Capítulo 4. Primeros pasos en la nube
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En los dos capítulos anteriores, te hemos explicado lo esencial de la genómica y la tecnología informática. Nuestro objetivo era asegurarnos de que tuvieras una base suficiente en ambos campos, independientemente de si te acercas a esto más desde un lado o desde el otro, o incluso desde otro campo; si es así, ¡bienvenido! Y aguanta.
Somos conscientes de que esos dos primeros capítulos pueden haberte parecido muy pasivos, ya que no incluían ejercicios prácticos. Así que aquí van las buenas noticias: por fin vas a poder hacer algo de trabajo práctico. Este capítulo trata de que te orientes y te sientas cómodo con los servicios de GCP que utilizamos a lo largo de este libro. En primer lugar, te guiaremos en la creación de una cuenta GCP y en la ejecución de comandos sencillos en Google Cloud Shell. Después, te enseñamos a configurar tu propia máquina virtual en la nube, a ejecutar Docker en ella y a configurar el entorno que utilizarás en el Capítulo 5 para ejecutar los análisis de GATK. Por último, te mostramos cómo configurar la VIG para acceder a los datos en Google Cloud Storage. Cuando tengas todo esto configurado, estarás listo para hacer genómica de verdad.
Configurar tu cuenta de Google Cloud y tu primer proyecto
Puedes registrarte para obtener una cuenta en GCP accediendo a https://cloud.google.com y siguiendo las instrucciones. Aquí somos deliberadamente poco detallistas porque se sabe que la interfaz para la configuración de cuentas ha cambiado. A un alto nivel, sin embargo, tus objetivos son establecer una nueva cuenta de Google Cloud, configurar una cuenta de facturación, aceptar los créditos de prueba gratuitos (si eres elegible), y crear un nuevo proyecto que se vincule a tu cuenta de facturación.
Si aún no tienes una identidad Google de algún tipo, puedes crear una con tu cuenta de correo electrónico habitual; no es necesario que utilices una cuenta de Gmail. Ten en cuenta también que si tu institución utiliza G Suite, es posible que tu correo electrónico del trabajo ya esté asociado a una identidad de Google, aunque el nombre de dominio no sea gmail.com.
Después de registrarte, dirígete a la consola de GCP, que proporciona una interfaz gráfica basada en web para gestionar los recursos de la nube. Puedes acceder a la mayoría de las funciones que ofrece la consola a través de una interfaz de línea de comandos pura. A lo largo del libro, te mostraremos cómo hacer algunas cosas a través de la interfaz web y otras a través de la línea de comandos, en función de lo que consideremos más cómodo y/o típico.
Crear un proyecto
Empecemos por crear tu primer proyecto, que es necesario para organizar tu trabajo, configurar la facturación y acceder a los servicios de GCP. En la consola, ve a la página "Gestionar recursos" y luego, en la parte superior de la página, selecciona Crear proyecto. Como se muestra en la Figura 4-1, tienes que dar un nombre a tu proyecto, que debe ser único dentro de todo GCP. También puedes seleccionar una organización si tu identidad de Google está asociada a una (lo que suele ocurrir si tienes una cuenta institucional/de trabajo de G Suite), pero si acabas de crear tu cuenta, puede que esto no sea aplicable a ti en este momento. Tener una organización seleccionada significa que los nuevos proyectos se asociarán a esa organización por defecto, lo que permite una gestión centralizada de los proyectos. A efectos de estas instrucciones, suponemos que estás configurando tu cuenta por primera vez y que no hay ninguna organización preexistente vinculada a ella.
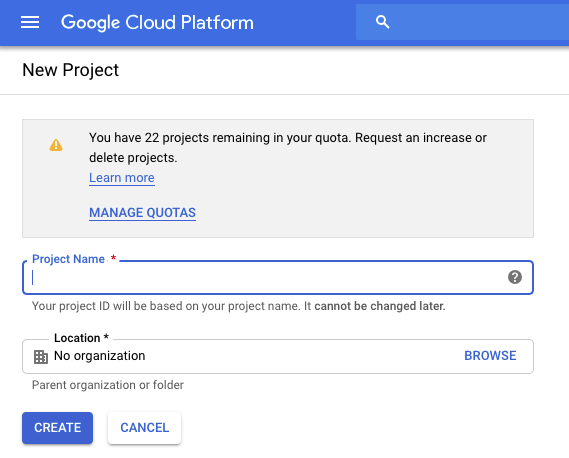
Figura 4-1. Crear un nuevo proyecto.
Comprobar tu cuenta de facturación y activar créditos gratuitos
Si has seguido el proceso de registro descrito en la sección anterior y has activado tu prueba gratuita, el sistema habrá configurado la información de facturación para ti como parte del proceso general de creación de la cuenta. Puedes consultar tu información de facturación en la sección Facturación de la consola, a la que también puedes acceder en cualquier momento desde el menú de la barra lateral.
Si puedes acogerte al programa de créditos gratuitos, uno de los paneles de la página de resumen de facturación resumirá el número de créditos y los días que te quedan para gastarlos. Ten en cuenta que si en el tuyo aparece un botón azul de Actualizar, como se muestra en la Figura 4-2, tu prueba aún no ha comenzado y necesitas activarla para poder beneficiarte del programa. También es posible que veas un banner "Estado de la prueba gratuita" en la parte superior de la ventana de tu navegador con un botón azul Activar. Alguien en GCP está trabajando muy duro para no dejarte escapar dinero gratis, así que haz clic en cualquiera de esos botones para iniciar el proceso y recibir tus créditos gratuitos.
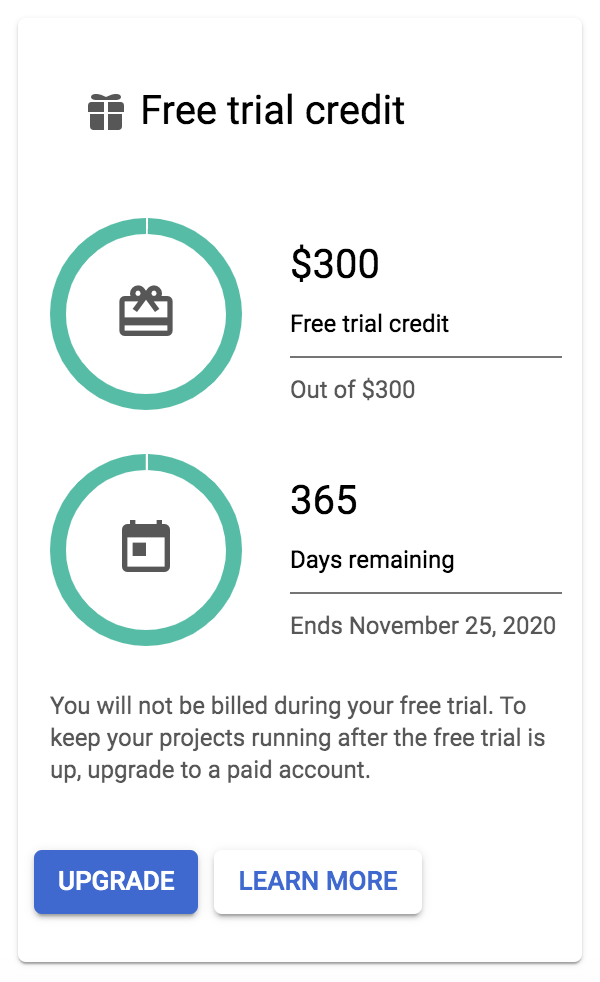
Figura 4-2. El panel de la consola de Facturación que resume la disponibilidad de créditos de prueba gratuitos.
En términos más generales, la página de resumen de facturación proporciona resúmenes de cuánto dinero (o créditos) has gastado hasta el momento, así como algunas previsiones básicas. Dicho esto, es importante que entiendas que el sistema no te muestra los costes en tiempo real: hay cierto desfase entre los momentos en que utilizas recursos facturables y cuando los costes se actualizan en tu página de facturación.
Muchas personas que se pasan a la nube afirman que controlar sus gastos es una de las partes más difíciles del proceso. También es la que les causa más ansiedad, porque puede ser muy fácil gastar grandes sumas de dinero muy rápidamente en la nube si no tienes cuidado. Una función que ofrece GCP que nos parece especialmente útil a este respecto es la configuración de "Presupuestos y alertas", como se muestra en la Figura 4-3. Esto te permite establecer alertas por correo electrónico que te notificarán a ti (o a quien sea el administrador de facturación de tu cuenta) cuando superes determinados umbrales de gasto. Para que quede claro, esto no impedirá que se ejecute nada ni que empieces un nuevo trabajo que te haría superar el umbral, pero al menos te permitirá saber a qué atenerte.
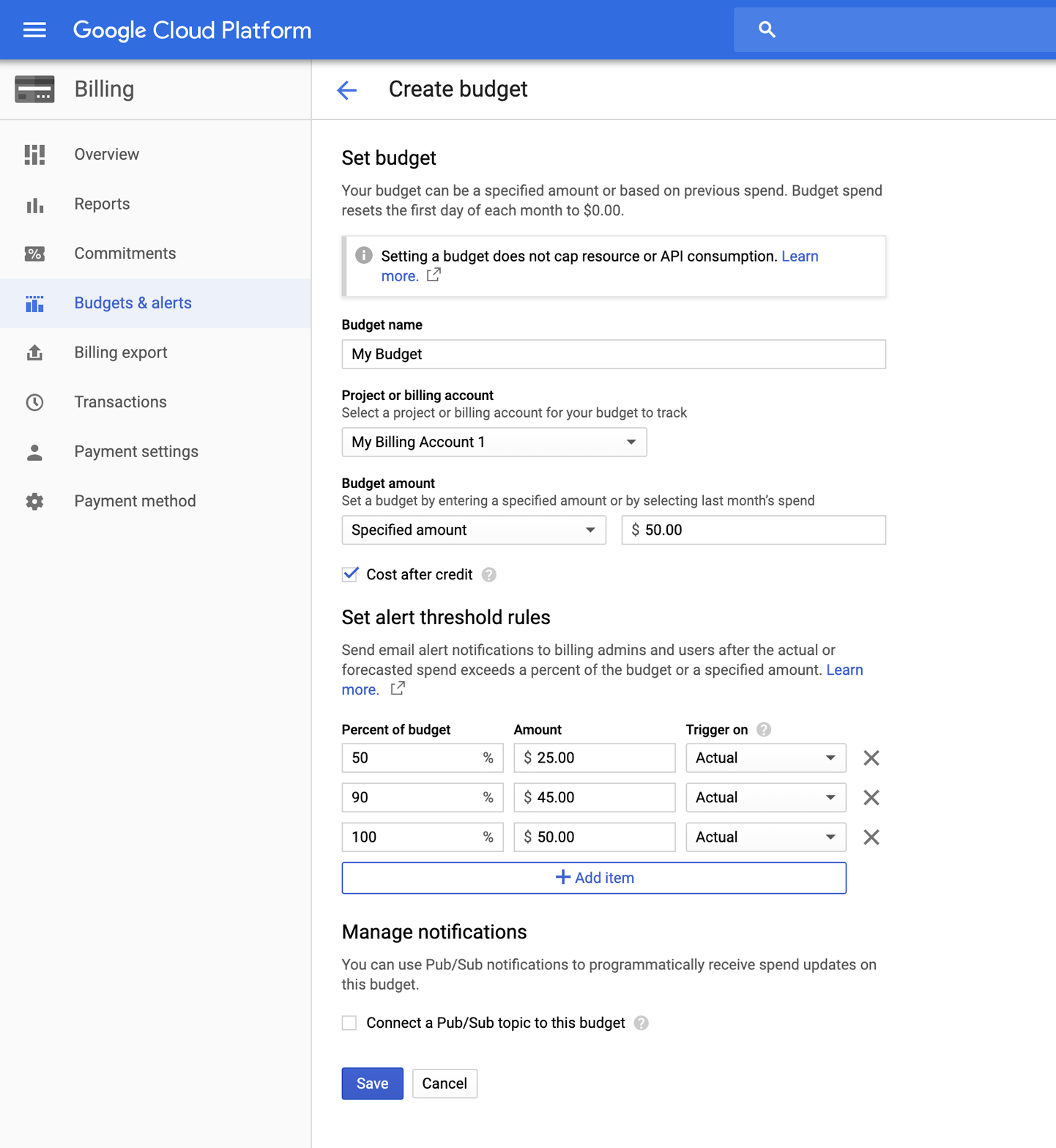
Figura 4-3. Administración de presupuestos y umbrales de alerta.
Para acceder a la función de notificaciones de facturación, en el menú principal de la consola de GCP, elige Facturación, selecciona la cuenta de facturación que acabas de crear y busca la opción Presupuestos y alertas. Después de seleccionarla, podrás configurar un nuevo presupuesto utilizando el formulario Crear presupuesto que se muestra en la Figura 4-3. Puedes crear varios presupuestos y establecer varios desencadenantes para distintos porcentajes del presupuesto, si quieres recibir avisos a medida que te acercas a la cantidad presupuestada. Pero como acabamos de mencionar, ten en cuenta que sigue siendo sólo un servicio de notificación y no evitará que incurras en cargos adicionales.
