Chapter 1. The Application Platform
Martin Fowler and James Lewis, who initially proposed the term microservices, define the architecture in their seminal blog post as:
…a particular way of designing software applications as suites of independently deployable services. While there is no precise definition of this architectural style, there are certain common characteristics around organization around business capability, automated deployment, intelligence in the endpoints, and decentralized control of languages and data.
Adopting microservices promises to accelerate software development by separating applications into independently developed and deployed components produced by independent teams. It reduces the need to coordinate and plan large-scale software releases. Each microservice is built by an independent team to meet a specific business need (for internal or external customers). Microservices are deployed in a redundant, horizontally scaled way across different cloud resources and communicate with each other over the network using different protocols.
A number of challenges arise due to this architecture that haven’t been seen previously in monolithic applications. Monolithic applications used to be primarily deployed on the same server and infrequently released as a carefully choreographed event. The software release process was the main source of change and instability in the system. In microservices, communications and data transfer costs introduce additional latencies and potential to degrade end-user experience. A chain of tens or hundreds of microservices now work together to create that experience. Microservices are released independently of each other, but each one can inadvertently impact other microservices and therefore the end-user experience, too.
Managing these types of distributed systems requires new practices, tools, and engineering culture. Accelerating software releases doesn’t need to come at the cost of stability and safety. In fact, these go hand in hand. This chapter introduces the culture of an effective platform engineering team and describes the basic building blocks of reliable systems.
Platform Engineering Culture
To manage microservices, an organization needs to standardize specific communication protocols and supporting frameworks. A lot of inefficiencies arise if each team needs to maintain its own full stack development, as does friction when communicating with other parts of a distributed application. In practice, standardization leads to a platform team that is focused on providing these services to the rest of the teams, who are in turn focused on developing software to meet business needs.
We want to provide guardrails, not gates.
Dianne Marsh, director of engineering tools at Netflix
Instead of building gates, allow teams to build solutions that work for them first, learn from them, and generalize to the rest of the organization.
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.
Conway’s Law
Figure 1-1 shows an engineering organization built around specialties. One group specializes in user interface and experience design, another building backend services, another managing the database, another working on business process automation, and another managing network resources.
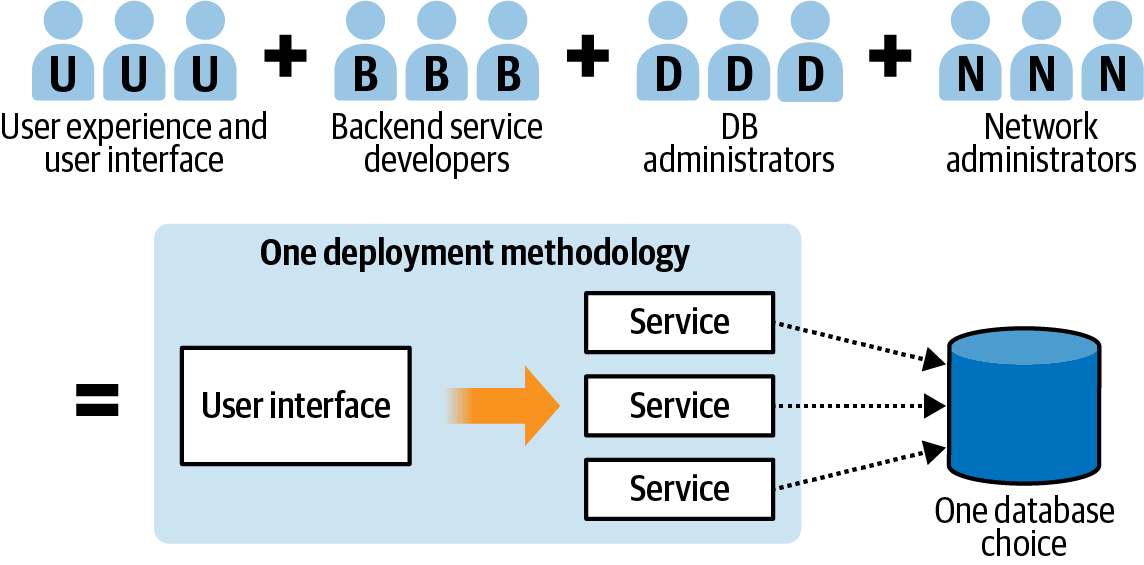
Figure 1-1. Organization built around technical silos
The lesson often taken from Conway’s Law is that cross-functional teams, as in Figure 1-2, can iterate faster. After all, when team structure is aligned to technical specialization, any new business requirement will require coordination across all of these specializations.
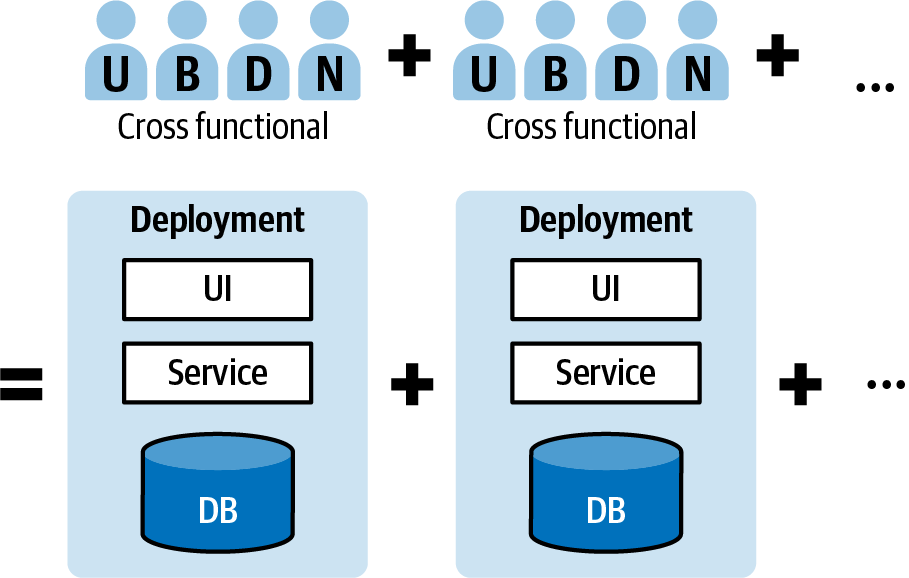
Figure 1-2. Cross-functional teams
There is obviously waste in this system as well though, specifically that specialists on each team are developing capabilities independently of one another. Netflix did not have dedicated site reliability engineers per team, as Google promotes in Site Reliability Engineering edited by Betsy Beyer et al. (O’Reilly). Perhaps because of a greater degree of homogenity to the type of software being written by product teams (mostly Java, mostly stateless horizontally scaled microservices), the centralization of product engineering functions was more efficient. Does your organization more resemble Google, working on very different types of products from automated cars to search to mobile hardware to browsers? Or does it more resemble Netflix, composed of a series of business applications written in a handful of languages running on a limited variety of platforms?
