Capítulo 4. Productos de transmisión de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En una malla de flujo de datos, los dominios son propietarios de sus datos. Esto crea una plataforma de datos descentralizada para ayudar a resolver los problemas relacionados con la agilidad y la escalabilidad en el lago de datos y los almacenes. Ahora los dominios tienen que servir a otros dominios sus datos. Por eso es importante que traten sus datos como productos de alta calidad y confianza.
Actualmente, los ingenieros de datos están muy acostumbrados a la idea de que todos sus datos están en un almacén central de datos, como un lago de datos o un almacén. Están acostumbrados a encontrar formas de "hervir el océano" (en este caso, el lago) cuando trabajan con datos. Una malla de datos en flujo nos permite evaporar esa idea. En este capítulo, esbozaremos los requisitos de los productos de streaming de datos.
En nuestras carreras como ingenieros de datos, nos hemos encontrado escribiendo muchas envolturas para Apache Spark, un motor analítico muy utilizado para el procesamiento de datos a gran escala. Sólo en los últimos años comprendimos plenamente por qué las empresas nos pedían que lo hiciéramos.
Las herramientas de big data como Apache Spark, Apache Flink y Apache Kafka Streams eran inaccesibles para muchos ingenieros encargados de resolver problemas de big data. Volviendo al Capítulo 1, romper el papel monolítico de un ingeniero de datos es un efecto secundario de una malla de datos.
Este es un punto muy importante porque un segundo efecto secundario es hacer que herramientas complejas de ingeniería de datos como Spark, Flink y Kafka Streams sean más accesibles a los ingenieros generalistas para que puedan resolver sus problemas de big data. Es la razón por la que estas empresas nos pidieron que envolviéramos motores de procesamiento de datos a gran escala. La Tabla 4-1 muestra una lista de proyectos en los que participamos para ayudar a ingenieros específicos a consultar big data almacenados en lagos de datos.
| El proyecto | El ingeniero |
|---|---|
Big Data Integrator-una envoltura de interfaz de usuario de Apache Spark con funciones de arrastrar y soltar |
Ingenieros de integración y analistas empresariales que necesitan procesar datos para elaborar informes en una herramienta de inteligencia empresarial. |
Sparknado-un wrapper de Apache Spark que utiliza la sintaxis de Airflow para construir DAGs de Spark |
Los ingenieros de Airflow crean aplicaciones Spark para trasladar los datos a Snowflake. |
Apache Envelope: una configuración de Spark basada en YAML |
Ingenieros que quieran definir un DAG Spark sin necesidad de saber codificar en Python o Scala. |
Splunk SPL a Spark: una sintaxis de tuberías que se asemeja a Splunk Search Language (SPL) |
Cazadores de amenazas de seguridad que estén familiarizados con Splunk para poder cazar amenazas en los registros de red almacenados en un lago de datos. |
Haber hecho esto tantas veces valida la necesidad de simplificar las herramientas de datos para que sean más accesibles a los ingenieros generalistas y a veces especialistas, y no tanto para reducir la carga de trabajo de los ingenieros de datos. Les permite reaccionar más rápidamente ante problemas anómalos y ofrecer resultados inmediatos a los clientes.
Al crear productos de datos, es importante comprender esto. Facilitar a los dominios el acceso a las herramientas de datos les permitirá resolver problemas de datos complejos. Esta capacidad estaba antes fuera de su alcance.
En las siguientes secciones, repasaremos los requisitos para definir y construir productos de datos que se publicarán en una malla de streaming de datos. Intentaremos mantener el alcance de los detalles en la construcción de productos de flujo de datos, y nos referiremos a los detalles relativos a los autoservicios y la gobernanza de datos en lo que se refiere a los productos de flujo de datos en sus capítulos correspondientes.
Definir los requisitos de los productos de datos
Esta sección de es un resumen de los requisitos de los productos de datos enumerados en la Tabla 4-2. El objetivo de estos requisitos es ofrecer a los consumidores y a los consumidores de dominio una experiencia de malla de datos fluida y agradable. La salud de la malla de datos viene determinada por la experiencia del consumidor de dominio con los productos de datos. Estos requisitos ayudarán a diseñar e implementar un producto de datos que satisfaga las necesidades de sus consumidores.
| Requisitos | Consideraciones sobre la aplicación |
|---|---|
Los productos de datos deben ser de alta calidad. |
|
Los productos de datos deben ser seguros y fiables. |
|
Los productos de datos deben ser interoperables. |
|
Los productos de datos deben ser fácilmente consumibles. |
|
Los productos de datos deben conservar el linaje. |
|
Los productos de datos deben poder buscarse fácilmente y ser autodescriptivos. |
|
Los productos de datos deben proporcionar datos históricos. |
|
Añadir retroactivamente requisitos de productos de datos podría resultar costoso en deuda técnica. Por ejemplo, es muy probable que el linaje sea un requisito difícil de añadir retroactivamente sin los metadatos referenciables necesarios para construirlo, por lo que es importante pensar en estos requisitos complejos pronto para evitar una costosa deuda técnica.
Cuando otros dominios soliciten productos de datos, asegúrate de que cumplen estos requisitos. Tenlos en cuenta cuando identifiques las fuentes que necesitarás para componer tus productos de datos.
Advertencia
Algunos han confundido los productos de datos con la masterización de datos. La masterización de datos es un proceso de construcción de una versión maestra indiscutible de un registro, denominada registro de oro. Los datos maestros son una característica de un producto de datos y no necesariamente un requisito del producto de datos. Si se requiere que tu producto de datos proporcione registros maestros de empleados, por ejemplo, entonces se necesitará una herramienta adecuada de gestión de datos maestros (MDM) dentro del dominio para realizar este trabajo.
Identificar los derivados de los productos de datos
Los productos de datos se derivan de las fuentes de datos de un dominio. También pueden enriquecerse a partir de productos de datos de otros dominios. Recuerda que los productos de datos son propiedad de los expertos del dominio que los produjeron. Si el producto de datos que estás construyendo requiere el enriquecimiento a partir de datos de otro dominio, tendrás que ingerir esos datos en tu propio dominio para enriquecer tus propios productos de datos. Estamos definiendo los derivados de datos como datos dentro del dominio y datos procedentes de otros dominios. Identificar estos derivados y comprender sus puntos de integración ayudará a definir soluciones para empezar a ingerirlos en la plataforma de streaming.
Hay dos tipos de datos: en reposo y en movimiento. Tenemos que empezar a ingerir datos derivados, lo que implicará conseguir que los datos en reposo sean datos en movimiento. También queremos conseguir que los datos ya en movimiento sigan en movimiento. Es importante pensar en la optimización de los datos al principio del proceso de ingestión, para que cualquier componente posterior pueda aprovechar esta optimización. Empieza por particionar los datos en los temas de origen en la plataforma de streaming. Tener suficientes particiones servirá eficientemente los productos de datos a los consumidores y creará un procesamiento equilibrado en el canal de datos.
Derivados de otros dominios
Los derivados que se originan en otros dominios como productos de datos deben ser referenciables para que pueda generarse una imagen completa del linaje. Esto podría incluir múltiples dominios atravesados recursivamente a través de la malla. Conservar una instantánea del linaje actual de un producto de datos acabará siendo obsoleto, ya que los derivados del producto de datos pueden haber evolucionado en calidad, escalabilidad y estructura, como en los esquemas. En capítulos posteriores, hablaremos de la gobernanza de los datos y la evolución de los esquemas como componente centralizado en la malla de datos. Las técnicas para preservar el linaje se tratarán con más detalle en el Capítulo 6.
Consumir otros productos de datos de otros dominios y enriquecer los tuyos propios es la verdadera esencia de trabajar en una malla de datos. La experiencia consistirá en solicitar acceso al producto de datos y, a continuación, suscribirse al flujo en tiempo real del producto de datos. Una vez hecho esto, debería aparecer un tema en la plataforma de streaming que represente el producto de datos de streaming en tiempo real procedente de otro dominio. Parte de esta suscripción al producto de datos no es sólo a los datos, sino también a los metadatos. Son estos metadatos los que permitirán un linaje que abarque múltiples dominios.
Ingesta de datos de productos derivados con Kafka Connect
Después de identificar en los derivados de nuestros productos de datos en streaming, tenemos que introducirlos en una plataforma de streaming. La forma más sencilla de introducir o extraer datos de una plataforma de streaming compatible con Kafka es aprovechar los conectores de Kafka . (Otras plataformas como Spark o Flink también tienen sus propios conectores.) Kafka Connect es un marco que permite la implementación para leer datos de una fuente de datos y llevarlos a una plataforma de streaming. A la inversa, también permite la implementación para escribir datos en un sumidero de datos desde la plataforma de streaming. Véase la Figura 4-1.
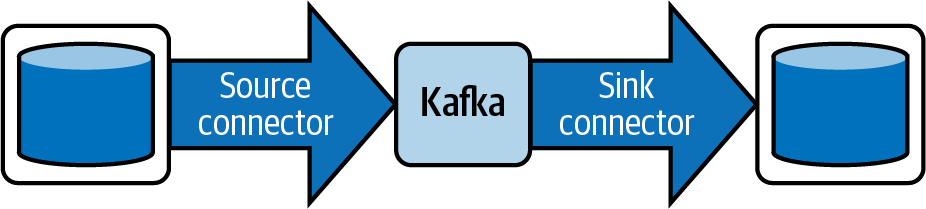
Figura 4-1. Una canalización de datos que ilustra un conector fuente de Kafka escribiendo en Kafka, y un conector sumidero de Kafka leyendo de Kafka
Kafka Connect también proporciona una experiencia de bajo código, lo que significa que no se requiere codificación para los ingenieros de dominio. Utilizaremos Kafka Connect para introducir los datos de origen en la plataforma de streaming. Hay otras formas de introducir datos en una plataforma de streaming, pero no muchas admiten los conectores de captura de datos de cambio (CDC) de que necesitamos. Hablaremos de CDC en "Conectores Debezium".
