Capítulo 4. Gestión de productos de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Puede que te estés preguntando por el término producto de datos: ¿essólo otra palabra de moda? En este capítulo, nos desharemos de la confusión para hablar de lo que son realmente los productos de datos. Cubriré toda la información esencial que necesitas tener para servir grandes cantidades de datos a otros dominios. Empezaremos con una desambiguación del término, porque los profesionales tienen muchas interpretaciones y definiciones diferentes. A continuación, examinaremos el patrón de Segregación de la Responsabilidad de Consulta de Comandos (CQRS) y por qué debe influir en el diseño de tus arquitecturas de productos de datos. Discutiremos varios principios de diseño de productos de datos, y aprenderás por qué un modelo de datos bien diseñado, integrable y de lectura optimizada es esencial para tus consumidores. Luego veremos las arquitecturas de los productos de datos: qué son, cómo pueden diseñarse, qué capacidades suelen necesitarse y el papel de los metadatos. Intentaré hacerlo lo más concreto posible mediante un ejemplo práctico. Al final de este capítulo, tendrás una buena comprensión de cómo las arquitecturas de productos de datos pueden ayudar a poner grandes cantidades de datos a disposición de los consumidores de datos.
¿Qué son los productos de datos?
Hacer que los productores de datos se responsabilicen de ellos y descentralizar la forma en que se sirven los datos es una gran forma de lograr la escalabilidad. Dehghani utiliza la frase "datos como producto" y introduce el concepto de "productos de datos", pero hay una gran diferencia entre ambos. Los datos como producto describe el pensamiento: los propietarios de los datos y los equipos de aplicación deben tratar los datos como un producto totalmente contenido del que son responsables, en lugar de un subproducto de algún proceso que otros gestionan. Se trata de cómo los proveedores de datos deben tratar a los consumidores de datos como clientes y proporcionarles experiencias que les deleiten; cómo deben definirse y moldearse los datos para proporcionar la mejor experiencia posible al cliente.
Un producto de datos difiere del pensamiento de los datos como producto porque aborda la arquitectura. Dentro de la comunidad de datos, se ven diferentes expectativas einterpretaciones de cómo se relacionan los productos de datos con la arquitectura . Algunos profesionales dicen que un producto de datos no es sólo un conjunto de datos que contiene datos relevantes de un contexto delimitado específico; también contiene todos los componentes necesarios para recopilar y servir datos, así como metadatos y código que transforma los datos. Esta interpretación concuerda con la descripción que hace Dehghani de un producto de datos como un quantum arquitectónico, un "nodo en la malla que encapsula tres componentes estructurales necesarios para su función, proporcionando acceso a [los] datos analíticos del dominio como producto". Esos tres componentes, según Dehghani, son el código, los datos y metadatos, y la infraestructura. Por tanto, su atención se centra claramente en la arquitectura de la solución, que puede incluir todos los componentes necesarios para obtener, transformar, almacenar, gestionar y compartir datos.
Algunos profesionales tienen distintos puntos de vista sobre los productos de datos. Por ejemplo, Accenture se refiere a conjuntos de datos, modelos analíticos e informes de cuadros de mando como productos de datos. Este punto de vista difiere significativamente del de Dehghani, porque se centra en la representación física de los datos, y no incluye necesariamente metadatos, código o infraestructura. Así que, antes de poder diseñar una arquitectura, primero tenemos que alinearnos en una terminología común para los productos de datos y determinar qué debe incluirse o no.
Problemas al combinar código, datos, metadatos e infraestructura
En un mundo ideal, los datos y los metadatos de se empaquetan y envían juntos como productos de datos. Ferd Scheepers, arquitecto jefe de información de ING Tech Group Services, hizo una presentación en Domain-Driven Design Europe 2022 sobre el tema de la gestión de metadatos. Durante esta presentación, explicó que los metadatos son fundamentales para la gestión de datos porque "los metadatos son datos que proporcionan información sobre otros datos". Para reforzar su importancia, hizo una analogía con la forma en que se distribuyen las flores en Holanda.
La Subasta de Flores de Aalsmeer es la mayor subasta de flores del mundo. De lunes a viernes se venden diariamente unos 43 millones de flores y 5 millones de plantas. Comerciantes de todo el mundo participan en la subasta cada día laborable. A su llegada, las flores se etiquetan y se envían a las instalaciones designadas. Para los compradores, todo el proceso es fluido: hacen pedidos digitalmente, envían cantidades e indican un precio y un destino. Lo mejor de todo es que la subasta está totalmente basada en metadatos. Todas las cajas de flores están equipadas con códigos de barras que incluyen información esencial sobre su contenido, como país y ciudad de origen, cantidades, precio de salida de la puja, peso, fechas de producción y caducidad, nombre del productor, etc. Cuando se venden flores, se añade otro código de barras con información para el envío: datos de propiedad del comprador, destino, instrucciones de envío, etc. Sin metadatos, la subasta de flores no podría funcionar.
En la subasta de flores, las flores y los metadatos siempre se gestionan y distribuyen juntos, porque los objetos físicos están conectados entre sí. Sin embargo, en el mundo digital, ¡no funciona así! Permíteme poner algunos ejemplos para que esto quede más claro. Si utilizas un catálogo de datos central para gestionar y describir todos tus datos, entonces los datos y los metadatos se gestionan separados entre sí. En este ejemplo, todos los metadatos se encuentran en tu catálogo de datos y todos los datos físicos se almacenan en otro lugar, probablemente en muchas otras ubicaciones. La misma separación se aplica, por ejemplo, a un marco de ingestión basado en metadatos que gestiona el proceso de extracción y carga de datos. Un marco de este tipo no rastrea metadatos de cientos de contenedores de productos de datos antes de empezar a procesarlos. Un marco de ingestión basado en metadatos, como componente arquitectónico, suele gestionar los metadatos en una base de datos independiente, que está separada de los propios datos. Utiliza estos metadatos para controlar el proceso y las dependencias a través de las cuales se extraen, combinan, transforman y cargan los datos.
Lo mismo ocurre con la información sobre el linaje y la calidad de los datos. Si los metadatos asociados se empaquetaran en el propio contenedor del producto de datos, tendrías que realizar complejas consultas federadas en todos los productos de datos para supervisar el linaje o la calidad de los datos de extremo a extremo. Como alternativa, podrías replicar todos los metadatos en otra ubicación central, pero eso complicaría enormemente tu arquitectura general. ¿Y cómo gestionarías la seguridad, las clasificaciones de privacidad, las etiquetas de sensibilidad o la información de propiedad de los mismos datos semánticos que tienen varias representaciones físicas? Si encolaras fuertemente los metadatos y los datos, los metadatos se duplicarían cuando se copiaran los productos de datos, porque ambos se asientan en la misma arquitectura. Entonces, todas las actualizaciones de metadatos tendrían que realizarse simultáneamente en varios contenedores de productos de datos. Esto sería una tarea compleja, que requeriría que todos estos contenedores estuvieran siempre disponibles y accesibles. Podrías implementar una arquitectura superpuesta para realizar estas actualizaciones de forma asíncrona, pero esto complicaría de nuevo drásticamente tu arquitectura general.
Para concluir, considerar un producto de datos como un contenedor que une código, datos y metadatos, e infraestructura, es en realidad demasiado ingenuo. La definición de un producto de datos necesita una revisión que refleje mejor la realidad de cómo funcionan las plataformas de datos en estos días .
Productos de datos como entidades lógicas
Si la anterior definición de no es buena, ¿cómo deberíamos definir un producto de datos? Creo firmemente que la gestión de los datos y la tecnología debe hacerse desde puntos de vista arquitectónicos diferentes: uno que aborde las preocupaciones de la gestión de los datos, y otro que aborde las preocupaciones de la gestión de la arquitectura tecnológica subyacente. La figura 4-1 muestra cómo podría ser esto.
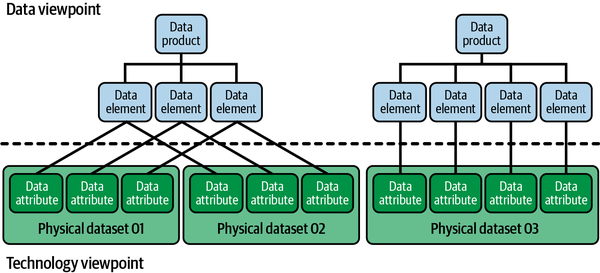
Figura 4-1. Puntos de vista separados para gestionar los datos y la tecnología
¿Por qué separar las preocupaciones de gestionar los datos y la tecnología? En primer lugar, porque puedes hacer que la arquitectura sea más rentable y reducir la sobrecarga de gestionar la complejidad de la infraestructura. Habilitas escenarios de uso de "arquitecturas de productos de datos" en los que se gestionan múltiples "productos de datos".
En segundo lugar, una separación de los datos y la arquitectura de facilita mejor los escenarios en los que los mismos datos (semánticos) deben distribuirse. Distribuir datos puede ser necesario, por ejemplo, al realizar una validación o enriquecimiento de datos entre dominios. A veces también es necesario duplicar y preprocesar los datos para facilitar varios casos de uso al mismo tiempo; por ejemplo, cuando se almacenan exactamente los mismos datos en formatos de archivo Parquet y Delta Lake. Cuando haces esto, duplicas los datos sin cambiar la semántica subyacente. Este escenario se refleja en la Figura 4-1: los conjuntos de datos físicos 01 y 02 comparten la misma semántica, y los atributos individuales de los datos físicos enlazan con los mismos elementos.
En tercer lugar, evitas el acoplamiento estrecho entre datos y metadatos. Imagina una situación en la que los datos y los metadatos se almacenan siempre juntos en el mismo contenedor. Si, por ejemplo, cambian los propietarios, las entidades empresariales o las clasificaciones, todos los metadatos correspondientes dentro de todas las arquitecturas de productos de datos tendrán que cambiar también. Además, ¿cómo garantizas una propiedad coherente de los datos? Si duplicas los metadatos, existe el riesgo potencial de que también cambie la propiedad de los datos. Esto no debería ser posible para los mismos datos semánticos que tienen diferentes representaciones físicas en distintas ubicaciones.
Separar los datos y los metadatos de cambia la definición de un producto de datos: un producto de datos es una entidad lógica autónoma que describe datos destinados al consumo. A partir de esta entidad lógica se establecen relaciones con la arquitectura tecnológica subyacente, es decir, con las ubicaciones físicas donde se almacenan los activos de datos físicos optimizados para la lectura y listos para el consumo. El producto de datos propiamente dicho incluye un nombre de conjunto de datos lógico; una descripción de las relaciones con el dominio de origen, los elementos de datos únicos y los términos empresariales; el propietario del conjunto de datos; y referencias a los activos de datos físicos (los datos propiamente dichos). Es semánticamente coherente para la empresa, pero podría tener múltiples formas y representaciones diferentes a nivel físico. Estos cambios requieren que un producto de datos se defina como agnóstico desde el punto de vista tecnológico. Estos metadatos se mantienen abstractos en aras de la flexibilidad.
Consejo
En el Capítulo 9, concretaré el punto de vista lógico de un producto de datos mostrando capturas de pantalla de un metamodelo para la gestión de productos de datos. Si no quieres esperar para aprender cómo funciona esto, te animo a que leas "El modelo de metadatos de la empresa", y luego vuelvas y sigas leyendo aquí.
Cuando defines los productos de datos como entidades lógicas , puedes describir, clasificar, etiquetar o vincular datos (por ejemplo, a dominios, propietarios de datos, metadatos organizativos, información de procesos y otros metadatos) sin ser específico en los detalles de implementación. Un nivel por debajo de un producto de datos, están los elementos de datos: unidades atómicas de información que actúan como clavijas de enlace con los datos físicos, los metadatos de interfaz, los metadatos de aplicación y los metadatos de modelado de datos. Para describir los datos físicos, necesitas metadatos técnicos, que incluyen información sobre esquemas, tipos de datos, etc.
Ahora que tenemos una idea clara de lo que son los productos de datos, continuemos examinando lo que influye en su diseño y arquitectura. Empezaremos con el CQRS, luego veremos el modelado optimizado para la lectura y otros principios de diseño. Después de todo esto, nos alejaremos un poco para examinar la arquitectura del producto de datos .
Patrones de diseño de productos de datos
Cambiar la definición de un producto de datos no significa que debamos abandonar el concepto de gestionar los datos como un producto. Los propietarios y equipos de aplicaciones deben tratar los datos como productos autónomos de los que son responsables, en lugar de como un subproducto de algún proceso que otros gestionan. Los productos de datos se crean específicamente para los consumidores de datos. Tienen formas, interfaces y ciclos de mantenimiento y actualización definidos, todos ellos documentados. Los productos de datos contienen datos de dominio procesados que se comparten con procesos posteriores a través de interfaces en un objetivo de nivel de servicio (SLO). A menos que se requiera otra cosa, los datos (técnicos) de tu aplicación deben procesarse, formarse, limpiarse, agregarse y (des)normalizarse para cumplir las normas de calidad acordadas antes de ponerlos a disposición para su consumo.
En el Capítulo 1, aprendiste sobre los problemas de ingeniería que supone limitar las transferencias de datos, diseñar sistemas transaccionales y gestionar un consumo de datos muy elevado. Extraer grandes volúmenes de datos de un sistema operativo muy ocupado puede ser arriesgado, porque los sistemas sometidos a demasiada carga pueden bloquearse o volverse impredecibles, no disponibles o, peor aún, corromperse. Por eso es inteligente hacer una versión de sólo lectura y optimizada para la lectura de los datos, que luego puede ponerse a disposición para su consumo. Echemos un vistazo a un patrón de diseño común de para esto: CQRS.
¿Qué es el CQRS?
