Kapitel 4. Beobachtbarkeit
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel geht es um die Beobachtung von Node.js-Diensten, die auf entfernten Rechnern laufen. Lokal ist das mit Werkzeugen wie dem Debugger oder console.log() ein einfacher Prozess. Sobald ein Dienst jedoch in einem fernen Land läuft, musst du zu anderen Werkzeugen greifen.
Beim lokalen Debugging geht es meist um eine einzelne Anfrage. Du fragst dich vielleicht: "Wenn ich diesen Wert in einer Anfrage übergebe, warum bekomme ich dann diesen Wert in der Antwort?" Indem du das Innenleben einer Funktion protokollierst, kannst du herausfinden, warum sich eine Funktion auf eine unerwartete Weise verhält. Dieses Kapitel befasst sich auch mit Technologien, die bei der Fehlersuche in einzelnen Anfragen nützlich sind. In "Logging mit ELK" geht es um die Erstellung von Protokollen, mit denen du Informationen pro Anfrage aufzeichnen kannst, ähnlich wie du sie mit console.log() ausdrucken könntest. In "Verteiltes Request Tracing mit Zipkin" geht es um ein Tool, mit dem du Anfragen verfolgen kannst, während sie weitergereicht werden, und das von verschiedenen Diensten erzeugte Logs miteinander verknüpft.
Du brauchst oft Einblicke in Situationen, die normalerweise nicht als schwerwiegende Fehler angesehen werden, wenn es um den Produktionsverkehr geht. Du musst dich zum Beispiel fragen: "Warum sind HTTP-Anfragen für Benutzer, die vor April 2020 angelegt wurden, 100 ms langsamer?" Ein solches Timing mag bei einer einzelnen Anfrage nicht besorgniserregend sein, aber wenn du solche Metriken über viele Anfragen hinweg betrachtest, kannst du Trends mit negativer Leistung erkennen. In "Metriken mit Graphite, StatsD und Grafana" wird dies näher erläutert.
Diese Tools zeigen die Informationen meist passiv in einer Art Dashboard an, das ein Techniker später konsultieren kann, um die Ursache eines Problems zu ermitteln. In "Alerting with Cabot" geht es darum, wie man einen Entwickler warnt, wenn die Leistung einer Anwendung unter einen bestimmten Schwellenwert fällt.
Bisher waren diese Konzepte reaktiv, d.h. ein Entwickler muss sich die Daten ansehen, die von einer Anwendung erfasst werden. In anderen Fällen ist es notwendig, proaktiv zu handeln. Bei den "Health Checks" geht es darum, wie eine Anwendung feststellen kann, ob sie gesund ist und in der Lage ist, Anfragen zu bedienen, oder ob sie ungesund ist und es verdient, beendet zu werden.
Umgebungen
Umgebungen sind ein Konzept zur Unterscheidung der laufenden Instanzen einer Anwendung und der Datenbanken voneinander. Sie sind aus verschiedenen Gründen wichtig, z. B. um auszuwählen, zu welchen Instanzen der Datenverkehr geleitet werden soll, um Metriken und Protokolle getrennt zu halten (was in diesem Kapitel besonders wichtig ist), um Dienste aus Sicherheitsgründen zu trennen und um das Vertrauen zu gewinnen, dass ein Checkout des Anwendungscodes in einerUmgebung stabil läuft, bevor er in die Produktion überführt wird.
Die Umgebungen sollten voneinander getrennt bleiben. Wenn du deine eigene Hardware kontrollierst, kann das bedeuten, dass du verschiedene Umgebungen auf verschiedenen physischen Servern laufen lässt. Wenn du deine Anwendung in der Cloud bereitstellst, bedeutet das eher, dass du verschiedene VPCs (Virtual Private Clouds) einrichtest - ein Konzept, das sowohl von AWS als auch von GCP unterstützt wird.
Als absolutes Minimum benötigt jede Anwendung mindestens eine einzige Produktionsumgebung. Das ist die Umgebung, die für die Bearbeitung der Anfragen der öffentlichen Nutzer zuständig ist. Du wirst jedoch ein paar mehr Umgebungen brauchen, vor allem, wenn deine Anwendung komplexer wird.
In der Regel verwenden Node.js-Anwendungen die Umgebungsvariable NODE_ENV, um anzugeben, in welcher Umgebung eine Instanz ausgeführt wird. Dieser Wert kann auf unterschiedliche Weise gesetzt werden. Zu Testzwecken kann er manuell gesetzt werden, wie im folgenden Beispiel. Für den produktiven Einsatz wird das Tool, das du für das Deployment verwendest, diesen Prozess abstrahieren:
$exportNODE_ENV=production$node server.js
Wie man entscheidet, welchen Code man in den verschiedenen Umgebungen einsetzt, welche Verzweigungs- und Zusammenführungsstrategien man anwendet und welches VCS (Versionskontrollsystem) man wählt, ist nicht Gegenstand dieses Buches. Letztendlich wird jedoch ein bestimmter Snapshot der Codebasis ausgewählt, um in einer bestimmten Umgebung eingesetzt zu werden.
Auch die Wahl der zu unterstützenden Umgebungen ist wichtig und liegt außerhalb des Rahmens dieses Buches. Normalerweise haben Unternehmen mindestens die folgendenUmgebungen:
- Entwicklung
-
Wird für die lokale Entwicklung verwendet. Vielleicht andere Dienste wissen, dass sie Nachrichten, die mit dieser Umgebung verbunden sind, ignorieren sollen. Einige der für die Produktion erforderlichen Sicherungsspeicher werden nicht benötigt; zum Beispiel können Protokolle in stdout geschrieben werden, anstatt sie an einen Collector zu übertragen.
- Inszenierung
-
Stellt eine exakte Kopie der Produktionsumgebung dar, z.B. Maschinenspezifikationen und Betriebssystemversionen. Vielleicht wird ein anonymisierter Datenbank-Snapshot aus der Produktion über einen nächtlichen Cron-Job in eine Staging-Datenbank kopiert.
- Produktion
-
Hier wird der echte Produktionsverkehr verarbeitet. Hier kann es mehr Service-Instanzen geben als im Staging; zum Beispiel laufen im Staging zwei Anwendungsinstanzen (immer mehr als eine), in der Produktion aber acht.
Der Umgebungsstring muss über alle Anwendungen hinweg konsistent bleiben, sowohl für Anwendungen, die mit Node.js geschrieben wurden, als auch für solche auf anderen Plattformen. Diese Konsistenz vermeidet viele Kopfschmerzen. Wenn ein Team eine Umgebung als " staging" und das andere als " preprod" bezeichnet, wird das Abfragen der Logs nach entsprechenden Meldungen zu einem fehleranfälligen Prozess.
Der Umgebungswert sollte nicht unbedingt für die Konfiguration verwendet werden - zum Beispiel für eine Lookup-Map, in der der Umgebungsname mit dem Hostnamen einer Datenbank verknüpft ist. Idealerweise sollte jede dynamische Konfiguration über Umgebungsvariablen bereitgestellt werden. Stattdessen wird der Umgebungswert hauptsächlich für Dinge verwendet, die mit der Beobachtbarkeit zu tun haben. So sollte z. B. bei Logmeldungen die Umgebung mit angegeben werden, damit die Logs mit der jeweiligen Umgebung in Verbindung gebracht werden können, was besonders wichtig ist, wenn ein Logging-Dienst über mehrere Umgebungen hinweg genutzt wird. In "Anwendungskonfiguration" wird die Konfiguration genauer betrachtet.
Loggen mit ELK
ELK, oder genauer gesagt, der ELK-Stack, ist eine Referenz für Elasticsearch, Logstash und Kibana, drei Open-Source-Tools, die von Elastic entwickelt wurden. In Kombination sind diese leistungsstarken Tools oft die Plattform der Wahl, um Logs vor Ort zu sammeln. Jedes dieser Tools erfüllt für sich genommen einen anderen Zweck:
- Elasticsearch
-
Eine Datenbank mit einer leistungsstarken Abfragesyntax, die Funktionen wie die natürliche Textsuche unterstützt. Sie ist in viel mehr Situationen nützlich als die, die in diesem Buch behandelt werden, und es lohnt sich, sie in Betracht zu ziehen, wenn du jemals eine Suchmaschine bauen musst. Sie stellt eine HTTP-API zur Verfügung und hat den Standardport
:9200. - Logstash
-
Ein Dienst für , der Logs aus verschiedenen Quellen aufnimmt und umwandelt. Du erstellst eine Schnittstelle, die Logs über das User Datagram Protocol (UDP) einlesen kann. Es gibt keinen Standardport, also verwenden wir einfach
:7777. - Kibana
-
Ein Webservice für zur Erstellung von Dashboards, die in Elasticsearch gespeicherte Daten visualisieren. Er stellt einen HTTP-Webdienst über den Port
:5601zur Verfügung.
In Abbildung 4-1 sind diese Dienste und ihre Beziehungen dargestellt. Außerdem wird gezeigt, wie sie in den folgenden Beispielen mit Docker gekapselt werden.

Abbildung 4-1. Der ELK-Stapel
Von deiner Anwendung wird erwartet, dass sie wohlgeformte JSON-Protokolle übermittelt, in der Regel ein Objekt, das ein oder zwei Ebenen tief ist. Diese Objekte enthalten allgemeine Metadaten über die protokollierte Nachricht, wie z. B. Zeitstempel, Host und IP-Adresse, sowie spezifische Informationen über die Nachricht selbst, wie z. B. Level/Severity, Umgebung und eine von Menschen lesbare Nachricht. Es gibt mehrere Möglichkeiten, ELK so zu konfigurieren, dass es solche Nachrichten empfängt, z. B. das Schreiben von Protokollen in eine Datei und die Verwendung des Filebeat-Tools von Elastic, um sie zu sammeln. In diesem Abschnitt wird Logstash so konfiguriert, dass es auf eingehende UDP-Nachrichten hört.
ELK über Docker ausführen
Um dir die Hände schmutzig zu machen, wirst du einen einzigen Docker-Container mit allen drei Diensten ausführen. (Achte darauf, dass du Docker installiert hast - weitere Informationen findest du in Anhang B.) In diesen Beispielen wird keine Festplattenpersistenz aktiviert. In einem größeren Unternehmen würde jeder dieser Dienste besser funktionieren, wenn er auf dedizierten Rechnern installiert wäre, und natürlich ist Persistenz wichtig.
Um Logstash so zu konfigurieren, dass es auf UDP-Nachrichten hört, muss zunächst eine Konfigurationsdatei erstellt werden. Der Inhalt dieser Datei ist in Beispiel 4-1 zu sehen und kann in einem neuen Verzeichnis unter misc/elk/udp.conf abgelegt werden. Sobald die Datei erstellt ist, musst du sie dem Logstash-Dienst, der im Docker-Container läuft, zur Verfügung stellen. Dazu verwendest du das -v volume Flag, mit dem ein lokaler Dateisystempfad in das Dateisystem des Containers eingebunden werden kann.
Beispiel 4-1. misc/elk/udp.conf
input {
udp {
id => "nodejs_udp_logs"
port => 7777
codec => json
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
document_type => "nodelog"
manage_template => false
index => "nodejs-%{+YYYY.MM.dd}"
}
}Hinweis
Der Einfachheit halber wird in diesen Beispielen UDP für den Nachrichtenversand verwendet. Dieser Ansatz bietet nicht die gleichen Funktionen wie andere, wie z. B. Zustellungsgarantien oder Rückdruckunterstützung, aber er reduziert den Overhead für die Anwendung. Informiere dich über das beste Tool für deinen Anwendungsfall.
Sobald die Datei erstellt wurde, kannst du den Container mit den Befehlen in Beispiel 4-2 starten. Wenn du Docker auf einem systembasierten Linux-Rechner ausführst, musst du den Befehl sysctl ausführen, damit der Container ordnungsgemäß läuft. Du kannst das Flag -e auch weglassen, wenn du möchtest. Wenn du Docker unter macOS ausführst, kannst du das sysctl Flag weglassen, aber du musst in den Docker-Desktop-Einstellungen auf der Registerkarte Ressourcen → Erweitert mindestens 4 GB Speicher zuweisen.
Beispiel 4-2. ELK in Docker ausführen
$sudo sysctl -w vm.max_map_count=262144# Linux Only$docker run -p 5601:5601 -p 9200:9200\-p 5044:5044 -p 7777:7777/udp\-v$PWD/misc/elk/udp.conf:/etc/logstash/conf.d/99-input-udp.conf\-eMAX_MAP_COUNT=262144\-it --name distnode-elk sebp/elk:683
Dieser Befehl lädt Dateien von Dockerhub herunter und konfiguriert den Dienst, was einige Minuten dauern kann. Sobald sich deine Konsole etwas beruhigt hat, rufe http://localhost:5601 in deinem Browser auf. Wenn du eine erfolgreiche Meldung siehst, ist der Dienst jetzt bereit, Nachrichten zu empfangen.
Übertragen von Logs aus Node.js
Für dieses Beispiel wirst du wieder damit beginnen, eine bestehende Anwendung zu modifizieren. Kopiere die in Beispiel 1-7 erstellte Datei web-api/consumer-http-basic.js nach web-api/consumer-http-logs.js als Ausgangspunkt. Als Nächstes änderst du die Datei so ab, dass sie wie der Code in Beispiel 4-3 aussieht.
Beispiel 4-3. web-api/consumer-http-logs.js
#!/usr/bin/env node// npm install fastify@3.2 node-fetch@2.6 middie@5.1constserver=require('fastify')();constfetch=require('node-fetch');constHOST=process.env.HOST||'127.0.0.1';constPORT=process.env.PORT||3000;constTARGET=process.env.TARGET||'localhost:4000';constlog=require('./logstash.js');(async()=>{awaitserver.register(require('middie'));server.use((req,res,next)=>{log('info','request-incoming',{path:req.url,method:req.method,ip:req.ip,ua:req.headers['user-agent']||null});next();});server.setErrorHandler(async(error,req)=>{log('error','request-failure',{stack:error.stack,path:req.url,method:req.method,});return{error:error.message};});server.get('/',async()=>{consturl=`http://${TARGET}/recipes/42`;log('info','request-outgoing',{url,svc:'recipe-api'});constreq=awaitfetch(url);constproducer_data=awaitreq.json();return{consumer_pid:process.pid,producer_data};});server.get('/error',async()=>{thrownewError('oh no');});server.listen(PORT,HOST,()=>{log('verbose','listen',{host:HOST,port:PORT});});})();
Die neue Datei logstash.js wird jetzt geladen.
