Capítulo 4. Los datos operativos son el nuevo petróleo
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Los datos operativos y su potencial para producir nuevo valor empresarial se aplican a todo tipo de organizaciones en todos los sectores de la sociedad y la economía. Todos los ámbitos generan y consumen datos operativos. La capacidad de las organizaciones para consumir suficientes tipos adecuados de datos operativos, generar perspectivas valiosas a partir de esos datos y, a continuación, tomar medidas correctas y oportunas, determina su capacidad para alcanzar y mantener nuevas cotas de éxito en la actual era de los negocios digitales.
El hecho de que un dicho sea un tópico no lo hace menos cierto. Muchos han declarado tantas veces que los datos son el nuevo petróleo que se ha convertido en un tópico. Pero también es una afirmación cierta, porque los datos operativos, como el petróleo, son un recurso sin refinar que, en última instancia, permite a las empresas extraer y crear valor en forma de derivados.
El petróleo es la base de más de 6.000 productos, como "el líquido lavavajillas, los paneles solares, los conservantes alimentarios, las gafas, los DVD, los juguetes infantiles, los neumáticos y las válvulas cardíacas".1 El valor de los datos operativos, como el del petróleo, depende en gran medida del refinamiento y los procesos de producción. De hecho, los datos en bruto tienen poco valor. Más bien, lo que produce valor es la información y los conocimientos obtenidos mediante un procesamiento y un análisis cuidadosos de los datos.
Ya vemos industrias tradicionales que adoptan los datos operativos para hacer crecer el negocio existente y crear nuevas líneas de ingresos. Las empresas que han trazado con éxito el camino para convertirse en un negocio basado en datos están sacando provecho de esta nueva capacidad estratégica. Por ejemplo, el minorista de comestibles Kroger no sólo cita la información como el principal motor de su extraordinario crecimiento (14,1% en 2020, ayudado por un aumento del 116% en las ventas por Internet),2 sino que también está entrando en el negocio de la información monetizando sus datos:
Tratando de aprovechar su escala y sus importantes conocimientos sobre los clientes, la empresa está tratando de transformar su modelo de negocio con ingresos alternativos, donde planea monetizar sus ricos datos y argumentar que puede proporcionar a las [empresas] CPG un ROI superior en dólares de publicidad/marketing (además del gasto comercial) frente a los canales tradicionales.3
Las arquitecturas, prácticas empresariales y conjuntos de competencias de no aportarán valor a partir de los datos operativos porque son estáticas y están diseñadas para una arquitectura empresarial que ya no refleja la anatomía real de sus sistemas empresariales. Las empresas estáticas simplemente no pueden adaptarse y seguir el ritmo de sus clientes y competidores. Para el CIO, el reto consiste no sólo en gestionar y ampliar las arquitecturas de datos empresariales existentes, sino también en poner en marcha las tecnologías, herramientas y equipos necesarios para operar una práctica de datos operativos a escala.
En este capítulo, exploramos el reto omnipresente para que las organizaciones se vuelvan más innovadoras y piensen en los datos operativos como un activo empresarial de primera clase. Los datos operativos, junto con las correspondientes prácticas empresariales y conjuntos de habilidades tecnológicas, permiten a una organización gobernar una plataforma de datos operativos con disciplina e intencionalidad, al igual que las finanzas corporativas, el cumplimiento y el riesgo. Este capítulo establece los principales cambios de enfoque, las ramificaciones arquitectónicas y el impacto en la inversión en habilidades técnicas en comparación con las empresas tradicionales (es decir, las empresas diseñadas para apoyar una línea de negocio estática frente a las diseñadas para innovar, y cómo avanzar hacia esta última).
Plataforma(s) de Datos Operativos
Una práctica de datos empresariales necesita una plataforma o grupo de plataformas para escalar su consumo de datos operativos (también conocidos como telemetría). Esta plataforma debe tener una arquitectura flexible para procesar los datos en el lugar adecuado y de la forma correcta, y para proporcionar un marco coherente en el que pueda ejecutarse un modelo de gobierno de datos.
Nuevas fuentes de datos
El primer paso para diseñar con éxito una plataforma de insights es comprender qué nuevos tipos de datos se definen como datos operativos y sus fuentes. Todas las aplicaciones, los entornos en los que se ejecutan y los recursos físicos utilizados para darles soporte tienen fuentes potenciales de datos operativos.
