Kapitel 1. Microservices verstehen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wenn du dich noch nicht mit Microservices auskennst, bekommst du in diesem Kapitel eine solide Grundlage dafür, was sie sind, wo sie ihre Vorteile haben und wo sie Herausforderungen darstellen. Außerdem gehe ich auf das Ökosystem ein, das mit Microservices einhergeht - die Technologien, die diese Architektur ermöglichen.
Beginnen wir damit, zu definieren, was Microservices sind.
Microservices sind unabhängig voneinander freigebbare Dienste, die um eine Geschäftsdomäne herum modelliert sind.1
Die Modellierung von Microservices um eine Geschäftsdomäne herum führt zu einer engeren Abstimmung zwischen Geschäft und IT und bedeutet, dass die meisten Änderungen innerhalb eines Microservices stattfinden, so dass dein Team die vollständige Kontrolle über die Änderung hat. Mit anderen Worten: Eine kostspielige Koordination kann vermieden werden.
Unabhängig freigebbare Dienste zu haben bedeutet, dass du eine Änderung freigeben kannst, sobald sie fertig ist. Normalerweise passiert das mehrmals am Tag.
Die Trennung zwischen diesen Diensten gibt den Teams mehr Möglichkeiten: Sie können in Bezug auf die verwendete Technologie flexibler sein, sie können Dienste mit unterschiedlichen Robustheitsgraden aufbauen und sie unabhängig voneinander skalieren. Diese Flexibilität macht auch Veränderungen einfacher, da die Ingenieure Probleme lösen können, wenn sie auftauchen.
All diese Aspekte bedeuten, dass Microservices den Teams die Möglichkeit geben, schnell zu handeln.
Definition des Microservices-Architekturstils
Gehen wir über eine Definition dessen, was Microservices sind, hinaus und betrachten wir eine Definition des Microservice-Architekturstils . Eine Microservice-Architektur besteht aus vielen Microservices, die über das Netzwerk miteinander kommunizieren, was bedeutet, dass es sich um eine verteilteArchitektur handelt.
Hier ist, was James Lewis und Martin Fowler in ihrem Artikel aus dem Jahr 2014 schrieben, in dem sie die damals neue Art der Architektur vonSoftwaresystemen definieren wollten:
Der Microservice-Architekturstil ist ein Ansatz zur Entwicklung einer einzelnen Anwendung als eine Reihe kleiner Dienste, die jeweils in einem eigenen Prozess laufen und mit leichtgewichtigen Mechanismen kommunizieren.... Diese Dienste sind um die Geschäftsfunktionen herum aufgebaut und können unabhängig voneinander durch vollautomatische Bereitstellungsmaschinen eingesetzt werden. Diese Dienste, die in verschiedenen Programmiersprachen geschrieben sein und unterschiedliche Technologien zur Speicherung von Daten verwenden können, werden nur minimal zentral verwaltet.
Lasst uns die wichtigsten Elemente dieser Definition herausgreifen:
-
Eine Reihe von Dienstleistungen
-
Jeder läuft in seinem eigenen Prozess
-
Mit leichtgewichtigen Mechanismen kommunizieren
-
Aufgebaut auf Geschäftsfähigkeiten
-
Unabhängig einsetzbar
-
Klein
-
Mit einem Minimum an zentraler Verwaltung
-
Heterogenität (kann in verschiedenen Programmiersprachen geschrieben sein oder verschiedene Technologien zur Speicherung von Daten verwenden)
Gehen wir nun der Reihe nach etwas näher auf die einzelnen Themen ein.
Eine Reihe von Dienstleistungen
Bei einer Microservice-Architektur wird der gesamte Code deines Systems nicht als eine einzige monolithische ausführbare Datei bereitgestellt, sondern du teilst ihn auf mehrere Dienste auf, die unabhängig voneinander bereitgestellt werden können. So kannst du den Code für nur einen Dienst freigeben, sobald er fertig ist, und du kannst flexibel entscheiden, wie du die einzelnen Dienste aufbaust.
Jeder läuft in seinem eigenen Prozess
Eine Microservice-Architektur ist eine verteilte Architektur. Jeder Microservice läuft in einem eigenen Prozess, was bedeutet, dass ein Methoden- oder Funktionsaufruf innerhalb eines einzelnen Prozesses in einem Monolithen nun über das Netzwerk erfolgt. Das schafft eine klareGrenze und macht es schwer, Teile des Systems versehentlich miteinander zu verbinden. Allerdings ist die Wahrscheinlichkeit, dass Aufrufe über das Netzwerk fehlschlagen, viel größer als bei prozessinternen Aufrufen. Du kannst nicht davon ausgehen, dass der Dienst, den du aufrufst, immer erreichbar und bereit ist, deine Anfragen so schnell zu bearbeiten, wie du es gerne hättest.
Mit leichtgewichtigen Mechanismen kommunizieren
Ein Grundsatz der Microservices-Architektur ist es, die Kommunikation zwischen den Diensten so einfach wie möglich zu halten, im Gegensatz zu früheren serviceorientierten Architekturen (die später in diesem Kapitel beschrieben werden), bei denen ein Großteil der Komplexität in der Nachrichtenschicht lag.
Eine einfache Kommunikation bedeutet, dass deine Dienste entweder direkte Aufrufe an andere Dienste machen sollten, zum Beispiel über HTTPS, oder Nachrichten über einen leichtgewichtigen Nachrichtenbus weitergeben. Dies hat den Vorteil, dass du kein tiefes Verständnis für eine komplizierte Spezifikation des Nachrichtenformats brauchst,2 und dass du die Geschäftslogik an einem Ort - dem Dienst - behältst, anstatt einen Teil dieser Logik in einer gemeinsamen Nachrichtenschicht zu haben, wo Änderungen an der Logik zwischen den Teams koordiniert werden müssen, was bedeutet, dass es länger dauert, diese Änderungen vorzunehmen.
Sprachen haben in der Regel die Fähigkeit , HTTPS-Aufrufe zu tätigen (du kannst natürlich auch andere Protokolle verwenden, z.B. gRPC), und es ist eine einfache Sache zu debuggen - für GET-Anfragen kannst du einen Aufruf über einen Browser tätigen.
Halte die ganze Komplexität in deinen Diensten. Sie sollten verstehen, welche Arten von Nachrichten sie senden oder empfangen müssen.
Aufgebaut um Geschäftsfähigkeiten
Teams, die an einer Microservice-Architektur arbeiten, sollten eine Geschäftsdomäne durchgängig besitzen, von der UI- oder API-Schicht über die Geschäftslogik bis hin zur Datenbank.
Die meisten Softwareänderungen finden innerhalb einer bestimmten Geschäftsdomäne statt. Solange du also die richtigen Grenzen findest (die in Kapitel 4 näher erläutert werden), solltest du feststellen, dass die Teams innerhalb einer Microservice-Architektur relativ unabhängig arbeiten können. Dadurch wird der Koordinationsaufwand für die Planung der Arbeit vermieden, der bei einer Architektur entsteht, bei der die Präsentations-, die Geschäftslogik- und die Datenschicht in den Händen verschiedener Teams liegen.
Hinweis
Es ist ideal, die Benutzeroberfläche in den Microservice einzubinden, aber ich habe festgestellt, dass das selten der Fall ist. Im Allgemeinen gibt es immer noch eine Unterscheidung zwischen dem Backend-Code, der die Geschäftslogik abwickelt und mit der Datenschicht kommuniziert, und dem Frontend-Code, der die Informationen für den Kunden anzeigt. Eine gute API zwischen den beiden und die Verwendung von Mikro-Frontends anstelle einer monolithischen Frontend-Anwendung sind hier wichtig.
Unabhängig einsatzfähig
Ein Microservice sollte seine eigene Build- und Deployment-Pipeline haben, die es ermöglicht, nur diesen Service zu veröffentlichen. Er sollte klar definierte Endpunkte haben, z. B. APIs, d. h. du solltest wissen, wo du eine Änderung vornimmst, die sich auf Personen außerhalb deines Teams auswirken könnte.
Vorausgesetzt, der Microservice ist sehr kohärent, d.h. du hast die richtigen Grenzen zwischen den Diensten gefunden (mehr dazu in Kapitel 4 ), sollten die meisten Änderungen innerhalb des Dienstes stattfinden, da sie spezifisch für die Geschäftsdomäne sind. Du solltest in der Lage sein, eine neue Version eines Microservices freizugeben, sobald sie fertig ist, ohne dass du andere Dienste freigeben oder dich mit jemandem außerhalb deines eigenen Teams abstimmen musst. Das hat zur Folge, dass du ganz natürlich zu kleineren Änderungen übergehst, die häufig veröffentlicht werden.
Um davon profitieren zu können, musst du deine Build- und Deployment-Pipeline automatisieren: Du kannst es dir nicht leisten, die Bereitstellung manuell vorzunehmen, da dies einen zu großen Aufwand bedeutet. Einmal in der Woche eine Stunde für eine manuelle Bereitstellung zu benötigen, mag in Ordnung sein, aber 10 Mal am Tag eine Stunde für eine manuelle Bereitstellung zu benötigen, ist keine gute Zeitverwendung. Deshalb ist es wichtig, in Automatisierung zu investieren.
Unabhängig implementierbar bedeutet auch unabhängig skalierbar. Wenn einige Teile deines Systems mit der Last zu kämpfen haben, kannst du mehr Instanzen genau dieses Microservices aufsetzen. Bei einem Monolithen bedeuten Engpässe, die den Durchsatz einschränken, in der Regel, dass du das ganze System skalieren musst.
Unabhängig einsatzfähig bedeutet auch, dass du Änderungen an deiner Architektur Service für Service vornehmen und ausrollen kannst, so dass zum Beispiel die Änderung einer Sprachversion nicht mehr als Big-Bang-Änderung für das gesamte System durchgeführt werden muss.
"Klein"
Microservices sind kleiner, weil du mehrere Dienste hast, von denen jeder eine bestimmte Geschäftsfunktion implementiert, anstatt einen einzigen, der alle Geschäftsfunktionen umfasst. Wie klein sie genau sind, ist allerdings eine Frage der Diskussion - und ich denke, die richtige Granularität zu finden, ist eine der Herausforderungen dieses Architekturstils (siehe "Die richtige Granularität finden").
Mit einem Minimum an zentraler Verwaltung
Viele Aspekte von Microservices wirken als dezentralisierende Kraft. Die Zuweisung der Verantwortung für bestimmte Bereiche an einzelne Teams, die Beibehaltung der Geschäftslogik innerhalb des Dienstes und die Möglichkeit, verschiedene Technologien einfacher zu nutzen, führen dazu, dass sich eine Organisation von der zentralen Verwaltung entfernt.
Um wirklich von Microservices zu profitieren, müssen Teams die Verantwortung für Dinge übernehmen, die früher zentral erledigt wurden - weil die Koordination mit einem anderen Team sie zu sehr verlangsamen würde. Zum Beispiel werden sie wahrscheinlich ihre eigenen Releases durchführen und ihre Systeme unterstützen, wenn etwas schief läuft.
Hinweis
Die Umstellung auf Microservices bedeutet nicht, dass alle Teams 24/7-Support leisten und Pager mit sich führen müssen. Ich bin jedoch der Meinung, dass es bei häufigen Änderungen an einem System Probleme geben wird, die durch den Code verursacht werden - und nicht durch die zugrunde liegende Infrastruktur - und die nur du und dein Team schnell beheben können. Ich werde in Kapitel 8 ausführlich darauf eingehen, denn dies war eine der größten Veränderungen, mit denen wir bei der Financial Times(FT) konfrontiert waren und die den Teams ziemlich viel Sorgen bereitet haben.
Dies kann auch Entscheidungen auf hoher Ebene über die verwendeten Technologien beinhalten, obwohl verschiedene Organisationen dies unterschiedlich handhaben. Ich persönlich bin der Meinung, dass es weniger Platz für ein zentrales Team gibt, das alle Technologien vorschreibt, die die Mitarbeiter/innen nutzen sollen, und mehr Platz für Teams, die spezielle Bedürfnisse haben, die etwas anderes erfordern.
Heterogenes
Mit den unabhängig voneinander einsetzbaren Microservices hast du die Möglichkeit, für verschiedene Dienste unterschiedliche Entscheidungen zu treffen. Vielleicht willst du den Code für deine Website in Node.js schreiben, aber Python für die Datenverarbeitung verwenden.
