Chapter 1. Introduction to Data Catalogs
In this chapter, you’ll learn how a data catalog works, who uses them, and why. First, we’ll go over the core functionalities of a data catalog and how it creates an overview of your organization’s IT landscape, how the data is organized, and how it makes searching for your data easy. Search is often underutilized and undervalued as part of a data catalog, which is a huge detriment to data catalogs. As such, we’ll talk about your data catalog as a search engine that will unlock the potential for success.
In this chapter, you’ll also learn about the benefits of a data catalog in an organization: a data catalog improves data discoverability, subsequently ensuring data governance and enhancing data-driven innovation. Moreover, you’ll learn about how to set up a data discovery team and you’ll learn who the users of your data catalog are. I’ll wrap up this chapter by explaining the roles and responsibilities in the data catalog.
OK, off we go.
The Core Functionality of a Data Catalog
At its core, a data catalog is an organized inventory of the data in your company. That’s it.
The data catalog provides an overview at a metadata level only, and thus no actual data values are exposed. This is the great advantage of a data catalog: you can let everyone see everything without fear of exposing confidential or sensitive data. In Figure 1-1, you can see a high-level description of a data catalog.

Figure 1-1. High-level view of a data catalog
A data catalog is basically a database with metadata that has been pushed or pulled from data sources in the IT landscape of a given company. The data catalog also has a search engine inside it that allows you to search the metadata collected from the data sources. A data catalog will almost always have a lot more features, but Figure 1-1 illustrates the necessary core components. And in this book, I argue that the search capability is the single most important feature of data catalogs.
In this section, we will discuss the three key features of the data catalog, namely that it creates an overview of the data in your IT landscape, it organizes your data, and it allows you to search your data. Let’s take a brief look at how data catalogs do this.
Note
With a data catalog, your entire organization is given the ability to see the data it has. Used correctly, that transparency can be very useful. For example, data scientists will no longer spend half their time searching for data, and they will have a much better overview of data that can really deliver value. Imagine the possibilities. They could be using their newfound time to analyze that data and discover insights that could lead the enterprise to developing better products!
Create an Overview of the IT Landscape
Creating an overview of your IT landscape involves finding and displaying all the data sources in it, along with listing the people or roles attached to it.
A data catalog can pull metadata with a built-in crawler that scans your IT landscape. Alternatively, it can get metadata pushed to it by having your data systems report metadata to your catalog. We will discuss push and pull in more detail in Chapters 2 and 6.
The IT landscape that is reflected in your data catalog will get business terminology added to it as “tags”—terms that are created in the data catalog and organized in glossaries. We will discuss glossary terms in Chapter 2 and how to search with them in Chapter 3. Besides glossary terms, you can also enhance your data catalog’s assets with metadata, complete with additional descriptions, classifications, and more.
Furthermore, a data catalog has various roles and permissions built in, such as data steward, data owner (data catalogs have different role type names), and other roles that all carry out specific tasks in the data catalog. I will describe those roles for you at the end of this chapter.
Once you have pulled/pushed your IT landscape and assigned selected terms, other metadata, and roles to it, it’s searchable in the catalog.
No employee can see all the data in the IT landscape. Even more confusing: no employee can see what data others can see. Basically, no one knows about all the data in the IT landscape: it’s opaque.1 This reality is also referred to as data silos.
Note
Data silos emerge when several groups of employees work with their own data in their own systems, isolated and unaware of the data in the rest of the organization.
This state—the data siloed state—is the root cause of an immense set of problems in many organizations, which the data catalog addresses and ultimately solves. These problems include data analytics applied to data lacking quality, incomplete datasets, and data missing security and sensitivity labels.
Tip
This perspective can also be flipped: data silos are connected, but no one can see it or knows how. This makes the data siloed state even more dangerous, but as you will see, capabilities in the data catalog can help map the data.
In the data catalog, it’s the complete opposite situation of the IT landscape itself. Everything in the data catalog is visible to all employees. Everyone can see everything—at the metadata level. And accordingly, all employees can get an idea of all the data in their company, based on that metadata. They are mindful and aware of the data outside their own, now past, data silo.