Las aplicaciones o pilas de aplicaciones incluyen el código de la aplicación y todo lo que ésta necesita para funcionar. Cualquier aplicación web tradicional o moderna, por ejemplo, comprende el propio código de la aplicación, así como un servidor web subyacente, un sistema operativo y, potencialmente, un hipervisor. La aplicación suele incluir también sistemas de gestión y orquestación. Recoge registros y métricas de todos estos sistemas para ampliar la superficie de análisis y correlacionar datos que de otro modo serían irrelacionables.
Los entornos apuntan a sistemas y servicios exclusivos de una nube o sustrato de colocación concretos. Los servicios de contenedores ofrecidos en muchas nubes públicas, por ejemplo, también ofrecen junto con ellos servicios de visibilidad operativa diseñados para informar de datos especializados exclusivos de su entorno. Recopila estos datos para determinar si la corrección adecuada debe centrarse en un inquilino determinado o en trasladar el trabajo a un proveedor de nube alternativo.
Los recursos físicos describen una variedad de posibles fuentes de datos operativos que pueden pasarse por alto porque están estrechamente ligados a la infraestructura física, como el espacio, la energía y la refrigeración. Podemos, por ejemplo, correlacionar una subida de tensión en un servidor que provocó un fallo en la aplicación e interrumpió un conjunto de compras de clientes.
Las plataformas de datos más eficaces se esforzarán por conseguir una visibilidad total. De hecho, la falta de visibilidad en toda la pila de TI se traduce en la falta de datos, que es el principal problema que señalan los expertos en TI para obtener la información que necesitan.4
Como mínimo, pueden recopilarse datos operativos de los registros, eventos y rastros existentes utilizados para monitorizar y solucionar problemas del entorno. Partiendo de esta base, las organizaciones deben considerar sus posibles puntos ciegos y trabajar para iluminar gradualmente esas lagunas en busca de una visibilidad total mediante la recopilación exhaustiva de datos.
Después de que logre una comprensión clara de todos los tipos potenciales de datos operativos, el siguiente paso es crear un inventario de los componentes que conforman una determinada aplicación/servicio/experiencia digital, tanto internos como externos. El resultado de este paso es un mapa de la malla de comunicaciones entre todos los componentes. A continuación, mediante una nueva agrupación de los componentes en función de los marcos de servicio que puedan utilizarse para agregar telemetría, puede crearse una visión reducida y refinada de las mejores fuentes de datos. Con esta visión, combinada con los resultados de la investigación de puntos ciegos, una organización ha construido la base adecuada para una estrategia de datos y observabilidad. Esa estrategia debe guiar el desarrollo de una nueva plataforma de insights e informa de los planes para mejorar la plataforma de acuerdo con los objetivos y capacidades de su organización.5
Nota
La composición de la propia aplicación cambia a medida que una organización adopta una nueva arquitectura digital. El número de microservicios y componentes de tiempo de ejecución nativos de la nube en uso puede ascender fácilmente a miles para una sola carga de trabajo. Esto incluye muchas más conexiones a servicios de software como servicio (SaaS) de terceros, en comparación con las aplicaciones tradicionales, que suelen diseñarse con muchos menos componentes y muy pocas interfaces SaaS de terceros, si es que hay alguna. Cada uno de estos componentes en tiempo de ejecución es una fuente de datos operativos viable. Identificar el conjunto completo de componentes, sus fuentes de telemetría y qué conjuntos de datos son los más valiosos es el objetivo agudo de los equipos de SRE que son los actores principales, como se describe en el Capítulo 6.
Otros puntos ciegos comunes en la pila de TI son las arquitecturas tradicionales y nativas de la nube/microservicios, incluyen la capa de cálculo, los puntos de vista no proxy y los servicios de terceros. Investigar nuevas fuentes de telemetría en estas tres áreas proporcionará un punto de partida a partir del cual los equipos de TI podrán determinar qué fuentes de datos sin explotar tiene más sentido buscar y en qué orden.
Un ejemplo de un punto ciego de la capa de cálculo son los datos de rastreo del procesador del servidor principal. En este caso, los datos están disponibles pero no se recopilan. Estas fuentes suelen proporcionar un voluminoso historial de ramas de ejecución del procesador que es necesario filtrar, pero que, no obstante, está listo para su consumo.6
Existen numerosos puntos de observación no proxy en, desde la parte superior de la pila digital hasta la inferior. El término "no proxy " tiene sentido porque los proxies suelen colocarse en línea con los flujos de tráfico, lo que les confiere varios niveles de visibilidad en función de cómo estén diseñados. El punto de observación proxy es una fuente natural de datos operativos, porque ya existe para realizar otras funciones críticas como la gestión del tráfico y la seguridad, lo que deja a los puntos de observación no proxy como los puntos ciegos más probables. Algunos ejemplos de puntos de observación no proxy son los siguientes:
-
Filtros de paquetes que pueden utilizarse para implementar u optimizar un proxy pero que, en sí mismos, no son conexiones de red proxy y, por tanto, son líneas de visión únicas.