Genauso kannst du verschiedene Arten von Datenspeichern verwenden, je nachdem, wie du auf die Daten zugreifen musst. Im Content-Publishing-Team der FT haben wir Artikel in einem Dokumentenspeicher gespeichert, und diese wurden in der Regel anhand einer eindeutigen ID als ganze Dokumente abgerufen. Die Beziehungen zwischen Personen, Organisationen, Inhalten und Themen haben wir in einer Graphdatenbank gespeichert, weil dies die Art von Abfragen unterstützte, die wir brauchten: zum Beispiel die 10 neuesten Artikel über Google oder alle Artikel eines bestimmten Autors. Außerdem konnten wir uns auf die Daten konzentrieren, die für jedes System wichtig waren: Der Graph brauchte zum Beispiel nicht den gesamten Inhalt eines Artikels zu speichern.
Warnung
Auch wenn du diesen polyglotten Ansatz verfolgen kannst, musst du bedenken, dass die Komplexität mit jeder neuen Sache zunimmt. Ich werde im Laufe des Buches noch viel mehr darüber sprechen. Generell gilt: Mach weiter, aber sei vorsichtig und wäge ab, ob der Vorteil von , das besser auf deine Bedürfnisse zugeschnitten ist, den Anstieg der Komplexität aufwiegt.
Vorläufer und Alternativen
Architekturentscheidungen sind mit einem Kompromiss verbunden. Es geht darum, die Stärken und Schwächen eines bestimmten Ansatzes zu betrachten und sie mit dem zu vergleichen, was für dein Unternehmen am wichtigsten ist.
In Kapitel 3 gehe ich darauf ein, wie du beurteilen kannst, ob Microservices der richtige Kompromiss für dich sind.
Zunächst werde ich kurz auf einige der architektonischen Alternativen eingehen, dannauf einigeVor- und Nachteile von Microservices. Dabei geht es nicht darum, eine umfassende Bewertung abzugeben, sondern eher darum, den Rahmen abzustecken. Was wurde durch Microservices ersetzt? Und für welche anderen Ersetzungen könntest du dich entscheiden? Das bedeutet, dass ich auch über die Technologien und Prozesse sprechen muss, die in der Regel zusammen mit Microservices eingesetzt werden, weil sie die Vorteile maximieren und dieNachteile minimieren.
Der Monolith
Ich möchte zuerst über den architektonischen Ansatz sprechen, mit dem wir Microservices im Allgemeinen vergleichen, sowohl weil er weit verbreitet war, bevor Microservices aufkamen, als auch weil er im Allgemeinen immer noch der erste Architekturstil ist, der für ein System verwendet wird: derMonolith.
Hinweis
Darauf gehe ich in Kapitel 3 näher ein, aber für kleine Teams lohnen sich die Kosten für die Einführung von Microservices in der Regel noch nicht. Ein Monolith sollte deine erste Wahl sein!
Ein Monolith ist ein Softwaresystem, bei dem der gesamte Code für viele verschiedene Geschäftsfunktionen gemeinsam eingesetzt wird.
Es wird wahrscheinlich eine gewisse Struktur innerhalb des Codes geben, um den Entwicklern die Navigation zu erleichtern - zum Beispiel verschiedene Pakete für verschiedene Geschäftsfunktionen - aber im Allgemeinen wird der Code in Paketen zusammengefasst, getestet und gemeinsam veröffentlicht.
Auch wenn wir von einem Monolithen sprechen, ist es in dieser Architektur üblich, mehrere Ebenen zu haben. Oft sind es drei: eine für Daten, eine für Geschäftslogik und eine für die Benutzeroberfläche. Da die Kommunikation zwischen den Schichten über das Netzwerk erfolgen kann und Monolithen mehrere Instanzen in verschiedenen Verfügbarkeitszonen oder Regionen haben können, sind Monolithen wahrscheinlich zumindest ein wenig verteilt.
Abbildung 1-1 zeigt die Art von Diagramm, um das mich die Interviewer regelmäßig gebeten haben, auf einem Whiteboard zu zeichnen. Es gibt drei Ebenen, und auf jeder Ebene arbeiten spezialisierte Teams mit bestimmten Fähigkeiten. So gut wie jede Änderung an der Geschäftsfunktionalität zieht Änderungen in den einzelnen Ebenen nach sich, was Kommunikation und Koordination zwischen diesen Teams bedeutet.
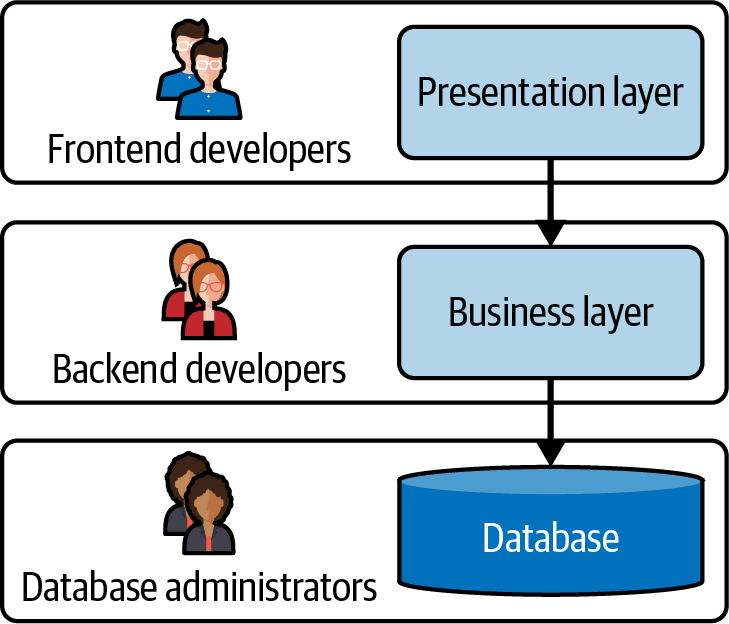
Abbildung 1-1. Der Monolith.
Da der gesamte Code gemeinsam genutzt wird, ist es leicht, dass ein Team eine Änderung am Code vornimmt und feststellt, dass diese unerwartete Auswirkungen auf eine andere Geschäftsfunktion hat. Außerdem ist es leicht, Code für verschiedene Anwendungsfälle wiederzuverwenden, ohne über die Auswirkungen nachzudenken. Wenn zum Beispiel zwei Teams, die in unterschiedlichen Bereichen arbeiten, beide das Konzept "Konto" haben, sollten sie es wahrscheinlich unterschiedlich modellieren, aber in einem Monolithen kann das nicht passieren.
Außerdem kann eine Freigabe ein bedeutendes Ereignis sein, weil sie so viel Zeit in Anspruch nimmt. Du musst alle Tests durchführen, um sicherzustellen, dass eine Änderung keine ungewollten Auswirkungen hat. Das bedeutet in der Regel weniger Veröffentlichungen und mehr Änderungen in jeder Veröffentlichung.
Der Vorteil eines Monolithen ist, dass er einfacher zu verstehen und zu bedienen ist als ein verteiltes System. Die meisten Aufrufe erfolgen prozessbegleitend; es gibt keine Netzwerkprobleme, die dich stören könnten. Die Architektur ist einfach zu zeichnen und ändert sich nicht so schnell, sodass du dich auf das Architekturdiagramm verlassen kannst, was bei einer Microservice-Architektur nicht unbedingt der Fall ist. Wenn etwas schief geht, kannst du auf eine Box springen und die Logs verfolgen. Die meisten Start-ups behalten einen Monolithen bei, bis sie eine Größe erreicht haben, bei der zu viele Leute daran arbeiten und die Tests zu lange dauern, um zu laufen.3
Ich möchte anmerken, dass die meisten Organisationen mehr als einen Monolithen haben. Als die Financial Times zum Beispiel monolithische Architekturen verwendete, hatten wir mehrere Monolithen. Darunter:
-
Das redaktionelle Content Management System
-
Die Website, einschließlich des Veröffentlichungsflusses
-
Mitgliedschaft und Abonnements
Diese Monolithen wurden in der Regel über direkt und über individuell programmierteIntegrationen integriert.
Modulare Monolithen
Es gibt Möglichkeiten, die ungewollte Kopplung zu reduzieren und Releases zu beschleunigen, ohne den Monolithen aufzugeben. Eine Möglichkeit besteht darin, den Code innerhalb eines Monolithen in logische Module zu unterteilen, die an Geschäftsbereiche gebunden sind. Dies führt zu einem so genannten modularen Monolithen.
Hier befindet sich der Code immer noch in einem einzigen Repository und wird als eine einzige Bereitstellungseinheit über eine einzige Build- und Bereitstellungspipeline bereitgestellt. Allerdings ist der Code logisch in Komponenten aufgeteilt, die verschiedenen Domänen zugeordnet sind, und die Grenzen zwischen diesen Domänen werden sorgfältig verwaltet.
Die logische Aufteilung sollte die Wahrscheinlichkeit verringern, dass eine Änderung, die von einem Team vorgenommen wird, eine andere Funktion zerstört. Es kann jedoch schwierig sein, eine versehentliche Überschreitung der Grenzen zu erkennen. Das kann auf Unerfahrenheit oder mangelndes Onboarding zurückzuführen sein, so dass die Mitarbeiter nicht erkennen, dass sie eine Grenze überschreiten. Und Teams, die unter Druck stehen, können beschließen, die Grenzen absichtlich zu überschreiten, um technische Schulden zu machen. Wenn sie in der Lage sind, diese Schulden schnell zurückzuzahlen, kann dies ein lohnender Kompromiss sein, aber die Gefahr ist, dass dein modularer Monolith viel stärker gekoppelt ist, als du es geplant hast.
Releases können trotzdem lange dauern - zum Beispiel, wenn sie jedes Mal die gesamte Testsuite ausführen. Hier gibt es mehrere Ansätze. Du kannst eine bestimmte Untergruppe von Tests für Änderungen in einem bestimmten Modul durchführen, was die Veröffentlichung beschleunigt, aber möglicherweise Probleme nicht erkennt, wenn es eine Kopplung gibt, von der du nichts wusstest.
Alternativ kannst du akzeptieren, dass die Freigabe eine Weile dauert, aber Mechanismen einrichten, die dafür sorgen, dass dein Code zu dem Zeitpunkt, an dem er in die Hauptversion eingebunden wird und freigegeben werden soll, die Pipeline mit großer Sicherheit durchläuft - zum Beispiel, indem du einen kompletten Satz Tests auf einem Zweig für diese Version durchführst, bevor du ihn einbindest. Manche Unternehmen fassen ein paar Codeänderungen zusammen, um zu vermeiden, dass mehrere Versionen gleichzeitig die Pipeline durchlaufen. Die Verwendung von Canary-Releases, bei denen der Code nur auf einer kleinen Teilmenge deiner Instanzen live ist, macht es auch einfacher, Änderungen rückgängig zu machen, die unerwartete Auswirkungen haben (ich werde in Kapitel 10 mehr über Canary-Releases erzählen).
Ein modularer Monolith ist ein guter Ansatz, wenn du anfängst, Probleme mit deiner monolithischen Architektur zu sehen. Im besten Fall werden sie dadurch gelöst. Im schlimmsten Fall hilft er dir, die Grenzen zu finden, an denen du Dienste herausnehmen kannst, wenn du auf eine Microservice-Architektur umsteigen willst.
In Kapitel 3 gebe ich eine detaillierte Fallstudie darüber, wie Shopify einen modularen monolithischen Ansatz verwendet hat. mehr Details dazu.
Service-orientierte Architektur
Für die Integration zwischen Monolithen waren früher benutzerdefinierte Punkt-zu-Punkt-Integrationen erforderlich, d.h. wenn zwei Systeme auf dieselben Informationen zugreifen wollten, mussten sie beide eine Integration erstellen.
Die serviceorientierte Architektur (SOA) war eine Antwort darauf. In einer SOA erstellen Teams Dienste, die bestimmte Geschäftsfunktionen bereitstellen: z. B. Informationen über den Abonnementstatus eines Lesers abrufen. Sie registrieren diese Dienste zentral, und jedes Team, das Zugriff benötigt, kann sie finden und nutzen. Diese Dienste können eine dünne Hülle um ein Altsystem sein: Der Vorteil ist, dass die Interaktionen vereinfacht und doppelter Aufwand und Code reduziert werden.
