Kapitel 1. Warum dezentral?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Node.js ist eine in sich geschlossene Laufzeitumgebung für die Ausführung von JavaScript-Code auf dem Server. Es bietet eine JavaScript-Sprach-Engine und Dutzende von APIs, von denen viele es dem Anwendungscode ermöglichen, mit dem zugrunde liegenden Betriebssystem und der Welt außerhalb davon zu interagieren. Aber das wusstest du wahrscheinlich schon.
In diesem Kapitel wird ein Überblick über Node.js gegeben, insbesondere darüber, was es mit diesem Buch zu tun hat. Es befasst sich mit der Single-Thread-Natur von JavaScript, die gleichzeitig eine seiner größten Stärken und Schwächen ist und ein Grund dafür ist, warum es so wichtig ist, Node.js verteilt zu betreiben.
Es enthält auch ein paar kleine Beispielanwendungen, die als Basis dienen und im Laufe des Buches immer wieder aktualisiert werden. Die erste Iteration dieser Anwendungen ist wahrscheinlich einfacher als alles, was du bisher in die Produktion gebracht hast.
Wenn du feststellst, dass du die Informationen in diesen ersten Abschnitten bereits kennst, kannst du direkt zu "Bewerbungsbeispiele" übergehen .
Die JavaScript-Sprache geht von einer Single-Thread-Sprache zu einer Multithreading-Sprache über. Das Atomics Objekt zum Beispiel bietet Mechanismen, um die Kommunikation zwischen verschiedenen Threads zu koordinieren, während Instanzen von SharedArrayBuffer über Threads hinweg geschrieben und gelesen werden können. Zum Zeitpunkt der Erstellung dieses Artikels hat sich JavaScript mit mehreren Threads in der Community noch nicht durchgesetzt.
JavaScript ist heute zwar multithreaded, aber es liegt immer noch in der Natur der Sprache und desÖkosystems, single-threaded zu sein.
Die Single-Threaded-Natur von JavaScript
JavaScript macht, wie die meisten Programmiersprachen , viel Gebrauch von Funktionen. Funktionen sind eine Möglichkeit, zusammenhängende Arbeitseinheiten zu kombinieren. Funktionen können auch andere Funktionen aufrufen. Jedes Mal, wenn eine Funktion eine andere Funktion aufruft, fügt sie Frames zu dem Aufrufstapel hinzu, was eine schicke Umschreibung dafür ist, dass der Stapel der aktuell ausgeführten Funktionen immer größer wird. Wenn du versehentlich eine rekursive Funktion schreibst, die sonst ewig laufen würde, bekommst du normalerweise einen RangeError: Maximale Größe des Aufrufstapels überschritten Fehler. In diesem Fall hast du die maximale Anzahl von Frames auf dem Aufrufstapel erreicht.
Hinweis
Die maximale Größe des Aufrufstapels ist normalerweise unerheblich und wird von der JavaScript-Engine festgelegt. Die V8-JavaScript-Engine, die von Node.js v14 verwendet wird, hat eine maximale Call-Stack-Größe von mehr als 15.000 Frames.
JavaScript unterscheidet sich jedoch von einigen anderen Sprachen darin, dass es sich nicht darauf beschränkt, während der gesamten Lebensdauer einer JavaScript-Anwendung in einem einzigen Call Stack zu laufen. Als ich zum Beispiel vor einigen Jahren PHP geschrieben habe, war die gesamte Lebensdauer eines PHP-Skripts (eine Lebensdauer, die direkt mit der Zeit verbunden ist, die es braucht, um eine HTTP-Anfrage zu bedienen) mit einem einzigen Stack verbunden, der wuchs und schrumpfte und dann verschwand, sobald die Anfrage beendet war.
JavaScript handhabt die Gleichzeitigkeit - das Ausführen mehrerer Dinge zur gleichen Zeit - mit Hilfe einer Ereignisschleife. Die von Node.js verwendete Ereignisschleife wird in "Die Node.js-Ereignisschleife" näher beschrieben , aber stell sie dir einfach als eine unendlich lange Schleife vor, die ständig überprüft, ob es etwas zu tun gibt. Wenn sie etwas findet, beginnt sie mit ihrer Aufgabe - in diesem Fall führt sie eine Funktion mit einem neuen Aufrufstapel aus - und wartet nach Abschluss der Funktion, bis weitere Aufgaben anstehen.
Das Codebeispiel in Beispiel 1-1 ist ein Beispiel dafür, wie dies geschieht. Zuerst wird die Funktion a() im aktuellen Stapel ausgeführt. Außerdem ruft die Funktion setTimeout() auf, die die Funktion x() in die Warteschlange stellt. Sobald der aktuelle Stapel abgeschlossen ist, prüft die Ereignisschleife, ob es noch weitere Aufgaben zu erledigen gibt. Die Ereignisschleife kann erst dann nach weiteren Aufgaben suchen, wenn ein Stapel vollständig ist. Sie prüft zum Beispiel nicht nach jeder Anweisung. Da in diesem einfachen Programm nicht viel los ist, wird die Funktion x() als Nächstes ausgeführt, nachdem der erste Stapel abgeschlossen ist.
Beispiel 1-1. Beispiel für mehrere JavaScript-Stapel
functiona(){b();}functionb(){c();}functionc(){/**/}functionx(){y();}functiony(){z();}functionz(){/**/}setTimeout(x,0);a();
Abbildung 1-1 ist eine Visualisierung des vorangegangenen Codebeispiels. Beachte, dass es zwei getrennte Stapel gibt und dass jeder Stapel an Tiefe zunimmt, wenn mehr Funktionen aufgerufen werden. Die horizontale Achse stellt die Zeit dar; der Code innerhalb jeder Funktion braucht natürlich Zeit, um ausgeführt zu werden.
