Chapter 4. Preparing Textual Data for Statistics and Machine Learning
Technically, any text document is just a sequence of characters. To build models on the content, we need to transform a text into a sequence of words or, more generally, meaningful sequences of characters called tokens. But that alone is not sufficient. Think of the word sequence New York, which should be treated as a single named-entity. Correctly identifying such word sequences as compound structures requires sophisticated linguistic processing.
Data preparation or data preprocessing in general involves not only the transformation of data into a form that can serve as the basis for analysis but also the removal of disturbing noise. Whatâs noise and what isnât always depends on the analysis you are going to perform. When working with text, noise comes in different flavors. The raw data may include HTML tags or special characters that should be removed in most cases. But frequent words carrying little meaning, the so-called stop words, introduce noise into machine learning and data analysis because they make it harder to detect patterns.
What Youâll Learn and What Weâll Build
In this chapter, we will develop blueprints for a text preprocessing pipeline. The pipeline will take the raw text as input, clean it, transform it, and extract the basic features of textual content. We start with regular expressions for data cleaning and tokenization and then focus on linguistic processing with spaCy. spaCy is a powerful NLP library with a modern API and state-of-the-art models. For some operations we will make use of textacy, a library that provides some nice add-on functionality especially for data preprocessing. We will also point to NLTK and other libraries whenever it appears helpful.
After studying this chapter, you will know the required and optional steps of data preparation. You will know how to use regular expressions for data cleaning and how to use spaCy for feature extraction. With the provided blueprints you will be able to quickly set up a data preparation pipeline for your own project.
A Data Preprocessing Pipeline
Data preprocessing usually involves a sequence of steps. Often, this sequence is called a pipeline because you feed raw data into the pipeline and get the transformed and preprocessed data out of it. In Chapter 1 we already built a simple data processing pipeline including tokenization and stop word removal. We will use the term pipeline in this chapter as a general term for a sequence of processing steps. Figure 4-1 gives an overview of the blueprints we are going to build for the preprocessing pipeline in this chapter.

Figure 4-1. A pipeline with typical preprocessing steps for textual data.
The first major block of operations in our pipeline is data cleaning. We start by identifying and removing noise in text like HTML tags and nonprintable characters. During character normalization, special characters such as accents and hyphens are transformed into a standard representation. Finally, we can mask or remove identifiers like URLs or email addresses if they are not relevant for the analysis or if there are privacy issues. Now the text is clean enough to start linguistic processing.
Here, tokenization splits a document into a list of separate tokens like words and punctuation characters. Part-of-speech (POS) tagging is the process of determining the word class, whether itâs a noun, a verb, an article, etc. Lemmatization maps inflected words to their uninflected root, the lemma (e.g., âareâ â âbeâ). The target of named-entity recognition is the identification of references to people, organizations, locations, etc., in the text.
In the end, we want to create a database with preprared data ready for analysis and machine learning. Thus, the required preparation steps vary from project to project. Itâs up to you to decide which of the following blueprints you need to include in your problem-specific pipeline.
Introducing the Dataset: Reddit Self-Posts
The preparation of textual data is particularly challenging when you work with user-generated content (UGC). In contrast to well-redacted text from professional reports, news, and blogs, user contributions in social media usually are short and contain lots of abbreviations, hashtags, emojis, and typos. Thus, we will use the Reddit Self-Posts dataset, which is hosted on Kaggle. The complete dataset contains roughly 1 million user posts with title and content, arranged in 1,013 different subreddits, each of which has 1,000 records. We will use a subset of only 20,000 posts contained in the autos category. The dataset we prepare in this chapter is the basis for the analysis of word embeddings in Chapter 10.
Loading Data Into Pandas
The original dataset consists of two separate CSV files, one with the posts and the other one with some metadata for the subreddits, including category information. Both files are loaded into a Pandas DataFrame by pd.read_csv() and then joined into a single DataFrame.
importpandasaspdposts_file="rspct.tsv.gz"posts_df=pd.read_csv(posts_file,sep='\t')subred_file="subreddit_info.csv.gz"subred_df=pd.read_csv(subred_file).set_index(['subreddit'])df=posts_df.join(subred_df,on='subreddit')
Blueprint: Standardizing Attribute Names
Before we start working with the data, we will change the dataset-specific column names to more generic names. We recommend always naming the main DataFrame df, and naming the column with the text to analyze text. Such naming conventions for common variables and attribute names make it easier to reuse the code of the blueprints in different projects.
Letâs take a look at the columns list of this dataset:
(df.columns)
Out:
Index(['id', 'subreddit', 'title', 'selftext', 'category_1', 'category_2',
'category_3', 'in_data', 'reason_for_exclusion'],
dtype='object')
For column renaming and selection, we define a dictionary column_mapping where each entry defines a mapping from the current column name to a new name. Columns mapped to None and unmentioned columns are dropped. A dictionary is perfect documentation for such a transformation and easy to reuse. This dictionary is then used to select and rename the columns that we want to keep.
column_mapping={'id':'id','subreddit':'subreddit','title':'title','selftext':'text','category_1':'category','category_2':'subcategory','category_3':None,# no data'in_data':None,# not needed'reason_for_exclusion':None# not needed}# define remaining columnscolumns=[cforcincolumn_mapping.keys()ifcolumn_mapping[c]!=None]# select and rename those columnsdf=df[columns].rename(columns=column_mapping)
As already mentioned, we limit the data to the autos category:
df=df[df['category']=='autos']
Letâs take a brief look at a sample record to get a first impression of the data:
df.sample(1).T
| 14356 | |
|---|---|
| id | 7jc2k4 |
| subreddit | volt |
| title | Dashcam for 2017 volt |
| text | Hello.<lb>Iâm looking into getting a dashcam. <lb>Does anyone have any recommendations? <lb><lb>Iâm generally looking for a rechargeable one so that I donât have to route wires down to the cigarette lighter. <lb>Unless there are instructions on how to wire it properly without wires showing. <lb><lb><lb>Thanks! |
| category | autos |
| subcategory | chevrolet |
Saving and Loading a DataFrame
After each step of data preparation, it is helpful to write the respective DataFrame to disk as a checkpoint. Pandas directly supports a number of serialization options. Text-based formats like CSV or JSON can be imported into most other tools easily. However, information about data types is lost (CSV) or only saved rudimentarily (JSON). The standard serialization format of Python, pickle, is supported by Pandas and therefore a viable option. It is fast and preserves all information but can only be processed by Python. âPicklingâ a data frame is easy; you just need to specify the filename:
df.to_pickle("reddit_dataframe.pkl")
We prefer, however, storing dataframes in SQL databases because they give you all the advantages of SQL, including filters, joins, and easy access from many tools. But in contrast to pickle, only SQL data types are supported. Columns containing objects or lists, for example, cannot simply be saved this way and need to be serialized manually.
In our examples, we will use SQLite to persist data frames. SQLite is well integrated with Python. Moreover, itâs just a library and does not require a server, so the files are self-contained and can be exchanged between different team members easily. For more power and safety, we recommend a server-based SQL database.
