Capítulo 1. Introducción Introducción
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Programar Kubernetes puede significar cosas distintas para personas distintas. En este capítulo, primero estableceremos el alcance y el enfoque de este libro. Además, compartiremos el conjunto de suposiciones sobre el entorno en el que estamos operando y lo que necesitarás aportar, idealmente, para beneficiarte al máximo de este libro. Definiremos qué entendemos exactamente por programar Kubernetes, qué son las aplicaciones nativas de Kubernetes y, mediante un ejemplo concreto, cuáles son sus características. Hablaremos de los fundamentos de los controladores y operadores, y de cómo funciona en principio el plano de control de Kubernetes basado en eventos. ¿Estás preparado? Manos a la obra.
¿Qué significa programar Kubernetes?
Suponemos que tienes acceso a un clúster de Kubernetes en funcionamiento, como Amazon EKS, Microsoft AKS, Google GKE o una de las ofertas de OpenShift.
Consejo
Tú pasarás bastante tiempo desarrollando localmente en tu portátil o entorno de escritorio; es decir, el clúster de Kubernetes contra el que estás desarrollando es local, en lugar de estar en la nube o en tu centro de datos. Cuando desarrollas localmente, tienes varias opciones disponibles. Dependiendo de tu sistema operativo y otras preferencias, puedes elegir una (o incluso más) de las siguientes soluciones para ejecutar Kubernetes localmente: kind, k3d o Docker Desktop.1
En también asumimos que eres un programador Go, es decir, que tienes experiencia o al menos una familiaridad básica con el lenguaje de programación Go. Ahora es un buen momento, si alguna de esas suposiciones no se aplica a ti, para formarte: para Go, recomendamos The Go Programming Language de Alan A. A. Donovan y Brian W. Kernighan (Addison-Wesley) y Concurrency in Go de Katherine Cox-Buday (O'Reilly). Para Kubernetes, consulta uno o varios de los siguientes libros:
-
Kubernetes en acción por Marko Lukša (Manning)
-
Kubernetes: Up and Running, 2ª Edición de Kelsey Hightower et al. (O'Reilly)
-
DevOps nativos en la nube con Kubernetes, de John Arundel y Justin Domingus (O'Reilly)
-
Gestión de Kubernetes por Brendan Burns y Craig Tracey (O'Reilly)
-
Kubernetes Cookbook de Sébastien Goasguen y Michael Hausenblas (O'Reilly)
Nota
¿Por qué nos centramos en programar Kubernetes en Go? Bueno, una analogía podría ser útil aquí: Unix se escribió en el lenguaje de programación C, y si querías escribir aplicaciones o herramientas para Unix utilizarías por defecto C. Además, para ampliar y personalizar Unix -incluso si utilizaras un lenguaje distinto de C- necesitarías al menos saber leer C.
Ahora, Kubernetes y muchas tecnologías nativas de la nube relacionadas, desde los tiempos de ejecución de contenedores hasta el monitoreo, como Prometheus, están escritas en Go. Creemos que la mayoría de las aplicaciones nativas estarán basadas en Go y por eso nos centramos en él en este libro. Si prefieres otros lenguajes, no pierdas de vista la organización kubernetes-client de GitHub. Es posible que, en el futuro, contenga un cliente en tu lenguaje de programación favorito.
Por "programar Kubernetes" en el contexto de este libro, entendemos lo siguiente: vas a desarrollar una aplicación nativa de Kubernetes que interactúa directamente con el servidor API, consultando el estado de los recursos y/o actualizando su estado. En no nos referimos a ejecutar aplicaciones comerciales, como WordPress o Rocket Chat o tu sistema CRM empresarial favorito, a menudo denominadas aplicaciones comerciales disponibles en el mercado (COTS). Además, en el Capítulo 7 no nos centramos demasiado en las cuestiones operativas, sino que nos ocupamos principalmente de la fase de desarrollo y pruebas. Así que, en pocas palabras, este libro trata sobre el desarrollo de aplicaciones genuinamente nativas de la nube. La Figura 1-1 puede ayudarte a asimilarlo mejor.
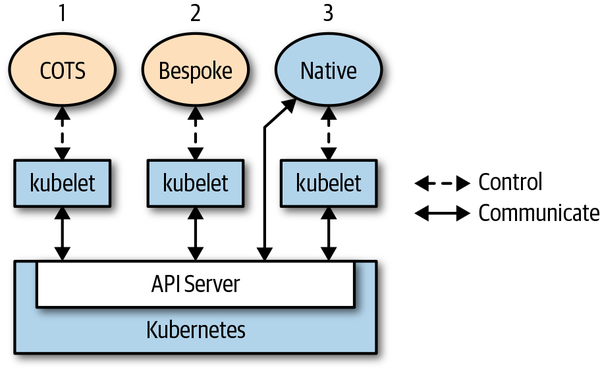
Figura 1-1. Diferentes tipos de aplicaciones que se ejecutan en Kubernetes
Como puedes ver en, hay diferentes estilos a tu disposición:
-
Toma un COTS como Rocket Chat y ejecútalo en Kubernetes. La propia aplicación no es consciente de que se ejecuta en Kubernetes, y normalmente no tiene por qué serlo. Kubernetes controla el ciclo de vida de la aplicación -encuentra el nodo que se va a ejecutar, extrae la imagen, lanza el contenedor o contenedores, realiza comprobaciones de estado, monta volúmenes, etc.- y ya está.
