Chapter 4. Exploring Snowflake SQL Commands, Data Types, and Functions
As we learned in previous chapters, Snowflake was built to store data in an optimized, compressed, columnar format within a relational database. Snowflake’s data end users need to access the stored data and be able to give instructions to perform tasks, call functions, and execute queries on the data. The way that can be accomplished is with the standard programming language for relational databases, Structured Query Language (SQL). Snowflake supports SQL:ANSI, the most common standardized version of SQL. In addition to SQL support for structured data, Snowflake offers native support for semi-structured data formats such as JSON and XML. Snowflake also supports unstructured data.
The main focus of this chapter is on learning the fundamentals of using Snowflake worksheets to execute a variety of SQL commands using different data types and functions. Other than using worksheets in the Snowflake web UI, it is possible to use a Snowflake-native command-line client, known as SnowSQL, to create and execute SQL commands. More detail about SnowSQL will be provided in Chapter 6.
Besides connecting to Snowflake via the web UI or SnowSQL, you can use ODBC and JDBC drivers to access Snowflake data through external applications such as Tableau and Looker. We’ll explore connections to Tableau and Looker in Chapter 12. Native connectors such as Python and Spark can also be used to develop applications for connecting to Snowflake.
To help you prepare for mastering advanced topics in upcoming chapters, we’ll want to focus first on learning the basics of Snowflake SQL commands, data types, and Snowflake functions.
Prep Work
Create a new worksheet titled Chapter4 Syntax Examples, Data Types, and Functions. Refer to “Navigating Snowsight Worksheets” if you need help creating a new worksheet. To set the worksheet context, make sure you are in the Syntax Examples worksheet and using the SYSADMIN role and the COMPUTE_WH virtual warehouse.
Working with SQL Commands in Snowflake
SQL can be divided into five different language command types. To create Snowflake objects, you need to use Data Definition Language (DDL) commands. Giving access to those objects requires the Data Control Language (DCL). Next, you’ll use Data Manipulation Language (DML) commands to manipulate the data into and out of Snowflake. Transaction Control Language (TCL) commands enable you to manage transaction blocks. Data Query Language (DQL) statements are then used to actually query the data. Following is a list of common SQL commands, organized by type:
- DDL commands:
-
CREATEALTERTRUNCATERENAMEDROPDESCRIBESHOWUSESET/UNSETCOMMENT
- DCL commands:
-
GRANTREVOKE
- DML commands:
-
INSERTMERGEUPDATEDELETECOPY INTOPUTGETLISTVALIDATEREMOVE
- TCL commands:
-
BEGINCOMMITROLLBACKCREATE
- DQL command:
-
SELECT
Each of these five different command language types, and their associated commands, will be discussed briefly in the following sections. A comprehensive list of all Snowflake SQL commands can be found in the Snowflake online documentation.
DDL Commands
DDL commands are the SQL commands used to define the database schema. The commands create, modify, and delete database structures. In addition, DDL commands can be used to perform account-level session operations, such as setting parameters, as we’ll see later in the chapter when we discuss the SET and UNSET commands. DDL commands include CREATE, ALTER, TRUNCATE, RENAME, DROP, DESCRIBE, SHOW, USE, and COMMENT. With the exception of the COMMENT command, each DDL command takes an object type and identifier.
Snowflake DDL commands manipulate objects such as databases, virtual warehouses, schemas, tables, and views; however, they do not manipulate data. Refer back to Chapter 3, which is devoted to demonstrating Snowflake DDL commands, for in-depth explanations and many hands-on examples.
DCL Commands
DCL commands are the SQL commands used to enable access control. Examples of DCL commands include GRANT and REVOKE. Chapter 5 will take you through a complete and detailed series of examples using DCL commands to show you how to secure Snowflake objects.
DML Commands
DML commands are the SQL commands used to manipulate the data. The traditional DML commands such as INSERT, MERGE, UPDATE, and DELETE exist to be used for general data manipulation. For data loading and unloading, Snowflake provides COPY INTO <table> and COPY INTO <location> commands. Additionally, Snowflake’s DML commands include some commands that do not perform any actual data manipulation but are used to stage and manage files stored in Snowflake locations. Some examples include VALIDATE, PUT, GET, LIST, and REMOVE. Chapter 6 will explore many of Snowflake’s DML commands.
TCL Commands
TCL commands are the SQL commands used to manage transaction blocks within Snowflake. Commands such as BEGIN, COMMIT, and ROLLBACK can be used for multistatement transactions in a session. A Snowflake transaction is a set of read and write SQL statements that are processed together as one unit. By default, and upon query success, a DML statement that is run separately will be committed individually or will be rolled back at the end of the statement, if the query fails.
DQL Command
The DQL command is the SQL command used as either a statement or a clause to retrieve data that meets the criteria specified in the SELECT command. Note that the SELECT command is the only DQL command; it is used to retrieve data and does so by specifying the location and then using the WHERE statement to include attributes necessary for data selection inclusion.
The Snowflake SELECT command works on external tables and can be used to query historical data. In certain situations, using the SELECT statement will not require a running virtual warehouse to return results; this is because of Snowflake caching, as described in Chapter 2. Examples of the SELECT statement, the most common SQL statement, can be found throughout most of the chapters in this book. The following section provides details on how to make the most of the SELECT command.
SQL Query Development, Syntax, and Operators in Snowflake
Within Snowflake, SQL development can be undertaken natively, using Snowflake UI worksheets or SnowSQL, as well as via the many third-party SQL tools available.
Query syntax is how Snowflake SQL queries are structured or built. Often there are many different ways to write a SQL query that will yield the desired result. It is important to consider how to optimize the query for the best database performance and lowest cost. Chapter 9 includes a section devoted to discussing the topic of analyzing query performance and optimization techniques.
Query operators include terms reserved to specify conditions in a SQL query statement and are most often used in the WHERE clause. They can also be used as conjunctions for multiple conditions in a statement. We’ll explore query operators later in this section.
SQL Development and Management
There are two native Snowflake options for developing and querying data. It is easy to get started with Snowflake SQL development using the Worksheets browser-based SQL editor within the Snowflake interface. Using Snowflake Worksheets requires no installation or configuration. Thus far, we’ve used only the Snowflake Worksheets for creating objects and querying data.
An alternative to Worksheets is SnowSQL, a Python-based client that can be downloaded from the Snowflake client repository and used to perform Snowflake tasks such as querying or executing DDL and DML commands. SnowSQL is frequently used for loading and unloading data. We’ll get some hands-on experience with SnowSQL in Chapter 6.
Snowflake provides SnowSQL versions for Linux, macOS, and Microsoft Windows. Executable SnowSQL can be run as an interactive shell or in batch mode. Snowflake provides complete instructions on how to download and install SnowSQL for all supported platforms.
You can view the recently used client versions, including the SnowSQL version, in your Snowflake account by querying Snowflake’s query history. To view that information, click Activity → Query History if you are using the new Snowsight web interface. Should you not see the client driver information right away, click the Columns button and select Client Driver (as shown in Figure 4-1).