We use pd.to_sql() to save our DataFrame as table posts into an SQLite database. The DataFrame index is not stored, and any existing data is overwritten:
importsqlite3db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df.to_sql("posts",con,index=False,if_exists="replace")con.close()
The DataFrame can be easily restored with pd.read_sql():
con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts",con)con.close()
Cleaning Text Data
When working with user requests or comments as opposed to well-edited articles, you usually have to deal with a number of quality issues:
- Special formatting and program code
- The text may still contain special characters, HTML entities, Markdown tags, and things like that. These artifacts should be cleaned in advance because they complicate tokenization and introduce noise.
- Salutations, signatures, addresses, etc.
- Personal communication often contains meaningless polite phrases and salutations by name that are usually irrelevant for the analysis.
- Replies
- If your text contains answers repeating the question text, you need to delete the duplicate questions. Keeping them will distort any model and statistics.
In this section, we will demonstrate how to use regular expressions to identify and remove unwanted patterns in the data. Check out the following sidebar for some more details on regular expressions in Python.
Take a look at the following text example from the Reddit dataset:
text="""After viewing the [PINKIEPOOL Trailer](https://www.youtu.be/watch?v=ieHRoHUg)it got me thinking about the best match ups.<lb>Here's my take:<lb><lb>[](/sp)[](/ppseesyou) Deadpool<lb>[](/sp)[](/ajsly)Captain America<lb>"""
It will definitely improve the results if this text gets some cleaning and polishing. Some tags are just artifacts from web scraping, so we will get rid of them. And as we are not interested in the URLs and other links, we will discard them as well.
Blueprint: Identify Noise with Regular Expressions
The identification of quality problems in a big dataset can be tricky. Of course, you can and should take a look at a sample of the data. But the probability is high that you wonât find all the issues. It is better to define rough patterns indicating likely problems and check the complete dataset programmatically.
The following function can help you to identify noise in textual data. By noise we mean everything thatâs not plain text and may therefore disturb further analysis. The function uses a regular expression to search for a number of suspicious characters and returns their share of all characters as a score for impurity. Very short texts (less than min_len characters) are ignored because here a single special character would lead to a significant impurity and distort the result.
importreRE_SUSPICIOUS=re.compile(r'[&#<>{}\[\]\\]')defimpurity(text,min_len=10):"""returns the share of suspicious characters in a text"""iftext==Noneorlen(text)<min_len:return0else:returnlen(RE_SUSPICIOUS.findall(text))/len(text)(impurity(text))
Out:
0.09009009009009009
You almost never find these characters in well-redacted text, so the scores in general should be very small. For the previous example text, about 9% of the characters are âsuspiciousâ according to our definition. The search pattern may of course need adaption for corpora containing hashtags or similar tokens containing special characters. However, it doesnât need to be perfect; it just needs to be good enough to indicate potential quality issues.
For the Reddit data, we can get the most âimpureâ records with the following two statements. Note that we use Pandas apply() instead of the similar map() because it allows us to forward additional parameters like min_len to the applied function.1
# add new column to data framedf['impurity']=df['text'].apply(impurity,min_len=10)# get the top 3 recordsdf[['text','impurity']].sort_values(by='impurity',ascending=False).head(3)
| text | impurity | |
|---|---|---|
| 19682 | Looking at buying a 335i with 39k miles and 11 months left on the CPO warranty. I asked the deal... | 0.21 |
| 12357 | Iâm looking to lease an a4 premium plus automatic with the nav package.<lb><lb>Vehicle Price:<ta... | 0.17 |
| 2730 | Breakdown below:<lb><lb>Elantra GT<lb><lb>2.0L 4-cylinder<lb><lb>6-speed Manual Transmission<lb>... | 0.14 |
Obviously, there are many tags like <lb> (linebreak) and <tab> included. Letâs check if there are others by utilizing our word count blueprint from Chapter 1 in combination with a simple regex tokenizer for such tags:
fromblueprints.explorationimportcount_wordscount_words(df,column='text',preprocess=lambdat:re.findall(r'<[\w/]*>',t))
| freq | token |
|---|---|
| <lb> | 100729 |
| <tab> | 642 |
Now we know that although these two tags are common, they are the only ones.
Blueprint: Removing Noise with Regular Expressions
Our approach to data cleaning consists of defining a set of regular expressions and identifying problematic patterns and corresponding substitution rules.2 The blueprint function first substitutes all HTML escapes (e.g., &) by their plain-text representation and then replaces certain patterns by spaces. Finally, sequences of whitespaces are pruned:
importhtmldefclean(text):# convert html escapes like & to characters.text=html.unescape(text)# tags like <tab>text=re.sub(r'<[^<>]*>',' ',text)# markdown URLs like [Some text](https://....)text=re.sub(r'\[([^\[\]]*)\]\([^\(\)]*\)',r'\1',text)# text or code in brackets like [0]text=re.sub(r'\[[^\[\]]*\]',' ',text)# standalone sequences of specials, matches &# but not #cooltext=re.sub(r'(?:^|\s)[&#<>{}\[\]+|\\:-]{1,}(?:\s|$)',' ',text)# standalone sequences of hyphens like --- or ==text=re.sub(r'(?:^|\s)[\-=\+]{2,}(?:\s|$)',' ',text)# sequences of white spacestext=re.sub(r'\s+',' ',text)returntext.strip()
Warning
Be careful: if your regular expressions are not defined precisely enough, you can accidentally delete valuable information during this process without noticing it! The repeaters + and * can be especially dangerous because they match unbounded sequences of characters and can remove large portions of the text.
Letâs apply the clean function to the earlier sample text and check the result:
clean_text=clean(text)(clean_text)("Impurity:",impurity(clean_text))
Out:
After viewing the PINKIEPOOL Trailer it got me thinking about the best match ups. Here's my take: Deadpool Captain America Impurity: 0.0
That looks pretty good. Once you have treated the first patterns, you should check the impurity of the cleaned text again and add further cleaning steps if necessary:
df['clean_text']=df['text'].map(clean)df['impurity']=df['clean_text'].apply(impurity,min_len=20)
df[['clean_text','impurity']].sort_values(by='impurity',ascending=False)\.head(3)
| clean_text | impurity | |
|---|---|---|
| 14058 | Mustang 2018, 2019, or 2020? Must Haves!! 1. Have a Credit score of 780\+ for the best low interest rates! 2. Join a Credit Union to finance the vehicle! 3. Or Find a Lender to finance the vehicle... | 0.03 |
| 18934 | At the dealership, they offered an option for foot-well illumination, but I cannot find any reference to this online. Has anyone gotten it? How does it look? Anyone have pictures. Not sure if this... | 0.03 |
| 16505 | I am looking at four Caymans, all are in a similar price range. The major differences are the miles, the years, and one isnât a S. https://www.cargurus.com/Cars/inventorylisting/viewDetailsFilterV... | 0.02 |
Even the dirtiest records, according to our regular expression, look pretty clean now. But besides those rough patterns we were searching for, there are also more subtle variations of characters that can cause problems.
