Chapter 4. Commits
A commit is a snapshot capturing the current state of a repository at a moment in time. Commit snapshots are chained together, with each new snapshot pointing to its predecessor. Over time, a sequence of changes is represented as a series of commits.
Git uses a commit as a means to record changes to a repository. At face value, a Git commit is comparable to a check-in or commit found in other version control systems. However, the similarities are only at the surface. Under the hood, the inner mechanics of how Git creates and manages commits are entirely unique.
When you make a commit, Git takes a snapshot of the current state of the index directory and stores it in the object store as discussed briefly in Chapter 2. The snapshot does not contain a copy of every file and directory in the index. Instead, Git compares the current state of the index to the previous commit snapshot and derives a list of affected files and directories when you are creating a new commit. Based on this list, Git creates new blob objects for any file that is changed and new tree objects for any directory that has changed, and it reuses any blob or tree object that has not changed.
We will discuss how to prepare the index directory for a commit in Chapter 5. In this chapter, we will focus on what happens when you make a commit. First we will first explore how commits are introduced and understand the importance of atomic changesets. Then we will look at how to identify commits and how to view commit histories.
Git is well suited to frequent commits and provides a rich set of commands for manipulating them. We will show you how several commits, each with small, well-defined changes, can also lead to better organization of changes and easier manipulation of patch sets.
Commits: Recorded Units of Change
A commit is the only method for introducing changes to a repository. This mandate provides auditability and accountability. Under no circumstances should repository data change without a record of the change via a commit! Imagine the chaos if content in the repository changed somehow and there was no record of how it happened, who did it, or why.
Commits are explicitly introduced by developers; this is the most typical scenario. However, there are occasions when Git itself can introduce a commit. For instance, a merge operation creates a new commit in the repository, in addition to any commits made by the developers before the merge. You will learn more about this in Chapter 6.
The frequency with which you create commits is pretty much up to you. Logically, you should introduce a commit at well-defined points in time when your development is at a latent stage, such as when all test suites pass.
You might think it would be time-consuming to compare the entire index to some prior state, yet the whole process is remarkably fast. This is because, as you may recall from Chapter 2, every Git object has an SHA1 hash, and if two objects, even two subtrees, have the same SHA1 hash, the objects in comparison are identical. Thus, Git can avoid swaths of recursive comparisons by pruning subtrees that have the same content.
Nevertheless, this should not mean that you should hesitate to introduce commits regularly.
Atomic Changesets
Every Git commit represents a single atomic changeset with respect to the previous state. Regardless of the number of directories, files, lines, or bytes that change with a commit,1 either all changes apply or none do.
From the perspective of the underlying Git object model, the rationale behind atomicity becomes clearer. A commit snapshot represents the state of the total set of modified files and directories, which also means that it represents a given tree state. Thus, a changeset between two snapshots represents a complete transformation from one tree state to another. Again, you can only switch from one state to the other; you cannot make incremental switches. We will discuss how to derive the differences between commits in Chapter 7.
As a developer, this is an important principle that you should not undermine. Consider the following workflow of moving a function from one file to another. If you remove the function from the first file with one commit and then add it to the second file with another commit, a small âsemantic gapâ remains in the history of your repository during which time the function is gone. Two commits occurring in the reverse order is also problematic. In each case, before the first commit and after the second one, your code is semantically consistent, but after the first commit, the code is faulty.
However, with an atomic commit that simultaneously deletes the function from the first file and adds it to the second file, no such semantic gap appears in the history. An understanding of this concept allows you to structure your commits more appropriately.
Git doesnât care why files are changing. That is, the content of the changes doesnât matter. You might move a function from one file to another and expect this to be handled as one unitary move. Alternatively, you can commit the removal and then later commit the addition. Git doesnât care. It has nothing to do with the semantics of what is in the files.
Identifying Commits
Every commit in Git can be referenced explicitly or implicitly. Being able to identify individual commits is an essential task for your routine development requirements. For example, to create a branch, you must choose a commit from which to diverge; to compare code variations, you must specify two commits; and to edit the commit history, you must provide a collection of commits.
When you reference a commit explicitly, you are referencing it using its absolute commit names, and when you reference a commit implicitly, you are doing so using its refs, symrefs, or relative commit names.
Youâve already seen examples of explicit commit references and implicit commit references in code snippets in Chapters 1 through 3. The unique, 40-digit hexadecimal SHA1 commit ID is an explicit reference, whereas HEAD, which always points to the most recent commit in a branch, is an implicit reference; see Table 4-1.
| Explicit | Implicit | |
|---|---|---|
Identified via |
Absolute commit name |
Refs, symrefs, relative commit names |
Example |
|
|
At times, when discussing a particular commit with a colleague working on the same data but in a distributed environment, itâs best to use a commit name that is guaranteed to be the same in both repositories. On the other hand, if youâre working within your own repository and need to refer to the state a few commits back on a branch, a simple relative name works perfectly.
Fortunately, Git provides many different mechanisms for naming a commit, each with advantages and some more useful than others, depending on the context.
Absolute Commit Names
The most rigorous name for a commit is its object ID, the SHA1 hash identifier. The SHA1 hash ID is an absolute name, meaning it can only refer to exactly one commit. It doesnât matter where the commit is in the repositoryâs history; the SHA1 hash ID always points to and identifies the same commit.
