Chapter 1. Getting Started
A path lies ahead,
Brambles and thorns, then it clears.
Almost there. Patience.
You’ve likely gathered by now that the Internet of Things can be vast, unwieldy, and very difficult to tame. To plan a way forward, we’ll first want to identify a problem area to tackle and then create an architecture from which to design and build our IoT solution.
Let’s start with a few key questions to establish a baseline: What problem are you trying to solve? Where does it start and end? Why does it require an IoT ecosystem? How will all of the pieces work together to solve this problem? What outcome can you expect if everything works as designed? We’ll explore each of these questions in detail, and along the way we’ll construct an end-to-end, integrated IoT solution that meets our needs.
What You’ll Learn in This Chapter
To help you really understand how an IoT system can and should be constructed, I’ll dig into some basic architectural concepts based on the preceding questions and use this as the basis for each programming activity. From there, you’ll build a solution that addresses the problem layer by layer, adding more functionality as you work through each subsequent chapter.
It goes without saying, of course, that the right development tools will likely save you time and frustration, not to mention help you with testing, validation, and deployment. There are many excellent open source and commercial development tools and frameworks available to support you.
If you’ve been a developer for any length of time, I expect you have your own specific development environment preferences that best suit your programming style and approach. I certainly have mine, and while the examples I present will be based on my preferred set of tools, my goal in this chapter is not to specify those you must use but to help you ramp up IoT development in a way that enables you to move out quickly and eventually choose your own tools for future development projects.
The concepts I present will be what matter most; the programming languages, tools (and their respective versions), and methods can be changed. These concepts represent some of the fundamentals of consistent software development: system design, coding, and testing.
Defining Your System
Creating a problem statement is probably the most important part of this puzzle. Let’s start by drafting something that is reasonably straightforward but is enough to encompass a variety of interesting IoT challenges:
I want to understand the environment in my home, how it changes over time, and make adjustments to enhance comfort while saving money.
Seems simple enough, but this is a very broad goal. We can narrow it down by defining the key actions and objects in our problem statement. Our goal is to isolate the what, why, and how. Let’s first look at the what and the why and then identify any action(s) that the design should consider as part of this process.
Breaking Down the Problem
The exercises in this book will focus on building an IoT solution that can help you understand your home environment and respond appropriately. The assumption is that you’ll want to know what’s going on within your house (within reason) and take some sort of action if it’s warranted (for example, turn on the air conditioning if the temperature is too hot).
This part of your design approach considers three key activities:
- Measure: Collect data
-
Let’s define this in terms of what can be sensed, like temperature, humidity, and so on. This is centered on the capture and transmission of telemetry (measurement data). The action—or rather, the action category—will be named data collection and will include the following data items (you can add more later):
-
Temperature
-
Relative Humidity
-
Barometric Pressure
-
System Performance (utilization metrics for CPU, memory, storage)
-
- Model: Determine relevant changes from a given baseline
- To decide which data is relevant and whether or not a change in value is important, we need not only to collect data but also to store and trend time-series data on the items we can sense (like temperature, humidity, etc., as indicated in the preceding definition). This is typically known as data → information conversion. I’ll refer to this category as data management.
- Manage: Take action
- We’ll establish some basic rules to determine whether we’ve crossed any important thresholds, which simply means we’ll send a signal to something if a threshold is crossed that requires some type of action (for instance, turning a thermostat up or down). This is typically known as information → knowledge conversion. I’ll refer to this category as system triggers.
In my university IoT course, I talk about Measure, Model, and Manage often. To me, they represent the core aspects of any IoT design that ultimately drive toward achieving the system’s specified business objectives, or outcomes.
Defining Relevant Outcomes
Now that we know what steps we need to take, let’s explore the why portion of our problem statement. We can summarize this using the following two points:
-
Increase comfort: Ideally, we’d like to maintain a consistent temperature and humidity in our living environment. Things get a bit more complicated when we consider the number of rooms, how they’re used, and so forth. I refer to this action category as configuration management, and it goes hand in hand with both data management and system triggers.
-
Save money: This gets a bit tricky. The most obvious way to save money is to not spend it! Since we’ll likely need to allocate financial resources to heat, cool, or humidify a given area, we want to optimize—not too much (wasteful), and not too little (we could end up with frozen water pipes in the winter). Since we might have some complexity to deal with here—including utility costs, seasonal changes, and so on, as well as anything related to configuration management—we’ll probably need some more advanced analytics to handle these concerns. I’ll call this action category analytics.
You’ve likely noticed that each step in the what and why sections has an action category name that will help with the solution design once we move on to the how. As a reminder, these categories are data collection, data management, system triggers, configuration management, and analytics. We’ll dig further into each of these as part of our implementation approach.
Although the problem statement seems rather banal on the surface, it turns out that the things you’ll need to do to address the problem are actually quite common within many IoT systems. There’s a need to collect data at its source, to store and analyze that data, and to take action if some indicator suggests doing so would be beneficial. Once you define your IoT architecture and start building the components that implement it—even though it will be specific to this problem—you’ll see how it can be applied to many other problem areas.
Let’s take a quick look at a simple data flow that represents this decision process; in the data flow diagram depicted in Figure 1-1, each action category is highlighted.
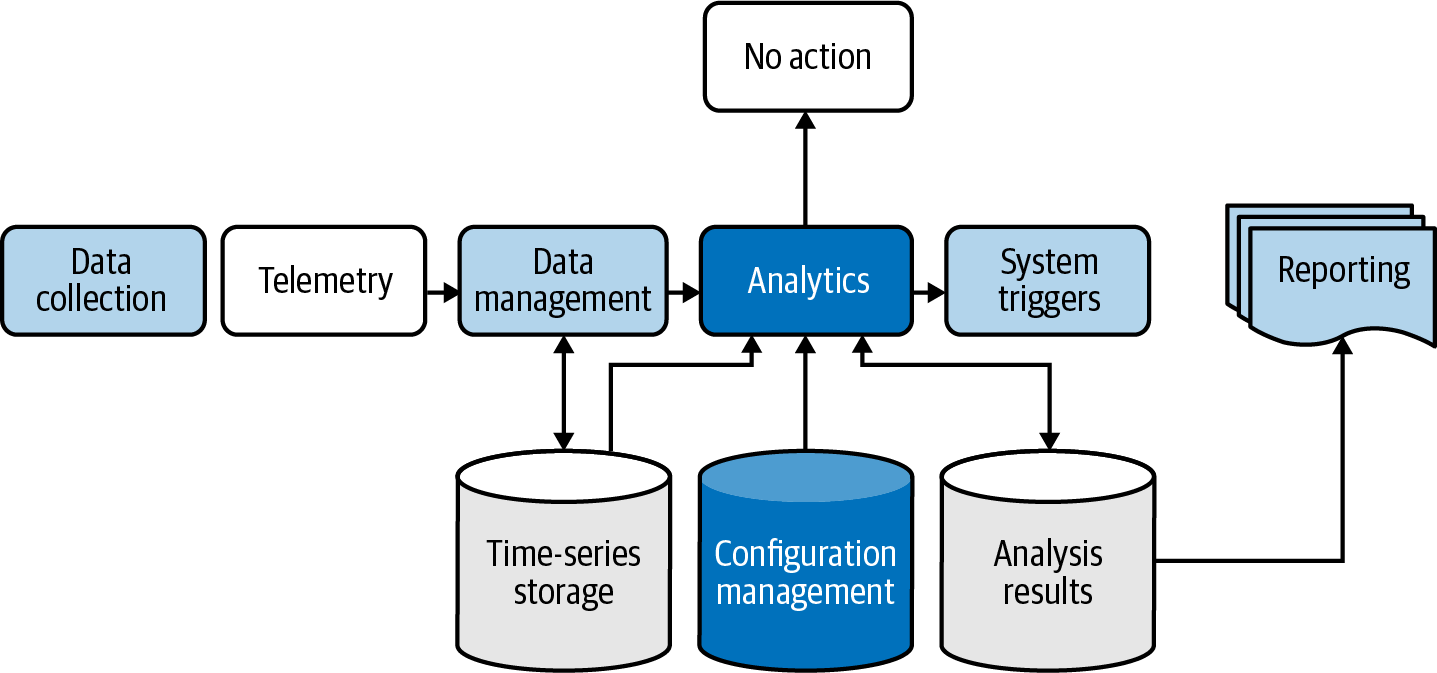
Figure 1-1. Simple IoT data flow
Most IoT systems will require at least some of the five action categories I’ve called out. This means we can define an architecture that maps these into a systems diagram and then start creating software components that implement part of the system.
This is where the fun starts for us engineers, so let’s get going with an architecture definition that can support our problem statement (and will in fact be reusable for others).
Architecting a Solution
Organization, structure, and clarity are hallmarks of a good architecture, but too much can make for a rigid system that doesn’t scale well for future needs. And if we try to establish an architecture that will meet all our plausible needs, we’ll never finish (or perhaps never even get started)! It’s about balance, so let’s define the architecture with future flexibility in mind, but let’s also keep things relatively well bounded. This will allow you to focus on getting to a solution quickly, while still permitting updates in the future. But first, there are a few key terms that need to be defined to help establish a baseline architectural construct to build your solution on.
As you may recall from Figure P-1 in the preface, IoT systems are generally designed with at least two (and sometimes three or more) architectural tiers in mind. This allows for the separation of functionality both physically and logically, which permits for flexible deployment schemes. All of this is to say that the cloud services running within the Cloud Tier can, technically speaking, be anywhere in the world, while the devices running within the Edge Tier must be in the same location as the physical systems that are to be measured. Just as Figure P-1 implies, an example of this tiering may include a constrained device with sensors or actuators talking to a gateway device, which in turn talks to a cloud-based service, and vice versa.
Since we need a place for these five categories of functionality to be implemented, it’s important to identify their location within the architecture so we can have some things running close to where the action is, and others running in the cloud where you and I can access (and even tweak) the functionality easily. Recalling the Edge Tier and Cloud Tier architecture from the preface, let’s see how to map each of the action categories from the what and why into each tier:
-
Edge Tier (constrained devices and gateway devices): Data collection, data management, device triggers, configuration management, and analytics
-
Cloud Tier (cloud services): Data management, configuration management, and analytics
Why do the Edge Tier and Cloud Tier include similar functionality? This is partly out of necessity, but also because, well, we can. The technical boundaries and separation of responsibilities between edge and cloud are becoming fuzzier as computing power increases and as business needs dictate “as close to the edge as possible” computation and analytics capabilities. For instance, some autonomous decisions may not require messages to traverse the internet out to the cloud and back again, as the Edge Tier can manage them directly (and should in some cases). So it’s important to account for this capability whenever and wherever reasonable.
Figure 1-2 shows how the simple data flow from Figure 1-1 fits within a tiered architecture.
