Chapter 4. Service Mesh: Service-to-Service Traffic Management
In the previous chapter you explored how to expose your APIs and manage associated ingress traffic from end users and other external systems in a reliable, observable, and secure way using an API gateway. Now you will learn about managing traffic for internal APIs, i.e., service-to-service communication, with similar goals.
At a fundamental level, service mesh implementations provide functionality for routing, observing, and securing traffic for service-to-service communication. It is worth saying that even this choice of technology is not a slam dunk; as with all architectural decisions, there are trade-offs; there is no such thing as a free lunch when you are performing the role of architect!
In this chapter you will evolve the case study by extracting the sessions-handling functionality from the legacy conference system into a new internally facing Session service. As you do this you will learn about the communication challenges introduced by creating or extracting new services and APIs that are deployed and run alongside the existing monolithic conference system. All of the API and traffic management techniques you explored in the previous chapter will apply here, and so your natural inclination may be to use an API gateway to expose the new Session service. However, given the requirements, this would most likely result in a suboptimal solution. This is where the service mesh pattern and associated technologies can provide an alternative approach.
Is Service Mesh the Only Solution?
Practically every web-based software application needs to make service-to-service-like calls, even if this is simply a monolithic application interacting with a database. Because of this, solutions to manage this type of communication have long existed. The most common approach is to use a language-specific library, such as a software development kit (SDK) library or database driver. These libraries map application-based calls to service API requests and also manage the corresponding traffic, typically via the use of HTTP or TCP/IP protocols. As the design of modern applications has embraced service-oriented architectures, the problem space of service-to-service calls has expanded. It is a very common requirement for a service to need to call another serviceâs API to satisfy a userâs request. In addition to providing a mechanism of routing traffic, you will typically also require reliability, observability, and security.
As you will learn throughout this chapter, both a library and service meshâbased solution can often satisfy your service-to-service communication requirements. We have seen a rapid adoption of service meshes, particularly within an enterprise context, and as the number of consumers and providers increases, it is often the most scalable, maintainable, and secure option. Because of this, we have primarily focused this chapter on the service mesh pattern.
Guideline: Should You Adopt Service Mesh?
Table 4-1 provides a series of ADR Guidelines to help you decide whether you should adopt service mesh technology in your organization.
Case Study: Extracting Sessions Functionality to a Service
For the next evolution of our conference system case study you will focus on the conference ownersâ requests to support a core new feature: View and manage an attendeeâs conference sessions via the mobile application.
This is a major change that would warrant the creation of an ADR. Table 4-2 is an example ADR that might have been proposed by the engineering team owning the conference system.
| Status | Proposed |
|---|---|
Context |
The conference owners have requested another new feature to the current conference system. The marketing team believes that conference attendee engagement will increase if an attendee can view details of and indicate their interest in conference sessions via the mobile application. The marketing team also wants to be able to see how many attendees are interested in each session. |
Decision |
We will take an evolutionary step to split out the Session component into a standalone service. This will allow API-first development against the Session service and allow the API to be invoked from the legacy conference service. This will also allow the Attendee service to call the API of the Session service directly in order to provide session information to the mobile application. |
Consequences |
The legacy application will call the new Session service when handling all session-related queries, both for existing and new functionality. When a user wants to view, add, or remove sessions they are interested in at a conference, the Attendee service will need to call the Session service. When a conference admin wants to see who is attending each session, the Session service will need to call the Attendee service in order to determine who is attending each session. The Session service could become a single point of failure in the architecture and we may need to take steps to mitigate the potential impact of running a single Session service. Because the viewing and managing of sessions by attendees increases dramatically during a live conference event, we will also need to account for large traffic spikes and potentially one or more Session services becoming overloaded or acting in a degraded fashion. |
The C4 Model showing the proposed architectural change is shown in Figure 4-1.
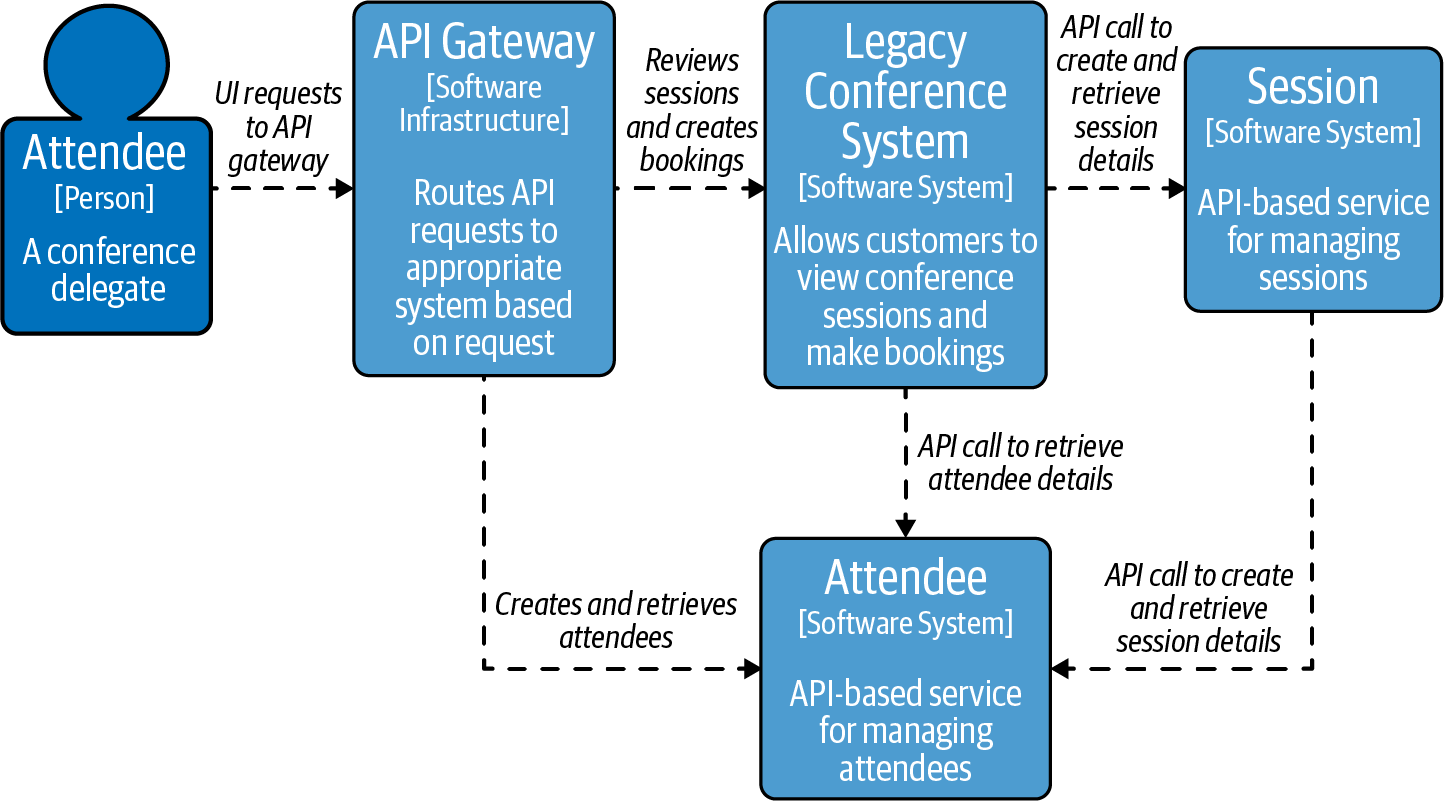
Figure 4-1. C4 Model showing the extraction of the Session service from the conference system
Note that even though the new Session service does not need to be exposed externally, you could easily meet the routing and reliability requirements stated in the preceding ADR by exposing this service via the API gateway and configuring both the legacy system and Attendee service to call this new service via the gatewayâs external address. However, this would be an example of the âAPI gateway loopbackâ antipattern you learned about in âCommon API Gateway Implementation Pitfallsâ. This antipattern can lead to internally destined traffic potentially leaving your network, which has performance, security, and (cloud vendor) cost implications. Letâs now explore how a service mesh can help you meet your new requirements while avoiding this antipattern.
What Is Service Mesh?
Fundamentally, âservice meshâ is a pattern for managing all service-to-service (or application-to-application) communication within a distributed software system. There is a lot of overlap between the service mesh and API gateway patterns, with the primary differences being twofold. First, service mesh implementations are optimized to handle service-to-service, or eastâwest, traffic within a cluster or data center. Second, following from this, the originator of the communication is typically a (somewhat) known internal service, rather than a userâs device or a system running external to your applications.
Service Mesh Is Not Mesh Networking
Service mesh is not to be confused with mesh networking, which is a lower-level networking topology. Mesh networking is becoming increasingly prevalent in the context of Internet of Things (IoT) and also for implementing mobile communication infrastructure in remote or challenging scenarios (such as disaster relief). Service mesh implementations build on top of existing networking protocols and topologies.
