Capítulo 4. Utilizar recursos personalizados
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En este capítulo te presentamos los recursos personalizados (RC), uno de los mecanismos centrales de extensión utilizados en todo el ecosistema de Kubernetes.
Recursos personalizados se utilizan para objetos de configuración pequeños e internos, sin la correspondiente lógica de controlador, definidos de forma puramente declarativa. Pero los recursos personalizados también desempeñan un papel central para muchos proyectos de desarrollo serios sobre Kubernetes que quieren ofrecer una experiencia de API nativa de Kubernetes. Algunos ejemplos son las mallas de servicios como Istio, Linkerd 2.0 y AWS App Mesh, todas ellas con recursos personalizados en su núcleo.
¿Recuerdas "Un ejemplo motivador" del capítulo 1? En el fondo, tiene una RC parecida a ésta:
apiVersion:cnat.programming-kubernetes.info/v1alpha1kind:Atmetadata:name:example-atspec:schedule:"2019-07-03T02:00:00Z"status:phase:"pending"
Los recursos personalizados de están disponibles en todos los clústeres de Kubernetes desde la versión 1.7. Se almacenan en la misma instancia etcd que los recursos principales de la API de Kubernetes y los sirve el mismo servidor de la API de Kubernetes. Como se muestra en la Figura 4-1, las solicitudes vuelven a apiextensions-apiserver, que sirve los recursos definidos mediante CRD, si no son ninguno de los siguientes:
-
Gestionado por servidores API agregados (ver Capítulo 8).
-
Recursos nativos de Kubernetes.
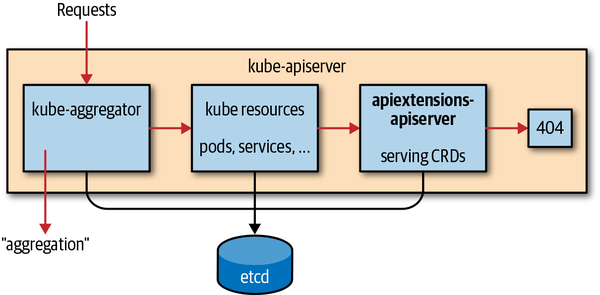
Figura 4-1. El servidor API Extensions dentro del servidor API de Kubernetes
Una CustomResourceDefinition (CRD) es un recurso Kubernetes en sí mismo. Describe los CR disponibles en el clúster. Para el ejemplo de CR anterior, la CRD correspondiente tiene este aspecto:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:ats.cnat.programming-kubernetes.infospec:group:cnat.programming-kubernetes.infonames:kind:AtlistKind:AtListplural:atssingular:atscope:Namespacedsubresources:status:{}version:v1alpha1versions:-name:v1alpha1served:truestorage:true
El nombre del CRD -en este caso, ats.cnat.programming-kubernetes.info- debe coincidir con el nombre plural seguido del nombre del grupo. Define el tipo At CR en el grupo API cnat.programming-kubernetes.info como un recurso con espacio de nombres llamado ats.
Si este CRD se crea en un clúster, kubectl detectará automáticamente el recurso, y el usuario podrá acceder a él a través de:
$ kubectl get ats
NAME CREATED AT
ats.cnat.programming-kubernetes.info 2019-04-01T14:03:33ZInformación sobre el descubrimiento
Detrás de las escenas, kubectl utiliza la información de descubrimiento del servidor API para conocer los nuevos recursos. Profundicemos un poco más en este mecanismo de descubrimiento.
Tras aumentar el nivel de verbosidad de kubectl, podemos ver realmente cómo aprende sobre el nuevo tipo de recurso:
$kubectl get ats -v=7 ... GET https://XXX.eks.amazonaws.com/apis/cnat.programming-kubernetes.info/ v1alpha1/namespaces/cnat/ats?limit=500 ... Request Headers: ... Accept: application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json User-Agent: kubectl/v1.14.0(darwin/amd64)kubernetes/641856d ... Response Status:200OK in607milliseconds NAME AGE example-at 43s
Los pasos del descubrimiento en detalle son
-
Inicialmente,
kubectlno conoceats. -
Por lo tanto,
kubectlpregunta al servidor API sobre todos los grupos API existentes a través del punto final de descubrimiento /apis. -
A continuación,
kubectlpregunta al servidor API por los recursos de todos los grupos API existentes a través de los puntos finales de descubrimiento de grupos /apis/group version. -
A continuación,
kubectltraduce el tipo dado,ats, a un triple de:-
Grupo (aquí
cnat.programming-kubernetes.info) -
Versión (aquí
v1alpha1) -
Recurso (aquí
ats).
-
Los puntos finales de descubrimiento proporcionan toda la información necesaria para realizar la traducción en el último paso:
$ http localhost:8080/apis/
{
"groups": [{
"name": "at.cnat.programming-kubernetes.info",
"preferredVersion": {
"groupVersion": "cnat.programming-kubernetes.info/v1",
"version": "v1alpha1“
},
"versions": [{
"groupVersion": "cnat.programming-kubernetes.info/v1alpha1",
"version": "v1alpha1"
}]
}, ...]
}
$ http localhost:8080/apis/cnat.programming-kubernetes.info/v1alpha1
{
"apiVersion": "v1",
"groupVersion": "cnat.programming-kubernetes.info/v1alpha1",
"kind": "APIResourceList",
"resources": [{
"kind": "At",
"name": "ats",
"namespaced": true,
"verbs": ["create", "delete", "deletecollection",
"get", "list", "patch", "update", "watch"
]
}, ...]
}
Todo esto se implementa mediante el descubrimiento RESTMapper. También vimos este tipo muy común de RESTMapper en "Mapeo REST".