Figure 4-1. Available columns for reviewing query history activity in Snowsight
Alternatively, click the History tab in the Classic Console web interface. From there, you can view the Client Info column by clicking the Column button at the upper right and selecting Client Driver. Interestingly, the Client Info column in the Classic Console web interface includes an icon to indicate whether the client version is support, unsupported, or nearing the end of support. We’ve been using the Snowsight web UI, so we’ll see that the Go client driver has been used and it is supported, as indicated by a checkmark (as shown in Figure 4-2).
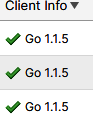
Figure 4-2. The Client Info column from the History tab (Classic Console web interface)
In addition to native Snowflake tools, a wide variety of third-party SQL tools are available for modeling, developing, and deploying SQL code in Snowflake applications. Some of these third-party tools, such as DataOps.live and SqlDBM, are available for a free trial by using Snowflake Partner Connect. You can visit the Snowflake online documentation for a more comprehensive list of third-party SQL tools available for use with Snowflake.
Note
For drivers and connectors that support sending a SQL statement for preparation before execution, Snowflake will prepare DML commands, and will execute SELECT and SHOW <objects> SQL statements received from those drivers and connectors. Other types of SQL statements received from drivers and connectors will be executed by Snowflake without preparation.
Query Syntax
Snowflake SQL queries begin with either the WITH clause or the SELECT command. The WITH clause, an optional clause that precedes the SELECT statement, is used to define common table expressions (CTEs) which are referenced in the FROM clause. Most queries, however, begin with the SELECT command and other syntax which appears afterward. The other syntax, described in Table 4-1, is evaluated in the following order:
-
FROM -
WHERE -
GROUP BY -
HAVING -
WINDOW -
QUALIFY -
ORDER BY -
LIMIT
| Query syntax | Query clause | Comments |
|---|---|---|
WITH |
Optional clause that precedes the body of the SELECT statement |
|
TOP<n> |
Contains the maximum number of rows returned, recommended to include ORDER BY |
|
FROM |
AT | BEFORE, CHANGES, CONNECT BY, JOIN, MATCH_RECOGNIZE, PIVOT or UNPIVOT, SAMPLE or TABLESAMPLE_VALUE |
Specifies the tables, views, or table functions to use in a SELECT statement |
WHERE |
Specifies a condition that matches a subset of rows; can filter the result of the FROM clause; can specify which rows to operate on in an UPDATE, MERGE, or DELETE |
|
GROUP BY |
GROUP BY CUBE, GROUP BY GROUPING SETS, GROUP BY ROLLUP, HAVING |
Groups rows with the same group-by-item expressions and computes aggregate functions for resultant group; can be a column name, a number referencing a position in the SELECT list, or a general expression |
QUALIFY |
Filters the results of window functions | |
ORDER BY |
Specifies an ordering of the rows of the result table from a SELECT list |
|
LIMIT/FETCH |
Constrains the maximum number of rows returned; recommended to include ORDER BY |
Note that QUALIFY is evaluated after a window function; QUALIFY works with window functions in much the same way as HAVING does with the aggregate functions and GROUP BY clauses. More information on window functions can be found later in this chapter.
Subqueries, derived columns, and CTEs
A subquery is a query within another query and can be used to compute values that are returned in a SELECT list, grouped in a GROUP BY clause, or compared with other expressions in the WHERE or HAVING clause.
A Snowflake subquery is a nested SELECT statement supported as a block in one or more of the following Snowflake SQL statements:
-
CREATE TABLE AS -
SELECT -
INSERT -
INSERT INTO -
UPDATE -
DELETE
To prepare for our hands-on exercises for subqueries and derived columns, we need to create a few simple tables and insert some values into those tables. We’ll create one database for this chapter. We’ll also create a schema and table for our subqueries and derived column examples. Navigate to the Chapter4 worksheet in Snowsight to execute the following statements:
USEROLESYSADMIN;USEWAREHOUSECOMPUTE_WH;CREATEORREPLACEDATABASEDEMO4_DB;CREATEORREPLACESCHEMASUBQUERIES;CREATEORREPLACETABLEDEMO4_DB.SUBQUERIES.DERIVED(IDinteger,AMTinteger,Totalinteger);INSERTINTODERIVED(ID,AMT,Total)VALUES(1,1000,4000),(2,2000,3500),(3,3000,9900),(4,4000,3000),(5,5000,3700),(6,6000,2222);SELECT*FROMDEMO4_DB.SUBQUERIES.DERIVED;
Your results should match what is shown in Figure 4-3.

Figure 4-3. Results of inserting values into a new Snowflake DERIVED table
We’ll need a second table in the SUBQUERIES schema; after adding the table, we’ll see the results shown in Figure 4-4:
CREATEORREPLACETABLEDEMO4_DB.SUBQUERIES.TABLE2(IDinteger,AMTinteger,Totalinteger);INSERTINTOTABLE2(ID,AMT,Total)VALUES(1,1000,8300),(2,1001,1900),(3,3000,4400),(4,1010,3535),(5,1200,3232),(6,1000,2222);SELECT*FROMDEMO4_DB.SUBQUERIES.TABLE2;

Figure 4-4. Results of inserting values into a new Snowflake TABLE2 table
Having now created both tables, we can write an uncorrelated subquery:
SELECTID,AMTFROMDEMO4_DB.SUBQUERIES.DERIVEDWHEREAMT=(SELECTMAX(AMT)FROMDEMO4_DB.SUBQUERIES.TABLE2);
You’ll notice that an uncorrelated subquery is an independent query, one in which the value returned doesn’t depend on any columns of the outer query. An uncorrelated subquery returns a single result that is used by the outer query only once. On the other hand, a correlated subquery references one or more external columns. A correlated subquery is evaluated on each row of the outer query table and returns one result per row that is evaluated.
Let’s try executing a correlated subquery now:
SELECTID,AMTFROMDEMO4_DB.SUBQUERIES.DERIVEDWHEREAMT=(SELECTAMTFROMDEMO4_DB.SUBQUERIES.TABLE2WHEREID=ID);
We receive an error message telling us that a single-row subquery returns more than one row (as shown in Figure 4-5). This probably isn’t what you expected.

