Chapter 1. AWS for Data
It is a capital mistake to theorize before one has data.
Sherlock Holmes
Data is ubiquitous and powers everything we do today. Who would have thought you could generate data just by walking and monitor your steps in real time on your wrist as you call your friend? From mobile phones, smartwatches, and web clicks to the Internet of Things (IoT), we are generating various types of data in abundance, and organizations are faced with the challenge of deriving meaning out of all of this data to deliver insights. You have to analyze this data to present unbiased information in a simple way for leaders to make business decisions. Data is the underlying force that fuels the insights and predictions that lead to better decision making and innovation. Although challenging, it is imperative that you harness this data and reinvent your business to stay relevant now and in the future. Amazon Redshift is a fully managed, petabyte (PB)-scale data warehouse service in the cloud that powers a modern data architecture to store data from all sources in a centralized or decentralized architecture. It enables you to query data across your data warehouses, data lakes, and operational databases to gain faster and deeper insights not possible otherwise.
In this chapter, we will cover the core tenants of the Amazon Web Services (AWS) for data framework including what makes “Data-Driven Organizations” successful, the core tenants of a “Modern Data Strategy”, and what goes into building a “Modern Data Architecture”. Finally, we’ll dive into some popular ways organizations are using “Data Mesh and Data Fabric” to satisfy their needs for each analytics user group in a scalable way.
Data-Driven Organizations
Data-driven organizations treat data like an asset; they make it available and accessible not just to business users, but to all who need data to make decisions so they can make more informed decisions. These organizations recognize the intrinsic value of data and realize the value that good data brings to the organization and its economic impact. They democratize data and make it available for business decision makers to measure the key performance indicators (KPIs). The saying “You can’t improve what you don’t measure,” attributed to Peter Drucker, is all the more relevant for today’s businesses.
Most businesses have a range of KPIs that they regularly monitor to drive growth and improve productivity. These KPIs could range from the common ones like growth, sales, market share, number of customers, and cost of customer acquisition to more domain-specific ones like sell through, capacity utilization, email opt-out rates, or shopping cart abandonment rates. A good KPI is specific, measurable, and impactful to overall business goals and could vary from business to business.
Though some attributes like employee morale, confidence, and integrity of an organization cannot really be measured, there is a lot that can get measured and monitored for progress. Having access to this data means leaders can employ strategies to move the business in a certain direction. For example, after acquiring a power tool company, a manufacturer was flying blind until their IT team integrated the data into the core enterprise resource planning (ERP) system. The executive remarked that it was like turning the lights on for them to see where they were headed on the road with this business.
In his book Infonomics (Gartner, Inc.), Doug Laney talks about how it is essential for organizations to go beyond thinking and merely talking about information as an asset to actually valuing and treating it as one. He argues that information should be considered a new asset class in that it has measurable economic value and should be administered like any other type of asset. Laney provides a framework for businesses to monetize, manage, and measure information as an actual asset. He talks about how monetizing is not all about selling data, or exchange of cash. It is about realizing the value of information and thinking more broadly about the methods used to have an impact on your customers and generate profits. It is about working backward from your customers’ requirements and interests and aligning your business and operational strategy to fulfill the priorities of your customer. Analytics helps organizations make better decisions and enables key strategic initiatives. It also helps you improve relationships with both your customers and your business partners.
At AWS re:Invent 2021, Adam Selipsky talked about how Florence Nightingale analyzed soldier mortality rates from the Crimean War. Nightingale, a nurse, used data and analytics to gain an insight that the majority of soldiers had not died in combat, but instead from preventable diseases caused by poor sanitary conditions in the hospital. Nightingale analyzed the data she collected and created a simple but powerful visualization diagram (Figure 1-1) depicting the causes of soldier mortality. This Rose Chart, also known as a polar area chart, allowed multiple comparisons in one diagram showing mortality rates for each month from diseases, wounds, and other causes. This visual helped Nightingale convince Queen Victoria and generals that more men had died from disease than from wounds, especially in winter, and highlighted the need for hospital reform and care for soldiers. This is a great example of the storytelling impact of data; it really changed the conversation to help save lives.
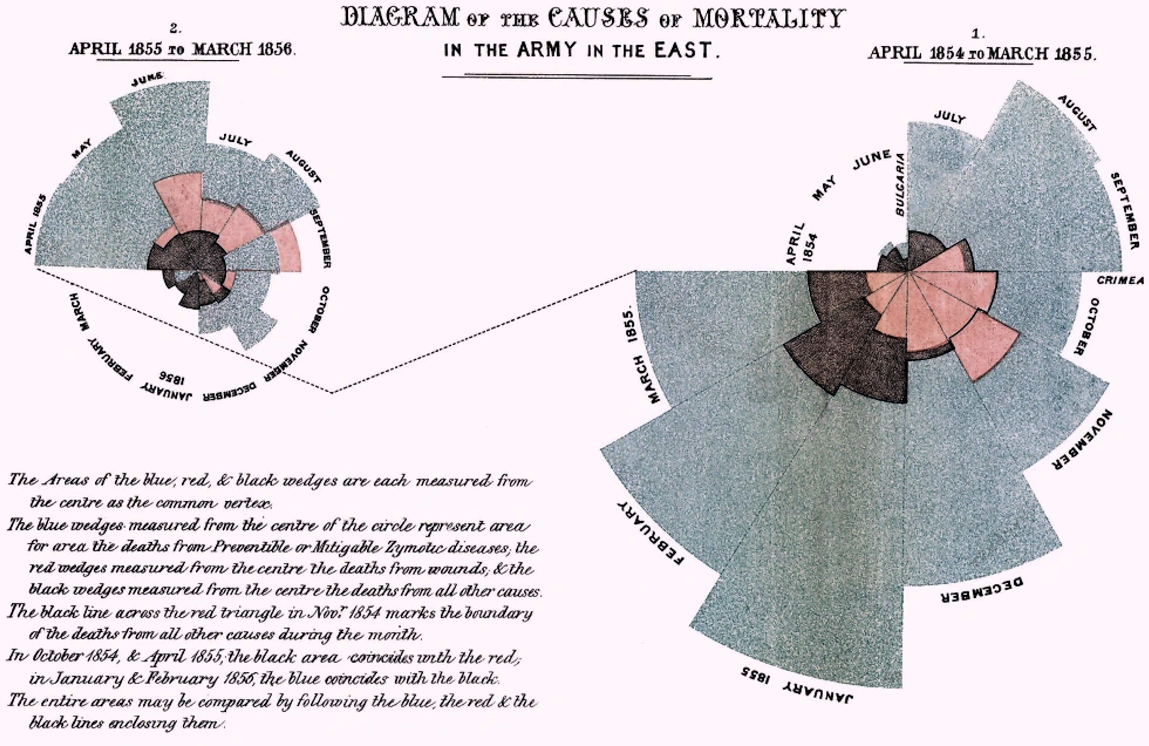
Figure 1-1. Florence Nightingale’s Rose Chart for causes of mortality
Today, you may expect to have real-time insights and prefer to access the data as soon as it lands. There are many inspiring examples of data-driven companies focusing on and adapting to changes in their customers’ preferences by using analytics. Dow Jones, a global news provider, increased response rates by 50% to 100% for mail communication by using analytics and making data accessible. Magellan Rx modernized its data warehouse and is able to improve patient outcomes by bringing drugs to market sooner and reduce operational costs by 20%. Moderna is using Amazon Redshift for simple, cost-effective data warehousing to avoid silos and establish a single source of truth for data across the organization. Nasdaq migrated its growing data warehouse to a more modern data lake architecture and was able to support the jump from 30 billion records to 70 billion records a day because of the flexibility and scalability of Amazon Simple Storage Service (S3) and Amazon Redshift. Netflix uses data to create blockbuster hit series like House of Cards. Their managers have collected and analyzed data from the digital transformation of media and entertainment to build lucrative markets where none previously existed. Coco Cola Andina, which produces and distributes products licensed by The Coca-Cola Company within South America, increased the productivity of its analysis team by 80% by creating a data lake that became the single source of data generated by SAP ERP and other legacy databases.
A common theme with these successful data-driven companies is the democratization of data and placing insights in the hands of decision makers. Having reliable data is the foundation to getting actionable insights, and a well-designed data architecture and technology stack can enhance the reliability of data. Limiting movement of data within the organization is one way to avoid data inconsistencies, and enhance integrity and trust in the data. This does not necessarily mean building a single store for all data. With Amazon S3, you can store data from different sources in different formats in a single store. But organizations are also looking to query data in place from source systems or independent data warehouses. This has given rise to new concepts like data mesh and data fabric, which we will see later in this chapter. Organizations that are data driven and focus on building trust and scale with the data are better positioned to gain real-time insights to compete in the marketplace.
Business Use Cases
From small businesses to global corporations, data and analytics are critical to gain insights into the state of the business or organization. We have picked some of the common use cases to demonstrate how you can derive business insights using AWS analytics services with specific data models in this book. Let’s look at some of the most common use cases and how analytics can deliver business outcomes.