The more the data catalog expands, the more everyone can see. If this makes you think that a data catalog holds remarkable potential, you’re not wrong—and you will discover the magnitude of that potential in this book.
Based on my experience, I suggest you organize data in a data catalog in the following way.
Organize Data
As a data catalog crawls the IT landscape, it organizes the metadata for data entities within the landscape as assets pertaining to a data source and stores them in domains. However, you play a big part in this: you must design the domains and part of the metadata that the assets are assigned. And keep in mind that most data catalogs offer automation of this process—it should not be a manual task to add metadata to assets.
What is an asset? An asset is an entity of data that exists in your IT landscape. It could be a file, folder, or table, stored in a data source such as an application or database, etc. Assets are, for example, documents in a data lake, SQL tables in a database, and so on. When the data catalog collects metadata about the asset, whether by push or pull methods, it obtains information such as the asset’s name, creation date, owner, column name, schema name, filename, and folder structure. Overall, the collected metadata depends on the data source and the data that sits in it. You must add metadata to the asset beyond what was populated by the push/pull operation. We’ll talk more about this in Chapter 5.
And so what is a data source? Simply put, a data source refers to where the data that is being exposed at a metadata level in the data catalog comes from. It can be an IT system, application, or platform, but it can also be a spreadsheet. In the context of this book, the type of data source is irrelevant because all data sources can be treated in the same way.
You must be aware that data catalogs that crawl IT landscapes (i.e., that pull, not push) come with standard connectors to only a selected set of data sources. So, not everything will be crawlable by the data catalog. Therefore, sometimes, useful assets have to be manually entered, by stewards or other subject-matter experts.
A domain is a group of assets that logically belong together. These assets may stem from one or more data sources. For example, a domain with finance data may both have analytics data sources and budget data sources. It is critical to define your domains with care because they should be intuitive for employees outside that domain—and they should be intriguing to explore for those employees—a data catalog is an initial step toward breaking data silos!
Note
So far, data catalogs have only been described in the data-management literature. In that literature, the understanding of domains refers solely to domain-driven design (DDD), as an attempt to push DDD thinking into the mapping of data in the entire IT landscape. In this book, you’ll find domain thinking extended to the century-long tradition of domain studies in information science. This will provide you with a deeper, more functional understanding of domains than in normal data-management literature—you’ll find all this in Chapter 2.
Now that you have a better idea of how assets, data sources, and domains work, let’s look at a few examples of how they all fit together. Figure 1-2 shows a table in a database (also known as a data source, in a data catalog) and how it’s visible as an asset in the data catalog.

Figure 1-2. Table in a data source and how it’s visible as an asset in the data catalog
As you can see to the right side of the figure, no values are included in the asset in the data catalog. In this case, sensitive data—customer names—is not visible in the data catalog as it is in the data source. In the data catalog, only the column name is displayed. In this way, everyone can see everything in the data catalog. It’s the actual values in, for example, tables that have prevented a complete overview of data in your company. With the data catalog, those days are over, and you can ignite data-driven innovation and enhance data governance.
Warning
Dataset names, column names, and other metadata visible in the data catalog can also contain sensitive or confidential data. When you push or pull metadata into your data catalog, methods must be in place to make sure that such metadata is not visible to the users of the data catalog.
You can add metadata to your asset—in this case, a table—both at the table level and for each column. Every piece of metadata added to your asset will inscribe it with context relevant to the knowledge universe of your organization. This will make your asset more searchable. We’ll talk more about how to organize it in Chapter 2 and how to search for it in Chapter 3.
Furthermore, it’s important to understand that assets should be organized into vertical, horizontal, and relational structures, as can be seen in Figure 1-3 and more exhaustively in Figure 2-12 in Chapter 2.
Vertical organization enables you to pinpoint exactly what kind of data your asset represents. This is achieved through domains and subdomains. In the Product Sales Details asset in Figure 1-3, the vertical organization specifies which part of the company the data comes from; for example, finance.