Advertencia
La CLI kubectl también mantiene una caché de tipos de recursos en ~/.kubectl para no tener que volver a recuperar la información de descubrimiento en cada acceso. Esta caché se invalida cada 10 minutos. Por tanto, un cambio en el CRD puede aparecer en la CLI del usuario correspondiente hasta 10 minutos después.
Definiciones de tipo
Ahora veamos el CRD y las funciones que ofrece con más detalle: como en el ejemplo de cnat, los CRD son recursos de Kubernetes en el grupo de API apiextensions.k8s.io/v1beta1 proporcionados por el apiextensions-apiserver dentro del proceso del servidor de API de Kubernetes.
El esquema de los CRD es el siguiente:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:namespec:group:groupnameversion:versionnamenames:kind:uppercasenameplural:lowercasepluralnamesingular:lowercasesingularname# defaulted to be lowercase kindshortNames:listofstringsasshortnames# optionallistKind:uppercaselistkind# defaulted to bekindListcategories:listofcategorymembershiplike"all"# optionalvalidation:# optionalopenAPIV3Schema:OpenAPIschema# optionalsubresources:# optionalstatus:{}# to enable the status subresource (optional)scale:# optionalspecReplicasPath:JSONpathforthereplicanumberinthespecofthecustomresourcestatusReplicasPath:JSONpathforthereplicanumberinthestatusofthecustomresourcelabelSelectorPath:JSONpathoftheScale.Status.Selectorfieldinthescaleresourceversions:# defaulted to the Spec.Version field-name:versionnameserved:booleanwhethertheversionisservedbytheAPIserver# defaults to falsestorage:booleanwhetherthisversionistheversionusedtostoreobject-...
Muchos de los campos son opcionales o están predeterminados. Explicaremos los campos con más detalle en las secciones siguientes.
Después de que cree un objeto CRD, el apiextensions-apiserver dentro de kube-apiserver comprobará los nombres y determinará si entran en conflicto con otros recursos o si son coherentes en sí mismos. Tras unos instantes, informará del resultado en el estado del CRD, por ejemplo:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:ats.cnat.programming-kubernetes.infospec:group:cnat.programming-kubernetes.infonames:kind:AtlistKind:AtListplural:atssingular:atscope:Namespacedsubresources:status:{}validation:openAPIV3Schema:type:objectproperties:apiVersion:type:stringkind:type:stringmetadata:type:objectspec:properties:schedule:type:stringtype:objectstatus:type:objectversion:v1alpha1versions:-name:v1alpha1served:truestorage:truestatus:acceptedNames:kind:AtlistKind:AtListplural:atssingular:atconditions:-lastTransitionTime:"2019-03-17T09:44:21Z"message:no conflicts foundreason:NoConflictsstatus:"True"type:NamesAccepted-lastTransitionTime:nullmessage:the initial names have been acceptedreason:InitialNamesAcceptedstatus:"True"type:EstablishedstoredVersions:-v1alpha1
Puedes ver que los campos de nombre que faltan en la especificación se establecen por defecto y se reflejan en el estado como nombres aceptados. Además, se establecen las siguientes condiciones:
-
NamesAccepteddescribe si los nombres dados en la especificación son coherentes y están libres de conflictos. -
Establisheddescribe que el servidor API sirve el recurso dado con los nombres que figuran enstatus.acceptedNames.
Ten en cuenta que algunos campos pueden modificarse mucho después de haber creado el CRD. Por ejemplo, puedes añadir nombres cortos o columnas. En este caso, se puede establecer un CRD -es decir, servirlo con los nombres antiguos- aunque los nombres de las especificaciones tengan conflictos. Por tanto, la condición NamesAccepted sería falsa y los nombres de las especificaciones y los nombres aceptados diferirían.
Funciones avanzadas de los recursos personalizados
En esta sección hablamos de las características avanzadas de los recursos personalizados, como la validación o los subrecursos.
Validar recursos personalizados
Los CR pueden ser validados por el servidor API durante su creación y actualización. Esto se hace basándose en el esquema OpenAPI v3 especificado en los campos validation de la especificación CRD.
Cuando una solicitud crea o muta un CR, el objeto JSON de la especificación se valida con respecto a esta especificación y, en caso de error, el campo conflictivo se devuelve al usuario en una respuesta de código HTTP 400. La Figura 4-2 muestra dónde tiene lugar la validación en el gestor de solicitudes dentro de apiextensions-apiserver.
Las validaciones más complejas pueden implementarse en webhooks de admisión de validaciones, es decir, en un lenguaje de programación Turing-completo. La Figura 4-2 muestra que estos webhooks se llaman directamente después de las validaciones basadas en OpenAPI descritas en esta sección. En "Webhooks de admisión", veremos cómo se implementan y despliegan los webhooks de admisión. Allí veremos las validaciones que tienen en cuenta otros recursos y, por tanto, van mucho más allá de la validación OpenAPI v3. Por suerte, para muchos casos de uso los esquemas OpenAPI v3 son suficientes.