Das
middiePaket ermöglicht es Fastify, generische Middleware zu verwenden.
Eine Middleware, die eingehende Anfragen protokolliert.

Ein Aufruf an den Logger, der die Anfragedaten übergibt.

Eine generische Middleware für die Protokollierung von Fehlern.

Informationen über ausgehende Anfragen werden protokolliert.

Auch Informationen über Serverstarts werden protokolliert.
Diese Datei protokolliert einige wichtige Informationen. Als erstes wird protokolliert, wann der Server startet. Die zweite Gruppe von Informationen stammt von einem generischen Middleware-Handler. Er protokolliert Daten über jede eingehende Anfrage, einschließlich des Pfades, der Methode, der IP-Adresse und des User Agents. Dies ist vergleichbar mit dem Zugriffsprotokoll eines herkömmlichen Webservers. Schließlich verfolgt die Anwendung auch ausgehende Anfragen an , den recipe-api-Dienst.
Der Inhalt der Datei logstash.js könnte interessanter sein. Es gibt viele Bibliotheken, die auf npm verfügbar sind, um Logs an Logstash zu übermitteln (@log4js-node/logstashudp ist ein solches Paket). Diese Bibliotheken unterstützen einige Methoden zur Übertragung, darunter UDP. Da der Mechanismus zum Senden von Logs so einfach ist, wirst du eine Version von Grund auf nachbauen. Für Lehrzwecke ist das gut geeignet, aber für eine Produktionsanwendung ist ein vollwertiges Paket von npm die bessere Wahl.
Erstelle eine neue Datei namens web-api/logstash.js. Im Gegensatz zu den anderen JavaScript-Dateien, die du bisher erstellt hast, wird diese Datei nicht direkt ausgeführt. Füge den Inhalt aus Beispiel 4-4 in diese Datei ein.
Beispiel 4-4. web-api/logstash.js
constclient=require('dgram').createSocket('udp4');consthost=require('os').hostname();const[LS_HOST,LS_PORT]=process.env.LOGSTASH.split(':');constNODE_ENV=process.env.NODE_ENV;module.exports=function(severity,type,fields){constpayload=JSON.stringify({'@timestamp':(newDate()).toISOString(),"@version":1,app:'web-api',environment:NODE_ENV,severity,type,fields,host});console.log(payload);client.send(payload,LS_PORT,LS_HOST);};
Das eingebaute
dgramModul sendet UDP-Nachrichten.Der Speicherort von Logstash wird in
LOGSTASHgespeichert.In der Protokollnachricht werden mehrere Felder gesendet.
Dieses grundlegende Logstash-Modul exportiert eine Funktion, die der Anwendungscode aufruft, um ein Protokoll zu senden. Viele der Felder werden automatisch generiert, wie @timestamp, das die aktuelle Zeit angibt. Das Feld app ist der Name der laufenden Anwendung und muss vom Aufrufer nicht überschrieben werden. Andere Felder, wie severity und type, sind Felder, die die Anwendung ständig ändern wird. Das Feld fields steht für zusätzliche Schlüssel/Wertpaare, die die Anwendung möglicherweise bereitstellen möchte.
Das Feld severity (in anderen Logging-Frameworks oft Log-Level genannt) gibt an, wie wichtig das Log ist. Die meisten Logging-Pakete unterstützen die folgenden sechs Werte, die ursprünglich durch den npm-Client bekannt wurden: error, warn, info, verbose, debug, silly. Es ist ein gängiges Muster bei "vollständigeren" Logging-Paketen, einen Schwellenwert für die Protokollierung über eine Umgebungsvariable festzulegen. Wenn du zum Beispiel den minimalen Schweregrad auf verbose setzt, werden alle Meldungen mit einem niedrigeren Schweregrad (nämlich debug und silly) ausgelassen. Das allzu einfache Modul logstash.js unterstützt dies nicht.
Sobald die Nutzlast erstellt wurde, wird sie in einen JSON-String umgewandelt und auf der Konsole ausgegeben, damit du weißt, was vor sich geht. Zum Schluss versucht der Prozess, die Nachricht an den Logstash-Server zu übermitteln (die Anwendung hat keine Möglichkeit zu erfahren, ob die Nachricht zugestellt wurde; das ist der Nachteil von UDP).
Nachdem die beiden Dateien erstellt wurden, ist es nun an der Zeit, die Anwendung zu testen. Führe die Befehle in Beispiel 4-5 aus. Dadurch wird eine Instanz des neuen web-api-Dienstes und eine Instanz des vorherigen recipe-api-Dienstes gestartet und eine Reihe von Anfragen an die web-api gesendet. Ein Log wird sofort nach dem Start der Web-Api gesendet und zwei weitere Logs werden für jede eingehende HTTP-Anfrage gesendet. Beachte, dass die Befehle watch den folgenden Befehl kontinuierlich in der gleichen Zeile ausführen und daher in separaten Terminalfenstern ausgeführt werden müssen.
Beispiel 4-5. Ausführen der web-api und Erstellen von Protokollen
$ NODE_ENV=developmentLOGSTASH=localhost:7777\node web-api/consumer-http-logs.js$node recipe-api/producer-http-basic.js$brew install watch# required for macOS$watch -n5 curl http://localhost:3000$watch -n13 curl http://localhost:3000/error
Ist das nicht aufregend? Nun, noch nicht ganz. Jetzt springst du in Kibana und wirfst einen Blick auf die gesendeten Logs. Lass die watch Befehle im Hintergrund weiterlaufen; sie halten die Daten frisch, während du mit Kibana verwendest.
Ein Kibana Dashboard erstellen
Jetzt, wo die Anwendung Daten an Logstash sendet und Logstash die Daten in Elasticsearch speichert, ist es an der Zeit, Kibana zu öffnen und diese Daten zu untersuchen. Öffne deinen Browser und rufe http://localhost:5601 auf. Jetzt solltest du das Kibana-Dashboard sehen.
Im Dashboard klickst du auf die letzte Registerkarte auf der linken Seite mit dem Titel Management. Als Nächstes suchst du den Abschnitt Kibana-Optionen und klickst dann auf die Option Indexmuster. Klicke auf Indexmuster erstellen. Für Schritt 1 gibst du das Indexmuster nodejs-* ein. Du solltest unten eine kleine Erfolgsmeldung sehen, wenn Kibana deine Abfrage mit einem Ergebnis verknüpft. Klicke auf Nächster Schritt. Für Schritt 2 klickst du auf das Dropdown-Menü Zeitfilter und dann auf das Feld @timestamp. Zum Schluss klickst du auf Indexmuster erstellen. Du hast jetzt einen Index mit dem Namennodejs-* erstellt, mit dem du diese Werte abfragen kannst.
Klicke auf die zweite Registerkarte auf der linken Seite mit der Überschrift Visualisieren. Klicke dann auf die Schaltfläche Neue Visualisierung erstellen in der Mitte des Bildschirms. Du erhältst verschiedene Möglichkeiten, eine Visualisierung zu erstellen, darunter auch die in Abbildung 4-2 gezeigten, aber klicke zunächst nur auf die Option Vertikales Balkendiagramm.
Abbildung 4-2. Kibana-Visualisierungen
Wähle den nodejs-* Index, den du gerade erstellt hast. Danach wird ein neuer Bildschirm angezeigt, in dem du die Visualisierung feinjustieren kannst. Die Standardgrafik ist nicht sonderlich interessant: Sie besteht aus einem einzelnen Balken, der die Anzahl aller Logs anzeigt, die mit dem Index nodejs-* übereinstimmen. Aber nicht für lange.
Das Ziel ist es nun, ein Diagramm zu erstellen, das die Rate der eingehenden Anfragen an den Web-Api-Dienst anzeigt. Füge also zunächst einige Filter hinzu, um die Ergebnisse einzugrenzen und nur zutreffende Einträge zu erhalten. Klicke auf den Link Filter hinzufügen in der oberen linken Ecke des Bildschirms. Für das Dropdown-Menü Feld gibst du den Wert type ein. Setze für das Feld Operator den Wert is ein. Gib in das Feld Wert den Wert request-incoming ein und klicke dann auf Speichern. Klicke als Nächstes erneut auf Filter hinzufügen und mache dasselbe, aber setze diesmal das Feld auf app, den Operator wieder auf is und den Wert auf web-api.
Im Abschnitt "Metriken" solltest du die Anzahl der Anfragen anzeigen lassen, da die entsprechenden Logmeldungen eins zu eins mit den tatsächlichen Anfragen korrelieren.
Für den Abschnitt Buckets sollte die Gruppierung nach Zeit gewählt werden. Klicke auf den Link Eimer hinzufügen und wähle X-Achse. Wähle für das Dropdown-Menü Aggregation die Option Datumshistogramm. Klicke auf die blaue Schaltfläche mit dem Spielsymbol über dem Abschnitt Metriken (sie trägt den Titel Änderungen übernehmen) und das Diagramm wird aktualisiert. Die Standardeinstellung der Gruppierung nach @timestamp mit einem automatischen Intervall ist in Ordnung.
In der oberen rechten Ecke befindet sich ein Dropdown-Menü, mit dem du den Zeitbereich der abgefragten Logs ändern kannst. Klicke auf das Dropdown-Menü und stelle es so ein, dass die Logs der letzten Stunde angezeigt werden, und klicke dann auf die große Schaltfläche Aktualisieren rechts neben dem Dropdown-Menü. Wenn alles nach Plan läuft, sollte dein Bildschirm wie in Abbildung 4-3 aussehen.
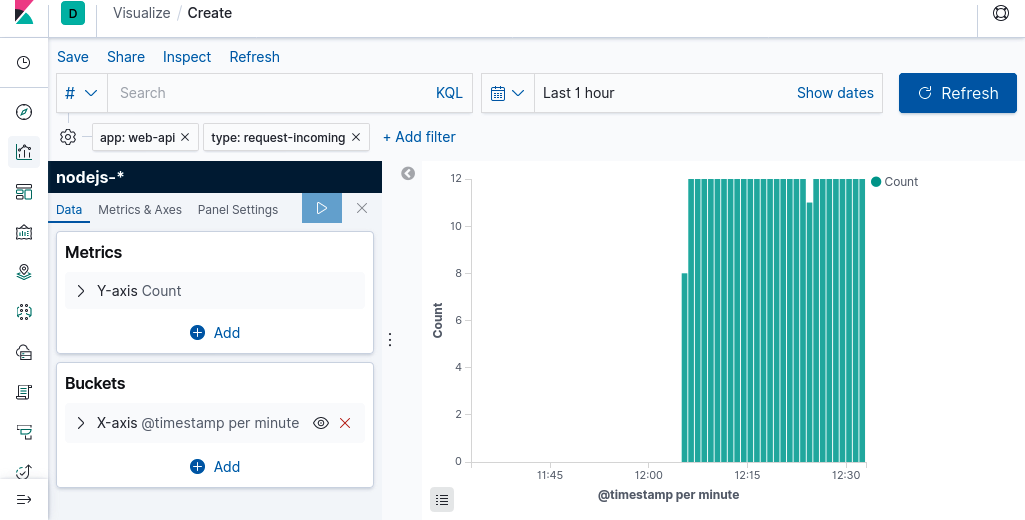
Abbildung 4-3. Anfragen im Zeitverlauf in Kibana
Wenn dein Diagramm fertig ist, klicke auf den Link Speichern oben im Kibana-Bildschirm. Benenne die Visualisierung web-api eingehende Anfragen. Als Nächstes erstellst du eine ähnliche Visualisierung, aber diesmal setzt du das Typfeld auf request-outgoing und nennst diese Visualisierung web-api ausgehende Anfragen. Schließlich erstellst du eine dritte Visualisierung mit dem Typ listen und nennst sie web-api server starts.
Als Nächstes wirst du ein Dashboard für diese drei Visualisierungen erstellen. Wähle die dritte Option in der Seitenleiste mit dem Titel Dashboard. Dann klickst du auf Neues Dashboard erstellen. Es erscheint ein modales Fenster mit deinen drei Visualisierungen. Klicke auf jede Visualisierung und sie wird dem Dashboard hinzugefügt. Wenn du jede Visualisierung hinzugefügt hast, schließe das Modalfenster. Klicke auf den Link Speichern am oberen Rand des Bildschirms und speichere das Dashboard als Web-ApiÜbersicht.
Herzlichen Glückwunsch! Du hast ein Dashboard mit Informationen erstellt, die aus deiner Anwendung extrahiert hat.
Ad-hoc-Abfragen durchführen
Manchmal musst du beliebige Abfragen auf die protokollierten Daten ausführen, ohne ein entsprechendes Dashboard zu haben. Das ist in einmaligen Debugging-Situationen hilfreich. In diesem Abschnitt schreibst du beliebige Abfragen, um Fehler in derAnwendung zu finden.
Klicke auf die erste Registerkarte in der linken Seitenleiste, die mit Entdecken betitelt ist. Hier kannst du bequem Abfragen durchführen, ohne sie in einem Dashboard speichern zu müssen. Standardmäßig wird eine Liste aller kürzlich eingegangenen Nachrichten angezeigt. Klicke in das Suchfeld oben auf dem Bildschirm. Gib dann die folgende Abfrage in das Suchfeld ein und drücke die Eingabetaste:
app:"web-api" AND (severity:"error" OR severity:"warn")
Die Syntax dieser Abfrage ist in der Kibana Query Language (KQL) geschrieben. Sie besteht im Wesentlichen aus drei Klauseln. Es wird nach Logs gefragt, die zur Web-Api-Anwendung gehören und deren Schweregrad entweder auf Fehler oder auf Warnung eingestellt ist (mit anderen Worten: Dinge, die sehr wichtig sind).
