Chapter 4. Serverless and Security
We can only see a short distance ahead, but we can see plenty there that needs to be done.
Alan Turing
Utilizing serverless technologies means some traditional security concerns go away, such as patching operating system flaws and securing network connections. Yet, as with any technological advancement, serverless introduces new challenges while solving existing problems. Serverless security is no different. This chapter examines the security threats to a serverless application and delves into key security primitives and how they map to serverless engineering on AWS.
Unfortunately, software developers commonly only consider security once the entire application has been developed, usually in the weeks or days before going live. Even then, they tend to focus those last-minute efforts solely on securing the application’s perimeter. There are two factors that contribute to this: firstly, security seems inherently complex to engineers, and secondly, engineers often feel that implementing security measures runs counter to the practice of failure-driven iteration.
While software engineering teams can utilize security tools and delegate certain tasks to these tools, security must always be a core engineering and operational concern.
Modern software engineering teams have a long-established development process. Traditionally, this has looked something like this: design, build, test, deploy. The DevOps movement ensured the operation of software became embedded in the software development lifecycle. Security must now also be part of the entire development process.
The popular recommendation is to shift left on security, bringing it into the development lifecycle much earlier, and to leverage identity and access management to provide defense in depth, not just at the perimeter. Serverless engineering presents an opportunity to embed a secure-by-design approach into your daily work. As you design, build, and operate your application, always have in mind the attack vectors, potential vulnerabilities, and mitigations available to you (see Figure 4-1).
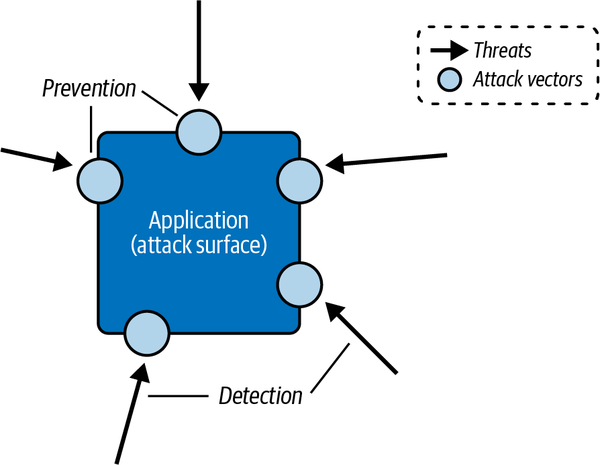
Figure 4-1. Application security involves detecting threats and applying preventative measures to attack vectors
The practice of threat modeling is increasingly becoming an essential tool to continually identify and guard against threats. It was added to the respected Thoughtworks Technology Radar in 2015, with the observation that “throughout the lifetime of any software, new threats will emerge and existing ones will continue to evolve thanks to external events and ongoing changes to requirements and architecture.”
As a software engineer, you must also recognize and embrace your limitations. Engineering teams will typically have limited practical experience or working knowledge of application security. Consult with security teams early in your software design and development cycles. Security teams can usually help with arranging penetration testing and security audits before you launch new applications and major features, as well as supporting vulnerability detection efforts and incident response. Always be aware of your organization’s cybersecurity strategy, which should include guidance on securing cloud accounts and preserving data privacy.
Before we go any further, let’s take a moment to establish an important point: security can be simple!
Security Can Be Simple
Given the stakes, ensuring the security of a software application can be a daunting task. Breaches of application perimeters and data stores are often dramatic and devastating. Besides the immediate consequences, such as data loss and the need for remediation, these incidents usually have a negative impact on trust between consumers and the business, and between the business and its technologists.
Security Challenges
Securing cloud native serverless applications can be particularly challenging for several reasons, including:
- Managed services
-
Throughout this book, you will see that managed services are core to serverless applications and, when applied correctly, can support clear separation of concerns, optimal performance, and effective observability. While managed services provide a solid foundation for your infrastructure, as well as several security benefits—primarily through the shared responsibility model, discussed later in this chapter—the sheer number of them available to teams building on AWS presents a problem: in order to utilize (or even evaluate) a managed service, you must first understand the available features, pricing model, and, crucially, security implications. How do IAM permissions work for this service? How is the shared responsibility model applied to this service? How will access control and encryption work?
- Configurability
-
An aspect all managed services share is configurability. Every AWS service has an array of options that can be tweaked to optimize throughput, latency, resiliency, and cost. The combination of services can also yield further optimizations, such as the employment of SQS queues between Lambda functions to provide batching and buffering. Indeed, one of the primary benefits of serverless that is highlighted in this book is granularity. As you’ve seen, you have the ability to configure each of the managed services in your applications to a fine degree. In terms of security, this represents a vast surface area for the inadvertent introduction of flaws like excessive permissions and privilege escalation.
- Emergent standards
-
AWS delivers new services, new features, and improvements to existing features and services at a consistently high rate. These new services and features could either be directly related to application or account security or present new attack vectors to analyze and secure. There are always new levers to pull and more things to configure. The community around AWS and, in particular, serverless also moves at a relatively fast pace, with new blog posts, video tutorials, and conference talks appearing every day. The security aspect of software engineering perhaps moves slightly slower than other elements, but there is still a steady stream of advice from cybersecurity professionals along with regular releases of vulnerability disclosures and associated research. Keeping up with all the AWS product updates and the best practices when it comes to securing your ever-evolving application can easily become one of your biggest challenges.
While cloud native serverless applications present unique security challenges, there are also plenty of inherent benefits when it comes to securing this type of software. The architecture of serverless applications introduces a unique security framework and provides the potential to work in a novel way within this framework. You have a chance to redefine your relationship to application security. Security can be simple.
Next, let’s explore how to start securing your serverless application.
Getting Started
Establishing a solid foundation for your serverless security practice is pivotal. Security can, and must, be a primary concern. And it is never too late to establish this foundation.
As previously alluded to, security must be a clearly defined process. It is not a case of completing a checklist, deploying a tool, or deferring to other teams. Security should be part of the design, development, testing, and operation of every part of your system.
Working within sound security frameworks that fit well with serverless and adopting sensible engineering habits, combined with all the support and expertise of your cloud provider, will go a long way toward ensuring your applications remain secure.
When applied to serverless software, two modern security trends can provide a solid foundation for securing your application: zero trust and the principle of least privilege. The next section examines these concepts.
Once you have established a zero trust, least privilege security framework, the next step is to identify the attack surface of your applications and the security threats that they are vulnerable to. Subsequent sections examine the most common serverless threats and the threat modeling process.
Combining the Zero Trust Security Model with Least Privilege Permissions
There are two modern cybersecurity principles that you can leverage as the cornerstones of your serverless security strategy: zero trust architecture and the principle of least privilege.
Zero trust architecture
The basic premise of zero trust security is to assume every connection to your system is a threat. Every single interface should then be protected by a layer of authentication (who are you?) and authorization (what do you want?). This applies both to public API endpoints, or the perimeter in the traditional castle-and-moat model, and private, internal interfaces, such as Lambda functions or DynamoDB tables. Zero trust controls access to each distinct resource in your application, whereas a castle-and-moat model only controls access to the resources at the perimeter of your application.
Imagine a knight errant galloping up to the castle walls, presenting likely-looking credentials to the guards and persuading them of their honorable intentions before confidently entering the castle across the lowered drawbridge. If these perimeter guards form the extent of the castle’s security, the knight is now free to roam the rooms, dungeons, and jewel store, collecting sensitive information for future raids or stealing valuable assets on the spot. If, however, each door or walkway had additional suspicious guards or sophisticated security controls that assumed zero trust by default, the knight would be entirely restricted and might even be deterred from infiltrating this castle at all.
Another scenario to keep in mind is a castle that cuts a single key for every heavy-duty door: should the knight gain access to one copy of this key, they’ll be able to open all the doors, no matter how thick or cumbersome. With zero trust, there’s a unique key for every door. Figure 4-2 shows how the castle-and-moat model compares to a zero trust architecture.
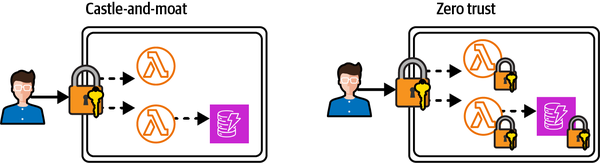
Figure 4-2. Castle-and-moat perimeter security compared to zero trust architecture
There are various applications of zero trust architecture, such as remote computing and enterprise network security. The next section briefly discusses how the zero trust model can be interpreted and applied to serverless applications.
