Chapter 1. Introduction to Flow
At the time of writing this, the world is in crisis. The COVID-19 pandemic has disrupted just about all aspects of our personal and professional lives, and there are severe challenges in getting the pandemic contained. While we can take a number of personal actions, such as wearing masks and washing our hands, there is plenty of evidence that shows real containment requires real-time cooperation among communities, countries, and humanity as a whole.
I hope that by the time you read this, the crisis has passed, and you are back to gathering with friends, family, and even total strangers to enjoy the incredible experiences we have created for ourselves as a species. However, the relative success in containing the virus in countries like Malaysia and South Korea demonstrates that other countries struggling with containment could shorten—or at least lessen—the crisis in part with better tools and programs for activities like contact tracing and resource distribution.
Those two examples in particular—contact tracing and resource distribution—are examples of activities that require real-time data coordination worldwide. COVID-19 knows no political or geographical boundaries. Its spread is dictated by the movement of people. To contain it—and support the medical community’s response—we must understand where and how people are moving and making contact with each other. And we need to know that as close to when it happens as possible.
We can’t quickly create tools to share data in real time in part because there are no consistent mechanisms to do so. Each software system involved in generating or processing the necessary data has its own way of making data available to other systems, including how those systems request or receive the data, and how the data is packaged.
For example, mobile applications can use Bluetooth connections to capture information on those we’ve had contact with. However, getting that captured data to agencies coordinating a response to positive COVID-19 tests requires those agencies, cellular network companies, and phone manufacturers to negotiate the means and the terms for data sharing. Even when everyone is motivated to solve the problem, that can take weeks or even months.
Resource coordination should be easier, but every manufacturer, distributor, and hospital system has systems that are disparate and cannot share data easily. In the early days of the pandemic, finding supplies was done by human beings; first by searching the websites of distributors and manufacturers, then by briefly resorting to personal contacts and professional networks when that wasn’t fruitful. There have been several cases of fraud1 related to personal protective equipment sales, as organizations have found themselves more and more desperate for large amounts of highly contested resources.
This book is not about COVID-19, or the response to COVID-19. It is about technologies that are evolving toward a better technology ecosystem for solving these problems and a myriad of others. This book is about an evolution toward interfaces and protocols that make the integration of real-time event streams standardized and common. This is a book about flow.
As more and more of our businesses and other organizations “go digital,” more and more of the economic interaction between them is digital. Financial transactions are executed in their entirety without human intervention. Inventory ordering is sized and timed by computers projecting production demand. The security of our food supply increasingly relies on producers, shippers, and wholesale and retail operators maintaining a digital “chain of evidence” that is difficult to spoof.
The groundwork is in place to fundamentally change how real-time data is exchanged across organization boundaries, whether in business, government, education, nonprofits, or even our personal lives. Advances in event-driven architectures, stream flow control, and early attempts at standardizing event metadata are slowly converging on establishing a well-defined mechanism to do so.
Custom examples of the value of this type of integration can already be seen in real-time inventory management in retail and machine automation systems in factories. However, because each interface is different, each protocol defined for a specific use, there is uncertainty and expense involved in executing event-driven integration across our economy.
The hypothetical article you read before I began this chapter is an example of what the world might be like if you removed much of this expense. When you lower the expense of utilizing a key resource, you open the door to experimentation and innovations that would otherwise have been cost prohibitive. The innovations described in the article demonstrate advancements in key parts of how our economy works, and hopefully paint a picture of how flow might create an explosion of new opportunities for business and real-time cooperation between disparate institutions.
If flow was in place before this pandemic started, we might have seen a different response. Once contact tracing data was captured, it could have easily been shared with anyone who was authorized to use it. Real-time data from different brands of smartphones and other disparate sources could have been more easily combined to create a holistic view of a person’s contact risks. The up-to-date inventory data of every supplier of medical equipment could quickly have been combined into a single view of national or even global supply. As new providers of masks, face shields, and other critical equipment started producing goods, they could have added their data to that inventory without having to develop code to manage the connections, data packaging, and flow control needed to do so.
Let’s begin our exploration of the future where real-time data sharing is ubiquitous with an overview of flow, and why it will likely have a significant impact on the way our economy works. We’ll start by defining flow, describe a few key properties of flow, and walk through why flow is an important change to the way organizations integrate via software. I’ll give a few examples of how flow might be used, and summarize the mechanisms that need to be in place to support those use cases. We’ll then outline the key topics we’ll cover in the rest of the book.