Each commit ID is globally unique, not just for one repository but for any and all repositories. If you compare a reference to a specific commit ID in your repository with another developerâs repository and the same commit ID is found, you can be assured that both of you have the same commit and content.
Furthermore, because the data that contributes to a commit ID contains the state of the whole repository tree as well as the prior commit state, you can also be certain that both of you are referencing the same complete line of development leading up to and including the commit.
Because a 40-digit hexadecimal SHA1 number makes for a tedious and error-prone entry, Git allows you to shorten this number to a unique prefix within a repositoryâs object database. Letâs take a look at an example from Gitâs own repository:
$git log -1 --pretty=oneline HEAD30cc8d0f147546d4dd77bf497f4dec51e7265bd8 ... A regression fix for 2.37 $git log -1 --pretty=oneline 30cfatal: ambiguous argument '30c': unknown revision or path not in the working tree. Use '--' to separate paths from revisions, like this: 'git <command> [<revision>...] -- [<file>...]' $git log -1 --pretty=oneline 30cc8da5828ae6b52137b913b978e16cd2334482eb4c1f ... A regression fix for 2.37
Note
Although a tag name isnât a globally unique name, it is absolute in that it points to a unique commit and doesnât change over time (unless you explicitly change it, of course).
Refs and Symrefs
A ref points to an SHA1 hash ID within the Git object store. Technically, a simple ref may point to any Git object, but generally it refers to a commit object. A symbolic reference, or symref, is a name that indirectly points to a Git object. Think of it as a shortcut pointing to the actual Git object. It is still just a ref.
Each symbolic ref has a definitive, full name that begins with refs/, and each is stored hierarchically within the repository in the .git/refs/ directory. There are basically three different namespaces represented in refs/:
-
refs/heads/reffor your local branches -
refs/remotes/reffor your remote tracking branches -
refs/tags/reffor your tags
Local branch names, remote tracking branch names, and tag names are some examples of refs. As an example, a local feature branch named dev is really a short form of refs/heads/dev. Whereas remote tracking branches are in the refs/remotes/ namespace, so origin/main is a short form of refs/remotes/origin/main. Finally, a tag such as v1.8.17 is short for refs/tags/v1.8.17.
When searching or referencing a ref, you may use the fully qualified ref name (refs/heads/main) or its abbreviation (main). In the event that you are searching for a branch and there is a tag with the same name, Git applies a disambiguation heuristic and uses the first match according to this list from the git rev-parse man page:
.git/ref.git/refs/ref.git/refs/tags/ref.git/refs/heads/ref.git/refs/remotes/ref.git/refs/remotes/ref/HEAD
The first matching rule (.git/ref) is usually used by Git internally. They are HEAD, ORIG_HEAD, FETCH_HEAD, CHERRY_PICK_HEAD, and MERGE_HEAD.
Note
Technically, the name of the Git directory, .git, can be changed. Thus, Gitâs internal documentation uses the variable $GIT_DIR instead of the literal .git.
Git internally maintains the following symrefs automatically for particular reasons:
HEAD-
HEADalways refers to the most recent commit on the current branch. When you change branches, Git automatically updatesHEADto refer to the new branchâs latest commit. ORIG_HEAD-
Certain operations, such as merge and reset, record the previous version of
HEADinORIG_HEADjust prior to adjusting it to a new value. You can useORIG_HEADto recover or revert to the previous state or to make a comparison. FETCH_HEAD-
When remote repositories are used,
git fetchrecords the heads of all branches fetched in the file .git/FETCH_HEAD.FETCH_HEADis a shorthand for the head of the last branch fetched and is valid only immediately after a fetch operation. Using this symref, you can find theHEADof commits fromgit fetcheven if an anonymous fetch that doesnât specifically name a branch is used. Thefetchoperation is covered in Chapter 11. MERGE_HEAD-
When a merge is in progress, the tip of the other branch is temporarily recorded in the symref
MERGE_HEAD. In other words,MERGE_HEADis the commit that is being merged intoHEAD. CHERRY_PICK_HEAD-
When cherry-picking is used via the
git cherry-pickcommand, theCHERRY_PICK_HEADsymref will record the commits you have selected for the intended operation. Thegit cherry-pickcommand is covered in Chapter 8.
All of these symbolic references are managed by the low-level plumbing command git symbolic-ref.
Warning
Although it is possible to create your own branch with one of these special symbolic names, it isnât a good idea. Also, newer versions of Git have safeguards in place that prevent you from using certain symbolic names (e.g., HEAD).
There is a whole raft of special character variants for ref names. The two most common, the caret (^) and tilde (~), are described in the next section. In another twist on refs, colons can be used to refer to alternate versions of a common file involved in a merge conflict. This procedure is described in Chapter 6.
Relative Commit Names
In addition to Git using absolute commit names, and refs, and symrefs, Git also provides mechanisms for identifying a commit relative to another reference, commonly the tip of a branch. This comes in handy when you are working on your local repository and need to quickly reference changes in past commits.
Again, youâve seen some of these names already, such as main and main^`, where main^ always refers to the penultimate commit on the main branch. There are others as well: you can use main^^, main~2, and even a complex name like main~10^2~2^2.
Except for the first or root commit,2 each commit is derived from at least one earlier commit and possibly many, where direct ancestors are called parent commits. For a commit to have multiple parent commits, it must be the result of a merge operation. As a result, there will be a parent commit for each branch contributing to a merge commit.
Within a single generation, the caret is used to select a different parent. Given a commit C, C^1 is the first parent, C^2 is the second parent, and C^n is the n^th^ parent, as shown in Figure 4-1.
