Capítulo 4. Objetivos de nivel de servicio
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Es imposible gestionar un servicio correctamente, y mucho menos bien, sin comprender qué comportamientos son realmente importantes para ese servicio y cómo medir y evaluar esos comportamientos. Para ello, queremos definir y ofrecer un determinado nivel de servicio a nuestros usuarios, tanto si utilizan una API interna como un producto público.
Utilizamos la intuición, la experiencia y la comprensión de lo que quieren los usuarios para definir los indicadores de nivel de servicio (SLI), los objetivos (SLO) y losacuerdos (SLA). Estas medidas describen las propiedades básicas de las métricas que importan, qué valores queremos que tengan esas métricas y cómo reaccionaremos si no podemos prestar el servicio esperado. En última instancia, elegir las métricas adecuadas ayuda a impulsar la acción correcta si algo va mal, y también da a un equipo de SRE la confianza de que un servicio está en buen estado.
Este capítulo describe el marco que utilizamos para lidiar con los problemas del modelado métrico, la selección métrica y el análisis métrico. Gran parte de esta explicación sería bastante abstracta sin un ejemplo, así que utilizaremos el servicio Shakespeare descrito en"Shakespeare: Un servicio de ejemplo" para ilustrar nuestros puntos principales.
Terminología del nivel de servicio
Es probable que muchos lectores estén familiarizados con el concepto de un ANS, pero también merece la pena definir cuidadosamente los términos ANS y ANL, porque en el uso común, el término ANS está sobrecargado y ha adoptado varios significados dependiendo del contexto. Preferimos separar esos significados para mayor claridad.
Indicadores
Un SLI es un indicadordel nivel de servicio : unamedida cuantitativa cuidadosamente definida de algún aspecto del nivel de servicio que se presta.
La mayoría de los servicios consideran la latencia de las solicitudes -eltiempo que se tarda en devolver una respuesta a una solicitud- como un SLI clave. Otros SLI comunes son latasa de error, a menudo expresada como una fracción de todas las solicitudes recibidas, y el rendimiento del sistema, medido normalmente en solicitudes por segundo. Las mediciones suelen ser agregadas: es decir, los datos brutos se recogen a lo largo de una ventana de medición y luego se convierten en una tasa, media o percentil.
Idealmente, el SLI mide directamente un nivel de servicio de interés, pero a veces sólo se dispone de un proxy porque la medida deseada puede ser difícil de obtener o interpretar. Por ejemplo, la latencia del lado del cliente suele ser la métrica más relevante para el usuario, pero puede que sólo sea posible medir la latencia en el servidor.
Otro tipo de SLI importante para las SRE es la disponibilidad, o la fracción de tiempo en que un servicio es utilizable. A menudo se define en términos de la fracción de peticiones bien formadas que tienen éxito, lo que a veces se denomina rendimiento.(La durabilidad -laprobabilidad de que los datos se conserven durante un largo periodo de tiempo- es igualmente importante para los sistemas de almacenamiento de datos). Aunque la disponibilidad del 100% es imposible, a menudo se puede alcanzar fácilmente una disponibilidad cercana al 100%, y el sector suele expresar los valores de alta disponibilidad en términos del número de "nueves" en el porcentaje de disponibilidad. Por ejemplo, las disponibilidades del 99% y del 99,999% pueden denominarse disponibilidad de "2 nueves" y "5 nueves", respectivamente, y el objetivo actual publicado para la disponibilidad de Google Compute Engine es de "tres nueves y medio": 99,95% de disponibilidad.
Objetivos
Un SLO es un objetivo de nivel de servicio: un valor objetivo o rango de valores para un nivel de servicio que se mide mediante un SLI. Una estructura natural para los OLS es, por tanto, SLI ≤ objetivo, o límite inferior ≤ SLI ≤ límite superior. Por ejemplo, podemos decidir que devolveremos los resultados de la búsqueda de Shakespeare "rápidamente", adoptando un SLI según el cual nuestra latencia media de las solicitudes de búsqueda debe ser inferior a 100 milisegundos.
Elegir un SLO adecuado es complejo. Para empezar, ¡no siempre puedes elegir su valor! Para las solicitudes HTTP entrantes desde el mundo exterior a tu servicio, la métrica de consultas por segundo (QPS) viene determinada esencialmente por los deseos de tus usuarios, y realmente no puedes establecer un SLO para eso.