Klicke auf das Pfeilsymbol neben einem der Log-Einträge in der folgenden Liste. Dadurch wird der einzelne Logeintrag erweitert und du kannst die gesamte JSON-Nutzlast anzeigen, die mit dem Log verbunden ist. Die Möglichkeit, beliebige Logmeldungen auf diese Weise einzusehen, macht das Logging so mächtig. Mit diesem Tool kannst du jetzt alle Fehler finden, die vom Dienst protokolliert werden.
Wenn du mehr Daten protokollierst, kannst du die Details bestimmter Fehlersituationen aufschlüsseln. Du könntest z. B. feststellen, dass Fehler auftreten, wenn ein bestimmter Endpunkt innerhalb einer Anwendung unter bestimmten Umständen angesprochen wird (z. B. wenn ein Nutzer ein Rezept über PUT /recipe in einer Anwendung mit vielen Funktionen aktualisiert). Mit dem Stack Trace und genügend Kontextinformationen über die Anfragen kannst du die Bedingungen lokal nachstellen, den Fehler reproduzieren und eine Lösung finden.
Warnung
In diesem Abschnitt geht es um die Übertragung von Protokollen aus einer Anwendung heraus, die von Natur aus asynchron abläuft. Leider werden Protokolle, die beim Absturz eines Prozesses erstellt werden, möglicherweise nicht rechtzeitig gesendet. Viele Deployment-Tools können Nachrichten von stdout lesen und im Namen der Anwendung übermitteln, was die Wahrscheinlichkeit erhöht, dass sie zugestellt werden.
In diesem Abschnitt ging es um die Speicherung von Logs. Natürlich können diese Protokolle verwendet werden, um numerische Informationen in Diagrammen anzuzeigen, aber es ist nicht unbedingt das effizienteste System dafür, da die Protokolle komplexe Objekte speichern. Der nächste Abschnitt, "Metriken mit Graphite, StatsD und Grafana", befasst sich mit der Speicherung interessanterer numerischer Daten mit anderen Tools.
Metriken mit Graphite, StatsD und Grafana
In "Logging with ELK" wurde untersucht, wie die Logs eines laufenden Node.js-Prozesses überträgt. Solche Logs werden als JSON formatiert und sind pro Log indizierbar und durchsuchbar. Das ist ideal, um Nachrichten zu lesen, die sich auf einen bestimmten laufenden Prozess beziehen, wie z.B. das Lesen von Variablen und Stack Traces. Manchmal ist man jedoch nicht unbedingt an einzelnen numerischen Daten interessiert, sondern möchte stattdessen wissen, wie diese Werte im Laufe der Zeit wachsen und schrumpfen.
In diesem Abschnitt geht es um das Senden von Metriken. Metriken sind numerische Daten, die mit der Zeit verbunden sind. Dazu gehören z. B. Anfrageraten, die Anzahl der 2XX- gegenüber 5XX-HTTP-Antworten, Latenzzeiten zwischen der Anwendung und einem Backing-Dienst, Speicher- und Festplattennutzung und sogar Geschäftsstatistiken wie Umsätze oder stornierte Zahlungen. Die Visualisierung solcher Informationen ist wichtig, um den Zustand der Anwendung und die Systemauslastung zu verstehen.
Ähnlich wie im Abschnitt über die Protokollierung wird ein Stapel von Tools verwendet, anstatt eines einzigen. Allerdings hat dieser Stack kein so einprägsames Akronym wie ELK, und es ist ziemlich üblich, verschiedene Komponenten auszutauschen. Der hier betrachtete Stack besteht aus Graphite, StatsD und Grafana:
- Graphit
-
Eine Kombination aus einem Dienst(Carbon) und Zeitreihen-Datenbank(Whisper). Es wird auch mit einer Benutzeroberfläche(Graphite Web) geliefert, obwohl oft die leistungsfähigere Grafana-Schnittstelle verwendet wird.
- StatsD
-
Ein Daemon (gebaut mit Node.js) zum Sammeln von Metriken. Er kann Statistiken über TCP oder UDP abfragen, bevor er die Daten an ein Backend wie Graphite sendet.
- Grafana
-
Ein Webservice, der Zeitreihen-Backends (wie Graphite) abfragt und Informationen in konfigurierbaren Dashboards anzeigt.
Abbildung 4-4 zeigt ein Diagramm dieser Dienste und wie sie miteinander verbunden sind. Die Docker-Grenzen stellen dar, was die folgenden Beispiele verwenden werden.

Abbildung 4-4. Graphite, StatsD und Grafana
Ähnlich wie im Abschnitt über die Protokollierung werden die Daten in diesen Beispielen per UDP übertragen. Da die Metriken sehr schnell erzeugt werden, hilft die Verwendung von UDP dabei, die Anwendung nicht zu überlasten.
Betrieb über Docker
Beispiel 4-6 startet zwei separate Docker-Container. Der erste, graphiteapp/graphite-statsd, enthält StatsD und Graphite. Von diesem Container aus sind zwei Ports zugänglich. Die Graphite UI/API ist über den Port :8080 zugänglich, während der StatsD UDP-Metriken-Kollektor als :8125 zugänglich ist. Der zweite , grafana/grafana, enthält Grafana. Ein einziger Port für das Webinterface, :8000, wird für diesen Container bereitgestellt.
Beispiel 4-6. StatsD + Graphite und Grafana ausführen
$docker run\-p 8080:80\-p 8125:8125/udp\-it --name distnode-graphite graphiteapp/graphite-statsd:1.1.6-1$docker run\-p 8000:3000\-it --name distnode-grafana grafana/grafana:6.5.2
Sobald die Container eingerichtet sind und läuft, öffne einen Webbrowser und besuche das Grafana-Dashboard unter http://localhost:8000/. Hier wirst du aufgefordert, dich anzumelden. Die Standard-Anmeldedaten lauten admin / admin. Sobald du dich erfolgreich angemeldet hast, wirst du aufgefordert, dein Passwort zu ändern. Dieses Passwort wird für die Verwaltung von Grafana verwendet, nicht aber für den Code.
Sobald du das Passwort festgelegt hast, , wirst du zu einem Assistenten für die Konfiguration von Grafana weitergeleitet. Im nächsten Schritt musst du Grafana so konfigurieren, dass es mit dem Graphite-Image kommuniziert. Klicke auf die Schaltfläche Datenquelle hinzufügen und dann auf die Option Graphite. Im Graphite-Konfigurationsbildschirm gibst du die in Tabelle 4-1 angezeigten Werte ein.
Name |
Dist-Knoten Graphit |
URL |
http://<LOCAL_IP>:8080 |
Version |
1.1.x |
Hinweis
Aufgrund der Art und Weise, wie diese Docker-Container ausgeführt werden, kannst du nicht localhost für den Platzhalter <LOCAL_IP> verwenden. Stattdessen musst du deine lokale IP-Adresse verwenden. Wenn du unter Linux arbeitest, versuche es mit hostname -Iund wenn du unter macOS arbeitest, versuche es mit ipconfig getifaddr en0. Wenn du dies auf einem Laptop ausführst und sich deine IP-Adresse ändert, musst du die Datenquelle in Grafana neu konfigurieren, damit sie die neue IP-Adresse verwendet, sonst erhältst du keine Daten.
Sobald du die Daten eingegeben hast, klickst du auf Speichern & Testen. Wenn du die Meldung "Data source is working" siehst, konnte Grafana mit Graphite kommunizieren und du kannst auf die Schaltfläche Zurück klicken. Wenn du die Meldung "HTTP Error Bad Gateway" erhältst, vergewissere dich, dass der Graphite-Container läuft und dass die Einstellungen korrekt eingegeben wurden.
Jetzt, wo Graphite und Grafana miteinander sprechen, ist es an der Zeit, einen der Node.js-Dienste so zu ändern, dass er Metriken sendet.
Übertragen von Metriken aus Node.js
Das von StatsD verwendete Protokoll ist extrem einfach, wahrscheinlich sogar einfacher als das von Logstash verwendete UDP. Eine Beispielnachricht, die eine Metrik mit dem Namen foo.bar.baz erhöht, sieht wie folgt aus:
foo.bar.baz:1|c
Solche Interaktionen können ganz einfach mit dem Modul dgram nachgebaut werden, wie im vorherigen Abschnitt beschrieben. In diesem Codebeispiel wird jedoch ein bestehendes Paket verwendet. Es gibt einige davon, aber dieses Beispiel verwendet das Paket statsd-client.
Auch hier beginnst du damit, eine Version des Verbraucherdienstes neu zu erstellen. Kopiere die in Beispiel 1-7 erstellte Datei web-api/consumer-http-basic.js nach web-api/consumer-http-metrics.js als Ausgangspunkt. Ändere die Datei dann so ab, dass sie Beispiel 4-7 ähnelt. Führe den Befehl npm install aus, um auch das benötigte Paket zu erhalten.
Beispiel 4-7. web-api/consumer-http-metrics.js (erste Hälfte)
#!/usr/bin/env node// npm install fastify@3.2 node-fetch@2.6 statsd-client@0.4.4 middie@5.1constserver=require('fastify')();constfetch=require('node-fetch');constHOST='127.0.0.1';constPORT=process.env.PORT||3000;constTARGET=process.env.TARGET||'localhost:4000';constSDC=require('statsd-client');conststatsd=new(require('statsd-client'))({host:'localhost',port:8125,prefix:'web-api'});(async()=>{awaitserver.register(require('middie'));server.use(statsd.helpers.getExpressMiddleware('inbound',{timeByUrl:true}));server.get('/',async()=>{constbegin=newDate();constreq=awaitfetch(`http://${TARGET}/recipes/42`);statsd.timing('outbound.recipe-api.request-time',begin);statsd.increment('outbound.recipe-api.request-count');constproducer_data=awaitreq.json();return{consumer_pid:process.pid,producer_data};});server.get('/error',async()=>{thrownewError('oh no');});server.listen(PORT,HOST,()=>{console.log(`Consumer running at http://${HOST}:${PORT}/`);});})();
Metrische Namen werden mit
web-apieingeleitet.Eine generische Middleware, die eingehende Anfragen automatisch verfolgt.
Dies verfolgt das wahrgenommene Timing der recipe-api.
Auch die Anzahl der ausgehenden Anfragen wird verfolgt.
Bei dieser neuen Reihe von Änderungen gibt es ein paar Dinge zu beachten. Erstens wird das Paket statsd-client benötigt und konfiguriert eine Verbindung zum StatsD-Dienst, der auf localhost:8125. Außerdem wird das Paket so konfiguriert, dass der Präfixwert web-api verwendet wird. Dieser Wert steht für den Namen des Dienstes, der die Metriken meldet (wenn du ähnliche Änderungen an recipe-api vornehmen würdest, würdest du auch den Präfix entsprechend setzen). Graphite arbeitet mit einer Hierarchie für die Benennung von Metriken. Daher haben alle Metriken, die von diesem Dienst gesendet werden, denselben Präfix, um sie von den Metriken eines anderen Dienstes zu unterscheiden.
Der Code nutzt eine generische Middleware aus dem Paket statsd-client. Wie der Name der Methode schon sagt, wurde sie ursprünglich für Express entwickelt, aber Fastify unterstützt größtenteils dieselbe Middleware-Schnittstelle, sodass diese Anwendung sie wiederverwenden kann. Das erste Argument ist ein weiterer Präfixname, und inbound bedeutet, dass die Metriken, die hier gesendet werden, mit eingehenden Anfragen verbunden sind.
Als Nächstes werden zwei Werte manuell erfasst. Der erste ist die Zeit, die die Web-api glaubt, dass die recipe-api gebraucht hat. Diese Zeit sollte immer länger sein als die Zeit, die die recipe-api für die Antwort benötigt. Der Grund dafür ist der Overhead, der beim Senden einer Anfrage über das Netzwerk entsteht. Dieser Zeitwert wird in eine Metrik namens outbound.recipe-api.request-time geschrieben. Die Anwendung verfolgt auch, wie viele Anfragen gesendet werden. Dieser Wert wird als outbound.recipe-api.request-count angegeben. Du kannst hier sogar noch detaillierter werden. Bei einer Produktionsanwendung könnten zum Beispiel auch die Statuscodes verfolgt werden, mit denen die recipe-api antwortet, wodurch eine erhöhte Fehlerquote sichtbar würde.
Als Nächstes führst du die folgenden Befehle jeweils in einem separaten Terminalfenster aus. Dadurch wird dein neu erstellter Dienst gestartet, eine Kopie des Producers ausgeführt, Autocannon gestartet, um einen Strom von guten Anfragen zu erhalten, und auch einige schlechte Anfragen ausgelöst:
$ NODE_DEBUG=statsd-client node web-api/consumer-http-metrics.js$node recipe-api/producer-http-basic.js$autocannon -d300-R5-c1http://localhost:3000$watch -n1 curl http://localhost:3000/error
Diese Befehle erzeugen einen Datenstrom, der an StatsD weitergegeben wird, bevor er an Graphite gesendet wird. Jetzt, wo du einige Daten hast, kannst du ein Dashboard erstellen, um sie auf anzuzeigen.
Ein Grafana Dashboard erstellen
Als Eigentümer des Web-Api-Dienstes gibt es (mindestens) drei verschiedene Sätze von Metriken, die extrahiert werden sollten, damit du seinen Zustand messen kannst. Dazu gehören die eingehenden Anfragen und - ganz wichtig - die Unterscheidung zwischen 200 und 500. Dazu gehört auch die Zeit, die recipe-api, , ein vorgeschalteter Dienst, braucht, um zu antworten. Die letzte erforderliche Information ist die Rate der Anfragen an den recipe-api Dienst. Wenn du feststellst, dass der web-api Dienst langsam ist, kannst du diese Informationen nutzen, um herauszufinden, dass der recipe-api Dienst ihn ausbremst.
