Chapter 4. Apply Search: From Simple to Advanced Patterns
In the previous chapter, we discussed how search works in a data catalog and how understanding the search mechanics can improve how you search and thus drive up the value of your data catalog. You have to remember that search is dependent on how well you organize the data in your data catalog. Even if you compose the perfect query statement for what you need, the search will struggle to return anything if the data catalog has poor metadata.
This brings us to how to apply search. Applying search is a craft that is different from understanding the technology itself. First of all, when searching for data, you need to search like a librarian who is trained in searching for data, and not like a data scientist who is trained to search in data. With a librarian’s mindset, you will find creative ways to unlock search features. Simple search can be used in a variety of ways that increase and decrease precision in order to search more broadly or for only very few hits. Browsing enables navigation in data and understanding its context—and an additional benefit is that this context can be used to refine both simple and complex search. And just as simple search can be used in many different ways, so can complex search.
What you will learn in this chapter is only the beginning. You will need to further adapt and refine applied search so that it matches the language and purpose of your company.
Search Like Librarians—Not Like Data Scientists
Data scientists excel at analyzing data—from small to massive datasets, they have the tools and mindset to search in the data to extract the findings they need. That’s their superpower. Searching for the data for them to work on, however, can be a real challenge because the skills that make them very good at searching in data don’t necessarily apply to searching for data. As you’ll recall from Chapter 3, there’s a significant difference between searching for data versus searching in data.
Librarians, on the other hand, are very good at locating all kinds of material under the sun— books, periodicals, papers, everything! If you ask for it, they could probably search for it and find it. And their superpowers also include searching for data and knowing what data you need.
Unlike data science, which has gained importance only in the last decades, library and information science (LIS) has existed for hundreds of years, with as many years perfecting the art of organizing knowledge and searching for it.
To search as a librarian means, first and foremost, being good at assessing an information need, because the information need determines how you search for data. Information need was coined as a term in 1962 by Robert S. Taylor as the way we ask questions to reference databases.1
Your information need can be big or small. Ask yourself whether you are searching for:
-
Everything
-
A few good things
-
The sole right thing
-
A thing you need again2
Your information need determines how you search for data, as needs express different sizes and intentions.
Everything entails complex search—and you’re aiming for high recall at the expense of precision. But you can do this in many different ways, as you will see later in this chapter.
A few good things is an information need that is not that clear cut. You can be searching for either relatively high recall or relatively high precision, but not both.
The sole right thing, as the name alludes, aims at finding just one asset, or one precisely defined set of assets. Therefore, these searches strive for precision.
Finally, a thing you need again relies on assets that you already know. It also strives for precision, but it’s less difficult to search for than the sole right thing.
What you need to keep in mind is that searching for data in metadata repositories like a data catalog can be a long process (just as Taylor already pointed out in 1962). So don’t get impatient. We are used to being able to google everything, but that’s simple search playing tricks on you. Searching for data is not always like that; it can take many steps before you find what you are searching for, and that’s OK. You may need to make adjustments to searches, both of the translations of what is intended with a search into how the specific IRQL of the system works and, from that point on, what terms are included, which of those are subsequently excluded or modified, and so on, in a multiple-step long search for the most relevant and valuable hits. This means that search is not just a matter of translating one information need into one search. The process is way more subtle, and it takes experience.
Searching for data is like driving a car. Sometimes, you’re just out for a short ride to pick up stuff. Occasionally, you’re on a long, tiresome road on a straight line. Once in a while, you cross mountains with endless sharp corners, the feeling of vertigo, up and down, until you reach the destination. Or it happens that you go one place only to discover that you need to go to a second place, then a third place, before you can return home with the things you were out to get. Sometimes you find yourself in areas with no rules, sometimes the traffic is overwhelming, sometimes the roads are old and full of holes. And sometimes, you just go as fast as you possibly can because it’s fun.
Librarians combine all sorts of methods and techniques when they search—you should, too. The next sections will go over some of the most commonly applied search patterns. Although they each can work fine in isolation, they work best when combined.