Por otra parte, puedes decir que quieres que la latencia media por solicitud sea inferior a 100 milisegundos, y fijar ese objetivo podría motivarte a escribir tu frontend con comportamientos de baja latencia de diversos tipos o a comprar determinados tipos de equipos de baja latencia. (100 milisegundos es obviamente un valor arbitrario, pero en general las cifras de latencia más bajas son buenas. Hay excelentes razones para creer que lo rápido es mejor que lo lento, y que la latencia experimentada por el usuario por encima de ciertos valores en realidad ahuyenta a la gente; para más detalles, véase "La velocidad importa" [Bru09] ).
De nuevo, esto es más sutil de lo que podría parecer a primera vista, en el sentido de que esos dos SLIs -QPS y latencia- podrían estar conectados entre bastidores: un QPS más alto suele conllevar latencias mayores, y es habitual que los servicios tengan un precipicio de rendimiento más allá de cierto umbral de carga.
Elegir y publicar los SLO para los usuarios crea expectativas sobre cómo funcionará un servicio. Esta estrategia puede reducir las quejas infundadas a los propietarios del servicio sobre, por ejemplo, la lentitud del servicio. Sin un SLO explícito, los usuarios suelen desarrollar sus propias creencias sobre el rendimiento deseado, que pueden no estar relacionadas con las creencias de las personas que diseñan y operan el servicio. Esta dinámica puede conducir tanto a un exceso de confianza en el servicio, cuando los usuarios creen erróneamente que un servicio estará más disponible de lo que realmente está (como ocurrió con Chubby: véase "La interrupción planificada global de Chubby"), como a una falta de confianza, cuando los posibles usuarios creen que un sistema es más escaso y menos fiable de lo que realmente es.
Acuerdos
Por último, los ANS son acuerdos de nivel de servicio: un contrato explícito o implícito con tus usuarios que incluye las consecuencias de cumplir (o incumplir) los ANS que contienen. Las consecuencias se reconocen más fácilmente cuando son económicas -un reembolso o una penalización-, pero pueden adoptar otras formas. Una forma fácil de distinguir entre un SLO y un SLA es preguntarse "¿qué ocurre si no se cumplen los SLO?": si no hay consecuencias explícitas, es casi seguro que estás ante un SLO.1
La SRE no suele participar en la elaboración de los ANS, porque éstos están estrechamente ligados a las decisiones empresariales y de producto. Sin embargo, la SRE sí se involucra en ayudar a evitar que se desencadenen las consecuencias del incumplimiento de los SLI. También pueden ayudar a definir los SLA: obviamente, tiene que haber una forma objetiva de medir los SLO en el acuerdo, o surgirán desacuerdos.
La Búsqueda de Google es un ejemplo de un servicio importante que no tiene un SLA para el público: queremos que todo el mundo utilice la Búsqueda con la mayor fluidez y eficacia posibles, pero no hemos firmado un contrato con todo el mundo. Aun así, sigue habiendo consecuencias si la Búsqueda no está disponible: la indisponibilidad supone un golpe para nuestra reputación, así como una caída de los ingresos por publicidad. Muchos otros servicios de Google, como Google for Work, tienen acuerdos de nivel de servicio explícitos con sus usuarios. Tanto si un servicio concreto tiene un SLA como si no, es valioso definir los SLI y los SLO y utilizarlos para gestionar el servicio.
Hasta aquí la teoría, ahora la experiencia.
Indicadores en la práctica
Dado que ya hemos explicado por qué es importante elegir las métricas adecuadas para medir tu servicio, ¿cómo puedes identificar qué métricas son significativas para tu servicio o sistema?
¿Qué os importa a ti y a tus usuarios?
No debes utilizar como SLI todas las métricas que puedas rastrear en tu sistema de monitoreo; una comprensión de lo que tus usuarios quieren del sistema informará la selección juiciosa de unos pocos indicadores. Elegir demasiados indicadores dificulta prestar el nivel adecuado de atención a los indicadores que importan, mientras que elegir muy pocos puede dejar sin examinar comportamientos significativos de tu sistema. Normalmente consideramos que un puñado de indicadores representativos son suficientes para evaluar y razonar sobre la salud de un sistema.
Los servicios tienden a clasificarse en algunas grandes categorías en cuanto a los SLI que consideran relevantes:
-
Los sistemas de servicio de cara al usuario, como los frontales de búsqueda de Shakespeare, suelen preocuparse por la disponibilidad, la latencia y elrendimiento. En otras palabras: ¿Pudimos responder a la solicitud? ¿Cuánto tardamos en responder? ¿Cuántas solicitudes se podían gestionar?
