Chapter 1. Principles and Concepts
Yes, this is a practical guide, but we do need to cover a few cloud-relevant security principles and concepts at a high level before we dive into the practical bits. If you’re a seasoned security professional, but new to the cloud, you may want to skim down to “The Cloud Shared Responsibility Model”.
The reason for covering these principles and concepts first is because they are used implicitly throughout the rest of the book when I discuss designing and implementing security controls to stop attackers. Conceptual gaps and misunderstandings in security can cause lots of issues. For example:
-
If you’re not familiar with least privilege, you may understand authorization for cloud services well, but still grant too much access to people or automation in your cloud account or on a cloud database with sensitive information.
-
If you’re not familiar with defense in depth, then having multiple layers of authentication, network access control, or encryption may not seem useful.
-
If you don’t know a little about threat modeling—the likely motivations of attackers, and the trust boundaries of the system that you’re designing—you may be spending time and effort protecting the wrong things.
-
If you don’t understand the cloud service delivery models and the shared responsibility model, you may spend time worrying about risks that are your cloud provider’s responsibility and miss risks that are your responsibility to address.
-
If you don’t know a little about risk management, you may spend too much time and effort on low risks rather than managing your higher risks.
I’ll cover this foundational information quickly so that we can get to cloud security controls.
Least Privilege
The principle of least privilege simply states that people or automated tools should be able to access only what they need to do their jobs, and no more. It’s easy to forget the automation part of this; for example, a component accessing a database should not use credentials that allow write access to the database if write access isn’t needed.
A practical application of least privilege often means that your access policies are deny by default. That is, users are granted no (or very few) privileges by default, and they need to go through the request and approval process for any privileges they require.
For cloud environments, some of your administrators will need to have access to the cloud console—a web page that allows you to create, modify, and destroy cloud assets such as virtual machines. With many providers, anyone with access to your cloud console will have godlike privileges by default for everything managed by that cloud provider. This might include the ability to read, modify, or destroy data from any part of the cloud environment, regardless of what controls are in place on the operating systems of the provisioned systems. For this reason, you need to tightly control access to and privileges on the cloud console, much as you tightly control physical data center access in on-premises environments, and record what these users are doing.
Defense in Depth
Many of the controls in this book, if implemented perfectly, would negate the need for other controls. Defense in depth is an acknowledgment that almost any security control can fail, either because an attacker is sufficiently determined and skilled or because of a problem with the way that security control is implemented. With defense in depth, you create multiple layers of overlapping security controls so that if one fails, the one behind it can still catch the attackers.
You can certainly go to silly extremes with defense in depth, which is why it’s important to understand the threats you’re likely to face. However, as a general rule, you should be able to point to any single security control you have and say, “What if this fails?” If the answer is unacceptable, you probably have insufficient defense in depth. You may also have insufficient defense in depth if a single failure can make several of your security controls ineffective, such as an inventory issue that causes multiple tools to miss a problem.
Zero Trust
Many products and services today claim to be zero trust, or to support zero trust principles. The name is confusing, because zero trust does not mean a complete lack of trust in anything, and the confusion is worse because it’s used for so many different marketing purposes. There are many different definitions and different ideas about what is meant by zero trust.
We are probably stuck with the term at this point, but “zero trust” should really be called something else, such as “zero implicit trust” or “zero assumed trust without a good reason.”1 The core principle is that trust from a user or another system should be earned, rather than given simply because the user is able to reach you on the network, or has a company-owned device, or some other criterion that’s not well controlled.
The implementation of zero trust will differ widely depending on whether you’re talking about trusting devices, network connections, or something else. One commonly used implementation of zero trust is requiring encryption and authentication for all connections, even ones that originate and terminate in supposedly trusted networks. This was always a good idea, but it’s even more important in cloud environments where the perimeter is less strictly designed and internet connectivity is easy.
Another common implementation of zero trust principles is limiting users’ network access to only the applications that they need, challenging the implicit trust that all users should be able to connect to all applications, even if they cannot log in. If you think this sounds a lot like least privilege and defense in depth, you’re right. There is considerable overlap between zero trust principles and some of the other principles in this chapter.