Ejecutar comandos básicos en Google Cloud Shell
Ahora que has establecido tu cuenta, configurado la facturación y creado tu proyecto, el siguiente paso es iniciar sesión en tu primera máquina virtual. Para nuestros ejercicios aquí, utilizamos Google Cloud Shell, que no requiere ninguna configuración para empezar y es completamente gratuito, aunque viene con algunas limitaciones importantes que discutiremos en un momento.
Iniciar sesión en la VM de Cloud Shell
Para crear una conexión segura a una Cloud Shell VM utilizando el protocolo SSH, en la esquina superior derecha de la consola, haz clic en el icono del terminal:

Esto lanza un nuevo panel en la parte inferior de la consola; si quieres, también puedes sacar el terminal a su propia ventana. Esto te da acceso shell a tu propia máquina virtual Linux basada en Debian y dotada de recursos modestos, incluidos 5 GB de almacenamiento libre (montado en $HOME) en un disco persistente. Algunos paquetes básicos están preinstalados y listos para funcionar, incluido el SDK de Google Cloud (también conocido como gcloud), que proporciona un rico conjunto de herramientas basadas en la línea de comandos para interactuar con los servicios de GCP. Lo utilizaremos en unos minutos para probar algunos comandos básicos de gestión de datos. Mientras tanto, siéntete libre de explorar esta máquina virtual Debian, echar un vistazo y ver qué herramientas hay instaladas.
Nota
Ten en cuenta que las cuotas de uso semanales limitan el tiempo que puedes dedicar a ejecutar el Shell Nube; en el momento de escribir esto, es de 50 horas semanales. Además, si no lo utilizas con regularidad (en un plazo de 120 días, a partir de este escrito), el contenido del disco que te proporciona almacenamiento gratuito podría acabar borrándose.
Cuando te conectas a Cloud Shell por primera vez, te pide que especifiques un ID de proyecto utilizando la utilidad antes mencionada gcloud:
Welcome to Cloud Shell! Type "help" to get started. To set your Cloud Platform project in this session use “gcloud config set project [PROJECT_ID]”
Puedes encontrar tu ID de Proyecto en la página de Inicio de la consola, como se muestra en la Figura 4-4.
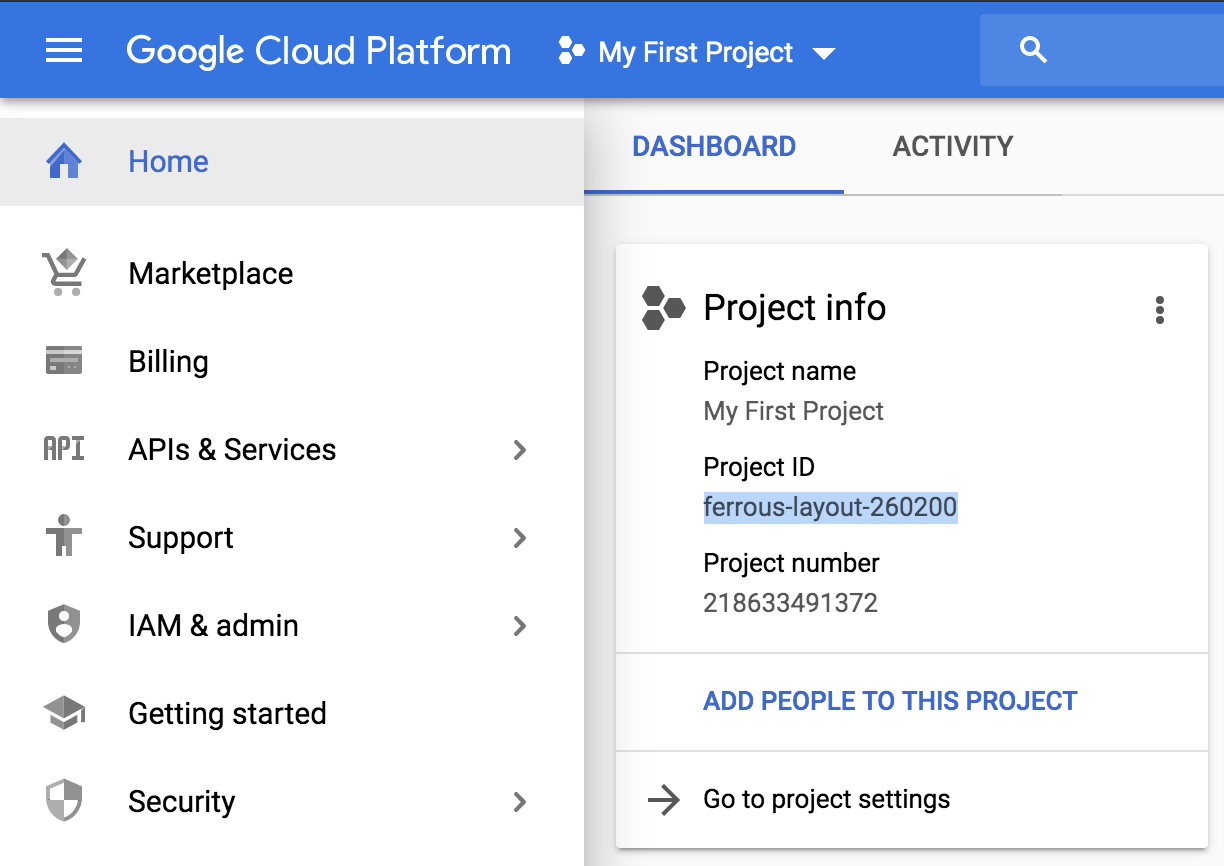
Figura 4-4. Localización del ID del Proyecto en la consola de GCP.
Cuando tengas tu ID de proyecto, ejecuta el siguiente comando en la Shell de la Nube, sustituyendo el ID de proyecto por el que se muestra aquí:
genomics_book@cloudshell:~$ gcloud config set project ferrous-layout-260200 Updated property [core/project]. genomics_book@cloudshell:~ (ferrous-layout-260200)$
Observa que tu símbolo del sistema incluye ahora el ID de tu Proyecto. Es bastante largo, así que, en adelante, mostrará sólo el último carácter del símbolo del sistema -en este caso, el símbolo del dólar ($)- cuando demostremos la ejecución de comandos. Por ejemplo, si listamos el contenido del directorio de trabajo utilizando el comando ls, tendrá este aspecto:
$ ls README-cloudshell.txt
Y, oye, aquí ya hay algo: un archivo README, que, como su nombre indica, realmente quiere que lo leas. Puedes hacerlo ejecutando el comando cat:
$ cat README-cloudshell.txt
Esto muestra un mensaje de bienvenida que resume algunas instrucciones de uso y recomendaciones para obtener ayuda. Y con eso, ya estás listo para utilizar Cloud Shell para empezar a interactuar con los servicios básicos de GCP. ¡Manos a la obra!
Utilizar gsutil para acceder y gestionar archivos
Ahora que tenemos acceso a esta máquina virtual gratuita (aunque bastante limitada) y extremadamente fácil de poner en marcha, vamos a utilizarla para ver si podemos acceder al paquete de datos de ejemplo que se proporciona con este libro. El paquete de datos reside en Google Cloud Storage (GCS), que es una forma de almacén de objetos (es decir, se utiliza para almacenar archivos) con unidades de almacenamiento llamadas buckets. Puedes ver el contenido de los buckets de GCS y realizar tareas básicas de gestión en ellos a través de la web mediante la sección del navegador de almacenamiento de la consola de GCP, pero la interfaz es bastante limitada. El enfoque más potente es utilizar la herramienta gcloud, gsutil (Google Storage Utilities), desde la línea de comandos. Puedes acceder a los buckets a través de su ruta GCS, que no es más que su nombre prefijado con gs://.
Como ejemplo, la ruta del bucket de almacenamiento público de este libro es gs://genomics-in-the-cloud. Puedes listar el contenido del bucket escribiendo el siguiente comando en tu shell de la nube:
$ gsutil ls gs://genomics-in-the-cloud gs://genomics-in-the-cloud/hello.txt gs://genomics-in-the-cloud/v1/
Debería haber un archivo llamado hola.txt. Vamos a utilizar la versión gsutil del comando Unix cat, que nos permite leer el contenido de archivos de texto para ver qué contiene este archivo hola.txt:
$ gsutil cat gs://genomics-in-the-cloud/hello.txt HELLO, DEAR READER!
También puedes intentar copiando el archivo en tu disco de almacenamiento:
$ gsutil cp gs://genomics-in-the-cloud/hello.txt . Copying gs://genomics-in-the-cloud/hello.txt... / [1 files][ 20.0 B/ 20.0 B] Operation completed over 1 objects/20.0 B.
Si vuelve a listar el contenido de tu directorio de trabajo utilizando ls, ahora deberías tener una copia local del archivo hola.txt:
$ ls hello.txt README-cloudshell.txt
Mientras estamos jugando con gsutil, ¿qué tal si hacemos algo que será útil más adelante: crear un cubo de almacenamiento propio, para que puedas almacenar salidas en GCS. Tendrás que sustituir my-bucket en el comando que se muestra aquí porque los nombres de los cubos deben ser únicos en todo GCS:
$ gsutil mb gs://my-bucket
Si no has cambiado el nombre del cubo o has probado con un nombre que ya estaba ocupado por otra persona, es posible que aparezca el siguiente mensaje de error:
Creating gs://my-bucket/... ServiceException: 409 Bucket my-bucket already exists.
Si es así, prueba con otra cosa que tenga más probabilidades de ser única. Sabrás que ha funcionado cuando veas el símbolo Creating name... en la salida y vuelvas al prompt sin más quejas de gsutil. Cuando lo hayas hecho, vas a crear una variable de entorno que servirá de alias para el nombre de tu cubo. De ese modo, te ahorrarás teclear y podrás copiar y pegar comandos posteriores sin tener que sustituir cada vez el nombre del cubo:
$ export BUCKET="gs://my-bucket"
Puedes ejecutar el comando echo en tu nueva variable para verificar que el nombre de tu cubo se ha almacenado correctamente:
$ echo $BUCKET gs://my-bucket
Ahora, vamos a ponerte cómodo con el uso de gsutil. Primero, copia el archivo hola.txt a tu nuevo cubo. Puedes hacerlo directamente desde el cubo original:
$ gsutil cp gs://genomics-in-the-cloud/hello.txt $BUCKET/
O puedes hacerlo desde tu copia local; por ejemplo, si has hecho modificaciones que quieres guardar:
$ gsutil cp hello.txt $BUCKET/
Por último, como un ejemplo más de gestión básica de archivos, puedes decidir que el archivo resida en su propio directorio en tu cubo:
$ gsutil cp $BUCKET/hello.txt $BUCKET/my-directory/
Como puedes ver, los comandos gsutil están configurados para que sean lo más parecidos posible a sus homólogos originales de Unix. Así, por ejemplo, también podrás utilizar -r para que los comandos cp y mv sean recursivos y se apliquen a los directorios. Para transferencias de archivos grandes, puedes utilizar algunas optimizaciones específicas de la nube para acelerar el proceso, como la opción gsutil -m, que paraleliza las transferencias de archivos. Convenientemente, el sistema suele informarte en la salida del terminal de cuándo puedes aprovechar esas optimizaciones, por lo que no necesitas ir a memorizar la documentación antes de ponerte en marcha.

Figura 4-5. Navegador de almacenamiento de la consola de GCP.
Esto abre un formulario de configuración razonablemente sencillo. Lo más importante aquí es elegir un buen nombre, porque el nombre que elijas debe ser único en todo Google Cloud, ¡así que sé creativo! Si eliges un nombre que ya está en uso, el sistema te lo hará saber cuando hagas clic en Continuar en el formulario de configuración, como se muestra en la Figura 4-6.