SOA entstand in den späten 1990er Jahren, aber so richtig in Schwung kam sie erst Anfang der 2000er Jahre mit dem Aufkommen der Webservice-Standards und insbesondere mit SOAP (Simple Object Access Protocol), einem XML-basierten Nachrichtenprotokoll. Die damaligen SOA-Implementierungen stützten sich häufig auf eine zentrale Softwarekomponente (den Enterprise Service Bus oder ESB), die den Überblick über die Dienste behielt, alle notwendigen Transformationen durchführte und die Nachrichten an die richtige Stelle weiterleitete.
Meine Erfahrung mit SOA war, dass diese Middleware ein Engpass sein konnte, da sie eine Menge Logik enthielt: Jede Anwendung musste den ESB nutzen und konfigurieren, und Änderungen, die für einen Zweck vorgenommen wurden, konnten sich auf andere auswirken. Manchmal enthielt der ESB sogar Geschäftslogik, was bedeutete, dass die Anwendung und ein ESB-Patch im Gleichschritt eingesetzt werden mussten. Außerdem stellte ich fest, dass Kommunikationsprotokolle wie SOAP kompliziert zu handhaben waren und ich viel Zeit damit verbrachte, Änderungen an Schemata zu verwalten.
Ich sehe Microservices als eine Weiterentwicklung von SOA, die von anderen Veränderungen in der technischen Welt abhängt. Als die Leute mit SOA anfingen, richteten wir im Allgemeinen unsere eigenen Server manuell ein. Unsere Daten befanden sich in relationalen Datenbanken mit vielen Tabellen, und unser Freigabeprozess war langsam und ebenfalls meist manuell. All das ist heute nicht mehr der Fall.
Das Microservices-Ökosystem
Microservices sind eine Weiterentwicklung von SOA, die durch neue Technologien und neue Arbeitsweisen, die in den letzten zehn Jahren verfügbar geworden sind, ermöglicht wurde.
Zu diesen Veränderungen gehören die Arten von Infrastrukturen, auf denen wir unsere Anwendungen ausführen können: mit der Verfügbarkeit neuer Bereitstellungstechnologien wie Container und Orchestrierung, Serverless und Platform as a Service (PaaS) im Zuge der Verlagerung in die Cloud. Dazu gehören auch die Vorteile der Automatisierung, sowohl bei der Bereitstellung der Infrastruktur als auch bei der Implementierung des Codes. Dazu gehören auch Veränderungen in unserer Arbeitsweise, wie der Aufstieg von DevOps als Ansatz für die Entwicklung und den Betrieb unserer Systeme und die Verlagerung von der Überwachung zum umfassenderen Konzept der Beobachtbarkeit.
Dies sind die Grundlagentechnologien und Ansätze für Microservices, d.h. ohne sie wäre es schwer, Microservices zu realisieren, und ich denke, es wäre unmöglich, damit erfolgreich zu sein. Wenn du dieses Kapitel liest und diese Grundlagentechnologien noch nicht einsetzt, solltest du deine ersten Anstrengungen auf sie konzentrieren.
Zusammen ermöglichen diese Technologien - neue Bereitstellungsoptionen in der Cloud, Automatisierung, DevOps und Beobachtbarkeit - einen Cloud-Native-Ansatz: die Entwicklung von Anwendungen, die so konzipiert sind, dass sie das Beste aus der Cloud herausholen, anstatt einen Monolithen in einem Rechenzentrum anzuheben und zu verschieben.
Bei Cloud Native geht es um Geschwindigkeit und Skalierung. Kannst du dich schnell bewegen und skalieren, wenn du es brauchst? Microservices sind hier eine gute Lösung.
Lass uns diese Technologien genauer unter die Lupe nehmen.
Infrastruktur als Code
Als ich 2011 bei der FT anfing, sollte ich aufbauen, die erste Content API, die internen Teams und bestimmten Dritten Zugang zu den Artikeln und Bildern der FTverschafft. Für dieses neue Projekt brauchten wir einen Server, und es dauerte sechs Monate, ihn zu kaufen, zu bauen, aufzustellen, zu konfigurieren, DNS einzurichten usw. Der gesamte Prozess wurde manuell durchgeführt.
In den nächsten Jahren hat die FT stark in Technologien investiert, um diesen Prozess zu beschleunigen. Zunächst richteten wir eine private Cloud in unseren Rechenzentren ein.
Das US National Institute of Standards and Technology (NIST) definiert Cloud als Zugang zu einem Pool von Rechenressourcen (Server, Speicherung, Netzwerke, Dienste usw.), die schnell und mit minimalem Aufwand bereitgestellt werden können .4
Die FT hat eine Infrastructure-as-a-Service (IaaS)-Plattform entwickelt, mit der eine neue virtuelle Maschine (VM) bei Bedarf gestartet und eine Anwendung darauf installiert werden kann, anstatt dass jemand einen neuen physischen Server kaufen und einrichten und dann alles Notwendige konfigurieren muss.
Sobald du VMs aufsetzen kannst, ist es sinnvoll, den Prozess zu automatisieren, damit er in wenigen Minuten erledigt ist. Das hat den zusätzlichen Vorteil, dass die VMs, die du hochfährst, einheitlich sind, weil du für alle dieselbe Server-Image-Vorlage verwendest.
Server haben jedoch die Tendenz, sich im Laufe der Zeit immer mehr voneinander zu unterscheiden ("Konfigurationsdrift"). Das kann daran liegen, dass Menschen manuelle Ad-hoc-Änderungen vorgenommen haben oder dass du die Vorlage für das Server-Image geändert hast, so dass neue Server anders aussehen als alte. Diese Inkonsistenz kann zu unerwartetem Verhalten und Instabilität führen.
Infrastructure as Code ist die Lösung für dieses Problem. Wie du vielleicht schon vermutet hast, geht es darum, deine Infrastruktur in Code zu definieren und diesen Code immer wieder neu auszuführen, damit deine Infrastruktur konsistent bleibt.
Wie Kief Morris in Infrastructure as Code schreibt:5
Infrastructure as Code ist ein Ansatz zur Automatisierung der Infrastruktur, der auf Praktiken aus der Softwareentwicklung basiert. Er legt den Schwerpunkt auf konsistente, wiederholbare Routinen für die Bereitstellung und Änderung von Systemen und deren Konfiguration. Du nimmst Änderungen am Code vor und nutzt dann die Automatisierung, um diese Änderungen zu testen und auf deine Systeme anzuwenden.
Da es sich bei der Infrastrukturkonfiguration um Code handelt, wird sie in der Versionskontrolle gespeichert. So lässt sich leicht feststellen, was sich geändert hat und wer diese Änderung vorgenommen hat, und man kann bei Bedarf zu einem bestimmten Zeitpunkt zurückkehren - zum Beispiel, wenn etwas schiefgegangen ist.
Da der Änderungsprozess automatisiert abläuft, kannst du sicherstellen, dass du ein Audit-Protokoll erstellst, in dem die Änderungen und die Person, die sie vorgenommen hat, festgehalten werden: ein großer Vorteil für die Sicherheit.
Infrastruktur als Code bedeutet, dass wir Server erstellen, bereitstellen, aktualisieren und abbauen können, indem wir die Software ausführen, und die Ergebnisse sind immer gleich. In einer Microservice-Architektur sind dies Dinge, die wir häufig tun, weshalb Infrastruktur als Code wichtig ist.
Kontinuierliche Lieferung
Die Freigabe von Code auf unserem selbstgebauten Server im Jahr 2011 war auch ein sehr manueller Prozess. Die Schritte waren in einer Excel-Tabelle festgelegt und es gab mehr als 50 davon. Da es ein manueller Prozess war, war er sehr fehleranfällig.
Außerdem war es langsam und dauerte Stunden. Und da Journalisten währenddessen keine Inhalte veröffentlichen konnten, war es uns nicht möglich, es während der normalen Arbeitszeiten zu tun. Das bedeutete, dass wir unseren Code an einem Samstagmorgen für die Produktion freigaben,6 und nicht öfter als einmal im Monat.
Du kannst Microservices nur dann erfolgreich umsetzen, wenn du den Prozess der Codefreigabe automatisierst. Aber das ist noch nicht alles. Du musst auch in der Lage sein, Änderungen mit vernachlässigbarer Ausfallzeit freizugeben, damit du das jederzeit tun kannst. Und schließlich musst du die Zeit für das Testen verkürzen, indem du dich auf automatisierte Tests konzentrierst, die keine komplexe Einrichtung oder eine gemeinsame Staging-Umgebung erfordern.
Du musst eine kontinuierliche Lieferung durchführen (siehe Abbildung 1-2).
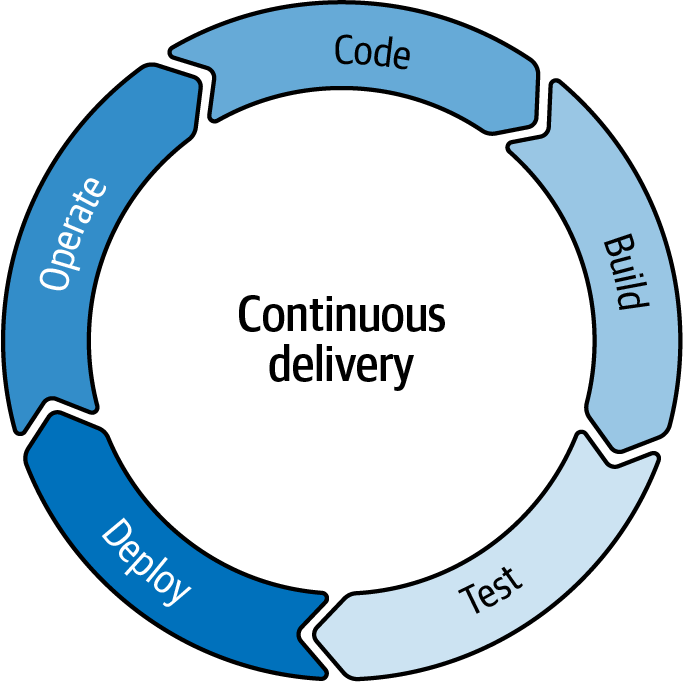
Abbildung 1-2. Der kontinuierliche Lieferzyklus.
Bei der kontinuierlichen Bereitstellung geht es um die kontinuierliche Freigabe kleiner Änderungen durch eine automatisierte Build- und Deployment-Pipeline, die auch automatisierte Tests umfasst.
Ohne eine lose gekoppelte Architektur ist es schwierig, in kleinen Batches zu arbeiten - eines der wichtigsten Prinzipien der kontinuierlichen Lieferung -, d.h. eine Architektur, in der du Teile des Systems ändern und nur diese Änderungen testen kannst.
Es ist auch schwer, von einem Wechsel zu Microservices zu profitieren, wenn du nicht kontinuierlich lieferst!
Hinweis
In diesem Buch wird nur kurz auf Continuous Delivery eingegangen. Ausführliche Informationen findest du in Jez Humble und Dave Farley's Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation (Upper Saddle River, NJ: Addison-Wesley, 2010).
Bei der FT hat die Umstellung auf Continuous Delivery und die Einführung von Microservices für die Content-Publishing-Plattform dazu geführt, dass wir von 12 Releases pro Jahr auf rund 2.500 gestiegen sind. Das sind etwa 10 Releases pro Arbeitstag - also etwa 200 Mal so oft.
Die öffentliche Cloud
Die FT hat zwar mit einer privaten Cloud begonnen ( ), ist aber schon bald dazu übergegangen, die Vorteile der öffentlichen Cloud zu nutzen und Amazon Web Services (AWS) einzusetzen. Eine öffentliche Cloud bedeutet, dass die Hardware jemand anderem gehört.
Ich erinnere mich an die Bedenken in den frühen 2010er Jahren, was es bedeutete, seinen Code auf fremden Rechnern laufen zu lassen - was würde passieren, wenn sie den Preis erhöhen? War es sicher, unsere Daten dort zu speichern? Könnten sie pleite gehen? Im Laufe der Zeit, als immer mehr Menschen in die öffentliche Cloud wechselten, wurden wir mit den Risiken immer sicherer. Und es gibt erhebliche Vorteile.
