Capítulo 4. Conceptos básicos de copia de seguridad y recuperación
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Ahora que he definido qué son las copias de seguridad y los archivos y cómo mantenerlos a salvo, tenemos que profundizar en algunos conceptos básicos de copia de seguridad y recuperación. Empezaré hablando del importantísimo concepto de prueba de recuperación, seguido del concepto de niveles de copia de seguridad. A continuación, examinaré muchas métricas de los sistemas de copia de seguridad, especialmente los conceptos de RTO y RPO y cómo determinan (más que ninguna otra cosa) el diseño de las copias de seguridad. Luego hablo de las copias de seguridad a nivel de imagen frente a las copias de seguridad a nivel de archivo y de cómo se selecciona el contenido de las copias de seguridad. Sin embargo, el primer concepto básico de copia de seguridad, y posiblemente el más importante, es que todas las copias de seguridad deben probarse.
Pruebas de recuperación
En no hay concepto más básico de copia de seguridad y recuperación que comprender que la única razón por la que hacemos copias de seguridad es para poder restaurarlas. Y la única forma de saber si puedes restaurar las cosas que proteges es probar tu capacidad para hacerlo. Las pruebas periódicas de recuperación deben ser una parte fundamental de tu sistema de copias de seguridad.
Además de comprobar la validez del sistema de copia de seguridad y su documentación, las pruebas periódicas también ayudan a formar a tu personal. Si la primera vez que ejecutan una gran restauración es cuando la hacen en producción, dicha restauración será una situación mucho más estresante y más propensa a errores. Si han hecho esa restauración multitud de veces, deberían ser capaces de seguir su procedimiento habitual.
Debes comprobar regularmente la recuperación de todo aquello de lo que seas responsable. Esto incluye cosas pequeñas y cosas muy grandes. La frecuencia de las pruebas de cada cosa debe estar relacionada con la frecuencia con que se produce una restauración de tal cosa. Unas cuantas veces al año podría ser adecuado para una gran prueba de DR, pero deberías restaurar archivos individuales y máquinas virtuales al menos una vez a la semana por persona.
La nube ha facilitado mucho todo esto, porque no tienes que pelearte por los recursos a utilizar para la recuperación. Sólo tienes que configurar los recursos adecuados en la nube y luego restaurar en esos recursos. Esto es especialmente cierto en el caso de los grandes recursos de RD; debería ser muy fácil configurar todo lo que necesitas para hacer una prueba completa de RD en la nube. Y hacerlo con regularidad hará que hacerlo en producción sea mucho más fácil. Las pruebas también deben incluir la restauración de cosas comunes en los servicios SaaS, como usuarios, carpetas y archivos o correos electrónicos individuales.
Nota
¡Una copia de seguridad no es una copia de seguridad hasta que no se ha probado!
-Ben Patridge
Niveles de copia de seguridad
Existen esencialmente dos categorías muy amplias de lo que la industria de las copias de seguridad denomina niveles de copia de seguridad: o bien haces una copia de seguridad de todo (es decir, una copia de seguridad completa) o bien haces una copia de seguridad sólo de lo que ha cambiado (es decir, una copia de seguridad incremental). Cada uno de estos tipos generales tiene variaciones que se comportan de forma ligeramente diferente. La mayoría de los niveles de copia de seguridad son retrocesos a una era pasada de cintas, pero de todos modos merece la pena repasar sus definiciones. Luego explicaré los niveles que siguen siendo relevantes en "¿Importan los niveles de copia de seguridad?".
Copia de seguridad completa tradicional
Una copia de seguridad completa tradicional de copia todo lo que hay en el sistema del que se hace la copia de seguridad (excepto lo que le hayas dicho específicamente que excluya) en el servidor de copias de seguridad. Esto significa todos los archivos de un sistema de archivos (datos no estructurados) o todos los registros de una base de datos (datos estructurados).
Requiere una cantidad importante de entrada/salida (E/S), lo que puede crear un impacto significativo en el rendimiento de tu aplicación. Esto es especialmente cierto si estás simulando que tus máquinas virtuales son máquinas físicas, y resulta que estás realizando múltiples copias de seguridad tradicionales completas y simultáneas en varias máquinas virtuales del mismo nodo hipervisor.
La Figura 4-1 muestra una configuración típica de copia de seguridad completa semanal, con tres tipos de copias de seguridad incrementales que trataré a continuación.
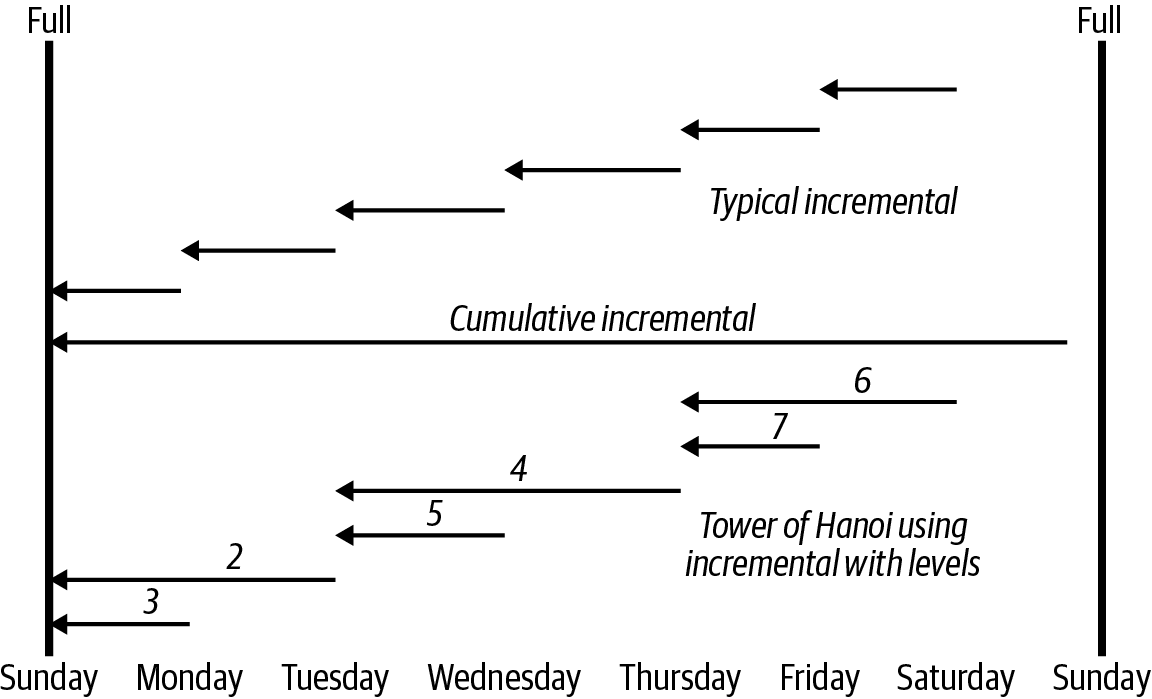
Figura 4-1. Copias de seguridad completas e incrementales
Copia de seguridad incremental tradicional
Una copia de seguridad incremental tradicional de hará una copia de seguridad de todos los archivos del sistema de archivos o registros de la base de datos que hayan cambiado desde una copia de seguridad anterior. Hay distintos tipos de copias de seguridad incrementales, y los distintos productos utilizan una terminología diferente para los distintos tipos. Lo que sigue es mi mejor intento de resumir los distintos tipos.
A menos que se especifique lo contrario, las copias de seguridad incrementales son copias de seguridad incrementales de archivo completo, lo que significa que el sistema hará una copia de seguridad de un archivo si ha cambiado la hora de modificación o se ha activado su bit de archivo en Windows. Aunque el usuario sólo haya modificado un bloque del archivo, se hará una copia de seguridad del archivo completo. Las copias de seguridad incrementales a nivel de bloque y las copias de seguridad con deduplicación del lado del origen (ambas se tratan más adelante en este capítulo) son las únicas copias de seguridad incrementales que no se comportan de esta manera.
Copia de seguridad incremental típica
Una copia de seguridad incremental típica de hará una copia de seguridad de todos los datos que hayan cambiado desde la copia de seguridad anterior, sea del tipo que sea. Tanto si la copia de seguridad anterior era una copia de seguridad completa como si era otra copia de seguridad incremental, la siguiente copia de seguridad incremental hará una copia de seguridad sólo de los datos que hayan cambiado desde la última copia de seguridad. Éste es el tipo más común de copia de seguridad incremental. Puedes ver este comportamiento en la Figura 4-1.
Copia de seguridad incremental acumulativa
Una copia de seguridad incremental acumulativa hace una copia de seguridad de todos los datos que han cambiado desde la última copia de seguridad completa. Esto requiere más E/S del cliente de copia de seguridad que una incremental típica, y requiere más ancho de banda para transmitir y más almacenamiento para guardar (suponiendo que no utilices deduplicación). La ventaja de este tipo de copia de seguridad es que sólo necesitas restaurar a partir de la copia de seguridad completa y de la última copia de seguridad incremental acumulativa. Compáralo con la típica copia de seguridad incremental, en la que necesitas restaurar a partir de la copia de seguridad completa y de cada copia de seguridad incremental posterior. Sin embargo, la ventaja de este tipo de copia incremental se esfuma si utilizas el disco como destino de la copia de seguridad.
En la Figura 4-1, puedes ver cómo se ejecuta una copia de seguridad incremental acumulativa el sábado por la noche. Hace una copia de seguridad de todo lo que haya cambiado desde la copia de seguridad completa del domingo. Esto ocurriría independientemente de la noche en que se ejecute.
Este tipo de copia de seguridad suele denominarse diferencial, pero prefiero no utilizar ese término, porque algunos productos de software de copia de seguridad utilizan ese término para significar algo muy diferente. Por lo tanto, utilizo el término incremental acumulativa.
Copia de seguridad incremental con niveles
Este tipo de copia de seguridad incremental de utiliza el concepto de niveles, cada uno especificado por un número, donde 0 representa una copia de seguridad completa, y 1-9 representa otros niveles de copia de seguridad incremental. Una copia de seguridad incremental de un determinado número hará una copia de seguridad de todo lo que haya cambiado desde una copia de seguridad anterior de un nivel inferior. Por ejemplo, si ejecutas una copia de seguridad de nivel 2, hará una copia de seguridad de todo lo que haya cambiado desde la última copia de seguridad de nivel 1. Puedes mezclar y combinar estos niveles para obtener distintos resultados.