- Supply chain management
-
With the impact of ecommerce on traditional brick-and-mortar retailers, companies have to use analytics to transform the way they define and manage supply chains. Using data and quantitative methods, demand and supply planners can improve decision making across the supply chain cycle. Manufacturers and retailers can apply statistical methods to improve supply chain decision making to have the product at the right time at the right place for their consumers. They can analyze inventory and plan their supply based on demand signals. A good example is Amazon, which processes 51,000 daily queries to drive supply chain excellence using Amazon Redshift.
- Finance
-
Financial and banking organizations help their customers make investment decisions and provide money management solutions. Today, many banks use artificial intelligence (AI) and machine learning (ML) to identify fraud, predict customer churn, and proactively engage to prevent fraud or churn. For example, you may have had your credit card disabled at some point while you were on a vacation or visiting a new place. This is ML working behind the scenes to detect unusual activity and block a possible fraud transaction before it is too late. Having the right data available and easily accessible makes this possible.
- Customer relationship management (CRM)
-
Implementing a data warehousing data model for CRM can enable businesses to consolidate customer data from multiple touchpoints, such as sales, marketing, and customer support. By analyzing this data, businesses can gain insights into customer behavior, preferences, and satisfaction levels. This information can be used to personalize marketing campaigns, improve customer service, and foster long-term customer relationships.
- Education
-
Analytics in education can make a big difference in student experience and outcomes. The traditional educational method of classroom teaching has its challenges for today’s children immersed in a digital world. Schools are dealing with high dropout rates, ineffective outcomes, and outdated syllabi. Moving to a personalized learning approach would mean students can take advantage of flexibility and learn at their own pace. This also means adopting hybrid learning with online learning management solutions with the ability to provide customized content for learners. Data from student interactions with online learning environments combined with data from test scores can be used to analyze and provide insights into where the student might need additional help. With AI and machine learning, educators could predict the outcomes of individual students and take proactive steps to provide a positive outcome and experience.
- Healthcare industry
-
Data plays a crucial role in the healthcare industry, revolutionizing the way patient care is delivered, medical research is conducted, and rising costs are controlled with operational efficiency. Healthcare organizations can unlock valuable insights that drive evidence-based decision making by harnessing the power of data to improve patient outcomes and enhance overall healthcare delivery. By identifying patterns, trends, and correlations in large datasets, healthcare professionals can gain a deeper understanding of diseases and treatment effectiveness based on patient response. With predictive analytics, these organizations can detect diseases early and administer personalized medicine for at-risk patient groups. These organizations can also detect fraudulent claims by analyzing claims data and identifying patterns of fraudulent activities.
New Business Use Cases with Generative AI
Generative AI and data warehousing can complement each other to enhance various aspects of data analysis and decision-making processes. Next, we will outline some ways in which generative AI can be integrated with data warehousing:
- Code generation
-
Generative AI models can be trained on vast code repositories and programming languages to generate code completions and suggestions. When developers are writing code, the AI model can provide real-time suggestions that help programmer efficiency by suggesting or writing snippets. This can also help reduce errors and improve overall developer productivity to bring products to market quicker.
- Natural language generation
-
Data warehousing often involves extracting insights and presenting them in a meaningful way to stakeholders. Generative AI models can generate human-readable reports or narratives based on the data stored in the warehouse. This can also be summarizing or automated generation of descriptive analytics, making it easier for decision makers to understand and interpret the data or the content of a report.
- Synthetic data generation
-
To train a machine learning model, the quality of data determines the accuracy of the prediction. Generative AI models can be used to generate synthetic data that mimics the characteristics of real-world data. This synthetic data can be combined with actual data in a data warehouse to expand the dataset and create more comprehensive and diverse training sets for machine learning models. It helps overcome data scarcity issues and improves the accuracy and robustness of analytical models.
- Anomaly detection
-
Generative AI models, such as Generative Adversarial Networks (GANs), can be employed for anomaly detection in data warehousing. By training the GAN on normal data patterns, it can learn to identify anomalies by comparing the generated data with the actual data stored in the warehouse. This can help you detect unusual patterns and outliers for you to identify potential fraudulent transactions or operations.
- Data imputation and augmentation
-
Incomplete or missing data can affect the accuracy of data analysis and decision making. Generative AI techniques can be used to impute missing values by learning the underlying patterns in the available data. By training a generative model on the existing data, it can generate plausible values for missing data points, filling in the gaps and improving the integrity of the data warehouse. You can augment existing datasets in a data warehouse generating new synthetic samples based on the existing data, and create a larger and more diverse dataset for training analytical models. This can improve the performance and generalization ability of machine learning algorithms and enable better predictions and insights.
- Recommendation systems
-
Generative AI techniques can enhance recommendation systems by generating personalized recommendations for users. By leveraging user behavior data stored in a data warehouse, generative models can learn user preferences and generate personalized recommendations for products, services, or content. This helps businesses improve customer engagement and drive sales or user satisfaction.
Integrating generative AI with data warehousing expands the capabilities of data analysis, enhances data quality, and enables advanced analytics and decision-making processes. However, it’s essential to ensure ethical considerations, privacy, and security when generating and utilizing synthetic data.
Modern Data Strategy
The concept of data gravity was first coined by Dave McCrory in 2010. In his analogy, he compares data to a planet and talks about data mass that is built when organizations collect data in one place. Applications and services are attracted to this mass because proximity to data leads to better performance and throughput. This accelerates growth of data, and eventually it becomes almost impossible to move data around. Data generated by IoT, smart devices, cloud applications, and social media is continuing to grow exponentially. You need ways to easily and cost-effectively analyze all of this data with minimal time-to-insight, regardless of the format or where the data is stored.
Data is at the center of every application, process, and business decision. It is the cornerstone of almost every organization’s digital transformation. It fuels new experiences and leads to insights that spur innovation. But building a strategy that unlocks the value of data for your entire organization is not an easy and straightforward journey. Data systems are often sprawling, siloed, and complex, with diverse datasets spread out across data lakes, data warehouses, cloud databases, software as a service (SaaS) applications, IoT devices, and on-premises systems. Many organizations are sitting on a treasure trove of data, but don’t know where to start to get value out of it. Companies struggle to get a handle on where all their data sits, how to connect and act on that data effectively, and how to manage access to that data. And as data volumes grow, this only gets more difficult. The inability to use data effectively can hinder rapid decision making and sustained innovation.
To harness the value of their data, organizations need more than a single database, data lake, data warehouse, or business intelligence service. The reality is that each organization has multiple use cases, types of data, and users and applications that require different tools. And these needs will evolve over time. To truly unlock the value of your data to drive timely insights and innovation, you need to implement an end-to-end data strategy that makes working with data easier at every step of the data journey for everyone who needs it in your organization. An end-to-end data strategy combines tools, resources, and processes for ingesting, storing, and querying data, analyzing data, and building machine learning models, and ultimately helping end users develop data-driven insights. This end-to-end data strategy must have:
- A comprehensive set of capabilities for any data use case
-
A comprehensive set of tools that accounts for the scale, variety of data, and many purposes for which you want to use it now and in the future
- An integrated set of tools to easily connect all your data
-
The ability to integrate data stored and analyzed in different tools and systems to gain a better understanding of your business and predict what will happen
- End-to-end data governance
-
Governance of all your data to securely give data access when and where your users need it
With these three pillars (shown in Figure 1-2), you can store the ever-increasing data at scale, access that data seamlessly, and manage who has access to the data with security and governance controls.
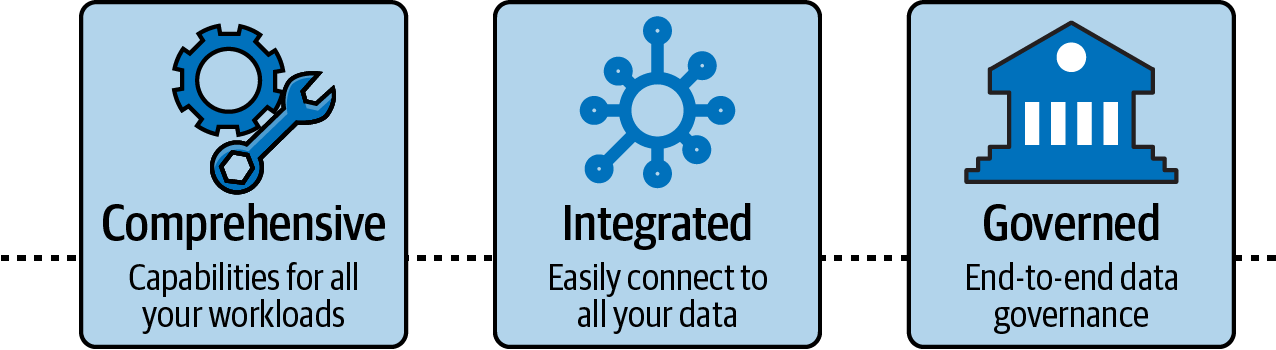
Figure 1-2. Pillars of end-to-end modern data strategy
AWS provides you with the capabilities you need for an end-to-end data strategy with built-in intelligence and automation in its data services. Let’s dive a bit deeper into each of these pillars and learn what it entails.
