Capítulo 4. Tokenización
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Este es nuestro primer capítulo de la sección de PNL desde cero. En los tres primeros capítulos, te hemos guiado a través de los componentes de alto nivel de un canal de PNL. A partir de aquí y hasta el capítulo 9, abordaremos muchos de los detalles subyacentes para comprender realmente cómo funcionan los sistemas modernos de PNL. Los componentes principales son:
-
Tokenización
-
Incrustaciones
-
Arquitecturas
Anteriormente, todos estos pasos estaban abstraídos en las bibliotecas que utilizamos (spaCy, transformers, y fastai). Pero ahora, intentaremos comprender cómo funcionan realmente estas bibliotecas y cómo puedes modificar tu código a bajo nivel para construir aplicaciones PNL asombrosas más allá de los sencillos ejemplos que presentamos en este libro.
Una cosa a tener en cuenta: "bajo nivel" es un término subjetivo. Mientras que algunos pueden llamar a PyTorch una biblioteca de aprendizaje profundo de bajo nivel , otros pueden burlarse de usar ese término para cualquier cosa que no sea construir un asignador de memoria personalizado en ensamblador x86. Es una cuestión de perspectiva. Es una cuestión de perspectiva. Lo que queremos decir con bajo nivel aquí es que después de aprender estas cosas, tendrás una comprensión suficiente para construir aplicaciones útiles con PNL en el mundo real y que también serás capaz de entender y seguir las últimas investigaciones en este campo. No hablaremos de nada que vaya demasiado más allá del ámbito de la PNL. Por ejemplo, aprender sobre cómo funciona CUDA es ciertamente interesante y útil, y haremos un poco de eso en el Apéndice B. Pero la propia CUDA como herramienta es útil para muchas cosas fuera de la PNL, por lo que la consideraríamos fuera del alcance de este libro. En la medida de lo posible, intentaremos centrarnos en cosas que realmente mejoren el rendimiento de tus modelos en producción.
Cada uno de los elementos de la lista que acabamos de ver (es decir, los tokenizadores, las incrustaciones y los modelos) puede considerarse una función independiente, que recibe una entrada y genera una salida. Para ser más concretos, pasamos el texto tokenizado a la capa de incrustación, y pasamos las incrustaciones al modelo. Si lo deseas, puedes tratar estas funciones como cajas negras y centrarte sólo en una de ellas cada vez. Examinaremos cada una por separado, primero los tokenizadores.
Un Tokenizador Mínimo
Cuando empezamos a pensar en partes de bajo nivel de la pila de aprendizaje profundo, es útil entender los componentes en términos de cuáles son sus entradas y salidas.
¿Cuáles son las entradas y salidas aquí? La entrada es texto. Normalmente, se proporciona como un archivo .txt o cualquier otra cosa que se lee en un objeto Python. La salida es una secuencia de tokens. Uno de los temas principales de este capítulo será la discusión sobre qué es exactamente un "token" y qué debe hacer.
Como siempre, una de las mejores formas de entender algo es mirar el código. Así que esto es esencialmente lo que es un tokenizador:
text=open('example.txt','r').read()words=text.split(" ")tokens={v:kfork,vinenumerate(words)}
tokens{'The': 0,
'quick': 1,
'brown': 2,
'fox': 3,
'jumps': 4,
'over': 5,
'the': 6,
'lazy': 7,
'dog.': 8}
Un tokenizador lee el texto y devuelve una correspondencia entre palabras e índices. Esencialmente, crea un diccionario (tanto en sentido figurado como literal, ya que el ejemplo anterior crea un diccionario Python) que mapea palabras a números. Esto es extremadamente útil, porque ahora tenemos una representación del texto fuente que puede introducirse en un modelo de PNL:
token_map=map(lambdat:tokens[t],words)list(token_map)
[0, 1, 2, 3, 4, 5, 6, 7, 8]
Por supuesto, se trata de un ejemplo drásticamente simplificado. En la práctica, nunca querrías hacer la tokenización de esta manera: es lenta, para empezar, y no tiene en cuenta muchas complejidades de las distintas lenguas. Además, este simple tokenizador no tiene en cuenta la puntuación, la gramática o la estructura de las palabras compuestas (es decir, el hecho de que las palabras que terminan en "-ing", "-ify", etc., estén relacionadas) de ninguna manera significativa. No obstante, es un comienzo.
He aquí una forma más precisa de expresar en lo que debe ser un tokenizador: un tokenizador es un programa que convierte una secuencia de caracteres en una secuencia de tokens. Los tokenizadores como herramienta general son muy útiles incluso fuera de la PNL. Siempre que sea necesario analizar un texto, es probable que exista algún tipo de tokenizador. Tomemos un ejemplo del mundo de los compiladores, porque resulta que la tokenización es algo muy antiguo, fundamental y útil.