-
Toma una aplicación a medida, algo que hayas escrito desde cero, con o sin tener en mente Kubernetes como entorno de ejecución, y ejecútala en Kubernetes. Se aplica el mismo modus operandi que en el caso de una COTS.
-
El caso en el que nos centramos en este libro es el de una aplicación nativa de la nube o de Kubernetes que es plenamente consciente de que se ejecuta en Kubernetes y aprovecha en cierta medida las API y los recursos de Kubernetes.
El precio de que pagas al desarrollar contra la API de Kubernetes merece la pena: por un lado, ganas en portabilidad, ya que tu aplicación se ejecutará en cualquier entorno (desde una implementación local a cualquier proveedor de nube pública), y por otro, te beneficias del mecanismo limpio y declarativo que proporciona Kubernetes.
Pasemos ahora a un ejemplo concreto.
Un ejemplo motivador
Para demostrar en la potencia de una aplicación nativa de Kubernetes, supongamos que quieres implementar at, es decir, programar la ejecución de un comando en un momento dado.
A esto lo llamamos cnat o nube nativa at, y funciona de la siguiente manera. Supongamos que quieres ejecutar el comando echo "Kubernetes native rocks!" a las 2 de la madrugada del 3 de julio de 2019. Esto es lo que harías con cnat:
$cat cnat-rocks-example.yaml apiVersion: cnat.programming-kubernetes.info/v1alpha1 kind: At metadata: name: cnrex spec: schedule:"2019-07-03T02:00:00Z"containers: - name: shell image: centos:7command: -"bin/bash"-"-c"-echo"Kubernetes native rocks!"$kubectl apply -f cnat-rocks-example.yaml cnat.programming-kubernetes.info/cnrex created
Entre bastidores, intervienen los siguientes componentes:
-
Un recurso personalizado llamado
cnat.programming-kubernetes.info/cnrex, que representa el horario. -
Un controlador para ejecutar la orden programada a la hora correcta.
Además, sería útil un complemento de kubectl para la CLI UX, que permitiera un manejo sencillo mediante comandos como kubectl at "02:00 Jul 3" echo "Kubernetes native rocks!" No escribiremos esto en este libro, pero puedes consultar la documentación de Kubernetes para obtener instrucciones.
A lo largo del libro, utilizaremos este ejemplo para discutir aspectos de Kubernetes, su funcionamiento interno y cómo ampliarlo.
Para los ejemplos más avanzados de los Capítulos 8 y 9, simularemos una pizzería con objetos pizza y aderezo en el cluster. Consulta "Ejemplo: Una pizzería" para más detalles.
Patrones de extensión
Kubernetes es un sistema potente e inherentemente extensible. En general, existen múltiples formas de personalizar y/o ampliar Kubernetes: mediante archivos de configuración y banderas para componentes del plano de control como kubelet o el servidor API de Kubernetes, y a través de una serie de puntos de extensión definidos:
-
Los llamados proveedores de nube, que tradicionalmente estaban dentro del árbol como parte del gestor controlador. A partir de la versión 1.11, Kubernetes hace posible el desarrollo fuera del árbol proporcionando un proceso personalizado
cloud-controller-managerpara integrarse con una nube. Los proveedores de nube permiten el uso de herramientas específicas del proveedor de nube, como equilibradores de carga o Máquinas Virtuales (VM). -
Plug-ins binarios
kubeletpara red, dispositivos (como GPU), almacenamiento y tiempos de ejecución de contenedores. -
Plug-ins binarios
kubectl. -
Accede a extensiones en el servidor API, como el control de admisión dinámico con webhooks (consulta el Capítulo 9).
-
Recursos personalizados (ver Capítulo 4) y controladores personalizados; ver la sección siguiente.
-
Servidores API personalizados (ver Capítulo 8).
-
Extensiones del programador, como utilizar un webhook para implementar tus propias decisiones de programación.
-
Autenticación con webhooks.
En el contexto de este libro nos centramos en los recursos personalizados, controladores, webhooks y servidores API personalizados, junto con los patrones de extensión de Kubernetes. Si te interesan otros puntos de extensión, como el almacenamiento o los complementos de red, consulta la documentación oficial.