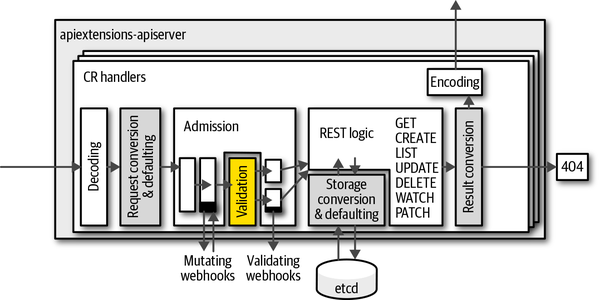
Figura 4-2. Paso de validación en la pila de manejadores del apiextensions-apiserver
El lenguaje de esquemas OpenAPI se basa en el estándar JSON Schema, que utiliza el propio JSON/YAML para expresar un esquema. Aquí tienes un ejemplo:
type:objectproperties:apiVersion:type:stringkind:type:stringmetadata:type:objectspec:type:objectproperties:schedule:type:stringpattern:"^\d{4}-([0]\d|1[0-2])-([0-2]\d|3[01])..."command:type:stringrequired:-schedule-commandstatus:type:objectproperties:phase:type:stringrequired:-metadata-apiVersion-kind-spec
Este esquema especifica que el valor es en realidad un objeto JSON;1 es decir, es un mapa de cadenas y no una porción o un valor como un número. Además, tiene (aparte de metadata, kind, y apiVersion, que se definen implícitamente para los recursos personalizados) dos propiedades adicionales: spec y status.
Cada uno de ellos es también un objeto JSON. spec tiene los campos obligatorios schedule y command, ambos son cadenas. schedule tiene que coincidir con un patrón para una fecha ISO (esbozado aquí con algunas expresiones regulares). La propiedad opcional status tiene un campo de cadena llamado phase.
Crear esquemas OpenAPI manualmente puede ser tedioso. Por suerte, se está trabajando para hacer esto mucho más fácil mediante la generación de código: el proyecto Kubebuilder -ver "Kubebuilder"- hadesarrollado crd-gen en sig.k8s.io/controller-tools, y se está ampliando paso a paso para que sea utilizable en otros contextos. El generador crd-schema-gen es una bifurcación de crd-gen en esta dirección.
Nombres cortos y categorías
Al igual que los recursos nativos de , los recursos personalizados pueden tener nombres de recursos largos. Son geniales a nivel de API, pero tediosos de escribir en la CLI. Los CR también pueden tener nombres cortos, como el recurso nativo daemonsets, que puede consultarse con kubectl get ds. Estos nombres cortos también se conocen como alias, y cada recurso puede tener cualquier número de ellos.
Para ver en todos los nombres cortos disponibles, utiliza el comando kubectl api-resources del siguiente modo:
$kubectl api-resources NAME SHORTNAMES APIGROUP NAMESPACED KIND bindingstrueBinding componentstatuses csfalseComponentStatus configmaps cmtrueConfigMap endpoints eptrueEndpoints events evtrueEvent limitranges limitstrueLimitRange namespaces nsfalseNamespace nodes nofalseNode persistentvolumeclaims pvctruePersistentVolumeClaim persistentvolumes pvfalsePersistentVolume pods potruePod statefulsets sts appstrueStatefulSet ...
De nuevo, kubectl se entera de los nombres cortos a través de la información de descubrimiento(consulta "Información de descubrimiento"). He aquí un ejemplo:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:ats.cnat.programming-kubernetes.infospec:...shortNames:-at
Después, un kubectl get at listará todas las CR de cnat en el espacio de nombres.
Además, los RC -como cualquier otro recurso- pueden formar parte de categorías. El uso más común es la categoría all, como en kubectl get all. Enumera todos los recursos orientados al usuario en un clúster, como pods y servicios.
Los CR definidos en el clúster pueden unirse a una categoría o crear su propia categoría a través del campo categories:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:ats.cnat.programming-kubernetes.infospec:...categories:-all
Con esto, kubectl get all también listará el cnat CR en el espacio de nombres.
Columnas de impresión
La herramienta kubectl CLI utiliza la impresión del lado del servidor para mostrar la salida de kubectl get. Esto significa que consulta al servidor de la API las columnas a mostrar y los valores de cada fila.
Los recursos personalizados también admiten columnas de impresión del lado del servidor, a través de additionalPrinterColumns. Se llaman "adicionales" porque la primera columna es siempre el nombre del objeto. Estas columnas se definen así:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionmetadata:name:ats.cnat.programming-kubernetes.infospec:additionalPrinterColumns:(optional)-name:kubectlcolumnnametype:OpenAPItypeforthecolumnformat:OpenAPIformatforthecolumn(optional)description:human-readabledescriptionofthecolumn(optional)priority:integer,alwayszerosupportedbykubectlJSONPath:JSONpathinsidetheCRforthedisplayedvalue
El campo name es el nombre de la columna, el type es un tipo OpenAPI tal y como se define en la sección de tipos de datos de la especificación, y el format (tal y como se define en el mismo documento) es opcional y podría ser interpretado por kubectl u otros clientes.
Además, description es una cadena opcional legible por humanos, que se utiliza con fines de documentación. priority controla en qué modo de verbosidad de kubectl se muestra la columna. En el momento de escribir esto (con Kubernetes 1.14), sólo se admite el cero, y todas las columnas con mayor prioridad están ocultas.
Por último, JSONPath define qué valores se van a mostrar. Se trata de una ruta JSON simple dentro de la CR. Aquí, "simple" significa que admite la sintaxis de campos objeto como .spec.foo.bar, pero no rutas JSON más complejas que hagan bucles sobre matrices o similares.
Con esto, el ejemplo de CRD de la introducción podría ampliarse con additionalPrinterColumns así:
additionalPrinterColumns:#(optional)-name:scheduletype:stringJSONPath:.spec.schedule-name:commandtype:stringJSONPath:.spec.command-name:phasetype:stringJSONPath:.status.phase
Entonces kubectl representaría un recurso cnat de la siguiente manera:
$kubectl get ats NAME SCHEDULER COMMAND PHASE foo 2019-07-03T02:00:00Zecho"hello world"Pending
A continuación, echaremos un vistazo a los subrecursos.
