Chapter 4. Evaluating the Current Streaming Market
In previous chapters, we established what flow is, why businesses will be motivated to adopt it, and used two modeling techniques, Wardley Mapping and Promise Theory, to understand what the core technical components of flow are likely to be. In this chapter, we will evaluate the current state of those components by looking at many of the specific technologies that can fill those needs.
We are going to start by briefly reviewing some of the workloads that are driving the growth of streaming architectures. Having some context for why things have evolved the way they have is important for understanding how they work. As I describe these architectures, I will map the architectural components involved to the components we defined in our Wardley Map, demonstrating the common structures emerging in flow.
I won’t be doing an in-depth breakdown of these architectures, however. If you are interested in studying streaming architectures in more depth, I suggest Tyler Akidau, Slava Chernyak, and Reuven Lax’s Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing (O’Reilly), Fabian Hueske and Vasiliki Kalavri’s Stream Processing with Apache Flink (O’Reilly), or Gerard Maas and Francois Garillot’s Stream Processing with Apache Spark (O’Reilly). Each demonstrates a different approach to stream processing using an appropriate open source platform for the purpose.
We will follow our brief survey with an overview of four architectural patterns that use these technologies to support a number of flow use cases. These patterns—Distributor, Collector, Signal Processor, and Facilitator—are well represented in our example companies, and will be used in Chapter 5 to explore how flow will evolve and what you can do today to prepare for the future.
The goal of this chapter is not to give you a complete survey of all the vendors and open source projects that are addressing some aspect of streaming. That would be impossible. Not only are there too many vendors in too many technology categories, but also this book is static, and the market is changing—and will continue to change—rapidly.
Instead, it is my hope that you walk away from this chapter with a good sense of where things stand today, and the amount of work left to do fully achieve the promise of flow. Flow’s future is visible because of the hard work of many technologists over the last several decades. However, as we shall see, we are still in the formative stages of what will come over the next decade.
Step one of our evaluation of streaming technologies is to understand the key technologies that drive their development and evolution. By understanding how developers have built and modified systems that rely on real-time or “timely” state updates, either through events or raw data streams, we get a sense of the different building blocks on which we must rely.
I’ve picked three high-level technology categories that utilize the components that we covered in our Wardley Map. For each category, I’ll outline the common supporting architectures, and map each component of those architectures to a component on our Wardley Map. I may also use several examples of these components, including proprietary products, open source options, and occasionally custom software examples as I describe each architecture.
Service Buses and Message Queues
The earliest attempts at real-time data sharing were simply to allow shared access to a file or database. By sharing data in this way, multiple applications were able to see the same state, and any application that changed that state instantly changed it for all applications that subsequently read that same data.
If you don’t have to scale beyond the limits of your data storage method, data integration is still an incredibly powerful method of real-time data exchange. It virtually guarantees a common view of the state of the world. However, as most enterprises have discovered over the past four or five decades, there are big drawbacks if your computing needs grow beyond those scale limits, or if the data environment is subject to frequent change.
For example, imagine a company that acquires another and wishes to combine the two IT portfolios. If two existing applications each have their own existing databases and need to share the same state—say customer profile data—it is often very expensive to do. Combining databases involves either rewriting (and “rewiring,” e.g., opening new network ports) the existing applications, or inserting new technology to synchronize data between the two applications’ databases (which is, essentially, creating a data stream between the two databases).
Message Queues
For this reason, a new form of intersystem communication evolved in parallel to databases, known as message-oriented middleware (MOM). These products took a page from the way operating systems and some applications would handle communication internally, especially between running processes. In those cases, the software would use a message queue to enable asynchronous communication, in which data was packaged into messages by the producer, and placed into a temporary hold (a topic in the queue) until the consumer was ready to read the message.
Early MOM was mostly focused on both decoupling message senders (producers) from message receivers (consumers), and providing various delivery guarantees, which are executed using various acknowledgment protocols. These protocols generally consist of a series of signals exchanged between the message queue software and the message producer or consumer. There are a variety of types of message delivery guarantees. Some examples include “deliver exactly once,” “deliver at least once,” and “deliver at most once.” Queues managed those guarantees between producers and consumers.
Message queues are still wildly popular today. This is partly because this architecture allows distributed and disparate components in a system to evolve and change independently of the integrations between components. By decoupling producers and consumers, new consumers and new producers can be added to the system by simply pointing them to the right queue and reading or writing messages. Existing producers and consumers can also be updated independently, barring a change to the interfaces and protocols used in the integration.
These publish and subscribe mechanisms (or “pub/sub” for short) succeed at both decoupling the producer from the consumer and enabling precise routing of messages to the consumers that requested them. This is why pub/sub remains a key feature of messaging systems today.
Typically, the architecture of a simple queuing use case might look like Figure 4-1.
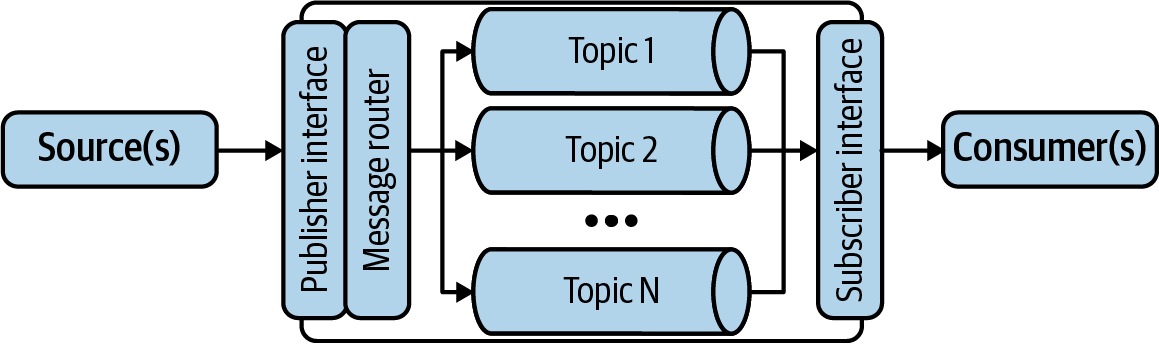
Figure 4-1. Conceptual architecture of a message queue
In Figure 4-1, the producer publishes a message to a publisher interface, which incorporates some logic system to deliver the message to the appropriate topic. (This logic could be as simple as reading the intended topic name from the message itself.) Separately, a consumer utilizes a subscriber interface to request messages from the appropriate topic. Some systems only allow consumers to poll for new messages, while others transmit messages to consumers as they are added to the topic.