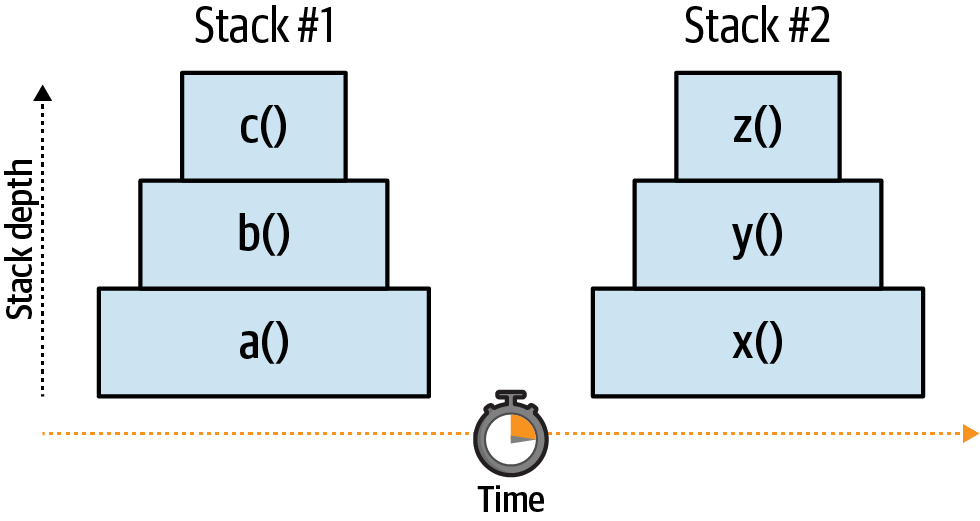
Abbildung 1-1. Visualisierung von mehreren JavaScript-Stapeln
Die Funktion setTimeout() sagt im Wesentlichen: "Versuche, die bereitgestellte Funktion in 0 ms auszuführen." Die Funktion x() wird jedoch nicht sofort ausgeführt, da der Aufrufstapel a() noch nicht abgeschlossen ist. Sie wird auch nicht sofort ausgeführt, nachdem der a() -Aufrufstapel abgeschlossen ist. Die Ereignisschleife benötigt eine Zeit ungleich Null, um zu prüfen, ob noch mehr Arbeit zu erledigen ist. Sie braucht auch Zeit, um den neuen Aufrufstapel vorzubereiten. Obwohl x() so geplant wurde, dass es in 0 ms ausgeführt wird, kann es in der Praxis einige Millisekunden dauern, bis der Code ausgeführt wird - eine Diskrepanz, die mit zunehmender Anwendungslast noch größer wird.
Eine weitere Sache, die du beachten solltest, ist, dass Funktionen sehr lange brauchen können, um ausgeführt zu werden. Wenn die Funktion a() 100 ms braucht, um ausgeführt zu werden, kann x() frühestens nach 101 ms aufgerufen werden. Betrachte daher das Argument time als den frühesten Zeitpunkt, zu dem die Funktion aufgerufen werden kann. Eine Funktion , die sehr lange braucht, um ausgeführt zu werden, blockiert die Ereignisschleife: Dadie Anwendung bei der Verarbeitung von langsamem, synchronem Code feststeckt, ist die Ereignisschleife vorübergehend nicht in der Lage, weitere Aufgaben zu verarbeiten.
Jetzt, wo die Anrufstapel aus dem Weg geräumt sind, ist es Zeit für den interessanten Teil dieses Abschnitts.
Da JavaScript-Anwendungen meist im Single-Thread-Verfahren ausgeführt werden, können nicht zwei Aufrufstapel gleichzeitig existieren, was mit anderen Worten bedeutet, dass zwei Funktionen nicht parallel laufen können.1 Das bedeutet, dass mehrere Kopien einer Anwendung auf irgendeine Weise gleichzeitig ausgeführt werden müssen, damit die Anwendung skaliert werden kann.
Es gibt mehrere Tools, die die Verwaltung mehrerer Kopien einer Anwendung erleichtern . In "Das Cluster-Modul" geht es um die Verwendung des eingebauten cluster Moduls zur Weiterleitung eingehender HTTP-Anfragen an verschiedene Anwendungsinstanzen. Das eingebaute worker_threads Modul hilft auch dabei, mehrere JavaScript-Instanzen gleichzeitig auszuführen. Das child_process Modul kannauch verwendet werden, um einen kompletten Node.js-Prozess zu starten und zu verwalten.
Bei all diesen Ansätzen kann jedoch immer nur eine einzige JavaScript-Zeile gleichzeitig in einer Anwendung ausgeführt werden. Das bedeutet, dass bei jeder Lösung jede JavaScript-Umgebung immer noch ihre eigenen globalen Variablen hat und keine Objektreferenzen zwischen ihnen ausgetauscht werden können.
Da Objekte mit den drei oben genannten Ansätzen nicht direkt gemeinsam genutzt werden können, ist eine andere Methode zur Kommunikation zwischen den verschiedenen isolierten JavaScript-Kontexten erforderlich. Eine solche Funktion existiert und wird Message Passing genannt. Bei der Nachrichtenübermittlung wird eine Art serialisierte Darstellung eines Objekts/einer Datei (z. B. JSON) zwischen den einzelnen Kontexten ausgetauscht. Das ist notwendig, weil ein direkter Austausch von Objekten nicht möglich ist, ganz zu schweigen davon, dass es eine schmerzhafte Erfahrung bei der Fehlersuche wäre, wenn zwei getrennte Isolate das gleiche Objekt gleichzeitig ändern könnten. Diese Art von Problemen wird unter als Deadlocks und Race Conditions bezeichnet.
Hinweis
Durch die Verwendung von worker_threads ist es möglich, den Speicher zwischen zwei verschiedenen JavaScript-Instanzen zu teilen. Dazu wird eine Instanz von SharedArrayBuffer erstellt und von einem Thread an den anderen weitergegeben, wobei dieselbe postMessage(value) Methode verwendet wird, die auch für die Nachrichtenübermittlung im Worker-Thread verwendet wird. So entsteht ein Array von Bytes, das beide Threads gleichzeitig lesen und beschreiben können.
Beim Message Passing entsteht ein Overhead, wenn Daten serialisiert und deserialisiert werden. In Sprachen, die Multithreading unterstützen, muss dieser Overhead nicht sein, da Objekte direkt gemeinsam genutzt werden können.
Dies ist einer der wichtigsten Faktoren, die es erforderlich machen, Node.js-Anwendungen verteilt auszuführen. Um die Skalierung zu bewältigen, müssen genug Instanzen laufen, damit eine einzelne Instanz eines Node.js-Prozesses die verfügbare CPU nicht vollständig auslastet.
Nachdem du dir nun JavaScript - die Sprache, die Node.js antreibt - angeschaut hast, ist es an der Zeit, sich Node.js selbst anzuschauen.
Die Lösung der Überraschungsfrage findest du in Tabelle 1-1. Der wichtigste Teil ist die Reihenfolge, in der die Nachrichten gedruckt werden, und der Bonus ist die Zeit, die sie zum Drucken brauchen. Betrachte deine Bonusantwort als richtig, wenn du nur wenige Millisekunden von der Zeitangabe abweichst.
Logge |
B |
E |
A |
D |
C |
Zeit |
1ms |
501ms |
502ms |
502ms |
502ms |
Das erste, was auf passiert, ist, dass die Funktion zur Protokollierung von A mit einem Timeout von 0 ms geplant wird. Das bedeutet nicht, dass die Funktion innerhalb von 0 ms ausgeführt wird. Stattdessen wird sie so geplant, dass sie bereits nach 0 Millisekunden ausgeführt wird, aber nachdem der aktuelle Stapel endet. Als Nächstes wird die Methode log B direkt aufgerufen, so dass sie als erste gedruckt wird. Dann wird die Funktion log C so geplant, dass sie bereits in 100 ms ausgeführt wird, und die Funktion log D wird so geplant, dass sie bereits in 0 ms ausgeführt wird.