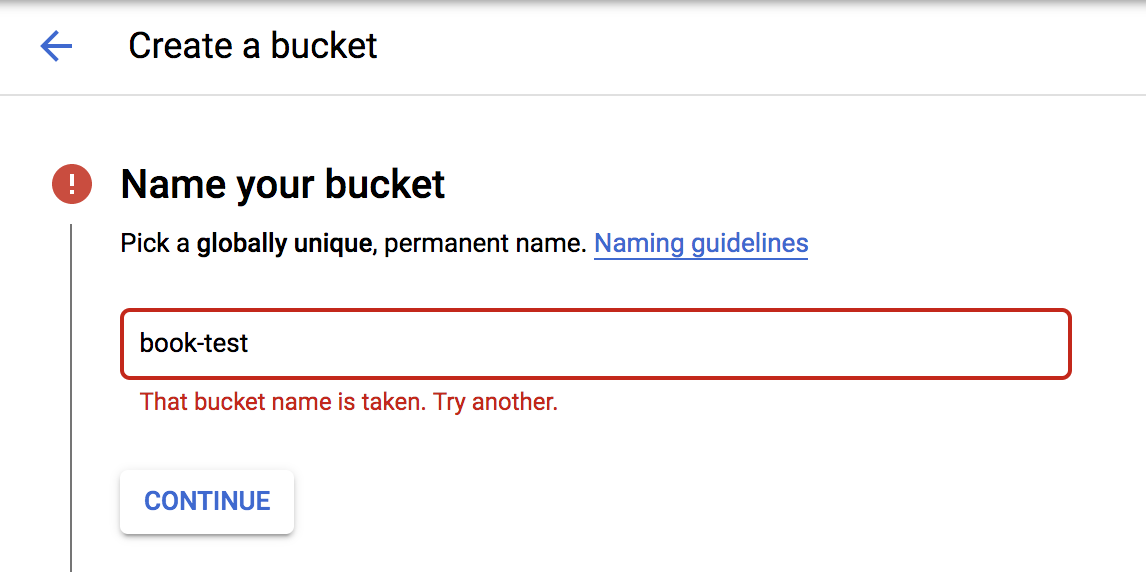
Figura 4-6. Poner nombre a tu cubo.
Cuando tengas un nombre único, el sistema te permitirá pasar al siguiente paso ampliando las opciones del menú. Éstas te permiten personalizar la ubicación de almacenamiento y los controles de acceso de tu cubo, pero por el momento, no dudes en aceptar los valores predeterminados y hacer clic en Crear. Al hacerlo, volverás a la lista de cubos, que en este momento debería incluir el que acabas de crear. Puedes hacer clic en su nombre para ver su contenido, pero por supuesto aún está vacío, así que la vista no será especialmente interesante, como se muestra en la Figura 4-7.
La interfaz ofrece algunas opciones básicas de gestión, como borrar cubos y archivos, así como subir archivos y carpetas. Ten en cuenta que incluso puedes arrastrar y soltar archivos y carpetas desde tu máquina local a la ventana de contenido del cubo, lo cual es asombrosamente fácil (adelante, pruébalo), pero no es algo que puedas esperar hacer muy a menudo en el curso de tu trabajo genómico. En el mundo real, es más probable que utilices la utilidad de línea de comandos gsutil. Una de las ventajas de utilizar la ruta de la línea de comandos es que puedes guardar esos comandos como un script, por su procedencia y para poder reproducir tus pasos si es necesario.
Figura 4-7. Ver el contenido de tu cubo.
Extraer una imagen Docker y poner en marcha el contenedor
Cloud Shell es el regalo que sigue dando: la aplicación Docker (que presentamos en el Capítulo 3) viene preinstalada, ¡así que también puedes empezar con ella! Vamos a utilizar un simple contenedor Ubuntu para ilustrar la funcionalidad básica de Docker. Aunque existe una imagen Docker para GATK -y es la que vamos a utilizar durante buena parte de los próximos capítulos-, no vamos a utilizarla aquí porque es bastante grande, por lo que tarda un poco en ponerse en marcha. En realidad, no podríamos ejecutar ningún análisis realista con él en la Shell gratuita de la Nube debido a la pequeña cantidad de recursos de CPU y memoria asignados a esta VM gratuita.
Nota
Lo primero que hay que hacer para aprender a utilizar los contenedores Docker en este contexto es... bueno, ¡evitar la documentación online de Docker! En serio. No porque sea mala, sino porque la mayoría de esos documentos están escritos principalmente para personas que quieren ejecutar aplicaciones web en la nube. Si eso es lo que quieres hacer, mejor para ti, pero estás leyendo el libro equivocado. Lo que te ofrecemos aquí son instrucciones a medida que te enseñarán a utilizar Docker para ejecutar software de investigación en contenedores.
Como acabamos de señalar, vamos a utilizar un ejemplo muy genérico: una imagen que contiene el SO Linux Ubuntu. Es una imagen oficial que se proporciona como parte de la biblioteca central en un repositorio público de imágenes de contenedores, Docker Hub, así que sólo tenemos que indicar su nombre. Verás más adelante que las imágenes aportadas por la comunidad llevan como prefijo el nombre de usuario del contribuidor o el nombre de la organización. Estando aún en tu terminal Cloud Shell (no importa dónde esté tu directorio de trabajo), ejecuta el siguiente comando para recuperar la imagen de Ubuntu de la biblioteca de imágenes oficiales (certificadas) de Docker Hub:
$ docker pull ubuntu Using default tag: latest latest: Pulling from library/ubuntu 7413c47ba209: Pull complete 0fe7e7cbb2e8: Pull complete 1d425c982345: Pull complete 344da5c95cec: Pull complete Digest: sha256:d91842ef309155b85a9e5c59566719308fab816b40d376809c39cf1cf4de3c6a Status: Downloaded newer image for ubuntu:latest docker.io/library/ubuntu:latest
El comando pull obtiene la imagen y la guarda en tu máquina virtual. La versión de la imagen contenedora viene indicada por su tag (que puede ser cualquier cosa que el creador de la imagen quiera asignarle) y por su hash sha256 (que se basa en el contenido de la imagen). Por defecto, el sistema nos da la última versión disponible porque no especificamos una etiqueta concreta; en un ejercicio posterior, verás cómo solicitar una versión concreta por su etiqueta. Ten en cuenta que las imágenes contenedoras suelen estar compuestas por varias rebanadas modulares, que se extraen por separado. Están organizadas de forma que la próxima vez que extraigas una versión de la imagen, el sistema omitirá la descarga de las partes que no hayan cambiado con respecto a la versión que ya tienes.
Ahora vamos a poner en marcha el contenedor. Hay tres opciones principales para ponerlo en marcha, pero lo complicado es que normalmente sólo hay una forma correcta de hacerlo, tal y como pretendía su autor, y es difícil saber cuál es si la documentación no lo especifica (lo que ocurre taaaan a menudo). ¿Estás confundido? Repasemos los casos para concretar un poco más, y verás por qué te hacemos pasar por esta frustración y misterio momentáneos: es para ahorrarte posibles desgracias en el futuro.
- Primera opción
-
$ docker run ubuntu
- Resultado
-
Una breve pausa y luego vuelve el símbolo del sistema. No hay salida. ¿Qué ha ocurrido? De hecho, Docker puso en marcha el contenedor, pero éste no estaba configurado para hacer nada en esas condiciones, así que básicamente se encogió de hombros y volvió a apagarse.
- Segunda opción
-
Ejecútalo con un comando adjunto:
$ docker run ubuntu echo "Hello World!" Hello World!
- Resultado
-
Se hizo eco de
Hello World!, como se pedía, y luego se volvió a apagar. Vale, ahora sabemos que podemos pasar órdenes al contenedor, y si es una orden reconocida por algo de lo que hay dentro, se ejecutará. Luego, cuando se hayan completado todas y cada una de las órdenes, el contenedor se apagará. Un poco perezoso, pero razonable. - Tercera opción
-
Ejecútalo interactivamente utilizando la opción
-it:$ docker run -it ubuntu /bin/bash root@d84c079d0623:/#
- Resultado
-
¡Ajá! ¡Un nuevo símbolo del sistema (Bash en este caso)! Pero con un símbolo de shell diferente:
#en lugar de$. Esto significa que el contenedor se está ejecutando y que tú estás en él. Ahora puedes ejecutar cualquier comando que utilizarías normalmente en un sistema Ubuntu, incluso instalar nuevos paquetes si quieres. Prueba a ejecutar algunos comandos Unix comolsols -lapara curiosear y ver qué puede hacer el contenedor. Más adelante en el libro, en concreto en el Capítulo 12, tratamos algunas de las implicaciones de esto, incluyendo instrucciones prácticas sobre cómo empaquetar y redistribuir una imagen que hayas personalizado para compartir tu propio análisis de forma reproducible.
Cuando hayas terminado de husmear, escribe exit en el símbolo del sistema (o pulsa Ctrl+D) para terminar el shell. Dado que éste es el proceso principal que estaba ejecutando el contenedor, al terminarlo se cerrará el contenedor y volverá al propio Shell Nube. Para que quede claro, esto cerrará el contenedor y todos los comandos que se estén ejecutando en ese momento.
Si tienes curiosidad: sí, es posible salir del contenedor sin apagarlo; a esto se le llama desacoplarse. Para ello, pulsa Ctrl+P+Q en lugar de utilizar el comando exit. Entonces podrás volver al contenedor en cualquier momento, siempre que puedas identificarlo. Por defecto, Docker asigna a tu contenedor un identificador único universal (UUID), así como un nombre aleatorio legible por humanos (que suelen sonar un poco tontos). Puedes ejecutar docker ps para listar los contenedores que se están ejecutando actualmente o docker ps -a para listar los contenedores que se han creado. Esto muestra una lista de contenedores indexados por sus ID de contenedor que debería tener este aspecto:
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c2b4f8a0c7a6 ubuntu "/bin/bash" 5 minutes ago Up 5 minutes vigorous_rosalind 9336068da866 ubuntu "echo ’Hello World!’" 8 minutes ago Exited (0) 8 minutes ago objective_curie
Estamos mostrando que dos entradas corresponden a las dos últimas invocaciones de Docker, cada una con un identificador único, el CONTAINER ID. Vemos que el contenedor con ID c2b4f8a0c7a6 que se está ejecutando actualmente se llamaba vigorous_rosalind y tiene el estado Up 5 minutes. Puedes saber que el otro contenedor, objective_curie, no se está ejecutando porque su estado es Exited (0) 8 minutes ago. Los nombres que vemos aquí se asignaron al azar (¡Lo juramos! ¿Qué probabilidades hay?), así que hay que admitir que no son terriblemente significativos. Si tienes varios contenedores ejecutándose al mismo tiempo, esto puede resultar un poco confuso, por lo que querrás una forma mejor de identificarlos. La buena noticia es que puedes darles un nombre significativo añadiendo --name=meaningful_name inmediatamente después de docker run en tu comando inicial, sustituyendo meaningful_name por el nombre que quieras darle al contenedor.
Para entrar en el contenedor, simplemente ejecuta docker attach c2b4f8a0c7a6 (sustituyendo el ID de tu contenedor), pulsa Intro, y te encontrarás de nuevo al mando (puede que en tu teclado aparezca Retorno en lugar de Intro). Puedes abrir una segunda pestaña de comandos en Cloud Shell si quieres poder ejecutar comandos fuera del contenedor junto con el trabajo que estás haciendo dentro del contenedor. Ten en cuenta que puedes tener varios contenedores ejecutándose al mismo tiempo en una única VM -esa es una de las grandes ventajas del sistema de contenedores-, pero competirán por los recursos de CPU y memoria de la VM, que en Cloud Shell son más bien mínimos. Más adelante en este capítulo, te mostraremos cómo hacer girar las máquinas virtuales con capacidades más potentes.
Montar un Volumen para Acceder al Sistema de Archivos desde el Contenedor
Una vez completado el ejercicio anterior, ya eres capaz de recuperar y ejecutar una instancia de cualquier imagen de contenedor compartida en un repositorio público. Muchas herramientas bioinformáticas de uso común, incluido GATK, están disponibles preinstaladas en contenedores Docker. La idea es que, si sabes utilizarlas desde un contenedor Docker, no tendrás que preocuparte de tener el sistema operativo o el entorno de software correctos. Sin embargo, todavía hay un truco que tenemos que enseñarte para que eso te funcione de verdad: cómo acceder al sistema de archivos de tu máquina desde dentro del contenedor montando un volumen.
¿Qué significa esto último? Por defecto, cuando estás dentro del contenedor, no puedes acceder a ningún dato que resida en el sistema de archivos fuera del contenedor. El contenedor es una caja cerrada. Hay formas de copiar cosas de un lado a otro entre el contenedor y tu sistema de archivos, pero eso se vuelve tedioso muy rápidamente. Así que vamos a seguir el camino más fácil, que es establecer un enlace entre un directorio fuera del contenedor de forma que parezca que está dentro del contenedor. En otras palabras, vamos a hacer un agujero en la pared del contenedor, como se muestra en la Figura 4-8.