Zero trust and serverless
Zero trust is often touted as the next big thing in network security. Buzzwords and hype aside, you will find that it is a natural fit for applying security to distributed, serverless systems. Indeed, zero trust is often the de facto methodology for securing serverless applications. Approaching application security with a zero trust mindset supports the development of good habits, such as inter-service message verification and internally accessible API security.
You cannot simply move from a castle-and-moat model to zero trust. You first need a supporting application architecture. For example, if your API, business logic, and database are running in a single containerized application, it will be very difficult to apply the granular, resource-based permissions needed to support zero trust. Serverless provides the optimum application architecture for zero trust as resources are naturally isolated across API, compute, and storage and each can have highly granular access control in place.
The principle of least privilege
Identity and access control is essential for an effective zero trust architecture. If the security perimeter must now be around every resource and asset in your system, you are going to need a highly reliable and granular authentication and authorization layer to implement this perimeter.
As your application resources interact with each other, they must be granted the minimum permissions required to complete their operations. This is an application of the principle of least privilege, introduced in Chapter 1.
Let’s take a relatively simple example. Suppose you have a DynamoDB table and two Lambda functions that interact with the table (see Figure 1-11). One Lambda function needs to be able to read items from the table, and the other function should be able to write items to the table.
You might be tempted to apply blanket permissions to an access control policy and share it between the two Lambda functions, like this:
{"Version":"2012-10-17","Statement":[{"Sid":"FullAccessToTable","Effect":"Allow","Action":["dynamodb:*"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
However, this would give each function more permissions than it needs, violating the principle of least privilege. Instead, a least privilege policy for the read-only Lambda function would look like this:
{"Version":"2012-10-17","Statement":[{"Sid":"ReadItemsFromTable","Effect":"Allow","Action":["dynamodb:GetItem","dynamodb:Query","dynamodb:Scan"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
And a least privilege policy for the write-only Lambda function would look like this:
{"Version":"2012-10-17","Statement":[{"Sid":"WriteItemsToTable","Effect":"Allow","Action":["dynamodb:PutItem","dynamodb:UpdateItem"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Fortunately, the underlying permissions engine used by all AWS resources, called AWS Identity and Access Management (IAM), applies a deny by default stance: you must explicitly grant permissions, layering in new permissions over time as required. Let’s take a closer look at the power of AWS IAM.
The Power of AWS IAM
AWS IAM is the one service you will use everywhere—but it’s also often seen as one of the most complex. Therefore, it’s important to understand IAM and learn how to harness its power. (You don’t have to become an IAM expert, though—unless you want to, of course!)
The power of AWS IAM lies in roles and policies. Policies define the actions that can be taken on certain resources. For example, a policy could define the permission to put events onto a specific EventBridge event bus. Roles are collections of one or more policies. Roles can be attached to IAM users, but the more common pattern in a modern serverless application is to attach a role to a resource. In this way, an EventBridge rule can be granted permission to invoke a Lambda function, and that function can in turn be permitted to put items into a DynamoDB table.
IAM actions can be split into two categories: control plane actions and data plane actions. Control plane actions, such as PutEvents and GetItem (e.g., used by an automated deployment role) manage resources. Data plane actions, such as PutEvents and GetItem (e.g., used by a Lambda execution role), interact with those resources.
Let’s take a look at a simple IAM policy statement and the elements it is composed of:
{"Sid":"ListObjectsInBucket",# Statement ID, optional identifier for# policy statement"Action":"s3:ListBucket",# AWS service API action(s) that will be allowed# or denied"Effect":"Allow",# Whether the statement should result in an allow or deny"Resource":"arn:aws:s3:::bucket-name",# Amazon Resource Name (ARN) of the# resource(s) covered by the statement"Condition":{# Conditions for when a policy is in effect"StringLike":{# Condition operator"s3:prefix":[# Condition key"photos/",# Condition value]}}}
See the AWS IAM documentation for full details of all the elements of an IAM policy.
Lambda execution roles
A key use of IAM roles in serverless applications is Lambda function execution roles. An execution role is attached to a Lambda function and grants the function the permissions necessary to execute correctly, including access to any other AWS resources that are required. For example, if the Lambda function uses the AWS SDK to make a DynamoDB request that inserts a record in a table, the execution role must include a policy with the dynamodb:PutItem action for the table resource.
The execution role is assumed by the Lambda service when performing control plane and data plane operations. The AWS Security Token Service (STS) is used to fetch short-lived, temporary security credentials which are made available via the function’s environment variables during invocation.
Each function in your application should have its own unique execution role with the minimum permissions required to perform its duty. In this way, single-purpose functions (introduced in Chapter 6) are also key to security: IAM permissions can be tightly scoped to the function and remain extremely restricted according to the limited functionality.
IAM guardrails
As you are no doubt beginning to notice, effective serverless security in the cloud is about basic security hygiene. Establishing guardrails for the use of AWS IAM is a core part of promoting a secure approach to everyday engineering activity. Here are some recommended guardrails:
- Apply the principle of least privilege in policies.
-
IAM policies should only include the minimum set of permissions required for the associated resource to perform the necessary control or data plane operations. As a general rule, do not use wildcards (*) in your policy statements. Wildcards are the antithesis of least privilege, as they apply blanket permissions for actions and resources. Unless the action explicitly requires a wildcard, always be specific.
- Avoid using managed IAM policies.
-
These are policies provided by AWS, and they’re often tempting shortcuts, especially when you’re just getting started or using a service for the first time. You can use these policies early in prototyping or development, but you should replace them with custom policies as soon as you understand the integration better. Because these policies are designed to be applied to generic scenarios, they are simply not restricted enough and will usually violate the principle of least privilege when applied to interactions within your application.
- Prefer roles to users.
-
IAM users are issued with static, long-lived AWS access credentials (an access key ID and secret access key). These credentials can be used to directly access the application provider’s AWS account, including all the resources and data in that account. Depending on the associated IAM roles and policies, the authenticating user may even have the ability to create or destroy resources. Given the power they grant the holder, the use and distribution of static credentials must be limited to reduce the risk of unauthorized access. Where possible, restrict IAM users to an absolute minimum (or, even better, do not have any IAM users at all).
- Prefer a role per resource.
-
Each resource in your application, such as an EventBridge rule, a Lambda function, and an SQS queue, should have its own unique role. Permissions for those roles should be fine-grained and least-privileged.
The AWS Shared Responsibility Model
AWS uses a shared responsibility model to define the remit of application security consumers and the cloud provider (see Figure 4-3). The important thing here is the shift in security responsibility to AWS when using cloud services. This is increased when using fully managed serverless services, such as compute with AWS Lambda: AWS manages patching of the Lambda runtime, function execution isolation, and so on.
Serverless applications are made up of business logic, infrastructure definitions, and managed services. Ownership of these elements is split between AWS and the consumers of its public cloud services. As a serverless application engineer and AWS customer, you are responsible the for security of:
-
Your function code and third-party libraries used in that code
-
Configuration of the AWS resources used in your application
-
The IAM roles and policies governing access control to the resources and functions in your application
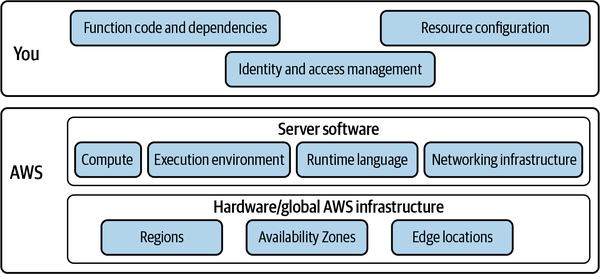
Figure 4-3. The cloud security shared responsibility model: you are responsible for security in the cloud, and AWS is responsible for security of the cloud
Think Like a Hacker
With your foundational zero trust, least privilege security strategy and a clear delineation of responsibility in place, the next step is to identify the potential attack vectors in your application and be aware of the possible threats to the security and integrity of your systems.
When you imagine the threats to your systems, you may picture bad actors who are external to your organization—hackers. While external threats certainly exist, they must not overshadow internal threats, which must also be guarded against. Internal threats could, of course, be deliberately malicious, but the more likely scenario is that the vulnerabilities are introduced unintentionally. The engineers of an application can often be the architects of their own security flaws and data exposures, often through weak or missing security configuration of cloud resources.
The popular depiction of a hacker performing an obvious denial of service attack on a web application or infiltrating a server firewall is still a very real possibility, but subtler attacks on the software supply chain are now just as likely. These insidious attacks involve embedding malicious code in third-party libraries and automating exploits remotely once the code is deployed in production workloads.
It is essential to adopt the mindset of a hacker and fully understand the potential threats to your serverless applications in order to properly defend against them.