Blueprint: Character Normalization with textacy
Take a look at the following sentence, which contains typical issues related to variants of letters and quote characters:
text = "The café âSaint-Raphaëlâ is loca-\nted on Côte dʼAzur."
Accented characters can be a problem because people do not consistently use them. For example, the tokens Saint-Raphaël and Saint-Raphael will not be recognized as identical. In addition, texts often contain words separated by a hyphen due to the automatic line breaks. Fancy Unicode hyphens and apostrophes like the ones used in the text can be a problem for tokenization. For all of these issues it makes sense to normalize the text and replace accents and fancy characters with ASCII equivalents.
We will use textacy for that purpose. textacy is an NLP library built to work with spaCy. It leaves the linguistic part to spaCy and focuses on pre- and postprocessing. Thus, its preprocessing module comprises a nice collection of functions to normalize characters and to treat common patterns such as URLs, email addresses, telephone numbers, and so on, which we will use next. Table 4-1 shows a selection of textacyâs preprocessing functions. All of these functions work on plain text, completely independent from spaCy.
| Function | Description |
|---|---|
normalize_hyphenated_words |
Reassembles words that were separated by a line break |
normalize_quotation_marks |
Replaces all kind of fancy quotation marks with an ASCII equivalent |
normalize_unicode |
Unifies different codes of accented characters in Unicode |
remove_accents |
Replaces accented characters with ASCII, if possible, or drops them |
replace_urls |
Similar for URLs like https://xyz.com |
replace_emails |
Replaces emails with _EMAIL_ |
replace_hashtags |
Similar for tags like #sunshine |
replace_numbers |
Similar for numbers like 1235 |
replace_phone_numbers |
Similar for telephone numbers +1 800 456-6553 |
replace_user_handles |
Similar for user handles like @pete |
replace_emojis |
Replaces smileys etc. with _EMOJI_ |
Our blueprint function shown here standardizes fancy hyphens and quotes and removes accents with the help of textacy:
importtextacy.preprocessingastprepdefnormalize(text):text=tprep.normalize_hyphenated_words(text)text=tprep.normalize_quotation_marks(text)text=tprep.normalize_unicode(text)text=tprep.remove_accents(text)returntext
When this is applied to the earlier example sentence, we get the following result:
(normalize(text))
Out:
The cafe "Saint-Raphael" is located on Cote d'Azur.
Note
As Unicode normalization has many facets, you can check out other libraries. unidecode, for example, does an excellent job here.
Blueprint: Pattern-Based Data Masking with textacy
Text, in particular content written by users, often contains not only ordinary words but also several kinds of identifiers, such as URLs, email addresses, or phone numbers. Sometimes we are interested especially in those items, for example, to analyze the most frequently mentioned URLs. In many cases, though, it may be better to remove or mask this information, either because it is not relevant or for privacy reasons.
textacy has some convenient replace functions for data masking (see Table 4-1). Most of the functions are based on regular expressions, which are easily accessible via the open source code. Thus, whenever you need to treat any of these items, textacy has a regular expression for it that you can directly use or adapt to your needs. Letâs illustrate this with a simple call to find the most frequently used URLs in the corpus:
fromtextacy.preprocessing.resourcesimportRE_URLcount_words(df,column='clean_text',preprocess=RE_URL.findall).head(3)
| token | freq |
|---|---|
| www.getlowered.com | 3 |
| http://www.ecolamautomotive.com/#!2/kv7fq | 2 |
| https://www.reddit.com/r/Jeep/comments/4ux232/just_ordered_an_android_head_unit_joying_jeep/ | 2 |
For the analysis we want to perform with this dataset (in Chapter 10), we are not interested in those URLs. They rather represent a disturbing artifact. Thus, we will substitute all URLs in our text with replace_urls, which is in fact just a call to RE_URL.sub. The default substitution for all of textacyâs replace functions is a generic tag enclosed by underscores like _URL_. You can choose your own substitution by specifying the replace_with parameter. Often it makes sense to not completely remove those items because it leaves the structure of the sentences intact. The following call illustrates the functionality:
fromtextacy.preprocessing.replaceimportreplace_urlstext="Check out https://spacy.io/usage/spacy-101"# using default substitution _URL_(replace_urls(text))
Out:
Check out _URL_
To finalize data cleaning, we apply the normalization and data masking functions to our data:
df['clean_text']=df['clean_text'].map(replace_urls)df['clean_text']=df['clean_text'].map(normalize)
Data cleaning is like cleaning your house. Youâll always find some dirty corners, and you wonât ever get your house totally clean. So you stop cleaning when it is sufficiently clean. Thatâs what we assume for our data at the moment. Later in the process, if analysis results are suffering from remaining noise, we may need to get back to data cleaning.
We finally rename the text columns so that clean_text becomes text, drop the impurity column, and store the new version of the DataFrame in the database.
df.rename(columns={'text':'raw_text','clean_text':'text'},inplace=True)df.drop(columns=['impurity'],inplace=True)con=sqlite3.connect(db_name)df.to_sql("posts_cleaned",con,index=False,if_exists="replace")con.close()
Tokenization
We already introduced a regex tokenizer in Chapter 1, which used a simple rule. In practice, however, tokenization can be quite complex if we want to treat everything correctly. Consider the following piece of text as an example:
text="""2019-08-10 23:32: @pete/@louis - I don't have a well-designedsolution for today's problem. The code of module AC68 should be -1.Have to think a bit... #goodnight ;-) ð©ð¬"""
Obviously, the rules to define word and sentence boundaries are not that simple. So what exactly is a token? Unfortunately, there is no clear definition. We could say that a token is a linguistic unit that is semantically useful for analysis. This definition implies that tokenization is application dependent to some degree. For example, in many cases we can simply discard punctuation characters, but not if we want to keep emoticons like :-) for sentiment analysis. The same is true for tokens containing numbers or hashtags. Even though most tokenizers, including those used in NLTK and spaCy, are based on regular expressions, they apply quite complex and sometimes language-specific rules.
We will first develop our own blueprint for tokenization-based regular expressions before we briefly introduce NLTKâs tokenizers. Tokenization in spaCy will be covered in the next section of this chapter as part of spaCyâs integrated process.
Blueprint: Tokenization with Regular Expressions
Useful functions for tokenization are re.split() and re.findall(). The first one splits a string at matching expressions, while the latter extracts all character sequences matching a certain pattern.