Wechsle zurück zu deinem Webbrowser mit der Grafana-Oberfläche. In der Seitenleiste befindet sich ein großes Plus-Symbol; klicke darauf, um zum Bildschirm " Neues Dashboard" zu gelangen. Auf diesem Bildschirm siehst du ein Rechteck mit einem neuen Panel. Darin befindet sich eine Schaltfläche Abfrage hinzufügen. Klicke auf diese Schaltfläche, um zum Abfrage-Editor-Bildschirm zu gelangen.
Auf diesem neuen Bildschirm siehst du oben ein leeres Diagramm und darunter Eingaben zur Beschreibung des Diagramms. In der Benutzeroberfläche kannst du die Abfrage mit zwei Feldern beschreiben. Das erste Feld heißt Reihe und hier kannst du den Namen der hierarchischen Metrik eingeben. Das zweite Feld heißt Funktionen. Beide Felder bieten eine Autovervollständigung für passende Metriknamen. Beginne mit dem Feld Serie. Klicke auf den Text "Metrik auswählen" neben der Beschriftung Serie und dann auf stats_count aus dem Dropdown-Menü. Klicke dann erneut auf "Metrik auswählen" und wähle web-api. Fahre damit für die Werte inbound, response_code und schließlich * fort ( * ist ein Platzhalter und passt zu jedem Wert). Jetzt wurde das Diagramm aktualisiert und sollte zwei Einträge enthalten.
Die Diagrammbeschriftungen sind noch nicht sehr freundlich. Sie zeigen den gesamten Namen der Hierarchie an, statt nur die leicht zu lesenden Werte 200 und 500. Mit einer Funktion kannst du das Problem beheben. Klicke auf das Pluszeichen neben der Beschriftung Funktionen, dann auf Alias und anschließend aufaliasByNode(). Dadurch wird die Funktion eingefügt und auch automatisch ein Standardargument von 4 bereitgestellt. Das liegt daran, dass das Sternchen in der Abfrage der vierte Eintrag im (nullbasierten) Namen der Hierarchiemetrik ist. Die Diagrammbeschriftungen wurden aktualisiert und zeigen jetzt nur noch 200 und 500 an.
In der oberen rechten Ecke des Bereichs mit den Feldern Reihe und Funktionen befindet sich ein Bleistiftsymbol mit der Überschrift Textbearbeitungsmodus umschalten. Wenn du darauf klickst, wird die grafische Eingabe in eine Textversion umgewandelt. Das ist hilfreich, um schnell eine Abfrage zu schreiben. Der Wert, den du erhalten solltest, sieht wie folgt aus:
aliasByNode(stats_counts.web-api.inbound.response_code.*, 4)
Klicke in der linken Spalte auf das Zahnradsymbol mit der Aufschrift Allgemein. Auf diesem Bildschirm kannst du die allgemeinen Einstellungen für dieses Diagramm ändern. Klicke auf das Feld Titel und gib den Wert Incoming Status Codes ein. Klicke anschließend auf den großen Pfeil in der oberen linken Ecke des Bildschirms. Damit verlässt du den Panel-Editor und kehrst zum Dashboard-Bearbeitungsbildschirm zurück. Jetzt hat dein Dashboard nur noch ein einziges Panel.
Als Nächstes klickst du auf die Schaltfläche Panel hinzufügen in der oberen rechten Ecke des Bildschirms und dann erneut auf die Schaltfläche Abfrage hinzufügen. Dadurch kannst du dem Dashboard ein zweites Panel hinzufügen. Dieses nächste Panel wird die Zeit aufzeichnen, die für die Abfrage der Rezept-Api benötigt wird. Erstelle die entsprechenden Serien- und Funktionseinträge, um das Folgende zu reproduzieren:
aliasByNode(stats.timers.web-api.outbound.*.request-time.upper_90, 4)
Hinweis
StatsD generiert einige dieser Metriknamen für dich. Zum Beispiel ist stats.timers ein StatsD-Präfix, web-api.outbound.recipe-api.request-time wird von der Anwendung bereitgestellt, und die zeitbezogenen Metriknamen darunter (wie upper_90) werden wiederum von StatsD berechnet. In diesem Fall sucht die Abfrage nach den TP90-Zeitwerten.
Da dieses Diagramm die Zeit misst und kein allgemeiner Zähler ist, sollten auch die Einheiten geändert werden (diese Informationen werden in Millisekunden gemessen). Klicke auf die zweite Registerkarte auf der linken Seite mit dem Tooltip "Visualisierung". Scrolle dann im Abschnitt Achsen nach unten, suche die Gruppe Linke Y und klicke dann auf das Dropdown-Menü Einheit. Klicke auf Zeit und dann auf Millisekunden (ms). Das Diagramm wird dann mit den richtigen Einheiten aktualisiert.
Klicke erneut auf die dritte Registerkarte "Allgemein" und setze den Titel des Panels auf "Outbound Service Timing". Klicke erneut auf den Zurück-Pfeil, um zum Bearbeitungsbildschirm des Dashboards zurückzukehren.
Klicke abschließend erneut auf die Schaltfläche Panel hinzufügen und erstelle ein letztes Panel. Dieses Panel trägt den Titel "Anzahl der ausgehenden Anfragen", benötigt keine besonderen Einheiten und verwendet die folgende Abfrage:
aliasByNode(stats_counts.web-api.outbound.*.request-count, 3)
Klicke ein letztes Mal auf die Schaltfläche Zurück, um zum Dashboard-Editor zurückzukehren. Klicke in der oberen rechten Ecke des Bildschirms auf das Symbol Dashboard speichern, gib dem Dashboard den Namen Web-API-Übersicht und speichere das Dashboard. Das Dashboard ist nun gespeichert und wird mit einer URL versehen. Wenn du eine dauerhaft installierte Grafana-Instanz für deine Organisation verwendest, wäre diese URL ein Permalink, den du anderen zur Verfügung stellen könntest und der sich hervorragend für die README deines Projekts eignen würde.
Du kannst die Felder so lange verschieben und in der Größe verändern, bis sie dir ästhetisch zusagen. In der oberen rechten Ecke des Bildschirms kannst du auch den Zeitbereich ändern. Setze ihn auf "Letzte 15 Minuten", da du wahrscheinlich keine Daten hast, die älter sind als das. Wenn du fertig bist, sollte dein Dashboard ungefähr so aussehen wie in Abbildung 4-5.
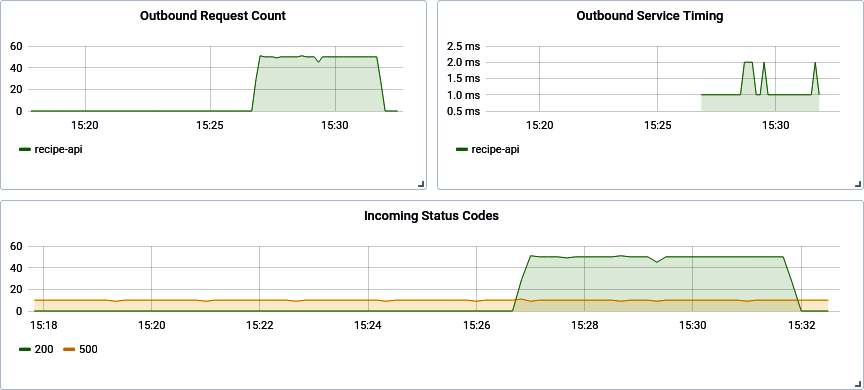
Abbildung 4-5. Fertiges Grafana Dashboard
Node.js Gesundheitsindikatoren
Es gibt einige allgemeine Gesundheitsinformationen über einen laufenden Node.js-Prozess, die ebenfalls für das Dashboard gesammelt werden sollten. Ändere deine Datei web-api/consumer-http-metrics.js, indem du den Code aus Beispiel 4-8 an das Ende der Datei anfügst. Starte den Dienst neu und beobachte die Daten, die erzeugt werden. Diese neuen Metriken stellen Werte dar, die im Laufe der Zeit steigen oder fallen können und besser als Gauges dargestellt werden.
Beispiel 4-8. web-api/consumer-http-metrics.js (zweite Hälfte)
constv8=require('v8');constfs=require('fs');setInterval(()=>{statsd.gauge('server.conn',server.server._connections);constm=process.memoryUsage();statsd.gauge('server.memory.used',m.heapUsed);statsd.gauge('server.memory.total',m.heapTotal);consth=v8.getHeapStatistics();statsd.gauge('server.heap.size',h.used_heap_size);statsd.gauge('server.heap.limit',h.heap_size_limit);fs.readdir('/proc/self/fd',(err,list)=>{if(err)return;statsd.gauge('server.descriptors',list.length);});constbegin=newDate();setTimeout(()=>{statsd.timing('eventlag',begin);},0);},10_000);
Anzahl der Verbindungen zum Server
Heap-Auslastung des Prozesses
V8 Heap-Auslastung
Dateideskriptoren öffnen, ironischerweise mit einem Dateideskriptor
Verzögerung der Ereignisschleife
Dieser Code fragt den Node.js-Unterbau alle 10 Sekunden nach wichtigen Informationen über den Prozess ab. Als Übung für deine neu erworbenen Grafana-Kenntnisse erstellst du fünf neue Dashboards, die diese neu erfassten Daten enthalten. In der Hierarchie der Metrik-Namensräume beginnen die Guage-Metriken mit stats.gauges, während der Timer mit stats.timers beginnt.
Der erste Datensatz, der als server.conn bereitgestellt wird, ist die Anzahl der aktiven Verbindungen zum Webserver. Die meisten Node.js-Webframeworks stellen diesen Wert auf irgendeine Weise zur Verfügung; sieh dir die Dokumentation des Frameworks deiner Wahl an.
Informationen über den Speicherverbrauch des Prozesses werden ebenfalls erfasst. Dieser wird als zwei Werte aufgezeichnet: server.memory.used und server.memory.total. Bei der Erstellung eines Diagramms für diese Werte sollte die Einheit auf Daten/Bytes gesetzt werden, und Grafana ist intelligent genug, um spezifischere Einheiten wie MB anzuzeigen. Ein sehr ähnliches Panel könnte dann auf der Grundlage der V8 Heap-Größe und -Limit erstellt werden.
Die Metrik Ereignisschleifenverzögerung zeigt an, wie lange die Anwendung braucht, um eine Funktion aufzurufen, die so geplant war, dass sie bereits null Millisekunden nach dem Aufruf von setTimeout() ausgeführt wurde. Das Diagramm sollte den Wert in Millisekunden anzeigen. Eine gesunde Ereignisschleife sollte eine Zahl zwischen null und zwei haben. Bei überlasteten Diensten kann es schon mal zehn Millisekunden dauern.
Schließlich kann die Anzahl der offenen Dateideskriptoren auf ein Leck in einer Node.js-Anwendung hinweisen. Manchmal werden Dateien geöffnet, aber nie geschlossen. Das kann zum Verbrauch von Serverressourcen führen und einen Prozessabsturz zur Folge haben.
Wenn du die neuen Bereiche hinzugefügt hast, könnte dein Dashboard wie in Abbildung 4-6 aussehen. Speichere das geänderte Dashboard, damit du deine Änderungen nicht verlierst.
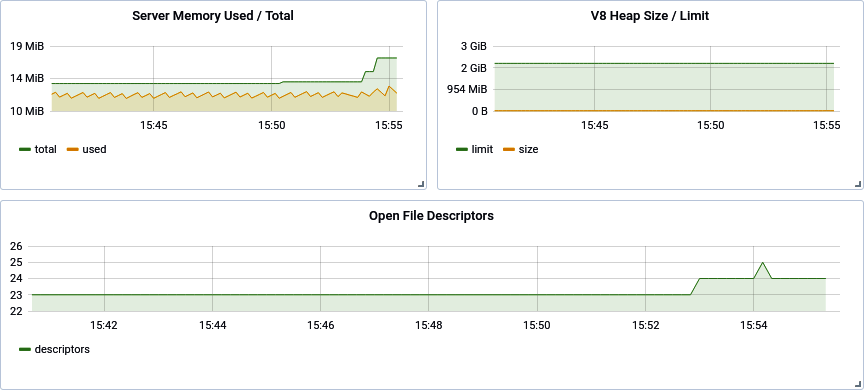
Abbildung 4-6. Aktualisiertes Grafana Dashboard
Dieser Abschnitt behandelt nur die Grundlagen dessen, was mit dem StatsD-, Graphite- und Grafana-Stack gemacht werden kann. Es gibt viele Abfragefunktionen, die nicht behandelt wurden, darunter andere Formen der Visualisierung, wie man einzelne Zeitreiheneinträge manuell einfärbt (z. B. grün für 2XX, gelb für 4XX und rot für 5XX) usw.
Verteiltes Request Tracing mit Zipkin
In "Logging with ELK" ging es um die Speicherung von Logs von einem Node.js-Prozess. Solche Logs enthalten Informationen über die internen Vorgänge eines Prozesses. In "Metriken mit Graphite, StatsD und Grafana" ging es um die Speicherung numerischer Metriken. Diese Metriken sind nützlich, um numerische Daten über eine Anwendung zu betrachten, z. B. den Durchsatz und die Ausfallraten eines Endpunkts. Keines der beiden Tools ermöglicht es jedoch, eine bestimmte externe Anfrage mit allen internen Anfragen zu verknüpfen, die dadurch ausgelöst werden können.
Betrachte zum Beispiel eine etwas komplexere Version der bisher behandelten Dienste. Statt nur einer Web-Api und einem Rezept-Api-Dienst gibt es jetzt zusätzlich eine Benutzer-Api und einen Benutzer-Speicher-Dienst. Die Web-Api ruft nach wie vor den Rezept-Api-Dienst auf, aber jetzt ruft die Web-Api auch den User-Api-Dienst auf, der wiederum den User-Store-Dienst aufruft. Wenn in diesem Szenario einer der Dienste einen 500-Fehler produziert, wird dieser Fehler auftauchen und die gesamte Anfrage wird mit einer 500 fehlschlagen. Wie würdest du mit den bisher verwendeten Tools die Ursache für einen bestimmten Fehler finden?