-
El nuevo conjunto de rutas de datos, control y gestión descritas en el Capítulo 2 -DPUs- en las queel procesamiento de la infraestructura se descarga de los procesadores principales a centros de procesamiento alternativos. Esto incluye matrices de puertas programables en campo (FPGA), GPU u otros complejos informáticos auxiliares .7
-
Código instrumentado de forma nativa en una aplicación o servicio. El propósito de la instrumentación es rastrear la ruta de un usuario típico a través de un flujo de negocio, a medida que atraviesa los diversos componentes y servicios que conforman ese flujo.
Otro punto ciego habitual de son los componentes de terceros. Al suscribirte a las API de telemetría de terceros, esta fuente de información, que de otro modo sería invisible, aumenta la precisión y el valor global de los conocimientos que se pueden generar. Un ejemplo de comercio electrónico es el procesamiento de pagos. Los servicios de pago digital se consumen habitualmente como un componente SaaS de terceros. Además de integrar el propio componente para completar los pedidos, también debería consumirse el servicio de telemetría asociado, también expuesto mediante una API, para que esta fuente de datos pueda transmitirse a la plataforma de información. Otro tipo común de fuente de telemetría de terceros es la que proporcionan los servicios de nube pública a través de determinadas API que exponen a sus inquilinos.
La proliferación de API y su idoneidad para un flujo de datos operativo ligero pero eficaz abre la oportunidad de estandarizar la arquitectura de recopilación. Los formatos de datos agnósticos del lenguaje, como la Notación de Objetos de JavaScript (JSON), unifican el formato de los datos que deben serializarse, y tecnologías como Protobuf unifican el enfoque de la serialización de datos estructurados transmitidos a almacenes de datos de series temporales diseñados para ingerir y conservar esta información. Curiosamente, una nueva técnica que aborda el reto de la ingestión de datos a escala produce datos de series temporales multivariantes, un conjunto de datos más compacto que puede procesarse 25 veces más eficazmente que los flujos unidimensionales. Los avances rápidos como éste se adoptan fácilmente mediante plataformas de insights con arquitecturas flexibles. Se adaptan a las mejoras al tiempo que mantienen ciertos estándares para mantener equilibrada la ecuación de eficiencia y coste. Esto produce un valor creciente de la plataforma para el negocio a lo largo del tiempo.8
Las organizaciones se sienten atraídas por el software libre y de código abierto para construir nuevas capacidades para sí mismas, y la colaboración entre usuarios acelera el progreso para todos los participantes. En el espacio de la recopilación de datos operativos empresariales, OpenTelemetry, presentado en el Capítulo 2, es un ejemplo actual de este tipo de líder. Formado a partir de la fusión de dos proyectos anteriores y relacionados, este proyecto en incubación dentro de la CNCF lidera el camino. Las bibliotecas, API, herramientas y kits de desarrollo de software (SDK) gratuitos y abiertos de esta comunidad abierta simplifican y aceleran la implantación informática de un marco común para instrumentar y recopilar datos operativos. Una vez implementadas en una empresa, las API utilizadas para conectar las fuentes de datos a sus almacenes de datos de destino están estandarizadas, lo que impulsa aún más la capacidad de automatizar la recopilación de datos.
Las plataformas de datos más eficaces de emplearán una arquitectura flexible para instrumentar los sistemas y recopilar datos operativos. Dando prioridad a los formatos y API estándar, pero manteniendo una aceptación liberal de los recopiladores de datos y los traductores de formatos de diversos formatos y técnicas de serialización específicos de cada proveedor, los equipos informáticos pueden trabajar para conseguir con el tiempo formatos y API cada vez más estándar. Este enfoque no es nuevo. Lo que es nuevo con respecto a los datos operativos es que la ingestión de una variedad tan amplia de datos en diversos formatos requiere una decisión sobre cómo exponer estos datos tanto a los equipos humanos de SRE que necesitan solucionar rápidamente los problemas y remediar los sistemas que sufren, como a las máquinas que aplican modelos de análisis predefinidos para generar nuevas perspectivas o remediar los problemas mediante la automatización. Así pues, la observabilidad para los humanos y la analítica para las máquinas tienen requisitos distintos sobre los datos operativos que es mejor que determinen los profesionales de SRE y de ciencia de datos, respectivamente.