What Is Flow?
Flow is networked software integration that is event-driven, loosely coupled, and highly adaptable and extensible. It is principally defined by standard interfaces and protocols that enable integration with a minimum of conflict and toil. To my knowledge, there is no universally agreed upon standard to do this today. However, we shall see that flow will drive fundamental changes to the way we integrate businesses and other institutions. I also argue that it is inevitable.
This definition leaves a lot to be desired in terms of the mechanics of flow, so let’s define some key properties that differentiate flow from other integration options. In information theory—which studies the quantification, storage, and communication of information—the sender of a set of information is called the producer, and the receiver is known as the consumer (the terms source and receiver are also used, but I prefer producer and consumer). With this in mind, flow is the movement of information between disparate software applications and services characterized by the following:
Consumers (or their agents) request streams from producers through self-service interfaces
Producers (or their agents) choose which requests to accept or reject
Once a connection is established, consumers do not need to actively request information—it is automatically pushed to them as it is available
Producers (or their agents) maintain control of the transmission of relevant information—i.e., what information to transmit when, and to whom
Information is transmitted and received over standard network protocols—including to-be-determined protocols specifically aligned with flow mechanics
Flow allows an information consumer to locate and request data from independently operated information producers without requiring those producers—or agents that manage flow on the producer’s behalf, such as serverless cloud services or network services that manage flow—to know of the consumer’s existence ahead of time. Flow also allows producers (or agents working on their behalf) to maintain control over the format, protocols, and policies by which the information will be shared.
Note
There are many technologists involved in event-driven systems that would argue that producers and consumers should be decoupled from the systems that manage the connection mechanisms, event routing, and other elements involved in transmitting data between parties. The “agents” in our definition of flow represent the variety of external services that might take various actions—e.g., policy management, network optimization, or generating telemetry—on behalf of producers and consumers. As we don’t know for sure what form flow will take, for now I will use the term producers to mean both the producer and any agents acting on their behalf, and consumer to mean the consumer and any agent acting on their behalf.
Flow is only valuable if there are services and applications that prepare the data for streaming, consume the stream when received, or otherwise manipulate the streams. We call the act of processing data on either side of the flow connection flow interaction. The importance of the relationship between data flow in a general sense and interaction was first introduced to me in 2016 by Mark Anderson, CEO of Strategic News Service. As he told me then, without interaction, flow is just the movement of data. Value is created by interacting with that flow.
Flow and flow interaction depend on the ability of consumers to receive data passively and respond only to pertinent signals. In the technical world, the signals we care about typically represent some sort of state change—the creation or updating of some form of data somewhere in the system. For example, a sensor might signal that a key temperature in a manufacturing process has increased, or a stock market might signal that the asking price for a given stock has changed. Those are fairly well-known, fine-grained signals. Signals of larger, less frequent state changes are also interesting, such as a truck indicating it now has available cargo capacity, or even a business signalling its intent to file for an initial public offering.
Before I go further, I should define a couple of terms I’ve already used to make sure there is no confusion. When we package the information about that state change with some additional context (such as the time the change took place, or an ID associated with what changed), we call that an event. The producer that captures and packages that information will then publish the event for eventual consumption by consumers. The transmission of a series of events between two parties (e.g., the producer and the consumer) is called an event stream.
It is important to note that there are two different ways that data can be streamed on a network, as shown in Figure 1-1.