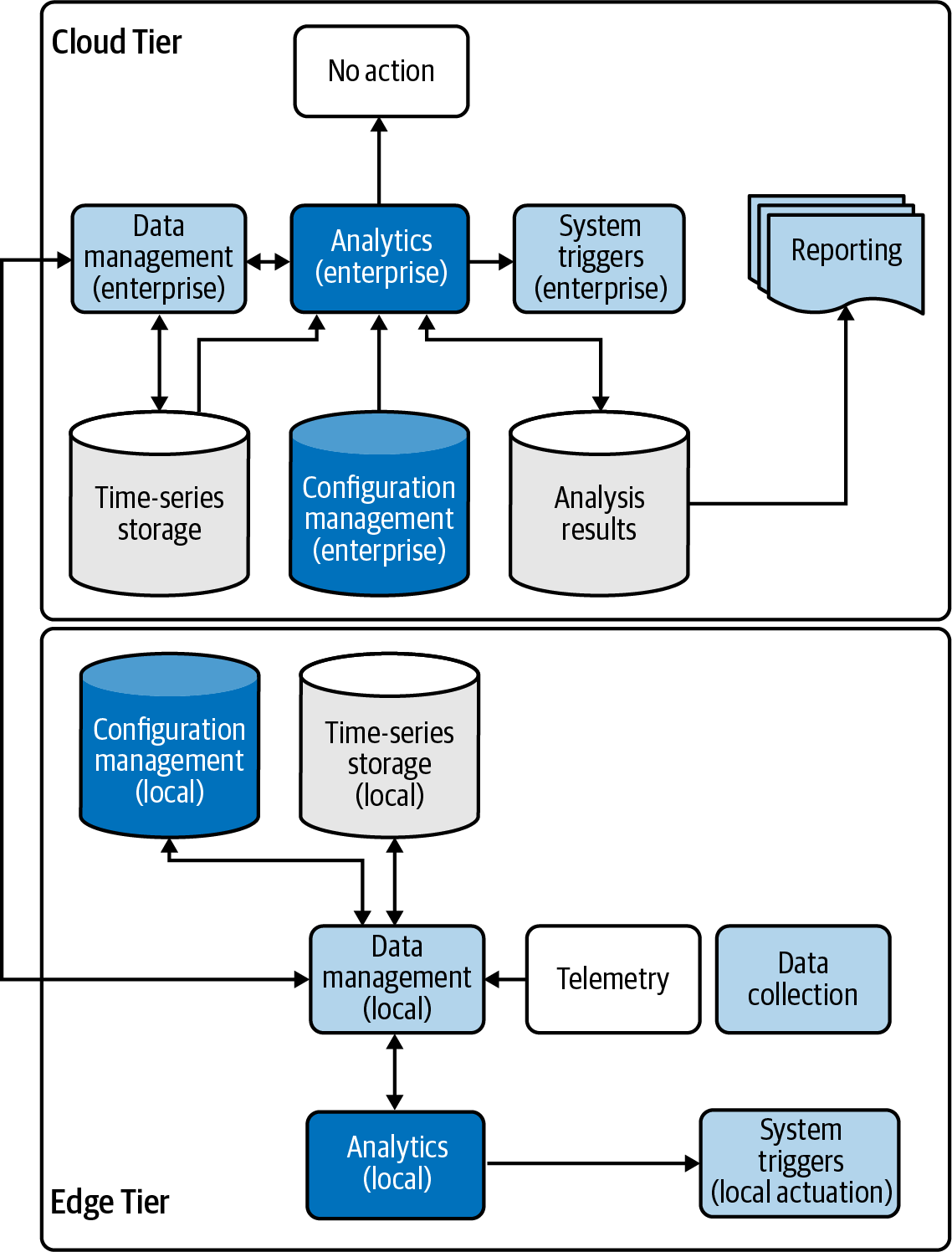
Figure 1-2. Notional IoT data flow between the Edge and Cloud Tiers
Again, notice that we have some shared responsibility, where some of the action categories are implemented within both tiers. Normally, duplication of effort is a bad thing—but in this case, it can be an advantage! Analytics can be used to determine whether a trigger should be sent to a device based on some basic settings—for example, if the temperature in your home exceeds 30ºC, you’ll probably want to trigger the HVAC straight away and start cooling things down to, say, 22ºC. There’s no need to depend on a remote cloud-based service in the Cloud Tier to do this, although it would be useful to notify the Cloud Tier that this is happening, and to perhaps store some historical data for later analysis.
Our architecture is starting to take shape. Now we just need a way to map it to a systems diagram so we can interact with the physical world (using sensors and actuators). It would also be good to structure things within the Edge Tier to avoid exposing components to the internet unnecessarily. This functionality can be implemented as an application that can run either directly on the device or on a laptop or other generic computing system with simulation logic that can emulate sensor and actuator behavior. This will serve as the basis for one of the two applications you’ll develop, beginning in this chapter.
Since you’ll want to access the internet eventually, your design should include a gateway to handle this need and other needs. This functionality can be implemented as part of a second application you’ll begin developing in this chapter. This application will be designed to run on a gateway device (or, again, on a laptop or other generic computing system). Your Gateway Device Application and Constrained Device Application will comprise the “edge” of your IoT design, which I’ll refer to as the Edge Tier of your architecture going forward.
You’ll also want to deploy analytics services, storage capabilities, and event managers in a way that’s secure but accessible from your gateway device and also by human beings. There are many ways to do this, although I’ll focus on the use of one or more cloud services for much of this functionality.
Figure 1-3 provides a new view that will give further insight into what you’re going to build and how you can begin incorporating the five action categories I mentioned. It represents, in grey boxes, cloud services within the Cloud Tier and the two applications within the Edge Tier that will contain the functionality of your constrained device and your gateway device, respectively.
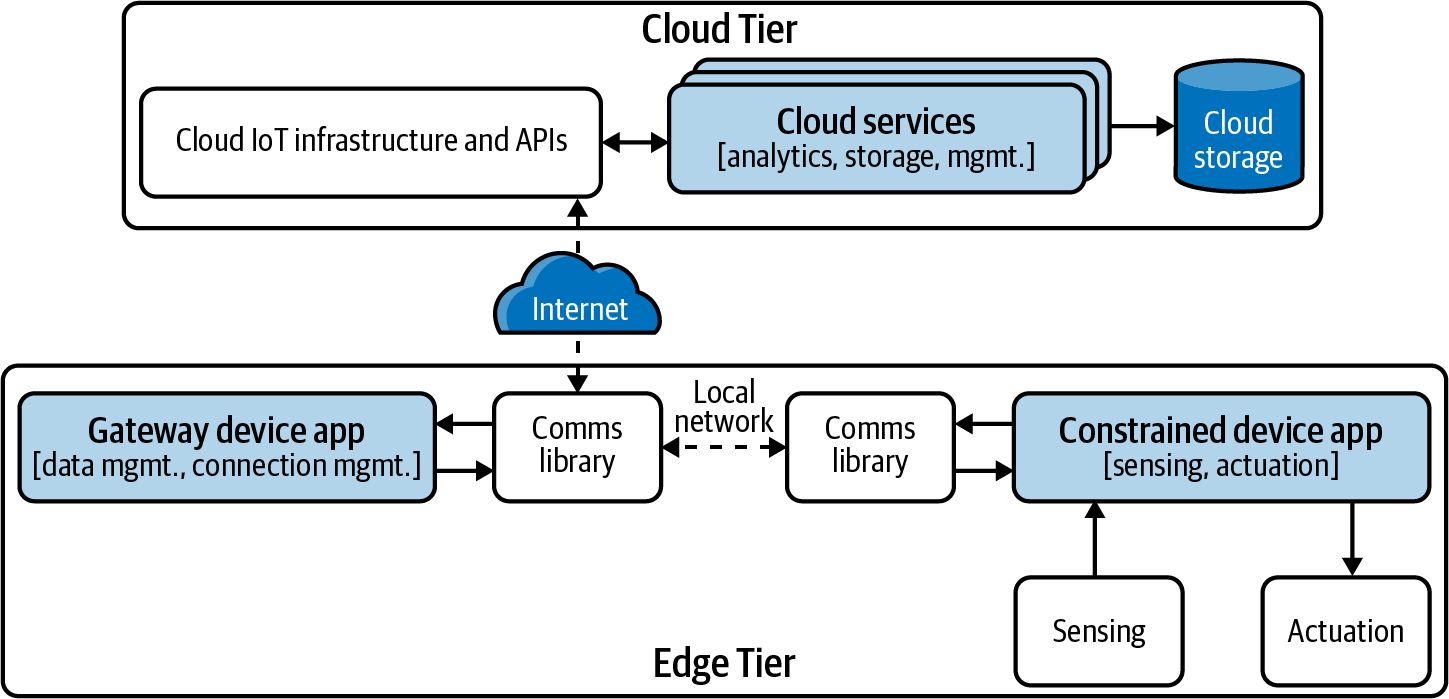
Figure 1-3. Notional IoT simplified logical architecture with Edge and Cloud Tiers
Let’s dig into each a bit further:
- Constrained Device Application (CDA)
- You’ll build this software application to run as part of a simulated constrained device within your development environment, and it will provide data collection and system triggers functionality. It will handle the interface between the device’s sensors (which read data from the environment) and actuators (which trigger actions, such as turning the HVAC on or off). It will also play a role in taking action when an actuation is needed. Eventually, it will be connected to a communications library to send messages to, and receive messages from, the gateway device app.
- Gateway Device Application (GDA)
- You’ll build this software application to run as part of a simulated gateway device within your development environment, and it will provide data management, analytics, and configuration management functionality. Its primary role is to manage data and the connections between the CDA and cloud services that exist within the Cloud Tier. It will manage data locally as appropriate and will sometimes take action by sending a command to the constrained device that triggers an actuation. It will also manage some of the configuration settings—that is, those that represent nominal ranges for your environment—and will perform some initial analytics when new telemetry is received.
- Cloud services
- All cloud services applications and functionality often do much of the heavy data processing and storage work, as they can theoretically scale ad infinitum. This simply means that, if they are designed well, you can add as many devices as you want, store as much data as you want, and do in-depth analysis of that data—trends, highs, lows, configuration values, and so on—all while passing any relevant insights along to a human end user, and perhaps even generating Edge Tier actions based on any defined threshold crossing(s). Technically, cloud services within an IoT environment can handle all the action categories previously mentioned, with the exception of data collection (meaning they don’t perform sensing or actuation actions directly). You will build some cloud services to handle this functionality but mostly will utilize those generic services already available from some cloud service providers.
Putting it all together into a detailed logical architecture, Figure 1-4 shows how each major logical component within our two architectural tiers interacts with the other components.
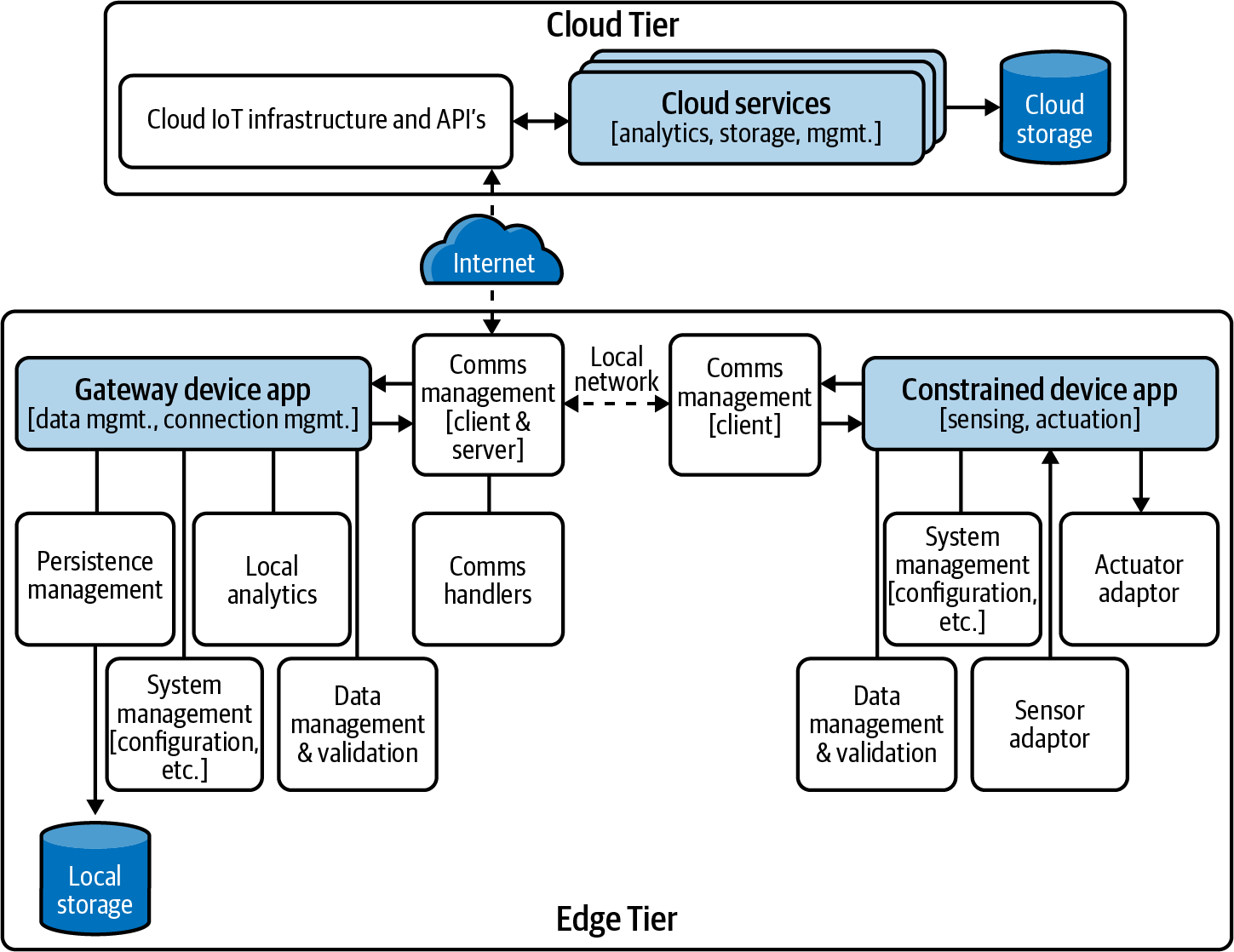
Figure 1-4. Notional IoT detailed logical architecture with Edge and Cloud Tiers
We’ll use Figures 1-3 and 1-4 as our baseline architecture for all the exercises in this book.