Las nuevas fuentes de datos, como los servicios de entrega de aplicaciones y seguridad analizados en el Capítulo 3, requieren un nuevo modelo operativo de consumo, procesamiento, análisis y gestión. Los grupos de TI que construyen una plataforma para capturar todo tipo de datos para su procesamiento humano y mecánico preparan a sus organizaciones para pasar a la siguiente fase de la transformación: el procesamiento de datos. La arquitectura correcta para el procesamiento tendrá en cuenta la ubicación en la que se generan los datos, los tipos de conocimientos que pueden extraerse de un conjunto de datos determinado, la disponibilidad de procesamiento y almacenamiento, y el coste relativo de almacenar, trasladar y procesar datos en distintas ubicaciones. El modelo operativo correcto tendrá en cuenta el volumen de datos, la velocidad de procesamiento y los principios para la toma de decisiones. Exploramos ambos aspectos y cómo se relacionan en la siguiente sección.
Una vez establecido el esquema de las fuentes de datos operativos asignadas a una aplicación determinada (también conocida como carga de trabajo o conjunto de cargas de trabajo que componen una experiencia digital), la atención puede centrarse en las características clave de un motor de procesamiento de datos para la plataforma de datos operativos.
Canalización de datos y prácticas
A medida que surgen más tipos de datos operativos como fundamentales para la arquitectura de la empresa digital, la mayoría de las empresas no podrán construir el almacenamiento, el procesamiento, la seguridad y la privacidad de todos esos datos a escala global. Además, a los líderes tecnológicos les resultará difícil exponer y utilizar todos esos datos a los sistemas, procesos e individuos adecuados dentro de su organización de una forma que cumpla las normas. Por estas razones se necesita una plataforma de datos e información. Esto es similar a los esfuerzos tradicionales de consolidación de datos y al uso de plataformas de inteligencia empresarial para datos empresariales y centrados en el cliente. Hoy en día se requieren esfuerzos similares para los datos operativos, a fin de permitir que el análisis descubra las perspectivas que faltan y produzca valor empresarial.
¿Cómo se obtiene valor empresarial de los datos recopilados? Esto depende del talento humano cualificado en los diversos aspectos de la gestión de datos, del mismo modo que el talento en ingeniería de software fue la clave para extraer valor empresarial transaccional de los sistemas de línea de negocio diseñados y codificados para satisfacer las necesidades empresariales de la generación anterior. De hecho, los artefactos de código como algoritmos, aplicaciones para dispositivos móviles y modelos de datos se convierten en tipos de datos que caen bajo la gobernanza y gestión del equipo de datos recién formado. Al tratar el código como un tipo de datos institucionales, un equipo de TI empieza a dar muestras de impulsar un nuevo valor empresarial desde una mentalidad de "los datos primero". Esos artefactos de código pueden revisarse, implementarse y eliminarse adecuadamente como materias primas utilizadas para impulsar el negocio digital.
Esto es similar al enfoque adoptado por DevOps a la hora de diseñar una canalización de desarrollo. Los pipelines de datos, como el descrito en la Figura 4-1, requieren procesos similares; por tanto, muchas de las prácticas comunes a las operaciones DevOps y SRE relativas al uso de herramientas para ofrecer resultados empresariales más rápidamente pueden aplicarse a las DataOps. DataOps es una práctica relativamente joven pero, al igual que DevOps y SRE, promete transformar los procesos tradicionales en formas de trabajo modernas y más eficientes.
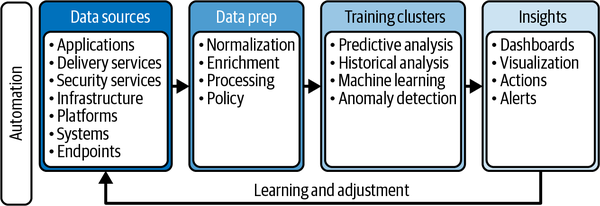
Figura 4-1. Una canalización de datos típica con automatización para permitir operaciones en tiempo real
En la capa de plataforma, una arquitectura eficaz da cabida a los requisitos de adquisición, protección, gestión, procesamiento y exposición de datos. A diferencia de ser un activo transaccional relativamente estático (por ejemplo, los perfiles y el historial de los clientes) con recursos de ingeniería asignados para mantener un sistema o sistemas, los datos se convierten en una materia prima dinámica que merece sus propios recursos de ingeniería asignados para conservarlos, buscarlos, analizarlos y procesarlos para resolver problemas, descubrir perspectivas y enriquecerlos con el tiempo. Esto creará naturalmente una tensión a medida que aumente la competencia entre los ingenieros de software tradicionales y los ingenieros centrados en los datos con habilidades en el diseño de datos, la curación de datos y la ciencia de datos. Invertir en el talento de los datos hace que la organización sea más innovadora y capaz de aprovechar sus activos de datos.