Search Patterns
Have you ever noticed that how you search depends on what you’re searching for? In this section, I will discuss typical patterns of applied search. You will see how recall, precision, serendipity, exhaustivity, specificity, and other concepts are at play when you search.
All the search patterns are listed in Table 4-1, with a search name, search type, a short description, and the search’s relative level of precision and recall. Note that precision and recall are not applicable to browsing.
Tip
Notice how the search type softens the distinction between simple search and complex search.
| Search name | Search type | Description | Precision | Recall |
|---|---|---|---|---|
| Basic simple search | Simple search | A few precise hits and a lot of noise | High | Low |
| Detailed simple search | Simple combinatorial search | Slowly formulated simple search, because the search must be precisely formulated | High | Low |
| Flexible simple search | Simple combinatorial search | Truncated search that eases and broadens a simple search | Low | High |
| Range search | Complex combinatorial search | Range search that allows retrieval of assets between two values | High | Low |
| Block search | Complex combinatorial search | Combination of selected terms to depict a topic | Low | High |
| Statement search | Complex combinatorial search | Long statement of precise conditions assets must meet | High | Low |
| Glossary browsing | Browse search | Lookups after specific word results in lists of words in the glossary that can be browsed | — | — |
| Domain browsing | Browse search | Domains as explained in Chapter 3 | — | — |
| Lineage browsing | Browse search | Lineage as explained in Chapter 3 | — | — |
| Graph browsing | Browse search | Graphs as explained in Chapter 3 | — | — |
Let’s talk about each one.
Basic Simple Search
In general, your casual searches during a typical workday are probably basic simple searches with a couple words in the search bar. You do these kinds of searches when you are not aiming for anything near total recall—you just want something good, fast. What matters in this type of search is the hit at the top of the search results. That hit, seen in isolation from the rest of the search result, must be a perfect precision hit. Anything below that top hit doesn’t matter.
Simple searches use plain-language search terms and not query language. Basic simple search is the least complicated kind of search you can do, as it consists of only one or two plain-language search terms, such as “good weather” or “summer.”
For example, let’s say that a sales rep for Hugin & Munin assigned to Sweden wants to find the latest, most relevant sales BI report for their area. They might do a basic simple search for sales, as shown in Figure 4-1. The sales rep, being an average end user, expects the top result to be the exact thing they were looking for. If it’s not, then they move on to more-complex search patterns to try to find what they are looking for. Because simple search takes into account all of the technologies mentioned in Chapter 3, such as prediction, fuzzy logic, and history of search behavior, it does a good job of figuring out what the average user wants.

Figure 4-1. Simple search for sales
The sales rep will expect to get the latest, most relevant sales BI report for the area the user is a sales rep in. This reflects the most precise, relevant hit on top, based on who the user is, what kind of data most interests the user, and how the user has previously searched.
Tip
If your data catalog is based on a knowledge graph, expect to have a very powerful simple search feature. Search results will enlighten you as to the business contexts of a given asset and be ranked with high precision. This is, for example, the case with Google’s Knowledge Graph.
Basic simple search will be the only way many end users will use the data catalog. This search engine–like experience creates an impression of ambient findability—but that’s not what it is. It’s the easiest kind of search. It will offer end users precision at the expense of recall. Users will be able to find the one right thing at the top of the search results.
Warning
It’s common for data catalog providers to demonstrate basic simple search as the only way to search in sales material—it’s often this exact way of searching that handles whatever users are searching for. Nevertheless, it’s impossible for this kind of search to deliver on all information needs. But other kinds of searches are more difficult and time-consuming, and therefore rarely promoted.
Detailed Simple Search
Sometimes you are looking for one type of thing and only that—and you know how to express it, if you concentrate. This is a relatively simple search that is not fast, because you have to get your search syntax right; it’s detailed. You might even have to do a couple of initial searches to test that everything works as intended.