Subrecursos
En mencionamos brevemente los subrecursos en "Subrecursos de estado: ActualizarEstado". Los subrecursos son puntos finales HTTP especiales, que utilizan un sufijo añadido a la ruta HTTP del recurso normal. Por ejemplo, la ruta HTTP estándar del pod es /api/v1/namespace/namespace/pods/ name. Los pods tienen una serie de subrecursos, como /logs, /portforward, /exec y /status. Las rutas HTTP de los subrecursos correspondientes son:
-
/api/v1/namespace/
namespace/pods/name/logs -
/api/v1/namespace/
namespace/pods/name/portforward -
/api/v1/namespace/
namespace/pods/name/exec -
/api/v1/namespace/
namespace/pods/name/status
Los puntos finales de los subrecursos utilizan un protocolo diferente al del punto final del recurso principal.
En el momento de escribir esto, los recursos personalizados admiten dos subrecursos: /escala y /estado. Ambos son opcionales, es decir, deben activarse explícitamente en el CRD.
Subrecurso de estado
El subrecurso /status se utiliza para separar la especificación proporcionada por el usuario de una instancia de CR del estado proporcionado por el controlador. La principal motivación para ello es la separación de privilegios:
-
Normalmente, el usuario no debe escribir los campos de estado.
-
El controlador no debe escribir campos de especificación.
El mecanismo RBAC de para el control de acceso no permite reglas a ese nivel de detalle. Esas reglas son siempre por recurso. El subrecurso /status resuelve esto proporcionando dos puntos finales que son recursos por sí mismos. Cada uno puede controlarse con reglas RBAC de forma independiente. A esto se le suele llamar división especificación-estado. Aquí tienes un ejemplo de una regla de este tipo para el recurso ats, que sólo se aplica al subrecurso /status (mientras que "ats" coincidiría con el recurso principal):
apiVersion:rbac.authorization.k8s.io/v1kind:Rolemetadata:...rules:-apiGroups:[""]resources:["ats/status"]verbs:["update","patch"]
Los recursos (incluidos los recursos personalizados) que tienen un subrecurso /status han cambiado de semántica, también para el punto final del recurso principal:
-
Ignoran los cambios de estado en el punto final HTTP principal durante la creación (el estado sólo se elimina durante una creación) y las actualizaciones.
-
Del mismo modo, el punto final del subrecurso /estado ignora los cambios ajenos al estado de la carga útil. No es posible realizar una operación de creación en el punto final /estado.
-
Siempre que cambie algo fuera de
metadatay fuera destatus(esto significa especialmente cambios en la especificación), el punto final del recurso principal aumentará el valor demetadata.generation. Esto puede utilizarse como desencadenante para que un controlador indique que el deseo del usuario ha cambiado.
Ten en cuenta que normalmente se envían tanto spec como status en las peticiones de actualización, pero técnicamente podrías omitir la otra parte respectiva en la carga útil de una petición.
Ten en cuenta también que el punto final /estado ignorará todo lo que quede fuera del estado, incluidos los cambios de metadatos como etiquetas o anotaciones.
La división especificación-estado de un recurso personalizado se activa de la siguiente manera:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionspec:subresources:status:{}...
Observa aquí que al campo status de ese fragmento YAML se le asigna el objeto vacío. Esta es la forma de establecer un campo que no tiene otras propiedades. Basta con escribir
subresources:status:
dará lugar a un error de validación porque en YAML el resultado es un valor null para status.
Advertencia
Activar la división especificación-estado es un cambio de ruptura para una API. Los controladores antiguos escribirán en el punto final principal. No se darán cuenta de que el estado siempre se ignora a partir del momento en que se activa la división. Del mismo modo, un nuevo controlador no podrá escribir en el nuevo punto final /estado hasta que se active la división.
En Kubernetes 1.13 y posteriores, los subrecursos pueden configurarse por versión. Esto nos permite introducir el subrecurso /status sin un cambio de ruptura:
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionspec:...versions:-name:v1alpha1served:truestorage:true-name:v1beta1served:truesubresources:status:{}
Esto habilita el subrecurso /status para v1beta1, pero no para v1alpha1.
Nota
La semántica de concurrencia optimista(ver "Concurrencia optimista") es la misma que para los puntos finales del recurso principal; es decir, status y spec comparten el mismo contador de versión del recurso y las actualizaciones de /status pueden entrar en conflicto debido a escrituras en el recurso principal, y viceversa. En otras palabras, no hay división de spec y status en la capa de almacenamiento.
Subrecurso Escala
El segundo subrecurso disponible para los recursos personalizados es /escala. El subrecurso /scale es una vista (proyectiva)2 sobre el recurso, permitiéndonos ver y modificar únicamente los valores de las réplicas. Este subrecurso es bien conocido para recursos como Implementaciones y Conjuntos de réplicas en Kubernetes, que obviamente pueden escalarse hacia arriba y hacia abajo.
El comando kubectl scale utiliza el subrecurso /escala; por ejemplo, lo siguiente modificará el valor de réplica especificado en la instancia dada:
$kubectlscale--replicas=3your-custom-resource-v=7I042921:17:53.13835366743round_trippers.go:383]PUThttps://host/apis/group/v1/your-custom-resource/scale
apiVersion:apiextensions.k8s.io/v1beta1kind:CustomResourceDefinitionspec:subresources:scale:specReplicasPath:.spec.replicasstatusReplicasPath:.status.replicaslabelSelectorPath:.status.labelSelector...
