Capítulo 1. Introducción a la PNL
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
¿Qué crees que puede hacer tu ordenador? ¿Mostrarte correos electrónicos? ¿Editar algunos archivos? ¿Hacer girar una hoja de Excel, tal vez?
Pero, ¿y si te dijéramos que tu ordenador sabe leer?
fromtransformersimportpipelineclassifier=pipeline('sentiment-analysis')classifier('I am reading the greatest NLP book ever!')
[{'label': 'POSITIVE', 'score': 0.9996862411499023}]
text_generator=pipeline("text-generation")text_generator("Welcome to the ",max_length=5,do_sample=False)
Y, lo que es más impresionante, lo entiende:
nlp=pipeline("question-answering")context="""Natural language processing (NLP) is a subfield of linguistics,computer science, and artificial intelligence concerned with theinteractions between computers and human language, in particularhow to program computers to process and analyze large amounts ofnatural language data. The result is a computer capable of"understanding" the contents of documents, including the contextualnuances of the language within them. The technology can then accuratelyextract information and insights contained in the documents as wellas categorize and organize the documents themselves."""nlp(question="What is NLP?",context=context)
{'score': 0.9869255423545837,
'start': 1,
'end': 28,
'answer': 'Natural language processing'}
Lo que antes era la fantasía de un futuro lejano no sólo está aquí, sino que es accesible a cualquiera con un ordenador y una conexión a Internet. La capacidad de comprender y comunicarse en lenguaje natural, uno de los activos más valiosos que la humanidad ha desarrollado a lo largo de nuestra existencia, ahora es práctico hacerlo en máquinas.
"¡Por supuesto!", proclamas. "¡La tecnología siempre mejora, y hace siglos que tenemos reconocimiento de voz y Google Translate!".
Pero incluso hace sólo cinco años, la "PNL" era algo más adecuado para los artículos de TechCrunch que para las bases de código de producción reales. En los últimos tres años, hemos asistido a un crecimiento exponencial de los avances en este campo; los modelos que se están implementando en producción hoy en día son muy superiores a las tablas de clasificación de la investigación más oscura de los días pasados.
Pero nos estamos adelantando. Antes de profundizar, empecemos con una visión general de alto nivel del campo. Una vez que hayamos cubierto los aspectos básicos, introduciremos temas más avanzados. Nuestro objetivo es ayudarte a construir intuición y experiencia trabajando con PNL, capítulo a capítulo, para que al final del libro seas capaz de construir aplicaciones reales que añadan valor real al mundo.
En la primera mitad de este capítulo, definiremos la PNL, exploraremos algunas aplicaciones comerciales de la tecnología y recorreremos cómo ha evolucionado el campo desde sus orígenes en la década de 1950.
En la segunda mitad del capítulo, presentaremos una biblioteca de PNL muy eficaz y popular en la empresa, y la utilizaremos para realizar tareas básicas de PNL. Aunque estas tareas son elementales, cuando se combinan, permiten a los ordenadores procesar y analizar datos del lenguaje natural de formas complejas que hacen posibles aplicaciones comerciales asombrosas como los chatbots y los voicebots.
En cierto modo, el proceso por el que las máquinas aprenden a procesar el lenguaje es similar al modo en que los niños pequeños empiezan a aprender el lenguaje balbuceando y tanteando las palabras, para más tarde hablar con frases y párrafos completos. A medida que avancemos en el libro, nos basaremos en las tareas básicas de la PNL tratadas en este capítulo.
¿Qué es la PNL?
Empecemos por definir qué es el procesamiento del lenguaje natural. He aquí cómo se define el PLN en Wikipedia (consultado en marzo de 2021):
Procesamiento del lenguaje natural (PLN) es un subcampo de la lingüística, la informática, la ingeniería de la información y la inteligencia artificial que se ocupa de las interacciones entre los ordenadores y las lenguas humanas (naturales), en particular de cómo programar ordenadores para procesar y analizar grandes cantidades de datos del lenguaje natural.
Los retos del procesamiento del lenguaje natural en implican con frecuencia el reconocimiento del habla, la comprensión del lenguaje natural y la generación del lenguaje natural.
Vamos a desgranar esta definición. Cuando en decimos "lenguaje natural", nos referimos al "lenguaje humano" en contraposición a los lenguajes de programación. El lenguaje natural se refiere no sólo a datos textuales, sino también a datos de voz y audio.
Genial, pero ¿y si ahora los ordenadores pueden trabajar con grandes cantidades de datos de texto, voz y audio? ¿Por qué es esto tan importante?
Imagina por un segundo el mundo sin lengua. ¿Cómo nos comunicaríamos mediante texto o voz? ¿Cómo leeríamos libros, escucharíamos música o comprenderíamos películas y programas de TV? La vida tal como la conocemos dejaría de existir; estaríamos atrapados en la época de las cavernas, capaces de procesar la información visualmente pero incapaces de compartir nuestros conocimientos entre nosotros o de comunicarnos de forma significativa.1
Del mismo modo, si las máquinas sólo pueden trabajar con datos numéricos y visuales, pero no pueden procesar el lenguaje natural, estarían limitadas en el número y la variedad de aplicaciones que tendrían en el mundo real. Sin la capacidad de manejar el lenguaje natural, las máquinas nunca podrán acercarse a la inteligencia artificial general ni a nada que se parezca a la inteligencia humana actual.
Afortunadamente, por fin las máquinas pueden procesar razonablemente bien los datos del lenguaje natural. Exploremos qué aplicaciones comerciales son posibles gracias a esta capacidad relativamente nueva de los ordenadores para trabajar con datos del lenguaje natural.
Aplicaciones populares
Gracias a los avances en PNL de , las máquinas son capaces de manejar una amplia gama de tareas de lenguaje natural, al menos de forma rudimentaria. He aquí algunas aplicaciones habituales de la PNL en la actualidad:
- Traducción automática
-
La traducción automática es el proceso de utilizar máquinas para traducir de una lengua a otra sin intervención humana. El ejemplo más popular con diferencia es Google Translate, que admite más de 100 idiomas y presta servicio a más de 500 millones de personas al día. Cuando se lanzó por primera vez en 2006, el rendimiento de Google Translate era notablemente peor que el actual. El rendimiento actual se acerca rápidamente al nivel de un experto humano.2
- Reconocimiento de voz
-
Puede parecer chocante, pero la tecnología de reconocimiento de voz existe desde hace más de 50 años. Ningún software de reconocimiento de voz tenía un buen rendimiento ni se había generalizado hasta hace muy poco, impulsado por el auge del aprendizaje profundo. Hoy en día, Amazon Alexa, Apple Siri, Google Assistant, Microsoft Cortana, los asistentes de voz digitales de tu coche y otros programas son capaces de reconocer la voz con un nivel de precisión tan alto que el software es capaz de procesar la información en tiempo real y responder de forma razonable en la mayoría de los casos. Hace tan sólo 15 años, la capacidad de estas máquinas para reconocer el habla y responder de forma coherente era abismal.
- Respuesta a la pregunta
-
Para que estos asistentes digitales ofrezcan una experiencia agradable a los humanos que hacen preguntas, el reconocimiento del habla es sólo la primera mitad del trabajo. El software necesita (a) reconocer el habla y (b), dado el habla reconocida, obtener una respuesta adecuada. Esta segunda mitad se conoce como respuesta a las preguntas (QA).
- Resumen de texto
-
Una de las tareas más comunes que los humanos hacen cada día, especialmente en trabajos de oficina, es leer documentos largos y resumir su contenido. Las máquinas son ahora capaces de realizar este resumen, creando un resumen más corto de un documento de texto más largo. El resumen de textos reduce el tiempo de lectura de los humanos. Los humanos que analizan muchos textos a diario (abogados, asistentes jurídicos, analistas empresariales, estudiantes, etc.) pueden examinar los resúmenes breves de documentos largos generados por las máquinas y, basándose en ellos, elegir los documentos relevantes para leerlos más detenidamente.
- Chatbots
-
Si últimamente has pasado algún tiempo en , te habrás dado cuenta de que cada vez más sitios tienen un chatbot que interviene automáticamente para interactuar con el usuario humano. El chatbot suele saludar al humano de forma amistosa y no amenazadora, y luego le hace preguntas para evaluar el propósito y la intención de la visita al sitio. A continuación, el chatbot intenta responder automáticamente a cualquier pregunta que tenga el usuario sin intervención humana. Estos chatbots están automatizando la relación con el cliente digital.
- Texto a voz y voz a texto
-
Ahora el software es capaz de convertir texto en audio de alta fidelidad muy fácilmente. Por ejemplo, Google Cloud Text-to-Speech es capaz de convertir texto en habla similar a la humana en más de 180 voces en más de 30 idiomas. Del mismo modo, Google Cloud Speech-to-Text es capaz de convertir audio en texto en más de 120 idiomas, proporcionando una oferta verdaderamente global.
- Voicebots
-
Hace diez años, los agentes de voz automatizados de eran toscos. A menos que los humanos respondieran de forma bastante limitada (por ejemplo, con respuestas del tipo sí o no), los agentes de voz al teléfono no podían procesar la información. Ahora, los robots de voz con IA, como los que proporciona VOIQ, pueden ayudar a aumentar y automatizar las llamadas de los equipos de ventas, marketing y éxito del cliente.