Service Buses
In the 1990s, a new distributed systems architecture known as service-oriented architecture (SOA) started to get some traction in the enterprise. The idea behind SOA was that core, shared functions and data can be delivered by software running on computers in data centers to user facing applications—most of which was running on personal computers at the time. The software components maintained in data centers are called services, and typically offer request/response APIs or other network-based connection methods by which applications request the offered functions or data.
While connecting applications directly to services is allowable, enterprises with large numbers of services soon discovered that managing the myriad of connections between software components was complicated and prone to mistakes. Part of the problem is simply the diverse set of products and custom software that need to be linked together in this way. Many of these have their own interfaces and protocols to expose their functionality, and often a simple integration of two components requires translating between the outbound protocol of the producer and the inbound protocol of the consumer, which can be complicated and subject to frequent change.
The solution is to introduce a message queue between applications and services (and, often, between applications or between services). Here, the queue acts as a bus; a common communication plane for all the applications and services connected to it. This bus has a way to plug in specialized software, known as adaptors, that enables the bus to send or receive data in formats that each integrated application or service would understand.
Both the adaptors and the service bus, known as an enterprise service bus (ESB), might also support other key elements of enterprise integration, such as various security protocols, monitoring technologies, and even process automation technologies. The ESB’s many-to-many architecture is depicted in Figure 4-2.
This was a very desirable architecture for the enterprise architects in the 1990s, as it created a point of control for component connections. For example, some ESB products simply enabled IT architects to decide which applications would connect to which services. Others went as far as enabling data transformation and routing functions to be executed in the bus, independent of the producer or the consumer of a connection.
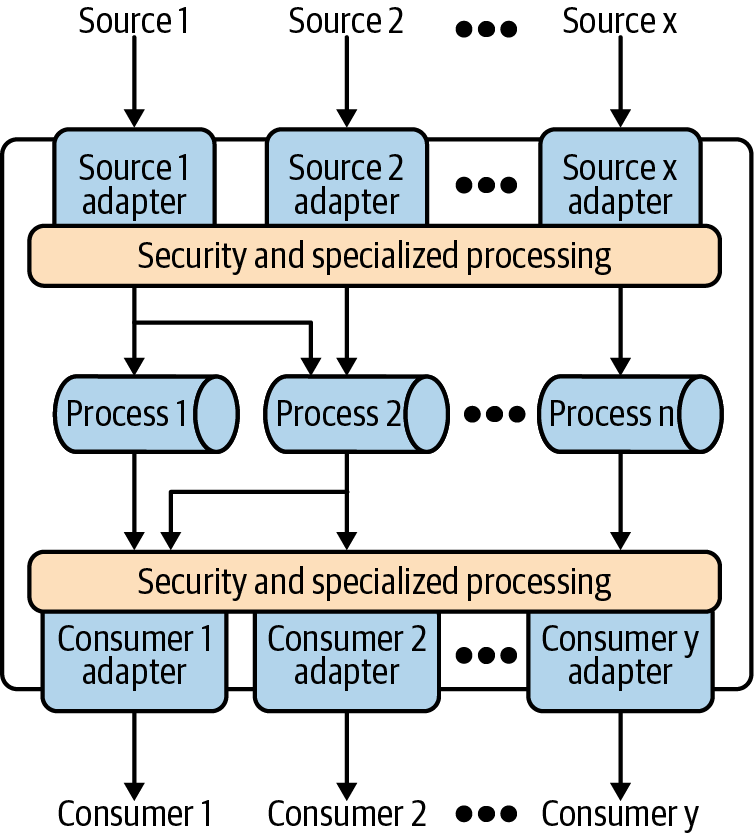
Figure 4-2. Conceptual architecture of an enterprise service bus
Message queues and ESBs are important to the development of streaming architectures, but they often have technological limitations with respect to scale and performance. The highly centralized nature of the ESB concept works great for systems in which the number of connections and rate of change is manageable, but quickly becomes a challenge when system complexity increases beyond those manageable limits.
The idea that you could centralize all communication control for an entire enterprise turns out to be too complicated and subject to technical limitations, so ESBs, where they are still used, are typically focused on specific clusters of applications and services within an enterprise. However, the core concept of decoupling producer and consumer greatly informed the streaming architectures that have gained popularity since.
Mapping Service Buses and Message Queues
Table 4-1 demonstrates how the components of our ESB and message queue architectures relate to the components in our Wardley Map from Chapter 3.
| Architecture component | Wardley Map component(s) |
|---|---|
| Message queue | Queue |
| ESB | Processor (for advanced functions, e.g., security or process automation) Queue (for routing and store-and-forward functions) |
This is pretty straightforward. Message queues clearly map to the queue component of our map, as they are literally queues. An ESB did a little bit more, acting both as a queue and as a platform for data translation, routing, process management, and so on, so it fits both the processor and queue components.