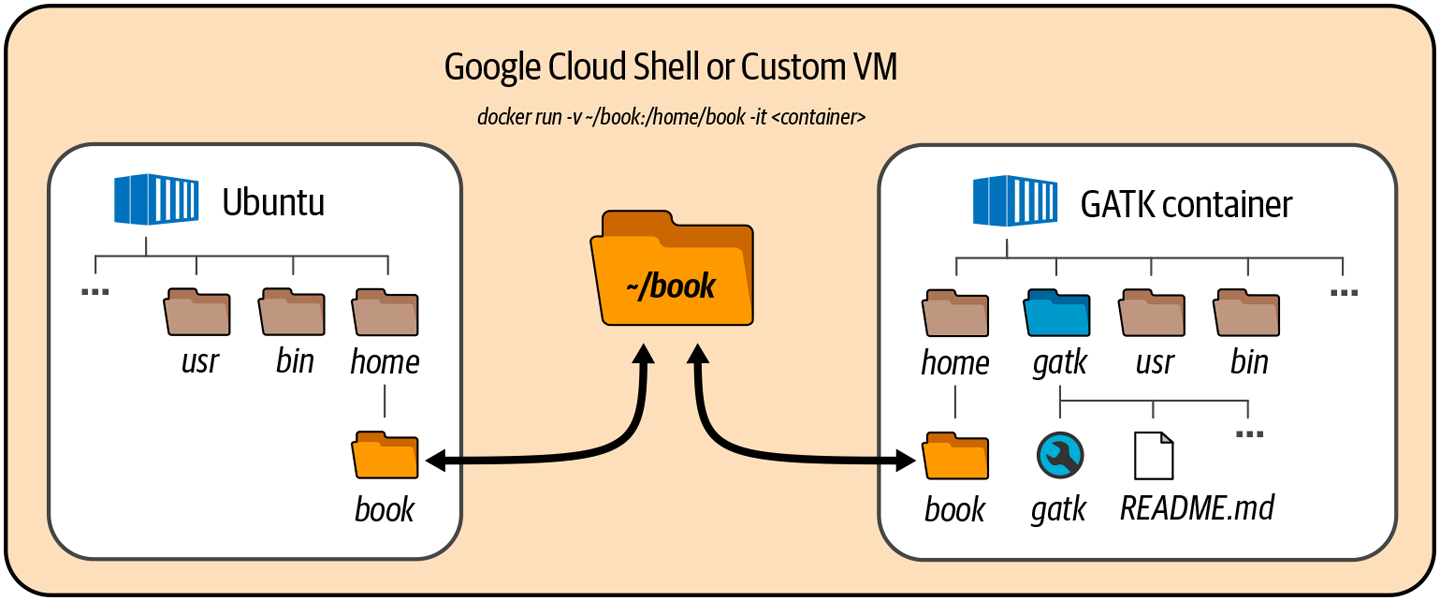
Figura 4-8. Montar un directorio desde tu máquina virtual Google Cloud Shell en un contenedor Docker : Contenedor Ubuntu utilizado en este capítulo (izquierda); contenedor GATK introducido en el Capítulo 5 (derecha).
A modo de ejemplo, vamos a crear un nuevo directorio llamado libro en el directorio principal de nuestra máquina virtual Cloud Shell, y a colocar en él el archivo hola.txt de antes:
$ mkdir book $ mv hello.txt book/ $ ls book hello.txt
Así que esta vez, vamos a ejecutar el comando para poner en marcha nuestro contenedor de Ubuntu utilizando el argumento -v (donde v es para volumen), que nos permite especificar una ubicación del sistema de archivos y un punto de montaje dentro del contenedor:
$ docker run -v ~/book:/home/book -it ubuntu /bin/bash
La parte -v ~/book_data:/home/book del comando vincula la ubicación que has especificado a la ruta /home/libro directorio dentro del contenedor Docker. La parte /home de la ruta es un directorio que ya existe en el contenedor, mientras que la parte book puede ser cualquier nombre que decidas darle. Ahora podrás acceder a todo lo que haya en el directorio book de tu sistema de archivos desde el directorio /home/book del contenedor Docker:
# ls home/book hello.txt
Aquí, estamos utilizando el mismo nombre para el punto de montaje que para la ubicación real que estamos montando porque así es más intuitivo, pero podrías utilizar un nombre diferente si quisieras. Ten en cuenta que si das a tu punto de montaje el nombre de un directorio o archivo que ya existe con esa ruta en el contenedor, se "aplastará" la ruta existente, lo que significa que no se podrá acceder a esa ruta mientras el volumen esté montado.
Conviene conocer algunos otros trucos de Docker, pero por ahora, esto es suficiente como demostración de la funcionalidad básica de Docker que vas a utilizar en el Capítulo 5. Entraremos en los detalles de opciones más sofisticadas a medida que las encontremos.
Configurar tu propia máquina virtual personalizada
Ahora que has ejecutado con éxito algunos comandos básicos de gestión de archivos y has aprendido a interactuar con contenedores Docker, es hora de pasar a cosas más grandes y mejores. El entorno Google Cloud Shell es excelente para empezar rápidamente con algunas tareas ligeras de codificación y ejecución, pero la máquina virtual asignada a Cloud Shell es realmente poco potente y definitivamente no dará la talla cuando se trate de ejecutar análisis reales de GATK en el Capítulo 5.
En esta sección, te mostramos cómo configurar tu propia máquina virtual en la nube (a veces llamada instancia) utilizando el servicio Compute Engine de Google, que te permite seleccionar, configurar y ejecutar máquinas virtuales del tamaño que necesites.
Crear y configurar tu instancia de máquina virtual
Primero, ve al Motor de Cálculo o accede a la página a través del menú de la barra lateral de la izquierda, como se muestra en la Figura 4-9.
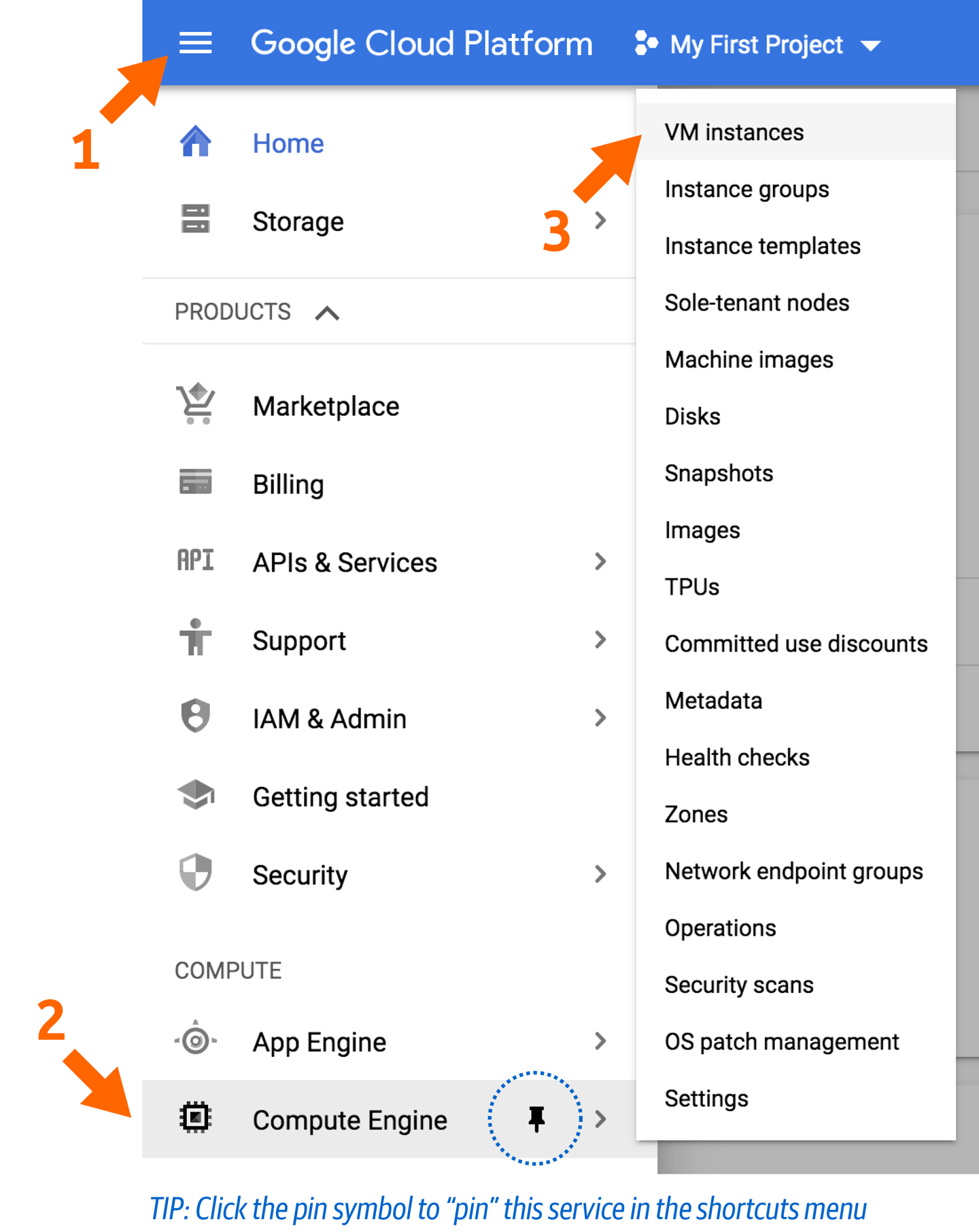
Figura 4-9. Menú Motor de Computación mostrando el elemento de menú Instancias VM.
Haz clic en el enlace Instancias VM de este menú para ir a una vista general de las imágenes en ejecución. Si se trata de una cuenta nueva, no tendrás ninguna en ejecución. Observa que en la parte superior hay una opción para Crear Instancia. Haz clic en ella y vamos a recorrer el proceso de creación de una nueva máquina virtual sólo con los recursos que necesitas.
A continuación, en la barra de menú superior, haz clic en Crear Instancia, como se muestra en la Figura 4-10. Aparecerá un formulario de configuración, como se muestra en la Figura 4-11.

Figura 4-10. Crear una instancia VM.
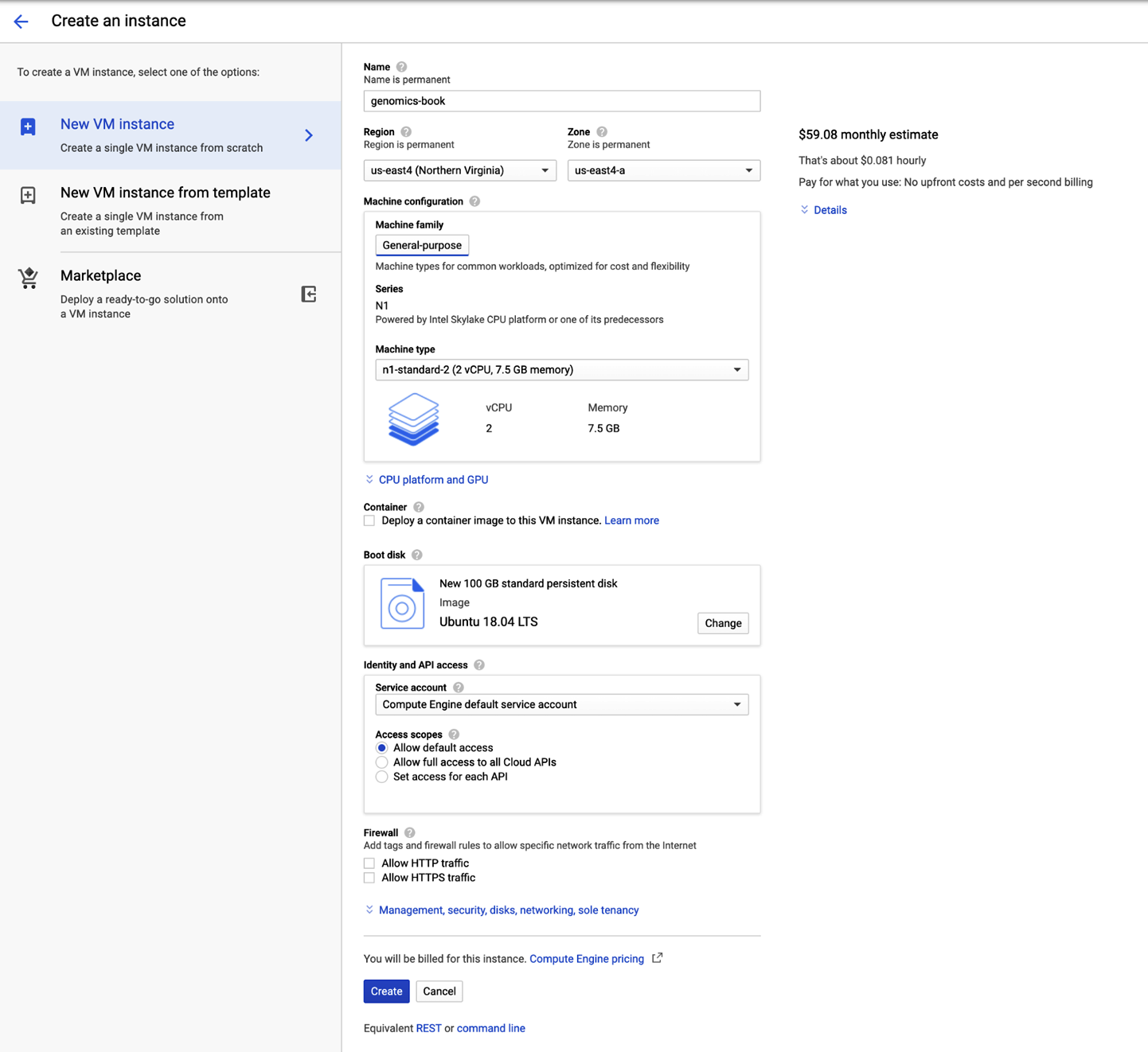
Figura 4-11. Panel de configuración de la instancia VM.