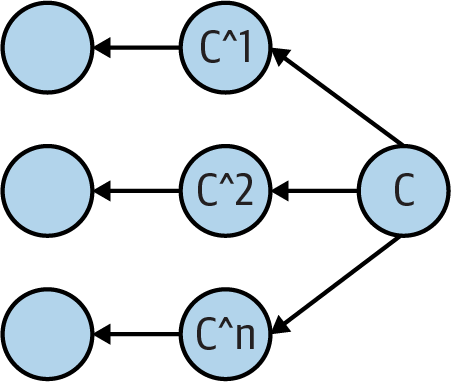
Figure 4-1. Multiple parent names
The tilde is used to go back before an ancestral parent and select a preceding generation. Again, given the commit C, C~1 is the first parent, C~2 is the first grandparent, and C~3 is the first great-grandparent. When there are multiple parents in a
generation, the first parent of the first parent is followed. You might also notice that both C^1 and C~1 refer to the first parent; either name is correct, as shown in Figure 4-2.
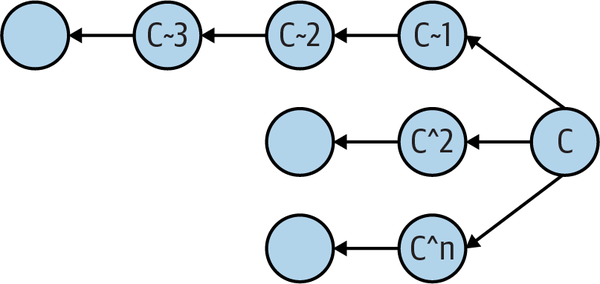
Figure 4-2. Multiple parent names with ancestors
Git supports other abbreviations and combinations as well. The abbreviated forms C^ and C~ are the same as C^1 and C~1, respectively. Also, C^^; is the same as C^1^1, and, because that means âthe first parent of the first parent of commit C,â it refers to the same commit as C~2.
Keep in mind that, in the presence of a merge operation, an abbreviated expression such as C^ or C^^ may not return a result that you expect, as it would if you were working on a branch with a linear commit history. Figure 4-3 illustrates that C^^ is not the same as C^2.
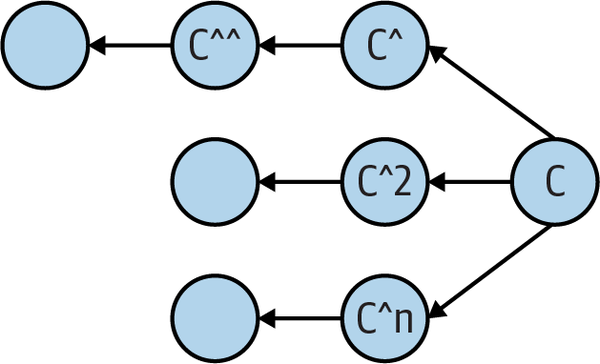
Figure 4-3. C^^ versus C^2
By combining a ref and instances of carets and tildes, arbitrary commits may be selected from the ancestral commit graph of ref. Remember, though, that these names are relative to the current value of ref. If a new commit is made on top of ref, the commit graph is amended with a new generation, and each âparentâ name shifts farther back in the history and graph.
Hereâs an example from Gitâs own history when its main branch was at commit a5828ae6b52137b913b978e16cd2334482eb4c1f. Using the command:
git show-branch --more=25
and limiting the output to the final 25 lines, you can inspect the graph history and examine a complex branch merge structure:
$git reset --hard a5828ae6b52137b913b978e16cd2334482eb4c1fHEAD is now at a5828ae6b5 Git 2.31 $git show-branch --more=25[main] Git 2.31 [main^] Merge branch 'jn/mergetool-hideresolved-is-optional' [main^^2] doc: describe mergetool configuration in git-mergetool(1) [main^^2^] mergetool: do not enable hideResolved by default [main^^2~2] mergetool: add per-tool support and overrides for the hideResolved flag [main~2] Merge branch 'tb/pack-revindex-on-disk' [main~2^2] pack-revindex.c: don't close unopened file descriptors [main~3] Merge tag 'l10n-2.31.0-rnd2' of git://github.com/git-l10n/git-po [main~3^2] l10n: zh_CN: for git v2.31.0 l10n round 1 and 2 [main~3^2^] Merge branch 'master' of github.com:vnwildman/git [main~3^2^^2] l10n: vi.po(5104t): for git v2.31.0 l10n round 2 [main~3^2~2] Merge branch 'l10n/zh_TW/210301' of github.com:l10n-tw/git-po [main~3^2~2^2] l10n: zh_TW.po: v2.31.0 round 2 (15 untranslated) [main~3^2~3] Merge branch 'po-id' of github.com:bagasme/git-po [main~3^2~3^2] l10n: Add translation team info [main~3^2~4] Merge branch 'master' of github.com:Softcatala/git-po [main~3^2~4^2] l10n: Update Catalan translation [main~3^2~5] Merge branch 'russian-l10n' of github.com:DJm00n/git-po-ru [main~3^2~5^2] l10n: ru.po: update Russian translation [main~3^2~6] Merge branch 'pt-PT' of github.com:git-l10n-pt-PT/git-po [main~3^2~6^2] l10n: pt_PT: add Portuguese translations part 1 [main~3^2~7] l10n: de.po: Update German translation for Git v2.31.0 [main~4] Git 2.31-rc2 [main~5] Sync with Git 2.30.2 for CVE-2021-21300 [main~5^2] Git 2.30.2 [main~6] Merge branch 'jt/transfer-fsck-across-packs-fix' $git rev-parse main~3^2~2^8278f870221711c2116d3da2a0165ab00368f756
Between main~3 and main~4, a merge took place that introduced a couple of other merges as well as a simple commit named main~3^2~2^2. That happens to be commit 8278f870221711c2116d3da2a0165ab00368f756.