For example, in Chapter 1 we used the regex library with the POSIX pattern [\w-]*\p{L}[\w-]* to find sequences of alphanumeric characters with at least one letter. The scikit-learn CountVectorizer uses the pattern \w\w+ for its default tokenization. It matches all sequences of two or more alphanumeric characters. Applied to our sample sentence, this yields the following result:3
tokens=re.findall(r'\w\w+',text)(*tokens,sep='|')
Out:
2019|08|10|23|32|pete|louis|don|have|well|designed|solution|for|today problem|The|code|of|module|AC68|should|be|Have|to|think|bit|goodnight
Unfortunately, all special characters and the emojis are lost. To improve the result, we add some additional expressions for the emojis and create a reusable regular expression RE_TOKEN. The VERBOSE option allows readable formatting of complex expressions. The following tokenize function and the example illustrate the use:
RE_TOKEN=re.compile(r"""( [#]?[@\w'â\.\-\:]*\w # words, hashtags and email addresses| [:;<]\-?[\)\(3] # coarse pattern for basic text emojis| [\U0001F100-\U0001FFFF] # coarse code range for unicode emojis)""",re.VERBOSE)deftokenize(text):returnRE_TOKEN.findall(text)tokens=tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|@pete|@louis|I|don't|have|a|well-designed|solution for|today's|problem|The|code|of|module|AC68|should|be|-1|Have|to|think a|bit|#goodnight|;-)|ð©|ð¬
This expression should yield reasonably good results on most user-generated content. It can be used to quickly tokenize text for data exploration, as explained in Chapter 1. Itâs also a good alternative for the default tokenization of the scikit-learn vectorizers, which will be introduced in the next chapter.
Tokenization with NLTK
Letâs take a brief look at NLTKâs tokenizers, as NLTK is frequently used for tokenization. The standard NLTK tokenizer can be called by the shortcut word_tokenize. It produces the following result on our sample text:
importnltktokens=nltk.tokenize.word_tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|:|@|pete/|@|louis|-|I|do|n't|have|a|well-designed solution|for|today|'s|problem|.|The|code|of|module|AC68|should|be|-1|. Have|to|think|a|bit|...|#|goodnight|;|-|)||ð©ð¬
The function internally uses the TreebankWordTokenizer in combination with the PunktSentenceTokenizer. It works well for standard text but has its flaws with hashtags or text emojis. NLTK also provides a RegexpTokenizer, which is basically a wrapper for re.findall() with some added convenience functionality. Besides that, there are other regular-expression-based tokenizers in NLTK, like the TweetTokenizer or the multilingual ToktokTokenizer, which you can check out in the notebook on GitHub for this chapter.
Recommendations for Tokenization
You will probably need to use custom regular expressions if you aim for high precision on domain-specific token patterns. Fortunately, you can find regular expressions for many common patterns in open source libraries and adapt them to your needs.4
In general, you should be aware of the following problematic cases in your application and define how to treat them:5
- Tokens containing periods, such as
Dr.,Mrs.,U.,xyz.com - Hyphens, like in
rule-based - Clitics (connected word abbreviations), like in
couldn't,we'veorje t'aime - Numerical expressions, such as telephone numbers (
(123) 456-7890) or dates (August 7th, 2019) - Emojis, hashtags, email addresses, or URLs
The tokenizers in common libraries differ especially with regard to those tokens.
Linguistic Processing with spaCy
spaCy is a powerful library for linguistic data processing. It provides an integrated pipeline of processing components, by default a tokenizer, a part-of-speech tagger, a dependency parser, and a named-entity recognizer (see Figure 4-2). Tokenization is based on complex language-dependent rules and regular expressions, while all subsequent steps use pretrained neural models.

Figure 4-2. spaCyâs NLP pipeline.
The philosophy of spaCy is that the original text is retained throughout the process. Instead of transforming it, spaCy adds layers of information. The main object to represent the processed text is a Doc object, which itself contains a list of Token objects. Any range selection of tokens creates a Span. Each of these object types has properties that are determined step-by-step.
In this section, we explain how to process a document with spaCy, how to work with tokens and their attributes, how to use part-of-speech tags, and how to extract named entities. We will dive even deeper into spaCyâs more advanced concepts in Chapter 12, where we write our own pipeline components, create custom attributes, and work with the dependency tree generated by the parser for knowledge extraction.
Warning
For the development of the examples in this book, we used spaCy version 2.3.2. If you already use spaCy 3.0, which is still under development at the time of writing, your results may look slightly different.
Instantiating a Pipeline
Letâs get started with spaCy. As a first step we need to instantiate an object of spaCyâs Language class by calling spacy.load() along with the name of the model file to use.6 We will use the small English language model en_core_web_sm in this chapter. The variable for the Language object is usually called nlp:
importspacynlp=spacy.load('en_core_web_sm')
This Language object now contains the shared vocabulary, the model, and the processing pipeline. You can check the pipeline components via this property of the object:
nlp.pipeline
Out:
[('tagger', <spacy.pipeline.pipes.Tagger at 0x7fbd766f84c0>),
('parser', <spacy.pipeline.pipes.DependencyParser at 0x7fbd813184c0>),
('ner', <spacy.pipeline.pipes.EntityRecognizer at 0x7fbd81318400>)]
The default pipeline consists of a tagger, parser, and named-entity recognizer (ner), all of which are language-dependent. The tokenizer is not explicitly listed because this step is always necessary.
spaCyâs tokenizer is pretty fast, but all other steps are based on neural models and consume a significant amount of time. Compared to other libraries, though, spaCyâs models are among the fastest. Processing the whole pipeline takes about 10â20 times as long as just tokenization, where each step is taking a similar share of the total time. If tokenization of 1,000 documents takes, for example, one second, tagging, parsing, and NER may each take an additional five seconds. This may become a problem if you process big datasets. So, itâs better to switch off the parts that you donât need.
Often you will only need the tokenizer and the part-of-speech tagger. In this case, you should disable the parser and named-entity recognition like this:
nlp=spacy.load("en_core_web_sm",disable=["parser","ner"])
If you just want the tokenizer and nothing else, you can also simply call nlp.make_doc on a text.
Processing Text
The pipeline is executed by calling the nlp object. The call returns an object of type spacy.tokens.doc.Doc, a container to access the tokens, spans (ranges of tokens), and their linguistic annotations.