Sigue las instrucciones paso a paso de las subsecciones siguientes para configurar la máquina virtual. Hay montones de opciones y el proceso puede ser bastante confuso si no tienes experiencia con la terminología, así que hemos trazado el camino más sencillo a través del formulario de configuración que te permitirá ejecutar todos los ejercicios de comandos de los primeros capítulos de este libro. Asegúrate de que utilizas exactamente la misma configuración que se muestra aquí, a menos que sepas realmente lo que estás haciendo.
Pon un nombre a tu VM
Dale un nombre a tu máquina virtual; por ejemplo, genomics-book, como se muestra en la Figura 4-12. Éste debe ser único dentro de tu proyecto, pero a diferencia de los nombres de bucket, no necesita ser único en todo GCP. A algunas personas les gusta utilizar su nombre de usuario para que otras personas con acceso al proyecto puedan identificar al instante quién creó el recurso.

Figura 4-12. Pon un nombre a tu instancia de máquina virtual.
Elige una región (¡importante!) y una zona (no tan importante)
Existen diferentes ubicaciones físicas para la nube. Como la mayoría de los proveedores de nubes comerciales, GCP mantiene centros de datos en muchas partes del mundo y te ofrece la opción de elegir cuál quieres utilizar. Las regiones son la distinción geográfica de más alto nivel, con nombres razonablemente descriptivos (como us-west2, que se refiere a una instalación en Los Ángeles). Cada región se divide a su vez en dos o más zonas designadas por letras simples (a, b, c, etc.), que corresponden a centros de datos separados con su propia infraestructura física (energía, red, etc.), aunque en algunos casos pueden compartir el mismo edificio.
Este sistema de regiones y zonas desempeña un papel importante a la hora de limitar el impacto de problemas localizados como los cortes de electricidad, y todos los principales proveedores de la nube utilizan alguna versión de esta estrategia. Para saber más sobre este tema, consulta esta entretenida entrada de blog de Kyle Galbraith sobre cómo las regiones y zonas de la nube (en su caso, en AWS) podrían desempeñar un papel importante en caso de apocalipsis zombi.
Nota
La posibilidad de elegir regiones y zonas específicas para tus proyectos es cada vez más útil para hacer frente a las restricciones normativas sobre dónde pueden almacenarse los datos de sujetos humanos, ya que te permite especificar una ubicación conforme para todos los recursos de almacenamiento y computación. Sin embargo, algunas partes del mundo aún no están bien cubiertas por los servicios en la nube o los distintos proveedores de la nube las cubren de forma diferente, por lo que puede que tengas que tener en cuenta las ubicaciones de los centros de datos disponibles a la hora de elegir un proveedor.
Para elegir una región para tu proyecto, puedes consultar la lista completa de regiones y zonas disponibles de Google Cloud y tomar una decisión basada en la proximidad geográfica. Como alternativa, puedes utilizar una utilidad en línea que mida lo cerca que estás efectivamente de cada centro de datos en términos de tiempo de respuesta de red, como http://www.gcping.com. Por ejemplo, si ejecutamos esta prueba desde la pequeña ciudad de Sunderland, al oeste de Massachusetts (resultados en la Tabla 4-1), comprobamos que se tarda 38 milisegundos en obtener una respuesta de la región us-east4 situada en el norte de Virginia (a 698 km), frente a los 41 milisegundos de la región northamerica-northeast1 situada en Montreal (a 441 km). Esto nos demuestra que la proximidad geográfica no se correlaciona directamente con la proximidad de la región de red. Como ejemplo aún más llamativo, comprobamos que estamos bastante más "cerca" de la región europe-west2 de Londres (a 5.353 km), con un tiempo de respuesta de 102 milisegundos, que de la región us-west2 de Los Ángeles (a 4.697 km), que nos da un tiempo de respuesta de 180 milisegundos.
| Región | Ubicación | Distancia (km) | Respuesta (ms) |
|---|---|---|---|
| us-este4 | Norte de Virginia, EE.UU. | 698 | 38 |
| norteamérica-nordeste1 | Montreal | 441 | 41 |
| europa-oeste2 | Londres | 5,353 | 102 |
| us-oeste2 | Los Angeles | 4,697 | 180 |
Esto nos lleva de nuevo a la configuración de nuestra Máquina Virtual. Para la Región, vamos a utilizar us-east4 (Virginia del Norte) porque es la más cercana a la que menos viaja (Geraldine), y para la Zona elegimos al azar us-east4-a. Debes asegurarte de que eliges tu región basándote en la discusión anterior, tanto por tu propio beneficio (será más rápido) como para evitar que se estropee ese único centro de datos de Virginia en el improbable caso de que los 60.000 usuarios registrados del software GATK empiecen a trabajar en estos ejercicios al mismo tiempo -aunque esa es una forma de poner a prueba la cacareada "elasticidad" de la nube.
Selecciona un tipo de máquina
Aquí es donde puedes configurar los recursos de la máquina virtual que vas a lanzar. Puedes controlar tanto la RAM como la CPU. Para algunos tipos de instancia (disponibles en Personalizar) puedes incluso seleccionar VMs con GPUs, que se utilizan para acelerar determinados programas. El problema es que lo que selecciones aquí determinará cuánto se te facturará por segundo de tiempo de actividad de la máquina virtual; cuanto más grande y potente sea la máquina, más te costará. La parte derecha de la página debería mostrar cómo cambia el coste por hora y por mes cuando cambias el tipo de máquina. Ten en cuenta también que se te factura por el tiempo que la máquina virtual está conectada, no por el tiempo que pasas utilizándola. Más adelante veremos estrategias para limitar los costes, pero tenlo en cuenta.
Aquí, selecciona n1-standard-2; se trata de una máquina bastante básica que no va a costar mucho, como se muestra en la Figura 4-13.
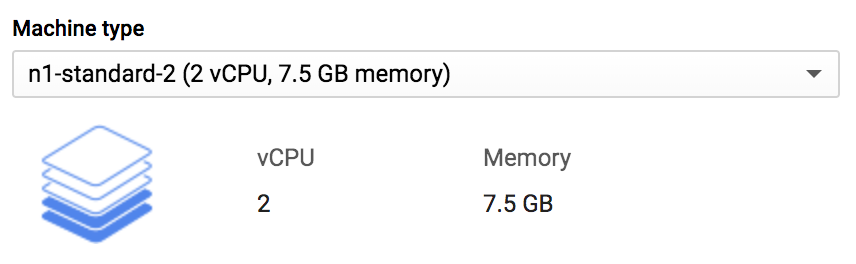
Figura 4-13. Seleccionar un tipo de máquina.
¿Especificar un contenedor? (no)
No vamos a rellenar esto. Esto es útil si quieres utilizar una configuración muy específica utilizando una imagen de contenedor personalizada que hayas preseleccionado o generado tú mismo. De hecho, podríamos haberte preconfigurado un contenedor y saltarnos un montón de la configuración que viene a continuación. Pero entonces no tendrías la oportunidad de aprender a hacer esas cosas por ti mismo, ¿verdad? Así que, por ahora, vamos a saltarnos esta opción.
Personalizar el disco de arranque
Al igual que el Tipo de Máquina, éste es otro ajuste realmente útil. Aquí puedes definir dos cosas: el SO que quieres utilizar y la cantidad de espacio en disco que deseas. Lo primero es especialmente importante si necesitas utilizar un tipo y una versión concretos de SO. Y, por supuesto, lo segundo es importante si no quieres quedarte sin espacio en disco a mitad de tu análisis.
Por defecto, el sistema propone un determinado sabor del SO Linux, acompañado de unos míseros 10 GB de espacio en disco, como se muestra en la Figura 4-14. Vamos a necesitar un barco más grande.
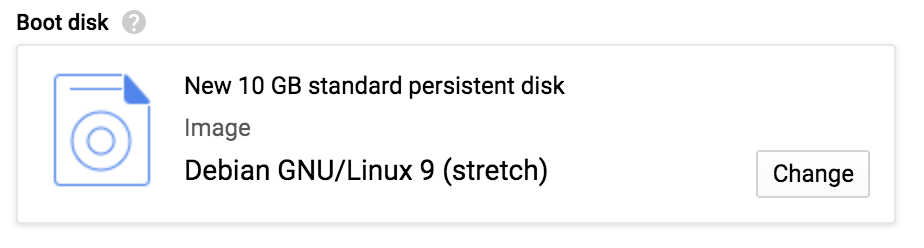
Figura 4-14. Elegir un tamaño y una imagen de disco de arranque.
Para acceder al menú de configuración de esto, haz clic en Cambiar. Esto abre una nueva pantalla con un menú de opciones predefinidas. También puedes crear tus propias imágenes personalizadas, o incluso encontrar más imágenes en Google Cloud Marketplace.
Para nuestros propósitos inmediatos, preferimos Ubuntu 18.04 LTS, que es la versión más reciente del lanzamiento a largo plazo de Ubuntu, en el momento de escribir esto. Puede que no sea tan puntera como Ubuntu 19.04, pero la LTS, que significa soporte a largo plazo, garantiza que se mantendrá en cuanto a vulnerabilidades de seguridad y actualizaciones de paquetes durante cinco años desde su lanzamiento. Esta imagen de Ubuntu tiene un montón de cosas que ya necesitamos, listas para usar e instaladas, incluidas varias herramientas estándar de Linux y las herramientas de línea de comandos del SDK de GCP, de las que dependeremos en gran medida.
Selecciona Ubuntu en el menú Sistema Operativo y, a continuación, selecciona Ubuntu 18.04 LTS en el menú Versión, como se muestra en la Figura 4-15.
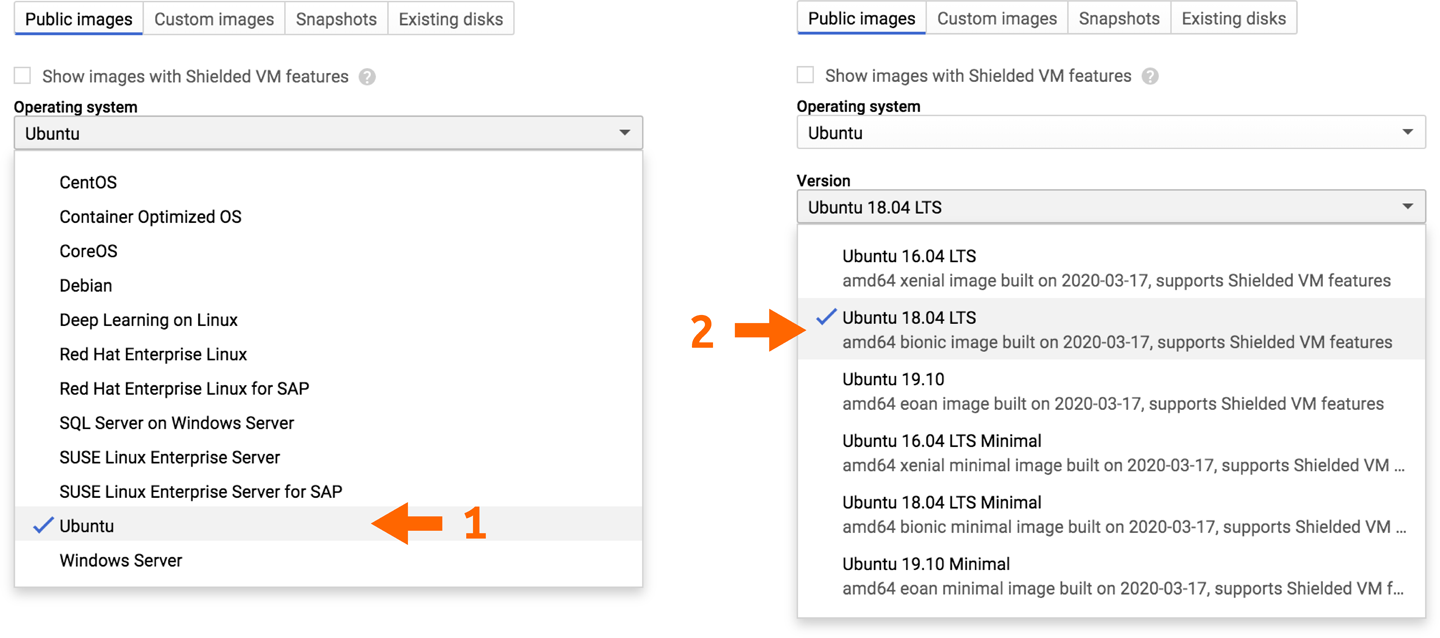
Figura 4-15. Seleccionar una imagen base.