Now that we have a handle on what we’re up against, let’s get our development environment set up so we can start slinging code.
Setting Up Your Development and Test Environment
Building and deploying code across different operating systems, hardware configurations, and configuration systems is no walk in the park. With typical IoT projects, we have to deal not only with different hardware components but also with the myriad ways to develop and deploy across these platforms, not to mention the various continuous integration/continuous deployment (CI/CD) idiosyncrasies of the various cloud service provider environments we often work within.
With all these challenges, how do we even get started? First things first—what problem are we trying to solve? As a developer, you want to implement your IoT design in code, test it, package it into something that can be easily distributed to one or more systems, and deploy it safely. We can think of our development challenges in terms of build, test, and deploy phases that also map into two architectural tiers: Edge Tier (telemetry generation and actuation) and Cloud Tier (remote compute infrastructure). I’ll cover the functionality within the Cloud Tier later in Part IV, while Parts I, II and III will focus on the Edge Tier.
Although the Edge Tier of a typical IoT ecosystem could have specialized hardware to deal with, for our purposes, you can simulate much of the required system behavior, and even emulate some hardware components within your local development environment. This will make deployment much easier and is perfectly fine for all the required exercises in this book.
There are many ways to get up and running with IoT development. The exercises in this book focus on building an integrated simulated deployment approach, mentioned next. Hardware integration is completely optional, and is out of scope for the book, but will be very briefly referenced as an optional exercise in Chapter 4.
- Integrated simulated deployment
- This approach doesn’t require any specialized device and allows you to use your development workstation (laptop) as both gateway device and constrained device. This means you’ll run your GDA and CDA in your local computing environment. You’ll emulate your sensing and actuation hardware by building elementary software simulators to capture this functionality within your CDA. All of the book’s required exercises, with the exception of the optional Chapter 4 exercises posted online, should be implementable using this deployment approach.
- Separated physical deployment
-
This requires a hardware device, such as a Raspberry Pi, that gives you the ability to connect to and interact with real sensors and actuators. Although many off-the-shelf single-board computing (SBC) devices can be used as full-blown computing workstations, I’ll refer to this as your constrained device, and it will run your CDA directly on the device. As with the integrated simulated deployment approach, you’ll run the GDA in your local computing environment.
Note
As referenced in the preface, the IETF RFC 7228 document defines various classes of constrained devices (also referred to as constrained nodes). These classes include Class 0 (very constrained), Class 1 (constrained), and Class 2 (somewhat constrained).1 For our purposes, we’ll assume our CDA can run on Class 2 or even more powerful devices, which typically support full IP-based networking stacks, meaning the protocols we’ll deal with in this book will generally work on these types of devices. Although it’s technically feasible to connect Class 2 devices directly to the internet, all of the examples and exercises will interact indirectly with the internet via the GDA.
- Blended physical deployment
- This approach is nearly identical to the separated deployment approach but will run both your CDA and your GDA on the SBC device. This technically means you can choose to deploy each app to a different SBC, although it isn’t necessary for any of the exercises listed.
While the exercises in the book focus on the integrated simulated deployment approach, if you choose either of the last two paths for your deployment, there are a wide range of inexpensive SBCs that may work for you. The only exercises in this book that require hardware are the optional exercises in Chapter 4, and while you could possibly implement these on other hardware platforms, they are designed with the following hardware in mind: Raspberry Pi Model 3 or 4 and the Sense HAT board (which connects to its general-purpose input/output [GPIO] and uses the Inter-Integrated Circuit [I2C] bus for device communications). If you select a different device for these exercises, you may want to consider one that includes the following: GPIO functionality, I2C, TCP/IP and UDP/IP networking via WiFi or Ethernet, support for a Linux-based operating system (such as Debian or a derivative), and support for both Python 3 and Java 11 (or higher).
The exercises in the book will focus on the integrated simulated deployment path. Part II introduces the concept of integration with the physical world, and I’ll address some hardware integration concepts in Chapter 4 while maintaining focus on simulated data and emulated hardware.
Irrespective of the selected deployment path, all exercises and examples assume you’ll do your development and deployment on a single workstation. This involves a three-step process that includes preparing your development environment, defining your testing strategy, and identifying a build and deployment automation approach. I’ll cover the basics of these steps to get you started in this chapter but will also add to each as you dig into later exercises that have additional dependencies and testing and automation needs.
Note
You may already have experience developing applications in both Java and Python using your own development environment. If so, be sure to review the first step—preparation of your development environment—to ensure that your development environment, including your operating system, Java runtime, and Python interpreter, are all compatible with the exercise requirements.
Step I: Prepare Your Development Environment
Recall that your CDA will be written in Python, and your GDA will be written in Java. While this technically means that any OS supporting Python 3.7 or higher and Java 11 or higher may work for most exercises, there are some Linux-specific dependencies you should be aware of prior to setting up your development environment:
-
Chapter 4: The hardware emulator I’ll discuss in this chapter requires a Unix-based environment along with an X11 server to support its graphical user interface (GUI). Linux and macOS should work, whereas Windows will require Windows Subsystem for Linux (WSL)2 plus an X11 server.
-
Chapter 8: The Python-based CoAP3 server is an optional exercise and has been partially tested with the Java client from Chapter 9 on Windows 10, macOS, and Linux. As of this writing, you’ll probably need to run these tests within a Linux-based environment.
-
Chapter 9: Some of the Python-based CoAP client exercises currently depend on Linux-specific bindings. As of this writing, you’ll probably need to run these tests within a Linux-based environment.
Although I’ll discuss setup for Linux, macOS, and Windows, I’d suggest you use Linux as your development environment to avoid some of the integration challenges I just mentioned. Be sure to read through PIOT-CFG-01-001 for more information on operating environment setup and library compatibility considerations. Many of the open source libraries the exercises depend on are actively maintained; however, this is not universally the case. Please be sure to check each library for the latest tested version, its license and usage, and its operating environment compatibility constraints.
Note
Most of my own development is done on Windows 10, with a majority of application execution and testing done using WSL with an Ubuntu 20.04LTS kernel. If you must use a non-Linux operating environment, you can still build your end-to-end IoT solution by skipping the exercises in Chapter 4, Chapter 8, and Chapter 9 and relying instead on the data simulators described in Chapter 3 and the MQTT4 protocol for connectivity. Be sure to read through them all, however, as each will provide further insights into how to evolve your applications in the future.
You can make sure your workstation has the right stuff installed to support these languages and their associated dependencies by following these steps:
-
Ensure Python 3.7 or higher is installed on your workstation (the latest version as of this writing is 3.10, although my original development and testing was primarily done within WSL using Python 3.8.5). To check if it’s already installed, do the following:
-
Open a terminal or console window and type the following (be sure to use two dashes before the parameter)
-
Linux/macOS:
$ python3 –-version
-
Windows:
C:\programmingtheiot> python –-version
-
-
It should return output similar to the following:
Python 3.8.5
-
If the version returned is less than 3.7, or if you get an error (e.g., “not found”), you’ll need to install Python 3.7 or higher. Follow the instructions for your operating system (Windows, macOS, Linux) at https://www.python.org/downloads.
Note
In some cases, you may need to download the source code for Python and then build and install the executables. Check out the instructions at https://devguide.python.org/setup/ if you need to go down this path. As a heads-up, this process may take a while.
-
-
Ensure pip is installed on your workstation. If not, you can install pip by downloading the bootstrapping and installation script. If you’re using WSL or Ubuntu, you may need to install pip using the apt package manager.
-
Open a terminal or console window and type the following (again using two dashes before the parameter):
$ pip –-version
-
It should return output similar to the following:
pip 21.0.1
-
If pip is not installed, or if your version is out of date, use Python to execute the pip installation script. Type the following command:
-
Linux/macOS:
$ python3 get-pip.py
-
Windows:
C:\programmingtheiot> python get-pip.py
-
-
-
Ensure Java 11 or higher is installed on your workstation (the latest version of OpenJDK as of this writing is JDK 18). You can check if it’s already installed, or install it if not, using the following steps:
-
Open a terminal or console window and type the following (there are two dashes before the parameter, although it will likely work with just one):
$ java –-version
-
It should return something like the following (make sure it’s at least Java 11):
openjdk 14.0.2 2020-07-14 OpenJDK Runtime Environment (build 14.0.2+12-Ubuntu-120.04) OpenJDK 64-Bit Server VM (build 14.0.2+12-Ubuntu-120.04, mixed mode, sharing)
-
If you get an error (e.g., “not found”), you’ll need to install Java 11 or higher. Follow the instructions for your platform (Windows, macOS, or Linux) on the OpenJDK website.
-
-
Ensure Git is installed on your workstation. If not, you can install Git easily enough. Go to “Installing Git” and review the instructions for your specific operating system.
A prerequisite for any of the exercises in this book, and for setting up your development environment, is a basic understanding of Git, a source code management and versioning tool. Many IDEs come with source code management already enabled via an embedded Git client. In a previous step, you installed Git via the command line so that you can run Git commands independently of your IDE. For more information on using Git from the command line, see the Git tutorial documentation.
Tip
You can use Git as a stand-alone source code management tool on your local development workstation and manage your source code in the cloud using a variety of free and commercial services. GitHub5 is the service I use to host the code repositories and latest exercise instructions (which also embed many of the solutions). Be sure to follow along with the book’s Kanban board while you go through each exercise in this book, as it will contain the latest information.
-
Create a working development directory, and download the source code and unit tests for this book:
-
Open a terminal or console window, create a new working development directory, and then change to that directory. Then type the following:
-
Linux/macOS:
mkdir $HOME/programmingtheiot cd $HOME/programmingtheiot
-
Windows:
mkdir C:\programmingtheiot cd C:\programmingtheiot
-
-
Clone the following two source code repositories for this book by typing the following (you can also simply clone the repositories from within the IDE):
$ git clone https://github.com/programmingtheiot/python-components.git $ git clone https://github.com/programmingtheiot/java-components.git
-
-
Set up your Python environment. It’s usually easiest, but not required, to use a virtual environment for isolating your Python dependencies and libraries.
There are a handful of ways to establish a virtual execution environment for Python on your system, and my goal in this step isn’t to discuss them all. Python 3.3 or higher provides a virtual environment module, so you don’t have to install virtualenv unless that’s your preferred approach for Python virtualization. You can read more about using the venv module at https://docs.python.org/3/library/venv.html.
-
Create a virtual Python environment. Open a terminal or console window, change your directory to your desired virtual environment installation path (for example, $HOME/programmingtheiot/piotvenv, although you can choose any directory you’d like), and create a virtual environment (venv) as follows:
-
Linux/macOS:
$ python3 -m venv $HOME/programmingtheiot/piotvenv
-
Windows:
C:\programmingtheiot> python -m venv C:\programmingtheiot\piotvenv
-
-
Install the requisite Python modules. You can do this by typing the following:
-
Linux/macOS:
$ cd $HOME/programmingtheiot $ . piotvenv/bin/activate (piotvenv) $ pip install -r ./python-components/requirements.txt
-
Windows:
cd C:\programmingtheiot C:\programmingtheiot> piotvenv\Scripts\activate.bat (piotvenv) C:\programmingtheiot> pip install -r .\python-components\requirements.txt
-
-
Ensure your virtualenv can be activated. You can
activate(using the activate script) and thendeactivatevirtualenv (using the deactivate command) from your command line easily enough:-
Linux/macOS:
$ . piotvenv/bin/activate (piotvenv) $ deactivate
-
Windows:
C:\programmingtheiot> piotvenv\Scripts\activate.bat (piotvenv) C:\programmingtheiot> deactivate
-
-
At this point, your development workstation is mostly configured. The next step is to configure your development environment and clone the sample source code for the book.
Configuring an integrated development environment (IDE)
There are many excellent tools and IDEs that help you, the developer, write, test, and deploy applications written in both Java and Python. There are tools that I’m very familiar with and work well for my development needs. My guess is you’re much the same and have your own tool preferences. It doesn’t really matter which toolset you use, provided the tools meet some basic requirements. For me, these include code highlighting and completion, code formatting and refactoring, debugging, compiling and packaging, unit and other testing, and source code control.
I developed the examples in this book using the Eclipse IDE with PyDev installed, as it meets the requirements I’ve specified and provides a bunch of other convenient features that I regularly use in my development projects. You may be familiar with other IDEs, such as Visual Studio Code and IntelliJ IDEA, both of which also support Java and Python. The choice of IDE for the exercises in this book is, of course, completely up to you.
If you’re already familiar with writing, testing, and managing software applications using a different IDE, most of this section will be old hat. I do recommend you read through it, however, as this section sets the stage for the development of your GDA and CDA.