Detailed simple search is when you need to use a bit of query language to formulate your search statement. This search is slow, because it relies on users to type exact values, which requires attention, and this slows down the search process. The search type is a simple combinatorial search, because it’s a relatively simple search statement that is combined with only one Boolean operator. If you take a look at the spectrum of search in Figure 3-4, we are moving away from easy toward difficult.
In Hugin & Munin, our fictional sustainable architecture company, end users make use of their well-curated global glossary, which allows them to search in finely granulated words, e.g., for types of wood: heartwood, spruce, pine, and so on. Words for wood in the global glossary are the standard English names for kinds of wood combined with their Latin name. Let’s say you want to search for assets with the steward John Miller that hold data about ash trees from the global glossary, like this:
| GlobalGlossary:Ash Fraxinus AND AssetSteward:John Miller |
It’s possible to type this in the simple search view without completely losing the overview of the search typed inside the simple search bar, as in Figure 4-2.

Figure 4-2. Detailed simple search
This search gathers all the assets with the global glossary term “Ash Fraxinus” that have “John Miller” as an asset steward. In this search, the user would perhaps need to determine the right way to express the type of wood in the global glossary before performing the search. This search will take some time to build but will deliver precise results, as only the assets with the distinct characteristics of the search are returned. So, unlike basic simple search, all hits are relevant here, precision is high and recall is low, and the search itself takes a little time to create.
You can also loosen the syntax and move away from a detailed simple search pattern into a flexible search pattern. In that case, simple searches are not totally precise but become relatively fast.
Flexible Simple Search
You may also sometimes need to perform searches that are imprecise and that will require some perusing through the search results to find the assets you had in mind.
That’s flexible simple search, and it’s a little faster to write than detailed simple search because it depends less on exact syntax; you don’t need to know the exact values in your query statement. Flexible simple search is also a simple combinatorial search, but it allows for a larger set of search hits and a higher recall, at the expense of precision.
For example, a group of Hugin & Munin employees in the communications department need to know what kinds of wood the company uses in order to include some details in a press release. They heard that the info is in a CSV file. They don’t know how the asset is described in the catalog except that it contains data on wood and it’s a CSV file. They might search the following, shown in Figure 4-3:
| FreeGlossary:*Wood* AND FormatDefault:.csv |

Figure 4-3. Flexible simple search
This search results in all assets that represent CSV files and that have folksonomy terms with the word “wood” in them, but truncated on both sides so that the results are open to all combinations with wood. So, for example, free glossary terms such as “wooden floor,” “beautiful wood,” “woods,” and so on are automatically included in the search.
This type of search will provide high recall and therefore compromise on precision. And that’s the point: the end user does not know how to search this in a way that delivers complete precision and must therefore aim for higher recall to retrieve a group of assets wherein the asset is located.
Range Search
Sometimes you have to search for something between two points, such as dates or anything that holds organizational logic in serial numbers.
That’s done with range search. It’s a more refined complex combinatorial search type, which uses one or more Boolean operators and at least two values that establish a range.
For example, if you were looking for a given set of hypotheses that were tested sometime around when particular projects were carried out, you might search research projects like this:
| > RES.100.7.1003 AND < RES.100.7.1837 |
It can also be room numbers on floor plans, equipment, and so on.
For example, a project team in Hugin & Munin wants to analyze all pictures of heartwood between November 2012 and February 2018. They search like this, shown in Figure 4-4:
| AssetTypeFree:Picture of heartwood AND (< 01.31.2018 AND > 10.31.2012) |
That search returns all hits that refer to pictures of heartwood in the specified period of time.

Figure 4-4. Range search
Block Search
Say an unhappy customer has decided to file a lawsuit against Hugin & Munin. The house Hugin & Munin built for him has cracks in the facade, and the customer argues the wood that the house is built of is not solid enough.
Block search is a very comprehensive complex combinatorial search, where you are searching for an entire topic. Generally, a lot of different things and words are at play in such a search, and you order those in related groups as blocks, hence the name block search.