- Generación de texto y audio
-
Hace años, la generación de texto se basaba en plantillas y sistemas basados en reglas. Esto limitaba el ámbito de aplicación. Ahora, el software es capaz de generar texto y audio utilizando el aprendizaje automático, ampliando considerablemente el ámbito de aplicación. Por ejemplo, Gmail es ahora capaz de sugerir frases enteras basándose en frases anteriores que hayas redactado, y es capaz de hacerlo sobre la marcha mientras escribes. Aunque la generación de lenguaje natural es la mejor para fragmentos cortos de texto (frases parciales), pronto estos sistemas podrán producir contenidos largos razonablemente buenos. Una aplicación comercial popular de la generación de lenguaje natural es el software de conversión de datos en texto, que genera resúmenes textuales de bases de datos y conjuntos de datos. El software de conversión de datos en texto incluye el análisis de datos y la generación de texto. Entre las empresas de este sector se encuentran Narrative Science y Automated Insights.
- Análisis del sentimiento
-
Con la explosión de contenido de las redes sociales , cada vez es más necesario automatizar el análisis de los sentimientos de los clientes, diseccionando tuits, publicaciones y comentarios en busca de sentimientos como positivo frente a negativo frente a neutro o enfadado frente a triste frente a feliz. Este software también se conoce como IA de las emociones.
- Extracción de información
-
Uno de los principales retos de la PNL es crear datos estructurados a partir de documentos no estructurados y/o semiestructurados. Por ejemplo, el software de reconocimiento de entidades con nombre es capaz de extraer personas, organizaciones, ubicaciones, fechas y divisas de textos largos, como las noticias principales. La extracción de información también implica la extracción de relaciones, identificando las relaciones entre entidades, si las hay.
El número de aplicaciones de la PNL en la empresa se ha disparado en la última década, desde el reconocimiento del habla y la formulación de preguntas y respuestas hasta los robots de voz y los chatbots capaces de generar lenguaje natural por sí solos. Esto es bastante asombroso teniendo en cuenta dónde estaba el campo hace unas décadas.
Para poner en perspectiva el progreso actual de la PNL, repasemos cómo ha progresado la PNL, empezando por sus orígenes en 1950.
Historia
El campo del procesamiento del lenguaje natural existe desde hace casi 70 años. Quizá el más famoso sea Alan Turing , que sentó las bases de este campo al desarrollar el test de Turing en 1950. El test de Turing es una prueba de la capacidad de una máquina para demostrar una inteligencia indistinguible de la humana. Para que la máquina supere la prueba de Turing, debe generar respuestas similares a las humanas, de modo que un evaluador humano no pueda distinguir si las respuestas han sido generadas por un humano o por una máquina (es decir, las respuestas de la máquina son de calidad humana).3
El test de Turing lanzó un importante debate en el entonces incipiente campo de la inteligencia artificial e impulsó a los investigadores a desarrollar modelos de procesamiento del lenguaje natural que sirvieran como bloques de construcción para una máquina que algún día pudiera superar el test de Turing, una búsqueda que continúa hasta hoy.
Al igual que el campo más amplio de la inteligencia artificial, la PNL ha sufrido muchos auges y caídas, pasando de ciclos de bombo publicitario a inviernos de IA. En 1954, la Universidad de Georgetown e IBM construyeron con éxito un sistema que podía traducir automáticamente más de 60 frases rusas al inglés. En aquel momento, los investigadores de la Universidad de Georgetown pensaban que la traducción automática sería un problema resuelto en un plazo de tres a cinco años. El éxito en EEUU también animó a la Unión Soviética a lanzar esfuerzos similares. El éxito de Georgetown-IBM, unido a la mentalidad de Guerra Fría, hizo que aumentara la financiación de la PNL en estos primeros años.
Sin embargo, en 1966, el progreso se había estancado, y el Comité Asesor de Procesamiento Automático del Lenguaje (conocido como ALPAC) -una agencia gubernamental estadounidense creada para evaluar los avances en lingüística computacional- publicó un informe aleccionador. El informe afirmaba que la traducción automática era más cara, menos precisa y más lenta que la traducción humana, y que era improbable que alcanzara el nivel de rendimiento humano en un futuro próximo. El informe dio lugar a una reducción de la financiación de la investigación en traducción automática y, tras él, la investigación en este campo estuvo a punto de desaparecer durante casi una década.
A pesar de estos contratiempos, el campo de la PNL resurgió en la década de 1970. En los años 80, la potencia de cálculo había aumentado considerablemente y los costes habían bajado lo suficiente, lo que abrió el campo a muchos más investigadores de todo el mundo.
A finales de los años 80, la PNL volvió a cobrar protagonismo en con el lanzamiento de los primeros sistemas de traducción automática estadística, dirigidos por investigadores del Centro de Investigación Thomas J. Watson de IBM. Antes del auge de la traducción automática estadística, la traducción automática se basaba en reglas lingüísticas elaboradas a mano por humanos. Estos sistemas se denominaban traducción automática basada en reglas. Las reglas ayudaban a corregir y controlar los errores que solían cometer los sistemas de traducción automática, pero su elaboración era un procesolaborioso y minucioso. Como consecuencia, los sistemas de traducción automática también eran frágiles; si se encontraban con situaciones límite para las que no se habían desarrollado reglas, fallaban, a veces gravemente.
La traducción automática estadística ayudó a reducir la necesidad de reglas humanas hechas a mano, y se basó mucho más en el aprendizaje a partir de datos. Utilizando como datos un corpus bilingüe con textos paralelos (es decir, dos textos idénticos salvo por la lengua en que están escritos), estos sistemas dividían las frases en pequeños subconjuntos y traducían los subconjuntos segmento a segmento de la lengua de partida a la lengua de llegada. Cuantos más datos (es decir, corpus de textos bilingües) tuviera el sistema, mejor sería la traducción. La traducción automática estadística seguiría siendo el método de traducción automática más estudiado y utilizado hasta el auge de la traducción automática neuronal a mediados de la década de 2010.
En la década de 1990, estos éxitos llevaron a los investigadores a ir más allá del texto, al reconocimiento del habla. El reconocimiento del habla, al igual que la traducción automática, existía desde principios de los años 50, impulsado por los primeros éxitos de empresas como Bell Labs e IBM. Pero los sistemas de reconocimiento del habla tenían graves limitaciones. En los años 60, por ejemplo, estos sistemas podían aceptar órdenes de voz para jugar al ajedrez, pero no hacían mucho más.
A mediados de los años 80, IBM aplicó un enfoque estadístico al reconocimiento del habla y lanzó una máquina de escribir activada por la voz llamada Tangora, que podía manejar un vocabulario de 20.000 palabras.
DARPA, los Laboratorios Bell y la Universidad Carnegie Mellon también obtuvieron éxitos similares a finales de la década de 1980. Para entonces, los sistemas de software de reconocimiento del habla tenían vocabularios más amplios que el humano medio y podían realizar un reconocimiento continuo del habla, lo que supuso un hito en la historia del reconocimiento del habla.
En la década de 1990, varios investigadores del sector abandonaron los laboratorios de investigación y las universidades para trabajar en la industria, lo que dio lugar a más aplicaciones comerciales del reconocimiento del habla y la traducción automática.
Los pesos pesados actuales de la PNL, como Google, contrataron a sus primeros empleados de reconocimiento del habla en 2007. El gobierno estadounidense también se implicó entonces; la Agencia de Seguridad Nacional empezó a etiquetar grandes volúmenes de conversaciones grabadas en busca de palabras clave específicas, facilitando el proceso de búsqueda a los analistas de la NSA.
A principios de la década de 2010, los investigadores en PNL, tanto del mundo académico como de la industria , empezaron a experimentar con redes neuronales profundas para tareas de PNL. Los primeros éxitos impulsados por el aprendizaje profundo procedían de un método de aprendizaje profundo denominado memoria a largo plazo (LSTM). En 2015, Google utilizó dicho método para renovar Google Voice.
Los métodos de aprendizaje profundo condujeron a mejoras espectaculares en el rendimiento de las tareas de PNL, lo que estimuló la inversión de más dinero en este campo. Estos éxitos han llevado a una integración mucho más profunda del software de PNL en nuestra vida cotidiana.
Por ejemplo, los coches de de principios de la década de 2010 tenían un software de reconocimiento de voz que podía manejar un conjunto limitado de órdenes vocales. Ahora, los coches tienen tecnología que puede manejar un conjunto mucho más amplio de órdenes en lenguaje natural, deduciendo el contexto y la intención con mucha más claridad.
Si echamos la vista atrás, el progreso de la PNL ha sido lento pero constante, pasando de los sistemas basados en reglas en los primeros tiempos a la traducción automática estadística en los años 80 y a los sistemas basados en redes neuronales en los años 2010. Aunque la investigación académica en este campo ha sido intensa durante bastante tiempo, la PNL no se ha convertido en un tema dominante hasta hace poco. Examinemos los principales puntos de inflexión de los últimos años que han contribuido a que la PNL se convierta en uno de los temas más candentes en la IA actual.
Puntos de inflexión
La PNL y la visión por ordenador son ambos subcampos de la inteligencia artificial, pero la visión por ordenador ha tenido más éxitos comerciales hasta la fecha. La visión por ordenador tuvo su punto de inflexión en 2012 (el llamado momento "ImageNet"), cuando la solución AlexNet, basada en el aprendizaje profundo, diezmó la anterior tasa de error de los modelos de visión por ordenador.
En los años transcurridos desde 2012, la visión por ordenador ha impulsado aplicaciones como el etiquetado automático de fotos y vídeos, los coches autoconducidos, las tiendas sin cajeros, la autenticación de dispositivos basada en el reconocimiento facial, los diagnósticos radiológicos y mucho más.