Comprehensive Set of Capabilities
To understand your business and scale with changing workloads, streamline processes, and make better decisions, you need to build data strategies that can meet your needs now and in the future. It takes more than just a single data lake, data warehouse, or business intelligence tool to effectively harness data. You need a comprehensive set of tools that accounts for the scale, variety of data, and many purposes for which you want to use it.
You can modernize your data architecture at various stages of the data journey, and that means breaking free from legacy databases and moving to fully managed and purpose-built data services. If you are running legacy, on-premises data stores or self-managing databases in the cloud, you still have to take care of management tasks such as database provisioning, patching, configuration, and backups. By transitioning to managed services on AWS cloud or other hyperscalers, you can benefit from the cloud providers’ experience, maturity, reliability, security, and performance for hosting and managing your applications.
For an end-to-end data strategy, you need to store data in databases optimized for your type of workloads, integrating from multiple sources and enabling access to business decision makers using the tool of their choice to act on the information. As shown in Figure 1-3, AWS provides a comprehensive set of data capabilities to store, integrate, act, and govern for various types of data workloads. A one-size-fits-all approach to modernizing the analytics platform can eventually lead to compromises, so AWS offers purpose-built engines to support diverse data models, including relational, key-value, document, in-memory, graph, time series, wide column, and ledger databases. These sets of capabilities help you access data wherever it resides, analyze it, and act on the insights.
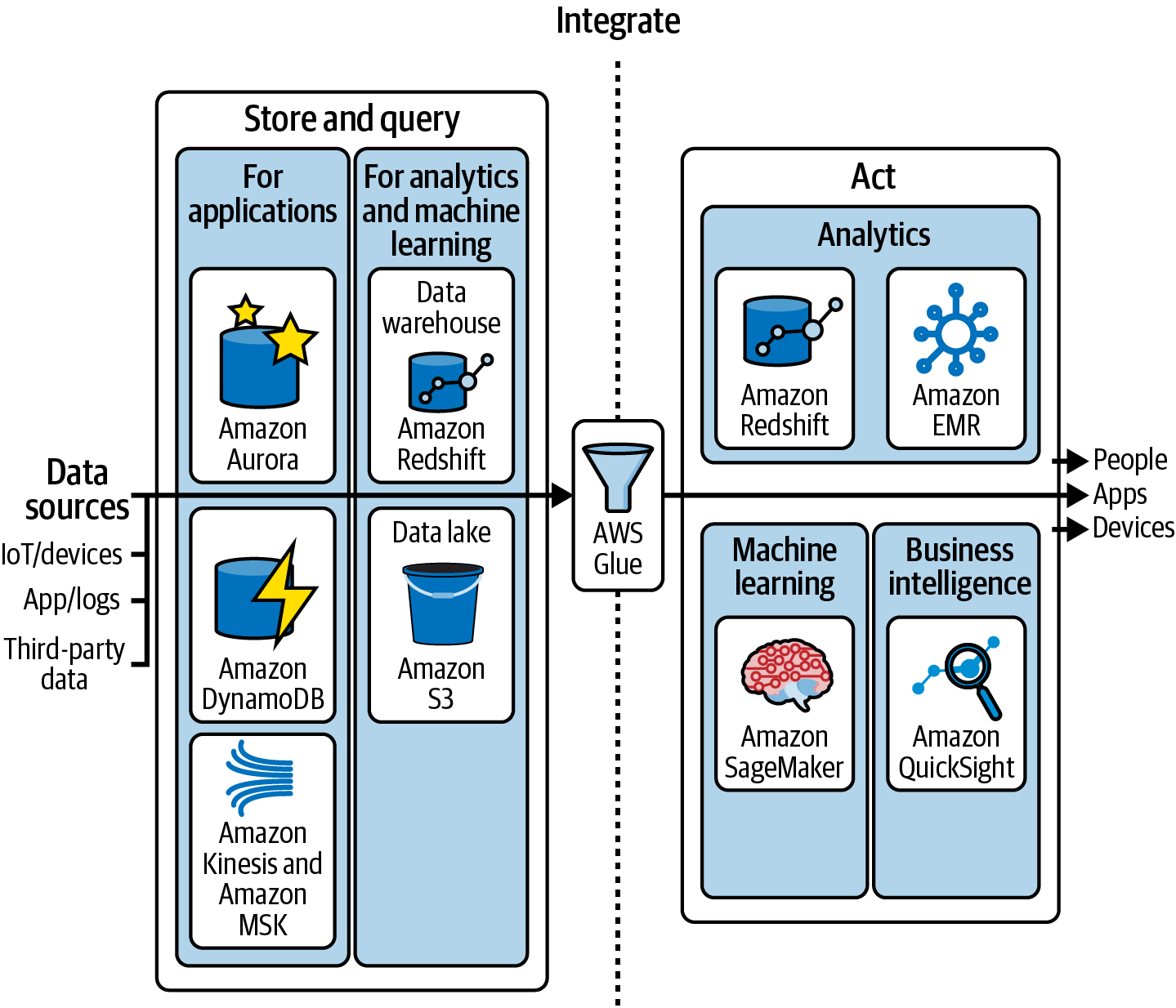
Figure 1-3. End-to-end data strategy
These data services and analysis tools are optimized for specific types of workloads, and AWS provides tools to integrate and govern the data stored in the purpose-built data services:
- AWS Glue
-
A serverless, scalable extract, transform, and load (ETL) and data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics and machine learning.
- Amazon DynamoDB
-
A fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multiregion replication, in-memory caching, and data import and export tools.
- Amazon EMR
-
A big data solution for PB-scale data processing on the cloud with capabilities for interactive analytics and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
- OpenSearch
-
A distributed, community-driven, Apache 2.0-licensed, open source search and analytics suite used for a broad set of use cases like real-time application monitoring, log analytics, and website search.
- Amazon Simple Storage Service (Amazon S3)
-
An object storage service offering high scalability, data availability, security, and performance. You can store and protect structured and unstructured data for use cases such as data lakes, cloud native applications, and mobile apps.
- Amazon QuickSight
-
A serverless service for users that helps you meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics, and natural language queries.
- Amazon Kinesis
-
Makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis offers capabilities to cost-effectively process streaming data at scale, along with the flexibility to choose the tools that best suit the requirements of your application.
- Amazon Redshift
-
A fully managed, PB-scale data warehouse service in the cloud. With Amazon Redshift, you can modernize your data warehouse on the cloud with compliance, security, and governance, and leverage the scaling feature to meet your variable requirements. You can securely ingest, combine, and run historical, real-time, or predictive analytics on all your data using a serverless or provisioned deployment option.
- Amazon SageMaker
-
A fully managed service to prepare data and build, train, and deploy machine learning models for any use case with fully managed infrastructure, tools, and workflows.
These services are tightly integrated and can talk to each other to leverage data from each other.
Integrated Set of Tools
The most impactful data-driven insights come from getting a full picture of your business and your customers. This can be achieved only when you connect the dots between your different data sources across multiple departments, services, on-premises tools, and third-party applications such as business intelligence (BI) systems or statistical modeling tools. Typically, connecting data across different data sources requires data replication or complex ETL pipelines, which can take hours, if not days. That’s just not fast enough to keep up with the speed of decision making. ETL needs to be easier and in many cases, eliminated.
Great business leaders see opportunities to transform their business all along the value chain. But making such a transformation requires data that enables decision makers to get a full picture of the business and single source of truth. This necessitates breaking down data silos and making data accessible and shared in a secure way to unlock the value of data across the organization.
To make decisions quickly, you need new data stores that will scale and grow as your business needs change. You also want to be able to connect everything together, including your data lake, data warehouse, and all the purpose-built data stores into a coherent system that is secure and well governed.
That consolidated view can be achieved in many ways: federated querying, low/no-code data synchronization, or tradition ETL using serverless or server-based execution. Amazon Redshift provides options for each of these, with tight integration with other AWS services. The zero-ETL feature between Amazon Aurora and Amazon Redshift enables you to near real-time synchronize transactional data into your data warehouse. Amazon Redshift allows for querying data from your Amazon S3 data lake, and the federated query feature allows querying data securely and directly from operational databases. For analytics workloads, where you want to isolate compute, you may build ETL pipelines to extract, transform, and load data into a target data store. The tight integration with AWS Glue allows you to easily create spark-based jobs in AWS Glue Studio for execution using a serverless framework. For more details on Amazon Redshift data transformation strategies, see Chapter 4, “Data Transformation Strategies”.
For exposing your data to data analysts and data scientists, Amazon Redshift has simplified the access path. In the past, machine learning has been limited to highly skilled data scientists or programmers with deep skills in programming languages such as Python, R, etc. With tight integration with Amazon SageMaker, Amazon Redshift data analysts can use Amazon Redshift ML to run machine learning workloads from within the data warehouse or data lake without having to select, build, or train an ML model. For more details on Amazon Redshift machine learning, see Chapter 6, “Amazon Redshift Machine Learning”. In addition, business analysts can use tools like Amazon QuickSight to autodiscover their Amazon Redshift data warehouse and connect to the data stores to quickly produce impactful dashboards with business insights. For more details on the different options for getting to your Amazon Redshift data warehouse, see Chapter 2, “Getting Started with Amazon Redshift”.