Internet of Things
One of the first technology categories to really define data flow in terms of events was the control and automation systems in manufacturing, energy production, and other industrial applications. These systems rely heavily on data received from electronic sensors, and often have to react in a fraction of a second to that data.
Initially, these types of systems were implemented with direct wire connections between sensors, controllers, and the devices that could be manipulated by those controllers (such as servo motors, or electronic dials and switches). But the rise of the standard networking technologies (such as Ethernet and WiFi) led to their adaptation in industrial systems.
Today, a myriad of products from devices to controllers to process managers to analytics systems can communicate using TCP/IP—often crossing geographic and organizational boundaries via the internet. As network-based integration grew in the late 1990s, a term was coined to describe the phenomenon of nonhumans supplying data to computer systems via the internet: the Internet of Things (IoT).
For many IoT applications, the basic protocols of web traffic—TCP/IP, HTTP, and TLS—are adequate for transmitting both data and commands between systems. However, for time-critical applications, or for devices where energy consumption is a critical factor, or situations where data loss is likely and tolerated, these protocols are too inefficient. This has led to the introduction of a plethora of new protocols at the transport and application layers to address these use cases.
Table 4-2 contains some examples. If you are interested in the details of any of these, information is readily available on the internet. I only provide them here to show the explosion of options to address different use cases.
| Purpose | Example protocol(s) |
|---|---|
| Transport and internet layer protocols | IPv6, UDP, TCP, QUIC, DTLS (TSL for datagram protocols), Aeron, uIP |
| Low power/“lossy” network protocols | 6LoWPAN, ROLL/RPL |
| Discovery protocols | mDNS, Physical Web, HyperCat, Universal Plug-n-Play (UPnP) |
| Messaging protocols | MQTT, AQMP, CoAP, SMCP, STOMP, XMPP, DDS, Reactive Streams, HTTP, WebSocket |
| Wireless protocols | 2G/3G, Bluetooth/BLE, 802.15.4, LTE, SigFox, Weightless, Wi-Fi, Zigbee, ZWave |
Today, for many applications, such as low-power close-range communications, there is high competition among a number of standards. For other use cases, such as longer range networks, already adopted standards do not yet address evolving needs, so the possibility of new standards is likely.
But you can see from Table 4-2 that the world of IoT communications is fractured and at times quite confusing. Luckily, that is beginning to change, as a few de facto standards are beginning to emerge. While Wi-Fi, Bluetooth, and other common transport level protocols are critical to reaching and establishing connections with the various elements of an IoT solution, they are not unique to IoT. Others, such as Zigbee and ZWave, play a huge role in establishing a common communication layer for device-to-device and device-to-web applications, and are generally used only in specific contexts.
MQTT
One protocol in particular, however, is helping to not only enable integration in the IoT space, but also establish a message-based architecture for many IoT applications. Message Queue Telemetry Transport, or MQTT, is specifically designed as a lightweight publish-and-subscribe messaging protocol that enables just about anything with a processor to act as a publisher of data for consumption by just about anything else with a processor.
MQTT is a publish-and-subscribe protocol. In MQTT parlance, clients can be either producers or consumers, and a broker is the software that manages routing messages between producers (as publishers) and consumers (as subscribers). The basic operation looks like this:
A client—acting as a publisher, a subscriber, or both—requests a connection to the broker. This connection is assigned a connection ID, and is monitored by both the client and the broker.
The broker manages a list of topics, which enable it to identify groups of subscribers interested in a collection of messages. All messages will contain their relevant topic name.
Clients acting as subscribers request a subscription to one or more topics.
Clients acting as publishers send messages to the broker containing the relevant topic name.
The broker then uses the topic name to route the message to the appropriate clients.
The MQTT server does not have to be a queue—it is valid to simply route messages directly to subscribers without storing them on the server—but in order to support asynchronous communication, most do have queue capabilities.
Every command in MQTT requires an acknowledgment, and both creating a connection and creating a subscription have their opposite commands to close their respective entities.
A basic architecture for MQTT would look something like Figure 4-3.
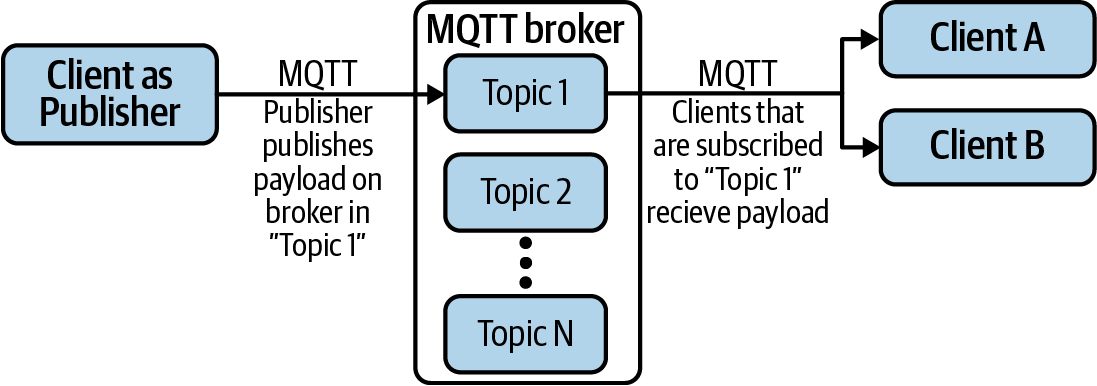
Figure 4-3. A high-level MQTT architecture
Figure 4-3 demonstrates a client acting as a publisher sending a message marked for “Topic 1” to the MQTT Broker server. The broker then directs that message to all clients that have subscribed to “Topic 1.”