The service mesh pattern focuses on providing traffic management (routing), resilience, observability, and security for service-to-service communication. Donât worry if you havenât heard much about this pattern, as it was only in 2016 that the Buoyant team coined the term to explain the functionality of their Linkerd technology.1 This, in combination with the introduction of other related technologies like the Google-sponsored Istio, led to the rapid adoption of the term âservice meshâ within the domains of cloud computing, DevOps, and architecture.
Much like an API gateway, a service mesh is implemented with two high-level fundamental components: a control plane and data plane. In a service mesh these components are always deployed separately. The control plane is where operators interact with the service mesh and define routes, policies, and required telemetry. The data plane is the location where all of the work specified in the control plane occurs and where the network packets are routed, the policies enforced, and telemetry emitted.
If we take configuring service-to-service traffic within a Kubernetes cluster as an example, a human operator will first define routing and policy using Custom Resource configurationâfor example, in our case study, specifying that the Attendee service can call the Session serviceâand then âapplyâ this to the cluster via a command-line tool, like kubectl, or continuous delivery pipeline. A service mesh controller application running within the Kubernetes cluster acts as the control plane, parsing this configuration and instructing the data planeâtypically a series of âsidecarâ proxies running alongside each of the Attendee and Session servicesâto enact this.
All service-to-service traffic within the Kubernetes cluster is routed via the sidecar proxies, typically transparently (without the underlying applications recognizing that a proxy is involved), which enables all of this traffic to be routed, observed, and secured as required. An example topology of the services and service mesh control plane and data plane is shown in Figure 4-2.
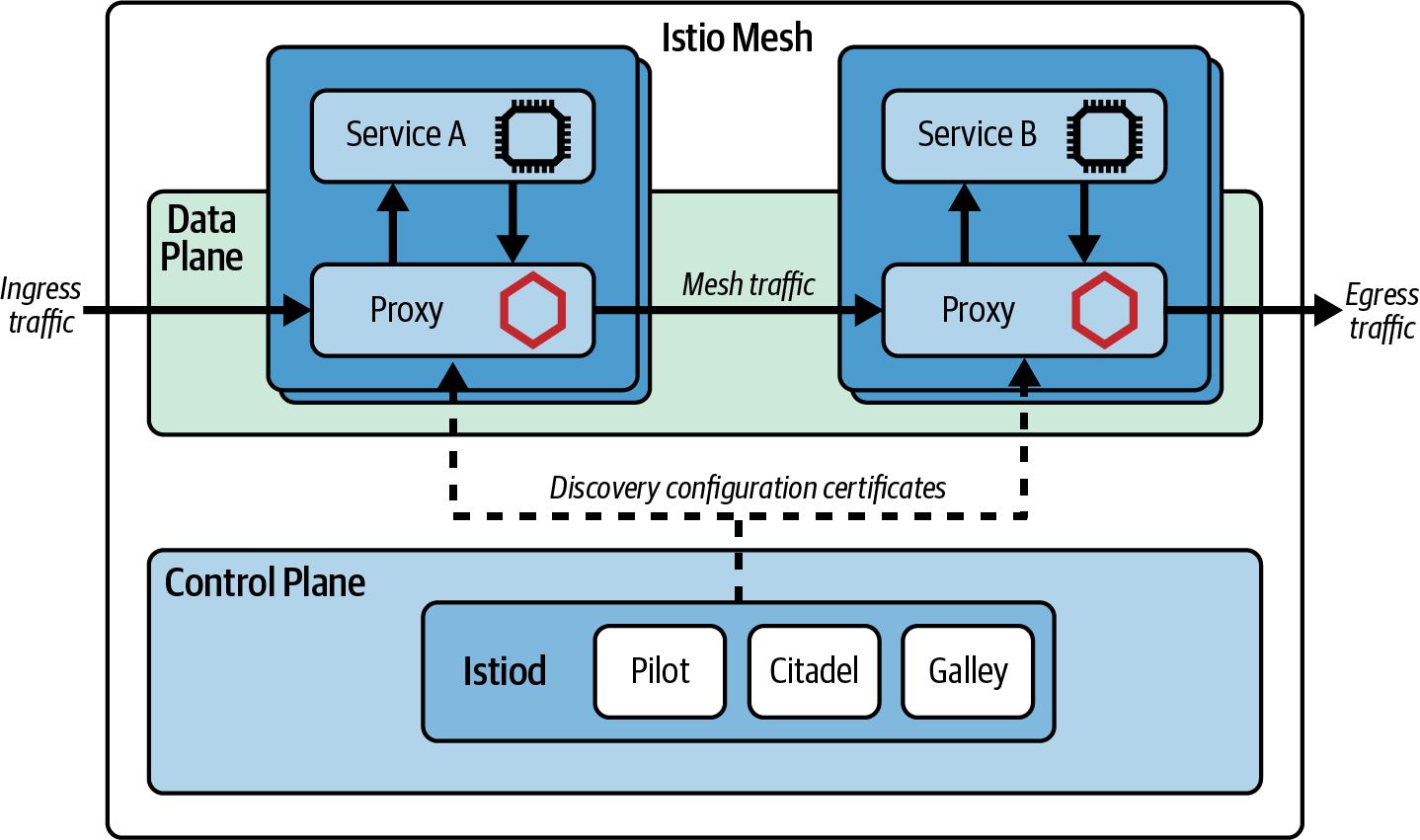
Figure 4-2. Topology of services and control plane and data plane of a service mesh (using Istio as an example)
What Functionality Does a Service Mesh Provide?
At a network level, a service mesh proxy acts as a full proxy, accepting all inbound traffic from other services and also initiating all outbound requests to other services. This includes all API calls and other requests and responses. Unlike an API gateway, the mapping from a service mesh data plane to a service is typically one-to-one, meaning that a service mesh proxy does not aggregate calls across multiple services. A service mesh provides cross-cutting functionality such as user verification, request rate limiting, and timeouts/retries, and can provide metrics, logs, and trace data in order to support the implementation of observability within the system. This is exactly the functionality that we require for evolving our case study by extracting the Session service and calling this from both the legacy conference system and the Attendee service.
Although less common in comparison with an API gateway, some service meshes provide additional features that enable developers to manage the lifecycle of an API. For example, an associated service catalog may assist with the onboarding and management of developers using the service APIs, or a developer portal will provide account administration and access control. Some service meshes also provide auditing of policies and traffic management in order to meet enterprise governance requirements.
Where Is a Service Mesh Deployed?
A service mesh is deployed within an internal network or cluster. Large systems or networks are typically managed by deploying several instances of a service mesh, often with each single mesh spanning a network segment or business domain.
An example service mesh networking topology is shown in Figure 4-3.

Figure 4-3. A typical service mesh topology, deployed across two clusters (with solid arrows showing service mesh traffic)
How Does a Service Mesh Integrate with Other Networking Technologies?
A modern networking stack can have many layers, particularly when working with cloud technologies where virtualization and sandboxing occur at multiple levels. A service mesh should work in harmony with these other networking layers, but developers and operators also need to be aware of potential interactions and conflict. Figure 4-4 shows the interaction between physical (and virtualized) networking infrastructure, a typical networking stack, and a service mesh.

Figure 4-4. OSI model showing that a service mesh operates between layers 3 and 7
As an example, when deploying applications into a Kubernetes cluster, a Service can locate and address another Service within the same cluster via a prescribed name that maps to an IP address.
Fundamental traffic control security policies can be implemented with NetworkPolicies, which control traffic at the IP address and port level (OSI layer 3 or 4), and additional policy controls are often provided by a clusterâs Container Networking Interface (CNI) plug-in.2
Service meshes can override the default CNI service-to-IP address resolution and routing and also provide additional functionality. This includes transparent routing across clusters, enforcement of layer 3/4 and 7 security (such as user identity and authorization), layer 7 load balancing (which is useful if you are using multiplexed keepalive protocol like gRPC or HTTP/2), and observability at the service-to-service level and throughout the networking stack.
Why Use a Service Mesh?
In a similar fashion to deciding why you should deploy an API gateway into your existing architecture, determining why to adopt a service mesh is a multi-faceted topic. You need to balance both short-term implementation gains and costs against the long-term maintainability requirements. There are many API-related cross-cutting concerns that you might have for each or all of your internal services, including product lifecycle management (incrementally releasing new versions of a service), reliability, multilanguage communication support, observability, security, maintainability, and extensibility. A service mesh can help with all of these.
This section of the chapter will provide you with an overview of the key problems that a service mesh can address, such as:
-
Enable fine-grained control of service routing, reliability, and traffic management
-
Improve observability of interservice calls
-
Enforce security, including transport encryption, authentication, and authorization
-
Support cross-functional communication requirements across a variety of languages
-
Separate ingress and service-to-service traffic management
Fine-grained Control of Routing, Reliability, and Traffic Management
Routing traffic with a distributed microservices-based system can be more challenging than it may first appear. Typically there will be multiple instances of a service deployed into an environment with the goals of improving both performance (load balancing across services) and reliability (providing redundancy). In addition, many modern infrastructure platforms are built on âcommodity hardwareâ that manifests as ephemeral computing resources that can shut down, restart, or disappear at a momentâs notice; and this means the location of a service can change from day-to-day (or minute-to-minute!).