The horizontal organization of assets allows you to display how the asset moves in your IT landscape. This is done with data lineage. Data lineage depicts how data travels from system to system and, ideally, how the data is transformed as it travels. In the Product Sales Details in Figure 1-3, lineage would, for example, display that the dataset resides in a database and that it is used in a business intelligence (BI) report, indicated by an arrow to the right of the asset, pointing toward the BI report.
The relational organization of assets depicts how parts of any asset relates to other assets and, if done correctly, can render these relations in a graph database. In the Product Sales Details assets in Figure 1-3, the relational organization of the Size column could, for example, be related to other volume metrics data in other assets, e.g., from manufacture data, referring to machine volume capacity, and so on.
All together, a fully organized table asset in a data catalog is depicted in Figure 1-3.

Figure 1-3. A fully organized asset in a data catalog
Once your assets have been organized into neat vertical, horizontal, and relational structures (for examples of this, check out Chapter 2), you might be tempted to think that your job is done and you no longer need to work on your magical data catalog. That is not the case! You should not consider a data catalog to be a repository that only needs to be organized once. You should always be open to reorganizing assets and improving the metadata quality and coverage. Not only will it ensure things are neat and tidy, but it will optimize your assets for search.
Accordingly, let’s take a first look at searching a data catalog.
Enable Search of Company Data
Search is one of the key functionalities of a data catalog. It is often treated as just a feature, but it can be so much more than that if you make it the driving factor of your data catalog strategy. Think of your data catalog as a search engine, the same kind of search engine that you’d use to peruse the web. A data catalog and a web search engine are similar in that they both crawl and index their landscapes and allow you to search that landscape. The main difference is that while a web search engine covers the web as a landscape, a data catalog covers your organization’s IT landscape.
So, what does it look like when you treat your data catalog as a search engine? Let’s take a look at one in action.
Note
Throughout this book, we’ll be looking at the data catalog of Hugin & Munin. Hugin & Munin is a fictitious Scandinavian architecture company that specializes in sustainable construction that uses wood from forests close to their building sites.
The Hugin & Munin data catalog revolves around organizing data and searching for it. Figure 1-4 shows the interface for the Hugin & Munin catalog. The search bar allows you to enter terms to do a regular search of the data catalog, but you can click the Advanced button to do a more detailed search. The magnifying glass allows you to use the browser function and a pile of books icon gives you access to the glossaries. Note that this looks very similar to most popular web search engines.

Figure 1-4. The data catalog frontend in Hugin & Munin
Let’s look at how you might use this data catalog. Say that you are an employee at Hugin & Munin and you overhear a group of people in the canteen during lunch.2 They talk about this clever data scientist named Kris, mentioning that he’s an asset steward for some SQL table assets in your company’s data catalog (you’ll learn about asset stewards later in this chapter; right now it’s not important). Such SQL tables could be useful in the projects you are currently working on. Before you can ask the group about how to contact Kris, they’ve collected their food and left the canteen. Back at your desk, you search the data catalog as depicted in Figure 1-5.

Figure 1-5. First search for Kris
That search returns an enormous number of hits. The Kris you’re looking for is most likely in there somewhere, but there are too many imprecise hits to go through them all. Instead, you narrow the search to look only for asset stewards, as depicted in Figure 1-6.

Figure 1-6. Second search for Kris
That’s definitely better, but there are still so many different people called Kris that you need another way to find what you are searching for. Perhaps you can search for the term “data science” in the central glossary? You give it a go, as illustrated in Figure 1-7.