Figure 4-4 is a more complex architecture example using MQTT. This is based on an architecture for a monitoring system in a chemistry lab. Connected to the lab broker in this system are some MQTT-capable sensors, as well as an analog-to-digital converter that reads the voltage levels sent by connected devices and generates MQTT messages as a publisher with the corresponding data as payloads.
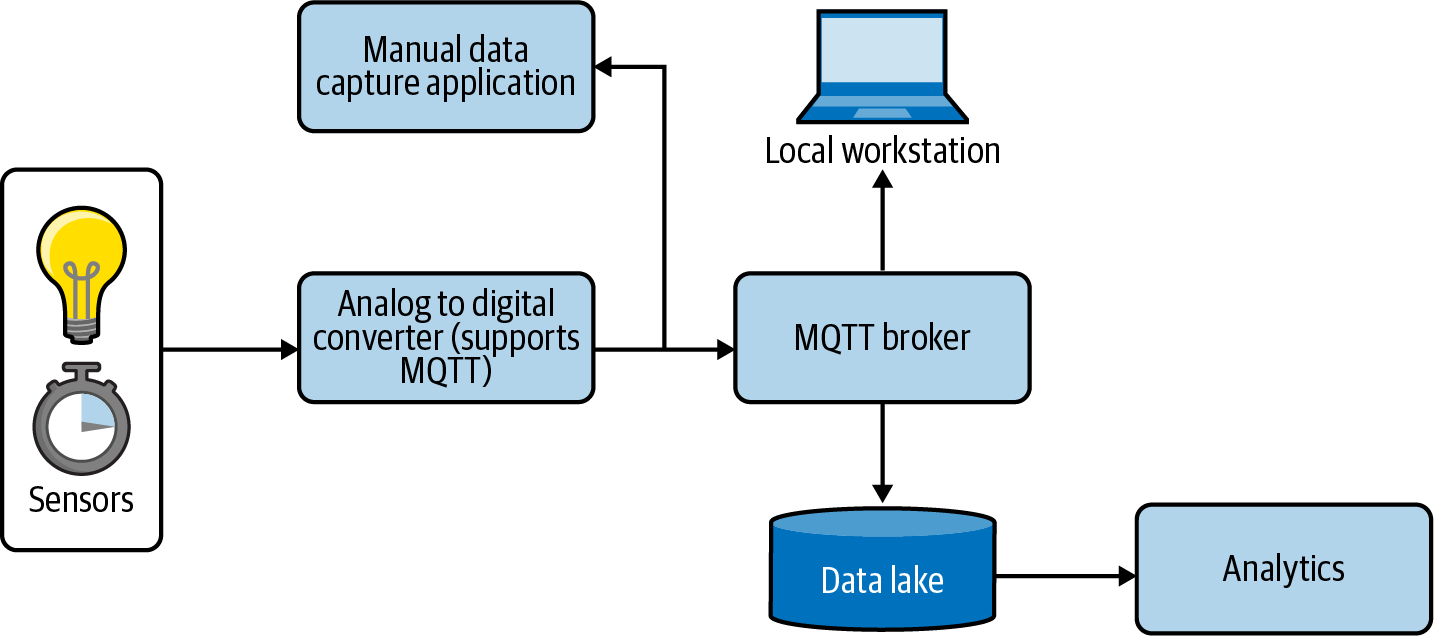
Figure 4-4. Example lab environment use case for MQTT
In Figure 4-3 and Figure 4-4, a modern “MQTT broker” is actually any publish-and-subscribe messaging environment that can utilize the MQTT protocol. There are a number of these on the market, such as HiveMQ, Solace PubSub+, and Inductive Automation’s platform, Ignition. There are also a number of open source projects building MQTT brokers, including the Eclipse Foundation’s Mosquito project, and commercial open source projects like EMQ and VerneMQ.
The major cloud providers today include MQTT brokers in their IoT offerings. Amazon Web Services’ IoT Core service is an MQTT broker that allows devices to publish and subscribe to topics, while also providing connectivity to other AWS services for other forms of communication and processing. Microsoft Azure IoT and Google Cloud IoT Core have similar support.
There are also a number of general purpose message brokers that can manage MQTT messages with plug-ins or extensions. The Apache Kafka event processor, which we will discuss in “Event Processing”, has a connector that can act as a client for an MQTT broker. This enables Kafka to act as either a producer that provides messages to a broker or a consumer that receives messages from a broker—or both.
A myriad of message queues do something similar—acting as a client rather than a broker. Others, such as RabbitMQ and IBM MQ, have plug-ins that enable them to appear as a broker to MQTT publishers and subscribers. I discuss queues a bit more in “Queue/Log”. However, for device communications over wireless and wired networks, MQTT has built a substantial ecosystem, and is definitely being used to share IoT events across organization boundaries.
HTTP and WebSocket
The last two IoT protocols I will highlight are the Hypertext Transfer Protocol (HTTP) and WebSocket, which actually have a slightly higher adoption rate than MQTT among IoT developers.1 HTTP is inherently a request-and-reply protocol (not a publish-and-subscribe protocol, like MQTT), and thus is not designed to support arbitrary two-way conversations between connected parties. However, it can work as a streaming solution with some of the capabilities in HTTP/2, the version of HTTP most clients (like web browsers) and servers use today.
WebSocket, on the other hand, is a communication protocol designed to allow two-way conversations over a TCP connection. It is distinct from HTTP, but has been designed to work seamlessly with HTTP. Many use WebSocket today as the core connection protocol for distributed systems that have to send information back and forth in order to complete a task.
The exchange of information in HTTP and WebSocket is more “point to point” than MQTT. There are no publish-and-subscribe semantics for either protocol. There is no concept of a “topic” with which to connect and receive specific data. The consumer simply makes a request to the producer via a standard HTTP (or WebSocket) request message, and the server opens and maintains a connection for an indeterminate amount of time. In the case of HTTP, the connection will be optimized for the producer to stream to the consumer. WebSocket, on the other hand, will readily support streaming in both directions.
