Chapter 4. Identity and Access Management
Identity and access management (IAM) is perhaps the most important set of security controls. In breaches involving web applications, lost or stolen credentials have been attackers’ most-used tool for several years running.1 If attackers have valid credentials to log in to your system, all of the patches and firewalls in the world won’t keep them out!
Identity and access management are often discussed together, but it’s important to understand that they are distinct concepts:
-
An identity is how a person (or automation) is represented in the system.2 The process of verifying that the entity making a request is really the owner of the identity is called authentication (often abbreviated as “authn”).
-
Access management is about allowing identities to perform the tasks they need to perform (and, in a least privilege environment, only the tasks they need to perform). The process of checking what privileges an identity should have is called authorization (often abbreviated as “authz”).
Authentication is proving that you are who you say you are. In the physical world, this might take the form of presenting an ID card, which was issued by a trusted authority and has your picture on it. Anyone can inspect that credential, look at you, and decide whether to believe that you are who you say you are. As an example, if you drive up to a military base and present your driver’s license, you’re attempting to authenticate yourself with the guard. The guard may choose to believe you, or may decide you’ve provided someone else’s driver’s license or that it’s been forged, or may tell you that the base only accepts military IDs and not driver’s licenses.
Authorization refers to the ability to perform a certain action, and generally depends first on authentication (knowing who someone is). For example, the guard at the base may say, “Yes, I believe you are who you say you are, but you’re not allowed to enter this base.” Or you may be allowed in, but not allowed access to most buildings once inside.
In IT security, we often muddle these two concepts. For example, we may create an identity for someone (with associated credentials such as a password) and then implicitly allow anyone with a valid identity to access all data on the system. Or we may revoke someone’s access by deleting the person’s identity—that works, but it’s like tearing up their driver’s license instead of just denying them access. Although these solutions may be appropriate in some cases, it’s important to understand the distinction. Is it really appropriate to authorize every user for full access to the system? What if you have to give someone outside the organization an identity in order to allow them to access some other area of the system—will that user also automatically gain access to internal resources?
Note that the concepts (and analogies) can get complicated very quickly. For example, imagine a system where instead of showing your license everywhere, you check out an access badge that you show to others, and a refresh badge that you need to show only to the badge issuer. The access badge authenticates you to everyone, but works for only one day, after which you have to go to the badge office and show the refresh badge to get a new access badge. Each site where you present your access badge verifies the signature on it to make sure it’s valid, and then calls a central authority to ask whether you’re on the list for access to that resource. This is similar to the way some IT access systems work, although fortunately your browser and the systems providing service to you take care of these details for you!
An important principle with identity and access management, as well as in other areas of security, is to minimize the number of organizations and people whom you have to trust. For example, except for cases where zero-knowledge encryption will work,3 you’re going to have to trust your cloud provider’s authentication and authorization processes to keep your data from being seen by unauthorized people. You have to accept the risk that if your provider is completely compromised, your data is compromised. However, since you’ve already decided to trust the cloud provider, you want to avoid trusting any other people or organizations if you can instead leverage that existing trust without incurring additional risk.4 Think of it like paying an admission fee; once you’ve paid the “fee” of trusting a particular organization, you should use it for all it’s worth to avoid introducing additional risk into the system.
Differences from Traditional IT
In traditional IT environments, access management is often performed in part by physical access controls (who can enter the building) or network access controls (who can connect to the network remotely). As an example, you may be able to count on a perimeter firewall as a second layer of protection if you fire an admin and forget to revoke their access to one of the servers.
It’s important to note that even in a non-cloud environment, this is often a very weak level of security—are you confident that the access controls for all of your Ethernet ports, wireless access points, and VPN endpoints will stand up to even casual attack? In most organizations, someone could ask to use the bathroom and plug a $5 remote access device into an Ethernet port on the way there, or steal wireless or VPN credentials to get in without even stepping foot on the premises. The chance of any given individual having their credentials stolen might be small, but the overall odds of having unauthorized people on the network increase quickly as you add more and more people to the environment.5 This is doubly true in cloud environments, where all access is remote access and the odds are even higher that you will have unauthorized people on a supposedly secure network.
In traditional environments, access control is sometimes performed simply by revoking a user’s entire identity, so that they can no longer log in at all. But when using cloud environments, this often won’t take care of the entire problem. For convenience, many services provide long-lived authentication tokens that will continue to work even without the ability to log in on a new session. Unless you’re careful to have an “offboarding” feed that notifies applications when someone leaves so that the application can revoke all access, people may retain access to things you didn’t intend. As an example, if you use a webmail service, when was the last time you typed in your webmail password? Changing your password or preventing you from using the login page wouldn’t do any good if webmail providers didn’t also revoke the access tokens stored in your browser cookies during a password change operation.
There are many examples of data breaches caused by leaving Amazon S3 buckets open to public access. If these were file shares left open to anyone in the company behind a corporate firewall, they might not have been found by an attacker or researcher on the internet. (In any organization of a reasonable size, there are almost certainly bad actors on the internal network who could have stolen that information, perhaps without detection, but the likelihood of attack is higher when it’s internet-facing.)
The point behind these examples is that many organizations find that they’ve lived with lax IAM controls on-premises, and need to improve them significantly for the cloud. Fortunately, there are services available to make this easier.
Life Cycle for Identity and Access
Many people make the mistake of thinking of IAM as only authentication and authorization. Although those are both very important, IAM also includes other parts of the identity life cycle. In the earlier example about attempting to enter a military base, we assumed that you, the requester, already had an identity (your driver’s license)—but how did you get that? And who put your name on the list of people who were allowed on the base?
Many organizations handle this poorly. Requesting an identity might be done by calling or messaging an administrator, who approves and creates the identity without keeping any record of it. This might work fine for really small organizations or low-risk environments, but many times you need a system to record when someone requests access, how the requester was authenticated, and who approved the new identity or the access.
Even more important is the backend of the life cycle. You need a system that will automatically check every so often if a user’s identity and access are still needed. Perhaps the person has left the company, or moved to a different department, and should no longer have access. (Or worse, imagine having the unpleasant task of firing someone, and realizing a month later that due to human error the person still has access to an important system!)
There are many different versions of IAM life cycle diagrams, with varying amounts of detail in the steps. The one in Figure 4-1 shows the minimum number of steps, and addresses both creation and deletion of identities along with creation and deletion of access rules for those identities. Identity and access may be handled by different systems or the same system, but the steps are similar.