En cuanto al diseño de la nueva plataforma de datos e insights, una arquitectura compuesta tiene en cuenta la ubicación de los datos, los tipos de insights que pueden obtenerse de un determinado conjunto de datos, la disponibilidad de procesamiento y almacenamiento, y el coste relativo de almacenar, trasladar y procesar datos en distintas ubicaciones. A diferencia de los datos tradicionales de clientes y empresas, que suelen estar consolidados en una ubicación central, es probable que los datos operativos estén más distribuidos.
Por ejemplo, algunos de los datos se procesarán en el perímetro utilizando ML diseñado para tomar decisiones en tiempo real o casi real basándose en modelos AI/ML adecuados. Alrededor del 35% de las organizaciones esperan que la computación de perímetro soporte el procesamiento y análisis de datos en tiempo real, donde las respuestas en menos de 20 milisegundos son críticas.10 Esto suele ser un requisito en las industrias manufacturera y sanitaria. Un subconjunto de estos datos se agregará para su procesamiento y análisis adecuado para consultas que utilicen otros tipos de modelos de IA/ML para descubrir un conjunto diferente de conocimientos en línea con las necesidades de ese punto de agregación superior. En última instancia, los datos más antiguos se almacenarán en las ubicaciones más centralizadas especializadas en análisis de mayor alcance. Un buen ejemplo actual es ServiceNow, que ofrece una plataforma para la información operativa.
Identificar qué datos hay que procesar y dónde, qué datos hay que almacenar y qué tipos de análisis hay que realizar sobre qué conjuntos de datos son cuestiones que se responden en esta área de la arquitectura de la nueva empresa digital. Los modelos de ML deben implementarse allí donde los conocimientos que produzcan puedan ser más útiles, ya sea a nivel local o central. Los factores que dictan esto son los siguientes:
-
¿Dónde pueden almacenarse los datos recogidos?
-
¿Dónde se almacena localmente el modelo de datos para procesar estos datos?
-
¿Cuánto tiempo hay que almacenar esos datos antes de procesarlos?
-
¿Qué tipo de tratamiento se necesita?
-
¿Dónde está ubicada la capacidad de procesamiento con respecto a la ubicación de almacenamiento de datos?
Por ejemplo, en una videollamada, el dispositivo local es la ubicación más probable para que se generen datos operativos sobre la calidad de la experiencia. Dado que en el dispositivo también existe el tipo adecuado de capacidad de procesamiento y almacenamiento, el ML necesario para detectar cuándo es necesario ajustar la velocidad de bits para preservar la experiencia se ejecuta mejor en el propio dispositivo. Dado un intervalo de ajuste de 10 segundos, aunque el flujo de datos operativos sea constante, el dispositivo local sólo necesita almacenar 10 segundos de esos datos a la vez mientras se ejecuta el ML local, tras lo cual se pueden expurgar. Además, sólo es necesario enviar un conjunto de datos de referencia, y eso sólo ocurre si se ha necesitado un ajuste en cualquier periodo de 10 segundos; de lo contrario, no se envía nada.
Una vez establecido un diseño de base respondiendo a las preguntas anteriores a nivel de dispositivo local, el proceso puede repetirse a niveles superiores de agregación, produciendo la estratificación adecuada de almacenamiento de datos, procesamiento, ajustes de servicio y reenvío de datos operativos. Para una videollamada originada o terminada en un smartphone, el siguiente nivel de agregación podría ser una única torre celular. En este nivel, se vuelven útiles las cuestiones que afectan a la experiencia de todos los usuarios conectados a esa torre, como el fallo al iniciar una llamada o las desconexiones involuntarias. Aplicando este razonamiento hasta la ubicación informática centralizada (normalmente un centro de datos metropolitano o regional), los datos necesarios se almacenan en silos apropiados y/o se entremezclan con confluencias apropiadas de datos de diversas fuentes para servir a cada propósito predefinido. Los datos innecesarios se eliminan en cada punto. Este enfoque por capas produce conocimientos específicos de forma eficaz porque la arquitectura tiene en cuenta los usos previstos de cada conjunto de datos en cada capa y en cada punto de la experiencia del usuario. La arquitectura proporciona un análisis y un tratamiento de los datos orientados a un fin, lo que a su vez garantiza que se obtenga el valor empresarial adecuado.