Thus, the basic HTTP- and WebSocket-based event connections look like Figure 4-5.
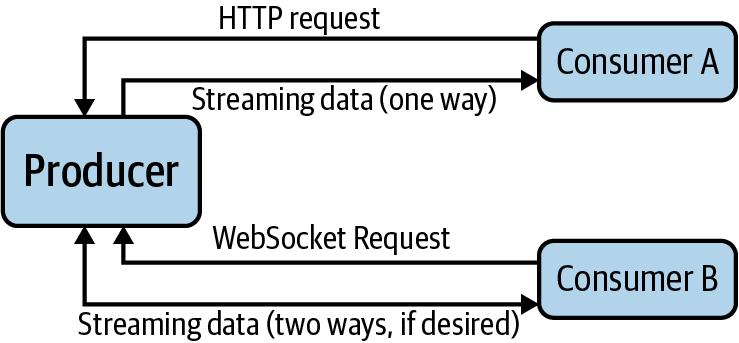
Figure 4-5. HTTP and WebSocket connections
HTTP/3, intended to succeed HTTP/2 as a ubiquitous internet protocol, is in the development stage at the time I am writing this. It takes advantage of a potential replacement to the TCP protocol, called QUIC (QUIC does not, strangely, stand for anything) to deliver streams over many connections simultaneously. This will improve the performance of HTTP streaming significantly, especially if you have a network problem on one connection and start losing packets of data.
The Internet Engineering Task Force is currently in the process of writing the HTTP/3 specification, but it is far enough along that several browsers and web servers have already announced early support.
Mapping Internet of Things Architectures
The core components of these architectures map to our Wardley Map as shown in Table 4-3.
| Architecture component | Wardley Map component(s) |
|---|---|
| MQTT | Protocol |
| MQTT broker | Queue (can be a message queue or ESB) |
| HTTP | Protocol |
| WebSocket | Protocol |
Event Processing
The last architecture I want to summarize is one in which tools are introduced specifically to process event stream traffic. Messaging systems and network protocols play a role in distributing events to places where they will be processed, but they were not originally intended to be a place where other forms of interaction happen.
As noted in Chapter 1, flow without interaction is just moving data around. Interaction from applications that only prepare events to be submitted to a stream, or that only consume events from a stream, are certainly critical to flow, but neither of those enable the continuation of flow in a way that boosts the impact of those events across a system of applications.
There are a number of tools today that have adapted to the need to process events “in flow,” so to speak—meaning reading events from a stream, taking an action on that event, then forwarding the (potentially modified) event to a new destination. These tools have functionality that enables them to work quickly and reactively to incoming events. Many also can receive the input of multiple streams and create aggregate events or trigger events from that set of data.
A very basic view of adding processing to flow looks something like Figure 4-6.
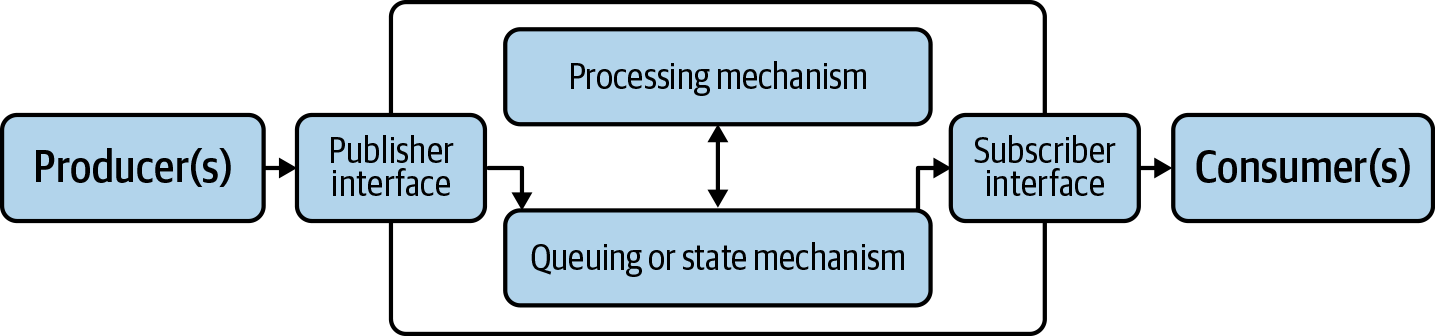
Figure 4-6. High-level architecture of an event processing system
The key concept for event processing is that there is some form of state or data management for incoming events, and a mechanism by which that state or data is processed. State management will often be some sort of queueing mechanism, but some platforms use alternative methods to maintain state.
There are three primary engines for event processing in the market today: functions (including low-code or no-code processors), log-based event streaming platforms, and real-time stateful systems. Let’s briefly discuss the three from an architectural perspective.
Functions, Low-Code, and No-Code Processors
One of the biggest advancements in distributed systems development in the last 10 years is new services that greatly simplify attaching simple functions to event streams. These functions can be used for a number of tasks, including (but not limited to) sorting, filtering, routing, calculation, and aggregation. Some functions may even interact directly with user interfaces for display or control purposes.
While writing some code that triggers whenever a message or event is received in a queue has been common for decades, what is new is the low-toil approaches available today. Common patterns for triggering, executing, and managing code execution in response to events are being delivered as products and services, such as AWS Lambda and a number of Apache projects, such as Flink and Storm. The exact model of execution can differ somewhat between various products and services, but the end result is essentially the same: an event is detected and some code is executed in response.