End-to-End Data Governance
Establishing the right governance lets you balance control and access and gives people within your organization trust and confidence in the data. It encourages innovation, rather than restricts it, because the right people can quickly find, access, and share data when they need it.
To spur innovation, organizations should endorse the concept of data security as meaning how you can set your data free in a secure manner, rather than meaning how you can secure data and limit access to your users. With end-to-end data governance on AWS, you have control over where your data sits, who has access to it, and what can be done with it at every step of the data workflow.
For data engineers and developers, AWS has fine-grained controls, catalogs, and metadata within services like AWS Glue and AWS Lake Formation. AWS Glue enables you to catalog data across data lakes, data warehouses, and databases. AWS Glue comes with data quality rules that check for data freshness, accuracy, and integrity. With AWS Lake Formation, you can govern and audit the actions taken on the data in your data lake on Amazon S3 and data sharing in Amazon Redshift. If you have a data lake on Amazon S3, you can also use Amazon S3 Access Points to create unique access control policies and easily control access to shared datasets.
Data scientists can use governance controls in SageMaker to gain end-to-end visibility into ML models, including training, version history, and model performance all in one place.
Finally, Amazon DataZone is a data management service to catalog, discover, share, and govern data. It makes it easy for data engineers, data scientists, product managers, analysts, and other business users to discover, use, and collaborate with that data to drive insights for your business.
In summary, it is becoming increasingly clear that harnessing data is the next wave of digital transformation. Modernizing means unifying the best of data lakes and purpose-built data stores and making it easy to innovate with ML. With these three pillars—comprehensive, integrated, and governance—your modern data strategy with AWS can help you build an architecture that scales based on demand and reduce operational costs.
Modern Data Architecture
When you embark on a modern data strategy, you have to think about how to handle any amount of data, at low cost, and in open, standards-based data formats. The strategy should also let you break down data silos, empower your teams to run analytics or machine learning using their preferred tool or technique, and manage who has access to data with the proper security and data governance controls.
To execute a modern data strategy, you need a modern data architecture. You may have heard about data warehouses, data lakes, and data mesh, and you may also be considering one of these strategies. A data warehouse enables you to store structured data and enable fast query access on a large mass of data. A data lake is a central repository where you store all structured and unstructured data and have it easily accessible. A data mesh allows you to access data in place while decentralizing ownership and governance of data. A modern data architecture needs to support all of these aspects to gain business insights from the ever-increasing data mass.
AWS modern data architecture is built on a model that includes purpose-built data stores to optimize for scale, availability, performance, and cost. It enables integrating a data lake, a data warehouse, and purpose-built stores, enabling unified governance and easy data movement. Amazon Redshift and Amazon S3 form the core for your modern data architecture, with tight integration with other purpose-built services.
In the modern data architecture shown in Figure 1-4, there are three different patterns for data movement: inside-out, outside-in, and around the perimeter.
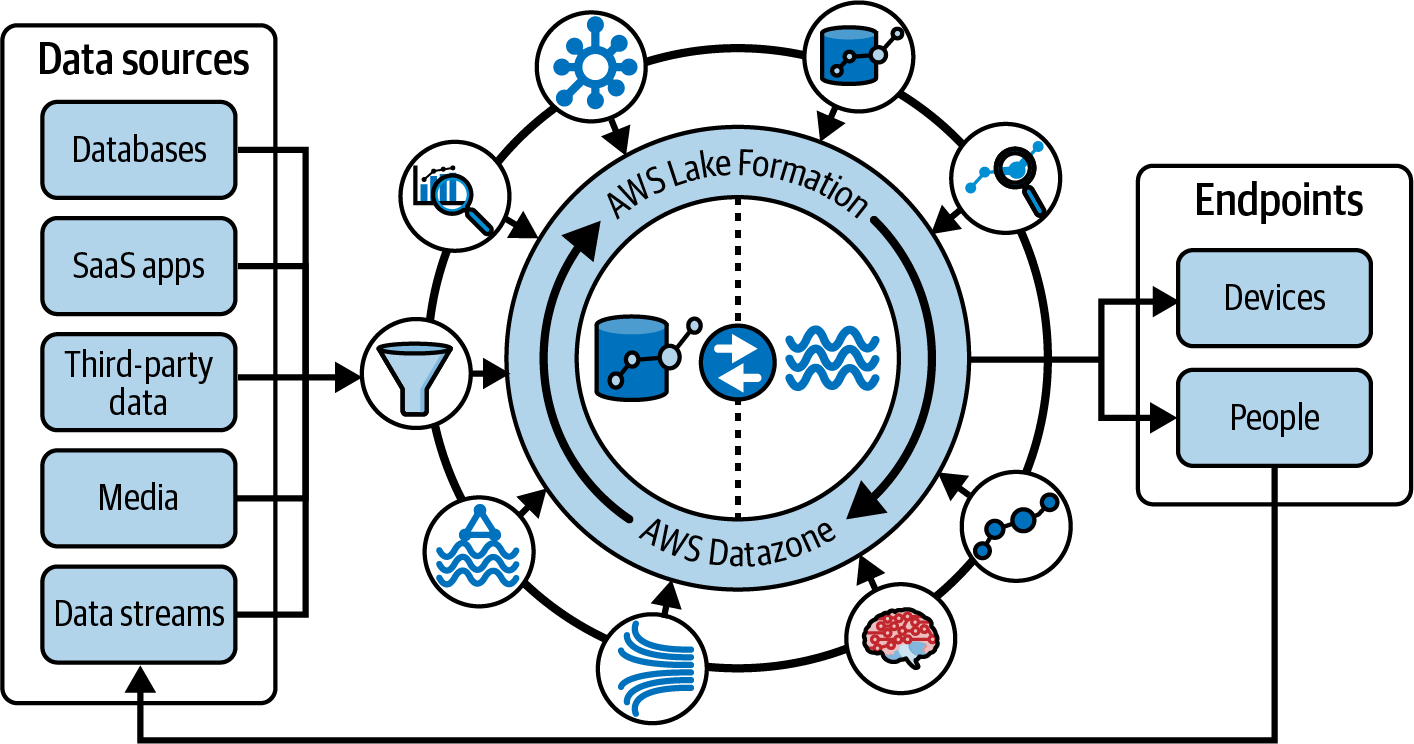
Figure 1-4. Modern data architecture using purpose-built services
- Inside-out data movement
-
A subset of data in a central data store is sometimes moved to a purpose-built data store, such as Amazon Redshift for online analytical processing (OLAP) workloads, Amazon OpenSearch Service cluster, or Amazon Neptune cluster to support specialized analytics such as search analytics, building knowledge graphs, or both. In the context of Amazon Redshift, you may use Amazon Redshift for your central data store where other services like AWS Glue or other Amazon Redshift data warehouses can access the data through data sharing. Alternatively, you can consume data from an Amazon S3 data lake into Amazon Redshift by loading it via the
COPYcommand or directly querying it as an external Amazon S3 schema. - Outside-in data movement
-
Organizations start with data stores that best fit their applications and later move that data into a central data store for collaboration. For example, to offload historical data that is not frequently accessed, you may want to
UNLOADthis data from Amazon Redshift to your Amazon S3 data lake. A gaming company might choose Amazon DynamoDB as the data store to maintain game state, player data, session history, and leaderboards. This data can later be exported to an Amazon S3 data lake for additional analytics to improve the gaming experience for its players. - Around the perimeter
-
There are also scenarios where the data is moved from one specialized data store to another. For example, you can use the federated query capability of Amazon Redshift to query data directly from operational data stores like Amazon Aurora or use Amazon Redshift ML capability to run a model that will trigger a process in Amazon SageMaker.
You can innovate at various stages of the modern data strategy by moving away from building tightly coupled monolithic applications. Instead, you can build modular applications with independent components called microservices. These native, purpose-built, integrated AWS services are well suited for building modular applications while leveraging new emerging technologies like ML and AI.
Role of Amazon Redshift in a Modern Data Architecture
Amazon Redshift powers the modern data architecture and enables you to store data in a centralized or decentralized architecture and break down data silos by enabling access to all data in your organization. With a modern data architecture, you can store and access data within the data warehouse tables in structured columnar format and open file formats in your Amazon S3 data lake. The capability to query data across your data warehouse, data lake, and operational databases with security and governance helps unify and make data easily available to your business users and other applications.
Some of the key capabilities of Amazon Redshift and the benefit of tight integration to native services are shown in Figure 1-5.