Ahora que tienes una comprensión básica de los patrones de extensión de Kubernetes y del alcance de este libro, pasemos al corazón del plano de control de Kubernetes y veamos cómo podemos extenderlo.
Controladores y operadores
En esta sección aprenderás sobre los controladores y operadores en Kubernetes y cómo funcionan.
Según el glosario de Kubernetes, un controlador implementa un bucle de control, observando el estado compartido del clúster a través del servidor API y realizando cambios en un intento de mover el estado actual hacia el estado deseado.
Antes de sumergirnos en el funcionamiento interno del controlador, definamos nuestra terminología:
-
Los controladores pueden actuar sobre recursos básicos, como Implementaciones o servicios, que suelen formar parte del gestor de controladores de Kubernetes en el plano de control, o pueden observar y manipular recursos personalizados definidos por el usuario.
-
Los operadores son controladores que codifican algunos conocimientos operativos, como la gestión del ciclo de vida de las aplicaciones, junto con los recursos personalizados definidos en el Capítulo 4.
Naturalmente, dado que este último concepto se basa en el primero, veremos primero los controladores y luego trataremos el caso más especializado de un operador.
El bucle de control
En general, el bucle de control tiene el siguiente aspecto:
-
Lee el estado de los recursos, preferiblemente en función de los eventos (utilizando relojes, como se explica en el Capítulo 3). Para más detalles, consulta "Eventos" y "Activadores por perímetro frente a activadores por nivel".
-
Cambia el estado de los objetos del clúster o del mundo clúster-externo. Por ejemplo, lanza un pod, crea un endpoint de red o consulta una API de la nube. Consulta "Cambiar los objetos del clúster o del mundo externo" para más detalles.
-
Actualiza el estado del recurso en el paso 1 a través del servidor API en
etcd. Consulta "Concurrencia optimista" para más detalles. -
Repite el ciclo; vuelve al paso 1.
No importa lo complejo o sencillo que sea tu controlador, estos tres pasos -leer el estado del recurso ˃ cambiar el mundo ˃ actualizar el estado del recurso- siguen siendo los mismos. Profundicemos un poco más en cómo se implementan realmente estos pasos en un controlador de Kubernetes. El bucle de control se representa en la Figura 1-2, que muestra las partes móviles típicas, con el bucle principal del controlador en el centro. Este bucle principal se ejecuta continuamente dentro del proceso del controlador. Este proceso suele ejecutarse dentro de un pod en el clúster.
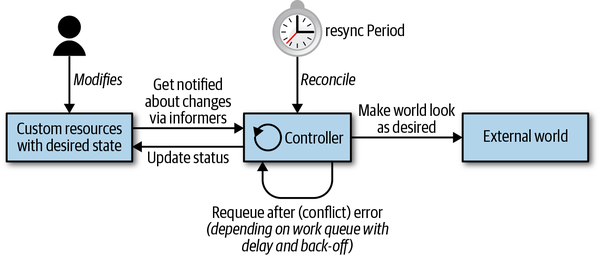
Figura 1-2. Bucle de control de Kubernetes
Desde el punto de vista de la arquitectura, un controlador suele utilizar las siguientes estructuras de datos (como se explica detalladamente en el Capítulo 3):
- Informadores
-
Los informadores vigilan el estado deseado de los recursos de forma escalable y sostenible. También implementan un mecanismo de resincronización (para más detalles, consulta "Informadores y almacenamiento en caché" ) que impone la reconciliación periódica, y a menudo se utiliza para asegurarse de que el estado del clúster y el supuesto estado almacenado en caché en la memoria no se desvían (por ejemplo, debido a errores o problemas de red).
- Colas de trabajo
-
Esencialmente, una cola de trabajo es un componente que puede ser utilizado por el manejador de eventos para gestionar la cola de cambios de estado y ayudar a implementar reintentos. En
client-goesta funcionalidad está disponible a través del paqueteworkqueue (ver "Cola de trabajo"). Los recursos se pueden volver a poner en cola en caso de error al actualizar el mundo o escribir el estado (pasos 2 y 3 del bucle), o simplemente porque tengamos que reconsiderar el recurso pasado un tiempo por otros motivos.
Para un debate más formal sobre Kubernetes como motor declarativo y las transiciones de estado, lee "The Mechanics of Kubernetes" de Andrew Chen y Dominik Tornow.
Echemos ahora un vistazo más de cerca al bucle de control, empezando por la arquitectura basada en eventos de Kubernetes.
Eventos
El plano de control de Kubernetes emplea en gran medida eventos y el principio de componentes débilmente acoplados. Otros sistemas distribuidos utilizan llamadas a procedimientos remotos (RPC) para activar el comportamiento. Kubernetes no lo hace. Los controladores de Kubernetes observan los cambios que se producen en los objetos de Kubernetes en el servidor API: adiciones, actualizaciones y eliminaciones. Cuando se produce un evento de este tipo, el controlador ejecuta su lógica de negocio.