Erstens musst du die zugrunde liegenden Ressourcen nicht mehr kaufen, aufbauen und verwalten. Dadurch kannst du Geld sparen, obwohl du sicherstellen musst, dass du die Rechnung im Auge behältst, denn die Bereitstellung nach Bedarf kann bedeuten, dass viele Entwickler/innen Server bereitstellen, die mehr als groß genug sind, "um Probleme zu vermeiden", und dass sie Dinge bereitstellen, die sie dann vergessen. Die öffentliche Cloud verändert auch das Kostenmodell für den Kauf von Servern: von CAPEX (Investitionsausgaben: Kauf vieler Server im Voraus) zu OPEX (Betriebsausgaben: Anmieten von Maschinen, wenn du sie brauchst). Es lohnt sich, mit deiner Finanzabteilung zu sprechen, bevor du diese Umstellung vornimmst, denn sie könnte eine starke Meinung dazu haben, ob dies eine gute Sache ist!
Mit dem Wechsel in die Public Cloud sparst du definitiv Aufwand. Wenn du deine eigene private Cloud in einem Rechenzentrum betreibst, musst du immer noch Server und Netzwerkausrüstung kaufen und alle damit verbundenen Support- und Wartungskosten tragen, einschließlich eines internen Betriebsteams, das diese Infrastruktur betreut. Du musst dich um Patches und Upgrades kümmern und auf Sicherheitsprobleme reagieren. Bei der öffentlichen Cloud übernehmen die Provider diese Aufgaben für dich.
Bei einer privaten Cloud musst du immer noch eine Kapazitätsplanung vornehmen, um sicherzustellen, dass es einen physischen Server für die neuen VMs gibt, die jemand braucht. Bei einer öffentlichen Cloud hast du diese Einschränkung nicht. Du wirst selten bis nie nicht in der Lage sein, eine VM bereitzustellen, wenn du sie brauchst.
Außerdem bieten die Public Cloud-Provider viel mehr als nur elastische Rechenleistung. Sie bieten eine Vielzahl von Mehrwertdiensten an. Du kannst eine neue Datenbank, eine Warteschlange oder ein API-Gateway einrichten. Das sind Dinge, die du in einer Microservice-Architektur brauchst, und es ist viel schneller und einfacher, einen verwalteten Dienst deines Cloud-Providers zu nutzen, als dies selbst einzurichten. Und weil das schnell und einfach geht, kannst du Alternativen ausprobieren, um zu sehen, ob sie für deinen speziellen Anwendungsfall eine bessere Lösung bieten.
Im Content-Plattform-Team der FT haben wir mehrere neue Datenspeicher eingeführt, die bestimmte Anforderungen erfüllen. Der Unterschied zwischen der Installation und Verwaltung eines Datenbank-Clusters in zwei Regionen durch uns selbst und der Nutzung von Datenbank-as-a-Service-Optionen von AWS lag zwischen Wochen und Tagen an Aufwand. Das ist signifikant.
Die Kombination aus Infrastructure as Code und Elastic Provisioning ermöglichte es uns, unsere Server wie Vieh und nicht wie Haustiere zu behandeln.7 Dieses Konzept wurde zuerst von Randy Bias bekannt gemacht, der die Geschichte dazu aufgeschrieben hat. Ich habe es, wie viele andere auch, zum ersten Mal von Adrian Cockcroft gehört, der damals bei Netflix arbeitete.
Als wir unsere Server selbst gebaut haben, waren sie wie Haustiere. Wir gaben ihnen Namen und schenkten ihnen viel Aufmerksamkeit. Sie waren lange im Einsatz und konnten eine Betriebszeit in Jahren haben. Wir entwickelten eine emotionale Bindung zu ihnen, und wenn sie krank wurden, pflegten wir sie wieder gesund.
In der Cloud bleiben die virtuellen Maschinen nicht lange bestehen. Sie haben keine Namen, sondern sind nummeriert und mit dem Zweck versehen, dem sie dienen. Und wenn etwas schief geht, werden wir sie nicht wieder gesundpflegen. Es ist üblich, einen Server, der Probleme hat, zu schließen und einen neuen aufzusetzen.
Die Public Cloud ermöglicht vor allem Microservices durch die Dinge, die du auf ihr tun kannst, und insbesondere durch die neuen Bereitstellungsoptionen, die verfügbar sind.
Neue Bereitstellungsoptionen
Viele Menschen denken im Zusammenhang mit Microservices sofort an Container und Kubernetes. Das ist jedoch nicht die einzige Möglichkeit, eine Microservice-Architektur zu betreiben. Die FT hat Microservices auf Kubernetes laufen lassen (für die Plattform zur Veröffentlichung von Inhalten), aber auch auf Heroku (für ft.com)8 und nutzt auch Serverless in großem Umfang.
Ich möchte einen Schritt weiter gehen und darüber sprechen, was Dinge wie Container und Kubernetes darstellen: neue Bereitstellungsoptionen. Container und Orchestratoren, Serverless und PaaS-Optionen ermöglichen es Teams, einen Teil der Komplexität des Betriebs verteilter Systeme mit kleinen Diensten auszulagern und die damit verbundenen Kosten zu senken oder besser vorhersehbar zu machen.
Container
Zu Beginn unserer Einführung von Microservices bei der FT haben wir jeden Dienst auf einer eigenen virtuellen Maschine ausgeführt. Mit Virtualisierung kannst du einen physischen Rechner in mehrere kleinere virtuelle Maschinen aufteilen, die für die Anwendungen, die darauf laufen, wie ein normaler Server aussehen. Dies ermöglicht isolierte Ausführungsumgebungen und eine bessere Auslastung der zugrunde liegenden physischen Hardware.
Angesichts unserer winzigen Microservices waren diese Dienste jedoch selbst mit der kleinsten VM überdimensioniert, sodass wir mehr Geld ausgaben als nötig. Vor allem aber brauchten wir für jeden neu eingerichteten Dienst mehrere Schritte, um ihn bereitzustellen, zu konfigurieren und einzusetzen. Das war umständlich und eine Quelle der Reibung.
Das machte uns reif für die frühe Einführung von Containern.
Ein Container-Image ist ein leichtgewichtiges, eigenständiges, ausführbares Softwarepaket, das alles enthält, was zum Ausführen einer Anwendung benötigt wird: Code, Laufzeit, Systemtools, Systembibliotheken und Einstellungen.
Die Containerisierung umfasst ein Standard-Packaging-Format, eine Standardschnittstelle zur Steuerung eines laufenden Containers und eine Engine zur Ausführung von Containern. Container-Images werden zur Laufzeit zu Containern, in denen die Container-Engine die Anwendung so entpackt und ausführt, dass die Software von allen anderen Containern, die auf der gleichen Infrastruktur laufen, isoliert wird. Da dies viel leichter ist als eine VM, können Container schnell in Betrieb genommen werden. Außerdem sind sie unveränderlich. Wenn du deine Anwendung ändern willst, musst du das Container-Image aktualisieren und einen neuen Container bereitstellen.
Wir hätten zwar unsere vorherige Plattform ändern können, um mehr als einen Dienst auf einer VM laufen zu lassen, aber das wäre keine gute Idee gewesen, denn dann hätten wir die Isolierung zwischen den verschiedenen Anwendungen verloren. Container sind kleiner, isoliert und können gestapelt werden, was die Sache sehr einfach machte. Durch die Einführung von Containern konnten wir unsere AWS-Kosten um 40 % senken, weil wir jetzt mit acht sehr großen VMs arbeiten, anstatt mit mehreren hundert sehr kleinen VMs. Außerdem mussten wir weniger Schritte unternehmen, um einen neuen Dienst einzurichten. Wir mussten keine VMs mehr bereitstellen oder Bereitstellungspipelines einrichten. Alles wurde in einer einzigen Konfigurationsdatei mit Versionskontrolle definiert.
Dennoch gab es einige Herausforderungen, denn wir waren so früh dran, dass das Container-Ökosystem noch nicht vorhanden war. Wir mussten unser eigenes System zur Verwaltung der Container aufbauen. Dazu gehörte, dass wir herausfinden mussten, wie viele Instanzen wir brauchten, wo sie laufen sollten, ob sie nacheinander eingesetzt werden sollten, wie wir Anfragen zwischen Containern weiterleiten konnten usw.
Wir haben unsere eigene Container-Orchestrierung entwickelt, denn nur so haben Container für uns funktioniert. Im Allgemeinen bin ich ein großer Fan davon, langweilige Technologien zu wählen. Wie Dan McKinley von Etsy geschrieben hat, sind langweilige Technologien diejenigen, die schon viele Menschen erfolgreich eingesetzt haben. Neue und innovative Technologien sind zwar aufregend, aber die Möglichkeiten und vor allem die Möglichkeiten, die sie falsch machen können, werden wahrscheinlich nicht gut verstanden. Dan schlägt vor, dass du die Menge an innovativen Dingen, die du auf einmal machen willst, begrenzen solltest, indem du dir vorstellst, dass du ein paar Token hast, die du ausgeben kannst: Achte darauf, dass du deine Innovations-Token sinnvoll ausgibst.
Für mein Team bei der FT war die Entwicklung unserer eigenen Container-Orchestrierung 2014 ein Innovations-Token, den wir bereit waren, auszugeben. Aber sobald wir Alternativen hatten, auf die wir umsteigen konnten, taten wir das.
Orchestrierung
Container-Orchestratoren wie Kubernetes verwalten einen Container-Cluster dynamisch für dich und kümmern sich um das Routing von Anfragen zwischen Diensten, den Neustart von fehlgeschlagenen Anwendungen, das Verschieben von Diensten, wenn es Probleme mit der CPU- oder Speichernutzung gibt, und um die Bereitstellung.
Kubernetes ist nicht selbst eine Plattform: Es gibt viele Dinge zu beachten, die über die Container-Verwaltung hinausgehen, z. B. Service-Meshes, API-Gateways, Log-Aggregation usw. Während das Container-Ökosystem reift, gibt es immer mehr Tools, die die Arbeit mit Containern und Kubernetes erleichtern. Die Cloud Native Computing Foundation unterhält mit eine interaktive Cloud Native Landscape, die ein sehr hilfreicher Leitfaden ist, aber bei der Vielzahl der verfügbaren Tools kann es schon ein wenig überwältigend sein. Und selbst wenn du dich für Kubernetes entscheidest, baust du deine eigene Plattform mit der damit verbundenen Flexibilität und Komplexität auf.
Meiner Meinung nach ist dies ein weiterer Punkt, an dem wir uns auf die Anbieter stützen und sie die schwere Arbeit machen lassen sollten. Die meisten öffentlichen Clouds bieten verwaltete Kubernetes-Dienste an, oder du kannst Drittanbieter beauftragen, die Verwaltung für dich zu übernehmen. Das sind die Optionen, die ich in Betracht ziehen würde, wenn ich Kubernetes jetzt einführen würde.
Ich würde aber auch überlegen, ob ich mich für eine Kubernetes-basierte Lösung entscheiden sollte. Kubernetes ist leistungsstark, aber komplex. Cloud-Provider bieten auch eigene Dienste für die Verwaltung von Containern an, die möglicherweise besser mit anderen Teilen des Ökosystems des Cloud-Providers integriert werden können.9
Die Leute entscheiden sich oft für Kubernetes, weil portabel ist. Ich bin nicht überzeugt, dass das ein guter Grund ist. Selbst wenn es einfacher ist, von Amazons Elastic Kubernetes Service zu Googles Kubernetes Engine zu wechseln als von Amazons Elastic Compute Service zu Google Cloud Run, wie wahrscheinlich ist es, dass du diesen Wechsel vollziehst? Ich würde mich lieber auf einen bestimmten Cloud-Provider festlegen und möglichst viele der von ihm angebotenen Managed Services nutzen, als Zeit und Mühe darauf zu verwenden, relativ anbieterneutral zu bleiben.
Plattform-as-a-Service-Optionen
Eine Alternative ist die Nutzung von Platform-as-a-Service (PaaS) Optionen. Hier stellst du deine Anwendungen auf einer Plattform bereit, die komplett für dich läuft und oft auch Dinge wie verwaltete Datenbanken anbietet.
Du verlierst etwas Flexibilität und die Kosten für den Betrieb der Anwendung werden höher sein, aber du musst die Plattform nicht mehr selbst entwickeln und warten, so dass die Gesamtkosten niedriger sein können. Außerdem können sich deine Teams darauf konzentrieren, den Geschäftswert zu steigern.