You can, of course, employ the routing technologies and associated techniques that you learned about in Chapter 3. The challenge here is that there are typically many more internal services and APIs in comparison with the number of external APIs that are exposed by your applications, and the pace of change with internal systems and their corresponding APIs and functionality is often much higher. Accordingly, the operational cost would increase dramatically if you were to deploy an API gateway in front of every internal service, both in regards to computing resources required and human maintenance costs.
Transparent routing and service name normalization
Fundamentally, routing is the process of selecting a path for traffic in a network or between or across multiple networks. Within web applications, network-level routing has typically been handled within the TCP/IP stack and associated networking infrastructure (at layer 3/4 of the OSI model). This means that only the IP address and port of both the connectionâs target and originator are required. Pre-cloud, and often with on-premises data centers, the IP addresses of internal services are often fixed and well-known. Even though DNS is widely used to map domain names to IP addresses, it is still the case that heritage applications and services use hardcoded IP addresses. This means that any changes to a serviceâs location require a redeployment of all services that call this service.
With the adoption of the cloud and the ephemeral nature of our infrastructure that comes with this, IP addresses of computing instances and their corresponding services regularly change. This in turn means that if you hardcode IP and port addresses, these will have to be frequently changed. As microservices-based architectures became more popular, the pain of redeploying increased in relation to the number of services within an application. Early microservice adopters created solutions to overcome this by implementing external âservice discoveryâ directories or registries containing a dynamic mapping of service names to IP address(es) and ports.3
Service meshes can handle this dynamic lookup of service name to location, externally to the service and also transparently without the need for code modification, redeployments, or restarts.
Another benefit of a service mesh is that it can normalize naming across environments using âenvironment awarenessâ in combination with configuration stored external to the application.
For example, a service mesh deployed to âproductionâ will recognize that it is running in this environment. The service mesh will then transparently map the code-level service name sessions-service to the environment-specific location AWS-us-east-1a/prod/sessions/v2 by looking up the location from a service registry (that may be integrated with the mesh or run externally).
The same code deployed to the staging environment with an appropriately configured service mesh will route sessions-service to internal-staging-server-a/stage/sessions/v3.
Reliability
The ephemeral nature of modern computing and cluster environments brings challenges related to reliability in addition to location changes. For example, every service must correctly handle communication issues with another service it is interacting with. You will learn more about âThe 8 Fallacies of Distributed Computingâ shortly, but issues to be aware of in this context include a serviceâs connection being interrupted, a service becoming temporarily unavailable, or a service responding slowly. These challenges can be handled in code using well-known reliability patterns such as retries, timeouts, circuit breakers, bulkheads, and fallbacks. Michael Nygardâs book Release It! Design and Deploy Production-Ready Software, now in its second edition, provides a comprehensive exploration and implementation guide. However, as you will explore in more depth in âSupporting Cross-Functional Communication Across Languagesâ, attempting to implement this functionality in code typically leads to inconsistent behavior, especially across different languages and platforms.
As a service mesh is involved with initiating and managing every service-to-service communication, it provides the perfect place to consistently implement these reliability patterns to provide fault-tolerance and graceful degradation. Depending on the implementation, a service mesh can also detect issues and share this information across the mesh, allowing each service within the mesh to make appropriate decisions on how to route trafficâe.g., if a serviceâs response latency is increasing, all services that call the target service can be instructed to instead initiate their fallback actions.
For the case study, a service mesh will enable you to define how to handle any failures when communicating with the new Session service. Imagine several thousand attendees at an event having just watched the morning conference keynote and wanting to view their schedule for the day. This sudden spike of traffic for the Session service may result in degraded behavior. For the majority of use cases you would define appropriate timeouts and retries, but you may also define a circuit-breaking action that triggers an application behavior. For example, if an API call from the Attendee service to the Session service to get an attendeeâs daily session schedule repeatedly fails, you may trigger a circuit breaker in the service mesh that rapidly fails all calls to this service (to allow the service to recover). Most likely within the mobile application you would handle this failure by âfalling backâ to rendering the entire conference session schedule rather than a personal schedule.
Advanced traffic routing: Shaping, policing, splitting, and mirroring
Since the dot-com boom of the late â90s, consumer web applications have increasingly handled more users and more traffic. Users have also become more demanding, both in regards to performance and features offered. Accordingly, the need to manage traffic to meet the needs of security, performance, and feature release has become more important. As you learned in âHow Does an API Gateway Integrate with Other Technologies at the Edge?â, the edge of the network saw the emergence of dedicated appliances to meet these requirements, but this infrastructure was not appropriate to deploy in front of every internal service. In this section of the chapter you will learn more about the requirements that have become typical for a microservices-based application in regards to internal traffic shaping and policing.
Traffic shaping
Traffic shaping is a bandwidth management technique that delays some or all of the network traffic in order to match a desired traffic profile. Traffic shaping is used to optimize or guarantee performance, improve latency, or increase usable bandwidth for some kinds of traffic by delaying other kinds. The most common type of traffic shaping is application-based traffic shaping, where fingerprinting tools are first used to identify applications of interest, which are then subject to shaping policies. With eastâwest traffic, a service mesh can generate or monitor the fingerprints, such as service identity or some other proxy for this, or a request header containing relevant metadataâfor example, whether a request originated from a conference application free-tier user or a paying customer.
Traffic policing
Traffic policing is the process of monitoring network traffic for compliance with a traffic policy or contract and taking steps to enforce that contract. Traffic violating a policy may be discarded immediately, marked as noncompliant, or left as is, depending on administrative policy. This technique is useful to prevent a malfunctioning internal service from committing a denial of service (DoS) attack, or to prevent a critical or fragile internal resource from becoming overly saturated with traffic (e.g., a data store). Before the advent of cloud technologies and service meshes, traffic policing within internal networks was generally only implemented within an enterprise context using specialized hardware or software appliances such as an enterprise service bus (ESB). Cloud computing and software-defined networks (SDNs) made traffic-policing techniques easier to adopt through the use of security groups (SGs) and network access control lists (NACLs).
When managing eastâwest communications, services within the network or cluster boundary may be aware of a traffic contract and may apply traffic shaping internally in order to ensure their output stays within the contract. For example, your Attendee service may implement an internal rate limiter that prevents excessive calls to the Session service API within a specific time period.
Service mesh allows granular control of traffic shaping, splitting, and mirroring that makes it possible to gradually shift or migrate traffic from one version of a target service to another. In âRelease Strategiesâ, we will look at how this approach can be used to facilitate the separation of build and release for traffic-based release strategies.
Provide Transparent Observability
When operating any distributed system like a microservices-based application, the ability to observe both the end-user experience and arbitrary internal components is vitally important for fault identification and debugging corresponding issues. Historically, adopting system-wide monitoring required the integration of highly coupled runtime agents or libraries within applications, requiring a deployment of all applications during the initial rollout and all future upgrades.
A service mesh can provide some of the observability required, particularly application (L7) and network (L4) metrics, and do so transparently. A corresponding update of any telemetry collection components or the service mesh itself should not require a redeployment of all applications. There are, of course, limitations to the observability a service mesh can provide, and you should also instrument your services using language-specific metrics and log-emitting libraries. For example, in our case study the service mesh would provide metrics on the number, latency, and error rate of Session service API calls, and you would also typically decide to log business-specific metrics and KPIs of the API calls.
Enforce Security: Transport Security, Authentication, and Authorization
In much the same way as observability, service-to-service communication security has historically been implemented using language-specific libraries. These highly coupled approaches provide the same drawbacks and nuances. For example, implementing transport-level encryption within an internal network is a relatively common requirement, but different language libraries handle certificate management differently, which increased the operational burden of deploying and rotating certificates. Managing both service (machine) and user (human) identity for authentication and authorization was also difficult across differing languages. It was also often easy to accidentally (or deliberately) circumvent any security implementation by not including the required libraries.
As a service meshâs data plane is included within the path of any traffic within the system, it is relatively trivial to enforce the required security profile. For example, the service mesh data plane can manage service identities (for example, using SPIFFE) and cryptographic certificates, enabling mTLS, and service-level authentication and authorization. This enables us to easily implement mTLS within our case study without the need for code modifications.
Supporting Cross-Functional Communication Across Languages
As you create or extract services within a microservice-based application and move from in-process to out-of-process communication, you need to think about changes in routing, reliability, observability, and security. The functionality required to handle this can be implemented within application code, for example, as a library. However, if your application or system uses multiple programming languagesâand a polyglot approach is quite common with microservice-based systemsâthis means that you will have to implement each library for each language used. As a service mesh is typically implemented using the sidecar pattern, where all service communication is routed through a network proxy external to the service but running within the same network namespace, the functionality required can be implemented once within the proxy and reused across all the services. You can think of this as âinfrastructure dependency injection.â Within our case study this would enable us to rewrite our Attendee service using a different language (perhaps to meet new performance requirements) and still rely on the cross-functional aspects of service-to-service communication being handled consistently.