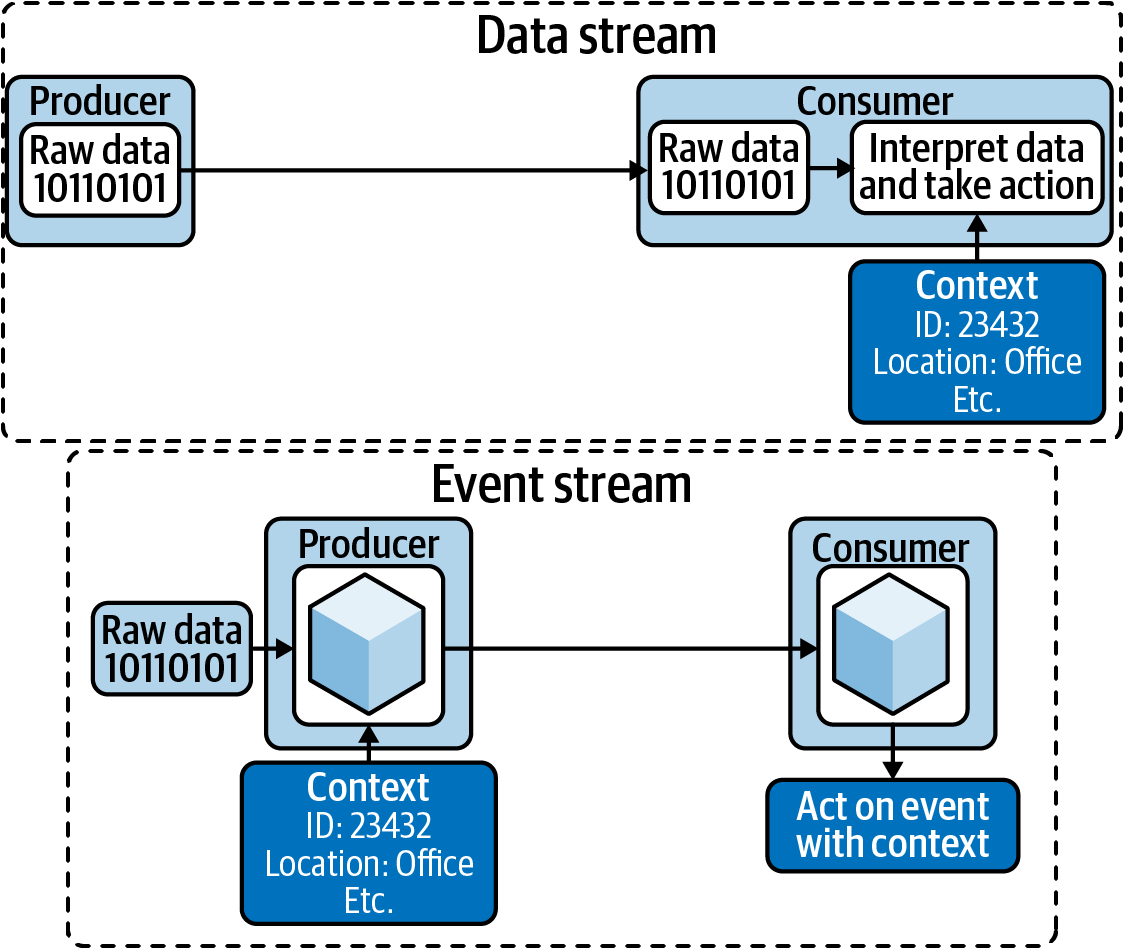
Figure 1-1. An event stream versus a raw data stream
The first way is to simply send each piece of data as it comes directly on the network without adding any context. This raw data stream requires the consumer to add context when it receives the data. This can be done based on knowing the source of the stream (e.g., the data came from a specific sensor), looking for clues in the data stream itself (e.g., the data contains representations of its source location, such as pictures from a camera), or capturing a timestamp from the consumer’s own clock to identify roughly when a state change occurred.
The second way is for the producer to assure there is contextual data packaged with the state change data itself. In my view, this is what turns a data stream into an event stream. The context included with the transmitted data allows the consumer to better understand the nature of that data. It greatly simplifies the work the consumer has to do to understand when and where the event occurred.
While technically flow could work on both raw data streams and event streams, I believe events will dominate streams used to integrate systems across organization boundaries. As such, you will see me focus mainly on event streams for the rest of the book.
In any case, the consumer must be able to connect to the producer, and to interpret any data they receive. The producer must be able to publish any available data, and understand how to send it in a format the consumer can consume. As with any integration in software, two things are required to achieve this: the interface by which the consumer can contact and initiate a connection with the producer, and the protocol by which the producer and consumer agree to format, package, and transport the data.
Flow and Integration
Event and data streams across institutional boundaries are especially interesting to me, as they play a key role in how our economic system evolves. We are quickly digitizing and automating the exchanges of value—information, money, and so on—that constitute our economy. We also spend considerable time and energy making sure we can execute key transactions with less human intervention, and with better, faster, more accurate results.