Set up your Gateway Device Application project
The first step in this process is to install the latest Eclipse IDE for Java development. You can find the latest download links for Eclipse at https://www.eclipse.org/downloads. You’ll notice that there are many different flavors of the IDE available. For our purposes, you can simply choose “Eclipse IDE for Java Developers.” Then follow the instructions for installing the IDE onto your local system.
Once installed, launch Eclipse, select File → Import, find Git → “Projects from Git,” and click Next.
Select “Existing local repository” and click Next. If you already have some Git repositories in your home path, Eclipse will probably pick them up and present them as options to import in the next dialog (not shown). To pull in the newly cloned repository, click Add, which will take you to the next dialog, shown in Figure 1-5. From here, you can add your new Git repository.
On my workstation, the repository I want to import is located at E:\aking\programmingtheiot\java-components. Yours will most likely have a different name, so be sure to enter it correctly! For Windows examples, I’ll mostly stick with the path C:\programmingtheiot.
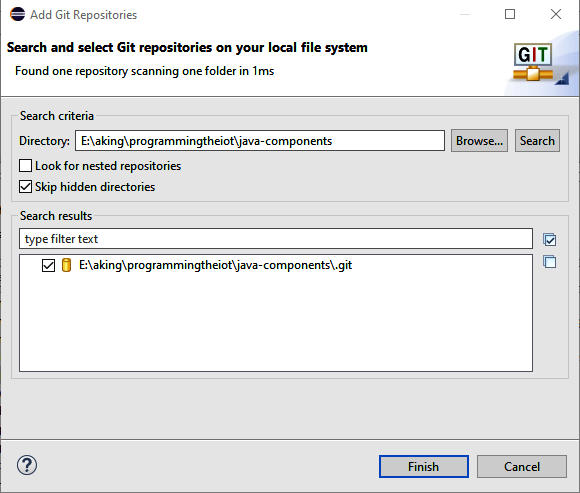
Figure 1-5. Import java-components from your local Git repository
Click Finish, and you’ll see your new repository added to the list of repositories you can import. Highlight this new repository and click Next. Eclipse will then present you with another dialog and ask you to import the project using one of several options, as shown in Figure 1-6.
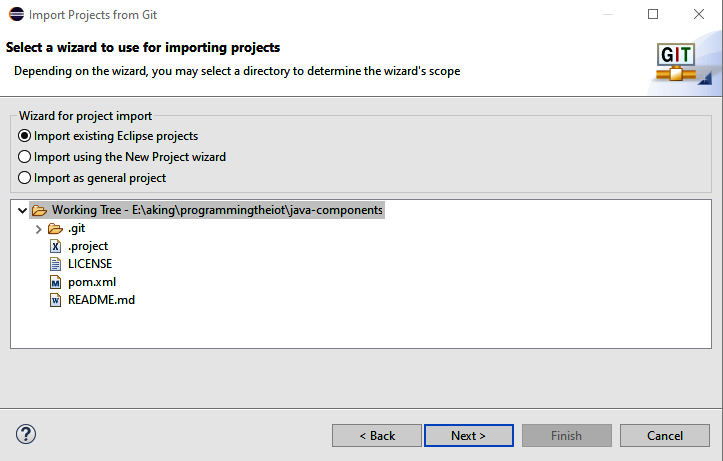
Figure 1-6. Import java-components as an existing Eclipse project
You now have a choice: you can import java-components as an existing Eclipse project using the new project wizard, or as a general project. Unless you want to fully customize your project environment, I’d recommend the first option—importing an existing Eclipse project. This process will look for a .project file in the working directory (which I’ve included in each of the repositories you’ve already cloned), resulting in a new Java project named java-components. If you’d prefer to create your own project, you can remove this and import as a new project using the appropriate wizard.
Click Finish, and you’ll see your new project added to the list of projects in the Eclipse Package Explorer, which by default should be on the left side of your IDE screen. If you don’t immediately see your project in the Package Explorer, simply change the IDE’s perspective to ‘Java’ (or ‘Python’ for the CDA).
Your GDA project is now set up in Eclipse, so let’s explore the files inside. Navigate to this project in Eclipse and click on the caret (>) symbol to expand it further, as shown in Figure 1-7.
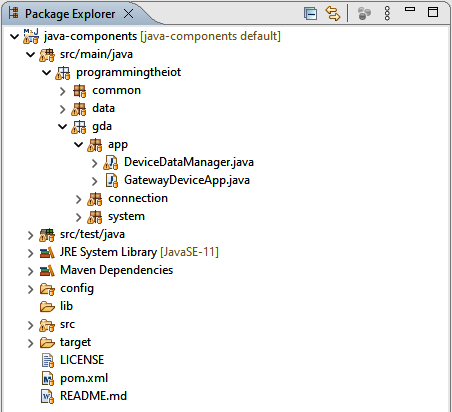
Figure 1-7. GDA project now set up and ready for use
Note
What if you don’t like the project name? No problem—you can right-click the java-components name, select Rename, type the new name, and click OK. Just know that I’ll continue to refer to the project by the original name throughout the book :).
You’ll notice that there are already a number of files included in the project—one is GatewayDeviceApp in the programmingtheiot.gda.app package, and the other one, at the top level, is called pom.xml. The GatewayDeviceApp is a placeholder to get you started, although you may replace it with your own. I’d recommend you keep the naming convention the same, however, as the pom.xml depends on this to compile, test, and package the code. If you know your way around Maven already, feel free to make any changes you’d like.
Bear in mind that if you plan on building your GDA from the command line, you’ll need to install Maven if it’s not already installed in your environment.
Tip
For those of you less familiar with Maven, the pom.xml is Maven’s primary configuration file and contains instructions for loading dependencies, their respective versions, naming conventions for your application, build instructions, and of course packaging instructions. Most of these dependencies are already included, although you may want to add your own if you find others to be useful. You’ll also notice that Maven has its own default directory structure, which I’ve kept in place for the Java repository. To learn more about these and other Maven features, I’d recommend you walk through the five-minute Maven tutorial.
Now, to make sure your GDA development environment is setup properly, you can build and run the GDA from within the IDE (this has been tested within Eclipse). Simply do the following:
-
Make sure your workstation is connected to the internet.
-
Run your GDA application within Eclipse.
-
Right-click on the project
java-componentsagain and scroll down to “Run As,” and this time click “Java application.” -
Check the output in the console at the bottom of the Eclipse IDE screen. The output similar to the following:
Jul 04, 2020 3:10:49 PM programmingtheiot.gda.app.GatewayDeviceApp initConfig INFO: Attempting to load configuration. Jul 04, 2020 3:10:49 PM programmingtheiot.gda.app.GatewayDeviceApp startApp INFO: Starting GDA... Jul 04, 2020 3:10:49 PM programmingtheiot.gda.app.GatewayDeviceApp startApp INFO: GDA ran successfully.
-
If you choose to build the GDA and run it from the command line, you’ll need to tell Maven to skip the tests, since they’ll fail (as there’s no implementation to test as of yet). Within a Linux shell, you can use the following command from within your GDA’s top level source directory:
$ mvn install -DskipTests
At this point, you’re ready to start writing your own code for the GDA. Now let’s get your development workstation set up for the CDA.
Set up your Constrained Device Application project
This process will mimic the GDA setup process but requires the addition of PyDev to Eclipse. Here’s a summary of activities to get you started.
If it’s not already running, launch the Eclipse IDE. In a separate window or screen, open your web browser and navigate to the PyDev Python IDE for Eclipse download page; drag the PyDev “Install” icon from the web page and drop it near the top of the Eclipse IDE (you’ll see a green “plus” icon show up, which is the indicator that you can drop it into the IDE). Eclipse will then automatically install PyDev and its dependencies for you.
Once PyDev is installed, you can switch the Python interpreter to use the venv (or virtualenv) environment if you chose to create it in the previous section. Select Preferences → PyDev → Interpreters → “Python Interpreter.” Eclipse will present a dialog similar to that shown in Figure 1-8.
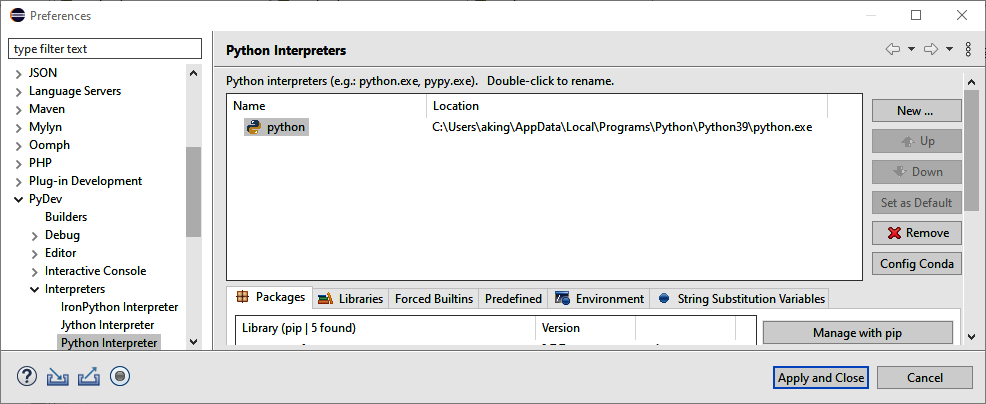
Figure 1-8. Add a new Python interpreter
Then add a new interpreter using the “Browse for python/pypy.exe” selection and provide the relevant information in the next pop-up window. Once complete, select the venv (or virtualenv) interpreter and click Up until it’s at the top of the list. At this point, venv (or virtualenv) will be your default Python interpreter, as Figure 1-9 indicates.
Click “Apply and Close.”
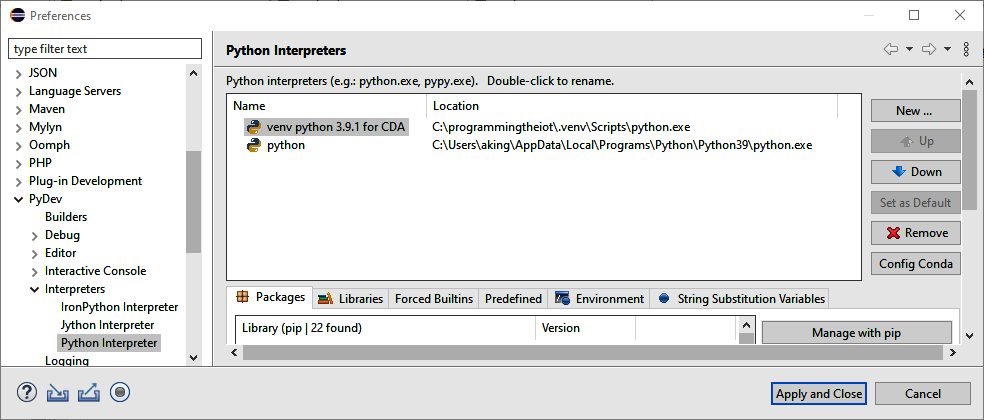
Figure 1-9. Virtualenv Python interpreter now set as default
Once these steps are complete, select File → Import and import the python-components Git repository you’ve already cloned from GitHub. Again, this is nearly identical to the previous steps shown in Figures 1-5, 1-6, and 1-7, except you’ll import the python-components Git repository you cloned from GitHub.
On my workstation, the repository I want to import is located at:
C:\programmingtheiot\python-components
As with the GDA, your repository name will likely be different, so be sure to use the correct path. I’ve also included the Eclipse .project file within this repository, so you can import it as an Eclipse project. This one will default to Python, so it will use PyDev as the project template. Again, you can import any way you’d like, but my recommendation is to import it as you did with the GDA.
Once you complete the import process, you’ll notice a new project in your Package Explorer named python-components. You now have the CDA components set up in your Eclipse IDE.
To view the files inside, navigate to python-components and click on the caret (>) to expand it further, as shown in Figure 1-10.
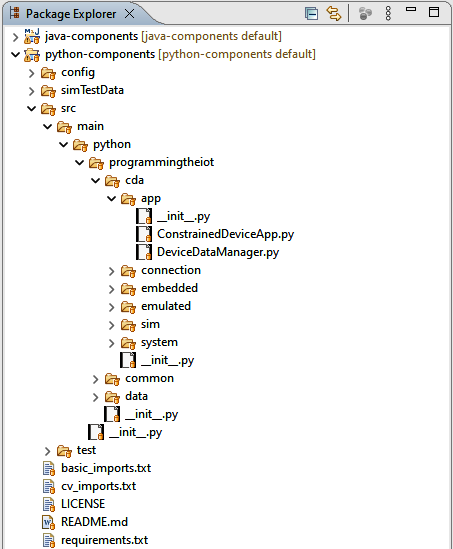
Figure 1-10. CDA project now set up and ready for use
You’ll notice that there are already many Python files included in the project, one of which is ConstrainedDeviceApp.py in the programmingtheiot.cda.app package, which is the application wrapper for the CDA. There are also __init__.py files in each package; these are empty files the Python interpreter uses to determine which directories to search for Python files (you can ignore these for now). Much like the GDA example previously given (and written in Java), the ConstrainedDeviceApp is simply a placeholder to get you started.