Por ejemplo, para lanzar un pod mediante una implementación, varios controladores y otros componentes del plano de control trabajan juntos:
-
El controlador de implementación (dentro de
kube-controller-manager) advierte (a través de un informador de implementación) que el usuario crea una implementación. Crea un conjunto de réplicas en su lógica de negocio. -
El controlador del conjunto de réplicas (de nuevo dentro de
kube-controller-manager) se da cuenta (a través de un informador del conjunto de réplicas) del nuevo conjunto de réplicas y, posteriormente, ejecuta su lógica de negocio, que crea un objeto pod. -
El programador (dentro del binario
kube-scheduler) -que también es un controlador- avisa al pod (a través de un pod informer) con un campospec.nodeNamevacío. Su lógica de negocio coloca el pod en su cola de programación. -
Mientras tanto, el
kubelet-otro controlador- se da cuenta del nuevo pod (a través de su informador de pods). Pero el campospec.nodeNamedel nuevo pod está vacío y, por tanto, no coincide con el nombre del nodokubelet's. Ignora el pod y vuelve a dormir (hasta el siguiente evento). -
El programador saca el pod de la cola de trabajo y lo programa en un nodo que tenga suficientes recursos libres, actualizando el campo
spec.nodeNamedel pod y escribiéndolo en el servidor API. -
El
kubeletse despierta de nuevo debido al evento de actualización del pod. Vuelve a comparar elspec.nodeNamecon su propio nombre de nodo. Los nombres coinciden, por lo quekubeletinicia los contenedores del pod e informa de que los contenedores se han iniciado escribiendo esta información en el estado del pod, de vuelta al servidor API. -
El controlador del conjunto de réplicas se da cuenta del pod cambiado, pero no tiene nada que hacer.
-
Finalmente, el pod termina. El
kubeletse dará cuenta de ello, obtendrá el objeto pod del servidor API y establecerá la condición "terminado" en el estado del pod, y lo escribirá de nuevo en el servidor API. -
El controlador del conjunto de réplicas se da cuenta del pod terminado y decide que hay que sustituirlo. Elimina el pod terminado en el servidor API y crea uno nuevo.
-
Y así sucesivamente.
Como puedes ver, una serie de bucles de control independientes se comunican exclusivamente a través de los cambios de objeto en el servidor API y los eventos que estos cambios desencadenan a través de informadores.
Estos eventos se envían desde el servidor de la API a los informadores dentro de los controladores a través de los relojes (ver "Relojes"), es decir, conexiones de streaming de eventos de reloj. Todo esto es casi invisible para el usuario. Ni siquiera el mecanismo de auditoría del servidor API hace visibles estos eventos; sólo son visibles las actualizaciones de los objetos. Sin embargo, los controladores suelen utilizar la salida de registro cuando reaccionan ante los eventos.
Si quieres saber más sobre los eventos, lee la entrada del blog de Michael Gasch "Eventos, el ADN de Kubernetes", donde proporciona más antecedentes y ejemplos.
Activadores por perímetro frente a activadores por nivel
Retrocedamos un poco en y veamos de forma más abstracta cómo podemos estructurar la lógica empresarial implementada en los controladores, y por qué Kubernetes ha optado por utilizar eventos (es decir, cambios de estado) para impulsar su lógica.
Hay dos opciones de principio para detectar el cambio de estado (el acontecimiento en sí):
- Activadores por perímetro
-
En, en el momento en que se produce el cambio de estado, se activa un controlador; por ejemplo, de ningún pod a pod en funcionamiento.
- Activadores por niveles
-
El estado se comprueba a intervalos regulares y si se cumplen determinadas condiciones (por ejemplo, pod en marcha), se activa un manejador.
La última es una forma de sondeo. No escala bien con el número de objetos, y la latencia de los controladores que notan los cambios depende del intervalo de sondeo y de lo rápido que pueda responder el servidor API. Con muchos controladores asíncronos implicados, como se describe en "Eventos", el resultado es un sistema que tarda mucho tiempo en implementar el deseo de los usuarios.
La primera opción es mucho más eficiente con muchos objetos. La latencia depende sobre todo del número de subprocesos de trabajadores en los eventos de procesamiento del controlador. De ahí que Kubernetes se base en eventos (es decir, activadores impulsados por perímetros).
En el plano de control de Kubernetes, varios componentes cambian objetos en el servidor API, y cada cambio da lugar a un evento (es decir, un perímetro). Llamamos a estos componentes fuentes de eventos o productores de eventos. En cambio, en el contexto de los controladores, nos interesa consumir eventos, es decir, cuándo y cómo reaccionar ante un evento (a través de un informador).
En un sistema distribuido hay muchos actores funcionando en paralelo, y los eventos llegan de forma asíncrona en cualquier orden. Cuando tenemos una lógica de controlador defectuosa, una máquina de estado ligeramente errónea o un fallo de un servicio externo, es fácil perder eventos en el sentido de que no los procesamos completamente. De ahí que tengamos que profundizar en cómo hacer frente a los errores en.