El framework de código abierto Kafka Connect permite la entrada y salida de datos de forma sencilla y escalable. Es una de las razones por las que hemos elegido esta solución para hablar de ella. Los conectores pueden conectarse a fuentes de datos específicas, así como a una plataforma de streaming compatible con Kafka para transmitir datos, como Redpanda. Otros productos, como Apache Pulsar, permiten a los clientes de Kafka producir y consumir mensajes de Kafka en su plataforma.
Los conectores Kafka no se ejecutan solos. Se ejecutan en un clúster Kafka Connect que les permite ser distribuibles y altamente disponibles. Cada nodo del clúster Connect se denomina trabajador Connect. Cada conector contiene una propiedad de configuración llamada tasks.max. Las tareas son los procesos principales que transmiten datos en un conector. Cuando se configura con varias tareas, el clúster connect puede distribuirlas entre sus trabajadores para que se ejecuten en paralelo, lo que permite la escalabilidad. Si uno de los trabajadores connect del cluster sufriera una interrupción, los datos se redistribuyen entre los trabajadores restantes (ver Figura 4-2). La propiedad task.max define el número máximo de tareas que deben crearse para este conector en un cluster connect. El conector puede crear menos tareas si no puede alcanzar este nivel de paralelismo.
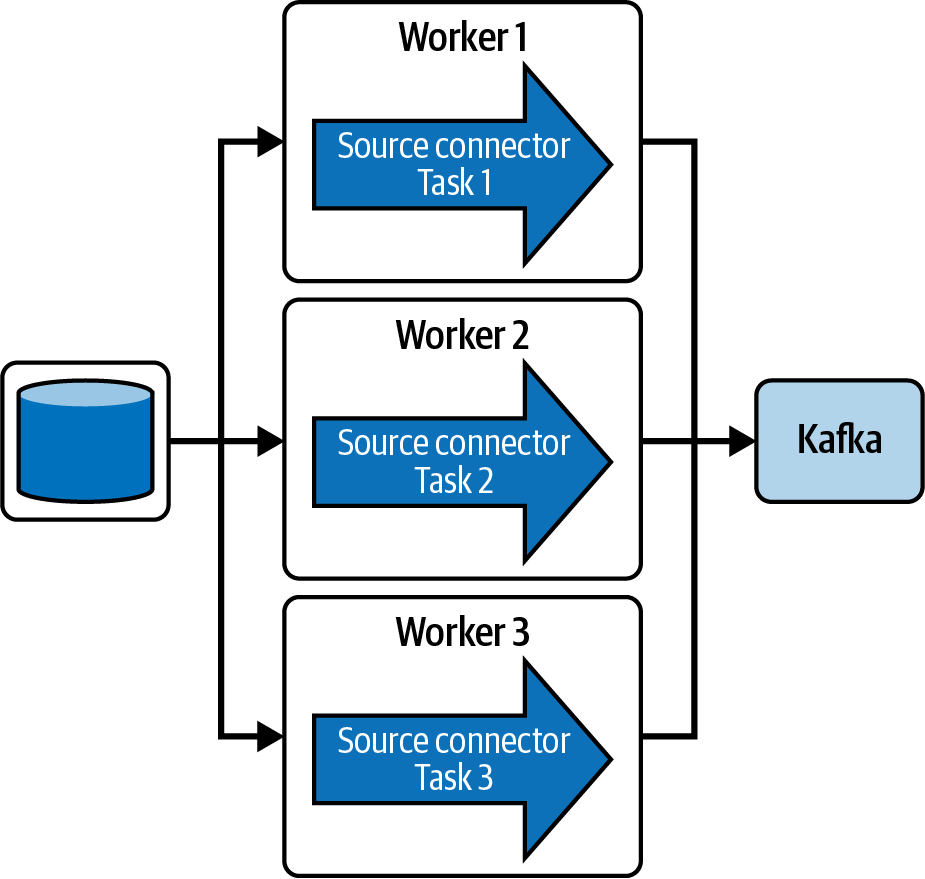
Figura 4-2. Un conector de fuente única cuyas tres tareas se distribuyen entre tres connect workers en un clúster de Kafka Connect; los connect workers pueden desplegarse en máquinas separadas para una alta disponibilidad y escalabilidad.
Utilizar Kafka Connect y los numerosos conectores preconstruidos hace que la construcción de la malla de datos en flujo sea mucho más rápida y cede el desarrollo y el soporte a terceros proveedores. Ya se han creado conectores para bases de datos populares y almacenes de datos en la nube. Muchos de ellos son desarrollados por los propios proveedores y vienen con planes de soporte. Si no se dispone de un conector, el equipo de la malla de datos centralizada debe tener la capacidad para construir uno y proporcionarlo a los dominios de la malla de datos para su uso.
Otra razón por la que Kafka Connect es una buena solución es que estandariza la ingesta, simplificando la implementación y gestión del conector. El clúster de Kafka Connect proporciona una interfaz RESTful y puede integrarse fácilmente con una canalización CI/CD como Jenkins, Kubernetes, Ansible o Terraform.
Kafka Connect tiene algunas capacidades de transformación llamadas transformaciones de mensaje único (SMT), pero se limitan a transformaciones simples. Eso significa que no hay uniones ni agregaciones. La transformación de datos se consolida mejor en los procesos de flujo, donde se admiten transformaciones simples y complejas. Las transformaciones se tratarán en "Transformación de derivados de datos en productos de datos".
Consejo
Es una buena práctica realizar las transformaciones en un procesador de flujo que pueda conservar el estado y no en los conectores que no pueden conservar el estado. Además, capturar transformaciones en un conector para preservar el linaje podría ser difícil, mientras que los procesadores de flujo que construyen grafos acíclicos dirigidos (DAG) que representan el flujo de trabajo de procesamiento pueden serializar sus DAG para preservar el linaje.
Al ingerir los derivados del producto de datos, hay que pensar desde el principio en el eventual producto de datos de flujo y en cómo garantizar su facilidad de consumo. Ten en cuenta también que el hecho de que los datos se ingieran de forma asíncrona o síncrona es un factor que influirá en la forma en que el dominio consumirá y utilizará tu producto de datos en flujo.
Consumibilidad
Consumibilidad es un requisito muy importante porque afectará directamente a la experiencia que tendrán los consumidores de dominios en una malla de transmisión de datos. Si otros dominios no pueden consumir fácilmente productos de datos de flujo, entonces pueden optar por no participar en la malla de datos de flujo y decidir construir sus propias integraciones a mano, eludiendo cualquier problema que encuentren con la malla de datos. Algunos factores a tener en cuenta al ingerir derivados de datos que afectarán a la consumibilidad de otros dominios son los siguientes:
-
Falta de escalabilidad
-
Falta de interoperabilidad
Escalabilidad
Cuando piensa en ingerir derivados de datos en la plataforma de streaming, es importante conocer la escala en la que necesitarás ingerir los datos. En la plataforma de streaming, tendrás que asegurarte de que el número de particiones puede soportar el rendimiento (o la velocidad) a la que se espera que se transmitan los datos. Cuantas más particiones tenga un tema Kafka, más rápido podrá transmitir los datos. Las particiones son la forma en que Kafka permite el paralelismo. En otras plataformas de streaming, tendrás que configurar sus temas equivalentes de forma similar.
Una fórmula aproximada propuesta por Jun Rao (desarrollador original de Apache Kafka) para determinar el recuento de particiones se basa en el rendimiento. Esta fórmula obtiene el recuento de particiones hallando el máximo entre estos dos valores:
-
El rendimiento deseado(t) dividido por el rendimiento de producir datos a la partición que puedes conseguir(p)
-
El rendimiento deseado(t) dividido por el rendimiento que consumen los datos de la partición que puedes conseguir(c)
La fórmula es la siguiente:
- max(t/p, t/c)
El siguiente ejemplo muestra un rendimiento deseado de 3 MBps (megabytes por segundo). El productor puede producir 1 MBps. Supongamos que 3 consumidores quieren suscribirse a los datos, lo que significa 3 MBps a 1 MBps cada uno. El resultado son 3 particiones. En este ejemplo, el recuento es realmente bajo para la mayoría de los casos de uso de Kafka. Tal vez quieras prepararte para futuros aumentos del rendimiento aumentando este recuento a 5 ó 6:
- max(3 MBps/1 MBps, 3 MBps/3 MBps) = max(3, 1)= 3 particiones
Otros factores pueden ayudar a conseguir el rendimiento deseado, pero quedan fuera del alcance de este libro.
Tras determinar el número de particiones, es importante comprender cómo distribuir los datos uniformemente por todas las particiones para conseguir un paralelismo equilibrado. En Apache Kafka, los datos se envían como un par de clave y valor. La clave se somete a hash para determinar a qué partición se asignará. Esta fórmula ilustra cómo funciona esto:
- clave % p = asignación de partición
Este algoritmo de hashing funciona bien cuando la clave está distribuida uniformemente en todos los registros de los datos enviados al tema Kafka. En otras palabras, la clave debe tener una cardinalidad alta y una distribución uniforme en todo el conjunto de datos. Una cardinalidad alta y una distribución uniforme crean un buen equilibrio de datos entre todas las particiones del tema. Una cardinalidad baja o una distribución desigual crean paralelismo desequilibrado. Un paralelismo desequilibrado en la ingesta crea desequilibrio en todos los componentes posteriores del canal de datos. En los temas de Kafka, esto se manifiesta como hot spotting, donde sólo una o unas pocas particiones están haciendo la mayor parte del trabajo, provocando que toda tu canalización de datos funcione con lentitud. Sería beneficioso perfilar tus datos para tener una idea de su cardinalidad y de la distribución de las claves en los datos. Definir claves con alta cardinalidad y distribución uniforme es un paso importante en el procesamiento distribuido, porque la mayoría de los sistemas distribuidos distribuyen la carga de trabajo a sus trabajadores por claves.