Por ejemplo, podrías hacer una copia de seguridad de nivel 0 (es decir, completa) el domingo y luego una de nivel 1 cada día. Cada copia de seguridad de nivel 1 contendría todos los datos que hayan cambiado desde la de nivel 0 del domingo. También podrías hacer una copia de seguridad de nivel 0 el primer día del mes, una de nivel 1 cada domingo, y una serie de copias de seguridad con niveles crecientes el resto de la semana (por ejemplo, 2, 3, 4, 5, 6, 7). La copia de seguridad de cada domingo sería un incremental acumulativo (es decir, todos los datos cambiados desde el nivel 0), y el resto de las copias de seguridad se comportarían como copias de seguridad incrementales típicas, como en la mitad superior de la Figura 4-1.
Una idea interesante que utiliza niveles se llama plan de reserva de la Torre de Hanoi (TOH), que se ilustra en la mitad inferior de la Figura 4-1. Se basa en un antiguo rompecabezas de progresión matemática del mismo nombre. Si sigues haciendo copias de seguridad en cinta y te preocupa que un solo trozo de soporte arruine una restauración, TOH puede ayudarte con eso.
El juego consiste en tres clavijas y una serie de anillas de distintos tamaños insertadas en esas clavijas. No se puede colocar un anillo encima de otro con un radio menor. El objetivo del juego es mover todos los anillos de la primera clavija a la tercera, utilizando la segunda clavija para almacenarlos temporalmente cuando sea necesario.1
Uno de los objetivos de la mayoría de los programas de copia de seguridad es obtener los archivos modificados en más de un volumen, reduciendo al mismo tiempo el uso total del volumen. El TOH lo consigue mejor que cualquier otro programa. Si utilizas una progresión TOH para tus niveles de copia de seguridad, la mayoría de los archivos modificados se copiarán dos veces, pero sólo dos veces. Aquí tienes dos versiones de la progresión. (Por cierto, están relacionadas con el número de anillos de las tres clavijas).
0 3 2 5 4 7 6 9 8 9
0 3 2 4 3 5 4 6 5 7 6 8 7 9 8
Estas progresiones matemáticas son en realidad bastante fáciles. Cada una consta de dos series intercaladas de números (por ejemplo, 2 3 4 5 6 7 8 9 intercalada con 3 4 5 6 7 8 9). Consulta la Tabla 4-1 para ver cómo funcionaría.
| Domingo | Lunes | Martes | Miércoles | Jueves | Viernes | Sábado |
|---|---|---|---|---|---|---|
| 0 | 3 | 2 | 5 | 4 | 7 | 6 |
Como puedes ver en la Tabla 4-1, comienza con un nivel 0 (completo) el domingo. Supongamos que el lunes se modifica un archivo. El nivel 3 del lunes haría una copia de seguridad de todo desde el nivel 0, por lo que ese archivo modificado se incluiría en la copia de seguridad del lunes. Supongamos que el martes cambiamos otro archivo. Entonces, el martes por la noche, la copia de seguridad de nivel 2 debe buscar un nivel inferior, ¿no? El nivel 3 del lunes no es inferior, por lo que también hará referencia al nivel 0. Así que se vuelve a hacer copia de seguridad del archivo que se modificó el lunes, así como del archivo que se modificó el martes. El miércoles, el nivel 5 hará una copia de seguridad sólo de lo que cambió ese día, ya que hará referencia al nivel 2 del martes. Pero el jueves, el nivel 4 no hará referencia al nivel 5 del miércoles, sino al nivel 2 del martes.
Observa que el archivo que cambió el martes sólo se copió una vez. Para evitar este problema, utilizamos una progresión TOH modificada, bajando a una copia de seguridad de nivel 1 cada semana, como se muestra en la Tabla 4-2.
|
|
|
|
Si no te confunde a ti y a tu metodología de copia de seguridad,2 la programación que se muestra en la Tabla 4-2 puede ser muy útil. Cada domingo, obtendrás una copia de seguridad incremental completa de todo lo que haya cambiado desde la copia de seguridad completa mensual. Durante el resto de la semana, se hará una copia de seguridad de cada archivo modificado dos veces, excepto de los archivos del miércoles. Esto te protege de los fallos de los soportes mejor que cualquiera de los programas mencionados anteriormente. Necesitarás más de un volumen para hacer una restauración completa, por supuesto, pero esto no es un problema si tienes una sofisticada utilidad de copia de seguridad con gestión de volúmenes.
Copia de seguridad incremental a nivel de bloque
Una copia de seguridad incremental a nivel de bloque sólo hace copias de seguridad de los bytes o bloques que han cambiado desde la última copia de seguridad. En este contexto, un bloque es cualquier sección contigua de bytes que sea menor que un archivo. El diferenciador clave aquí es que algo rastrea qué bytes o bloques han cambiado, y ese mecanismo de rastreo determinará cuáles de esos bloques, bytes o segmentos de bytes se envían en una copia de seguridad incremental.
Esto requiere mucha menos E/S y ancho de banda que el enfoque incremental de archivo completo. Se ha hecho mucho más popular con la llegada de los discos al sistema de copia de seguridad, porque crea muchas copias de seguridad más pequeñas, todas las cuales hay que leer en una restauración. Esto sería muy problemático en un mundo de cintas, pero no es un gran problema si tus copias de seguridad están en disco.
El lugar más común en el que se produce una copia de seguridad incremental a nivel de bloque hoy en día es en la copia de seguridad de los hipervisores. El hipervisor y sus subsiguientes máquinas virtuales mantienen un mapa de bits que contiene un mapa de todos los bits que han cambiado desde un momento dado. El software de copia de seguridad puede simplemente consultar el mapa de bits en busca de todos los bytes que han cambiado desde la fecha especificada, y el hipervisor responderá con los resultados después de consultar el mapa de bits.
Deduplicación en origen
Deduplicación enorigen (o simplemente deduplicación en origen, para diferenciarla de la deduplicación en destino) se tratará con más detalle en el Capítulo 5, pero técnicamente es un tipo de incremental. En concreto, es una extensión del enfoque de copia de seguridad incremental a nivel de bloque, salvo que se aplica un procesamiento adicional a los bloques nuevos o modificados antes de enviarlos al servidor de copia de seguridad. El proceso de deduplicación de origen intenta identificar si los bloques "nuevos" han sido vistos antes por el sistema de copia de seguridad. Si, por ejemplo, un bloque nuevo ya ha sido copiado en otro lugar, no será necesario volver a copiarlo. Esto puede ocurrir si haces una copia de seguridad de un archivo compartido entre muchas personas, o si haces una copia de seguridad del sistema operativo que comparte muchos archivos con otros sistemas. Esto ahorra tiempo y ancho de banda incluso más de lo que lo hace la copia de seguridad incremental a nivel de bloque.
Copias de seguridad completas sintéticas
La razón tradicional de las copias de seguridad completas periódicas es hacer más rápida una restauración típica. Si sólo realizaras una copia de seguridad completa (con un producto de copia de seguridad tradicional), seguida de incrementales para siempre, una restauración tardaría mucho tiempo. El software de copia de seguridad tradicional restauraría todos los datos encontrados en la copia de seguridad completa, aunque algunos de los datos de esa cinta hubieran sido sustituidos por versiones más nuevas encontradas en las copias de seguridad incrementales. El proceso de restauración comenzaría entonces a restaurar los archivos nuevos o actualizados de las distintas copias de seguridad incrementales en el orden en que se crearon.
Este proceso de realizar múltiples restauraciones, algunas de las cuales están restaurando datos que se sobrescribirán, es cuando menos ineficaz. Como las restauraciones tradicionales procedían de cintas, también había que añadir el tiempo necesario para insertar y cargar cada cinta, buscar el lugar adecuado en la cinta y expulsar la cinta cuando ya no se necesitaba. Este proceso podía llevar más de cinco minutos por cinta.
Esto significa que con este tipo de configuración, cuanto más frecuentes sean tus copias de seguridad completas, más rápidas serán tus restauraciones porque pierden menos tiempo. (Sólo desde el punto de vista de la restauración, lo ideal sería realizar copias de seguridad completas todas las noches.) Por eso era muy habitual realizar una copia de seguridad completa una vez a la semana en todos los sistemas. A medida que los sistemas se automatizaron, algunos profesionales pasaron a realizar copias de seguridad completas mensuales o trimestrales.
Sin embargo, realizar una copia de seguridad completa en un servidor activo o en una máquina virtual crea una carga significativa en ese servidor. Esto supone un incentivo para que el administrador de copias de seguridad reduzca la frecuencia de las copias de seguridad completas en la medida de lo posible, aunque ello conlleve restauraciones que tarden más tiempo. Este tira y afloja entre la eficacia de la copia de seguridad y la de la restauración es la razón principal por la que surgieron las copias de seguridad completas sintéticas. Una copia de seguridad completa sintética es una copia de seguridad que se comporta como una copia de seguridad completa durante las restauraciones, pero que no se produce mediante una copia de seguridad completa típica. Hay tres métodos principales para crear una copia de seguridad completa sintética.
Sintético completo copiando
El primer método, y el más habitual, de crear una copia de seguridad completa sintética es crearla copiando las copias de seguridad disponibles en de un dispositivo a otro. El sistema de copia de seguridad mantiene un catálogo de todos los datos que encuentra durante cada copia de seguridad, por lo que, en un momento dado, conoce todos los archivos o bloques -y qué versiones de esos archivos o bloques- que habría en una copia de seguridad completa si la creara de la forma tradicional. Simplemente copia cada uno de esos archivos de un soporte a otro. Este método funcionará con cinta o disco siempre que haya varios dispositivos disponibles.
La gran ventaja de este método de crear una copia de seguridad completa sintética es que este proceso puede ejecutarse a cualquier hora del día sin que afecte a los clientes de la copia de seguridad, porque los servidores o máquinas virtuales para los que estás creando la copia de seguridad completa sintética no están implicados en absoluto. Una vez completada, la copia de seguridad resultante suele ser idéntica a una copia de seguridad completa tradicional, y las copias de seguridad incrementales posteriores pueden basarse en esa copia de seguridad completa.
Este método tiene dos inconvenientes, el primero de los cuales es que el proceso de copia de datos puede llevar bastante tiempo pero, como ya se ha mencionado, puedes hacerlo en cualquier momento, incluso en mitad del día. El otro inconveniente es que también puede crear bastante carga de E/S en los sistemas de disco que se utilicen como origen y destino de esta copia de seguridad. Esto no era tanto problema en el mundo de la cinta, porque los dispositivos de origen y destino eran obviamente dispositivos separados. Pero si tienes un dispositivo de deduplicación de destino único, una copia de seguridad completa sintética creada con este método es el equivalente en E/S de una restauración completa y una copia de seguridad completa al mismo tiempo. El grado en que esto afecte a tu dispositivo dependerá del mismo.