CQRS es una aplicación patrón de diseño basado en hacer una copia de los datos para lecturas intensivas.
Los comandos operativos y las consultas analíticas (a menudo denominadas escrituras y lecturas) son operaciones muy diferentes y se tratan por separado en el patrón CQRS (como se muestra en la Figura 4-2). Cuando examines la carga de un sistema ocupado, probablemente descubrirás que el lado de los comandos está utilizando la mayor parte de los recursos informáticos. Esto es lógico, porque para que una operación de escritura, actualización o eliminación tenga éxito (es decir, sea duradera), la base de datos suele tener que realizar una serie de pasos:
-
Comprueba la cantidad de almacenamiento disponible.
-
Asigna almacenamiento adicional para la escritura.
-
Recupera los metadatos de la tabla/columna (tipos, restricciones, valores por defecto, etc.).
-
Encuentra los registros (en caso de actualización o eliminación).
-
Bloquea la tabla o los registros.
-
Escribe los nuevos registros.
-
Verifica los valores insertados (por ejemplo, que sean únicos, de tipos correctos, etc.).
-
Realiza la confirmación.
-
Libera el bloqueo.
-
Actualiza los índices.
La lectura de la base de datos , en comparación con la escritura, requiere una menor cantidad de recursos informáticos porque hay que realizar menos tareas de este tipo. Para su optimización, CQRS separa las escrituras (comandos) de las lecturas (consultas) mediante dos modelos, como se ilustra en esta figura. Una vez separados, deben mantenerse sincronizados, lo que suele hacerse publicando eventos con cambios. Esto se ilustra con la "flecha de eventos" (el icono del rayo) en la Figura 4-2.
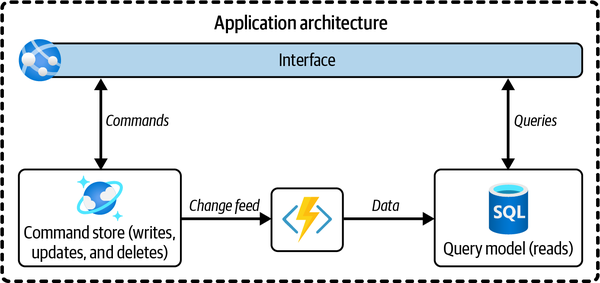
Figura 4-2. Una aplicación que utiliza CQRS separa las consultas y los comandos utilizando dos modelos de datos diferentes: un modelo de comandos para las transacciones y un modelo de consultas para las lecturas
Una ventaja de CQRS es que no estás atado al mismo tipo de base de datos tanto para las escrituras como para las lecturas.1 Puedes dejar la base de datos de escritura objetivamente compleja, pero optimizar la base de datos de lectura para el rendimiento de lectura. Si tienes requisitos diferentes para casos de uso diferentes, puedes incluso crear más de una base de datos de lectura, cada una con un modelo de lectura optimizado para el caso de uso específico que se esté implementando. Los distintos requisitos también te permiten tener distintos modelos de consistencia entre almacenes de lectura, aunque el almacén de datos de escritura siga siendo el mismo.
Otra ventaja de CQRS es que no es necesario escalar simultáneamente las operaciones de lectura y escritura. Cuando te quedes sin recursos, puedes escalar una u otra. La última gran ventaja de no tener un único modelo que sirva tanto a las escrituras como a las lecturas es la flexibilidad tecnológica. Si necesitas que la lectura se ejecute muy rápidamente o necesitas estructuras de datos diferentes, puedes elegir una tecnología distinta para el almacén de lectura, sin dejar de respetar las propiedades de las bases de datos ACID de (atomicidad, consistencia, aislamiento y durabilidad), que son necesarias para el almacén de órdenes.
Aunque el CQRS es un patrón de diseño de ingeniería de software que puede ayudar a mejorar el proceso de diseño de sistemas específicos (y posiblemente más grandes), debería inspirar en gran medida el diseño y la visión de tu arquitectura de productos de datos. El modelo futuro de una arquitectura debe ser que se cree o utilice al menos un almacén de datos de lectura por aplicación siempre que otras aplicaciones quieran leer los datos de forma intensiva. Este enfoque simplificará el futuro diseño e implementación de la arquitectura. También mejora la escalabilidad para el consumo intensivo de datos.
Nota
CQRS tiene una fuerte relación con las vistas materializadas.2 Una vista materializada de dentro de una base de datos es una copia física de los datos que las tablas subyacentes actualizan constantemente. Las vistas materializadas se utilizan a menudo para optimizar el rendimiento. En lugar de consultar los datos de las tablas subyacentes, la consulta se ejecuta contra el subconjunto precalculado y optimizado que vive dentro de la vista materializada. Esta segregación de las tablas subyacentes (utilizadas para las escrituras) y el subconjunto materializado (utilizado para las lecturas) es la misma segregación que se observa en CQRS, con la sutil diferencia de que ambas colecciones de datos viven en la misma base de datos en lugar de en dos bases de datos diferentes.
Leer réplicas como productos de datos
Utilizar las réplicas como fuente de lectura de datos en no es nuevo. De hecho, cada lectura de una réplica, copia, almacén de datos o lago de datos puede considerarse como alguna forma de CQRS. Dividir los comandos y las consultas entre los sistemas de procesamiento de transacciones en línea (OLTP), que suelen facilitar y gestionar las aplicaciones orientadas a las transacciones, y un almacén de datos operativos (ODS, utilizado para los informes operativos) es similar. El ODS, en este ejemplo, es una versión replicada de los datos del sistema OLTP. Todos estos patrones siguen la filosofía de CQRS: construir bases de datos de lectura a partir de bases de datos operativas.
Nota
Martin Kleppmann utiliza el patrón "dar la vuelta a la base de datos", otra encarnación de CQRS que hace hincapié en la recopilación de hechos mediante la transmisión de eventos. Veremos este patrón en el Capítulo 6.
Las arquitecturas de productos de datos también deben seguir la filosofía CQRS. Adoptan la posición de una copia replicada de los datos y se utilizan para permitir a los consumidores de datos una lectura intensiva. Están muy gobernadas y heredan su contexto de los dominios y aplicaciones subyacentes. A alto nivel, esto significa que siempre que los proveedores y los consumidores de datos quieran intercambiar datos, como se muestra en la Figura 4-3, debe utilizarse una arquitectura de productos de datos.
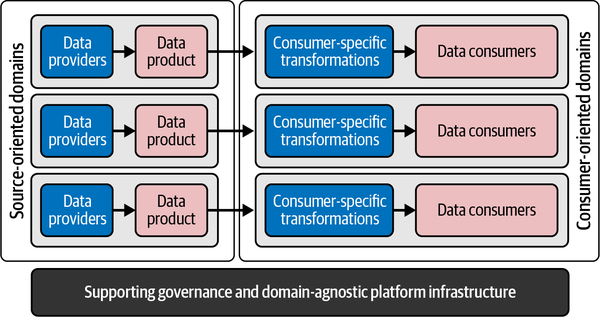
Figura 4-3. Colaboración descentralizada de proveedores y consumidores de datos
Observa que los productos de datos se sitúan a la izquierda, cerca de los proveedores de datos, y los pasos de transformación cerca de los consumidores de datos. Este posicionamiento tiene su origen en el enfoque unificado de servir datos a los consumidores. En lugar de utilizar un único modelo de datos unificado, se cambia el diseño para proporcionar versiones limpias y fácilmente consumibles de los datos del dominio a todas las aplicaciones consumidoras. Estos datos no están pensados para proporcionar comportamiento o funcionalidad. La naturaleza de los datos, comparada con la de los datos operativos, es por tanto diferente: están optimizados para una legibilidad intensiva, lo que permite a todos convertir rápidamente los datos en valor.
Principios de diseño de los productos de datos
Crear datos de lectura optimizada y fáciles de usar es el camino a seguir. Esto parece sencillo, pero en la práctica suele ser más difícil de lo esperado. Concretamente, tienes que considerar cómo deben capturarse, estructurarse y modelarse los datos. Las dificultades surgen cuando tienes que crear productos de datos repetidamente y en paralelo con muchos equipos. Quieres hacerlo con eficacia, evitando situaciones en las que cada nuevo consumidor de datos lleve a un nuevo producto de datos desarrollado, o a un largo ciclo de estudio de estructuras de datos complejas y de resolución de problemas de calidad de los datos. ¡Quieres la máxima reutilización y datos fáciles con los que trabajar! Esta sección presenta un conjunto de principios de diseño que son consideraciones útiles a la hora de desarrollar productos de datos. Te advertimos de que es una lista larga.
Diseño optimizado para la lectura orientado a los recursos
Los modelos analíticos que se reentrenan constantemente leen grandes volúmenes de datos. Esto repercute en el diseño de los productos de datos, porque tenemos que optimizar para la legibilidad de los datos. Una buena práctica es fijarse en la orientación a recursos para diseñar API. Una API orientada a recursos se modela generalmente como una jerarquía de recursos, donde cada nodo es un recurso simple o un recurso de colección. Por comodidad, suelen denominarse recursos y colecciones, respectivamente.
Para los productos de datos, puedes seguir el mismo enfoque de orientación a los recursos, agrupando lógicamente los datos y agrupándolos en torno a áreas temáticas, en las que cada conjunto de datos representa una colección de datos homogéneos. Este diseño hace que los datos de los productos de datos estén precalculados, desnormalizados y materializados. Por el lado del consumo, esto conduce a un consumo posterior más sencillo y rápido, porque no hay necesidad de realizar uniones costosas desde el punto de vista computacional. También reduce el tiempo que se tarda en encontrar los datos correctos, porque los datos que van juntos se agrupan de forma lógica.
Al aplicar un diseño orientado a los recursos a tus productos de datos, entonces, en consecuencia, los modelos de datos físicos muy normalizados o demasiado técnicos deben traducirse en conjuntos de datos más reutilizables y ordenados lógicamente. El resultado son modelos de datos más desnormalizados y optimizados para la lectura, similares a un esquema de estrella de Kimball o a un mercado de datos de Inmon. Esto también significa que hay que abstraer la lógica compleja de la aplicación. Los datos deben servirse a otros dominios con un nivel adecuado de granularidad para satisfacer al mayor número posible de consumidores. Para cualquier producto de datos enlazados, esto implica que las referencias cruzadas y las relaciones de clave externa deben ser coherentes en todo el conjunto de productos de datos. Los dominios consumidores, por ejemplo, ¡no deberían tener que manipular claves para unir diferentes conjuntos de datos! Construir productos de datos utilizando este enfoque significa, en consecuencia, que los dominios poseen la lógica semántica y son responsables de cómo se transforman los datos para mejorar su legibilidad. Pero basta de hablar de esto: veamos otras buenas prácticas y principios de diseño.
Los datos de los productos de datos son inmutables
Producto de datos los datos son inmutables y, por tanto, de sólo lectura. ¿Por qué tus almacenes de datos de sólo lectura deben ser inmutables? Esta propiedad garantiza que podamos regenerar los mismos datos una y otra vez. Si utilizamos un diseño de sólo lectura, no existirán diferentes versiones de la verdad para los mismos datos de dominio. Las arquitecturas de productos de datos que siguen este principio no crean nuevos datos semánticos. La verdad sólo puede modificarse en la aplicación fuente de oro.
Utilizar el lenguaje ubicuo
Es esencial que comprenda el contexto de cómo se han creado los datos. Aquí es donde entra en juego el lenguaje ubicuo: un lenguaje construido y formalizado, acordado por las partes interesadas y los diseñadores, para servir a las necesidades del diseño. El lenguaje ubicuo debe estar alineado con el dominio, es decir, con las funciones y objetivos empresariales. El contexto del dominio determina el diseño de los productos de datos. Una implementación común es tener un catálogo de datos en el que se almacene toda esta información, junto con la información de los dominios. Publicar el contexto y aclararde forma transparente las definiciones a los dominios permite a todos ver y acordar el origen y significado de los datos.
Algunas organizaciones exigen que los dominios utilicen nombres de columna amigables para el ser humano en los conjuntos de datos físicos de sus productos de datos. Esto no es esencial, siempre que se proporcione el mapeo del modelo de datos físicos al modelo de datos conceptuales. Esta vinculación permite a tus dominios traducir los conceptos empresariales del lenguaje ubicuo a los datos físicos.
Captura directamente de la fuente
En mi anterior puesto, aprendí que las empresas suelen tener largas cadenas de datos en las que éstos pasan de un sistema a otro. Para la gestión de datos, esto puede ser un problema porque el origen no está tan claro. Por tanto, siempre debes capturar los datos del sistema de origen. Utilizar datos únicos de las fuentes de oro garantiza que haya una única fuente de verdad tanto para el acceso a los datos como para su gestión. Esto implica que los productos de datos son distintos y explícitos: pertenecen a un único dominio, lo que significa que están aislados y no pueden tener dependencias directas con aplicaciones de otros dominios. Este principio de diseño también significa que los dominios no pueden encapsular datos de otros dominios con diferentes propietarios de datos, porque eso ofuscaría la propiedad de los datos.
Normas claras de interoperabilidad
Es importante definir cómo se sirven los productos de datos a otros dominios. Un producto de datos puede servirse como una base de datos, un formato de archivo estandarizado, un gráfico, un punto final de API, un flujo de eventos o cualquier otra cosa. En todos los casos, debes estandarizar las especificaciones de la interfaz. Si todos tus dominios definen su propio conjunto de normas, el consumo de datos se vuelve terriblemente difícil. Por tanto, la normalización es fundamental. Esto requiere que definas claramente tus diferentes tipos de distribución (por ejemplo, orientada a lotes, API y eventos), las normas de metadatos, etc. Sé específico sobre cómo es la arquitectura de un producto de datos; por ejemplo, los productos de datos por lotes se publican en formato Delta y deben registrarse en un catálogo de datos.