Otra forma de mejorar la escalabilidad es utilizar un formato de serialización de datos adecuado, del que hablaremos a continuación.
Interoperabilidad y serialización de datos
Tener en mente la escalabilidad y la interoperabilidad de es fundamental cuando empezamos a hablar de cómo ingerir realmente los datos en una plataforma de streaming. La interoperabilidad es la capacidad de intercambiar información o trabajar sin problemas con otros sistemas. En el caso de una malla de datos en flujo, esto puede lograrse creando esquemas que definan los objetos o modelos del dominio y eligiendo un formato de serialización de datos adecuado. Los esquemas ayudarán a los dominios de la malla de flujo de datos a intercambiar información fácilmente y a trabajar sin problemas con otros dominios, y el formato de serialización de datos permitirá el intercambio de información entre sistemas que normalmente son incompatibles entre sí.
La interoperabilidad y la serialización de datos son requisitos de la malla de datos que entran dentro del pilar de la gobernanza de datos, tratado en el Capítulo 5, por lo que allí entraremos en más detalles. Pero es fundamental que empecemos a pensar en ellos en la ingesta de datos, porque esto afecta a todos los sistemas y componentes del conducto de datos aguas abajo. En primer lugar, tenemos que definir el esquema que representa el derivado de datos. Un esquema es básicamente una definición de cómo se estructurarán los datos cuando se muevan por el conducto de flujo de datos. Por ejemplo, supongamos que estás ingiriendo estadísticas globales COVID-19. La forma de tus datos puede parecerse a la Tabla 4-3, que sólo proporciona dos países. (Observa que la Tabla 4-4 es una continuación de los datos de la Tabla 4-3).
| País | CódigoPaís | Fecha | ID |
|---|---|---|---|
Estados Unidos de América |
EE.UU. |
2022-04-07T19:47:08.275Z |
2291245c-5bf8-460f-af77-05ce78cc60c9 |
Filipinas |
PH |
2022-04-07T19:47:08.275Z |
82aa04f7-05a1-4caa-b309-0e7cfbfae5ea |
| NuevoConfirmado | NuevasMuertes | NuevoRecuperado | TotalConfirmado | TotalMuertes | TotalRecuperado |
|---|---|---|---|---|---|
40176 |
1241 |
0 |
80248986 |
983817 |
0 |
0 |
0 |
0 |
3680244 |
59422 |
0 |
La fuente de datos COVID-19 que estamos leyendo se sirve como registros JSON, por lo que crearíamos el formato de serialización de datos como JSON. En el Ejemplo 4-1 mostramos una definición de esquema JSON que coincide con la estructura de la Tabla 4-3.
Ejemplo 4-1. Esquema JSON que define la estructura de la tabla 4-3
{"$schema":"http://json-schema.org/draft-04/schema#","type":"object","properties":{"ID":{"type":"string"},"Country":{"type":"string"},"CountryCode":{"type":"string"},"NewConfirmed":{"type":"integer"},"TotalConfirmed":{"type":"integer"},"NewDeaths":{"type":"integer"},"TotalDeaths":{"type":"integer"},"NewRecovered":{"type":"integer"},"TotalRecovered":{"type":"integer"},"Date":{"type":"string"}},"required":["ID","Country","CountryCode","NewConfirmed","TotalConfirmed","NewDeaths","TotalDeaths","NewRecovered","TotalRecovered","Date"]}
Lista los campos y sus tipos de datos
Enumera los campos obligatorios
La Tabla 4-5 muestra algunos formatos de serialización de datos entre los que puedes elegir y que son adecuados para la transmisión de datos. Existen muchos otros formatos de serialización, como Parquet y ORC, pero no son adecuados para el flujo de datos. Son más adecuados para datos en reposo en lagos de datos.
| Nombre | Mantenedor | Binario | Legible por humanos |
|---|---|---|---|
JSON |
Douglas Crockford |
No |
Sí |
Apache Avro |
Fundación para el Software Apache |
Sí |
Parcial |
Búferes de protocolo (protobuf) |
Sí |
Parcial |
Muchos formatos de serialización de datos, como Parquet y ORC, ayudan a que las consultas se ejecuten de forma más eficiente en un lago de datos. Otros mejoran el rendimiento en una malla de servicios (intercomunicación de microservicios), como Avro y protobuf. JSON es probablemente el formato de serialización de datos más utilizado por su facilidad de uso y legibilidad humana.
Todas las opciones de la Tabla 4-5 pueden definirse mediante un esquema. Hablaremos más sobre cómo estos esquemas crean contratos entre los dominios productores y consumidores, y sobre sus funciones de apoyo a la gobernanza de los datos en la malla de streaming de datos en el Capítulo 5.
Fuentes de datos síncronas
En al principio de esta sección hablamos de cómo consumirán los dominios los productos de streaming de datos: de forma sincrónica o asincrónica. Describamos primero el consumo síncrono de datos en términos de cliente y servidor, donde el cliente solicita los datos y el servidor los sirve.
El consumo de datossíncrono (también llamado por lotes) significa que el consumidor (el cliente) de los datos sigue una relación de solicitud y respuesta con el servidor. El cliente solicita datos a un servicio de datos, y el servicio devuelve rápidamente una instantánea del resultado de la fuente.
Cuando solicita estas páginas, estás solicitando resultados utilizando marcos como ODBC o JDBC para conectar y recuperar estos lotes de una fuente de datos. Este enfoque te obliga a capturar instantáneas de datos que siguen la semántica de los lotes. Cada instantánea se considera un lote.
La Figura 4-3 muestra al cliente solicitando la instantánea inicial de los datos de la base de datos. Cuando el cliente solicita otra instantánea, tienes que restar la segunda de la instantánea inicial para encontrar sólo los cambios incrementales. O bien, puedes sobrescribir la instantánea inicial con la segunda instantánea, pero perderás lo que haya cambiado. Si los cambios en la base de datos tienen que desencadenar una acción, tendrás que encontrar los cambios incrementales.
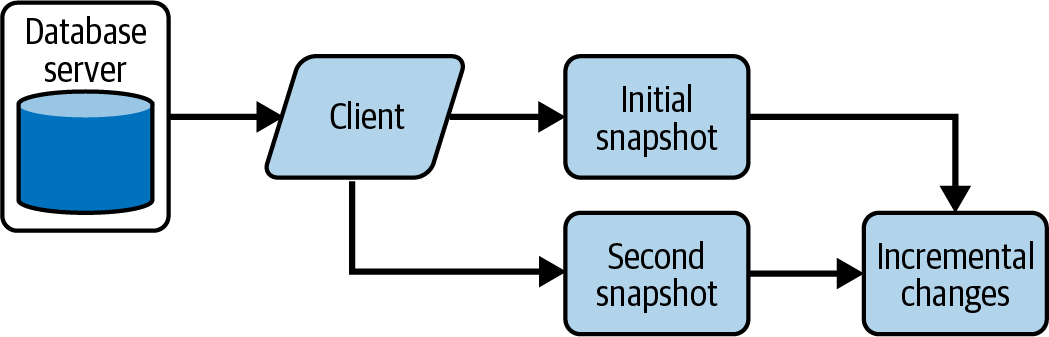
Figura 4-3. Determinar cambios incrementales a partir de una instantánea de base de datos
Además, si se producen cambios entre las instantáneas de los clientes, se perderán los cambios que reviertan a su valor original. En la Tabla 4-6, se pierden los eventos que cambiaron de Robert a Bob y luego de nuevo a Robert.
| Tiempo | Eventos |
|---|---|
12:00 |
Instantánea inicial |
12:01 |
Nombre cambiado de Robert a Bob |
12:03 |
Nombre cambiado de nuevo de Bob a Robert |
12:05 |
Segunda instantánea |
Este ejemplo ilustra cómo las API de datos síncronas obligan a los clientes que solicitan datos a una semántica de procesamiento por lotes que podría provocar alguna pérdida de datos, como se ha visto con las instantáneas incrementales. Algunos sistemas de aplicación basados en eventos intentarán utilizar API síncronas y adaptarlas a flujos de datos en tiempo real. Vemos esto con bastante frecuencia porque muchos sistemas no tienen soporte para el streaming, así que nos queda emular un flujo de datos emitido desde esas fuentes de datos.
Los consumidores de estos datos tendrán que saber que los resultados se toman utilizando instantáneas y que deben esperar perder algunos datos.
Fuentes de Datos Asíncronas y Captura de Datos de Cambios
Las fuentes de datosasíncronas siguen un enfoque diferente: los clientes se suscriben a los cambios en los datos en lugar de tomar instantáneas. Cada vez que se produce un cambio, se hace una entrada en el registro de cambios, y los clientes suscritos reciben una notificación y pueden reaccionar ante el cambio. Este se denomina captura de datos de cambios(CDC).
Los conectores Kafka que admiten CDC leen el registro de confirmaciones de la base de datos y capturan los cambios de una tabla de la base de datos. Estos cambios son flujos en tiempo real de cambios en la tabla de la base de datos, incluyendo inserciones, actualizaciones y eliminaciones. Esto significa que no pierdes los cambios descritos en la Tabla 4-6.
Consejo
Si es posible, ingiere los datos derivados por CDC y no por instantáneas, para asegurarte de que se capturan todas las transacciones.
Volviendo a la "división de datos", el objetivo era trasladar los datos de las bases de datos operativas al plano analítico. Esas bases de datos operativas contienen transacciones que impulsan el negocio. Perder transacciones entre instantáneas podría ser un problema crítico en muchos casos de uso. Lo mejor es utilizar un conector Kafka que pueda realizar el CDC desde la base de datos operativa y transmitirlo a la plataforma de streaming.