Separating Ingress and Service-to-Service Traffic Management
Recall in âCase Study: An Evolutionary Stepâ that we briefly introduced the key concepts of northâsouth and eastâwest traffic. Generally speaking, northâsouth traffic is traffic that is ingressing from an external location into your system. Eastâwest traffic is transiting internally from system-to-system or service-to-service. The definitions can become tricky when you look further into the definition of âyour systemsâ; for example, does this definition extend to systems designed and operated by only your team, your department, your organization, or your trusted third-parties, etc.
Several contributors to the API space, including Marco Palladino from Kong, have argued that the use of northâsouth and eastâwest is largely irrelevant and is more of a hangup from the previous generation of computer networking when boundaries between systems were clearer. Weâll explore this argument in more detail in Chapter 9, as this touches the idea of API as a product (including API lifecycle management) and layer 7 and layer 4 service connectivity (from the OSI model of networking.) The differences between the core properties and features of ingress and service-to-service traffic are shown in Table 4-3.
| Ingress (n/s) | Service-to-service (e/w) | |
|---|---|---|
Traffic source |
External (user, third-party, internet) |
Internal (within trust boundary) |
Traffic destination |
Public or business-facing API, or website |
Service or domain API |
Authentication |
âuserâ (real world entity) focused |
âserviceâ (machine entity) and âuserâ (real-world entity) focused |
Authorization |
âuserâ roles or capability level |
âserviceâ identity or network segment focused, and âuserâ roles or capability level |
TLS |
One-way, often enforced (e.g., protocol upgrade) |
Mutual, can be made mandatory (strict mTLS) |
Primary implementations |
API gateway, reverse proxy |
Service mesh, application libraries |
Primary owner |
Gateway/networking/ops team |
Platform/cluster/ops team |
Organizational users |
Architects, API managers, developers |
Developers |
As illustrated, the properties and associated requirements for managing the two traffic types are often quite different. For example, handling external end-user traffic destined for a product API has fundamentally different requirements in comparison with handling internal service-to-service traffic destined for an internal business, domain, or component API. In practice this means that the control planes for both an API gateway and service mesh must offer different capabilities in order to support the configuration of the respective data planes. As an example in our case study, the Session service development team may want to specify that the service can only be called by the legacy conference application and Attendee service, whereas the Attendee service team would not typically specify which external systems can or cannot call the public APIâthis would be the responsibility of the associated gateway or networking team.
This difference between managing ingress and service-to-service API calls can be better understood if you compare the evolution and usage of API gateway technology, as explored in âA Modern History of API Gatewaysâ, with the evolution of service mesh technology, as described in the following section.
Evolution of Service Mesh
Although the term âservice meshâ was coined in 2016, several of the early âunicornâ organizations like Twitter, Netflix, Google, and Amazon were creating and using related technologies within their internal platforms from the late 2000s and early 2010s. For example, Twitter created its Scala-based Finagle RPC framework, which was open sourced in 2011. Netflix created and released its âOSSâ Java-based microservice shared libraries in 2012, including Ribbon, Eureka, and Hystrix.4 Later the Netflix team released the Prana sidecar to enable non-JVM-based services to take advantage of these libraries. The creation of the Finagle libraries and adoption of sidecars ultimately spawned Linkerd, arguably the first sidecar-based service mesh and also an initial project in the CNCF when this foundation was formed. Google quickly followed suit by releasing the Istio service mesh that built upon the Envoy Proxy project that had emerged from the Lyft Engineering team.
In a turn that looks like the industry coming full circle, service mesh capabilities are getting pushed back into shared libraries, as weâre seeing with gRPC, or added to the OS kernel. This evolution can be seen in Figure 4-5. Although the development and usage of many of these earlier components and platforms are now deprecated, it is useful to take a quick tour of their evolution as this highlights several challenges and limitations of using the service mesh pattern, some of which still remain.

Figure 4-5. Evolution of service mesh technology
Early History and Motivations
In the â90s, Peter Deutsch and others at Sun Microsystems compiled âThe 8 Fallacies of Distributed Computingâ, in which they list assumptions that engineers tend to make when working with distributed systems. They made the point that although these assumptions might have been true in more primitive networking architectures or the theoretical models, they donât hold true in the modern networks:
-
The network is reliable
-
Latency is zero
-
Bandwidth is infinite
-
The network is secure
-
Topology doesnât change
-
There is one administrator
-
Transport cost is zero
-
The network is homogeneous
Peter and team state that these fallacies âall prove to be false in the long run and all cause big trouble and painful learning experiences.â Engineers cannot just ignore these issues; they have to explicitly deal with them.
Ignore the Fallacies of Distributed Computing at Your Peril!
Because the â8 Fallacies of Distributing Computingâ were coined in the â90s, it is tempting to think of them as a computing relic. However, this would be a mistake! Much like many of the other timeless computing laws and patterns derived in the â70s and â80s, the issues remain the same, even as the technology changes. When working in the architect role, you must constantly remind your teams that many networking challenges captured within these fallacies hold true today, and you must design systems accordingly!
As distributed systems and microservice architectures became popular in the 2010s, many innovators in the space, such as James Lewis, Sam Newman, and Phil Calçado, realized the importance of building systems that acknowledged and offset these fallacies over and above functionality provided in standard networking stacks. Building on Martin Fowlerâs initial set of âMicroservice Prerequisites,â Phil created âCalçadoâs Microservices Prerequisitesâ and included âstandardized RPCâ as a key prerequisite that encapsulated many of the practical lessons he had learned from the fallacies of distributed computing. In his later 2017 blog post, Phil stated that âwhile the TCP/IP stack and general networking model developed many decades ago is still a powerful tool in making computers talk to each other, the more sophisticated [microservice-based] architectures introduced another layer of requirements that, once more, have to be fulfilled by engineers working in such architectures.â5
Implementation Patterns
Although the most widely deployed implementation of service meshes today utilize the proxy-based âsidecarâ model of deployment, this was not always the case. And it may not be the case in the future. In this section of the chapter you will learn how service mesh implementation patterns have so far evolved and explore what the future may hold.
Libraries
Although many technical leaders realized the need for a new layer of networking functionality within microservice-based systems, they understood that implementing these technologies would be nontrivial. They also recognized that a lot of effort would be repeated, both within and across organizations. This led to the emergence of microservice-focused networking frameworks and shared libraries that could be built once and reused, first across an organization, and later open sourced for wider consumption.
In his aforementioned blog post, Phil Calçado commented that even core networking functionality such as service discovery and circuit breaking was challenging to implement correctly. This led to the creation of large, sophisticated libraries like Twitterâs Finagle and the Netflix OSS stack. These became very popular as a means to avoid rewriting the same logic in every service and also as projects to focus shared efforts on ensuring correctness. Some smaller organizations took on the burden themselves of writing the required networking libraries and tools, but the cost was typically high, especially in the long term. Sometimes this cost was explicit and clearly visibleâfor example, the cost of engineers assigned to teams dedicated to building tooling. But more often the true expense was difficult to fully quantify as it manifests itself as time taken for new developers to learn proprietary solutions, resources required for operational maintenance, or other forms of taking time and energy away from working on your customer-facing products.
Phil also observed that the use of libraries that expose functionality via language bindings or an SDK limited the tools, runtimes, and languages you can use for your microservices. Libraries for microservices are often written for a specific platform, be it a programming language or a runtime like the JVM. If you use platforms other than the one supported by the library, you will most likely need to port the code to the new platform itself, with your costs increasing in relation to the number of languages.
Service Mesh Libraries and the Price of Polyglot
Many organizations embrace a polyglot approach to coding applications and use a variety of languages, choosing the most appropriate one for a service in order to accomplish the requirements. For example, using Java for long-running business services, Go for infrastructure services, and Python for data science work. If you embrace the library-based approach to implementing a service mesh, you will need to be aware that you will have to build, maintain, and upgrade all of your libraries in lock-step in order to avoid compatibility issues or provide a suboptimal developer experience for some languages. You may also find subtle differences between implementations across language platforms, or bugs that only affect a specific runtime.
Sidecars
In the early 2010s, many engineers were embracing the approach to polyglot programming, and it was not uncommon for a single organization to have services written in multiple languages that were deployed to production. The desire to write or maintain one library that handled all of the required networking abstractions led to the creation of libraries that ran externally to a service as standalone processes. The microservice âsidecarâ was born. In 2013, Airbnb wrote about âSynapse and Nerve,â its open source implementation of a service discovery sidecar. One year later, Netflix introduced Prana, a sidecar that exposed an HTTP interface for non-JVM applications to integrate with the rest of the Netflix OSS ecosystem for service discovery, circuit breaking, and more. The core concept here was that a service did not connect directly to its downstream dependencies, but instead all of the traffic went through the Prana sidecar that transparently added the desired networking abstraction and features.
As the use of the microservices architecture style increased, we saw the rise of a new wave of proxies that were flexible enough to adapt to different infrastructure components and communication requirements. The first widely known system on this space was Linkerd, created by Buoyant and based on its engineering experience of having worked on Twitterâs microservices platform. Soon after, the engineering team at Lyft announced Envoy Proxy, which followed a similar principle and was quickly adopted by Google in its Istio service mesh. When using the sidecar pattern, each of your services will have a companion proxy process that runs standalone next to your application. This sidecar typically shares the same process, file, and networking namespace, and specific security guarantees are provided (e.g., that any communication with the âlocalâ network is isolated from the external network). Given that services communicate with each other only through the sidecar proxy, we end up with a deployment similar to the diagram in Figure 4-6.
