Chapter 12. Building a Knowledge Graph
In this book, we have been working through many blueprints for text analysis. Our goal was always to identify patterns in the data with the help of statistics and machine learning. In Chapter 10 we explained how embeddings can be used to answer questions like âWhat is to Germany like Paris is to France?â Embeddings represent some kind of implicit knowledge that was learned from the training documents based on a notion of similarity.
A knowledge base, in contrast, consists of structured statements of the form âBerlin capital-of Germany.â In this case, âcapital-ofâ is a precisely defined relation between the two specific entities Berlin and Germany. The network formed by many entities and their relations is a graph in the mathematical sense, a knowledge graph. Figure 12-1 shows a simple knowledge graph illustrating the example. In this chapter, we will introduce blueprints to extract structured information from unstructured text and build a basic knowledge graph.
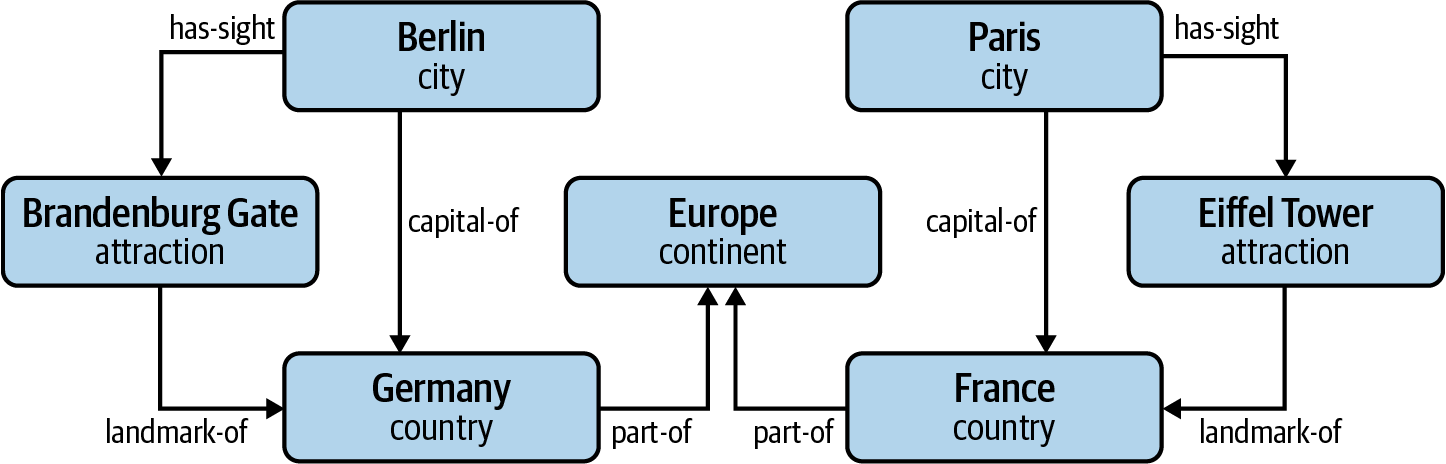
Figure 12-1. A simple knowledge graph.
What Youâll Learn and What Weâll Build
Information extraction is one of the hardest tasks in natural language processing because of the complexity and inherent ambiguity of language. Thus, we need to apply a sequence of different steps to discover the entities and relationships. Our example use case in this section is the ...
Get Blueprints for Text Analytics Using Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