However, most of the integrations we execute across organizational boundaries today are not in real time, and they require the use of mostly proprietary formats and protocols to complete. There are still a lot of “batch” exchanges of data, such as depositing text or media files into someone else’s filesystem or cloud storage, which must then be discovered and read at a later time by the consumer. Without a mechanism to trigger an action as soon as a file arrives, the consumer may choose to wait until a specified time of day to look for and process files. Alternatively, they may poll to discover files every so often (say, every hour). With batch processing, there is a built-in delay between sending a signal and taking action on that signal.
Some industries have settled on data formats for exchanging information between companies, such as electronic data interchange (EDI) records. However, those are limited to specific transactions, and represent a fraction of all organizational integrations. Even where application programming interfaces (APIs) exist for streaming, which can enable action as soon as the signal is sent, those APIs are largely proprietary for each offering. Twitter, for example, has a widely used API for consuming their social media streams, but it is completely proprietary to them. There is no consistent and agreed-upon mechanism for exchanging signals for immediate action across companies or industries.
Today, cross-organization integration—especially real-time integration—is a “do it yourself” exercise. Developers find themselves having to put a lot of work into understanding (or even defining) the plumbing by which they exchange data. Producer and consumer have to resolve fundamental concerns around network connectivity, security, flow control, and more just to pass a simple data set between them. And, if they wish for a real-time data exchange, they have to hope that the source of the data has created an API and protocol that is easily consumable. It’s expensive to integrate real-time data today, so that process is reserved for the most time-critical data.
Now consider what will happen when event streams are created and consumed through a well-known mechanism. Every developer would know how to publish, find, and subscribe to event streams. Furthermore, if the protocols for encoding and transmitting this information are equally well understood, every developer could interact with event streams in whatever development languages and platforms developers choose. Libraries and services could exist that eliminate most, if not all, of the toil required to produce and consume arbitrary event streams. The cost of real-time integration would drop precipitously, and a world of innovative new uses for streams would commence.
In order to support the ever-changing structure of human interaction, flow architectures must be designed to be asynchronous, highly adaptable, and extensible. It must be straightforward for consumers to connect to and consume a stream (as demonstrated in Figure 1-2). Consumers must also be able to close those connections at will. Any single consumer’s connection activity must not negatively affect any producer’s ability to operate. These requirements require the producer to be decoupled from the consumer as much as possible, which may encourage the evolution of a separate set of services to handle flow on their behalf.
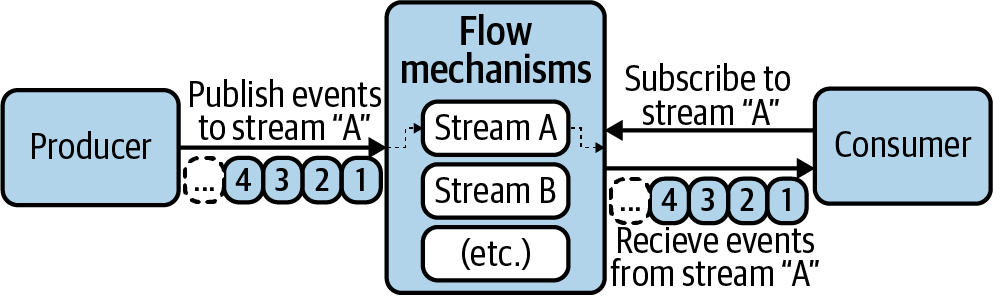
Figure 1-2. Simple example of flow
Furthermore, adaptability requires that new technologies be easily introduced into the flow ecosystem, and that consumers and producers are able to choose from those technologies as their requirements dictate. There are a lot of variables involved here, and as a result it will take time for such a flow ecosystem to develop.
Flow creates immense opportunity for creative innovation in how we tie activities together across disparate domains. A flow of real-time particulate data from smart city sensors, for instance, could be combined with personal biometric data to help you understand which particulates are most detrimental to your health or athletic performance. A flow of weather model data combined with traffic data and shipping demand data might help a logistics company optimize package routing. Your personal skills profile might be built from inputs provided by your employers (past and present), your educational institutions, and even your ebook application and YouTube. And you might signal gaining new skills right back to your employer’s HR system, which may then signal the change to managers interested in those skills.
The thing is, this is only an infinitesimal fraction of the possibilities fluent architecture will open for developers and entrepreneurs. The more streams there are from more sources, the more flow consumers will be drawn to those streams and the more experimentation there will be. This experimentation will lead to new ways to combine that data to create new value.