Conectores Debezium
Un conjunto de conectores CDC de , llamados conectores Debezium, capturan los cambios en una base de datos a partir de un registro de cambios y los envían a una plataforma de streaming. Los conectores más utilizados son los siguientes:
-
MySQL CDC
-
MongoDB
-
PostgreSQL
-
Oracle
-
Servidor SQL
-
IBM Db2
-
Apache Cassandra
-
Vitess
Para plataformas de streaming que no sean Kafka, se puede utilizar un servidor Debezium como alternativa a la ejecución de un clúster Kafka Connect. La Figura 4-4 ilustra cómo el servidor Debezium puede sustituir al clúster Kafka Connect para enviar a otras plataformas de streaming. Los eventos de cambio pueden serializarse a distintos formatos, como JSON o Apache Avro, y luego enviarse a uno de los diversos sistemas de mensajería.
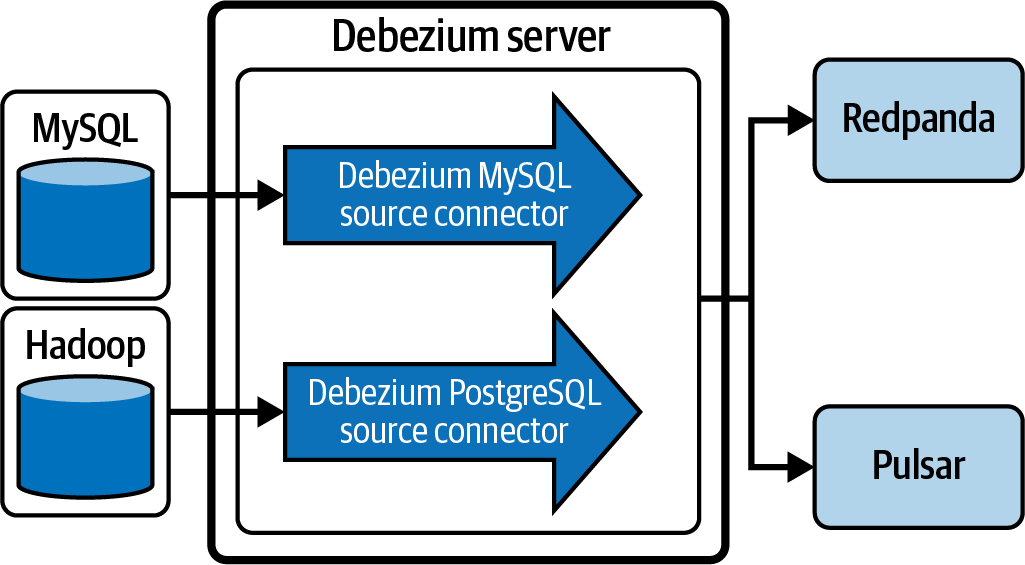
Figura 4-4. Un servidor Debezium sustituyendo a un clúster Kafka Connect para servir conectores a plataformas de streaming alternativas: Redpanda y Apache Pulsar
El servidor Debezium también puede servir a otras plataformas de streaming que no tengan un registro de confirmaciones. Esas plataformas no aparecen en la Figura 4-4. Es importante recordar que sólo las plataformas de streaming que mantienen datos en un registro de confirmaciones pueden soportar mejor las arquitecturas Kappa y, en última instancia, una malla de datos de streaming, como se menciona en el Capítulo 2.
Pensar en la consumabilidad desde el principio te ahorrará las quejas de los consumidores del dominio más adelante. Dejar claro cómo se recuperan los productos de flujo de datos (síncrono o asíncrono) les ayudará a entender qué esperar.
El resultado de la ingesta de datos en una plataforma de streaming será un tema para cada derivado de datos. Transformaremos y enriqueceremos estos derivados para componer el producto final de datos en streaming.
Transformar los Derivados de Datos en Productos de Datos
En la sección anterior, ingerimos los derivados de datos para que nuestros productos de datos en flujo fueran consumibles, centrándonos en la escalabilidad y la interoperabilidad. Esta sección se centrará en la transformación de los derivados de datos para garantizar que nuestros productos de flujo de datos sean de alta calidad y seguros.
También sugeriremos algunas herramientas sencillas para transformar los datos derivados en productos de datos en flujo. Estas herramientas aprovecharán SQL para transformar los datos. Utilizar SQL es una habilidad omnipresente para muchos ingenieros, incluidos los ingenieros de dominio. Es la forma preferida de permitir que los ingenieros de dominio construyan productos de flujo de datos.
Normalización de datos
En es una buena práctica establecer normas de formato cuando se comparten datos con otros dominios. Estas normas forman parte de un conjunto de políticas de gobernanza de datos que se aplican en todos los dominios (trataremos la gobernanza de datos en el Capítulo 5). Estandarizar los datos crea coherencia en todos tus dominios y facilita su uso. De lo contrario, todos los dominios tendrán que saber cómo convertir los distintos formatos de cada dominio que no siga la norma. Así que, como parte de la transformación de los datos derivados, tendremos que transformar los datos para que se adhieran a estas normas. Por ejemplo, las políticas de gobierno de datos pueden exigir que todos los números de teléfono tengan un formato estándar como 1-234-567-8900. Pero los datos de la fuente original pueden no proporcionar los números en ese formato. Tenemos que asegurarnos de que se aplican todas las normas de formato a los datos antes de publicarlos como producto de flujo de datos.
Proteger la información sensible
también debes asegurarte de que la información sensible se ofusca mediante su tokenización,encriptación u omisión. Para ejemplo, la información sanitaria protegida (PHI) y la información personal identificable (PII) se consideran datos sensibles. Los datos PHI y PII están sujetos a normas reguladoras como la Ley de Portabilidad y Responsabilidad de los Seguros Sanitarios (HIPAA) y el Reglamento General de Protección de Datos (GDPR). Las normativas que van más allá de la HIPAA y el GDPR quedan fuera del alcance de este libro.
La norma de privacidad de la HIPAA protege toda la información sanitaria identificable individualmente que posea o transmita una entidad cubierta o su socio comercial, en cualquier forma o medio, ya sea electrónico, en papel u oral. La norma de privacidad llama a esta información "información sanitaria protegida (PHI)". La información sanitaria identificable individualmente es información, incluidos los datos demográficos, que se refiere a cualquiera de los siguientes aspectos:1
La salud o el estado físico o mental pasado, presente o futuro de la persona
La prestación de asistencia sanitaria al individuo
El pago pasado, presente o futuro por la prestación de asistencia sanitaria alindividuo
El RGPD exige a las empresas de toda la UE que protejan la privacidad y salvaguarden los datos que guardan sobre sus empleados, clientes y terceros proveedores. Las empresas tienen ahora la obligación legal de mantener esta IIP a salvo y segura.2
La Tabla 4-7 muestra algunos métodos para ofuscar datos sensibles como PHI y PII para mantenerlos dentro de las normativas que los protegen.
| Método | Propósito |
|---|---|
Tokenización |
Sustituye los datos por un testigo. Más tarde, el token puede consultarse para obtener el valor original, siempre que el sistema que consulta el token tenga permiso para recuperarlo. A menudo, al tokenizar los datos se mantiene su formato original y se expone un valor parcial. Por ejemplo, un número de tarjeta de crédito puede mostrar los cuatro últimos dígitos: xxxx-xxxx-xxxx-1234 |
Cifrado |
Sustituye el valor por un valor encriptado. El valor puede descifrarse con una clave. Un sistema puede solicitar descifrar los datos para obtener su valor original siempre que disponga de la clave. El formato no se conserva en este método. He aquí un ejemplo de tarjeta de crédito: 1234-5678-9012-3456 cifrado a MTIzNDEyMzQxMjM0MTIzNAo= |
Filtrado |
Este método omite por completo la información sensible. |
El lenguaje SQL puede ampliarse con funciones definidas por el usuario para permitir estos métodos de ofuscación, de los que hablaremos más adelante.
SQL
Como ya hemos mencionado en, SQL es el lenguaje preferido para las transformaciones de productos de flujo de datos, porque es accesible para muchos ingenieros de dominio. Por lo tanto, tendremos que elegir una plataforma de procesamiento de datos en flujo que admita SQL. No hay muchos motores de procesamiento de datos en flujo en el momento de escribir esto. Revisaremos dos opciones: un procesador de flujo SaaS y ksqlDB.
Procesador de flujos SaaS
Un procesador de streaming SaaS es un producto SaaS en la nube que utiliza SQL para transformar los datos consumidos desde una plataforma de streaming como Kafka. Suelen implementarse en Apache Flink (que ofrece un streaming verdaderamente nativo) en contraposición al streaming estructurado de Apache Spark (que ofrece microlotes de baja latencia que sólo emulan el streaming). Apache Flink procesa los eventos en tiempo real con una latencia menor en comparación con el streaming estructurado de Apache Spark.
Apache Flink no se ve en las interfaces de usuario. En su lugar, se muestra al usuario una interfaz SQL. Los ingenieros de productos de datos pueden consumir desde una plataforma de streaming como Kafka, realizar transformaciones con estado y, a continuación, escribir la salida en un sumidero u otra plataforma de streaming, como se muestra en la Figura 4-5.
El modelo de Flink para el procesamiento de flujos incluye un componente llamado connectors que actúa como fuentes y sumideros de datos (similar a los conectores Kafka). El componente llamado stream representa flujos de datos que contienen flujos de datos. Por último, un componente llamado pipeline puede unir y agregar flujos utilizando SQL para crear nuevos flujos. En conjunto, estos componentes crean una herramienta de procesamiento de datos sencilla y fácil de usar para construir canalizaciones de datos en flujo.