-
Los sistemas de almacenamiento suelen hacer hincapié en la latencia, la disponibilidad y ladurabilidad. Dicho de otro modo: ¿Cuánto tardan en leerse o escribirse los datos? ¿Podemos acceder a los datos bajo demanda? ¿Siguen estando ahí los datos cuando los necesitamos? Consulta el Capítulo 26 para profundizar en estas cuestiones.
-
Los sistemas de big data, como los pipelines de procesamiento de datos, tienden a preocuparse por el rendimiento y la latencia de extremo a extremo. Dicho de otro modo: ¿Cuántos datos se procesan? ¿Cuánto tardan los datos en progresar desde la ingesta hasta la finalización? (Algunas canalizaciones también pueden tener objetivos de latencia en etapas de procesamiento individuales).
-
Todos los sistemas deberían preocuparse por la corrección: ¿se ha devuelto la respuesta correcta, se han recuperado los datos correctos, se ha realizado el análisis correcto? Es importante hacer un seguimiento de la corrección como indicador de la salud del sistema, aunque a menudo sea una propiedad de los datos del sistema y no de la infraestructura en sí, y por tanto no sea una responsabilidad de la SRE.
Recopilación de indicadores
Muchas métricas de indicadores se recopilan de forma más natural en el lado del servidor, utilizando un sistema de monitoreo como Borgmon (ver Capítulo 10) o Prometheus, o con análisis periódicos de registros, por ejemplo, respuestas HTTP 500 como fracción de todas las solicitudes. Sin embargo, algunos sistemas deben instrumentarse con recopilación del lado del cliente, porque no medir el comportamiento en el cliente puede pasar por alto una serie de problemas que afectan a los usuarios pero no afectan a las métricas del lado del servidor. Por ejemplo, concentrarse en la latencia de respuesta del backend de búsqueda de Shakespeare puede pasar por alto una mala latencia del usuario debida a problemas con el JavaScript de la página: en este caso, medir cuánto tarda una página en ser utilizable en el navegador es una mejor aproximación a lo que experimenta realmente el usuario.
Agregación
Por simplicidad y facilidad de uso, a menudo agregamos las mediciones brutas. Esto debe hacerse con cuidado.
Algunas métricas son aparentemente sencillas, como el número de solicitudes por segundo servidas, pero incluso esta medición aparentemente sencilla agrega implícitamente datos a lo largo de la ventana de medición. ¿La medición se obtiene una vez por segundo, o promediando las solicitudes a lo largo de un minuto? Esto último puede ocultar tasas de peticiones instantáneas mucho más altas en ráfagas que duran sólo unos segundos. Considera un sistema que atiende 200 peticiones/s en los segundos pares, y 0 en los demás. Tiene la misma carga media que uno que sirve 100 solicitudes/s constantes, pero tiene una carga instantánea que es el doble de grande que la media. Del mismo modo, promediar las latencias de las solicitudes puede parecer atractivo, pero oculta un detalle importante: es perfectamente posible que la mayoría de las solicitudes sean rápidas, pero que una larga cola de solicitudes sea mucho, mucho más lenta.
La mayoría de las métricas se consideran mejor como distribuciones que como promedios. Por ejemplo, para un SLI de latencia, algunas solicitudes se atenderán rápidamente, mientras que otras tardarán invariablemente más, a veces mucho más. Una simple media puede ocultar estas latencias de cola, así como los cambios en ellas. La Figura 4-1 ofrece un ejemplo: aunque una solicitud típica se atiende en unos 50 ms, ¡el 5% de las solicitudes son 20 veces más lentas! El monitoreo y la alerta basados sólo en la latencia media no mostrarían ningún cambio en el comportamiento a lo largo del día, cuando en realidad hay cambios significativos en la latencia de cola (la línea superior).