Sintético virtual completo
Hay otro enfoque para las copias de seguridad completas sintéticas de que sólo es posible con los sistemas de deduplicación de destino (explicados con más detalle en los Capítulos 5 y 12). En un sistema de deduplicación de destino, todas las copias de seguridad se dividen en trozos pequeños para identificar qué trozos son redundantes.3 A continuación, cada trozo se almacena como un objeto independiente en el almacenamiento del dispositivo de deduplicación de destino, lo que hace que cada archivo o bloque modificado esté representado por muchos trozos pequeños almacenados en el sistema de deduplicación de destino. Esto significa que es posible que este dispositivo simule crear una copia de seguridad completa creando una nueva copia de seguridad que simplemente apunte a bloques de otras copias de seguridad.
Este método requiere integración con el producto de copia de seguridad. Aunque el sistema de deduplicación pueda crear una copia de seguridad completa sin el producto de copia de seguridad, éste no lo sabría y no podría utilizarla para restauraciones o para basar en ella las copias de seguridad incrementales. Así que el producto de copia de seguridad indica al sistema de deduplicación de destino que cree una copia de seguridad completa sintética virtual, tras lo cual crea una de forma prácticamente instantánea. No hay movimiento de datos, por lo que este método es muy eficiente, pero puede estar limitado a ciertos tipos de copia de seguridad, como las máquinas virtuales, las copias de seguridad de sistemas de archivos y ciertas bases de datos compatibles .
Incremento para siempre
La idea de una copia de seguridad completa sintética es utilizar diversas formas de crear algo que se comporte como una copia de seguridad completa sin tener que hacer realmente otra copia de seguridad completa. Los sistemas de copia de seguridad más recientes se han creado desde cero para no necesitar nunca más otra copia de seguridad completa, sintética o de otro tipo. Aunque las primeras implementaciones de esta idea se dieron en el mundo de la cinta, la idea de las copias de seguridad incrementales para siempre (también llamadas incrementales para siempre) despegó realmente en el mundo de las copias de seguridad en disco.
Un verdadero incremento para siempre sólo es factible si utilizas el disco como destino principal, porque el sistema de copia de seguridad tendrá que acceder a todas las copias de seguridad al mismo tiempo para que funcione. Otro cambio es que las copias de seguridad no pueden almacenarse dentro de un contenedor opaco (por ejemplo, tar o un formato de copia de seguridad propietario), como la mayoría de los productos de copia de seguridad. (Por favor, no confundas este término contenedor con los contenedores Docker. Simplemente no tengo una palabra mejor). En su lugar, el sistema de copia de seguridad almacenará cada elemento modificado de la última copia de seguridad incremental como un objeto independiente, normalmente en un sistema de almacenamiento de objetos.
Esto funcionará tanto si tu producto de software de copia de seguridad incremental para siempre realiza copias de seguridad de archivos enteros, partes de archivos o bloques de datos (como se explica en "Copia de seguridad incremental a nivel de bloque"). Tu software de copia de seguridad almacenaría cada objeto por separado -incluso el más pequeño (por ejemplo, archivo, subarchivo, bloque o trozo)-, lo que le permitiría acceder a todas las copias de seguridad como una gran colección.
Durante cada copia de seguridad incremental, el sistema de copia de seguridad también verá el estado actual de cada servidor, máquina virtual o aplicación de la que hace copia de seguridad, y sabe dónde están todos los bloques que representan su estado actual (es decir, la copia de seguridad completa). No necesita hacer nada más que conservar esa información. Cuando llegue el momento de una restauración, sólo necesita saber dónde están todos los objetos que representan una copia de seguridad completa y entregarlos al proceso de restauración. Esto significa que todas las copias de seguridad serán copias de seguridad incrementales, pero cada copia de seguridad se comportará como una copia de seguridad completa desde el punto de vista de la restauración, sin tener que hacer ningún movimiento de datos para crear esa copia de seguridad completa.
Este método de copia de seguridad crea una copia de seguridad completa cada día sin ninguno de los inconvenientes de hacer eso, o de hacerlo con copias de seguridad completas sintéticas. El único inconveniente real de este método es que debe incorporarse al sistema de copia de seguridad desde el principio. Sólo funciona si el sistema de copia de seguridad se construye desde el principio para no buscar nunca más una copia de seguridad completa, sintética o de otro tipo. .
¿Importan los niveles de copia de seguridad?
Los niveles de copia de seguridad son en realidad un retroceso a una época pasada, e importan mucho menos que antes. Cuando empecé a hacer copias de seguridad a principios de los 90, los niveles de copia de seguridad importaban mucho. Querías hacer una copia de seguridad completa cada semana y una incremental acumulativa (todos los cambios desde la completa) cada día, si podías. Hacer copias de seguridad de ese modo significaba que necesitabas dos cintas para hacer una restauración. También significaba que gran parte de los datos modificados se encontraban en varias cintas, ya que cada incremental acumulativo a menudo realizaba una copia de seguridad de muchos de los archivos que estaban en el incremental acumulativo anterior. Este método era popular cuando, literalmente, intercambiaba cintas a mano en una unidad cuando necesitaba hacer una restauración, por lo que realmente querías minimizar el número de cintas que tenías que coger del cajón de cintas (o traer de Iron Mountain), porque tenías que intercambiarlas dentro y fuera de la unidad hasta que terminaba la restauración. ¿Quién quería hacer eso con 30 cintas (lo que tendrías que hacer si hicieras copias de seguridad completas mensuales)?
Avanzamos unos pocos años, y el software comercial de copia de seguridad y las bibliotecas de cintas robotizadas tomaron realmente el relevo. No tenía que intercambiar cintas para una restauración, pero una restauración que necesitara muchas cintas tenía un inconveniente. Si el robot tenía que intercambiar 30 cintas para una restauración, el proceso duraba unos 45 minutos más. Esto se debía a que se tardaba una media de 90 segundos en cargar la cinta y llegar al primer byte de datos. Modifiqué mi configuración típica para utilizar una copia de seguridad mensual, copias de seguridad incrementales típicas diarias y una copia de seguridad incremental acumulativa semanal. Esto significaba que una restauración en el peor de los casos necesitaría ocho cintas, lo que añadiría unos 12 minutos en lugar de 45. Y así estuvieron las cosas durante mucho tiempo.
Para los que han abandonado la cinta como destino de las copias de seguridad, la mayoría de las razones por las que hacíamos copias de seguridad de varios niveles ya no son válidas. Incluso hacer una copia de seguridad completa cada día no desperdicia almacenamiento si utilizas un buen sistema de deduplicación de destino. Tampoco hay que cargar 30 cintas de copia de seguridad incremental cuando todas tus copias de seguridad están en disco. Por último, hay sistemas de copia de seguridad más recientes que realmente sólo hacen un nivel de copia de seguridad: incremental a nivel de bloque. Todo esto viene a decir que cuanto más utilices el disco y otras tecnologías modernas, menos debería importarte la sección anterior.
Métricas
Al diseñar y mantener un sistema de protección de datos, tienes que determinar y monitorear una serie de métricas. Lo determinan todo, desde cómo diseñas el sistema hasta cómo sabes si el sistema está haciendo lo que debe hacer. Las métricas también determinan cuánta capacidad de cálculo y almacenamiento estás utilizando y cuánto te queda antes de tener que comprar capacidad adicional.
Métricas de recuperación
No hay métricas más importantes que las que tienen que ver con la recuperación. A nadie le importa cuánto tardas en hacer una copia de seguridad; sólo le importa cuánto tardas en restaurar. En realidad, sólo hay dos métricas que determinan si tu sistema de copia de seguridad está haciendo su trabajo: lo rápido que puedes restaurar y la cantidad de datos que pierdes al restaurar. Esta sección explica estas métricas y cómo se determinan y miden.
Objetivo de tiempo de recuperación (RTO)
El objetivo de tiempo de recuperación (RTO) es la cantidad de tiempo, acordada por todas las partes, que debe durar una restauración tras algún tipo de incidente que requiera una restauración. La duración de un RTO aceptable para cualquier organización suele depender de la cantidad de dinero que perderá cuando los sistemas estén inactivos.
Si una empresa determina que perderá millones de dólares de ventas por hora durante el tiempo de inactividad, normalmente querrá un RTO muy ajustado. Empresas como las de comercio financiero, por ejemplo, buscan tener un RTO lo más cercano posible a cero. Las organizaciones que pueden tolerar periodos más largos de inactividad informática podrían tener un RTO medido en semanas. Lo importante es que el RTO se ajuste a las necesidades de la organización.
Calcular un RTO para una organización gubernamental, o una empresa sin ánimo de lucro, puede ser un poco más problemático. Lo más probable es que no pierdan ingresos si están fuera de servicio durante un periodo de tiempo. Sin embargo, es posible que tengan que calcular la cantidad de horas extraordinarias que pueden tener que pagar para ponerse al día si se produce una interrupción prolongada.
No es necesario tener un único RTO en toda la organización. Es perfectamente normal y razonable tener un RTO más estricto para las aplicaciones más críticas y un RTO más relajado para el resto del centro de datos.
Es importante que, al calcular el RTO, comprendas que el reloj comienza cuando se produce el incidente, y se detiene cuando la aplicación está completamente en línea y el negocio ha vuelto a la normalidad. Demasiadas personas centradas en las copias de seguridad piensan que el RTO es la cantidad de tiempo que tienen para restaurar los datos, pero definitivamente no es así. El proceso real de copiar los datos de las copias de seguridad al sistema recuperado es en realidad una pequeña parte de las actividades que tienen que tener lugar para recuperarse de algo que acabe con una aplicación. Puede que haya que hacer un pedido de hardware, o que haya que resolver algún otro contrato o problema logístico antes de que puedas iniciar realmente una restauración. Además, puede que tengan que ocurrir cosas adicionales después de que realices tu restauración antes de que la aplicación esté lista para el público. Así que recuerda al determinar tu RTO que es mucho más que la restauración para lo que tienes que hacer tiempo.
Recuerda que el RTO es el objetivo. Si puedes cumplir ese objetivo es una cuestión diferente que se explica en "Tiempo de recuperación real y punto de recuperación real". Pero primero tenemos que hablar del RPO, u objetivo de punto de recuperación.
Objetivo de punto de recuperación (RPO)
RPO es la cantidad de pérdida de datos aceptable tras un incidente grave, medida en tiempo. Por ejemplo, si acordamos que podemos perder una hora de datos, habremos acordado un RPO de una hora. Al igual que el RTO, es perfectamente normal tener varios RPO en toda la organización, en función de la criticidad de los distintos conjuntos de datos.