Als die FT mit dem Aufbau von Microservices begann, entschieden sich viele Teams für Heroku und profitierten von der Benutzerfreundlichkeit und den gut durchdachten Tools. Ich glaube nicht, dass wir jetzt unbedingt die gleiche Wahl treffen würden - in den letzten Jahren sind nicht viele neue Funktionen hinzugekommen. Es gibt zwar immer noch viele Anbieter, die PaaS-Lösungen anbieten - wie Render, fly.io, Netlify, platform.sh - aber ich habe viel mehr von Leuten gehört, die relativ einfache Anwendungen darauf laufen lassen, als von komplizierten Microservice-Architekturen.
Diese Optionen sind auf jeden Fall eine Überlegung wert, vor allem für Unternehmen, die keine hohen Arbeitslasten oder Skalierungsanforderungen zu bewältigen haben. Für eine komplizierte Architektur solltest du dich jedoch besser bei Public Cloud-Providern umsehen, denn dort hast du viele Möglichkeiten, was du neben den Anwendungen installieren und betreiben kannst: Datenbanken, Nachrichtenwarteschlangen, Speicherung usw.
Wenn du dies tust, solltest du auch überlegen, ob eine ereignisbasierte Serverless-Compute-Option besser zu deinen Anforderungen passt.
Serverlos
Serverless ist eine weitere Option für den Aufbau einer lose gekoppelten Architektur. Mit Serverless kannst du Anwendungen entwickeln, ohne dir Gedanken über die Server zu machen, auf denen sie laufen.
Viele der verwalteten Dienste, die Cloud-Provider anbieten, sind serverlos. Amazon bietet zum Beispiel S3 für die Speicherung von Dateien, SNS für Messaging und Aurora für die Speicherung von Daten über PostgreSQL. In all diesen Fällen musst du dich nicht um Skalierung, Backups, Clustering usw. kümmern; du konfigurierst den Dienst und kannst ihn sofort nutzen.
Cloud-Provider bieten auch Serverless Compute an (woran die meisten Leute denken, wenn sie Serverless hören). AWS Lambda ist ein Beispiel für Function as a Service (FaaS), ein ereignisgesteuertes Modell, bei dem dein Code aufgerufen wird, wenn ein Ereignis eintritt - wenn eine Datei geschrieben oder eine Nachricht gesendet wird.
Du kannst FaaS definitiv als eine Art von Microservice-Architektur betrachten,10 obwohl du vielleicht feststellen wirst, dass du einen logischen Microservice als mehrere Funktionen einsetzen musst. Sam Newman hat in seinem Buch Building Microservices eine sehr ausführliche Diskussion darüber.
Gemeinsam ist den serverlosen Optionen, dass sie nach Verbrauch abgerechnet werden, d.h. nach der Anzahl der Anfragen oder nach der Menge der verwendeten Speicherung.
Deine Wahl treffen
Generell solltest du darauf achten, dass dein Cloud-Provider so viel wie möglich von dem übernimmt, was Werner Vogels von Amazon als "undifferenzierte Schwerarbeit" bezeichnet. Vogels beschreibt undifferenzierte Aufgaben als "Aufgaben, die erledigt werden müssen, aber keinen Wettbewerbsvorteil bringen". Für die meisten Unternehmen gehören zu diesen Aufgaben Dinge wie Servermanagement, Lastausgleich und das Aufspielen von Sicherheitspatches." (Wenn du mehr darüber erfahren möchtest, schau dir diesen interessanten Überblick darüber an, wie AWS bei derSoftwareentwicklung vorgeht).
Im Allgemeinen solltest du keine eigenen Nachrichtenwarteschlangen oder Datenbank-Cluster betreiben. Diese zusätzliche Arbeit bringt dir nicht viel. Wo immer du kannst, solltest du Managed Services nutzen.
Ob du deinen Anwendungscode als kurzlebige Funktionen oder als längerlebige Dienste oder eine Mischung aus beidem bereitstellst, ist nicht so eindeutig. Es hängt davon ab, was du tust und wie deine Arbeitslast aussieht. Das Reagieren auf Ereignisse kann ein großartiger Anwendungsfall für FaaS sein. Wenn du einen ziemlich konstanten Strom von Anfragen an deine Website hast, ist es vielleicht besser, diese als containerisierten Dienst auszuführen.
Bei der FT hatten wir in vielen unserer Teams eine Mischung aus serverlosen Funktionen und längerfristigen Diensten. Ich denke, das ist ziemlich üblich.
DevOps
Wenn die Leute, die den Code entwickeln, von den Leuten, die ihn betreiben, getrennt sind, gibt es ein Missverhältnis der Anreize. Ein Entwickler möchte seinen Code freigeben und sich der nächsten Funktion zuwenden. Ein Betriebsmitarbeiter möchte das System am Laufen halten und weiß, dass die Freigabe von Code in hohem Maße mit Fehlern verbunden ist.
Bei DevOps geht es darum, dass Entwickler und Betreiber zusammenarbeiten, und es ist ein kultureller Wandel. Sobald ihr zusammenarbeitet, werdet ihr euch besser abstimmen können. Betriebsingenieure beginnen, mehr Probleme durch Softwareentwicklung zu lösen - sie schreiben Code und automatisieren Dinge. Die Entwickler/innen übernehmen mehr Verantwortung für den Betrieb ihrer Software, sei es, um die Beobachtbarkeit einzubauen oder auf Produktionsprobleme zu reagieren. Das ist eine gute Sache, denn du baust bessere Systeme, wenn du vielleicht um 3 Uhr morgens aufwachen musst, weil etwas schief gelaufen ist.
Wenn du viele kleine Releases durchführst, wie es bei Microservices möglich ist, ist es viel unwahrscheinlicher, dass jedes Release Probleme verursacht, und es ist viel einfacher, es wieder zurückzunehmen, wenn du feststellst, dass es Probleme verursacht. Allerdings müssen diese Releases von den Entwicklern durchgeführt werden, denn du kannst sie nicht zehnmal am Tag an ein anderes Team weitergeben. Das bedeutet, dass die Entwickler in der Lage sein müssen, den Code in der Produktion zu unterstützen. DevOps ist also unerlässlich für den erfolgreichen Einsatz von Microservices.
Ich bin der festen Überzeugung, dass DevOps eine Denkweise ist und kein Job, den man macht. In der Branche sieht man jedoch häufig, dass Leute DevOps-Ingenieure einstellen oder ein DevOps-Team aufbauen. DevOps-Teams und -Ingenieure sind diejenigen, die Werkzeuge und Prozesse entwickeln, um Ingenieure bei der Entwicklung eines Produkts zu unterstützen. In ihrem Buch Team Topologies,11 nennen Matthew Skelton und Manuel Pais diese Plattformteams.
In Kapitel 8 wird viel mehr darüber gesprochen, wie man zu "You build it, you run it" übergeht. Auch die übrigen Kapitel in Teil II befassen sich damit, warum das wichtig ist. In Kapitel 5 werden die verschiedenen Teamtypen in Team-Topologien ausführlich besprochen .
Beobachtbarkeit
Eine Microservice-Architektur bietet dir viele Stellen, an denen etwas schief gelaufen sein könnte. Bei einem komplizierten Netz von Diensten, das mit der Erwartung aufgebaut wurde, dass das System als Ganzes auch dann noch funktioniert, wenn einige Instanzen von Diensten nicht verfügbar sind, kann dir die Überwachung nicht unbedingt sagen, ob etwas wirklich kaputt ist. Du kannst eine Warnung für eine Instanz erhalten, die gerade aktualisiert wird, während der gesamte Datenverkehr erfolgreich um sie herumgeleitet wird.
Im Allgemeinen ist es viel schwieriger, vorherzusagen, welche Informationen du brauchen wirst. Überwachungsmaßnahmen und Dashboards der alten Schule bringen dich nur bedingt weiter (wie Liz Fong-Jones und Charity Majors sagten: "Dashboards sind das Narbengewebe früherer Vorfälle", was bedeutet, dass sie dir vielleicht nicht zeigen, was du für diesen Vorfall brauchst!)
Glücklicherweise gibt es immer mehr neue Tools, die sich auf Beobachtbarkeit konzentrieren. Diese gehen über die Aggregation von Protokollen und die Nachverfolgung von Ereignissen hinaus (obwohl beides wichtig ist) und ermöglichen es dir, Informationen über Ereignisse mit hoher Kardinalität und hoher Dimensionalität zu erfassen. Hohe Kardinalität bedeutet, dass du viele mögliche Werte für ein einzelnes Attribut hast, z. B. userID. Hohe Dimensionalität bedeutet, dass du viele verschiedene Schlüssel-Wert-Paare hast. Das bedeutet, dass du detaillierte Fragen dazu stellen kannst, was in deiner Produktionsumgebung passiert ist. So hast du gute Chancen, die Lösung für einige ziemlich esoterische Fehler zu finden, bei denen das Problem nur bei einer kleinen Untergruppe von Nutzern oder bei einer ungewöhnlichen Kombination von Umständen auftritt. Das geht natürlich nur, wenn die Ingenieure an die Beobachtbarkeit gedacht haben, als sie den Code geschrieben haben!
Vorteile von Microservices
Die Vorteile von Microservices ergeben sich aus zwei Aspekten. Erstens wird das System durch Microservices in viele kleine Teile aufgeteilt. Das bedeutet, dass du diese Teile separat skalieren kannst und dass du eine höhere Ausfallsicherheit erhältst, weil der Ausfall eines Teils nicht bedeutet, dass das ganze System ausfällt.
Zweitens ist eine Microservice -Architektur lose gekoppelt: Du kannst einen Dienst ändern, ohne etwas anderes ändern zu müssen. Das bedeutet, dass du die Releases nicht zwischen den Teams koordinieren musst. Das bedeutet auch, dass du je nach den Bedürfnissen der einzelnen Dienste unterschiedliche Technologien wählen kannst. Und wenn du etwas Neues ausprobieren willst, kannst du das ganz einfach tun. Du musst nicht das ganze System migrieren.
Microservices konzentrieren sich auf eine möglichst lose Kopplung und erreichen dies unter anderem dadurch, dass sie ihre eigenen Daten besitzen und eine Kopplung durch zentralisierte Datenbankschemata vermeiden. Sie bevorzugen leichtgewichtige Kommunikationsmechanismen und vermeiden übermäßig komplexe oder intelligente Integrationstechnologien (z. B. einen Enterprise Service Bus), die einen Engpass für Veränderungen darstellen können. Sie sind bewusst um die Geschäftsfähigkeiten herum aufgebaut, d.h. die meisten Änderungen sollten innerhalb des Dienstes oder der Dienste stattfinden, die einem einzigen Team gehören. Wenn du die Domänengrenzen richtig ziehst, wird die Schnittstelle für den Microservice stabil sein und sich relativ selten ändern. Das bedeutet, dass du nicht viel Zeit damit verbringen musst, dich mit anderen Teams abzustimmen, bevor du eine Änderung vornehmen kannst. Das bedeutet auch, dass du als Ingenieur nicht das ganze System verstehen musst, sondern nur deine eigenen Dienste und die Schnittstellen, die sie anbieten oder nutzen.
Wir wollen diese Vorteile genauer beschreiben.
Unabhängig skalierbar
Bei einem Monolithen musst du den gesamten Monolithen skalieren, wenn du erhöhten Datenverkehr bewältigen musst. Bei Microservices kannst du nur den Teil des Systems skalieren, der einer erhöhten Belastung ausgesetzt ist. Bei der Financial Times zum Beispiel kann es sein, dass der Traffic auf der Homepage stark ansteigt, wenn es ein großes Nachrichtenereignis gibt, aber die Anzahl der Suchanfragen ist davon nicht betroffen. Mit Microservices kannst du nur die Homepage skalieren.
Du kannst natürlich auch selbständig Dinge verkleinern, indem du den Umfang einer Komponente reduzierst, wenn sie nicht stark genutzt wird, und das wirkt sich sowohl auf die Kosten als auch auf die Nachhaltigkeit aus.
Du kannst auch verschiedene Teile des Systems unterschiedlich behandeln. Wenn zum Beispiel ein Teil deines Systems CPU-gebunden ist und ein anderer speichergebunden, kannst du sie auf verschiedenen Hardwaretypen laufen lassen.