Figure 4-5. The error message received when executing a correlated subquery without an aggregate
Logically, we know there is only one row per ID; so, the subquery won’t be returning more than one row in the result set. However, the server can’t know that. We must use a MIN, MAX, or AVG function so that the server can know for certain that only one row will be returned each time the subquery is executed.
Let’s go ahead and add MAX to the statement to see for ourselves how this works:
SELECTID,AMTFROMDEMO4_DB.SUBQUERIES.DERIVEDWHEREAMT=(SELECTMAX(AMT)FROMDEMO4_DB.SUBQUERIES.TABLE2WHEREID=ID);
Success! We get a result set of one row with the ID equal to the value of 3. Let’s see what happens if we change the equals sign to a greater-than sign:
SELECTID,AMTFROMDEMO4_DB.SUBQUERIES.DERIVEDWHEREAMT>(SELECTMAX(AMT)FROMDEMO4_DB.SUBQUERIES.TABLE2WHEREID=ID);
Now we get a result set with three values (as shown in Figure 4-6).
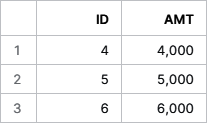
Figure 4-6. A correlated query result set with three values
Let’s see what happens if we change MAX to AVG:
SELECTID,AMTFROMDEMO4_DB.SUBQUERIES.DERIVEDWHEREAMT>(SELECTAVG(AMT)FROMDEMO4_DB.SUBQUERIES.TABLE2WHEREID=ID);
There are five records in the result set. You may want to try different operators in the WHERE clause and different aggregators in the SELECT clause to see for yourself how correlated subqueries actually work.
Correlated subqueries are used infrequently because they result in one query per row, which is probably not the best scalable approach for most use cases.
Subqueries can be used for multiple purposes, one of which is to calculate or derive values that are then used in a variety of different ways. Derived columns can also be used in Snowflake to calculate another derived column, can be consumed by the outer SELECT query, or can be used as part of the WITH clause. These derived column values, sometimes called computed column values or virtual column values, are not physically stored in a table but are instead recalculated each time they are referenced in a query.
Our next example demonstrates how a derived column can be used in Snowflake to calculate another derived column. We’ll also discover how we can use derived columns in one query, in subqueries, and with CTEs.
Let’s create a derived column, AMT1, from the AMT column and then directly use the first derived column to create the second derived column, AMT2:
SELECTID,AMT,AMT*10asAMT1,AMT1+20asAMT2FROMDEMO4_DB.SUBQUERIES.DERIVED;
The results of running that query can be seen in Figure 4-7.

Figure 4-7. Results of running the query with two derived columns
We can achieve the same results by creating a derived column, AMT1, which can then be consumed by an outer SELECT query. The subquery in our example is a Snowflake uncorrelated scalar subquery. As a reminder, the subquery is considered to be an uncorrelated subquery because the value returned doesn’t depend on any outer query column:
SELECTsub.ID,sub.AMT,sub.AMT1+20asAMT2FROM(SELECTID,AMT,AMT*10asAMT1FROMDEMO4_DB.SUBQUERIES.DERIVED)ASsub;
Lastly, we get the same results by using a derived column as part of the WITH clause. You’ll notice that we’ve included a CTE subquery which could help increase modularity and simplify maintenance. The CTE defines a temporary view name, which is CTE1 in our example. Included in the CTE are the column names and a query expression, the result of which is basically a table:
WITHCTE1AS(SELECTID,AMT,AMT*10asAMT2FROMDEMO4_DB.SUBQUERIES.DERIVED)SELECTa.ID,b.AMT,b.AMT2+20asAMT2FROMDEMO4_DB.SUBQUERIES.DERIVEDaJOINCTE1bON(a.ID=b.ID);
A major benefit of using a CTE is that it can make your code more readable. With a CTE, you can define a temporary table once and refer to it whenever you need it instead of having to declare the same subquery every place you need it. While not demonstrated here, a CTE can also be recursive. A recursive CTE can join a table to itself many times to process hierarchical data.
Caution about multirow inserts
Now is a good time for a brief pause to learn a little more about multirow inserts. One or more rows of data can be inserted using a select query, or can be inserted as explicitly stated values in a comma-separated list. To keep things simple, we’ve been inserting values in comma-separated lists in this chapter.
There is one important thing to be aware of regarding multirow inserts. When inserting multiple rows of data into a VARCHAR data type, each data type being inserted into VARCHAR columns must be the same or else the insert will fail. A VARCHAR data type can accept data values such as the word one or the number 1, but never both types of values in the same INSERT statement. We can best see this with some examples.
We’ll first create a new schema and table to do some multirow insert testing. In the first example, we’ll insert the value one into the VARCHAR DEPT column:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.TEST;CREATEORREPLACETABLEDEMO4_DB.TEST.TEST1(IDinteger,DEPTVarchar);INSERTINTOTEST1(ID,DEPT)VALUES(1,'one');SELECT*FROMDEMO4_DB.TEST.TEST1;
As expected, the value was entered successfully. Let’s see what happens if we instead insert a numerical value into the VARCHAR column:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.TEST;CREATEORREPLACETABLEDEMO4_DB.TEST.TEST1(IDinteger,DEPTVarchar);INSERTINTOTEST1(ID,DEPT)VALUES(1,1);SELECT*FROMDEMO4_DB.TEST.TEST1;
Again, the value was entered successfully. Now let’s try inserting both types into the column within the same INSERT statement:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.TEST;CREATEORREPLACETABLEDEMO4_DB.TEST.TEST1(IDinteger,DEPTVarchar);INSERTINTOTEST1(ID,DEPT)VALUES(1,'one'),(2,2);SELECT*FROMDEMO4_DB.TEST.TEST1;
When we try to insert two different data types into the VARCHAR column at the same time, we experience an error, as shown in Figure 4-8.