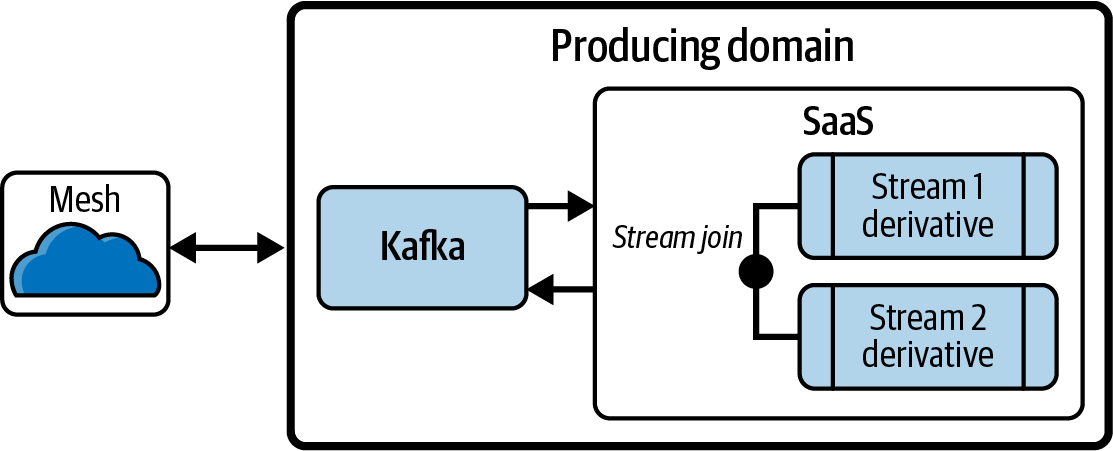
Figura 4-5. Procesador de flujo SaaS que une/enriquece derivados de datos, uno de los cuales es un producto de datos de otro dominio, y lo publica de nuevo en la malla
Apache Flink también permite a los dominios replicar los datos del dominio productor en el suyo propio, construyendo en última instancia la malla, como se muestra en la Figura 4-6.
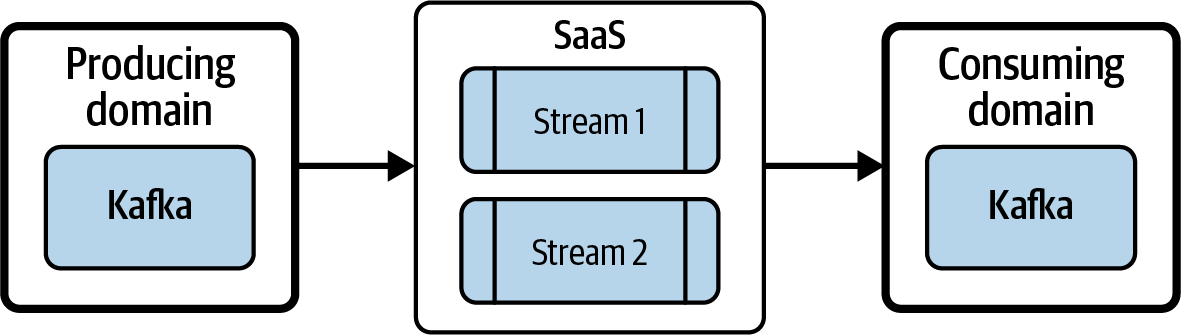
Figura 4-6. Apache Flink replicando datos del dominio productor al consumidor
Cada stream en Flink representa datos de flujo que pueden ser tratados como un nuevo producto de datos de flujo y consumidos por muchos otros dominios.
Una gran ventaja de Flink es que puede consumir desde muchos clusters de Kafka. También puede consumir desde plataformas de streaming alternativas, como Redpanda y Apache Pulsar, y unirlas en una única canalización de streaming. Además, puede mezclar plataformas de flujo (como RabbitMQ o Kinesis) que no utilicen un registro de confirmación, proporcionando así una solución de procesamiento de flujo totalmente agnóstica, como se muestra en la Figura 4-7.
Apache Flink también puede proporcionar autoservicios para aprovisionar y crear fácilmente canalizaciones de datos en streaming. Elimina las tareas de aprovisionamiento de infraestructura y escritura de código que requieren conocimientos especializados.
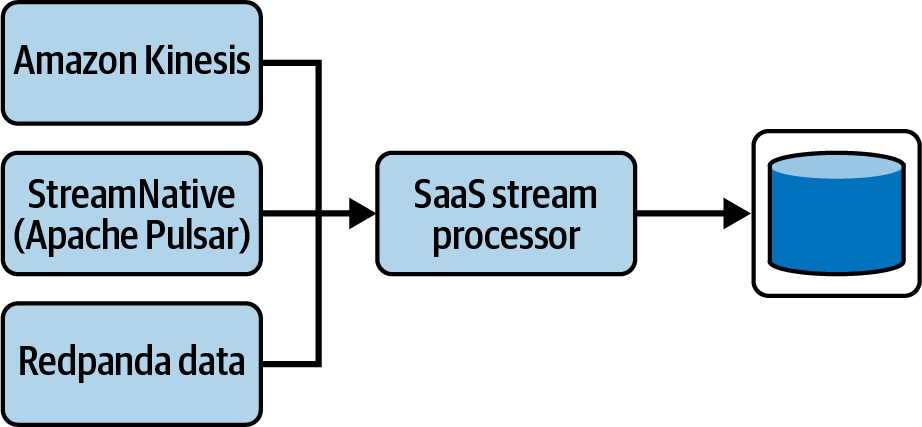
Figura 4-7. Una canalización de streaming implementada como SQL que puede unir varias plataformas de streaming, incluso las que no utilizan un registro de confirmaciones, para permitir el aprovisionamiento de eventos
ksqlDB
ksqlDB es otra herramienta de procesamiento de flujos que proporciona una interfaz SQL para construir canalizaciones de datos sobre Kafka. El lenguaje similar a SQL de ksqlDB abstrae la implementación real de los flujos de Kafka. ksqlDB crea estructuras similares a tablas a partir de temas de Kafka. Puede unir y agregar datos entre temas Kafka y proporcionar capacidades de arquitectura Kappa.
ksqlDB sigue la muy reconocida norma SQL-92, que es la tercera revisión de la norma. Está definida por el Instituto Nacional Americano de Normalización (ANSI), que se encarga de mantener esta norma para las especificaciones SQL.
Una implementación de ksqlDB se limita a un único clúster de Kafka. No puede combinar varias plataformas de streaming. Sí proporciona una forma de aprovisionar conectores. Permite a los ingenieros de dominio permanecer totalmente dentro de una única herramienta para construir canalizaciones de datos en streaming.
Aprovisionamiento de conectores en ksqlDB
ksqlDB no sólo ejecuta transformaciones con estado, sino que también tiene la capacidad única de crear conectores Kafka para la entrada y salida de datos. Los ingenieros de dominio ya no tienen que salir de una herramienta para importar y exportar datos. Desde una única interfaz de línea de comandos (CLI) de ksqlDB, los ingenieros de dominio pueden construir toda una canalización de datos, desde las fuentes hasta los productos de datos publicados, completamente dentro del patrón de arquitectura Kappa.
El Ejemplo 4-2 muestra cómo crear un conector Kafka de origen. En este ejemplo, un conector fuente Debezium CDC se conectará a una base de datos MySQL. El conector leerá todas las operaciones en el orden en que se envían a la base de datos: inserciones, actualizaciones y eliminaciones.
Ejemplo 4-2. Sentencia ksqlDB que crea un conector de origen Kafka para introducir datos en Kafka; a continuación, se podría crear un flujo/tabla a partir del tema resultante
/*creates a connector that reads from MySQL*/CREATESOURCECONNECTORapp_dataWITH('connector.class':'io.debezium.connector.mysql.MySqlConnector','tasks.max':'1','database.hostname':'mysql','database.port':'3306','database.user':'debezium','database.password':'dbz','database.server.id':'184054','database.server.name':'dbserver1','database.include.list':'inventory','database.history.kafka.bootstrap.servers':'kafka:9092','database.history.kafka.topic':'schema-changes.inventory');
SOURCEpara los conectores de origen.io.debezium.connector.mysql.MySqlConnectores el nombre de la clase del conector. Si construyes tu propio conector, su nombre de clase irá aquí.
El número de tareas que creará el conector.

El nombre de host de la base de datos.

El servidor de arranque de Kafka.
Del mismo modo, en el Ejemplo 4-3, puedes crear un conector de sumidero para sacar datos de la plataforma de streaming. En este caso, la sentencia crea un conector sumidero que toma los datos de un tema Kafka y los escribe en un sumidero de Amazon S3.
Ejemplo 4-3. Sentencia ksqlDB que crea un conector Kafka sink que lee de un tema y escribe en un destino
/*creates a connector that writes to a data lake*/CREATESINKCONNECTORtrainingWITH('connector.class':'S3_SINK','tasks.max':'1','aws.access.key.id':'$AWS_ACCESS_KEY_ID','aws.secret.access.key':'$AWS_SECRET_ACCESS_KEY','s3.bucket.name':'$S3_BUCKET','time.interval':'HOURLY','data.format':'BYTES','topics':'$KAFKA_TOPIC_NAME_OUT2');
SINKpalabra clave para conectores de fregadero.S3_SINKes un alias del nombre de la clase del conector del sumidero S3.La clave de acceso a AWS.
El secreto de AWS.
El cubo S3.

Establece cómo se agrupan tus mensajes en el bucket S3. Las entradas válidas son
DAILYoHOURLY.
Puedes definir transformaciones entre las sentencias origen y destino para crear una canalización de datos en flujo. También puedes guardar las sentencias SQL en un archivo para que se ejecuten de una vez. Esto se puede utilizar para promover tu canalización de datos en streaming desde el desarrollo, a la puesta en escena y, finalmente, a la producción.
Funciones definidas por el usuario en ksqlDB
En ksqlDB, estás limitado al lenguaje SQL a la hora de definir transformaciones de datos en streaming. No tiene la capacidad de representar la lógica compleja que sí pueden los lenguajes de programación imperativos, como C++, Java, Python, etc. Para realizar una lógica más compleja, se podría escribir una función definida por el usuario (UDF) en Java para contener la lógica compleja que no se puede representar en SQL. Esa UDF podría llamarse entonces en ksqlDB sin romper la gramática SQL que utiliza ksqlDB.