La mayoría de las organizaciones, sin embargo, se conforman con valores muy superiores a una hora, como 24 horas o más. Esto se debe principalmente a que cuanto menor sea tu RPO, más frecuentemente deberás ejecutar tu sistema de copia de seguridad. No tiene mucho sentido acordar un RPO de una hora y luego ejecutar las copias de seguridad sólo una vez al día. Lo mejor que podrás hacer con un sistema así es un RPO de 24 horas, y eso es ser optimista.
Negociar tu RPO y RTO
Muchas organizaciones de pueden querer un RTO y un RPO muy ajustados. De hecho, casi todas las conversaciones sobre RTO y RPO en las que he participado empezaban con la pregunta de qué quería la organización para estos valores. La respuesta era casi siempre un RTO y RPO de cero. Esto significa que si se produjera un desastre, la unidad empresarial/operativa quiere que reanudes las operaciones sin tiempo de inactividad y sin pérdida de datos. Eso no sólo no es técnicamente posible, ni siquiera con el mejor de los sistemas, sino que sería increíblemente caro de conseguir.
Por tanto, la respuesta a una solicitud de este tipo debe ser el coste propuesto del sistema necesario para satisfacer dicha solicitud. Si la organización puede justificar un RTO y un RPO de 0 -o algo cercano a esos valores-, debe poder respaldarlo con una hoja de cálculo que muestre el coste potencial de una interrupción para la organización.
Entonces puede haber una negociación entre lo que es técnicamente factible y asequible (según determine la organización) y lo que ocurre actualmente con el sistema de recuperación ante catástrofes. Por favor, no te limites a tomar cualquier RTO y RPO que te den y luego simplemente lo ignores. Por favor, tampoco te inventes un RTO y un RPO sin consultar a las unidades de negocio/operativas porque creas que van a pedir algo poco razonable. Esta conversación es importante y tiene que producirse, por eso el Capítulo 2 está dedicado a ella.
Tiempo de recuperación real y punto de recuperación real
Las métricas de punto de recuperación real (RPA) y tiempo de recuperación real (RTA) sólo se miden si se produce una recuperación, ya sea real o mediante una prueba. El RTO y el RPO son objetivos; el RPA y el RTA miden el grado en que cumpliste esos objetivos tras una restauración. Es importante medir esto y compararlo con el RTO y el RPO para evaluar si necesitas considerar un rediseño de tu sistema de copia de seguridad y recuperación.
La realidad es que los RTA y RPA de la mayoría de las organizaciones no se acercan ni de lejos a los RTO y RPO acordados para la organización. Lo importante es sacar a la luz esta realidad y reconocerla. O ajustamos el RTO y el RPO, o rediseñamos el sistema de copias de seguridad. No tiene sentido tener un RTO o RPO ajustados si el RTA y el RPA no se acercan a ellos.
Consejo
Los fallos consecutivos en las copias de seguridad ocurren mucho en el mundo real, y eso puede afectar a tu RPA. Una regla empírica que utilizo para asegurarme de que los fallos en las copias de seguridad no afectan a mi RPA es determinar la frecuencia de las copias de seguridad dividiendo el RPO por tres. Por ejemplo, un RPO de tres días requeriría una frecuencia de copia de seguridad de un día. De este modo, puedes tener hasta dos fallos de copia de seguridad consecutivos sin perder tu RPO. Por supuesto, si tu sistema de copia de seguridad sólo es capaz de realizar copias de seguridad diarias como frecuencia más frecuente, eso significaría que tu OPR sería de tres días si tuvieras dos fallos de copia de seguridad consecutivos que no se solucionaran. Dado que los fallos consecutivos en las copias de seguridad ocurren a menudo en el mundo real, el OPR típico de 24 horas rara vez se cumplirá, a menos que seas capaz de realizar copias de seguridad con más frecuencia que una vez al día.
-Stuart Liddle
Pruebas de recuperación
Éste es un momento perfecto para señalar que debes probar las recuperaciones de. La razón es que la mayoría de las organizaciones rara vez llegan a disparar su sistema de copia de seguridad con furia; por tanto, deben fingir que lo hacen con regularidad. No tendrás ni idea de cómo funciona realmente tu sistema de copia de seguridad si no lo pruebas.
No sabrás lo fiable que es tu sistema de copias de seguridad si no lo pruebas con recuperaciones. No sabrás qué tipo de recursos utiliza una recuperación a gran escala y en qué medida supone una tarea para el resto del entorno. No tendrás ni idea de cuáles son tu RTA y tu RPA si no realizas de vez en cuando una restauración a gran escala y ves cuánto tarda y cuántos datos pierdes.
Dentro de unas páginas hablaré de las métricas de éxito. El éxito de las copias de seguridad es una métrica importante, pero siempre habrá copias de seguridad fallidas. Si tu sistema está haciendo lo que se supone que debe hacer, las restauraciones frecuentes mostrarán un éxito de restauración del 100% (o al menos cercano a él). Anunciar esta métrica ayudará a generar confianza en tu sistema de recuperación.
Después de haber participado en unas cuantas recuperaciones a gran escala en las que no conocía muy bien las capacidades del sistema, puedo decirte que la primera pregunta que te van a hacer es: "¿Cuánto tardará esto?". Si no has estado haciendo restauraciones de prueba con regularidad, no podrás responder a esa pregunta. Eso significa que estarás sentado con nudos en el estómago todo el tiempo, sin saber qué decir a la alta dirección.
Familiarízate con las restauraciones tanto como con las copias de seguridad. La única forma de hacerlo es probando.
Métricas de capacidad
Tanto si utilizas un sistema local como uno basado en la nube, necesitas monitorizar la cantidad de almacenamiento, cálculo y red de que dispones y ajustar tu diseño y configuración según sea necesario. Como verás en estas secciones, ésta es un área en la que un sistema basado en la nube puede destacar realmente.
Uso de la licencia/carga de trabajo
Tu producto o servicio de copia de seguridad tiene un número determinado de licencias para cada cosa de la que hagas copia de seguridad. Debes hacer un seguimiento de la utilización de esas licencias para saber cuándo te quedarás sin ellas.
Estrechamente relacionado con esto está el simple seguimiento del número de cargas de trabajo de las que estás haciendo copias de seguridad. Aunque esto puede no dar lugar a un problema de licencia, es otra métrica que puede mostrarte el crecimiento de tu sistema de copias de seguridad.
Capacidad de almacenamiento y uso
Empecemos con una métrica muy básica: ¿Tiene tu sistema de copia de seguridad suficiente capacidad de almacenamiento para satisfacer tus necesidades actuales y futuras de copia de seguridad y recuperación? ¿Tiene tu sistema de recuperación ante desastres suficiente capacidad de almacenamiento y cálculo para tomar el relevo del centro de datos principal en caso de desastre? ¿Puede hacerlo a la vez que realiza copias de seguridad? Tanto si se trata de una biblioteca de cintas como de una matriz de almacenamiento, tu sistema de almacenamiento tiene una capacidad finita, y necesitas monitorear esa capacidad y el porcentaje de la misma que estás utilizando a lo largo del tiempo.
No monitorear el uso y la capacidad de almacenamiento puede hacer que te veas obligado a tomar decisiones de emergencia que podrían ir en contra de las políticas de tu organización. Por ejemplo, la única forma de crear capacidad adicional sin comprar más es borrar las copias de seguridad más antiguas. Sería una lástima que el hecho de no monitorizar la capacidad de tu sistema de almacenamiento te impidiera cumplir los requisitos de retención que haya establecido tu organización.
Esto es mucho más fácil si el almacenamiento que utilizas en la nube es de objetos. Tanto el almacenamiento de objetos como el de bloques tienen una capacidad prácticamente ilimitada en la nube, pero sólo el almacenamiento de objetos crece automáticamente para satisfacer tus necesidades. Si tu sistema de copia de seguridad requiere que crees volúmenes basados en bloques en la nube, seguirás teniendo que monitorear la capacidad, porque necesitarás crear y hacer crecer volúmenes virtuales para manejar el crecimiento de tus datos. Esto no es un requisito si utilizas almacenamiento de objetos.
Además de las desventajas de tener que crear, gestionar, monitorear y hacer crecer estos volúmenes, también está la diferencia en cómo se cobran. Los volúmenes de bloques en la nube tienen un precio basado en la capacidad aprovisionada, no en la utilizada. El almacenamiento de objetos, en cambio, sólo te cobra por el número de gigabytes que almacenas en un mes determinado.
Capacidad de rendimiento y uso
Los sistemas típicos de copia de seguridad tienen capacidad para aceptar un determinado volumen de copias de seguridad al día, que suele medirse en megabytes por segundo o terabytes por hora. Debes conocer este número y asegurarte de que monitorea el uso que hace de él tu sistema de copia de seguridad. Si no lo haces, las copias de seguridad pueden tardar más y prolongarse durante la jornada laboral. Al igual que ocurre con la utilización de la capacidad de almacenamiento, no monitorizar esta métrica puede obligarte a tomar decisiones de emergencia que podrían ir en contra de las políticas de tu organización.
Monitorear la capacidad de transferencia y el uso de la cinta es especialmente importante. Como explicaré con más detalle en "Unidades de cinta", es muy importante que el rendimiento de tus copias de seguridad coincida con el rendimiento de la capacidad de transferencia de datos de tu unidad de cinta. Concretamente, el rendimiento que suministres a tu unidad de cinta debe ser superior a la velocidad mínima de la unidad de cinta. De lo contrario, se producirá un fallo del dispositivo y de la copia de seguridad. Consulta la documentación de la unidad y el sistema de asistencia del proveedor para averiguar cuál es la velocidad mínima aceptable, e intenta acercarte lo más posible a ella. Es poco probable que te acerques a la velocidad máxima de la unidad de cinta, pero también debes monitorizarlo.
Ésta es un área en la que la nube ofrece tanto ventajas como inconvenientes. La ventaja es que el rendimiento de la nube es prácticamente ilimitado (como el almacenamiento de objetos basado en la nube), suponiendo que el producto o servicio basado en la nube que estés utilizando pueda escalar su uso del ancho de banda de que dispone. Si, por ejemplo, su diseño utiliza un software de copia de seguridad estándar que se ejecuta en una VM en la nube, estarás limitado al caudal de esa VM, y tendrás que actualizar el tipo de VM (porque los distintos tipos de VM obtienen distintos niveles de ancho de banda). En algún momento, sin embargo, alcanzarás los límites de lo que tu software de copia de seguridad puede hacer con una VM y necesitarás añadir VM adicionales para añadir ancho de banda adicional. Algunos sistemas pueden añadir automáticamente ancho de banda a medida que crecen tus necesidades.