Figure 4-8. The error message that is received when attempting to insert two different data types into a VARCHAR column in one multirow INSERT statement
Let’s try again, but this time we’ll insert two values with the same data type:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.TEST;CREATEORREPLACETABLEDEMO4_DB.TEST.TEST1(IDinteger,DEPTVarchar);INSERTINTOTEST1(ID,DEPT)VALUES(1,'one'),(2,'two');SELECT*FROMDEMO4_DB.TEST.TEST1;
We’re also successful if we insert two numerical values into the VARCHAR column:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.TEST;CREATEORREPLACETABLEDEMO4_DB.TEST.TEST1(IDinteger,DEPTVarchar);INSERTINTOTEST1(ID,DEPT)VALUES(1,1),(2,2);SELECT*FROMDEMO4_DB.TEST.TEST1;
You’ll notice that we are able to successfully load two different data types into the VARCHAR column, but not at the same time. And once we have two different data types in the VARCHAR column, we can still add additional values:
INSERTINTOTEST1(ID,DEPT)VALUES(5,'five');SELECT*FROMDEMO4_DB.TEST.TEST1;
Multirow inserts are one way of getting data into Snowflake. Chapter 6 is devoted to data loading and unloading, and includes an in-depth discussion of bulk data loading options and continuous data loading options.
Query Operators
There are several different types of query operators, including arithmetic, comparison, logical, subquery, and set operators.
Arithmetic operators, including +, –, *, /, and %, produce a numeric output from one or more inputs. The scale and precision of the output depends on the scale and precision of the input(s). Note that subtraction is the only arithmetic operation allowed on DATE expressions.
Comparison operators, typically appearing in a WHERE clause, are used to test the equality of two inputs. Comparison operators include the following:
-
Equal (
=) -
Not equal (
!=or<>) -
Less than (
<) -
Less than or equal (
<=) -
Greater than (
>) -
Greater than or equal (
>=)
Tip
Remember that TIMESTAMP_TZ values are compared based on their times in UTC, which does not account for daylight saving time. This is important because, at the moment of creation, TIMESTAMP_TZ stores the offset of a given time zone, not the actual time zone.
Logical operators can only be used in the WHERE clause. The order of precedence of these operators is NOT then AND then OR. Subquery operators include [NOT] EXISTS, ANY or ALL, and [NOT] IN. Queries can be combined when using set operators such as INTERSECT, MINUS or EXCEPT, UNION, and UNION ALL.
The default set operator order of preference is INTERSECT as the highest precedence, followed by EXCEPT, MINUS, and UNION, and finally UNION ALL as the lowest precedence. Of course, you can always use parentheses to override the default. Note that the UNION set operation is costly because it needs to sort the records to eliminate duplicate rows.
Warning
When using set operators, make sure each query selects the same number of columns and the data type of each column is consistent, although an explicit type cast can be used if the data types are inconsistent.
Long-Running Queries, and Query Performance and Optimization
The Snowflake system will cancel long-running queries. The default duration for long-running queries is two days, but the STATEMENT_TIMEOUT_IN_SECONDS duration value can always be set at an account, session, object, or virtual warehouse level.
During the Snowflake SQL query process, one of the things that happens is the optimization engines find the most efficient execution plan for a specific query. In Chapter 9, we’ll learn more about analyzing query performance and optimization techniques as well as how to use Snowflake’s query profiler.
Snowflake Query Limits
SQL statements submitted through Snowflake clients have a query text size limit of 1 MB. Included in that limit are literals, including both string and binary literals. The query text size limit applies to the compressed size of the query. However, because the compression ratio for data varies widely, it is recommended to keep the uncompressed query text size below 1 MB.
Additionally, Snowflake limits the number of expressions allowed in a query to 16,384. There are ways to resolve this type of error depending on what are you trying to do with your SQL query statement. If you’re attempting to insert data when you receive the error, try breaking up the statement into smaller queries. However, an even better choice would probably be to use the COPY INTO command instead of the INSERT command.
Another type of query limit error occurs when using a SELECT statement with an IN clause that has more than 16,384 values. Here is an example of what that code might look like:
SELECT<column_1>FROM<table_1>WHERE<column_2>IN(1,2,3,4,5,...);
One solution would be to use a JOIN or UNION command after placing those values in a second table. The SQL code could look like this:
SELECT<column_1>FROM<table_1>aJOIN<table_2>bONa.<column_2>=b.<column_2>;
Introduction to Data Types Supported by Snowflake
Snowflake supports the basic SQL data types including geospatial data types, and a Boolean logical data type which provides for ternary logic. Snowflake’s BOOLEAN data type can have an unknown value, or a TRUE or FALSE value. If the Boolean is used in an expression, such as a SELECT statement, an unknown value returns a NULL. If the Boolean is used as a predicate, such as in a WHERE clause, the unknown results will evaluate to FALSE. There are a few data types not supported by Snowflake, such as Large Object (LOB), including BLOB and CLOB, as well as ENUM and user-defined data types.
Snowflake offers native support for geospatial features such as points, lines, and polygons on the earth’s surface. The Snowflake GEOGRAPHY data type follows the WGS standard. Points on the earth are represented as degrees of longitude and latitude. Altitude is not currently supported.
Note
If you have geospatial data such as longitude and latitude, WKT, WKB, or GeoJSON, it is recommended that you convert and store this data in GEOGRAPHY columns rather than keeping the data in their original formats in VARCHAR, VARIANT, or NUMBER columns. This could significantly improve the performance of queries that use geospatial functionality.
In this section, we’ll take a deeper dive into several Snowflake data types including numeric, string and binary, date and time, semi-structured, and unstructured.
Numeric Data Types
Snowflake’s numeric data types include fixed-point numbers and floating-point numbers, as detailed in Table 4-2. Included in the table is information about each numeric data type’s precision and scale. Precision, the total number of digits, impacts storage, whereas scale, the number of digits following the decimal point, does not. However, processing numeric data values with a larger scale could cause slower processing.
| Fixed-point number data types | Precision | Comments |
|---|---|---|
NUMBER |
Optional (38, 0) | Numbers up to 38 digits; maximum scale is 37 |
DECIMAL, NUMERIC |
Optional (38,0) | Synonymous with NUMBER |
INT, INTEGER, BIGINT, SMALLINT, TINYINT, BYTEINT |
Cannot be specified; always (38,0) | Possible values: -99999999999999999999999999999999999999 to +99999999999999999999999999999999999999 (inclusive) |
| Floating-point number data types | Comments | |
FLOAT, FLOAT4, FLOAT8 |
Approximately 15 digits | Values range from approximately 10-308 to 10+308 |
DOUBLE, DOUBLE PRECISION, REAL |
Approximately 15 digits | Synonymous with FLOAT |
Note
It is a known issue that DOUBLE, DOUBLE PRECISION, and REAL columns are stored as DOUBLE but displayed as FLOAT.
Fixed-point numbers are exact numeric values and, as such, are often used for natural numbers and exact decimal values such as monetary amounts. In contrast, floating-point data types are used most often for mathematics and science.
You can see how fixed-point numbers vary based on the data type. Be sure to navigate to the Chapter4 worksheet and then try the following example:
USEROLESYSADMIN;CREATEORREPLACESCHEMADEMO4_DB.DATATYPES;CREATEORREPLACETABLENUMFIXED(NUMNUMBER,NUM12NUMBER(12,0),DECIMALDECIMAL(10,2),INTINT,INTEGERINTEGER);
To see what was created, you can run the DESC TABLE NUMFIXED statement to get the results shown in Figure 4-9.