El Ejemplo 4-4 muestra un ejemplo de una UDF ksqlDB que multiplica dos números. Las anotaciones aplicadas al código fuente Java permiten a los cargadores de clases ksqlDB registrar esta UDF como una función disponible para su uso.
Ejemplo 4-4. Una función definida por el usuario ksqlDB que es cargada por ksqlDB y puede utilizarse como función en una sentencia ksqlDB
packagecom.example;importio.confluent.ksql.function.udf.Udf;importio.confluent.ksql.function.udf.UdfDescription;importio.confluent.ksql.function.udf.UdfParameter;importjava.util.Map;@UdfDescription(name="Mul",author="example user",version="1.0.2",description="Multiplies 2 numbers together")publicclassMulUdf{@Udf(description="Multiplies 2 integers together.")publiclongformula(@UdfParameterintv1,@UdfParameterintv2){return(v1*v2);}@Udf(description="Multiplies 2 doubles together")publiclongformula(@UdfParameterdoublev1,@UdfParameterdoublev2){return((int)(Math.ceil(v1)*Math.ceil(v2)));}}
@UdfDescriptionproporciona una descripción de la clase.@Udfidentifica la UDF.@UdfParameteridentifica los parámetros de la función.
Esta función permite la sobrecarga de funciones para permitir múltiples tipos de datos. El Ejemplo 4-5 muestra cómo hacerlo.
Ejemplo 4-5. Un ejemplo de cómo utilizar la UDF en una sentencia ksqlDB
selectformula(col1,col2)asproductfrommytableemitchanges;
Invocación de la función
formula.Especifica una consulta push con una salida continua. Las consultas push son ilimitadas, es decir, no terminan porque los resultados se envían continuamente al consumidor. Por el contrario, las consultas pull son acotadas o terminan.
Nota
La autoría de UDFs en Java puede no ser una habilidad accesible a los ingenieros de dominio. En este caso, el equipo centralizado de malla de datos, que tiene las habilidades necesarias, debe codificar los UDF. Los ingenieros de datos que antes desarrollaban y mantenían las canalizaciones de datos en el lago de datos, ahora formarán parte del equipo central de malla de datos.
En esta sección hemos tratado dos soluciones para transformar derivados de datos. Ambas utilizaban SQL para realizar estas transformaciones. Transformamos los datos para garantizar que nuestros productos de datos en flujo sean de alta calidad y fiables. Otra razón para transformar los datos es añadir más información al producto de datos para que sea más útil a los consumidores del dominio. En la siguiente sección hablaremos de cómo enriquecer los datos utilizando conceptos de almacenamiento de datos.
Extraer, transformar y cargar
Hablemos ahora de transformando datos en un proceso de extracción, transformación y carga(ETL). Tradicionalmente, este proceso extrae datos de una fuente de datos, los transforma a un formato que pueda ser consumido por sus consumidores, y luego los carga en un sistema donde estos consumidores puedan leerlos (como un lago de datos o unalmacén de datos). ETL es un patrón que se suele utilizar para cotejar datos de múltiples sistemas dispares en un único sistema centralizado, como un almacén de datos, como se muestra en la Figura 4-8.
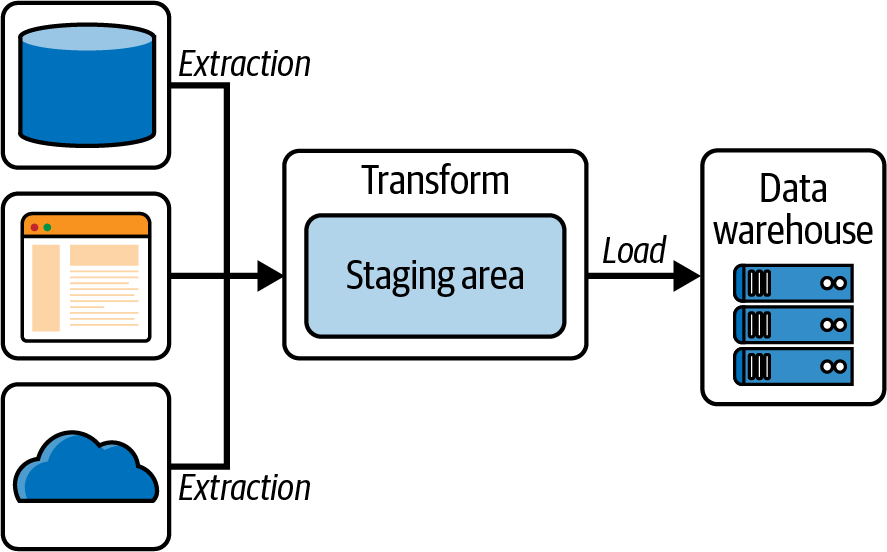
Figura 4-8. Una canalización de datos ETL que extrae datos de múltiples fuentes, los escribe en un lago de datos para su almacenamiento y transformación, y luego los carga en un almacén de datos para su consumo.
El área de preparación de la Figura 4-8 es donde se realizan las transformaciones. El área de preparación suele ser un lago de datos, porque puede contener una gran cantidad de datos. La transformación la ejecutan las aplicaciones de procesamiento paralelo masivo (MPP) de, así como los trabajos por lotes, que luego envían los datos a un almacén de datos.
La base de datos operativa es la fuente de información del almacén de datos. Incluye información detallada utilizada para llevar a cabo las operaciones diarias de la empresa. Los datos cambian con frecuencia en la base de datos operativa a medida que se realizan actualizaciones para reflejar el valor actual de las últimas transacciones empresariales. Para lograrlo, utiliza bases de datos de procesamiento de transacciones en línea (OLTP) para gestionar la naturaleza cambiante de los datos en tiempo real.
Los sistemas de almacén de datos sirven como almacenes de datos que facultan a los usuarios y responsables de la toma de decisiones para tomar decisiones empresariales. Estos sistemas pueden organizar y presentar la información en formatos específicos para adaptarse a las diversas necesidades de los distintos usuarios. Estos sistemas suelen denominarse sistemas de procesamiento analítico en línea (OLAP).
Tanto las bases de datos operativas como los almacenes de datos son bases de datos relacionales, pero cada una sirve para fines distintos. Los sistemas de bases de datos operativas manejan tanto datos operativos como transaccionales. Los datos operativos consisten en los datos contenidos en las operaciones de un sistema o unidad de negocio concretos. Por ejemplo, en el comercio minorista o electrónico, una base de datos operativa gestiona las compras discretas de artículos en tiempo real, además de hacer un seguimiento del inventario de artículos. Un almacén de datos, en cambio, conserva el registro histórico de las transacciones que se producen a lo largo de grandes cantidades de tiempo. Por ejemplo, si un gran minorista online quiere hacer un seguimiento del rendimiento de una marca o artículo concreto en los últimos 10 años, puede hacerlo consultando el almacén de datos. Esto puede proporcionar información útil, como el rendimiento de las campañas publicitarias, mostrar tendencias estacionales en el comportamiento de compra, o incluso ayudar a comprender mejor la cuota de mercado global de la marca.
La principal diferencia entre una base de datos operativa y un almacén de datos es que, mientras que una base de datos operativa es volátil y está sujeta a constantes actualizaciones, el almacén de datos es una instantánea histórica del estado más actual de cualquier transacción.
No todos los datos de un almacén de datos cambian al mismo ritmo. Siguiendo con el ejemplo actual del comercio minorista, la cesta total de un cliente puede cambiar muchas veces, y el estado de su cesta de la compra cambiará con cada adición y eliminación de un artículo hasta que el cliente decida pasar por caja y finalizar la compra. Las características del producto, como la marca, la talla, el color, el sabor o el peso, cambian mucho más lentamente que un conjunto de transacciones de venta. La información sobre el cliente, como ubicación, edad, intereses, junto con otros datos demográficos y firmográficos, puede no cambiar en absoluto o cambiar sólo cuando el cliente nos informa de dicho cambio o cuando recibimos un feed de datos demográficos coincidentes de una fuente de terceros.
Mantener los conceptos de almacén de datos
Incluso aunque una arquitectura de malla de datos pretende descomponer y descentralizar el plano analítico como el lago de datos o el almacén, no deben perderse ni comprometerse los conceptos que hacen que estos sistemas tengan éxito. El concepto de esquema en estrella (un modelo que se asemeja a una estrella al separar los hechos de los datos dimensionales), la forma en que se definen las transformaciones y la estructura de los datos hacen que el modelo de datos sea fácil de comprender y aplicar. Estos mismos conceptos pueden utilizarse fuera del almacén de datos para ayudar a diseñar conductos de datos ETL de flujo continuo y proporcionar productos de datos más utilizables.
Como introdujimos en el Capítulo 1, los datos de una empresa se dividen entre los planos operativo y analítico. Los dominios que residen en el plano analítico difieren mucho de los dominios que residen en el plano operativo. Los datos que se publican como productos de datos, procedentes del dominio operativo, suelen ser instantáneas inmutables con fecha y hora de los datos operativos a lo largo del tiempo. Históricamente, los cambios en los productos de datos del plano analítico evolucionan más lentamente que sus homólogos operativos. Por ello, un dominio de datos en el plano analítico es responsable de servir y proporcionar acceso eficiente a grandes cuerpos de datos a los consumidores. Los dominios de datos proporcionan una visión de los datos al mundo exterior, que son normas publicadas para el acceso a los datos. Los procesos entre bastidores, como el ETL, que se utilizan para crear el dominio no se exponen a los consumidores posteriores.