Consejo
Tan útil, de hecho, que había herramientas populares como lex y flex inventadas en los años 80 que generaban el código C para un tokenizador rápido, ¡dada una simple descripción del token que querías analizar!
Cuando se construye un compilador para un lenguaje de programación, una de las primeras cosas que hay que hacer es identificar y marcar palabras clave como if y for para pasarlas a la siguiente etapa. Aquí, el tokenizador lee un archivo y construye una nueva representación del código fuente en la que los caracteres ASCII/Unicode en bruto se sustituyen por tokens que representan estas palabras clave, que luego pueden utilizarse para construir una estructura de datos llamada árbol de análisis sintáctico.
Aquí no estamos construyendo un compilador, por lo que el árbol de análisis sintáctico no es del todo relevante y, en la práctica, utilizaremos bibliotecas en lugar de complejos procedimientos de generación de código. Pero queríamos ilustrar un ejemplo de cómo un tokenizador es un programa muy útil y robusto, incluso fuera de la PNL.
Sin embargo, el tipo de tokenizadores que nos interesan como profesionales del aprendizaje profundo no suelen proporcionarnos árboles de análisis sintáctico. Lo que queremos es un tokenizador que lea el texto y genere una secuencia de vectores de un solo golpe.
Esto es lo más importante que hay que entender sobre los tokenizadores desde nuestra perspectiva descendente. La entrada es texto en bruto, y la salida es una secuencia de vectores. Para ser aún más específicos, los vectores, en nuestro caso, son simplemente tensores PyTorch codificados en un punto que pasamos a una capann.Embedding. Una vez que llegamos a esa fase, en la que podemos pasar algo a una capa de incrustación (de la que hablaremos en el próximo capítulo), hemos terminado con la tokenización.
Ahora que entendemos las entradas y salidas, pasemos directamente a la implementación, tras lo cual veremos algunas de las nuevas ideas en este espacio, y las examinaremos con más detalle a bajo nivel.
En nuestra opinión, hay dos herramientas para la tokenización que son superiores a la mayoría de las demás: el tokenizador de SpaCy y la biblioteca Hugging Face tokenizers.
El tokenizador de spaCy es más utilizado, es más antiguo y algo más fiable. Tiene su propio algoritmo único de tokenización que suele funcionar bien para las tareas habituales de PNL. La biblioteca tokenizers es un paquete algo más moderno que se centra en implementar los algoritmos más recientes procedentes de las investigaciones más recientes.
Advertencia
Algunos modelos como BERT esperan ciertos tokens específicos, por lo que no puedes utilizar cualquier tokenizador que quieras en estos modelos. Para evitarlo, las versiones recientes de spaCy incluyen envoltorios alrededor de la biblioteca Hugging Face transformers, que te permiten combinar el resto de tu flujo de trabajo spaCy con transformadores. Pero entre bastidores, esto seguirá utilizando el tokenizador BERT, no spaCy.
Ya hemos utilizado spaCy en los Capítulos 1 y 3 , y volveremos a visitarlo cuando implementemos el modelo en la Parte III. Así que en este capítulo nos centraremos en la biblioteca Cara Abrazada tokenizers.
Tokenizadores de caras abrazadas
tokenizers es la herramienta oficial de tokenización de Hugging Face escrita en el lenguaje de programación Rust (que resulta ser el lenguaje de programación favorito de Ajay en el momento de escribir esto), con enlaces a Python y JavaScript. Aunque tokenizers podría utilizarse como tokenizador de uso general, al tratarse de Hugging Face, está diseñado para ser utilizado específicamente para el aprendizaje profundo y la PNL, con un enfoque específico en el tokenizador rápido de subpalabras (que veremos en detalle una vez que probemos el código primero).
La tokenización, a diferencia de otras partes del proceso de aprendizaje profundo, se realiza normalmente en la CPU. Pero eso no significa que tenga que ser lenta. La biblioteca de Hugging Face hace un buen uso de los múltiples núcleos que puedas tener en tu máquina, y puede tokenizar grandes conjuntos de datos a escala de gigabytes (que es bastante grande para la PNL no académica) en menos de un minuto.