En la Figura 1-3 puedes ver diferentes estrategias en funcionamiento:
-
Un ejemplo de lógica basada sólo en perímetros, en la que potencialmente se pasa por alto el segundo cambio de estado.
-
Un ejemplo de lógica activada por perímetro, que siempre obtiene el último estado (es decir, el nivel) al procesar un evento. En otras palabras, la lógica está activada por perímetro, pero impulsada por nivel.
-
Ejemplo de lógica por niveles activada por perímetro con resincronización adicional.
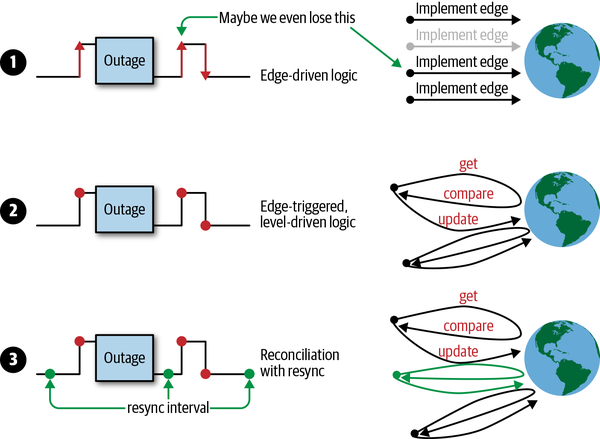
Figura 1-3. Opciones de disparo (por perímetro o por nivel)
La estrategia 1 no se las arregla bien con los eventos perdidos, ya sea porque una red rota le hace perder eventos, o porque el propio controlador tiene fallos o alguna API externa de la nube estaba caída. Imagina que el controlador del conjunto de réplicas sustituyera los pods sólo cuando terminaran. La pérdida de eventos significaría que el conjunto de réplica siempre funcionaría con menos vainas porque nunca reconcilia todo el estado.
La estrategia 2 se recupera de esos problemas cuando se recibe otro evento, porque implementa su lógica basándose en el último estado del clúster. En el caso del controlador del conjunto de réplicas, siempre comparará el recuento de réplicas especificado con los pods en ejecución en el clúster. Cuando pierda eventos, sustituirá todos los pods que falten la próxima vez que se reciba una actualización de pods.
La estrategia 3 añade una resincronización continua (por ejemplo, cada cinco minutos). Si no llegan eventos de pod, al menos se resincronizará cada cinco minutos, aunque la aplicación se ejecute de forma muy estable y no provoque muchos eventos de pod.
Dados los retos que plantean los activadores puramente impulsados por el perímetro, los controladores de Kubernetes suelen aplicar la tercera estrategia.
Si quieres saber más sobre los orígenes de los activadores y las motivaciones de la activación por niveles con reconciliación en Kubernetes, lee el artículo de James Bowes, "Activación por niveles y reconciliación en Kubernetes".
Con esto concluye la discusión sobre las distintas formas abstractas de detectar los cambios externos y de reaccionar ante ellos. El siguiente paso en el bucle de control de la Figura 1-2 es cambiar los objetos del cluster o cambiar el mundo externo siguiendo las especificaciones. Lo veremos ahora.
Cambiar los objetos del cluster o el mundo externo
En esta fase, el controlador cambia el estado de los objetos que está supervisando. Por ejemplo, el controlador ReplicaSet del gestor de controladores está supervisando pods. En cada evento (activado por perímetro), observará el estado actual de sus vainas y lo comparará con el estado deseado (activado por nivel).