The lawyers in Hugin & Munin start their due diligence by searching. Using their basic training in DCQL, they search the data catalog for reports and test data that examine the hardiness of different kinds of wood in the company’s own constructions. They combine a large selection of words to maximize recall—they have to get every single potentially relevant asset, with the consequence of having little precision, so they expect to be perusing quite a lot through the search results. They search as follows, shown in Figure 4-5:
| (DomainTerm:((Pine OR Ash OR Beech OR Oak OR Wood) NOT Linden) OR FreeTerm:Wood OR GlobalTerm:(Pine Pinus OR Ash Fraxinus OR Beech Fagus OR Oak Quercus) NOT Linden Tilia) AND DomainTerm:(Hardiness OR Solidity OR Endurance OR Resilience) |

Figure 4-5. Block search
The search results will show assets that have one or more combinations of terms for wood and terms for hardiness.
The search consists of domain glossary terms from different domains that describe types of wood in standard English. The assets must have one or more of these words, unless the asset holds the next value, the free glossary term wood, or one or more of the global glossary terms for wood—as the word “wood” is not a term found in the global glossary. It can also hold a mix of these words. If one or more of all these criteria are met, then these must be matched with the domain glossary terms for hardiness.
But not all lawyers have been trained in the data catalog’s query language, and they get a little dizzy trying to control the syntax while at the same time focusing on the semantics. Therefore, some of the lawyers just use the search builder. They enter the search builder from the advanced search field. The search builder allows end users to formulate their search with point-and-click options, which removes the stress of checking the syntax and focuses only on the semantics. You can see the search builder in Figure 4-6.
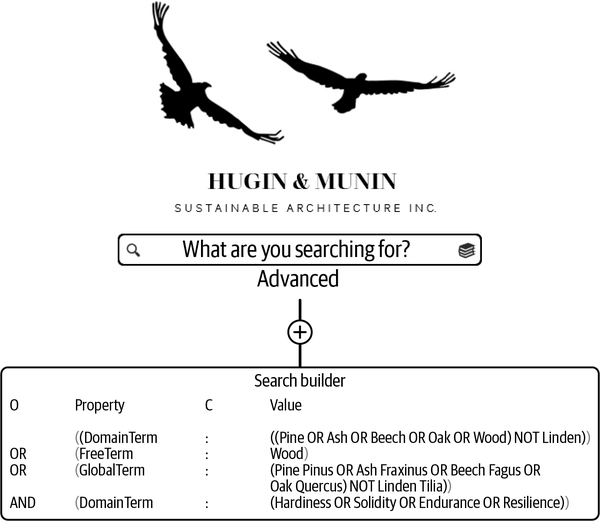
Figure 4-6. Search builder
The search builder in Hugin & Munin creates a visually navigable overview of long searches. O stands for operator, C for condition. All the parentheses that are gray are optional; they become active if the end user clicks them. This way of cutting up the complex search makes it easier to keep an overview of what the search does, so that the semantics especially are easy to keep an eye on.
Note
Search builders like the one in Figure 4-6 are standard components in reference databases such as PubMed. Many data catalogs, such as data.world, also have a search builder.
This type of search is also called block search in LIS. It’s practiced as a method to obtain large sets of search results for complex searches. Normally, this kind of search has several phases, where words are added, others removed, in a series of adjustments that make the searcher capable of translating what data is needed to the language and structure of the data catalog, based on analysis of the hits retrieved from the previous steps in the search.
Moreover, this is a kind of search that makes use of how your data catalog glossaries are applied. The higher the specificity—that is, the more the terms from the glossaries are actually applied on the assets in the data catalog (using the exhaustivity of the glossaries), the more your recall mechanism will work.
Tip
Remember Zipf’s law from Chapter 3? If you only rely on crawled metadata, your chance of success with block search is low. You need glossary terms applied by humans, not machines, to make your assets distinguishable from each other.
Block search is difficult to build, but it is very important to master. In legal, compliance, and complex searches for innovation use cases, block search is the kind of search that will make or break a positive outcome for your company.
And sometimes you have to do a complex search that is not really a well-defined topic with glossary terms assigned to it, but a more haphazard accumulation of things that someone happens to want to know more about.