Meet the OWASP Top 10
Cybersecurity is an incredibly well-researched area, with security professionals constantly assessing the ever-changing software landscape, identifying emerging risks and distributing preventative measures and advice. While as a modern serverless engineer you must accept the responsibility you have in securing the applications you build, it is absolutely crucial that you combine your own efforts with deference to professional advice and utilization of the extensive research that is publicly available.
Identifying the threats to the security of your software is one task that you should not attempt alone. There are several threat categorization frameworks available that can help here, but let’s focus on the OWASP Top 10.
The Open Web Application Security Project, or OWASP for short, is a “non-profit foundation that works to improve the security of software.” It does this primarily through community-led, open source projects, tools, and research. The OWASP Foundation has repeatedly published a list of the 10 most prevalent and critical security risks to web applications since 2003. The latest version, published in 2021, provides the most up-to-date list of security risks (at the time of writing).
While a serverless application will differ in some ways from a typical web application, Table 4-1 interprets the OWASP Top 10 through a serverless lens. Note that the list is in descending order, with the most critical application security risk, as classified by OWASP, in the first position. We’ve added the “serverless risk level” column as an indicator of the associated risk specific to serverless applications.
| Threat category | Threat description | Mitigations | Serverless risk level |
|---|---|---|---|
| Broken access control | Access control is the gatekeeper to your application and its resources and data. Controlling access to your resources and assets allows you to restrict users of your application so that they cannot act outside of their intended permissions. |
|
Medium |
| Cryptographic failures | Weak or absent encryption of data, both in transit between components in your application and at rest in queues, buckets, and tables, is a major security risk. |
|
Medium |
| Injection | Injection of malicious code into an application via user-supplied data is a popular attack vector. Common attacks include SQL and NoSQL injection. |
|
High |
| Insecure design | Implementing and operating an application that was not designed with security as a primary concern is risky, as it will be susceptible to gaps in the security posture. |
|
Medium |
| Security misconfiguration |
Misconfigurations of encryption, access control, and computational constraints represent vulnerabilities that can be exploited by attackers. Unintended public access of S3 buckets is a very common root cause of cloud data breaches. Lambda functions with excessive timeouts can be exploited to cause a DoS attack. |
|
Medium |
| Vulnerable and outdated components | Continued use of vulnerable, unsupported, or outdated software (operating systems, web servers, databases, etc.) makes your application susceptible to attacks that exploit known vulnerabilities. |
|
Low |
| Identification and authentication failures | These failures can permit unauthorized usage of APIs and integrated resources, like Lambda functions, S3 buckets, or DynamoDB tables. |
|
Medium |
| Software and data integrity failures |
The presence of vulnerabilities or exploits in third-party code is quickly becoming the most common risk to software applications. As application dependencies are bundled and executed with Lambda function code, they are granted the same permissions as your business logic. |
|
High |
| Security logging and monitoring failures |
Attackers rely on the lack of monitoring and timely response to achieve their goals without being detected. Without logging and monitoring, breaches cannot be detected or analyzed. Logs of applications and APIs are not monitored for suspicious activity. |
|
Medium |
| Server-side request forgery (SSRF) | In AWS this primarily concerns a vulnerability with running web servers on EC2 instances. The most devastating example was the Capital One data breach in 2019. |
|
Low |
There are two further noteworthy security risks that are relevant to serverless applications:
- Denial of service
-
This is a common attack where an API is constantly bombarded with bogus requests in order to disrupt the servicing of genuine requests. Public APIs will always face the possibility of DoS attacks. Your job is not always to completely prevent them, but to make them so tricky to execute that the deterrent alone becomes enough to secure the resources. Firewalls, rate limits, and resource throttle alarms (e.g., Lambda, DynamoDB) are all key measures to prevent DoS attacks.
- Denial of wallet
-
This kind of attack is fairly unique to serverless applications, due to the pay-per-use pricing model and high scalability of managed services. Denial of wallet attacks target the constant execution of resources to accumulate a usage bill so high it will likely cause severe financial damage to the business.
Tip
Setting up budget alerts can help ensure you are alerted to denial of wallet attacks before they can escalate. See Chapter 9 for more details.
Now that you have an understanding of the common threats to a serverless application, next you will explore how to use the process of threat modeling to map these security risks to your applications.
Serverless Threat Modeling
Before designing a comprehensive security strategy for any serverless application, it is crucial to understand the attack vectors and model potential threats. This can be done by clearly defining the surface area of the application, the assets worth securing, and the threats, both internal and external, to the application’s security.
As previously stated, security is a continuous process: there is no final state. In order to maintain the security of an application as it grows, threats must be constantly reviewed and attack vectors regularly assessed. New features are added over time, more users serviced and more data collected. Threats will change, their severity will rise and fall, and application behavior will evolve. The tools available and industry best practices will also evolve, becoming more effective and focused in reaction to these changes.
Introduction to threat modeling
By this point you should have a fairly clear understanding of your security responsibilities, a foundational security framework, and the primary threats to serverless applications. Next, you need to map the framework and threats to your application and its services.
Threat modeling is a process that can help your team to identify attack vectors, threats, and mitigations through discussion and collaboration. It can support a shift-left (or even start-left) approach to security, where security is primarily owned by the team designing, building, and operating the application and is treated as a primary concern throughout the software development lifecycle. This is also sometimes referred to as DevSecOps.
To ensure continuous hardening of your security posture, threat modeling should be a process that you conduct regularly, for example at task refinement sessions. Threats should initially be modeled early in the solution design process (see Chapter 6) and focused at the feature or service level.
Tip
Threat Composer is a tool from AWS Labs that can help guide and visualize your threat modeling process.
Next you will be introduced to a framework that adds structure to the threat modeling process: STRIDE.
STRIDE
The STRIDE acronym describes six threat categories:
- Spoofing
-
Pretending to be something or somebody other than who you are
- Tampering
-
Changing data on disk, in memory, on the network, or elsewhere
- Repudiation
- Information disclosure
- Denial of service
- Elevation of privilege
-
Performing actions on protected resources that you should not be allowed to perform
STRIDE-per-element, or STRIDE/element for short, is a way to apply the STRIDE threat categories to elements in your application. It can help to further focus the threat modeling process.
The elements are targets of potential threats and are defined as:
-
Human actors/external entities
-
Processes
-
Data stores
-
Data flows
It is important not to get overwhelmed by the threat modeling process. Securing an application can be daunting, but remember, as outlined at the beginning of this chapter, it can also be simple, especially with serverless. Start small, work as a team, and follow the process one stage at a time. Identifying one threat for each element/threat combination in the matrix in Figure 4-4 would represent a great start.
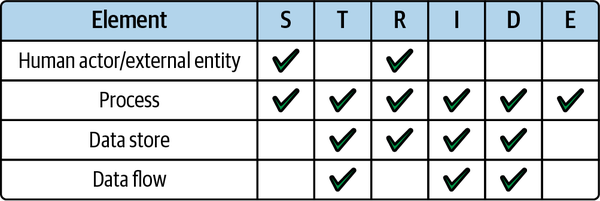
Figure 4-4. Applying the STRIDE threat categories per element in your application
A process for threat modeling
As preparation for your threat modeling sessions, you may find it conducive to productive meetings to have the following information prepared:
-
High-level architecture of the application
-
Solution design documents
-
Data models and schemas
-
Data flow diagrams
-
Domain-specific industry compliance standards
A typical threat modeling process will comprise the following steps:
-
Identify the elements in your application that could be targets for potential threats, including data assets, external actors, externally accessible entry points, and infrastructure resources.
-
Identify a list of threats for each element identified in step 1. Be sure to focus on threats and not mitigations at this stage.
-
For each threat identified in step 2, identify appropriate steps that can be taken to mitigate the threat. This could include encryption of sensitive data assets, applying access control to external actors and entry points, and ensuring each resource is granted only the minimum permissions required to perform its operations.
-
Finally, assess whether the agreed remediation adequately mitigates the threat or if there is any residual risk that should be addressed.
For a comprehensive threat modeling template, see Appendix C.
Securing the Serverless Supply Chain
Vulnerable and outdated components and supply chain–based attacks are quickly becoming a primary concern for software engineers.
Note
According to supply chain security company Socket, “supply chain attacks rose a whopping 700% in the past year, with over 15,000 recorded attacks.” One example they cite occurred in January 2022, when an open source software maintainer intentionally added malware to his own package, which was being downloaded an average of 100 million times per month. A notable casualty was the official AWS SDK.