The command git rev-parse is the final authority on translating any form of commit nameâtag, relative, shortened, or absoluteâinto an actual, absolute commit hash ID within the object database.
Commit History
The primary command to show the history of commits is git log. It has more options, parameters, bells, whistles, colorizers, selectors, formatters, and doodads than the fabled ls. But donât worry. Just as with ls, you donât need to learn all the details right away. Next, we will dive into the nooks and crannies of commit history for a repository.
Viewing Old Commits
When you execute the git log command, the output will include every associated commit and its log messages in your commit history, reachable from the specified starting point.
As an example, if you execute the git log command without any additional options, it is the same as executing the command git log HEAD. The result will be an output of all commits starting with the HEAD commit and all reachable commits way back through the commit graph (commit graphs will be discussed in the following section). The results are given in reverse chronological order by default, but keep in mind that, when Git traverses back through your commit history, the reverse order adheres to the commit graph and not the time when the snapshot was taken.
Being explicit on the starting point for the log output using the command git log commit can be useful for viewing the history of a branch. Letâs use the command to view an example output from the Git repository itself:
$ git log main -2
commit 30cc8d0f147546d4dd77bf497f4dec51e7265bd8 (HEAD -> main, ...)
Author: Junio C Hamano <gitster@pobox.com>
Date: Sat Jul 2 17:01:34 2022 -0700
A regression fix for 2.37
Signed-off-by: Junio C Hamano <gitster@pobox.com>
commit 0f0bc2124b25476504e7215dc2af92d5748ad327
Merge: e4a4b31577 4788e8b256
Author: Junio C Hamano <gitster@pobox.com>
Date: Sat Jul 2 21:56:08 2022 -0700
Merge branch 'js/add-i-delete'
Rewrite of "git add -i" in C that appeared in Git 2.25 didn't
correctly record a removed file to the index, which was fixed.
* js/add-i-delete:
add --interactive: allow `update` to stage deleted files
Log information is an authoritative source of truth. However, rolling back through the entire commit history of a large repository is likely not very practical or meaningful. Typically, a limited range of history is more informative and easier to work on.
One way to constrain history is to specify a commit range, a technique that we will cover later in this chapter. You are able to limit the history range using the form since..until. Given a range, git log shows all commits following since and running through until. You can also specify a count as a natural place to start, for example, git log -3.
Hereâs an example:
$ git log --pretty=short --abbrev-commit main~9..main~7
commit be7935ed8b
Author: Junio C Hamano <gitster@pobox.com>
Merged the open-eintr workaround for macOS
commit 58d581c344
Author: Elijah Newren <newren@gmail.com>
Documentation/RelNotes: improve release note for rename detection work
Here, git log shows the commits between main~9 and main~7, or the seventh and eighth prior commits on the main branch. Youâll learn about ranges in âCommit Rangesâ.
In the example, we introduced two formatting options, --pretty=short and --abbrev-commit. The former adjusts the amount of information about each commit and has several variations, including oneline, short, medium, and full, to name a few. The latter simply requests that the SHA1 hash IDs be abbreviated.
You can also use the format:string option to specify how the log information is customized and displayed.
Hereâs an example:
$ git log --pretty=format:"%an was the author of commit %h, %ar with%nthe commit titled: [%s]%n" \
> --abbrev-commit main~9..main~7
Junio C Hamano was the author of commit be7935ed8b, 12 days ago with
the commit titled: [Merged the open-eintr workaround for macOS]
Elijah Newren was the author of commit 58d581c344, 12 days ago with
the commit titled: [Documentation/RelNotes: improve release note for rename detection work]
You can provide the option -n together with the git log command to limit the output to at most n commits. This restricts the output according to the specified number. In addition, combining the -p option will print the patch, or changes introduced by the commit, while limiting the result sets. This helps you get more details regarding a commit by providing more context.
Hereâs an example:
$ git log -1 -p 4fe86488
commit 4fe86488e1a550aa058c081c7e67644dd0f7c98e
Author: Jon Loeliger <jdl@freescale.com>
Date: Wed Apr 23 16:14:30 2008 -0500
Add otherwise missing --strict option to unpack-objects summary.
Signed-off-by: Jon Loeliger <jdl@freescale.com>
Signed-off-by: Junio C Hamano <gitster@pobox.com>
diff --git a/Documentation/git-unpack-objects.txt b/Documentation/git-unpack-objects.txt
index 3697896..50947c5 100644
--- a/Documentation/git-unpack-objects.txt
+++ b/Documentation/git-unpack-objects.txt
@@ -8,7 +8,7 @@ git-unpack-objects - Unpack objects from a packed archive
SYNOPSIS
--------
-'git-unpack-objects' [-n] [-q] [-r] <pack-file
+'git-unpack-objects' [-n] [-q] [-r] [--strict] <pack-file
If you would like to know which files changed in a commit along with a tally of how many lines were modified in each file, the --stat option will be your go-to option.