Robust
Während ein Funktionsaufruf in einem Monolithen viel weniger wahrscheinlich fehlschlägt als ein Aufruf über das Netzwerk zwischen zwei Microservices, ist eine Microservice-Architektur insgesamt ziemlich robust.
Wenn in einem Monolithen etwas schief geht, verlierst du das ganze System. Wenn in einem Microservice etwas schief geht, hast du nur einen Teil des Systems verloren. Anders ausgedrückt: Der Radius, in dem etwas schief gehen kann, ist klein. Stell dir zum Beispiel die Startseite einer Website vor, auf der du Filme kaufen kannst und die eine Liste mit personalisierten Empfehlungen für dich enthält. Wenn dieser Dienst ausfällt, kannst du den Rest der Seite immer noch sehen. Du kannst immer noch nach einem Film suchen und ihn kaufen. Und vielleicht zeigt dir das System wieder eine Liste mit beliebten Filmen an, wenn die personalisierte Liste nicht abgerufen werden kann.
Das ist eine grobe Vereinfachung der Dinge. Erstens können Monolithen auf mehreren Rechnern eingesetzt werden, vielleicht in verschiedenen Regionen. Es kommt selten vor, dass der Ausfall eines Rechners das gesamte System lahmlegt. Und zweitens ist Robustheit in einer Microservice-Architektur mit Arbeit verbunden. Du musst dir Gedanken darüber machen, was passiert, wenn etwas schief geht. Das wird in Kapitel 12 ausführlich behandelt.
Leicht, kleine Änderungen häufig zu veröffentlichen
Bei einem Monolithen muss selbst bei der kleinsten Änderung die gesamte Anwendung bereitgestellt werden. Das kann eine Weile dauern, und deshalb ist es wahrscheinlicher, dass die Änderungen gebündelt werden. Ein Release fühlt sich riskant an und kann oft - wenn auch nicht immer - mit Ausfallzeiten verbunden sein. Das ist ein Teufelskreis, denn das Risiko führt dazu, dass du seltener Releases durchführst, wodurch jedes Release riskanter wird.
Die Einführung von Microservices sollte es dir ermöglichen, kleine Änderungen an einem Teil des Gesamtsystems vorzunehmen und dabei sicher zu sein, dass du nicht etwas Unerwartetes kaputt machst. Und da es sich um separate Dienste handelt, kannst du nur den Dienst bereitstellen, den du geändert hast.
Wenn etwas schief geht, ist es einfacher, darüber nachzudenken, weil es sich um eine kleine, in sich geschlossene Änderung handelt, die leicht rückgängig zu machen ist. Das macht die Freigabe von Code zu etwas Normalem und nicht zu etwas Beängstigendem.
Mit Microservices solltest du den Punkt erreichen, an dem du kleine Änderungen freigibst, sobald sie fertig sind, typischerweise zehn- oder sogar hundertmal am Tag. Die Financial Times hat im Jahr 2021 rund 100 Releases pro Tag veröffentlicht. Das bringt einen echten geschäftlichen Nutzen: Du kannst deine Ideen schnell umsetzen und bekommst dann echtes Feedback zu deinen Ideen.
Accelerate von Nicole Forsgren et al. geht der Frage nach, was leistungsstarke Technologieunternehmen gemeinsam haben und definiert Hochleistung als positive Auswirkung auf die Produktivität, die Rentabilität und den Marktanteil deines Unternehmens im Vergleich zur Konkurrenz.12
Ihre Untersuchungen ergaben, dass leistungsstarke Unternehmen eine höhere Bereitstellungshäufigkeit, eine kürzere Vorlaufzeit für Änderungen, eine geringere Fehlerquote bei Änderungen und eine kürzere Zeit zur Wiederherstellung des Dienstes haben, wenn etwas schief läuft. Microservices helfen bei all diesen Kennziffern.
Ich werde im Laufe des Buches immer wieder auf diese Kennzahlen zurückkommen, beginnend in Kapitel 2.
Flexible Technologieauswahl unterstützen
Bei einem Monolithen bist du gezwungen, eine einzige Programmiersprache und wahrscheinlich einen einzigen Datenspeicher zu verwenden. Es kann durchaus Stellen in der Codebasis geben, die von etwas anderem profitieren würden, aber sie müssen damit auskommen. Das bedeutet zum Beispiel, dass Daten, die von Natur aus graphähnlich sind, in eine relationale Datenbank gequetscht werden können.
Mit Microservices kannst du das richtige Tool für deine Bedürfnisse wählen. Frontend-Dienste können in Node.js geschrieben werden und Backend-Dienste in Go. Du kannst einen Artikel in einem Dokumentenspeicher speichern, weil du in der Regel das ganze Ding abrufen willst. Du kannst Metadaten in einem Graphen speichern, weil du in der Lage sein willst, in den Beziehungen zu navigieren.
Das bedeutet auch, dass Microservices Veränderungen unterstützen. Du kannst eine neue Technologie in einem Dienst ausprobieren, und wenn sie sich bewährt, kannst du andere Dienste darauf umstellen. Oder du kannst die anderen Dienste so belassen, wie sie sind - du hast die Wahl. Dasselbe gilt, wenn du die Technologie auf dem neuesten Stand halten willst: Es ist viel weniger beängstigend, die Version deiner Programmiersprache Microservice für Microservice zu aktualisieren, als dies bei einem Monolithen der Fall ist. Das sollte dir helfen, näher an den neuesten Versionen zu bleiben.
Herausforderungen von Microservices
Viele der Herausforderungen von Microservices liegen darin, dass es sich um verteilte Systeme handelt. Die Anzahl der verschiedenen Dienste und die Geschwindigkeit der Veränderungen können dies jedoch auf 11 erhöhen.13
Fast der gesamte Teil III dieses Buches beschäftigt sich damit, wie sich die Dinge ändern, wenn du eine Microservice-Architektur aufbaust und betreibst. Dabei konzentriere ich mich eher auf die Dinge, bei denen Microservices wirklich nicht gut funktionieren, als auf die Dinge, die du anders angehen musst, wie zum Beispiel das Testen.
Latenz
Da ein Aufruf über ein Netzwerk viel länger dauert als ein prozessinterner Aufruf, könnte ein großer Teil der Verarbeitungszeit auf Netzwerkaufrufe entfallen, wenn ein Fluss mehrere Microservices durchläuft.
Für viele Systeme ist das kein großes Problem, aber wenn die Latenzzeit für dein System wichtig ist, solltest du darauf achten, wie viele Netzwerkanrufe für einen bestimmten Vorgang erforderlich sind. Insbesondere solltest du Netzwerkanrufe über große Entfernungen vermeiden(als grober Richtwert gilt, dass ein TCP-Paket zwischen den USA und Europa ca. 150 ms braucht - in der gleichen Zeit hättest du wahrscheinlich 300 Roundtrips innerhalb eines einzigen Rechenzentrums machen können!) Diese Dinge können dich beißen, wenn du in einen Zustand des teilweisen Ausfalls gerätst. Wenn das bedeutet, dass einige Dienste in Europa andere Dienste in den USA anrufen und umgekehrt, kann es sein, dass du noch funktionierst, aber du könntest inakzeptabel langsam sein.
Komplexität des Nachlasses
Flexibilität bei der Auswahl der richtigen Technologie kann dazu führen, dass viele verschiedene Technologien eingesetzt werden. Hier kollidiert die lokale Optimierung (das Team möchte eine Graphdatenbank verwenden, weil die Daten in diesen Stil passen) mit der globalen Optimierung (die Organisation hat bereits fünf verschiedene Datenbanken, die in verschiedenen Teams verwendet werden, und sie müssen alle regelmäßig gepatcht werden und über Mechanismen zur Sicherung und Wiederherstellung verfügen).
Die Vielfalt der verwendeten Technologien erschwert auch die Bereitstellung von Werkzeugen und zentraler Unterstützung für Entwicklungsteams. Jede neue Programmiersprache bedeutet, dass die Bibliotheken und die Dokumentation für die gemeinsam genutzten Werkzeuge diese Sprache einbeziehen müssen, was bedeutet, dass dies ein Bereich ist, in dem Organisationen üblicherweise einige Einschränkungen auferlegen. Über das richtige Gleichgewicht zwischen Autonomie und Einfachheit spreche ich später in diesem Buch, insbesondere in Kapitel 11.
Operative Komplexität
Wir haben unseren Monolithen durch Mikrodienste ersetzt, damit jeder Ausfall eher einem Krimi gleicht.
@honest_update auf Twitter14
Es gibt drei Gründe, warum Microservices operativ komplex sind:
-
Sie sind verteilte Systeme.
-
Sie verändern sich schnell.
-
Sie sind lose gekoppelt.
Da es sich bei Microservices um verteilte Systeme handelt, sind die Dinge ein wenig unbeständiger. Ein Aufruf kann aufgrund von Netzwerk- oder DNS-Problemen fehlschlagen. Wir umgehen das, indem wir Resilienz einbauen (siehe Kapitel 12), aber das bedeutet, dass der genaue Weg, den eine Anfrage nimmt, nicht vorhergesagt werden kann, und wenn du nicht gut mit Fehlern umgehst, kann es zu Timeouts und Verkehrsspitzen kommen.
Ein verteiltes System zu sein bedeutet auch, dass du nicht einfach auf eine Box springen und die Logs abrufen kannst. Du brauchst eine Log-Aggregation, damit du einen Ort hast, an dem du dir alle Logs ansehen kannst - aber wenn etwas wirklich schief läuft, schaffen es diese Logs vielleicht nicht bis zum Aggregations-Tool. Und du brauchst etwas, mit dem du eine einzelne Anfrage durch dein System verfolgen kannst, unabhängig davon, welche Dienste sie durchläuft. Das kann durch ein spezielles verteiltes Tracing-Tool geschehen oder, wie wir es ursprünglich bei FT gemacht haben, indem wir alle Logs, die sich auf eine einzelne Anfrage beziehen, mit einer eindeutigen Korrelations-ID versehen haben.
Außerdem ändern sich die Dinge schnell, was bedeutet, dass dein Verständnis davon, wie das System aussieht, höchstwahrscheinlich nicht mehr aktuell ist. Das gilt besonders, wenn mehrere Teams an einem System arbeiten und sich den Support teilen. Wenn jemand aus dem Artikelseitenteam Support leistet und es ein Problem mit der Personalisierungsfunktion gibt, muss er herausfinden, wie das jetzt funktioniert, indem er seine Beobachtungswerkzeuge benutzt und sich die Codebasis ansieht.
Als ich noch an monolithischen Architekturen gearbeitet habe, war das Architekturdiagramm ziemlich nützlich. In der Regel konnte ich davon ausgehen, dass es auf dem neuesten Stand war und die richtigen Servernamen, Ports usw. enthielt. Die Komplexität lag innerhalb der Anwendung. Bei einer Microservice-Architektur ist es schwierig, ein Diagramm manuell auf dem neuesten Stand zu halten. Außerdem brauchst du verschiedene Ebenen von Architekturdiagrammen. Am nützlichsten ist vielleicht das Diagramm, das wir bei der FTam wenigsten hatten - eines, das die verschiedenen Systeme, die verschiedenen Teams gehören, und die Abläufe über diese Grenzen hinweg zeigt.
Schließlich sind Microservices lose gekoppelt. Das ist gut! Wenn du jedoch einen Ablauf hast, der sich über mehrere Teams erstreckt, gibt es vielleicht niemanden, der den gesamten Ablauf versteht. Ich habe das bei der FT erlebt, als es Probleme gab, wenn ein Artikel veröffentlicht wurde und auf der Startseite der Website auftauchte. Das ging durch drei verschiedene Teams: Redaktionelle Werkzeuge, Content Publishing und das ft.com-Team. Die erste Herausforderung bestand darin, herauszufinden, wo etwas schief gelaufen war.
Wir haben dies mit Tools gehandhabt, die es uns ermöglichten, die Schnittstellen zwischen den Systemen (und damit den Teams) zu betrachten, damit wir sehen konnten, wie weit eine Aktualisierung des Artikels erfolgreich gediehen ist. Darauf werde ich in Kapitel 13 eingehen.