En comparación, la PNL ha florecido relativamente tarde. La PNL causó sensación a partir de 2014 con el lanzamiento en de Amazon Alexa, una Siri de Apple renovada, Google Assistant y Microsoft Cortana. Google también lanzó una versión muy mejorada de Google Translate en 2016, y ahora los chatbots y los robots de voz son mucho más comunes.
Dicho esto, no fue hasta 2018 cuando la PNL tuvo su propio momento ImageNet con el lanzamiento de grandes modelos lingüísticos preentrenados y entrenados utilizando la arquitectura Transformer; el más notable de ellos fue el BERT de Google, que se lanzó en noviembre de 2018.
En 2019, los modelos generativos como el GPT-2 de OpenAI hicieron furor, generando nuevos contenidos sobre la marcha basándose en contenidos anteriores, una hazaña antes insuperable. En 2020, OpenAI lanzó una versión aún mayor y más impresionante, el GPT-3, basándose en sus éxitos anteriores.
De cara a 2021 y más allá, la PNL ya no es un subcampo experimental de la IA. Junto con la visión por ordenador, la PNL está ahora preparada para tener muchas aplicaciones de base amplia en la empresa. Con este libro, esperamos compartir algunos conceptos y herramientas que te ayudarán a crear algunas de estas aplicaciones en tu empresa.
Unas palabras finales
No existe un único enfoque para resolver las tareas de PNL. Los tres enfoques dominantes hoy en día son el basado en reglas, el aprendizaje automático tradicional (basado en estadísticas) y el basado en redes neuronales.
Exploremos cada enfoque:
- PNL basada en reglas
-
El software tradicional de PNL se basa en gran medida en reglas lingüísticas creadas por el ser humano; los expertos en la materia, normalmente lingüistas, elaboran estas reglas utilizando elementos como expresiones regulares y concordancia de patrones. La PNL basada en reglas funciona bien en casos de uso de alcance limitado, pero normalmente no se generaliza bien. Se necesitan cada vez más reglas para generalizar un sistema de este tipo, y esto hace que la PNL basada en reglas sea una solución laboriosa y frágil en comparación con los otros enfoques de la PNL. He aquí algunos ejemplos de reglas en un sistema basado en reglas: las palabras acabadas en -ing son verbos, las palabras acabadas en -er o -est son adjetivos, las palabras acabadas en 's son posesivos, etc. Piensa en cuántas reglas tendríamos que crear a mano para crear un sistema que pudiera analizar y procesar un gran volumen de datos de lenguaje natural. No sólo la creación de reglas sería un proceso alucinantemente difícil y tedioso, sino que también tendríamos que hacer frente a los muchos errores que se producirían al utilizar dichas reglas. Tendríamos que crear reglas de reglas para abordar todos los casos extremos de todas y cada una de las reglas.
- Aprendizaje automático tradicional (o clásico)
-
El aprendizaje automático tradicional se basa menos en las reglas y más en los datos. Utiliza un enfoque estadístico, extrayendo distribuciones de probabilidad de las palabras basándose en un gran corpus anotado. Los humanos siguen desempeñando un papel importante; los expertos en la materia tienen que realizar ingeniería de rasgos para mejorar el rendimiento del modelo de aprendizaje automático. Las características incluyen mayúsculas, singular frente a plural, palabras circundantes, etc. Después de crear estas características, tendrías que entrenar un modelo de ML tradicional para realizar tareas de PLN; por ejemplo, la clasificación de textos. Como el ML tradicional utiliza un enfoque estadístico para determinar cuándo aplicar determinadas características o reglas para procesar el lenguaje, la PNL basada en el ML tradicional es más fácil de construir y mantener que un sistema basado en reglas. También generaliza mejor que la PNL basada en reglas.
- Redes neuronales
-
Las redes neuronales abordan en las deficiencias del aprendizaje automático tradicional. En lugar de requerir que los humanos realicen ingeniería de características, las redes neuronales "aprenderán" las características importantes mediante el aprendizaje de representación. Para funcionar bien, estas redes neuronales sólo necesitan grandes cantidades de datos. La cantidad de datos necesaria para que estas redes neuronales funcionen bien es considerable, pero, en la era actual de Internet, no es demasiado difícil adquirir datos. Puedes pensar en las redes neuronales como aproximadores de funciones o creadores de "reglas" muy potentes; estas reglas y características son varios grados más matizadas y complejas que las reglas creadas por los humanos, lo que permite un aprendizaje más automatizado y una mayor generalización del sistema en el procesamiento de los datos del lenguaje natural.
De estas tres, la rama de la PNL basada en redes neuronales, impulsada por el auge de las redes neuronales muy profundas (es decir, el aprendizaje profundo), es la más potente y la que ha dado lugar a muchas de las principales aplicaciones comerciales de la PNL en los últimos años.
En este libro, nos centraremos sobre todo en los enfoques de la PNL basados en redes neuronales, pero también exploraremos los enfoques tradicionales del aprendizaje automático. Los primeros tienen un rendimiento puntero en muchas tareas de PNL, pero el aprendizaje automático tradicional se sigue utilizando activamente en aplicaciones comerciales.
No nos centraremos mucho en la PNL basada en reglas, pero, puesto que existe desde hace décadas, no te resultará difícil encontrar otros recursos sobre ese tema. La PNL basada en reglas tiene cabida entre los otros dos enfoques, pero normalmente sólo para tratar casos de perímetro.
PNL básica
Ahora que hemos definido la PNL, explorado las aplicaciones en boga hoy en día, cubierto su historia y puntos de inflexión, y aclarado los diferentes enfoques para resolver las tareas de la PNL, comencemos nuestro viaje realizando las tareas más básicas de la PNL.
Aprovecharemos una de las bibliotecas de código abierto más populares para su uso en aplicaciones comerciales de PNL para realizar estas tareas : spacy.
Antes de utilizar spacy, hablemos de estas tareas más básicas de la PNL. Como dijimos en la introducción del capítulo, son bastante elementales, parecidas a enseñar a un niño los fundamentos del lenguaje. Pero estas tareas básicas de la PNL, una vez combinadas, nos ayudan a realizar tareas más complejas, que son las que, en última instancia, impulsan las principales aplicaciones actuales de la PNL.
Las máquinas, como nosotros, deben caminar antes de correr.
Definir las tareas de la PNL
Anteriormente, en este capítulo, hemos explorado en varias aplicaciones de la PNL en boga hoy en día, entre las que se incluyen las siguientes:
-
Traducción automática
-
Reconocimiento de voz
-
Respuesta a la pregunta
-
Resumen de texto
-
Chatbots
-
Conversión de texto a voz y de voz a texto
-
Voicebots
-
Generación de texto y audio
-
Análisis del sentimiento
-
Extracción de información
Para que las máquinas puedan realizar estas aplicaciones complejas, necesitan realizar varias tareas de PNL más pequeñas, del tamaño de un bocado. En otras palabras, para crear aplicaciones comerciales de PNL con éxito, debemos dominar las tareas de PNL que sirven de bloques de construcción para esas aplicaciones.
Es importante señalar que los modelos modernos de PNL basados en redes neuronales realizan estas "tareas" automáticamente mediante el entrenamiento de la red neuronal; es decir, la red neuronal aprende por sí sola a realizar algunas de estas tareas. Nosotros, los operadores, no necesitamos realizar estas tareas explícitamente.
Estas tareas están un poco desfasadas por este motivo, pero siguen siendo relevantes hoy en día tanto para construir una mayor intuición sobre cómo aprenden las máquinas a trabajar con el lenguaje natural como para trabajar con modelos de PNL no basados en redes neuronales. La PNL clásica, no basada en redes neuronales, sigue siendo habitual en la empresa, aunque hoy esté en desuso en la investigación de vanguardia. Por estas razones, merece la pena aprender estas tareas.
Sin más preámbulos, aquí tienes algunas de estas tareas de PNL:
- Tokenización
-
La tokenización es el proceso de dividir el texto en unidades mínimas significativas, como palabras, signos de puntuación, símbolos, etc. Por ejemplo, la frase "Vivimos en París" podría tokenizarse en cuatro tokens: Vivimos, en, París. La tokenización suele ser el primer paso de todo proceso de PNL. La tokenización es un paso necesario porque la máquina necesita descomponer los datos del lenguaje natural en los elementos más básicos (o tokens) para poder analizar cada elemento en el contexto de los demás elementos. De lo contrario, tendría que analizar un largo fragmento de texto o audio como si fuera un elemento singular, lo que haría que el problema fuera intratable para la máquina. Igual que un estudiante principiante de una lengua descompone una frase en trozos más pequeños para aprender y procesar la información palabra por palabra, una máquina necesita hacer lo mismo. Incluso con cálculos numéricos complejos, las máquinas descomponen el problema en elementos básicos, realizando tareas como la suma, la resta, la multiplicación y la división de dos conjuntos de números. La mayor ventaja que tiene la máquina es que puede hacer esto a un ritmo y a una escala que ningún humano puede. Después de que la tokenización descomponga el texto en unidades mínimas significativas, la máquina necesita asignar metadatos a cada unidad, proporcionándole más información sobre cómo procesar cada unidad en el contexto de otras unidades.