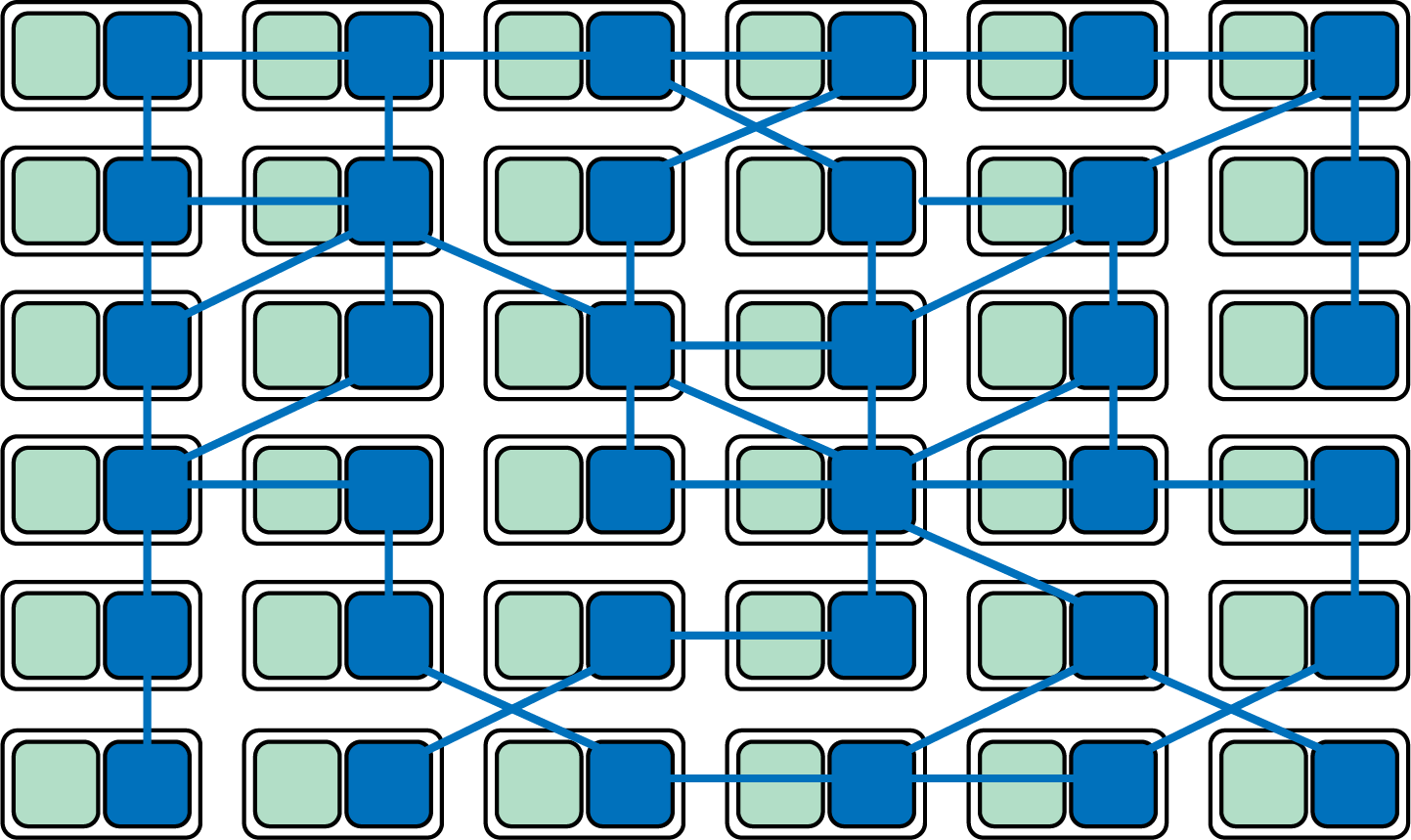
Figure 4-6. Service mesh proxies forming a higher-level networking abstraction
As noted by the likes of Phil Calçado and Buoyantâs William Morgan, the most powerful aspect of this integration of sidecar proxies is that it moves you away from thinking of proxies as isolated components and toward acknowledging the network they form as something valuable in itself.
In the mid-2010s, organizations began to move their microservices deployments to more sophisticated runtimes such as Apache Mesos (with Marathon), Docker Swarm, and Kubernetes, and organizations started using the tools made available by these platforms to implement a service mesh. This led to a move away from using a set of independent proxies working in isolation as we saw with the likes of Synapse and Nerve, toward the use of a centralized control plane. If you look at this deployment pattern using a top-down view, you can see that the service traffic still flows from proxy to proxy directly, but the control plane knows about and can influence each proxy instance. The control plane enables the proxies to implement features such as access control and metrics collection that require cooperation and coordination across services, as shown in Figure 4-7.
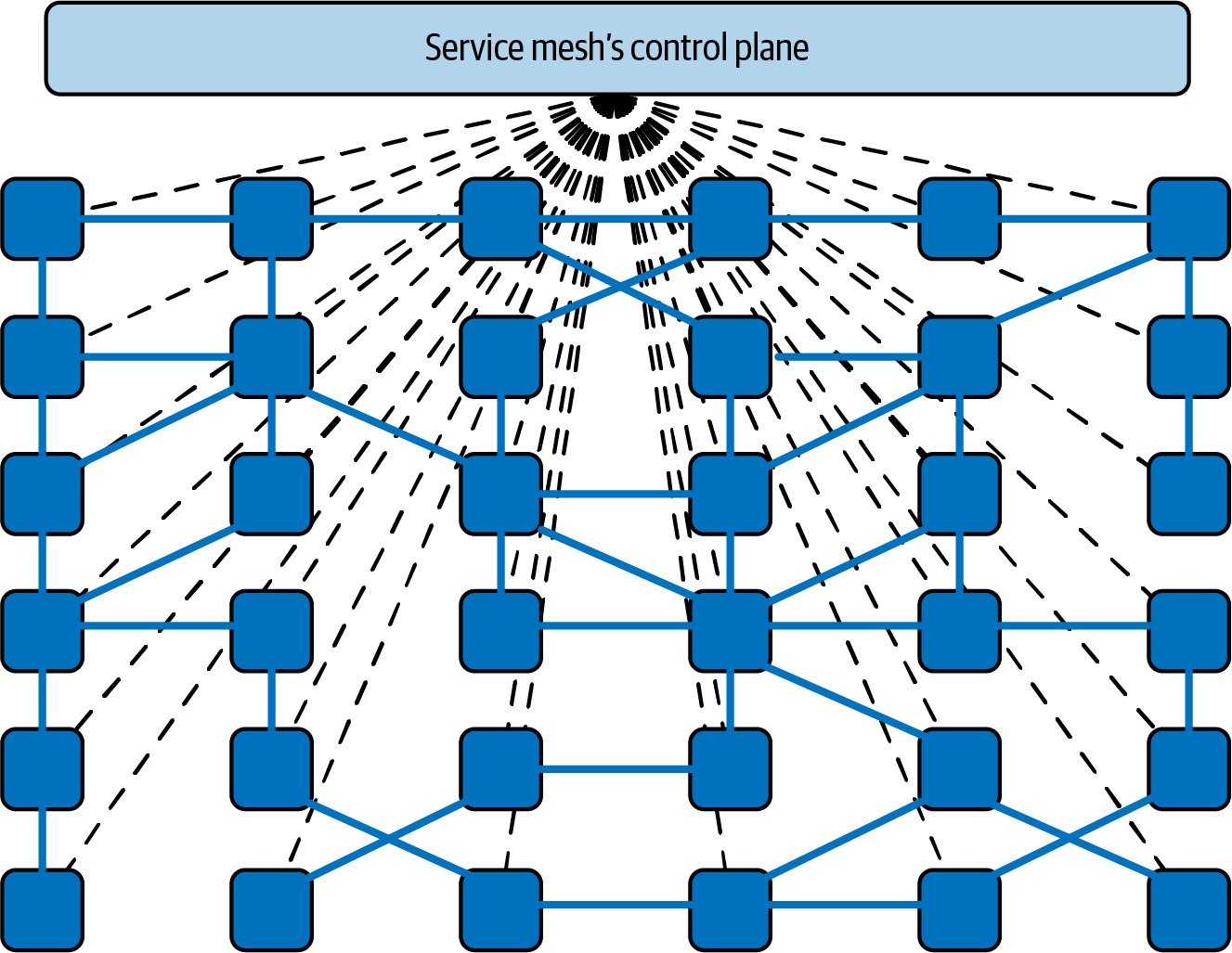
Figure 4-7. Controlling and coordinating a service mesh data plane
The sidecar-based approach is the most common pattern in use today and likely a good choice for our conference system. The primary costs of deploying a sidecar-based service mesh is in relation to the initial installation and ongoing operational maintenance and also the resources required to run all of the sidecarsâas our scalability needs are currently modest, we shouldnât require large amounts of computing power to run the sidecar proxies.