Note that you don’t necessarily need a fancy automated system to implement every one of these steps. In an environment with few requesters and few approvers, a mostly manual process can work fine as long as it’s consistently implemented and there are checks to prevent a single human error from causing problems. As of this writing, most automated systems to manage the entire life cycle (often called identity governance systems) are geared toward larger enterprises; they are usually expensive and difficult to implement. However, there is a growing trend to provide these governance solutions in the cloud like other services. These are often included as part of other identity and access services, so even smaller organizations will be able to benefit from them.
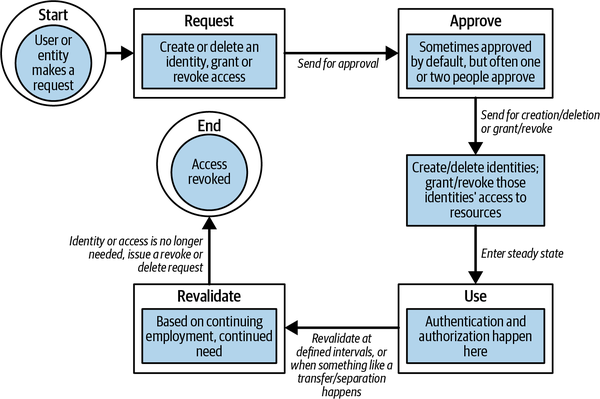
Figure 4-1. IAM life cycle
Also note that the processes and services used might differ considerably, depending on who the entities are. The types of identity and access management used to give your employees access to your cloud provider and your internal applications differ considerably from those used to grant your customers end-user access to your applications. I’ll distinguish between these two general cases in the following discussion.
Tip
Don’t forget about identities for non-human things in the system, such as applications. These need to be managed too, just like human identities. Many teams do a great job of controlling access for people, but have very lax controls on what automation is authorized to do.
Let’s go through each of these steps. The process starts when someone or something puts in a request. This might be the manager of a newly hired employee, or some automation such as your HR system.
Request
The life cycle begins when an entity makes an identity or access management request. This entity should usually be authenticated in some fashion. Inside your organization, you don’t want any anonymous requests for access, although in some cases the authentication may be as simple as someone visually or aurally recognizing the person.
When providing access to the general public—for example, for a web application—you often want to link to some other identity, such as an existing email address or a mobile phone number.
The common requests are:
-
Create an identity (and often implicitly grant that identity at least a base level of access).
-
Delete an identity, if the entity no longer needs to authenticate anywhere.
-
Grant access to an existing identity—for example, to a new system.
-
Revoke access from an existing identity.
In cloud environments, the request process often happens “out of band,” using a request process inside your organization that doesn’t involve the cloud IAM system yet.
Approve
In some cases, it’s acceptable to implicitly approve access. For example, when granting access to a publicly available web application, anyone who requests access is often approved automatically, provided that they meet certain requirements. These requirements might be anti-fraud in nature, such as providing a valid mobile number or email address, providing a valid credit card number, completing a CAPTCHA or “I am not a robot” form, or not originating from an anonymizing location such as an end-user VPN provider or a known Tor exit node.
However, inside an organization, most access requests should be explicitly approved. In many cases, two approvals are reasonable—for example, by the user’s immediate supervisor, as well as the owner of the system to which access is being requested. The important thing is that the approver or approvers are in a position to know whether the requested access is reasonable and necessary. This is also an internal process for your team that usually happens with no interaction with your cloud providers.
Create, Delete, Grant, or Revoke
After approval, the actual action to create an identity, delete an identity, grant access, or revoke access may happen automatically. For example, the request/approve system may use cloud provider APIs to create the identity or grant the access.
In other cases, this may generate a ticket, email, or other notification requiring a person to take manual action. For example, an admin may need to log in to the cloud portal to create the new identity and grant it a certain level of access. Automation is preferable, particularly for frequently requested items, to reduce the possibility of human error.
Authentication
So far, much of what has been discussed is not really different from access management in on-premises environments—before an identity exists, you have to request it and have a process to create it. However, authentication is where cloud environments begin to differ because of the many identity services available.
It’s important to distinguish between the identity store, which is the database that holds all of the identities, and the protocol used to authenticate users and verify their identities, which can be OpenID, SAML, LDAP, or others.
There are different cloud services available to help, depending on who is being authenticated:
-
Authenticating your organization’s employees with your cloud providers falls under business-to-business (B2B) authentication, and the cloud service is often called something like “Cloud IAM.”
-
Authenticating your organization’s customers with your own applications running in the cloud is often called business-to-consumer (B2C) authentication, and the cloud service is often called something like “Customer IAM” or “CIAM.”
-
Authenticating your organization’s employees with your own applications is often called business-to-employee (B2E) authentication; it may use the same services as B2C authentication or may be called something like “Workforce Identity.”
Cloud IAM Identities
Most cloud providers offer IAM services that must be used when accessing their cloud services. These are usually available for no additional charge. They allow you to have one central location to manage the identities of cloud administrators in your organization, along with the access that you have granted those identities to all of the services that cloud provider offers.
This can be a big help. If you are using dozens or hundreds of services from a cloud provider, it can be difficult to get a good picture of what level of access a given person has if you have to go separately to every service. It can also be difficult to make sure you’ve revoked all of their access when that person leaves your organization. Removing access is especially important, given that many of these services may be used directly from the internet!
Table 4-1 lists some examples of identity services to authenticate your cloud administrators with cloud provider services.
| Provider | Cloud identity service |
|---|---|
Amazon Web Services |
AWS IAM |
Microsoft Azure |
Azure Active Directory |
Google Cloud Platform |
Cloud IAM |
IBM Cloud |
Cloud IAM |
Business-to-Consumer and Business-to-Employee
In addition to the identities your organization uses for accessing cloud provider services, you may also need to manage identities for your end users, whether they are external customers or your own employees.
Although you can do customer identity management yourself by simply creating rows in a database with passwords, this is often not an ideal experience for your end users, who will have to juggle yet another login and password. In addition, there are significant security pitfalls to avoid when verifying passwords, as described in “Passwords, Passphrases, and API Keys”. There are two better options:
-
Use an existing identity service. This may be an internal identity service for your employees or your customers’ employees. For end users, it may also be an external service such as Facebook, Google, or LinkedIn. This requires you to trust that identity service to properly authenticate users for you. It also makes your association with the identity service obvious to your end users when they log in, which may not always be desirable.
-
Use customer identities specific to your application, and use a cloud service to manage these customer identities. Users still have another credential to deal with, but at least you don’t have to verify the credential.