Wenn du weißt, dass am Dienstag um 13:37 Uhr ein Fehler aufgetreten ist, könntest du versucht sein, die in ELK gespeicherten Logs zwischen 13:36 Uhr und 13:38 Uhr durchzusehen. Wenn es viele Logs gibt, kann das leider bedeuten, dass man sich durch Tausende von einzelnen Log-Einträgen wühlen muss. Noch schlimmer ist, dass andere Fehler, die zur gleichen Zeit auftreten, das Wasser trüben können, so dass es schwierig wird, herauszufinden, welche Logs tatsächlich mit der fehlerhaften Anfrage in Verbindung stehen.
Auf einer sehr grundlegenden Ebene können Anfragen , die tiefer innerhalb einer Organisation gestellt werden, mit einer einzelnen eingehenden externen Anfrage verknüpft werden, indem eine Anfrage-ID weitergegeben wird. Dabei handelt es sich um eine eindeutige Kennung, die beim Eingang der ersten Anfrage generiert wird und die dann irgendwie zwischen den vorgelagerten Diensten weitergegeben wird. Alle Logs, die mit dieser Anfrage verbunden sind, enthalten dann eine Art request_id Feld, das mit Kibana gefiltert werden kann. Dieser Ansatz löst zwar das Problem der zugehörigen Anfrage, aber es gehen Informationen über die Hierarchie der zugehörigen Anfragen verloren.
Zipkin, manchmal auch als OpenZipkin bezeichnet ( ), ist ein Tool, das entwickelt wurde, um Situationen wie diese zu entschärfen. Zipkin ist ein Dienst, der über eine HTTP-API läuft und diese zur Verfügung stellt. Diese API akzeptiert JSON-Payloads, die die Metadaten der Anfrage beschreiben, die sowohl von den Clients gesendet als auch von den Servern empfangen werden. Zipkin definiert auch eine Reihe von Headern, die vom Client an den Server weitergegeben werden. Diese Header ermöglichen es den Prozessen, ausgehende Anfragen von einem Client mit eingehenden Anfragen an einen Server zu verknüpfen. Es werden auch Zeitinformationen gesendet, die es Zipkin ermöglichen, eine grafische Zeitleiste einer Anfragehierarchie anzuzeigen.
Wie funktioniert Zipkin?
In dem oben beschriebenen Szenario mit den vier Diensten wird die Beziehung zwischen den Diensten über vier Anfragen hergestellt. In diesem Fall werden sieben Nachrichten an den Zipkin-Dienst gesendet. Abbildung 4-7 zeigt die Beziehungen zwischen den Diensten, die übermittelten Nachrichten und die zusätzlichen Kopfzeilen.
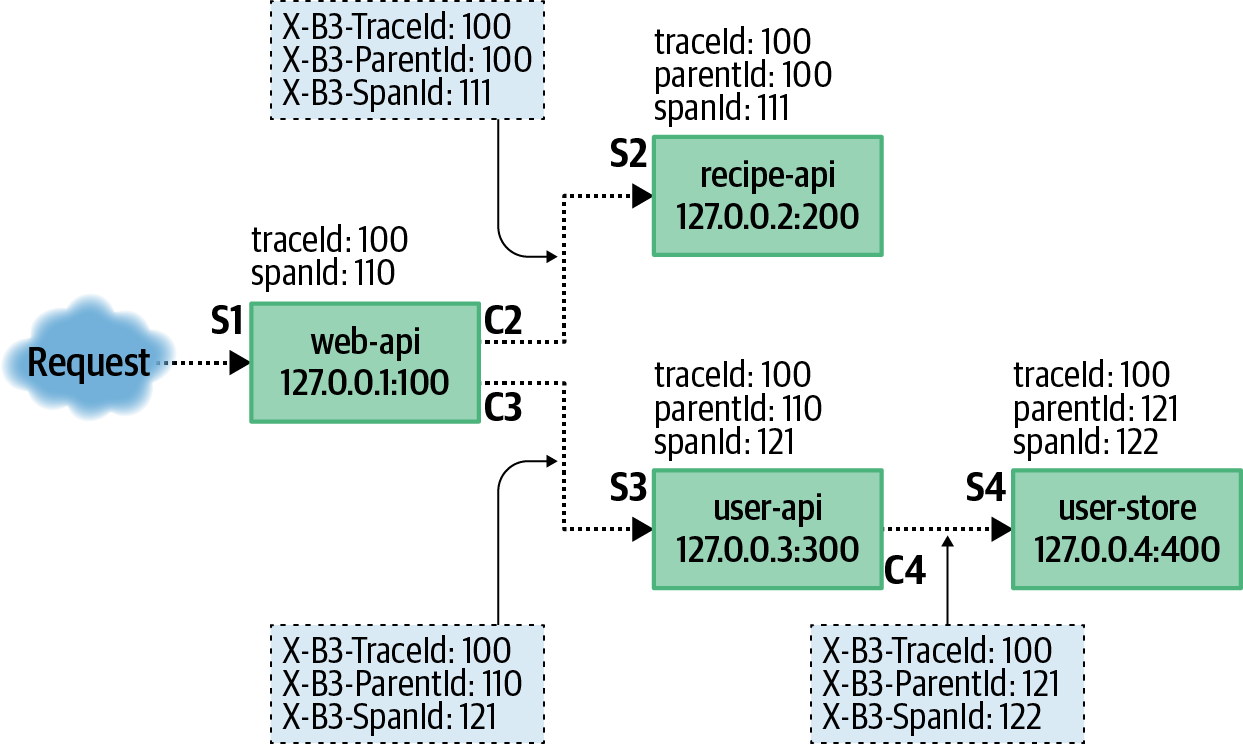
Abbildung 4-7. Beispielanfragen und Zipkin-Daten
Ein Konzept, das in diesem Buch schon ein paar Mal wiederholt wurde, ist , dass ein Client eine Latenzzeit einer Anfrage wahrnimmt, während ein Server eine andere Latenzzeit wahrnimmt. Ein Client wird immer feststellen, dass eine Anfrage länger dauert als der Server. Das liegt an der Zeit, die eine Nachricht braucht, um über das Netzwerk gesendet zu werden, und an anderen Dingen, die schwer zu messen sind, z. B. dass ein Webserver-Paket eine JSON-Anfrage automatisch parst, bevor der Benutzercode die Zeit messen kann.
Mit Zipkin kannst du den Unterschied in der Meinung zwischen Client und Server messen. Deshalb führen die vier Anfragen in der Beispielsituation, die in Abbildung 4-7 als durchgezogene Pfeile markiert sind, dazu, dass sieben verschiedene Nachrichten an Zipkin gesendet werden. Die erste Nachricht, die mit S1 endet, enthält nur eine Server-Nachricht. In diesem Fall meldet der Drittanbieter-Client seine wahrgenommene Zeit nicht, also gibt es nur die Server-Nachricht. Für die drei Anfragen, die mit S2, S3 und S4 enden, gibt es eine entsprechende Client-Nachricht, nämlich C2, C3 und C4.
Die verschiedenen Client- und Server-Nachrichten können von den verschiedenen Instanzen asynchron gesendet und in beliebiger Reihenfolge empfangen werden. Der Zipkin-Dienst fügt sie dann zusammen und visualisiert die Anfragehierarchie mithilfe der Zipkin-Web-UI. Die C2-Nachricht sieht dann etwa so aus:
[{"id":"0000000000000111","traceId":"0000000000000100","parentId":"0000000000000110","timestamp":1579221096510000,"name":"get_recipe","duration":80000,"kind":"CLIENT","localEndpoint":{"serviceName":"web-api","ipv4":"127.0.0.1","port":100},"remoteEndpoint":{"ipv4":"127.0.0.2","port":200},"tags":{"http.method":"GET","http.path":"/recipe/42","diagram":"C2"}}]
Diese Nachrichten können von einer Anwendung in eine Warteschlange gestellt und gelegentlich in Stapeln an den Zipkin-Dienst übertragen werden, weshalb der Stamm-JSON-Eintrag ein Array ist. In Beispiel 4-9 wird nur eine einzige Nachricht übertragen.
Die Client- und Server-Nachrichtenpaare enthalten dieselben Identifikatoren id, traceId und parentId. Das Feld timestamp steht für den Zeitpunkt, an dem der Client oder der Server die Anfrage zum ersten Mal wahrgenommen hat, und das Feld duration gibt an, wie lange die Anfrage nach Meinung des Dienstes gedauert hat. Diese beiden Felder werden in Mikrosekunden gemessen. Die Node.js Wanduhr, die über Date.now() erreichbar ist, hat nur eine Genauigkeit von Millisekunden, daher ist es üblich, diesen Wert mit 1.000 zu multiplizieren.1 Das Feld kind wird entweder auf CLIENT oder SERVER gesetzt, je nachdem, welche Seite der Anfrage protokolliert werden soll. Das Feld name stellt einen Namen für den Endpunkt dar und sollte nur eine begrenzte Anzahl von Werten enthalten (mit anderen Worten, es sollte kein Bezeichner verwendet werden).
Das Feld localEndpoint steht für den Dienst, der die Nachricht sendet (der Server mit einer SERVER Nachricht oder der Client mit einer CLIENT Nachricht). Der Dienst gibt hier seinen eigenen Namen, den Port, an dem er lauscht, und seine IP-Adresse an. Das Feld remoteEndpoint Feld enthält Informationen über den anderen Dienst (eine SERVER Nachricht kennt wahrscheinlich nicht die port des Clients und wahrscheinlich nicht einmal die name des Clients).
Das Feld tags enthält Metadaten über die Anfrage. In diesem Beispiel werden die Informationen über die HTTP-Anfrage als http.method und http.path angegeben. Bei anderenProtokollen würden andere Metadaten angehängt werden, z. B. ein gRPC-Dienst und der Name derMethode.
Die Identifikatoren, die in den sieben verschiedenen Nachrichten gesendet werden, sind in Tabelle 4-2 wiedergegeben.
| Nachricht | id |
parentId |
traceId |
kind |
|---|---|---|---|---|
S1 |
110 |
N/A |
100 |
SERVER |
C2 |
111 |
110 |
100 |
KUNDE |
S2 |
111 |
110 |
100 |
SERVER |
C3 |
121 |
110 |
100 |
KUNDE |
S3 |
121 |
110 |
100 |
SERVER |
C4 |
122 |
121 |
100 |
KUNDE |
S4 |
122 |
121 |
100 |
SERVER |
Abgesehen von den Nachrichten, die an den Server gesendet werden, ist der andere wichtige Teil von Zipkin die Metadaten, die vom Client zum Server gesendet werden. Verschiedene Protokolle haben unterschiedliche Standards für die Übermittlung dieser Metadaten. Bei HTTP werden die Metadaten über Header gesendet. Diese Header werden von C2, C3 und C4 bereitgestellt und von S2, S3 und S4 empfangen. Jeder dieser Header hat eine andere Bedeutung:
X-B3-TraceId-
Zipkin bezeichnet alle zusammenhängenden Anfragen als eine Spur. Dieser Wert ist Zipkins Konzept für eine Anfrage-ID. Dieser Wert wird zwischen allen zusammenhängenden Anfragen unverändert weitergegeben.
X-B3-SpanId-
Ein Span stellt eine einzelne Anfrage dar, die sowohl von einem Client als auch von einem Server (wie C3/S3) aus gesehen wird. Sowohl der Client als auch der Server senden eine Nachricht mit der gleichen Span-ID. Es kann mehrere Spans in einem Trace geben, die eine Baumstruktur bilden.
X-B3-ParentSpanId-
Ein Parent Span wird verwendet, um einen Child Span mit einem Parent Span zu verknüpfen. Dieser Wert fehlt bei der ursprünglichen externen Anfrage, ist aber bei tieferen Anfragen vorhanden.
X-B3-Sampled-
Dies ist ein Mechanismus, mit dem festgelegt wird, ob eine bestimmte Spur an Zipkin gemeldet werden soll. Eine Organisation kann sich zum Beispiel dafür entscheiden, nur 1% der Anfragen zu verfolgen.
X-B3-Flags-
Dies kann verwendet werden, um nachgelagerten Diensten mitzuteilen, dass es sich um eine Debug-Anfrage handelt. Die Dienste werden dann aufgefordert, ihre Logging-Ausführlichkeit zu erhöhen.
Im Wesentlichen erstellt jeder Dienst eine neue Span-ID für jede ausgehende Anfrage. Die aktuelle Span ID wird dann als übergeordnete ID in der ausgehenden Anfrage angegeben. So wird die Hierarchie der Beziehungen gebildet.
Nachdem du nun die Feinheiten von Zipkin verstanden hast, ist es an der Zeit, eine lokale Kopie des Zipkin-Dienstes zu starten und die Anwendungen so anzupassen, dass sie mit ihm interagieren.
Zipkin über Docker ausführen
Auch hier bietet Docker eine bequeme Plattform für den Betrieb des Dienstes. Im Gegensatz zu den anderen in diesem Kapitel behandelten Tools bietet Zipkin eine API und eine Benutzeroberfläche, die denselben Port verwenden. Zipkin verwendet dafür den Standardport 9411.
Führe diesen Befehl aus, um den Zipkin-Dienst herunterzuladen und zu starten:2
$docker run -p 9411:9411\-it --name distnode-zipkin\openzipkin/zipkin-slim:2.19
Übertragen von Traces aus Node.js
Für dieses Beispiel wirst du wieder damit beginnen, eine bestehende Anwendung zu ändern. Kopiere die in Beispiel 1-7 erstellte Datei web-api/consumer-http-basic.js nach web-api/consumer-http-zipkin.js als Ausgangspunkt. Ändere die Datei so ab, dass sie wie der Code in Beispiel 4-9 aussieht.