A third example of zero trust is the use of multi-factor authentication of users, with reauthentication required either periodically or when higher-risk transactions are requested. In this case, we’re challenging the implicit trust that whoever has the password for an account, or controls a particular session for an application, is the intended user.
When following zero trust principles, you should only trust an interaction if you have strong evidence that the trust is warranted, such as by proof of strong authentication, or authorization, or correct configuration. That evidence should either be from something you directly control (such as your own authentication system or device management system), or from some third party that you have explicitly evaluated as competent to make trust decisions for you. Like other principles in this chapter, it can be disruptive to the user experience if taken to extremes.
Threat Actors, Diagrams, and Trust Boundaries
There are different ways to think about your risks, but I typically favor an asset-oriented approach. This means that you concentrate first on what you need to protect, which is why I dig into data assets first, in Chapter 2.
It’s also a good idea to keep in mind who is most likely to cause you problems. In cybersecurity parlance, these are your potential “threat actors.” For example, you may not need to guard against a well-funded state actor, but you might be in a business where a cyber-criminal can make money by stealing your data, or where a “hacktivist” might want to deface your website for political or social reasons. Keep these people in mind when designing all of your defenses.
While there is plenty of information and discussion available on the subject of threat actors, motivations, and methods,2 in this book we’ll consider four main types of threat actors that you may need to worry about:
-
Organized crime or independent criminals, interested primarily in making money
-
Hacktivists, interested primarily in discrediting you by releasing stolen data, committing acts of vandalism, or disrupting your business
-
Inside attackers, usually interested in discrediting you or making money
-
State actors, who may be interested in stealing secrets or disrupting your business to advance a foreign government’s political mission or cause
To borrow a technique from the world of user experience design, you may want to imagine a member of each applicable group, give them a name, jot down a little about that “persona” on a card, and keep the cards visible when designing your defenses.
The second thing you have to do is figure out what needs to talk to what in your application, and the easiest way to do that is to draw a picture and figure out where your weak spots are likely to be. There are entire books on how to do this,3 but you don’t need to be an expert to draw something useful enough to help you make decisions. However, if you are in a high-risk environment, you should probably create formal diagrams with a suitable tool rather than draw stick figures.
Although there are many different application architectures, for the sample application used for illustration here, I will show a simple three-tier design. Here is what I recommend for a very simple application component diagram:
-
Draw a stick figure and label it “user.” Draw another stick figure and label it “administrator” (Figure 1-1). You may find later that you have multiple types of users and administrators, or other roles, but this is a good start.

Figure 1-1. User and administrator roles
-
Draw a box for the first component the user talks to (for example, the web servers), draw a line from the user to that first component, and label the line with how the user talks to that component (Figure 1-2). Note that at this point, the component may be a serverless function, a container, a virtual machine, or something else. This will let anyone talk to it, so it will probably be the first thing attacked. We really don’t want the other components trusting this one more than necessary.

Figure 1-2. First component
-
Draw other boxes behind the first for all of the other components that first system has to talk to, and draw lines going to those (Figure 1-3). Whenever you get to a system that actually stores data, draw a little symbol (I use a cylinder) next to it and jot down what data is there. Keep going until you can’t think of any more boxes to draw for your application.

Figure 1-3. Additional components
-
Now draw how the administrator (and any other roles you’ve defined) accesses the application. Note that the administrator may have several different ways of talking to this application; for example, via the cloud provider’s portal or APIs, or through the operating system, or in a manner similar to how a user accesses it (Figure 1-4).

Figure 1-4. Administrator access
-
Draw some trust boundaries as dotted lines around the boxes (Figure 1-5). A trust boundary means that anything inside that boundary can be at least somewhat confident of the motives of anything else inside that boundary, but requires verification before trusting anything outside of the boundary. The idea is that if an attacker gets into one part of the trust boundary, it’s reasonable to assume they’ll eventually have complete control over everything in it, so getting through each trust boundary should take some effort. Note that I drew multiple web servers inside the same trust boundary; that means it’s okay for these web servers to trust each other, and if someone has access to one, they effectively have access to all. Or, to put it another way, if someone compromises one of these web servers, no further damage will be done by having them all compromised.