The names of these Identity-as-a-Service (IDaaS) offerings do not always make it clear what they do. Table 4-2 lists some examples from major cloud infrastructure providers as well as third-party providers. There are many third-party providers in this space and they change often, so this isn’t an endorsement of any particular providers. For business-to-employee cases, most of these IDaaS services can also use your employee information store, such as your internal directory.
| Provider | Customer and workforce identity management cloud services |
|---|---|
Amazon Web Services |
Amazon Cognito |
Microsoft Azure |
Azure Active Directory B2C |
Google Cloud Platform |
Identity Platform |
IBM Cloud |
App ID |
Okta |
Customer Identity Cloud, Workforce Identity Cloud |
Ping |
PingOne for Customers, PingOne for Workforce |
Multi-Factor Authentication
Multi-factor authentication is one of the best ways to guard against weak or stolen credentials, and if implemented properly will only place a small additional burden on users. Most of the identity services shown in Table 4-2 support multi-factor authentication.
As background, the different authentication factors are commonly defined as:
-
Something you know. Passwords are the best-known examples, but personal identification numbers (PINs)—which, unlike a password, can only be used in conjunction with a specific device you have—are becoming more popular.
-
Something you have. For example, an access badge, a mobile phone, or a piece of data that is impractical to memorize, such as a randomly generated private key.
-
Something you are. For example, your fingerprint, face, or retinal pattern.
As the name implies, multi-factor authentication involves using more than one of these factors for authentication. Using two of the same factor, like two different passwords, doesn’t help much because the same attack could be used to get both passwords! The most common implementation is two-factor authentication (2FA), which uses something you know (like a password) and something you have (like your mobile phone).
Note
2FA does not require one of the factors to be a password. Passwordless logins that have two factors (such as a physical device you have and your fingerprint to unlock the device) can be considerably more secure and convenient than password authentication.
2FA should be the default for most access; if implemented correctly, it requires very little extra effort for most users. You should absolutely use 2FA any place where the impact of lost or stolen credentials would be high, such as for any privileged access, access to read or modify sensitive data, or access to systems such as email that can be leveraged to reset other passwords. For example, if you’re running a banking site, you may decide that the impact is low if someone is able to read a user’s bank balance, but high (with 2FA required) if someone is attempting to transfer money. Requiring additional authentication for higher-risk activities is called step-up authentication.
If you’re managing a cloud environment, unauthorized administrative access to the cloud portal or APIs is a very high risk to you, because an attacker with that access can usually leverage it to compromise all of your data. You should turn on two-factor authentication for this type of access; most cloud providers natively support this. Alternatively, if you’re using single sign-on (SSO), discussed in “Single Sign-On”, your SSO provider may already perform 2FA for you.
Many services offer multiple authentication methods. The most common methods are:
- Passwords and passphrases (something you know)
-
A password is not tied to a particular device, and will work from anywhere. The problems with passwords are plentiful and well known: many people choose passwords that are commonly used and subject to dictionary attacks, or are simple and short enough to be cracked with brute-force attacks, or are reused across multiple services so that compromising one service gives an attacker the password for another (which can be discovered through credential stuffing attacks). It’s really past time to stop using them, but change is hard.
- PINs (something you know)
-
On the surface, PINs may seem like they’re worse than passwords, because they’re usually simpler, but the important thing about PINs is that they are only useful when paired with a specific physical device. Someone who guesses your PIN without having the associated device (usually a mobile phone, laptop, or hardware security key) cannot gain access to it, which makes a successful attack much harder.
- SMS text messages to a mobile device (something you have)
-
This method has fallen out of favor because of the ease of stealing someone’s phone number (via SIM cloning or number porting) or intercepting the message, so new implementations should not use it, and existing implementations should move to another method. This does require cellular network access to receive the text messages.
- Time-based one-time passcodes, or TOTPs (something you have)
-
This method requires providing a mobile device with an initial “secret” (usually transferred by a 2D barcode). The secret is a formula for computing a one-time password every minute or so. The one-time password needs to be kept safe for only a minute or two, but the initial secret can allow any device to generate valid passwords and so should be destroyed or put in a physically safe place after use. After the initial secret is transferred, network access is not required for the mobile device, only a synchronized clock. The main drawback is that TOTPs are less convenient for users and are “phishable,” meaning that an attacker who fools you into entering both the password and the passcode into a fake site can gain access.
- Hash-based one-time passcodes, or HOTPs (something you have)
-
These are similar to TOTPs in both advantages and disadvantages, but use a counter instead of the time, so don’t require a synchronized clock. However, they can get out of sync if too many codes are generated and not used.
- Push notifications to a mobile device (something you have)
-
With this method, an already authenticated client application on a mobile device makes a connection to a server, which “pushes” back a one-time-use code or asks for permission. This is secure as long as the authentication for the already authenticated client application is secure, but does require network access for the mobile device. The primary drawback is that an attacker may be able to fool the user into saying yes either with a clever forgery site or by fatiguing the user with lots of requests.
- Fingerprint readers, face readers, and retina readers (something you are)
-
While these biometric methods are often foolable with enough effort (creating replica fingers or faces or eyes), the implementations continue to improve and they are good enough as a single factor to meet most security requirements.
- A hardware device, such as one complying with the FIDO Universal 2nd Factor (U2F) or FIDO2 standards (something you have)
-
FIDO U2F is only a second authentication factor, generally used with a password, while FIDO2 can function as a combined multi-factor device to allow passwordless authentication. FIDO2 devices are also called passkeys. This is by far the best option, because the passkey knows what application it’s talking to and can’t be fooled by fake sites. Initially, these were only available as standalone hardware security keys, but the technology is now built into most laptops and mobile devices. Use of this type of authentication is likely to become ubiquitous in the near future, integrated with smartphones and wearable technologies such as watches and rings. A FIDO2 device can be unlocked with a PIN or a biometric factor, which combines two factors into one device for very strong, phishing-resistant, passwordless authentication.
Warning
Note that many of these methods to verify “something you have” are vulnerable to social attacks, such as calling the user under false pretenses and asking for the one-time passcode! Even the strongest forms of authentication, such as FIDO2, can be subject to downgrade attacks if the user goes to a fake site that says, “That didn’t work, please try a different (weaker) method.” In addition to rolling out multi-factor authentication, you must provide some minimal training to users to help them recognize common attacks.
All major cloud providers offer ways to implement multi-factor authentication, although Google uses the friendlier term “2-Step Verification.”
Passwords, Passphrases, and API Keys
If you’re using multi-factor authentication, passwords or passphrases are no longer your only line of defense. That said, unless you’ve gone to a full passwordless model, it’s still important to choose good passwords. This is often even more true in cloud environments, because in many cases an attacker can guess passwords directly over the internet from anywhere in the world.