Dado que el acto de cambiar el estado de los recursos es específico del dominio o de la tarea, podemos proporcionar poca orientación. En su lugar, seguiremos examinando el controlador ReplicaSet que hemos introducido antes. ReplicaSets se utilizan en las implementaciones, y la línea de fondo del controlador correspondiente es: mantener un número definido por el usuario de réplicas de pods idénticas. Es decir, si hay menos pods de los especificados por el usuario -por ejemplo, porque un pod ha muerto o se ha aumentado el valor de la réplica-, el controlador lanzará nuevos pods. Si, por el contrario, hay demasiados pods, seleccionará algunos para su terminación. Toda la lógica de negocio del controlador está disponible a través del paquete replica_set.go, y el siguiente extracto del código Go se ocupa del cambio de estado (editado para mayor claridad):
// manageReplicas checks and updates replicas for the given ReplicaSet.// It does NOT modify <filteredPods>.// It will requeue the replica set in case of an error while creating/deleting pods.func(rsc*ReplicaSetController)manageReplicas(filteredPods[]*v1.Pod,rs*apps.ReplicaSet,)error{diff:=len(filteredPods)-int(*(rs.Spec.Replicas))rsKey,err:=controller.KeyFunc(rs)iferr!=nil{utilruntime.HandleError(fmt.Errorf("Couldn't get key for %v %#v: %v",rsc.Kind,rs,err),)returnnil}ifdiff<0{diff*=-1ifdiff>rsc.burstReplicas{diff=rsc.burstReplicas}rsc.expectations.ExpectCreations(rsKey,diff)klog.V(2).Infof("Too few replicas for %v %s/%s, need %d, creating %d",rsc.Kind,rs.Namespace,rs.Name,*(rs.Spec.Replicas),diff,)successfulCreations,err:=slowStartBatch(diff,controller.SlowStartInitialBatchSize,func()error{ref:=metav1.NewControllerRef(rs,rsc.GroupVersionKind)err:=rsc.podControl.CreatePodsWithControllerRef(rs.Namespace,&rs.Spec.Template,rs,ref,)iferr!=nil&&errors.IsTimeout(err){returnnil}returnerr},)ifskippedPods:=diff-successfulCreations;skippedPods>0{klog.V(2).Infof("Slow-start failure. Skipping creation of %d pods,"+" decrementing expectations for %v %v/%v",skippedPods,rsc.Kind,rs.Namespace,rs.Name,)fori:=0;i<skippedPods;i++{rsc.expectations.CreationObserved(rsKey)}}returnerr}elseifdiff>0{ifdiff>rsc.burstReplicas{diff=rsc.burstReplicas}klog.V(2).Infof("Too many replicas for %v %s/%s, need %d, deleting %d",rsc.Kind,rs.Namespace,rs.Name,*(rs.Spec.Replicas),diff,)podsToDelete:=getPodsToDelete(filteredPods,diff)rsc.expectations.ExpectDeletions(rsKey,getPodKeys(podsToDelete))errCh:=make(chanerror,diff)varwgsync.WaitGroupwg.Add(diff)for_,pod:=rangepodsToDelete{gofunc(targetPod*v1.Pod){deferwg.Done()iferr:=rsc.podControl.DeletePod(rs.Namespace,targetPod.Name,rs,);err!=nil{podKey:=controller.PodKey(targetPod)klog.V(2).Infof("Failed to delete %v, decrementing "+"expectations for %v %s/%s",podKey,rsc.Kind,rs.Namespace,rs.Name,)rsc.expectations.DeletionObserved(rsKey,podKey)errCh<-err}}(pod)}wg.Wait()select{caseerr:=<-errCh:iferr!=nil{returnerr}default:}}returnnil}
Puedes ver que el controlador calcula la diferencia entre la especificación y el estado actual en la línea diff := len(filteredPods) - int(*(rs.Spec.Replicas)) y luego implementa dos casos en función de ello:
-
diff<0Demasiadas pocas réplicas; hay que crear más vainas. -
diff>0Demasiadas réplicas; hay que eliminar las vainas.
También aplica una estrategia para elegir vainas en las que sea menos perjudicial eliminarlas en getPodsToDelete.
Sin embargo, cambiar el estado de los recursos no significa necesariamente que los propios recursos tengan que formar parte del clúster de Kubernetes. En otras palabras, un controlador puede cambiar el estado de recursos que se encuentran fuera de Kubernetes, como un servicio de almacenamiento en la nube. Por ejemplo, el Operador de Servicios de AWS te permite gestionar los recursos de AWS. Entre otras cosas, te permite gestionar cubos S3, es decir, el controlador S3 está supervisando un recurso (el cubo S3) que existe fuera de Kubernetes, y los cambios de estado reflejan fases concretas de su ciclo de vida: un cubo S3 se crea y en algún momento se elimina.
Esto debería convencerte de que con un controlador personalizado puedes gestionar no sólo recursos básicos, como los pods, y recursos personalizados, como nuestro ejemplo cnat, sino incluso recursos informáticos o de almacenamiento que existen fuera de Kubernetes. Esto hace que los controladores sean mecanismos de integración muy flexibles y potentes, que proporcionan una forma unificada de utilizar los recursos en distintas plataformas y entornos.
Concurrencia optimista
En "El bucle de control", comentamos en el paso 3 que un controlador -tras actualizar los objetos del clúster y/o el mundo externo según la especificación- escribe los resultados en el estado del recurso que activó la ejecución del controlador en el paso 1.
Esta y, en realidad, cualquier otra escritura (también en el paso 2) puede salir mal. En un sistema distribuido, este controlador es probablemente sólo uno de los muchos que actualizan recursos. Las escrituras concurrentes pueden fallar por conflictos de escritura.