Conceptos básicos de almacenamiento de datos
En el clima empresarial actual, las organizaciones necesitan disponer de informes y análisis fiables de grandes cantidades de datos. Los datos deben consolidarse e integrarse para distintos niveles de agregación con diversos fines informativos, sin afectar a los sistemas operativos de la organización. El almacén de datos lo hace posible creando un repositorio de los datos almacenados electrónicamente de una organización, extraídos de los sistemas operativos, y poniéndolos a disposición de consultas ad hoc e informes programados mediante procesos ETL.
Existen muchos enfoques para construir un almacén de datos, cada uno con su propio conjunto de pros y contras. Este libro se centra en el enfoque de esquema estrella para el almacén de datos y sus aplicaciones a la malla de datos y a la malla de datos en flujo. Aunque conocemos otros enfoques de almacén de datos y su posible aplicación a la malla de datos, como Data Vault 2.0, este libro no ofrece detalles específicos de esos enfoques.
El esquema en estrella es la forma más sencilla de un modelo dimensional utilizado en inteligencia empresarial y almacenamiento de datos. El esquema en estrella de consta de una o varias tablas de hechos que hacen referencia a cualquier número de tablas de dimensiones. Como su nombre indica, el modelo físico del esquema estrella se asemeja a la forma de una estrella, con una tabla de hechos en su centro y tablas de dimensiones a su alrededor, que representan los puntos de una estrella.
Una tabla de hechos contiene todas las claves primarias de cada dimensión, y los hechos o medidas asociados a esas dimensiones. Las tablas de dimensiones proporcionan información descriptiva de todas las medidas registradas en la tabla de hechos. Como las dimensiones son informativas y cambian mucho más lentamente que las tablas de hechos, las dimensiones son relativamente pequeñas en comparación con la tabla de hechos. Las dimensiones más utilizadas son las personas, los productos, el lugar (o geografía) y, sobre todo, el tiempo (véase la Figura 4-9).
Separar los datos de hechos de los datos dimensionales es muy importante para escalar un almacén de datos. Esta separación permite que los atributos de los hechos cambien con el tiempo sin necesidad de volver a teclear toda la tabla de hechos. Supongamos, por ejemplo, que hacemos el seguimiento de las ventas de un producto, y el propietario de una marca cambia con el tiempo. En un modelo de tabla única (modelos que aplanan los datos de hechos y los dimensionales en una sola tabla), se necesitarían costosas actualizaciones o truncamiento/carga para actualizar toda la tabla y reflejar el propietario adecuado de la marca. En un modelo dimensional, sólo es necesario cambiar el atributo de propietario de marca de la dimensión de producto. Este cambio se refleja entonces en las aplicaciones de informes y análisis posteriores sin mucha fanfarria.
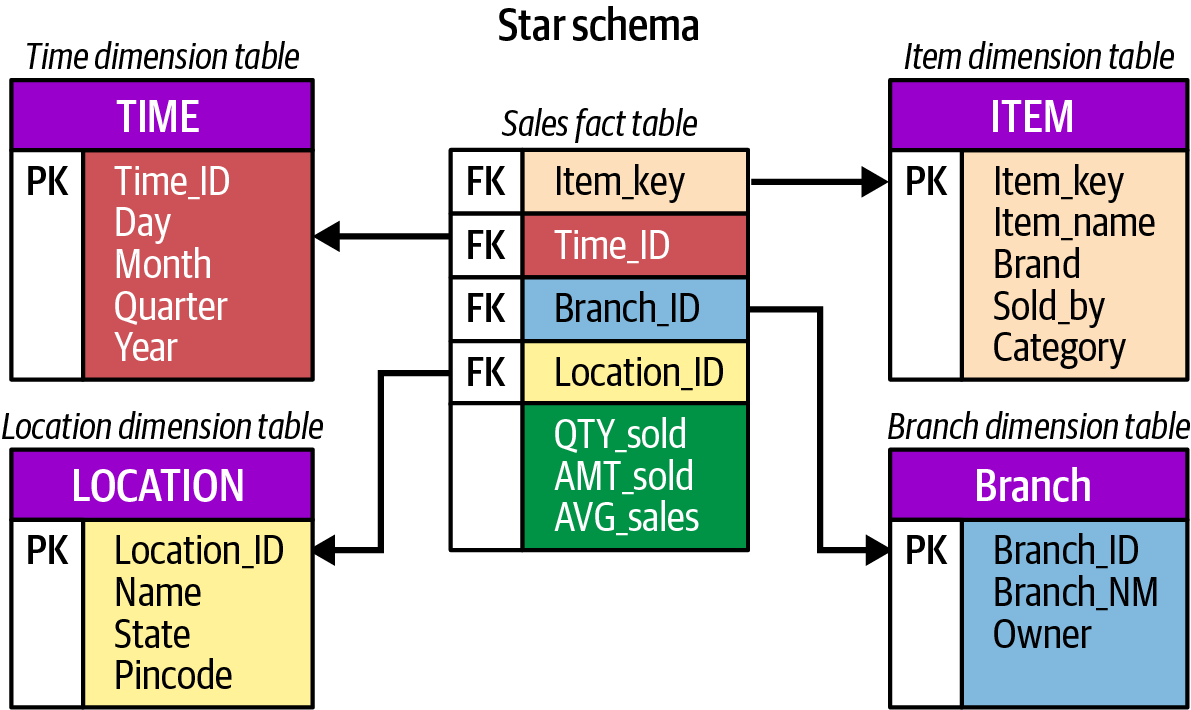
Figura 4-9. Un esquema simple en estrella sin dimensiones que cambian lentamente
A medida que los datos operativos se transforman en el esquema estrella, hay que tener muy en cuenta qué son datos de hechos y qué son datos dimensionales. Las consideraciones sobre el diseño de la base de datos tendrán un impacto directo en el ETL que alimenta el almacén de datos. Por ejemplo, los datos pueden añadirse a un almacén a nivel de transacción, o pueden importarse, transformarse e insertarse por lotes. Cualquiera de estos enfoques requiere ETL y una desnormalización adecuada para cumplir los requisitos del almacén de datos: la capacidad de consultar los datos rápidamente y satisfacer las solicitudes de datos.
Datos dimensionales frente a datos de hechos en un contexto de streaming
Tanto los datos de hechos como los dimensionales cambian de estado con el tiempo, pero a ritmos diferentes. Para comprender plenamente el comportamiento de un cliente durante una compra en línea, el almacén de datos debe ser capaz de realizar un seguimiento de cada interacción de un cliente con los productos, tal vez incluso hacer un seguimiento de lo que el cliente añadió a su cesta, lo que retiró y en qué orden. Para un sistema de almacén de datos tradicional, esto supone un reto, ya que cada inserción de datos por lotes en el almacén sólo tiene en cuenta el momento en que se tomó una instantánea. Pero, con la llegada de la arquitectura Kappa y el uso del almacenamiento por niveles, la complejidad de proporcionar datos procesables en tiempo real se simplifica y es factible. Ahora es posible proporcionar información casi en tiempo real, y el almacén de datos puede aprovecharse de ello en lo que respecta a la ingestión de datos.
Los datos dimensionales, como ya se ha dicho, también cambian con el tiempo. Éste es un tema importante que a menudo se pasa por alto al construir un modelo de datos de esquema en estrella. Estas dimensiones que cambian lentamente también requieren atención al detalle, porque para un análisis preciso, es importante poder ver los clientes, productos y ubicaciones tal y como se conocían en el momento de una transacción o conjunto de transacciones. Comprender los atributos de un producto concreto hoy es importante, pero también lo es comprender cómo era ese producto hace seis meses o incluso un año. Comprender el perfil demográfico de un cliente en el momento de la compra es importante para entender y predecir cómo pueden comportarse también otros clientes.
También las dimensiones que cambian lentamente han sufrido el tipo histórico de ingestión de almacenamiento de datos que vimos en el pasado. La arquitectura Kappa vuelve a simplificar la definición de dimensión de cambio lento. En lugar de materializar la información puntual sobre las dimensiones en determinados intervalos, comprender cómo es una dimensión en un momento concreto se convierte en una cuestión de observar un punto en el tiempo en un flujo y determinar sus características. Para llevar este concepto aún más lejos, en una malla de datos de flujo, las dimensiones de un modelo de datos se convierten en productos de datos, junto con los datos de hechos. Esto permite al ingeniero de productos de datos publicar una interfaz estandarizada para los datos dimensionales que permite búsquedas puntuales. En lugar de crear vistas basadas en algún tipo de configuración SCD Tipo 6, y consultar esta vista, la lógica empresarial para crear búsquedas puntuales ahora se encapsula en el propio producto de datos.
Vistas materializadas en secuencias
En sus términos más sencillos, las vistas materializadas son resultados preprocesados de consultas almacenados en disco. La idea es que el preprocesamiento de la consulta esté siempre en ejecución, de modo que en cualquier momento un usuario pueda consultar la vista materializada y esperar obtener los últimos resultados. Por el contrario, una vista tradicional es una consulta que no se preprocesa y se ejecuta en el momento en que se consulta la vista. Los resultados de una vista tradicional no se almacenan en disco.
Tanto las vistas materializadas como las tradicionales devolverán el mismo resultado, con la diferencia de que la vista materializada se ejecutará más rápido porque los resultados ya están precalculados, mientras que la vista tradicional necesita procesar primero la vista antes de devolver el resultado. Como el preprocesamiento en una vista materializada se produce en segundo plano, tiene características asíncronas. Por el contrario, como una vista tradicional sólo procesa la consulta cuando se le solicita y responde con el resultado, tiene características síncronas.
Profundicemos en estos conceptos. En "Ingesta de derivados de productos de datos con Kafka Connect", hablamos de las diferencias entre fuentes de datos síncronas y asíncronas. La principal diferencia es que las fuentes de datos síncronas siguen una semántica de procesamiento por lotes, mientras que las fuentes de datos asíncronas siguen una semántica de flujo.