Datenkonsistenz
Microservices (n,pl): ein effizientes Instrument zur Umwandlung von Geschäftsproblemen in verteilte Transaktionsprobleme
@drsnooks auf Twitter15
Innerhalb eines Monolithen, mit einer einzigen Datenbank, könntest du Transaktionen verwenden, um sicherzustellen, dass eine einzelne logische Aktualisierung entweder komplett erfolgreich war oder komplett fehlgeschlagen ist.
Sobald du Daten an mehr als einem Ort gespeichert hast, kannst du dich nicht mehr auf Transaktionen verlassen.
Meine Empfehlung wäre, dies zu nutzen, um die Grenzen innerhalb deines Systems zu entwerfen: Wenn du ein einzelnes logisches Update hast, solltest du es, wo immer möglich, in einem einzelnen Microservice durchführen, in dem du die ganze Sache festschreiben oder zurücksetzen kannst. Das wird nicht immer möglich sein. Du kannst das Saga-Pattern verwenden, um kompensierende Änderungen vorzunehmen, wenn ein Teil einer Änderung fehlschlägt, aber das macht die Art und Weise, wie du dein System baust, testest und betreibst, noch komplexer. Einfacher ist es, wenn du ein System hast, bei dem du eine eventuelle Konsistenz akzeptieren kannst: Die Daten können inkonsistent sein, sollten aber schließlich konvergieren undkonsistent werden.
Bei meiner Arbeit auf der Veröffentlichungsplattform der FThabe ich von zwei Dingen profitiert. Das erste war, dass wir nicht die Quelle der Wahrheit für die Artikel waren. Diese Quelle der Wahrheit war das Content Management System (CMS), das vom Redaktionsteam betrieben wurde. Wenn wir unsere Kopie eines Artikels verloren haben, konnten wir sie im CMS wiederfinden. Wir profitierten auch davon, dass die Veröffentlichung eines Artikels idempotent ist. Du kannst die Veröffentlichung eines Artikels so oft wiederholen, wie du willst, und es gibt keine Nebeneffekte. Oft haben wir unsere Interaktionen mit Datenbanken vereinfacht, indem wir:
-
Behandlung von Clustern in verschiedenen Regionen als völlig getrennt
-
Veröffentlichung für beide
-
Überwachung nutzen, um Ungereimtheiten aufzudecken
-
Manuelles Beheben dieser Unstimmigkeiten durch Drücken der Schaltfläche "erneut veröffentlichen" für diesen Artikel
Es ist zwar von Vorteil, wenn jeder Microservice seine eigenen Daten besitzt, aber in der Praxis musst du einige dieser Daten duplizieren; denk zum Beispiel an eine Auftragsverwaltung. Logischerweise muss der Dienst Order Management nur eine Kunden-ID speichern, aber du willst nicht jedes Mal, wenn du eine Bestellung abrufst, den Dienst Customer aufrufen müssen, um den Namen und die Adresse des Kunden zu erfahren, denn das würde ein sehr gesprächiges System ergeben.
Diese Duplizierung bringt jedoch eine Herausforderung mit sich: Wie stellst du sicher, dass jeder Dienst weiß, dass er den Namen oder die Adresse des Kunden aktualisieren muss, wenn sie sich ändern? Du hast einige Möglichkeiten (z. B. das Einstellen von Cache-Timeouts oder die Bereitstellung eines Benachrichtigungsprozesses), aber was auch immer du tust, du musst wissen, welche Dienste Informationen zwischenspeichern und welcher Dienst die kanonische Quelle dafür ist.
Sicherheit
In einem verteilten System gibt es viel mehr zu sichern. Aufrufe, die früher innerhalb einer einzelnen Anwendung stattfanden, laufen jetzt über das Netzwerk. Das bedeutet, dass du die Daten, die du verschickst, sichern und den Zugang zu deinen Microservice-Endpunkten verriegeln musst. Und das musst du konsequent und überall tun, denn du bist nur so sicher wie der unsicherste Teil deines Systems. Das bedeutet, dass jedes Team die Grundsätze der Sicherung von Daten und Diensten verstehen muss und dass dies Teil des Prozesses für die Bereitstellung eines Dienstes in der Produktion sein muss.
Es gibt jedoch auch einige Vorteile einer Microservice-Architektur, wenn du deinen Ansatz für die Sicherheit richtig wählst. Wenn deine Daten in verschiedenen Datenspeichern mit unterschiedlichen Zugangsdaten gespeichert werden, hat ein Angreifer, der sich Zugang zu einem dieser Speicher verschafft, keinen Zugriff auf alle deine Daten. Du kannst auch die sensibelsten Daten in bestimmten Datenspeichern speichern, z. B. die Daten mit personenbezogenen Daten (PII).
Diese Berechtigungsnachweise sind jedoch eine Herausforderung. Du solltest eine große Anzahl von Berechtigungsnachweisen haben, weil du nicht willst, dass ein einziger Berechtigungsnachweis wiederverwendet wird und dir einen breiten Zugang zu deiner Software ermöglicht.
Den richtigen Grad an Granularität finden
Microservices sind klein. Aber wie klein?
Viele der frühen Definitionen von Microservices , auf die ich vor fast einem Jahrzehnt gestoßen bin, konzentrierten sich auf die Größe, und das war verwirrend, weil sie sehr unterschiedlich waren. War ein Microservice etwas, das "nicht größer als ein paar hundert Codezeilen" war16 oder etwas, das von einem einzigen "Zwei-Pizza"-Team betrieben wird? Was bedeutet es, dass ein Microservice "eine Sache gut machen" sollte?
Ich halte es für eine schlechte Idee, sich zu sehr auf die Idee zu konzentrieren, dass es sich um Microservices handelt. Ich möchte die Frage nach dem "wie klein" umdrehen und stattdessen fragen: Wie viele Microservices brauchst du?
Verschiedene Unternehmen verfolgen hier einen unterschiedlichen Ansatz. Das eine Extrem ist ein Unternehmen wie Monzo, das viele Hunderte von Microservices hat.17
Ich habe das Publikum auf verschiedenen Konferenzen nach Microservices gefragt, und im Allgemeinen haben die Leute ein oder zwei Größenordnungen weniger Microservices als das - zwischen 15 und 150. Bei der FT waren wir auf der höheren Seite: Wir hatten viele Hunderte von Microservices, und Teams konnten 10 bis 50 Microservices haben, die sie regelmäßig änderten oder die sie unterstützen mussten.
Wie entscheidest du also, wo in diesem Spektrum du sitzen solltest?
Erstens sollten deine Microservices so klein sein, dass sie von einem einzigen Team betrieben werden können. Wenn mehrere Teams in einem Bereich arbeiten, solltest du einen Weg finden, diesen Bereich so aufzuteilen, dass jedes Team einen Teil davon besitzt. Andernfalls müssen die Teams ihre Arbeit koordinieren, was sie ausbremst. Für die Content-Publishing-Plattform der FThatten wir mehrere Entwicklungsteams und haben den Bereich entsprechend aufgeteilt. Ein Team war für die Inhalte zuständig - Artikel, Videos, Bilder. Das andere Team kümmerte sich um die Metadaten - Informationen über die Themen, Personen und Organisationen, die in den Inhalten behandelt werden, um zum Beispiel automatisch Themenseiten auf der Website zu erstellen.
Außerdem sollen deine Microservices so klein sein, dass die Mitarbeiter in deinem Team den gesamten Dienst verstehen können. Insbesondere sollte eine neue Person, die zu deinem Team stößt, in der Lage sein, sich den Code anzusehen und recht schnell zu verstehen, was der Dienst tut.
Das konnte ich definitiv nicht, als ich den Code für einen Monolithen mit 70 Paketen schrieb - ich brauchte Monate oder sogar Jahre, um das zu verstehen.
Microservices sind nicht nur leichter zu verstehen, weil es weniger Code gibt, sondern auch, weil es eine klar definierte Schnittstelle gibt. In der Regel gibt es nur einen Weg in den Dienst hinein und aus ihm heraus, und wenn du diese Schnittstelle verstehst, verstehst du auch viel über den Dienst.
Ein schöner Vorteil ist die oft zitierte Möglichkeit, einen Microservice mit geringem Risiko und ohne großen Zeitaufwand komplett zu ersetzen. Ich habe das auch schon erlebt (wenn auch nicht so oft), z. B. wenn ein Dienst an ein anderes Team übergeben wurde, das in einer anderen Programmiersprache arbeitet, oder wenn eine Lösung für die Speicherung von Daten durch eine andere ersetzt wurde.
Allerdings solltest du dich nicht zu klein machen. Das liegt zum Teil daran, dass je mehr Microservices du hast, desto öfter musst du dieselbe Änderung vornehmen, wenn du zum Beispiel eine Bibliothek aktualisieren musst. Automatisierung kann helfen, und du wirst Dinge, die du regelmäßig machst, automatisieren müssen. Aber selbst wenn du einen Großteil des Bibliotheks-Upgrades automatisierst, indem du z. B. Pull-Requests für jeden betroffenen Dienst erstellst, musst du immer noch jeden einzelnen davon genehmigen/prüfen.
Aber wenn du zu klein bist, wird es für den Microservice sehr schwierig, seine eigenen Daten zu besitzen und nicht auf die Daten eines anderen Dienstes zugreifen zu müssen.
Kyle Brown und Sharir Daya von IBM gehen in ihrem Blogbeitrag "What's the Right Size for a Microservice?" aus dem Jahr 2020 darauf ein, dass ein häufiger Fehler von Teams, die Microservices einführen, darin besteht, zu klein zu sein. Sie argumentieren, dass es sich dabei um den Irrglauben handelt, dass jeder Microservice nur eine REST-Schnittstelle bereitstellen sollte, z. B. dass ein Account Service nur Vorgänge für ein einziges Konto abwickelt, wie z. B. Open, Close, Credit, Debit.
Wenn du Geld zwischen Konten überweisen musst, hast du zwei Möglichkeiten. Eine Möglichkeit ist, einen separaten Transfer Dienst einzurichten, der zuerst von einem Konto abbucht und dann eine Gutschrift auf einem anderen Konto vornimmt. Aber das ist eine Transaktion, bei der du willst, dass sowohl die Abbuchung als auch die Gutschrift erfolgreich sind. Verteilte Transaktionen sind schwierig. Einfacher wäre es, einen Überweisungsvorgang zum Dienst Account hinzuzufügen.
Wenn du deine Microservices entwirfst und die Grenzen findest, solltest du dich an den Transaktionsgrenzen orientieren. Wenn du merkst, dass der Umgang mit deinen Daten kompliziert wird, solltest du überlegen, ob es nicht sinnvoll ist, deine Microservices zu kombinieren.
Wenn du also feststellst, dass du immer zwei Microservices gleichzeitig änderst, sollten es vielleicht nicht zwei Microservices sein.
Du musst nicht gleich beim ersten Mal richtig machen - du kannst Microservices aufteilen oder kombinieren, wenn du merkst, dass du die Grenzen oder die Größe nicht richtig gewählt hast. Wie du die richtigen Grenzen festlegst, werde ich in Kapitel 4 ausführlicher erläutern.
Umgang mit Veränderungen
Upgrades und Migrationen sind eine Tatsache des Lebens. Es wird immer etwas geben, das repariert werden muss:
-
Vielleicht hast du etwas von Grund auf neu aufgebaut und jetzt gibt es etwas, das du zukaufen kannst. Ein Beispiel: Wir haben unsere eigene Service-Orchestrierung entwickelt und sind dann auf Kubernetes umgestiegen, als es produktionsreif war.
-
Oder vielleicht musst du deine Programmiersprache aktualisieren, weil die Version, die du verwendest, bald veraltet ist.
-
Oder vielleicht gibt es eine Bibliothek, die aktualisiert werden muss, weil sie eine Sicherheitslücke aufweist.
Der springende Punkt dabei ist, dass diese Änderungen global vorgenommen werden müssen, d.h. überall dort, wo der Dienst, die Programmiersprache oder die Bibliothek verwendet wird, und in der Regel mit einer gewissen Frist - Versionen, die das Ende ihrer Lebensdauer erreichen oder bei denen eine Lizenzperiode abläuft. Dies ist die Kehrseite eines der Vorteile von Microservices. Du kannst Microservices mit geringerem Risiko einzeln aktualisieren als einen Monolithen, aber es besteht immer das Risiko, dass du feststellst, dass 50 Services noch auf einer Java-Version laufen, die seit Monaten oder sogar Jahren nicht mehr unterstützt wird!