Figure 4-9. Results showing the Snowflake fixed-point number data type
Now you can compare fixed-point numbers to floating-point numbers by using this next example:
USEROLESYSADMIN;USESCHEMADEMO4_DB.DATATYPES;CREATEORREPLACETABLENUMFLOAT(FLOATFLOAT,DOUBLEDOUBLE,DPDOUBLEPRECISION,REALREAL);
Once again, use the Desc command to see the results, as shown in Figure 4-10:
DESCTABLENUMFLOAT;

Figure 4-10. Results showing the Snowflake floating-point number data type
In traditional computing, float data types are known to be faster for computation. But is that still an accurate statement about float data types in modern data platforms such as Snowflake? Not necessarily. It is important to consider that integer values can be stored in a compressed format in Snowflake, whereas float data types cannot. This results in less storage space and less cost for integers. Querying rows for an integer table type also takes significantly less time.
Warning
Because of the inexact nature of floating-point data types, floating-point operations could have small rounding errors and those errors can accumulate, especially when using aggregate functions to process a large number of rows.
Snowflake’s numeric data types are supported by numeric constants. Constants, also referred to as literals, represent fixed data values. Numeric digits 0 through 9 can be prefaced by a positive or negative sign. Exponents, indicated by e or E, are also supported in Snowflake numeric constants.
String and Binary Data Types
Snowflake supports both text and binary string data types, the details of which can be seen in Table 4-3.
| Text string data types | Parameters | Comments |
|---|---|---|
VARCHAR |
Optional parameter (N), max number of characters |
Holds Unicode characters; no performance difference between using full-length VARCHAR (16,777,216) or a smaller length |
CHAR, CHARACTERS |
Synonymous with VARCHAR; length is CHAR(1) if not specified |
|
STRING, TEXT |
Synonymous with VARCHAR |
|
| Binary string data types | Comments | |
BINARY |
Has no notion of Unicode characters, so length is always measured in bytes; if length is not specified, the default is 8 MB (the maximum length) | |
VARBINARY |
Synonymous with BINARY |
You can see how the text string data types vary by attempting the following example, which creates the text string fields and then describes the table:
USEROLESYSADMIN;USESCHEMADEMO4_DB.DATATYPES;CREATEORREPLACETABLETEXTSTRING(VARCHARVARCHAR,V100VARCHAR(100),CHARCHAR,C100CHAR(100),STRINGSTRING,S100STRING(100),TEXTTEXT,T100TEXT(100));DESCTABLETEXTSTRING;
If you followed along with the example, you should see the output shown in Figure 4-11.

Figure 4-11. Results of creating a TEXTSTRING table
Snowflake’s string data types are supported by string constants, which are always enclosed between delimiters, either single quotes or dollar signs. Using dollar sign symbols as delimiters is especially useful when the string contains many quote characters.
Date and Time Input/Output Data Types
Snowflake uses the Gregorian calendar, rather than the Julian calendar, for all dates and timestamps. The Snowflake date and time data types are summarized in Table 4-4.
| Date and time data types | Default mapping | Comments |
|---|---|---|
DATE |
Single DATE type; most common date forms are accepted; all accepted timestamps are valid inputs with TIME truncated; the associated time is assumed to be midnight |
|
DATETIME |
Alias for TIMESTAMP_NTZ |
|
TIME |
Single TIME type in the form HH:MI:SS, internally stored as wall clock time; time zones not taken into consideration |
|
TIMESTAMP |
Default is TIMESTAMP_NTZ |
User-specified alias of one of the three TIMESTAMP_ variations |
TIMESTAMP_LTZ |
Internally UTC time with a specified precision; TIMESTAMP with local time zone |
|
TIMESTAMP_NTZ |
Internally wall clock time; TIMESTAMP without time zone |
|
TIMESTAMP_TZ |
Internally UTC time with a time zone offset; TIMESTAMP with time zone |
Snowflake’s data and time data types are supported by interval constants as well as date and time constants. Interval constants can be used to add or subtract a specific period of time to or from a date, time, or timestamp. The interval is not a data type; it can be used only in date, time, or timestamp arithmetic and will represent seconds if the date or time portion is not specified.
Note
The order of interval increments is important because increments are added or subtracted in the order in which they are listed. This could be important for calculations affected by leap years.
Semi-Structured Data Types
Structured data, known as quantitative data, can be easily stored in a database table as rows and columns whereas semi-structured data, such as XML data, is not schema dependent, which makes it more difficult to store in a database. In some situations, however, semi-structured data can be stored in a relational database.
Snowflake supports data types for importing and operating on semi-structured data such as JSON, Avro, ORC, Parquet, and XML data. Snowflake does so through its universal data type VARIANT, a special column type which allows you to store semi-structured data. Table 4-5 provides more information about Snowflake semi-structured data types. Note that it is possible for a VARIANT value to be missing, which is considered to be different from a true null value.
| Semi-structured data types | Characteristics | Comments |
|---|---|---|
VARIANT |
Can store OBJECT and ARRAY |
Stores values of any other type, up to a maximum of 16 MB uncompressed; internally stored in compressed columnar binary representation |
OBJECT |
Represents collections of key-value pairs with the key as a nonempty string and the value of VARIANT type |
|
ARRAY |
Represents arrays of arbitrary size whose index is a non-negative integer and values have VARIANT type |
Warning
When loaded into a VARIANT column, non-native values such as dates and timestamps are stored as strings. Storing values in this way will likely cause operations to be slower and to consume more space as compared to storing date and timestamp values in a relational column with the corresponding data type.
The hands-on exercises for semi-structured data will use the Snowflake sample weather data, which is stored in native JSON format. We’ll spend some time getting a feel for the data that exists and then we’ll learn how to use the FLATTEN function to produce a lateral view of the semi-structured data.
Warning
At the time of this writing, the weather dataset was available in the Snowflake free trial accounts. However, Snowflake may be deprecating this dataset over time. Please see https://github.com/SnowflakeDefinitiveGuide for further information.Let’s first just take a quick look at a few rows of data:
USEROLESYSADMIN;USESCHEMASNOWFLAKE_SAMPLE_DATA.WEATHER;SELECT*FROMDAILY_16_TOTALLIMIT5;
You should see that there are two columns: one VARIANT column (V) and one TIMESTAMP column (T), as shown in Figure 4-12.

Figure 4-12. Two columns in the Snowflake weather sample data table
Let’s focus on the data in the VARIANT column:
SELECTv:cityFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
Once the results are returned, click V:CITY at the top of the column. This will highlight the column and give you the details you need to see that there are four distinct object keys in this column (as shown in Figure 4-13). In order, the object keys relating to V:CITY are coordinates, country, ID, and name.