La biblioteca tokenizers subdivide aún más la tarea de tokenización en pasos más pequeños y manejables. Aquí tienes la descripción que hace Hugging Face de los componentes del proceso de tokenización en su biblioteca:
- Normalizador
-
Ejecuta todas las transformaciones iniciales de sobre la cadena de entrada inicial. Por ejemplo, cuando necesites poner en minúsculas algún texto, tal vez eliminarlo, o incluso aplicar uno de los procesos habituales de normalización Unicode, añadirás un Normalizador.
- PreTokenizer
-
Se encarga de dividir la cadena de entrada inicial. Es el componente que decide dónde y cómo presegmentar la cadena
origin. El ejemplo más sencillo sería como vimos antes, dividir en espacios. - Modelo
-
Se encarga de todo el descubrimiento y generación del subtoken . Esta parte es entrenable y depende realmente de tus datos de entrada.
- Post-procesador
-
Proporciona funciones avanzadas de construcción de para que sea compatible con algunos de los modelos SOTA basados en Transformer. Por ejemplo, para BERT envolvería la frase tokenizada alrededor de los tokens [CLS] y [SEP].
- Descodifica
-
Se encarga de devolver una entrada tokenizada a la cadena original. El descodificador suele elegirse según el
PreTokenizerque hemos utilizado anteriormente. - Entrenador
Cada uno de esos módulos lógicos tiene múltiples opciones/implementaciones en la biblioteca:
- Normalizador
-
Minúsculas, Unicode (NFD, NFKD, NFC, NFKC), Bert, Strip...
- PreTokenizer
-
ByteLevel, WhitespaceSplit, CharDelimiterSplit, Metaspace, ...
- Modelo
-
PalabraNivel, BPE, PalabraPieza, ...
- Post-procesador
-
BertProcessor, ... - Descodificador
-
PalabraNivel, BPE, PalabraPieza, ...
Tienes cierta libertad a la hora de elegirlos, pero lo más habitual es que te limites a los componentes admitidos por el modelo preentrenado que estés utilizando. En la práctica, querrás utilizar lo que se sugiere en la documentación de tu modelo, por lo que te sugerimos que la revises si/cuando encuentres errores.
Instalar la biblioteca es tan sencillo como ejecutar lo siguiente:
pip install tokenizers
Pero, por supuesto, ya hemos incluido esto en nuestros archivos requirements.txty environment.yml en el repositorio de GitHub:
importtokenizers
Tokenización de subpalabras
Si sigues buscando en a través de la documentación de tokenizers, te darás cuenta de que hay un montón de algoritmos diferentes que se implementan en la biblioteca. Pero la tokenización parece una tarea bastante sencilla, ¿verdad? ¿Qué ocurre?
Pues bien, resulta que hay muchas formas en las que puedes decidir formar un "token" a partir de una cadena de texto.
Por ejemplo, considera las cadenas "cat" y "cats". Una subtokenización válida de "cats" sería [cat, ##s], donde el doble hashtag representa un subtoken prefijo de la entrada inicial. La ventaja de este enfoque es que obtienes la información semántica que proporcionan los tokenizadores basados en palabras sin incurrir en el coste de un vocabulario muy amplio. Estos algoritmos de entrenamiento podrían extraer subtokens como "##ing" y "##ed" sobre un corpus de inglés.
Este enfoque tiene pros y contras en términos de coste computacional. Por un lado, tendrás menos palabras en tu vocabulario, lo que significa una matriz de incrustación más pequeña (de la que hablaremos en el Capítulo 5). Pero, por otra parte, una palabra tendrá ahora varios tokens, por lo que podrás encajar menos palabras en un modelo que acepte un número fijo de tokens.
Como se ilustra en la Figura 4-1, los tokenizadores más sencillos basados en caracteres generalmente nunca producirán tokens desconocidos, pero también romperán una palabra en muchos trozos pequeños, lo que puede causar cierta pérdida de información. Por otra parte, puedes representar las palabras de forma completa y precisa con la tokenización a nivel de palabra, pero entonces necesitarás un vocabulario muy amplio, o te arriesgas a tener muchos tokens sin identificar.