Sin datos brutos
Un producto de datos es lo contrario de los datos brutos, porque exponer los datos brutos requiere una reelaboración por parte de todos los dominios consumidores. Así que, en todos los casos, debes encapsular los sistemas heredados o complejos y ocultar los datos técnicos de aplicación. Si insistes en poner a disposición datos brutos, por ejemplo para análisis de investigación, asegúrate de que estén marcados y sean temporales por defecto. Los datos brutos o inalterados no ofrecen garantías.
El principio de que no hay datos sin procesar, tal y como se expone en el Capítulo 2, también se aplica a los proveedores de datos externos: partes externas que operan fuera de los límites lógicos del ecosistema de tu empresa. Generalmente operan en ubicaciones de red separadas y no controladas. Pide a los socios de tu ecosistema que se ajusten a tu norma o apliquen la mediación a través de un dominio intermedio: un dominio consumidor que actúe como intermediario abstrayendo la complejidad y garantizando un consumo estable y seguro.
No te conformes con los consumidores
Es probable que los mismos productos de datos sean utilizados repetidamente por diferentes equipos de dominio para una amplia gama de casos de uso. Así que tus equipos no deben adaptar sus productos de datos a las necesidades específicas de los consumidores de datos (individuales). El principal principio de diseño debe ser maximizar la productividad del dominio y promover el consumo y la reutilización.
Por otra parte, los productos de datos pueden evolucionar, y de hecho lo hacen, en función de las opiniones de los usuarios. Aquí hay que tener cuidado. Puede ser tentador para los equipos incorporar requisitos específicos de los consumidores. Pero si los consumidores introducen lógica empresarial en los productos de datos de un dominio productor, se crea una dependencia estricta con el proveedor para realizar cambios. Esto puede desencadenar una intensa coordinación cruzada y negociación de backlog entre los equipos de dominio. Una recomendación en este sentido es introducir un órgano de gobierno que supervise que los productos de datos no se crean para consumidores específicos. Este órgano puede intervenir para orientar a los equipos de dominio, organizar sesiones de intercambio de información y conocimientos, proporcionar información práctica y resolver problemas entre los equipos.
Valores perdidos, valores por defecto y tipos de datos
He vivido acalorados debates en sobre cómo deben interpretarse los datos omitidos, de baja calidad o por defecto. Por ejemplo, supongamos que el formulario web de un sistema operativo requiere un valor para la fecha de nacimiento del usuario, pero éste no facilita este dato. Si no se proporciona ninguna orientación, los empleados podrían rellenar un valor aleatorio. Este comportamiento podría dificultar que los consumidores supieran si los datos son exactos o contienen valores por defecto. Proporcionar una orientación clara, como poner siempre por defecto las fechas de nacimiento que faltan en valores absurdos o futuros, como 9999-12-31, permite a los clientes identificar que realmente faltan datos.
También es posible que quieras introducir orientaciones sobre tipos de datos o datos que deban tener un formato coherente en todo el conjunto de datos. Especificar la precisión decimal correcta, por ejemplo, garantiza que los consumidores de datos no tengan que aplicar una lógica de aplicación compleja para utilizar los datos. Podrías establecer estos principios a nivel de sistema o dominio, pero también veo que las grandes empresas proporcionan orientaciones genéricas sobre qué formatos y tipos de datos deben utilizarse en todos los productos de datos.
Coherencia semántica
Los productos de datos deben ser semánticamente coherentes en todos los métodos de entrega: por lotes, orientados a eventos y basados en API. A mí esto me parece obvio, pero todavía hoy veo organizaciones que proporcionan orientaciones separadas para los datos orientados a lotes, a eventos y a API. Puesto que el origen de los datos es el mismo para todos los patrones de distribución, te animo a que la orientación sea coherente para todos los patrones. Volveré sobre este punto en el Capítulo 7.
Atomicidad
Los atributos de los productos de datos deben ser atómicos. Representan el nivel más bajo de granularidad y tienen un significado o semántica precisos. Es decir, no debe ser posible descomponerlos en otros componentes significativos. En un estado ideal, los atributos de datos están vinculados uno a uno con los elementos de negocio dentro de tu catálogo de datos. La ventaja es que los consumidores de datos no se ven obligados a dividir o concatenar datos.4 Otra ventaja de utilizar datos atómicos es que cualquier norma política puede desvincularse de los datos. Si la normativa te obliga a reconsiderar las etiquetas sensibles, por ejemplo, no tienes que volver a etiquetar todos tus datos físicos. Con un buen modelo de metadatos y datos atómicos, cualquier cambio debería heredarse automáticamente de tus metadatos empresariales.
Compatibilidad
Los productos de datos deben permanecer estables y desacoplados de las aplicaciones operativas/transaccionales. Esto requiere un mecanismo para detectar la deriva del esquema y evitar cambios perturbadores. También requiere el control de versiones y, en algunos casos, que se ejecuten en paralelo canalizaciones independientes, dando a tus consumidores de datos tiempo para migrar de una versión a otra.
El proceso de mantener la compatibilidad de los productos de datos no es tan sencillo como parece. Puede implicar mover datos históricos entre productos de datos antiguos y nuevos. Este ejercicio puede ser una empresa compleja, ya que implica tareas de ETL, como mapear, limpiar y proporcionar una lógica predeterminada.
Datos de referencia volátiles abstractos
Es posible que quieras que proporcione orientación sobre cómo se mapean los valores de referencia complejos a valores de referencia más abstractos y amigables con el producto de datos. Esto requiere un matiz para los desajustes de agilidad: si el ritmo de cambio es alto en el lado del consumidor, tu principio rector debe ser que se mantengan tablas de mapeo complejas en el lado del consumidor; si el ritmo de cambio es más rápido en el lado del proveedor, el principio rector es que se pida a los propietarios de productos de datos que abstraigan o transfieran valores de referencia locales detallados a valores de referencia más genéricos (menos granulares) agnósticos para el consumidor. Esta orientación también implica que el consumidor podría realizar un trabajo adicional, como la asignación de los valores de referencia más genéricos a valores de referencia específicos del consumidor.
Nuevos datos significan nueva propiedad
Cualquier dato que se cree debido a una transformación empresarial (un cambio semántico mediante lógica empresarial) y se distribuya se considera nuevo, y cae bajo la propiedad del dominio creador. Los principios de distribución de datos tratados en este capítulo deben aplicarse a cualquier dato de nueva creación que se comparta.
Advertencia
Es fundamentalmente erróneo clasificar los datos integrados basados en casos de uso como productos de datos (alineados con el consumidor). Si permites que los datos específicos de un caso de uso sean consumidos directamente por otros dominios, éstos dependerán en gran medida de los detalles de implementación del caso de uso consumidor subyacente. Por tanto, crea siempre una capa adicional de abstracción y desvincula tu caso de uso de otros consumidores. Este enfoque de tomar datos específicos del consumidor y convertirlos en un nuevo producto de datos permite que tus dominios evolucionen independientemente de otros dominios.
Una preocupación al distribuir datos recién creados es la trazabilidad: saber qué ocurre con los datos. Para mitigar los riesgos de transparencia, pide a los consumidores de datos que cataloguen sus adquisiciones y las secuencias de acciones y transformaciones que aplican a los datos. Estos metadatos del linaje de deben publicarse de forma centralizada. Volveré sobre esto en los Capítulos 10 y 11.
Patrones de seguridad de los datos
Para la seguridad de los datos, necesitas definir orientaciones para los proveedores de datos. Esto debería incluir lo siguiente:
-
Orientación sobre la encapsulación de metadatos para el filtrado y el acceso a nivel de filas. Al proporcionar metadatos junto con los datos, puedes crear políticas o vistas para ocultar o mostrar determinadas filas de datos, dependiendo de si un consumidor tiene permiso para ver esas filas.
-
Orientación sobre etiquetas o clasificaciones para el acceso a nivel de columna y el enmascaramiento dinámico de datos. Estas etiquetas o clasificaciones se utilizan como entrada para políticas o vistas.
-
Orientación sobre el almacenamiento eficaz de datos en tablas separadas para proporcionar seguridad de grano grueso, mejorar el rendimiento y facilitar el mantenimiento.
Hablaremos más de estos temas en el capítulo 8.
Establecer un Metamodelo
Para que gestione adecuadamente los productos de datos y sus metadatos correspondientes, te recomiendo encarecidamente que crees un metamodelo coherente en el que definas cómo se relacionan entre sí las entidades (como dominios de datos, productos de datos, propietarios de datos, términos empresariales, datos físicos y otros metadatos).5 Cuando trabajes en tu metamodelo, lo mejor es utilizar un catálogo de datos para imponer la captura de todos los metadatos necesarios. Por ejemplo, cada vez que instancias un nuevo producto de datos en tu catálogo, puede desencadenar un flujo de trabajo que comience pidiendo al proveedor de datos que proporcione una descripción y conecte el producto de datos a un propietario de datos, aplicación de origen, dominio de datos, etc. A continuación, el catálogo puede pedir al proveedor que vincule todos los elementos del producto de datos a términos empresariales y atributos técnicos (físicos) de los datos. A continuación, podría ejecutar pruebas automatizadas para comprobar si estas ubicaciones físicas son direccionables, y pedir clasificaciones e información sobre restricciones de uso.
Permitir el Autoservicio
Los productos de datos son sobre la democratización de los datos. Para mejorar la experiencia de creación de productos de datos, considera la posibilidad de crear un mercado de datos y ofrecer capacidades de autoservicio para descubrir, gestionar, compartir y observar. Por ejemplo, permite a los ingenieros utilizar la interfaz REST del catálogo de datos para que el registro de productos de datos pueda automatizarse. Si se hace correctamente, los ingenieros pueden registrar sus productos de datos como parte de sus conductos de integración continua/entrega continua (CI/CD). En el Capítulo 9 se ofrece más orientación sobre este tema.
Relaciones entre dominios
En el mundo operativo , los sistemas suelen estar entrelazados o fuertemente conectados. Imagina un sistema de pedidos a través del cual los clientes pueden hacer pedidos. Es probable que dicho sistema contenga datos de la base de datos de clientes. De lo contrario, no podría vincular los pedidos a los clientes.
Si los dominios desarrollan productos de datos independientemente de otros dominios, ¿cómo reconocen los consumidores que ciertos datos pertenecen juntos o están relacionados? Para gestionar estas dependencias, considera la posibilidad de utilizar un catálogo o un grafo de conocimiento que describa las relaciones entre los conjuntos de datos y haga referencia a las claves de unión o claves foráneas entre los productos de datos.
Al orientar sobre la gestión de las relaciones entre dominios, es importante que los datos sigan estando siempre orientados al dominio. La alineación entre los datos y la propiedad de los datos debe ser sólida, por lo que no debe realizarse ninguna integración entre dominios antes de entregar cualquier dato a otros dominios.
Coherencia empresarial
Una fuerte descentralización hace que los datos se aíslen dentro de los dominios individuales. Esto causa preocupaciones sobre la accesibilidad y usabilidad de los datos, porque si todos los dominios empiezan a servir datos individualmente, se hace más difícil integrar y combinar los datos en el lado del consumidor. Para superar estos problemas, puedes introducir cierta coherencia empresarial proporcionando orientación para incluir valores de referencia empresariales (códigos de moneda, códigos de país, códigos de producto, códigos de segmentación de clientes, etc.). Si procede, puedes pedir a los propietarios de tus productos de datos que asignen sus valores de referencia locales a los valores de las listas empresariales.
Algunos profesionales de los datos argumentarán que el uso de valores de referencia empresariales no se ajusta a una verdadera implementación de malla de datos. Esto es cierto hasta cierto punto, pero sin ninguna integridad referencial verás duplicados los esfuerzos de armonización e integración en todos los dominios. Ten en cuenta que no estoy sugiriendo que construyas un modelo de datos canónico para toda la empresa, como se ve en la mayoría de las arquitecturas de almacenes de datos empresariales, sino que simplemente proporciones algunos datos de referencia como orientación. La coherencia resultante puede ser útil en una organización a gran escala en la que muchos dominios dependen de los mismos valores de referencia.
La misma orientación se aplica a los números de identificación maestros, que enlazan los datos maestros y los datos de los sistemas locales. Estos elementos de datos son fundamentales para rastrear qué datos se han masterizado y cuáles pertenecen juntos, por lo que puedes pedir a tus dominios locales que incluyan estos identificadores maestros en sus productos de datos. En el Capítulo 10 encontrarás más buenas prácticas en este ámbito .
Historización, reentregas y sobrescrituras
Para satisfacer las necesidades de los consumidores de , los proveedores de datos a menudo necesitan conservar los datos históricos en su contexto original. Por ejemplo, los consumidores pueden necesitar estos datos para realizar análisis retrospectivos de tendencias y predecir lo que ocurrirá a continuación. Para hacerlo bien, recomiendo formular orientaciones basadas en el diseño del sistema, el tipo de datos y cómo deben historizarse para su posterior análisis. Por ejemplo, los conjuntos de datos con datos maestros siempre deben transformarse en dimensiones que cambien lentamente. Veremos el tratamiento de los datos históricos con más detalle en "Historización de datos".
Capacidades empresariales con múltiples propietarios
Cuando se comparten capacidades empresariales , recomiendo definir una metodología para manejar los datos compartidos. Esto puede implicar utilizar nombres de columna reservados dentro de tus productos de datos para definir la propiedad, crear físicamente varios productos de datos o incrustar metadatos dentro de tus productos de datos.