Cross-functional teams and completely siloed teams are just on the opposite ends of a spectrum. Effective platform engineering can reduce the need for a specialist per team for some set of problems. An organization with dedicated platform engineering is more of a hybrid, like in Figure 1-3. A central platform engineering team is strongest when it views product teams as customers that need to be constantly won over and exercises little to no control over the behavior of its customers.
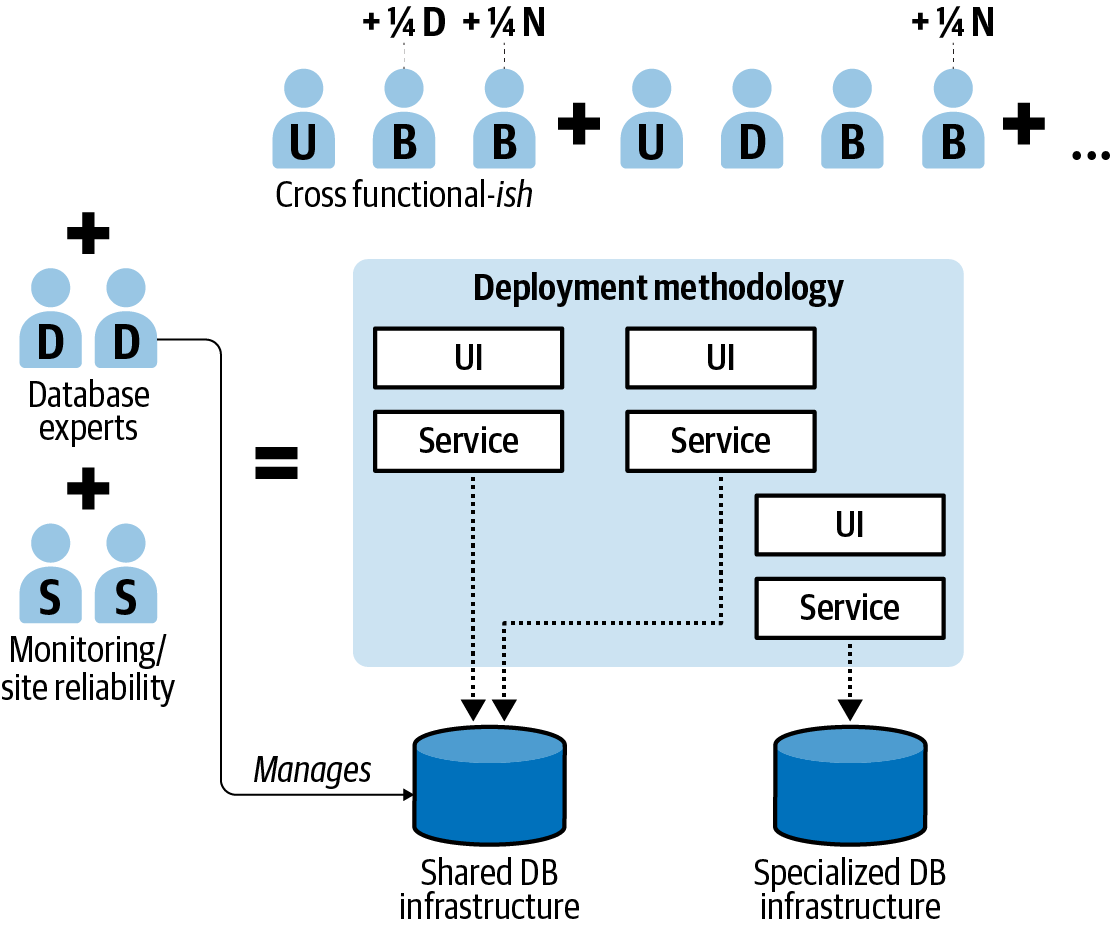
Figure 1-3. Product teams with dedicated platform engineering
For example, when monitoring instrumentation is distributed throughout the organization as a common library included in each microservice, it shares the hard-won knowledge of availability indicators known to be broadly applicable. Each product team can spend just a little time adding availability indicators that are unique to its business domain. It can communicate with the central monitoring team for information and advice on how to build effective signals as necessary.
At Netflix, the strongest cultural current was “freedom and responsibility,” defined in a somewhat famous culture deck from 2001. I was a member of the engineering tools team but we could not require that everyone else adopt a particular build tool. A small team of engineers managed Cassandra clusters on behalf of many product teams. There is an efficiency to this concentration of build tool or Cassandra skill, a natural communication hub through which undifferentiated problems with these products flowed and lessons were transferred to product-focused teams.
The build tools team at Netflix, at its smallest point, was just two engineers serving the interests of roughly 700 other engineers while transitioning between recommended build tools (Ant to Gradle) and performing two major Java upgrades (Java 6 to 7 and then Java 7 to 8), among other daily routines. Each product team completely owned its build. Because of “freedom and responsibility,” we could not set a hard date for when we would completely retire Ant-based build tooling. We could not set a hard date for when every team had to upgrade its version of Java (except to the extent that a new Oracle licensing model did this for us). The cultural imperative drove us to focus so heavily on developer experience that product teams wanted to migrate with us. It required a level of effort and empathy that could only be guaranteed by absolutely preventing us from setting hard requirements.