Who is responsible for protecting against these vulnerabilities and attacks? Serverless compute on AWS Lambda provides you with a clear example of the shared responsibility model presented earlier in this chapter. It is the responsibility of AWS to keep the software in the runtime and execution environment updated with the latest security patches and performance improvements, and it is the responsibility of the application engineer to secure the function code itself. This includes keeping the libraries used by the function up-to-date.
Given that it is your responsibility as a cloud application developer to secure the code you deliver to the cloud and run in your Lambda functions, what are the attack vectors and threat levels here, and how can you mitigate the related security issues?
Securing the Dependency Supply Chain
Open source software is an incredible enabler of rapid software development and delivery. As a software engineer, you can rely on the expertise and work of others in your community when composing your applications. However, this relationship is built on a fragile layer of trust. Every time you install a dependency, you are implicitly trusting the myriad contributors to that package and everything in that package’s own tree of dependencies. The code of hundreds of programmers becomes a key component of your production software.
You must be aware of the risks involved in installing and executing open source software, and the steps you can take to mitigate such risks.
Think before you install
You can start securing the serverless supply chain by scrutinizing packages before installing them. This is a simple suggestion that can make a real difference to securing your application’s supply chain, and to general maintenance at scale.
Use as few dependencies as necessary, and be aware of dependencies that obfuscate the data and control flow of your app, such as middleware libraries. If it is a trivial task, always try to do it yourself. It’s also about trust. Do you trust the package? Do you trust the contributors?
Before you install the next package in your serverless application, adopt the following practices:
- Analyze the GitHub repository.
-
Review the contributors to the package. More contributors represents more scrutiny and collaboration. Check whether the repository uses verified commits. Assess the history of the package: How old is it? How many commits have been made? Analyze the repository activity to understand if the package is actively maintained and used by the community—GitHub stars provide a crude indicator of popularity, and things like the date of the most recent commit and number of open issues and pull requests indicate usage. Also ensure the package’s license adheres to any restrictions in place in your organization.
- Use official package repositories.
-
Only obtain packages from official sources, such as NPM, PyPI, Maven, NuGet, or RubyGems, over secure (i.e., HTTPS) links. Prefer signed packages that can be verified for integrity and authenticity. For example, the JavaScript package manager NPM allows you to audit package signatures.
- Review the dependency tree.
-
Be aware of the package’s dependencies and the entire dependency tree. Pick packages with zero runtime dependencies where available.
- Try before you buy.
-
Try new packages on as isolated a scale as possible and delay rollout across the codebase for as long as possible, until you feel confident.
- Check if you can do it yourself.
-
Don’t reinvent the wheel for the sake of it, but one very simple way of removing opaque third-party code is to not introduce it in the first place. Examine the source code to understand if the package is doing something simple that is easily portable to a first-party utility. Logging libraries are a perfect example: you can trivially implement your own logger rather than distributing a third-party library across your codebase.
- Make it easy to back out.
-
Development patterns like service isolation, single-responsibility Lambda functions, and limiting shared code (see Chapter 6 for more information on these patterns) make it easier to evolve your architecture and avoid pervasive antipatterns or vulnerable software taking over your codebase.
- Lock to the latest.
-
Always use the latest version of the package, and always use an explicit version rather than a range or “latest” flag.
- Uninstall any unused packages.
-
Always uninstall and clear unused packages from your dependencies manifest. Most modern compilers and bundlers will only include dependencies that are actually consumed by your code, but keeping your manifest clean adds extra safety and clarity.
Scan packages for vulnerabilities
You should also run continuous vulnerability scans in response to new packages, package upgrades, and reports of new vulnerabilities. Scans can be run against a code repository using tools such as Snyk or GitHub’s native Dependabot alerts system.
Automate dependency upgrades
Out of all the suggestions for securing your supply chain, this is the most crucial. Even if you have a serverless application with copious packages distributed across multiple services, make sure upgrades of all dependencies are automated.
Warning
While automating upgrades of your application’s dependencies is generally a recommended practice, you should always keep in mind the “think before you install” checklist from the previous section. You should be particularly mindful of the integrity of the incoming updates, in case a bad actor has published a malicious version of a package.
Keeping package versions up-to-date ensures that you not only have access to the latest features but, crucially, to the latest security patches. Vulnerabilities can be found in earlier versions of software after many later versions have been published. Navigating an upgrade across several minor versions can be difficult enough, depending on the features of the package, the adherence to semantic versioning by the authors, and the prevalence of the package throughout your codebase—but upgrading from one major version to another is typically not trivial, given the likelihood of the next version containing breaking changes that affect your usage of the package.
Runtime updates
As well as dependency upgrades, it is highly recommended to keep up-to-date with the latest version of the AWS Lambda runtime you are using. Make sure you are subscribed to news about runtime support and upgrade as soon as possible.
Warning
By default, AWS will automatically update the runtime of your Lambda functions with any patch versions that are released. Additionally, you have the option to control when the runtime of your functions is updated through Lambda’s runtime management controls.
These controls are primarily useful for mitigating the rare occurrence of bugs caused by a runtime patch version that is incompatible with your function’s code. But, as these patch versions will likely include security updates, you should use these controls with caution. It is usually safest to keep your functions running on the latest version of the runtime.
The same is true for any delivery pipelines you maintain, as these will likely run on virtual machines and runtimes provided by the third party. And remember, you do not need to use the same runtime version across pipelines and functions. For example, you should use the latest version of Node.js in your pipelines even before it is supported by the Lambda runtime.
Going Further with SLSA
The SLSA security framework (pronounced salsa, short for Supply chain Levels for Software Artifacts) is “a checklist of standards and controls to prevent tampering, improve integrity, and secure packages and infrastructure.” SLSA is all about going from “safe enough” to maximum resiliency across the entire software supply chain.
If you’re at a fairly high level of security maturity, you may find it useful to use this framework to measure and improve the security of your software supply chain. Follow the SLSA documentation to get started. The Software Component Verification Standard (SCVS) from OWASP is another framework for measuring supply chain security.
Lambda Code Signing
The last mile in the software supply chain is packaging and deploying your function code to the cloud. At this point, your function will usually consist of your business logic (code you have authored) and any third-party libraries listed in the function’s dependencies (code someone else has authored).
Lambda provides the option to sign your code before deploying it. This enables the Lambda service to verify that a trusted source has initiated the deployment and that the code has not been altered or tampered with in any way. Lambda will run several validation checks to verify the integrity of the code, including that the package has not been modified since it was signed and that the signature itself is valid.
To sign your code, you first create one or more signing profiles. These profiles might map to the environments and accounts your application uses—for example, you may have a signing profile per AWS account. Alternatively, you could opt to have a signing profile per function for greater isolation and security. The CloudFormation resource for a signing profile looks like this, where the PlatformID denotes the signature format and signing algorithm that will be used by the profile:
{"Type":"AWS::Signer::SigningProfile","Properties":{"PlatformId":"AWSLambda-SHA384-ECDSA",}}
Once you have defined a signing profile, you can then use it to configure code signing for your functions:
{"Type":"AWS::Lambda::CodeSigningConfig","Properties":{"AllowedPublishers":[{"SigningProfileVersionArns":["arn:aws:signer:us-east-1:123456789123:/signing-profiles/my-profile"]}],"CodeSigningPolicies":{"UntrustedArtifactOnDeployment":"Enforce"}}}
Finally, assign the code signing configuration to your function:
{"Type":"AWS::Lambda::Function","Properties":{"CodeSigningConfigArn":["arn:aws:lambda:us-east-1:123456789123:code-signing-config:csc-config-id",]}}
Now, when you deploy this function the Lambda service will verify the code was signed by a trusted source and has not been tampered with since being signed.
Protecting Serverless APIs
According to the OWASP Top 10 list we looked at earlier in this chapter, the number one threat to web applications is broken access control. While serverless helps to mitigate some of the threats posed by broken access control, you still have work to do in this area.
When applying the zero trust security model, you must apply access control to each isolated component as well as the perimeter of your system. For most serverless applications the security perimeter will be an API Gateway endpoint. If you are building a serverless application that exposes an API to the public internet, you must design and implement an appropriate access control mechanism for this API.
In this section, we’ll explore the available authorization strategies for applying access control to serverless APIs and when to use each one. The access control options for API Gateway are summarized in Table 4-2.