Figure 4-13. Four distinct object keys for CITY data in the VARIANT column
Let’s now manually break out some of the CITY data and list them in a more logical order (as shown in Figure 4-14):
SELECTv:city:id,v:city:name,v:city:country,v:city:coordFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;

Figure 4-14. Detail of the CITY data in the VARIANT column
The latitude and longitude details are nested in the coordinate information. Let’s separate those out and give the columns some appropriate names:
SELECTv:city:idASID,v:city:nameASCITY,v:city:countryASCOUNTRY,v:city:coord:latASLATITUDE,v:city:coord:lonASLONGITUDEFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
We can convert a variant data type to another data type. In the next example, we’ll cast the city and country VARIANT data to a VARCHAR data type, and we’ll assign meaningful labels to the columns:
SELECTv:city:idASID,v:city:name::varcharAScity,v:city.country::varcharAScountry,v:city:coord:lonASlongitude,v:city:coord:latASlatitudeFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
The results are shown in Figure 4-15.

Figure 4-15. Casting of the city and country VARIANT data to a VARCHAR data type
We can confirm that we successfully cast the two columns by asking Snowflake to describe the results of our last query:
DESCRESULTLAST_QUERY_ID();
Next, let’s look at more data in the VARIANT column:
SELECTv:dataFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
Once the results are returned, click V:DATA at the top of the column. This will highlight the column and give you column details that you’ll see on the right side (as shown in Figure 4-16). You’ll notice that there is one array in this column relating to the DATA information.

Figure 4-16. The weather data array in the VARIANT column
Because the DATA information is stored as an array, we can look at a particular element in the array. Be sure to click each result row to see that only one element was selected for each row:
SELECTv:data[5]FROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
We can further limit the information returned by taking a look at the humidity value for a particular day for a specific city and country:
SELECTv:city:nameAScity,v:city:countryAScountry,v:data[0]:humidityASHUMIDITYFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT10;
Now let’s do a quick review. When we look at the DATA array, v:data AS DATA in the following statement, we notice that each row contains a complete data array. Within each data array there are 16 elements for each distinct piece of data (as shown in Figure 4-17). In our SQL query, we’ll include the first two data elements for the humidity and the day temperature:
SELECTv:data[0]:dt::timestampASTIME,v:data[0]:humidityASHUMIDITY0,v:data[0]:temp:dayASDAY_TEMP0,v:data[1]:humidityASHUMIDITY1,v:data[1]:temp:dayASDAY_TEMP1,v:dataASDATAFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTALLIMIT100;

Figure 4-17. One DATA array element (path) per row
Let’s see how we can leverage the FLATTEN table function. The FLATTEN function produces a lateral view of a VARIANT, OBJECT, or ARRAY column. We’ll demonstrate how FLATTEN works on the DATA array in the sample weather data table:
SELECTd.value:dt::timestampASTIME,v:city:nameASCITY,v:city:countryASCOUNTRY,d.pathASPATH,d.value:humidityASHUMIDITY,d.value:temp:dayASDAY_TEMP,v:dataASDATAFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTAL,LATERALFLATTEN(input=>daily_16_total.v:data)dLIMIT100;
You’ll notice that the same DATA array appears for each of the 16 flattened rows, but the HUMIDITY and DAY_TEMP reported in each row are associated with the specific PATH of the array (as shown in Figure 4-18).

Figure 4-18. The flattened DATA array
The temperature information in the DATA array has six nested values: day, eve, max, min, morn, and night. We can use a nested FLATTEN to further flatten the DATA array. When we do this, each DATA row appears 96 times, six times for each of the 16 PATH values (as shown in Figure 4-19):
SELECTd.value:dt::timestampASTIME,t.key,v:city:nameASCITY,v:city:countryASCOUNTRY,d.pathASPATH,d.value:humidityASHUMIDITY,d.value:temp:dayASDAY_TEMP,d.value:temp:nightASNIGHT_TEMP,v:dataASdataFROMSNOWFLAKE_SAMPLE_DATA.WEATHER.DAILY_16_TOTAL,LATERALFLATTEN(input=>daily_16_total.v:data)d,LATERALFLATTEN(input=>d.value:temp)tWHEREv:city:id=1274693LIMIT100;