Serverless
The entire serverless market category represents a collection of services that enable application development through composition and events. These services are designed so that developers can focus on the specific code or workflows that differentiate their applications, and minimize any required “glue code” and operational work. There are several categories of services that fit this description, but the two that stand out flow are FaaS and workflow automation.
AWS Lambda stands out as the flagship service in Amazon’s serverless portfolio, and serves as a great example of what FaaS can do. By offering trigger hooks in a wide range of their service portfolio, AWS has enabled developers to build a variety of application categories simply by linking a trigger to a function to a sink or another trigger. Want to take action when a new record is added to your DynamoDB data store? There is a Lambda trigger for that. Want to run a function when an API is called in API Gateway? There is a Lambda trigger for that, as well.
AWS has also included triggers for core operations activities in their portfolio. Amazon CloudWatch events allow you to trigger a Lambda function whenever state changes in key AWS resources. For example, if you’d like to fire off a function whenever an error occurs while building a new EC2 VM, you can connect CloudWatch events to their notification services, which, in turn, can call your Lambda function. It’s a very powerful suite of tools.
Of course, Microsoft Azure and Google Cloud Platform (GCP) are also building suites of event-driven services to support serverless programming and operations. Both have FaaS offerings, as well as messaging options that easily link to event flows produced by other services.
Low-code and no-code platforms
A few products have even taken a different approach by reducing or eliminating the need for code altogether. The low-code or no-code platforms instead enable some form of visual design of the execution to take place when an event is detected. For example, low-code real-time application platform VANTIQ uses a flow diagram to link activities triggered by one or more events, as in Figure 4-7.
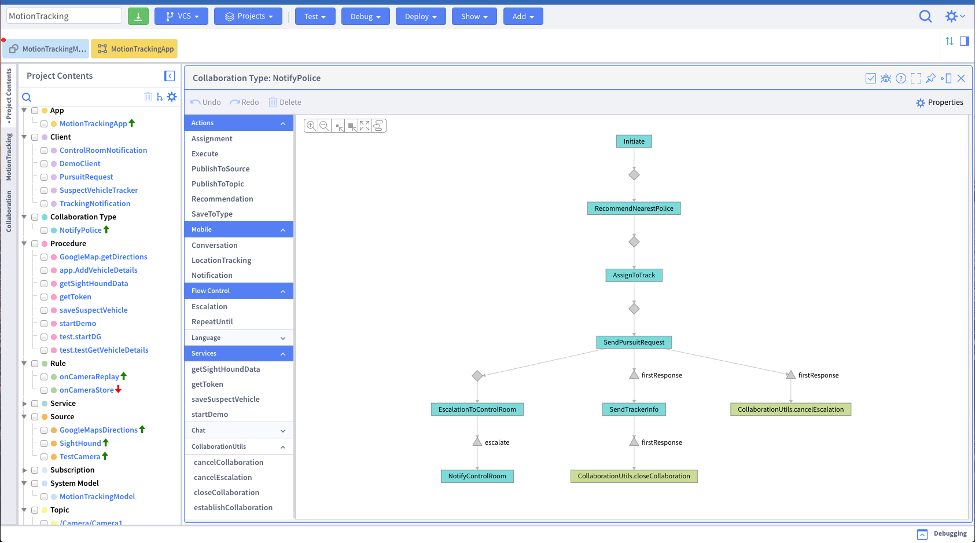
Figure 4-7. VANTIQ Modelo modeling interface
Another event-driven low-code and no-code platform example is Mendix. Both Mendix and VANTIQ are built to integrate with queueing platforms, including both traditional message queues and log-based queues. Most have similar capabilities to build data flow models, which can be used to connect different streaming systems.
It has to be noted that most platforms that call themselves “low-code” or “no-code” are not built for event-driven applications or event processing. The vast majority of vendors claiming these labels are targeting web and mobile applications. However, I believe we’ll see an explosion of competition in the event-driven or “realtime” low-code platform space in the coming three to five years.
Log-Based Stream Processing Platforms
In messaging systems, the event data resides in some form of queue until they can be processed. Consumers simply request the next item from a topic (or possibly from a filtered view of the topic) and process that.
Log-based event processing platforms are a variant of a queueing system in which events are tracked in sequence for an extended period of time. Apache Kafka, perhaps the most recognizable of the streaming platforms on the market today, describes each recorded event as a record which is captured in a topic. (Note the consistent use of the term topic across message queues and streaming platforms.)
In order to handle scale, the topic may be divided by some criteria of the event, such as the first letter of the producer ID that generated the event, or the geographic location from which the event was generated. Interfaces are then provided to allow a consumer to locate the correct partition for the events they are interested in, or to enable reading from the entire topic as a single stream. This approach is depicted in Figure 4-8.
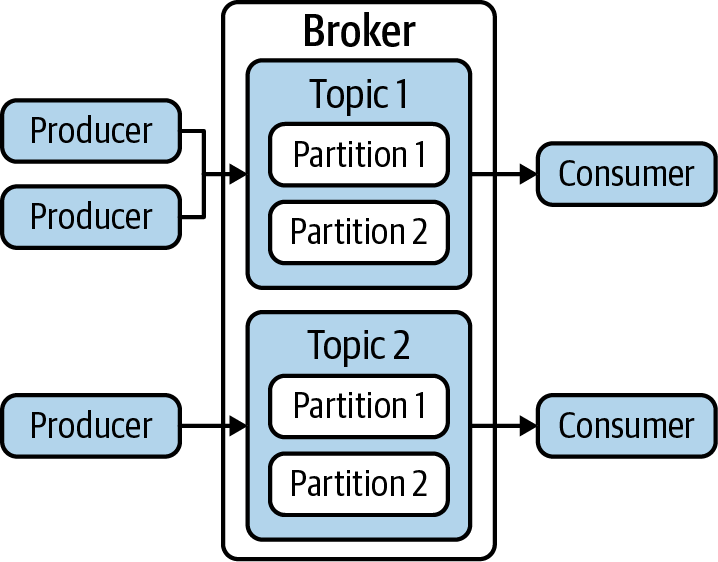
Figure 4-8. Typical log-based event processing architecture
When a producer wants to signal an event, it simply publishes it to a topic, much like any message queue software. However, the record that is created from the event must have a key, a value, and a timestamp. The timestamp is used to maintain the order of incoming events so that when a consumer asks to read from the topic, it has some choices.