“Passphrase” is just a term for a longer, more secure password, so I’ll use the more generic term “password” here. While there is lots of advice and debate about good passwords, my recommendations for choosing passwords are simple:
-
Never reuse passwords unless you genuinely don’t care about an unauthorized user getting access to the resources protected by that password. For example, you might use the same password on a dozen forum systems because you don’t really care if someone posts as you on any or all of those forums. (Even then, though, there is still some risk that the user can somehow leverage that access to reset other passwords, so it’s best not to reuse passwords at all.) When you type a password into a site, you should assume that the site’s administrators are malicious and will use the password you have provided to break into other sites.
-
Not reusing passwords means you’ll end up with a lot of passwords, so use a reputable password wallet to keep track of them. Store copies of any master passwords or recovery keys in a physically secured location, such as a good safe or a bank safe deposit box.
-
For passwords that you do not need to remember (for example, that you can copy and paste from your password wallet), use a secure random generator. Twenty characters is a good target, although you may find some systems that won’t accept that many characters; for those, use as varied a character set as possible.6
-
For passwords you do need to remember, such as the password for your password wallet, create a six-word Diceware password7 and put the same non-alphabetic character, such as a dollar sign, equals sign, or comma, between each word. Feel free to regenerate the password a few times until you find one that you can construct some sort of silly story about to help you remember it. This will be easy to memorize quickly and nearly impossible for an attacker to guess. The only drawback is that it takes a while to type, so you don’t want to have to type it constantly!
API keys are very similar to passwords but are designed for use by automation, not people. For that reason, you cannot use multi-factor authentication with API keys, and they should be long random strings, as noted in item 3 in the preceding list. Unlike most user identities where you have a public user ID and a private password, you usually have only a private API key that tells the system who you are and also authenticates you.
Shared IDs
Shared IDs are identities for which more than one person has the password or other credentials, such as the built-in root or Administrator account on a system. These can be difficult to handle well in cloud environments, just as they are on-premises.
Where possible, every user or tool should have its own ID that’s not used by anyone or anything else. Many systems allow users to assume a privileged role or separate higher-privileged ID for some activities, such as by using sudo on Unix-like systems. When you do need to use shared IDs, you need to be able to tell exactly which individual (or automated tooling) was using the ID for any access.
If you do have to share an ID, such as root, the system you’re using the shared ID on has no way of distinguishing who was using it. That means you need to have a separate process and tooling to check out the shared credentials and then change them when they’re checked back in. This tooling is usually called a privileged access management (PAM) or privileged identity management (PIM) system, and it can also perform other functions, such as recording the session or prohibiting the use of some commands.
Federated Identity
Federated identity is a concept, not a specific technology. It means that you may have identities on two different systems, and the administrators of those systems can both agree to use technologies that link those identities together so that you don’t have to manually create separate accounts on each system. From your perspective as a user, you have only a single identity.
In practice what this usually means is that Company A and Company B both use your corporate email address, such as user@company-a.com, as your identity, and Company B defers to Company A to actually authenticate you. Company A will then pass an assertion or token back with its seal of approval: “Yes, this is indeed user@company-a.com; I have verified them, here is my signature to prove that it’s me, and you’ve already agreed that you’ll trust me to authenticate users with identifiers that end in @company-a.com.”
Single Sign-On
Single sign-on (SSO) is a set of technology implementations that rely upon the concept of federated identity.
In the bad old days, every website had a separate login and password. That’s a lot of passwords for users to keep track of! The predictable result is that users often reuse the same password across multiple sites, meaning that the user’s password is only as well protected as the weakest site.
Enter SSO. The idea is that instead of a website asking for a user’s ID and password, the website instead redirects the user to a centralized identity provider (IdP) that it trusts. (Note that the identity provider may not even be part of the same organization—the only requirement is that the website trusts it.) The IdP will do the work of authenticating the user, via means such as a username and password, and hopefully an additional authorization factor. It will then send the user back to the original website with proof that it has verified the user. In some cases, the IdP will also send information (such as group membership) that the website can use to make authorization decisions, such as whether the user should be allowed in as a regular user, as an administrator, or not at all.
For the most part, SSO works only for websites and mobile applications, although this is beginning to change. You may need a different protocol (such as LDAP, Kerberos, TACACS+, or RADIUS) for performing centralized authentication to non-web assets like network devices or operating systems.
Rarely do you find something that’s both easier for users and provides better security! Users only have to remember one set of credentials, and because these credentials are only ever seen by the identity provider (and not any of the individual sites), a compromise of those sites won’t compromise the user’s credentials. In addition, your SSO provider can implement controls that follow other zero trust principles, such as checking whether an unmanaged or out-of-date device is being used, or if the user’s credentials are being used from two different countries at the same time. These types of controls are very difficult to implement individually on each application.
The only drawback to SSO is that it is slightly more difficult for a website to implement than poor authentication mechanisms, such as comparing against a plain-text password or an insecurely hashed password in a database.
SAML and OIDC
As of this writing, Security Assertion Markup Language (SAML—the abbreviation rhymes with “camel”) and OpenID Connect (OIDC) are the most common SSO technologies. While the end results are similar, the mechanisms they use are somewhat different.
The current SAML version is 2.0, and it has been around since 2005. This is one of the most common SSO technologies, particularly for large enterprise applications. While there are many in-depth explanations of how SAML works, here is a very simplified version:
-
You point your web browser at a web page you want to access (called a service provider, or SP).
-
The SP web page says, “Hey, you don’t have a SAML cookie, so I don’t know who you are. Go over here to this identity provider web page and get one,” and redirects you.
-
You go to the IdP and log in using your username, password, and hopefully a second factor, or a passwordless method.
-
When the IdP is satisfied it’s really you, it gives your browser a cookie with a cryptographically signed XML “assertion” that says, “I’m the identity provider, and this user is authenticated,” and then redirects you back.
-
Your web browser hands that cookie back to the first web page (SP). The SP verifies the cryptographic signature and says, “You managed to convince the IdP of your identity, so that’s good enough for me. Come on in.”
After you’ve logged in once, this all happens automatically for a while until those assertion documents expire, at which point you have to log in to the IdP again.
One important thing to note is that there was never any direct communication between the initial web page and the identity provider—your browser did all of the hard work to get the information from one place to another. That can be important in some cases where network communications are restricted.
Also note that SAML provides only identity information, by design. Whether or not you’re authorized to log in or take other actions is a different question, although some SAML implementations pass additional information along with the assertion (such as group membership) that can be used by the application to make authorization decisions.