When a platform engineer like myself serves the interests of so many diverse product teams in a focused technical speciality like build tooling, inevitably patterns emerge. My team saw the same script playing out over and over again with binary dependency problems, plug-in versioning, release workflow problems, etc. We worked initially to automate the discovery of these patterns and emit warnings in build output. Without the freedom-and-responsibility culture, perhaps we would have skipped warnings and just failed the build, requiring product teams to fix issues. This would have been satisfying to the build tools team—we wouldn’t be responsible for answering questions related to failures that we tried to warn teams about. But from the product team perspective, every “lesson” the build tools team learned would be disruptive to them at random points in time, and especially disruptive when they had more pressing (if temporary) priorities.
The softer, non-failing warning approach was shockingly ineffective. Teams rarely paid any attention to successful build logs, regardless of how many warnings were emitted. And even if they did see the warnings, attempting to fix them incurred risk: a working build with warnings is better than a misbehaving one without warnings. As a result, carefully crafted deprecation warnings could go ignored for months or years.
The “guardrails not gates” approach required our build tools team to think about how we could share our knowledge with product teams in a way that was visible to them, required little time and effort to act on, and reduced the risk of coming along with us on the paved path. The tooling that emerged from this was almost over the top in its focus on developer experience.
First, we wrote tooling that could rewrite the Groovy code of Gradle builds to autoremediate common patterns. This was much more difficult than just emitting warnings in the log. It required making indentation-preserving abstract syntax tree modifications to imperative build logic, an impossible problem to solve in general, but surprisingly effective in specific cases. Autoremediation was opt-in though, through the use of a simple command that product teams could run to accept recommendations.
Next, we wrote monitoring instrumentation that reported patterns that were potentially remediable but for which product teams did not accept the recommendation. We could monitor each harmful pattern in the organization over time, watch as it declined in impact as teams accepted remediations. When we reached the long tail of a small number of teams that just wouldn’t opt in, we knew who they were, so we could walk over to their desks and work with them one on one to hear their concerns and help them move forward. (I did this enough that I started carrying my own mouse around. There was a suspicious correlation between Netflix engineers who used trackballs and Netflix engineers who were on the long tail of accepting remediations.) Ultimately, this proactive communication established a bond of trust that made future recommendations from us seem less risky.
We went to fairly extreme lengths to improve the visibility of recommendations without resorting to breaking builds to get developers’ attention. Build output was carefully colorized and stylized, sometimes with visual indicators like Unicode check marks and X marks that were hard to miss. Recommendations always appeared at the end of the build because we knew that they were the last thing emitted on the terminal and our CI tools by default scrolled to the end of the log output when engineers examined build output. We taught Jenkins how to masquerade as a TTY terminal to colorize build output but ignore cursor movement escape sequences to still serialize build task progress.
Crafting this kind of experience was technically costly, but compare it with the two options:
- Freedom and responsibility culture
-
Led us to build self-help autoremediation with monitoring that helped us understand and communicate with the teams that struggled.
- Centralized control culture
-
We probably would have been led to break builds eagerly because we “owned” the build experience. Teams would have been distracted from their other priorities to accommodate our desire for a consistent build experience. Every change, because it lacked autoremediation, would have generated far more questions to us as the build tools team. The total amount of toil for every change would have been far greater.
An effective platform engineering team cares deeply about developer experience, a singular focus that is at least as keen as the focus product teams place on customer experience. This should be no surprise: in a well-calibrated platform engineering organization, developers are the customer! The presence of a healthy product management discipline, expert user experience designers, and UI engineers and designers that care deeply about their craft should all be indicators of a platform engineering team that is aligned for the benefit of their customer developers.
More detail on team structure is out of the scope of this book, but refer to Team Topologies by Matthew Skelton and Manuel Pais (IT Revolution Press) for a thorough treatment of the topic.
Once the team is culturally calibrated, the question becomes how to prioritize capabilities that a platform engineering team can deliver to its customer base. The remainder of this book is a call to action, delivered in capabilities ordered from (in my view) most essential to less essential.
Monitoring
Monitoring your application infrastructure requires the least organizational commitment of all the stages on the journey to more resilient systems. As we’ll show in the subsequent chapters, framework-level monitoring instrumentation has matured to such an extent that you really just need to turn it on and start taking advantage. The cost-benefit ratio has been skewed so heavily toward benefit that if you do nothing else in this book, start monitoring your production applications now. Chapter 2 will discuss metrics building blocks, and Chapter 4 will provide the specific charts and alerts you can employ, mostly based on instrumentation that Java frameworks provide without you having to do any additional work.
Metrics, logs, and distributed tracing are three forms of observability that enable the measure of service availability and aid in debugging complex distributed systems problems. Before going further in the workings of any of these, it is useful to understand what capabilities each enables.
Monitoring for Availability
Availability signals measure the overall state of the system and whether that system is functioning as intended in the large. It is quantified by service level indicators (SLIs). These indicators include signals for the health of the system (e.g., resource consumption) and business metrics like number of sandwiches sold or streaming video starts per second. SLIs are tested against a threshold called a service level objective (SLO) that sets an upper or lower bound on the range of an SLI. SLOs in turn are a somewhat more restrictive or conservative estimate than a threshold you agree upon with your business partners about a level of service you are expected to provide, or what’s known as a service level agreement (SLA). The idea is that an SLO should provide some amount of advance warning of an impending violation of an SLA so that you don’t actually get to the point where you violate that SLA.
Metrics are the primary observability tool for measuring availability. They are a measure of SLIs. Metrics are the most common availability signal because they represent an aggregation of all activity happening in the system. They are cheap enough to not require sampling (discarding some portion of the data to limit overhead), which risks discarding important indicators of unavailability.
Metrics are numerical values arranged in a time series representing a sample at a particular time or an aggregate of individual events that have occurred in an interval:
- Metrics
-
Metrics should have a fixed cost irrespective of throughput. For example, a metric that counts executions of a particular block of code should only ship the number of executions seen in an interval regardless of how many there are. By this I mean that a metric should ship “N requests were observed” at publish time, not “I saw a request N distinct times” throughout the publishing interval.
- Metrics data
-
Metrics data cannot be used to reason about the performance or function of any individual request. Metrics telemetry trades off reasoning about an individual request for the application’s behavior across all requests in an interval.