Note
Amazon API Gateway provides two types of APIs: REST APIs and HTTP APIs. They offer different features at different costs. One of the differences is the access control options available. The compatibility for each of the access control methods we’ll explore in this section is indicated in Table 4-2.
| Access control strategy | Description | REST API | HTTP API |
|---|---|---|---|
| Cognito authorizers | Direct integration with the access management service Amazon Cognito and API Gateway REST APIs. Cognito client credentials are exchanged for access tokens, which are validated directly with Cognito. | Yes | No |
| JWT authorizers | Can be used to integrate an access management service that uses JSON Web Tokens (JWTs) for access control, such as Amazon Cognito or Okta, with API Gateway HTTP APIs. | Noa | Yes |
| Lambda authorizers | Lambda functions can be used to implement custom authorization logic when using an access management service other than Cognito or to verify incoming webhook messages where user-based authentication is not available. | Yes | Yes |
a You can still use JWTs to authorize and authenticate REST API requests, but you will need to write a custom Lambda authorizer that verifies incoming tokens. | |||
Securing REST APIs with Amazon Cognito
There are of course many access management services and identity providers available, including Okta and Auth0. We’ll focus on using Cognito to secure a REST API, as it is native to AWS and for this reason provides minimal overhead.
Amazon Cognito
Before we dive in, let’s define the building blocks you will need. Cognito is often viewed as one of the most complex AWS services. It is therefore important to have a foundational understanding of Cognito’s components and a clear idea of the access control architecture you are aiming for. Here are the key components for implementing access control using Cognito:
- User pools
-
A user pool is a user directory in Amazon Cognito. Typically you will have a single user pool in your application. This user pool can be used to manage all the users of your application, whether you have a single user or multiple users.
- Application clients
-
You may be building a traditional client/server web application where you maintain a frontend web application and a backend API. Or you may be operating a multitenant business-to-business platform, where tenant backend services use a client credentials grant to access your services. In this case, you can create an application client for each tenant and share the client ID and secret with the tenant backend service for machine-to-machine authentication.
- Scopes
-
Scopes are used to control an application client’s access to specific resources in your application’s API.
Cognito and API Gateway
Cognito authorizers provide a fully managed access control integration with API Gateway, as illustrated in Figure 4-5. API consumers exchange their credentials (a client ID and secret) for access tokens via a Cognito endpoint. These access tokens are then included with API requests and validated via the Cognito authorizer.
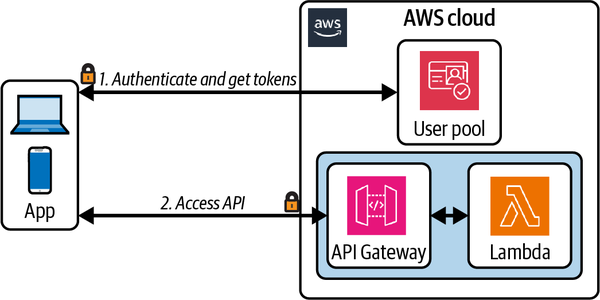
Figure 4-5. API Gateway Cognito authorizer
Additionally, an API endpoint can be assigned a scope. When authorizing a request to the endpoint, the Cognito authorizer will verify the endpoint’s scope is included in the client’s list of permitted scopes.
Securing HTTP APIs
If you are using an API Gateway HTTP API, rather than a REST API, you will not be able to use the native Cognito authorizer. Instead, you have a few alternative options. We’ll explore examples of the most convenient two: Lambda authorizers and JWT authorizers.
Tip
JWT authorizers can also be used to authenticate API requests with Amazon Cognito when using HTTP APIs.
JWT authorizers
If your authorization strategy simply involves a client submitting a JSON Web Token for verification, using a JWT authorizer will be a good option. When you use a JWT authorizer, the whole authorization process is managed by the API Gateway service.
Note
JWT is an open standard that defines a compact, self-contained way of securely transmitting information between parties as JSON objects. JWTs can be used to ensure the integrity of a message and the authentication of both the message producer and consumer.
JWTs can be cryptographically signed and encrypted, enabling verification of the integrity of the claims contained within the token while keeping those claims hidden from other parties.
You first configure the JWT authorizer and then attach it to a route. The CloudFormation resource will look something like this:
{"Type":"AWS::ApiGatewayV2::Authorizer","Properties":{"ApiId":"ApiGatewayId","AuthorizerType":"JWT","IdentitySource":["$request.header.Authorization"],"JwtConfiguration":{"Audience":["https://my-application.com"],"Issuer":"https://cognito-idp.us-east-1.amazonaws.com/userPoolID"},"Name":"my-authorizer"}}
The IdentitySource should match the location of the JWT provided by the client in the API request; for example, the Authorization HTTP header. The JwtConfiguration should correspond to the expected values in the tokens that will be submitted by clients, where the Audience is the HTTP address for the recipient of the token (usually your API Gateway domain) and the Issuer is the HTTP address for the service responsible for issuing tokens, such as Cognito or Okta.
Lambda authorizers
Lambda functions with custom authorization logic can be attached to API Gateway HTTP API routes and invoked whenever requests are made. These functions are known as Lambda authorizers and can be used when you need to apply access control strategies beyond the ones the managed Cognito or JWT authorizers support. The functions’ responses will either approve or deny access to the requested resources (see Figure 4-6).
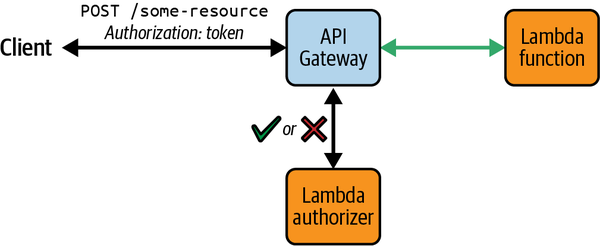
Figure 4-6. Controlling access to API Gateway resources with a Lambda authorizer
Lambda authorizers support various locations for providing authorization claims in API requests. These are known as identity sources and include HTTP headers and query string parameters (for example, the Authorization header). The identity source you use will be required in requests made to API Gateway; any requests without the required property will immediately receive a 401 Unauthorized response and the Lambda authorizer will not be invoked.
Lambda authorizer responses can also be cached. The responses will be cached according to the identity source provided by the API’s clients. If a client provides the same values for the required identity sources within the configured cache period, or TTL, API Gateway uses the cached authorizer result instead of invoking the authorizer function.
Tip
Caching the responses of your Lambda authorizers will result in quicker responses to API requests as well as a reduction in costs, as the Lambda function will be invoked significantly less frequently.
The Lambda function used to authorize requests can return an IAM policy or what is known as a simple response. The simple response will usually suffice, unless your use case requires an IAM policy response or more granular permissions. When using the simple response, the authorizer function must return a response matching the following format, where isAuthorized is a Boolean value that denotes the outcome of your authorization checks and context is optional and can include any additional information to pass to API access logs and Lambda functions integrated with the API resource:
{"isAuthorized":true/false,"context":{"key":"value"}}
Validating and Verifying API Requests
There are other ways to protect your serverless API beyond the access control mechanisms we have explored so far in this section. In particular, publicly accessible APIs should always be protected against deliberate or unintentional misuse and incoming request data to those APIs should always be validated and sanitized.
API Gateway request protection
API Gateway offers two ways of protecting against denial of service and denial of wallet attacks.
First, requests from individual API clients can be throttled via API Gateway usage plans. Usage plans can be used to control access to API stages and methods and to limit the rate of requests made to those methods. By rate limiting API requests, you can prevent any of your API’s clients from deliberately or inadvertently abusing your service. Usage plans can be applied to all methods in an API, or to specific methods. Clients are given a generated API key to include in every request to your API. If a client submits too many requests and is throttled as a result, they will begin to receive 429 Too Many Requests HTTP error responses.
API Gateway also integrates with AWS WAF to provide granular protection at the request level. With WAF, you can specify a set of rules to apply to each incoming request, such as IP address throttling.
Note
WAF rules are always applied before any other access control mechanisms, such as Cognito authorizers or Lambda authorizers.
API Gateway request validation
Requests to API Gateway methods can be validated before being processed further. Say you have a Lambda function attached to an API route that accepts the API request as an input and applies some operations to the request body. You can supply a JSON Schema definition of the expected input structure and format, and API Gateway will apply those data validation rules to the body of a request before invoking the function. If the request fails validation, the function will not be invoked and the client will receive a 400 Bad Request HTTP response.
Note
Implementing request validation via API Gateway can be particularly useful when using direct integrations to AWS services other than Lambda. For example, you may have an API Gateway resource that integrates directly with Amazon EventBridge, responding to API requests by putting events onto an event bus. In this architecture you will always want to validate and sanitize the request payload before forwarding it to downstream consumers.
For more information about functionless integration patterns, refer to Chapter 5.
In the following example JSON model, the message property is required, and the request will be rejected if that field is missing from the request body:
{"$schema":"http://json-schema.org/draft-07/schema#","title":"my-request-model","type":"object","properties":{"message":{"type":"string"},"status":{"type":"string"}},"required":["message"]}
Deeper input validation and sanitization should be performed in Lambda functions where data is transformed, stored in a database or delivered to an event bus or message queue. This can secure your application from SQL injection attacks, the #3 threat in the OWASP Top 10 (see Table 4-1).