OpenID Connect is a much newer authentication layer, finalized in 2014, on top of OAuth 2.0. It uses JSON Web Tokens (JWTs, sometimes pronounced “jots”) instead of XML, and uses somewhat different terminology (“relying party” is usually used in OIDC versus “service provider” in SAML, for example).
OIDC offers both Authorization Code Flows (for traditional web applications) and Implicit Flows (for applications implemented using JavaScript on the client side). While there are numerous differences from SAML, the end results are similar in that the application you’re authenticating with never sees your actual password, and you don’t have to reauthenticate for every application.
Some services can take requests from OIDC-enabled applications and “translate” these to requests to a SAML IdP. In larger organizations, it’s very common to have both standards in use, and most IdPs support both.
SSO with legacy applications
What if you want to provide single sign-on to a legacy application that doesn’t support it? One option is to put something in front of the application that handles the SSO requests and then tells the legacy application who the users are.
The legacy application will trust this frontend service (often a reverse proxy) to perform authentication, but it’s very important that it not accept connections from anything else. Techniques like this are sometimes needed when moving an existing application to the cloud, until the application can be reworked to allow SSO natively. Many of the Identity-as-a-Service providers listed earlier also offer ways to SSO-enable legacy applications.
Instance Metadata and Identity Documents
As mentioned earlier in this chapter, we often assume that automation, such as a program running on a system, has already been assigned an identity and a way to prove that identity. For example, if I start up a new system, I can create a username and password for that system to use and supply that username and password to the system as part of the process of creating it. However, in many cloud environments, there are easier ways.
A process running on a particular system can contact a well-known endpoint that will tell it all about the system it’s running on, and the process will also provide a cryptographically signed way to prove that system’s identity. The exact details differ from provider to provider, but conceptually it looks like Figure 4-2.
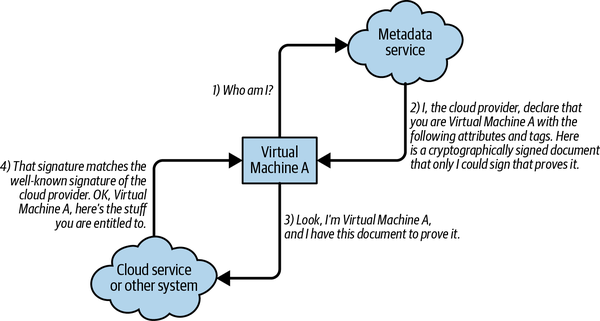
Figure 4-2. Using identity documents
This is not foolproof, however, in that any process on the system can request this metadata, regardless of its privilege level on the system. This means you either need to put only processes of the same trust level on the system, or take actions to block lower-privileged processes from assuming the identity of the entire system. This can be a particular concern in container environments, where any container on a host system could request the identity document and then pretend to be that host system. In cases like this, you need to block the containers from reaching the metadata service.
This system also requires the cloud service to recognize the particular type of document and signature that the metadata service is using. If only there were a standard format for these documents and signatures, so that the cloud service could choose to trust containers created in a particular cluster or virtual machines created in a specific cloud account! Enter SPIFFE, which is a standard method for allowing a workload (which may be a container, a virtual machine, a multi-node application, etc.) to authenticate with something else. SPIRE is a reference implementation of the SPIFFE specification. As of this writing, SPIFFE is not widely used, but eventually it or a similar specification is likely to eliminate the widespread use of static API keys for authentication. Instead of configuring the system to trust anyone who gets the API key, you’ll configure it to only trust those workloads that can both show you a valid ID and are on your list of things to trust.
If you can use identity documents, then you don’t need to do as much secrets management. As a workload, I can make a simple request and be given the secrets that I need to access other resources, and then forget the secrets and ask again if I need them later. However, given that identity documents are not yet in widespread use, and that many types of resources don’t accept them yet, you’ll need some tools and techniques for managing secrets. We’ll look at those next.
Secrets Management
I talked about passwords earlier primarily in the context of a person authenticating with a system. Administrative users and end users have had secrets management techniques for as long as there have been secrets, ranging from good (password wallets and physical safes) to really bad (the ubiquitous Post-it note on the monitor or under the keyboard). While the term secrets management generally applies any time you have a secret to remember, it’s usually used more specifically to refer to secrets used by one system to talk to another.
For example, let’s look at the case where an application server needs to talk to a database server. Clearly, multi-factor authentication can’t be used here; the application server doesn’t have a hardware security key or a fingerprint!8 This means you need to be very careful with the authentication credentials for system-to-system connections, because they may be your only line of authentication defense.
System-to-system authentication credentials may involve a password, API key, cryptographic token, or public/private key pair. All of these solutions have something that needs to be kept secret. We refer to all of these things simply as secrets, and secrets management is about making them available to the entity that needs them—and nobody else. (In addition, you may have items unrelated to authentication that need to be kept secret, such as encryption keys; while these are also technically secrets, they’re usually covered more specifically under encryption key management.)
Secrets are dangerous things that should be handled carefully. Here are some principles for managing secrets:
-
Secrets should be easy to change at regular intervals and whenever there’s any reason to think they may have leaked out. If changing the secret means that you have to take the application down and manually change it in many places, that’s a problem.
-
Secrets should always be encrypted at rest and in motion, and they should be distributed to systems only after proper authentication and authorization.
-
If possible, no human should know the secrets—not the developers who write the code, not the operators who can look at the running system, nobody. This often is not possible, but we should at least strive to minimize number of people who know secrets!
-
The system storing and handing out the secrets should be well protected. If you put all the secrets in a vault and then hand out keys to the vault to dozens of people, that’s a problem.
-
Secrets should be as useless to an attacker as possible while allowing the system to function. This is again an instance of least privilege; try not to keep secrets around that offer the keys to the kingdom, such as providing root access to all systems, but instead have limited secrets, such as a secret that allows read-only access to a specific database.
-
All accesses and changes to secrets should be logged.
Even organizations that do a great job with authentication and authorization often overlook secrets management. For example, you may do a great job keeping track of which people have personal IDs with access to a database, but how many people know the password that the application server uses to talk to the database? Does it get changed regularly, and immediately if someone leaves the team? In the worst case, this password is in the application server code and checked into some public repository, such as GitHub.9
There have been many breaches resulting from accidentally storing secrets, such as AWS API keys, in source code. The code needs the credentials to function when it’s deployed, but putting secrets directly into source code (or into the source code repository as part of a configuration file) is a really bad idea, for two reasons:
-
The source code repository likely was not designed primarily for keeping information secret. Its primary function is protecting the integrity of the source code—preventing unauthorized modification to insert a backdoor, for example. In many cases, it may show the source code to everyone by default as part of a social coding initiative.