Dann ist die Anwendung mit den Berechnungen der while-Schleife beschäftigt, die eine halbe Sekunde CPU-Zeit verschlingt. Sobald die Schleife beendet ist, wird der letzte Aufruf für das Protokoll E direkt gemacht und es ist nun der zweite, der gedruckt wird. Der aktuelle Stapel ist nun vollständig. Zu diesem Zeitpunkt ist nur ein einziger Stapel ausgeführt worden.
Sobald das erledigt ist, sucht die Ereignisschleife nach weiteren Aufgaben. Sie überprüft die Warteschlange und stellt fest, dass drei Aufgaben anstehen. Die Reihenfolge der Aufgaben in der Warteschlange richtet sich nach dem angegebenen Timerwert und der Reihenfolge, in der die Aufrufe von setTimeout() gemacht wurden. Also wird zuerst die Funktion log A abgearbeitet. Zu diesem Zeitpunkt läuft das Skript bereits seit etwa einer halben Sekunde und stellt fest, dass Log A etwa 500 ms überfällig ist, also wird diese Funktion ausgeführt. Das nächste Element in der Warteschlange ist die Funktion log D, die ebenfalls etwa 500 ms überfällig ist. Schließlich wird die Funktion log C ausgeführt, die etwa 400 ms überfällig ist.
Schnelle Node.js Übersicht
Node.js nutzt das Continuation-Passing-Style (CPS)-Muster in seinen internen Modulen mit Hilfe von Callbacks - Funktionen die weitergereicht und von der Ereignisschleife aufgerufen werden, sobald eine Aufgabe abgeschlossen ist. In der Node.js-Sprache heißt das, dass Funktionen, die in der Zukunft mit einem neuen Stapel aufgerufen werden, asynchron ausgeführt werden. Umgekehrt gilt: Wenn eine Funktion eine andere Funktion im selben Stapel aufruft, wird dieser Code synchron ausgeführt.
Die Arten von Aufgaben, die langwierig sind, sind in der Regel E/A-Aufgaben. Stell dir zum Beispiel vor, dass deine Anwendung zwei Aufgaben ausführen möchte. Aufgabe A ist es, eine Datei von der Festplatte zu lesen, und Aufgabe B ist es, eine HTTP-Anfrage an einen Drittanbieterdienst zu senden. Wenn ein Vorgang von der Ausführung beider Aufgaben abhängt, z. B. die Beantwortung einer eingehenden HTTP-Anfrage, kann die Anwendung die Vorgänge parallel ausführen, wie in Abbildung 1-2 gezeigt. Könnten sie nicht gleichzeitig ausgeführt werden, sondern müssten nacheinander ablaufen, würde die Antwort auf die eingehende HTTP-Anfrage insgesamt länger dauern.
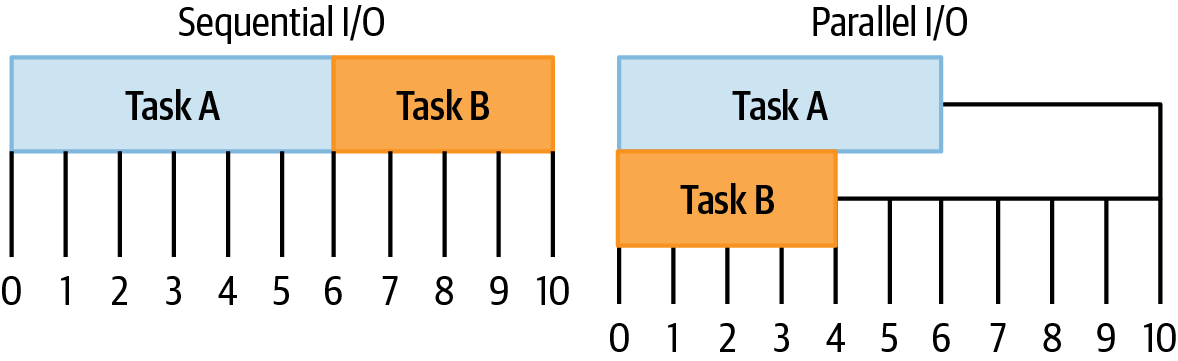
Abbildung 1-2. Visualisierung von sequentiellen und parallelen E/A
Auf den ersten Blick scheint dies gegen die Single-Thread-Natur von JavaScript zu verstoßen. Wie kann eine Node.js-Anwendung gleichzeitig Daten von der Festplatte lesen und eine HTTP-Anfrage stellen, wenn JavaScript single-threaded ist?
Hier fangen die Dinge an , interessant zu werden. Node.js selbst ist multithreaded. Die unteren Ebenen von Node.js sind in C++ geschrieben. Dazu gehören Tools von Drittanbietern wie libuv, das Betriebssystemabstraktionen und E/A verwaltet, sowie V8 (die JavaScript-Engine) und andere Module von Drittanbietern. Die darüber liegende Schicht, die Node.js-Bindungsschicht, enthält ebenfalls ein wenig C++. Nur die obersten Schichten von Node.js sind inJavaScript geschrieben, wie z. B. die Teile der Node.js-APIs, die direkt mit Objekten aus dem Userland arbeiten.2 Abbildung 1-3 zeigt die Beziehung zwischen diesen verschiedenen Schichten.