To effectively monitor the availability of a Java microservice, a variety of availability signals need to be monitored. Common signals are given in Chapter 4, but in general they fall into four categories, known together as the L-USE method:1
- Latency
-
This is a measure of how much time was spent executing a block of code. For the common REST-based microservice, REST endpoint latency is a useful measure of the availability of the application, particularly max latency. This will be discussed in greater detail in “Latency”.
- Utilization
-
A measure of how much of a finite resource is consumed. Processor utilization is a common utilization indicator. See “CPU Utilization”.
- Saturation
-
Saturation is a measurement of extra work that can’t be serviced. “Garbage Collection Pause Times” shows how to measure the Java heap, which during times of excessive memory pressure leads to a buildup of work that cannot be completed. It’s also common to monitor pools like database connection pools, request pools, etc.
- Errors
-
In addition to looking at purely performance-related concerns, it is essential to find a way to quantify the error ratio relative to total throughput. Measurements of error include unanticipated exceptions yielding unsuccessful HTTP responses on a service endpoint (see “Errors”), but also more indirect measures like the ratio of requests attempted against an open circuit breaker (see “Circuit Breakers”).
Utilization and saturation may seem similar at first, and internalizing the difference will have an impact on how you think about charting and alerting on resources that can be measured both ways. A great example is JVM memory. You can measure JVM memory as a utilization metric by reporting on the amount of bytes consumed in each memory space. You can also measure JVM memory in terms of the proportion of time spent garbage collecting it relative to doing anything else, which is a measure of saturation. In most cases, when both utilization and saturation measurements are possible, the saturation metric leads to better-defined alert thresholds. It’s hard to alert when memory utilization exceeds 95% of a space (because garbage collection will bring that utilization rate back below this threshold), but if memory utilization routinely and frequently exceeds 95%, the garbage collector will kick in more frequently, more time will be spent proportionally doing garbage collection than anything else, and the saturation measurement will thus be higher.
Some common availability signals are listed in Table 1-1.
| SLI | SLO | L-USE criteria |
|---|---|---|
Process CPU usage |
<80% |
Saturation |
Heap utilization |
<80% of available heap space |
Saturation |
Error ratio for a REST endpoint |
<1% of total requests to the endpoint |
Errors |
Max latency for a REST endpoint |
<100 ms |
Latency |
Google has a much more prescriptive view on how to use SLOs.
Google’s approach to SLOs
Site Reliability Engineering by Betsy Beyer et al. (O’Reilly) presents service availability as a tension between competing organizational imperatives: to deliver new features and to run the existing feature set reliably. It proposes that product teams and dedicated site reliability engineers agree on an error budget that provides a measurable objective for how unreliable a service is allowed to be within a given window of time. Exceeding this objective should refocus the team on reliability over feature development until the objective is met.
The Google view on SLOs is explained in great detail in the “Alerting on SLOs” chapter in The Site Reliability Workbook edited by Betsy Beyer et al. (O’Reilly). Basically, Google engineers alert on the probability that an error budget is going to be depleted in any given time frame, and they react in an organizational way by shifting engineering resources from feature development to reliability as necessary. The word “error” in this case means exceeding any SLO. This might mean exceeding an acceptable ratio of server failed outcomes in a RESTful microservice, but could also mean exceeding an acceptable latency threshold, getting too close to overwhelming file descriptors on the underlying operating system, or any other combination of measurements. With this definition, the time that a service is unreliable in a prescribed window is the proportion when one or more SLOs were not being met.
Your organization doesn’t need to have separate functions for product engineer and site reliability engineer for error budgeting to be a useful concept. Even a single engineer working on a product completely alone and wholly responsible for its operation can benefit from thinking about where to pause feature development in favor of improving reliability and vice versa.
I think the overhead of the Google error budget scheme is overkill for a lot of organizations. Start measuring, discover how alerting functions fit into your unique organization, and once practiced at measuring, consider whether you want to go all in on Google’s process or not.
Collecting, visualizing, and alerting on application metrics is an exercise in continuously testing the availability of your services. Sometimes an alert itself will contain enough contextual data that you know how to fix a problem. In other cases, you’ll want to isolate a failing instance in production (e.g., by moving it out of the load balancer) and apply further debugging techniques to discover the problem. Other forms of telemetry are used for this purpose.
A less formal approach to SLOs
A less formal system worked well for Netflix, where individual engineering teams were responsible for their services’ availability, there was no SRE/product engineer separation of responsibility on individual product teams, and there wasn’t such a formalized reaction to error budgets, at least not cross-organizationally. Neither system is right or wrong; find a system that works well for you.
For the purpose of this book, we’ll talk about how to measure for availability in simpler terms: as tests against an error rate or error ratio, latencies, saturation, and utilization indicators. We won’t present violations of these tests as particular “errors” of reliability that are deducted from an error budget over a window of time. If you want to then take those measurements and apply the error-budgeting and organizational dynamics of Google’s SRE culture to your organization, you can do that by following the guidance given in Google’s writings on the topic.
Monitoring as a Debugging Tool
Logs and distributed traces, covered in detail in Chapter 3, are used mainly for troubleshooting, once you have become aware of a period of unavailability. Profiling tools are also debuggability signals.
It is very common (and easy, given a confusing market) for organizations to center their entire performance management investment around debuggability tools. Application performance management (APM) vendors can sometimes sell themselves as an all-in-one solution, but with a core technology built entirely on tracing or logging and providing availability signals by aggregating these debugging signals.
In order to not single out any particular vendor, consider YourKit, a valuable profiling (debuggability) tool that does this task well without selling itself as more. YourKit excels at highlighting computation- and memory-intensive hotspots in Java code, and looks like Figure 1-4. Some popular commercial APM solutions have a similar focus, which, while useful, is not a substitute for a focused availability signal.