-
Even if the source code repository is perfectly safe, it’s very unlikely that everyone who has access to the source code should also be authorized to see the secrets used in the production environment.
The most obvious solution is to take the secrets out of the source code and place them somewhere else, such as in a safe place in your deployment tooling or on a dedicated secrets server.
In most cases, a deployment of an application will consist of three pieces that come together:
-
The application code
-
The configuration for this particular deployment
-
The secrets needed for this particular deployment
Storing all three of these things together is a really bad idea, as previously discussed. Having configuration and secrets together is also often a bad idea, because systems designed to hold configuration data may not be properly designed for keeping that data secret.
Let’s take a look at four reasonable approaches to secrets management, ranging from minimally secure to highly secure.
The first approach is to use existing configuration management systems and deployment systems for storing secrets. Many popular systems today have some ability to hold secrets in addition to normal configuration data—for example, Ansible Vault and Chef encrypted data bags. This can be a reasonable approach if the deployment tooling is careful with the secrets, and more importantly if access to the deployment system and encryption keys is tightly controlled. However, there are often too many people who can read the secrets. In addition, changing secrets usually requires redeploying the system, which may be more difficult in some environments.
The second approach is to use a secrets server. With a separate secrets server, you need only a reference to the secret in the configuration data and the ability to talk to the secrets server. At that point, either the deployment software or the application can get the secret by authenticating with the secrets server using a secrets server password…but you see the problem, right? Now you have another secret (the password to the secrets server) to worry about.
Although imperfect, there’s still considerable value to this approach to secrets management:
-
The secrets server requests can be logged, so you may be able to detect and prevent an unauthorized user or deployment from accessing the secrets. This is discussed more in Chapter 7.
-
The secrets server may use other ways to determine that the request is legitimate than just the password, such as the IP address range requesting the secret. As discussed in Chapter 6, IP allowlisting usually isn’t sufficient by itself, but it is a useful secondary control.
-
You can easily update the secrets later, and all of your systems that retrieve the secrets will get the new ones automatically.
The third approach has all of the benefits of a secrets server, but uses a secure introduction method to reduce the likelihood that an attacker can get the credentials to access the secrets server:
-
Your deployment tooling communicates with the secrets server to get a one-time-use secret, which it passes along to the application.
-
The application then trades that in for the real secret to the secrets server, and it uses that to obtain all the other secrets it needs and hold them in memory. If someone has already used the one-time secret, this step will fail, and the application can send an alert that something is wrong.
Your deployment tooling still needs one set of static credentials to your secrets server, but this allows it only to obtain one-time keys and not to view secrets directly. (If your deployment tooling is completely compromised, then an attacker could deploy a fake copy of an application to read secrets, but that’s more difficult than reading the secrets directly and is more likely to be detected.)
Operations personnel cannot view the secrets, or the credentials to the secrets server, without more complicated memory-scraping techniques. For example, instead of simply reading the secret out of a configuration file, a rogue operator would have to dump the system memory out and search through it for the secret, or attach a debugger to a process to find the secret.
The fourth approach, if available, is to leverage some offerings built into your cloud platform by its provider to avoid the “turtles all the way down” problem:
-
Some cloud providers offer instance metadata or identity documents to systems provisioned in the cloud. Your application can retrieve this identity document, which will say something like, “I am server ABC. The cloud provider cryptographically signed this document for me, which proves my identity.”
-
The secrets server then knows the identity of the server, as well as metadata such as tags attached to the server. It can use this information to authenticate and authorize an application running on the server and provide it the rest of the secrets it needs to function. In the future, you may be able to use the identity document directly with most cloud services, and not need the secrets server at all!
Let’s summarize the four reasonable approaches to secrets management:
-
The first approach stores secrets only in the deployment system, using features designed to hold secrets, and tightly controls access to the deployment system. Nobody sees the secrets by default, and only authorized individuals have the technical ability to view or change them in the deployment system.
-
The second approach is to use a secrets server to hold secrets. Either the deployment server or the deployed application contacts the secrets server to get the necessary secrets and use them. In many cases the secrets are still visible in the configuration files or environment variables of the running application after deployment, so operations personnel may be able to easily view the secrets or the credentials to the secrets server.
-
The third approach has the deployment server only able to get a one-time token and pass it to the application, which then retrieves the secrets and holds them in memory. This protects you from having the credentials to the secrets server or the secrets themselves intercepted.
-
The fourth approach leverages the deployment platform itself as the root of trust. For example, an IaaS provider hands out signed identity documents to virtual machines that the secrets server can use to decide which secrets to provide to that virtual machine.
Several products and services are available to help you manage secrets. HashiCorp Vault and Keywhiz are standalone products that may be implemented on-premises or in the cloud, and AWS Secrets Manager is available through an as-a-service model.
Authorization
Once you’ve completed the authentication phase and you know who your users are, it’s time to make sure they are limited to performing only the actions they are supposed to perform. Some examples of authorization include granting permission to access an application at all, to access an application with write access, to access a portion of the network, or to access the cloud console.
End-user applications often handle authorization themselves. For example, there may be a database row or document for each user listing the access level that user has. This makes some sense, because each application may have specific functions to authorize, but it means that you have to visit every application to see all of the access a user has.
The most important concepts to remember for authorization are least privilege and separation of duties. As a reminder, least privilege means that your users, systems, or tools should be able to access only what they need to do their jobs, and no more. In practice, this usually means that you have a “deny by default” policy in place, so that unless you specifically authorize something, it’s not allowed.
Separation (or segregation) of duties actually comes from the world of financial controls, where two signatures may be needed for checks over a certain amount. In the world of cloud security, this usually translates more generally into making sure that no one person can completely undermine the security of the entire environment. For example, someone with the ability to make changes on systems should not also have the ability to alter the logs from those systems, or the responsibility for reviewing the logs from those systems.
For cloud services and internal applications, centralized authorization is becoming more popular.
Centralized Authorization
The problems with the old, ad hoc practice of scattering identities all over the place have been solved through federated identities and single sign-on. However, you may still have authorization records scattered all over the place—every application may be keeping its own record of who’s allowed to do what in that application.
You can deauthorize someone completely by deleting their identity (assuming persistent access tokens don’t keep them authorized for a while), but what about revoking only some access? The ability to remove someone’s identity is important, but it’s a pretty heavy-handed way to perform access management. You often need more fine-grained ways to manage access. Centralized authorization can let you see and control what your users have access to in a single place.