Hereâs an example:
$ git log --pretty=short --stat main~9..main~7
commit be7935ed8bff19f481b033d0d242c5d5f239ed50
Author: Junio C Hamano <gitster@pobox.com>
Merged the open-eintr workaround for macOS
Documentation/RelNotes/2.31.0.txt | 5 +++++
1 file changed, 5 insertions(+)
commit 58d581c3446cb616b216307d6b47539bccd494cf
Author: Elijah Newren <newren@gmail.com>
Documentation/RelNotes: improve release note for rename detection work
Documentation/RelNotes/2.31.0.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Commit Graphs
So far we have been using the git log command with options that display results in a linear format. Although it is useful to understand the commit history leading up to a certain point in the timeline of a project, it isnât always clear in this flattened view that two consecutive commits may not belong to a single branch.
The --graph option used in combination with the git log command prints out a textual representation of the repositoryâs commit history. In this view, you are able to visualize the forks from a commit and the point in which branches merge in the timeline of the repository.
Following is a simplified commit history for the Git source code from its early days:
$ git log 89d21f4b649..0a02ce72d9 --oneline --graph
* 0a02ce72d9 Clean up the Makefile a bit.
* 839a7a06f3 Add the simple scripts I used to do a merge with content conflicts.
* b51ad43140 Merge the new object model thing from Daniel Barkalow
|\
| * b5039db6d2 [PATCH] Switch implementations of merge-base, port to parsing
| * ff5ebe39b0 [PATCH] Port fsck-cache to use parsing functions
| * 5873b67eef [PATCH] Port rev-tree to parsing functions
| * 175785e5ff [PATCH] Implementations of parsing functions
| * 6eb8ae00d4 [PATCH] Header files for object parsing
* | a4b7dbef4e [PATCH] fix bug in read-cache.c which loses files when merging...
* | 1bc992acac [PATCH] Fix confusing behaviour of update-cache --refresh on...
* | 6ad6d3d36c Update README to reflect the hierarchical tree objects...
* | 64982f7510 [PATCH] (resend) show-diff.c off-by-one fix
* | 75118b13bc Pass a "merge-cache" helper program to execute a merge on...
* | 74b2428f55 [PATCH] fork optional branch point normazilation
* | d9f98eebcd Ignore any unmerged entries for "checkout-cache -a".
* | 5e5128ed1c Remove extraneous ',' ';' and '.' characters from...
* | 08ca0b04ba Make the revision tracking track the object types too.
* | d0d7cbe730 Make "commit-tree" check the input objects more carefully.
* | 7d60ad7cc9 Make "parse_commit" return the "struct revision" for the commit.
|/
* 6683463ed6 Do a very simple "merge-base" that finds the most recent...
* 15000d7899 Make "rev-tree.c" use the new-and-improved "mark_reachable()"
* 01796b0e91 Make "revision.h" slightly better to use.
The repositoryâs commit history is usually visualized as a graph3 for the purpose of reference when discussing certain Git commands. It is most often related to operations that might modify the commit history of the repository. We will discuss rewriting commit histories in Chapter 8.
If you recall, in the âVisualizing the Git Object Storeâ, we included a figure to help you visualize the layout and relationship between objects stored in the Git object store. That figure is reproduced here as Figure 4-4.
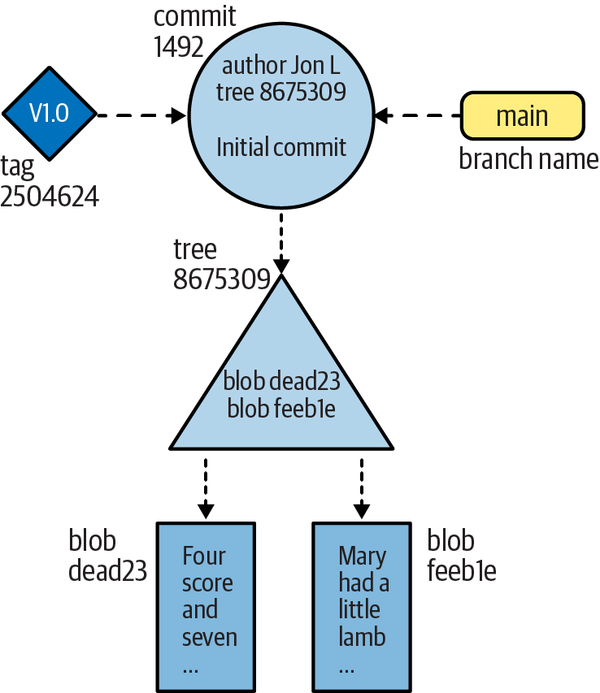
Figure 4-4. Git objects
If we were to map out a repositoryâs commit history using Figure 4-4, even for a small repository with just a handful of commits, merges, and patches, that map would become too unwieldy to render in this kind of detail. Figure 4-5 shows a more complete but still somewhat simplified commit graph in the same format. Imagine how it would appear if all commits and all data structures were rendered.
Figure 4-6 shows the same commit graph as Figure 4-5 but without depicting the tree and blob objects. Branch names are also shown in the commit graphs as supporting reference.
We can further simplify Figure 4-5 with an important observation about commits: each commit introduces a tree object that references one or more blob objects and represents the entire state of the repository when a commit snapshot was made. Therefore, a commit can be pictured as just a name, simplifying the blueprint of the repositoryâs commit history immensely.