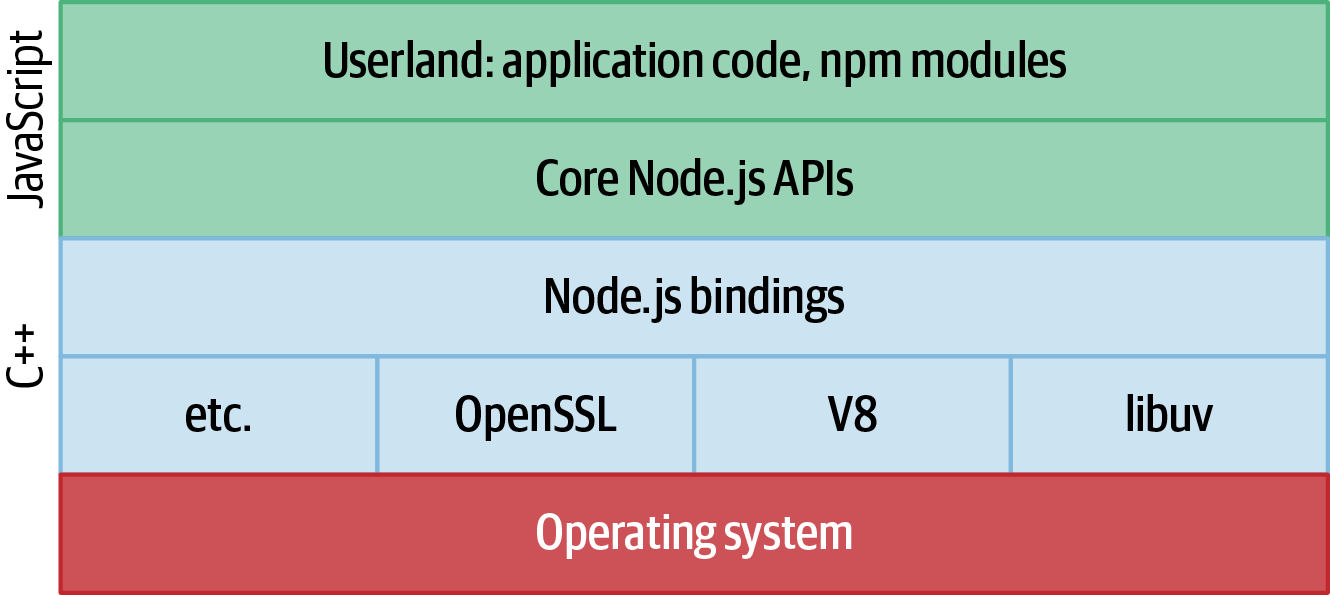
Abbildung 1-3. Die Schichten von Node.js
Intern unterhält libuv einen Thread-Pool für die Verwaltung von E/A-Operationen sowie von CPU-lastigen Operationen wie crypto und zlib. Es handelt sich dabei um einen Pool mit begrenzter Größe, in dem E/A-Operationen durchgeführt werden können. Wenn der Pool nur vier Threads enthält, können auch nur vier Dateien gleichzeitig gelesen werden. In Beispiel 1-3 versucht die Anwendung, eine Datei zu lesen, erledigt einige andere Aufgaben und bearbeitet dann den Inhalt der Datei. Obwohl der JavaScript-Code in der Anwendung ausgeführt werden kann, ist ein Thread in den Eingeweiden von Node.js damit beschäftigt, den Inhalt der Datei von der Festplatte in den Speicher zu lesen.
Beispiel 1-3. Node.js-Threads
#!/usr/bin/env nodeconstfs=require('fs');fs.readFile('/etc/passwd',(err,data)=>{if(err)throwerr;console.log(data);});setImmediate(()=>{console.log('This runs while file is being read');});
Node.js liest
/etc/passwd. Es wird von libuv geplant.
Node.js führt einen Callback in einem neuen Stack aus. Er wird von V8 geplant.

Sobald der vorherige Stapel endet, wird ein neuer Stapel erstellt und eine Nachricht gedruckt.

Sobald die Datei fertig gelesen ist, übergibt libuv das Ergebnis an die V8-Ereignisschleife.
Tipp
Die Poolgröße des libuv-Threads ist standardmäßig auf vier und maximal auf 1.024 begrenzt und kann durch Setzen der Umgebungsvariablen UV_THREADPOOL_SIZE=<threads> überschrieben werden. In der Praxis ist es nicht üblich, sie zu ändern und sollte nur nach einem Benchmarking der Auswirkungen in einer perfekten Replikation der Produktion vorgenommen werden. Eine App, die lokal auf einem macOS-Laptop läuft, wird sich ganz anders verhalten als eine App in einem Container auf einem Linux-Server.
Intern verwaltet Node.js eine Liste mit asynchronen Aufgaben, die noch erledigt werden müssen. Diese Liste wird verwendet, um den Prozess am Laufen zu halten. Wenn ein Stapel abgeschlossen ist und die Ereignisschleife nach weiteren Aufgaben sucht, wird der Prozess beendet, wenn es keine weiteren Aufgaben mehr gibt, um ihn am Leben zu erhalten. Deshalb kann eine sehr einfache Anwendung, die nichts Asynchrones tut, beendet werden, wenn der Stack endet. Hier ist ein Beispiel für eine solcheAnwendung:
console.log('Print, then exit');
Sobald jedoch eine asynchrone Aufgabe erstellt wurde, reicht dies aus, um einen Prozess am Leben zu erhalten, wie in diesem Beispiel:
setInterval(()=>{console.log('Process will run forever');},1_000);
Es gibt viele Node.js-API-Aufrufe , die zur Erstellung von Objekten führen, die den Prozess am Leben erhalten. Ein weiteres Beispiel: Wenn ein HTTP-Server erstellt wird, bleibt der Prozess für immer am Laufen. Ein Prozess, der sofort nach der Erstellung eines HTTP-Servers geschlossen wird, wäre nicht sehr nützlich.
Es gibt ein gängiges Muster in den Node.js-APIs, bei dem solche Objekte so konfiguriert werden können, dass sie den Prozess nicht mehr am Leben halten. Einige davon sind offensichtlicher als andere. Wenn z. B. ein HTTP-Server-Port geschlossen wird, kann der Prozess das Ende wählen. Außerdem sind viele dieser Objekte mit zwei Methoden verbunden, .unref() und .ref(). Die erste Methode wird verwendet, um dem Objekt mitzuteilen, dass es den Prozess nicht länger am Leben erhalten soll, während die zweite Methode das Gegenteil bewirkt.Beispiel 1-4 zeigt, wie das geschieht.
Beispiel 1-4. Die gemeinsamen Methoden .ref() und .unref()
constt1=setTimeout(()=>{},1_000_000);constt2=setTimeout(()=>{},2_000_000);// ...t1.unref();// ...clearTimeout(t2);
Jetzt gibt es eine asynchrone Operation, die Node.js am Leben erhält. Der Prozess sollte in 1.000 Sekunden beendet sein.
Es gibt jetzt zwei solcher Vorgänge. Der Vorgang sollte jetzt in 2.000Sekunden beendet sein.
Der Timer t1 wurde auf nicht referenziert. Sein Callback kann immer noch in 1.000 Sekunden ausgeführt werden, aber er wird den Prozess nicht am Leben erhalten.
Der Timer t2 wurde gelöscht und wird nicht mehr ausgeführt. Ein Nebeneffekt davon ist, dass er den Prozess nicht mehr am Leben hält. Da keine asynchronen Operationen mehr den Prozess am Leben erhalten, beendet die nächste Iteration der Ereignisschleife den Prozess.
Dieses Beispiel verdeutlicht auch eine weitere Besonderheit von Node.js: Nicht alle APIs, die es in Browser-JavaScript gibt, verhalten sich in Node.js gleich. Die Funktion setTimeout() zum Beispiel gibt in Webbrowsern eine ganze Zahl zurück. Die Node.js-Implementierung gibt ein Objekt mit mehreren Eigenschaften und Methoden zurück.
Die Ereignisschleife wurde schon ein paar Mal erwähnt, aber sie verdient es wirklich, genauer betrachtet zu werden.