Beispiel 4-9. web-api/consumer-http-zipkin.js
#!/usr/bin/env node// npm install fastify@3.2 node-fetch@2.6 zipkin-lite@0.1constserver=require('fastify')();constfetch=require('node-fetch');constHOST=process.env.HOST||'127.0.0.1';constPORT=process.env.PORT||3000;constTARGET=process.env.TARGET||'localhost:4000';constZIPKIN=process.env.ZIPKIN||'localhost:9411';constZipkin=require('zipkin-lite');constzipkin=newZipkin({zipkinHost:ZIPKIN,serviceName:'web-api',servicePort:PORT,serviceIp:HOST,init:'short'});server.addHook('onRequest',zipkin.onRequest());server.addHook('onResponse',zipkin.onResponse());server.get('/',async(req)=>{req.zipkin.setName('get_root');consturl=`http://${TARGET}/recipes/42`;constzreq=req.zipkin.prepare();constrecipe=awaitfetch(url,{headers:zreq.headers});zreq.complete('GET',url);constproducer_data=awaitrecipe.json();return{pid:process.pid,producer_data,trace:req.zipkin.trace};});server.listen(PORT,HOST,()=>{console.log(`Consumer running at http://${HOST}:${PORT}/`);});
Das Paket
zipkin-litewird benötigt und instanziiert.web-api nimmt externe Anfragen an und kann Trace-IDs erzeugen.
Hooks werden aufgerufen, wenn Anfragen beginnen und enden.
Jeder Endpunkt muss seinen Namen angeben.
Ausgehende Anfragen werden manuell instrumentiert.
Hinweis
Diese Beispiele verwenden das Paket zipkin-lite. Dieses Paket erfordert eine manuelle Instrumentierung, was so viel bedeutet wie, dass du als Entwickler verschiedene Hooks aufrufen musst, um mit dem Paket zu interagieren. Ich habe es für dieses Projekt ausgewählt, um die verschiedenen Teile des Zipkin-Meldeprozesses zu demonstrieren. Für eine produktive Anwendung ist das offizielle Zipkin-Paket die bessere Wahl, zipkineine bessere Wahl.
Der Verbraucherdienst ist der erste Dienst, mit dem ein externer Kunde kommunizieren wird. Aus diesem Grund wurde das Konfigurationsflag init aktiviert. Dies ermöglicht es dem Dienst, eine neue Trace-ID zu erzeugen. Theoretisch kann ein Reverse Proxy so konfiguriert werden, dass er auch die ersten Kennzeichnungswerte erzeugt. Die Felder serviceName, servicePort und serviceIp werden für die Meldung von Informationen über den laufenden Dienst an Zipkin verwendet.
Die Hooks onRequest und onResponse ermöglichen es dem Paket zipkin-lite, sich in die Anfragen einzuschalten. Der onRequest Handler wird zuerst ausgeführt. Er zeichnet die Startzeit der Anfrage auf und injiziert eine req.zipkin Eigenschaft, die während des gesamten Lebenszyklus der Anfrage verwendet werden kann. Später wird der onResponse Handler aufgerufen. Dieser berechnet die Gesamtzeit, die die Anfrage gedauert hat, und sendet eine SERVER Nachricht an den Zipkin-Server.
Innerhalb eines Request Handlers müssen zwei Dinge passieren. Erstens muss der Name des Endpunkts festgelegt werden. Dies geschieht durch den Aufruf von req.zipkin.setName(). Zweitens müssen für jede ausgehende Anfrage die entsprechenden Kopfzeilen eingefügt und die Zeit berechnet werden, die die Anfrage benötigt hat. Dazu rufst du zunächst req.zipkin.prepare() auf. Bei diesem Aufruf wird ein weiterer Zeitwert aufgezeichnet und eine neue Span-ID erstellt. Diese ID und die anderen erforderlichen Kopfzeilen werden im zurückgegebenen Wert angegeben, der hier der Variablen zreq zugewiesen wird.
Diese Kopfzeilen werden dann über zreq.headers an die Anfrage weitergegeben. Sobald die Anfrage abgeschlossen ist, wird zreq.complete() aufgerufen, wobei die Anfragemethode und die URL übergeben werden. Daraufhin wird die Gesamtzeit berechnet und die Nachricht CLIENT an den Zipkin-Server gesendet.
Als Nächstes sollte auch der produzierende Dienst geändert werden. Das ist wichtig, denn es sollte nicht nur das Timing aus Sicht des Clients( in diesem Fallweb-api ) gemeldet werden, sondern auch das Timing aus Sicht des Servers(recipe-api). Kopiere die in Beispiel 1-6 erstellte Datei recipe-api/producer-http-basic.js nach recipe-api/producer-http-zipkin.js als Ausgangspunkt. Ändere die Datei so ab, dass sie wie der Code in Beispiel 4-10 aussieht. Den größten Teil der Datei kannst du so lassen, wie er ist, sodass nur die erforderlichen Änderungenangezeigt werden.
Beispiel 4-10. recipe-api/producer-http-zipkin.js (gekürzt)
constPORT=process.env.PORT||4000;constZIPKIN=process.env.ZIPKIN||'localhost:9411';constZipkin=require('zipkin-lite');constzipkin=newZipkin({zipkinHost:ZIPKIN,serviceName:'recipe-api',servicePort:PORT,serviceIp:HOST,});server.addHook('onRequest',zipkin.onRequest());server.addHook('onResponse',zipkin.onResponse());server.get('/recipes/:id',async(req,reply)=>{req.zipkin.setName('get_recipe');constid=Number(req.params.id);
Beispiel 4-10 agiert nicht als Root-Dienst, daher wurde das init Konfigurationsflag weggelassen. Wenn er eine Anfrage direkt empfängt, erzeugt er keine Trace-ID, anders als der Web-Api-Dienst. Beachte auch, dass die gleiche Methode req.zipkin.prepare() in diesem neuen recipe-api-Dienst verfügbar ist , auch wenn das Beispiel sie nicht verwendet. Wenn du Zipkin in deinen eigenen Diensten implementierst, solltest du die Zipkin-Header an so viele vorgelagerte Dienste wie möglich weitergeben.
Achte darauf, dass du den npm install zipkin-lite@0.1 Befehl in beidenProjektverzeichnissen auszuführen.
Wenn du die beiden neuen Servicedateien erstellt hast, führe sie aus und generiere dann eine Anfrage an die Web-Api, indem du die folgenden Befehle ausführst:
$node recipe-api/producer-http-zipkin.js$node web-api/consumer-http-zipkin.js$curl http://localhost:3000/
In der Ausgabe des Befehls curl sollte nun ein neues Feld mit dem Namen trace zu finden sein. Dies ist die Trace-ID für die Reihe von Anfragen, die zwischen den Diensten weitergeleitet wurden. Der Wert sollte aus 16 hexadezimalen Zeichen bestehen, und in meinem Fall erhielt ich den Wert e232bb26a7941aab.
Visualisierung eines Anforderungsbaums
Die Daten über die Anfragen wurden an deine Zipkin-Serverinstanz gesendet. Jetzt ist es an der Zeit, das Webinterface zu öffnen und zu sehen, wie die Daten visualisiert werden. Öffne die folgende URL in deinem Browser:
http://localhost:9411/zipkin/
Du solltest jetzt mit der Zipkin-Weboberfläche begrüßt werden. Sie ist noch nicht allzu aufregend. Die linke Seitenleiste enthält zwei Links. Der erste, der wie ein Vergrößerungsglas aussieht, führt dich zum aktuellen Entdecken-Bildschirm. Der zweite Link, der wie ein Netzwerkknoten aussieht, führt zum Bildschirm "Abhängigkeiten". Am oberen Rand des Bildschirms befindet sich ein Pluszeichen, mit dem du angeben kannst, nach welchen Anfragen gesucht werden soll. Mit diesem Tool kannst du Kriterien wie den Dienstnamen oder Tags angeben. Aber die kannst du erst einmal ignorieren. In der oberen rechten Ecke befindet sich eine einfache Suchschaltfläche, mit der du dir die letzten Anfragen anzeigen lassen kannst. Klicke auf das Lupensymbol, um die Suche durchzuführen.
Abbildung 4-8 ist ein Beispiel dafür, wie die Oberfläche nach einer Suche aussehen sollte. Angenommen, du hast den Befehl curl nur einmal ausgeführt, solltest du nur eineneinzigen Eintrag sehen.
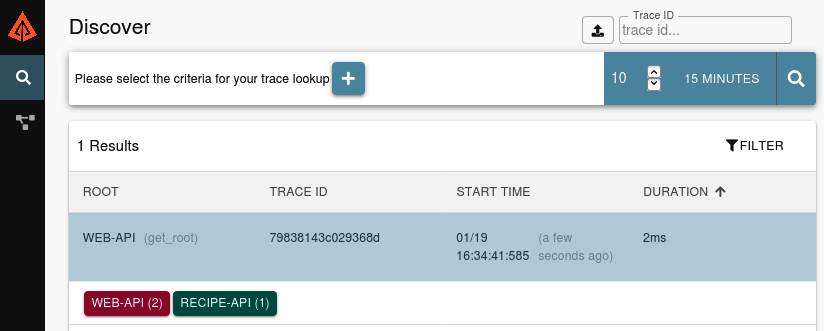
Abbildung 4-8. Zipkin discover interface
Klicke auf den Eintrag, um zur Seite mit der Zeitleiste zu gelangen. Diese Seite zeigt den Inhalt in zwei Spalten an. Die Spalte auf der linken Seite zeigt eine Zeitleiste der Anfragen. Die horizontale Achse stellt die Zeit dar. Die Einheiten am oberen Rand der Zeitleiste zeigen an, wie viel Zeit seit der allerersten SERVER Abfrage mit der angegebenen Abfrage-ID vergangen ist. Die vertikalen Zeilen stellen die Tiefe der Anfrage dar; mit jeder weiteren Anfrage eines Dienstes wird eine neue Zeile hinzugefügt.
In deiner Zeitleiste solltest du zwei Zeilen sehen. Die erste Zeile wurde von der Web-Api erstellt und hat einen Aufruf namens get_root. Die zweite Zeile wurde von der recipe-api generiert und hat einen Aufruf namens get_recipe. Eine komplexere Version der Zeitleiste, die du siehst, basiert auf dem zuvor erwähnten System mit einer zusätzlichen Benutzer-API und einem Benutzerspeicher und wird in Abbildung 4-9 dargestellt.
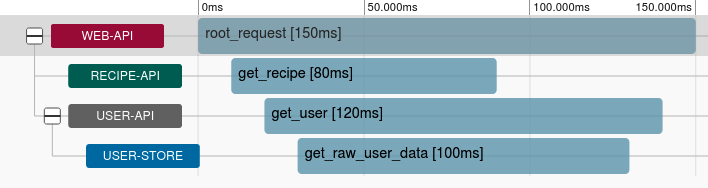
Abbildung 4-9. Beispiel einer Zipkin-Trace-Zeitleiste
Klicke auf die zweite Zeile. Die rechte Spalte wird aktualisiert und zeigt zusätzliche Metadaten über die Anfrage an. In der Anmerkungsleiste wird eine Zeitleiste für die angeklickte Spanne angezeigt. Je nach Geschwindigkeit der Anfrage siehst du zwischen zwei und vier Punkten. Der äußerste linke und der äußerste rechte Punkt zeigen die Zeit an, die der Kunde für die Anfrage benötigt hat. Wenn die Anfrage langsam genug war, solltest du zwei innere Punkte sehen, die die Zeit angeben, die der Server für die Anfrage benötigt hat. Da diese Dienste so schnell sind, können sich die Punkte überschneiden und werden von der Zipkin-Oberfläche verdeckt.
Im Abschnitt Tags werden die mit der Anfrage verbundenen Tags angezeigt. So kannst du herausfinden, welche Endpunkte am längsten für die Bearbeitung brauchen und welche Dienstinstanzen (anhand der IP-Adresse und des Ports) dafür verantwortlich sind.
Visualisierung von Microservice-Abhängigkeiten
Die Zipkin-Benutzeroberfläche kann auch verwendet werden , um aggregierte Informationen über die eingegangenen Anfragen anzuzeigen. Klicke auf den Link "Abhängigkeiten" in der Seitenleiste, um zum Bildschirm "Abhängigkeiten" zu gelangen. Der Bildschirm sollte größtenteils leer sein. Oben befindet sich ein Selektor, mit dem du einen Zeitbereich angeben und eine Suche durchführen kannst. Die Standardwerte sollten in Ordnung sein, also klicke auf das Lupensymbol, um eine Suche durchzuführen.
Der Bildschirm wird dann aktualisiert und zeigt zwei Knotenpunkte an. Zipkin hat die verschiedenen Zeitspannen durchsucht, die der Zeitspanne entsprechen. Anhand dieser Informationen hat es ermittelt, wie die Dienste zueinander in Beziehung stehen. Bei den beiden Beispielanwendungen ist die Oberfläche nicht besonders interessant. Auf der linken Seite solltest du einen Knoten sehen, der die Web-Api repräsentiert (von der die Anfragen ausgehen), und auf der rechten Seite einen Knoten, der die Rezept-Api repräsentiert (der tiefste Dienst im Stack). Kleine Punkte bewegen sich von der linken Seite des Bildschirms nach rechts und zeigen so den relativen Umfang des Datenverkehrs zwischen den beiden Knotenpunkten an.
Wenn du Zipkin mit vielen verschiedenen Diensten innerhalb einer Organisation verwendest, würdest du eine viel komplexere Karte der Beziehungen zwischen den Diensten sehen. In Abbildung 4-10 siehst du ein Beispiel dafür, wie die Beziehungen zwischen den vier Diensten in dem komplexeren Beispiel aussehen würden.