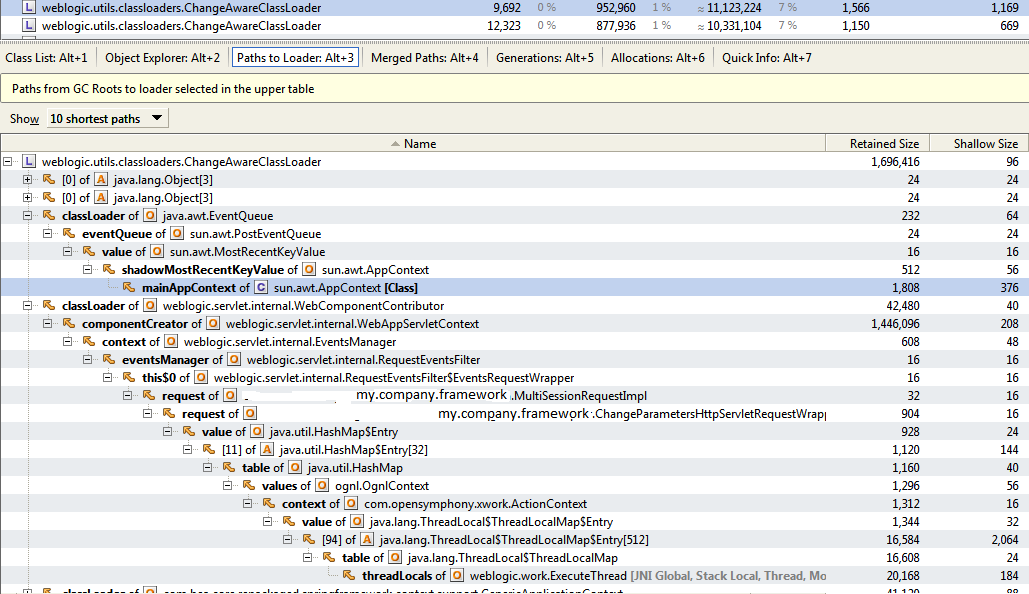
Figure 1-4. YourKit excels at profiling
These solutions are more granular, recording in different ways the specifics of what occurred during a particular interaction with the system. With this increased granularity comes cost, and this cost is frequently mitigated with downsampling or even turning off these signals entirely until they are needed.
Attempts to measure availability from log or tracing signals generally force you to trade off accuracy for cost, and neither can be optimized. This trade-off exists for traces because they are generally sampled. The storage footprint for traces is higher than for metrics.
Learning to Expect Failure
If you aren’t already monitoring applications in a user-facing way, as soon as you start, you’re likely to be confronted with the sobering reality of your software as it exists today. Your impulse is going to be to look away. Reality is likely to be ugly.
At a midsize property-casualty insurance company, we added monitoring to the main business application that the company’s insurance agents use to conduct their normal business. Despite strict release processes and a reasonably healthy testing culture, the application manifested over 5 failures per minute for roughly 1,000 requests per minute. From one perspective, this is only a 0.5% error ratio (maybe acceptable and maybe not), but the failure rate was still a shock to a company that thought its service was well tested.
The realization that the system is not going to be perfect switches the focus from trying to be perfect to monitoring, alerting, and quickly resolving issues that the system experiences. No amount of process control around the rate of change will yield perfect outcomes.
Before evolving the delivery and release process further, the first step on the path to resilient software is adding monitoring to your software as it is released now.
With the move to microservices and changing application practices and infrastructure, monitoring has become even more important. Many components are not directly under an organization’s control. For example, latency and errors can be caused by failures in the networking layer, infrastructure, and third-party components and services. Each team producing a microservice has the potential to negatively impact other parts of the system not under its direct control.
End users of software also do not expect perfection, but do want their service provider to be able to effectively resolve issues. This is what is known as the service recovery paradox, when a user of the service will trust a service more after a failure than they did before the failure.
Businesses need to understand and capture the user experience they want to provide to the end users—what type of system behavior will cause issues to the business and what type of behavior is acceptable to users. Site Reliability Engineering and The Site Reliability Workbook have more on how to pick these for your business.
Once identified and measured, you can adopt Google style, as seen in “Google’s approach to SLOs”, or Netflix’s more informal “context and guardrails” style, or anywhere in between to help you reason about your software or the next steps. See the first chapter on Netflix in Seeking SRE by David N. Blank-Edelman (O’Reilly) to learn more about context and guardrails. Whether you follow the Google practice or a simpler one is up to your organization, the type of software you develop, and the engineering culture you want to promote.
With the goal of never failing replaced with the goal of being able to meet SLAs, engineering can start building multiple layers of resiliency into systems, minimizing the effects of failures on end-user experience.
Effective Monitoring Builds Trust
In certain enterprises, engineering can still be seen as a service organization rather than a core business competency. At the insurance company with a five-failures-per-minute error rate, this is the prevailing attitude. In many cases where the engineering organization served the company’s insurance agents in the field, the primary interaction between them happened through reporting and tracking software issues through a call center.
Engineering routinely prioritized bug resolution, based on defects learned from the call center, against new feature requests and did a little of both for each software release. I wondered how many times the field agents simply didn’t report issues, either because a growing bug backlog suggested that it wasn’t an effective use of their time or because the issue had a good-enough workaround. The problem with becoming aware of issues primarily through the call center is that it made the relationship entirely one way. Business partners report and engineering responds (eventually).
A user-centric monitoring culture makes this relationship more two-way. An alert may provide enough contextual information to recognize that rating for a particular class of vehicle is failing for agents in some region today. Engineering has the opportunity to reach out to the agents proactively with enough contextual information to explain to the agent that the issue is already known.
Delivery
Improving the software delivery pipeline lessens the chance that you introduce more failure into an existing system (or at least helps you recognize and roll back such changes quickly). It turns out that good monitoring is a nonobvious prerequisite to evolving safe and effective delivery practices.
The division between continuous integration (CI) and continuous delivery (CD) tends to be blurred by the fact that teams frequently script deployment automation and run these scripts as part of continuous integration builds. It is easy to repurpose a CI system as a flexible general-purpose workflow automation tool. To make a clear conceptual delineation between the two, regardless of where the automation runs, we’ll say that continuous integration ends at the publication of a microservice artifact to an artifact repository, and delivery begins at that point. In Figure 1-5, the software delivery life cycle is drawn as a sequence of events from code commit to deployment.