In this context, zero trust principles lead us to reduce these trust boundaries to the smallest reasonable size—for example, a single component, which here might be an individual server or a cluster of servers with the same data and purpose.

Figure 1-5. Component trust boundaries
-
To some extent, we trust our entire system more than the rest of the world, so draw a dotted line around all of the boxes, including the admin, but not the user (Figure 1-6). Note that if you have multiple admins, like a web server admin and a database admin, they might be in different trust boundaries. The fact that there are trust boundaries inside of trust boundaries shows the different levels of trust. For example, the servers here may be willing to accept network connections from servers in other trust boundaries inside the application, but still verify their identities. On the other hand, they may not be willing to accept connections from systems outside of the whole application trust boundary.

Figure 1-6. Whole application trust boundary
We’ll use this diagram of an example application throughout the book when discussing the shared responsibility model, asset inventory, controls, and monitoring. Right now, there are no cloud-specific controls shown in the diagram, but that will change as we progress through the chapters. Look at any place a line crosses a trust boundary. These are the places we need to focus on securing first!
Cloud Service Delivery Models
There is an unwritten law that no book on cloud computing is complete without an overview of Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Rather than give the standard overview, I’d like to quickly say that IaaS services typically allow you to create virtual computers, storage, and networks; PaaS services are typically higher-level services, such as databases, that enable you to build applications; and SaaS services are applications used by end users. You can find many expanded definitions and subdivisions of these categories, but these are the core definitions.
These service models are useful only for a general understanding of concepts; in particular, the line between IaaS and PaaS is becoming increasingly blurred. Is a content delivery network service that caches information for you around the internet to keep it close to users a PaaS or an IaaS? It doesn’t really matter. What’s important is that you understand what is (and isn’t!) provided by the service, not whether it fits neatly into any particular category.
The Cloud Shared Responsibility Model
The most basic security question you must answer is, “What aspects of security am I responsible for?” This is often answered implicitly in an on-premises environment. The development organization is responsible for code errors, and the operations organization (IT) is responsible for everything else. Many organizations now run a DevOps model where those responsibilities are shared, and team boundaries between development and operations are blurred or nonexistent. Regardless of how it’s organized, almost all security responsibility is inside the company.
Perhaps one of the most jarring changes when moving from an on-premises environment to a cloud environment is a more complicated shared responsibility model for security. In an on-premises environment, you may have had some sort of internal document of understanding or contract with IT or some other department that ran servers for you. However, in many cases business users of IT were used to handing the requirements or code to an internal provider and having everything else done for them, particularly in the realm of security.
Even if you’ve been operating in a cloud environment for a while, you may not have stopped to think about where the cloud provider’s responsibility ends and where yours begins. This line of demarcation is different depending on the types of cloud services you’re purchasing. Almost all cloud providers address this in some way in their documentation and training materials, but the best way to explain it is to use the analogy of eating pizza.
With Pizza as a Service,4 let’s say you’re hungry for pizza. There are a lot of choices! You could just make a pizza at home, although you’d need to have quite a few ingredients and it would take a while. You could run to the grocery store and grab a take and bake; that only requires you to have an oven and a place to eat it. You could call your favorite pizza delivery place. Or, you could just go sit down at a restaurant and order a pizza. If we draw a diagram of the various components and who’s responsible for them, we get something like Figure 1-7.