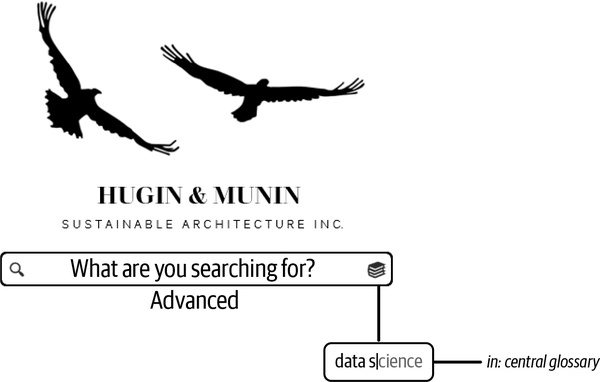
Figure 1-7. Searching for the glossary term “data science”
And you receive tons of hits. But wait! You can filter on asset types, and you remember the group of people mentioning SQL tables. You filter on SQL tables tagged with the term “data science.” And then, you get the idea of ranking those hits alphabetically by the asset steward—yes! There we go, you see the assets associated with Kris displayed on the screen! They’re all nicely arranged; each column in the SQL tables has been given descriptions and glossary terms. You would definitely like to take a look at this data, so you push the “request access” button that pings Kris for your request. You succeeded. Then, you realize that you could have just used an advanced search like in Figure 1-8.

Figure 1-8. Advanced search for the exact information you need
You’ve got a glimpse of how search works in the example, but search is described in full depth in Chapter 3. The more searchable your data is, the more you enable the one big benefit of a data catalog: data discovery.
Data Discovery
A data catalog enables all employees to search all data in their company. Searching and actually finding data is called data discovery, and that’s what a data catalog is all about.
Nevertheless, data discovery is rarely thought of as searching for data, but often as searching in data, in databases, to find new insights about customers, products, etc.
Searching for data can be haphazard conversations with colleagues, by memory, or it can be structured, meaning that searching for data takes place in a formalized manner in a solution designed for the purpose of searching for data,3 for example, a data catalog. The difference between searching for data and searching in data may strike you as not very important—but it is! And we will discuss it in detail in Chapter 3.
Put simply, data discovery begins with discovering that certain data exists at all, not what’s inside it. Once you get your data catalog up and running, you will exponentially accelerate data discovery in data, because the preceding search for data is remarkably more effective with a data catalog than without it.
Data discovery for data, in a data catalog, has a distinct target state: ambient findability. This term was coined by Peter Morville in the first literature that shed an intellectual light on the powerful search engines on the web that arose in 1995–2005:
Ambient findability describes a fast emerging world where we can find anyone or anything from anywhere at anytime.4
Today, data catalogs are emerging as the company equivalent of web search engines. And data catalogs, too, should strive for ambient findability. That’s how smooth data discovery for data must be: in your data catalog, you should be able to find anyone or anything from anywhere at any time—in your company.
Note
Ambient findability is completely unrelated to how you search in data. Searching in data is so persnickety and subtle that an entire field has evolved out of it: data science. I discuss this extensively in Chapter 3.
Data discovery in a data catalog serves two purposes:
-
Data analytics
-
Data governance
Data analytics supported by a data catalog is pretty simple: data scientists—analysts and similar profiles—all need data. Without a unified, global overview of all data in your company, these highly paid employees just work with the data they happen to know—in their data silo—and not the best-fit data for what they want to do. You can change that with a data catalog and create a complete overview of all the data in your company. This means that data-driven innovation can accelerate and deliver substantially more value.
Data governance supported by a data catalog has many advantages, and I’ll discuss these in depth in Chapter 4. The most important one is the capability to classify all data in your IT landscape both in terms of sensitivity and confidentiality. This will be of great value for your data protection officer (DPO) and your chief information security officer (CISO)—indeed, for your entire company. A data catalog applies rules to its pull/push capability so that all its assets are automatically assigned a sensitivity classification and a confidentiality classification. You can take a look in Chapter 2 about this for more details. For now, just remember that the power of automated classification of sensitivity and confidentiality directly on your IT landscape is a bedazzling feature that won’t be difficult to sell.
Tip
Data catalogs are also used by people who do not have many tech skills; I discuss them in the following as everyday end users.
The Data Discovery Team
A data management job—including managing a data catalog—is not the job of one person alone. Rather, it is the work of an entire team to implement, maintain, and promote the usage of the data catalog across your organization. Although you could call this your data catalog team, I encourage you to call this your data discovery team instead. This tells everyone not just what technology you use, but on what capability you deliver, which is data discovery.