En toda la arquitectura y a través de cada capa, los datos, los modelos de ML y los conocimientos resultantes se tratan como objetos gestionados -como el código- de los que se derivan continuamente versiones, acciones y valor. Tienen un ciclo de vida similar al del código de una aplicación: se crean de acuerdo con requisitos predeterminados, se implementan en lugares específicos y se ejecutan en condiciones específicas para lograr determinados resultados. Los ajustes en los datos recopilados, la forma en que se analizan, las perspectivas obtenidas y las acciones resultantes perpetúan el ciclo de vida de los datos y del modelo de datos impulsado por los requisitos empresariales, de forma similar a como el código de una aplicación itera en un ciclo virtuoso de mejora.
Más allá de la detección automatizada y la corrección de problemas, tratar los datos y los modelos de datos como código aumenta la capacidad de una organización para sacar el máximo partido de los conocimientos que descubre. Siguiendo con el ejemplo del vídeo, el modelo de datos utilizado para detectar la degradación de la experiencia del usuario en un dispositivo local puede gestionarse como el código: guardado en una ubicación central, controlado por versiones, actualizado y enviado a los dispositivos cuando proceda. El siguiente paso en la evolución de la tecnología en este caso sería agregar los datos de ajuste a una ubicación central o semicentral, de modo que pueda utilizarse un modelo ML de orden superior para detectar oportunidades de ajustar el modelo ML local (y qué cambiar), de modo que se automatice la actualización del propio modelo ML local. De este modo, el uso inteligente de los datos, los modelos de datos y el procesamiento son adaptables, unprincipio clave de la arquitectura de la empresa digital.
Aunque la tensión entre el negocio digital estático y transaccional frente al adaptable e impulsado por los datos se manifiesta ciertamente en términos de inversión en nuevos talentos de ingeniería, la ingeniería de datos debe tratarse como una expansión de las habilidades y una oportunidad de crecimiento, en lugar de como un detractor. Las organizaciones pueden y deben fomentar e invertir en el desarrollo de habilidades relacionadas con los datos de su personal de ingeniería. Las eficiencias de ingeniería obtenidas al optimizar el mantenimiento de las aplicaciones de línea de negocio existentes deberían utilizarse como palanca para trasladar el aprendizaje y la asignación de talento de ingeniería a la captura, gestión y gobierno de datos para la organización.
A medida que se adquiere experiencia en el funcionamiento y perfeccionamiento de la canalización de datos operativos, el patrón de búsqueda de los datos adecuados, desarrollo de los algoritmos, entrenamiento de los algoritmos, y evaluación y ajuste de los resultados se vuelve más natural. Además, los catálogos de modelos disponibles y las capacidades asociadas están cada vez más disponibles como servicio de terceros proveedores, lo que ofrece a las organizaciones opciones cada vez mejores para las necesidades empresariales más comunes de IA y ML. La transformación hacia datos y algoritmos por encima del código se acelerará a medida que las aplicaciones se vuelvan más dinámicas, más basadas en microservicios, más dependientes de los servicios y más globales por naturaleza. Por tanto, se recomienda el enfoque combinado de crear experiencia interna y aprovechar los avances de los proveedores del sector y las comunidades abiertas.
Privacidad y soberanía de los datos
A medida que los datos sobre todo se vuelven más valiosos, la sociedad institucionaliza la protección de esos datos, lo que conduce a estructuras de gobernanza que pueden ajustarse y sintonizarse con las necesidades cambiantes de la sociedad. La gobernanza está evolucionando para incluir la seguridad, la privacidad, la soberanía, los algoritmos, los modelos de datos, el uso, los usos derivados y las responsabilidades en cascada. Todas estas facetas de la gobernanza de los datos operativos apuntan a la capacidad de una organización para ser más adaptable.
El entorno normativo, las normas de soberanía y las protecciones de la intimidad, junto con las exigencias de cumplimiento de los datos especializados, serán un motor general de cómo se gestionan los datos, dónde se almacenan, cómo se procesan y quién/qué máquinas tienen acceso a ellos. Están surgiendo nuevos casos porque algunos datos generados por máquinas, que antes estaban aislados, ahora se comparten directamente, se agregan o se accede a ellos de otro modo desde fuera de su sistema. En los próximos años, casi todos los datos estarán sometidos a algún tipo de régimen de cumplimiento para ayudar a minimizar la exposición de clientes y empresas.