nlp=spacy.load("en_core_web_sm")text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)
spaCy is object-oriented as well as nondestructive. The original text is always retained. When you print the doc object, it uses doc.text, the property containing the original text. But doc is also a container object for the tokens, and you can use it as an iterator for them:
fortokenindoc:(token,end="|")
Out:
My|best|friend|Ryan|Peters|likes|fancy|adventure|games|.|
Each token is actually an object of spaCyâs class Token. Tokens, as well as docs, have a number of interesting properties for language processing. Table 4-2 shows which of these properties are created by each pipeline component.7
| Component | Creates |
|---|---|
| Tokenizer | Token.is_punct, Token.is_alpha, Token.like_email, Token.like_url |
| Part-of-speech tagger | Token.pos_ |
| Dependency parser | Token.dep_, Token.head, Doc.sents, Doc.noun_chunks |
| Named-entity recognizer | Doc.ents, Token.ent_iob_, Token.ent_type_ |
We provide a small utility function, display_nlp, to generate a table containing the tokens and their attributes. Internally, we create a DataFrame for this and use the token position in the document as an index. Punctuation characters are skipped by default in this function. Table 4-3 shows the output of this function for our example sentence:
defdisplay_nlp(doc,include_punct=False):"""Generate data frame for visualization of spaCy tokens."""rows=[]fori,tinenumerate(doc):ifnott.is_punctorinclude_punct:row={'token':i,'text':t.text,'lemma_':t.lemma_,'is_stop':t.is_stop,'is_alpha':t.is_alpha,'pos_':t.pos_,'dep_':t.dep_,'ent_type_':t.ent_type_,'ent_iob_':t.ent_iob_}rows.append(row)df=pd.DataFrame(rows).set_index('token')df.index.name=Nonereturndf
| text | lemma_ | is_stop | is_alpha | pos_ | dep_ | ent_type_ | ent_iob_ | |
|---|---|---|---|---|---|---|---|---|
| 0 | My | -PRON- | True | True | DET | poss | O | |
| 1 | best | good | False | True | ADJ | amod | O | |
| 2 | friend | friend | False | True | NOUN | nsubj | O | |
| 3 | Ryan | Ryan | False | True | PROPN | compound | PERSON | B |
| 4 | Peters | Peters | False | True | PROPN | appos | PERSON | I |
| 5 | likes | like | False | True | VERB | ROOT | O | |
| 6 | fancy | fancy | False | True | ADJ | amod | O | |
| 7 | adventure | adventure | False | True | NOUN | compound | O | |
| 8 | games | game | False | True | NOUN | dobj | O |
For each token, you find the lemma, some descriptive flags, the part-of-speech tag, the dependency tag (not used here, but in Chapter 12), and possibly some information about the entity type. The is_<something> flags are created based on rules, but all part-of-speech, dependency, and named-entity attributes are based on neural network models. So, there is always some degree of uncertainty in this information. The corpora used for training contain a mixture of news articles and online articles. The predictions of the model are fairly accurate if your data has similar linguistic characteristics. But if your data is very differentâif you are working with Twitter data or IT service desk tickets, for exampleâyou should be aware that this information is unreliable.
Warning
spaCy uses the convention that token attributes with an underscore like pos_ yield the readable textual representation. pos without an underscore returns spaCyâs numeric identifier of a part-of-speech tag.8 The numeric identifiers can be imported as constants, e.g., spacy.symbols.VERB. Make sure not to mix them up!
Blueprint: Customizing Tokenization
Tokenization is the first step in the pipeline, and everything depends on the correct tokens. spaCyâs tokenizer does a good job in most cases, but it splits on hash signs, hyphens, and underscores, which is sometimes not what you want. Therefore, it may be necessary to adjust its behavior. Letâs look at the following text as an example:
text="@Pete: choose low-carb #food #eat-smart. _url_ ;-) ðð"doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low|-|carb|#|food|#|eat|-|smart|.|_|url|_|;-)|ð|ð|
spaCyâs tokenizer is completely rule-based. First, it splits the text on whitespace characters. Then it uses prefix, suffix, and infix splitting rules defined by regular expressions to further split the remaining tokens. Exception rules are used to handle language-specific exceptions like canât, which should be split into ca and nât with lemmas can and not.9
As you can see in the example, spaCyâs English tokenizer contains an infix rule for splits at hyphens. In addition, it has a prefix rule to split off characters like # or _. It works well for tokens prefixed with @ and emojis, though.
One option is to merge tokens in a postprocessing step using doc.retokenize. However, that will not fix any miscalculated part-of-speech tags and syntactical dependencies because these rely on tokenization. So it may be better to change the tokenization rules and create correct tokens in the first place.
The best approach for this is to create your own variant of the tokenizer with individual rules for infix, prefix, and suffix splitting.10 The following function creates a tokenizer object with individual rules in a âminimally invasiveâ way: we just drop the respective patterns from spaCyâs default rules but retain the major part of the logic:
fromspacy.tokenizerimportTokenizerfromspacy.utilimportcompile_prefix_regex,\compile_infix_regex,compile_suffix_regexdefcustom_tokenizer(nlp):# use default patterns except the ones matched by re.searchprefixes=[patternforpatterninnlp.Defaults.prefixesifpatternnotin['-','_','#']]suffixes=[patternforpatterninnlp.Defaults.suffixesifpatternnotin['_']]infixes=[patternforpatterninnlp.Defaults.infixesifnotre.search(pattern,'xx-xx')]returnTokenizer(vocab=nlp.vocab,rules=nlp.Defaults.tokenizer_exceptions,prefix_search=compile_prefix_regex(prefixes).search,suffix_search=compile_suffix_regex(suffixes).search,infix_finditer=compile_infix_regex(infixes).finditer,token_match=nlp.Defaults.token_match)nlp=spacy.load('en_core_web_sm')nlp.tokenizer=custom_tokenizer(nlp)doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low-carb|#food|#eat-smart|.|_url_|;-)|ð|ð|
Warning
Be careful with tokenization modifications because their effects can be subtle, and fixing a set of cases can break another set of cases. For example, with our modification, tokens like Chicago-based wonât be split anymore. In addition, there are several Unicode characters for hyphens and dashes that could cause problems if they have not been normalized.
Blueprint: Working with Stop Words
spaCy uses language-specific stop word lists to set the is_stop property for each token directly after tokenization. Thus, filtering stop words (and similarly punctuation tokens) is easy:
text="Dear Ryan, we need to sit down and talk. Regards, Pete"doc=nlp(text)non_stop=[tfortindocifnott.is_stopandnott.is_punct](non_stop)
Out:
[Dear, Ryan, need, sit, talk, Regards, Pete]
The list of English stop words with more than 300 entries can be accessed by importing spacy.lang.en.STOP_WORDS. When an nlp object is created, this list is loaded and stored under nlp.Defaults.stop_words.
We can modify spaCyâs default behavior by setting the is_stop property of the respective words in spaCyâs vocabulary:11
nlp=spacy.load('en_core_web_sm')nlp.vocab['down'].is_stop=Falsenlp.vocab['Dear'].is_stop=Truenlp.vocab['Regards'].is_stop=True
If we rerun the previous example, we get the following result:
[Ryan, need, sit, down, talk, Pete]
Blueprint: Extracting Lemmas Based on Part of Speech
Lemmatization is the mapping of a word to its uninflected root. Treating words like housing, housed, and house as the same has many advantages for statistics, machine learning, and information retrieval. It can not only improve the quality of the models but also decrease training time and model size because the vocabulary is much smaller if only uninflected forms are kept. In addition, it is often helpful to restrict the types of the words used to certain categories, such as nouns, verbs, and adjectives. Those word types are called part-of-speech tags.
Letâs first take a closer look at lemmatization. The lemma of a token or span can be accessed by the lemma_ property, as illustrated in the following example:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)(*[t.lemma_fortindoc],sep='|')
Out:
-PRON-|good|friend|Ryan|Peters|like|fancy|adventure|game|.
The correct assignment of the lemma requires a lookup dictionary and knowledge about the part of speech of a word. For example, the lemma of the noun meeting is meeting, while the lemma of the verb is meet. In English, spaCy is able to make this distinction. In most other languages, however, lemmatization is purely dictionary-based, ignoring the part-of-speech dependency. Note that personal pronouns like I, me, you, and her always get the lemma -PRON- in spaCy.
The other token attribute we will use in this blueprint is the part-of-speech tag.