Tip
Data discovery teams can focus solely on data catalogs or more widely on all metadata repositories. You should push for the latter: preferably, the data discovery team owns and curates all metadata repositories like the CMDB (configuration management database), data sharing agreement system, etc. that describe everything within the IT landscape. In this way, it can promote data discovery from the totality of sources where these are exposed at a metadata level.
Who works in a data discovery team? You can divide data discovery team members into two basic profiles: architects, for frontend, and engineers, for backend.
Data Architects
A data architect provides advice to all end users of the data catalog and works in the data catalog frontend. Data architects provide counseling in specific contexts of organizing data and searching it. They have the ultimate responsibility for the map of the IT landscape in logical domains, and they oversee the expansion of the map according to that structure. Data architects are responsible for monitoring the lifecycle of assets. In that context, they ensure that no assets are left without relevant roles assigned to them and that the retention times for the assets are correctly managed.
A time-consuming task for data architects is to educate end users to be independent and work with only a minimum of support from the data discovery team itself. Accordingly, data architects design and teach courses in the data catalog about how to organize data and search data:
- Organize data
-
This includes topics that will make end users capable of adding and managing their data sources in the catalog themselves, such as:
-
Pushing/pulling data sources into the data catalog. This includes identifying the data source, attaching all the roles to it, and using rules for automated classification of data. (We’ll discuss roles and responsibilities later in this chapter.)
-
Designing and applying automated processes of adding metadata to assets. For example, descriptions and terminology from the glossaries, either via usage of APIs or via built-in functions in the frontend of the data catalog.
-
Creating and managing glossary terms.
-
- Search data
-
This includes teaching end users how to search for data using techniques such as:
-
Simple search, what it does, and how you can use it. Most likely, simple search won’t be as smooth and intuitive as search engines on the web, but there are ways to get close to that state.
-
Browsing in all dimensions, that is, vertical in domains and subdomains, horizontal in data lineage, and relational in associative structures connected to your asset.
-
The information retrieval query language (IRQL) behind the advanced search feature and what this query language allows and is unfit for, compared to simple search and browse.
-
Furthermore, two additional tasks can be assigned to the data architects, in setups where the data discovery team is oriented more toward data governance:
- Perform second-level support across the company under inspections from authorities
-
If the data catalog is used in a highly regulated industry, it can be a powerful tool to answer complex questions from inspectors. Questions asked by an inspecting authority are typically subject to short deadlines—they need fast answers. Each department should be capable of searching its own data in the data catalog and answering questions during inspections. But if they are unable to find what they are searching for, the data catalog steward functions as a second-level support, capable of searching absolutely anything in the data catalog.
- Execute or design queries to perform all legal holds across the company
-
Legal holds compel a company not to delete data, called electronically stored information (ESI), by the US Federal Rules of Civil Procedure. In order to do so, data needs to be identified and blocked from deletion. Accordingly, a data catalog can play a vital role in correctly addressing and enforcing legal holds.
Finally, the data architects maintain the most conceptual overview of the data catalog, called the metamodel. You can see an example of a metamodel in Figure 1-9. The metamodel is the model that provides an overview of all entities in the data catalog. The metamodel also includes all relations between the entities. For example, departments have people, perform processes, and are supported by technology. Basically, the metamodel defines how you can physically structure your data catalog, based on conceptual metadata structures.

Figure 1-9. Example of a metamodel in a data catalog
Consider the metamodel in Figure 1-9. In this hypothetical example, a company has two entities, departments and domains. Departments and domains are not alike, as we will discuss in Chapter 2. A department has people, performs a process, and is supported by technology. Furthermore, a department possesses a capability. Capability defines a domain, and domain groups the data that the technology contains.
At a first glance, a metamodel may provoke dizziness. But the metamodel is there to provide the best possible structure for the data that is represented in the data catalog. It organizes data into its most relevant dimensions so that it is as easy to search for as possible.