Figure 4-19. The flattened, nested DATA array
As we’ve just seen, the Snowflake FLATTEN function is used to convert semi-structured data to a relational representation.
Unstructured Data Types
There are many advantages to using unstructured data to gain insight. Unstructured data is often qualitative, but it can also be quantitative data lacking rows, columns, or delimiters, as would be the case with a PDF file that contains quantitative data. Media logs, medical images, audio files of call center recordings, document images, and many other types of unstructured data can be used for analytical purposes and for the purpose of sentiment analysis. Storing and governing unstructured data is not easy. Unstructured data is not organized in a predefined manner, which means it is not well suited for relational databases. Typically, unstructured data has been stored in blob storage locations, which has several inherent disadvantages, making it difficult and time-consuming to search for files.
To improve searchability of unstructured data, Snowflake recently launched built-in directory tables. Using a tabular file catalog for searches of unstructured data is now as simple as using a SELECT * command on the directory table. Users can also build a table stream on top of a directory table, which makes it possible to create pipelines for processing unstructured data. Additionally, Snowflake users can create secure views on directory tables and, thus, are also able to share those secure views with others.
How Snowflake Supports Unstructured Data Use
Unstructured data represents an increasingly larger percentage of data being generated today. Examples of unstructured data types include video, audio, or image files, logfiles, sensor data, and social media posts. Unstructured data, which can be human generated or machine generated, has an internal structure but not one that is storable in a structured database format.
There are many reasons why you’d want to make use of all this unstructured data. Such use cases could include deriving insights like sentiment analysis from call center recordings; extracting text for analytics by using optical character recognition processes on insurance cards or prescription pills; using machine learning on DICOM medical images; or extracting key-value pairs from stored PDF documents.
It’s no secret that unstructured data is complex; hence, there are many challenges to storing, searching, and analyzing it. Traditional data warehouses and data lakes have been unable to adequately support the workload demands of today’s data formats, especially unstructured data. However, Snowflake is not your traditional data warehouse or data lake. Instead, it is a data platform built from the ground up for the cloud; therefore, it has removed much of the difficulty associated with storing, searching, and analyzing or processing unstructured data.
The first consideration in using unstructured data is how and where to store the unstructured files. When using Snowflake, there are two ways to do this: internal stages and external stages. We’d use an internal stage if we wanted to store data internally on Snowflake; especially if we were looking for a simple, easy-to-manage solution. That is because Snowflake automatically manages the scalability, encryption, data compression, and other aspects of storage. We’d alternatively use an external stage, known as bring your own storage, if we have legacy data stored elsewhere across the cloud as there is no need to move all your data into Snowflake.
While it is possible to store unstructured data internally in a Snowflake table using the VARIANT column type, it is usually not recommended because there is a file storage limitation of 16 MB. If we instead use a stage, there are no size limitations other than those imposed by the major cloud providers upon which your Snowflake instance is built: 5 TB of data for AWS and GCP or 256 GB of data for Azure.
Whether you use internal or external Snowflake stages, control access to data is easily achieved through role-based access controls. By using GRANT and REVOKE statements, privileges can be given to Snowflake resources like stages by granting permissions to roles which are then granted to individuals. It’s easy to understand and learn how to give fine-grain access to data in an internal or external stage, or to a subset of the data stored in views which are Snowflake objects created on top of stages. For a refresher about Snowflake access controls, refer to Chapter 5.
Using Snowflake, storing and granting access to unstructured data can be done in three different ways: stage file URLs, scoped URLs, or presigned URLs.
Stage file URL access
A stage file URL is used to create a permanent URL to a file on a Snowflake stage and is used most frequently for custom applications. Access to a file URL is through a GET request to the REST API endpoint along with the authorization token. Note that the user must have read privileges on the stage. Stage file URLs have a unique feature in that they can be listed in a Snowflake directory table.
The ability to create a directory table, like a file catalog, which you can easily search to retrieve file URLs to access the staged files as well as other metadata, is a unique feature that Snowflake provides for unstructured data. Snowflake roles that have been granted privileges can query a directory table to retrieve URLs to access staged files.
Whether you want to, for example, sort by file size or by last modified date, or only take the top 100 files or the largest files, it is possible to do so with Snowflake directory tables. You can also use Snowflake streams and tasks with directory tables for a powerful combination. Using table streams, for example, you can easily find all the new files that were recently added. Because a directory table is a table, you can perform fine-grain select and search operations. Search operations in regular blob stores are extremely difficult because they don’t have the catalog information in a tabular format.
A Snowflake directory table is a built-in read-only table. As such, you cannot add more columns or modify the columns in a directory table. What you can do is use Snowflake streams and tasks to calculate values and put them into a new table with a column containing the results of the calculation. You’ll then be able to join that table with the directory table by creating a view. You can also add tags, if desired.
Scoped URL access
A scoped URL is frequently used for custom applications; especially in situations where access to the data will be given to other accounts using the data share functionality or when ad hoc analysis is performed internally using Snowsight. Sharing unstructured data securely in the cloud is easy with Snowflake. No privileges are required on the stage. Instead, you’d create a secure view, and using the scoped URL, you would share the contents of the secure view. The scoped URL is encoded, so it is not possible to determine the account, database, schema, or other storage details from the URL.
Access to files in a stage using scoped URL access is achieved in one of two ways. One way is for a Snowflake user to click a scoped URL in the results table in Snowsight. The other way is to send the scoped URL in a request which results in Snowflake authenticating the user, verifying the scoped URL has not expired, and then redirecting the user to the staged file in the cloud storage service. Remember, the location of the staged file in the cloud storage is encoded, so the user is unable to determine the location. The scoped URL in the output from the API call is valid for 24 hours, the current length of time the result cache exists.
Note
For security reasons, it is impossible to share a scoped URL that has been shared with you. If you were to share the link with someone else who does not have similar access granted to them, the message access denied would appear.
Presigned URL access
A presigned URL is most often used for business intelligence applications or reporting tools that need to display unstructured file contents for open files. Because the presigned URLs are already authenticated, a user or application can directly access or download files without the need to pass an authorization token.
The GET_PRESIGNED_URL function generates the presigned URL to a stage file using the stage name and relative file path as inputs. Access to files in a stage using a presigned URL can be accomplished in three different ways: use the presigned URL in a web browser to directly navigate to the file, click a presigned URL in the results table in Snowsight, or send the presigned URL in a REST API call request.
Processing unstructured data with Java functions and external functions
The ability to run processes on the unstructured data inside files is one of the most exciting features offered by Snowflake. Currently, there are two ways to process unstructured data using Snowflake: Java functions and external functions. In the future, Snowflake plans to add the ability to process unstructured data using Python functions.
If you already have Java code that you’ve written for use on unstructured data, it makes sense to use a Java user-defined function (UDF). Note that Java UDFs are executed directly in Snowflake, using a Snowflake virtual warehouse. As such, Java UDFs do not make any API calls outside the boundaries of Snowflake. Everything is tightly secured and managed within the Snowflake environment.
If there are external API services such as machine learning models, geocoders, or other custom code that you want to utilize, external functions can be used. External functions make it possible to use existing machine learning services to extract text from images, or to process PDF files to extract key-value pairs. In an external function, you can use any of the AWS, Azure, or GCP functionalities, including AWS Rekognition or Azure Cognitive Services. External functions executed on unstructured data, whether stored within internal or external stages, can be used to eliminate the need to export and reimport data.
Snowflake SQL Functions and Session Variables
Snowflake offers users the ability to create UDFs and to use external functions, as well as to access many different built-in functions. Session variables also extend Snowflake SQL capabilities.
Using System-Defined (Built-In) Functions
Examples of Snowflake built-in functions include scalar, aggregate, window, table, and system functions.
Scalar functions accept a single row or value as an input and then return one value as a result, whereas aggregate functions also return a single value but accept multiple rows or values as inputs.
Scalar functions
Some scalar functions operate on a string or binary input value. Examples include CONCAT, LEN, SPLIT, TRIM, UPPER and LOWER case conversion, and REPLACE. Other scalar file functions, such as GET_STAGE_LOCATION, enable you to access files staged in Snowflake cloud storage.
Additionally, you can do many things in Snowflake with date and time data types. Some examples of scalar date and time functions and data generation functions include the following:
-
Construct/deconstruct (extract) using month, day, and year components.
-
Truncate or “round up” dates to a higher level.
-
Parse and format dates using strings.
-
Add/subtract to find and use date differences.
-
Generate system dates or a table of dates.
Aggregate functions
A Snowflake aggregate function will always return one row even when the input contains no rows. The returned row from an aggregate function where the input contains zero rows could be a zero, an empty string, or some other value. Aggregate functions can be of a general nature, such as MIN, MAX, MEDIAN, MODE, and SUM. Aggregate functions also include linear regression, statistics and probability, frequency estimation, percentile estimation, and much more.
Snowflake window functions are a special type of aggregate function that can operate on a subset of rows. This subset of related rows is called a window. Unlike aggregate functions which return a single value for a group of rows, a window function will return an output row for each input row. The output depends not only on the individual row passed to the function but also on the values of the other rows in the window passed to the function.
Window functions are commonly used for finding a year-over-year percentage change, a moving average, and a running or cumulative total, as well as for ranking rows by groupings or custom criteria.
Let’s compare an aggregate function with a window function. In this first example, we’ll create an aggregate function by using the vowels in the alphabet and their corresponding locations:
SELECTLETTER,SUM(LOCATION)asAGGREGATEFROM(SELECT'A'asLETTER,1asLOCATIONUNIONALL(SELECT'A'asLETTER,1asLOCATION)UNIONALL(SELECT'E'asLETTER,5asLOCATION))asAGG_TABLEGROUPBYLETTER;
The results of this query are shown in Figure 4-20.