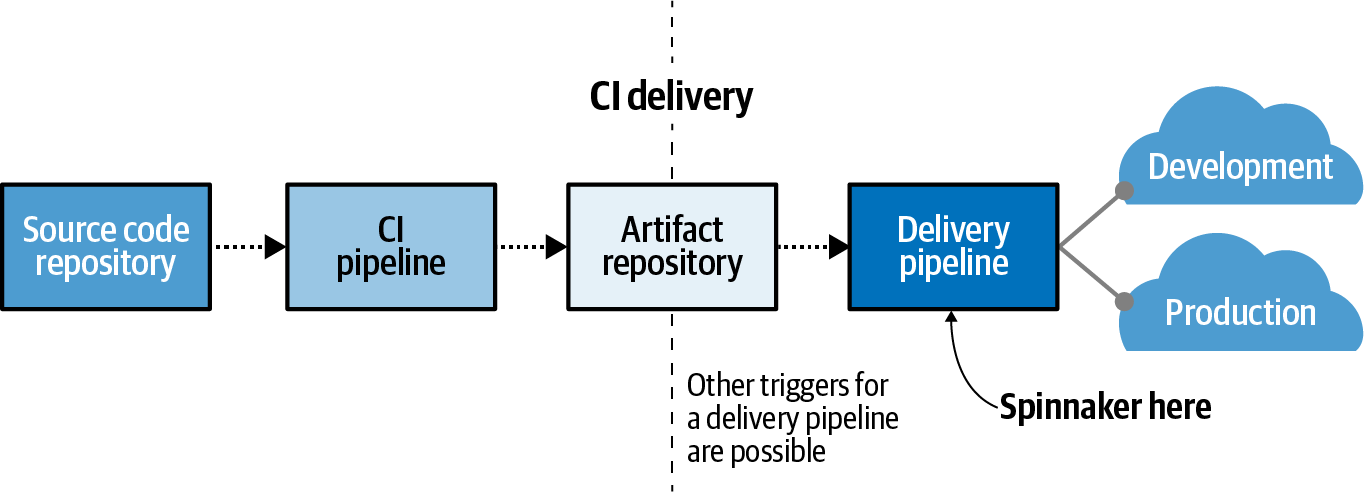
Figure 1-5. The boundary between continuous integration and delivery
The individual steps are subject to different frequencies and organizational needs for control measures. They also have fundamentally different goals. The goal of continuous integration is to accelerate developer feedback, fail fast through automated testing, and encourage eager merging to prevent promiscuous integration. The goal of delivery automation is to accelerate the release cycle, ensure security and compliance measures are met, provide safe and scalable deployment practices, and contribute to an understanding of the deployed landscape for the monitoring of deployed assets.
The best delivery platforms also act as an inventory of currently deployed assets, further magnifying the effect of good monitoring: they help turn monitoring into action. In Chapter 6, we’ll talk about how you can build an end-to-end asset inventory, ending with a deployed asset inventory, that allows you to reason about the smallest details of your code all the way up to your deployed assets (i.e., containers, virtual machines, and functions).
Continuous Delivery Doesn’t Necessarily Mean Continuous Deployment
Truly continuous deployment (every commit passing automated checks goes all the way to production automatically) may or may not be a goal for your organization. All things being equal, a tighter feedback loop is preferable to a longer feedback loop, but it comes with technical, operational, and cultural costs. Any delivery topics discussed in this book apply to continuous delivery in general, as well as continuous deployment in particular.
Once effective monitoring is in place and less failure is being introduced into the system by further changes to the code, we can focus on adding more reliability to the running system by evolving traffic management practices.
Traffic Management
So much of a distributed system’s resiliency is based on the expectation of and compensation for failure. Availability monitoring reveals these actual points of failure, debuggability monitoring helps understand them, and delivery automation helps prevent you from introducing too many more of them in any incremental release. Traffic management patterns will help live instances cope with the ever-present reality of failure.
In Chapter 7, we’ll introduce particular mitigation strategies involving load balancing (platform, gateway, and client-side) and call resilience patterns (retrying, rate limiters, bulkheads, and circuit breakers) that provide a safety net for running systems.
This is covered last because it requires the highest degree of manual coding effort on a per-project basis, and because the investment you make in doing the work can be guided by what you learn from the earlier steps.
Capabilities Not Covered
Certain capabilities that are common focuses of platform engineering teams are not included in this book. I’d like to call out a couple of them, testing and configuration management, and explain why.
Testing Automation
My view on testing is that testing automation available in open source takes you a certain way. Any investment beyond that is likely to suffer from diminishing returns. Following are some problems that are well solved already:
-
Unit testing
-
Mocking/stubbing
-
Basic integration testing, including test containers
-
Contract testing
-
Build tooling that helps separate computationally expensive and inexpensive test suites
There are a couple other problems that I think are worth avoiding unless you really have a lot of resources (both computationally and in engineering time) to expend. Contract testing is an example of a technique that covers some of what both of these test, but in a far cheaper way:
-
Downstream testing (i.e., whenever a commit happens to a library, build all other projects that depend on this library both directly or indirectly to determine whether the change will cause failure downstream)
-
End-to-end integration testing of whole suites of microservices
I’m very much for automated tests of various sorts and very suspicious of the whole enterprise. At times, feeling the social pressure of testing enthusiasts around me, I may have gone along with the testing fad of the day for a little while: 100% test coverage, behavior-driven development, efforts to involve nonengineer business partners in test specification, Spock, etc. Some of the cleverest engineering work in the open source Java ecosystem has taken place in this space: consider Spock’s creative use of bytecode manipulation to achieve data tables and the like.
Traditionally, working with monolithic applications, software releases were viewed as the primary source of change in the system and therefore potential for failure. Emphasis was placed on making sure the software release process didn’t fail. Much effort was expended to ensure that lower-level environments mirrored production to verify that pending software releases were stable. Once deployed and stable, the system was assumed to remain stable.