Con esto, se escribe una actualización del valor de la réplica en spec.replicas y se devuelve desde allí durante una GET.
El selector de etiquetas no puede modificarse a través del subrecurso /estado, sólo leerse. Su finalidad es dar a un controlador la información para contar los objetos correspondientes. Por ejemplo, el controlador ReplicaSet cuenta las vainas correspondientes que satisfacen este selector.
El selector de etiquetas es opcional. Si la semántica de tus recursos personalizados no se ajusta a los selectores de etiqueta, simplemente no especifiques la ruta JSON para uno.
En el ejemplo anterior de kubectl scale --replicas=3 ... el valor 3 se escribe en spec.replicas. Por supuesto, se puede utilizar cualquier otra ruta JSON simple; por ejemplo, spec.instances o spec.size sería un nombre de campo sensato, dependiendo del contexto.
El tipo de objeto leído o escrito en el punto final es Scale desde el grupo de la API autoscaling/v1. Esto es lo que parece:
typeScalestruct{metav1.TypeMeta`json:",inline"`// Standard object metadata; More info: https://git.k8s.io/// community/contributors/devel/api-conventions.md#metadata.// +optionalmetav1.ObjectMeta`json:"metadata,omitempty"`// defines the behavior of the scale. More info: https://git.k8s.io/community/// contributors/devel/api-conventions.md#spec-and-status.// +optionalSpecScaleSpec`json:"spec,omitempty"`// current status of the scale. More info: https://git.k8s.io/community/// contributors/devel/api-conventions.md#spec-and-status. Read-only.// +optionalStatusScaleStatus`json:"status,omitempty"`}// ScaleSpec describes the attributes of a scale subresource.typeScaleSpecstruct{// desired number of instances for the scaled object.// +optionalReplicasint32`json:"replicas,omitempty"`}// ScaleStatus represents the current status of a scale subresource.typeScaleStatusstruct{// actual number of observed instances of the scaled object.Replicasint32`json:"replicas"`// label query over pods that should match the replicas count. This is the// same as the label selector but in the string format to avoid// introspection by clients. The string will be in the same// format as the query-param syntax. More info about label selectors:// http://kubernetes.io/docs/user-guide/labels#label-selectors.// +optionalSelectorstring`json:"selector,omitempty"`}
Una instancia tendrá este aspecto:
metadata:name:cr-namenamespace:cr-namespaceuid:cr-uidresourceVersion:cr-resource-versioncreationTimestamp:cr-creation-timestampspec:replicas:3status:replicas:2selector:"environment=production"
Ten en cuenta que la semántica de concurrencia optimista es la misma para el recurso principal y para el subrecurso /escala. Es decir, las escrituras del recurso principal pueden entrar en conflicto con las escrituras de /escala, y viceversa.
El punto de vista de un desarrollador sobre los recursos personalizados
A los recursos personalizados se puede acceder desde Golang utilizando varios clientes. Nos centraremos en:
-
Utilizando el cliente dinámico
client-go(ver "Cliente dinámico") -
Utilizar un cliente mecanografiado:
-
Según lo proporcionado por kubernetes-sigs/controller-runtime y utilizado por el SDK de Kubernetes y Kubebuilder(ver "Controller-runtime Cliente del SDK de Kubernetes y Kubebuilder")
-
Como el generado por
client-gen, como el de k8s.io/client-go/kubernetes (ver "Cliente tipificado creado mediante client-gen")
-
La elección de qué cliente utilizar depende principalmente del contexto del código que se vaya a escribir, especialmente de la complejidad de la lógica implementada y de los requisitos (por ejemplo, ser dinámico y admitir GVK desconocidos en tiempo de compilación).
La lista anterior de clientes:
-
Disminuye la flexibilidad para manejar GVK desconocidos.
-
Aumenta la seguridad de los tipos.
-
Aumento de la exhaustividad de las funciones de la API de Kubernetes que proporcionan.
Cliente dinámico
El cliente dinámico en k8s.io/client-go/dynamic es totalmente agnóstico a los GVK conocidos. Ni siquiera utiliza ningún tipo Go aparte de unstructured.Unstructured, que sólo envuelve json.Unmarshal y su salida.
El cliente dinámico no utiliza ni un esquema ni un RESTMapper. Esto significa que el programador tiene que proporcionar manualmente todo el conocimiento sobre los tipos proporcionando un recurso (ver "Recursos") en forma de GVR:
schema.GroupVersionResource{Group:"apps",Version:"v1",Resource:"deployments",}
Si dispone de una configuración de cliente REST (consulta "Crear y utilizar un cliente"), el cliente dinámico puede crearse en una sola línea:
client,err:=NewForConfig(cfg)
El acceso REST a un GVR determinado es igual de sencillo:
client.Resource(gvr).Namespace(namespace).Get("foo",metav1.GetOptions{})
Esto te da la implementación foo en el espacio de nombres dado.
Nota
Debes conocer el ámbito del recurso (es decir, si es de ámbito de nombre o de ámbito de grupo). Los recursos de ámbito clúster simplemente omiten la llamada a Namespace(namespace).
La entrada y salida del cliente dinámico es un *unstructured.Unstructured, es decir, un objeto que contiene la misma estructura de datos que json.Unmarshal emitiría al desmarcarse:
-
Los objetos se representan mediante
map[string]interface{}. -
Las matrices se representan mediante
[]interface{}. -
Los tipos primitivos son
string,bool,float64, oint64.