Note
In the article presented before this chapter, I presented numerous examples of how cloud might enable new business integrations. There are four fictional projects in that example that I will refer back to from time to time. Those companies or government programs each represent a flow pattern that I will discuss in more detail in Chapter 5. However, they are also useful as examples of concepts presented elsewhere in the book.
A brief summary of each is presented in Table 1-1 so that you will have some context when I discuss them elsewhere.
| Company or Program | Pattern | Purpose |
|---|---|---|
| WeatherFlow | Distributor | A fictional service offered by the United States National Weather Service to deliver minute-by-minute updates to current and predicted weather for almost every populated area on the planet. WeatherFlow is an example of a flow interaction that takes events generated from just a few models and broadcasts them to thousands or millions of consumers. |
| AnyRent | Collector | A fictional startup that has built one of the most successful online rental businesses in the world without owning a single piece of inventory. It does this by gathering available rental data from almost every major rental company in the world, and providing a single virtual inventory to customers. AnyRent is an example of a company that collects data from hundreds (perhaps even hundreds of thousands) of producers, and generates a consolidated event stream or user interface for downstream consumption. |
| Real Time Economy (RTE) | Signal Processor | A fictional service provided by the United States Federal Reserve Bank that collects relevant economic data from tens of thousands of sources, does deep economic analysis on that data, then—based on the results of that analysis—sends events to relevant subscribers, including the press, financial services companies, and other organizations. RTE is an example of a service that processes incoming event streams to find signals that require action by others that then receive an event to that effect. |
| LoadLeader | Facilitator | LoadLeader is a fictional shipping consolidator that has figured out how to quickly match available room with partial-load shippers with small cargo lots from businesses all over North America. This has led to new forms of cargo being made available to these shippers. LoadLeader is an example of a service that matches supply and demand as quickly as possible through flow processing. |
The pinnacle of fluent architectures will be when any source of activity data can be connected to any authorized software that can create value from that data. Over time, organizations will find new ways to tie activities together to generate new value. Like water finding its path downhill in search of sea level, activities will find their way to value. A growing graph of activity flow will emerge, with activity data being interpreted, combined, and often redirected to new consumers. This global graph of flowing data, and the software systems where that data is analyzed, transformed, or otherwise processed, will create an activity network that will rival the extent and importance of the World Wide Web.
This global graph of activity is what I call the World Wide Flow (WWF). The WWF promises not only to democratize the distribution of activity data, but to create a platform on which new products or services can be discovered through trial and error at low cost. And the WWF promises to enable automation at scales ranging from individuals to global corporations or even global geopolitical systems. It doesn’t replace the World Wide Web, which is a similar network of linked knowledge. Instead, the WWF will often be intertwined with the Web, adding to the ways the internet is making our global world a little smaller.
Flow and Event-Driven Architectures
It stands to reason that not all digital information exchanged over a network is flow. For example, traditional methods of requesting information synchronously via a “request-response” API would not meet this definition. In those interfaces, the consumer may initiate the connection, but the producer is required to send information only when the consumer requests it. And the consumer has no indication of the availability of data before they make a request, so data generally cannot be delivered in real time.
For the first six decades or so of business computing, the speed and manner that information could be passed between institutions was limited by the available technology. Shipping data on paper, punch cards, or tape—clearly not real-time methods—was the first way digital data was exchanged between organizations. Networking technologies, such as the TCP/IP networks that make up the internet, revolutionized the way this data was shared, although network-based integration across company boundaries didn’t really take off until the growth of the internet in the 1980s and 1990s.
Early long-distance computer networking technologies suffered from so many performance limitations that data was rarely shared in real time. Businesses instead depended on “batch” approaches, where large sets of data were packaged into one artifact that was shared with another party, who then processed it as a single unit of work. Today, most—perhaps all—digital financial transactions in the world economy still rely on batch processing at some point in the course of settlement. Real-time integration was rare until the new millennium began.
Today, we increasingly see real-time integrations take place through API-based models. There are two such models: consumers can make API calls to producers requesting current state, or producers can make API calls to consumers to send real-time data when some agreed-to condition is met. The former has similar problems that batch processing has: the consumer must either send API requests nearly continuously or schedule API calls at a rate that delays the “real-time” nature of the data.