Una desventaja de utilizar la nube como destino de tus copias de seguridad es que el ancho de banda de tu sitio no es ilimitado, como tampoco lo es el número de horas al día. Incluso con la replicación a nivel de byte o la deduplicación en origen (que se explican más adelante en este capítulo), existe la posibilidad de que superes el ancho de banda de carga de tu sitio. Esto te obligará a ampliar el ancho de banda o, potencialmente, a cambiar de diseño o de proveedor. (El ancho de banda que necesitan los distintos proveedores no es el mismo).
Capacidad y uso del ordenador
La capacidad de tu sistema de copia de seguridad también depende de la capacidad del sistema informático que lo respalda. Si la capacidad de procesamiento de los servidores de copia de seguridad o de la base de datos que hay detrás del sistema de copia de seguridad es incapaz de mantener el ritmo, también puede ralentizar tus copias de seguridad y hacer que se cuelen en la jornada laboral. También debes monitorizar el rendimiento de tu sistema de copia de seguridad para ver hasta qué punto ocurre esto.
Una vez más, ésta es otra área en la que la nube puede ayudar: si tu sistema de copia de seguridad está diseñado para la nube. Si es así, puede escalar automáticamente la cantidad de computación necesaria para hacer el trabajo. Algunos pueden incluso ampliar y reducir el cálculo a lo largo del día, reduciendo el coste total de propiedad al disminuir el número de máquinas virtuales, contenedores o procesos sin servidor que se utilizan.
Por desgracia, muchos sistemas y servicios de copia de seguridad que se ejecutan en la nube utilizan el mismo software que ejecutarías en tu centro de datos. Dado que el concepto de añadir automáticamente computación adicional nació realmente en la nube, los productos de software de copia de seguridad escritos para el centro de datos no tienen este concepto. Eso significa que si te quedas sin capacidad de cálculo en el backend, tendrás que añadir manualmente capacidad adicional, y las licencias que la acompañan, tú mismo.
Ventana de copia de seguridad
Un sistema de copia de seguridad tradicional de tiene un impacto significativo en el rendimiento de tus sistemas primarios durante la copia de seguridad. Los sistemas de copia de seguridad tradicionales realizan una serie de copias de seguridad completas e incrementales, cada una de las cuales puede pasar factura a los sistemas de los que se hace la copia de seguridad. Por supuesto, las copias de seguridad completas se cobran un peaje porque lo copian todo. Las copias de seguridad incrementales también son un reto si son lo que se llaman incrementales de archivo completo, lo que significa que el sistema hace una copia de seguridad de todo el archivo aunque sólo haya cambiado un byte. Cambia el bit de modificación en Linux o el bit de archivo en Windows, y se hace una copia de seguridad de todo el archivo. Dado que la copia de seguridad típica puede afectar realmente al rendimiento de los sistemas de los que se hace copia de seguridad, debes acordar de antemano el tiempo que se te permite ejecutar copias de seguridad, lo que se denomina ventana de copia de seguridad.
En mi época, una ventana de copia de seguridad típica era de 6 de la tarde a 6 de la mañana de lunes a jueves, y de 6 de la tarde del viernes a 6 de la mañana del lunes. Esto era para un entorno de trabajo típico en el que la mayoría de la gente no trabajaba los fines de semana, y menos gente utilizaba los sistemas por la noche.
Si tienes una ventana de copia de seguridad, tienes que monitorizar cuánto la estás llenando. Si estás a punto de llenar toda la ventana con copias de seguridad, es hora de reevaluar la ventana o de rediseñar el sistema de copias de seguridad.
También creo que deberías asignar una ventana a tus productos de copia de seguridad y dejar que se encargue de la programación dentro de esa ventana. Algunas personas intentan sobredimensionar su sistema de copia de seguridad, programando miles de copias de seguridad individuales con su programador externo. Nunca he encontrado una situación en la que un programador externo pueda ser tan eficiente con los recursos de copia de seguridad como el programador incluido. Creo que es más eficiente y mucho menos tedioso. Pero estoy seguro de que alguien que lea esto opinará completamente distinto.
Las organizaciones que utilizan técnicas de copia de seguridad que entran en la categoría de incrementales para siempre (por ejemplo, protección continua de datos [CDP], near-CDP, copias de seguridad incrementales a nivel de bloque o copias de seguridad con deduplicación del lado de la fuente, todas las cuales se explican en otra parte de este libro) no suelen tener que preocuparse por una ventana de copia de seguridad. Esto se debe a que estas copias de seguridad suelen ejecutarse durante periodos muy cortos (es decir, unos pocos minutos) y transfieren una pequeña cantidad de datos (es decir, unos pocos megabytes). Estos métodos suelen tener un impacto muy bajo en el rendimiento de los sistemas primarios o, al menos, menor que la configuración típica de copias de seguridad completas ocasionales y copias de seguridad incrementales diarias de archivos completos. Por eso, los clientes que utilizan estos sistemas suelen realizar copias de seguridad a lo largo del día, con una frecuencia de hasta una vez por hora o incluso cada cinco minutos. En realidad, un verdadero sistema CDP funciona continuamente, transfiriendo cada nuevo byte a medida que se escribe. (Técnicamente, si no funciona de forma totalmente continua, no es un sistema de protección continua de datos. Es un decir).
Éxito y fracaso de las copias de seguridad y recuperación
Alguien en debería llevar la cuenta de cuántas copias de seguridad y recuperaciones realizas y qué porcentaje de ellas tiene éxito. Aunque deberías aspirar al 100% en ambos casos, es muy poco probable, especialmente en el caso de las copias de seguridad. Sin embargo, deberías monitorear esta métrica y observarla a lo largo del tiempo. Aunque el sistema de copia de seguridad rara vez será perfecto, observarlo a lo largo del tiempo puede indicarte si las cosas están mejorando o empeorando.
También es importante abordar cualquier fallo en la copia de seguridad o recuperación. Si una copia de seguridad o restauración se vuelve a ejecutar correctamente, al menos puedes tachar el fallo de tu lista de preocupaciones. Sin embargo, sigue siendo importante hacer un seguimiento de esos fallos a efectos de tendencias.
Retención
Aunque técnicamente no es una métrica, la retención es una de las cosas que se monitorizan en tu sistema de copia de seguridad y archivo. Debes asegurarte de que se cumplen las políticas de retención definidas.
Al igual que el RTO y el RPO, la configuración de la retención de tu sistema de protección de datos debe determinarla la organización. Nadie en TI debe determinar cuánto tiempo deben conservarse las copias de seguridad o los archivos; esto debe determinarse en función de los requisitos legales, organizativos y normativos.
Otra cosa que hay que mencionar al hablar de la retención es cuánto tiempo deben conservarse las cosas en cada nivel de almacenamiento. Atrás quedaron los días en que todas las copias de seguridad y archivos se guardaban en cinta. De hecho, la mayoría de las copias de seguridad actuales no se guardan en cinta, sino en disco. El disco tiene varias clases desde el punto de vista del rendimiento y del coste. La retención también debe especificar cuánto tiempo deben guardarse las cosas en cada nivel.
Una vez que determines tus políticas de retención, también debes revisar si tu sistema de protección de datos cumple las políticas que se han determinado. (Me refiero a las políticas de la organización, no a la configuración del sistema de copia de seguridad). Determina cuáles son tus políticas de retención y documéntalas. A continuación, revisa periódicamente tus sistemas de copia de seguridad y archivo para asegurarte de que las políticas de retención que se han establecido en estos sistemas coinciden con las políticas que determinaste para tu organización. Ajústalas e informa si es necesario.
Utilizar métricas
Una de las formas de aumentar la confianza en tu sistema de copias de seguridad es documentar y publicar todas las métricas mencionadas aquí. Haz que tus directivos sepan hasta qué punto tu sistema de copias de seguridad funciona según lo diseñado. Hazles saber cuántas copias de seguridad y recuperaciones realizas, y lo bien que funcionan y cuánto tiempo pasará antes de que necesiten comprar capacidad adicional. Sobre todo, asegúrate de que conocen la capacidad de tu sistema de copia de seguridad y recuperación para cumplir los RTO y RPO acordados. Ocultar tus RTA y RPA no servirá de nada a nadie si se produce una interrupción.
Recuerdo saber cuáles eran los RTO y RPO de nuestra empresa y saber que nuestros RTA y RPA no se acercaban ni de lejos a esas cifras. Teníamos un RTO de cuatro horas y apenas podía recuperar cintas de nuestro proveedor de bóvedas en ese tiempo. La restauración en sí de un servidor completo solía durar más de cuatro horas, y yo sabía que la restauración no podía empezar hasta que sustituyéramos el hardware que se había dañado. Recuerdo que todos nos reíamos de estas mediciones. No lo hagas. La Figura 4-2 lo explica perfectamente.

Figura 4-2. No seas Curtis
Sé la persona de la sala lo suficientemente valiente como para levantar la mano en una reunión y señalar que el RTO y el RPO no se acercan ni de lejos al RTA y al RPA. Presiona para que se cambien los objetivos o el sistema. En cualquier caso, tú ganas.
Hablando de reuniones, me gustaría disipar algunos mitos sobre la copia de seguridad y el archivo que es probable que oigas en ellas. Espero que esto te permita responder a ellos en tiempo real.
Mitos sobre las copias de seguridad y los archivos
Hay muchos mitos en el espacio de las copias de seguridad y los archivos. He discutido cada uno de los mitos de esta sección innumerables veces con gente en persona e incluso con más gente en Internet. La gente está convencida de una idea concreta y, a menudo, ningún número de hechos parece hacerles cambiar de opinión, pero ésta es mi respuesta a estos mitos:
- No necesitas hacer copias de seguridad RAID.
- Los sistemas de discos redundantes no obvian la necesidad de hacer copias de seguridad. Podrías pensar que esto no tendría que debatirse, pero surge con más frecuencia de lo que crees. RAID en todas sus formas y niveles, así como las tecnologías similares a RAID, como la codificación de borrado, sólo protegen contra los fallos físicos de los dispositivos. Los distintos niveles de RAID protegen contra distintos tipos de fallos de dispositivo, pero al final, el RAID se diseñó para proporcionar redundancia en el propio hardware. Nunca se diseñó para sustituir a las copias de seguridad por una razón muy importante: RAID protege el volumen, no el sistema de archivos situado sobre el volumen. Si borras un archivo, te entra un ransomware y lo encripta, o se te cae una tabla de una base de datos que no querías borrar, el RAID no puede hacer nada para ayudarte. Por eso debes hacer copias de seguridad de los datos en una matriz RAID, sea del nivel que sea.