Table 4-3 shows that each token in a spaCy doc has two part-of-speech attributes: pos_ and tag_. tag_ is the tag from the tagset used to train the model. For spaCyâs English models, which have been trained on the OntoNotes 5 corpus, this is the Penn Treebank tagset. For a German model, this would be the Stuttgart-Tübingen tagset. The pos_ attribute contains the simplified tag of the universal part-of-speech tagset.12 We recommend using this attribute as the values will remain stable across different models.
Table 4-4 shows the complete tag set descriptions.
| Tag | Description | Examples |
|---|---|---|
| ADJ | Adjectives (describe nouns) | big, green, African |
| ADP | Adpositions (prepositions and postpositions) | in, on |
| ADV | Adverbs (modify verbs or adjectives) | very, exactly, always |
| AUX | Auxiliary (accompanies verb) | can (do), is (doing) |
| CCONJ | Connecting conjunction | and, or, but |
| DET | Determiner (with regard to nouns) | the, a, all (things), your (idea) |
| INTJ | Interjection (independent word, exclamation, expression of emotion) | hi, yeah |
| NOUN | Nouns (common and proper) | house, computer |
| NUM | Cardinal numbers | nine, 9, IX |
| PROPN | Proper noun, name, or part of a name | Peter, Berlin |
| PRON | Pronoun, substitute for noun | I, you, myself, who |
| PART | Particle (makes sense only with other word) | |
| PUNCT | Punctuation characters | , . ; |
| SCONJ | Subordinating conjunction | before, since, if |
| SYM | Symbols (word-like) | $, © |
| VERB | Verbs (all tenses and modes) | go, went, thinking |
| X | Anything that cannot be assigned | grlmpf |
Part-of-speech tags are an excellent alternative to stop words as word filters. In linguistics, pronouns, prepositions, conjunctions, and determiners are called function words because their main function is to create grammatical relationships within a sentence. Nouns, verbs, adjectives, and adverbs are content words, and the meaning of a sentence depends mainly on them.
Often, we are interested only in content words. Thus, instead of using a stop word list, we can use part-of-speech tags to select the word types we are interested in and discard the rest. For example, a list containing only the nouns and proper nouns in a doc can be generated like this:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)nouns=[tfortindocift.pos_in['NOUN','PROPN']](nouns)
Out:
[friend, Ryan, Peters, adventure, games]
We could easily define a more general filter function for this purpose, but textacyâs extract.words function conveniently provides this functionality. It also allows us to filter on part of speech and additional token properties such as is_punct or is_stop. Thus, the filter function allows both part-of-speech selection and stop word filtering. Internally it works just like we illustrated for the noun filter shown previously.
The following example shows how to extract tokens for adjectives and nouns from the sample sentence:
importtextacytokens=textacy.extract.words(doc,filter_stops=True,# default True, no stopwordsfilter_punct=True,# default True, no punctuationfilter_nums=True,# default False, no numbersinclude_pos=['ADJ','NOUN'],# default None = include allexclude_pos=None,# default None = exclude nonemin_freq=1)# minimum frequency of words(*[tfortintokens],sep='|')
Out:
best|friend|fancy|adventure|games
Our blueprint function to extract a filtered list of word lemmas is finally just a tiny wrapper around that function. By forwarding the keyword arguments (**kwargs), this function accepts the same parameters as textacyâs extract.words.
defextract_lemmas(doc,**kwargs):return[t.lemma_fortintextacy.extract.words(doc,**kwargs)]lemmas=extract_lemmas(doc,include_pos=['ADJ','NOUN'])(*lemmas,sep='|')
Out:
good|friend|fancy|adventure|game
Note
Using lemmas instead of inflected words is often a good idea, but not always. For example, it can have a negative effect on sentiment analysis where âgoodâ and âbestâ make a difference.
Blueprint: Extracting Noun Phrases
In Chapter 1 we illustrated how to use n-grams for analysis. n-grams are simple enumerations of subsequences of n words in a sentence. For example, the sentence we used earlier contains the following bigrams:
My_best|best_friend|friend_Ryan|Ryan_Peters|Peters_likes|likes_fancy fancy_adventure|adventure_games
Many of those bigrams are not very useful for analysis, for example, likes_fancy or my_best. It would be even worse for trigrams. But how can we detect word sequences that have real meaning? One way is to apply pattern-matching on the part-of-speech tags. spaCy has a quite powerful rule-based matcher, and textacy has a convenient wrapper for pattern-based phrase extraction. The following pattern extracts sequences of nouns with a preceding adjective:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)patterns=["POS:ADJ POS:NOUN:+"]spans=textacy.extract.matches(doc,patterns=patterns)(*[s.lemma_forsinspans],sep='|')
Out:
good friend|fancy adventure|fancy adventure game
Alternatively, you could use spaCyâs doc.noun_chunks for noun phrase extraction. However, as the returned chunks can also include pronouns and determiners, this function is less suited for feature extraction:
(*doc.noun_chunks,sep='|')
Out:
My best friend|Ryan Peters|fancy adventure games
Thus, we define our blueprint for noun phrase extraction based on part-of-speech patterns. The function takes a doc, a list of part-of-speech tags, and a separator character to join the words of the noun phrase. The constructed pattern searches for sequences of nouns that are preceded by a token with one of the specified part-of-speech tags. Returned are the lemmas. Our example extracts all phrases consisting of an adjective or a noun followed by a sequence of nouns:
defextract_noun_phrases(doc,preceding_pos=['NOUN'],sep='_'):patterns=[]forposinpreceding_pos:patterns.append(f"POS:{pos} POS:NOUN:+")spans=textacy.extract.matches(doc,patterns=patterns)return[sep.join([t.lemma_fortins])forsinspans](*extract_noun_phrases(doc,['ADJ','NOUN']),sep='|')
Out:
good_friend|fancy_adventure|fancy_adventure_game|adventure_game
Blueprint: Extracting Named Entities
Named-entity recognition refers to the process of detecting entities such as people, locations, or organizations in text. Each entity can consist of one or more tokens, like San Francisco. Therefore, named entities are represented by Span objects.
As with noun phrases, it can be helpful to retrieve a list of named entities for further analysis.
If you look again at Table 4-3, you see the token attributes for named-entity recognition, ent_type_ and ent_iob_. ent_iob_ contains the information if a token begins an entity (B), is inside an entity (I), or is outside (O). Instead of iterating through the tokens, we can also access the named entities directly with doc.ents. Here, the property for the entity type is called label_. Letâs illustrate this with an example:
text="James O'Neill, chairman of World Cargo Inc, lives in San Francisco."doc=nlp(text)forentindoc.ents:(f"({ent.text}, {ent.label_})",end=" ")
Out:
(James O'Neill, PERSON) (World Cargo Inc, ORG) (San Francisco, GPE)
spaCyâs displacy module also provides visualization for the named-entity recognition, which makes the result much more readable and visually supports the identification of misclassified entities:
fromspacyimportdisplacydisplacy.render(doc,style='ent')

The named entities were identified correctly as a person, an organization, and a geo-political entity (GPE). But be aware that the accuracy for named-entity recognition may not be very good if your corpus is missing a clear grammatical structure. Check out âNamed-Entity Recognitionâ for a detailed discussion.