The Cost of Running Sidecars at Scale
Many of todayâs popular service mesh solutions require you to add and run a proxy sidecar container, such as Envoy, Linkerd-proxy, or NGINX, to every service or application running within your cluster. Even in a relatively small environment with, say, 20 services, each running five pods spread across three nodes, you will have 100 proxy containers running. However small and efficient the proxy implementation is, the sheer duplication of the proxies will impact resources.
Depending on the service mesh configuration, the amount of memory used by each proxy may increase in relation to the number of services that it needs to be able to communicate with. Pranay Singhal wrote about his experiences configuring Istio to reduce consumption from around 1 GB per proxy to a much more reasonable 60â70 MB each. However, even in the small, imaginary environment with 100 proxies on three nodes, this optimized configuration still requires approximately 2 GB per node.
Proxyless gRPC libraries
In an evolution that appears we may have come full circle, the Google Cloud began promoting âproxyless gPRCâ in early 2021, where the networking abstractions are once again moved back into a language-specific library (albeit a library maintained by Google and a large OSS community). These gRPC libraries are included within each service and act as the data plane within the service mesh. The libraries require access to an external control plane for coordination, such as the Google Traffic Director service. Traffic Director uses open source âxDS APIsâ to configure the gRPC libraries within the applications directly.6 These gRPC applications act as xDS clients, connecting to Traffic Directorâs global control plane that enables global routing, load balancing, and regional failover for service mesh and load-balancing use cases. Traffic Director even supports a âhybridâ mode of operation, including deployments that incorporate both sidecar proxy-based services and proxyless services, as shown in Figure 4-8.
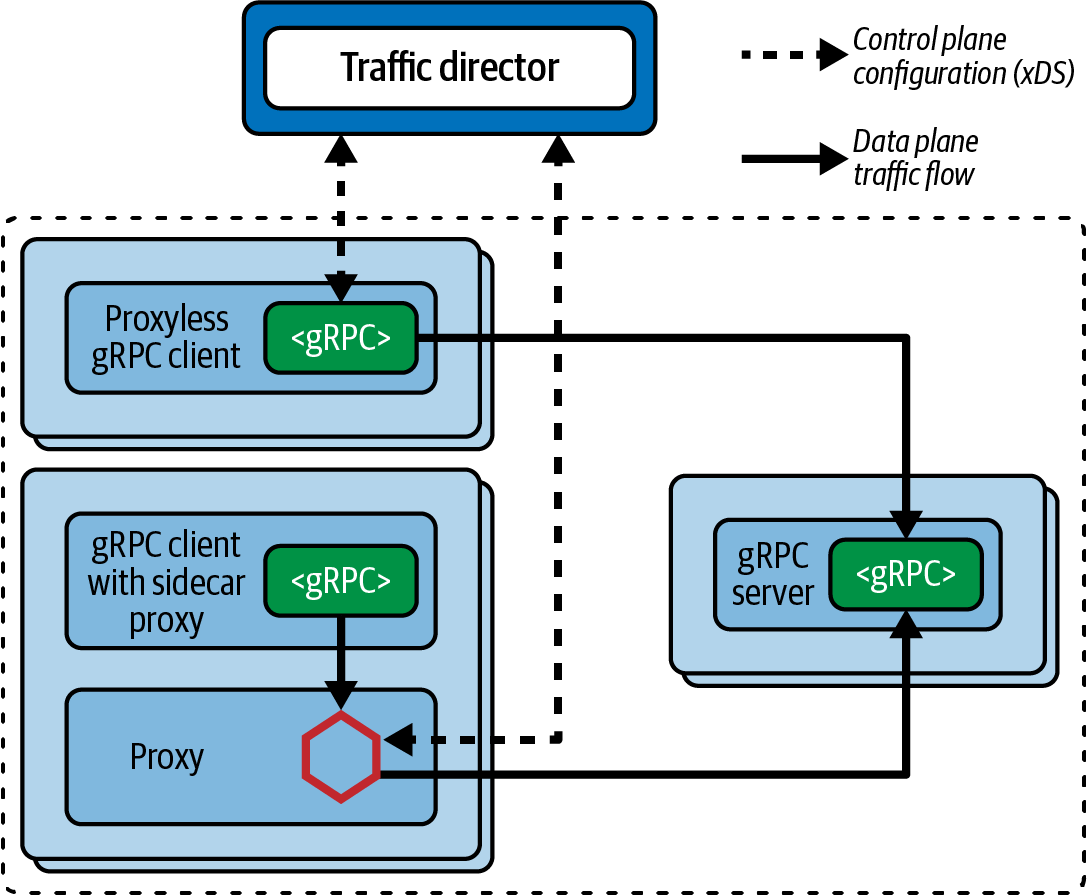
Figure 4-8. Example network diagram of services using both sidecars and proxyless communication
As our conference system uses REST APIs in addition to gRPC APIs, this would currently exclude this choice of a service mesh implementation. If our use of REST APIs internally was deprecated, or the gRPC libraries are enhanced to provide support for non-gRPC-based communication, using this approach could be reevaluated.
Sidecarless: Operating system kernel (eBPF) implementations
Another emerging alternative service mesh implementation is based on pushing the required networking abstractions back into the operation system (OS) kernel itself. This has become possible thanks to the rise and wide adoption of eBPF, a kernel technology that allows custom programs to run sandboxed within the kernel. eBPF programs are run in response to OS-level events, of which there are thousands that can be attached to. These events include the entry to or exit from any function in kernel or user space, or âtrace pointsâ and âprobe points,â andâimportantly for service meshâthe arrival of network packets. As there is only one kernel per node, all the containers and processes running on a node share the same kernel. If you add an eBPF program to an event in the kernel, it will be triggered regardless of which process caused that event, whether itâs running in an application container or directly on the host. This should remove any potential attempts to circumvent the service mesh, accidentally or otherwise.
The eBPF-based Cilium project provides the capabilities to secure and observe network connectivity between container workloads. Cilium brings this âsidecarlessâ model to the world of service mesh. Use of Cilium can reduce latency between service calls, as some functionality can be provided by the kernel without the need to perform a network hop to a sidecar proxy.7 As well as the conventional sidecar model, Cilium supports running a service mesh data plane using a single Envoy Proxy instance per node, reducing resource usage. Figure 4-9 shows how two services can communicate using Cilium and a single Envoy Proxy per node.
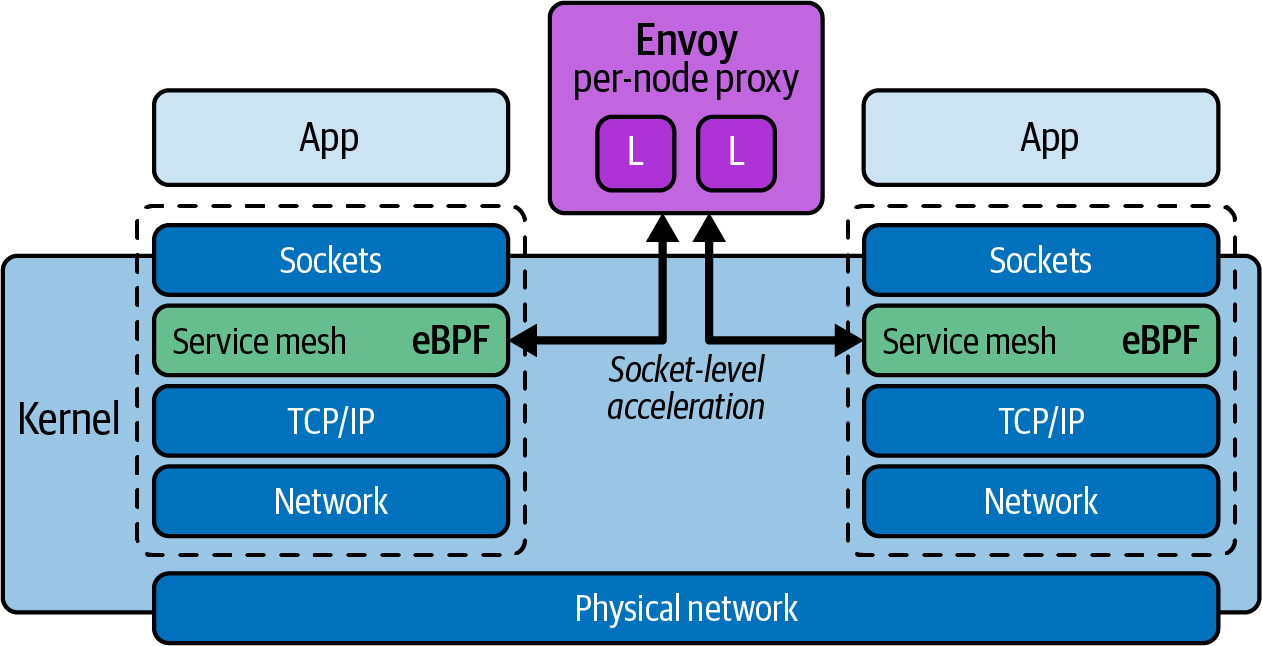
Figure 4-9. Using Cilium, eBPF, and a single Envoy Proxy per node to implement service mesh functionality
Service Mesh Taxonomy
Table 4-4 highlights the difference between the three service mesh implementation styles as discussed in the previous section.