Modelo operativo
El éxito en el desarrollo de productos de datos requiere un modelo operativo que garantice una gestión eficaz de los datos, el establecimiento de normas y buenas prácticas, el seguimiento del rendimiento y la garantía de calidad. Un equipo típico de productos de datos suele estar formado por un arquitecto de apoyo, ingenieros de datos, modeladores de datos y científicos de datos. Este equipo debe contar con el apoyo y la financiación adecuados para construir y mejorar continuamente sus productos de datos. Además, debe existir un órgano organizativo que instituya y supervise las normas y buenas prácticas para crear productos de datos en toda la organización. En mi opinión, las organizaciones tienen más éxito cuando elaboran guías de : documentos que describen todos los objetivos, procesos, flujos de trabajo, compensaciones, listas de comprobación, funciones y responsabilidades de la empresa. Estas guías suelen alojarse en repositorios abiertos, para que todos puedan contribuir.
Establecer buenas normas y buenas prácticas incluye definir cómo pueden medir los equipos el rendimiento y la calidad, así como diseñar cómo deben encajar los servicios necesarios para cada patrón de consumo, de modo que puedan reutilizarse en todos los productos de datos. Para garantizar que los productos de datos satisfacen las necesidades de los consumidores y mejoran continuamente, los equipos deben medir el valor y el éxito de sus actividades. Las métricas relevantes pueden incluir el número de consumidores de un determinado producto de datos, los problemas de calidad pendientes y abiertos, las puntuaciones de satisfacción, el rendimiento de la inversión o los casos de uso habilitados.
Ahora que hemos explorado las bases para el necesario cambio de mentalidad de gestionar los datos como productos, abordemos las preguntas que los arquitectos reciben con más frecuencia: ¿Cuál es una buena estrategia para crear productos de datos? ¿Debe facilitarse con una plataforma proporcionada centralmente, o deben los dominios atender a sus propias necesidades?
Arquitectura de productos de datos
Para reducir significativamente la complejidad de tu arquitectura, necesitas encontrar el equilibrio adecuado entre centralización y descentralización. En un extremo del espectro está un enfoque totalmente federado y autónomo, que permita a cada dominio albergar su propia arquitectura y elegir su propia pila tecnológica. Sin embargo, esto puede conducir a una proliferación de productos de datos, protocolos de interfaz, información de metadatos, etc. También dificulta mucho la gobernanza y el control de los datos, porque cada dominio debe aplicar con precisión disciplinas centrales como el archivo, el linaje, la calidad de los datos y la seguridad de los datos. Elaborar todas estas competencias en los propios dominios sería un reto y conduciría a una complejidad fragmentada y en silos.
En el otro extremo está un enfoque federado y gobernado centralmente, no con un único silo, sino con múltiples instancias de plataforma o planos de zonas de aterrizaje que comparten los mismos servicios de infraestructura estándar. Los componentes estandarizados y la infraestructura compartida reducen los costes, disminuyen el número de interfaces y mejoran el control. Lo ideal sería que varias arquitecturas de productos de datos estuvieran alojadas en la misma infraestructura de plataforma, pero aisladas lógicamente entre sí.
Diseño de plataformas de alto nivel
Desgranemos la arquitectura y los componentes necesarios para crear productos de datos. Exponer los datos como un producto permite a los consumidores de datos descubrirlos fácilmente, encontrarlos, comprenderlos y acceder a ellos de forma segura en muchos dominios. Dicho esto, las capacidades de la plataforma común para la distribución de productos de datos deben centrarse principalmente en capturar datos, transformarlos en versiones de lectura optimizada y servirlos de forma segura a otros dominios. Cualquier capacidad analítica o de elaboración de informes para desarrollar casos de uso para la toma de decisiones basada en datos se añadirá a la arquitectura más adelante; éstas se tratan en el Capítulo 11.
Profundizando un poco más, como mínimo tu arquitectura de productos de datos debe tener las siguientes capacidades:
-
Capacidades para capturar, ingerir e incorporar datos a través de sus puertos de entrada
-
Capacidades para servir o proporcionar datos a diversos dominios a través de sus puertos de salida
-
Capacidades de metadatos para documentar, descubrir, monitorizar, asegurar y gobernar los datos.
-
Capacidades de ingeniería de datos para desarrollar, implementar y ejecutar el código del producto de datos.
-
Capacidades de calidad de datos y gestión de datos maestros
-
Capacidades de mercado de datos para ofrecer una experiencia de compra de datos unificada
La Figura 4-5 es un diseño lógico de la arquitectura de un producto de datos, que muestra cómo se capturan, transforman y sirven los datos a otros dominios. Entraremos en más detalles sobre cada componente individual, pero primero proporcionaré una visión general de alto nivel. En la parte superior, hay una capa de metadatos que proporciona información sobre los datos disponibles, sus propiedades y las relaciones con otras áreas de gestión de datos. Dentro de esta capa hay repositorios de metadatos para la orquestación, la observabilidad, la gestión de contratos, etc. Éstos son los puntos de enlace entre tu mercado de datos y la arquitectura del producto de datos.
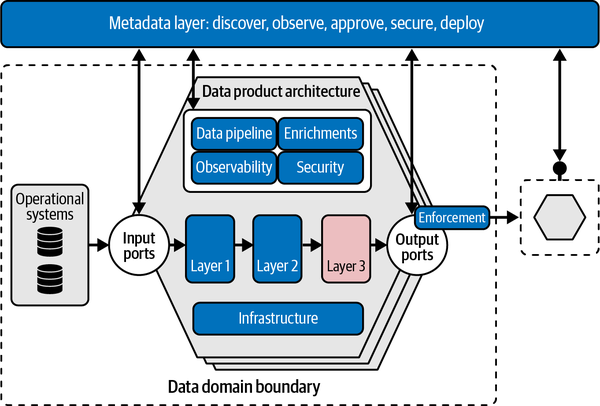
Figura 4-5. Ejemplo de arquitectura de un producto de datos
Cuando utilizas una infraestructura compartida, las diferentes arquitecturas de productos de datos están aisladas y no se comparten directamente entre los dominios de . Cada arquitectura de producto de datos, y la responsabilidad, siguen perteneciendo al proveedor de datos. Un proveedor de datos, y por tanto un dominio, tiene su propia instancia de arquitectura de producto de datos y su propia canalización, y asume la responsabilidad de la calidad e integridad de los datos.
La clave de la ingeniería de plataformas compartidas y arquitecturas de productos de datos es proporcionar un conjunto de componentes centrales fundacionales y agnósticos del dominio y tomar diversas decisiones de diseño para abstraer los problemas repetitivos de los dominios y hacer que la gestión de datos sea un reto menor. En las siguientes secciones, destacaré las consideraciones más importantes de , basándome en observaciones sobre el terreno.
Capacidades para capturar e incorporar datos
La incorporación de datos es el primer paso fundamental para construir con éxito una arquitectura de datos. Sin embargo, el proceso de extracción de datos del sistema fuente también sigue siendo uno de los problemas más difíciles cuando se utilizan datos en general. Requiere varias consideraciones.
Método de ingestión
En primer lugar, debes determinar la velocidad a la que deben entregarse o sincronizarse los datos. A grandes rasgos, puedes elegir entre dos escenarios:
- Tratamiento por lotes
-
A los consumidores que necesitan datos de sólo periódicamente se les puede facilitar el procesamiento por lotes, que se refiere al proceso de transferir un gran volumen de datos de una vez. El lote suele ser un conjunto de datos con millones de registros almacenados en un archivo. ¿Por qué seguimos necesitando el procesamiento por lotes? En muchos casos, es la única forma de recopilar nuestros datos. La mayoría de los sistemas de gestión de bases de datos relacionales (SGBDR) importantes tienen componentes de procesamiento por lotes para soportar el movimiento de datos por lotes. La conciliación de datos, el proceso de verificar los datos durante este movimiento, suele ser una preocupación.6 Verificar que tienes todos los datos es esencial, especialmente en los procesos financieros. Además, muchos sistemas son complejos, con un enorme número de tablas, y el Lenguaje de Consulta Estructurado (SQL) es la única forma adecuada de seleccionar y extraer sus datos.
- Ingesta de datos en tiempo real
-
Los consumidores que desean actualizaciones de datos incrementales o casi en tiempo real pueden facilitarse mejor con la ingestión basada en eventos o API. Este tipo de procesamiento nos permite recopilar y procesar datos con relativa rapidez y funciona bien para casos de uso en los que las cantidades de datos son relativamente pequeñas, los cálculos realizados con los datos son relativamente sencillos y se necesitan latencias cercanas al tiempo real. Muchos casos de uso pueden gestionarse con la ingesta basada en eventos, pero si la exhaustividad y los datos voluminosos son una preocupación importante, la mayoría de los equipos recurrirán a los lotes tradicionales. Prestaremos más atención a esto en el Capítulo 6.
Aunque la ingesta de datos en tiempo real ha empezado a ganar popularidad, una arquitectura sólo de streaming (Kappa) nunca sustituirá totalmente al procesamiento por lotes para todos los casos de uso. En la mayoría de las empresas, espero que ambos métodos de ingesta se utilicen uno al lado del otro .
Paquetes de software complejos
Para toda la incorporación de datos, es importante reconocer la diversidad de paquetes de software especializados. Muchos son extremadamente difíciles de interpretar o de acceder. Los esquemas de las bases de datos suelen ser terriblemente complejos, y la integridad referencial suele mantenerse mediante programación a través de la aplicación en lugar de la base de datos. Algunos proveedores incluso protegen sus datos, de modo que sólo pueden extraerse con ayuda de una solución de terceros.
En todas estas situaciones complejas, te recomiendo que evalúes para cada sistema fuente si necesitas complementar tu arquitectura con servicios adicionales que permitan extraer datos. Tales servicios podrían ocultar estas complejas estructuras del sistema fuente y protegerte de largos y costosos ejercicios de mapeo. También te protegen del acoplamiento estrecho, porque normalmente el esquema de datos de un producto complejo de un proveedor no lo controlas tú directamente. Si el proveedor lanza una actualización de la versión del producto y cambian las estructuras de datos, se rompen todas tus canalizaciones de datos. En resumen, merece la pena invertir en un componente de terceros.
API externas y proveedores de SaaS
Los proveedores externos de API o SaaS también suelen requerir una atención especial. He examinado situaciones en las que se necesitaba un conjunto de datos completo, pero el proveedor de SaaS sólo proporcionaba una cantidad relativamente pequeña de datos a través de una API. Otros proveedores pueden aplicar un estrangulamiento: una cuota o un límite para el número de solicitudes. También hay proveedores con planes de pago caros por cada llamada que hagas. En todas estas situaciones, recomiendo obtener una herramienta que admita la extracción desde API o construir un componente personalizado que obtenga datos periódicamente.
Una implementación personalizada correctamente diseñada podría dirigir primero todas las llamadas a la API a tu arquitectura de productos de datos. Si la misma solicitud se ha realizado recientemente, los resultados se sirven directamente desde la arquitectura del producto de datos. Si no, se activa la API del proveedor de SaaS y se devuelven los resultados, que también se almacenan en tu arquitectura de productos de datos para cualquier llamada posterior. Con este patrón, se puede poblar eventualmente una colección completa de datos para servir a los consumidores.
Linaje y metadatos
Para todos tus componentes de extracción de datos y onboarding de , es importante prestar mucha atención a la extracción del linaje de datos. Para las organizaciones es importante saber qué datos se han extraído y qué transformaciones se han aplicado sobre ellos. Estandarizar y determinar cómo se integrarían los conectores con tu repositorio de linaje de datos es un ejercicio importante. Deberías hacer esta investigación por adelantado, para saber qué se integrará y qué no. El linaje puede ser difícil de añadir retrospectivamente, dada su estrecha dependencia de los marcos de transformación y las herramientas ETL; es mejor seleccionar, probar, validar y estandarizar antes de iniciar la implementación real.
Calidad de los datos
La calidad de los datos es otra consideración importante del diseño. Cuando los conjuntos de datos se introducen en la arquitectura del producto de datos, debe validarse su calidad. Esto tiene dos aspectos:
En primer lugar, debes validar la integridad de tus datos, comparándolos con los esquemas publicados. Haces esto porque quieres asegurarte de que los nuevos datos son de alta calidad y se ajustan a tus normas y expectativas, y tomar medidas en caso contrario. Esta primera línea de defensa es responsabilidad de los propietarios de los datos, los administradores de datos y los ingenieros de datos. Estos son los miembros del equipo que crean y obtienen los datos. De ellos depende que los datos cumplan los requisitos de calidad estipulados por los reguladores o por los consumidores de datos.
En segundo lugar, hay comprobaciones de calidad que son más federadas por naturaleza. Esta validación depende menos de los equipos individuales de productos de datos, porque otros equipos definen lo que constituye una buena calidad de datos. Este tipo de controles de calidad de los datos suelen ejecutarse de forma asíncrona y señalan o/y notifican a las partes respectivas. Los controles federados suelen ser comprobaciones funcionales: integridad, exactitud, coherencia, verosimilitud, etc. La integridad de los datos y la calidad de los datos federados son dos disciplinas diferentes que a veces tienen su propio repositorio de metadatos en el que se almacenan los metadatos del esquema o las reglas de validación funcional. En este caso, cada una tiene sus propios servicios de plataforma estándar.
Para el diseño de tu plataforma, una ventaja al utilizar la infraestructura compartida para las arquitecturas de productos de datos es que puedes aprovechar la potencia de big data para el procesamiento de la calidad de los datos. Por ejemplo, Apache Spark proporciona la potencia de procesamiento distribuido necesaria para procesar cientos de millones de filas de datos. Para utilizarlo eficazmente, puedes usar un marco para documentar, probar y perfilar los datos para la calidad de los datos. Great Expectations y Soda, por ejemplo, son estándares abiertos para la calidad de los datos que utilizan muchas grandes organizaciones. Otra ventaja de gestionar la calidad de los datos en una infraestructura compartida es que puedes realizar comprobaciones de integridad referencial entre dominios. Los sistemas fuente suelen hacer referencia a datos de otras aplicaciones o sistemas. Al comprobar la integridad de las referencias y comparar y contrastar distintos conjuntos de datos, encontrarás errores y correlaciones que no sabías que existían.