Statement Search
Most complex combinatorial searches are statement searches: an assorted blend of people, systems, domains, and everything else you can build searches from. These kinds of searches are necessary to make in many disparate situations, ranging from managing the data catalog, to gathering data for a project, to ensuring that assets associated with a given steward who is changing position are passed on to a new steward (for this latter use case, check out Chapter 7 on lifecycles).
Figure 4-7 shows an example of a search performed by the Hugin & Munin data discovery team. They want to find out how many Tableau reports do not have an asset owner in Legal, Finance, or IT.
This search returns all Tableau reports from those departments that have been created after January 1, 2022, that do not have an owner.
The data discovery team will use this search result to reach out to the data stewards for the assets to ask that an owner of the asset be added.

Figure 4-7. Statement search
Browsing Patterns
Browsing patterns are in fact search patterns, but they usually don’t require the end user to phrase search statements (except for glossary lookups). Instead, browsing works by clicking back and forth in either lists of glossary terms, lineage, or graphs. Think of browsing as a phase between other types of search that makes users discover and learn the language and domains of their company. It will allow them to search with more savvy if they can browse the data landscape.
Glossary Browsing
Sometimes, you may just want to explore a topic to better understand a domain. You have many options, but one of the ways is to browse glossaries.
An example from Hugin & Munin is a new employee wanting to better understand how paint is used as the surface treatment for wooden houses. The user types “paint” in the dedicated glossary search bar, as seen in Figure 4-8.
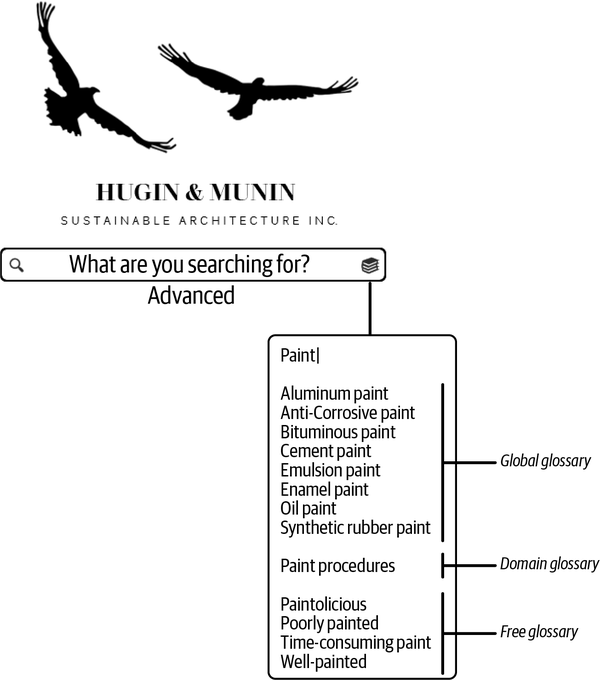
Figure 4-8. Glossary browsing after paint
Here, the difference between the different glossaries stands out clearly: the global glossary is made up of highly controlled terms that apply across the company, the domain glossary refers to a single domain, and the free glossary just adds whatever people like. Clicking deeper into the glossaries reveals the level of organization in them, as depicted in Figure 2-11.
Domain Browsing
Domain browsing is when you go through the capabilities or processes in your company. These kinds of browsings are often driven by lack of context—they allow you to get ideas of where potentially relevant assets could be located. For example, maybe someone is working on a project regarding customer profiles and they want to know if it falls under the purview of Customer Information Management or Customer Preference Management. This might tell them who they need to speak to regarding issues.
They can also just be driven by sheer curiosity—and that kind of browsing is never a waste of time, as it allows you to better understand the data landscape of your company. If you want to see how domain browsing looks, go back to Figure 3-7.