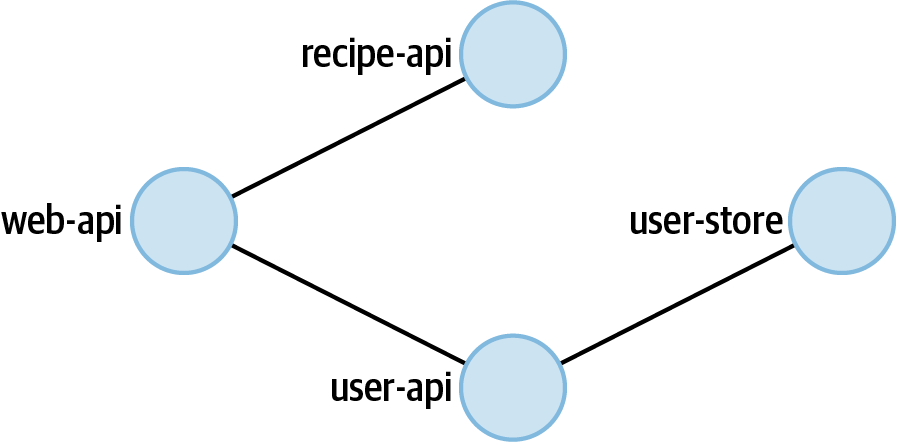
Abbildung 4-10. Beispiel für die Zipkin-Abhängigkeitsansicht
Wenn man davon ausgeht, dass jeder Dienst innerhalb einer Organisation Zipkin nutzt, wäre ein solches Diagramm ein sehr leistungsfähiges Werkzeug, um die Verbindungen zwischen den Diensten zu verstehen.
Gesundheitschecks
In"Load Balancing and Health Checks" haben wir uns angesehen, wie HAProxy so konfiguriert werden kann, dass es eine laufende Service-Instanz automatisch entfernt und wieder in den Pool der Kandidaten-Instanzen aufnimmt, an die Anfragen weitergeleitet werden. HAProxy kann dies tun, indem es eine HTTP-Anfrage an einen Endpunkt deiner Wahl stellt und den Statuscode überprüft. Ein solcher Endpunkt ist auch nützlich, um die Liveness eines Dienstes zu überprüfen - ein Begriff, der bedeutet, dass ein neu eingerichteter Dienst die Startphase abgeschlossen hat und bereit ist, Anfragen zu empfangen (z. B. eine Datenbankverbindung herzustellen). Auch Kubernetes, das in Kapitel 7 behandelt wird, kann einen solchen Liveness-Check nutzen. Im Allgemeinen ist es für eine Anwendung nützlich zu wissen, ob sie gesund ist oder nicht.
Eine Anwendung kann in der Regel als gesund gelten, wenn sie in der Lage ist, auf eingehende Anfragen mit korrekten Daten zu antworten, ohne dass es zu unerwünschten Nebenwirkungen kommt. Wie man das genau misst, hängt von der jeweiligen Anwendung ab. Wenn eine Anwendung eine Verbindung zu einer Datenbank herstellen muss und diese Verbindung unterbrochen wird, kann die Anwendung die eingehenden Anfragen wahrscheinlich nicht bearbeiten. (Beachte, dass deine Anwendung versuchen sollte, die Verbindung zu Datenbanken wiederherzustellen; dies wird in "Ausfallsicherheit von Datenbankverbindungen" behandelt) . In einem solchen Fall ist es sinnvoll, dass sich die Anwendung selbst für ungesund erklärt.
Andererseits sind einige Funktionen eine Art Grauzone. Wenn ein Dienst zum Beispiel keine Verbindung zu einem Caching-Dienst herstellen kann, aber immer noch in der Lage ist, sich mit einer Datenbank zu verbinden und Anfragen zu bedienen, kann er sich wahrscheinlich als gesund bezeichnen. Die Grauzone liegt in diesem Fall bei der Antwortzeit. Wenn der Dienst nicht mehr in der Lage ist, sein SLA zu erfüllen, kann es gefährlich sein, ihn zu betreiben, weil er dein Unternehmen Geld kosten könnte. In diesem Fall könnte es sinnvoll sein, den Dienst als "degraded" zu deklarieren.
Was würde in dieser Situation passieren, wenn der gestörte Dienst sich selbst für ungesund erklären würde? Der Dienst könnte durch ein Einsatzmanagement-Tool neu gestartet werden. Wenn das Problem jedoch darin besteht, dass der Caching-Dienst ausgefallen ist, würde vielleicht jeder einzelne Dienst neu gestartet werden. Das kann dazu führen, dass kein Dienst mehr zur Verfügung steht, um Anfragen zu bedienen. Dieses Szenario wird in "Alarmierung mit Cabot" behandelt . Betrachte langsame/degradierte Dienste erst einmal als gesund.
Gesundheitsprüfungen werden in der Regel in regelmäßigen Abständen durchgeführt. Manchmal werden sie durch eine Anfrage eines externen Dienstes ausgelöst, z. B. wenn HAProxy eine HTTP-Anfrage stellt (ein Vorgang, der standardmäßig alle zwei Sekunden erfolgt). Manchmal werden sie intern ausgelöst, z. B. durch einen Aufruf von setInterval(), der den Zustand der Anwendung prüft, bevor er einem externen Discovery-Dienst wie Consul meldet, dass sie gesund ist (eine Prüfung, die vielleicht alle 10 Sekunden erfolgt). In jedem Fall sollte der Aufwand für die Gesundheitsprüfung nicht so hoch sein, dass der Prozess verlangsamt oder die Datenbank überlastet wird.
Einen Gesundheitscheck erstellen
In diesem Abschnitt wirst du einen Gesundheitscheck für einen eher langweiligen Dienst erstellen. Diese Anwendung wird sowohl eine Verbindung zu einer Postgres Datenbank haben, die einem persistenten Datenspeicher ähnelt, als auch eine Verbindung zu Redis, das einen Cache darstellt.
Bevor du mit dem Schreiben von Code beginnst, musst du die beiden Backing-Dienste starten. Führe die Befehle in Beispiel 4-11 aus, um eine Kopie von Postgres und Redis zum Laufen zu bringen. Du musst jeden Befehl in einem neuen Terminalfenster ausführen. Mit der Tastenkombination Strg + C kannst du beide Dienste beenden.
Beispiel 4-11. Postgres und Redis ausführen
$docker run\--rm\-p 5432:5432\-ePOSTGRES_PASSWORD=hunter2\-ePOSTGRES_USER=tmp\-ePOSTGRES_DB=tmp\postgres:12.3$docker run\--rm\-p 6379:6379\redis:6.0
Als Nächstes erstellst du eine neue Datei mit dem Namen basic-http-healthcheck.js. Füge den Inhalt aus Beispiel 4-12 in deine neu erstellte Datei ein.
Beispiel 4-12. basic-http-healthcheck.js
#!/usr/bin/env node// npm install fastify@3.2 ioredis@4.17 pg@8.3constserver=require('fastify')();constHOST='0.0.0.0';constPORT=3300;constredis=new(require("ioredis"))({enableOfflineQueue:false});constpg=new(require('pg').Client)();pg.connect();// Note: Postgres will not reconnect on failureserver.get('/health',async(req,reply)=>{try{constres=awaitpg.query('SELECT $1::text as status',['ACK']);if(res.rows[0].status!=='ACK')reply.code(500).send('DOWN');}catch(e){reply.code(500).send('DOWN');}// ... other down checks ...letstatus='OK';try{if(awaitredis.ping()!=='PONG')status='DEGRADED';}catch(e){status='DEGRADED';}// ... other degraded checks ...reply.code(200).send(status);});server.listen(PORT,HOST,()=>console.log(`http://${HOST}:${PORT}/`));
Redis-Anfragen schlagen fehl, wenn sie offline sind.
Vollständig fehlschlagen, wenn Postgres nicht erreicht werden kann.
Übergebe mit einem degradierten Zustand, wenn Redis nicht erreicht werden kann.
Diese Datei nutzt das Paket ioredis , um sich mit Redis zu verbinden und Abfragen zu stellen. Außerdem nutzt sie das Paket pg für die Arbeit mit Postgres. Wenn ioredis instanziiert wird, stellt es standardmäßig eine Verbindung zu einem lokal laufenden Dienst her, weshalb Verbindungsdetails nicht notwendig sind. Das enableOfflineQueue Flag gibt an, ob Befehle in eine Warteschlange gestellt werden sollen, wenn der Node.js-Prozess keine Verbindung zur Redis-Instanz herstellen kann. Der Standardwert ist true, was bedeutet, dass Anfragen in die Warteschlange gestellt werden können. Da Redis als Caching-Dienst und nicht als primärer Datenspeicher verwendet wird, sollte das Flag auf false gesetzt werden. Andernfalls könnte eine Anfrage in der Warteschlange für den Zugriff auf den Cache langsamer sein als die Verbindung mit dem echten Datenspeicher.
Das Paket pg stellt standardmäßig eine Verbindung zu einer lokal laufenden Postgres-Instanz her, aber es benötigt trotzdem einige Verbindungsinformationen. Diese werden über Umgebungsvariablen bereitgestellt.
Dieser Endpunkt für den Gesundheitscheck ist so konfiguriert, dass er zunächst die Funktionen überprüft, die für die Ausführung wichtig sind. Wenn eine dieser Funktionen fehlt, schlägt der Endpunkt sofort fehl. In diesem Fall wird nur der Postgres-Check durchgeführt, aber eine reale Anwendung könnte mehr Funktionen haben. Danach werden die Prüfungen durchgeführt, die zu einer Beeinträchtigung des Dienstes führen. In diesem Fall kommt nur die Redis-Prüfung zum Tragen. Beide Prüfungen funktionieren, indem sie den Backing Store abfragen und auf eine vernünftige Antwort prüfen.
Beachte, dass ein gestörter Dienst einen Statuscode 200 zurückgibt. HAProxy könnte z.B. so konfiguriert werden, dass Anfragen weiterhin an diesen Dienst weitergeleitet werden. Wenn der Dienst gestört ist, kann eine Warnmeldung erzeugt werden (siehe "Warnmeldungen mit Cabot"). Herauszufinden, warum der Cache nicht funktioniert, ist etwas, worüber sich unsere Anwendung keine Gedanken machen sollte. Das Problem könnte sein, dass Redis selbst abgestürzt ist oder dass es einNetzwerkproblem gibt.
Jetzt, wo die Servicedatei fertig ist, führe den folgenden Befehl aus, um den Dienst zu starten:
$ PGUSER=tmpPGPASSWORD=hunter2PGDATABASE=tmp\node basic-http-healthcheck.js
Die Postgres-Verbindungsvariablen wurden als Umgebungsvariablen bereitgestellt und werden von dem zugrunde liegenden Paket pg verwendet. Die explizite Benennung der Variablen im Code ist ein besserer Ansatz für Produktionscode, und diese Variablen werden nur der Kürze halber verwendet.
Jetzt, wo dein Dienst läuft, ist es an der Zeit , die Gesundheitsprüfungen zu nutzen.
Den Gesundheitscheck testen
Wenn der Prozess läuft und eine Verbindung zu den Datenbanken herstellt, sollte er sich in einem gesunden Zustand befinden. Gib die folgende Anfrage ein, um den Status der Anwendung zu überprüfen:
$ curl -v http://localhost:3300/health
Die Antwort sollte die Nachricht OK enthalten und mit einem 200 Statuscode versehen sein.
Jetzt können wir eine gestörte Situation simulieren. Setze den Fokus auf den Redis-Dienst und drücke Strg + C, um den Prozess zu beenden. Du solltest sehen, dass einige Fehlermeldungen des Node.js-Prozesses ausgibt. Sie beginnen schnell und werden dann langsamer, da das Modul ioredis beim Versuch, sich erneut mit dem Redis-Server zu verbinden, einen exponentiellen Backoff verwendet. Das bedeutet, dass es die Versuche schnell wiederholt und dann langsamer wird.
Da die Anwendung nun nicht mehr mit Redis verbunden ist, führe denselben curl Befehl erneut aus. Diesmal sollte die Antwort die Nachricht DEGRADED enthalten, obwohl sie immer noch den Statuscode 200 hat.
Wechsle zurück zu dem Terminalfenster, mit dem du Redis zuvor ausgeführt hast. Starte den Redis-Dienst erneut, wechsle zurück zu dem Terminal, in dem du curl ausgeführt hast, und führe die Anfrage erneut aus. Je nach Zeitplan erhältst du vielleicht immer noch die Meldung DEGRADED,aber sobald ioredis dieVerbindung wiederherstellen kann, bekommstdu die Meldung OK .
Beachte, dass das Beenden von Postgres auf diese Weise die Anwendung zum Absturz bringt. Die Bibliothek pg bietet nicht die gleiche automatische Wiederverbindungsfunktion wie ioredis. Damit das funktioniert, muss der Anwendung eine zusätzliche Logik zur Wiederherstellung der Verbindung hinzugefügt werden. Unter "Database Connection Resilience" findest du ein Beispieldafür.
Alarmierung mit Cabot
Es gibt bestimmte Probleme, die einfach nicht durch das automatische Beenden und Neustarten eines Prozesses behoben werden können. Ein Beispiel dafür sind Probleme mit zustandsbehafteten Diensten, wie der im vorigen Abschnitt erwähnte ausgefallene Redis-Dienst. Erhöhte 5XX-Fehlerraten sind ein weiteres häufiges Beispiel. In diesen Situationen ist es oft notwendig, einen Entwickler zu alarmieren, um die Ursache eines Problems zu finden und es zu beheben. Wenn solche Fehler zu Umsatzeinbußen führen können, ist es notwendig, die Entwickler mitten in der Nacht zu wecken.
In diesen Situationen ist das Handy in der Regel das beste Medium, um einen Entwickler zu wecken, oft durch einen tatsächlichen Anruf. Andere Nachrichtenformate wie E-Mails, Chatroom-Nachrichten und Textnachrichten werden normalerweise nicht von einem lästigen Klingelton begleitet und reichen oft nicht aus, um den Entwickler zu alarmieren.
In diesem Abschnitt richtest du eine Instanz von Cabot ein. Cabot ist ein Open-Source-Tool, mit dem du den Zustand einer Anwendung abfragen und Alarme auslösen kannst. Cabot unterstützt verschiedene Formen von Gesundheitsprüfungen, z. B. die Abfrage von Graphite und den Vergleich der gemeldeten Werte mit einem Schwellenwert sowie das Anpingen eines Hosts. Cabot unterstützt auch HTTP-Anfragen, um die es in diesem Abschnitt geht.