Cuando el monitoreo de la calidad de los datos se aplica correctamente, no sólo detecta y observa los problemas de calidad de los datos, sino que pasa a formar parte del marco general de control de la calidad de los datos, que comprueba y añade nuevos datos a los ya existentes en .7 Si por cualquier motivo la calidad cae por debajo de un umbral especificado, el marco puede aparcar los datos y pedir a los propietarios de los datos que les echen un vistazo y los avalen, los eliminen o los vuelvan a entregar. Disponer de un marco de control de la calidad de los datos significa que existe un circuito cerrado de retroalimentación que corrige continuamente los problemas de calidad y evita que vuelvan a producirse. La calidad de los datos se monitorea continuamente; las variaciones en el nivel de calidad se abordan de inmediato. Ten en cuenta que los problemas de calidad de los datos deben resolverse en los sistemas fuente, no en la arquitectura de tu producto de datos. Solucionar los problemas de calidad de los datos en la fuente garantiza que no aparecerán en otros lugares.
No hay que subestimar el impacto de la calidad de los datos. Si la calidad de los datos es mala, los consumidores se enfrentarán al trabajo repetitivo de limpiar y corregir los datos. También quiero destacar en la importancia de la normalización. Si los equipos individuales deciden sus propios marcos de calidad de datos, será imposible comparar las métricas y los resultados entre dominios.
Historización de datos
Gestionar correctamente los datos históricos de es fundamental para una empresa, porque sin ello no puede ver las tendencias a lo largo del tiempo ni hacer predicciones para el futuro. También hay que tener en cuenta las normas para gestionar los datos históricos. Esta sección proporciona algunos antecedentes y explora algunas representaciones y enfoques diferentes para gestionar estos datos.
La organización de los datos históricos es un aspecto clave del almacenamiento de datos . En este contexto, oyes a menudo los términos no volátil y variable en el tiempo. No volátil significa que los datos anteriores no se borran cuando se les añaden nuevos datos. Variable en el tiempo implica que los datos son consistentes dentro de un periodo determinado; por ejemplo, los datos se cargan a diario o sobre alguna otra base periódica, y no cambian dentro de ese periodo.
Los productos de datos desempeñan un papel importante en el almacenamiento y la gestión de grandes cantidades de datos históricos. Pero, ¿cómo abordar esto en una arquitectura descentralizada? Una diferencia respecto al almacenamiento de datos es que los productos de datos conservan los datos en su contexto original. No se espera ninguna transformación a un modelo de datos empresarial porque los productos de datos están alineados con los dominios; el contexto original (de dominio) no se pierde. Esta es una gran ventaja: significa que los dominios pueden "perrear" sus propios productos de datos para sus propios casos de uso operativo, como el aprendizaje automático, mientras sirven datos a otros dominios al mismo tiempo. Como consecuencia, los dominios tienen una necesidad intrínseca de cuidar los datos que poseen. En última instancia, esta práctica de utilizar los propios productos de datos mejorará tanto su calidad como la satisfacción del cliente.
Aunque una arquitectura de producto de datos es un concepto agnóstico a la tecnología, es probable que muchas de estas arquitecturas se diseñen con sistemas de archivos distribuidos de menor coste, como los servicios de lago de datos. Esto significa que se necesitan diferentes formas de procesar los datos para actualizar y sobrescribir los datos maestros, transaccionales y de referencia. Por lo tanto, recomiendo considerar uno o una combinación de los siguientes enfoques, cada uno de los cuales implica un compromiso entre la inversión y la gestión de los datos entrantes y la facilidad de consumo de los datos. Cada enfoque tiene pros y contras.
Punto en el tiempo
El primer enfoque para gestionar los datos históricos es almacenar los datos originales como una referencia histórica, normalmente inmutable. Piensa en un depósito en el que los datos se ingieren mediante una actividad de copia. En este enfoque de sólo inserción, se recomienda particionar los datos lógicamente, por ejemplo, utilizando una separación lógica fecha/hora (ver Figura 4-6).8
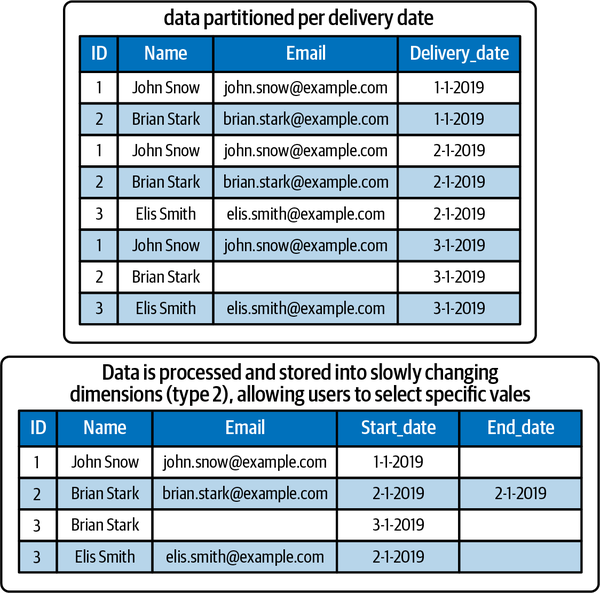
Figura 4-6. Ejemplos del aspecto de los datos cuando se particionan con instantáneas de dimensiones completas o dimensiones que cambian lentamente (tipo 2)
Gestionar sólo instantáneas completas es fácil de implementar. En cada ciclo ETL, toda la salida se almacena como una instantánea inmutable. Después, los esquemas de las tablas pueden sustituirse utilizando la ubicación en la que se almacenan los nuevos datos. El contenedor es una colección de todas estas instantáneas puntuales. Algunos profesionales podrían argumentar que este enfoque da lugar a la duplicación de datos. Yo no lo considero un problema, porque el almacenamiento en la nube es relativamente barato hoy en día. Las instantáneas completas también facilitan la redistribución, o reconstrucción de un conjunto de datos integrado que contenga todos los cambios realizados a lo largo del tiempo. Si un sistema fuente descubre que se entregaron datos incorrectos, puede volver a enviarlos y sobrescribirá la partición.
Nota
Utilizar sólo un enfoque de representación puntual podría ser adecuado cuando los datos que se facilitan ya contienen todos los datos históricos necesarios; por ejemplo, si los datos se facilitan de tal forma que ya contienen las fechas de inicio y fin de todos los registros.
Un inconveniente de la instantánea de conjuntos de datos completos es que el análisis (retrospectivo) de los datos es más difícil. Las comparaciones entre periodos de tiempo concretos son problemáticas si no se dispone de las fechas de inicio y fin, porque los consumidores tendrán que procesar y almacenar todos los datos históricos. Procesar datos históricos de tres años, por ejemplo, puede requerir procesar más de mil archivos en secuencia. El procesamiento de datos puede ocupar mucho tiempo y capacidad de cálculo, dependiendo del tamaño de los datos. Por eso, se recomienda a que considere también un enfoque por intervalos.
Intervalo
Otro enfoque para gestionar y presentar datos históricos en es crear conjuntos de datos históricos en los que se comparen y procesen todos los datos. Por ejemplo, puedes crear conjuntos de datos utilizando dimensiones de cambio lento (SCD)9 que muestran todos los cambios a lo largo del tiempo. Este proceso requiere ETL porque necesitas tomar la entrega de datos existente y compararla con cualquier entrega anterior. Tras la comparación, los registros se abren y/o se cierran. En este proceso, normalmente se asigna una fecha de finalización a los valores que se actualizan y una fecha de inicio a los nuevos valores. Para la comparación, se recomienda excluir todos los datos no funcionales.10
El enfoque de comparar intervalos y acumular datos históricos tiene la ventaja de almacenar los datos de forma más eficiente, ya que se procesan, deduplican y combinan. Como puedes ver en la Figura 4-6, la dimensión que cambia lentamente en el lado derecho ocupa la mitad de filas. En consecuencia, la consulta de los datos, por ejemplo mediante una base de datos relacional, es más fácil y rápida. Limpiar los datos o eliminar registros individuales, como podrías necesitar para cumplir la GDPR, también será más fácil, ya que no tendrás que crujir todos los conjuntos de datos entregados previamente.
El inconveniente, sin embargo, es que la construcción de dimensiones que cambian lentamente requiere más gestión. Hay que procesar todos los datos. Los cambios en los datos fuente subyacentes deben detectarse en cuanto se producen y, a continuación, procesarse. Esta detección requiere código y capacidad de cálculo adicionales. Otra consideración es que los consumidores de datos suelen tener requisitos de historización diferentes. Por ejemplo, si los datos se procesan diariamente, pero un consumidor requiere una representación por meses, tendrá que realizar un paso de procesamiento adicional.
Además, el proceso de reprocesamiento puede ser doloroso y difícil de gestionar, porque podrían procesarse datos incorrectos y pasar a formar parte de las dimensiones. Esto puede solucionarse con una lógica de reprocesamiento, versiones adicionales o fechas de validez, pero sigue siendo necesaria una gestión adicional. El escollo aquí es que la gestión correcta de los datos puede convertirse en responsabilidad de un equipo central, por lo que esta escalabilidad requiere una gran cantidad de funciones inteligentes de autoservicio.
Otro inconveniente de crear datos históricos para el consumo genérico de todos los consumidores es que éstos podrían seguir necesitando hacer algún procesamiento siempre que omitan columnas en sus selecciones. Por ejemplo, si un consumidor hace una selección más restringida, podría acabar con registros duplicados y, por tanto, necesitaría procesar los datos de nuevo para desduplicarlos. Por escalabilidad y para ayudar a los consumidores, también puedes considerar mezclar los dos enfoques, manteniendo instantáneas de dimensiones completas y proporcionando "datos históricos como servicio". En este escenario, se ofrece un pequeño marco de cálculo a todos los dominios consumidores, mediante el cual pueden programar la creación de datos históricos en función del ámbito (diario, semanal o mensual), el lapso de tiempo, los atributos y los conjuntos de datos que necesiten. Con instancias de procesamiento de corta duración en la nube pública, puedes incluso hacer que esto sea rentable. La gran ventaja de este enfoque es que conservas la flexibilidad para las redistribuciones, pero no necesitas un equipo de ingenieros para gestionar y preparar los conjuntos de datos. Otra ventaja es que puedes adaptar los intervalos de tiempo, los alcances y los atributos a las necesidades de cada uno.
Sólo para apéndices
Algunos estilos de entrega de datos de pueden facilitarse mejor con un enfoque de sólo anexar. Con este método, sólo cargas registros nuevos o modificados desde la base de datos de la aplicación y los añades al conjunto de registros existente. Esto funciona tanto para datos transaccionales como para datos basados en eventos, que trataremos en el Capítulo 6. El enfoque de sólo anexar suele combinarse con la captura de datos de cambios, en la que estableces un flujo de cambios identificando y capturando los cambios realizados en tablas estándar, tablas de directorio y vistas.
Definir tu estrategia de historización
El enfoque de historización adecuado para un producto de datos depende de los tipos de datos, los requisitos del consumidor y la normativa. Todos los enfoques para historizar y construir productos de datos pueden combinarse, y puedes utilizar diferentes enfoques para diferentes tipos de datos. Los datos maestros, por ejemplo, pueden suministrarse desde una aplicación y construirse utilizando el estilo de dimensiones que cambian lentamente. Los datos de referencia pueden procesarse fácilmente mediante instantáneas, mientras que los datos transaccionales del mismo sistema pueden manejarse mediante la entrega de sólo anexos. Puedes conservar instantáneas completas de todas las entregas y, al mismo tiempo, construir dimensiones que cambien lentamente.
Para tener éxito en el desarrollo y diseño de productos de datos, la clave es una estrategia integral. Las buenas prácticas deben centrarse en cómo estratificar los datos y crear un historial dentro de cada uno de tus dominios. Esta estrategia de estratificación puede incluir el desarrollo y mantenimiento de guiones y servicios estándar, como los servicios de captura de datos de cambios.12
Las buenas prácticas esbozadas aquí pretenden aportar ideas, pero también se comparten para mostrar que la gestión de productos de datos es una empresa pesada. En la siguiente sección, profundizaremos en algunos de los aspectos del diseño de soluciones a la hora de desarrollar una arquitectura. Lo haremos utilizando un ejemplo del mundo real y teniendo en cuenta lo que ya hemos comentado.
Diseño de soluciones
Ahora que estás familiarizado con algunas buenas prácticas y principios de diseño, ha llegado el momento de algo más práctico: construir abstracciones optimizadas para la lectura sobre los datos de tus aplicaciones complejas utilizando soluciones y servicios. Las tecnologías y metodologías que aplican las organizaciones para desarrollar productos de datos suelen diferir significativamente de una empresa a otra. También es un tema difícil de abordar porque no existen plataformas ni productos que gestionen el ciclo de vida completo de los productos de datos. Haría falta otro libro para describir todas las formas diferentes de implantar una arquitectura de productos de datos de extremo a extremo, así que en su lugar me centraré en los puntos de consideración clave antes de comentar un ejemplo concreto:
-
La nube se ha convertido en en la infraestructura por defecto para procesar datos a gran escala, porque ofrece ventajas significativas sobre los entornos locales. Todas las plataformas de nube populares proporcionan un conjunto de servicios de datos de autoservicio que son suficientes para poner en marcha cualquier implementación.