- Etiquetado de parte del discurso
-
Etiquetado de partes del discurso (POS) es el proceso de asignar tipos de palabras a los tokens, como sustantivo, pronombre, verbo, adverbio, adjetivo, conjunción, preposición, interjección, etc. Para "Vivimos en París", las partes de la oración son: pronombre, verbo, preposición y sustantivo. Este etiquetado de las partes de la oración da a cada token un poco más de metadatos, lo que facilita a la máquina la asignación de relaciones entre cada token y todos los demás tokens. En la frase "Pateo el balón", "yo" y "balón" son sustantivos y "patear" es un verbo. Utilizando estos metadatos, podemos deducir que "patear" conecta de algún modo "yo" y la "pelota", lo que nos permite formar una relación entre las palabras. Por eso son tan importantes las partes de la oración. Sin saber que algunas palabras son sustantivos y otras son verbos, etc., la máquina no podría trazar las relaciones entre los tokens.
- Análisis sintáctico de dependencias
-
Análisis sintáctico de dependencias consiste en etiquetar las relaciones entre los tokens individuales, asignando una estructura sintáctica a la frase. Una vez etiquetadas las relaciones, toda la frase puede estructurarse como una serie de relaciones entre conjuntos de tokens. Es más fácil para la máquina procesar el texto una vez que ha identificado la estructura inherente entre el texto. Piensa en lo difícil que te resultaría comprender una frase si te presentaran todas las palabras de la frase desordenadas y no tuvieras conocimientos previos de las reglas gramaticales. Del mismo modo, hasta que la máquina no realiza el análisis sintáctico de las dependencias, apenas conoce la estructura del texto que ha convertido en tokens. Una vez que la estructura es evidente, procesar el texto se vuelve un poco más fácil.
El análisis sintáctico de dependencias puede ser complicado, así que la mejor forma de entenderlo es visualizar las relaciones mediante un árbol de análisis sintáctico. AllenNLP tiene una magnífica demostración de análisis sintáctico de dependencias, que hemos utilizado para generar el grafo de dependencias de la Figura 1-1. Este gráfico de dependencias nos permite visualizar las relaciones entre los tokens. Como puedes ver en la figura, "Nosotros" es el pronombre personal (PRP) y el sujeto nominal (NSUBJ) de "vivir", que es el verbo presente singular (VBP) no tercera persona . "Vivir" está conectado a la frase preposicional (PREP) "en París". "En" es la preposición (IN), y "París" es el objeto de la preposición (POBJ) y es a su vez un nombre propio singular (NNP). Estas relaciones son muy complejas de modelar, y una de las razones por las que es muy difícil dominar realmente cualquier lengua. La mayoría de nosotros aplicamos las reglas gramaticales sobre la marcha, habiendo aprendido el lenguaje a lo largo de años de experiencia. Una máquina hace el mismo tipo de análisis, pero para realizar el procesamiento del lenguaje natural tiene que realizar estas operaciones una tras otra a velocidades vertiginosas.
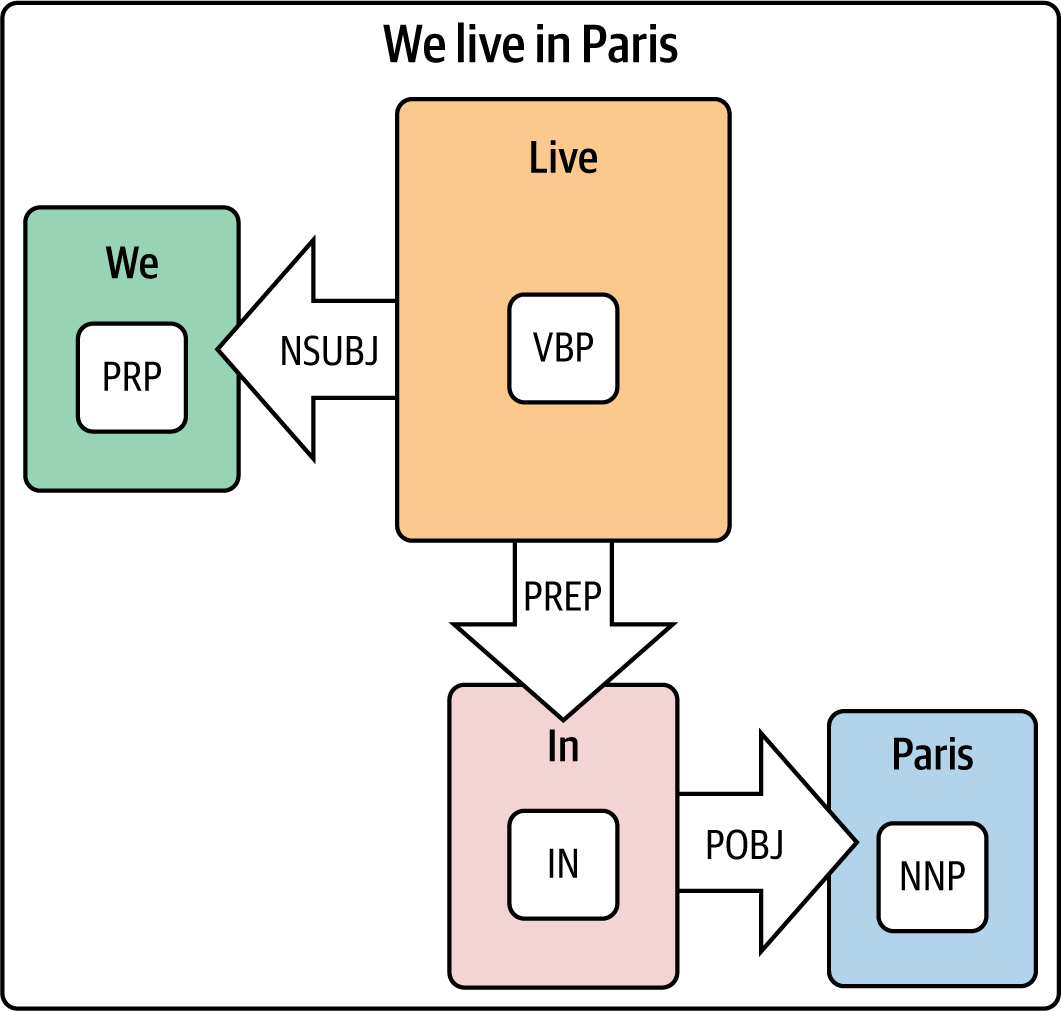
Figura 1-1. Análisis sintáctico de dependencias
- Agrupar
-
El chunking consiste en combinar tokens relacionados en un único token, creando grupos de sustantivos relacionados, grupos de verbos relacionados, etc. Por ejemplo, "Ciudad de Nueva York" podría tratarse como un único token/chunk en lugar de como tres tokens separados. La fragmentación es el proceso que lo hace posible. Es importante realizar la fragmentación una vez que la máquina ha dividido el texto original en fichas, ha identificado las partes de la oración y ha etiquetado la relación de cada ficha con otras fichas del texto. La fragmentación combina fichas similares, lo que facilita el proceso general de análisis del texto. Por ejemplo, en lugar de tratar "Nueva", "York" y "Ciudad" como tres tokens distintos, podemos deducir que están relacionados y agruparlos en un solo grupo (o chunk). Luego, podemos relacionar el trozo con otros trozos del texto. Una vez que hayamos hecho esto con todo el conjunto de tokens, tendremos un conjunto mucho más pequeño de tokens y trozos con los que trabajar.
- Lematización
-
La lematización es el proceso de convertir palabras en sus formas base. Por ejemplo, la lematización convierte "caballos" en "caballo", "dormido" en "sueño" y "mayor" en "grande". Permite a la máquina simplificar el trabajo de procesamiento de texto que tiene que realizar. En lugar de trabajar con una variante de la palabra base, puede trabajar directamente con la palabra base después de haber realizado la lematización.
- Stemming
-
La separación de palabras es un proceso relacionado con la lematización, pero más sencillo. Reduce las palabras a sus raíces. Los algoritmos de "stemming" suelen basarse en reglas. Por ejemplo, la palabra "mayor" se reduciría a "grande", pero la palabra "dormido" no se reduciría en absoluto. A veces, la reducción da lugar a subpalabras sin sentido, y por eso preferimos la lematización a la reducción. La lematización devuelve una palabra a su forma base o canónica, según el diccionario. Pero es un proceso más costoso que la separación por raíz, porque requiere conocer la parte de la oración de la palabra para funcionar bien.
Nota
La tokenización, el etiquetado de partes del discurso, el análisis sintáctico de dependencias, el chunking, la lematización y el stemming son tareas de procesamiento del lenguaje natural para aplicaciones posteriores de PNL; en otras palabras, son medios para conseguir un fin. Técnicamente, las dos "tareas" siguientes -reconocimiento de entidades con nombre y enlace de entidades- no son tareas del lenguaje natural, sino que están más próximas a las aplicaciones de la PNL. El reconocimiento de entidades con nombre y el enlace de entidades pueden ser fines en sí mismos, y no sólo medios para un fin. Pero, como también se utilizan para aplicaciones posteriores de PNL, las incluiremos aquí en la sección "tareas".
- Reconocimiento de entidades con nombre
-
El reconocimiento de entidades con nombre (NER), es el proceso de asignar etiquetas a objetos (o entidades) conocidos, como persona, organización, lugar, fecha, moneda, etc. En "Vivimos en París", se marcaría "París" como la ubicación. NER es muy potente. Permite a las máquinas etiquetar los tokens más importantes con etiquetas de entidad con nombre, y esto es muy importante para las aplicaciones de recuperación de información de la PNL. Por ejemplo, si queremos buscar al ex presidente de EE.UU. George W. Bush en un conjunto de documentos, querríamos que la máquina etiquetara a todas las personas de todos los documentos mediante el reconocimiento de entidades con nombre, y luego buscaríamos dentro de esta lista de personas el conjunto de documentos relevantes para seguir investigando.