Figure 4-20. Results of an aggregate function query
Next, we’ll create a window function using the same logic:
SELECTLETTER,SUM(LOCATION)OVER(PARTITIONBYLETTER)asWINDOW_FUNCTIONFROM(SELECT'A'asLETTER,1asLOCATIONUNIONALL(SELECT'A'asLETTER,1asLOCATION)UNIONALL(SELECT'E'asLETTER,5asLOCATION))asWINDOW_TABLE;
Notice, in Figure 4-21, how the letter A has the same sum value in the window function as in the aggregate function, but repeats in the results because the input has two separate A listings.

Figure 4-21. Results of a window function
Table functions
Table functions, often called tabular functions, return results in a tabular format with one or more columns and none, one, or many rows. Most Snowflake table functions are 1-to-N functions where each input row generates N output rows, but there exist some M-to-N table functions where a group of M input rows produces a group of N output rows. Table functions can be system defined or user defined. Some examples of system-defined table functions include VALIDATE, GENERATOR, FLATTEN, RESULT_SCAN, LOGIN_HISTORY, and TASK_HISTORY.
System functions
Built-in system functions return system-level information or query information, or perform control operations.
One oft-used system information function is SYSTEM$CLUSTERING_INFORMATION, which returns clustering information, including the average clustering depth, about one or more columns in a table.
System control functions allow you to execute actions in the system. One example of a control function is SYSTEM$CANCEL_ALL_QUERIES and requires the session ID. You can obtain the session ID by logging in as the ACCOUNTADMIN. From the Main menu in Snowsight, go to Activity → Query History and then use the Column button to select the session ID so that it will be displayed. Alternatively, go to Account → Sessions in the Classic Console interface:
SELECTSYSTEM$CANCEL_ALL_QUERIES(<session_id>);
If you need to cancel queries for a specific virtual warehouse or user rather than the session, you’ll want to use the ALTER command along with ABORT ALL QUERIES instead of a system control function.
Creating SQL and JavaScript UDFs and Using Session Variables
SQL functionality can be extended by SQL UDFs, Java UDFs, Python UDFs, and session variables. We took a deep dive into both SQL and JavaScript UDFs in Chapter 3, so we’ll focus on learning more about session variables in this section.
Snowflake supports SQL variables declared by the user, using the SET command. These session variables exist while a Snowflake session is active. Variables are distinguished in a Snowflake SQL statement by a $ prefix and can also contain identifier names when used with objects. You must wrap a variable inside the identifier, such as IDENTIFIER($Variable), to use a variable as an identifier. Alternatively, you can wrap the variable inside an object in the context of a FROM clause.
To see all the variables defined in the current session, use the SHOW VARIABLES command.
Some examples of session variable functions include the following:
-
SYS_CONTEXTandSET_SYS_CONTEXT -
SESSION_CONTEXTandSET_SESSION_CONTEXT -
GETVARIABLEandSETVARIABLE
All variables created during a session are dropped when a Snowflake session is closed. If you want to destroy a variable during a session, you can use the UNSET command.
External Functions
An external function is a type of UDF that calls code which is stored and executed outside of Snowflake. Snowflake supports scalar external functions, which means the remote service must return exactly one row for each row received. Within Snowflake, the external function is stored as a database object that Snowflake uses to call the remote service.
It is important to note that rather than calling a remote service directly, Snowflake most often calls a proxy service to relay the data to the remote service. The Amazon API Gateway and Microsoft Azure API management service are two examples of proxy services that can be used. A remote service can be implemented as an AWS Lambda function, a Microsoft Azure function, or an HTTPS server (e.g., Node.js) running on an EC2 instance.
Any charges by providers of remote services will be billed separately. Snowflake charges normal costs associated with data transfer and virtual warehouse usage when using external functions.
There are many advantages of using external functions. External functions can be created to be called from other software programs in addition to being called from within Snowflake. Also, the code for the remote services can be written in languages such as Go or C#—languages that cannot be used within other UDFs supported by Snowflake. One of the biggest advantages is that the remote services for Snowflake external functions can be interfaced with commercially available third-party libraries, such as machine learning scoring libraries.
Code Cleanup
Code cleanup for this chapter is simple. You can use the following command to drop the database we created earlier:
DROPDATABASEDEMO4_DB;
Notice that we don’t have to remove all the tables first, because dropping the database will automatically drop the associated tables.
Summary
In this chapter, we created and executed all our Snowflake queries using the SYSADMIN role. This was done intentionally so that we could focus on learning the basics of Snowflake SQL commands, functions, statements, and data types without adding the complexity of needing to navigate Snowflake access controls. Now it’s time to build on this foundational knowledge, along with what we learned in Chapter 3 about creating and managing architecture objects.
In the next chapter, we’ll take a deep dive into leveraging Snowflake access controls. If you expect to be assigned administrator responsibilities for one of the core admin roles, the next chapter will likely be one of the most important chapters for you in your Snowflake journey of learning. Even if you never expect to perform administrator duties, you’ll still need to know how to leverage the full functionality of Snowflake within the permissions you are assigned. Also, even if you are not assigned a Snowflake admin role, it’s still likely that you will be given access to perform some functions once reserved only for administrators.
Snowflake has taken great care to design and build access controls that address some of the weaknesses of other platforms. One example of this is that Snowflake has purposely designed an access control system that removes the concept of a super user, a major risk of many platforms. That said, it is important to recognize that there is still much you can learn about Snowflake’s unique access controls even if you have experience with access controls built for other platforms.
Knowledge Check
The following questions are based on the information contained in this chapter:
-
What can you use to ensure that a line of text is a comment rather than having it be treated as code?
-
Snowflake’s string data types are supported by string constants. What delimiters can be used to enclose strings?
-
What are some advantages of using external functions?
-
What is the default duration Snowflake uses to determine when to cancel long-running queries? Can you change that duration and, if so, how would you do that?
-
What are the risks of using floating-point number data types?
-
How does a window function differ from an aggregate function?
-
Does Snowflake support unstructured data types?
-
What semi-structured data types does Snowflake support?
-
Does Snowflake’s
TIMESTAMPdata type support local time zones and daylight saving time? Explain. -
What are derived columns and how can they be used in Snowflake?
-
What are the three ways you can gain access to unstructured data files in Snowflake?
-
List some examples of unstructured data.
-
What type of table is a directory table?
Answers to these questions are available in Appendix A.
Get Snowflake: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