Nota
Un amigo mío utilizaba NT4 Workstation en una matriz RAID1, pero no tenía copias de seguridad, porque era RAID1 y, por tanto, "seguro". Era administrador de bases de datos (DBA) y fotógrafo semiprofesional, con muchos miles de fotos en la misma partición que el SO. Un parche para el SO corrompió su sistema de archivos debido a una incompatibilidad de controladores, pero sus discos estaban bien. Perdió todas sus fotos por este mito. Intenté ayudarle a recuperarlas, pero las herramientas de que disponía no sirvieron de nada.
-Kurt Buff
- No necesitas hacer copias de seguridad de los datos replicados.
- La respuesta a esto es realmente la misma que la de la sección sobre RAID. Replicación, no importa cuántas veces lo hagas, replica todo, no sólo lo bueno. Si le ocurren cosas malas a los datos que están en tu volumen replicado, la replicación simplemente copiará esas cosas a otra ubicación. De hecho, a menudo hago el chiste de que la replicación no arregla tu error ni detiene el virus; sólo hace que tu error o el virus sean más eficientes. Replicará tu error o virus en cualquier lugar que le indiques. Donde esto se plantea hoy en día es en las bases de datos multinodo y fragmentadas como Cassandra y MongoDB. Algunos DBA de estos productos mencionan que cada shard se replica en al menos tres nodos, por lo que debería ser capaz de sobrevivir a múltiples fallos de nodos. Eso es cierto, pero ¿qué ocurre si eliminas una tabla que no querías eliminar? Toda la replicación del mundo no lo arreglará. Por eso debes hacer copias de seguridad de los datos replicados.
- No necesitas hacer copias de seguridad de IaaS y PaaS.
-
No suelo entrar en demasiadas discusiones con gente que cree que no necesita hacer copias de seguridad de su infraestructura de nube pública. Los proveedores de IaaS y PaaS suelen ofrecer facilidades para que puedas hacer tus propias copias de seguridad, pero no conozco ninguno que haga copias de seguridad en tu nombre. Los recursos en la nube son maravillosos e infinitamente escalables. Muchos de ellos también incorporan funciones de alta disponibilidad. Pero al igual que la replicación y el RAID, la alta disponibilidad no tiene nada que ver con lo que ocurre cuando cometes un error o te atacan, o el centro de datos se convierte en un cráter por una explosión.
El punto principal que quiero destacar aquí es que es realmente importante sacar tus copias de seguridad de la nube de tu cuenta en la nube y de la región donde se crearon. Sí, ya sé que es más difícil. Sí, sé que incluso puede costar un poco más hacerlo así. Pero dejar tus copias de seguridad en la misma cuenta que las creó y almacenarlas en la misma región que los recursos que estás protegiendo no sigue la regla 3-2-1. Lee la barra lateral "Hay una nueva" para saber qué puede ocurrir cuando no haces esto.
- No necesitas hacer copias de seguridad del SaaS
- A estas alturas, discuto este mito dos o tres veces por semana. Todo el mundo parece pensar que las copias de seguridad deberían estar o ya están incluidas como parte del servicio cuando contratas a un proveedor de SaaS como Microsoft 365 o Google Workspace. Pero he aquí un hecho realmente importante: estos servicios casi nunca están incluidos en los principales proveedores de SaaS. Si dudas de mí, intenta encontrar las palabras copia de seguridad, recuperación o restauración en tu contrato de servicios. Intenta también encontrar la palabra copia de seguridad en la documentación del producto. He buscado todas ellas, y no encuentro nada que cumpla la definición básica de copia de seguridad, que es la regla 3-2-1. En el mejor de los casos, estos productos ofrecen funciones de restauración de conveniencia que utilizan el control de versiones y papeleras de reciclaje y cosas por el estilo, que no están protegidas contra un fallo o ataque catastrófico. Este tema se trata con más detalle en "Software como servicio (SaaS)".
- Las copias de seguridad deben almacenarse durante muchos años
-
El Capítulo 3 ofrece una definición sólida de copia de seguridad y archivo. Los productos de copia de seguridad no suelen estar diseñados para hacer el trabajo de archivo. Si tu producto de copia de seguridad requiere que conozcas el nombre del host, el nombre de la aplicación, el nombre del directorio y el nombre de la pestaña, y una única fecha para iniciar una restauración, entonces se trata de un producto de copia de seguridad tradicional y no de uno diseñado para hacer recuperaciones. Si puedes buscar información por un contexto diferente, como quién escribió el correo electrónico, qué palabras había en el correo o en el asunto, y un intervalo de fechas -yno necesitas saberdequé servidor procedía-, entonces tu producto de copia de seguridad puede hacer recuperaciones, y tú puedes ir a leer un mito diferente.
Pero la mayoría de vosotros estáis tratando con un producto de copia de seguridad que sólo sabe hacer copias de seguridad y restauraciones, lo que significa que no sabe hacer archivos y recuperaciones. (De nuevo, si no conoces la diferencia, necesitas leer el Capítulo 3, que trata este tema en detalle). Si tu producto de copia de seguridad no sabe hacer recuperaciones y vas a almacenar copias de seguridad durante varios años, te estás buscando problemas. Porque si los datos son accesibles y recibes una solicitud de e-discovery, legalmente estarás obligado a satisfacerla. Si lo que tienes es un producto de copia de seguridad y no un producto de archivo, te enfrentas a un proceso potencialmente multimillonario para satisfacer una sola solicitud de e-discovery. Si crees que exagero, lee la barra lateral " Las copias de seguridad son archivos realmente caros".
La mayoría de las restauraciones son de las últimas 24 horas. He hecho muchísimas restauraciones a lo largo de mi carrera, y muy pocas han sido de cualquier momento excepto los últimos días, y aún menos eran más antiguas que las últimas semanas. Personalmente, me gusta fijar la retención del sistema de copia de seguridad en 18 meses, lo que da cuenta de un archivo que sólo utilizas una vez al año y no te diste cuenta de que se había borrado o corrompido el año pasado.
Después, las cosas se complican mucho más. Los nombres de los servidores cambian, los nombres de las aplicaciones cambian, y ya ni siquiera sabes dónde está el archivo. El archivo también puede ser incompatible con la versión actual del software que estés ejecutando. Esto es especialmente cierto en las copias de seguridad de bases de datos.
Si tienes una necesidad organizativa de conservar datos durante muchos años, necesitas un sistema que sea capaz de ello. Si eres una de las raras organizaciones que utilizan un sistema de copia de seguridad que es realmente capaz tanto de hacer copias de seguridad como de archivar, vete en paz. Pero si eres una de las muchas organizaciones que utilizan su sistema de copia de seguridad para conservar datos durante siete años o -Dios no lo quiera- para siempre, reconsidera seriamente esa política. Te estás buscando problemas.
- La cinta está muerta
-
Personalmente, no he utilizado una unidad de cinta para hacer una copia de seguridad desde hace varios años. No he diseñado un nuevo sistema de copia de seguridad para que utilice unidades de cinta como destino inicial de la copia de seguridad desde hace al menos 10 años, probablemente más. Con muy pocas excepciones, la cinta está prácticamente muerta para mí como destino inicial de las copias de seguridad por todas las razones expuestas en "Unidades de cinta".(Consideraré la posibilidad de utilizarla como destino de una copia de seguridad, tema que trataré en el Capítulo 9).
No tengo esta opinión porque piense que la cinta no es fiable. Como comento en la sección "Unidades de cinta" antes mencionada, creo que la cinta es fundamentalmente incompatible con la forma en que hacemos las copias de seguridad hoy en día. Las cintas quieren ir mucho más rápido de lo que van las copias de seguridad típicas, y la incompatibilidad entre estos dos procesos crea la falta de fiabilidad que algunas personas creen que tienen las unidades de cinta.
Lo irónico es que las unidades de cinta son mejores que el disco para escribir unos y ceros; también son mejores que el disco para retener unos y ceros durante más tiempo. Pero intentar contentar a una unidad de cinta que quiere ir a 1 GB por segundo con una copia de seguridad que va a unas decenas de megabytes por segundo es sencillamente imposible.
Y, sin embargo, hoy se vende más cinta que nunca. Se están vendiendo bibliotecas de cintas gigantescas a diestro y siniestro, y esas bibliotecas de cintas están almacenando algo. Como ya he dicho en otro lugar, el secreto peor guardado de la computación en nube es que estos grandes proveedores de nubes compran muchas bibliotecas de cintas. Entonces, ¿para qué se utiliza toda esa cinta?
Creo que el uso perfecto de la cinta son los archivos a largo plazo. No intentes enviar una copia de seguridad incremental directamente a cinta; te estás buscando problemas. Pero si por casualidad creas un gran archivo de unos cuantos terabytes de datos y lo tienes almacenado en disco justo al lado de esa unidad de cinta, no deberías tener ningún problema para enviar ese archivo directamente a cinta y mantener contenta a esa unidad de cinta. La unidad de cinta escribirá esos datos en cinta de forma fiable y los conservará durante mucho tiempo. Puedes crear tres o más copias por muy poco dinero y distribuirlas por todo el mundo.
La cinta es un medio increíblemente barato. No sólo el soporte y las unidades que lo crean son increíblemente baratos, sino que la energía y la refrigeración de una biblioteca de cintas cuestan mucho menos que la energía y la refrigeración de un sistema de discos. De hecho, un sistema de discos costaría más aunque los propios discos fueran gratuitos. (Con el tiempo, los costes de alimentación y refrigeración de las unidades de disco superarán los costes de alimentación y refrigeración y el coste de adquisición de las unidades de cinta).
Probablemente estés utilizando más cinta de lo que crees si utilizas un almacenamiento de objetos muy barato en la nube. No lo sé a ciencia cierta, pero el comportamiento de muchos de estos sistemas se parece muchísimo al de la cinta. Así que, aunque la cinta se esté retirando del negocio de las copias de seguridad y la recuperación, tiene una larga vida en el negocio del almacenamiento a largo plazo.