- Vinculación de entidades
-
La vinculación de entidades es el proceso de desambiguar entidades a una base de datos externa, vinculando el texto de una forma a otra. Esto es importante tanto para las aplicaciones de resolución de entidades (por ejemplo, la deduplicación de conjuntos de datos) como para las aplicaciones de recuperación de información. En el ejemplo de George W. Bush, querríamos resolver todas las instancias de "George W. Bush" a "George W. Bush", pero no a "George H. W. Bush", padre de George W. Bush y también ex presidente de EEUU. Esta resolución y vinculación a la versión correcta del presidente Bush es un proceso complicado y espinoso, pero que una máquina es capaz de realizar dado todo el contexto textual del que dispone. Una vez que una máquina ha realizado el reconocimiento y la vinculación de entidades, la recuperación de información se convierte en un juego de niños, que es una de las aplicaciones de la PNL más relevantes comercialmente en la actualidad.
Esto es sólo un resumen rápido de las tareas más básicas de la PNL. Querrás investigar más sobre estas tareas; hay muchos recursos disponibles en Internet. Pero, por ahora, esto es suficiente información para empezar.
Ahora que conoces las tareas básicas de la PNL que sirven como bloques de construcción para aplicaciones de PNL más ambiciosas, vamos a utilizar la biblioteca de PNL de código abierto spacy para realizar algunas de estas tareas básicas de PNL.
Configurar el entorno de programación
Para realizar las tareas básicas de PNL, primero tendremos que configurar nuestroentorno de programación.
En este libro, utilizaremos uno de estos entornos de programación más fáciles de usar de los que disponen hoy en día los científicos de datos: Colaboratorio de Google. Google Colab es un entorno gratuito de Jupyter Notebook que se ejecuta íntegramente en la nube. En el Capítulo 2, hablaremos con más detalle de Google Colab y de otros entornos de programación alternativos de .
Utilizaremos GitHub como repositorio de código.4
Si prefieres ejecutar el código localmente en tu máquina, tenemos instrucciones para configurar tu entorno local en nuestro repositorio de GitHub.
Dicho esto, empecemos a codificar las tareas básicas de la PNL.
spaCy, fast.ai y Cara de abrazo
En este libro, utilizaremos las bibliotecas de software de código abierto que ofrecen tres grandes empresas : spacy fast.ai, y Hugging Face- para realizar PNL. Estas bibliotecas son de alto nivel, y abstraen gran parte del trabajo de bajo nivel que de otro modo tendríamos que hacer. Piensa en estas bibliotecas como hermosas envolturas para que podamos aplicar rápidamente la PNL. Las tres bibliotecas son eficaces y comercialmente viables, y puedes elegir cualquiera de ellas para realizar tu propio trabajo aplicado; no tienes por qué elegir las tres. Dicho esto, conviene conocer bien las tres, porque tienen sus respectivos puntos fuertes y débiles, y a veces una será más rápida que las otras a la hora de adoptar los últimos avances en PNL. Presentemos rápidamente cada una de las tres antes de avanzar con spacy en este capítulo. En el Capítulo 2, trabajaremos con fast.ai y Cara de Abrazo.
spaCia
Publicado por primera vez en en 2015, spacy es una biblioteca de código abierto para la PNL con un rendimiento rapidísimo, que aprovecha tanto Python como Cython. Antes de spacy, el Natural Language Toolkit (NLTK) era la biblioteca de PNL líder entre los investigadores, pero NLTK era anticuada (se publicó inicialmente en 2001) y su escalabilidad era deficiente. spacy
fue la primera biblioteca moderna de PNL destinada al público comercial; se construyó pensando en el escalado en producción. Ahora es una de las bibliotecas a las que se recurre para aplicaciones de PNL en la empresa, ya que es compatible con más de 64 lenguajes y con TensorFlow y PyTorch.
Antes de 2021, spacy 2.x se basaba en las redes neuronales recurrentes (RNN) de , de las que hablaremos más adelante en el libro, en lugar de los modelos basados en transformadores líderes del sector. Pero, a partir de enero de 2021, spacy ahora también es compatible con las canalizaciones de última generación basadas en transformadores, lo que consolida su posición entre las principales bibliotecas de PLN que se utilizan hoy en día.
spacyLa empresa creadora de y matriz de , Explosion AI, también ofrece una excelente plataforma de anotación llamada Prodigy, que utilizaremos en el Capítulo 3. De las tres bibliotecas, spacy es la más madura y la más extensible, dadas todas las integraciones que sus creadores han creado y soportado en los últimos más de seis años. Es la más adecuada para su uso en producción en la actualidad.
rápido.ai
fast.ai (la empresa) lanzó su biblioteca de código abierto fastai en 2018, construida sobre PyTorch. fast.ai, la empresa, construyó su reputación ofreciendo cursos online masivos y abiertos (MOOC) a programadores que desean una introducción más práctica al aprendizaje automático, y la biblioteca fastai refleja este espíritu. Tiene componentes de alto nivel que permiten a los programadores producir rápida y fácilmente resultados de vanguardia. Al mismo tiempo, fastai tiene componentes de bajo nivel para que los investigadores puedan mezclarlos y combinarlos para resolver problemas personalizados. Los creadores de fastai también crearon ULMFiT, uno de los primeros métodos de aprendizaje por transferencia en PNL, que utilizaremos en el Capítulo 2. Para quienes deseen cursos y vídeos junto a una biblioteca rápida y fácil de usar, fastai es una gran opción. Sin embargo, es menos madura y menos adecuada para el trabajo de producción que spacy y Hugging Face.
Cara de abrazo
Fundada en 2016, Hugging Face es la más reciente del bloque , pero probablemente la mejor financiada y la de mayor crecimiento de las tres en la actualidad; la empresa acaba de recaudar una Serie B de 40 millones de dólares en marzo de 2021. Hugging Face se centra exclusivamente en la PNL y se ha creado para ayudar a los profesionales a crear aplicaciones de PNL utilizando transformadores de última generación. Su biblioteca, denominada transformadores, está construida para PyTorch y TensorFlow y es compatible con más de 100 lenguajes. De hecho, es posible pasar de PyTorch y TensorFlow para el desarrollo y la implementación de forma bastante fluida. Hugging Face también tiene una API de canalización para la producción de modelos de PNL. Estamos muy ilusionados con el futuro de Hugging Face entre las tres bibliotecas y te recomendamos encarecidamente que dediques tiempo suficiente a familiarizarte con ella.
Realiza tareas de PNL con spaCy
Utilicemos ahora spacy para nuestras tareas de PNL.
En primer lugar, instalaremos spacy. Para más información sobre la instalación, visita el sitio web oficial de spaCy. Si aún no has instalado spacy, estos comandos te darán todo lo que necesitas (si los ejecutas en un cuaderno, antepone a cada línea un carácter ! ):
pip install -U spacy[cuda110,transformers,lookups]==3.0.3 pip install -U spacy-lookups-data==1.0.0 pip install cupy-cuda110==8.5.0 python -m spacy download en_core_web_trf
Descargar modelos lingüísticos preentrenados
spacy ha preentrenado los modelos lingüísticos de para su uso inmediato. Los modelos preentrenados son modelos que ya se han entrenado con muchos datos y están listos para que realicemos inferencias con ellos.
Estos modelos lingüísticos preentrenados nos ayudarán a resolver las tareas básicas de PNL, pero los usuarios más avanzados pueden afinarlos con los datos más específicos que elijan. Así obtendrás un rendimiento aún mejor para tus tareas específicas.
El ajuste fino es el proceso de tomar un modelo preentrenado y entrenarlo un poco más (es decir, ajustar el modelo) en un corpus más específico de texto que sea relevante para el dominio del usuario.5 Por ejemplo, si trabajáramos en finanzas, podríamos decidir afinar un modelo lingüístico genérico preentrenado en documentos financieros para generar un modelo lingüístico específico de finanzas. Este modelo lingüístico específico de las finanzas tendría un rendimiento aún mejor en las tareas de PLN relacionadas con las finanzas que el modelo lingüístico genérico preentrenado.
spacy divide sus modelos lingüísticos preentrenados en dos grupos: modelos básicos y modelos iniciales. Los modelos núcleo son modelos de uso general y nos ayudarán a resolver las tareas básicas de PNL. Los modelos starter son modelos base útiles para el aprendizaje por transferencia; estos modelos tienen pesos preentrenados, que podrías utilizar para inicializar y afinar tus propios modelos. Piensa en los modelos básicos como modelos listos para usar y en los modelos de base como kits de iniciación "hazlo tú mismo".
Utilizaremos los modelos básicos listos para usar para realizar las tareas básicas de PNL. Primero vamos a importar el modelo básico:6
# Import spacy and download language modelimportspacynlp=spacy.load("en_core_web_trf")
Ahora, vamos a realizar la primera de las tareas de PNL: la tokenización.
Tokenización
La tokenización es el punto de partida de todo el trabajo de PNL en ; antes de que la máquina pueda procesar el texto que ve, debe dividirlo en tokens del tamaño de un bocado. La tokenización segmentará el texto en palabras, signos de puntuación, etc.
spacy ejecuta automáticamente todo el proceso de PLN cuando ejecutas un modelo lingüístico en los datos (es decir, nlp(SENTENCE)), pero para aislar sólo el tokenizador, invocaremos sólo el tokenizador utilizandonlp.tokenizer(SENTENCE).