Un de los mayores retos actuales del uso de datos, sobre todo de los estructurados, es el enfoque de todo o nada: o se confía en que alguien vea todos los datos en bruto o no tiene acceso a ellos.11 Una solución que está surgiendo para hacer frente a esta tensión es privacidad diferencial. Proporciona una forma de acceder a conjuntos parciales de datos de tal manera que las personas vinculadas a esos datos no sean identificables. Algunas empresas emergentes ya están utilizando este concepto para proporcionar un nuevo nivel de privacidad en áreas críticas como la sanidad y los servicios financieros.12
Granularidad de control sobre el acceso a los datos es necesario para apoyar los requisitos de gobernanza y mitigar el riesgo asociado al acceso a los datos. Esta granularidad se mide en dos dimensiones: alcance y uso. Alcance es la precisión del conjunto de datos; más granular significa más pequeño (por campo frente a fila en una tabla, por ejemplo). El uso es el papel del usuario, el tipo de acceso y las condiciones asociadas. Por ejemplo, un mismo usuario puede tener varias funciones, lo que desencadena la necesidad de acceder a los datos con distintos fines, y cada fin puede tener restricciones asociadas, como ventanas temporales que limitan el acceso autorizado. El nivel de granularidad necesario aumentará con el tiempo, impulsado por los continuos casos de abusos en la exposición de datos y el endurecimiento de las restricciones normativas en respuesta a ellos.
La gobernanza de datos evoluciona
La capacidad de una organización para gestionar y gobernar los datos será la clave de su capacidad para modernizar el negocio con una arquitectura empresarial digital. Esto requiere un enfoque de gobernanza mucho más amplio que el utilizado anteriormente, ya que los procesos humanos incorporaban la gobernanza a los procesos empresariales realizados. La gobernanza debe incorporarse a la arquitectura de la empresa digital y a las prácticas empresariales.
La mayoría (80%) de las organizaciones afirman que la gobernanza de los datos es importante para conseguir resultados empresariales.13 A pesar de ello, menos de la mitad (43%) tienen un programa de gobierno de datos o han implantado una estrategia que se considera inmadura.14 Los factores que obstaculizan las prácticas de gobierno de datos son conocidos: el coste, la falta de patrocinio ejecutivo, la escasa o nula participación empresarial y la falta de priorización. Pero la realidad es que un negocio digital depende de los datos operativos. El tráfico peatonal y los patrones en las ubicaciones físicas proporcionaban a las empresas la información que necesitaban para tomar decisiones e impulsar el crecimiento. El equivalente digital son los datos operativos. La dependencia de un negocio digital de esos datos exige considerar el gobierno de los datos como una función empresarial de misión crítica, análoga a los controles fiduciarios que rigen las finanzas y las pruebas que rigen la calidad del código.
La gobernanza de los datos requiere un marco capaz de respaldar una práctica de operaciones de datos y aplicar políticas que rijan el acceso y el uso de los datos, cumpliendo al mismo tiempo los requisitos de soberanía y privacidad de los datos. La Figura 4-2 muestra un marco sencillo de gobernanza de datos que cumple estos requisitos.
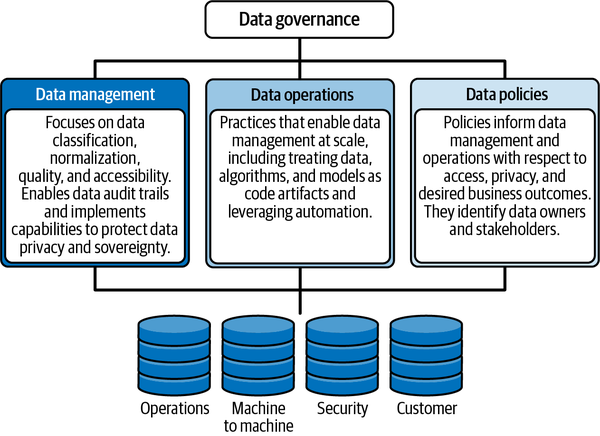
Figura 4-2. Un marco sencillo de gobernanza de datos
Ejecutar un marco de este tipo, aunque sea sencillo, será un reto sin emplear IA, ML y automatización, debido al volumen de datos ingeridos, la complejidad de los análisis aplicados y la velocidad a la que deben tomarse medidas de respuesta.