Message Verification in Event-Driven Architectures
Most of the access control techniques we’ve explored generally apply to synchronous, request/response APIs. But as you learned in Chapter 3, it is highly likely that, as you and the teams or third parties you interact with are building event-driven applications, at some point you will encounter an asynchronous API.
Message verification is typically required at the integration points between systems—for example, of incoming messages from third-party webhooks and messages sent by your application to other systems or accounts. In a zero trust architecture message verification is also important for messaging between services in your application.
Verifying messages between consumers and producers
Typically, in order to decouple services, the producer of an event is deliberately unaware of any downstream consumers of the event. For example, you might have an organization-wide event backbone architecture where multiple producers send events to a central event broker and multiple consumers subscribe to these events, as shown in Figure 4-7.
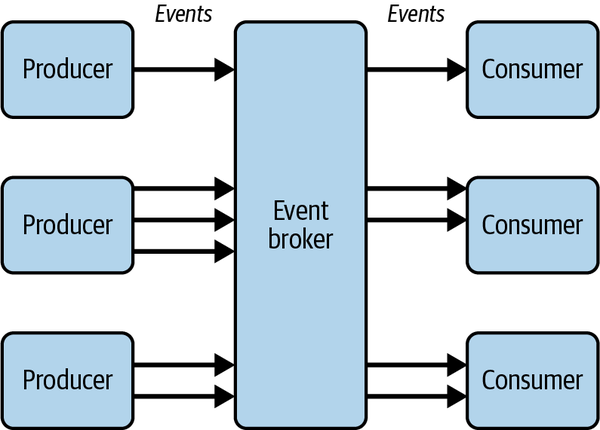
Figure 4-7. Decoupled producers and consumers in an event-driven architecture
Securing consumers of asynchronous APIs relies on the control of incoming messages. Consumers should always be in control of the subscription to an asynchronous API, and there will already be a certain level of trust established between the event producers and the event broker—but event consumers must also guard against sender spoofing and message tampering. Verification of incoming messages is crucial in event-driven systems.
Let’s assume the event broker in Figure 4-7 is an Amazon EventBridge event bus in a central account, part of your organization’s core domain. The producers are services deployed to separate AWS accounts, and so are the consumers. A consumer needs to ensure each message has come from a trusted source. A producer needs to ensure messages can only be read by permitted consumers. For a truly decoupled architecture, the event broker itself might be responsible for message encryption and key management (rather than the producer), but for the purpose of keeping the example succinct we’ll make this the producer’s responsibility.
Encrypted and verifiable messages with JSON Web Tokens
You can use JWT as your message transport protocol. To sign and encrypt the messages you can use a technique known as nested JWTs, illustrated in Figure 4-8.
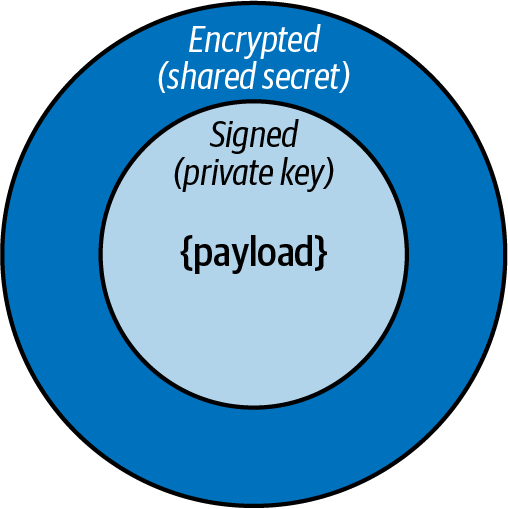
Figure 4-8. A nested JSON Web Token
The producer must first sign the message payload with the private key and then encrypt the signed message using a shared secret:
constpayload={data:{hello:"world"}};constsignedJWT=awaitnewSignJWT(payload).setProtectedHeader({alg:"ES256"}).setIssuer("urn:example:issuer").setAudience("urn:example:audience").setExpirationTime("2h").sign(privateKey);constencryptedJWT=awaitnewEncryptJWT(signedJWT).setProtectedHeader({alg:"dir",cty:"JWT",enc:"A256GCM"}).encrypt(sharedSecret);
Tip
Public/private encryption key pairs and shared secrets should be generated separately from the runtime message production and stored in AWS Key Management Service (KMS) or AWS Secrets Manager. The keys and secrets can then be fetched at runtime to sign and encrypt the message.
Upon receipt of a message, the consumer must first verify the signature using the producer’s public key and then decrypt the payload using the shared secret:
constdecryptedJWT=awaitDecryptJWT(encryptedJWT,sharedSecret);constdecodedJWT=awaitVerifyJWT(decryptedJWT,publicKey);// if verified, original payload available at decodedJWT.payload
Warning
Only the producer’s public key and the shared secret should be distributed to the message’s consumers. The private key should never be shared.
Built-in message verification for SNS
In addition to the approach outlined in the previous section, some AWS services, such as Amazon Simple Notification Service (SNS), are now beginning to support message signatures natively. SNS signs the messages delivered from your topic, enabling the subscribed HTTP endpoints to verify their authenticity.
Protecting Data
Data is the most valuable asset accumulated by any software application. This includes data personal to users of the application, data about third-party integrations with the application, and data about the application itself.
Cryptographic failure is the second of the OWASP Top 10 threats to web applications, after broken access control. This section examines the crucial role of data encryption in securing a serverless application and how you can encrypt your data as it moves through your system.
Data Encryption Everywhere
As you develop and operate your serverless application, you will discover both the power and the challenges that come with connecting components with events. Events allow you to decouple components and include rich data in their messages. Serverless compute is inherently stateless, which means the data a Lambda function or Step Functions workflow needs to perform its operations must either be queried from a data store, like DynamoDB or S3, or provided in the invocation payload.
In event-driven systems, data is everywhere. This means data encryption needs to be everywhere too. Data will be stored in databases and object stores. It will be moved through message queues and event buses. Dr. Werner Vogels, the CTO and VP of Amazon, once said on stage at re:Invent, “Dance like no one is watching. Encrypt like everyone is.”
What is encryption?
Encryption is a technique for restricting access to data by making it unreadable without a key. Cryptographic algorithms are used to obscure plain-text data with an encryption key. The encrypted data can only be decrypted with the same key.
Encryption is your primary tool in protecting the data in your application. It’s particularly important in event-driven applications, where data constantly flows between accounts, services, functions, data stores, buses, and queues. Encryption can be divided into two categories: encryption at rest and encryption in transit. By encrypting data both in transit and at rest, you ensure that your data is protected for its entire lifecycle and end-to-end as it passes through your system and into other systems.
Most AWS managed services offer native support for encryption as well as direct integration with AWS Secrets Manager and AWS KMS. This means the process of encrypting and decrypting data and managing the associated encryption keys is largely abstracted away from you. However, encryption is not usually enabled by default, so you are responsible for enabling and configuring encryption at the resource level.
Encryption in transit
Data is in transit in a serverless application as it moves from service to service. All AWS services provide secure, encrypted HTTP endpoints via Transport Layer Security (TLS). Whenever you are interacting with the API of an AWS service, you should use the HTTPS endpoint. By default, operations you perform with the AWS SDK will use the HTTPS endpoints of all AWS services. For example, this means when your Lambda function is invoked by an API Gateway request and you make an EventBridge PutEvents call from the function, the payloads are entirely encrypted when in transit.
In addition to TLS, all AWS API requests made using the AWS SDK are protected by a request signing process, known as Signature Version 4. This process is designed to protect against request tampering and sender spoofing.
Encryption at rest
Encryption at rest is applied to data whenever it is stored or cached. In a serverless application, this could be data in an EventBridge event bus or archive, a message on an SQS queue, an object in an S3 bucket, or an item in a DynamoDB table.
As a general rule, whenever a managed service offers the option to encrypt data at rest you should take advantage of it. However, this is especially important when you have classified the data at rest as sensitive.
You should always limit the storage of data at rest and in transit. The more data is stored, and the longer it is stored for, the greater the attack surface area and security risk. Only store or transport data if it is absolutely necessary, and continually review your data models and event payloads to ensure redundant attributes are removed.
Tip
There are also sustainability benefits to storing less data. See Chapter 10 for more information on this topic.