A continuación, imprimiremos la longitud de las fichas y las fichas individuales:
# Tokenizationsentence=nlp.tokenizer("We live in Paris.")# Length of sentence("The number of tokens: ",len(sentence))# Print individual words (i.e., tokens)("The tokens: ")forwordsinsentence:(words)
The number of tokens: 5 The tokens: We live in Paris .
La longitud de los tokens es 5, y los tokens individuales son "We, live,in, Paris, .". El punto al final de la frase es su propio token.
Ten en cuenta que el tokenizador de spacy tratará como tokens las líneas nuevas (\n), los tabuladores (\t) y los caracteres de espacio en blanco más allá de un solo espacio (").
Probemos el tokenizador con un ejemplo algo más complejo.
Cargaremos preguntas de Jeopardy disponibles públicamente y luego ejecutaremos el modelo lingüístico spacy completo en algunas de las preguntas:
importpandasaspdimportoscwd=os.getcwd()# Import Jeopardy Questionsdata=pd.read_csv(cwd+'/data/jeopardy_questions/jeopardy_questions.csv')data=pd.DataFrame(data=data)# Lowercase, strip whitespace, and view column namesdata.columns=map(lambdax:x.lower().strip(),data.columns)# Reduce size of datadata=data[0:1000]# Tokenize Jeopardy Questionsdata["question_tokens"]=data["question"].apply(lambdax:nlp(x))
Ya hemos creado fichas para cada una de las 1.000 preguntas de Jeopardy.
Para asegurarnos de que ha funcionado correctamente, veamos la primera pregunta y los tokens creados:
# View first questionexample_question=data.question[0]example_question_tokens=data.question_tokens[0]("The first questions is:")(example_question)
The first questions is: For the last 8 years of his life, Galileo was under house arrest for espousing > this man's theory
# Print individual tokens of first question("The tokens from the first question are:")fortokensinexample_question_tokens:(tokens)
The tokens from the first question are: For the last 8 years of his life , Galileo was under house arrest for espousing this man 's theory
Esta es la primera tarea básica de PNL que realizan las máquinas ; ahora podemos pasar a las demás tareas de PNL. ¡Bien hecho!
Etiquetado de parte del discurso
Después de la tokenización, las máquinas necesitan etiquetar cada token con metadatos relevantes, como la parte del discurso de cada token. Esto es lo que haremos ahora.
Como aplicamos todo el modelo lingüístico spacy a las preguntas de Jeopardy, los tokens generados ya tienen muchos de los atributos/metadatos significativos que nos interesan.
spacy utiliza modelos estadísticos precargados para predecir la parte de la oración de cada token. Hemos cargado antes el modelo estadístico de la lengua inglesa utilizando este código: spacy.load("en_core_web_sm").
Echemos un vistazo a los atributos de etiquetado POS de los tokens de la primera pregunta:
# Print Part-of-speech tags for tokens in the first question("Here are the Part-of-speech tags for each token in the first question:")fortokeninexample_question_tokens:(token.text,token.pos_,spacy.explain(token.pos_))
Here are the Part-of-speech tags for each token in the first question: For ADP adposition the DET determiner last ADJ adjective 8 NUM numeral years NOUN noun of ADP adposition his PRON pronoun life NOUN noun , PUNCT punctuation Galileo PROPN proper noun was AUX auxiliary under ADP adposition house NOUN noun arrest NOUN noun for ADP adposition espousing VERB verb this DET determiner man NOUN noun 's PART particle theory NOUN noun
El primer token "Para" está marcado como una adposición (por ejemplo, en, a, durante); el segundo token "el" es un determinante (por ejemplo, a, un, la); el tercer token "último" es un adjetivo, el cuarto token "8" es un numeral; el quinto token "años" es un sustantivo; y así sucesivamente.
La Tabla 1-1 muestra la lista completa de todas las etiquetas POS posibles, incluyendo descripciones y ejemplos de cada una.7
| TPV | Descripción | Ejemplo |
|---|---|---|
|
Adjetivo |
Grande, viejo, verde, incomprensible, primero |
|
Adposición |
En, a, durante |
|
Adverbio |
Muy, mañana, abajo, donde, allí |
|
Auxiliar |
Es, ha (hecho), hará (hará), debería (hacer) |
|
Conjunción |
Y, o, pero |
|
Conjunción coordinadora |
Y, o, pero |
|
Determinante |
A, an, el |
|
Interjección |
Psst, ouch, bravo, hola |
|
Sustantivo |
Niña, gato, árbol, aire, belleza |
|
Numeral |
1, 2017, uno, setenta y siete, IV, MMXIV |
|
Partículas |
no |
|
Pronombre |
Yo, tú, él, ella, yo mismo, ellos mismos, alguien |
|
Nombre propio |
Mary, John, Londres, OTAN, HBO |
|
Puntuación |
., (, ), ? |
|
Conjunción subordinante |
Si, mientras, que |
|
Símbolo |
×, %, §, ©, +, -, ×, ÷, =, :), |
|
Verbo |
Corre, corre, corriendo, come, comía, comiendo |
|
Otros |
Sfpksdpsxmsa |
|
Espacio |
|
Ahora que hemos utilizado el tokenizador para crear tokens para cada frase y el etiquetado de parte de discurso para etiquetar cada token con atributos significativos, vamos a etiquetar la relación de cada token con otros tokens de la frase. En otras palabras, encontremos la estructura inherente entre los tokens de dados los metadatos de parte de discurso que hemos generado.
Análisis sintáctico de dependencias
El análisis sintáctico de dependencias es el proceso de encontrar estas relaciones entre los tokens. Una vez realizado este paso, podremos visualizar las relaciones mediante un gráfico de análisis sintáctico de dependencias.
En primer lugar, veamos las etiquetas de análisis sintáctico de dependencias para cada uno de los tokens de la primerapregunta:
# Print Dependency Parsing tags for tokens in the first questionfortokeninexample_question_tokens:(token.text,token.dep_,spacy.explain(token.dep_))
For prep prepositional modifier the det determiner last amod adjectival modifier 8 nummod numeric modifier years pobj object of preposition of prep prepositional modifier his poss possession modifier life pobj object of preposition , punct punctuation Galileo nsubj nominal subject was ROOT None under prep prepositional modifier house compound compound arrest pobj object of preposition for prep prepositional modifier espousing pcomp complement of preposition this det determiner man poss possession modifier 's case case marking theory dobj direct object
El primer token "Para" está marcado como modificador preposicional; el segundo token "los" es un determinante; el tercer token "últimos" es un modificador adjetival; el cuarto token "8" es un modificador numérico; el quinto token "años" es objeto de preposición; etc.
La Tabla 1-2 enumera todas las posibles etiquetas de dependencia sintáctica, incluyendo descripciones y ejemplos de cada una.8
| Etiqueta | Descripción |
|---|---|
|
Modificador clausal del sustantivo (cláusula adjetival) |
|
Modificador de cláusula adverbial |
|
Modificador adverbial |
|
Modificador adjetival |
|
Modificador aposicional |
|
Auxiliar |
|
Marcado de casos |
|
Conjunción coordinadora |
|
Complemento de cláusula |
|
Clasificador |
|
Compuesto |
|
Conjunción |
|
Cópula |
|
Sujeto de la cláusula |
|
Dependencia no especificada |
|
Determinante |
|
Elemento del discurso |
|
Elemento dislocado |
|
Expletivo |
|
Corregida la expresión multipalabra |
|
Expresión plana multipalabra |
|
Combina con |
|
Objeto indirecto |
|
Lista |
|
Marcador |
|
Modificador nominal |
|
Sujeto nominal |
|
Modificador numérico |
|
Objeto |
|
Nominal oblicuo |
|
Huérfano |
|
Parataxis |
|
Puntuación |
|
Disfluencia anulada |
|
Raíz |
|
Vocativo |
|
Complemento clausal abierto |
Estas etiquetas ayudan a definir las relaciones entre los tokens; utilizando estas etiquetas, podemos comprender la estructura de relaciones entre los tokens que componen la frase.
El análisis sintáctico de las dependencias es difícil de desempaquetar, así que utilicemos el visualizador integrado de spacypara hacernos una mejor idea de las dependencias entre los tokens:
# Visualize the dependency parsefromspacyimportdisplacydisplacy.render(example_question_tokens,style='dep',jupyter=True,options={'distance':120})
La Figura 1-2 muestra la primera parte de la frase analizada.