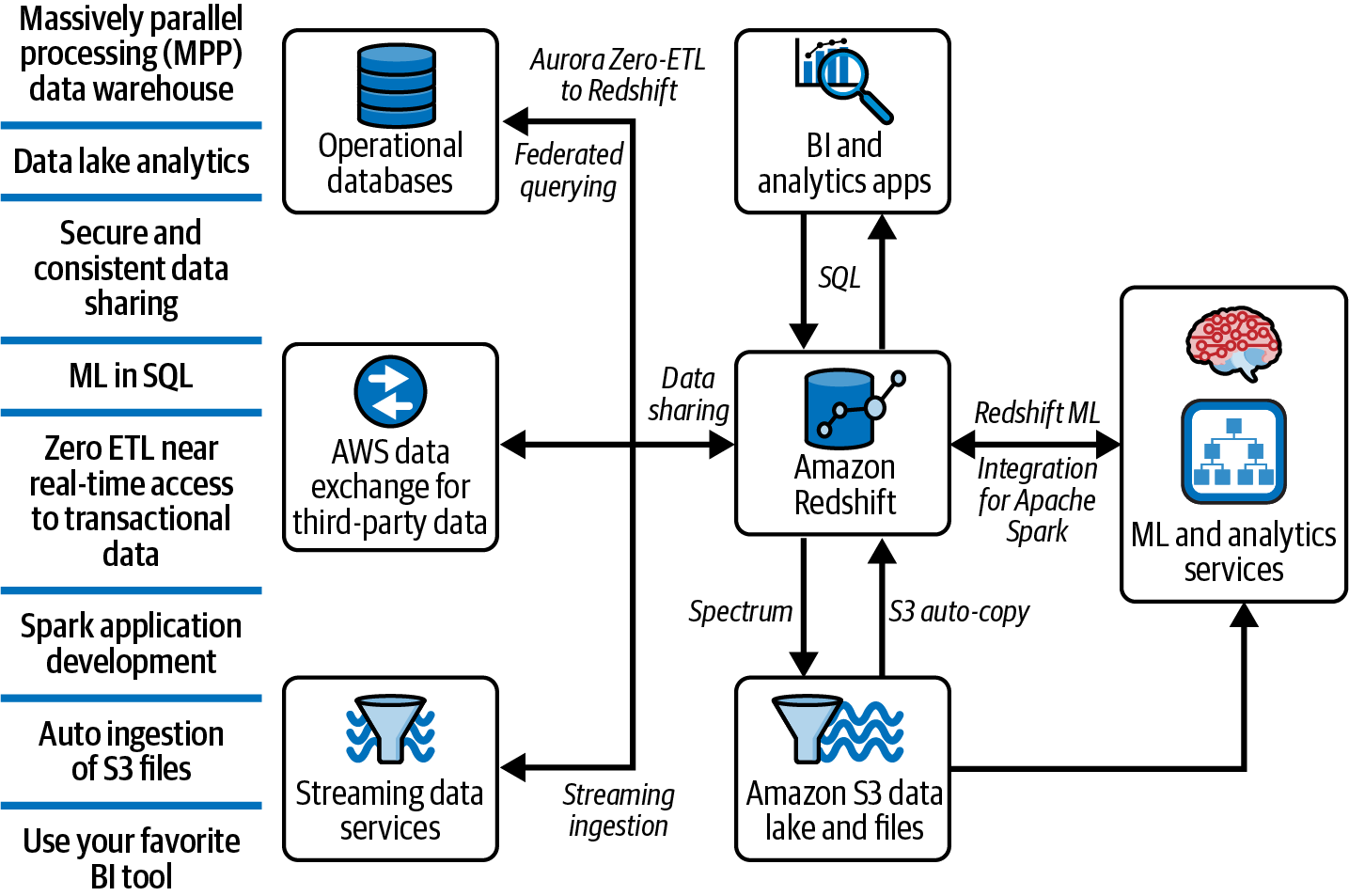
Figure 1-5. Amazon Redshift in a modern data architecture
We will discuss the features in detail in later chapters, but here is a brief summary of each:
- Massively parallel processing (MPP) data warehouse
-
Amazon Redshift is based on MPP architecture, which enables fast run of the complex queries operating on large amounts of data by distributing the query processing to multiple nodes and virtual processing units within each node of your data warehouse. An MPP architecture has the added benefit of co-locating like data in processing units through the use of distribution keys, therefore making analytics processing more cost performant. In Chapter 2, “Getting Started with Amazon Redshift”, you will learn more about the importance of MPP architecture.
- Separation of storage and compute
-
With the Redshift architecture generation 3 (RA3), Amazon Redshift has separation of storage and compute, which helps you to scale storage or compute independently based on the requirements of your workloads. In Chapter 2, you will learn more about the architecture of Amazon Redshift and how to get started.
- Serverless
-
Amazon Redshift offers a serverless option, so you can run and scale analytics without having to provision and manage data warehouses. With Amazon Redshift serverless, you don’t have to choose a node type or the number of nodes you need for a specific workload; instead, you set an initial configuration for compute unit, which is measured in Redshift Processing Unit (RPU). Amazon Redshift automatically provisions and scales data warehouse capacity to meet the requirements of demanding and unpredictable workloads, and you pay only for the capacity you use. Amazon Redshift serverless is compatible with the provisioned cluster, so you can migrate your applications from a provisioned cluster to serverless without changing your existing analytics or BI applications. In Chapter 2, “Getting Started with Amazon Redshift”, you will learn more about creating an Amazon Redshift serverless data warehouse.
- Data lake analytics
-
Amazon Redshift can efficiently query and transform structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables. Amazon Redshift queries external S3 data with only the required data sent to your Amazon Redshift data warehouse. In Chapter 3, “Setting Up Your Data Models and Ingesting Data”, you will learn more about how to query and transform data from Amazon S3.
- Secure and consistent data sharing
-
Amazon Redshift data sharing allows you to share live data between data warehouses internal within your organization or with external partners. This feature allows you to extend benefits of a single data warehouse to multiple data warehouse deployments without the need to copy or move it. This enables you to access and query data where it is stored by sharing data across organizational boundaries and different data domains where data mass is accumulated. In Chapter 7, “Collaboration with Data Sharing”, you will learn more about Amazon Redshift data sharing and how you can use this for collaboration with internal and external stakeholders.
- Machine learning using SQL
-
Amazon Redshift ML makes it easy for data analysts and database developers to create, train, and apply machine learning models using familiar Standard Query Language (SQL) commands in Amazon Redshift data warehouses. With Amazon Redshift ML, you can reduce ML model development time by using SQL-based prediction model creation and taking advantage of integration with Amazon SageMaker, a fully managed machine learning service, without learning new tools or languages. In Chapter 6, “Amazon Redshift Machine Learning”, you’ll learn more about the types of machine learning problems you can solve using Amazon Redshift ML.
- Zero-ETL
-
Amazon Aurora supports zero-ETL integration with Amazon Redshift to enable near real-time analytics using Amazon Redshift on transactional data. Using log-based replication, transactional data written into Aurora is available in Amazon Redshift within a few seconds. Once data is available in Amazon Redshift, you can query data as is or apply transformation rules using either SQL or stored procedures. In Chapter 3, you’ll learn more about how to set up zero-ETL integration with Amazon Redshift.
- Spark application development
-
With Apache Spark integration, you can build Apache Spark applications in a variety of languages such as Java, Scala, and Python, and the connector is natively installed on Amazon EMR (previously called Amazon Elastic MapReduce), AWS Glue, and SageMaker. These applications can read from and write to your Amazon Redshift data warehouse without compromising on the performance of the applications or transactional consistency of the data, as well as performance improvements with pushdown optimizations. In Chapter 3, you’ll learn how to take advantage of the Spark connector for ingestion and in Chapter 4, “Data Transformation Strategies”, you’ll learn how to use the Spark connector for data transformation.
- Auto ingestion of Amazon S3 files
-
You can set up continuous file ingestion rules to track your Amazon S3 paths and automatically load new files into Amazon Redshift without the need for additional tools or custom solutions. Using a
COPYcommand is the best practice for ingestion of data into Amazon Redshift. You can store aCOPYstatement into a copy job, which automatically loads the new files detected in the specified Amazon S3 path. In Chapter 3, we will describe the different options for loading data and how to configure auto ingestion.
- Query transactional data using federated query
-
With federated queries, you can incorporate live data as part of your BI and reporting applications. With this feature, you can query current real-time data from external databases like PostgreSQL or MySQL from within Amazon Redshift and combine it with historical data stored in data warehouses to provide a combined view for your business users. In Chapter 4, you’ll learn how to set up a federated source and query that data in real time for use in reporting and transformation.
- Use your favorite BI tool
-
You can use your BI tool of choice to query your Amazon Redshift data warehouses using standard Java Database Connectivity (JDBC) and Open Database Connectivity (ODBC) connections or using APIs and provide business insights. Amazon QuickSight is an AWS native service to create modern interactive dashboards, paginated reports, embedded analytics, and natural language queries on multiple data sources including Amazon Redshift. In Chapter 2, you’ll learn about the many ways you can connect your client tools to Amazon Redshift.
- Discover and share data
-
Amazon Redshift also supports integration with Amazon DataZone, which allows you to discover and share data at scale across organizational boundaries with governance and access controls. In Chapter 7, “Collaboration with Data Sharing”, you will learn how Amazon DataZone gives you federated data governance where the data owners and subject matter experts of that dataset can enforce security and access controls on their relevant data assets.