Figures 4-5 and 4-6 are examples of a directed acyclic graph (DAG). A DAG has the following important properties:
-
The edges within the graph are all directed from one node to another.
-
Starting at any node in the graph, there is no path along the directed edges that leads back to the starting node.
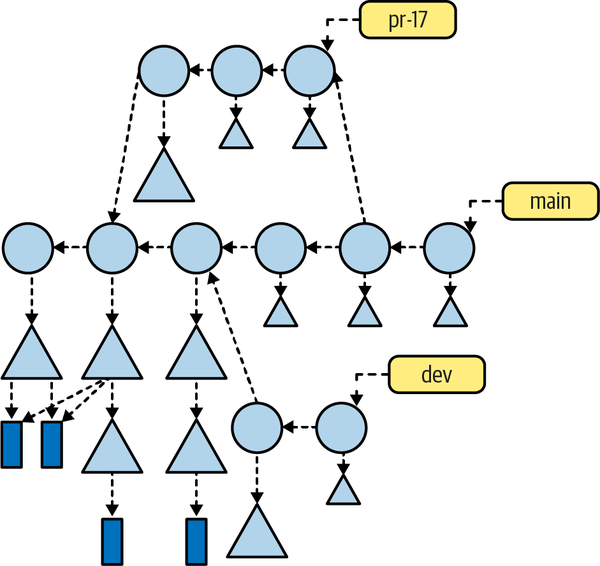
Figure 4-5. Full commit graph
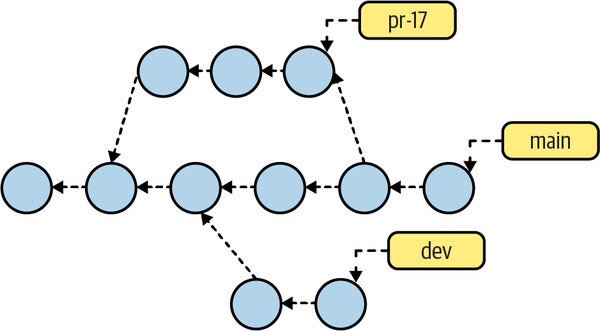
Figure 4-6. Simplified commit graph
Git implements the history of commits within a repository as a DAG. In the commit graph, each node is a single commit, and all edges are directed from one descendant node to another parent node, forming an ancestor relationship. The individual commit nodes are often labeled as shown in Figure 4-7, and they are used to describe the history of the commits and the relationship between them.
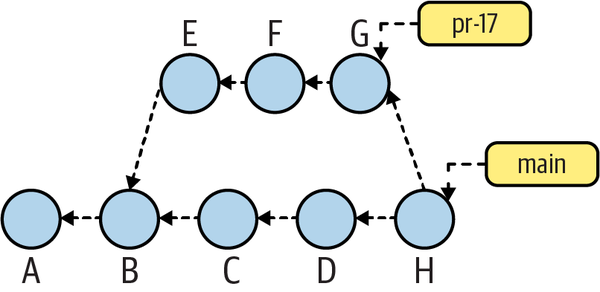
Figure 4-7. Labeled commit graph
An important facet of a DAG is that Git doesnât care about the time or timing (absolute or relative) of commits. The actual timestamp of a commit can be misleading because a computerâs clock can be set incorrectly or inconsistently. Within a distributed development environment, the problem is exacerbated. What is certain, though, is that if commit Y points to parent X, then X captures the repository state prior to the repository state of commit Y, regardless of what timestamps might be on the commits.
Building on that notion, Figure 4-7 shows the following:
-
Time is roughly left to right.
-
Ais the root commit because it has no parent, andBoccurred afterA. -
Both
EandCoccurred afterB, but no claim can be made about the relative timing betweenCandE; either could have occurred before the other. -
The commits
EandCshare a common parent,B. Thus,Bis the origin of a branch. -
The
mainbranch begins with commitsA,B,C, andD. -
Meanwhile, the sequence of commits
A,B,E,F, andGforms the branch namedpr-17. The branchpr-17points to commitG, as discussed in Chapter 3. -
Commit
His a merge commit, where thepr-17branch has been merged into themainbranch. The merge operation is discussed in more detail in Chapter 6. -
Because itâs a merge,
Hhas more than one commit parentâin this case,DandG. -
After this commit is made,
mainwill be updated to refer to the new commitH, butpr-17will continue to refer toG.
In time, as you learn and reference many DAG diagrams of commits, you will soon notice a recurring pattern:
-
Normal commits have exactly one parent, which is the previous commit in the history. When you make a change, your change is the difference between your new commit and its parent.
-
There is usually only one commit with zero parents: the root commit.
-
A merge commit has more than one parent commit.
-
A commit with more than one child is the place where history began to diverge and formed a new branch.
In practice, the fine points of intervening commits are considered unimportant. Also, the implementation detail of a commit pointing back to its parent is often elided, as shown in Figure 4-8.
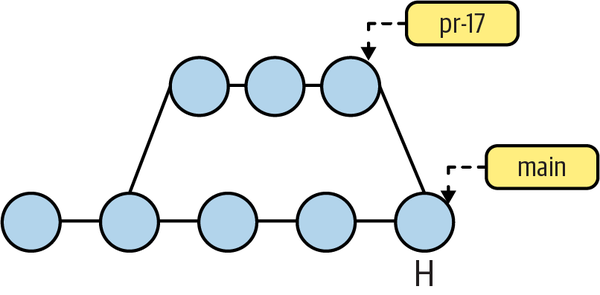
Figure 4-8. Commit graph without arrows
Time is still vaguely left to right, two branches are shown, and there is one identified merge commit (H), but the actual directed edges are simplified because they are implicitly understood.