There are also two .txt files: requirements.txt and basic_imports.txt. These should be the same - I had created the second to disambiguate with other requirements files that are not in use for this version of the book. The requirements.txt file will be used to install library dependencies required to support the upcoming CDA programming exercises.
Warning
If you’ve worked extensively with Python, you’re likely familiar with the PYTHONPATH environment variable. Since I’ve attempted to keep the GDA and CDA packaging scheme similar, you may need to tell PyDev (and your virtualenv environment) how to navigate this directory structure to run your application. Make sure the src/main/python and src/test/python paths are both set in PYTHONPATH by doing the following: right-click “python-components,” select “PyDev - PYTHONPATH,” and then click “Add source folder,” as shown in Figure 1-11. Select the python folder under main and click Apply. Do the same for the python folder under test. Click “Apply and Close” to finish.
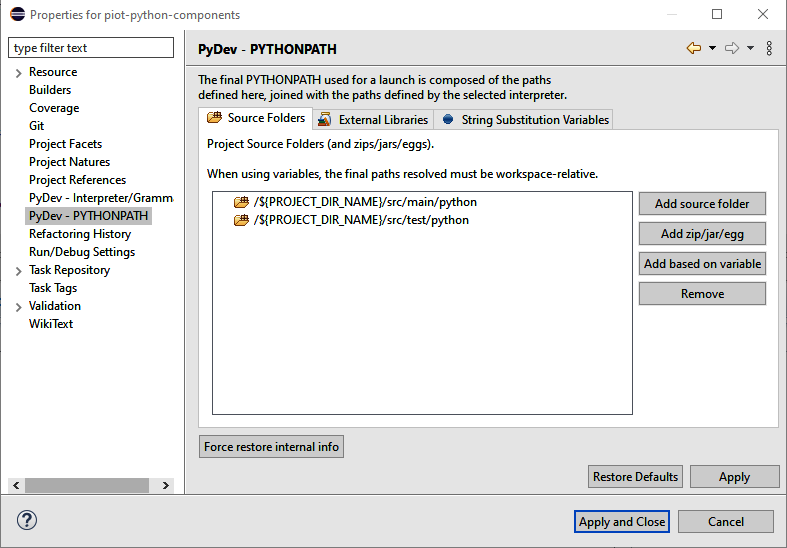
Figure 1-11. Updating the PYTHONPATH environment variable within PyDev and Eclipse
Run your CDA application within Eclipse.
-
Right-click on the project “python-components” again, scroll down to “Run As,” and this time click “Python Run.”
-
Check the output in the console at the bottom of the Eclipse IDE screen. As with your GDA test run, there should be no errors, with the output similar to the following:
2020-07-06 17:15:39,654:INFO:Attempting to load configuration... 2020-07-06 17:15:39,655:INFO:Starting CDA... 2020-07-06 17:15:39,655:INFO:CDA ran successfully.
Application configuration
After running the CDA and GDA, you’ve likely noticed the log messages related to configuration, and of course you recall the discussion of configuration management earlier in this chapter. Since you’ll be dealing with a number of different configuration parameters for each application, I’ve provided a basic utility class within each code repository to help with this—it’s named ConfigUtil.
In Python, ConfigUtil delegates to its built-in configparser module, and in Java, ConfigUtil delegates to Apache’s commons-configuration library. Both will allow you to load the default configuration file (./config/PiotConfig.props) or a customized version.
The easiest way to ensure each repository’s default configuration file is loaded correctly by the CDA and GDA is to update the DEFAULT_CONFIG_FILE_NAME config/PiotConfig.props' property to reference the fully qualified (absolute) file name for PiotConfig.props in each repository’s ConfigConst class (found in the ./programmingtheiot/common directory in each repository).
Here’s a Windows-specific example of the CDA’s updated DEFAULT_CONFIG_FILE_NAME property after modification (you’ll need to change to map to your own file and use a different path naming convention if/when using WSL or Linux, of course):
DEFAULT_CONFIG_FILE_NAME = "C:\programmingtheiot\python-components\config\
PiotConfig.props"
For the exercises in this book, many of the “consts” you’ll need are already defined in each repository’s ConfigConst class, although you can (and probably will need to) add your own.
The format of the configuration file is the same for both the CDA and the GDA. Here’s a brief sample from the CDA’s PiotConfig.props:
[ConstrainedDevice] deviceLocationID = constraineddevice001 enableEmulator = False enableSenseHAT = False enableMqttClient = True enableCoapClient = False enableLogging = True pollCycleSecs = 60 testGdaDataPath = /tmp/gda-data testCdaDataPath = /tmp/cda-data
And here’s a snippet from the GDA’s PiotConfig.props:
[GatewayDevice] deviceLocationID = gatewaydevice001 enableLogging = True pollCycleSecs = 60 enableMqttClient = True enableCoapServer = False enableCloudClient = False enableSmtpClient = False enablePersistenceClient = False testGdaDataPath = /tmp/gda-data testCdaDataPath = /tmp/cda-data
Notice that the sections are designated by a keyword contained in brackets, and the properties are in key = value format. This makes it easy to add new sections and key/value pairs alike.
One special case that’s addressed in each implementation of ConfigUtil is the ability to define—and load—a separate configuration file that contains credentials or other sensitive data that should not be part of your repository’s configuration. Each section allows you to specify a value for credFile, which is a key that maps to a local file that can and should be outside of your repository.
Warning
If you look at PiotConfig.props for the CDA and GDA, you’ll likely notice it contains a credFile entry for some sections. The reason for this is to move password references, user authentication tokens, API keys, and so forth out of the main configuration file so it can be referenced separately. It’s very important to keep secrets such as these out of your repos—you should NEVER commit usernames, passwords, private keys, or any other sensitive data to your Git repository. If you need a way to store this type of information, you may want to carefully read through the article “Encrypted Secrets” to learn more about this process in GitHub. Secure storage of credentials is an important topic, but one that’s outside the scope of this book.
The configuration approach I’ve described here is rather basic and is designed only for testing and prototyping purposes. If you’ve been programming for a while, you may already have an application configuration strategy and solution in place. Feel free to adapt the configuration functionality I’ve introduced here to suit your specific needs.
At this point, both your GDA and your CDA should be set up and working within your IDE, and you should be familiar with how the configuration logic functions. Now you’re ready to start writing your own code for both applications!
Before we jump into the exercises in Chapter 2, however, there are two more topics we should discuss: testing and automation.
Step II: Define Your Testing Strategy
Now that your development environment is established for your GDA and CDA, we can discuss how you’ll test the code you’re about to develop. Obviously, good testing is a critically important part of any engineering effort, and programming is no exception to this. Every application you build should be thoroughly tested, whether it works completely independently of other applications or it is tightly integrated with other systems. Further, every unit of code you write should be tested to ensure it behaves as expected. What exactly is a unit? For our purposes, a unit is always going to be represented as a function or method that you want to test.
Tip
What’s the difference between a function and a method? To grossly oversimplify, a function is a named grouping of code that performs a task (such as adding two numbers together) and returns a result. If the function accepts any input, it will be passed as one or more parameters. A method is almost identical to a function but is attached to an object. In object-oriented parlance, an object is just a class that’s been instantiated, and a class is the formal definition of a component—its methods, parameters, construction, and deconstruction logic. All of the Java examples in this book will be represented in class form with methods defined as part of each class. Python can be written in script form with functions or as classes with methods, but I prefer to write Python classes with methods and will do so for each Python example shown in this book, with only a few exceptions.
Unit, integration, and performance testing
There are many ways to test software applications and systems, and there are some excellent books, articles, and blogs on the subject. Developing a working IoT solution requires careful attention to testing—within an application and between different applications and systems. For the purposes of the solution you’ll develop, I’ll focus on just three: unit tests, integration tests, and performance tests.
Unit tests are code modules written to test the smallest possible unit of code that’s accessible to the test, such as a function or method. These tests are written to verify that a set of inputs to a given function or method returns an expected result. Boundary conditions are often tested as well, to ensure the function or method can handle these types of conditions appropriately.
Tip
A unit of code can technically be a single line, multiple lines of code, or even an entire code library. For our purposes, a unit refers to one or more lines of code, or an entire code library, that can be accessed through a single interface that is available on the local system—that is, a function or a method that encapsulates the unit’s functionality and can be called from your test application. This functionality can be, for example, a sorting algorithm, a calculation, or even an entry point to one or more additional functions or methods.
I use JUnit for unit testing Java code (included with Eclipse), and Python’s unittest framework6 for unit testing Python code (part of the standard Python interpreter, and available within PyDev). You don’t have to install any additional components to write and execute unit tests within your IDE if you’re using Eclipse and PyDev.
Note
In your GDA project, you’ve likely noticed two directory structures for your source code: one for Java source code located in ./src/main/java, and another Java unit test code located in ./src/test/java. This is the default convention for Maven projects, and so I’ve opted to use the same directory naming convention for the CDA as well (swapping “java” with “python,” of course).
You may have noticed that the CDA and GDA projects contain a ./src/test/python directory and a ./src/test/java directory, respectively. I provide most of the unit tests and many integration tests for you to use to check whether your implementation works, broken down by each chapter. These will work for the core exercises, although they are not intended to cover every possible edge case. For additional test coverage, and for all of the optional exercises, you’ll have to create your own unit and/or integration tests.
Here’s a simple unit test example in Java using JUnit that checks whether the method addTwoIntegers() behaves as expected:
@Test
public int testAddTwoIntegers(int a, int b)
{
// TODO: be sure to implement MyClass and the addTwoIntegers() method!
MyClass mc = new MyClass();
// baseline assertions
assertTrue(mc.addTwoIntegers(0, 0) == 0);
assertTrue(mc.addTwoIntegers(1, 2) == 3);
assertTrue(mc.addTwoIntegers(-1, 1) == 0);
assertTrue(mc.addTwoIntegers(-1, -2) == -3);
assertFalse(mc.addTwoIntegers(1, 2) == 4);
assertFalse(mc.addTwoIntegers(-1, -2) == -4);
}
What if you have a single test class with two individual unit tests, but you only want to run one? Simply add @Ignore before the @Test annotation, and JUnit will skip that particular test. Remove the annotation to reenable the test.
Let’s look at the same example in Python, using Python 3’s built-in unittest framework:
def testAddTwoIntegers(self, a, b): // TODO: be sure to implement MyClass and the addTwoIntegers() method! MyClass mc = MyClass() # baseline assertions self.assertTrue(mc.addTwoIntegers(0, 0) == 0) self.assertTrue(mc.addTwoIntegers(1, 2) == 3) self.assertTrue(mc.addTwoIntegers(-1, 1) == 0) self.assertTrue(mc.addTwoIntegers(-1, -2) == -3) self.assertFalse(mc.addTwoIntegers(1, 2) == 4) self.assertFalse(mc.addTwoIntegers(-1, -2) == -4)
The unittest framework, much like JUnit, allows you to disable specific tests if you wish. Add @unittest.skip("Put your reason here.") or @unittest.skip as the annotation before the method declaration, and the framework will skip over that specific test.
Note
Unit tests within the python-components and java-components repositories can be run as automated tests either from the command line or within the IDE. That is, you can script them to run automatically as part of your build, and each will either pass or fail, depending on the implementation of the unit under test.
Integration tests are super important for the IoT, as they can be used to verify that the connections and interactions between systems and applications work as expected. Let’s say you want to test a sorting algorithm using a basic data set embedded within the testing class—you’ll typically write one or more unit tests, execute each one, and verify all is well.
What if, however, the sorting algorithm needs to pull data from a data repository accessible via your local network or even the internet? So what, you might ask? Well, now you have another dependency just to run your sort test. You’ll need an integration test to verify that data repository connection is both available and working properly before exercising the sorting unit test.
These kinds of dependencies can make integration testing challenging with any environment, and even more so with the IoT, since it’s sometimes necessary to set up servers to run specialized protocols to test our stuff. For this reason, and to keep your test environment as uncomplicated as possible, all integration tests will be manually executed and verified.
Note
Manual execution and verification means that the integration tests within the python-components and java-components repositories are designed to be executed by you from the command line and must be observed to determine success or failure. While some can technically be exercised from within your IDE and can even be included within an automated test execution environment, others require some setup prior to execution (described within the test comments itself or within the requirements card for the module being tested). I’d suggest you stick with executing them from the command line only.