The latter (where the producer calls the consumer) is an excellent pattern for integrations in which there is a triggering action at the producer (e.g., a user clicks a button to start the transaction) and the consumer service is known ahead of time. However, this requirement—that the consumer and their needs be known ahead of time—is what limits the use of this pattern in commercial integrations. It is expensive for the consumer to negotiate a connection with the producer, and then implement an API endpoint that meets their expectations.
Because of this, neither API model has enabled the rapid evolution of real-time integration. It is still extremely rare for a company to make real-time data available for unknown consumers to process at will. It is just too expensive to do so. There are exceptions, however, such as Twitter, though even they limit the volume and types of data that can be freely consumed.
What promises to change the status quo is enabling low cost, simplified real-time data integration. This is why modern event-driven architecture (EDA) will enable profound changes in the way companies integrate. EDAs are highly decoupled architectures, meaning there are very few mutual dependencies between the parties at both ends of the exchange. EDAs meet the requirement that producers do not need to know the location or even existence of consumers. Consumers initiate all connections with a producer (or agent of a producer), and if a producer disappears, consumers will simply stop receiving events.
EDA is the set of software architecture patterns in which systems utilize events to complete tasks. For the sake of simplicity, I will sometimes include the use of data streams to communicate activity when I mention EDA, but acknowledge that not all uses of data streams meet the definition of flow, and data streams are not technically transmitting events. While there are some important differences between the two stream types, much of what is discussed in this book applies equally to both.
This book will discuss EDAs at length, but it is not intended to be an expert guide on the subject. Instead, we will explore the nature of several EDA patterns with an eye to how they inform critical properties of flow. They will also serve as baselines as we explore the ways in which EDAs may evolve to create fluent architectures.
It is also important to note that EDAs and flow do not remove the need for any aspect of today’s distributed application architectures, but merely add a new, powerful construct to connect activity in real time. The concept of composability is important here. Composable architectures allow the developer to assemble fine grained parts using consistent mechanisms for both inputting data and consuming the output. The “pipe” function (represented by the “|” symbol) found in various Unix and Linux shells is a great example of this. Developers can solve extremely complex problems by assembling collections of commands, passing only common text data between them through a pipe. The immense world of scripts that parse and manipulate text files—such as log files or stack traces—are a testament to its power. So is the growing library of shell script automation tools used in computer operations.
The analog to composable architectures is contextual architectures. In contextual architectures, the environment provides specific contexts in which integration can happen. To use these integration points, the developer must know a lot about the data that is available, the mechanism by which the data will be passed, the rules for coding and deploying the software, and so on. Software plug-ins, like those used in music recording applications or web browsers, are examples of contextual architectures. While contextual architectures are extremely useful in some contexts, they can be awkward to use and are frequently restrictive in unwanted ways.
EDA is a loosely coupled method of acquiring data where and when it is useful, like APIs, but its passive nature eliminates many time- and resource-consuming aspects of acquiring “real-time” data via APIs. EDA provides a much more composable and evolutionary approach to building event and data streams. These seemingly small differences are surprisingly important.
The Ancestors of Flow
There are plenty of examples of real-time data being passed between organizations today, but most aren’t really flow, as defined here. Generally, existing streaming interfaces are built around proprietary interfaces. The APIs and other interfaces that exist are generally designed by the producer for their purposes only, or are being utilized for a specific use case, such as industrial systems. Furthermore, connecting to a stream (at least initially) may not be “self-service” in the sense that completing the connection requires human interaction with the provider.
Among the most visible examples of this are the live stock market feeds that are consumed by, among others, high-frequency trading systems (HFT). Examples include NASDAQ’s long list of trading protocol options and NYSE Pillar, which supports a binary protocol and the Financial Information eXchange (FIX) protocol. Both exchanges use specialized integration interfaces that are built for speed and scale, and usually involve connecting directly to a specified port on a specific server IP address at the exchange.
This low-latency architecture is critical for the success of HFT. HFT accounts for anywhere between 10–40% of equities trades in the world today, and is credited with increasing market liquidity (as well as creating new sources of volatility). HFT is made possible because of the introduction of electronic trading in the early 1980s. Today’s HFT systems are highly automated trading algorithms that profit by discovering trading opportunities faster than both other HFT systems and human traders.