Tengo una última reflexión sobre el tema. Hace poco tuve una conversación con un compañero informático. Me estaba explicando que tenían centros de datos en una isla del Caribe que no disponía de una buena conexión a Internet, por lo que no consideraban que las copias de seguridad en la nube fueran una forma de salvaguardar sus datos, ya que no disponían del ancho de banda necesario. Así pues, utilizan copias de seguridad en disco para crear una copia de seguridad en las instalaciones que luego se replica en una matriz fuera de las instalaciones, que luego se copia en cinta y se envía a Iron Mountain. Le dije que las probabilidades de que alguna vez utilizaran realmente esa cinta eran casi nulas, y entonces me recordó un huracán que se llevó toda esa isla no hace mucho. Sólo tenían cintas. Como dije, las cintas no están muertas.
Ahora que esos mitos están fuera del camino, continuemos nuestro viaje a través de los fundamentos de la copia de seguridad y la recuperación. Lo siguiente en lo que debes pensar es en la unidad de la que vas a hacer la copia de seguridad. ¿Harás copias de seguridad de elementos individuales (por ejemplo, archivos) o de imágenes enteras?
Pudimos hacer tres restauraciones a la vez. Cada restauración llevó mucho tiempo y tuvo que ejecutarla alguien que supiera realmente lo que hacía. (Las restauraciones de Exchange en servidores alternativos no son ninguna broma.) Un equipo de consultores, contratados específicamente para la tarea, trabajó 24 horas al día durante varios meses para llevarla a cabo. Le costó al cliente 2 millones de dólares en honorarios de consultoría.
Como he dicho, las copias de seguridad hacen que los archivos sean realmente caros.
Copias de seguridad a nivel de elemento frente a nivel de imagen
En hay dos formas muy distintas de hacer una copia de seguridad de un servidor: la copia de seguridad a nivel de elemento y la copia de seguridad a nivel de imagen. El nivel de elemento suele denominarse nivel de archivo, aunque no siempre estás haciendo una copia de seguridad de archivos (pueden ser objetos). (Pueden ser objetos.) El nivel de imagen es actualmente el más popular cuando se hacen copias de seguridad de entornos virtualizados. Ambos tienen sus propias ventajas e inconvenientes.
Copia de seguridad a nivel de elemento
Una copia de seguridad a nivel de elemento realiza copias de seguridad de colecciones discretas de información que se tratan como elementos individuales, y el tipo más común de elemento es un archivo. De hecho, si esta sección se hubiera escrito hace varios años, lo más probable es que se llamara copia de seguridad a nivel de archivo.
El otro tipo de elemento que podría incluirse en una copia de seguridad a nivel de elemento es un objeto en un sistema de almacenamiento de objetos. Para muchos entornos, los objetos son similares a los archivos, en el sentido de que la mayoría de las organizaciones que utilizan el almacenamiento de objetos lo utilizan simplemente para guardar lo que de otro modo serían archivos, pero como se almacenan en un sistema de almacenamiento de objetos, no son archivos, porque los archivos se almacenan en un sistema de archivos. El contenido suele ser el mismo, pero recibe un nombre distinto porque se almacena de forma diferente.
Normalmente realizas una copia de seguridad a nivel de elemento si estás ejecutando un agente de copia de seguridad dentro del propio servidor o máquina virtual. El agente de copia de seguridad decide de qué archivos hacer una copia de seguridad mirando primero el sistema de archivos, como C:\Users o /Users. Si estás realizando una copia de seguridad completa, hará una copia de seguridad de todos los archivos del sistema de archivos. Si realizas una copia de seguridad incremental, hará una copia de seguridad de los archivos que hayan cambiado desde la última copia de seguridad. También estás realizando una copia de seguridad a nivel de elemento si haces una copia de seguridad de tu sistema de almacenamiento de objetos, como Amazon S3, Azure Blob o Google Cloud Storage. La idea de si hacer una copia de seguridad del almacenamiento de objetos se trata en "Almacenamiento de objetos en la nube".
La ventaja de una copia de seguridad a nivel de elemento es que es muy fácil de entender. Instala un agente de copia de seguridad en el lugar adecuado, y examinará tu sistema de archivos o de almacenamiento de objetos, encontrará todos los elementos y hará una copia de seguridad de ellos en el momento oportuno.
Copias de seguridad a nivel de imagen
Una copia de seguridad a nivel de imagen es el resultado de hacer una copia de seguridad de un dispositivo físico o virtual a nivel de bloque, creando una imagen de toda la unidad. Por eso, dependiendo de tu marco de referencia, las copias de seguridad a nivel de imagen también se denominan copias de seguridad a nivel de unidad, a nivel de volumen o a nivel de máquina virtual. El dispositivo podría estar almacenando diversos tipos de información, como un sistema de archivos estándar, almacenamiento de bloques para una base de datos, o incluso el volumen de arranque de una máquina física o virtual. En una copia de seguridad a nivel de imagen, estás haciendo una copia de seguridad de los bloques de construcción del sistema de archivos, en lugar de hacer una copia de seguridad de los archivos en sí.
Antes de la llegada de la virtualización, las copias de seguridad a nivel de imagen eran poco frecuentes porque hacer una copia de seguridad de la unidad física era mucho más difícil y requería desmontar el sistema de archivos mientras hacías la copia de seguridad de los bloques. De lo contrario, corrías el riesgo de hacer una copia de seguridad contaminada, en la que algunos de los bloques serían de un momento dado y otros de otro momento. La tecnología de instantáneas virtuales, como la que se encuentra en Windows Volume Shadow Services (VSS) o en las instantáneas de VMware, solucionó este problema subyacente.
Las copias de seguridad a nivel de volumen se hicieron mucho más populares cuando aparecieron en escena las máquinas virtuales. Las copias de seguridad a nivel de imagen te permiten realizar una copia de seguridad de una VM a nivel del hipervisor, donde tu software de copia de seguridad se ejecuta fuera de la VM y ve la VM como una o varias imágenes (por ejemplo, archivos VMDK en VMware).
Hacer copias de seguridad a nivel de imagen tiene varias ventajas. En primer lugar, proporciona copias de seguridad más rápidas y restauraciones mucho más rápidas. Las copias de seguridad a nivel de imagen evitan la sobrecarga del sistema de almacenamiento de archivos u objetos y van directamente al almacenamiento subyacente. Las restauraciones a nivel de imagen pueden ser mucho más rápidas porque las copias de seguridad a nivel de archivo requieren restaurar cada archivo individualmente, lo que requiere crear un archivo en el sistema de archivos, un proceso que conlleva bastante sobrecarga. Este problema aparece realmente cuando se restauran sistemas de archivos muy densos con millones de archivos, ya que el proceso de crear los archivos durante la restauración lleva más tiempo que el proceso de transferir los datos a los archivos. Las restauraciones a nivel de imagen no tienen este problema porque escriben los datos directamente en la unidad a nivel de bloque.
Una vez resuelto el problema de los bloques cambiantes con las instantáneas, a los sistemas de copia de seguridad se les presentó el segundo mayor reto de las copias de seguridad a nivel de imagen: las copias de seguridad incrementales de. Cuando haces copias de seguridad a nivel de unidad, volumen o imagen, cada archivo es una copia de seguridad completa. Por ejemplo, considera una máquina virtual representada por un archivo de disco de máquina virtual (VMDK). Si esa máquina virtual se está ejecutando y cambia un solo bloque de la máquina virtual, el tiempo de modificación de esa imagen mostrará que ha cambiado. Una copia de seguridad posterior hará entonces una copia de seguridad de todo el archivo VMDK, aunque sólo hayan cambiado unos pocos bloques de datos.
Este reto también se ha resuelto en el mundo de las VM mediante el seguimiento de bloques cambiados (CBT), que es un proceso que realiza un seguimiento de cuándo se creó una copia de seguridad anterior, y de los bloques que han cambiado desde esa última copia de seguridad. Esto permite que una copia de seguridad a nivel de imagen realice una copia de seguridad incremental a nivel de bloque, utilizando este protocolo para preguntar qué bloques han cambiado y luego copiar sólo esos bloques.
Recuperación a nivel de archivo de una copia de seguridad a nivel de imagen
Este nos deja una última desventaja de las copias de seguridad a nivel de imagen, y es la falta de recuperación a nivel de elemento. Normalmente, los clientes no quieren restaurar una máquina virtual entera, sino uno o dos archivos de esa máquina. ¿Cómo se restaura un único archivo de una máquina virtual cuando se ha hecho una copia de seguridad de toda la máquina virtual como una única imagen? Éste es también un problema que han resuelto muchas empresas de software de copia de seguridad. Por ejemplo, en el caso de una VM de VMware, entienden el formato de los archivos VMDK, lo que les permite hacer varias cosas.
Una opción que te permiten algunos productos de copia de seguridad es montar los archivos VMDK originales como un volumen virtual que puede estar disponible mediante el explorador de archivos del servidor de copia de seguridad o de cualquier cliente en el que se ejecute el software de copia de seguridad. A continuación, el cliente puede arrastrar y soltar el archivo o archivos que busque de esa imagen y decirle al software de copia de seguridad que la desmonte. En este caso, la imagen suele montarse en modo sólo lectura, lo que facilita estas restauraciones del tipo arrastrar y soltar. (Montar la imagen de la máquina virtual en modo lectura-escritura y ejecutar realmente la máquina virtual desde esa imagen se denomina recuperación instantánea y se trata en el Capítulo 9).
Otros productos de software de copia de seguridad pueden indexar las imágenes con antelación, para saber qué archivos utilizan qué bloques dentro de la imagen. Esto permite que estos productos admitan restauraciones regulares a nivel de archivo a partir de estas imágenes, sin necesidad de que el cliente monte la imagen y coja manualmente los archivos. El cliente utilizaría el mismo flujo de trabajo de siempre para seleccionar los archivos que desea restaurar, y el sistema de copia de seguridad haría lo que tuviera que hacer en segundo plano para restaurar los archivos en cuestión.
Combinar copias de seguridad a nivel de imagen y de archivo
La mayoría de los clientes de realizan copias de seguridad a nivel de imagen de sus máquinas virtuales, al tiempo que conservan la capacidad de realizar copias de seguridad incrementales y restauraciones a nivel de elemento. También quieren copias de seguridad incrementales a nivel de bloque, que en realidad son mucho más eficientes que las copias de seguridad incrementales a nivel de elemento.
Hacer copias de seguridad a nivel de la VM (es decir, a nivel de imagen) también conlleva la posibilidad de restaurar la VM fácilmente como una sola imagen. Esto hace que lo que antes llamábamos recuperación bare-metal sea mucho más fácil de lo que era. Obtienes todas las capacidades de recuperación bare-metal que necesitas sin tener que pasar por el aro de los problemas de bloques cambiantes que históricamente se encontraban en las copias de seguridad a nivel de imagen.