For the extraction of named entities of certain types, we again make use of one of textacyâs convenient functions:
defextract_entities(doc,include_types=None,sep='_'):ents=textacy.extract.entities(doc,include_types=include_types,exclude_types=None,drop_determiners=True,min_freq=1)return[sep.join([t.lemma_fortine])+'/'+e.label_foreinents]
With this function we can, for example, retrieve the named entities of types PERSON and GPE (geo-political entity) like this:
(extract_entities(doc,['PERSON','GPE']))
Out:
["James_O'Neill/PERSON", 'San_Francisco/GPE']
Feature Extraction on a Large Dataset
Now that we know the tools spaCy provides, we can finally build our linguistic feature extractor. Figure 4-3 illustrates what we are going to do. In the end, we want to create a dataset that can be used as input to statistical analysis and various machine learning algorithms. Once extracted, we will persist the preprocessed data âready to useâ in a database.
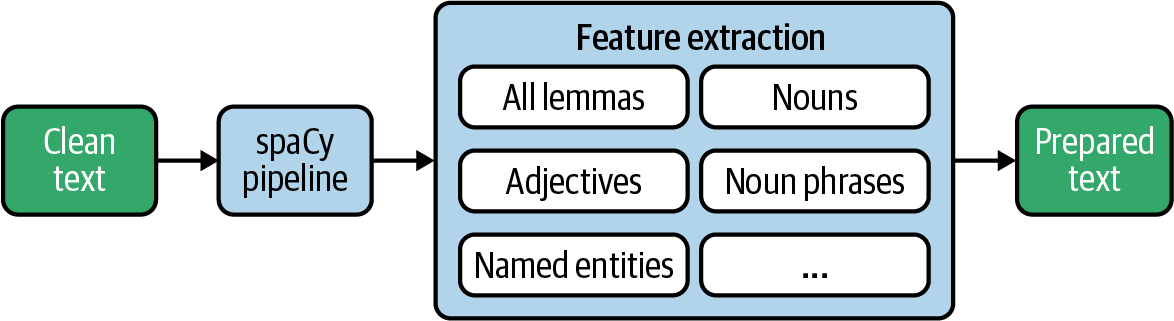
Figure 4-3. Feature extraction from text with spaCy.
Blueprint: Creating One Function to Get It All
This blueprint function combines all the extraction functions from the previous section. It neatly puts everything we want to extract in one place in the code so that the subsequent steps do not need to be adjusted if you add or change something here:
defextract_nlp(doc):return{'lemmas':extract_lemmas(doc,exclude_pos=['PART','PUNCT','DET','PRON','SYM','SPACE'],filter_stops=False),'adjs_verbs':extract_lemmas(doc,include_pos=['ADJ','VERB']),'nouns':extract_lemmas(doc,include_pos=['NOUN','PROPN']),'noun_phrases':extract_noun_phrases(doc,['NOUN']),'adj_noun_phrases':extract_noun_phrases(doc,['ADJ']),'entities':extract_entities(doc,['PERSON','ORG','GPE','LOC'])}
The function returns a dictionary with everything we want to extract, as shown in this example:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)forcol,valuesinextract_nlp(doc).items():(f"{col}: {values}")
Out:
lemmas: ['good', 'friend', 'Ryan', 'Peters', 'like', 'fancy', 'adventure', \
'game']
adjs_verbs: ['good', 'like', 'fancy']
nouns: ['friend', 'Ryan', 'Peters', 'adventure', 'game']
noun_phrases: ['adventure_game']
adj_noun_phrases: ['good_friend', 'fancy_adventure', 'fancy_adventure_game']
entities: ['Ryan_Peters/PERSON']
The list of returned column names is needed for the next steps. Instead of hard-coding it, we just call extract_nlp with an empty document to retrieve the list:
nlp_columns=list(extract_nlp(nlp.make_doc('')).keys())(nlp_columns)
Out:
['lemmas', 'adjs_verbs', 'nouns', 'noun_phrases', 'adj_noun_phrases', 'entities']
Blueprint: Using spaCy on a Large Dataset
Now we can use this function to extract features from all the records of a dataset. We take the cleaned texts that we created and saved at the beginning of this chapter and add the titles:
db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts_cleaned",con)con.close()df['text']=df['title']+': '+df['text']
Before we start NLP processing, we initialize the new DataFrame columns we want to fill with values:
forcolinnlp_columns:df[col]=None
spaCyâs neural models benefit from running on GPU. Thus, we try to load the model on the GPU before we start:
ifspacy.prefer_gpu():("Working on GPU.")else:("No GPU found, working on CPU.")
Now we have to decide which model and which of the pipeline components to use. Remember to disable unneccesary components to improve runtime! We stick to the small English model with the default pipeline and use our custom tokenizer that splits on hyphens:
nlp=spacy.load('en_core_web_sm',disable=[])nlp.tokenizer=custom_tokenizer(nlp)# optional
When processing larger datasets, it is recommended to use spaCyâs batch processing for a significant performance gain (roughly factor 2 on our dataset). The function nlp.pipe takes an iterable of texts, processes them internally as a batch, and yields a list of processed Doc objects in the same order as the input data.
To use it, we first have to define a batch size. Then we can loop over the batches and call nlp.pipe.
batch_size=50foriinrange(0,len(df),batch_size):docs=nlp.pipe(df['text'][i:i+batch_size])forj,docinenumerate(docs):forcol,valuesinextract_nlp(doc).items():df[col].iloc[i+j]=values
In the inner loop we extract the features from the processed doc and write the values back into the DataFrame. The whole process takes about six to eight minutes on the dataset without using a GPU and about three to four minutes with the GPU on Colab.