Finally, performance tests are useful for testing how quickly or efficiently a system handles a variety of conditions. They can be used with both unit and integration tests when, for instance, response time or the number of supported concurrent or simultaneous connections needs to be measured.
Let’s say there are many different systems that need to retrieve a list of data from your data repository, and each one wants that list of data sorted before your application returns it to them. Ignoring system design and database schema optimization for a moment, a series of performance tests can be used to time the responsiveness of each system’s request (from the initial request to the response), as well as the number of concurrent systems that can access your application before it no longer responds adequately.
Another aspect of performance testing is to test the load of the system your application is running on, which can be quite useful for IoT applications. IoT devices are generally constrained in some way—memory, CPU, storage, and so forth—whereas cloud services can scale as much as we need them to. It stands to reason, then, that our first IoT applications—coming up in Chapter 2—will set the stage for monitoring each device’s performance individually.
Since performance testing often goes hand in hand with both integration and unit testing, we’ll continue to use Maven and specialized unit tests for this as well, along with open source tools where needed.
Note
The performance tests within the python-components and java-components repositories are all designed as manual tests and must be observed to determine success or failure, in much the same way as the integration tests previously described. Again, automation is technically feasible but is outside the scope of this book. Be sure to review the setup procedures for each test prior to execution, which are described as part of the exercise or contained within the requirements card for the module.
There are many performance testing tools available, and you can also write your own. System-to-system and communications protocol performance testing is completely optional for the purposes of this book, and I’ll only briefly touch on this topic in Chapter 10. If you’d like to learn more about custom performance testing, you may want to look into tools designed for this purpose, such as Locust, which allows you to script your own performance tests and includes a web-based user interface (UI).
Testing tips for the exercises in this book
The sample code provided for each exercise in this book includes unit tests, which you can use to test the code you’ll write. These unit tests, which are provided as part of the java-components and python-components repositories you’ve already pulled into your GDA and CDA projects (respectively), are key to ensuring your implementation works properly.
Some exercises also have integration tests that you can use as is or modify to suit your specific needs. I’ve also included some sample performance tests you can use to test how well some of your code performs when under load.
Your implementation of each exercise should pass each provided unit test with 100% success. You’re welcome to add more unit tests if you feel they’ll be helpful in verifying the functionality you develop. The provided integration tests and performance tests will also be helpful validation tools as you implement each exercise.
Remember, tests are your friend—and like a friend, they shouldn’t be ignored. They can surely be time consuming to write and maintain, but any good friendship takes investment. These tests—whether unit, integration, or performance—will help you validate your design and verify your functionality is working properly.
Step III: Manage Your Design and Development Workflow
So you’ve figured out how you want to write your code and test it—terrific! But wouldn’t it be great if you could manage all your requirements, source code, and CI/CD pipelines? Let’s tackle this in our last step, which is all about managing your overall development process workflow. This includes requirements tracking, source code management, and CI/CD automation.
You’re probably sick of me saying that building IoT systems is hard, and that’s largely because of the nature of the Edge Tier (since we often have to deal with different types of devices, communication paradigms, operating environments, security constraints, and so on). Fortunately, there are many modern CI/CD tools that can be used to help navigate these troubled waters. Let’s look at some selection requirements for these tools, and then explore how to build out a CI/CD pipeline that will work for our needs.
Your IoT CI/CD pipeline should support secure authentication and authorization, scriptability from a Linux-like command line, integration with Git and containerization infrastructure, and the ability to run pipelines within your local environment as well as a cloud-hosted environment.
There are many online services that provide these features, some of which also provide both free and paid service tiers. When you downloaded the source code for this book, you pulled it from my GitHub repositories using Git’s clone feature. GitHub is an online service that supports overall developer workflow management, including source code control (using Git), CI/CD automation, and planning.
Each exercise will build, test, and deploy locally but will also assume your code is committed to an online repository using Git for source code management. You’re welcome to use the online service of your choice, of course. For this book, all examples and exercises will assume GitHub is being used.7
Note
There are lots of great resources, tools, and online services available that let you manage your development work and set up automated CI/CD pipelines. Read through this section, try things out, and then as you gain more experience, choose the tools and service that work best for you.
Managing requirements
Ah yes—requirements. What are we building, who cares, and how are we going to build it? Plans are good, are they not? And since they’re good, we should have a tool that embraces goodness, with features such as task prioritization, task tracking, team collaboration, and (maybe) integration with other tools.
The CDA and GDA repositories both include shell implementations (and some complete implementations) of the classes and interfaces you’ll complete by following each chapter’s coding exercise requirements. All of the requirements—including some informational notes—can be found in another GitHub repository I’ve made available in the Programming the IoT project. This is the best place to start, as it provides an ordered list of activities in columns and rows, as is typical in a Kanban board.
Note
From time to time, I’ll make updates to the Kanban board exercises and instructional cards, along with tweaks to the supporting Python and Java source code repositories. As such, the Kanban board will have the most up-to-date information on any exercises discussed in the book. If you find any discrepancies between the book and online GitHub content, defer to the latter, which should be the most accurate.
The specific requirements within each column are captured as cards and actually reference “Issues” from the book-exercise-tasks repository I’ve created to make centralized requirements management easier. You can easily drill down into any of these requirements by clicking on the name or by opening it in a separate tab.
The naming convention for each card should be relatively easy to understand: {book}-{app type}-{chapter}-{number}. For example, PIOT-CDA-01-001, which refers to Programming the Internet of Things (PIOT), Constrained Device App (CDA), Chapter 1 (01), requirement no. 1 (001).
That last number is important, as it indicates the sequence you should follow. For example, requirement no. 2 (002) would follow requirement no. 1 (001), and so on. The contents of each requirement contain the implementation instructions that you, the programmer, should follow, followed by the tests you should execute to verify the code works correctly.
There are two special numbers to keep in mind, although they, too, follow the sequence. All tasks ending with “000” are setup-related tasks, such as creating your branch. All tasks ending with “100” are merge- and validation-related tasks, such as merging your chapter branch into your primary and verifying that all functionality works as expected.
All of these cards and notes are organized into the book’s Kanban board, with a single column for each chapter, so that you can see all the things that need to be implemented for each chapter’s exercises. You’ve probably heard of Agile8 project management processes such as Scrum and Kanban. With a Kanban board, the idea is to select a card, start working on it, and—once it’s tested, verified, reviewed, and committed—close it out.
Even though you can’t pull down the cards I provide and close any of these issues, they are available for you to review and track on your own as you move through the exercises in each chapter. I’ll discuss a way to manage your CDA and GDA requirements within your own repositories beginning in Chapter 2, when you start writing code; for now I’ll provide a quick overview of how I’ve set up requirement cards (which are just references to one or more repositories’ issues) within the Programming the IoT Kanban board.
Note
I’m managing the activities for this book within a Kanban board, too. Each card on the board represents a task I or one of my team members needs to complete. A card moves to “Done” only after the team agrees it is complete.
GitHub provides an “Issues” tab to track requirements and other notes related to your repository. Figure 1-12 shows the task template I used for each requirement throughout the book. This is the stuff that goes into each task and can contain text, links, and so on. Notice that each of the requirement cards I’ve created contains five items: Title, Description, Actions, Estimate, and Tests.
Figure 1-12. Task template
Most of these categories are self-explanatory. But why only three levels of effort for Estimate? In this book, most of the activities should fall into one of the following “level of effort” categories: 2 hours or less (Small), about half a day (Medium), or about one day (Large). Keep in mind these are approximations only and will vary widely depending on a variety of factors.
For example, a “task” with the name Integrate IoT solution with three cloud services certainly represents work that may need to be done, but judging by the name only, it’s clearly way too big and complicated to be a single work activity. In this case, I may create multiple Issues, with a set of tests specific to each one. In other cases, I may have multiple modules that are each very basic with similar implementations—all of which would be contained within the same Issue. I try to keep each Issue self-contained as much as possible.
Figure 1-13 shows an example of the template filled in with highlights from the first coding task you’ll have—creating the Constrained Device Application (CDA).
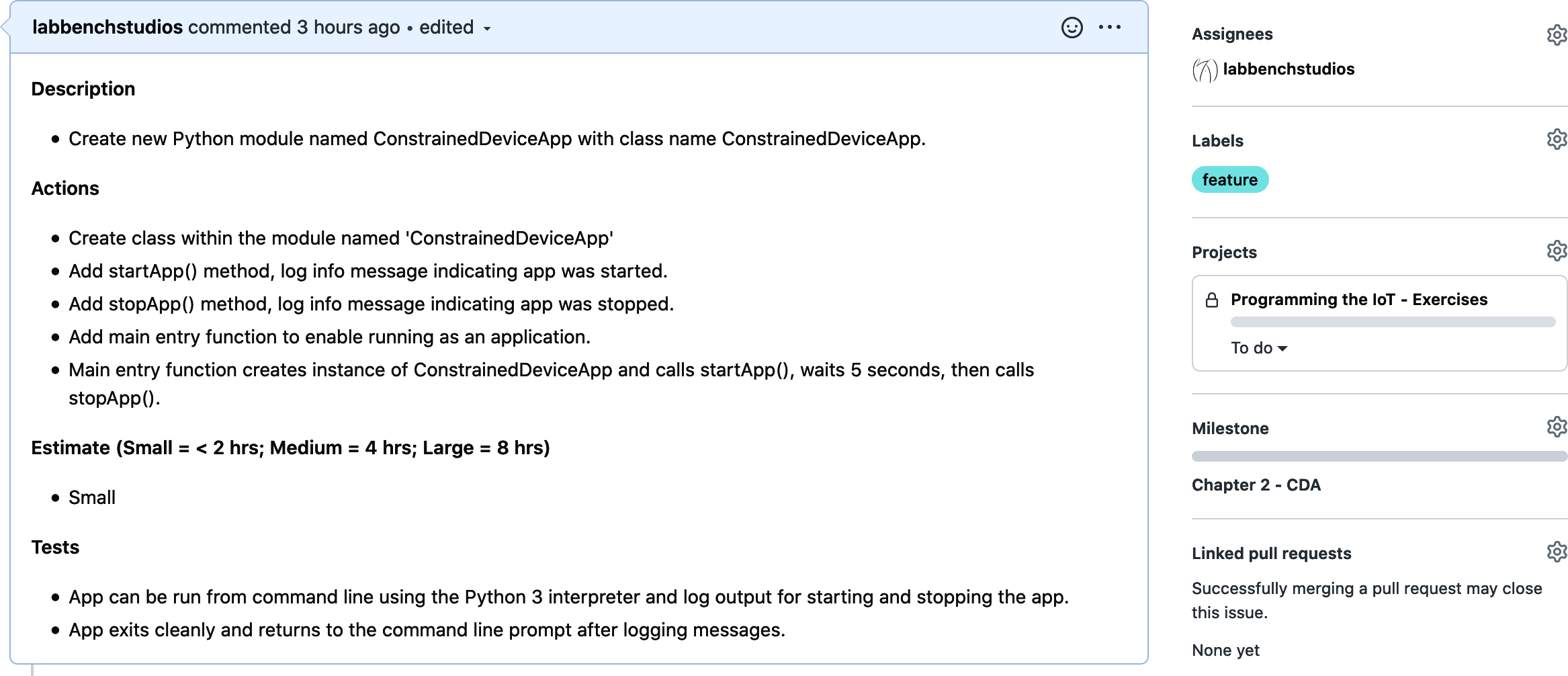
Figure 1-13. Example of a typical development task
And Figure 1-14 shows the result of adding the task as a Kanban card. This card was generated automatically after aligning the task to a project. Notice it’s been added to the “To do” column on the board, since it’s new and there’s no status as of yet. Once you start working on the task and change its status, it will move to “In progress.”
Again, the requirements are already written for you and are contained within the Programming the IoT Kanban board, but now you should have a better idea of how these requirements are defined, and even a template for creating your own, should you decide to do so.