AWS KMS
The key (pun intended) AWS service when it comes to encryption is AWS Key Management Service. AWS KMS is a fully managed service that supports the generation and management of the cryptographic keys that are used to protect your data. Whenever you use the native encryption controls of an AWS service like Amazon SQS or S3, as described in the previous sections, you will be using KMS to create and manage the necessary encryption keys. Whenever a service needs to encrypt or decrypt data, it will make a request to KMS to access the relevant keys. Access to keys is granted to these services via their attached IAM roles.
There are several types of KMS keys, such as HMAC keys and asymmetric keys, and these are generally grouped into two categories: AWS managed keys and customer managed keys. AWS managed keys are encryption keys that are created, managed, rotated, and used on your behalf by an AWS service that is integrated with AWS KMS. Customer managed keys are encryption keys that you create, own, and manage. For most use cases, you should choose AWS managed keys whenever available. Customer managed keys can be used in cases where you are required to audit usage of or retain additional control over the keys.
Note
The AWS documentation has a detailed explanation of KMS concepts if you’d like to read more about this topic.
Security in Production
Making security a part of your development process is key to a holistic security strategy. But what happens when your application is ready for production and, subsequently, running in production?
Going into production can be the most daunting time when it comes to asking yourself the question: is my application secure? To help ease the process, we’ve created a final security checklist to run through before releasing your application to your users that also prepares you to continuously monitor your application for vulnerabilities. Remember, security is a process and something to continually iterate on, just like every other aspect of your software.
Go-Live Security Checklist for Serverless Applications
Here’s a practical list of things to check before launching a serverless application. It can also form part of a security automation pipeline and your team’s security guardrails:
-
Commission penetration testing and security audits early in your application’s development.
-
Enable server-side encryption (SSE) on all S3 buckets containing valuable data.
-
Enable cross-account backups or object replication on S3 buckets containing business-critical data.
-
Enable encryption at rest on all SQS queues.
-
Enable WAF on API Gateway REST APIs with baseline managed rules.
-
Remove sensitive data from Lambda function environment variables.
-
Store secrets in AWS Secrets Manager.
-
Encrypt Lambda function environment variables.
-
Enable backups on all DynamoDB tables containing business-critical data.
-
Scan dependencies for vulnerabilities: resolve all critical and high security warnings, and minimize medium and low warnings.
-
Set up budget alarms in CloudWatch to guard against denial of wallet attacks.
-
Remove any IAM users where possible.
-
Remove wildcards from IAM policies wherever possible to preserve least privilege.
-
Generate an IAM credential report to identify unused roles and users that can be removed.
-
Create a CloudTrail trail to send logs to S3.
-
Conduct a Well-Architected Framework review with a focus on the Security pillar and the Serverless Lens’s security recommendations.
Maintaining Security in Production
In an enterprise, there are several AWS services that you can leverage to continue the process of securing your application once it is running in production.
Security monitoring with CloudTrail
AWS CloudTrail records all actions taken by IAM users, IAM roles, or an AWS service in an account. CloudTrail covers actions across the AWS console, CLI, SDK, and service APIs. This stream of events can be used to monitor your serverless application for unusual or unintended access and guard against attack #9 on the OWASP Top 10 list: security logging and monitoring failures.
Tip
CloudTrail is a critical tool in counteracting repudiation attacks, described in “STRIDE”.
You can use Amazon CloudWatch for monitoring CloudTrail events. CloudWatch Logs metric filters can be applied to CloudTrail events to match certain terms, such as ConsoleLogin events. These metric filters can then be assigned to CloudWatch metrics that can be used to trigger alarms.
CloudTrail is enabled by default for your AWS account. This allows you to search CloudTrail logs via the event history in the AWS console. However, to persist logs beyond 90 days and to perform in-depth analysis and auditing of the logs you will need to configure a trail. A trail enables CloudTrail to deliver logs to an S3 bucket.
Once your CloudTrail logs are in S3, you can use Amazon Athena to search the logs and perform in-depth analysis and correlation. For more information about Cloud Trail best practices, read Chloe Goldstein’s article on the AWS blog.
Continuous security checks with Security Hub
You can use AWS Security Hub to support the security practice of your team and to aggregate security findings from other services, such as Macie, which you will discover in the next section.
Security Hub is particularly useful for identifying potential misconfigurations, such as public S3 buckets or missing encryption at rest on an SQS queue, that could otherwise be difficult to track down. Security Hub reports will rank findings by severity, providing a full description of each finding with a link to remediation information where available and an overall security score.
Vulnerability scanning with Amazon Inspector
Amazon Inspector can be used to continuously scan Lambda functions for known vulnerabilities and report findings ranked by severity. Findings can also be viewed in Security Hub to provide a central security posture dashboard.
Warning
The security benefits of Amazon Inspector come at a cost. You should understand the pricing model before enabling Inspector.
Inspector can be used in addition to automated vulnerability scanning tools you may have running earlier in your development process, such as on the code repository itself.
Detecting Sensitive Data Leaks
As you saw in the previous section on protecting data, keeping your production data safe is critical. In particular, data that is classified as sensitive must be handled with the highest level of security.
The degree to which your application will receive, process, and store sensitive data, such as names, addresses, passwords, and credit card numbers, will depend on the purpose of the application. However, all but the simplest of applications will most likely handle some form of sensitive data.
There are four steps to managing sensitive data:
-
Understand protocols, guidance, and laws relating to data management. These could be organizational guidelines for data privacy or data protection regulations such as the Health Insurance Portability and Accountability Act (HIPAA), General Data Privacy Regulation (GDPR), Payment Card Industry Data Security Standard (PCI-DSS), and Federal Risk and Authorization Management Program (FedRAMP).
-
Identify and classify sensitive data in your system. This could be data received in API request bodies, generated by internal functions, processed in event streams, stored in a database, or sent to third parties.
-
Implement measures to mitigate improper handling and storage of sensitive data. There are often regulations preventing storing data beyond a certain period of time, logging sensitive data, or moving data between geographic regions.
-
Implement a system for detecting and remediating improper storage of sensitive data.
Mitigating sensitive data leaks
There are measures that can be applied to limit the potential of sensitive data being stored in databases, object stores, or logs, such as explicit logs and log redaction. However, it is crucial to design systems in a way that tolerates sensitive data being stored inadvertently and to react and remediate as soon as possible when this occurs. The possibility of mishandling sensitive data exists in any system that handles such data.
It is also advisable to only store data that is absolutely necessary for the operation of your application, and only store that data for as long as it is needed. Deletion of data after a certain period of time can be automated in various AWS data stores. For example, CloudWatch log groups should be configured with a minimum retention period, DynamoDB records can be given a TTL value, and the lifecycle of S3 objects can be controlled with expiration policies.
The following sections describe some techniques to detect sensitive data leaks in application logs and object storage.
Managed sensitive data detection
Some AWS services already offer managed sensitive data detection and other services may follow in the future. Amazon SNS offers native data protection for messages sent through SNS topics. Amazon CloudWatch offers built-in detection of sensitive data in application logs, for example from Lambda functions.
Amazon Macie
Amazon Macie is a fully managed data security service that uses machine learning to discover sensitive data in AWS workloads. Macie is capable of extracting and analyzing data stored in S3 buckets to detect various types of sensitive data, such as AWS credentials, PII, credit card numbers, and more.
Data can be routed from various components in your application to S3 and continually monitored for sensitive attributes by Macie. This could include events sent to EventBridge, API responses generated by Lambda functions, or messages sent to SQS queues. Macie findings events are sent to EventBridge and can be routed from there to alert you to sensitive data being stored or transmitted by your application.
Summary
The security paradox dictates that while software security should be of paramount importance to an enterprise, it is often not a primary concern for engineering teams. This disconnect is typically caused by a lack of actionable processes.
Security must, and can, be an integral part of your serverless software delivery lifecycle. You can achieve this by adopting key security strategies like zero trust architecture, the principle of least privilege, and threat modeling; following industry standards for data encryption, API protection, and supply chain security; and leveraging security tools provided by AWS, such as IAM and Security Hub.
Most importantly, remember that security can be simple, and by establishing a clear framework for securing your serverless application you can remove a lot of the usual fear and uncertainty for your engineers.
Interview with an Industry Expert
Nicole Yip, Principal Engineer
Nicole Yip has spent many years getting engineering teams up and running in AWS and helping them grow to operational maturity in Australia and the United Kingdom. Her interests in DevOps (in its many definitions), security, reliability, infrastructure, and overall system design have helped shape teams in a way that enables them to get their applications and services out to production safely and securely while maturing their understanding and processes around owning production systems (most notably a very popular global retail website).
You can find some conference talks and blog posts about her various interest areas online, but her main focus has been inspiring, challenging, and implementing growth in the teams around her in the companies she has been involved with.