-
Los servicios de lago de datos son una opción popular entre todo tipo de organizaciones. Con unos volúmenes de datos que aumentan a diario, colocar los datos, por ejemplo, en un almacenamiento de objetos en la nube compatible con HDFS es una forma excelente de hacer que tu arquitectura sea rentable. Las ventajas de este tipo de servicios incluyen la separación del almacenamiento y el cálculo, y la reducción de la duplicación de datos mediante el uso de servicios de consulta ligeros.13
-
Una pila popular es el procesamiento de datos con Spark, Python y cuadernos. Las motivaciones para este patrón incluyen una comunidad amplia y activa, las ventajas del código abierto y una fuerte interoperabilidad, y un amplio soporte para diversos casos de uso, desde la ingeniería de datos a la ciencia de datos. Aunque Spark es una opción excelente para ETL y aprendizaje automático, no está optimizado para realizar consultas interactivas y de baja latencia. Otra consideración al utilizar cuadernos es prestar atención a las actividades repetitivas, como la historización de datos, las transformaciones técnicas de datos y la validación de esquemas. Una buena práctica común al utilizar cuadernos es diseñar procedimientos comunes y un marco basado en metadatos, utilizando procedimientos configurables para destinos, validaciones, seguridad y , etc.14
-
Para la transformación y el modelado de datos , muchas organizaciones complementan su arquitectura con servicios adicionales, como dbt. Aunque se puede utilizar Spark con código personalizado para la transformación de datos, las empresas suelen pensar que los proyectos de mayor envergadura se pueden agilizar mejor mediante la creación de plantillas y la escritura de configuraciones. Tanto las herramientas de plantillas como los cuadernos son opciones viables, y además pueden complementarse entre sí. Veo muchas empresas que primero manejan la validación de datos, la transformación técnica y la historización con cuadernos, y luego integran sus datos con herramientas como dbt.
-
La orquestación y la automatización del flujo de trabajo son necesarias para gestionar el proceso desde la ingesta hasta el servicio de datos. Aunque la estandarización es clave para la observabilidad, es una buena práctica dar libertad a cada equipo para que desarrolle su propio conocimiento local y persiga prioridades locales. Otra buena práctica consiste en integrar tus procesos CI/CD y de flujo de trabajo, pero manteniendo tus canalizaciones independientes para cada aplicación o producto de datos.
-
Al seleccionar cualquier herramienta, recomiendo buscar una pila de datos moderna. Hay muchas opciones populares entre las que elegir, desde soluciones de código abierto a soluciones de código cerrado.
-
Servicios de gestión de metadatos , como catálogos de datos y herramientas de linaje de datos, a menudo se sitúan fuera de las arquitecturas de productos de datos. Estos servicios son ofrecidos como servicios genéricos por una autoridad central. Las consideraciones al respecto se tratarán en profundidad en el Capítulo 9.
Una pregunta habitual con respecto al diseño de productos de datos es cómo se relacionan los conceptos de lago de datos y malla de datos. Aunque a primera vista puedan parecer contradictorios, la tecnología subyacente de los lagos de datos complementa la visión del diseño de productos de datos. Por tanto, no hay nada malo en utilizar las tecnologías de los lagos de datos en una malla de datos.
Otra pregunta frecuente es si cada dominio de tiene autonomía para seleccionar su propia pila de datos moderna. Los entusiastas establecen rápidamente un paralelismo entre los microservicios y las arquitecturas de malla de datos, y argumentan que la plena autonomía permite a cada dominio hacer sus propias elecciones tecnológicas óptimas. Sin embargo, muchas organizaciones fracasan porque los equipos de dominio toman decisiones opuestas. Imagina que tienes 25 equipos "autónomos", todos implementando sus arquitecturas de productos de datos utilizando sus propias herramientas y formas de trabajar. Si todas las herramientas difieren, ¿cómo recopilarás el linaje, las métricas de calidad de los datos, las estadísticas de monitoreo y los resultados de la gestión de datos maestros? ¿Cómo puedes lograr la interoperabilidad entre plataformas cuando cada equipo utiliza su propio estándar? Abordaré estas cuestiones al final de este capítulo, pero es importante señalar que la identidad, la gobernanza y la interoperabilidad son las piedras angulares de cualquier patrón federado. Sacrifica cualquiera de estos pilares, y acabarás rápidamente con muchas soluciones punto a punto, que se vuelven arquitectónicamente caras y difíciles de gobernar. La autonomía comienza con la arquitectura empresarial, a nivel central, y requiere normalización. La flexibilidad tiene que ver con el acoplamiento flexible y la eliminación de dependencias. La autonomía no debe acabar en caos organizativo, proliferación incontrolada de tecnología, explosión de costes o una combinación de todo ello.
Ejemplo real
En esta sección, te guiaré a través de un ejemplo real de creación de una arquitectura de productos de datos. Este ejemplo no será tan complejo, aunque contiene los ingredientes esenciales para su posterior discusión y evaluación. Supongamos que la arquitectura del producto de datos se está diseñando para una organización en la que aproximadamente la mitad de los dominios son operativos y transaccionales por naturaleza. Estos sistemas están marcados como fuentes de oro y son el punto de partida para la ingestión de datos. Los demás dominios son de consumo; hay que servirles datos.
Consejo
Para ver un extenso recorrido por este ejemplo, con capturas de pantalla e instrucciones paso a paso, consulta la entrada de mi blog "Uso de DBT para construir una arquitectura de casa del lago medallón".
Si me encargaran diseñar una arquitectura de productos de datos para esta organización en Azure, podría proponer la solución que se ve en la Figura 4-7. Mi punto de partida sería aprovisionar una zona de aterrizaje de datos y algunos grupos de recursos con un conjunto estandarizado de servicios para mi primer dominio: Azure Data Factory (ADF), Azure Data Lake Storage (ALDS) y Azure Databricks. Posteriormente, recopilaría y cosecharía datos utilizando un servicio como ADF. En la medida de lo posible, utilizaría conectores prediseñados. Como alternativa, pediría a los propietarios de las aplicaciones que exportaran y pusieran en escena sus datos en ubicaciones intermedias. Podrían ser, por ejemplo, cuentas de Almacenamiento Blob, desde las que se recogerían los datos para su posterior procesamiento.
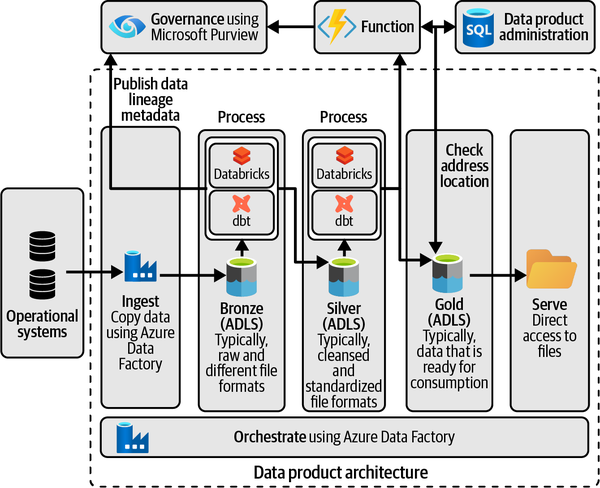
Figura 4-7. Una arquitectura sencilla de productos de datos que utiliza un diseño lakehouse: presenta servicios para la ingestión de datos, la creación de productos de datos y la gobernanza de datos.
Yo utilizaría ADLS para almacenar datos en mi arquitectura de productos de datos. Un patrón de diseño habitual para agrupar datos es utilizar tres contenedores :15
- Bronce
-
Datos en bruto que pueden estar en múltiples formatos y estructuras.
- Plata
-
Datos filtrados y depurados, almacenados utilizando un formato de archivo de datos normalizado orientado a columnas.
- Oro
-
Datos de lectura optimizada que están listos para ser consumidos por otros dominios. Algunas organizaciones llaman a estos conjuntos de datos de lectura optimizada o de consumofácil productos de datos.
Después de configurar mi lago de datos, continuaría el ejercicio creando mi primera canalización de datos. En primer lugar, utilizaría la actividad Copiar para copiar datos en la capa Bronce. Los datos de esta capa se almacenan en formato Parquet porque no es necesario versionarlos. Para historizar los datos, se utiliza un esquema de partición AAAAMMDD. Las versiones antiguas de los datos se conservan para análisis ad hoc o con fines de depuración.
A continuación, añadiría otra actividad de canalización para ejecutar cuadernos y pasar parámetros a Databricks.16 Databricks utilizará un cuaderno dinámico para validar los datos y, a continuación, eliminará los esquemas existentes y creará otros nuevos utilizando las ubicaciones de las particiones YYYYMMDD.
Para la capa Silver, mi formato de archivo preferido es Delta, que ofrece un rendimiento rápido y protección frente a la corrupción. La retención está activada para los casos en que necesites revertir cambios y restaurar datos a una versión anterior: por cada operación que modifica datos, Databricks crea una nueva versión de la tabla, almacenando 30 días de historial por defecto. Para seleccionar datos de la capa Bronce y transformarlos utilizando un diseño de tabla SCD de tipo 2, prefiero dbt. Aplico transformaciones limitadas al pasar los datos a Plata, seleccionando sólo datos funcionales. Antes de seleccionar cualquier dato, realizo una serie de pruebas para asegurarme de que los datos son de alta calidad y cumplen las normas de integridad. Una última nota para esta capa: si tengo fuentes diferentes, las trato como fuentes de datos separadas. La integración y combinación de todos los datos se gestiona en las capas siguientes.
Para trasladar los datos a la capa Oro, donde se integran y se preparan para el consumidor, necesito escribir lógica empresarial para mapear todos los objetos en conjuntos de datos fáciles de usar y consumir. De nuevo, utilizo plantillas dbt para ello, creando una plantilla y un modelo YML para cada entidad de datos lógica. Cada plantilla define las selecciones, uniones y transformaciones que deben aplicarse, y escribe en una carpeta única (por ejemplo, datos de clientes, datos de pedidos, datos de ventas, etc.). Cada salida agrupa lógicamente los datos en torno a un área temática. Los datos se materializan, y el formato del archivo vuelve a ser Delta.
Por último, guardaría y programaría mi pipeline dentro de ADF. Para todos los pasos individuales, añadiría pasos adicionales para capturar la fecha/hora de carga, el ID del proceso, el número de registros procesados, los mensajes de error o éxito, etc.
Para cada dominio adicional, repetiría todos estos pasos. Así, cada dominio almacenaría sus productos de datos en su propia arquitectura de productos de datos específica del dominio, gestionaría su propia canalización de datos y utilizaría la misma estratificación para crear productos de datos. Una vez que tuviera la capacidad de hacer esto de forma controlada a escala, empezaría a añadir variaciones a este diseño. Por ejemplo, podría tener varios puertos de salida que utilizaran los mismos datos semánticos para diferentes representaciones para diferentes consumidores.
Para las piezas de gobernanza, autoservicio y seguridad de la arquitectura , propondría utilizar una combinación de una base de datos Azure SQL, Azure Functions y Microsoft Purview, un servicio unificado de gobernanza de datos . Estos componentes pueden desplegarse en la zona de aterrizaje de gestión de datos y utilizarse para catalogar y supervisar todos los productos de datos.
Para publicar los productos de datos de , pediría a todos los dominios que publicaran sus productos de datos mediante una función declarativa, como parte de sus conductos CI/CD. Esta función podría, por ejemplo, tomar como entrada las especificaciones dbt YML de la capa Oro y almacenar estas especificaciones en una base de datos SQL. A continuación, la función validaría que la información proporcionada sobre la ubicación y el esquema representan el identificador universal de recursos (URI) y la estructura del producto de datos. Si es así, realizará otra llamada para publicar toda la información en el catálogo. Esta última llamada hace que los datos estén disponibles públicamente para otros consumidores.
Para proporcionar acceso a los datos a mis consumidores, propondría utilizar el autoservicio de descubrimiento y acceso a los datos. En segundo plano, esto creará listas de control de acceso (ACL) para productos de datos individuales. Las ACL no son geniales para el filtrado fino a nivel de columna o fila, pero para el propósito de este ejemplo del mundo real, están bien. En el Capítulo 8 se tratarán situaciones más complejas.
Nota
Este ejemplo del mundo real se ha simplificado con fines didácticos. En realidad, la gestión de productos de datos es más compleja porque hay que tener en cuenta factores como la seguridad, la elaboración de perfiles, las búsquedas complejas, las variaciones en la ingestión y el servicio de datos, y los distintos escenarios de enriquecimiento. Por ejemplo, puede haber restricciones específicas para el archivo de datos, la tokenización o el acceso a los datos dentro de un plazo determinado.
Recapitulemos rápidamente los puntos clave de este ejemplo. En primer lugar, sentamos rápidamente las bases para la creación de productos de datos. Hicimos al dominio responsable del ciclo de vida de los datos bajo su control, y de transformar los datos de la forma bruta capturada por las aplicaciones a una forma adecuada para su consumo por partes externas. En segundo lugar, la arquitectura puede ampliarse fácilmente añadiendo más dominios con arquitecturas de productos de datos adicionales. En tercer lugar, aplicamos varios principios de malla de datos, como la propiedad de los datos orientada al dominio, el pensamiento de los datos como producto, las plataformas de datos de autoservicio y la gobernanza computacional federada. En la siguiente sección, centraremos nuestra atención en las numerosas consideraciones que debes tener en cuenta al ampliar .