En la parte inferior del formulario, puedes cambiar el Tamaño del disco de arranque para disponer de más espacio. Como se muestra en la Figura 4-16, selecciona 100 GB en lugar de los 10 GB por defecto (los datos con los que vamos a trabajar pueden ocupar fácilmente mucho espacio). Puedes aumentarlo bastante más, según el tamaño y las necesidades de tu conjunto de datos. Aunque no puedes ajustarlo fácilmente después de que se inicie la máquina virtual, tienes la opción de añadir volúmenes de almacenamiento en bloque a la instancia en ejecución después de iniciarla; piensa en ello como el equivalente en la nube de conectar una unidad USB. Así, si te quedas sin espacio en disco, no estarás totalmente atascado.
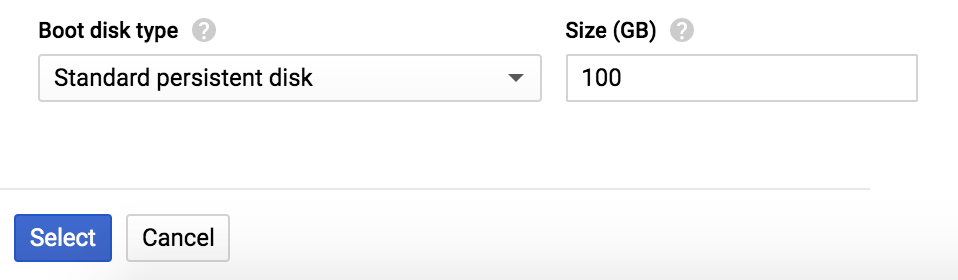
Figura 4-16. Configurar el tamaño del disco de arranque.
Cuando hayas hecho todo esto, pulsa Seleccionar; se cerrará la pantalla y volverás al formulario de creación de instancias, donde la sección "Disco de arranque" debería coincidir con la captura de pantalla de la Figura 4-17.
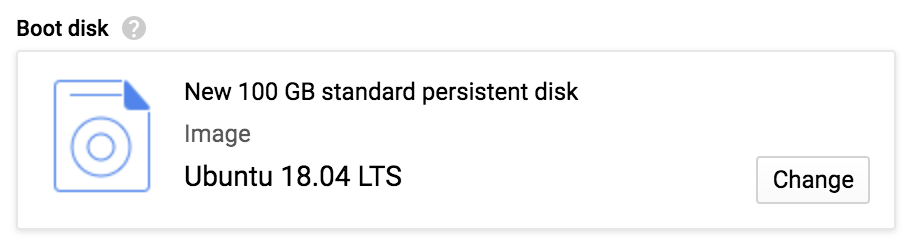
Figura 4-17. La selección actualizada del disco de arranque.
En la parte inferior del formulario, haz clic en Crear. Esto te devuelve a la página que enumera las instancias VM de Compute Engine, incluida tu instancia VM recién creada. Es posible que veas un icono giratorio delante de su nombre mientras se crea y arranca la instancia, y luego aparecerá un círculo verde con una marca de verificación cuando esté funcionando y lista para su uso, como se muestra en la Figura 4-18.

Figura 4-18. Ver el estado de la máquina virtual.
Iniciar sesión en tu máquina virtual mediante SSH
Hay varias formas de acceder a la máquina virtual después de que se esté ejecutando, sobre las que puedes informarte en la documentación de GCP. Vamos a mostrarte la forma más sencilla de hacerlo, utilizando la consola de Google Cloud y el terminal SSH incorporado. Es difícil de superar: en cuanto veas una marca de verificación verde en la consola de Google Cloud, sólo tienes que hacer clic en la opción SSH para abrir un menú desplegable, como se ilustra en la Figura 4-19. Selecciona la opción "Abrir en una ventana del navegador", y unos segundos después deberías ver un terminal SSH abierto en esta máquina virtual.
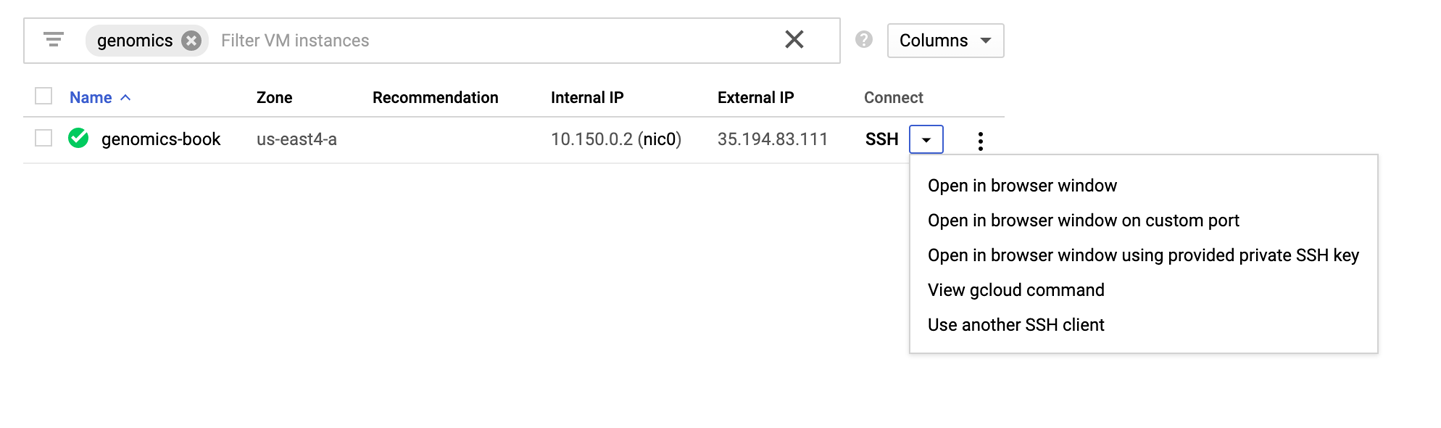
Figura 4-19. Opciones para acceder mediante SSH a tu máquina virtual.
Esto abre una nueva ventana con un terminal que te permite ejecutar comandos desde dentro de la instancia de la VM, como se muestra en la Figura 4-20. Puede tardar un minuto en establecerse la conexión.
Figura 4-20. Terminal de instancia VM.
No dudes en echar un vistazo y conocer tu flamante VM; vas a pasar mucho tiempo con ella en el transcurso de los próximos capítulos (pero, en el buen sentido).
Comprobar tu autenticación
Probablemente estés deseando ejecutar en algo interesante, pero empecemos por asegurarnos de que las credenciales de tu cuenta están configuradas correctamente para que puedas utilizar las herramientas de línea de comandos de GCP, que vienen preinstaladas en la imagen que hemos elegido. En el terminal SSH, ejecuta el siguiente comando:
$ gcloud init Welcome! This command will take you through the configuration of gcloud. Your current configuration has been set to: [default] You can skip diagnostics next time by using the following flag: gcloud init --skip-diagnostics Network diagnostic detects and fixes local network connection issues. Checking network connection...done. Reachability Check passed. Network diagnostic passed (1/1 checks passed). Choose the account you would like to use to perform operations for this configuration: [1] XXXXXXXXXXX-compute@developer.gserviceaccount.com [2] Log in with a new account Please enter your numeric choice:
La línea que empieza por [1] te indica que, por defecto, GCP te ha registrado con una cuenta de servicio: el dominio es @developer.gserviceaccount.com. Esto está bien para ejecutar herramientas dentro de tu máquina virtual, pero si quieres poder gestionar recursos, incluida la copia de archivos en los buckets de GCS, tienes que hacerlo bajo una cuenta con los permisos pertinentes. Es posible conceder a esta cuenta de servicio todos los permisos que necesitarás para estos ejercicios, pero eso nos llevaría un poco más lejos en las tripas de la administración de cuentas de GCP de lo que nos gustaría en este momento: ¡queremos que empieces a trabajar en genómica lo antes posible! Así que, en su lugar, vamos a utilizar la cuenta original que utilizaste para crear el proyecto al principio de este capítulo, dado que ya tiene esos permisos como propietario del proyecto.
Para iniciar sesión con esa cuenta, pulsa 2 en el indicador. Esto desencadena cierta interacción con el programa; GCP te advertirá de que utilizar tus credenciales personales en una máquina virtual es un riesgo para la seguridad, ya que si das acceso a la máquina virtual a otra persona, ésta podrá utilizar tus credenciales:
You are running on a Google Compute Engine virtual machine. It is recommended that you use service accounts for authentication. You can run: $ gcloud config set account `ACCOUNT` to switch accounts if necessary. Your credentials may be visible to others with access to this virtual machine. Are you sure you want to authenticate with your personal account? Do you want to continue (Y/n)?
La solución: no compartas el acceso a tu máquina virtual personal.1
Si tecleas Y para sí, el programa te dará un enlace:
Go to the following link in your browser: https://accounts.google.com/o/oauth2/auth?redirect_uri=<...> Enter verification code:
Cuando hagas clic en el enlace o lo copies y pegues en tu navegador, aparecerá una página de inicio de sesión de Google. Conéctate con la misma cuenta que utilizaste para el GCP para obtener tu código de autenticación y, a continuación, cópialo y pégalo de nuevo en la ventana de tu terminal. La utilidad gcloud confirmará tu identidad de inicio de sesión y te pedirá que selecciones el ID del proyecto que deseas utilizar de la lista de proyectos a los que tienes acceso. También te ofrecerá la opción de establecer tu zona de cálculo y almacenamiento preferida, que debería coincidir con la que estableciste anteriormente al crear la máquina virtual. Si no ves lo que esperas en la lista de ID de proyecto, puedes siempre volver a comprobar la página de gestión de recursos en la consola de GCP.
Copiar los materiales del libro a tu VM
A lo largo de los próximos capítulos, vas a ejecutar comandos y flujos de trabajo reales de GATK en tu máquina virtual, por lo que necesitas recuperar los datos de ejemplo, el código fuente y un par de paquetes de software. Hemos agrupado la mayor parte en un único lugar: un cubo de almacenamiento en la nube llamado genomics-in-the-cloud. La única pieza que está separada es el código fuente, que proporcionamos en GitHub.
En primer lugar, vas a copiar el paquete de datos desde el cubo a tu máquina virtual utilizando gsutil, la utilidad de almacenamiento de GCP que ya hemos utilizado anteriormente en la parte de este capítulo dedicada a Cloud Shell. En la ventana de terminal de tu máquina virtual, crea un nuevo directorio llamado booky ejecuta el comando gsutil para copiar el paquete de datos del libro en el espacio de almacenamiento asociado a tu máquina virtual:
$ mkdir ~/book $ gsutil -m cp -r gs://genomics-in-the-cloud/v1/* ~/book/
Esto copiará unos 10 GB de datos al almacenamiento de tu máquina virtual, por lo que puede tardar unos minutos, incluso con la bandera -m activando las descargas en paralelo. Como verás más adelante, es posible ejecutar algunos comandos de análisis directamente en los archivos del Almacenamiento en la Nube sin copiarlos primero, pero queremos mantener las cosas lo más sencillas posible al principio.
Ahora, ve a y recupera el código fuente del repositorio público en GitHub. Hacemos que el código esté disponible allí porque es una plataforma muy popular para compartir código bajo control de versiones, y nos comprometemos a proporcionar mantenimiento a largo plazo para el código que utilizamos en el libro. Para obtener una copia en tu máquina virtual, utiliza primero cd para moverte al directorio del libro recién creado y, a continuación, utiliza el comando git clone para copiar el contenido del repositorio:
$ cd ~/book $ git clone https://github.com/broadinstitute/genomics-in-the-cloud.git code
Esto crea un directorio(~book/code) que incluye todo el código de ejemplo que utilizamos a lo largo del libro. No sólo eso, sino que se configurará como un repositorio Git activo, por lo que podrás obtener los últimos cambios ejecutando el comando git pull en el directorio de código, como se indica a continuación:
$ cd ~/book/code $ git pull
Con esto, ya deberías tener la última y mejor versión del código del libro. Para saber qué ha cambiado desde la publicación original, consulta el archivo de texto README en el directorio del código.
Instalar Docker en tu máquina virtual
Vas a trabajar con Docker en tu máquina virtual, así que vamos a asegurarnos de que puedes ejecutarlo. Si simplemente ejecutas el comando docker en el terminal, obtendrás un mensaje de error porque Docker no viene preinstalado en la máquina virtual:
$ docker Command 'docker' not found, but can be installed with: snap install docker # version 18.09.9, or apt install docker.io See 'snap info docker' for additional versions.
El mensaje de error indica, con gran ayuda, cómo remediar la situación utilizando un paquete preinstalado llamado snap, pero en realidad vamos a utilizar una forma ligeramente distinta de instalar Docker: vamos a descargar y ejecutar un script del sitio web de Docker que automatizará en gran medida el proceso de instalación. De este modo, sabrás qué hacer si necesitas instalar Docker en algún lugar que no tenga una opción de gestor de paquetes integrada.
Ejecuta el siguiente comando para instalar Docker en la máquina virtual:
$ curl -sSL https://get.docker.com/ | sh
# Executing docker install script, commit: f45d7c11389849ff46a6b4d94e0dd1ffebca
32c1 + sudo -E sh -c apt-get update -qq >/dev/null
...