Realistically, this has never been the case. Engineering teams adopt and double down on automated testing practices as a cure for failure, only to have failure stubbornly persist. Management is skeptical of testing in the first place. When tests fail to capture problems, what little faith they had is gone. Production environments have a stubborn habit of diverging from test environments in subtle and seemingly always catastrophic ways. At this point, if you forced me to choose between having close to 100% test coverage and an evolved production monitoring system, I’d eagerly choose the monitoring system. This isn’t because I think less of tests, but because even in reasonably well-defined traditional businesses whose practices don’t change quickly, 100% test coverage is mythical. The production environment will simply behave differently. As Josh Long likes to say: “There is no place like it.”
Effective monitoring warns us when a system isn’t working correctly due to conditions we can anticipate (i.e., hardware failures or downstream service unavailability). It also continually adds to our knowledge of the system, which can actually lead to tests covering cases we didn’t previously imagine.
Layers of testing practice can limit the occurrence of failure, but will never eliminate it, even in industries with the tightest quality control practices. Actively measuring outcomes in production lowers time to discovery and ultimately remediation of failures. Testing and monitoring together are then complementary practices reducing how much failure end users experience. At their best, testing prevents whole classes of regressions, and monitoring quickly identifies those that inevitably remain.
Our automated test suites prove (to the extent they don’t contain logical errors themselves) what we know about the system. Production monitoring shows us what happens. An acceptance that automated tests won’t cover everything should be a tremendous relief.
Because application code will always contain flaws stemming from unanticipated interactions, environmental factors like resource constraints, and imperfect tests, effective monitoring might be considered even more of a requirement than testing for any production application. A test proves what we think will happen. Monitoring shows what is happening.
Chaos Engineering and Continuous Verification
There is a whole discipline around continuously verifying that your software behaves as you expect by introducing controlled failures (chaos experiments) and verifying. Because distributed systems are complex, we cannot anticipate all of their myriad interactions, and this form of testing helps surface unexpected emergent properties of complex systems.
The overall discipline of chaos engineering is broad, and as it is covered in detail in Chaos Engineering by Casey Rosenthal and Nora Jones (O’Reilly), I won’t go into it in this book.
Configuration as Code
The 12-Factor App teaches that configuration ought to be separated from code. The basic form of this concept, configuration stored as an environment variable or fetched at startup from a centralized configuration server like Spring Cloud Config Server, I think is straightforward enough to not require any explanation here.
The more complicated case involving dynamic configuration—whereby changes to a central configuration source propagates to running instances, influencing their behavior—is in practice exceedingly dangerous and must be handled with care. Pairing with the open source Netflix Archaius configuration client (which is present in Spring Cloud Netflix dependencies and elsewhere) was a proprietary Archaius server which served this purpose. Unintended consequences resulting from dynamic configuration propagation to running instances caused a number of production incidents of such magnitude that the delivery engineers wrote a whole canary analysis process around scoping and incrementally rolling out dynamic configuration changes, using the lessons they had learned from automated canary analysis for different versions of code. This is beyond the scope of this book, since many organizations will never receive substantial enough benefit from automated canary analysis of code changes to make that effort worthwhile.
Declarative delivery is an entirely different form of configuration as code, popularized again by the rise of Kubernetes and its YAML manifests. My early career left me with a permanent suspicion of the completeness of declarative-only solutions. I think there is always a place for both imperative and declarative configuration. I worked on a policy administration system for an insurance company that consisted of a backend API returning XML responses and a frontend of XSLT transformations of these API responses into static HTML/JavaScript to be rendered in the browser.
It was a bizarre sort of templating scheme. Its proponents argued that the XSLT lent the rendering of each page a declarative nature. And yet, it turns out that XSLT itself is Turing complete with a convincing existence proof. The typical point in favor of declarative definition is simplicity leading to an amenability to automation like static analysis and remediation. But as in the XSLT case, these technologies have a seemingly unavoidable way of evolving toward Turing completeness. The same forces are in play with JSON (Jsonnet) and Kubernetes (Kustomize). These technologies are undoubtedly useful, but I can’t be another voice in the chorus calling for purely declarative configuration. Short of making that point, I don’t think there is much this book can add.
Encapsulating Capabilities
As under fire as object-oriented programming (OOP) may be today, one of its fundamental concepts is encapsulation. In OOP, encapsulation is about bundling state and behavior within some unit, e.g., a class in Java. A key idea is to hide the state of an object from the outside, called information hiding. In some ways, the task of the platform engineering team is to perform a similar encapsulation task for resiliency best practices for its customer developer teams, hiding information not out of control, but to unburden them from the responsibility of dealing with it. Maybe the highest praise a central team can receive from a product engineer is “I don’t have to care about what you do.”
The subsequent chapters are going to introduce a series of best practices as I understand them. The challenge to you as a platform engineer is to deliver them to your organization in a minimally intrusive way, to build “guardrails not gates.” As you read, think about how you can encapsulate hard-won knowledge that’s applicable to every business application and how you can deliver it to your organization.
If the plan involves getting approval from a sufficiently powerful executive and sending an email to the whole organization requiring adoption by a certain date, it’s a gate. You still want buy-in from your leadership, but you need to deliver common functionality in a way that feels more like a guardrail:
- Explicit runtime dependencies
-
If you have a core library that every microservice includes as a runtime dependency, this is almost certainly your delivery mechanism. Turn on key metrics, add common telemetry tagging, configure tracing, add traffic management patterns, etc. If you have heavy Spring usage, use autoconfiguration classes. You can similarly conditionalize configuration with CDI if you are using Java EE.
- Service clients as dependencies
-
For traffic management patterns especially (fallbacks, retry logic, etc.), consider making it the responsibility of the team producing the service to also produce a service client that interacts with the service. After all, the team producing and operating it has more knowledge than anybody about where its weaknesses and potential failure points are. Those engineers are likely the best ones to formalize this knowledge in a client dependency such that each consumer of their service uses it in the most reliable way.
- Injecting a runtime dependency
-
If the deployment process is relatively standardized, you have an opportunity to inject runtime dependencies in the deployed environment. This was the approach employed by the Cloud Foundry buildpack team to inject a platform metrics implementation into Spring Boot applications running on Cloud Foundry. You can do something similar.
Before encapsulating too eagerly, find a handful of teams and practice this discipline explicitly in code in a handful of applications. Generalize what you learn.