Alineación con las cuentas de almacenamiento
Es importante que preste atención a la alineación de los datos del producto de datos y las cuentas de almacenamiento. En el diseño de ejemplo de la sección anterior, decidí compartir una arquitectura de productos de datos con varios conjuntos de datos de productos de datos de un único dominio. Una alternativa habría sido alinear cada conjunto de datos con una cuenta de almacenamiento dedicada y un pool Spark para el procesamiento de datos. Esta configuración uniría los datos, el código, los metadatos y la infraestructura necesaria, y estaría más cerca del concepto de producto de datos dentro de una malla de datos. Simplifica la gestión del acceso y permite la automatización para que puedas aprovisionar clusters de procesamiento y cuentas de almacenamiento sobre la marcha. Si, por ejemplo, tu capa Plata es temporal, puedes eliminarla cuando ya no sea necesaria. Por otra parte, vincular estrechamente los productos de datos y la infraestructura aumenta drásticamente la sobrecarga de la infraestructura y el número de conductos que necesitas gestionar. Por ejemplo, puede dar lugar a un gran número de permisos y puntos finales de red y servicios que hay que gestionar, asegurar, escanear y monitorizar, o generar una compleja red de cuentas de almacenamiento porque los productos de datos suelen derivarse de los mismos datos subyacentes. Por tanto, tendrás que sopesar hasta qué punto quieres alinear tus productos de datos con tu infraestructura.
¿Y si varios dominios comparten la misma cuenta de almacenamiento? Esto también es posible, pero hacer que varios dominios compartan la infraestructura de almacenamiento subyacente requiere una estructura de contenedores y carpetas diferente. Éste es un patrón que veo a menudo en organizaciones más pequeñas, porque el almacenamiento gestionado centralmente alivia la carga de gestión y otros problemas que suelen surgir al mover y proteger los datos. Por otro lado, requiere que todos los dominios compartan los mismos límites y elementos de configuración, como ACL y reglas de dirección IP. Probablemente tampoco sea el mejor enfoque si necesitas georedundancia y un rendimiento flexible.17 De nuevo, tendrás que considerar las compensaciones.
Como alternativa, podrías lograr un equilibrio entre los datos alineados local y centralmente, aplicando un enfoque híbrido que utilice cuentas de almacenamiento tanto locales al dominio como centrales. En este caso, cada dominio utiliza una cuenta de almacenamiento interna y dedicada en la que se realiza todo el procesamiento específico del dominio (por ejemplo, en las capas Bronce y Plata). Dicha cuenta está pensada sólo para uso interno y no estará expuesta a ningún otro dominio. Junto a estas cuentas de almacenamiento locales de dominio, hay una cuenta de almacenamiento compartida centralmente, destinada a distribuir los datos finales de los productos de datos (creados en la capa Oro) a otros dominios. Esta cuenta de almacenamiento compartido suele ser gestionada por un departamento central. La razón de ser de este diseño es proporcionar flexibilidad a los dominios, manteniendo al mismo tiempo la supervisión de todos los intercambios de datos de los productos de datos .
Alineación con los conductos de datos
Otra consideración importante de es la alineación de los conductos de datos y los productos de datos. Como has visto antes, un conducto de datos es una serie de pasos para mover y transformar datos. Generalmente utiliza metadatos y código, igual que en un marco de ingestión basado en metadatos, para determinar qué operaciones ejecutar con qué datos. En el ejemplo anterior, utilizamos la misma canalización para todos los productos de datos, pero algunos profesionales abogan por utilizar una canalización específica para cada uno de ellos. Así que la pregunta es, ¿qué enfoque es mejor para tu situación?
Para responder a esta pregunta, considera la granularidad de tus productos de datos y los conductos de datos correspondientes. Supón que procesas por lotes los datos de una aplicación y construyes varios productos de datos de grano grueso (conjuntos de datos) a partir de ellos, cada uno utilizando su propia canalización de datos. Es probable que varias canalizaciones procesen los mismos datos subyacentes del sistema fuente, porque los datos de entrada de los productos de datos a menudo se solapan. Esto significa que algunos pasos del procesamiento pueden repetirse, lo que dificulta el mantenimiento. Además, mover partes específicas de los datos a través de distintos conductos a intervalos diferentes provoca problemas de integridad, lo que dificulta que los consumidores combinen los datos más adelante.
Tener una configuración demasiado detallada de tus productos de datos y canalizaciones de datos también es un reto. Si un sistema fuente subyacente genera cientos de pequeños productos de datos, cada uno con su propia canalización de datos, será difícil solucionar los problemas y supervisar las dependencias: puede observarse una compleja red de pasos de procesamiento repetidos. Además, será difícil para los consumidores utilizar los datos, ya que tendrán que integrar muchos conjuntos de datos pequeños. La integridad referencial también es una gran preocupación en este caso, ya que se espera que muchos pipelines se ejecuten a intervalos ligeramente diferentes.
Para concluir, tener un pipeline dedicado para cada producto de datos no suele ser la solución ideal. Las buenas prácticas recomendadas consisten en crear una canalización utilizando la serie de pasos adecuada que tome todo el estado de la aplicación, lo copie y, a continuación, transforme los datos en conjuntos de datos fáciles de usar.
Capacidades para servir datos
Cambiemos al lado servidor de la arquitectura del producto de datos y veamos qué componentes y servicios necesitamos proporcionar allí. Para servir los datos de los puertos de salida18 hay distintas dimensiones del procesamiento de datos que influyen en la forma de diseñar las arquitecturas de productos de datos. El diseño de la arquitectura del producto de datos depende en gran medida de los casos de uso y los requisitos de los dominios consumidores. En muchos casos, procesas datos que no son críticos en el tiempo. A veces, responder a la pregunta o satisfacer la necesidad empresarial puede esperar unas horas o incluso unos días. Sin embargo, también hay casos de uso en los que los datos deben entregarse en pocos segundos.
Advertencia
La gestión de productos de datos no debe confundirse con la creación de valor de los datos, por ejemplo mediante aplicaciones de inteligencia empresarial y aprendizaje automático. A pesar del solapamiento, en el lado del consumidor se observa generalmente una gran diversificación en la forma de utilizar los datos. Por tanto, la creación de productos de datos debe gestionarse aparte de la creación de valor de datos.
En los últimos años, la variedad de servicios de almacenamiento y bases de datos disponibles ha aumentado enormemente. Tradicionalmente, los sistemas transaccionales y operativos se diseñan para una alta integridad y, por tanto, utilizan una base de datos relacional y conforme a ACID. Pero las bases de datos sin esquema no conformes con ACID (como los almacenes de documentos o de clave/valor) también están de moda porque relajan los controles de integridad más estrictos en favor de un rendimiento más rápido y permiten tipos de datos más flexibles, como los procedentes de dispositivos móviles, juegos, canales de medios sociales, sensores, etc. El tamaño de los datos puede marcar la diferencia: algunas aplicaciones almacenan cantidades relativamente pequeñas de datos, mientras que otras pueden depender de terabytes de datos.
La ventaja de utilizar una arquitectura de productos de datos es que puedes añadir múltiples diseños para los patrones de lectura específicos de los distintos casos de uso .19 Puedes duplicar los datos para dar soporte a diferentes estructuras de datos, velocidades y volúmenes, o para servir diferentes representaciones de los mismos datos. Podrías ofrecer un punto final basado en archivos para casos de uso ad hoc, exploratorios o analíticos, un punto final basado en relaciones para facilitar las consultas más complejas e impredecibles, un punto final basado en columnas para consumidores de datos que requieren agregaciones pesadas, o un punto final basado en documentos para consumidores de datos que requieren una mayor velocidad y un formato de datos semiestructurado (JSON). Incluso podrías modelar tus productos de datos con nodos y relaciones utilizando una base de datos gráfica.
Al proporcionar diferentes puntos finales o puertos de salida, todos deben gestionarse bajo el mismo paraguas de gobernanza de datos. La responsabilidad recae en el mismo dominio proveedor. Los principios para los datos reutilizables y de lectura optimizada también se aplican a todas las variaciones del producto de datos. Además, se espera que el contexto y la semántica sean los mismos; por ejemplo, la noción de "cliente" o "nombre de cliente" debe ser coherente para todos los datos que se sirvan. Debe utilizarse el mismo lenguaje ubicuo para todos los productos de datos que pertenezcan al mismo proveedor de datos. Veremos cómo se garantiza la coherencia semántica en todos los puntos finales y otros patrones de integración en el Capítulo 7.
Servicios de servidores de datos
Al hacer zoom en sobre las interacciones del usuario y la aplicación con las arquitecturas de productos de datos, descubrirás normalmente que hay una gran variedad de patrones de acceso a los datos que proporcionar. Estos patrones pueden incluir consultas ad hoc, informes directos, creación de capas semánticas o cubos, proporcionar Conectividad Abierta a Bases de Datos (ODBC) a otras aplicaciones, procesamiento con herramientas ETL, manipulación de datos o procesamiento científico de datos. Para darles soporte, es esencial dotar a tu arquitectura de productos de datos de suficientes funciones de rendimiento y seguridad.
Nota
Para todos los servicios que consumen datos, quieres que sea coherente en el acceso a los datos y la gestión de su ciclo de vida. Para eso están los contratos de datos; hablaremos de ellos en el Capítulo 8.
Los sistemas de archivos distribuidos, como el almacenamiento de objetos basado en la nube, son rentables cuando se trata de almacenar grandes cantidades de datos, pero no suelen ser lo suficientemente rápidos para las consultas ad hoc e interactivas. Muchos proveedores han reconocido este problema y ofrecen motores de consulta SQL o capas de virtualización ligeras para resolverlo. La ventaja de permitir que las consultas se ejecuten directamente contra los productos de datos es que éstos no tienen que duplicarse, lo que abarata la arquitectura. Estas herramientas también ofrecen un acceso de grano fino a los datos, y hacen que el almacén de datos operativos quede obsoleto. Los datos que se almacenan en una arquitectura de productos se convierten en candidatos para informes operativos y análisis ad hoc. Las opciones de virtualización de datos son buenas soluciones, pero sólo son adecuadas para casos de uso de informes sencillos. Si no es suficiente, considera alternativas como duplicar los datos de .
Servicio de Manipulación de Ficheros
Mientras hablamos de la duplicación de datos y el consumo de datos, algunos dominios tienen casos de uso o aplicaciones que sólo aceptan archivos planos (por ejemplo, archivos CSV) como entrada. Para estas situaciones, considera la posibilidad de crear un servicio de manipulación de archivos que enmascare o elimine automáticamente los datos sensibles que los consumidores no pueden ver. Este servicio, al igual que todos los demás puntos finales de consumo, debe estar conectado al modelo de seguridad central, que dicta que todo consumo de datos debe respetar los contratos de datos (ver "Contratos de datos"). También prescribe que los filtros deben aplicarse automáticamente y basarse siempre en clasificaciones y atributos de metadatos. Hablaremos de esto con más detalle en el Capítulo 8.
Servicio de Desidentificación
Cuando utilices directamente los productos de para la exploración de datos, la ciencia de datos, el aprendizaje automático y el intercambio de datos con terceros, es importante proteger los datos sensibles de los consumidores. Gracias a métodos de seguridad como la tokenización, el hashing, la codificación y el cifrado, puedes utilizar reglas y clasificaciones para proteger tus datos. Dependiendo de cómo diseñes la arquitectura del producto de datos, puedes aplicar los siguientes métodos:
-
Proteger los datos en tiempo de ejecución durante el consumo. Esta técnica protege los datos sensibles sin realizar ningún cambio en los datos almacenados, sino sólo cuando se consultan. Databricks, por ejemplo, utiliza una característica llamada funciones de vista dinámica para ocultar o enmascarar los datos cuando se accede a ellos.
-
Ofusca o enmascara los datos sensibles antes de que lleguen a una arquitectura de productos de datos (por ejemplo, utilizando la tokenización). La coincidencia desidentificada se produce entonces en la fase de consumo.
-
Duplica y procesa los datos de cada proyecto. Puedes personalizar tu protección definiendo qué clasificaciones y reglas de enmascaramiento y filtrado utilizas.
La seguridad de los datos se basa en la gobernanza de los datos. Estas dos disciplinas se tratarán en profundidad en el Capítulo 8.
Orquestación distribuida
El último aspecto que requiere consideraciones de diseño y estandarización es el apoyo a los equipos a medida que implementan, prueban y orquestan sus canalizaciones de datos. Construir y automatizar estos conductos de datos es un proceso iterativo que implica una serie de pasos como la extracción, preparación y transformación de datos. Debes permitir que los equipos prueben y monitoreen la calidad de todas sus canalizaciones de datos y artefactos, y apoyarles con cambios de código durante el proceso de implementación. Este enfoque de entrega de extremo a extremo se parece mucho a DataOps, en el sentido de que viene acompañado de mucha automatización, prácticas técnicas, flujos de trabajo, patrones arquitectónicos y herramientas.
Al estandarizar las herramientas y buenas prácticas de , recomiendo que las organizaciones establezcan un equipo centralizado o de plataforma que apoye a otros equipos proporcionando capacidades para tareas como la programación, la curación de metadatos, el registro de métricas, etc. Este equipo también debe ser responsable de supervisar el monitoreo de extremo a extremo, y debe intervenir cuando los conductos se interrumpan durante demasiado tiempo. Para abstraer la complejidad de las dependencias y las diferencias de intervalos de tiempo de los distintos proveedores de datos, este equipo también puede establecer un marco de procesamiento adicional que pueda, por ejemplo, informar a los consumidores cuando se puedan combinar varias fuentes con relaciones de dependencia.
Servicios de Consumo Inteligente
Basándote en todas las de estas distintas capacidades, también podrías ampliar la arquitectura del producto de datos con una capa (tejido) para aplicar transformaciones inteligentes de datos al consumirlos, como perfilado automático, filtrado, alineación de esquemas, combinación, etc. Esto permitiría a los consumidores de datos definir los datos que necesitan y recibirlos ya modelados con la forma que desean. Este tipo de servicio inteligente suele utilizarse también para desplegar una capa semántica que oculta la lógica compleja y luego presenta representaciones fáciles de usar a los usuarios empresariales. Utiliza en gran medida los metadatos, incluidos muchos otros servicios específicos de la gobernanza de datos. Un enfoque visionario sería alimentar tu tejido con tecnologías venideras como los grafos semánticos de conocimiento y el aprendizaje automático. Aunque esta tendencia es relativamente nueva, en el Capítulo 9 doy varias recomendaciones para prepararse a aplicar este enfoque.