The commit graphs are a fairly abstract representation of the actual commit history, in contrast to tools that provide concrete representations of commit history graphs. With these tools, though, time is usually represented from bottom to top, from the oldest to the most recent commit. Conceptually, it is the same information. In the next section we will briefly discuss the freely distributed gitk tool.4 In addition to gitk, a variety of other tools are available as either a paid or free version.
Using gitk to view the commit graph
A commit graph can help you visualize a complicated structure and relationship. The gitk command can draw a picture of a repository DAG representing the repositoryâs commit history.
Letâs look at an example of a simple repository with two branches and simple commits to add files:
$mkdir commit-graph-repo# Operations to add new files, create new branch and merge branch ... ... $gitk
The gitk program can do a lot of things, but letâs just focus on the DAG for now. The graph output looks something like Figure 4-9.

Figure 4-9. Merge viewed with gitk
Commit Ranges
The git log command operates on a series of commits and is one of many commands that allow you to traverse the commit history of your repository. To be precise, when you specify commit Y as a starting point to git log, you are actually requesting Git to show the log for all commits that are reachable from commit Y.
In a Git commit graph, the set of reachable commits is the set of commits that you can reach from a given commit by traversing the directed parent links. Conceptually and in terms of dataflow, the set of reachable commits is the set of ancestor commits that flow into and contribute to a given starting commit.
Note
In graph theory, a node X is said to be reachable from another node A if you can start at A, travel along the arcs of the graph according to the rules, and arrive at X. The set of reachable nodes for node A is the collection of all nodes reachable from A.
There are several options in Git that allow you to include and exclude commits within a specified range. These options are not limited to the git log command; they are also applicable for other supported Git subcommands. For example, you can exclude a specific commit X and all commits reachable from X with the expression ^X. Typically, a range is used to examine a branch or part of a branch.
A range is denoted with a double-period notion (..), as in start..end, where start and end may be specified as described in âIdentifying Commitsâ.
A commit range, start..end, is defined as the set of commits inclusive of end and exclusive of start. Usually this is simplified to just the phrase âin end but not start.â Figure 4-11 provides an illustrated explanation.
In âViewing Old Commitsâ, you saw how to use a commit range with git log. The example used the range main~9..main~7 to specify the eighth and seventh prior commits on the main branch. To visualize the range, consider the commit graph in Figure 4-10. Branch M is shown over a portion of its commit history that is linear.

Figure 4-10. Linear commit history
Recall that time flows from left to right, so M~11 is the oldest commit shown, M~6 is the most recent commit shown, and A is the eighth prior commit.
The range M~9..M~7 represents two commits, the eighth and seventh oldest commits, which are labeled A and B. The range does not include M~9 (recall the phrase âin M~7 but not M~9â).
Returning to the commit series from the earlier example, when viewed as a set operation, hereâs how M~9..M~7 specifies just two commits, A and B:
-
Begin with everything leading up to
M~7, as shown in the first line of Figure 4-11.-
Find everything leading up to and including
M~9, as shown in the second line of the figure.-
Subtract
M~9fromM~7to get the commits shown in the third line of the figure.
-
-
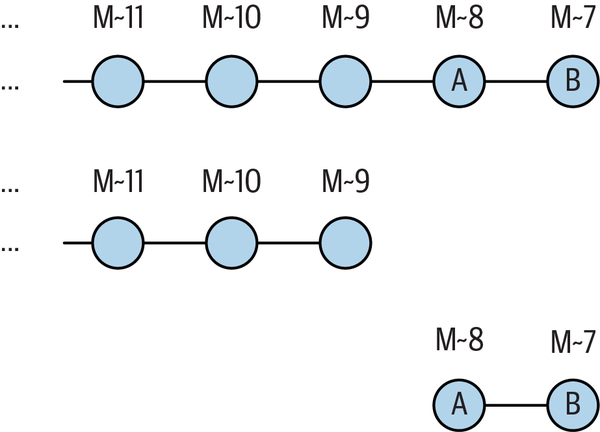
Figure 4-11. Interpreting ranges as set subtraction
When your repository history is a simple linear series of commits, itâs fairly easy to understand how a range works. But when branches or merges are involved in the graph, things can become a bit tricky, so itâs important to understand the rigorous definition.
Letâs look at a few more examples. Keep in mind that these examples are abstract representations only and are designed to be simple and easy to comprehend. The merge operation is used to support the concept, and its technical aspects will be described in detail in Chapter 6.
We start with the case of a main branch with a linear history, as shown in Figure 4-12. The sets B..E, ^B E, and C, D, and E are equivalent.

Figure 4-12. Simple linear history
In Figure 4-13, the main branch at commit V was merged into the feature branch
at B.
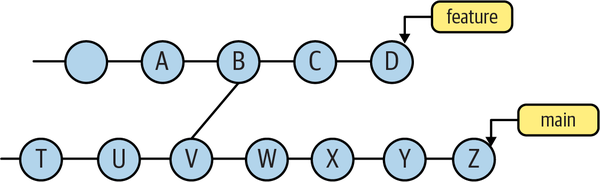
Figure 4-13. main branch merged into feature branch
The range feature..main represents those commits in main but not in feature. Because each commit on the main branch prior to and including V (i.e., the set {â¦â, T, U, V}) contributes to feature, those commits are excluded, leaving W, X, Y, and Z.