Real-World Benefits of Adopting a Modern Data Architecture
Results of research conducted by many analysts show us that organizations who make data accessible even by a few percentage points will see a significant increase in net income. According to Richard Joyce, senior analyst at Forrester, “Just a 10% increase in data accessibility will result in more than $65 million additional net income for a typical Fortune 1000 company.” Analytics can explore new markets or new lines of business through insights that can have an impact on the top line and cost of operations.
Here are some real-world examples:
-
Intuit migrated to an Amazon Redshift–based solution in an effort to make data more accessible. The solution scaled to more than 7 times the data volume and delivered 20 times the performance over the company’s previous solution. This resulted in a 25% reduction in team costs, 60% to 80% less time spent on maintenance, 20% to 40% cost savings overall, and a 90% reduction in time to deploy models. This freed up the teams to spend more time developing the next wave of innovations.
-
Nasdaq decreased time to market for data access from months to weeks by consolidating the company’s data products into a centralized location on the cloud. They used Amazon S3 to build a data lake, allowing them to ingest 70 billion records per day. The exchange now loads financial market data five hours faster and runs Amazon Redshift queries 32% faster.
-
The Expedia Group processes over 600 billion AI predictions per year with AWS data services powered by 70 PB of data. Samsung’s 1.1 billion users make 80,000 requests per second, and Pinterest stores over an exabyte of data on Amazon S3.
-
Toyota migrated from an on-premises data lake and now collects and combines data from in-vehicle sensors, operational systems, and data warehouses at PB scale. Their teams have secure access to that data when they need it, giving them the autonomy and agility to innovate quickly. Now Toyota can do things like monitor vehicle health and resolve issues before they impact customers. Philips built a secure and HIPAA-compliant digital cloud platform to serve as a base for application suites that could store, interpret, unify, and extract insights from customers’ data from different sources.
Reference Architecture for Modern Data Architecture
Now that you understand the benefits of a modern data architecture and the value of storing data in both a data lake and a data warehouse, let’s take a look at a reference architecture for a data warehouse workload using AWS analytics services. Figure 1-6 illustrates how you can use AWS services to implement various aspects of your modern data architecture from collecting or extracting data from various sources and applications into your Amazon S3 data lake to how you can leverage Amazon Redshift to ingest and process data, to how you can use Amazon QuickSight and Amazon SageMaker to analyze the data.
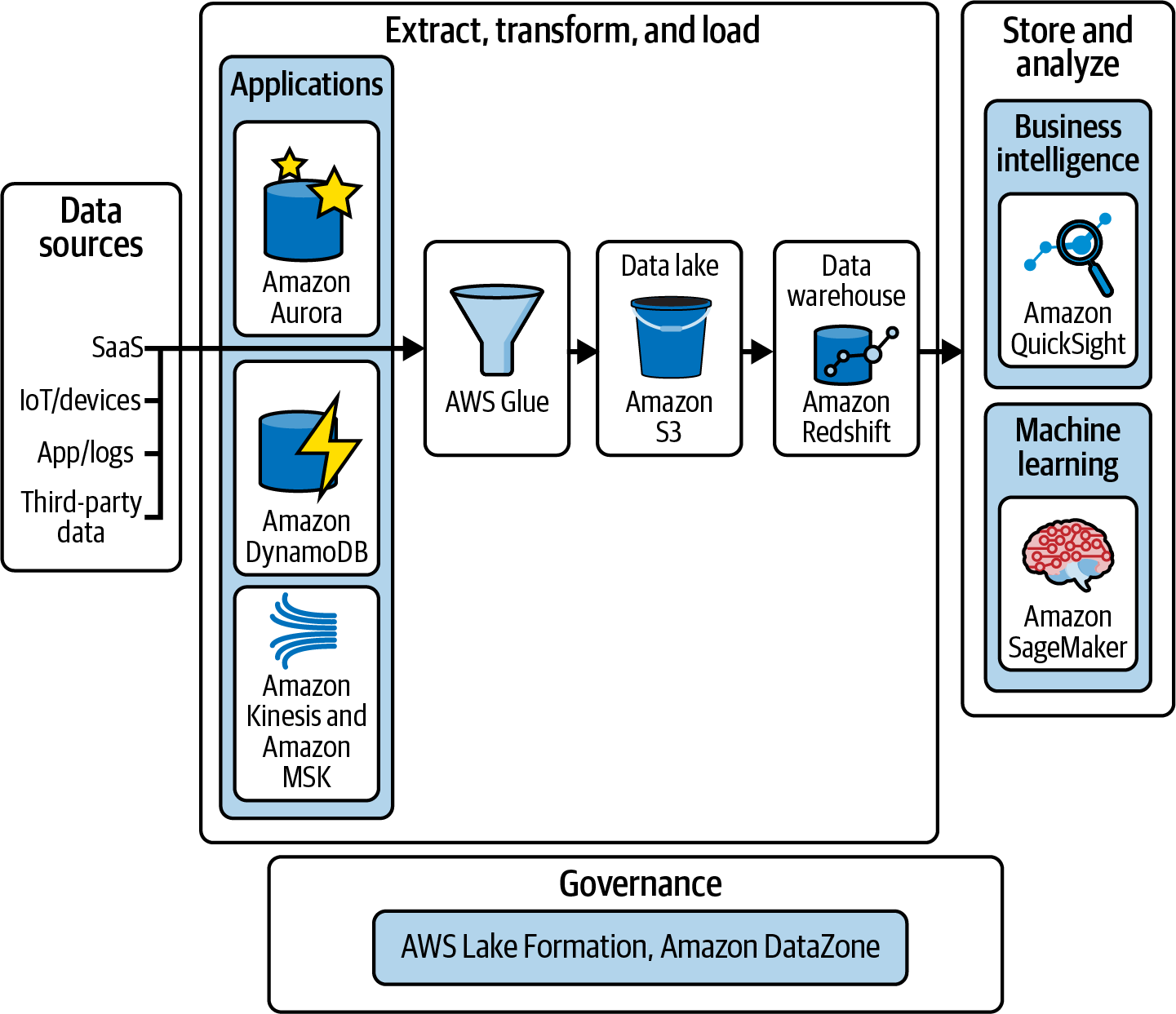
Figure 1-6. Modern data reference architecture
Data Sourcing
The modern data architecture enables you to ingest and analyze data from a variety of sources. Many of these sources such as line of business (LOB) applications, ERP applications, and CRM applications generate highly structured batches of data at fixed intervals. In addition to internal structured sources, you can receive data from modern sources such as web applications, mobile devices, sensors, video streams, and social media. These modern sources typically generate semistructured and unstructured data, often as continuous streams.
The data is either temporarily or persistently stored in Amazon S3 as a data lake in open file formats such as Apache Parquet, Avro, CSV, ORC, and JSON, to name a few. The same data from your Amazon S3 data lake can serve as your single source of truth and can be used in other analytical services such as Amazon Redshift, Amazon Athena, Amazon EMR, and Amazon SageMaker. The data lake allows you to have a single place to run analytics across most of your data while the purpose-built analytics services provide the speed you need for specific use cases like data warehouse, real-time dashboards, and log analytics.
Extract, Transform, and Load
The ETL layer is responsible for extracting data from multiple sources, transforming data based on business rules, and populating cleansed and curated areas of the storage layer. It provides the ability to connect to internal and external data sources over a variety of protocols. It can ingest and deliver batch as well as real-time streaming data into a data warehouse as well as a data lake.
To provide highly curated, conformed, and trusted data, prior to storing data, you may put the source data through preprocessing, validation, and transformation. Changes to data warehouse data and schemas should be tightly governed and validated to provide a highly trusted source of truth dataset across business domains.
A common architecture pattern you may have followed in the past was to store frequently accessed data that needed high performance inside a database or data warehouse like Amazon Redshift and cold data that was queried occasionally in a data lake. For example, a financial or banking organization might need to keep over 10 years of historical transactions for legal compliance purposes, but need only 2 or 3 years of data for analysis. The modern architecture provides the flexibility to store the recent three years of data in local storage, and persist the historical data beyond three years to the data lake.
Following this pattern, Amazon Redshift has a built-in tiered storage model when using the RA3 node type or the serverless deployment option. The storage and compute are separated where the data is stored in Amazon Redshift Managed Storage (RMS) so you scan scale your compute independent of storage. Amazon Redshift manages the hot and cold data by hydrating the frequently used blocks of data closer to the compute, replacing less-frequently used data. With this architecture, while you can still persist the historical data in your data lake to run analytics across other analytics services, you do not have to offload as much, if any, data from your data warehouse.
Storage
The data storage layer is responsible for providing durable, scalable, and cost-effective components to store and manage vast quantities of data. The data warehouse and data lake natively integrate to provide an integrated cost-effective storage layer that supports unstructured and semistructured as well as highly structured and modeled data. The storage layer can store data in different states of consumption readiness, including raw, trusted-conformed, enriched, and modeled.
Storage in the data warehouse
The data warehouse originated from the need to store and access large volumes of data. MPP–based architectures were built to distribute the processing across a scalable set of expensive, highly performant compute nodes.
Historically, the data warehouse stored conformed, highly trusted data structured into star, snowflake, data vault, or denormalized schemas and was typically sourced from highly structured sources such as transactional systems, relational databases, and other structured operational sources. The data warehouse was typically loaded in batches and performed OLAP queries.