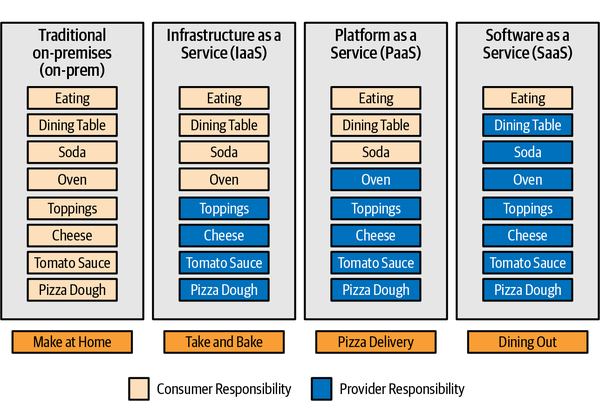
Figure 1-7. Pizza as a Service
The traditional on-premises world is like making a pizza at home. You have to buy a lot of different components and put them together yourself, but you get complete flexibility. Anchovies and cinnamon on wheat crust? If you can stomach it, you can make it.
When you use Infrastructure as a Service, though, the base layer is already done for you. You can bake it to taste and add a salad and drinks, and you’re responsible for those things. When you move up to Platform as a Service, even more decisions are already made for you, including how your pizza is baked. (As mentioned in the previous section, sometimes it can be difficult to categorize a service as IaaS or PaaS, and they’re growing together in many cases. The exact classification isn’t important; what’s important is that you understand what the service provides and what your responsibilities are.)
When you get to Software as a Service (compared to dining out in Figure 1-7), it seems like everything is done for you. It’s not, though. You still have a responsibility to eat safely, and the restaurant is not responsible if you choke on your food. In the SaaS world, this largely comes down to managing access control properly.
If we draw the diagram but focus on technology instead of pizza, it looks more like Figure 1-8.

Figure 1-8. Cloud shared responsibility model
The reality of cloud computing is unfortunately a little more complicated than eating pizza, so there are some gray areas. At the bottom of the diagram, things are concrete (often literally). The cloud provider has complete responsibility for physical infrastructure security—which often involves controls beyond what many companies can reasonably do on-premises, such as biometric access with anti-tailgating measures, security guards, slab-to-slab barriers, and similar controls to keep unauthorized personnel out of the physical facilities.
Likewise, if the provider offers virtualized environments, the virtualized infrastructure security controls keeping your virtual environment separate from other virtual environments are the provider’s responsibility. When the Spectre and Meltdown vulnerabilities came to light in early 2018, one of the potential effects was that users in one virtual machine could read the memory of another virtual machine on the same physical computer. For IaaS customers, fixing that part of the vulnerability was the responsibility of the cloud provider—Amazon, Microsoft, Google, and IBM all had to make updates to their hypervisors, for example—but fixing the vulnerabilities within the operating system was the customer’s responsibility.
Network security is shown as a shared responsibility in the IaaS section of Figure 1-8. Why? It’s hard to show on a diagram, but there are several layers of networking, and the responsibility for each lies with a different party. The cloud provider has its own network that is its responsibility, but there is usually a virtual network on top (for example, some cloud providers offer a virtual private cloud), and it’s the customer’s responsibility to carve this into reasonable security zones and put in the proper rules for access between them. Many implementations also use overlay networks, firewalls, and transport encryption that are the customer’s responsibility. This will be discussed in depth in Chapter 6.
Operating system security is usually straightforward: it’s your responsibility if you’re using IaaS, and it’s the provider’s responsibility if you’re purchasing platform or software services. In general, if you’re purchasing those services, you have no access to the underlying operating system. (As a general rule of thumb, if you have the ability to break it, you usually have the responsibility for securing it!)
Middleware, in this context, is a generic name for software such as databases, application servers, or queuing systems. They’re in the middle between the operating system and the application—not used directly by end users, but used to develop solutions for end users. If you’re using a PaaS, middleware security is often a shared responsibility; the provider might keep the software up to date (or make updates easily available to you), but you retain the responsibility for security-relevant settings such as encryption.
The application layer is what the end user actually uses. If you’re using SaaS, vulnerabilities at this layer (such as cross-site scripting or SQL injection) are the provider’s responsibility, but if you’re reading this book you’re probably not just using someone else’s SaaS. Even if all of the other layers have bulletproof security, a vulnerability at the application security layer can easily expose all of your information.
Finally, data access security is almost always your responsibility as a customer. If you incorrectly tell your cloud provider to allow access to specific data, such as granting incorrect object storage permissions, middleware permissions, or SaaS permissions, there’s really not much the provider can do other than try to detect the problem and warn you.