Die Node.js Ereignisschleife
Sowohl das JavaScript, das in deinem Browser läuft, als auch das JavaScript, das in Node.js läuft, haben eine Implementierung einer Ereignisschleife. Sie ähneln sich darin, dass sie asynchrone Aufgaben in separaten Stapeln planen und ausführen. Aber sie unterscheiden sich auch darin, dass die Ereignisschleife im Browser für moderne Single-Page-Anwendungen optimiert ist, während die Schleife in Node.js für den Einsatz auf einem Server optimiert wurde. In diesem Abschnitt wird die Ereignisschleife in Node.js auf hohem Niveau behandelt. Es ist wichtig, die Grundlagen der Ereignisschleife zu verstehen, denn sie steuert das gesamte Scheduling deines Anwendungscodes - und falsche Vorstellungen können zu schlechter Leistung führen.
Wie der Name schon sagt, läuft die Ereignisschleife in einer Schleife. Sie verwaltet eine Warteschlange von Ereignissen, die dazu dienen, Rückrufe auszulösen und die Anwendung voranzutreiben. Aber wie zu erwarten, ist die Implementierung viel ausgefeilter als das. Sie führt Callbacks aus, wenn E/A-Ereignisse eintreten, z. B. wenn eine Nachricht auf einem Socket empfangen wird, wenn sich eine Datei auf der Festplatte ändert, wenn ein setTimeout() Callback zur Ausführung bereit ist, usw.
Auf einer niedrigen Ebene benachrichtigt das Betriebssystem das Programm, dass etwas passiert ist. Dann erwacht der libuv-Code im Programm zum Leben und findet heraus, was zu tun ist. Gegebenenfalls wird die Nachricht an den Code einer Node.js-API weitergeleitet, der dann einen Rückruf im Anwendungscode auslösen kann. Die Ereignisschleife ermöglicht es, dass diese Ereignisse in einer niedrigeren Ebene von C++ die Grenze überschreiten und Code in JavaScript ausführen.
Phasen der Ereignisschleife
Die Ereignisschleife hat mehrere verschiedene Phasen. Einige dieser Phasen haben nicht direkt mit dem Anwendungscode zu tun, sondern führen zum Beispiel JavaScript Code aus, um den sich die internen Node.js-APIs kümmern. Einen Überblick über die Phasen, die sich mit der Ausführung von Userland-Code befassen, findest du in Abbildung 1-4.
Jede dieser Phasen unterhält eine Warteschlange von Rückrufen, die ausgeführt werden sollen. Die Rückrufe sind für verschiedene Phasen bestimmt, je nachdem, wie sie von der Anwendung verwendet werden. Hier sind einige Details zu diesen Phasen:
- Umfrage
-
Die Poll-Phase führt I/O-bezogene Callbacks aus. Dies ist die Phase, in der der Anwendungscode am ehesten ausgeführt wird. Wenn dein Hauptanwendungscode läuft, wird er in dieser Phase ausgeführt.
- Prüfe
-
In dieser Phase werden die Rückrufe ausgeführt, die über
setImmediate()ausgelöst werden. - Schließen
-
In dieser Phase werden Callbacks ausgeführt, die durch
EventEmittercloseEreignisse ausgelöst werden. Wenn zum Beispiel einnet.ServerTCP-Server geschlossen wird, sendet er eincloseEreignis, das einen Callback in dieser Phase ausführt. - Timer
-
Die Rückrufe , die mit
setTimeout()undsetInterval()geplant wurden, werden in dieser Phase ausgeführt. - Anhängig
-
Spezielle Systemereignisse werden in dieser Phase ausgeführt, zum Beispiel wenn ein
net.SocketTCP-Socket einenECONNREFUSEDFehler auslöst.
Um die Dinge ein wenig komplizierter zu machen, gibt es auch zwei spezielle Microtask-Warteschlangen, denen Rückrufe hinzugefügt werden können, während eine Phase läuft. Die erste Mikrotask-Warteschlange bearbeitet Rückrufe, die mit process.nextTick() registriert wurden.3 Die zweite Microtask-Warteschlange bearbeitet Versprechen, die abgelehnt oder aufgelöst werden. Rückrufe in den Microtask-Warteschlangen haben Vorrang vor Rückrufen in der normalen Warteschlange der Phase, und Rückrufe in der nächsten Tick-Microtask-Warteschlange werden vor Rückrufen in der Promise-Microtask-Warteschlange ausgeführt.

Abbildung 1-4. Bemerkenswerte Phasen der Node.js-Ereignisschleife
Wenn die Anwendung läuft, wird auch die Ereignisschleife gestartet und die Phasen werden nacheinander abgearbeitet. Während die Anwendung läuft, fügt Node.js je nach Bedarf Rückrufe zu verschiedenen Warteschlangen hinzu. Wenn die Ereignisschleife bei einer Phase ankommt, führt sie alle Rückrufe in der Warteschlange dieser Phase aus. Wenn alle Rückrufe in einer bestimmten Phase erschöpft sind, geht die Ereignisschleife zur nächsten Phase über. Wenn die Anwendung nichts mehr zu tun hat, aber auf den Abschluss von E/A-Operationen wartet, bleibt sie in der Poll-Phase hängen.
Code Beispiel
Die Theorie ist schön und schön, aber um wirklich zu verstehen, wie die Ereignisschleife funktioniert, musst du dir die Hände schmutzig machen. In diesem Beispiel werden die Phasen poll, check und timers verwendet. Erstelle eine Datei namens event-loop-phases.js und füge den Inhalt aus Beispiel 1-5 hinzu.
Beispiel 1-5. event-loop-phases.js
constfs=require('fs');setImmediate(()=>console.log(1));Promise.resolve().then(()=>console.log(2));process.nextTick(()=>console.log(3));fs.readFile(__filename,()=>{console.log(4);setTimeout(()=>console.log(5));setImmediate(()=>console.log(6));process.nextTick(()=>console.log(7));});console.log(8);
Wenn du Lust hast, kannst du versuchen, die Reihenfolge der Ausgabe zu erraten, aber sei nicht böse, wenn deine Antwort nicht übereinstimmt. Das ist ein etwas komplexes Thema.
Das Skript wird in der Poll-Phase Zeile für Zeile ausgeführt. Zuerst wird das Modul fs benötigt, und hinter den Kulissen passiert eine ganze Menge Magie. Als nächstes wird dersetImmediate() Aufruf ausgeführt, der den Callback-Druck 1 in die Warteschlange einfügt. Dann wird das Versprechen aufgelöst und Callback 2 in die Warteschlange der Microtask aufgenommen.
process.nextTick() läuft als nächstes und fügt Callback 3 der nächsten Tick-Microtask-Warteschlange hinzu. Sobald das erledigt ist, weist der Aufruf fs.readFile() die Node.js-APIs an, mit dem Lesen einer Datei zu beginnen und ihren Callback in die Poll-Warteschlange zu stellen, sobald sie fertig ist. Schließlich wird Log Nummer 8 direkt aufgerufen und auf dem Bildschirm ausgegeben.