If the consumer simply wants to get the latest event, it can certainly do so. However, log-based platforms add the ability to select a point in time in the topic, and read all events that occurred from that point forward. Alternatively, the consumer can specify a starting time and ending time and request all events in that range. It’s kind of like reading data from a tape storage device, if you’ve ever used one. Unlike message queues, events in log-based queues aren’t removed from a topic when they are read. Rather, they are maintained for some specified length of time, and can be retrieved when needed by any authorized consumer.
This has a wonderful side effect: it allows multiple consumers to read from different points in the same topic at the same time, as noted in Figure 4-9. While Consumer A is reading from offset 2, for example, Consumer B can be reading from offset 4. Each consumer is able to determine where they are in a given topic timeline, and to go forward or backward in that timeline if they see fit.
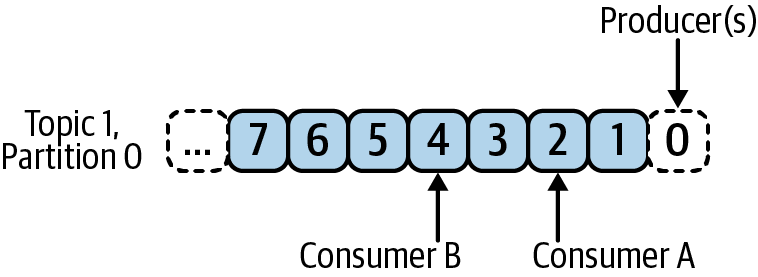
Figure 4-9. Reading events from a log-based queue
Using a queue this way, the topic effectively becomes a system of record for a specified source of activity. And increasingly, developers are using Kafka and its kin as exactly that: a storage system of record through an implementation pattern called event sourcing.
In event sourcing, the record of state for any given entity is represented entirely by the stream of state changes recorded in its topic. If a consumer wants to recreate the current state of that entity, it simply reads the entire log from beginning to end, and keeps track of the new state with every state change. When it gets to the end, it has an absolutely accurate representation of the current state that takes into account every aspect of how that state came to be.
Event sourcing allows developers to rebuild the state of complex sets of entities after a failure (or when restarting a system) without worrying about race conditions or failed database transactions. The log is built to be highly reliable, redundant, and distributed for better performance at scale.
As I noted earlier, Kafka is the most popular log-based event processor today, with others including Apache Pulsar, AWS Kinesis, and Microsoft Azure Event Hubs also implementing the model. Most enterprises doing stream processing use a log-based platform, but that may soon change with the growth of stateful stream processing platforms.
Stateful Stream Processing
An alternative to processing streams as queues or logs is to maintain running a model of system state and build your processing around that model. For example, imagine you run the traffic system in the town you live in, and you want to coordinate traffic light timing based on the current conditions at each intersection. You could use a log-based stream processor and have each intersection send its data to its own topic, and use the processing capabilities to react to state changes in some formulaic way.
However, this has a drawback in that it requires the developer to maintain entity state from event to event, either in memory or in a database, and requires them to maintain the relationships between entities, as well. The active state model doesn’t really reside in the stream processor at all.
In a stateful processing system, an understanding of the problem domain is used to create and maintain a stateful representation of the real world. In our traffic example, the model uses software agents—known as digital twins—to represent the intersections, and a data model to graph the relationships between these agents.
Digital twins are a powerful concept for many reasons. First, they enable agents to be intelligent about what their state means—adding behavior through code or rules models that can be used to communicate with other agents. Second, they enable agents that monitor overall system state to get a more holistic view of the relationships between agents and the resulting behavior.
Stateful stream processing platforms give you a digital representation of your real-world system that is constantly updated by the event stream used to define it. The products in this space today already provide sophisticated ways to find digital twin relationships, share the larger model among agents for broader calculations, and provide redundant ways to ensure state is accurately represented across a distributed computing environment.
Processing can then be handled in a number of ways. For example, Swim.ai, one such stateful event processing environment, builds its model dynamically from the event stream and provides built-in machine learning capabilities that enable both continuous learning and high performance model execution with minimal intervention by developers. EnterpriseWeb, which uses the concept of dataflows to build a processing pipeline based on the model state, is an alternative example.
Mapping Event Processing Platforms
The technologies we discussed for IoT map to our Wardley Map components as shown in Table 4-4.
| Architecture component | Wardley Map component(s) |
|---|---|
| Serverless platforms | Processor Queue Source Sink |
| Low-code or no-code event platform | Processor |
| Log-based stream processor | Processor Queue |
| Stateful stream processor | Processor |
Streaming Architectures and Integration Today
While event processing is a key aspect of flow, the core focus will be using event streaming to integrate activity across organization boundaries. Thus, it’s important to briefly explore how messaging and streaming are being used for integration today.
Most messaging and process automation architectures used today were designed to enable disparate, loosely coupled software entities to interact with each other. ESBs, message queues, integration Platform-as-a-Service (iPaaS) providers, and many other integration platforms have ecosystems of connectors and other integration tools that support a wide variety of commonly used enterprise software, public cloud services, and message sources.