The root cause of many security incidents is an assumption that the cloud provider is handling something, when it turns out nobody was handling it. Many real-world examples of security incidents stemming from poor understanding of the shared responsibility model come from open Amazon Simple Storage Service (Amazon S3) buckets. Sure, S3 storage is secure and encrypted, but none of that helps if you don’t set your access controls properly. This misunderstanding has caused the loss of:
-
Data on 198 million US voters
-
Auto-tracking company records
-
Wireless customer records
-
Over 3 million demographic survey records
-
Over 50,000 Indian citizens’ credit reports
-
Over 100,000 students’ grades and personal info
-
Thousands of hours of audio and video recordings that contain private conversations
There are many more examples. Although there has been considerable progress, the shared responsibility model is often still misunderstood. Many IT decision makers still believe that public cloud providers are responsible for securing not just the cloud services they offer, but also customer applications and data in the cloud. If you read your agreement with your cloud provider, you’ll find this just isn’t true!
Risk Management
Risk management is a deep subject, with entire books written about it. If you’re really interested in a deep dive, I recommend reading The Failure of Risk Management: Why It’s Broken and How to Fix It, by Douglas W. Hubbard (Wiley, 2020), and NIST Special Publication 800-30 Rev 1. In a nutshell, humans are really bad at assessing risk and figuring out what to do about it. This section is intended to give you just the barest essentials for managing the risk of security incidents and data breaches.
At the risk of stating the obvious, a risk is something bad that could happen. In most risk management systems, the level of risk is based on a combination of how probable it is that the bad thing will happen (likelihood), and how bad the result will be if it does happen (impact). For example, something that’s very likely to happen (such as someone guessing your password of “1234”) and will be very bad if it does happen (such as you losing all of your customers’ files and paying large fines) would be a high risk. Something that’s very unlikely to happen (such as an asteroid wiping out two different regional data centers at once) but that would be very bad if it does happen (going out of business) might only be a low risk, depending on the system you use for deciding the level of risk.5
In this book, I’ll talk about unknown risks (where we don’t have enough information to know what the likelihoods and impacts are) and known risks (where we at least know what we’re up against). Once you have an idea of the known risks, you can do one of four things with them:
-
Avoid the risk. In information security, this typically means you turn off the system—no more risk, but also none of the benefits you had from running the system in the first place.
-
Mitigate the risk. It’s still there, but you do additional things to lower either the likelihood that the bad thing will happen or the impact if it does happen. For example, you may choose to store less sensitive data so that if there is a breach, the impact won’t be as bad.
-
Transfer the risk. You pay someone else to manage things so that the risk is their problem. This is done a lot with the cloud, where you transfer many of the risks of managing the lower levels of the system to the cloud provider.
-
Accept the risk. After looking at the overall risk level and the benefits of continuing the activity, you may decide to write down that the risk exists, get all of your stakeholders to agree that it’s a risk, and then move on.
Any of these actions may be reasonable. However, what’s not acceptable is to either have no idea what your risks are, or to have an idea of what the risks are and accept them without weighing the consequences or getting buy-in from your stakeholders. At a minimum, you should have a list somewhere in a spreadsheet or document that details the risks you know about, the actions taken, and any approvals needed.
Conclusion
Even though there are often no perfect answers in the real world, understanding some foundational concepts will help you make better choices in securing your cloud environments.
Least privilege is basically just recognizing that giving privileged access to anything or anyone is a risk, and you don’t want to take more risks than necessary. It’s an art, of course, because there are sometimes trade-offs between risk and productivity, but the general principle is good—only give the minimum amount of privilege necessary. This is often overlooked for automation, but is arguably even more important there because many real-world attacks hinge upon fooling a system or automation into taking unexpected actions.