Consideraciones sobre el uso directo
Una consideración difícil del diseño es si los productos de datos deben poder actuar como fuentes directas para los dominios consumidores, o si éstos tienen que extraerlos y duplicarlos. Me refiero aquí a las transformaciones de datos persistentes, que se refieren al proceso por el que los datos se escriben y almacenan en una nueva ubicación (lago de datos o base de datos), fuera de los límites de la arquitectura del producto de datos. Es preferible evitar la creación de copias incontroladas de datos, pero puede haber situaciones en las que sea mejor tener una copia disponible cerca o dentro de la aplicación consumidora. Por ejemplo:
-
Si el producto de datos se utiliza para crear nuevos datos, lógicamente estos datos deben almacenarse en una nueva ubicación y requieren un propietario diferente.
-
Si quieres reducir la latencia global, puede que sea mejor duplicar los datos para que estén disponibles localmente, más cerca del destino de la aplicación consumidora. Examinaremos esto más detenidamente en el Capítulo 6, donde aprenderás a crear vistas materializadas distribuidas totalmente controladas.
-
Las transformaciones de datos directas y en tiempo real pueden ser tan pesadas que degraden la experiencia del usuario. Por ejemplo, las consultas sobre productos de datos pueden tardar tanto que los usuarios se sientan frustrados. Extraer, reestructurar y preprocesar los datos o utilizar un motor de base de datos más rápido puede aliviar esta frustración.
-
Cuando la aplicación consumidora es de tan alta importancia que es necesario desacoplarla para evitar fallos en la arquitectura del producto de datos, puede tener sentido duplicar los datos.
En todos estos casos, recomiendo implantar una forma de control de la arquitectura empresarial que dicte qué enfoque se adopta para cada producto de datos. Ten en cuenta que los datos duplicados son más difíciles de limpiar, y puede ser difícil obtener información sobre cómo se utilizan los datos. Si los datos pueden copiarse sin restricciones ni gestión, es posible que se sigan distribuyendo. Otro problema potencial es el cumplimiento de normativas como el GDPR o la CCPA; hablaremos de ello con más detalle en en el Capítulo 11.
Cómo empezar
La transición hacia la propiedad de los datos y el desarrollo de productos de datos puede ser un reto cultural y técnico para muchos equipos. Por ejemplo, no todos los equipos tienen los conocimientos necesarios, ven el valor de los datos o están dispuestos a invertir en ellos. Si quieres seguir una evolución natural hacia el desarrollo de productos de datos, ten en cuenta las siguientes buenas prácticas de:
-
Empieza poco a poco. Genera entusiasmo y empieza con uno o unos pocos dominios cuyos equipos hayan aceptado el concepto de desarrollo de productos de datos. Primero demuestra el éxito, antes de ampliar.
-
Crea una definición coherente de lo que significa un producto de datos para tu organización. Alinéalo con el metamodelo que se utiliza para la gestión de metadatos.
-
La gobernanza es importante, pero tómatelo con calma. Mantén un delicado equilibrio para fomentar la productividad. Céntrate en los elementos fundamentales, como la propiedad, los metadatos y las normas de interoperabilidad. Alinéate con las normas y buenas prácticas del sector siempre que sea posible.
-
Tus primeros productos de datos deben servir de ejemplo para el resto de tus dominios. Establece criterios de calidad de aceptación y diseño, y céntrate en el diseño del conjunto de datos. El diseño de API orientado a los recursos es un gran punto de partida para crear productos de datos de alta calidad.
-
No intentes construir una plataforma que soporte todos los casos de uso a la vez. Al principio, lo normal es que tu plataforma sólo admita un tipo de ingesta y consumo de datos: por ejemplo, movimientos de datos por lotes y archivos Parquet como formato de consumo.
-
Permite la centralización, junto a la descentralización. Tu implementación inicial de productos de datos no tiene por qué alterar inmediatamente tu estructura organizativa. Mantén las cosas centralizadas durante un tiempo antes de alinear a los ingenieros con los dominios, o aplica una alineación suave para que los ingenieros trabajen con expertos en la materia. Al principio, se pueden crear conjuntos de datos específicos de cada dominio con el apoyo del equipo central.
Cuando estés empezando, tómatelo con calma. Aprende e itera antes de pasar a la siguiente fase. Centralización frente a descentralización no es todo o nada, sino una calibración constante que incluye matices y evaluaciones periódicas.
Conclusión
Los productos de datos suponen un gran cambio en la forma de gestionar las dependencias entre dominios y aplicaciones. Cada vez que se cruzan los límites de una preocupación funcional o un contexto delimitado, los equipos deben ajustarse a la forma unificada de distribuir datos: servir datos como productos de datos a otros equipos. Esta forma de trabajar es importante porque al haber menos dependencias compartidas se necesita menos coordinación entre equipos.
Al principio de este capítulo, establecí una distinción entre los conceptos de "datos como producto" y "productos de datos". Recapitulando, los datos como producto es la mentalidad que aplicas al gestionar los datos en general. Se trata de crear confianza, establecer la gobernanza y aplicar el pensamiento de producto; es cuidar los datos que más valoras y poner en práctica los principios. Es una mentalidad que deben tener tus equipos de dominio. Deben asumir la propiedad de sus datos, solucionar los problemas de calidad de los datos en su origen, y servir los datos de forma que sean útiles para una gran audiencia. En lugar de que un equipo central absorba todos los cambios e integre los datos, tus equipos de dominio deben encapsular el modelo físico de datos dentro de los límites de su dominio. Esto es lo contrario de arrojar los datos brutos por encima de la valla y dejar que los consumidores resuelvan los problemas de calidad y modelado de los datos. Tus equipos de dominio deben modelar y servir los datos de forma que ofrezcan la mejor experiencia de usuario.
Un producto de datos es un concepto que tienes que desmitificar por ti mismo. Mi recomendación es que empieces por normalizar la forma de hablar de la gestión de productos de datos en tu organización, ya que puede haber variaciones en el lenguaje y las definiciones utilizadas. Considera la posibilidad de definir los productos de datos como construcciones lógicas, en lugar de utilizar un punto de vista que se centre exclusivamente en las representaciones físicas o en la arquitectura tecnológica subyacente. En algún momento puedes introducir un modelo semántico para tu organización, de modo que tus productos de datos se conviertan en representaciones gráficas a partir de las cuales se establezcan relaciones con dominios, propietarios de datos, aplicaciones de origen y representaciones físicas. Esto puede sonar un poco demasiado conceptual, pero las ventajas de gestionar así tus productos de datos te quedarán más claras cuando leas el Capítulo 9.
Hay una advertencia con los productos de datos. Es probable que sufran problemas similares a los que se observan en las arquitecturas de microservicios, donde los datos son demasiado finos y desarticulados, y deben extraerse de cientos de lugares diferentes. La solución a estos problemas es establecer buenas normas y una autoridad central que supervise todas las actividades de creación de productos de datos. Hay que establecer normas de interoperabilidad para los intercambios de datos. Hay que coordinar los cambios y la forma de modelar y servir los datos. Por desgracia, estas actividades no son fáciles. Como has aprendido, el desarrollo de productos de datos tiene una fuerte relación con el almacenamiento de datos, que consta de muchas disciplinas, como el modelado de datos (hacer que los datos sean coherentes, legibles, descubribles, direccionables, fiables y seguros). Algunas de estas actividades pueden ser complejas, como los aspectos de historización que hemos tratado en este capítulo.
Los productos de datos y la mentalidad de los datos como producto consisten en proporcionar datos. Consumir datos es la siguiente etapa. Aunque ciertas actividades y disciplinas pueden solaparse, como aprenderás en el Capítulo 11, las preocupaciones de proporcionar datos y consumirlos no son las mismas. Al gestionar los datos como productos y proporcionar los productos de datos como interfaces de dominio, eliminas las dependencias y aíslas mejor las aplicaciones con preocupaciones opuestas. Esto es importante porque menos dependencias compartidas significa que se necesita menos coordinación entre equipos.
La arquitectura del producto de datos debe diseñarse en colaboración y basarse en las necesidades de la organización. Proporciona planos genéricos a los equipos de dominio. Permite que otros equipos contribuyan o se unan temporalmente al equipo o equipos de la plataforma. Si, por ejemplo, se necesita un nuevo patrón de consumo, entrégalo de forma sostenible como patrón o componente reutilizable. Lo mismo se aplica a la captura e incorporación de datos. Al ampliar y construir una plataforma de datos moderna, se necesitarán muchos componentes de aplicación de autoservicio adicionales: probablemente incluirán marcos ETL gestionados centralmente, servicios de captura de datos de cambios y herramientas de ingestión en tiempo real.
Una nota final e importante: los productos de datos, tal y como se han tratado en este capítulo, están pensados para hacer que los datos estén disponibles. Todavía no hemos hablado de cómo hacer que los datos sean utilizables y convertirlos en valor real. Este aspecto tiene una dinámica diferente a la creación de productos de datos y tendrá que esperar hasta el Capítulo 11.
En el próximo capítulo, veremos la arquitectura API, que se utiliza para la comunicación de servicios y para distribuir pequeñas cantidades de datos para casos de uso en tiempo real y baja latencia.
1 Un inconveniente del CQRS es que complica las cosas: tendrás que mantener sincronizados los dos modelos con una capa adicional. Esto también podría generar cierta latencia adicional.
2 TechDifferences tiene una visión general de las diferencias entre una vista de base de datos y una vista materializada.
3 El artículo de Morris sobre Data Vault 2.0 describe "lo bueno, lo malo y lo francamente confuso" de este patrón de diseño.
4 Lo creas o no, una vez vi una aplicación heredada en la que se concatenaban varios valores de cliente en un solo campo utilizando operadores de doble tubería, como Nombre||Nombre medio||Apellido.
5 Un metamodelo es un marco para comprender qué metadatos deben capturarse al describir los datos.
6 La conciliación puede realizarse de muchas formas distintas. Por ejemplo, puedes comparar recuentos de filas, utilizar sumas de comprobación de columnas, trocear tablas grandes y reprocesarlas, o utilizar herramientas de comparación de datos como Redgate.
7 Para saber cómo Azure Synapse Analytics y Microsoft Purview pueden integrarse juntos para procesar y validar datos de forma inteligente mediante Great Expectations, consulta mi entrada de blog "Modern Data Pipelines with Azure Synapse Analytics and Azure Purview" (Canalizaciones de datos modernas con Azure Synapse Analytics y Azure Purview).
8 El particionamiento es una técnica común para organizar archivos o tablas en grupos distintos (particiones) para mejorar la manejabilidad, el rendimiento o la disponibilidad. Suele ejecutarse sobre atributos de los datos, como atributos geográficos (ciudad, país), basados en valores (identificadores únicos, códigos de segmento) o basados en el tiempo (fecha de entrega, hora).
9 Una dimensión de cambio lento es una dimensión que almacena y gestiona datos tanto actuales como históricos a lo largo del tiempo en un almacén de datos. Las tablas dimensionales en la gestión y el almacenamiento de datos pueden mantenerse mediante varias metodologías, denominadas de tipo 0 a 6. El Grupo Kimball describe las distintas metodologías.
10 Por ejemplo, en tu marco de procesamiento puedes utilizar la dirección exclude_from_delta_processing parameter a nivel de atributo para excluir datos de la comparación.
11 Algunos proveedores de bases de datos proporcionan una capa de consulta (virtual) de la base de datos, que también se denomina capa de virtualización de datos. Esta capa abstrae la base de datos y optimiza los datos para mejorar el rendimiento de lectura. Otra razón para abstraer es interceptar las consultas para mejorar la seguridad.
12 Una de las entradas de mi blog contiene un sencillo script de ejemplo para procesar tablas SCD en formato Delta utilizando pools de Spark.
13 Al separar el almacenamiento de la informática, puedes escalar automáticamente la infraestructura para adaptarla a las cargas de trabajo elásticas.
14 Consulta la entrada de mi blog "Diseño de un marco de procesamiento basado en metadatos para Azure Synapse y Azure Purview" para obtener más detalles sobre este concepto.
15 Si piensas crear un lago de datos, la "Guía del autoestopista del lago de datos" es un gran recurso con orientaciones y buenas prácticas.
16 Microsoft ha desarrollado un acelerador de soluciones junto con el proyecto OpenLineage. Este conector de código abierto transfiere los metadatos de linaje de las operaciones Spark en Azure Databricks a Microsoft Purview, permitiéndote ver un gráfico de linaje a nivel de tabla. El proyecto está alojado en GitHub.
17 La georedundancia se consigue distribuyendo componentes o infraestructuras críticas (por ejemplo, servidores) en varios centros de datos situados en diferentes ubicaciones geográficas. Por ejemplo, para el almacenamiento en la nube puedes elegir entre discos duros convencionales y unidades de estado sólido más rápidas
18 La recomendación para una malla de datos es compartir productos de datos utilizando interfaces altamente estandarizadas, que proporcionen acceso de sólo lectura y de lectura optimizada a los datos. Estas interfaces también se conocen como puertos de salida.
19 Cuando se utiliza un almacén de datos de empresa para la distribución de datos, suele ser difícil facilitar diversas formas y dimensiones de los datos. Los almacenes de datos empresariales suelen diseñarse con un único tipo de tecnología (el motor de base de datos RDBMS) y, por tanto, no dejan mucho margen a las variaciones.
Get Gestión de datos a escala, 2ª edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