Das war's für den aktuellen Stapel. Jetzt werden die beiden Microtask-Warteschlangen konsultiert. Die Mikrotask-Warteschlange für den nächsten Tick wird immer zuerst geprüft und Callback 3 aufgerufen. Da es nur einen Callback in der nächsten Tick-Microtask-Warteschlange gibt, wird als nächstes die Promise-Microtask-Warteschlange überprüft. Hier wird Callback 2 ausgeführt. Damit sind die beiden Microtask-Warteschlangen abgeschlossen und die aktuelle Abfragephase ist beendet.
Jetzt tritt die Ereignisschleife in die Prüfphase ein. In dieser Phase gibt es den Rückruf 1, der dann ausgeführt wird. Beide Mikrotask-Warteschlangen sind zu diesem Zeitpunkt leer, also endet die Prüfphase. Die Abschlussphase wird als Nächstes geprüft, ist aber leer, also geht die Schleife weiter. Das Gleiche geschieht mit der Timer-Phase und der Pending-Phase, und die Ereignisschleife geht zurück zur Poll-Phase.
Sobald sie wieder in der Abfragephase ist, hat die Anwendung nicht mehr viel zu tun und wartet, bis die Datei fertig gelesen ist. Sobald das passiert, wird derfs.readFile() Callback ausgeführt.
Die Zahl 4 wird sofort gedruckt, da sie die erste Zeile im Callback ist. Als Nächstes wird setTimeout() aufgerufen und Callback 5 wird der Timer-Warteschlange hinzugefügt. DersetImmediate() Aufruf erfolgt als nächstes und fügt Callback 6 zur Check-Warteschlange hinzu. Schließlich wird derprocess.nextTick() Aufruf durchgeführt, der Callback 7 zur nächsten Tick-Microtask-Warteschlange hinzufügt. Die Poll-Warteschlange ist nun fertig und die Microtask-Warteschlangen werden erneut konsultiert. Callback 7 wird von der nächsten Tick-Warteschlange ausgeführt, die Promise-Warteschlange wird konsultiert und für leer befunden, und die Poll-Phase endet.
Wieder wechselt die Ereignisschleife in die Prüfphase, in der der Rückruf 6 auftritt. Die Nummer wird gedruckt, die Microtask-Warteschlangen werden für leer befunden und die Phase endet. Die Abschlussphase wird erneut geprüft und für leer befunden. Schließlich wird die Timer-Phase konsultiert, in der Callback 5 ausgeführt wird. Wenn das erledigt ist, hat die Anwendung keine Arbeit mehr und wird beendet.
Die Logbucheinträge wurden in dieser Reihenfolge gedruckt: 8, 3, 2, 1, 4, 7, 6, 5.
Für async Funktionen, und Operationen, die das Schlüsselwort await verwenden, gelten immer noch die gleichen Regeln für Ereignisschleifen. Der Hauptunterschied liegt in der Syntax.
Hier ist ein Beispiel für einen komplexen Code, der erwartete Anweisungen mit Anweisungen verschachtelt, die Rückrufe auf eine einfachere Weise planen. Gehe es durch und schreibe die Reihenfolge auf, in der die Log-Anweisungen deiner Meinung nach gedruckt werden:
constsleep_st=(t)=>newPromise((r)=>setTimeout(r,t));constsleep_im=()=>newPromise((r)=>setImmediate(r));(async()=>{setImmediate(()=>console.log(1));console.log(2);awaitsleep_st(0);setImmediate(()=>console.log(3));console.log(4);awaitsleep_im();setImmediate(()=>console.log(5));console.log(6);await1;setImmediate(()=>console.log(7));console.log(8);})();
Wenn es um async Funktionen und Anweisungen geht, denen await vorangestellt ist, kannst du sie fast als syntaktischen Zucker für Code betrachten, der verschachtelte Rückrufe verwendet, oder sogar als eine Kette von .then() Aufrufen. Das folgende Beispiel ist eine weitere Möglichkeit, an das vorherige Beispiel zu denken. Schau dir den Code noch einmal an und schreibe die Reihenfolge auf, in der die Log-Befehle deiner Meinung nach gedruckt werden sollen:
setImmediate(()=>console.log(1));console.log(2);Promise.resolve().then(()=>setTimeout(()=>{setImmediate(()=>console.log(3));console.log(4);Promise.resolve().then(()=>setImmediate(()=>{setImmediate(()=>console.log(5));console.log(6);Promise.resolve().then(()=>{setImmediate(()=>console.log(7));console.log(8);});}));},0));
Bist du auf eine andere Lösung gekommen, als du das zweite Beispiel gelesen hast? War sie einfacher zu begründen? Dieses Mal kannst du die Regeln für die Ereignisschleife, die wir bereits behandelt haben, einfacher anwenden. In diesem Beispiel ist es hoffentlich klarer, dass derfolgende Code viel früher ausgeführt werden sollte, auch wenn die aufgelösten Versprechen den Anschein erwecken, dass sie immer noch auf die zugrunde liegendensetTimeout() oder setImmediate() warten müssen, bevor das Programm fortgesetzt werden kann.
Die Logbucheinträge wurden in dieser Reihenfolge gedruckt: 2, 1, 4, 3, 6, 8, 5, 7.
Tipps zur Ereignisschleife
Wenn es darum geht, eine Node.js-Anwendung zu erstellen, musst du nicht unbedingt so viele Details über die Ereignisschleife wissen. In vielen Fällen "funktioniert" sie einfach und du musst dir in der Regel keine Gedanken darüber machen, welche Callbacks zuerst ausgeführt werden. Trotzdem gibt es ein paar wichtige Dinge, die du bei der Ereignisschleife beachten solltest.
Lass die Ereignisschleife nicht verhungern. Wenn zu viel Code in einem einzigen Stapel ausgeführt wird, wird die Ereignisschleife abgewürgt und andere Rückrufe werden nicht ausgeführt. Eine Möglichkeit, dies zu beheben, ist, CPU-lastige Operationen auf mehrere Stacks zu verteilen. Wenn du z. B. 1.000 Datensätze verarbeiten musst, könntest du dies in 10 Stapel zu je 100 Datensätzen aufteilen und setImmediate() am Ende eines jeden Stapels verwenden, um mit der Verarbeitung des nächsten Stapels fortzufahren. Je nach Situation kann es sinnvoller sein, die Verarbeitung an einen untergeordneten Prozess auszulagern.
Du solltest niemals eine solche Arbeit mit process.nextTick() aufteilen. Das führt zu einer Mikrotask-Warteschlange, die sich nie leert - deine Anwendung wird für immer in derselben Phase gefangen sein! Im Gegensatz zu einer unendlich rekursiven Funktion wird der Code kein RangeError auslösen. Stattdessen bleibt er ein Zombie-Prozess, der die CPU auffrisst. Im Folgenden findest du ein Beispiel dafür:
constnt_recursive=()=>process.nextTick(nt_recursive);nt_recursive();// setInterval will never runconstsi_recursive=()=>setImmediate(si_recursive);si_recursive();// setInterval will runsetInterval(()=>console.log('hi'),10);
In diesem Beispiel repräsentiert setInterval() einige asynchrone Aufgaben, die die Anwendung ausführt, z. B. die Beantwortung eingehender HTTP-Anfragen. Sobald die Funktion nt_recursive() ausgeführt wird, endet die Anwendung mit einer Microtask-Warteschlange, die sich nie leert und die asynchrone Arbeit wird nie verarbeitet. Die alternative Version si_recursive() hat jedoch nicht denselben Nebeneffekt. Wenn du setImmediate() innerhalb einer Prüfphase aufrufst, werden die Rückrufe in die Warteschlange der Prüfphase der nächsten Iteration der Ereignisschleife eingefügt, nicht in die Warteschlange der aktuellen Phase.
