener un lenguaje común para describir los diseños del cerebro. A menudo hago diseños de cerebros en pizarra junto con expertos en la materia. A veces pido a otros diseñadores de cerebros que revisen mis diseños preliminares y me den su opinión. Cuando termino de diseñar un cerebro, lo paso al grupo quelo construirá.
No reinventemos la rueda a la hora de determinar un flujo de trabajo de diseño eficaz. Los diagramas de flujo de trabajo del estilo que se muestra en la Figura 4-26 ya proporcionan un lenguaje visual útil y bien conocido para los sistemas que procesan información, toman decisiones y eligen qué módulos activar.
Figura 4-26. Ejemplo de diagrama de flujo de trabajo estilizado
Los conceptos perceptivos procesan la información, los conceptos directivos toman decisiones y los conceptos selectivos eligen qué conceptos directivos activar, por lo que utilizo los diagramas de flujo de trabajo como lenguaje visual para los diseños cerebrales, con los símbolos descritos en la Tabla 4-11 utilizados como bloques de construcción para crear diagramas como el que se muestra en la Figura 4-27.
| Símbolo | Significado en el diagrama de flujo de trabajo | Función en el diseño del cerebro |
|---|---|---|
Oval |
Terminal (inicio o final de un flujo de trabajo) |
Entrada al cerebro, salida del cerebro |
Hexágono |
Procesador |
Concepto perceptivo |
Rectángulo |
Acción |
Concepto de directiva |
Diamante |
Decisión entre ramas del flujo de trabajo |
Concepto selectivo |
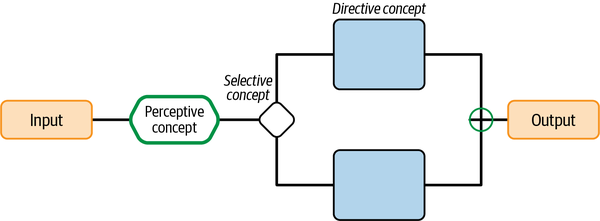
Figura 4-27. Diagrama de diseño cerebral que etiqueta los símbolos del flujo de trabajo que utilizo para describir entradas, salidas, conceptos perceptivos, conceptos directivos y conceptos selectivos
1 Gould, Stephen Jay, y Niles Eldredge. "Equilibrios puntuados: el ritmo y el modo de la evolución reconsiderados". Paleobiología 3, nº 2 (1977): 115-51. http://www.jstor.org/stable/2400177.
2 Herbert Blumer, Interaccionismo simbólico: Perspectiva y Método (University of California Press, 1986).
Get Diseñar IA autónoma now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