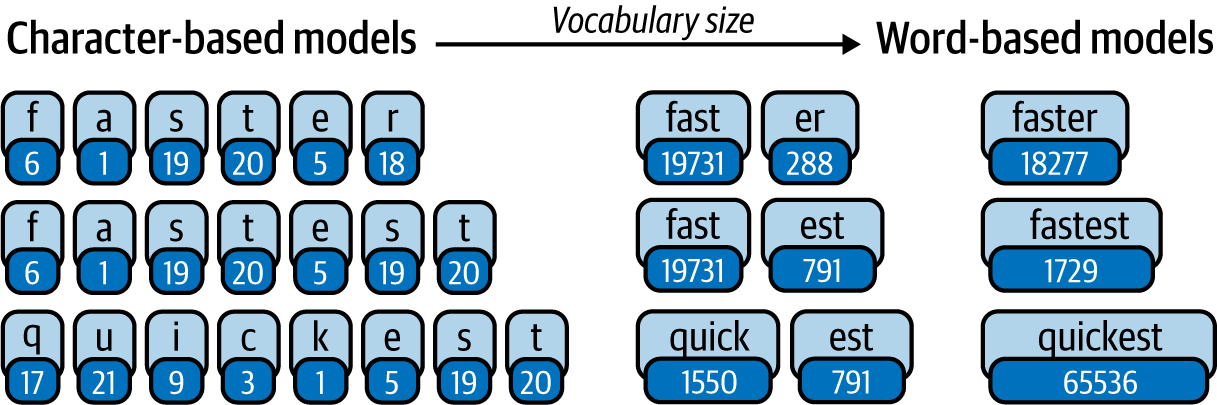
Figura 4-1. Subtokenización
Así pues, el objetivo aquí es doble:
-
Aumenta la cantidad de información por ficha.
-
Disminuye el número total de fichas (tamaño del vocabulario).
Los tokenizadores de subpalabras lo consiguen eficazmente encontrando un buen equilibrio entre caracteres, subpalabras y palabras.
Nota
Tokenización de subpalabras Los algoritmos de(al menos los más recientes) no están grabados en piedra. Hay una fase de "entrenamiento" antes de que podamos realmente tokenizar el texto. No se trata del entrenamiento del modelo lingüístico en sí, sino de un proceso que llevamos a cabo para encontrar el equilibrio óptimo entre la tokenización a nivel de carácter y a nivel de palabra.
La idea de utilizar prefijos y sufijos es bastante sencilla, y quizá podrías diseñar un tokenizador de subpalabras algo eficaz codificando reglas para subpalabras comunes como "##ing" y "##ed". Sin embargo, en la práctica, este planteamiento presenta una serie de dificultades:
-
Hay muchas lenguas diferentes, cada una con sus propias reglas. Construir un buen tokenizador de subpalabras significaría entonces comprender y aplicar un nuevo conjunto de reglas para cada lengua.
-
No hay garantía de que las reglas que crees sean realmente buenas. Como ejemplo extremo, puedes decidir crear un token de subpalabra para
"super##", pero puede que nunca aparezca en el texto. Así que esencialmente habrás desperdiciado un lugar en el diccionario. Podrías evaluar el número de tokens coincidentes y volver a ajustar tus reglas, pero en ese punto también podrías utilizar un algoritmo de entrenamiento. -
Puede que tú, como humano que lee el texto, no seas capaz de captar las complejidades de los patrones lingüísticos repetidos. Es mucho más sencillo hacer que un ordenador lea más de 40 GB de texto y descubra los tokens repetidos que leer tú mismo más de 40 GB de texto.
Así pues, el objetivo del procedimiento de entrenamiento es identificar el texto recurrente en un corpus y "refactorizarlo" en un token. Si un patrón concreto no se repite a menudo, no se incluye como token.
Por ejemplo, si tu corpus de texto tiene un equilibrio uniforme de las cadenas"car" y "cat" (junto con muchas otras palabras), entonces los tokens que podrías obtener serían ["ca##", "r", "t", ...]. Pero si tu corpus tiene muchas más apariciones de "cat" que de otras palabras, entonces podría ser beneficioso condensarlo en un único token, dando los tokens["cat", "ca##", "r" ...]. Idealmente, queremos evitar agrupar palabras enteras en un único token como ese, ya que aumenta el tamaño del vocabulario, como se muestra en la Figura 4-1. Pero cuando algo se repite a menudo, como la palabra the, es más eficaz agrupar esa información en un único token.
La tokenización de subpalabras también reduce el impacto del problema cuando el modelo encuentra una palabra nueva que nunca ha visto antes. Si tu corpus de entrenamiento tiene las cadenas swim, play y playing, un tokenizador a nivel de palabra identificaría la cadena swimming como una palabra desconocida. Sin embargo, "swimming" es simplemente una palabra nueva construida a partir de subpalabras primitivas que el modelo ha visto. Así que un tokenizador de subpalabras podría identificarla como ["swim", "##m##", "##ing"] y pasar información más relevante al modelo.
Veamos cómo se aplican estas ideas en en la biblioteca tokenizers.