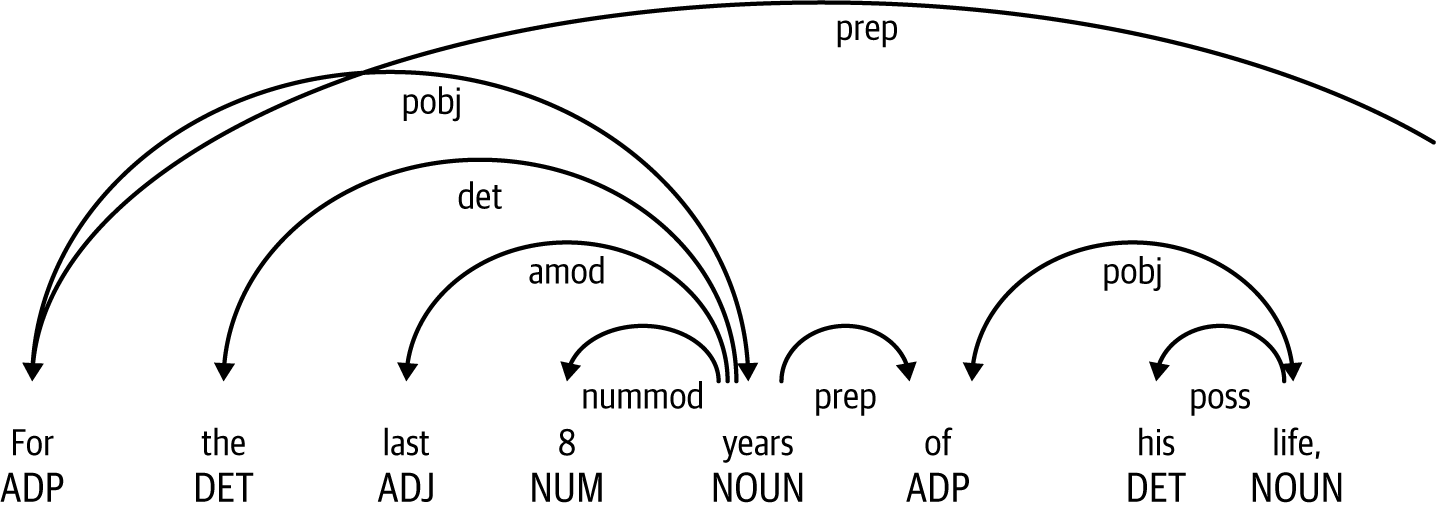
Figura 1-2. Ejemplo de análisis sintáctico de dependencias, parte 1
Fíjate en la importancia de "Para" y "años" en la frase preposicional: varios tokens corresponden a estos dos.
La Figura 1-3 muestra la segunda parte de la frase analizada.
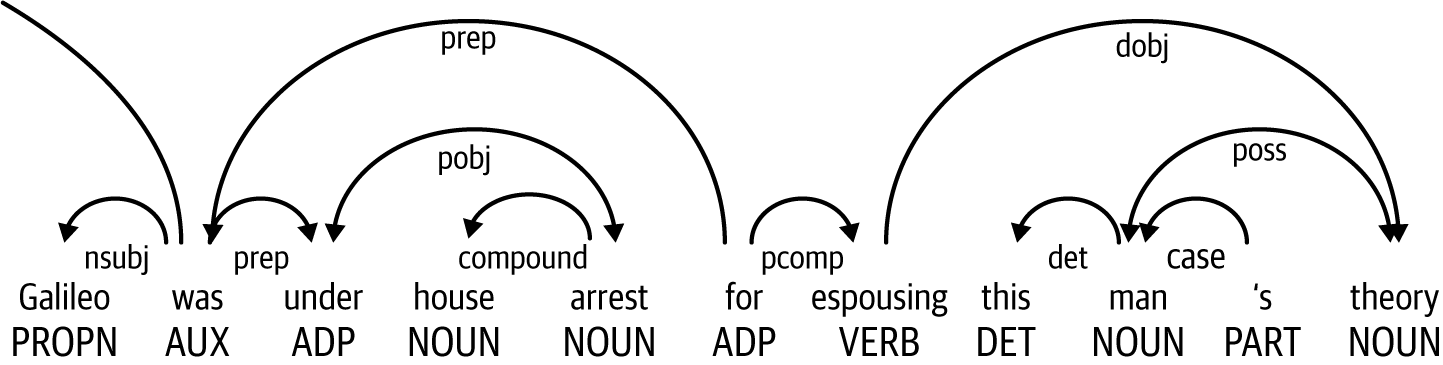
Figura 1-3. Ejemplo de análisis sintáctico de dependencias, parte 2
El token "estaba" conecta con el sujeto nominal "Galileo" y dos frases preposicionales: "bajo arresto domiciliario" y "por defender la teoría de este hombre".
Estas figuras muestran cómo se pueden agrupar determinados tokens y cómo se relacionan entre sí los grupos de tokens. Éste es un paso esencial en la PNL. En primer lugar, la máquina descompone la frase en tokens. A continuación, asigna metadatos a cada token (por ejemplo, parte de la oración), y luego conecta los tokens en función de su relación entre sí.
Pasemos al chunking, que es otra forma de agrupación de fichas relacionadas.
Agrupar
Realicemos el chunking en la frase "Mis padres viven en Nueva York":
# Print tokens for example sentence without chunkingfortokeninnlp("My parents live in New York City."):(token.text)
My parents live in New York City .
La fragmentación combina fichas relacionadas en una sola ficha.
Con el chunking, el modelo lingüístico spacy identificará "Mis padres" y "Nueva York" como trozos de sustantivos, igual que haría un humano al analizar una frase:
# Print chunks for example sentenceforchunkinnlp("My parents live in New York City.").noun_chunks:(chunk.text)
My parents New York City
Al agrupar los tokens relacionados en trozos, a la máquina le resultará más fácil procesar la frase. En lugar de ver cada token de forma aislada, la máquina reconoce ahora que ciertos tokens están relacionados con otros, un paso necesario en la PNL.
Lematización
Ahora, vayamos un paso más allá y realicemos la lematización. Si recuerdas, la lematización es el proceso de convertir palabras en sus formas básicas (o canónicas); por ejemplo, "caballos" en "caballo", "dormido" en "dormir" y "mayor" en "grande". Al igual que el etiquetado de partes del discurso, el análisis sintáctico de dependencias y el chunking, la lematización ayuda a la máquina a "procesar" los tokens. Con la lematización, la máquina puede simplificar los tokens convirtiendo algunos de ellos en sus formas más básicas.
La separación de palabras es un concepto relacionado, pero la separación de palabras es más sencilla. La separación reduce las palabras a sus raíces, a menudo mediante un enfoque basado en reglas.
La lematización es un proceso más difícil, pero suele dar mejores resultados; la separación de palabras a veces crea resultados sin sentido (sin palabras). De hecho, spacy ni siquiera admite el stemming; sólo admite la lematización.
Crearemos un DataFrame para almacenar y visualizar las versiones original y lematizada de los tokens, una al lado de la otra:
# Print lemmatization for tokens in the first questionlemmatization=pd.DataFrame(data=[],\columns=["original","lemmatized"])i=0fortokeninexample_question_tokens:lemmatization.loc[i,"original"]=token.textlemmatization.loc[i,"lemmatized"]=token.lemma_i=i+1lemmatization
| Original | Lemmatizado | |
|---|---|---|
| 0 | Para | para |
| 1 | el | el |
| 2 | último | último |
| 3 | 8 | 8 |
| 4 | años | año |
| 5 | de | de |
| 6 | su | su |
| 7 | vida | vida |
| 8 | , | , |
| 9 | Galileo | Galileo |
| 10 | era | escribe a |
| 11 | en | en |
| 12 | casa | casa |
| 13 | detención | detención |
| 14 | para | para |
| 15 | que propugna | defiende |
| 16 | este | este |
| 17 | hombre | hombre |
| 18 | 's | 's |
| 19 | teoría | teoría |
Como puedes ver, palabras como "años", "fue" y "espousing" se lematizan a sus formas base. Los demás tokens ya son sus formas básicas, por lo que el resultado lematizado es el mismo que el original. La lematización simplifica los tokens a sus formas más sencillas, siempre que sea posible, para simplificar el proceso de a la máquina para analizar frases.
Reconocimiento de entidades con nombre
Cuando se combinan, todo lo que hemos hecho hasta ahora -kenización, etiquetado de partes del discurso, análisis sintáctico de dependencias, fragmentación y lematización- hace posible que las máquinas realicen tareas de PLN más complejas. Un ejemplo de tarea compleja de PLN es el reconocimiento de entidades con nombre (también conocido como "NER"), que analiza entidades notables en el lenguaje natural y las etiqueta con su etiqueta de clase apropiada. Por ejemplo, el NER etiqueta los nombres de las personas con la etiqueta "Persona" y los nombres de las ciudades con la etiqueta "Lugar".
La NER sólo es posible porque la máquina es capaz de realizar la clasificación del texto utilizando los metadatos generados por las tareas anteriores de PLN que hemos tratado. Sin los metadatos de las tareas anteriores de PLN, la máquina tendría muchas dificultades para realizar la NER porque no tendría suficientes características para clasificar nombres de personas como "Persona", nombres de ciudades como "Lugar", etc.
NER es una valiosa tarea de PNL porque muchas organizaciones necesitan procesar montones y montones de documentos en volumen, y el simple acto de etiquetar entidades notables con la etiqueta de clase adecuada es un primer paso significativo en el análisis de la información textual, sobre todo para las tareas de recuperación de información (por ejemplo, encontrar la información que necesitas lo más rápidamente posible).