Führe kein Zalgo ein. Wenn eine Methode anbietet, die einen Callback benötigt, sollte dieser Callback immer asynchron ausgeführt werden. Es ist zum Beispiel viel zu einfach, etwas wie dieses zu schreiben:
// Antipatternfunctionfoo(count,callback){if(count<=0){returncallback(newTypeError('count > 0'));}myAsyncOperation(count,callback);}
Der Callback wird manchmal synchron aufgerufen, z. B. wenn count auf Null gesetzt wird, und manchmal asynchron, z. B. wenn count auf Eins gesetzt wird. Stelle stattdessen sicher, dass der Callback in einem neuen Stapel ausgeführt wird, wie in diesem Beispiel:
functionfoo(count,callback){if(count<=0){returnprocess.nextTick(()=>callback(newTypeError('count > 0')));}myAsyncOperation(count,callback);}
In diesem Fall ist es in Ordnung, entweder mit setImmediate() oder process.nextTick() zu verwenden; stelle nur sicher, dass du nicht versehentlich eine Rekursion einführst. In diesem überarbeiteten Beispiel wird der Callback immer asynchron ausgeführt. Es ist wichtig, dass der Callback konsequent ausgeführt wird, weil es folgende Situation gibt:
letbar=false;foo(3,()=>{assert(bar);});bar=true;
Das sieht vielleicht etwas konstruiert aus, aber das Problem ist, dass der Wert von bar geändert werden kann oder auch nicht, wenn der Callback manchmal synchron und manchmal asynchron ausgeführt wird. In einer realen Anwendung kann dies den Unterschied ausmachen, ob man auf eine Variable zugreift, die korrekt initialisiert wurde oder nicht.
Jetzt, wo du mit dem Innenleben von Node.js etwas vertrauter bist, ist es an der Zeit, ein paar Beispielanwendungen zu entwickeln.
Anwendungsbeispiele
In diesem Abschnitt wirst du ein paar kleine Node.js-Beispielanwendungen erstellen. Sie sind absichtlich einfach gehalten und verfügen nicht über die Funktionen, die echte Anwendungen benötigen. Im weiteren Verlauf des Buches wirst du die Komplexität dieser Basisanwendungen erhöhen.
Ich habe mit der Entscheidung gerungen, in diesen Beispielen keine Pakete von Drittanbietern zu verwenden (z. B. das interne Modul http ), aber die Verwendung dieser Pakete reduziert den Ballast und erhöht die Übersichtlichkeit. Es steht dir also frei, dein bevorzugtes Framework oder deine bevorzugte Bibliothek zu wählen. Es ist nicht die Absicht dieses Buches, ein bestimmtes Paket vorzuschreiben.
Wenn du zwei Dienste statt nur einem aufbaust, kannst du sie später auf interessante Weise kombinieren, z. B. indem du das Protokoll wählst, mit dem sie kommunizieren, oder die Art und Weise, wie sie sich gegenseitig entdecken.
Die erste Anwendung, die recipe-api, stellt eine interne API dar, auf die von außen nicht zugegriffen wird; nur andere interne Anwendungen können darauf zugreifen. Da du sowohl der Eigentümer des Dienstes als auch der Clients bist, die auf ihn zugreifen, kannst du später frei über das Protokoll entscheiden. Das gilt für jeden internen Dienst innerhalb einer Organisation.
Die zweite Anwendung stellt eine API dar, auf die Dritte über das Internet zugreifen können. Sie stellt einen HTTP-Server zur Verfügung, so dass Webbrowser leicht mit ihr kommunizieren können. Diese Anwendung wird Web-API genannt.
Dienstleistungsverhältnis
Der Web-Api-Dienst ist der Rezept-Api nachgelagert und umgekehrt ist die Rezept-Api der Web-Api vorgelagert. Abbildung 1-5 veranschaulicht die Beziehung zwischen diesen beiden Diensten.
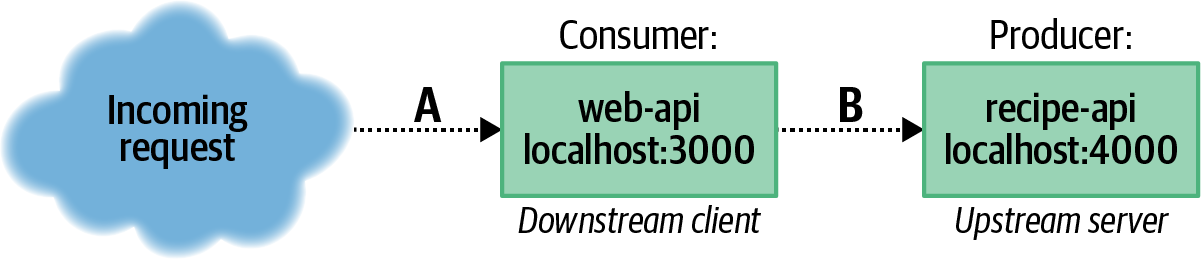
Abbildung 1-5. Die Beziehung zwischen web-api und recipe-api
Beide Anwendungen können als Server bezeichnet werden, da sie beide aktiv auf eingehende Netzwerkanfragen warten. Bei der Beschreibung der spezifischen Beziehung zwischen den beiden APIs (Pfeil B in Abbildung 1-5) kann die Web-API jedoch als Client/Verbraucher und die Rezept-API als Server/Produzent bezeichnet werden. Kapitel 2 befasst sich mit dieser Beziehung. Bei der Beziehung zwischen Webbrowser und Web-API (Pfeil A in Abbildung 1-5) wird der Browser als Kunde/Verbraucher und die Web-API als Server/Produzent bezeichnet.