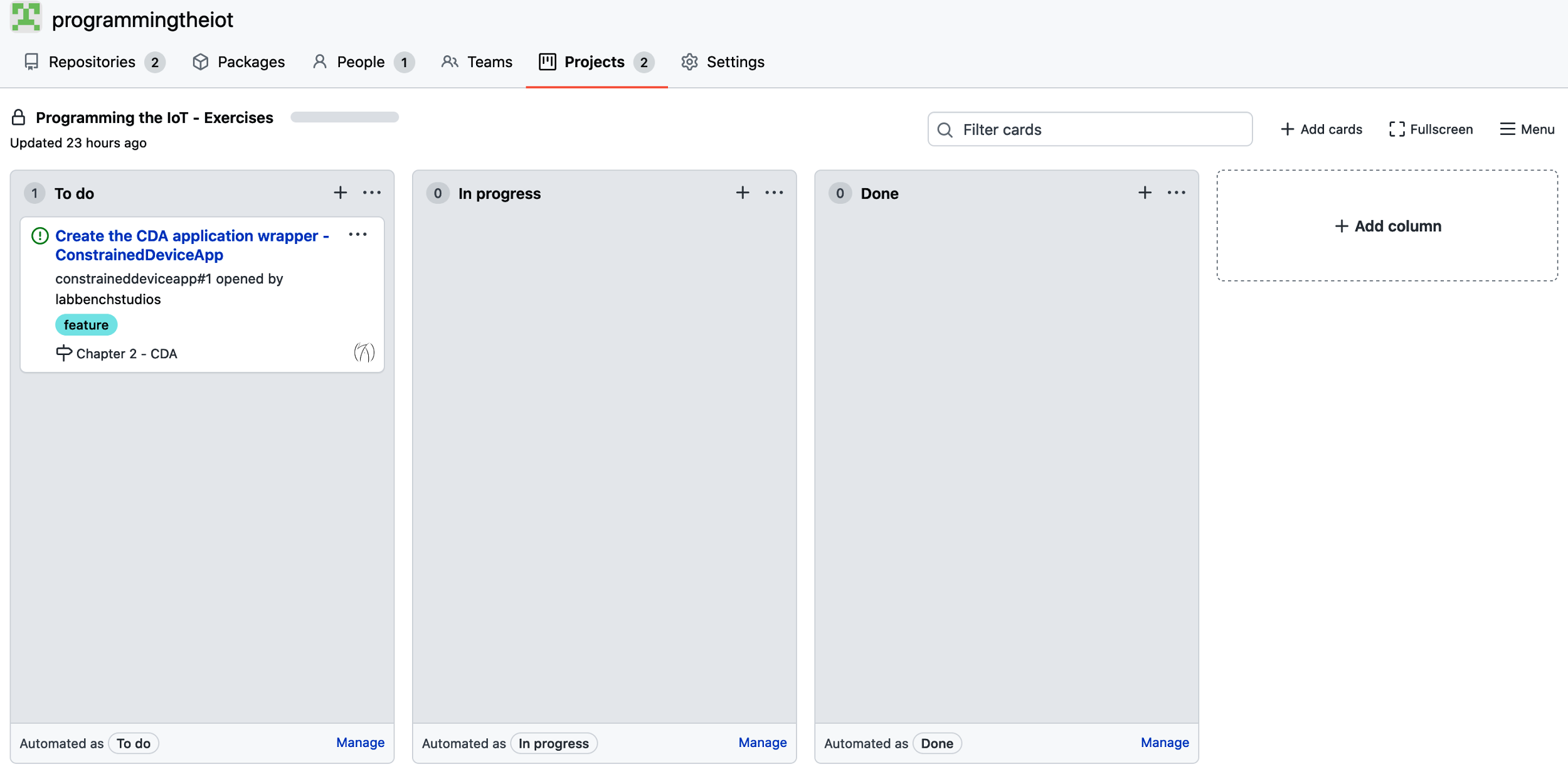
Figure 1-14. The new example task added into the Kanban board
Next, let’s get your remote Git repositories set up.
Setting up your remote repositories
There are many excellent cloud-based Git repository services available. As I mentioned, I’m using GitHub, and so I’ve provided some optional instructions here to help you get started:
-
Create a GitHub account. (If desired, create an organization associated with the GitHub account.)
-
Within your account (or organization), create the following:
-
A new private project named “Programming the IoT – Exercises”
-
A new private Git repository named “java-components”
-
A new private Git repository named “python-components”
-
-
Update the remote repository for both “java-components” and “python-components.”
-
From the command line, execute the following commands:
git remote set-url origin {your new URL} git commit -m “Initial commit.” git push -
IMPORTANT: Be sure to do this for both “java-components” and “python-components,” using the appropriate Git repository URL for each!
-
Once you complete these tasks, your Git repositories will be in place, and you will have the ability to manage your code locally and synchronize it with your remote instance.
Code management and branching
One of the key benefits of using Git is the ability to collaborate with others and synchronize your local code repository with a remote repository stored in the cloud. If you’ve worked with Git before, you’re already familiar with remotes and branching. I’m not going to go into significant detail here, but they’re important concepts to grasp as part of your automation environment.
Branching is a way of enabling each developer or team to segment their work without negatively impacting the main code base. In Git, this default main branch is currently called “master” and is typically used to contain the code that has been completed, tested, verified, and (usually) placed into production. This is the default branch for both “java-components” and “python-components,” and while you can leave it as is and simply work off this default branch, that’s generally not recommended for the reasons I’ve mentioned.
Branching strategies can differ from company to company and from team to team; the one I like to use has each chapter in a new branch, and then once all is working correctly and properly tested, the chapter branch gets merged into the master. From there, a new branch is created from the merged master for the next chapter, and so on.
This approach allows you to easily track changes between chapters, and even to go back to the historical record of an earlier chapter if you want to see what changed between, say, Chapter 2 and Chapter 5. In Eclipse, you can right-click on the project (either “java-components” or “python-components”) and choose Team → “Switch To” → “New Branch” to establish a new branch for your code.
I’d suggest you use the naming convention of “chapternn” for each branch name, where nn is the two-digit chapter number. For instance, the branch for Chapter 1 will be named “chapter01,” the Chapter 2 branch will be named “chapter02,” and so on. It’s useful to have a branching strategy that allows you to go back to a previous, “last known good” branch, or at least to see what changed between one chapter and the next. I’ve documented the chapter-based branching strategy within the requirements for each chapter as a reminder.
Note
The gory details on Git branching and merging are outside the scope of this book, so I’d recommend reading the guide “Git Branching—Basic Branching and Merging” if you’d like to dig into them.
Thoughts on Automation
Although outside the scope of this book, automation of software builds, testing, integration, and deployment is a key part of many development environments. I’ll discuss some concepts in this section but won’t be tackling this in this current book release.
Automated CI/CD in the cloud
Within Eclipse, you can write your CDA and GDA code, execute unit tests, and build and package both applications. This isn’t actually automated, since you have to start the process yourself by executing a command like mvn install from the command line or by invoking the Maven install process from within the IDE. This is great for getting both applications to a point where you can run them, but it doesn’t actually run them—you still need to manually start the applications and then run your integration and/or performance tests.
As a developer, part of your job is writing and testing code to meet the requirements that have been captured (in cards on a Kanban board, for example), so there’s always some manual work involved. Once you know your code units function correctly, having everything else run automatically—say, after committing and pushing your code to the remote dev branch (such as “chapter02,” for example)—would be pretty slick.
GitHub supports this automation through GitHub actions.9 I’ll talk more about this in Chapter 2 and help you set up your own automation for the applications you’re going to build.
Automated CI/CD in your local development environment
There are lots of ways to manage CI/CD within your local environment. GitHub actions can be run locally using self-hosted runners, for example.10 There’s also a workflow automation tool called Jenkins that can be run locally, integrates nicely with Git local and remote repositories, and has a plug-in architecture that allows you to expand its capabilities seemingly ad infinitum.
Warning
There are lots of great third-party Jenkins plug-ins and other utilities that I’ve found useful for my own build, test, and deployment environment, but you should do your own research to determine which ones are actively maintained and will add value for your specific environment. It’s easy to introduce system compatibility issues and even security vulnerabilities if you’re not fully aware of what a product will or will not do. It’s ultimately your responsibility to make this decision.
Once it is installed and secured, you can configure Jenkins to automatically monitor your Git repository locally or remotely and run a build/test/deploy/run workflow on your local system, checking the success at each step. If, for example, the build fails because of a compile error in your code, Jenkins will report on this and stop the process. The same is true if the build succeeds but the tests fail—the process stops at the first failure point. This ensures your local deployment won’t get overwritten with an update that doesn’t compile or fails to successfully execute the configured tests.
Setting up any local automation tool can be a complicated and time-consuming endeavor. It’s super helpful, however, as it basically automates all the stuff you’re going to do to build, test, and deploy your software. That said, it’s not required for any of the exercises in this book, and so I won’t go into it here.
Containerization
You’ve likely heard of containerization, which is a way to package your application and all its dependencies into a single image, or container, that can be deployed to many different operating environments. This approach is very convenient, since it allows you to build your software and deploy it in such a way as to make the hosting environment no longer a concern, provided the target environment supports the container infrastructure you’re using.
Docker11 is essentially an application engine that runs on a variety of operating systems, such as Windows, macOS, and Linux, and serves as a host for your container instance(s). Your GDA and CDA, for example, can each be containerized and then deployed to any hardware device that supports the underlying container infrastructure and runtime.
It’s worth pointing out that containerizing any application that has hardware-specific code may be problematic as it will not be portable to another, different hardware platform (even if the container engine is supported). If you want your hardware-specific application to run on any platform that supports Docker, that platform would require a hardware-specific emulator compatible with the code developed for the application.
For example, if your CDA has code that depends on Raspberry Pi–specific hardware, that is less of a concern for us at the moment, since you’ll be emulating sensors and actuators and won’t have any hardware-specific code to worry about until Chapter 4 (which, again, is optional). I’ll discuss this more in Chapter 4, along with strategies to overcome hardware specificity in your CDA.
When using CI/CD pipelines in a remote or cloud environment, you’ll notice that these services will likely deploy to virtual machines and run your code within a container that includes the required dependencies, all configured as part of the pipeline. For many cases, this makes perfect sense and can be an effective strategy to ensure consistency and ease of deployment. The caveat is that the target platform must support the container runtime environment you want to deploy. Cross-platform languages can make this easier, but it is a pain point that I don’t expect to go away any time soon.
To keep things simpler, I won’t walk through using containerization within your development environment and as part of your workstation, even though there are many benefits to doing so. The primary reason is that it adds another layer of complexity to manage initially, and I want to get you up and running with your own applications as soon as possible.
Programming Exercises
All the work you’ve done up to this point is to prepare you to build your CDA and GDA. You have some initial background in the IoT and a development environment setup and are ready to code. So far, so good, right?
If you look through your code base, you’ll see that you have a bunch of components already in place. In fact, most are just shell implementations of the components that are required for both the CDA and the GDA. But how are they all supposed to eventually work together?
The remaining chapters of the book will walk you through the requirements documented in the Programming the IoT Kanban board to achieve this end state. Figures 1-15 and 1-16 depict the overall design approach we’ll follow to get there for the CDA and the GDA, respectively.