El método UnstructuredContent() proporciona acceso a esta estructura de datos dentro de un objeto no estructurado (también podemos acceder simplemente a Unstructured.Object). Existen ayudantes en el mismo paquete para facilitar la recuperación de los campos y la manipulación del objeto, por ejemplo:
name,found,err:=unstructured.NestedString(u.Object,"metadata","name")
que devuelve el nombre de la implementación:"foo" en este caso. found es verdadero si el campo se encontró realmente (no sólo vacío, sino realmente existente). err informa si el tipo de un campo existente es inesperado (es decir, no es una cadena en este caso). Otras ayudas son las genéricas, una con copia profunda del resultado y otra sin ella:
funcNestedFieldCopy(objmap[string]interface{},fields...string)(interface{},bool,error)funcNestedFieldNoCopy(objmap[string]interface{},fields...string)(interface{},bool,error)
Hay otras variantes tipadas que hacen una conversión de tipo y devuelven un error si falla:
funcNestedBool(objmap[string]interface{},fields...string)(bool,bool,error)funcNestedFloat64(objmap[string]interface{},fields...string)(float64,bool,error)funcNestedInt64(objmap[string]interface{},fields...string)(int64,bool,error)funcNestedStringSlice(objmap[string]interface{},fields...string)([]string,bool,error)funcNestedSlice(objmap[string]interface{},fields...string)([]interface{},bool,error)funcNestedStringMap(objmap[string]interface{},fields...string)(map[string]string,bool,error)
Y, por último, un colocador genérico:
funcSetNestedField(obj,value,path...)
El cliente dinámico se utiliza en el propio Kubernetes para los controladores que son genéricos, como el controlador de recogida de basura, que borra los objetos cuyos padres han desaparecido. El controlador de recogida de basura funciona con cualquier recurso del sistema y, por tanto, hace un uso extensivo del cliente dinámico.
Clientes mecanografiados
Los clientes tipados no utilizan estructuras de datos genéricas similares a map[string]interface{}, sino que utilizan tipos Golang reales, que son diferentes y específicos para cada GVK. Son mucho más fáciles de usar, tienen una seguridad de tipos considerablemente mayor y hacen que el código sea mucho más conciso y legible. En el lado negativo, son menos flexibles porque los tipos procesados tienen que conocerse en tiempo de compilación, y esos clientes se generan, y esto añade complejidad.
Antes de entrar en dos implementaciones de clientes tipados, veamos la representación de los tipos en el sistema de tipos de Golang (consulta "Maquinaria API en profundidad" para conocer la teoría que hay detrás del sistema de tipos de Kubernetes).
Anatomía de un tipo
Kinds se representan como Golang structs. Normalmente, la estructura se denomina como el tipo (aunque técnicamente no tiene por qué ser así) y se coloca en un paquete correspondiente al grupo y versión del GVK de que se trate. Una convención habitual es colocar el GVK group/version.Kind en un paquete Go:
pkg/apis/group/version
y define una estructura Golang Kind en el archivo types.go.
Cada tipo Golang correspondiente a un GVK incorpora la estructura TypeMeta del paquete k8s.io/apimachinery/pkg/apis/meta/v1. TypeMeta sólo consta de los campos Kind y ApiVersion:
typeTypeMetastruct{// +optionalAPIVersionstring`json:"apiVersion,omitempty" yaml:"apiVersion,omitempty"`// +optionalKindstring`json:"kind,omitempty" yaml:"kind,omitempty"`}
Además, cada tipo de nivel superior -es decir, el que tiene su propio punto final y, por tanto, uno (o varios) GVR correspondientes (véase "Mapeo REST")- tiene que almacenar un nombre, un espacio de nombres para los recursos con espacio de nombres y un número bastante largo de otros campos de metanivel. Todos ellos se almacenan en una estructura denominada ObjectMeta en el paquete k8s.io/apimachinery/pkg/apis/meta/v1:
typeObjectMetastruct{Namestring`json:"name,omitempty"`Namespacestring`json:"namespace,omitempty"`UIDtypes.UID`json:"uid,omitempty"`ResourceVersionstring`json:"resourceVersion,omitempty"`CreationTimestampTime`json:"creationTimestamp,omitempty"`DeletionTimestamp*Time`json:"deletionTimestamp,omitempty"`Labelsmap[string]string`json:"labels,omitempty"`Annotationsmap[string]string`json:"annotations,omitempty"`...}
Hay varios campos adicionales. Te recomendamos encarecidamente que leas la extensa documentación en línea, porque te da una buena idea de la funcionalidad básica de los objetos Kubernetes.
Los tipos de nivel superior de Kubernetes (es decir, los que tienen un TypeMeta incrustado y un ObjectMeta incrustado y -en este caso- se persisten en etcd) se parecen mucho entre sí en el sentido de que suelen tener un spec y un status. Consulta este ejemplo de implementación de k8s.io/kubernetes/apps/v1/types.go:
typeDeploymentstruct{metav1.TypeMeta`json:",inline"`metav1.ObjectMeta`json:"metadata,omitempty"`SpecDeploymentSpec`json:"spec,omitempty"`StatusDeploymentStatus`json:"status,omitempty"`}
Aunque el contenido real de los tipos para spec y status difiere significativamente entre los distintos tipos, esta división en spec y status es un tema común o incluso una convención en Kubernetes, aunque no sea técnicamente necesaria. Por tanto, es una buena práctica seguir también esta estructura de los CRD. Algunas características de los CRD requieren incluso esta estructura; por ejemplo, el subrecurso /status para los recursos personalizados (ver "Subrecurso de estado")-cuando está activado- se aplica siempre sólo a la subestructura status de la instancia del recurso personalizado. No se le puede cambiar el nombre.