Service Mesh
As a last resort, encapsulate common platform functionality in sidecar processes (or containers) alongside the application, which when paired with a control plane managing them is called a service mesh.
The service mesh is an infrastructure layer outside of application code that manages interaction between microservices. One of the most recognizable implementations today is Istio. These sidecars perform functions like traffic management, service discovery, and monitoring on behalf of the application process so that the application does not need to be aware of these concerns. At its best, this simplifies application development, trading off increased complexity and cost in deploying and running the service.
Over a long enough time horizon, trends in software engineering are often cyclic. In the case of site reliability, the pendulum swings from increased application and developer responsibility (e.g., Netflix OSS, DevOps) to centralized operations team responsibility. The rise of interest in service mesh represents a shift back to centralized operations team responsibility.
Istio promotes the concept of managing and propagating policy across a suite of microservices from its centralized control plane, at the behest of an organizationally centralized team that specializes in understanding the ramifications of these policies.
The venerable Netflix OSS suite (the important pieces of which have alternative incarnations like Resilience4j for traffic management, HashiCorp Consul for discovery, Micrometer for metrics instrumentation, etc.) made these application concerns. Largely, though, the application code impact was just the addition of one or more binary dependencies, at which point some form of autoconfiguration took over and decorated otherwise untouched application logic. The obvious downside of this approach is language support, with support for each site reliability pattern requiring library implementations in every language/framework that the organization uses.
Figure 1-6 shows an optimistic view of the effect on this engineering cycle on derived value. With any luck, at each transition from decentralization to centralization and back, we learn from and fully encapsulate the benefits of the prior cycle. For example, Istio could conceivably fully encapsulate the benefits of the Netflix OSS stack, only for the next decentralization push to unlock potential that was unrealizable in Istio’s implementation. This is already underway in Resilience4j, for example, with discussion about adaptive forms of patterns like bulkheads that are responsive to application-specific indicators.
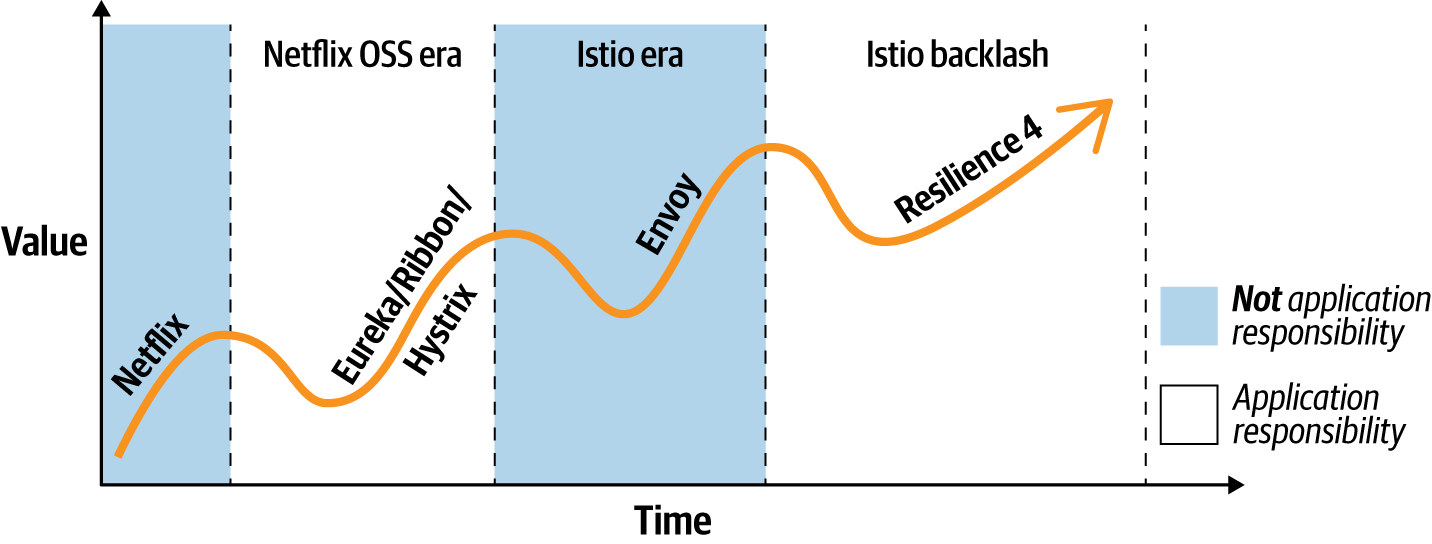
Figure 1-6. The cyclic nature of software engineering, applied to traffic management
Sizing of sidecars is also tricky, given this lack of domain-specific knowledge. How does a sidecar know that an application process is going to consume 10,000 requests per second, or only 1? Zooming out, how do we size the sidecar control plane up front not knowing how many sidecars will eventually exist?
Sidecars Are Limited to Lowest-Common-Denominator Knowledge
A sidecar proxy will always be weakest where domain-specific knowledge of the application is the key to the next step in resiliency. By definition, being separate from the application, sidecars cannot encode any knowledge this domain specific to the application without requiring coordination between the application and sidecar. That is likely at least as hard as implementing the sidecar-provided functionality in a language-specific library includable by the application.
I believe testing automation available in open source takes you a certain way. Any investment beyond that is likely to suffer from diminishing returns, as discussed in “Service Mesh Tracing”, and against using sidecars for traffic management, as in “Implementation in Service Mesh”, unpopular as these opinions might be. These implementations are lossy compared to what you can achieve via a binary dependency either explicitly included or injected into the runtime, both of which add a far greater degree of functionality that only becomes cost-prohibitive if you have a significant number of distinct languages to support (and even then, I’m not convinced).
Summary
In this chapter we defined platform engineering as at least a placeholder phrase for the functions of reliability engineering that we will discuss through the remainder of this book. The platform engineering team is most effective when it has a customer-oriented focus (where the customer is other developers in the organization) rather than one of control. Test tools, the adoption path for those tools, and any processes you develop against the “guardrails not gates” rule.
Ultimately, designing your platform is in part designing your organization. What do you want to be known for?
Get SRE with Java Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