Tradicionalmente, las organizaciones utilizan la interacción humana como mecanismo de gobierno de los datos. Los negocios digitales se basan en los datos para impulsar las decisiones tanto para el negocio como para las operaciones. Esto significa que la gobernanza digital debe incorporarse a la infraestructura y al ciclo de desarrollo, de modo que se automaticen las acciones de gestión de datos. Esto requiere que cada componente de toda la arquitectura sea capaz de ejecutar una acción de gobierno. Esta capacidad debe diseñarse en cada componente y aplicarse en todas partes, ser transparente, autorregulable y fácil de modificar por los propietarios. Las empresas de los sectores más regulados de la economía llevan ventaja, porque ya se les insta mediante mandatos a que adopten estructuras organizativas y procesos totalmente centrados en el acceso y uso de los datos en.15
Conclusión
Establecer una práctica de datos empresariales en es esencial para obtener un nuevo valor empresarial a partir de los conocimientos que se encuentran en todo tipo de datos, como ha puesto de relieve recientemente la aparición de los datos operativos en una empresa cada vez más digital. El camino suele ser gradual, ya que las limitaciones del mundo real en cuanto a tiempo, presupuesto y recursos cualificados ralentizan el uso de la tecnología disponible, ya sea de proveedores o de código abierto.
El éxito en la construcción de una práctica de datos depende del diseño de una plataforma de insights que utilice una arquitectura basada en estándares, con una flexibilidad que permita que las piezas individuales se actualicen a un ritmo acorde con cualquier limitación. Los tres elementos básicos de la plataforma de insights son la recopilación de datos, el procesamiento de datos y la gobernanza de datos.
Paralelamente, es primordial que las prácticas empresariales y los conjuntos de habilidades tecnológicas de una organización maduren al unísono, de modo que, a medida que aumentan la visibilidad operativa, el volumen de información y la calidad de ésta, los procesos empresariales y los procedimientos operativos también se vuelvan menos estáticos y más dinámicos. A medida que toda la organización se familiariza con el nuevo modo de funcionamiento, la TI pasa de desempeñar un papel de apoyo a convertirse en un facilitador estratégico de la transformación.
1 "Usos del petróleo", Asociación Canadiense de Productores de Petróleo, consultado el 30 de mayo de 2022, https://oreil.ly/D2R54.
2 Transcripción de Motley Fool, "Kroger (KR) Q3 2020 Earnings Call Transcript", 3 de diciembre de 2020, https://oreil.ly/dprcw.
3 Russell Redman, "Kroger Banks on Burgeoning Sources of Revenue", Supermarket News, 31 de octubre de 2018, https://oreil.ly/JDd3Q.
4 "El estado de la estrategia de aplicaciones en 2022", F5, 12 de abril de 2022, https://oreil.ly/LH0Yj.
5 Bradley Barth, "Uncontrolled API 'Sprawl' Creates Unique Visibility and Asset Management Challenges", SC Media, 5 de noviembre de 2021, https://oreil.ly/Ks9i1.
6 Juhi Batra, "Collecting Processor Trace in Intel System Debugger", Intel, consultado el 30 de mayo de 2022, https://oreil.ly/vbPJH.
7 "GPU Trace", NVIDIA Developer, consultado el 30 de mayo de 2022, https://oreil.ly/SQAKu.
8 Laurent Quérel, "Multivariate Metrics-Benchmark", GitHub, 23 de julio de 2021, https://oreil.ly/lEBYP.
9 Thomas H. Davenport y DJ Patil, "Científico de datos: El trabajo más sexy del siglo XXI", Harvard Business Review, octubre de 2012, https://oreil.ly/LdwKt.
10 F5, "El estado de la estrategia de aplicaciones en 2022".
11 Adrian Bridgwater, "Los 13 tipos de datos", Forbes, 15 de julio de 2008, https://oreil.ly/KvwID.
12 "5 Top Emerging Data Privacy Startups" StartUs Insights, consultado el 30 de mayo de 2022, https://oreil.ly/YHqZj.
13 Heather Devane, "This Is Why Your Data Governance Strategy Is Failing", Immuta, 8 de abril de 2021, https://oreil.ly/UHfvY.
14 Ataccama, "Datos: Nearly 8 in 10 Businesses Struggle with Data Quality, and Excel Is Still a Roadblock," Cision PR Newswire, 7 de abril de 2021, https://oreil.ly/o35qo.
15 Immuta y 451 Research, "DataOps Dilemma: Survey Reveals Gap in the Data Supply Chain", Immuta, agosto de 2021, https://oreil.ly/i4lIi.
Get Arquitectura empresarial para el negocio digital now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