Estos documentos incluyen contratos, arrendamientos, acuerdos de compra de bienes inmuebles, informes financieros, artículos de noticias, etc. Antes del reconocimiento de entidades con nombre, los humanos habrían tenido que etiquetar dichas entidades a mano (en muchas empresas, todavía lo hacen). Ahora, el reconocimiento de entidades con nombre proporciona una forma algorítmica de realizar esta tarea.
spacyes capaz de etiquetar muchos tipos de entidades notables ("objetos del mundo real"). La Tabla 1-3 muestra el conjunto actual de tipos de entidades que el modelo spacy es capaz de reconocer.
| Tipo | Descripción |
|---|---|
|
Personas, incluidas las ficticias |
|
Nacionalidades o grupos religiosos o políticos |
|
Edificios, aeropuertos, carreteras, puentes, etc. |
|
Empresas, organismos, instituciones, etc. |
|
Países, ciudades, estados |
|
Lugares no GPE, cadenas montañosas, masas de agua |
|
Objetos, vehículos, alimentos, etc. (no servicios) |
|
Nombra huracanes, batallas, guerras, acontecimientos deportivos, etc. |
|
Títulos de libros, canciones, etc. |
|
Documentos con nombre convertidos en leyes |
|
Cualquier lengua con nombre |
|
Fechas o periodos absolutos o relativos |
|
Tiempos inferiores a un día |
|
Porcentaje, incluido %. |
|
Valores monetarios, incluida la unidad |
|
Medidas, como de peso o distancia |
|
"Primero", "segundo", etc. |
|
Números que no pertenecen a otro tipo |
Es muy importante señalar que el NER es, en esencia, un modelo de clasificación. Utilizando el contexto que rodea al token de interés, el modelo NER predice el tipo de entidad del token de interés. El NER es un modelo estadístico, y el corpus de datos con el que se ha entrenado el modelo importa mucho. Para mejorar el rendimiento, los desarrolladores de estos modelos en la empresa afinarán los modelos NER base en su corpus particular de documentos para conseguir un mejor rendimiento frente al modelo NER base.
Vamos a probar el modelo NER de spacy. Realizaremos el NER en la primera frase del artículo de Wikipedia (consultado en marzo de 2021) que describe a George Washington, el primer presidente de Estados Unidos. Esta es la frase
George Washington fue un líder político, general militar, estadista y Padre Fundador estadounidense que ejerció como primer presidente de Estados Unidos de 1789 a 1797.
Como puedes ver, aquí hay que reconocer varios objetos del mundo real, como "George Washington" y "Estados Unidos":
# Print NER resultsexample_sentence="George Washington was an American political leader,\military general, statesman, and Founding Father who served as the\first president of the United States from 1789 to 1797.\n"(example_sentence)("Text Start End Label")doc=nlp(example_sentence)fortokenindoc.ents:(token.text,token.start_char,token.end_char,token.label_)
George Washington was an American political leader, military general, statesman, > and Founding Father who served as the first president of the United States > from 1789 to 1797. Text Start End Label George Washington 0 17 PERSON American 25 33 NORP first 119 124 ORDINAL the United States 138 155 GPE 1789 to 1797 161 173 DATE
Hay cuatro elementos en la salida. En primer lugar, el texto que compone la entidad; ten en cuenta que el texto puede ser un único token o un conjunto de tokens que compongan toda la entidad. Segundo, la posición inicial del texto en la frase. Tercero, la posición final del texto en la frase. Cuarto, la etiqueta de la entidad.
Para hacer aún más evidente el valor de NER, utilicemos el visualizador integrado de spacypara visualizar esta frase con las etiquetas de entidad pertinentes:
# Visualize NER resultsdisplacy.render(doc,style='ent',jupyter=True,options={'distance':120})
Como puedes ver en la Figura 1-4, el modelo NER de spacy hace un gran trabajo al etiquetar las entidades. "George Washington" es una persona, y el texto empieza en el índice 0 y termina en el índice 17. Su nacionalidad es "estadounidense". "Primero" se etiqueta como un número ordinal, "Estados Unidos" es una entidad geopolítica y "1789 a 1797" es una fecha.

Figura 1-4. Visualizar los resultados del NER
La frase está bellamente representada con etiquetas codificadas por colores según el tipo de entidad. Se trata de una tarea de PNL potente y significativa; puedes ver cómo hacer este etiquetado dirigido por máquinas a escala sin humanos podría añadir mucho valor a las empresas que trabajan con muchos datos textuales. Por supuesto, para entrenar un modelo así en primer lugar, necesitas tener muchos humanos que anoten los datos textuales. Y puede que necesites humanos en el bucle para tratar casos de perímetro en producción. Nunca estarás realmente libre de humanos, pero tal vez en última instancia puedas llegar a un proceso mayoritariamente libre de humanos.
Enlace de entidades con nombre
Otra tarea PNL compleja pero muy útil en la empresa es la vinculación de entidades con nombre (NEL ). El NEL resuelve una entidad textual con un identificador único en una base de conocimientos. En otras palabras, la NEL resuelve la entidad de tu texto fuente con una versión canónica en una base de conocimientos. Vamos a intentar vincular todas las entidades que tienen nombre de persona al Gráfico del Conocimiento de Google. Haremos una llamada a la API de Google Knowledge Graph para realizar esta vinculación de entidades con nombre.9
Aquí tienes la función para realizar esta llamada a la API:
# Import librariesimportrequests# Define Google Knowledge Graph API Result functiondefreturnGraphResult(query,key,entityType):ifentityType=="PERSON":=f"https://kgsearch.googleapis.com/v1/entities:search\?query={query}&key={key}"resp=requests.get()url=resp.json()['itemListElement'][0]['result']\['detailedDescription']['url']description=resp.json()['itemListElement'][0]['result']\['detailedDescription']['articleBody']returnurl,descriptionelse:return"no_match","no_match"
Vamos a realizar la vinculación de entidades en nuestro ejemplo de George Washington:
# Print Wikipedia descriptions and URLs for entitiesfortokenindoc.ents:url,description=returnGraphResult(token.text,key,token.label_)(token.text,token.label_,url,description)
Este es el resultado:
- George Washington
-
PERSON https://en.wikipedia.org/wiki/George_Washington George Washington was an American political leader, military general, statesman, and Founding Father, who also served as the first President of the United States from 1789 to 1797. - Americana
-
NORP no_match no_match - primero
-
ORDINAL no_match no_match - Estados Unidos
-
GPE no_match no_match - 1789 a 1797
-
DATE no_match no_match
Como puedes ver, George Washington es un PERSON y está enlazado correctamente con la URL y la descripción de Wikipedia "George Washington". El resto no son del tipo de entidad PERSON y no están enlazadas. Si lo deseas, también podríamos enlazar las demás entidades con nombre, como Estados Unidos, a los artículos pertinentes de Wikipedia.
La NEL tiene muchos casos de uso en la empresa, sobre todo porque la necesidad de vincular información a una taxonomía surge una y otra vez (por ejemplo, vincular teletipos de bolsa, medicamentos farmacéuticos, empresas que cotizan en bolsa, productos de consumo, etc., a versiones canónicas de en una taxonomía o base de conocimientos).
Conclusión
En este capítulo, hemos definido la PNL y tratado sus orígenes, incluidas algunas de las aplicaciones comerciales que son populares en la empresa hoy en día. A continuación, hemos definido algunas tareas básicas de PNL y las hemos realizado utilizando la biblioteca de PNL de gran rendimiento conocida como spacy. Deberías dedicar más tiempo a utilizarspacy, incluida la revisión de la documentación disponible en Internet, para perfeccionar lo que has aprendido en este capítulo.
Aunque las tareas que hemos realizado son muy básicas, cuando se combinan, las tareas de PLN como la tokenización, el etiquetado de partes del discurso, el análisis sintáctico de dependencias, el chunking y la lematización hacen posible que las máquinas realicen tareas de PLN aún más complejas, como el NER y el enlace de entidades. Esperamos que nuestro recorrido por estas tareas te haya ayudado a intuir cómo las máquinas son capaces de desempaquetar y procesar el lenguaje natural, desmitificando parte del espacio.
Hoy en día, la mayoría de las aplicaciones de PNL complejas no requieren que los profesionales realicen estas tareas manualmente, sino que las redes neuronales aprenden a realizarlas por sí solas. En el próximo capítulo, nos sumergiremos en algunos de los enfoques más avanzados utilizando la arquitectura Transformer y grandes modelos lingüísticos preentrenados de fast.ai y Hugging Face para mostrar lo fácil que es ponerse en marcha con la PNL hoy en día. Más adelante en el libro, volveremos a los fundamentos (con los que te hemos bromeado brevemente en este capítulo) y te ayudaremos a construir más conocimientos básicos de PNL.
1 Uno de los mayores saltos en la historia de la humanidad fue la formación de un lenguaje humano (también conocido como "natural"), que permitió a los humanos comunicarse entre sí, formar grupos y funcionar como unidades colectivas de personas en lugar de como individuos solitarios.
2 Para más información, lee el artículo de The New York Times Magazine de 2016 sobre la traducción automática neuronal de Google.
3 Para más información, consulta el artículo de Wikipedia sobre el Test de Turing.
4 Para más información sobre GitHub, visita el sitio web de GitHub y las instrucciones de Google Colab sobre la integración con GitHub.
5 La operación de tomar un modelo desarrollado para una tarea y utilizarlo como punto de partida para un modelo sobre una segunda tarea se conoce como aprendizaje por transferencia.
6 Un modelo lingüístico spacy no es lo mismo que lo que generalmente denominamos en la literatura de la PNL un modelo lingüístico. Para más información sobre el modelado lingüístico, consulta el Capítulo 2.
7 Visita la documentación despacy POS para más información.
8 Para más información, visita la documentación despacy .
9 Necesitarás tu propia clave API de Google Knowledge Graph para realizar esta llamada API en tu máquina. La realizaremos utilizando nuestra propia clave API con fines ilustrativos.
Get Procesamiento del Lenguaje Natural Aplicado en la Empresa now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