Amazon Redshift was the first fully managed MPP-based cloud data warehouse, supporting all the functions of a traditional data warehouse, but has evolved to have elastic storage, reducing the amount of compute nodes needed, store semistructured data, access real-time data, and perform predictive analysis. Figure 1-7 shows a typical data warehouse workflow.
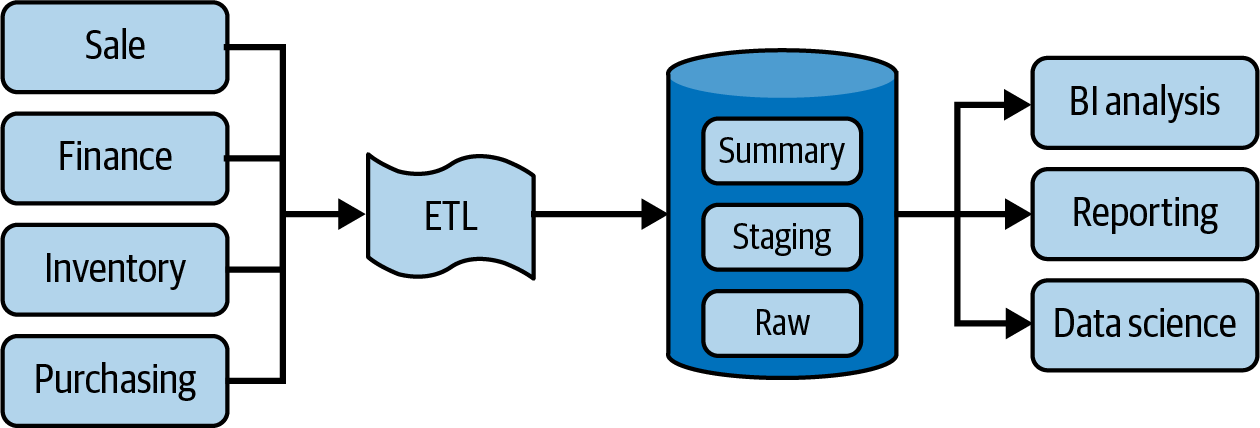
Figure 1-7. Typical data warehouse workflow
Storage in the data lake
A data lake is the centralized data repository that stores all of an organization’s data. It supports storage of data in structured, semistructured, and unstructured formats and can scale to store exabytes of data. Typically, a data lake is segmented into landing, raw, trusted, and curated zones to store data depending on its consumption readiness. Because data can be ingested and stored without having to first define a schema, a data lake can accelerate ingestion and reduce time needed for preparation before data can be explored. The data lake enables analysis of diverse datasets using diverse methods, including big data processing and ML. Native integration between a data lake and data warehouse also reduces storage costs by allowing you to access any of the data lake data you need to explore and load only that which is most valuable. A data lake built on AWS uses Amazon S3, as shown in Figure 1-8, as its primary storage platform.
Figure 1-8. Use cases for data lake
Analysis
You can analyze the data stored in the data lake and data warehouse with interactive SQL queries using query editors, visual dashboards using Amazon QuickSight, or by running prediction machine learning models using Amazon SageMaker.
When using these services, there is no need to continually move and transform data, and AWS has native and fully integrated services for core use cases rather than a collection of partially integrated services from other vendors.
Comparing transactional databases, data warehouses, and data lakes
While a transaction database, a data warehouse, and a data lake may all be organized into a similar collection of data stored and accessed electronically through simple Structured Query Language (SQL), let’s take a closer look at key differentiating characteristics of each of these.
A transactional database is a system where the underlying table structures are designed for fast and efficient data inserts and updates on individual rows. The data model is typically highly normalized, and the storage is designed to store a large number of transactions. To support a high transaction volume on particular rows of data, all the data in a row is physically stored together on disk (row-based storage). This type of database is used for building online transaction processing (OLTP) systems. Online purchases, sales orders, stock trades, and banking credits or debits are some of examples of use cases for a transactional database.
A data warehouse is a database optimized to analyze relational data coming from transactional systems and LOB applications and semistructured non-relational data from mobile apps, IoT devices, and social media. Data is cleaned, enriched, and transformed so it can act as the “single source of truth” that users can trust. The data structure and schema are optimized for fast summarizing of large quantities of data or large batch processing. The results are used for reporting and analysis. Some examples of analytical use cases include analyzing year-over-year retail and online sales, trend analysis for customer purchase preferences, and determining top 10 profitable products.
The key differentiating characteristics of transactional databases and data warehouses are listed in Table 1-1.
| Characteristics | Data warehouse | Transactional database |
|---|---|---|
Suitable workloads |
Analytics at scale, reporting, big data |
Transaction processing, operational reporting |
Data source |
Data collected and normalized from many sources |
Data captured as-is from a single source, such as a transactional system |
Data capture |
Bulk write operations typically on a predetermined batch schedule |
Optimized for continuous write operations as new data is available to maximize transaction throughput |
Data normalization |
Denormalized schemas, such as the star schema or snowflake schema |
Highly normalized, static schemas |
Data storage |
Optimized for simplicity of access and high-speed query performance using columnar storage |
Optimized for high throughout write operations to a single row-oriented physical block |
Data access |
Optimized to minimize I/O and maximize data throughput |
High volumes of small read operations |
A data lake also stores relational data from LOB applications and semistructured data, but it can also store completely unstructured data. The structure of the data or schema is not defined when data is captured. This means you can store data without initial design and create a catalog on top of the data based on business user query requirements.
As organizations with data warehouses see the benefits of data lakes, they require a platform that enables both use cases. They are evolving their warehouses to include data lakes and enable diverse query capabilities.
Table 1-2 includes key differentiating characteristics of data warehouses and data lakes.
| Characteristics | Data warehouse | Data lake |
|---|---|---|
Data |
Relational data from transactional systems, operational databases, JSON with streaming ingestion, and line of business applications |
All data, including structured, semistructured, and unstructured |
Schema |
Often designed prior to the data warehouse implementation but also can be written at the time of analysis (schema-on-write or schema-on-read) |
Written at the time of analysis (schema-on-read) |
Price/performance |
Fastest query results using local storage |
Query results getting faster using low-cost storage and decoupling of compute and storage |
Data quality |
Highly curated data that serves as the central version of the truth |
Any data that may or may not be curated (i.e., raw data) |
Users |
Business analysts, data scientists, data architects, and data engineers |
Business analysts (using curated data), data scientists, data developers, data engineers, and data architects |
Analytics |
Batch reporting, BI, and visualizations, machine learning |
Machine learning, exploratory analytics, data discovery, streaming, operational analytics, big data, and profiling |
Data Mesh and Data Fabric
Data mesh and data fabric are two approaches to implementing a modern data architecture in a distributed and complex environment. They share some common principles such as the use of distributed architectures and the importance of data quality and governance. However, they have different goals and approaches to data management. Data mesh is focused on decentralization and autonomy of data domains, while data fabric is focused on integration and consistency of data across different sources and systems. Data fabric is a top-down technology solution, whereas data mesh is a bottom-up approach focusing more on teams and processes and less about architecture enforcement.
Data Mesh
In a data mesh architecture, data is organized around business capabilities or domains, and each domain is responsible for its own data management, quality, and governance. The data is treated as a product, with data teams responsible for creating and maintaining data products that can be consumed by other teams. The goal of data mesh is to improve the agility and scalability of data management in a complex and rapidly changing environment by reducing dependencies and improving collaboration between teams.
Data mesh encourages distributed teams to own and architect their domain-oriented solution independently how they see fit; refer to Figure 1-9, which depicts domains for Sales, Marketing, Finance, R&D, and their own teams. This architecture then asks each team to provide data as a product via a self-service infrastructure platform, as shown in the last slab of Figure 1-9. For the data mesh to maintain global interoperability, the oversight is the responsibility of a federated governance team, as shown in the top slab of the figure.