The inverse of the previous example is shown in Figure 4-14. Here, feature has been merged into main.
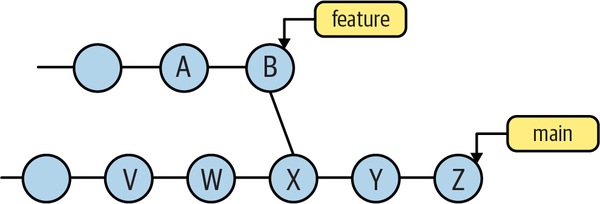
Figure 4-14. feature branch merged into main branch
In this example, the range feature..main, again representing those commits in main but not in feature, is the set of commits on the main branch leading up to and including V, W, X, Y, and Z.
However, we have to be a little careful and consider the full history of the feature branch. Consider the case where it originally started as a branch of main and then merged again, as shown in Figure 4-15.
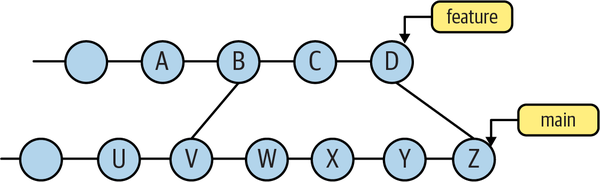
Figure 4-15. A branch and a merge
In this case, feature..main contains only the commits W, X, Y, and Z. Remember, the range will exclude all commits that are reachable (going back or left over the graph) from feature (i.e., the commits D, C, B, A, and earlier), as well as V, U, and earlier from the other parent of B. The result is just W through Z.
Finally, just as start..end can be thought of as representing a set subtraction operation, the notation Aâ¦âB (using three periods) represents the symmetric difference between A and B, or the set of commits that are reachable from either A or B but not from both. Because of the functionâs symmetry, neither commit can really be considered a start or end. In this sense, A and B are equal.
More formally, the set of revisions in the symmetric difference between A and B, Aâ¦âB is given by thte following:
$ git rev-list A B --not $(git merge-base --all A B)
Letâs look at the example in Figure 4-16.
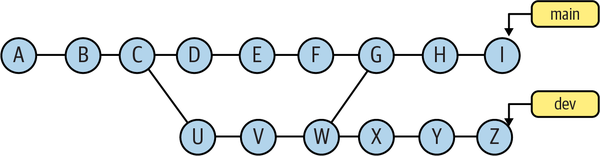
Figure 4-16. Example of symmetric difference
The commits that contribute to main are (I, H, . . . , B, A, W, V, U). The commits that contribute to dev are (Z, Y, . . . , U, C, B, A).
The union of those two sets is (A, . . . , I, U, . . . , Z). The merge base between main and dev is commit W. In more complex cases, there might be multiple merge bases, but here we have only one. The commits that contribute to W are (W, V, U, C, B, and A); those are also the commits that are common to both main and dev, so they need to be removed to form the symmetric difference: (I, H, Z, Y, X, G, F, E, D).
It may be helpful to think of the symmetric difference between two branches, A and B, as âshow everything in branch A or in branch B but only back to the point where the two branches diverged.â
We can compute each piece of the symmetric difference definition:
A...B = (A OR B) AND NOT (merge-base --all A B)
Now that weâve described what commit ranges are, how to write them, and how they work, itâs important to reveal that Git doesnât actually support a true range operator. It is purely a notational convenience that A..B represents the underlying ^A B form. Git actually allows much more powerful commit set manipulation on its command line. Commands that accept a range are actually accepting an arbitrary sequence of included and excluded commits. For example, you could use:
$ git log ^dev ^feature ^bugfix main
to select those commits in main but not in any of the dev, feature, or bugfix branches.
Once again, all of these examples may be a bit abstract, but the power of range representation really comes to light when you consider that any branch name can be used as part of the range. As described in âTracking Branchesâ, if one of your branches represents the commits from another repository, you can quickly discover the set of commits that are in your repository and are not in another repository!
Summary
We started this chapter by introducing commits as a recorded unit of change, further explaining the importance of commits needing to be recorded as an atomic changeset. Next, we gradually built up your proficiency in commits by first introducing you to the various ways in which a commit can be identified. We stressed the importance of learning how to identify commits because this is the building block for many intermediate to advanced Git commands and concepts that will help you confidently tackle any complex requirements that may come your way when dealing with repositories in future projects. We also discussed how you can view a repositoryâs commit history along with methods to effectively constrain a range or set of the history to better understand how a repository came to being in its current state. Understanding commit ranges may be tricky in the beginning, but you will be able to comprehend the overall idea when you start analyzing repository commit history with specific use cases, especially those that require you to traverse the commit history to a specific state of the repository.
1 Git also records a mode flag indicating the executability of each file. Changes in this flag are also part of a changeset.
2 Yes, you can actually introduce multiple root commits into a single repository. This happens, for example, when two different projects and their entire repositories are brought together and merged into one.
3 A graph is a collection of nodes and a set of edges between the nodes. Commonly, the directed acyclic graph (DAG) diagram is used when explaining Git commit history.
4 The gitk command is not a git subcommand; it is its own independent command and installable package.
Get Version Control with Git, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