Lineage Browsing
Sometimes, you might want to know where a given asset stems from (upstream), or where it has traveled to (downstream). Browsing upstream in lineage enables you to find out why a given data analytics report is broken. Lineage browsing also allows you to test what the consequences would be downstream of changes in a given asset upstream, if you were to make a change. You could also be browsing lineage to discover potential improvements to existing data processing flows or to discover unused assets in the environment (like a table with flows going in but no flows going out). Or you can search for lineage that has changed (or not changed) in time spans to identify old data pipelines.
A DPO can also document how sensitive data is processed downstream. I show such examples of applied lineage search in Chapter 5.
Note
Remember that lineage functionality will vary from vendor to vendor and that, accordingly, your applied search possibilities will vary: remember to assess lineage functionality in your vendor selection, if this criterion is important to you. This assessment is complex, and it requires substantial time to find the ups and downs of a given lineage functionality. You can, for example, expand lineage to include lineage from the past of a given asset, choose lineage functionality that enriches data lineage with additional metadata to track how high-quality data assets travel, and so on.
Graph Browsing
The ultimate way of browsing your data is by visually exploring your knowledge graph—if your data catalog is built on a knowledge graph, as discussed in Chapters 1 and 2. The knowledge graph links all parts of your data catalog beautifully together. It’s the manifestation of all the actual nodes in your metamodel. It’s the ideal way to maximize serendipity in your search, as you can click your way around everything in the catalog and discover new connections.
Graphs are excellent at providing overviews of social networks. Graphs are used as such in these two sectors, for example:
-
Law enforcement, military, and intelligence services
-
Universities and academia in general
For police, military, and intelligence services, networks of people and the things they use and have (such as phones, weapons, documents) visually laid out in a graph is an absolute must. In police investigations, graphs can map criminal organizations like Mafia families or gangs and help solve the crimes these organizations commit by displaying how people—and networks of people—are linked. Military strategies and tactics on the battlefield are nowadays powered by graphs; they are part of active warfare to map and defeat the enemy. For intelligence services, graphs generate overviews of networks of extremists under surveillance, such as political or religious extremists. The graph overview helps intelligence agencies to infiltrate and dissolve these networks before they act. Graph solutions for these kinds of organizations are provided by IBM and Palantir, for example.
For universities and academia in general, graphs are used to map and visualize networks of researchers or research topics. These are bibliometric maps (sometimes also called clusters and networks). A beautiful example is this bibliometric cluster of mental health research. Bibliometric maps are used to evaluate the performance of research activities in universities, and also in industrial predictions, since patent clusters indicate what kind of products specific industries are planning to launch.
Note
The examples are included to explain the value of browsing in graphs—and also potentially in data catalogs, where this feature is still in its infancy.
Let’s look at an example. In Figure 4-9, a PR manager in the communications department in Hugin & Munin searches for promotion data; some of the search results seem skewed, but it is hard to tell why. The PR manager then searches for “promotion” one more time. The top hit is a dataset with promotion planning details, and the PR manager opens that hit as a graph. The graph visualizes all the terms, processes, and data sources that relate to promotion. Suddenly, the PR manager understands why the results are skewed. Someone has added promotion as a free glossary term not to depict communication but to depict career advancement. That term is followed by an exclamation mark (!) because the data catalog automatically detects that it is a duplicate to the domain glossary term, which defines PR activities. Therefore, assets tagged with the free glossary term should be filtered out of the search. With this knowledge, the PR manager can better shape the search to reflect what they are searching for.