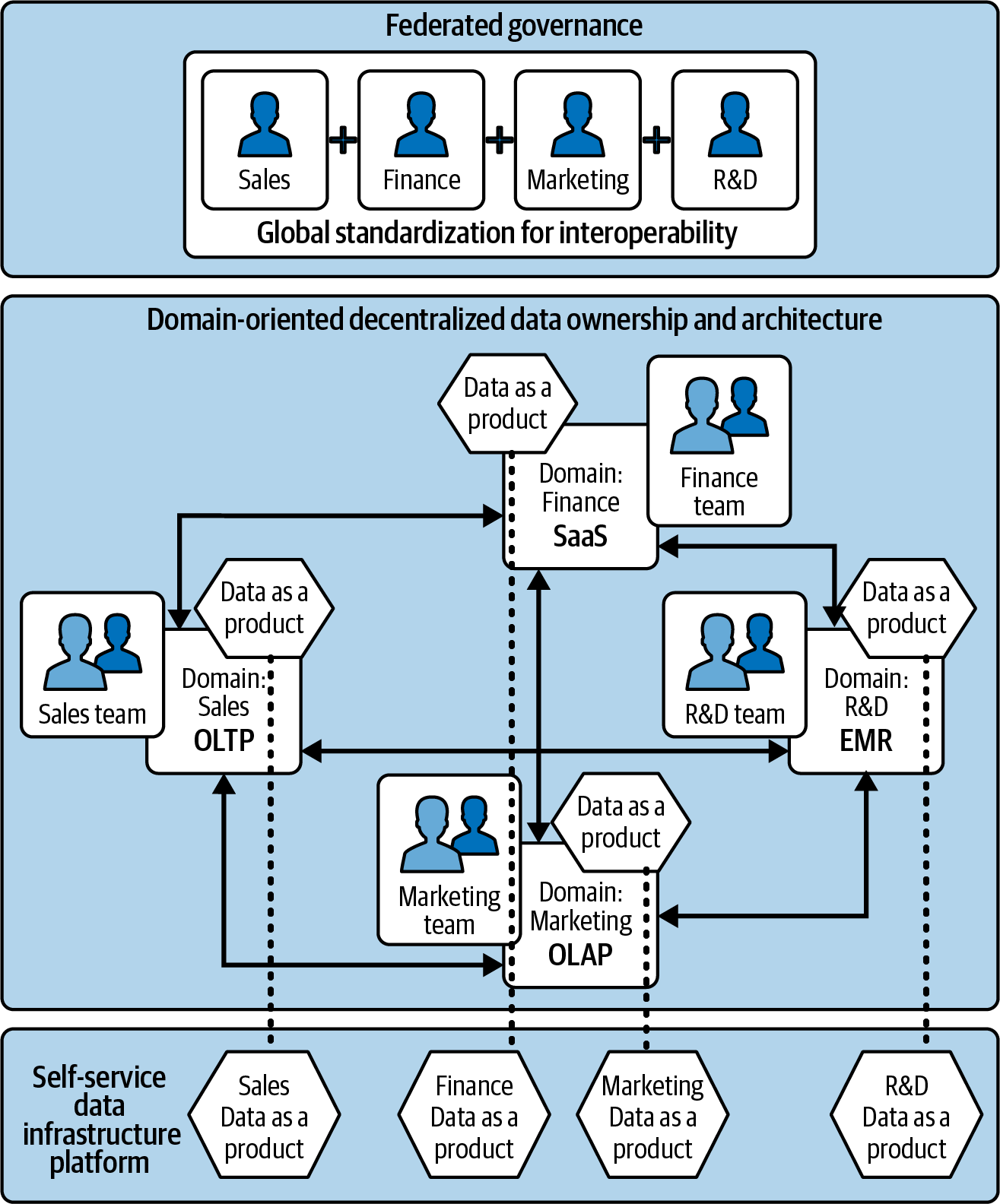
Figure 1-9. A data mesh architecture
This domain-oriented data ownership and architecture allows the ecosystem to scale as needed. Providing data as a product enables easy discovery across many domains. A self-service infrastructure platform enables the various domain teams to create data products as well as to consume data products by abstracting the complexity. The federated governance teams are responsible for defining global standardization rules for interoperability of the entire data mesh ecosystem and more importantly, to balance what needs global standardization and what should be left for the domain-oriented teams to decide.
With each team freely architecting their own solutions, the Amazon Redshift data sharing feature can provide the data infrastructure platform required to stand up the data mesh architecture. With Amazon DataZone, you can build a data mesh architecture where you can share data products with consumers with the decentralized and governed model.
Data Fabric
Data fabric is an approach to data integration and orchestration that emphasizes data consistency, quality, and accessibility across different sources and systems. In a data fabric architecture, data is organized into a unified virtual layer that provides a single view of the data to the users, regardless of its location or format. The data is transformed, enriched, and harmonized as it moves through the fabric, using a combination of automated and manual processes. The goal of data fabric is to simplify data access and analysis and to enable organizations to make faster and more accurate decisions based on trusted data.
Alongside the data that has been gathered are the challenges associated with access, discovery, integration, security, governance, and lineage. The data fabric solution delivers capabilities to solve these challenges.
The data fabric is a metadata-driven method of connecting data management tools to enable self-service data consumption. Referring to Figure 1-10, the central elements represent the tools provided by the data fabric. The actual data sources or silos (shown on the left) remain distributed, but the management is unified by the data fabric overlay. Having a singular data fabric layer over all data sources provides a unified experience to personas (shown in the top section: Reporting, Analytics and Data Science) that can both provide and use the data across the organization. The various components typically interchange data in JSON format via APIs.
The data fabric can be considered a living, breathing, and continuously learning element by incorporating AI and machine learning components that aid in automatic discovery and the lineage processes. The challenge here is to obtain agreement for the unified management from the various departments and teams owning and maintaining their individual datasets.
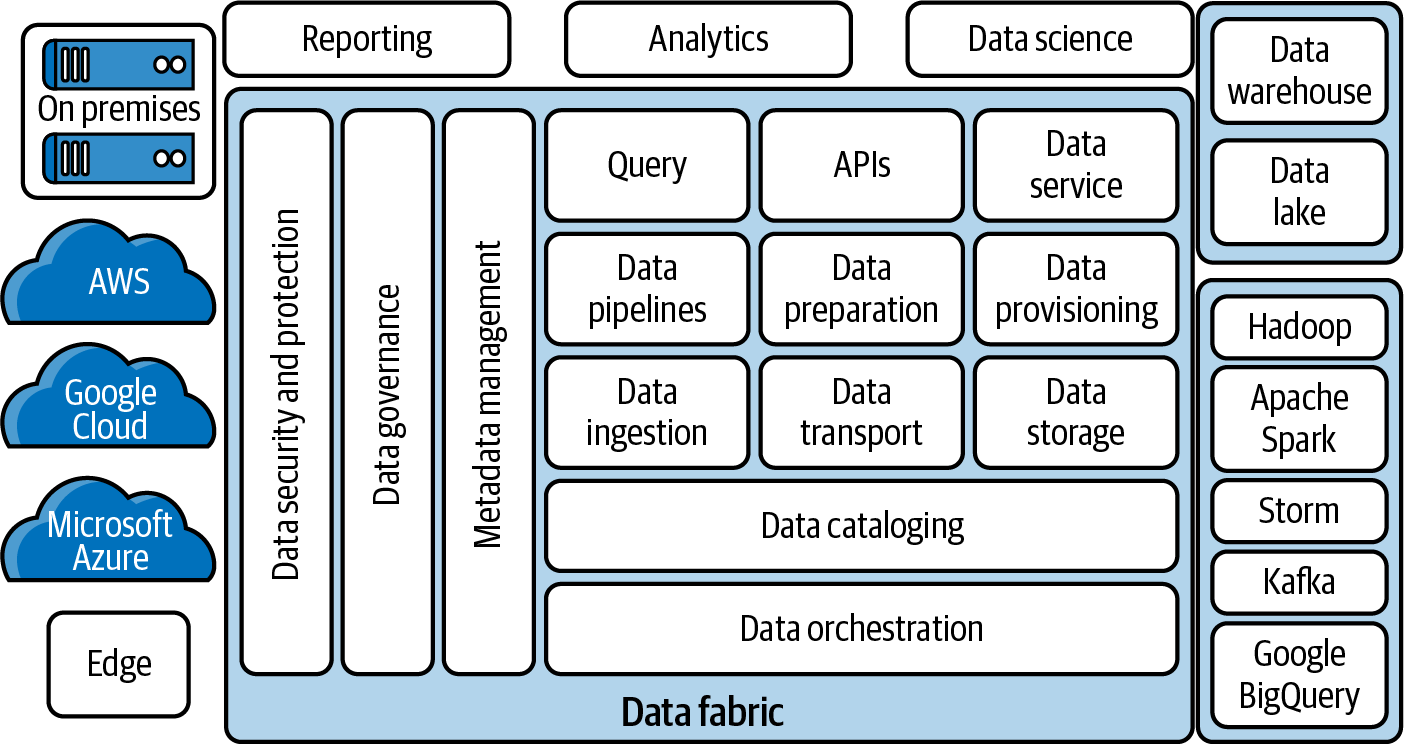
Figure 1-10. A data fabric consists of multiple data management layers (Image source: Eckerson Group)
Amazon Redshift’s integration with AWS Lake Formation can be used to provide ease of access, security, and governance. In Chapter 8, “Securing and Governing Data”, you’ll learn how to set up access controls when working with AWS Lake Formation. And, Amazon SageMaker can be leveraged to build the machine learning capabilities of the data fabric architecture on AWS. In Chapter 6, “Amazon Redshift Machine Learning”, you’ll learn how Amazon Redshift is tightly integrated with Amazon SageMaker.
Summary
In this chapter, we covered how organizations can become data-driven by building a modern data architecture using the purpose-built AWS for data services. A modern data strategy will help you drive your roadmap to migrate your data workloads to the cloud, and we saw how Amazon Redshift is the foundation for the modern data architecture.
The remaining chapters explore how you can use Amazon Redshift to transform your data workloads to the cloud, democratize data, and provide business insights to all your users. You will also learn how you can implement some of the modern architectures like data mesh using Amazon Redshift and leverage the tight integration with other AWS native analytics services.
Get Amazon Redshift: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