Client: Docker Engine - Community
Version: 19.03.5
...
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker genomics_book
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-
attack-surface for more information.
Esto puede tardar un poco en completarse, así que vamos a aprovechar ese tiempo para examinar el comando con un poco más de detalle. En primer lugar, utilizamos una pequeña y práctica utilidad llamada curl (abreviatura de URL de cliente) para descargar el script de instalación desde la URL del sitio web de Docker que proporcionamos, con unos cuantos parámetros de comando (-sSL) que indican al programa que siga cualquier enlace de redirección y guarde la salida como un archivo. A continuación, utilizamos el carácter de tubería (|) para entregar ese archivo de salida a un segundo comando, sh, que significa "ejecuta ese script que te acabamos de dar". La primera línea de salida te permite saber lo que está haciendo: Executing docker install script (omitimos partes de la salida anterior por brevedad).
Cuando termine, el script te pedirá que ejecutes el comando usermod en el ejemplo que sigue para concederte la capacidad de ejecutar comandos Docker sin utilizar sudo cada vez. Invocar sudo docker puede hacer que los archivos de salida sean propiedad de root, dificultando su gestión o acceso posterior, por lo que es muy importante realizar este paso:
$ sudo usermod -aG docker $USER
Esto no produce ninguna salida; en un minuto comprobaremos si ha funcionado correctamente. Primero, sin embargo, tienes que salir de tu máquina virtual y volver a entrar. Al hacerlo, el sistema reevaluará tu pertenencia a un grupo Unix, lo cual es necesario para que el cambio que acabas de hacer surta efecto. Simplemente escribe exit (o pulsa Ctrl+D) en el símbolo del sistema:
$ exit
Esto cierra la ventana de terminal de tu VM. Vuelve a la consola de GCP, busca tu máquina virtual en la lista de instancias de Compute Engine y haz clic en SSH para volver a iniciar sesión. Probablemente te parezca que tienes que pasar por muchos obstáculos, pero aguanta; estamos llegando a la parte buena.
Configuración de la imagen contenedora de GATK
Cuando vuelvas a en tu máquina virtual, prueba tu instalación Docker de sacando el contenedor GATK, que utilizaremos en el capítulo siguiente:
$ docker pull us.gcr.io/broad-gatk/gatk:4.1.3.0 4.1.3.0: Pulling from us.gcr.io/broad-gatk/gatk ae79f2514705: Pull complete 5ad56d5fc149: Pull complete 170e558760e8: Pull complete 395460e233f5: Pull complete 6f01dc62e444: Pull complete b48fdadebab0: Pull complete 16fb14f5f7c9: Pull complete Digest: sha256:e37193b61536cf21a2e1bcbdb71eac3d50dcb4917f4d7362b09f8d07e7c2ae50 Status: Downloaded newer image for us.gcr.io/broad-gatk/gatk:4.1.3.0 us.gcr.io/broad-gatk/gatk:4.1.3.0
Como recordatorio de , la última parte después del nombre del contenedor es la etiqueta de versión, que puedes cambiar para obtener una versión diferente de la que hemos especificado aquí. Ten en cuenta que si cambias la versión, algunos comandos podrían dejar de funcionar. No podemos garantizar que todos los ejemplos de código vayan a ser compatibles con el futuro, especialmente en el caso de las herramientas más recientes, algunas de las cuales aún están en desarrollo activo. Como se ha indicado anteriormente, para obtener materiales actualizados, consulta el repositorio GitHub de este libro.
La imagen del contenedor GATK es bastante grande, por lo que la descarga puede tardar un poco. La buena noticia es que la próxima vez que necesites extraer una imagen de GATK (por ejemplo, para obtener otra versión), Docker extraerá sólo los componentes que se hayan actualizado, por lo que irá más rápido.
Nota
Aquí estamos extrayendo la imagen GATK del Repositorio de Contenedores de Google (GCR) porque GCR está en la misma red que la máquina virtual en la que estamos ejecutando, por lo que será más rápido que extraerla de Docker Hub. Sin embargo, si estás trabajando en una plataforma diferente, puede que te resulte más rápido extraer la imagen del repositorio GATK en Docker Hub. Para ello, cambia la parte us.gcr.io/broad-gatk de la ruta de la imagen por sólo broadinstitute.
Ahora, ¿recuerdas las instrucciones que seguiste anteriormente en este capítulo para poner en marcha un contenedor con una carpeta montada? Vas a volver a utilizarlas para que el directorio book sea accesible para el contenedor GATK:
$ docker run -v ~/book:/home/book -it us.gcr.io/broad-gatk/gatk:4.1.3.0 /bin/bash
Ahora deberías poder navegar por el directorio book que configuraste en tu máquina virtual desde el contenedor. Estará ubicado en /home/libro. Por último, para volver a comprobar que el propio GATK funciona como es debido, prueba a ejecutar el comando gatk en la línea de comandos desde tu contenedor. Si todo funciona correctamente, deberías ver una salida de texto que describe la sintaxis básica de la línea de comandos de GATK y algunas opciones de configuración:
# gatk
Usage template for all tools (uses --spark-runner LOCAL when used with a Spark tool)
gatk AnyTool toolArgs
Usage template for Spark tools (will NOT work on non-Spark tools)
gatk SparkTool toolArgs [ -- --spark-runner <LOCAL | SPARK | GCS> sparkArgs ]
Getting help
gatk --list Print the list of available tools
gatk Tool --help Print help on a particular tool
Configuration File Specification
--gatk-config-file PATH/TO/GATK/PROPERTIES/FILE
gatk forwards commands to GATK and adds some sugar for submitting spark jobs
--spark-runner <target> controls how spark tools are run
valid targets are:
LOCAL: run using the in-memory spark runner
SPARK: run using spark-submit on an existing cluster
--spark-master must be specified
--spark-submit-command may be specified to control the Spark submit command
arguments to spark-submit may optionally be specified after --
GCS: run using Google cloud dataproc
commands after the -- will be passed to dataproc
--cluster <your-cluster> must be specified after the --
spark properties and some common spark-submit parameters will be translated
to dataproc equivalents
--dry-run may be specified to output the generated command line without running it
--java-options 'OPTION1[ OPTION2=Y ... ]'' optional - pass the given string of options to
the java JVM at runtime.
Java options MUST be passed inside a single string with space-separated values
Discutiremos lo que todo eso significa con detalle amoroso en el Capítulo 5; por ahora, ya has terminado de configurar el entorno que utilizarás para ejecutar las herramientas GATK en el transcurso de los tres capítulos siguientes.
Detener tu VM... para que no te cueste dinero
La máquina virtual que acabas de terminar de configurar te va a resultar útil a lo largo del libro; volverás a a esta máquina virtual para muchos de los ejercicios de los próximos capítulos. Sin embargo, mientras esté en funcionamiento, te estará costando créditos o dinero real. La forma más sencilla de solucionarlo es detenerla: ponla en pausa siempre que no la estés utilizando activamente.
Puedes reiniciarla bajo demanda; sólo se tarda uno o dos minutos en volver a ponerla en marcha, y conservará toda la configuración del entorno, el historial de lo que hayas ejecutado anteriormente y cualquier dato que tengas en el almacenamiento local. Ten en cuenta que se te cobrará una pequeña cantidad por ese almacenamiento, incluso mientras la máquina virtual no esté funcionando, y que no se te cobrará por la máquina virtual en sí. En nuestra opinión, merece la pena por la comodidad de poder volver a tu máquina virtual al cabo de un tiempo arbitrario y retomar el trabajo donde lo dejaste.
Para detener tu VM, en la consola de GCP, ve a la página de gestión de instancias VM , como se ha mostrado anteriormente. Busca tu instancia y haz clic en el símbolo vertical de tres puntos de la derecha para abrir el menú de controles y, a continuación, selecciona Detener, como se muestra en la Figura 4-21. El proceso puede tardar un par de minutos en completarse, pero puedes salir de esa página sin problemas. Para reiniciar tu instancia más adelante, sólo tienes que seguir los mismos pasos pero haciendo clic en Iniciar en el menú de controles.
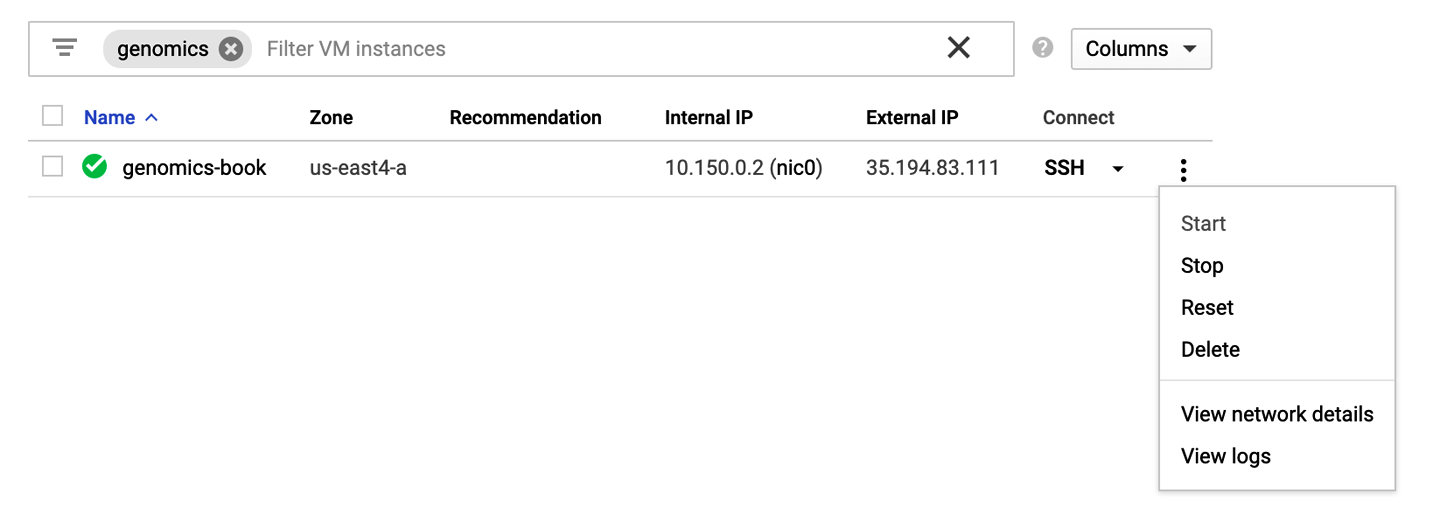
Figura 4-21. Detener, iniciar o eliminar tu instancia VM.
Alternativamente, puedes eliminar tu máquina virtual por completo, pero ten en cuenta que al eliminar la máquina virtual también se eliminarán todos los datos almacenados localmente, así que asegúrate de guardar primero en un cubo de almacenamiento todo lo que te interese.
Configurar IGV para leer datos de cubos GCS
Sólo queda un pequeño paso más antes de que pases al siguiente capítulo: vamos a instalar y configurar un navegador del genoma llamado Visor Integrado del Genoma (IGV) que puede trabajar directamente con archivos en GCP. Eso te permitirá examinar los datos de secuencia y las llamadas a variantes sin necesidad de copiar los archivos a tu máquina local.
En primer lugar, si aún no lo tienes instalado en tu máquina local, consigue el programa IGV en el sitio web y sigue las instrucciones de instalación. Si ya tienes una copia, considera la posibilidad de actualizarla a la última versión; nosotros estamos utilizando la 2.7.2 (versión para macOS). Una vez que tengas la aplicación abierta, elige Ver > Preferencias en la barra de menú superior, como se muestra en la Figura 4-22.
Figura 4-22. Seleccionar la opción de menú Preferencias.
Se abre el panel de Preferencias, mostrado en la Figura 4-23.
En el panel de Preferencias, marca la casilla "Habilitar acceso a Google", haz clic en Guardar y, a continuación, sal de IGV y vuelve a abrirlo para forzar una actualización de la barra de menú superior. Ahora deberías ver un elemento de menú de Google que antes no estaba; haz clic en él y selecciona Iniciar sesión, como se muestra en la Figura 4-24, para configurar IGV con las credenciales de tu cuenta de Google.