In a traditional application, all of the authorization work was performed internally in the application. In the world of centralized authorization, the responsibilities typically get divided up between the application and the centralized authorization system. There are more details in some systems, but here are the basic components:
- Policy Enforcement Point (PEP)
-
This point is implemented in the application, where the application controls access. If you don’t have the specified access in the policy, the service or application won’t let you perform that function. The application checks for access by asking the Policy Decision Point for a decision.
- Policy Decision Point (PDP)
-
This point is implemented in the centralized authorization system. The PDP takes the information provided by the application (such as identity and requested function), consults its policy, and gives the application its decision on whether access is granted for that particular function.
- Policy Administration Point (PAP)
-
This point is also implemented in the centralized authorization system. This is usually a web user interface and associated API where you can tell the centralized authorization system who’s allowed to do what.
Most cloud providers have a centralized access management solution that their services will consult for access decisions, rather than making the decisions on their own. You should use these mechanisms where available, so that you can see all of the access granted to a particular administrator in one place.
Roles
Many cloud providers offer roles or trusted profiles, which are similar to shared IDs in that you assume a role, perform actions that role allows, and drop the role. This is slightly different from the traditional definition of a role, which is a set of permissions or entitlements granted to a user or group.
The primary difference between shared IDs and cloud provider roles is that a shared ID is a standalone identity with fixed credentials. A cloud provider role is not a full identity; it is a special status taken on by another identity that is authorized to access a role, and is then assigned temporary credentials to access that role.
Role-based access can add an additional layer of security by requiring users or services to explicitly assume a separate role for more privileged operations, following the principle of least privilege. Most of the time the user can’t perform those privileged activities unless they explicitly put on the role “hat” and take it off when they’re done. The system can also log each request to take on a role, so administrators can later determine who had that role at a particular time and compare that information to actions on the system that have security consequences.
People aren’t the only entities who can assume roles. Some components (such as virtual machines) can assume a role when created and perform actions using the privileges assigned to that role.
Revalidate
At this point, your users and automation should have identities and be authorized to do only what they need to do. You need to make sure that this withstands the test of time.
As previously mentioned, the revalidation step is very important in both traditional and cloud environments, but in cloud environments you may not have any additional controls (such as physical building access or network controls) to save you if you forget to revoke access. You need to periodically check each authorization to ensure that it still needs to be there.
The first type of revalidation is automated revalidation based on certain parameters. For example, you should have a system that automatically puts in a request to revoke all access when someone leaves the organization. Note that simply deleting the user’s identity may not be sufficient, because the user may have cached credentials such as access tokens that can be used even without the ability to log in. In situations like this, you need an offboarding feed, which is a list of entities whose access should be revoked. Any system that hands out longer-lived credentials such as access tokens must process this offboarding feed at least daily and immediately revoke those entities’ access.
The second type of revalidation requires human judgment to determine whether a particular entity still needs access. There are generally two types of judgment-based revalidation:
- Positive confirmation
-
This is stronger—it means that access is lost unless someone explicitly says, “This access is still needed.”
- Negative confirmation
-
This is weaker—it means that access is retained unless someone says, “This access is no longer needed.”
Negative confirmation is appropriate for lower-impact authorization levels, but for types of access with high impact to the business, you should use positive confirmation. The drawbacks to positive confirmation are that it’s more work, and access may be accidentally revoked if the request isn’t processed in time (which may cause operational issues).
The largest risk addressed by revalidation is that someone who has left the organization (perhaps under contentious circumstances) retains access to systems. In addition to this, though, access tends to accumulate over time, like junk in the kitchen junk drawer (you know the one). Revalidation clears out this junk.
However, note that if it’s difficult to get access, your users will often claim they still need access, even if they no longer do. Your revalidation efforts will be much more effective at pruning unnecessary access if you also have a fast, easy process for granting access when needed. If that’s not possible, then it may be more effective to automatically revoke access if not used for a certain period of time instead of asking if it’s still needed. This also has risks, because you may find nobody available has access when needed!
Cloud Identity-as-a-Service offerings are increasingly offering management of the entire identity life cycle in addition to authentication and authorization services. In other words, providers are recognizing the importance of the relationship’s ending as well as the relationship’s beginning, and they are helping to streamline and formalize endings.
Putting It All Together in the Sample Application
Remember our simple web application from Chapter 1? Let’s add identity and access management information to the diagram, which now looks like Figure 4-3. I’ve removed the whole application trust boundary to simplify the diagram. A description of the steps, many of which have multiple parts, follows.
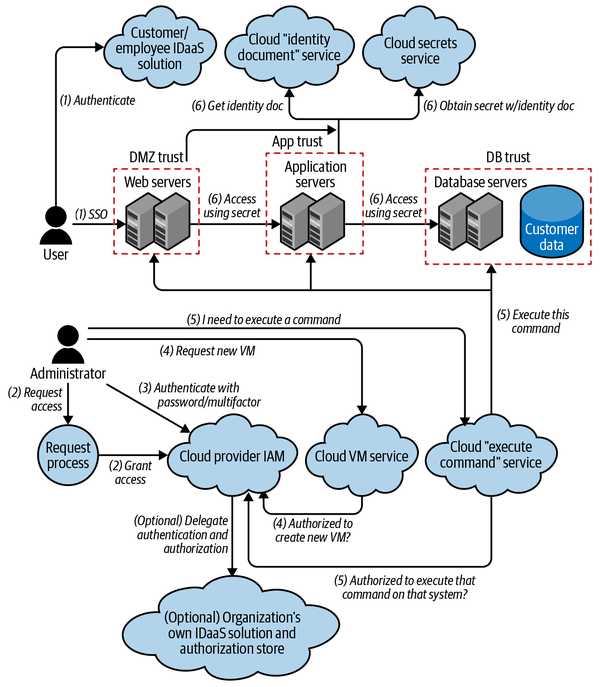
Figure 4-3. Sample application diagram with IAM
Unfortunately, that complicated the diagram quite a bit! Let’s look at some of the new interactions in detail:
-
The end user attempts to access the application and is automatically approved for access by virtue of having a valid identity and optionally passing some anti-fraud tests. The user logs in with SSO, so the application identity is federated with the user’s external identity provider, and the application doesn’t have to validate passwords. From the user’s perspective, they’re using the same identity as they do at their company or on their favorite social media site.
-
The administrator requests access to administer the application, which is approved. The administrator is then authorized in a centralized authorization system. The authorization may take place within the cloud’s IAM system, or the cloud’s IAM system may be configured to ask the organization’s own internal authorization system to perform the authorization.