Para entender mejor lo que ocurre, retrocedamos un poco y echemos un vistazo a la Figura 1-4.2
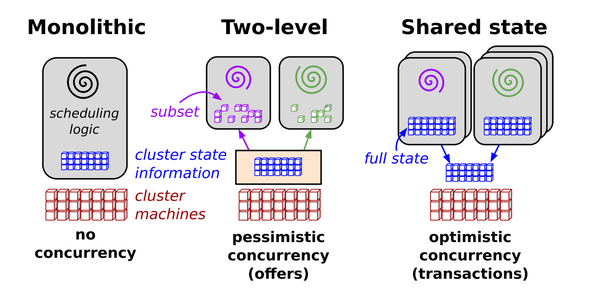
Figura 1-4. Arquitecturas de programación en sistemas distribuidos
La fuente define la arquitectura del programador paralelo de Omega como sigue:
Nuestra solución es una nueva arquitectura de programador paralelo construida en torno al estado compartido, que utiliza un control de concurrencia optimista sin bloqueos, para lograr tanto la extensibilidad de la implementación como la escalabilidad del rendimiento. Esta arquitectura se está utilizando en Omega, el sistema de gestión de clústeres de próxima generación de Google.
Aunque Kubernetes heredó muchos rasgos y lecciones aprendidas de Borg, esta característica específica del plano de control transaccional procede de Omega: para realizar operaciones concurrentes sin bloqueos, el servidor API de Kubernetes utiliza la concurrencia optimista.
Esto significa, en pocas palabras, que si el servidor API detecta intentos de escritura simultáneos, rechaza la última de las dos operaciones de escritura. Corresponde entonces al cliente (controlador, programador, kubectl, etc.) gestionar un conflicto y, potencialmente, reintentar la operación de escritura.
A continuación se muestra la idea de concurrencia optimista en Kubernetes:
var err errorforretries :=0;retries < 10;retries++{foo,err=client.Get("foo", metav1.GetOptions{})iferr !=nil{break}<update-the-world-and-foo> _,err=client.Update(foo)iferr !=nil&&errors.IsConflict(err){continue}elseiferr !=nil{break}}
El código muestra un bucle de reintento que obtiene el último objeto foo en cada iteración y, a continuación, intenta actualizar el mundo y el estado de foopara que coincidan con la especificación de foo. Los cambios realizados antes de la llamada a Update son optimistas.
El objeto devuelto foo de la llamada client.Get contiene una versión del recurso (parte de la estructura incrustada ObjectMeta -ver "ObjectMeta" para más detalles), que indicará a etcd en la operación de escritura tras la llamada client.Update que otro actor del clúster escribió el objeto foo mientras tanto. Si ese es el caso, nuestro bucle de reintento obtendrá un error de conflicto de versión de recurso. Esto significa que la lógica de concurrencia optimista ha fallado. En otras palabras, la llamada a client.Update también es optimista.
Nota
La versión del recurso es en realidad la versión clave/valor de etcd. La versión del recurso de cada objeto es una cadena en Kubernetes que contiene un número entero. Este número entero procede directamente de etcd. etcd mantiene un contador que aumenta cada vez que se modifica el valor de una clave (que contiene la serialización del objeto).
En todo el código de la maquinaria de la API, la versión del recurso se maneja (de forma más o menos consecuente) como una cadena arbitraria, pero con cierto orden en ella. El hecho de que se almacenen números enteros es sólo un detalle de implementación del actual backend de almacenamiento etcd.
Veamos un ejemplo concreto. Imagina que tu cliente no es el único actor del clúster que modifica un pod. En hay otro actor, concretamente el kubelet, que modifica constantemente algunos campos porque un contenedor se bloquea constantemente. Ahora tu controlador lee el último estado del objeto pod de la siguiente manera
kind:Podmetadata:name:fooresourceVersion:57spec:...status:...
Supón ahora que el controlador necesita varios segundos con sus actualizaciones del mundo. Siete segundos después, intenta actualizar el pod que ha leído; por ejemplo, establece una anotación. Mientras tanto, el kubelet se ha dado cuenta de que se ha reiniciado otro contenedor y ha actualizado el estado del pod para reflejarlo; es decir, resourceVersion ha pasado a ser 58.
El objeto que tu controlador envía en la solicitud de actualización tiene resourceVersion: 57. El servidor API intenta establecer la clave etcd para el pod con ese valor. etcd se da cuenta de que las versiones de los recursos no coinciden e informa de que 57 entra en conflicto con 58. La actualización falla.
La conclusión de este ejemplo es que, para tu controlador, eres responsable de implementar una estrategia de reintento y de adaptarte si falla una operación optimista. Nunca sabes quién más podría estar manipulando el estado, si otros controladores personalizados o controladores centrales como el controlador de implementación.
La esencia de esto es: los errores de conflicto son totalmente normales en los controladores. Espéralos siempre y manéjalos con elegancia.