Metamodels differ substantially from provider to provider, from very simple metamodels to very complex ones. Simple metamodels are not less desirable than complex ones; they both have pros and cons. Simple metamodels make your data catalog easy to implement but can show weakness in terms of the refinement of organizing your data catalog in the long run. Complex metamodels provide the latter but can be unduly intricate and difficult to implement.
Note
Knowledge graph–based data catalogs have flexible metamodels. The metamodel in such data catalogs can be visualized, expanded, and searched without limits. This technology is likely to gain more influence on the data catalog market, as it very powerfully caters to the most important feature in a data catalog: search.
Data Engineers
Data engineers work in the backend of the data catalog and assist the data architect on more technical issues for organizing data, searching it, and providing access to it.
The data catalog engineer supports data architects and end users in setting up the actual push/pulls of data sources into the data catalog. This may include usage of an API to curate assets with metadata, lineage, or the like. They oversee the functionality of rules that classify and profile data when pulling/pushing data into the data catalog, and they create additional rules for classifying data. The engineer merely ensures that the rules work, based on feedback and conversations with the data architect, who gathers knowledge from conversations with end users and employees from CISO and DPO functions.
The data catalog engineer ensures that data catalog search activity is appropriately logged and measured so that the data catalog counselor has the best chance of improving the search features of the catalog.
Once end users discover data that they want to access, the data catalog engineer is involved in providing guidance and practical help if needed. More simple access requests may simply include that the access requester is created as an end user in/of the data source. But if the data source has to be used in a software context, where the data in the source is to be exposed or processed, then the complexity of providing access to the source increases. There are three ways to get data from the data source to the one requesting it: read-only data stores (RDSs), APIs, and streaming.
Finally, the data catalog engineer manages the data catalog environments on test, dev, and prod (if more than one environment exists), including all security aspects and backend management of user profiles.
Data Discovery Team Setup
The data discovery team can be set up in three different ways, focusing on supporting:
-
Data governance
-
Chief data officer (CDO)
-
Data analytics
I discuss them in depth in Chapter 5. But briefly, the benefits of each way can be described as follows:
Data governance ensures that data is managed in accordance with regulations and standards. It also focuses on data quality aspects, ownership, etc. The advantage of placing the data discovery team in a data governance part of the company is that it leads to better data compliance and efficiency of the operational backbone. You will ensure that confidential and sensitive data is protected. Nevertheless, if such an approach is used, a data catalog should merely be considered an expense to ensure data governance, and not as the key component it is intended to be for data-driven innovation.
Having a CDO responsible for the data discovery team is the ideal, but also a rare setup for a data catalog. In this case, the data discovery team is a staff function for the CDO. The CDO writes and puts into action the executive data strategy of a company and should therefore have a full overview of all data at hand. In such a case, the executive data strategy is based on empirical facts, and outcomes are measurable.
Placing the data catalog in a data analytics business unit puts the data catalog directly into action where it delivers the most value: innovation. However, the risk of this setup is a lack of control. Without firm data governance, the data catalog can risk exposing confidential data or processing sensitive data in a way that is a liability to your company or in a way data subjects have not consented to. It can also create difficulties for data quality, which is a time-consuming effort that an energized team seeking results could be tempted to neglect.
End-User Roles and Responsibilities
End users of a data catalog fall into three categories:
-
Data analytics end users
-
Governance end users
-
Everyday (efficiency) end users
Data analytics end users search the data catalog for data sources to inform innovation, and their data discovery does not end in the data catalog when they search for data. Data discovery for data leads to data discovery and data exploration in data, as we will discuss in Chapter 3. Data analytics end users should be considered the most important end users of the catalog, as they will deliver the return on investment (ROI) for the data catalog. They do so by innovating new offerings to customers, based on data they have searched, found, analyzed, and used for business opportunities and growth.
Governance end users primarily search the data catalog for either confidential data or sensitive data—or both—in order to protect that data. They do so both as the catalog expands with new data sources (I discuss this in Chapter 5) and on an ongoing basis, when performing risk assessments and during daily operations. They also use the data catalog to get a more managed approach to who can see what data in the organization. The data catalog will enable them to increase the data governance of the company, but an ROI is more difficult to document in comparison with data analytics end users.