-
The administrator authenticates with the cloud IAM service using a strong password and multi-factor authentication and gets an access token to give to any other services. Again, optionally, the cloud IAM service may be configured to send the user to the organization’s internal authentication system.
-
The administrator makes requests to cloud provider services, such as to create a new virtual machine or container. (Behind the scenes, the cloud VM service asks the cloud IAM service whether the administrator is authorized.)
-
The administrator uses a cloud provider service to execute commands on the virtual machines or containers as needed. (Behind the scenes, the cloud “execute command” service asks the cloud’s IAM service whether the administrator is authorized to execute that command on that virtual machine or container.) If this feature isn’t available from a particular cloud provider, the administrator might use a more traditional method, such as SSH, with the virtual machine using the LDAP protocol to authenticate and authorize administrators against an identity store. Note that in a container environment, executing commands may not even be needed for normal maintenance and upgrades, because the administrator can deploy a new container and delete the old one rather than making changes to the existing container.
-
A secrets service is used to hold the password or API key for the application server to access the database system. Figure 4-3 shows the application server getting an identity document from the cloud provider, accessing the secrets server directly to get the secret, and accessing the database. If the database will accept the identity document directly, you may not even need the secrets server! The same process could happen for the authentication between the web server and the application server, but only one secrets service interaction is shown for simplicity. The secrets service may be run by the organization, or may be an as-a-service offering from a cloud provider.
Note that every time one of our application’s trust boundaries is crossed, the entity crossing the trust boundary must be authenticated and authorized in order to perform an action. There are other trust boundaries outside the application that are not pictured, such as the trust boundaries around the cloud and organization systems.
Conclusion
Many organizations have historically been somewhat lax about identity and access management in on-premises environments, and have relied too much upon other controls (such as physical security and network controls). However, IAM is supremely important in cloud environments. Although the concepts are similar in both cloud and on-premises deployments, there are new technologies and cloud services that improve security and make the job easier.
In the whole identity and access life cycle, it is easy to forget about the request, approval, and revalidation steps. Although they can be performed manually, many as-a-service offerings that initially handled only the authentication and authorization steps now provide workflows for the approval step as well, and this trend is accelerating.
Centralized authentication systems give administrators and end users a single identity to be used across many different applications and services. While these have been around in different forms for a long time, they are even more necessary in cloud environments, where they are available by default. Given the proliferation of cloud systems and services, managing identities individually for each system and service can quickly become a nightmare in all but the smallest deployments. Old, forgotten identities may be used by their former owners or by attackers looking for an easy way in. Even with centralized authentication, you must still use good passwords and multi-factor authentication. Cloud administrators and end users often authenticate via different systems.
As with the authentication systems, centralized authorization systems allow you to see and modify everything an entity is authorized to do in one place. This can make granting and revalidating access easier, and make separation of duties conflicts more obvious. Make sure you follow the principles of least privilege and separation of duties when authorizing both people and automation for tasks, and avoid having super-powered identities and credentials for daily use.
Secrets management is a quickly maturing field, where secrets used for system-to-system access are maintained separately from other configuration data and handled according to strict principles of confidentiality and auditing. In some cases, system-to-system authentication can be performed using identity documents, which can reduce the need to have separately maintained secrets. Secrets management capabilities are available in existing configuration management products, standalone secrets server products, and as-a-service cloud offerings.
Now that you understand how to avoid one of the biggest causes of breaches—insufficient identity and access management—let’s look at one of the other biggest causes, insufficient vulnerability management.
Exercises
-
What steps are commonly used in an access management life cycle? Select all that apply.
-
Request access
-
Approve access
-
Use access
-
Revalidate access
-
-
Which of the following statements about authentication is true?
-
Authentication is about proving that you are who you say you are.
-
Authentication is all you need to access an application.
-
API keys can be used for multi-factor authentication.
-
Authentication is not required for internal communications.
-
-
Which of the following statements about authorization are true? Select all that apply.
-
Authorization is about being allowed to access a particular application or take a particular action.
-
Unless everyone is authorized for a particular action, authorization is only useful when combined with authentication.
-
Authorization can be effective when either centralized or decentralized.
-
-
Which of the following are true statements about cloud identity services? Select all that apply.
-
A cloud identity service usually provides a central service that can authenticate users.
-
A cloud identity service usually provides a central service that can authorize users.
-
A cloud identity service usually provides a central service for storing secrets.
-
Cloud identity services come in multiple forms, such as business-to-consumer and business-to-employee.
-
-
Which of the following statements about federation and single sign-on are true? Select all that apply.
-
Federation and single sign-on are different technologies that accomplish similar goals.
-
Federated identity is the concept of linking identities together on two different systems.
-
Single sign-on is a way to use federated identities.
-
Single sign-on is easier for users, but often comes with a trade-off of lower security.
-
1 See, for example, the Verizon Data Breach Investigations Report.
2 There is also the process of verifying that a person is who they say they are before giving them an identity, generally called identity proofing. That’s usually performed by corporate onboarding processes and help desk password recovery processes, and is not normally the responsibility of users of cloud services.
3 Zero-knowledge encryption means that your provider has no technical way of decrypting the data, usually because you only send encrypted data without the keys. This sharply limits what the provider can do, and is most suitable for backup services where the provider just needs to hold a lot of data without any processing.
4 I like to jokingly refer to this as the “principle of already screwed.” It’s good to have a way to monitor your provider’s actions, though, to detect a potential compromise.
5 If you are 99.9% sure that any given user’s credentials won’t be stolen in a year, and you have 1,000 users, then you’re only 36.7% sure that none of your users’ credentials will be stolen in a year. Probabilities are fun!
6 Password strength is usually measured in “bits of entropy.” A very oversimplified explanation is that if you give an attacker all of the information you can about how a password is constructed but not the actual password, such as “it’s 20 uppercase alphabetic characters,” the number of bits of entropy is about log2(number of possible passwords).
7 Diceware is based on the idea that it’s far easier for humans to remember phrases than characters, and that almost everyone can find some six-sided dice. You can download the Diceware word list, then roll dice to randomly pick five or six words off the list. There are also web pages that generate a passphrase locally for you. The result is an extremely secure password that’s easy to remember.
8 Some applications can remember a TOTP secret and use it to log in along with a password, but this is usually only done in cases where a testing tool is pretending to be a user logging in. If an attacker gets into that application, they’ll find both the password and the TOTP secret in the same place, so in this situation the second factor doesn’t really help from a security perspective.
9 There is actually a common term for secrets found in public GitHub repositories: “GitHub dorks.” This has been such a widespread issue that GitHub now has ways to block code pushes that contain secrets.
Get Practical Cloud Security, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