Estructura de los paquetes Golang
Como hemos visto en, los tipos Golang se colocan tradicionalmente en un archivo llamado types. go en el paquete pkg/apis/group/ version. Además de ese archivo, hay un par de archivos más que queremos revisar ahora. Algunos de ellos los escribe manualmente el desarrollador, mientras que otros se generan con generadores de código. Para más detalles, consulta el Capítulo 5.
El archivo doc. go describe la finalidad de la API e incluye una serie de etiquetas de generación de código global del paquete:
// Package v1alpha1 contains the cnat v1alpha1 API group//// +k8s:deepcopy-gen=package// +groupName=cnat.programming-kubernetes.infopackagev1alpha1
A continuación, register.go incluye ayudantes para registrar los tipos Golang de recursos personalizados en un esquema (consulta "Esquema"):
packageversionimport(metav1"k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/apimachinery/pkg/runtime""k8s.io/apimachinery/pkg/runtime/schema"group"repo/pkg/apis/group")// SchemeGroupVersion is group version used to register these objectsvarSchemeGroupVersion=schema.GroupVersion{Group:group.GroupName,Version:"version",}// Kind takes an unqualified kind and returns back a Group qualified GroupKindfuncKind(kindstring)schema.GroupKind{returnSchemeGroupVersion.WithKind(kind).GroupKind()}// Resource takes an unqualified resource and returns a Group// qualified GroupResourcefuncResource(resourcestring)schema.GroupResource{returnSchemeGroupVersion.WithResource(resource).GroupResource()}var(SchemeBuilder=runtime.NewSchemeBuilder(addKnownTypes)AddToScheme=SchemeBuilder.AddToScheme)// Adds the list of known types to Scheme.funcaddKnownTypes(scheme*runtime.Scheme)error{scheme.AddKnownTypes(SchemeGroupVersion,&SomeKind{},&SomeKindList{},)metav1.AddToGroupVersion(scheme,SchemeGroupVersion)returnnil}
A continuación, zz_generated.deepcopy.go define los métodos de copia profunda en los tipos de nivel superior Golang de recursos personalizados (es decir, SomeKind y SomeKindList en el código de ejemplo anterior). Además, todas las subestructuras (como las de los tipos spec y status) pasan a ser también copiables en profundidad.
Como el ejemplo utiliza la etiqueta +k8s:deepcopy-gen=package en doc.go, la generación de deep-copy se realiza sobre una base de exclusión; es decir, se generan métodos DeepCopy para todos los tipos del paquete que no se excluyan con +k8s:deepcopy-gen=false. Consulta el Capítulo 5 y especialmente "Etiquetas deepcopy-gen" para más detalles.
Cliente tipificado creado mediante client-gen
Con el paquete API pkg/apis/group / version en su sitio, el generador de clientes client-gen crea un cliente tipado (para más detalles, véase el Capítulo 5, especialmente "Etiquetas del generador de clientes"), en pkg/generated/clientset/versioned por defecto (pkg/client/clientset/versioned en versiones antiguas del generador). Más concretamente, el objeto de nivel superior generado es un conjunto de clientes. Subsume una serie de grupos de API, versiones y recursos.
El archivo de nivel superior tiene el siguiente aspecto:
// Code generated by client-gen. DO NOT EDIT.packageversionedimport(discovery"k8s.io/client-go/discovery"rest"k8s.io/client-go/rest"flowcontrol"k8s.io/client-go/util/flowcontrol"cnatv1alpha1".../cnat/cnat-client-go/pkg/generated/clientset/versioned/)typeInterfaceinterface{Discovery()discovery.DiscoveryInterfaceCnatV1alpha1()cnatv1alpha1.CnatV1alpha1Interface}// Clientset contains the clients for groups. Each group has exactly one// version included in a Clientset.typeClientsetstruct{*discovery.DiscoveryClientcnatV1alpha1*cnatv1alpha1.CnatV1alpha1Client}// CnatV1alpha1 retrieves the CnatV1alpha1Clientfunc(c*Clientset)CnatV1alpha1()cnatv1alpha1.CnatV1alpha1Interface{returnc.cnatV1alpha1}// Discovery retrieves the DiscoveryClientfunc(c*Clientset)Discovery()discovery.DiscoveryInterface{...}// NewForConfig creates a new Clientset for the given config.funcNewForConfig(c*rest.Config)(*Clientset,error){...}
El conjunto de clientes está representado por la interfaz Interface y da acceso a la interfaz de cliente del grupo API de cada versión; por ejemplo, CnatV1alpha1Interface en este código de ejemplo:
typeCnatV1alpha1Interfaceinterface{RESTClient()rest.InterfaceAtsGetter}// AtsGetter has a method to return a AtInterface.// A group's client should implement this interface.typeAtsGetterinterface{Ats(namespacestring)AtInterface}// AtInterface has methods to work with At resources.typeAtInterfaceinterface{Create(*v1alpha1.At)(*v1alpha1.At,error)Update(*v1alpha1.At)(*v1alpha1.At,error)UpdateStatus(*v1alpha1.At)(*v1alpha1.At,error)Delete(namestring,options*v1.DeleteOptions)errorDeleteCollection(options*v1.DeleteOptions,listOptionsv1.ListOptions)errorGet(namestring,optionsv1.GetOptions)(*v1alpha1.At,error)List(optsv1.ListOptions)(*v1alpha1.AtList,error)Watch(optsv1.ListOptions)(watch.Interface,error)Patch(namestring,pttypes.PatchType,data[]byte,subresources...string)(result*v1alpha1.At,errerror)AtExpansion}
Se puede crear una instancia de un conjunto de clientes con la función de ayuda NewForConfig. Esto es análogo a los clientes para los recursos centrales de Kubernetes que se tratan en "Crear y utilizar un cliente":
import(metav1"k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/client-go/tools/clientcmd"client"github.com/.../cnat/cnat-client-go/pkg/generated/clientset/versioned")kubeconfig=flag.String("kubeconfig","~/.kube/config","kubeconfig file")flag.Parse()config,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)clientset,err:=client.NewForConfig(config)ats:=clientset.CnatV1alpha1Interface().Ats("default")book,err:=ats.Get("kubernetes-programming",metav1.GetOptions{})
Como puedes ver, la maquinaria de generación de código nos permite programar lógica para recursos personalizados del mismo modo que para los recursos principales de Kubernetes. También existen herramientas de nivel superior, como los informadores; consulta informer-gen en el Capítulo 5.