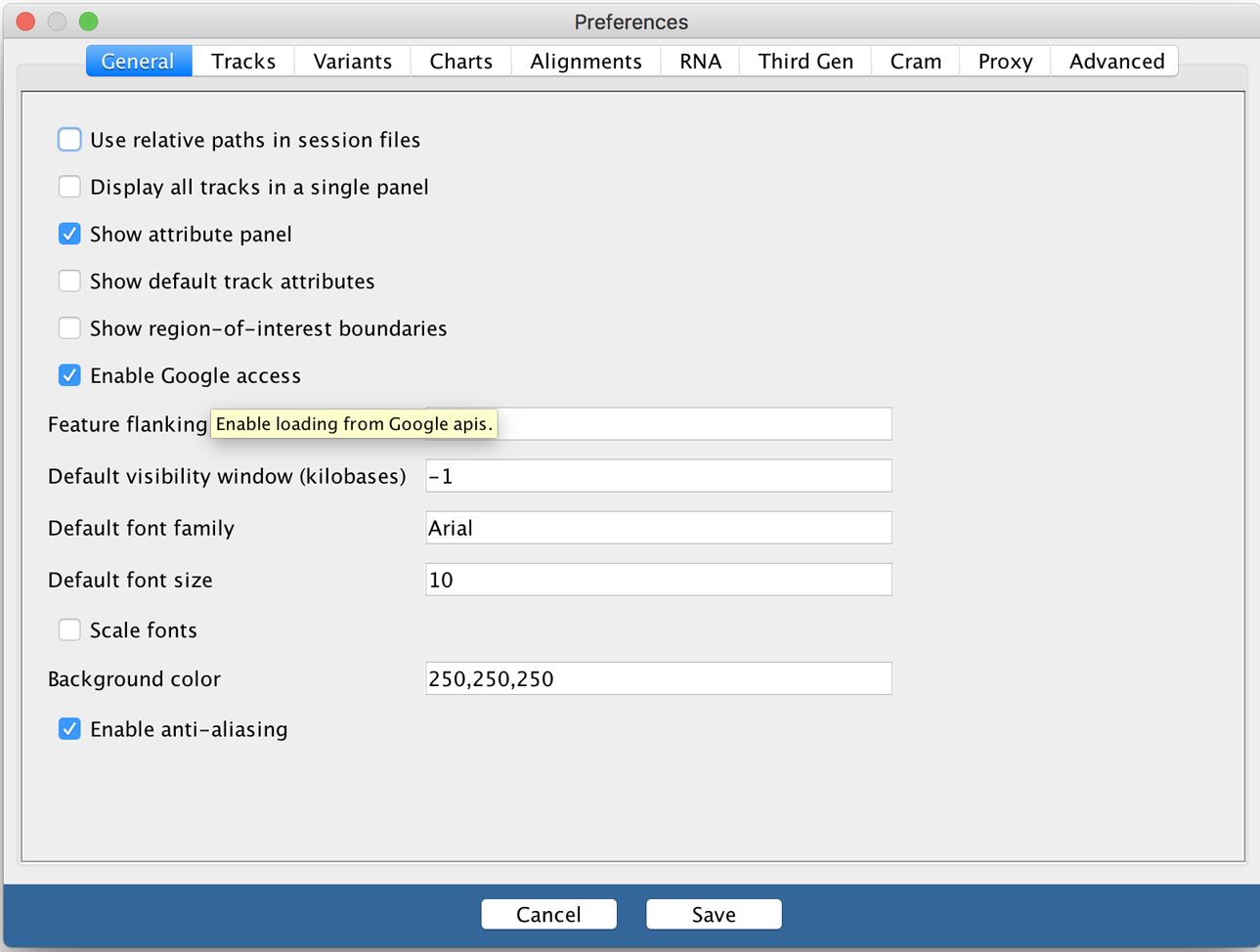
Figura 4-23. Panel de Preferencias de IGV.

Figura 4-24. Seleccionar la opción de menú Inicio de sesión en Google.
Esto te llevará a una página de inicio de sesión de Google en tu navegador web; sigue las indicaciones para permitir que IGV acceda a los permisos pertinentes de tu cuenta de Google. Una vez completado esto, deberías ver una página web que simplemente diga OK. Volvamos a IGV y comprobemos que funciona. En el menú superior, haz clic en Archivos > Cargar desde URL, como se muestra en la Figura 4-25, asegurándote de no seleccionar una de las otras opciones por error (se parecen, así que es fácil confundirse). Asegúrate también de que el menú desplegable de referencia de la esquina superior izquierda de la ventana IGV está ajustado a "Human hg19".
Nota
Si tienes dudas sobre las diferencias entre las referencias humanas, consulta las notas de "El genoma de referencia como marco común" sobre hg19 y GRCh38.
Figura 4-25. La opción de menú Cargar desde URL.
Por último, introduce la ruta del archivo GCS para un de los archivos BAM de muestra que proporcionamos en el paquete de datos del libro en la ventana de diálogo que aparece (por ejemplo, madre.bam, como se muestra en la Figura 4-26), y luego haz clic en Aceptar. Recuerda que puedes obtener una lista de los archivos del bucket utilizando gsutil desde tu VM o desde Cloud Shell, o puedes examinar el contenido del bucket utilizando el navegador de almacenamiento de la consola de Google Cloud. Si utilizas la interfaz del navegador para obtener la ruta del archivo, tendrás que componer la ruta del archivo GCS eliminando la primera parte de la URL antes del nombre del cubo; por ejemplo, elimina https://console.cloud.google.com/storage/browser y sustitúyelo por gs://. Haz lo mismo con el archivo índice que acompaña al BAM, que debe tener el mismo nombre de archivo y ruta, pero termina en .bai.2
Figura 4-26. Cuadro de diálogo Cargar desde URL.
Esto hará que los datos estén disponibles para ti en IGV como una nueva pista de datos, pero por defecto no se cargará nada en el visor principal. Para comprobar que puedes ver los datos, en la ventana de búsqueda, introduce las coordenadas genómicas 20:9,999,830-10,000,170 y haz clic en Ir. Estas coordenadas te llevarán a la 10 millonésima base de ADN ±170 del 20º cromosoma humano, como se muestra en la Figura 4-27, donde verás el perímetro izquierdo del corte de datos de secuencia que proporcionamos en este archivo de muestra. Explicaremos detalladamente cómo interpretar la salida visual de IGV en el Capítulo 5, cuando lo utilicemos para investigar el resultado de un análisis real (pequeño).
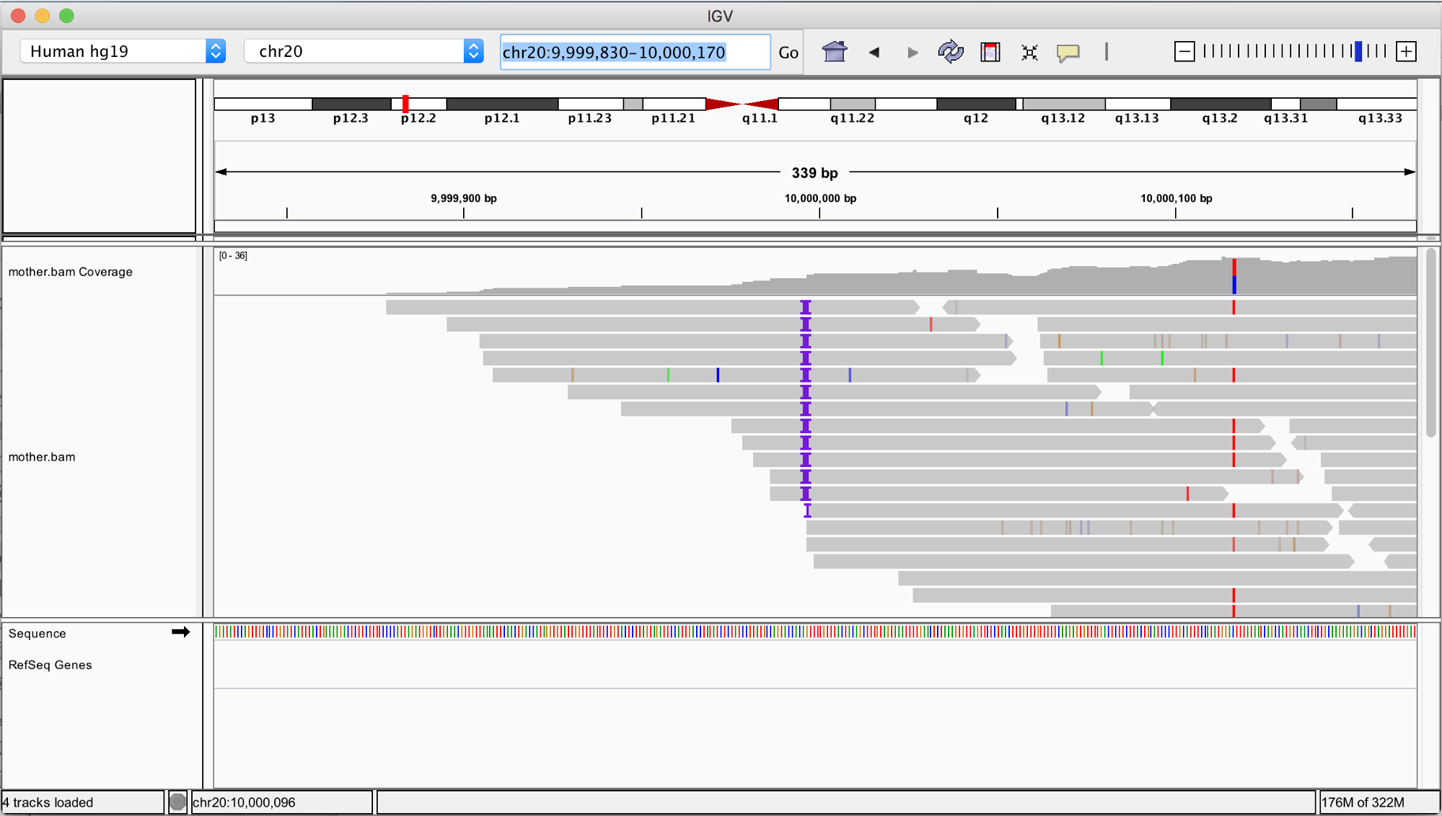
Figura 4-27. Vista IGV de un archivo BAM ubicado en un cubo GCS.
IGV sólo recupera pequeños fragmentos de datos cada vez, por lo que la transferencia debería ser muy rápida, a menos que tengas una conexión a Internet especialmente lenta. Ten en cuenta, sin embargo, que GCP, como todos los proveedores de nubes comerciales, cobrará una tarifa de salida por transferir datos fuera de la nube. Lo bueno es que es una tarifa pequeña, proporcional a la cantidad de datos que transfieras. Así que el coste de ver fragmentos de datos en IGV es trivial -del orden de fracciones de céntimos- ¡y es definitivamente preferible a lo que costaría transferir todo el archivo para navegar sin conexión!
Puedes ver el contenido de otros archivos de datos de , como los archivos VCF, utilizando el mismo conjunto de operaciones, siempre que los archivos estén almacenados en un bucket de GCP. Desgraciadamente, esto significa que no funcionará con los archivos que estén en el almacenamiento local de tu máquina virtual, así que cada vez que quieras examinar uno de ellos, tendrás que copiarlo primero a un bucket. Te harás muy amigo de gsutil en poco tiempo.
Ah, una última cosa mientras tengas IGV abierto: haz clic en la pequeña burbuja amarilla de llamada de la barra de herramientas de la ventana IGV, que controla el comportamiento del visor de detalles, como se muestra en la Figura 4-28. Hazte un favor y cambia el ajuste de Mostrar detalles al pasar el ratón por encima a Mostrar detalles al hacer clic. Sea cual sea la acción que elijas, aparecerá un pequeño cuadro de diálogo que te dará información detallada sobre cualquier parte de los datos sobre la que hagas clic o pases el ratón; por ejemplo, para una lectura de secuencia, te dará toda la información de mapeado, así como la secuencia completa y las calidades de las bases. Puedes probarlo ahora con los datos que acabas de cargar. Como verás, la funcionalidad de visualización de detalles en sí misma es muy cómoda, pero la versión "al pasar el ratón" de este comportamiento puede resultar un poco abrumadora cuando eres nuevo en la interfaz; de ahí nuestra recomendación de cambiar a "al hacer clic".

Figura 4-28. Cambiar el comportamiento del visor de detalles de "al pasar el ratón por encima" a "al hacer clic".
Recapitulación y próximos pasos
En este capítulo, te mostramos cómo empezar con los recursos de GCP , desde la creación de una cuenta, el uso de la Shell de la Nube superbásica y, a continuación, el paso a tu propia VM personalizada. Aprendiste a gestionar archivos en GCS, a ejecutar contenedores Docker y a administrar tu VM. Por último, recuperaste los datos del libro y el código fuente, terminaste de configurar tu VM personalizada para trabajar con el contenedor GATK, y configuraste IGV para ver los datos almacenados en cubos. En el Capítulo 5, te iniciaremos en el propio GATK, y antes de que te des cuenta, estarás ejecutando herramientas genómicas reales sobre datos de ejemplo en la nube.
1 Ten en cuenta que si creas cuentas para otros usuarios en tu proyecto GCP, también podrán acceder mediante SSH a tus máquinas virtuales. Es posible restringir aún más el acceso a tus máquinas virtuales en un proyecto compartido, pero eso va más allá de la sencilla introducción que presentamos aquí.
2 Por ejemplo, https://console.cloud.google.com/storage/browser/genomics-in-the-cloud/v1/data/germline/bams/mother.bam se convierte en gs://genomics-in-the-cloud/v1/data/germline/bams/mother.bam.
Get Genómica en la nube now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