Zwei Dinge machen dies in einer Microservice-Architektur noch schwieriger. Erstens: Wenn du zum Beispiel mehrere Datenspeicher hast, gibt es auch mehrere Upgrade-Pfade. Fünfmal so viele Datenbanken können fünfmal so viele Upgrades bedeuten. Hoffentlich ist jedes Upgrade einfacher und nimmt weniger Zeit in Anspruch, aber das ist nicht immer der Fall.
Nutzen Sie Managed Services, wo immer möglich
Ein weiterer guter Grund für die Inanspruchnahme von Managed Services, wie z. B. Managed Databases, ist, dass jemand anderes die meisten Upgrades für dich übernimmt. Aber auch hier wird es Änderungen geben, die so bedeutend sind, dass du selbst etwas tun musst - zum Beispiel, wenn es Upgrades gibt, die nicht vollständig abwärtskompatibel sind und du daher Änderungen an deiner Anwendung vornehmen musst.
Zweitens: Je mehr Microservices du hast, desto mehr Stellen musst du ändern. Du musst die Dinge so aufbauen, dass die Migration von 150 Diensten auf etwas Neues nicht wochenlang dauert. Und das bedeutet, dass du in Automatisierung investieren musst. Du solltest zum Beispiel versuchen, deine Bereitstellungspipeline mit Templates zu versehen, damit du alle Pipelines leicht ändern kannst, wenn du einen neuen Schritt in die Bereitstellung einfügst (z. B. um die Sicherheitsüberprüfung zu verbessern). Du musst auch herausfinden, wie du schnell alle Dienste patchen kannst, die eine bestimmte Version einer Bibliothek verwenden, insbesondere wenn es ein Sicherheitsproblem gibt. Vielleicht kannst du dies durch die automatische Erstellung eines Pull Requests (PR) erreichen, aber du musst den gesamten Code trotzdem freigeben.
Automatisierung kann die Dinge beschleunigen und Fehler reduzieren, die durch manuelle Wiederholungen entstehen können. Aber es erfordert immer noch, dass Menschen etwas Zeit in etwas investieren, das nicht die Entwicklung neuer Funktionen ist, und selbst wenn du die Änderungen am Code automatisierst, musst du diese Änderungen immer noch überprüfen und testen. In Kapitel 14 beschreibe ich, wie du das angehen kannst. Für Teams kann das ein echter Killer sein, denn sie haben das Gefühl, dass sie sich in einer Tretmühle aus uninteressanten, aber wichtigen Updates befinden.
Organisatorische Änderungen erforderlich machen
Deine Teams müssen sowohl autonom als auch befähigt sein. Das wird nicht funktionieren, wenn du z.B. immer noch eine Reihe von Toren hast, durch die die Leute gehen müssen, um den Code in dieProduktion zu bringen.
Deinen Teams wirklich zu vertrauen, dass sie das Richtige tun, und dafür zu sorgen, dass sie verstehen, was das Richtige ist, kann für viele Unternehmen eine große Umstellung sein.
Der gesamte zweite Teil dieses Buches befasst sich mit der Organisationsstruktur und -kultur, die es wahrscheinlicher machen, dass du mit Microservices erfolgreich sein wirst. Bei der FT hat dieser organisatorische Wandel Jahre gedauert.
Verändere das Entwicklererlebnis
Als ich zu Microservices wechselte, war ich sehr überrascht, wie sehr sich die Dinge, an denen ich als Entwickler arbeitete, und die Art und Weise, wie ich diese Arbeit erledigte, veränderten.
Das Gleichgewicht, in dem ich meine Zeit verbrachte, verschob sich. Bei der Arbeit an einem Monolithen habe ich hauptsächlich Code geschrieben, der innerhalb der bestehenden Anwendung eingesetzt wurde. Bei einer Microservice-Architektur richtete ich regelmäßig neue Dienste ein, was bedeutete, dass ich jetzt viel mehr über die Infrastruktur wissen musste. Die Wahl unserer eigenen Datenspeicher bedeutete, dass ich sie einrichten und verstehen musste, wie sie funktionieren.
Auch mein Entwicklungszyklus hat sich geändert. Mit dem Monolithen habe ich Code und Tests geschrieben und die Unit-Tests in meiner IDE ausgeführt. Aber ich habe auch oft die Anwendung gestartet und manuell getestet. Ich konnte einen Debugger an die laufende Anwendung anschließen und den Code durchgehen.
Bei Microservices haben wir zunächst versucht, große Teile des Systems lokal zu betreiben. Vor der Containerisierung war das nicht so einfach möglich. Wir mussten zum Beispiel oft feststellen, dass zwei Personen denselben Port für den lokalen Betrieb eines Dienstes gewählt hatten. Aber wir konnten es schaffen, weil wir meistens unsere eigenen Datenbanken und Warteschlangen auf EC2-Instanzen bei AWS installierten, anstatt AWS-spezifische Alternativen zu verwenden.
Ich bin der Meinung, dass du stattdessen die Mehrwertdienste deines Cloud-Providers nutzen solltest, weil du damit einen Teil der Arbeit an jemand anderen als dein Team abgibst. Das hat außerdem den angenehmen Nebeneffekt, dass du nicht mehr versuchen musst, ein komplettes Replikat deines Systems lokal zu betreiben.
Ein ganzes System lokal zu betreiben, ermutigt dich dazu, End-to-End-Akzeptanztests zu verwenden, die deine Microservices zusammenkoppeln und zu einem verteilten Monolithen machen (mehr zu diesem Antipattern findest du in Kapitel 10 ), anstatt dich auf Unit-Tests und Contract-Tests zu konzentrieren. Ich denke, du solltest darauf abzielen, höchstens kleine Teile deines Systems lokal auszuführen. Und wenn du eine umfassendere Umgebung brauchst, solltest du eine Remote-Umgebung verwenden. Aber auch hier gilt, dass du so wenig wie möglich von deinem kompletten System laufen lassen solltest.
Hinweis
Um es klar zu sagen: Ich sehe den Wert von End-to-End-Tests, aber ich würde es vorziehen, eine kleine Anzahl davon zu haben und solche, die nichts über die internen Implementierungen der einzelnen Microservices wissen.
Die erste Suite von Akzeptanztests, die wir für die Content-Plattform geschrieben haben, enthielt Fixtures, die Daten für jeden Microservice, der an der Veröffentlichung eines Artikels beteiligt ist, einrichten sollten. Sie waren schwer zu aktualisieren, dauerten länger als der Code und schränkten die Reihenfolge ein, in der wir Änderungen in unsere Staging- und Produktionsumgebung einspielten, da Änderungen an verschiedenen Microservices die Änderung desselben Satzes von Akzeptanztests bedeuten konnten.
Wir haben unsere Produktionsumgebung nirgendwo vollständig repliziert. Ein Grund dafür waren dieKosten - mein Team hatte eine Staging-Umgebung, aber wir haben sie nicht multiregional betrieben. Oft werden nicht so viele Instanzen betrieben. Das bedeutet, dass es eine ganze Reihe von Problemen im Zusammenhang mit der Konfiguration und dem Failover gibt, die man in der Staging-Umgebung nicht erkennen kann. Der zweite Grund ist, dass andere Dienste und Ressourcen, mit denen du interagierst, im Staging zwangsläufig auf einer anderen Version laufen als in der Produktion. Bei der FT hatten viele Teams keine Staging-Umgebung, was bedeutete, dass du bestenfalls ihre Produktionsumgebung nutzen konntest (solange dein Datenverkehr nichts schrieb und sie nicht überlastete).
All dies bedeutete, dass es Probleme gab, die nur in der Produktion auftreten und dort diagnostiziert werden konnten. Ordnungsgemäße Beobachtungswerkzeuge und die Möglichkeit, Funktionen schnell abzuschalten, wurden viel wichtiger, als Dinge lokal zu replizieren.
In Kapitel 10 werde ich erläutern, warum ich glaube, dass das Testen in der Produktion eine natürliche Konsequenz der Umstellung auf Microservice Architekturen ist und einen großen Wert darstellt.
In der Zusammenfassung
Eine Microservice-Architektur unterteilt ein System in viele unabhängig voneinander einsetzbare Dienste, die sich an Geschäftsbereichen orientieren. Es gibt sie seit fast einem Jahrzehnt und sie kann sehr gut funktionieren.
Der Hauptvorteil einer Microservice-Architektur ist, dass sie dir die Möglichkeit gibt, schnell zu handeln. Du kannst kleine Änderungen an einem Teil des Gesamtsystems mit einem hohen Maß an Sicherheit vornehmen, dass du nichts Unerwartetes kaputt machst. Du kannst diese kleinen Änderungen nach Bedarf freigeben, in der Regel Hunderte Male am Tag. Das ist es, was einen echten geschäftlichen Nutzen bringt: Du kannst deine Ideen schnell umsetzen und bekommst dann ein echtes Feedback dazu.
Das bringt jedoch auch eine höhere Komplexität mit sich: Es handelt sich um ein verteiltes System mit vielen beweglichen Teilen.
In Kapitel 3 gehe ich darauf ein, wie du herausfinden kannst, ob eine Microservice-Architektur der richtige Ansatz für dich ist. Aber zuerst werde ich im nächsten Kapitel über die anderen Dinge sprechen, die zeigen, ob deine Software-Lieferorganisation effektiv ist. Wir werden uns ansehen, wie die Microservice-Architektur abschneidet und welche Werkzeuge, Techniken und Prozesse dir helfen werden, erfolgreich zu sein, wenn du dich für diesen Ansatz entscheidest.
1 Das ist die prägnante Definition, die Sam Newman in seinem BuchBuilding Microservices, 2.
2 Ich werde nicht die einzige Person sein, die froh war, von SOAP für den Nachrichtenversand zwischen Diensten wegzukommen!
3 Zu viele und zu lange sind zwangsläufig vage. Sie sind von Organisation zu Organisation unterschiedlich.
4 Ich habe die hervorragende NIST-Definition von Cloud Computing auf der Website von Martin Fowler gefunden. Ich empfehle die vollständige Normungsdokumentation des NIST als eine wirklich klare Erklärung eines Begriffs, der oft ein wenig... nebulös ist.
5 Kief Morris, Infrastructure as Code, 2. Aufl. (Sebastopol: O'Reilly, 2020).
6 Die FT konzentriert sich auf Wirtschaftsnachrichten, was bedeutet, dass es am Wochenende ein paar Stunden ohne viel neue Inhalte geben kann.
7 Diese Metapher funktioniert meiner Erfahrung nach auch sehr gut, wenn es darum geht, Nichttechnikern moderne Softwareentwicklungsmethoden zu erklären!
8 Ich bin mir nicht sicher, ob ich mich 2024 für Heroku entscheiden würde, aber 2016 war dies eine erfolgreiche Wahl.
9 Wenn du deinen Cloud-Provider um eine Empfehlung bittest, wird diese wahrscheinlich eher Serverless als Container lauten. Adrian Cockcroft, der früher bei Amazon gearbeitet hat, empfiehlt einen Serverless-First-Ansatz für schnelles Feedback und einen Wechsel zu Containern nur dann, wenn dies aus Kostengründen notwendig ist.
10 Wie in diesem Blogbeitrag von Surya Sreedevi Vedula und Ashish Bhalgat von Thoughtworks.
11 Matthew Skelton und Manuel Pais, Team Topologies, 2nd ed. (Portland, OR: IT Revolution, 2019).
12 Nicole Forsgren, Jez Humble, und Gene Kim, Accelerate: The Science of Building and Scaling High Performing Technology Organizations (Portland, OR: IT Revolution, 2018).
13 Wie Nigel Tufnel in Spinal Tap sagt, ist das definitiv mindestens eine Nummer lauter.
14 Tweet von Honest Update, @honest_update, October 7th, 2015.
15 Tweet von Al Davidson, @drsnooks, October 6th, 2015.
16 Es ist schwer herauszufinden, wer das zuerst gesagt hat, aber ich bin mir ziemlich sicher, dass ich das zum ersten Mal von Fred George in einem Vortrag um 2012 herum gehört habe. Für mich als Java-Entwickler war das zu diesem Zeitpunkt eine kleine Herausforderung!
17 Im Jahr 2020, Matt Heath und Suhail Patel zitiert 1.600+ and growing, Modern Banking in 1600 Microservices, InfoQ.
Get Erfolgreiche Microservices ermöglichen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