Incluso tenemos copias de seguridad a nivel de imagen de servidores físicos de Windows, ya que la mayoría de la gente utiliza Windows VSS para crear una instantánea de cada sistema de archivos antes de hacer la copia de seguridad. Esto permite al producto de software de copia de seguridad hacer copias de seguridad a nivel de imagen sin arriesgarse a que se corrompan los datos.
Una vez que hayas decidido de qué vas a hacer copia de seguridad, tienes que saber cómo selecciona el producto de copia de seguridad las cosas de las que se va a hacer copia de seguridad. Esta sección es muy importante, porque elegir el método equivocado puede crear lagunas importantes en tu sistema de copia de seguridad.
Métodos de selección de copias de seguridad
Comprender en cómo se incluyen los sistemas, directorios y bases de datos en el sistema de copia de seguridad es la clave para asegurarte de que los archivos de los que crees que se está haciendo una copia de seguridad, realmente se están haciendo. Nadie quiere descubrir que el sistema o la base de datos que creía protegidos no lo estaban en absoluto.
Pero hay una advertencia. Tus métodos de selección de copias de seguridad sólo funcionan una vez que tu sistema de copias de seguridad sabe de qué sistemas se está haciendo una copia de seguridad. Eso significa que el primer paso hacia este objetivo es asegurarte de que los servidores y servicios de los que quieres hacer copia de seguridad están registrados en tu sistema de copia de seguridad y recuperación.
Por ejemplo, si empiezas a utilizar un nuevo SaaS como Salesforce, el sistema de copia de seguridad no notará automáticamente esa adición y empezará a hacer copias de seguridad por ti. Si estás totalmente virtualizado en VMware y tu sistema de copia de seguridad está conectado a vCenter, los sistemas se darán cuenta automáticamente si añades un nuevo nodo a la configuración. Pero si empiezas a utilizar Hyper-V o una máquina virtual de núcleo (KVM), el sistema de copia de seguridad no se dará cuenta automáticamente de que hay un nuevo hipervisor en el centro de datos y empezará a hacer copias de seguridad. Y, por supuesto, el sistema de copia de seguridad no se dará cuenta de que has instalado un nuevo servidor físico. Así que estos métodos de selección vienen con esta advertencia.
Inclusión selectiva frente a exclusión selectiva
En hay dos categorías muy amplias de cómo se pueden incluir elementos en un sistema de copia de seguridad: inclusión selectiva y exclusión selectiva.
En la inclusión selectiva, el administrador especifica individualmente de qué sistemas de archivos, bases de datos u objetos hará copia de seguridad el sistema de copia de seguridad. Por ejemplo, si un administrador dice que quiere hacer una copia de seguridad sólo de la unidad D:\, o sólo de la base de datos Apollo, está practicando la inclusión selectiva.
En la exclusión selectiva, también conocida como inclusión automática, un administrador especifica que se haga una copia de seguridad de todo lo que hay en el servidor excepto de lo que se excluye específicamente. Por ejemplo, un administrador puede seleccionar todos los sistemas de archivos excepto /tmp en un sistema Linux o los directorios iTunes o Movies de un usuario en un portátil Windows.
Es muy común que los administradores piensen que administran los sistemas de tal manera que no tiene sentido hacer copias de seguridad del sistema operativo. Saben que quieren hacer una copia de seguridad de C:\Users en un portátil con Windows, de /Users en un MacBook, o de algo como /data o /home en un sistema Linux. No le ven sentido a hacer una copia de seguridad del sistema operativo o de las aplicaciones, así que seleccionan manualmente sólo los sistemas de archivos de los que quieren hacer una copia de seguridad. Lo mismo ocurre con las bases de datos. Puede que no quieran que hagas copias de seguridad de las bases de datos de prueba, así que incluyen selectivamente de qué bases de datos quieren hacer copias de seguridad.
El problema de la inclusión selectiva son los cambios de configuración. Cada vez que se añade una nueva base de datos o un sistema de archivos con datos a un sistema, alguien tiene que cambiar la configuración de la copia de seguridad; de lo contrario, nunca se hará una copia de seguridad del nuevo recurso. Por eso la inclusión selectiva es mucho menos segura que la exclusión selectiva.
Con la exclusión selectiva, el peor efecto secundario posible es que hagas una copia de seguridad de datos sin valor (suponiendo que hayas olvidado excluirlos). Compáralo con el peor efecto secundario posible de la inclusión selectiva, en la que los datos importantes quedan completamente excluidos del sistema de copia de seguridad. Sencillamente, no hay comparación entre ambos. Puede parecer que la inclusión selectiva ahorra dinero porque se almacenan menos datos, pero es mucho más arriesgada.
Es fácil excluir datos que sabes que no tienen valor, como /tmp o /temp en un sistema Linux. Si no ves ninguna razón para hacer una copia de seguridad del sistema operativo, también podrías excluir /, /user, /usr, /var, y /opt, aunque yo haría una copia de seguridad de esos directorios. En un sistema Windows, podrías excluir C:\Windows y C:\Program Files si realmente no quieres hacer una copia de seguridad del sistema operativo y de los programas de aplicación.
Sin embargo, hay que tener en cuenta el efecto que la deduplicación puede tener en esta decisión. Una cosa es saber que estás haciendo copias de seguridad de cientos o miles de sistemas de archivos que no tienen ningún valor, y desperdiciando un valioso espacio de almacenamiento en tu matriz de discos o biblioteca de cintas. Pero, ¿y si el sistema operativo que estás dedicando tanto tiempo a excluir sólo se almacena en realidad una vez?
La deduplicación garantizaría que sólo se almacena realmente una copia del sistema operativo Windows o Linux en tu sistema de copia de seguridad. Teniendo esto en cuenta, quizá podrías dejar el sistema de copia de seguridad con su configuración por defecto y no preocuparte de excluir el sistema operativo, porque el coste para tu sistema de copia de seguridad será muy pequeño.
Inclusión basada en etiquetas y carpetas
Otra forma de añadir datos de copia de seguridad al sistema de copia de seguridad automáticamente es mediante la inclusión basada en etiquetas y carpetas. Esto se ha hecho popular en el mundo de la virtualización, donde a cada nueva VM o base de datos que se crea se le puede dar una o más etiquetas (o colocarse en una carpeta concreta) que se pueden utilizar para clasificar el tipo de VM o base de datos.
Por ejemplo, todos los servidores de bases de datos nuevos podrían recibir la etiqueta de base de datos o colocarse en la carpeta de bases de datos, indicando a otros muchos procesos que se trata de una máquina virtual relacionada con bases de datos. Esto podría indicar a ciertos sistemas de monitoreo que monitoricen si la base de datos está disponible. También podría aplicar automáticamente determinadas reglas de seguridad y cortafuegos a esa máquina virtual. Y en muchos sistemas de copia de seguridad, también puede aplicar automáticamente a esa máquina virtual una política de copia de seguridad centrada en la base de datos.
Una cosa importante a tener en cuenta cuando utilices este método: Necesitas una política de copia de seguridad predeterminada. Debes crear una política de copia de seguridad que tu software de copia de seguridad utilice automáticamente si no se encuentran etiquetas adecuadas, o si una máquina virtual no está en una carpeta determinada. Luego, asegúrate de monitorear esa política por defecto para detectar cualquier sistema nuevo que aparezca, porque significa que los datos de esos sistemas podrían no estar siendo respaldados correctamente. Si tu producto de software de copia de seguridad no admite una política de copia de seguridad predeterminada cuando se utiliza con este método, puede que sea mejor no utilizar esta funcionalidad, porque conlleva el riesgo de que no se realice una copia de seguridad de las nuevas máquinas virtuales o bases de datos.
Nota
Tenemos automatizado el proceso de creación de nuestro servidor y las máquinas virtuales se copian mediante un ANS añadido a la carpeta en la que van las máquinas virtuales. Para las copias de seguridad de las bases de datos, tenemos que añadir un agente y añadirlas a nuestro software de copia de seguridad y añadir un ANS. Todo esto se hace durante la compilación del servidor, cuando se comprueba la BD. Así esperamos no perdernos una copia de seguridad de la que no éramos conscientes.
-Julie Ulrich
Para llevar
Si estás diseñando u operando un sistema de copia de seguridad para el que no tienes un SLA acordado para RTO y RPO, te estás buscando problemas. Tómate el tiempo necesario para documentar uno, y recuerda que debe proceder de la organización, node TI. Además, si tienes un RTO y un RPO documentados y sabes que tu RTA y tu RPA no se acercan a ellos, ahora es el momento de hablar.
En cuanto a los mitos de las copias de seguridad, todos dicen que no necesitas hacer copias de seguridad de X, Y o Z. Eso casi nunca es cierto. Si tienes un sistema que realmente tiene copias de seguridad y recuperación como parte de su conjunto de funciones, asegúrate de conseguirlo por escrito.
En cuanto a los niveles de copia de seguridad, creo que la mayoría de la gente no necesita toda esa sección. La mayoría de los productos de copia de seguridad modernos hacen copias de seguridad incrementales a nivel de bloque desde siempre y realmente no utilizan los niveles de copia de seguridad de antaño.
Por defecto, exclusión selectiva (es decir, inclusión automática). Dedica tu valioso tiempo a otras actividades de administrador, sin tener que preocuparte de si se está haciendo una copia de seguridad de tu nueva base de datos. Las prioridades de las copias de seguridad deben ser siempre la seguridad y la protección en primer lugar, y el coste en segundo lugar. Nunca se ha despedido a nadie porque su sistema de copias de seguridad hiciera copias de demasiados datos, pero sí se ha despedido a mucha gente por no hacer copias de suficientes datos.
El siguiente capítulo está dedicado a la forma en que la mayoría de la gente hace copias de seguridad hoy en día: el disco como objetivo principal. Trataré las distintas formas en que la gente utiliza el disco en sus sistemas de copia de seguridad y seguiré con las distintas formas en que la gente se recupera.
1 Para una historia completa del juego y una URL donde puedes jugarlo en la web, consulta http://www.math.toronto.edu/mathnet/games/towers.html.
2 Esto es siempre así para cualquier recomendación de este libro. Si te confunde a ti o a tu metodología de copias de seguridad, ¡no es bueno! Si tus copias de seguridad te confunden, ¡no querrás ni intentar restaurar! Mantenlo siempre simple SA . (K.I.S.S.).
3 Un trozo es una colección de bytes. La mayoría de la gente utiliza el término trozo frente al de bloque, porque los bloques suelen tener un tamaño fijo, y los trozos pueden tener cualquier tamaño. Algunos sistemas de deduplicación utilizan incluso trozos de tamaño variable.
Get Protección de datos moderna now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