This requires speed, which is why most HFT systems are physically hosted in the exchange data centers, and are directly connected to the exchange servers to minimize network latency. While HFT systems can execute trades, they do so in response to a steady stream of stock or other tradable instrument ticker information. The direct network connection to the trading system enables HFTs to receive pricing data and issue instructions through that connection, and rely on it to capitalize on arbitrage opportunities before others beat them to it.
However, the connection between the traders and the market system is explicitly negotiated between the parties before the dedicated network connection is used to send the data. There is no self-service interface for the consumers (the HFT systems) to connect to the producer (the exchange or market). This is in contrast to our flow definition, in that consumers cannot create and destroy connections at will. Instead, the producer is very aware of each and every HFT (or other consumer of its data), as they have to open a port on their exchange server to establish the connection.
The point is, there is work that has to be done by the producer (e.g., opening network ports and establishing security credentials) directly on behalf of the client. Set up requires coordinated action by both parties, which means a business relationship has to be established before a prospective HFT can experiment with the exchange’s feed. Furthermore, the HFT must understand the producer’s mechanisms for receiving and interpreting data, which may vary from producer to producer. This creates implementation friction, which increases both the cost and timetable to establish a new connection. A flow architecture would eliminate most of this friction.
Another example is Twitter’s PowerTrack API. The Twitter community generates over 500 million tweets per day, which is a reasonably large data stream.2 But it’s also an overwhelmingly valuable data stream, and Twitter’s customers consume it for a variety of purposes, including customer sentiment analysis, advertising evaluation, and discovery of breaking news events. PowerTrack allows consumers to filter the data stream at the source, targeting only the tweets that are relevant to its analysis. (For example, the retailer Target might filter a stream to only contain tweets with their brand name in the text.)
Like with stock streams, use of PowerTrack requires consumers to come to an arrangement with Twitter before they can begin using the product. However, in this case there is very little set up required by Twitter to support each new customer. In fact, in this sense, PowerTrack is very much like what I envision will be the case for flow: the consumer requests a stream via an API call, and Twitter opens a connection with that consumer through which the data streams in.
There is an important difference between Twitter and the stock market feeds that should be noted here. Twitter enables developers to create and destroy connections at will, while the stock market feeds are set up with the intention to maintain the connections at all times. Connections are not created and destroyed at will in the latter case. The reason for this has mostly to do with time sensitivity (and, perhaps to a certain extent, the era in which the technology was engineered). With the stock feeds, microseconds matter, so the data feeds must be set up with a minimum of intervening processing or routing. With Twitter, the standard speeds of the open internet are fine, so developers prefer the ubiquity and flexibility that its API approach offers.
This is, I think, a clue to the diversity of use cases that the WWF will have to support, which we will explore in Chapter 2.
Code and Flow
If we are looking at the basis for flow, we have to look at one other key trend that is setting the stage. “Serverless” programming is dependent on the flow of events and data through a system. The increased adoption of managed queuing technologies such as Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Google Cloud Pub/Sub, combined with the rapid growth of functions as a service (FaaS) code packaging and execution, such as AWS Lambda and Microsoft Azure Functions, is a true signal that flow is already in its infancy.
Amazon Web Services (AWS) was one of the first to the serverless programming paradigm, and is perhaps still the most complete ecosystem to watch the birth of flow in action. The linchpin of the AWS serverless story is its FaaS offering, Lambda. Lambda allows developers to simply “run code without provisioning or managing servers,” which is important, because it removes most of the operational set-up toil from running custom software.
Simply write your function, configure a few things about dependencies and connectivity, deploy, and it runs each time an applicable event is fired. And, much like offerings from competitors like Google and Microsoft, consumers only pay for the time the code runs. If the code is idle (not being used), the developer pays nothing.
AWS is one of many who see this “serverless” model as being the future of application development. By eliminating as much of the toil of application configuration and deployment as possible, using a model that is highly composable and offers a wide variety of service options, the belief is that developers will have little reason to turn to more traditional architectures for the majority of software tasks.
However, just introducing Lambda to developers wasn’t enough to attract those developers to the platform. AWS needed a way to give developers a reason to try the service. They came up with a brilliant idea. They created triggers in many of their own core operational services, ranging from software build automation to data stores to API gateways and more. Developers were then able to write custom Lambda functions to respond to triggers from any of the supported services.