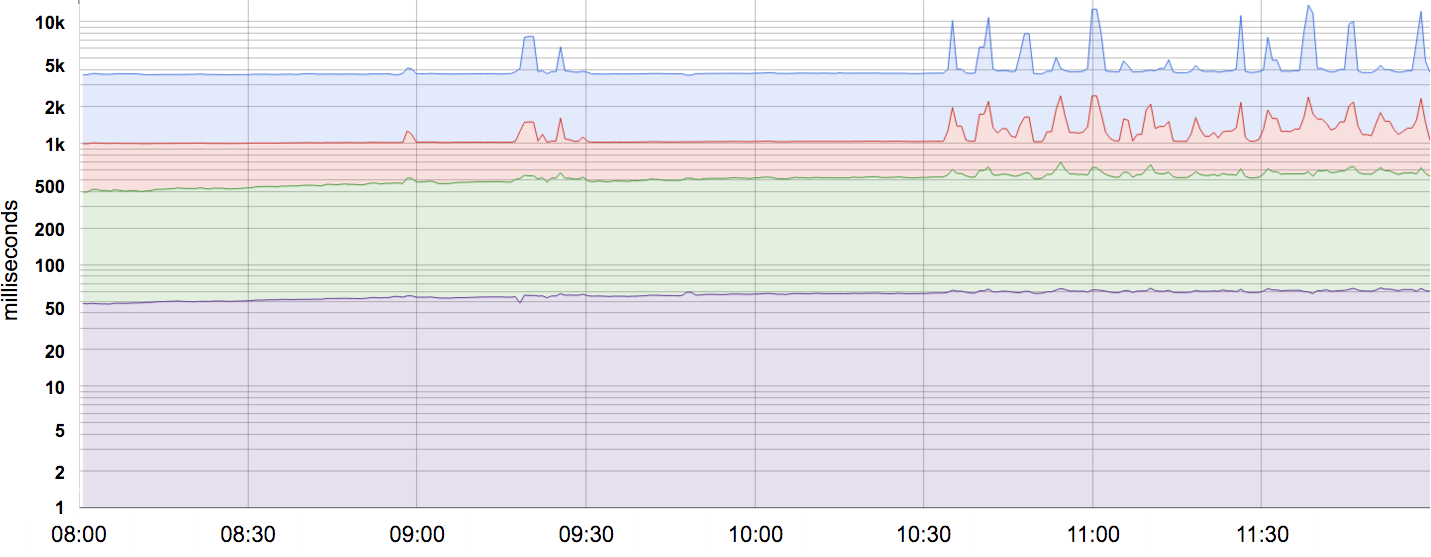
Figura 4-1. Latencias percentil 50, 85, 95 y 99 de un sistema. Observa que el eje Y tiene una escala logarítmica.
Utilizar percentiles para los indicadores te permite considerar la forma de la distribución y sus diferentes atributos: un percentil de orden alto, como el 99 o el 99,9, te muestra un valor plausible del peor caso, mientras que utilizar el percentil 50 (también conocido como mediana) enfatiza el caso típico. Cuanto mayor sea la varianza en los tiempos de respuesta, más se verá afectada la experiencia típica del usuario por el comportamiento de cola larga, un efecto exacerbado a alta carga por los efectos de las colas. Los estudios de usuarios han demostrado que la gente suele preferir un sistema ligeramente más lento a uno con una alta varianza en el tiempo de respuesta, por lo que algunos equipos de SRE se centran sólo en los valores de percentil alto, basándose en que si el comportamiento del percentil 99,9 es bueno, entonces la experiencia típica sin duda lo será.
Normalizar los indicadores
Te recomendamos que estandarices las definiciones comunes para los SLI, de modo que no tengas que razonar sobre ellos desde los primeros principios cada vez. Cualquier característica que se ajuste a las plantillas de definición estándar puede omitirse en la especificación de un SLI individual, por ejemplo
-
Intervalos de agregación: "Promedio de 1 minuto"
-
Regiones de agregación: "Todas las tareas de un cluster"
-
Con qué frecuencia se realizan las mediciones: "Cada 10 segundos"
-
Qué peticiones se incluyen: "GETs HTTP de trabajos de monitoreo de caja negra"
-
Cómo se adquieren los datos: "A través de nuestro monitoreo, medido en el servidor"
-
Latencia de acceso a los datos: "Tiempo hasta el último byte"
Para ahorrar esfuerzo, construye un conjunto de plantillas SLI reutilizables para cada métrica común; éstas también hacen que sea más sencillo para todos entender lo que significa un SLI específico.
Objetivos en la práctica
Empieza por pensar (¡o averiguar!) qué les importa a tus usuarios, no qué puedes medir. A menudo, lo que les importa a tus usuarios es difícil o imposible de medir, por lo que acabarás aproximándote a las necesidades de los usuarios de alguna manera. Sin embargo, si empiezas simplemente por lo que es fácil de medir, acabarás con SLO menos útiles. En consecuencia, a veces hemos comprobado que trabajar desde los objetivos deseados hacia atrás, hasta los indicadores específicos, funciona mejor que elegir los indicadores y luego plantear los objetivos.