Es importante señalar que la concurrencia optimista encaja perfectamente con la lógica basada en niveles, porque al utilizar la lógica basada en niveles sólo tienes que volver a ejecutar el bucle de control (ver "Disparadores basados en perímetros frente a disparadores basados en niveles"). Otra ejecución de ese bucle deshará automáticamente los cambios optimistas del anterior intento optimista fallido, e intentará actualizar el mundo al estado más reciente.
Pasemos a un caso específico de controladores personalizados (junto con los recursos personalizados): el operador.
Operarios
Los operadores como concepto en Kubernetes fueron introducidos por CoreOS en 2016. En su entrada seminal del blog, "Introducing Operators: Putting Operational Knowledge into Software", el CTO de CoreOS, Brandon Philips , definió los operadores de la siguiente manera:
Un Site Reliability Engineer (SRE) es una persona [que] opera una aplicación escribiendo software. Es un ingeniero, un desarrollador, que sabe cómo desarrollar software específicamente para un dominio de aplicación concreto. El software resultante tiene programado el conocimiento del dominio operativo de una aplicación.
[...]
A esta nueva clase de software la llamamos Operadores. Un Operador es un controlador específico de la aplicación que amplía la API de Kubernetes para crear, configurar y gestionar instancias de aplicaciones complejas con estado en nombre de un usuario de Kubernetes. Se basa en los conceptos básicos de recursos y controladores de Kubernetes, pero incluye conocimientos específicos del dominio o de la aplicación para automatizar tareas comunes.
En el contexto de este libro, utilizaremos los operadores tal y como los describe Philips y, más formalmente, exigiremos que se cumplan las tres condiciones siguientes (véase también la Figura 1-5):
-
Hay algún conocimiento operativo específico del dominio que te gustaría automatizar.
-
Las buenas prácticas de este conocimiento operativo son conocidas y pueden hacerse explícitas: por ejemplo, en el caso de un operador de Cassandra, cuándo y cómo reequilibrar los nodos, o en el caso de un operador de una malla de servicios, cómo crear una ruta.
-
Los artefactos enviados en el contexto del operador son:
-
Un conjunto de definiciones de recursos personalizados (CRD) que capturan el esquema específico del dominio y los recursos personalizados que siguen a las CRD y que, a nivel de instancia, representan el dominio de interés.
-
Un controlador personalizado, que supervisa los recursos personalizados, potencialmente junto con los recursos centrales. Por ejemplo, el controlador personalizado podría poner en marcha un pod.
-
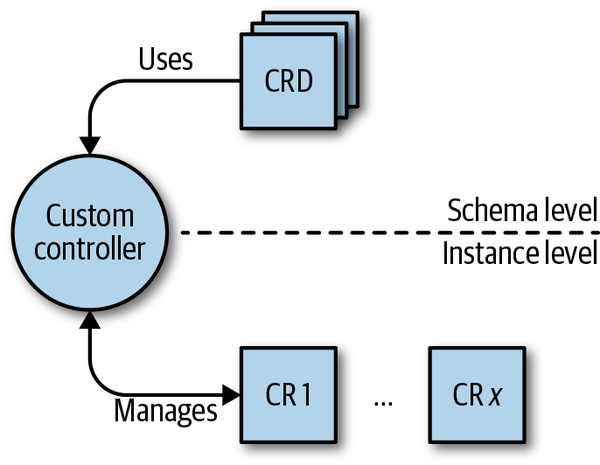
Figura 1-5. El concepto de operador
Operadores ha recorrido un largo camino desde el trabajo conceptual y la creación de prototipos en 2016 hasta el lanzamiento de OperatorHub.io por Red Hat (que adquirió CoreOS en 2018 y continuó desarrollando la idea) a principios de 2019. Véase en la Figura 1-6 una captura de pantalla del hub a mediados de 2019 con unos 17 operadores, listos para ser utilizados.

Figura 1-6. Captura de pantalla de OperatorHub.io
Resumen
En este primer capítulo hemos definido el alcance de nuestro libro y lo que esperamos de ti. Explicamos lo que entendemos por programar Kubernetes y definimos las aplicaciones nativas de Kubernetes en el contexto de este libro. Como preparación para ejemplos posteriores, también proporcionamos una introducción de alto nivel a los controladores y operadores.
Así que, ahora que sabes qué esperar del libro y cómo puedes beneficiarte de él, vamos a meternos de lleno en el tema. En el próximo capítulo, veremos más de cerca la API de Kubernetes, el funcionamiento interno del servidor API y cómo puedes interactuar con la API utilizando herramientas de línea de comandos como curl.
1 Para más información sobre este tema, consulta "A Kubernetes Developer Workflow for MacOS" de Megan O'Keefe , Medium, 24 de enero de 2019; y la entrada del blog de Alex Ellis, "Be KinD to yourself", 14 de diciembre de 2018.
2 Fuente: "Omega: Flexible, Scalable Schedulers for Large Compute Clusters", por Malte Schwarzkopf y otros, Google AI, 2013.
Get Programación de Kubernetes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