Since the mechanisms are similar, I thought I’d briefly discuss the ways in which platforms support integration ecosystems. What I describe here (as a high-level abstraction) is pretty much what is used today in all of the event-driven queues and processors that support direct integration to other software products and services.
Recall the overview of contextual versus composable systems in Chapter 1. The most common integration approaches today are contextual. This means that the platform offers a specific mechanism by which developers can extend the platform to support integration with their products. These mechanisms typically only support integration for specific functions of the underlying platform. For most platforms, this typically includes at least ingress and egress processing of messages.
Figure 4-10 is a simple model of a process automation platform, like Dell Boomi or MuleSoft, that supports using connectors to enable external applications to trigger a process (ingress processing), take action at any process step (intermediate processing), and fire an event to an external system at the end of the process (egress processing). Note that the connector is a software component—usually an executable or a library—that is called when the appropriate platform function executes. Typically, these connectors are only called when the platform is explicitly configured to use a connector for that action.
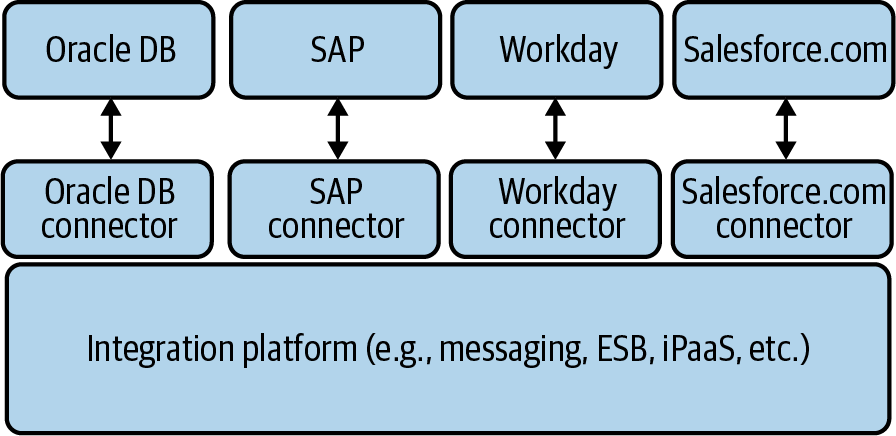
Figure 4-10. Connector architecture for integration platforms
This looks similar to the diagram of an enterprise service bus we saw in Figure 4-2.
If you have been a user of a service like If This Then That (IFTTT), you have experienced using a collection of connectors for different systems to create a process. IFTTT has a huge library of connectors from hundreds of software and consumer product companies to allow users to automate everyday life. For example, they describe how connectors from Litter-Robot, a self-cleaning litter box, can be linked with connectors from robotic vacuum vendors, like iRobot, to activate the vacuum immediately after a cat is detected leaving the litter box. (As a geeky former cat owner, I think that’s ingenious.)
Connectors are a desirable approach for platform vendors because they enable consistency in the way an ecosystem is formed and marketed. By controlling who and what can extend your platform, you can control brand, market fit, and utility. You can also avoid many of the weird, unanticipated uses of the platform that a more composable approach would offer.
However, not all integration use cases benefit from a connector approach. We talked about the Linux command line when I described composable systems—Linux utilities can be linked together in arbitrary ways through the operating system’s pipe feature. With this approach, a developer has to build a process by connecting the utilities in the right way. It’s more work in the sense of the developer needing to set all context and configuration for a process to work, but it is also infinitely more flexible to unanticipated needs.
Composable systems generally don’t appear in commercial platforms, as those platforms attempt to remove work by predefining key processes or elements of process automation. This is why, I believe, you don’t see a lot of composable event-driven ecosystems, though if you look at the AWS serverless ecosystem, that may be changing fast.
While we will have connector-based architectures for many years to come, the rise of assembling solutions using events and serverless technologies promises to shift the attention from connector-based platforms to other forms of integration, such as specialized functions and services. This move is positive for those who will develop flow systems, as there is both less to manage and more flexibility in the solutions you develop.
Figure 4-11 shows a more composable integration environment.
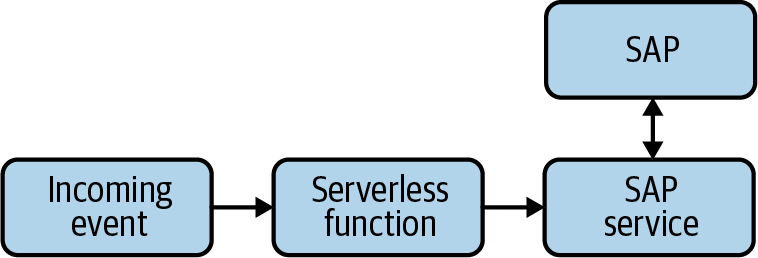
Figure 4-11. Integration through a composition of a serverless function and a specialized service
Next Steps
In the end, there is no “right” or “wrong” way to process or integrate streams, as long as the event processor can handle the pace and volume of data being provided to it by producers. Some forms of event processing are better for certain uses than others, however, so it is important to understand the strengths and weaknesses of each.
In Chapter 5, I will discuss some of the ways that these technologies will evolve in light of flow, and some of the ways in which we will see flow emerge in the technology ecosystem. I’ll use our Wardley Map to explore the ways in which flow’s components will evolve, look at the requirements we captured in Chapter 2 to explore how major gaps will be filled, and describe a number of architectural patterns that I believe will define flow architectures over the next decade or so. Then, in Chapter 6, I will go through the things your organization can do today to identify opportunities for flow, and create software systems ready to integrate into the WWF once those interfaces and protocols are defined.
1 According to the 2019 Eclipse IoT Developer Survey, 49% of respondents were using HTTP versus 42% using MQTT.
Get Flow Architectures now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