Jetzt ist es an der Zeit, den Quellcode der beiden Dienste zu untersuchen. Da sich diese beiden Dienste im Laufe des Buches weiterentwickeln werden, wäre jetzt ein guter Zeitpunkt, um einige Beispielprojekte für sie zu erstellen. Lege ein Verzeichnis distributed-node/ an, in dem du alle Codebeispiele, die du für dieses Buch erstellen wirst, ablegen kannst. Die meisten Befehle, die du ausführen wirst, erfordern, dass du dich in diesem Verzeichnis befindest, sofern nicht anders angegeben. Erstelle in diesem Verzeichnis ein web-api/, ein recipe-api/ und ein shared/ Verzeichnis. Die ersten beiden Verzeichnisse enthalten verschiedeneDienstrepräsentationen. Das Verzeichnis shared/ enthält gemeinsame Dateien, um die Anwendung der Beispiele in diesem Buch zu erleichtern.4
Außerdem musst du die erforderlichen Abhängigkeiten installieren. Führe in beiden Projektverzeichnissen den folgenden Befehl aus:
$ npm init -yDies erstellt grundlegende package.json Dateien für dich. Sobald das erledigt ist, führst du die entsprechenden npm install Befehle aus dem oberen Kommentar der Codebeispiele aus. Die Code-Beispiele verwenden diese Konvention im ganzen Buch, um zu zeigen, welche Pakete installiert werden müssen, sodass du die Befehle init und install danach selbst ausführen musst. Beachte, dass jedes Projekt anfängt, überflüssige Abhängigkeiten zu enthalten, da die Codebeispiele Verzeichnisse wiederverwenden. In einem echten Projekt sollten nur die notwendigen Pakete als Abhängigkeiten aufgeführt werden.
Produzentenservice
Jetzt, da die Einrichtung abgeschlossen ist, ist es Zeit, den Quellcode zu betrachten. Beispiel 1-6 ist ein interner Recipe-API-Dienst, ein vorgelagerter Dienst, der Daten bereitstellt. In diesem Beispiel werden lediglich statische Daten bereitgestellt. Eine reale Anwendung könnte stattdessen Daten aus einer Datenbank abrufen.
Beispiel 1-6. recipe-api/producer-http-basic.js
#!/usr/bin/env node// npm install fastify@3.2constserver=require('fastify')();constHOST=process.env.HOST||'127.0.0.1';constPORT=process.env.PORT||4000;console.log(`worker pid=${process.pid}`);server.get('/recipes/:id',async(req,reply)=>{console.log(`worker request pid=${process.pid}`);constid=Number(req.params.id);if(id!==42){reply.statusCode=404;return{error:'not_found'};}return{producer_pid:process.pid,recipe:{id,name:"Chicken Tikka Masala",steps:"Throw it in a pot...",ingredients:[{id:1,name:"Chicken",quantity:"1 lb",},{id:2,name:"Sauce",quantity:"2 cups",}]}};});server.listen(PORT,HOST,()=>{console.log(`Producer running at http://${HOST}:${PORT}`);});
Tipp
Die erste Zeile in diesen Dateien ist bekannt als " Shebang". Wenn eine Datei mit dieser Zeile beginnt und ausführbar gemacht wird (indem man chmod +x filename.js./filename.js
Sobald dieser Dienst fertig ist, kannst du in zwei verschiedenen Terminalfenstern damit arbeiten.5 Führe die folgenden Befehle aus. Der erste startet den recipe-api-Dienst und der zweite testet, ob er läuft und Daten zurückgeben kann:
$node recipe-api/producer-http-basic.js# terminal 1$curl http://127.0.0.1:4000/recipes/42# terminal 2
Du solltest dann eine JSON-Ausgabe wie die folgende sehen (Leerzeichen wurden der Übersichtlichkeit halber hinzugefügt):
{"producer_pid":25765,"recipe":{"id":42,"name":"Chicken Tikka Masala","steps":"Throw it in a pot...","ingredients":[{"id":1,"name":"Chicken","quantity":"1 lb"},{"id":2,"name":"Sauce","quantity":"2 cups"}]}}
Verbraucherservice
Der zweite Dienst, ein öffentlicher Web-API-Dienst, enthält nicht so viele Daten, ist aber komplexer, da er eine ausgehende Anfrage stellen wird. Kopiere den Quellcode aus Beispiel 1-7 in die Datei web-api/consumer-http-basic.js.
Beispiel 1-7. web-api/consumer-http-basic.js
#!/usr/bin/env node// npm install fastify@3.2 node-fetch@2.6constserver=require('fastify')();constfetch=require('node-fetch');constHOST=process.env.HOST||'127.0.0.1';constPORT=process.env.PORT||3000;constTARGET=process.env.TARGET||'localhost:4000';server.get('/',async()=>{constreq=awaitfetch(`http://${TARGET}/recipes/42`);constproducer_data=awaitreq.json();return{consumer_pid:process.pid,producer_data};});server.listen(PORT,HOST,()=>{console.log(`Consumer running at http://${HOST}:${PORT}/`);});
Vergewissere dich, dass der recipe-api-Dienst noch läuft. Wenn du die Datei erstellt und den Code hinzugefügt hast, führe den neuen Dienst aus und generiere eine Anfrage mit den folgenden Befehlen:
$node web-api/consumer-http-basic.js# terminal 1$curl http://127.0.0.1:3000/# terminal 2
Das Ergebnis dieser Operation ist eine Obermenge des JSON, das bei der vorherigen Anfrage bereitgestellt wurde:
{"consumer_pid":25670,"producer_data":{"producer_pid":25765,"recipe":{...}}}
Die pid Werte in den Antworten sind die numerischen Prozess-IDs der einzelnen Dienste. Diese PID-Werte werden von Betriebssystemen verwendet, um laufende Prozesse zu unterscheiden. Sie sind in den Antworten enthalten, um deutlich zu machen, dass die Daten von zwei verschiedenen Prozessen stammen. Diese Werte sind für ein bestimmtes Betriebssystem eindeutig, d. h. es sollte keine Duplikate auf demselben Rechner geben, obwohl es auf verschiedenen Rechnern, ob virtuell oder nicht, zu Kollisionen kommen kann.
1 Selbst eine Multithreading-Anwendung unterliegt den Beschränkungen einer einzelnen Maschine.
2 "Userland" ist ein Begriff aus der Welt der Betriebssysteme und bezeichnet den Bereich außerhalb des Kernels, in dem die Anwendungen des Benutzers laufen können. Im Fall von Node.js-Programmen bezieht er sich auf den Anwendungscode und die npm-Pakete - also auf alles, was nicht in Node.js integriert ist.
3 Ein "Tick" bezieht sich auf einen kompletten Durchlauf durch die Ereignisschleife. Es ist verwirrend, dass setImmediate() einen Tick braucht, um ausgeführt zu werden, während process.nextTick() unmittelbarer ist, so dass die beiden Funktionen einen Namenstausch verdienen.
4 In einem realen Szenario sollten alle gemeinsam genutzten Dateien über die Versionskontrolle eingecheckt oder als externe Abhängigkeit über ein npm-Paket geladen werden.
5 Bei vielen Beispielen in diesem Buch musst du mehrere Prozesse ausführen, von denen einige als Clients und andere als Server fungieren. Aus diesem Grund musst du die Prozesse oft in separaten Terminalfenstern ausführen. Wenn du einen Befehl ausführst und er nicht sofort beendet wird, brauchst du wahrscheinlich ein eigenes Terminal.
Get Verteilte Systeme mit Node.js now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