Construir tu propio tokenizador
Los tokenizadores de subpalabras listos para usar son estupendos, pero a veces, realmente necesitas un tokenizador que recoja matices específicos de tu dominio textual. Los ejemplos canónicos son los textos jurídicos y médicos. Estos dominios suelen tener un conjunto específico de términos de uso frecuente que son lo suficientemente importantes como para merecer su propio token (piensa en nombres de moléculas o secciones específicas de documentos legales).
Nota
Sí, hemos dicho "entrenar", porque los tokenizadores de subpalabras necesitan algún criterio para decidir cómo dividir las palabras, y el aprendizaje suele ser la mejorsolución.
Si quieres entrenar tu propio tokenizador, hay algunas opciones populares. Aquí tienes algunas referencias al estado del arte de la investigación en tokenizadores:
- Codificación de pares de bytes (BPE)
-
Véase R. Sennrich et al., "Traducción automática neuronal de palabras raras con unidades de subpalabras", arXiv, 2015, https://oreil.ly/dlFNw.
- WordPiece
-
Véase M. Schuster y K. Nakajima, "Japanese and Korean Voice Search", International Conference on Acoustics, Speech and Signal Processing, IEEE (2012), https://oreil.ly/fvGTh.
- Fragmento de frase
-
Véase T. Kudo y J. Richardson, "SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing", arXiv, 2018, https://oreil.ly/YNFhP.
En realidad, obtener datos médicos del mundo real es bastante difícil debido a la normativa y a la falta de técnicas de aprendizaje automático que preserven la privacidad. Así que, por ahora, utilizaremos el conjunto de datos WikiText-103, que es el conjunto de artículos de Wikipedia que utilizamos en el Capítulo 2. Debes saber que si tus datos de texto representan los patrones literarios típicos de Internet, no tendrás que entrenar tus propios tokenizadores desde cero la mayoría de las veces.
En primer lugar, necesitamos obtener el conjunto de datos (en caso de que aún no lo hayas descargado):
wget https://s3.amazonaws.com/research.metamind.io/wikitext/ wikitext-103-raw-v1.zip unzip wikitext-103-raw-v1.zip
Utilizar un tokenizador establecido es bastante sencillo con la biblioteca tokenizers de Hugging Face. Aquí, primero configuramos un tokenizador de codificación de pares de bytes (una forma de tokenización de subpalabras) en una sola línea de código:
fromtokenizersimportTokenizerfromtokenizers.modelsimportBPEtokenizer=Tokenizer(BPE(unk_token="[UNK]"))
A continuación, inicializamos un objeto especial BpreTrainer. Esto sólo es necesario si estás entrenando un nuevo tokenizador desde cero:
fromtokenizers.trainersimportBpeTrainertrainer=BpeTrainer(special_tokens=["[UNK]","[CLS]","[SEP]","[PAD]","[MASK]"])
Por último, especificamos los archivos y entrenamos nuestro tokenizador BPE:
files=[f"data/wikitext-103-raw/wiki.{split}.raw"forsplitin["test","train","valid"]]tokenizer.train(files,trainer)
Conclusión
En este capítulo, hemos examinado la primera etapa de una vista de nivel inferior del pipeline de la PNL: los tokenizadores. Los tokenizadores no son la etapa de la pila que la mayoría de la gente debería optimizar, porque los diferentes tokenizadores no tendrán un impacto significativo en el rendimiento de tu aplicación en el mundo real, pero no dejan de ser un componente vital. En la práctica, deberías utilizar spacyo tokenizers, ya que tendrán implementadas las últimas versiones de los tokenizadores más recientes de la investigación. Si tienes un conjunto de datos personalizado con mucho vocabulario específico del dominio (como en las aplicaciones jurídicas o médicas), tiene sentido volver a entrenar un algoritmo tokenizador establecido como WordPiece o SentencePiece.
También exploramos algunos de los matices del desarrollo de tokenizadores rápidos. En concreto, exploramos cómo la elección del lenguaje de programación puede influir en el rendimiento de tu tokenizador.
Ahora tenemos una comprensión práctica de bajo nivel de los tokenizadores, y si quieres deberías ser capaz de construir el tuyo propio desde cero (en la práctica, por supuesto, no es tan útil). Esto nos permite tomar grandes archivos de texto y generar tokens que nuestro modelo puede utilizar para resolver problemas complejos de PNL.
Pero no podemos pasar tokens sin procesar al modelo. Los tokens siguen siendo esencialmente índices de diccionarios, lo que no es semánticamente útil para un modelo de aprendizaje profundo. En su lugar, pasamos lo que se denomina "incrustaciones" de los tokens, que es de lo que trata el siguiente capítulo.
Get Procesamiento del Lenguaje Natural Aplicado en la Empresa now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