controller-runtime Cliente de Operator SDK y Kubebuilder
En aras de la exhaustividad, queremos echar un vistazo rápido al tercer cliente, que aparece como segunda opción en "La visión de un desarrollador sobre los recursos personalizados". El proyecto controller-runtime proporciona la base para las soluciones de operador Operator SDK y Kubebuilder presentadas en el Capítulo 6. Incluye un cliente que utiliza los tipos Go presentados en "Anatomía de un tipo".
A diferencia del cliente generado por client-gendel anterior "Cliente tipificado creado mediante cliente-gen" , y de forma similar al "Cliente dinámico", este cliente es una instancia, capaz de manejar cualquier tipo que se registre en un esquema determinado.
En se utiliza la información de descubrimiento del servidor API para asignar los tipos a rutas HTTP. Ten en cuenta que en el Capítulo 6 se explicará con más detalle cómo se utiliza este cliente como parte de esas dos soluciones de operador.
Aquí tienes un ejemplo rápido de cómo utilizar controller-runtime:
import("flag"corev1"k8s.io/api/core/v1"metav1"k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/client-go/kubernetes/scheme""k8s.io/client-go/tools/clientcmd"runtimeclient"sigs.k8s.io/controller-runtime/pkg/client")kubeconfig=flag.String("kubeconfig","~/.kube/config","kubeconfig file path")flag.Parse()config,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)cl,_:=runtimeclient.New(config,client.Options{Scheme:scheme.Scheme,})podList:=&corev1.PodList{}err:=cl.List(context.TODO(),client.InNamespace("default"),podList)
El método List() del objeto cliente acepta cualquier runtime.Object registrado en el esquema dado, que en este caso es el tomado de client-go con todos los tipos estándar de Kubernetes registrados. Internamente, el cliente utiliza el esquema dado para asignar el tipo Golang *corev1.PodList a un GVK. En un segundo paso, el método List() utiliza la información de descubrimiento para obtener el GVR para pods, que es schema.GroupVersionResource{"", "v1", "pods"}, y por tanto accede a /api/v1/namespace/default/pods para obtener la lista de pods en el espacio de nombres pasado.
La misma lógica puede utilizarse con recursos personalizados. La principal diferencia es utilizar un esquema personalizado que contenga el tipo Go pasado:
import("flag"corev1"k8s.io/api/core/v1"metav1"k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/client-go/kubernetes/scheme""k8s.io/client-go/tools/clientcmd"runtimeclient"sigs.k8s.io/controller-runtime/pkg/client"cnatv1alpha1"github.com/.../cnat/cnat-kubebuilder/pkg/apis/cnat/v1alpha1")kubeconfig=flag.String("kubeconfig","~/.kube/config","kubeconfig file")flag.Parse()config,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)crScheme:=runtime.NewScheme()cnatv1alpha1.AddToScheme(crScheme)cl,_:=runtimeclient.New(config,client.Options{Scheme:crScheme,})list:=&cnatv1alpha1.AtList{}err:=cl.List(context.TODO(),client.InNamespace("default"),list)
Observa cómo la invocación del comando List() no cambia en absoluto.
Imagina que escribes un operador que accede a muchos tipos diferentes utilizando este cliente. Con el cliente tipado de "Cliente tipado creado mediante client-gen", tendrías que pasar muchos clientes distintos al operador, lo que haría que el código de fontanería fuera bastante complejo. En cambio, el cliente controller-runtime presentado aquí es un solo objeto para todos los tipos, suponiendo que todos ellos estén en un mismo esquema.
Los tres tipos de clientes tienen su utilidad, con ventajas e inconvenientes según el contexto en que se utilicen. En los controladores genéricos que manejan objetos desconocidos, sólo se puede utilizar el cliente dinámico. En los controladores en los que la seguridad de tipos ayuda mucho a reforzar la corrección del código, los clientes generados son una buena opción. El propio proyecto Kubernetes tiene tantos colaboradores que la estabilidad del código es muy importante, incluso cuando es ampliado y reescrito por tanta gente. Si lo importante es la comodidad y la alta velocidad con una fontanería mínima, el cliente controller-runtime es una buena opción.
Resumen
En este capítulo te hemos presentado los recursos personalizados, los mecanismos centrales de extensión utilizados en el ecosistema Kubernetes. A estas alturas ya deberías conocer bien sus características y limitaciones, así como los clientes disponibles.
Pasemos ahora a la generación de código para gestionar dichos recursos.
1 No confundas aquí los objetos Kubernetes y JSON. Estos últimos no son más que otro término para un mapa de cadenas, utilizado en el contexto de JSON y en OpenAPI.
2 "Proyectivo" significa aquí que el objeto scale es una proyección del recurso principal, en el sentido de que sólo muestra determinados campos y oculta todo lo demás.
Get Programación de Kubernetes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