Q: There is a perception in the software industry that security is hard and should be left to cybersecurity specialists. Has the cloud changed this, or should engineers still be scared of security?
In the software industry it’s true that security is seen as hard and intimidating, but I would break that down to say that it’s seen as “yet another requirement” and a rabbit hole, combined.
Security is seen as “hard” because it’s another nonfunctional requirement to be included at every stage, from design to implementation and even to ongoing operations. Security is also hard because there is a lot to discover when you enter the world of security—it’s not just the code you write, the architecture you design, or the access controls around the applications you use to meet certain standards and protocols. There are also entire categories of threats like physical security and social engineering that wouldn’t come to mind when just looking at security from a software engineering point of view but can still be just as, if not more, damaging as entry points to your system.
For those in security teams, InfoSec tooling that used to be manual, cumbersome, and scheduled monthly or less frequently as a result has improved and become way more user-friendly and integrated with the software development lifecycle, making it easier for issues to be flagged before making it to production or even automatically patching vulnerable dependencies as they get reported in the community.
Software engineers are typically very curious, so I don’t think they should be scared of security as a topic—it’s one of those things where the more aware you are, the more you naturally make more informed decisions when choosing how to host that application, or whether to click on that link. Security is everyone’s responsibility and absolutely shouldn’t be “left” to security experts—each line of code written or design decision made changes the security posture of the system, so the more security-aware everyone involved in the software development lifecycle is, the less likely it is that a bad actor will be able to find enough vulnerabilities to successfully do some damage.
Where the cloud comes in is that securing parts of your system becomes the cloud provider’s responsibility—security of your data centers and data at rest become a contractual agreement with the cloud provider. For small businesses that is a blessing as it is yet another thing that would need to be figured out and enforced if they had chosen to self-host and build a server room.
By using a cloud provider you are guided into configuring a more secure system by default without realizing it. The choice to start setting up an application in the cloud can already have you making decisions about security because you are presented with those decisions when configuring the services.
You can still build a system with vulnerabilities in the cloud, so stay curious; learn as much as you can about attack vectors (threat modeling helps to identify these) and the real business implications to your system when someone discovers and exploits them. It’s not “if” but “when.”
What does “security” mean?
The end goal is to allow your system to be used in the intended way, and all other potential abuses and access should be mitigated (limited) or not possible to begin with.
It’s a risk acceptance scale—you secure a system to the point where you as a business accept the likelihood and impact of the potential attack vectors in your system. Why? Because some attack vectors you can’t prevent—like insider threats from a bad actor in your development team!
Q: Serverless shifts the responsibility of infrastructure management to AWS, allowing engineers to focus on the code that is deployed to that infrastructure. Does the delegation of infrastructure management in serverless make security easier or harder?
It depends which lens you are looking from, as an infrastructure/networking engineer or as a software engineer. Overall I think serverless makes security a little easier as the environments are sandboxed, which reduces the ability to persist an entry point. But when you start introducing more complex use cases that for example introduce networking (if running in a VPC), authentication and authorization of clients (that call your APIs)… then the level of security expertise required remains the same. Instead of the responsibility maybe resting with an operations or infrastructure team who are already in the habit of thinking about network-level threats, that responsibility is then taken on by the software engineering team.
A conscious effort needs to be put in to raise the level of expectations on software engineers venturing further down the stack into serverless and infrastructure—it’s not good enough to just configure the libraries you use to their recommended security levels, you now also need to consider how many permissions does the container running your code actually need to operate, how much connectivity does it need to other resources—should they be in the same network or can they be isolated on their own?
Q: You have led software teams for many years and played an active role in the cloud and DevOps community. Have you observed any shifts in the role of a software engineer as they become increasingly responsible for securing their applications when using serverless technology?
Yes, but not necessarily because software engineers become increasingly responsible for securing their applications. Software engineers typically start out in a specialty—frontend, backend, database administrator, etc.—and they learn the leading frameworks, patterns, and nonfunctional requirements (including security) for designing reliable solutions within that specialty. They then start to expand out and collect specialties and aim to become this mythical “full stack” engineer. “Full stack” used to broadly include frontend, backend, and database specialties but that can easily now include operations, networking, and infrastructure with the prevalence of cloud hosting platforms. With serverless especially this has reduced the barrier to entry to new specialties they can expand out to, including data (migration and management), machine learning, and so much more.
As I mentioned before, security is one of those nonfunctional requirements that exists in all parts of the stack, and all those specialty areas I mentioned before need to understand security and privacy with different lenses for their areas of the stack.
With serverless this enables software engineers get a foot in the door to learn networking and infrastructure with a helping hand on security and privacy built into the usage of the platform.
For example, network engineers use firewalls to block out connections from unwanted networks and on unused ports—when requesting an AWS VPC and setting up your subnets and route tables, these are all locked down by default and you specify the ports and networks that need access (although let’s ignore the fact the default networking resources in new AWS accounts don’t adhere to that).
The opportunities and avenues for a software engineer to grow and evolve their role will continue to expand. New technologies will emerge every few years (currently GenAI and prompt engineering) that lower the barrier for entry to other specialties (e.g., data science and creative industries) and can then add a new line into the description of what a full stack engineer could be.
Q: You have played a crucial role in the serverless and DevOps adoption at large enterprises. From your experience, how can teams and organizations foster a culture of security?
There are two things I have leveraged to foster a culture around security. First of all, by building a strong engineering team culture and keeping security topics in the day-to-day conversation to maintain security awareness.
High-performing engineering cultures tend to have transparency, fail fast, and no-blame principles at their core. In addition to building trust this also allows teams to learn collectively. No one person will be able to review an architecture and lock it down 100% with no risks to accept. Everyone has unknown unknowns, and there are just some attack vectors you can’t lock down. So when something does happen, having a culture that has clear runbooks on what to do when a breach occurs and doesn’t penalize someone for identifying and reporting a breach will become more security-mature much faster than a team without these principles actively being fostered.
The second is keeping security in the conversation and having enough support for slack/innovation/curiosity time. Tooling and shift-left principles highlight security concerns early on in the software development lifecycle, which generates the conversation when they are surfaced in a constructive way. Putting in requirements for threat modeling as part of the design process brings the discussion about security even further to the left. But in addition to those, what you really need is engineers who are curious, who are constantly wondering what if, and then have enough slack time to pursue those trains of thought. Regular lunch and learn sessions about the latest breach that was reported in the industry or a security concept can trigger those moments of “what if…?” That little prompt for an engineer to think about the thing they are working on in the moment and realize that the vulnerability that allowed that breach or that concept could also apply to the thing they are writing is what you’re looking for—and then make sure they are supported if they go and try it out or play through the “what if…?” scenario. They could actually add in a mitigation before that feature gets to production!
It’s those lenses on the code from a high level (threat modeling) to a low level (dependency and static analysis tools) that can supplement the secure design and implementation of a system, but it’s engineers who will be able to secure the system with the business logic and constraints in mind as each line of code is being written and each part of the system is being configured. Give them the space and the knowledge to trigger their curiosity and do so!
Q: There are several standards and best practices for security on AWS, including the principle of least privilege, the shared responsibility model for cloud security, and the AWS Well-Architected Framework. For an enterprise adopting serverless, where do you think they can make a start in terms of security awareness?
The first thing to keep in mind is that security is everyone’s responsibility.
I would say start at the enterprise level and go with the assumption you’ll be breached tomorrow. Do you have good security foundations in place in your company? Would you know if and when you were breached, and do you know how to react and remediate?
Prevention and mitigation measures are always needed but never reduce the risk of a breach to 0%. As I’ve mentioned before, there are some attack vectors you cannot close and can only mitigate as best you can to bring them down to an acceptable risk level.
Some basic enterprise-level security capabilities include:
- Detection
-
Security information and event management (SIEM) alerts that go to a responsive team
- Response
-
Integrity assured evidence capturing system, sandboxes and isolated networks, experience in security response
- Prevention
-
Guardrails, training, golden paths, audits, penetration tests
Zooming in from looking at the enterprise level and into platform teams, platform teams should build in security golden paths to their products that pipe everything built on that platform into their company SIEM and surface prioritized alerts to the teams. They can also support application teams by integrating security tooling into their toolchain and deployment pipelines and surfacing the results in effective ways.
Application teams should be engaged in regular security education to stay up-to-date with the latest threats out there—whether that’s joining presentations breaking down the latest hack on a relevant application layer, completing company training, or being curious and learning more about security best practices from the tools in use (AWS Well-Architected Framework, GitHub Dependabot findings, static and/or dynamic analysis tools, penetration tests, etc.).
Get Serverless Development on AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