In diesem Abschnitt erstellst du auch ein kostenloses Twilio-Testkonto. Mit diesem Konto kann Cabot sowohl SMS-Nachrichten versenden als auch Anrufe tätigen. Du kannst diesen Teil überspringen, wenn du kein Twilio-Konto erstellen möchtest. In diesem Fall siehst du nur ein Dashboard, dessen Farbe von einem fröhlichen Grün zu einem wütenden Rot wechselt.
In den Beispielen in diesem Abschnitt erstellst du einen einzelnen Benutzer in Cabot, der alle Benachrichtigungen erhält. In der Praxis wird eine Organisation Zeitpläne einrichten, die normalerweise als Bereitschaftsdienst bezeichnet werden. In diesen Fällen hängt die Person, die eine Benachrichtigung erhält, von dem Zeitplan ab. Zum Beispiel könnte die Person in der ersten Woche Alice sein, in der zweiten Woche Bob, in der dritten Woche Carol und in der vierten Woche wieder Alice.
Hinweis
Eine weitere wichtige Funktion in einer realen Organisation ist ein sogenanntes Runbook. Ein Runbook ist normalerweise eine Seite in einem Wiki, die mit einer bestimmten Meldung verknüpft ist. Das Runbook enthält Informationen darüber, wie man ein Problem diagnostiziert und behebt. Wenn also ein Techniker um 2 Uhr morgens eine Benachrichtigung über die Datenbank-Latenzmeldung erhält, kann er nachlesen, wie er auf die Datenbank zugreifen und eine Abfrage durchführen kann. Für dieses Beispiel wirst du kein Runbook erstellen, aber bei realen Alarmen musst du das sorgfältig tun.
Ein Twilio-Probekonto erstellen
Gehe zu diesem Zeitpunkt auf zu https://twilio.com und erstelle ein Testkonto. Wenn du ein Konto erstellst, erhältst du zwei Daten, die du für die Konfiguration von Cabot benötigst. Die erste Information ist die Konto-SID. Das ist eine Zeichenfolge, die mit AC beginnt und eine Reihe von hexadezimalen Zeichen enthält. Die zweiteInformation ist das Auth Token. Dieser Wert sieht aus wie normale hexadezimaleZeichen.
Über die Schnittstelle musst du auch eine Versuchsnummer einrichten. Das ist eine virtuelle Telefonnummer, die du mit diesem Projekt verwenden kannst. Die Telefonnummer beginnt mit einem Pluszeichen, gefolgt von einer Landesvorwahl und dem Rest der Nummer. Du musst diese Nummer innerhalb deines Projekts verwenden, einschließlich des Pluszeichens und der Landesvorwahl. Die Nummer, die du erhältst, könnte wie +15551234567 aussehen.
Schließlich musst du die Telefonnummer deines persönlichen Handys als verifizierte Nummer/verifizierteAnrufer-ID in Twilio konfigurieren. Damit kannst du Twilio bestätigen, dass die Telefonnummer zu dir gehört und dass du Twilio nicht nur benutzt, um Spam-Nachrichten an Fremde zu senden - ein Prozess, der eine Einschränkung des Twilio-Testkontos ist. Nachdem du deine Telefonnummer verifiziert hast, kannst du Cabot so konfigurieren, dass es eine SMS an diese Nummer sendet.
Cabot über Docker ausführen
Cabot ist ein wenig komplexer als die anderen in diesem Kapitel behandelten Dienste. Er benötigt mehrere Docker-Images, nicht nur ein einziges. Aus diesem Grund musst du Docker Compose verwenden, um mehrere Container zu starten, anstatt nur einen einzigen mit Docker zu starten. Führe die folgenden Befehle aus, um das Git-Repository aufzurufen und einen Commit auszuchecken, von dem bekannt ist, dass er mit diesem Beispiel kompatibel ist:
$git clone git@github.com:cabotapp/docker-cabot.git cabot$cdcabot$git checkout 1f846b96
Als Nächstes erstellst du eine neue Datei mit dem Namen conf/production.env in diesem Repository. Beachte, dass sie sich nicht in dem Verzeichnis distributed-node befindet, in dem du alle anderen Projektdateien erstellt hast. Füge den Inhalt aus Beispiel 4-13 zu dieser Datei hinzu.
Beispiel 4-13. config/production.env
TIME_ZONE=America/Los_AngelesADMIN_EMAIL=admin@example.orgCABOT_FROM_EMAIL=cabot@example.orgDJANGO_SECRET_KEY=abcd1234WWW_HTTP_HOST=localhost:5000WWW_SCHEME=http# GRAPHITE_API=http://<YOUR-IP-ADDRESS>:8080/TWILIO_ACCOUNT_SID=<YOUR_TWILIO_ACCOUNT_SID>TWILIO_AUTH_TOKEN=<YOUR_TWILIO_AUTH_TOKEN>TWILIO_OUTGOING_NUMBER=<YOUR_TWILIO_NUMBER>
Setze diesen Wert auf deine TZ-Zeitzone.
Als Bonus kannst du eine Graphite-Quelle mit deiner IP-Adresse konfigurieren.
Lass diese Zeilen weg, wenn du Twilio nicht verwendest. Achte darauf, dass du der Telefonnummer ein Pluszeichen und die Landesvorwahl voranstellst.
Tipp
Wenn du abenteuerlustig bist, konfiguriere die Zeile GRAPHITE_API so, dass sie dieselbe Graphite-Instanz verwendet, die du in "Metriken mit Graphite, StatsD und Grafana" erstellt hast . Später, wenn du die Cabot-Schnittstelle verwendest, kannst du auswählen, für welche Metriken du einen Alarm erstellen möchtest. Dies ist nützlich, wenn du eine Kennzahl, wie z. B. die Anfragetaktung, nimmst und eine Warnung ausgibst, sobald sie einen bestimmten Schwellenwert überschreitet, z. B. 200 ms. Aus Gründen der Kürze wird in diesem Abschnitt jedoch nicht beschrieben, wie du das einrichtest, und du kannst die Zeile weglassen.
Wenn du die Konfiguration von Cabot abgeschlossen hast, führe den folgenden Befehl aus, um den Cabot-Dienst zu starten:
$ docker-compose upDaraufhin werden mehrere Docker-Container gestartet. Im Terminal solltest du den Fortschritt beim Herunterladen der einzelnen Images sehen, gefolgt von einer farbigen Ausgabe für jeden Container, sobald er läuft. Sobald sich alles beruhigt hat, kannst du zum nächsten Schritt übergehen: .
Einen Gesundheitscheck erstellen
Für dieses Beispiel verwendest du die Datei basic-http-healthcheck.js aus Beispiel 4-12, die du im vorherigen Abschnitt erstellt hast. Führe diese Datei aus und starte den Postgres-Dienst wie in Beispiel 4-11 konfiguriert. Danach kann Cabot so konfiguriert werden, dass es den Endpunkt /health nutzt, den der Node.js-Dienst bereitstellt.
Wenn der Node.js-Dienst jetzt läuft, öffne den Cabot-Webdienst mit deinem Webbrowser, indem du http://localhost:5000 aufrufst .
Du wirst zunächst aufgefordert, ein Administratorkonto zu erstellen. Verwende den Standard-Benutzernamen admin. Gib dann deine E-Mail-Adresse und ein Passwort ein und klicke auf Erstellen. Dann wirst du zur Eingabeaufforderung aufgefordert, dich einzuloggen. Gib admin in das Feld für den Benutzernamen ein, gib dein Passwort erneut ein und klicke auf Anmelden. Schließlich gelangst du zu dem Bildschirm mit den Diensten, der keine Einträge enthält.
Klicke auf dem Bildschirm mit den leeren Diensten auf das große Plus-Symbol, um zum Bildschirm mit dem neuen Dienst zu gelangen. Gib dann die Informationen aus Tabelle 4-3 in das Formular zum Erstellen einer Dienstleistung ein.
Name |
Dist Node Service |
Url |
http://<LOCAL_IP>:3300/ |
Benutzer zu benachrichtigen |
admin |
Warnungen |
Twilio SMS |
Warnungen aktiviert |
geprüft |
Auch hier musst du <LOCAL_IP> durch deine IP-Adresse ersetzen. Sobald du die Informationen eingegeben hast, klicke auf die Schaltfläche Senden. Du gelangst nun zu einem Bildschirm, auf dem du die Übersicht des Dist Node Service einsehen kannst.
Scrolle auf diesem Bildschirm nach unten zum Abschnitt "Http-Kontrollen" und klicke auf das Pluszeichen, um zum Bildschirm " Neue Kontrolle" zu gelangen. Auf diesem Bildschirm gibst du die Informationen aus Tabelle 4-4 in das Formular "Check erstellen" ein.
Name |
Dist Node HTTP Health |
Endpunkt |
http://<LOCAL_IP>:3300/health |
Statuscode |
200 |
Bedeutung |
Kritisch |
Aktiv |
geprüft |
Service-Set |
Dist Node Service |
Wenn du diese Informationen eingegeben hast, klicke auf die Schaltfläche Senden. Dadurch gelangst du zurück zum Übersichtsbildschirm des Dist Node Service.
Als Nächstes muss das admin Konto so konfiguriert werden, dass es Benachrichtigungen per Twilio SMS erhält. Klicke auf in der oberen rechten Ecke des Bildschirms auf das Dropdown-Menü Admin und dann auf Profileinstellungen. In der linken Seitenleiste klickst du auf den Link Twilio Plugin. In diesem Formular wirst du nach deiner Telefonnummer gefragt. Gib deine Telefonnummer ein, beginnend mit einem Pluszeichen und der Landesvorwahl. Diese Nummer sollte mit der verifizierten Nummer übereinstimmen, die du zuvor in deinem Twilio-Konto eingegeben hast. Wenn du fertig bist, klicke auf die Schaltfläche Senden.
Sobald du deine Telefonnummer eingegeben hast, klicke auf den Link Schecks in der oberen Navigationsleiste. Dadurch gelangst du auf die Seite mit der Liste der Checks, die den einen Eintrag enthalten sollte, den du erstellt hast. Klicke auf den Eintrag Dist Node HTTP Health, um zur Liste der Gesundheitschecks zu gelangen. Zu diesem Zeitpunkt solltest du nur ein oder zwei Einträge sehen, da sie alle fünf Minuten durchgeführt werden. Diese Einträge sollten ein grünes Etikett mit der Aufschrift "erfolgreich" tragen. Klicke auf das kreisförmige Pfeilsymbol oben rechts, um einen weiteren Gesundheitscheck auszulösen.
Wechsle nun zurück in das Terminalfenster, in dem dein Node.js-Dienst läuft. Beende ihn mit Strg + C. Wechsle dann wieder zu Cabot und klicke auf das Symbol, um den Test erneut auszuführen. Diesmal wird der Test fehlschlagen und du bekommst einen neuen Eintrag in der Liste mit rotem Hintergrund und dem Wort "failed".
Du solltest auch eine Textnachricht mit Informationen über den Alarm erhalten. Die Nachricht, die ich erhalten habe, ist hier abgebildet:
Sent from your Twilio trial account - Service Dist Node Service reporting CRITICAL status: http://localhost:5000/service/1/
Wenn Cabot richtig auf einem echten Server mit einem echten Hostnamen installiert wäre, würde die Textnachricht einen funktionierenden Link enthalten, der auf deinem Handy geöffnet werden könnte. Da Cabot aber wahrscheinlich auf deinem Laptop läuft, macht die URL in diesem Zusammenhang nicht viel Sinn.
Klicke auf den Link Dienste am oberen Rand des Bildschirms und dann erneut auf den Link Dist Node Service. Auf diesem Bildschirm siehst du jetzt ein Diagramm, das den Status des Dienstes anzeigt, sowie ein Banner, das besagt, dass der Dienst kritisch ist, wie in Abbildung 4-11. Klicke jetzt auf die Schaltfläche Alarm quittieren, um die Alarme für 20 Minuten zu unterbrechen. So hast du Zeit, dich um das Problem zu kümmern, ohne immer wieder alarmiert zu werden. Jetzt ist es an der Zeit, den fehlschlagenden Dienst zu reparieren.
Abbildung 4-11. Bildschirmfoto des Cabot-Dienststatus
Wechsle zurück zu dem Terminal, in dem du den Node.js-Prozess ausgeführt hast, und starte ihn erneut. Dann wechselst du wieder zum Browser. Navigiere zurück zu der von dir erstellten HTTP-Prüfung. Klicke auf das Symbol, um die Prüfung erneut auszulösen. Diesmal sollte die Prüfung erfolgreich sein und es erscheint wieder die grüne Meldung "erfolgreich".
Cabot bietet, wie auch andere Alarmierungstools, die Möglichkeit, verschiedenen Diensten unterschiedliche Benutzer zuzuweisen. Das ist wichtig, da verschiedene Teams innerhalb einer Organisation unterschiedliche Dienste besitzen. Bei der Erstellung einer HTTP-Warnung war es auch möglich, eine Regex anzugeben, die auf den Textkörper angewendet wird. Damit lässt sich ein gestörter Dienst von einem ungesunden Dienst unterscheiden. Cabot kann dann so konfiguriert werden, dass ein ungesunder Dienst einen Techniker alarmiert, während ein gestörter Dienst lediglich in der Benutzeroberfläche hervorgehoben wird.
An diesem Punkt bist du mit den Cabot-Docker-Containern fertig. Wechsle zu dem Fenster, in dem du Cabot ausgeführt hast, und drücke Strg + C, um es zu beenden. Führe dann den folgenden Befehl aus, um die Container von deinem System zu entfernen:
$dockerrmcabot_postgres_1cabot_rabbitmq_1\cabot_worker_1cabot_beat_1cabot_web_1
Get Verteilte Systeme mit Node.js now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