Definición de objetivos
Para una mayor claridad, los SLO deben especificar cómo se miden y las condiciones en las que son válidos. Por ejemplo, podríamos decir lo siguiente (la segunda línea es igual que la primera, pero se basa en los valores por defecto del SLI de la sección anterior para eliminar redundancias):
-
El 99% (media de 1 minuto) de las llamadas RPC a
Getse completarán en menos de 100 ms (medido en todos los servidores backend). -
El 99% de las llamadas RPC de
Getse completarán en menos de 100 ms.
Si la forma de las curvas de rendimiento es importante, puedes especificar varios objetivos SLO:
-
El 90% de las llamadas RPC de
Getse completarán en menos de 1 ms. -
El 99% de las llamadas RPC de
Getse completarán en menos de 10 ms. -
El 99,9% de las llamadas RPC de
Getse completarán en menos de 100 ms.
Si tienes usuarios con cargas de trabajo heterogéneas, como una tubería de procesamiento masivo que se preocupa por el rendimiento y un cliente interactivo que se preocupa por la latencia, puede ser conveniente definir objetivos distintos para cada clase de carga de trabajo:
-
El 95% de las llamadas RPC a
Setde los clientes de rendimiento se completarán en < 1 s. -
El 99% de las llamadas RPC de los clientes de latencia
Setcon cargas útiles < 1 kB se completarán en < 10 ms.
No es realista ni deseable insistir en que los SLO se cumplan el 100% de las veces: hacerlo puede reducir el ritmo de innovación e implementación, requerir soluciones caras y demasiado conservadoras, o ambas cosas. En lugar de eso, es mejor dejar un margen de error -la tasa a la que se pueden incumplir los ODS- y hacer un seguimiento diario o semanal. La alta dirección probablemente querrá también una evaluación mensual o trimestral. (¡Un presupuesto de errores no es más que un SLO para cumplir otros SLO!)
La tasa de infracción del SLO puede compararse con el presupuesto de errores (véase "Motivación de los presupuestos de errores"), y la diferencia se utiliza como entrada para el proceso que decide cuándo lanzar nuevas versiones.
Elegir objetivos
La elección de objetivos (SLO) no es una actividad puramente técnica debido a las implicaciones del producto y del negocio, que deben reflejarse tanto en los SLI como en los SLO (y quizá en los SLA) que se seleccionen. Del mismo modo, puede ser necesario compensar ciertos atributos del producto con otros, dentro de las limitaciones impuestas por el personal, el tiempo de comercialización, la disponibilidad de hardware y la financiación. Aunque la SRE debe formar parte de esta conversación, y asesorar sobre los riesgos y la viabilidad de las distintas opciones, hemos aprendido algunas lecciones que pueden ayudar a que esta discusión sea más productiva:
- No elijas un objetivo basándote en los resultados actuales
-
Aunque comprender los méritos y los límites de un sistema es esencial, adoptar valores sin reflexión puede encerrarte en el apoyo a un sistema que requiere esfuerzos heroicos para cumplir sus objetivos, y que no puede mejorarse sin un rediseño significativo.
- Hazlo sencillo
-
Las agregaciones complicadas en los SLI pueden oscurecer los cambios en el rendimiento del sistema, y además son más difíciles de razonar.
- Evita los absolutos
-
Aunque es tentador pedir un sistema que pueda escalar su carga "infinitamente" sin ningún aumento de latencia y que esté "siempre" disponible, este requisito no es realista. Incluso un sistema que se acerque a tales ideales probablemente tardará mucho tiempo en diseñarse y construirse, y será caro de operar -y probablemente resulte ser innecesariamente mejor de lo que los usuarios estarían contentos (o incluso encantados) de tener.
- Tener el menor número posible de SLO
-
Elige sólo los SLO suficientes para proporcionar una buena cobertura de los atributos de tu sistema. Defiende los SLO que elijas: si nunca puedes ganar una conversación sobre prioridades citando un SLO concreto, probablemente no merezca la pena tener ese SLO.2 Sin embargo, no todos los atributos del producto son susceptibles de SLO: es difícil especificar el "placer del usuario" con un SLO.
- La perfección puede esperar
-
Siempre puedes perfeccionar las definiciones y objetivos de SLO con el tiempo, a medida que aprendas sobre el comportamiento de un sistema. Es mejor empezar con un objetivo flexible que irás ajustando, que elegir un objetivo demasiado estricto que tengas que relajar cuando descubras que es inalcanzable.