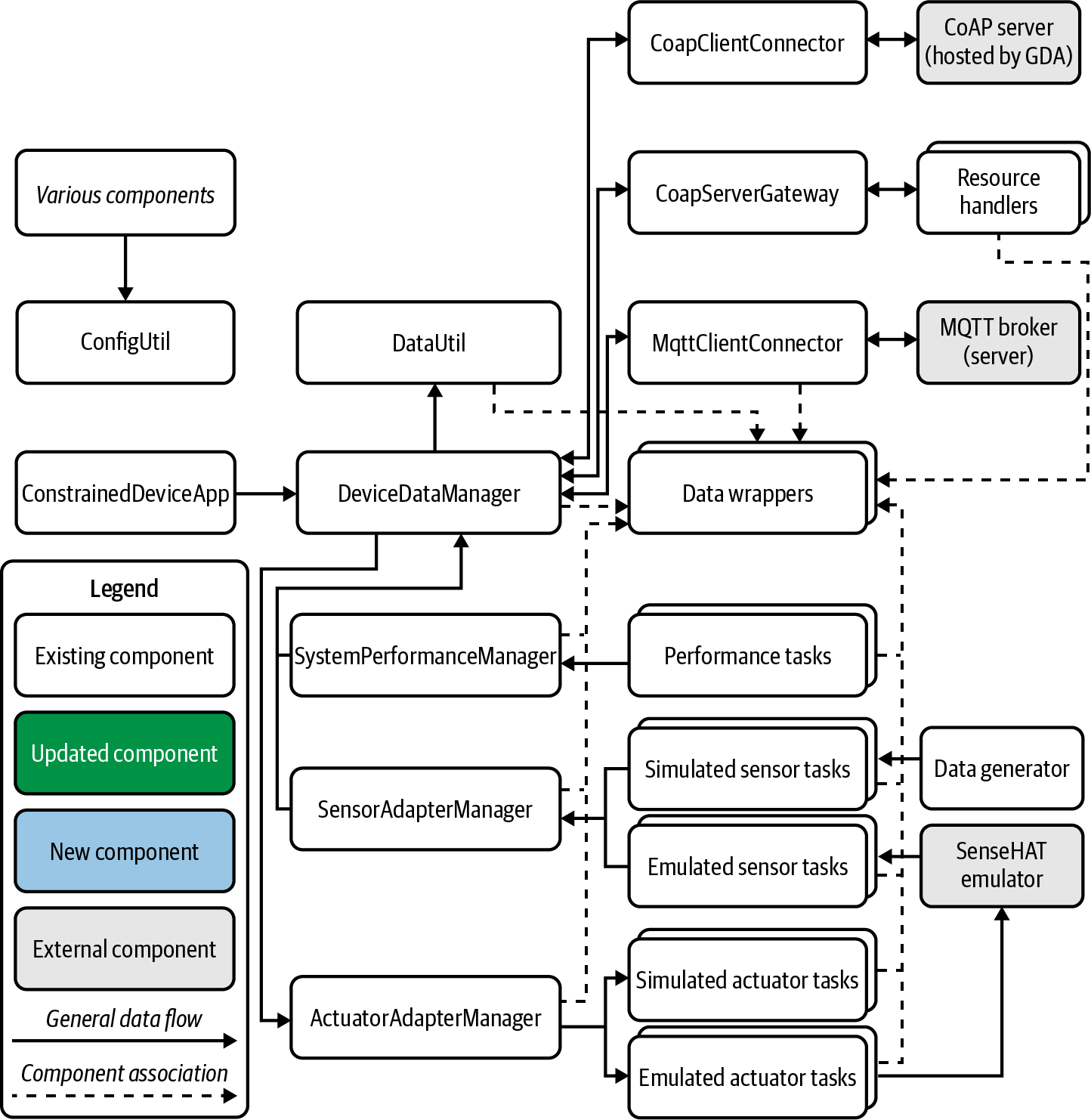
Figure 1-15. CDA end-state design
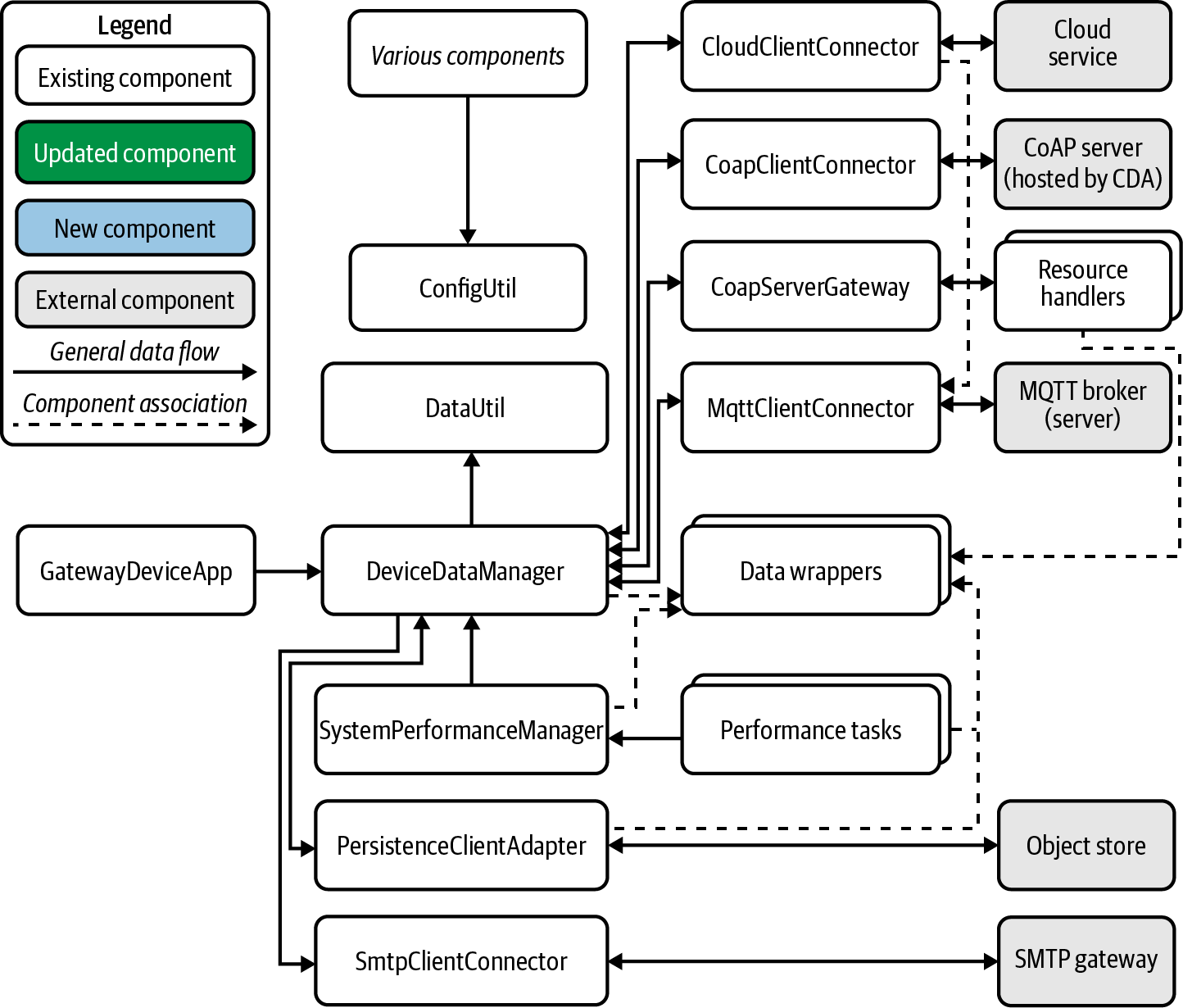
Figure 1-16. GDA end-state design
Looks like a ton of work! But don’t worry—we’ll take things step by step. Each chapter adds more functionality to each of these diagrams using the color coding in the legend (for existing, new, and changed components), along with drilling down into each area that the chapter addresses.
Let’s take a look at the specific designs of the CDA and GDA that are relevant for this chapter and walk through the exercises (there’s only one for each application). You can review the details for each online: PIOT-CDA-01-001 for the CDA and PIOT-GDA-01-001 for the GDA.
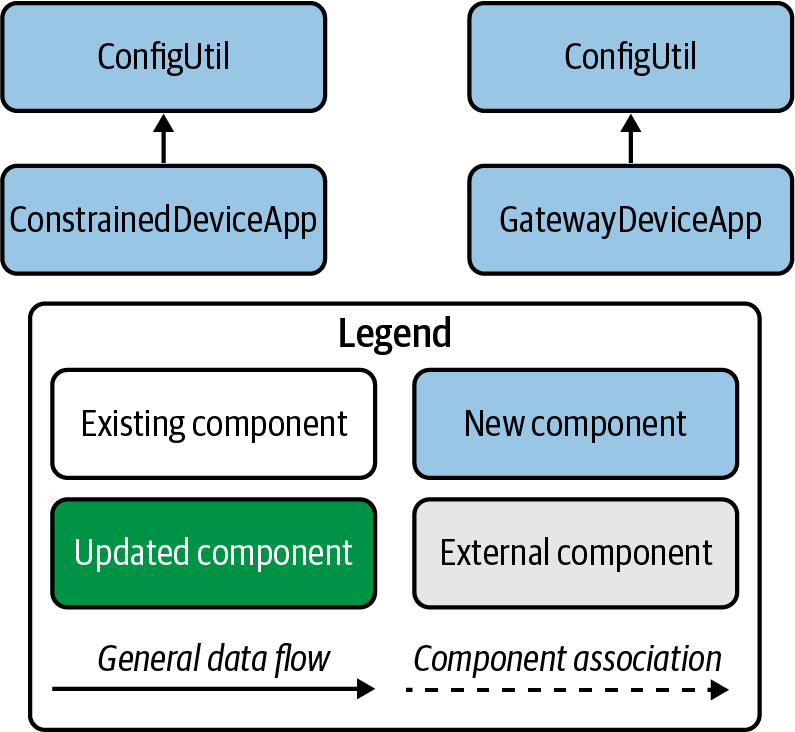
These look a bit more tractable! In fact, you’ve already completed the first—and perhaps most important—of them all and implemented all the requirements for Chapter 1! All that remains is to test them out. In the Test section of each requirement card, you’ll see that you need to execute each application as a manual integration test.
Testing the Constrained Device App
For the CDA, navigate to the ./src/main/python/programmingtheiot/part01/integration/app path. You’ll see the ConstrainedDeviceAppTest. After you’ve executed this test, your output should look similar to the following:
Finding files... done. . 2020-12-30 13:54:32,915 - MainThread - root - INFO - Testing ConstrainedDeviceApp class... 2020-12-30 13:54:32,915 - MainThread - root - INFO - Initializing CDA... 2020-12-30 13:54:32,915 - MainThread - root - INFO - Starting CDA... 2020-12-30 13:54:32,916 - MainThread - root - INFO - Loading config: ../../../../../../../config/PiotConfig.props 2020-12-30 13:54:32,917 - MainThread - root - DEBUG - Config: ['Mqtt.GatewayService', 'Coap.GatewayService', 'ConstrainedDevice'] 2020-12-30 13:54:32,917 - MainThread - root - INFO - Created instance of ConfigUtil: <programmingtheiot.common.ConfigUtil.ConfigUtil object at 0x0000026B463E0E48> 2020-12-30 13:54:32,917 - MainThread - root - INFO - CDA started. 2020-12-30 13:54:32,917 - MainThread - root - INFO - CDA stopping... 2020-12-30 13:54:32,917 - MainThread - root - INFO - CDA stopped with exit code 0. ---------------------------------------------------------------------- Ran 1 test in 0.002s OK
You may notice numerous module loading log output statements (which I’ve excluded)—that’s OK. If your output generally follows the pattern shown here, you can move on to testing the GDA.
Testing the Gateway Device App
To test the GDA, navigate to the ./src/main/java/programmingtheiot/part01/integration/app path. You’ll see the GatewayDeviceAppTest. Your output will look a bit like the following:
Dec 30, 2020 1:45:50 PM programmingtheiot.gda.app.GatewayDeviceApp <init> INFO: Initializing GDA... Dec 30, 2020 1:45:50 PM programmingtheiot.gda.app.GatewayDeviceApp parseArgs INFO: No command line args to parse. Dec 30, 2020 1:45:50 PM programmingtheiot.gda.app.GatewayDeviceApp startApp INFO: Starting GDA... Dec 30, 2020 1:45:50 PM programmingtheiot.gda.app.GatewayDeviceApp startApp INFO: GDA started successfully. Dec 30, 2020 1:45:51 PM programmingtheiot.gda.app.GatewayDeviceApp stopApp INFO: Stopping GDA... Dec 30, 2020 1:45:51 PM programmingtheiot.gda.app.GatewayDeviceApp stopApp INFO: GDA stopped successfully with exit code 0.
If your output looks similar, then you’re ready to actually start writing code.
Conclusion
Congratulations—you’ve just completed the first chapter of Programming the Internet of Things! You learned about some basic IoT principles, created a problem statement to drive your IoT solution, and established a baseline IoT systems architecture that includes the Cloud Tier and the Edge Tier.
Perhaps most importantly, you now have the shell of two applications in place—the GDA and the CDA—which will serve as the foundation for much of your IoT software development throughout this book. Finally, you set up your development environment and workflow; learned about requirements management; explored unit, integration, and performance testing; and considered some basic CI/CD concepts to help automate your builds and deployment.
You’re now ready to start building real IoT functionality into your CDA and GDA using Python and Java. If you’re ready to move on, I’d suggest you grab some water or a good cup of coffee or tea, and then we’ll dig in.
1 Carsten Bormann, Mehmet Ersue, and Ari Keränen, “Terminology for Constrained-Node Networks”, IETF Informational RFC 7228, May 2014, 8–10.
2 Learn more about WSL and how to install it on your platform at https://oreil.ly/YK9Rb.
3 CoAP, or Constrained Application Protocol, is a messaging protocol that I’ll discuss in Part III (specifically, in Chapters 8 and 9).
4 MQTT, or Message Queuing Telemetry Transport, is a messaging protocol that I’ll discuss in Part III (specifically, in Chapters 6 and 7).
5 More information can be found on the GitHub website.
6 Detailed information on Python 3’s unittest library can be found in the unittest documentation.
7 You can learn more about GitHub and its hosting features and create a free account on the GitHub website.
8 You can find out more by reading the Agile Manifesto.
9 GitHub actions is a feature available within GitHub that allows customized workflows to be created for those who have an account within GitHub.
10 Self-hosted runners, part of GitHub actions, allow you to run your action workflows locally. There are caveats, of course, and security considerations. You can read more about self-hosted runners in the GitHub actions documentation.
11 You can read more about containerization concepts and Docker containerization products on the Docker website.
Get Programming the Internet of Things now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