The result is that developers and operators running applications on AWS are able to easily automate activity based on real-time events simply by writing and deploying code. No servers, no containers, no using APIs to determine if the code should fire. Just set it and forget it.
Thus, in addition to being an easy to operate application platform, AWS Lambda became a scripting environment for using their other cloud services. The uptake has been tremendous, and AWS keeps adding new triggers for new use cases, which in turn draws in more and more developers. Once these developers see the value of the serverless portfolio, they start dreaming up ways to write applications using this model.
There are many experienced distributed systems professionals who believe the future belongs to some form of serverless programming, as it minimizes friction for developers while being able to scale running applications and services from zero to vast numbers. Given its event-driven approach, the serverless model also looks to be a key foundation for the future success of the WWF. It provides a low-cost, low-toil way to interact with event streams, using a model that fits the flow definition nicely. Function developers can link the function to event producers as they see fit (and as authorized), which meets the criteria that consumers control connectivity. Meanwhile, producers maintain control of the flows themselves. This both greatly reduces the amount of effort required to consume events, as well as boosts the number of use cases to which fluent architectures apply.
The Chapters Ahead
Understanding why flow is all but inevitable starts with understanding why businesses would want to integrate via events and data streams. Without creating value for business or society, there is no reason for systems to evolve in the direction of real-time activity processing. So, Chapter 2 will focus on why businesses, governments, and other institutions need to adopt flow dynamics.
We will start by exploring the key drivers for flow adoption: customer experience, operational efficiency, and innovation. We’ll then explore how flow changes the metaphorical math to enable its adoption, namely by lowering cost, increasing flexibility, and delivering more choices. Finally, we’ll ask how flow adoption might change the way organizations cooperate, and the positive and negative effects of that change.
Once we’ve established the evolutionary drivers for flow, we’ll step back to take a look at a value chain for flow integration. To do this, Chapter 3 will take our first look at Wardley Mapping. Wardley Mapping is a visualization technique for gaining situational awareness about technology usage and evolution. We’ll start by building a value chain, then use another modeling technique, Promise Theory, to validate the cooperative relationships between our components. With a validated value chain in hand, we will then map each technology component to its general evolutionary stage.
There is actually a surprisingly diverse landscape of solutions available today that lay the groundwork for flow, but our value chain will simplify flow’s needs to 14 key components. Those components cover the key needs of both flow transmission and flow interaction, and form the basis for analyzing the current EDA market.
In Chapter 4, we’ll walk through some basic concepts behind today’s event-driven systems marketplace, including key platforms and services that are in use by enterprises and other institutions. We’ll evaluate service buses and message queues, the Internet of Things (IoT), and event processing platforms as they exist today.
In Chapter 5, I’ll execute some speculative game play on the Wardley Map we created in Chapter 3. How might the components we have identified evolve from where they are today? For the elements that don’t have good solutions, where might they come from? Who might be the likely sources of critical interfaces and protocols required to move beyond purely custom stream integrations?
We’ll discover the importance of both open source software solutions and large scale cloud providers to the future solution. We’ll also discuss several integration patterns that are being worked on by companies today that will likely have significant influence on the way real-time events flow in the future.
In Chapter 6, I’ll give some suggestions for how institutions can begin to prepare for integrating into the WWF. While I honestly believe we are looking at a five- to ten-year timeline for flow to become mainstream, I also believe it is vitally important to architect and build our software to take advantage of flow today. It is critical for institutions to adopt the development, release, and operations practices that will enable them to take advantage of the rapid experimentation that flow will offer. Obviously, predicting a complete, detailed, and accurate picture of what flow will look like is impossible. However, understanding the “shape” of what is to come will be hugely advantageous to those who wish to take advantage of it.
The book will conclude with an Appendix A that can serve as a simple survey of the diverse products and services available to deliver the component promises in our value chain. This is not by any means an exhaustive list, but I do believe that it will give a fair overview of the different approaches vendors and open source projects are taking toward solving common streaming problems. For those wishing to have a better understanding of what forms the genesis of flow evolution, it should be an insightful list.
1 The Federal Trade Commission filed suits against three such companies in August 2020.
2 There are much larger data streams out there. I know of systems, such as cellular phone networks, that generate petabytes of data a day. To contrast that, Twitter streams data on the order of terabytes a day. A terabyte is 1/1000 of a petabyte.
Get Flow Architectures now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