Everyday end users are likely to become the most substantial group of end users in the future. You can go to Chapter 8 to check what that future looks like in detail. At the point where the data catalog truly evolves to become a company search engine, employees are going to use it for everyday information needs. These are expressed with simple searches and are aimed at reports, strategy papers, SOPs, and basic access to systems. Currently, everyday end users of a data catalog are not a very big group. But you can plan your implementation in such a way that everyday end users become larger in numbers, with the effect that the data catalog gets more traction in your company. I discuss this in Chapter 5.
All end users have one or more of the following roles and responsibilities in the data catalog:
- Data source owner
-
The data source owner is also known as simply the system owner or data custodian in traditional data management.
- Domain owner
-
A domain owner manages a specific collection of assets. The domain owner ultimately defines which assets belong in the domain and who should have the different roles in the domain.
- Domain steward
-
A domain steward takes on more practical tasks such as conducting interviews with upcoming data source owners, managing the domain architecture, and providing access to data.
- Asset owner
-
The asset owner is the owner of the data in the data source. Typically, data ownership spans multiple data sources (as data ownership spans multiple systems), and it can also in rare cases span multiple domains. It is the asset owner that grants access to data upon request.
- Asset steward
-
An asset steward has expertise on a particular subset of assets (an entire data source or parts of data sources) in a domain.
- Term owner
-
Term owners typically own a large subpart of glossaries related to one or more domains in the data catalog.
- Term steward
-
Term stewards are responsible for managing term lifecycles. (See Chapter 7 for details.)
- Everyday end user
-
Everyday end users are able to search the data catalog and request data from asset owners.
Tip
Collectively, the end users of a data catalog constitute a social network. If they can work in groups independently of the data discovery team, the data catalog will provide the most value. See Chapter 5 for details on this.
Summary
You have now gotten the first impression of a data catalog. This unique tool represents a powerful step for your company toward better, more secure use of your data.
Here are the key takeaways of the chapter:
-
Data catalogs are organized in domains that contain assets. The assets are metadata representations of data in source systems. The assets have either been pulled (crawled) or pushed into the data catalog.
-
Organized to its maximum capacity, your data catalog will be able to cater to a completely free and flexible search, from simple search, to various ways of browsing, to advanced search.
-
The strategic benefit of a data catalog is data discovery. For the first time, companies are now able to discover all their data in a structured and endless way.
-
Data discovery serves data-driven innovation and data governance. Innovation is the most important and is the reason why data catalogs emerged in the first place. Data governance, on the other hand, is not as profitable but is important in its own right—it secures data.
-
Accordingly, end user types fall into categories of data analytics, governance, and everyday users. The end users can have different and even multiple roles and responsibilities in the data catalog.
-
Instead of having a “data catalog team,” promote the capability that such a team delivers by calling it a “data discovery team.” The data discovery team consists of architects working in the frontend of the data catalog and engineers in the backend.
-
There are three possible setups for data discovery teams:
-
The team can be focused on data governance, with the risk of losing the innovative potential of the data catalog.
-
The team can be focused on innovation, with the risk of compromising data governance.
-
The best possible setup is as a staff function for a CDO, who should take every strategic decision based on the data that’s actually in the company, be it for innovative or governance purposes.
-
In the next chapter, we’ll talk about how you organize data in the data catalog.
1 If your IT department is very well organized, a few employees may have a very high-level overview of all types of data via tools such as a configuration management database (CMDB) and an Active Directory (AD). Remember that Figure 1-1 illustrates the states for the vast majority of employees in the company, not the select few in an IT department.
2 In some European countries, it is common for companies to maintain a small cafeteria or snack bar on their premises where employees can buy food and eat together.
3 G. G. Chowdhury, Introduction to Modern Information Retrieval (New York: Neal-Schuman Publishers, 2010), chaps. 1 and 2.
4 Peter Morville, Ambient Findability: What We Find Changes Who We Become (Sebastopol, CA: O’Reilly, 2005), 6.
Get The Enterprise Data Catalog now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