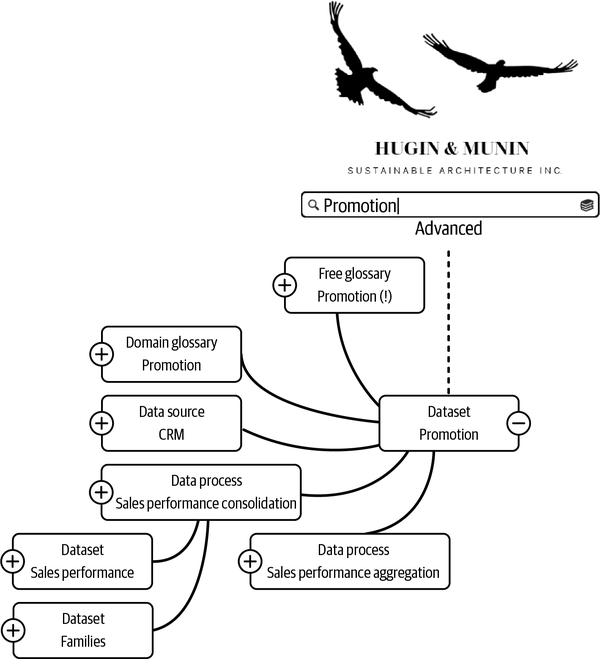
Figure 4-9. Graph browsing
Searching a Graph-Based Data Catalog
As depicted in Figure 3-4, search can be divided into a spectrum. It goes from easy executable simple searches to more-complex advanced searches. In the latter case, the end user has to remember both the syntax of the IRQL and assess if the semantics of the query statement actually reflect what is being searched for. This is demanding, but useful. The IRQL that the user searches with has been designed by the data catalog provider—I consider DCQL as the minimum acceptable IRQL. It is likely that the IRQL will expand over time, as the technology evolves with the feedback from customers. But an IRQL will never allow you to search for everything.
However, for knowledge graph–based data catalogs, it is possible to push search even further and actually search for everything in the data catalog. It requires search skills beyond the IRQL of the specific catalog: instead, here you would have to master the DQL that matches the technology of the catalog in question, for example, SPARQL, Cypher, or Gremlin. Take into consideration that data lineage can be graph-based as well and that, if so, this makes data lineage searchable in a similar fashion.
Searching with a DQL inside a data catalog requires a technical skill set that not all data catalog use cases rely upon. But if you truly want to organize your data just as you like, and search it however you want, then this is what it takes. Think of it like this: an IRQL is always designed by the provider; it will contain some of the elements that are useful to search for, and leave others out. But the graph DQL lets you search for everything you want because it is set up to search for everything that the metamodel contains, however it has been defined.
Summary
In this chapter you have become familiar with how to apply search. Key takeaways include:
-
When searching for data, you need to apply the mindset of a librarian, not a data scientist. Searching for data is a discipline that relies on search mechanics, but it also takes experience and understanding your company’s data and language.
-
Basic simple search is the way of searching that most end users will apply. A well-structured data catalog will deliver precise simple search, especially if it’s based on a knowledge graph. But expect a lot of mess deeper down in the search results also.
-
Detailed simple search requires you to know the syntax of the IRQL in your data catalog. So it takes a little time to write, or just experience, but you get super-precise hits in return.
-
Flexible simple search also depends on understanding IRQL, but it opens up the search to give more results, increasing your recall and decreasing your precision, while at the same time still being a better way to target a well-defined topic than basic simple search.
-
Range search is searching in intervals, e.g., a time span. This kind of search will result in high precision and low recall.
-
Block search is a structured way to search for a complex topic using IRQL. It works best if your glossaries are exhaustive and used with great specificity.
-
Statement search is a way to search for a complex topic; it simply puts a lot of things together in a search. It’s not unstructured, but it’s haphazard.
-
Glossary browsing is searching in which you go exploring to get informed and enlightened about business terminology.
-
Domain browsing, lineage browsing, and graph browsing are ways of searching vertically, horizontally, and relationally, respectively, by clicking through the data landscape.
In the next chapter, we will look at how engaging with stakeholders makes all the difference when implementing the data catalog. If everyone understands the value of the data catalog and uses it properly, implementation will go very smoothly. But that is not always the case, and the next chapter goes through how to unite stakeholders for a well-developed data catalog.
1 Robert S. Taylor, “The Process of Asking Questions,” American Documentation 13, no. 4 (October 1962): 391–96.
2 Information needs can be grouped differently; this grouping is from Louis Rosenfeld et al., Information Architecture: For the Web and Beyond (Sebastopol, CA: O’Reilly, 2015), 45.
Get The Enterprise Data Catalog now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