The newly created columns are perfectly suited for frequency analysis with the functions from Chapter 1. Letâs check for the most frequently mentioned noun phrases in the autos category:
count_words(df,'noun_phrases').head(10).plot(kind='barh').invert_yaxis()
Out:
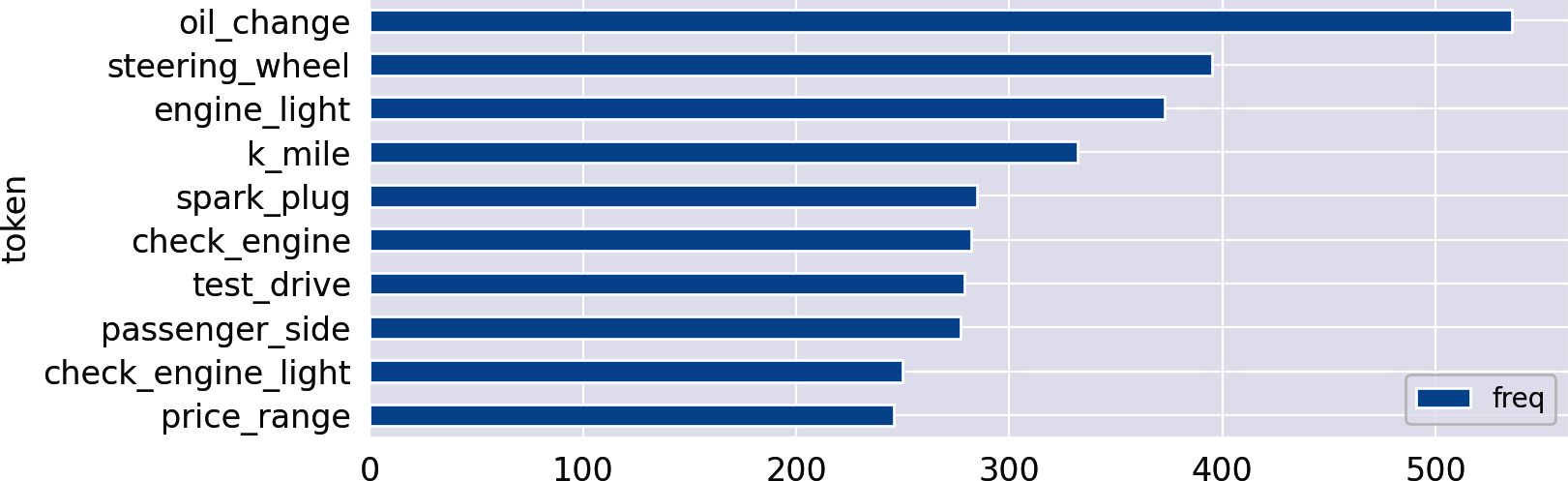
Persisting the Result
Finally, we save the complete DataFrame to SQLite. To do so, we need to serialize the extracted lists to space-separated strings, as lists are not supported by most databases:
df[nlp_columns]=df[nlp_columns].applymap(lambdaitems:' '.join(items))con=sqlite3.connect(db_name)df.to_sql("posts_nlp",con,index=False,if_exists="replace")con.close()
The resulting table provides a solid and ready-to-use basis for further analyses. In fact, we will use this data again in Chapter 10 to train word embeddings on the extracted lemmas. Of course, the preprocessing steps depend on what you are going to do with the data. Working with sets of words like those produced by our blueprint is perfect for any kind of statistical analysis on word frequencies and machine learning based on a bag-of-words vectorization. You will need to adapt the steps for algorithms that rely on knowledge about word sequences.
A Note on Execution Time
Complete linguistic processing is really time-consuming. In fact, processing just the 20,000 Reddit posts with spaCy takes several minutes. A simple regexp tokenizer, in contrast, takes only a few seconds to tokenize all records on the same machine. Itâs the tagging, parsing, and named-entity recognition thatâs expensive, even though spaCy is really fast compared to other libraries. So if you donât need named entities, you should definitely disable the parser and name-entity recognition to save more than 60% of the runtime.
Processing the data in batches with nlp.pipe and using GPUs is one way to speed up data processing for spaCy. But data preparation in general is also a perfect candidate for parallelization. One option to parallelize tasks in Python is using the library multiprocessing.
Especially for the parallelization of operations on dataframes, there are some scalable alternatives to Pandas worth checking, namely Dask, Modin, and Vaex. pandarallel is a library that adds parallel apply operators directly to Pandas.
In any case, it is helpful to watch the progress and get a runtime estimate. As already mentioned in Chapter 1, the tqdm library is a great tool for that purpose because it provides progress bars for iterators and dataframe operations. Our notebooks on GitHub use tqdm whenever possible.
There Is More
We started out with data cleaning and went through a whole pipeline of linguistic processing. Still, there some aspects that we didnât cover in detail but that may be helpful or even necessary in your projects.
Language Detection
Many corpora contain text in different languages. Whenever you are working with a multilingual corpus, you have to decide on one of these options:
- Ignore other languages if they represent a negligible minority, and treat every text as if it were of the corpusâs major language, e.g., English.
- Translate all texts to the main language, for example, by using Google Translate.
- Identify the language and do language-dependent preprocessing in the next steps.
There are good libraries for language detection. Our recommendation is Facebookâs fastText library. fastText provides a pretrained model that identifies 176 languages really fast and accurately. We provide an additional blueprint for language detection with fastText in the GitHub repository for this chapter.
textacyâs make_spacy_doc function allows you to automatically load the respective language model for linguistic processing if available. By default, it uses a language detection model based on Googleâs Compact Language Detector v3, but you could also hook in any language detection function (for example, fastText).
Spell-Checking
User-generated content suffers from a lot of misspellings. It would be great if a spell-checker could automatically correct these errors. SymSpell is a popular spell-checker with a Python port. However, as you know from your smartphone, automatic spelling correction may itself introduce funny artifacts. So, you should definitely check whether the quality really improves.
Token Normalization
Often, there are different spellings for identical terms or variations of terms that you want to treat and especially count identically. In this case, it is useful to normalize these terms and map them to a common standard. Here are some examples:
- U.S.A. or U.S. â USA
- dot-com bubble â dotcom bubble
- München â Munich
You could use spaCyâs phrase matcher to integrate this kind of normalization as a post-processing step into its pipeline. If you donât use spaCy, you can use a simple Python dictionary to map different spellings to their normalized forms.
Closing Remarks and Recommendations
âGarbage in, garbage outâ is a frequently cited problem in data projects. This is especially true for textual data, which is inherently noisy. Therefore, data cleaning is one of the most important tasks in any text analysis project. Spend enough effort to ensure high data quality and check it systematically. We have shown many solutions to identify and resolve quality issues in this section.
The second prerequisite for reliable analyses and robust models is normalization. Many machine learning algorithms for text are based on the bag-of-words model, which generates a notion of similarity between documents based on word frequencies. In general, you are better off with lemmatized text when you do text classification, topic modeling, or clustering based on TF-IDF. You should avoid or use only sparingly those kinds of normalization or stop word removal for more complex machine learning tasks such as text summarization, machine translation, or question answering where the model needs to reflect the variety of the language.
1 The Pandas operations map and apply were explained in âBlueprint: Building a Simple Text Preprocessing Pipelineâ.
2 Libraries specialized in HTML data cleaning such as Beautiful Soup were introduced in Chapter 3.
3 The asterisk operator (*) unpacks the list into separate arguments for print.
4 For example, check out NLTKâs tweet tokenizer for regular expressions for text emoticons and URLs, or see textacyâs compile regexes.
5 A good overview is âThe Art of Tokenizationâ by Craig Trim.
6 See spaCyâs website for a list of available models.
7 See spaCyâs API for a complete list.
8 See spaCyâs API for a complete list of attributes.
9 See spaCyâs tokenization usage docs for details and an illustrative example.
10 See spaCyâs tokenizer usage docs for details.
11 Modifying the stop word list this way will probably become deprecated with spaCy 3.0. Instead, it is recommended to create a modified subclass of the respective language class. See the GitHub notebook for this chapter for details.
12 See Universal Part-of-speech tags for more.
Get Blueprints for Text Analytics Using Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