| Use case | Library-based (and âproxylessâ) | Sidecars, Proxy-based | OS/kernel-based |
|---|---|---|---|
Language/platform support |
Single-language libraries, platform agnostic |
Language agnostic, wide platform support |
Language agnostic, OS-level support |
Runtime mechanism |
Packaged and run within the application |
Run alongside application in a separate process |
Run as part of the OS kernel, with full access to user and kernel space |
Upgrading service mesh components |
Requires rebuild and redeployment of entire application |
Requires redeployment of sidecar components (can often be zero-downtime) |
Requires kernel program update/patching |
Observability |
Complete insight into application and traffic, with ability to propagate context easily |
Insight into traffic only, propagating context requires language support or shim |
Insight into traffic only, propagating context requires language support or shim |
Security threat model |
Library code runs as part of application |
Sidecars typically share process and network namespace with application |
Case Study: Using a Service Mesh for Routing, Observability, and Security
In this section of the chapter you will explore several concrete examples of how to use a service mesh to implement the common requirements of routing, observing, and securely segmenting (via authorization) your service-to-service traffic. All of these examples will use Kubernetes, as this is the most common platform on which service meshes are deployed, but the concepts demonstrated apply to all platforms and infrastructure for which each service mesh supports. Although we recommend choosing and adopting only one service mesh implementation within your applicationâs technology stack, weâll demonstrate the configuration of the conference system using three different service meshes, purely for educational purposes.
Routing with Istio
Istio can be installed into your Kubernetes cluster with the istioctl tool. The main prerequisite for using Istio is enabling the automatic injection of the proxy sidecars to all services that are running within your cluster. This can be done as follows:
$ kubectl label namespace default istio-injection=enabled
With the auto-injection configured, the two primary Custom Resources you will be working with are VirtualServices and DestinationRules.8 A VirtualService defines a set of traffic routing rules to apply when a host is addressedâe.g., http://sessions. A DestinationRule defines policies that apply to traffic intended for a service after routing has occurred. These rules specify configuration for load balancing, connection pool size from the sidecar, and outlier detection settings to detect and evict unhealthy hosts from the load balancing pool.
For example, to enable routing to your Session and Attendee services within the case study, you can create the following VirtualServices:
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sessions
spec:
hosts:
- sessions
http:
- route:
- destination:
host: sessions
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: attendees
spec:
hosts:
- attendees
http:
- route:
- destination:
host: attendees
subset: v1
The following DestinationRules can also be created. Note how the attendees DestinationRule specifies two versions of the service; this is the foundation for enabling canary routing for the new v2 version of the service:
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sessions
spec:
host: sessions
subsets:
- name: v1
labels:
version: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: attendees
spec:
host: attendees
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
With Istio installed and the preceding VirtualServices and DestinationRules configured, you can begin routing traffic and API calls between the Attendee and Session services. It really is this easy to get started, although configuring and maintaining Istio in a production environment can be more involved. Istio will handle the routing and also generate telemetry related to each connection. Letâs learn more about observability using the Linkerd service mesh.
Observing Traffic with Linkerd
You can install Linkerd into a Kubernetes cluster by following the âGetting Startedâ instructions. Linkerdâs telemetry and monitoring features are enabled automatically, without requiring you to make any configuration changes to the default installation. These observability features include:
-
Recording of top-line (âgoldenâ) metrics (request volume, success rate, and latency distributions) for HTTP, HTTP/2, and gRPC traffic
-
Recording of TCP-level metrics (bytes in/out, etc.) for other TCP traffic
-
Reporting metrics per service, per caller/callee pair, or per route/path (with Service Profiles)
-
Generating topology graphs that display the runtime relationship between services
-
Live, on-demand request sampling
You can consume this data in several ways:
-
Through the Linkerd CLI, e.g., with linkerd viz stat and linkerd viz routes
-
Through the Linkerd dashboard and prebuilt Grafana dashboards
-
Directly from Linkerdâs built-in Prometheus instance
To gain access to Linkerdâs observability features, you only need to install the viz extension and open the dashboard using your local browser:
linkerd viz install | kubectl apply -f -linkerd viz dashboard
This provides access to service graphs showing traffic flow. In Figure 4-10, you can see traffic flowing across the mesh from the webapp to the book and authors services.

Figure 4-10. Using Linkerd viz to observe traffic flow between services
You can also view the top-line traffic metrics using the prebuilt Grafana dashboards, as shown in Figure 4-11.
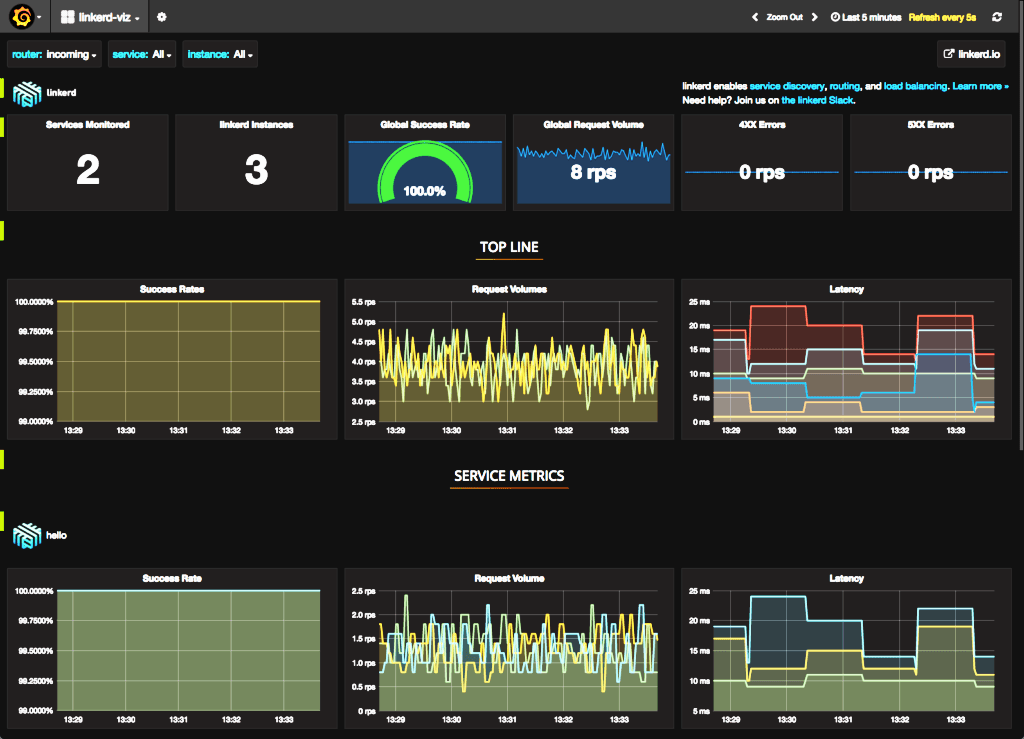
Figure 4-11. Viewing the Linkerd viz Grafana dashboards
Using a service mesh to provide observability into your applications is useful during both development and production. Although you should always automate detection of invalid service-to-service traffic in production, you can also use this service mesh observability tooling to identify when internal APIs or services are being called incorrectly. Letâs now explore using policy to specify exactly which services can communicate with each other in the service mesh using HashiCorpâs Consul.
Network Segmentation with Consul
You can install and configure Consul as a service mesh within a Kubernetes cluster by following the âGetting Started with Consul Service Mesh for Kubernetesâ guide. Before microservices, authorization of interservice communication was primarily enforced using firewall rules and routing tables. Consul simplifies the management of interservice authorization with intentions that allow you to define service-to-service communication permissions by service name.
Intentions control which services can communicate with each other and are enforced by the sidecar proxy on inbound connections. The identity of the inbound service is verified by its TLS client certificate, and Consul provides each service with an identity encoded as a TLS certificate. This certificate is used to establish and accept connections to and from other services.9 The sidecar proxy then checks if an intention exists that authorizes the inbound service to communicate with the destination service. If the inbound service is not authorized, the connection will be terminated.
An intention has four parts:
- Source service
-
Specifies the service that initiates the communication. It can be the full name of a service or be â*â to refer to all services.
- Destination service
-
Specifies the service that receives the communication. This will be the âupstreamâ (service) you configured in your service definition. It can be the full name of a service or also be â*â to refer to all services.
- Permission
-
Defines whether the communication between source and destination is permitted. This can be set to either allow or deny.
- Description
-
Optional metadata field to associate a description with an intention.