Los SLO pueden -y deben- ser un motor importante para priorizar el trabajo de los SRE y los desarrolladores de productos, porque reflejan lo que les importa a los usuarios. Un buen SLO es una función forzosa útil y legítima para un equipo de desarrollo. Pero un SLO mal planteado puede dar lugar a un trabajo desperdiciado si un equipo realiza esfuerzos heroicos para cumplir un SLO demasiado agresivo, o a un mal producto si el SLO es demasiado laxo. Las SLO son una palanca enorme: úsalas con sabiduría.
Medidas de control
Los SLI y los SLO son elementos cruciales en los bucles de control utilizados para gestionar los sistemas:
-
Monitorea y mide los SLI del sistema.
-
Compara los SLI con los SLO y decide si es necesario actuar o no.
-
Si es necesario actuar, averigua qué hay que hacer para cumplir el objetivo.
-
Emprende esa acción.
Por ejemplo, si el paso 2 muestra que la latencia de las solicitudes está aumentando, y que no se alcanzará el SLO en unas horas a menos que se haga algo, el paso 3 podría incluir probar la hipótesis de que los servidores están saturados de CPU, y decidir añadir más de ellos para repartir la carga. Sin el SLO, no sabrías si (o cuándo) tomar medidas.
Los objetivos estratégicos fijan expectativas
La publicación de los SLO establece expectativas sobre el comportamiento del sistema. Los usuarios (y los usuarios potenciales) a menudo quieren saber qué pueden esperar de un servicio para comprender si es apropiado para su caso de uso. Por ejemplo, un equipo que quiera crear un sitio web para compartir fotos quizá quiera evitar utilizar un servicio que promete una durabilidad muy sólida y un bajo coste a cambio de una disponibilidad ligeramente inferior, aunque el mismo servicio podría encajar perfectamente en un sistema de gestión de registros archivísticos.
Para establecer expectativas realistas para tus usuarios, puedes plantearte utilizar una o ambas de las siguientes tácticas:
- Mantén un margen de seguridad
-
Utilizar un SLO interno más ajustado que el SLO anunciado a los usuarios te da margen para responder a los problemas crónicos antes de que se hagan visibles externamente. Un búfer de SLO también permite acomodar reimplementaciones que cambian el rendimiento por otros atributos, como el coste o la facilidad de mantenimiento, sin tener que decepcionar a los usuarios.
- No te excedas
-
Los usuarios se basan en la realidad de lo que ofreces, más que en lo que dices que suministrarás, sobre todo en el caso de los servicios de infraestructura. Si el rendimiento real de tu servicio es mucho mejor que su SLO declarado, los usuarios llegarán a confiar en su rendimiento actual. Puedes evitar la dependencia excesiva desconectando deliberadamente el sistema de vez en cuando (el servicio Chubby de Google introdujo interrupciones planificadas en respuesta a su excesiva disponibilidad),3 limitando algunas peticiones, o diseñando el sistema para que no sea más rápido con cargas ligeras.
Comprender hasta qué punto un sistema está cumpliendo sus expectativas ayuda a decidir si hay que invertir en hacerlo más rápido, más disponible y más resistente. Alternativamente, si el servicio va bien, quizá el tiempo del personal deba dedicarse a otras prioridades, como saldar la deuda técnica, añadir nuevas funciones o introducir otros productos.
Acuerdos en la práctica
La elaboración de un SLA requiere que los equipos empresariales y jurídicos elijan las consecuencias y sanciones adecuadas en caso de incumplimiento. El papel de la SRE es ayudarles a comprender la probabilidad y dificultad de cumplir los SLO contenidos en el SLA. Gran parte de los consejos sobre la construcción de los SLO también son aplicables a los SLA. Es aconsejable ser conservador en lo que anuncias a los usuarios, ya que cuanto más amplio sea el grupo de destinatarios, más difícil será cambiar o suprimir los SLA que resulten imprudentes o difíciles de cumplir.
1 La mayoría de la gente quiere decir SLO cuando dice "SLA". Una pista: si alguien habla de una "violación del SLA", casi siempre se refiere a un SLO incumplido. Una violación real del ANS podría desencadenar un proceso judicial por incumplimiento de contrato.
2 Si nunca puedes ganar una conversación sobre los SLO, probablemente no merezca la pena tener un equipo de SRE para el producto.
3 La inyección de fallos [Ben12] tiene un propósito diferente, pero también puede ayudar a establecer expectativas.
Get Ingeniería de Fiabilidad del Sitio now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