Defense in depth is recognizing that we’re not perfect, and the systems we design will not be perfect. It’s also a nod to the basic laws of probability—if you have two independent things that both have to fail for a bad thing to happen, it’s a lot less likely to happen. If you have to flip a coin and get tails twice in a row, your chances of that are only 25%, compared to the 50% chance of getting tails on one coin flip. We aspire to have security controls that are much more effective than a coin toss, but the principle is the same. If you have two overlapping, independent controls that are 95% effective, then the combination of the two will be 99.75% effective! There are diminishing returns with this approach, however, so five or six layers in the same area is probably not a good use of resources.
Threat modeling is the process of understanding who is likely to attack your system and why, and understanding the components of your system and how they work together. With those two pieces of information, you can look at your system through the eyes of potential attackers, and try to spot areas where the attackers may be able to do something undesirable. Then, for each of those areas, you can put obstacles (or, more formally, “controls” and “mitigations”) in place to thwart the attackers. In general, the most effective places to put mitigations are on trust boundaries, which are the places where one part of your system needs to trust another part.
Understanding cloud delivery models can help you focus on the parts of the overall system that you’re responsible for, so that you don’t waste time trying to do your cloud provider’s job, and so that you don’t assume that your cloud provider is taking care of something that’s really your responsibility. While there are standardized terms for different cloud delivery models, such as IaaS, PaaS, and SaaS, some services don’t fit neatly into those buckets. They’re conceptually useful, though, and the most important thing is to understand where your provider’s responsibility ends and yours begins in the cloud shared responsibility model. In an on-premises world, the security of the entire system will often be the responsibility of a single organization within a company, whereas in cloud deployments, it’s almost always split among at least two different companies!
Finally, while humans are pretty good at assessing risk in “is this predator going to eat me?” types of situations, we’re not naturally very good at it in more abstract situations. Risk management is a discipline that makes us better at assessing risk and figuring out what to do about it. The easiest form of risk management is estimating the likelihood that something bad will happen and the impact of how bad it will be if it does happen, and then making decisions based on the combination of likelihood and impact. Risk management can lower our overall risk by letting us focus on the biggest risks first.
Now that we have these concepts and principles in our tool kit, let’s put them to use in protecting the data and other assets in our cloud environments.
Exercises
-
Which of these are good examples of the principle of least privilege in action? Select all that apply.
-
Having different levels of access within an application, with users only able to access the functions that they require for their work
-
Requiring both a password and a second factor in order to log in
-
Giving an inventory tool read-only access rather than read/write access
-
Use of a tool such as sudo to allow a user to only execute certain commands
-
-
Which of these are good examples of the principle of defense in depth? Select all that apply.
-
Encrypting valuable data, and also keeping people from reading the encrypted data unless they need to see it
-
Having very strict firewall controls
-
Ensuring that your trust boundaries are well defined
-
Having multi-factor authentication
-
-
What are some common motivations for threat actors? Select all that apply.
-
Stealing money
-
Stealing secrets
-
Disrupting your business
-
Embarrassing you
-
-
Which of these items is always the cloud provider’s responsibility?
-
Physical infrastructure security
-
Network security
-
Operating system security
-
Data access security
-
-
What are the most important factors in assessing how severe a risk is? Select the two that apply.
-
The chances, or likelihood, that an event will happen
-
How bad the impact will be if an event happens
-
Whether or not you can transfer the risk to someone else
-
Whether the actions causing the risk are legal or illegal
-
1 If you’re expecting tips on how to pick catchy marketing names, you’re probably reading the wrong book!
2 The Verizon Data Breach Investigations Report is an excellent free resource for understanding different types of successful attacks, organized by industry and methods, and the executive summary is very readable.
3 I recommend Threat Modeling: Designing for Security, by Adam Shostack (Wiley, 2014).
4 Original concept from Albert Barron’s 2014 LinkedIn article, “Pizza as a Service”.
5 Risks can also interact, or aggregate. There may be two risks that each have relatively low likelihood and limited impacts, but they may be likely to occur together, and the impacts can combine to be more severe. For example, the impact of either power line in a redundant pair going out may be negligible, but the impact of both going out may be really bad. This is often difficult to anticipate; the Atlanta airport power outage in 2017 is a good example.
Get Practical Cloud Security, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