The first intention you will create changes the âallow allâ policy, where all traffic is allowed unless denied in specific rules, to a âdeny allâ policy where all traffic is denied and only specific connections are enabled:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: deny-all
spec:
destination:
name: '*'
sources:
- name: '*'
action: deny
By specifying the wildcard character (*) in the destination field, this intention will prevent all service-to-service communication. Once you have defined the default policy as deny all, you can authorize traffic between the conference system legacy service, the Attendee service, and the Session service by defining a ServiceIntentions CRD for each required service interaction. For example:
---
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: legacy-app-to-attendee
spec:
destination:
name: attendee
sources:
- name: legacy-conf-app
action: allow
---
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: legacy-app-to-sessions
spec:
destination:
name: sessions
sources:
- name: legacy-conf-app
action: allow
---
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: attendee-to-sessions
spec:
destination:
name: sessions
sources:
- name: attendee
action: allow
---
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: sessions-to-attendee
spec:
destination:
name: attendee
sources:
- name: sessions
action: allow
Applying this configuration to the Kubernetes cluster will enable these interactionsâand only these service-to-service interactionsâto process as required. Any other interactions will be prevented, and the API call or request will be dropped.
In addition to Consulâs intentions, the Open Policy Agent (OPA) project is a popular choice for implementing similar functionality within a service mesh. You can find an example of using OPA to configure service-to-service policy within Istio in the âOPA Tutorial documentationâ.
Now that you have explored example configuration that will be applied as we evolve the conference system, letâs turn our attention to running and managing the service mesh implementation itself.
Deploying a Service Mesh: Understanding and Managing Failure
Regardless of the deployment pattern and number of instances running within a system or network, a service mesh is typically on the critical path of many, if not all, user requests moving through your system. An outage of a service mesh instance within a cluster or network typically results in the unavailability of the entire system within that networkâs blast radius. For this reason the topics of understanding and managing failure are vitally important to learn.
Service Mesh as a Single Point of Failure
A service mesh is often on the hot path of all traffic, which can be a challenge in relation to reliability and failover. Obviously, the more functionality you are relying on within the service mesh, the bigger the risk involved and the bigger the impact of an outage. As a service mesh is often used to orchestrate the release of application services, the configuration is also continually being updated. It is critical to be able to detect and resolve issues and mitigate any risks. Many of the points discussed in âAPI Gateway as a Single Point of Failureâ can be applied to understanding and managing service mesh failure.
Common Service Mesh Implementation Challenges
As service mesh technologies are newer in comparison with API gateway technologies, some of the common implementation challenges are yet to be discovered and shared widely. However, there are a core set of antipatterns to avoid.
Service Mesh as ESB
With the emergence of service mesh plug-ins or traffic filters, and supporting technologies like Web Assembly (Wasm), it is increasingly tempting to think of service meshes as offering ESB-like functionality, such as payload transformation and translation. For all the reasons already discussed throughout this book, we strongly discourage adding business functionality or coupling too many âsmartsâ with the platform or infrastructure.
Service Mesh as Gateway
As many service mesh implementations provide some form of ingress gateway, we have seen organizations wanting to adopt an API gateway but instead choosing to deploy a service mesh and only using the gateway functionality. The motivation makes sense, as engineers in the organization realize that they will soon want to adopt service meshâlike functionality, but their biggest pain point is managing ingress traffic. However, the functionality provided by most service mesh gateways is not as rich in comparison with a fully fledged API gateway. You will also most likely encounter the installation and operational costs of running a service mesh without getting any of the benefits.
Too Many Networking Layers
We have seen some organizations provide a rich set of networking abstractions and features that will meet the current service-to-service communication requirements, but the development teams either donât know about this or refuse to adopt this for some reason. As development teams attempt to implement a service mesh on top of the existing networking technologies, additional issues appear, such as incompatibilities (e.g., existing networking technologies stripping headers), increased latency (owing to multiple proxy hops), or functionality being implemented multiple times within the networking stack (e.g., circuit breaking occurring in both the service mesh and the lower-level networking stack). For this reason, we always recommend that all involved teams coordinate and collaborate with service mesh solutions.
Selecting a Service Mesh
Now that you learned about the functionality provided by a service mesh, the evolution of the pattern and technologies, and how a service mesh fits into to the overall system architecture, next is a key question: how do you select a service mesh to be included in your applicationâs technology stack?
Identifying Requirements
As discussed in relation to selecting an API gateway, one of the most important steps with any new infrastructure project is identifying the related requirements. This may appear obvious, but Iâm sure you can recall a time that you were distracted by shiny technology, magical marketing, or good sales documentation!
You can look back to the earlier section âWhy Use a Service Mesh?â of this chapter to explore in more detail the high-level requirements you should be considering during a service mesh selection process. It is important to ask questions that are both focused on current pain points and also your future roadmap.
Build Versus Buy
In comparison with the API gateway build versus buy decision, the related discussions with service mesh are less likely to be had upfront, especially with organizations that have heritage or legacy systems. This can partially be attributed to service mesh being a relatively new category of technology. In our experience, in most vintage systems that are somewhat distributed (e.g., more than a LAMP stack), partial implementations of a service mesh will be scattered throughout an organizationâfor example, with some departments using language-specific libraries, others using an ESB, and some using simple API gateways or simple proxies to manage internal traffic.
In general, if you have decided to adopt the service mesh pattern, we believe that it is typically best to adopt and standardize on an open source implementation or commercial solution rather than build your own. Presenting the case for build versus buy with software delivery technology could take an entire book, and so in this section we only want to highlight some common challenges:
- Underestimating the total cost of ownership (TCO)
-
Many engineers discount the cost of engineering a solution, the continued maintenance costs, and the ongoing operational costs.
- Not thinking about opportunity cost
-
Unless you are a cloud or platform vendor, it is highly unlikely that a custom service mesh will provide you with a competitive advantage. You can instead deliver more value to your customers by building functionality aligned to your core value proposition.
- Operational costs
-
Not understanding the onboarding and operational cost of maintaining multiple different implementations that solve the same problems.
- Awareness of technical solutions
-
Both the open source and commercial platform component space move fast, and it can be challenging to keep up-to-date. Staying aware and informed, however, is a core part of the role of being a technical leader.
Checklist: Selecting a Service Mesh
The checklist in Table 4-5 highlights the key decisions that you and your team should be considering when deciding whether to implement the service mesh pattern and when choosing the related technologies.
Summary
In this chapter you have learned what a service mesh is and explored what functionality, benefits, and challenges adopting this pattern and associated technologies provides:
-
Fundamentally, âservice meshâ is a pattern for managing all service-to-service communication within a distributed software system.
-
At a network level, a service mesh proxy acts as a full proxy, accepting all inbound traffic from other services and also initiating all outbound requests to other services.
-
A service mesh is deployed within an internal network or cluster. Large systems or networks are typically managed by deploying several instances of a service mesh, often with each single mesh spanning a network segment or business domain.
-
A service mesh may expose endpoints within a network demilitarized zone (DMZ), or to external systems, or additional networks or clusters, but this is frequently implemented by using an âingress,â âterminating,â or âtransitâ gateway.
-
There are many API-related cross-cutting concerns that you might have for each or all of your internal services, including: product lifecycle management (incrementally releasing new versions of a service), reliability, multilanguage communication support, observability, security, maintainability, and extensibility. A service mesh can help with all of these.
-
A service mesh can be implemented using language-specific libraries, sidecar proxies, proxyless communication frameworks (gRPC), or kernel-based technologies like eBPF.
-
The most vulnerable component of a service mesh is typically the control plane. This must be secured, monitored, and run as a highly available service.
-
Service mesh usage antipatterns include: service mesh as ESB, service mesh as gateway, and using too many networking layers.
-
Choosing to implement a service mesh, and selecting the technology to do so, are Type 1 decisions. Research, requirements analysis, and appropriate design must be conducted.
-
If you have decided to adopt the service mesh pattern we believe that it is typically best to adopt and standardize on an open source implementation or commercial solution rather than build your own.
Regardless of your decision to adopt a service mesh, it is important to consider both external and internal operations and security for your APIs. This is the focus of the next section of this book.
1 The Linkerd project emerged from Twitterâs Finagle technology that was built to provide a communication framework for developers building Twitterâs distributed applications. Linkerd has now evolved into a graduated Cloud Native Computing Foundation (CNCF) project.
2 You can learn more about Kubernetes networking concepts via the official docs: Service, NetworkPolicies, and Container Networking Interface (CNI).
3 Airbnbâs SmartStack was one of the first implementations of external microservice service discovery.
4 You should note that the Finagle RPC framework and Netflix OSS libraries are now both deprecated and not recommended for use in modern production systems.
5 You can learn more via these websites for Fowlerâs âMicroservice Prerequisitesâ, âCalçadoâs Microservices Prerequisitesâ, and Philâs blog âPattern: Service Meshâ.
6 You can learn more about Traffic Director and the Envoy Proxyâinspired xDS protocol via their respective documentation websites.
7 Learn more about this in âHow eBPF will solve Service MeshâGoodbye Sidecarsâ.
8 You can learn more about VirtualServices and DestinationRules via the Istio docs.
9 The identity is encoded in the TLS certificate in compliance with the SPIFFE X.509 Identity Document, which enables Connect services to establish and accept connections with other SPIFFE-compliant systems.
Get Mastering API Architecture now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