Esta descripción de las vistas materializadas se ha explicado en el contexto de una única base de datos. En realidad, las vistas materializadas no existen en una única base de datos. La semántica de vista materializada del preprocesamiento de datos existe cuando se replican datos de una instancia activa de una base de datos a una instancia pasiva, como se ve en la Figura 4-10.
En esta ilustración de una solución de recuperación ante desastres, la aplicación utiliza la base de datos "activa" y falla a la base de datos "pasiva" en caso de que la base de datos activa falle. Los datos pasan por el registro de escritura anticipada (WAL) y se "materializan" en la base de datos pasiva. Cada transacción ocurrida en la base de datos activa se registra en el WAL y se ejecuta en la base de datos pasiva en segundo plano. Por tanto, esta replicación de datos se produce de forma asíncrona y es un ejemplo de vista materializada en la que intervienen dos bases de datos.
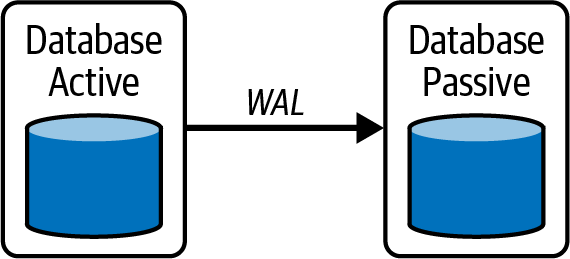
Figura 4-10. Replicación de bases de datos utilizando un registro de escritura anticipada creando una vista materializada en la base de datos pasiva
El conector Debezium del que hemos hablado anteriormente, en realidad lee la WAL de las bases de datos que soporta para capturar los cambios, pero en lugar de enviarla a otra base de datos de la misma instancia, la envía a Kafka (ver Figura 4-11).
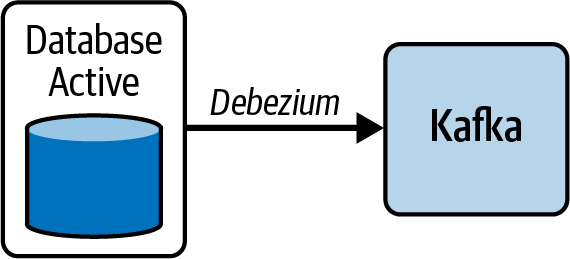
Figura 4-11. Replicación de la base de datos utilizando una WAL para poblar Kafka contransacciones CDC
A partir de este punto, puedes construir múltiples vistas materializadas. Como en el caso de la Figura 4-12, puedes crear una vista materializada en ksqlDB o en otra base de datos pasiva utilizando Flink.
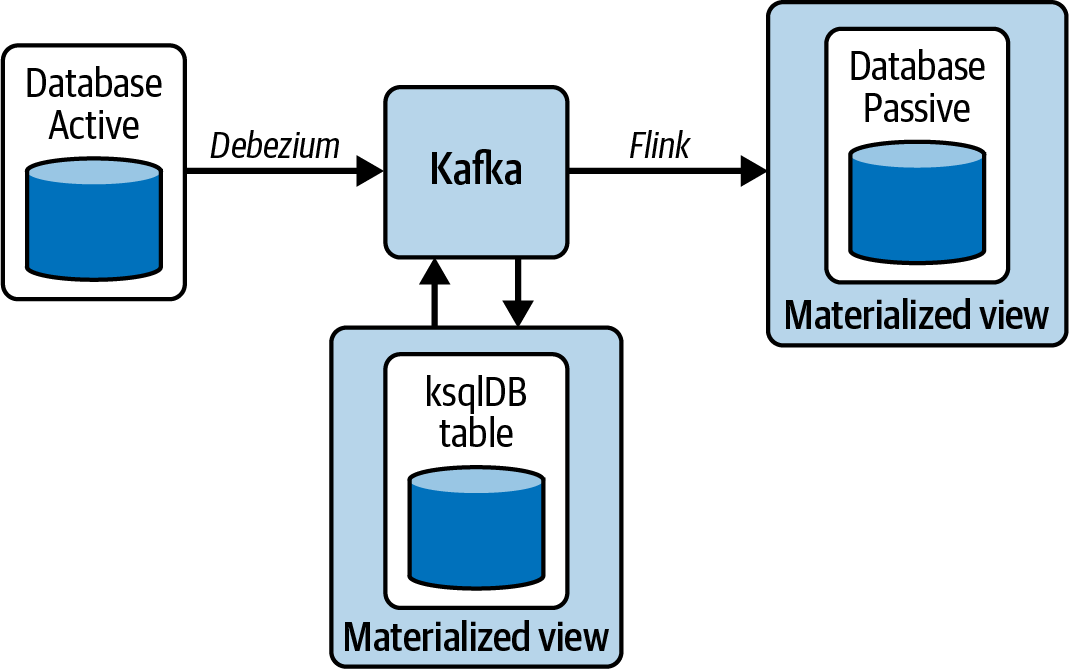
Figura 4-12. Construcción de múltiples vistas materializadas a partir de un único conector CDC Debezium que lee de la WAL
Los casos de uso CDC se utilizan realmente para modelos o entidades que son los resultados de DDD. Estas entidades no cambian a menudo, por lo que cambian lentamente. En los conductos ETL, estas entidades son los datos dimensionales utilizados para enriquecer los datos de hechos.
Streaming ETL con diseño orientado al dominio
Vayamos ahora a y relacionemos esta información con el ETL de flujo. En resumen, los datos dimensionales se obtienen mediante vistas materializadas, que se obtienen mediante flujos CDC, que se obtienen de los WAL de las bases de datos fuente originales. Ahora tenemos una canalización de datos totalmente de flujo para datos dimensionales que se utilizará para enriquecer los datos de hechos. También es nuestra solución a una ETL de flujo completo, en la que tanto los datos dimensionales como los datos de hechos están respaldados por flujos.
Éste es el objetivo que perseguimos: permitir el streaming ETL en todos los dominios. Para lograrlo, necesitamos dos tipos de productos de datos: dimensionales y de hechos. Si los convirtiéramos en productos de datos en flujo, serían distintos tipos de productos de datos en flujo: un flujo CDC para datos dimensionales y un flujo de sólo apéndices para datos de hechos. Los flujos CDC contienen sólo los cambios capturados de los WAL en una base de datos fuente operativa (transaccional), y los flujos de sólo apéndice contienen datos de hechos.
En DDD, el modelo de dominio define las entidades, sus interrelaciones y sus interacciones basadas en la lógica empresarial. Los datos fácticos son estos eventos de interacción entre entidades vinculados con el tiempo y el estado. Los datos dimensionales son los eventos de creación, actualización y eliminación relacionados con las entidades y sus interrelaciones.
Por ejemplo, un visitante de un sitio web no cambia de nombre a menudo, por lo que se trata de una dimensión que cambia lentamente. Pero puede que haga muchos clics en el sitio, por ejemplo, añadiendo y quitando artículos de su cesta. Se trata de datos de hechos que llegan rápidamente y están asociados al tiempo. Unir los datos de hechos con los datos dimensionales es un proceso ETL que enriquece los datos de hechos con datos dimensionales para que los analistas puedan saber quién hizo clic, y puedan deducir por qué, cuándo y dónde hizo clic el usuario para mejorar su experiencia. El entrenamiento del modelo requiere capturar el estado dimensional no de las tablas dimensionales, sino de los datos de hechos enriquecidos (enriquecidos a partir de los dimensionales) para que pueda capturar el estado actual de una dimensión junto con el tiempo con el evento de clic.
Publicación de productos de datos con AsyncAPI
Hemos definido los requisitos del producto de flujo de datos basándonos en los requisitos proporcionados por otros dominios. También identificamos los derivados del producto de datos (y nos suscribimos a los productos de otros dominios si era necesario). A continuación, extrajimos y transformamos los datos para crear un nuevo producto de datos. En este punto, el producto de datos está listo para su publicación en la malla de datos. Además, utilizaremos AsyncAPI para definir el punto de consumo del contenido del producto de datos.
AsyncAPI es un proyecto de código abierto creado para simplificar y estandarizar las definiciones de las fuentes de datos en streaming. AsyncAPI es un lenguaje de definición de interfaces (IDL) que permite a las aplicaciones escritas en un lenguaje interactuar con aplicaciones escritas en otros lenguajes. En este caso, AsyncAPI es un IDL que define una API asíncrona. Permite que otras aplicaciones creen integraciones con el producto de flujo de datos agnósticas a cualquier lenguaje de programación. El proceso de publicación de un producto de datos implicará crear un documento YAML AsyncAPI y registrarlo en la malla de streaming de datos.
Registrar el producto de transmisión de datos
Los documentos AsyncAPI están escritos en YAML, un formato de documento legible por máquina que puede ser editado fácilmente por un ingeniero de dominio, por lo que también es, en cierto modo, legible por humanos. Cuando registremos un producto de datos, crearemos un documento YAML AsyncAPI y lo registraremos en un catálogo de datos de flujo, del que hablaremos más en el Capítulo 5. Por ahora, el catálogo de datos de flujo contendrá todos los productos de datos de la malla de datos de flujo, para que los compradores de productos de datos tengan un único lugar donde buscar productos de datos de flujo y suscribirse a ellos.
AsyncAPI extiende OpenAPI, que se conoce formalmente como Swagger (para más detalles, consulta la Figura 4-13 ). OpenAPI también es una IDL basada en YAML que describe las API síncronas. Hoy en día, las API síncronas se registran en pasarelas de API, como Kong y Apigee, donde los compradores de API pueden examinar y buscar API específicas en función de sus casos de uso. El objetivo de AsyncAPI es aplicar ese sencillo enfoque también a las fuentes de datos asíncronas. AsyncAPI nos proporciona una forma sencilla de habilitar los autoservicios necesarios para crear una buena experiencia para todos los usuarios/consumidores de la malla de datos en streaming.
El documento AsyncAPI YAML nos permitirá definir específicamente cómo pueden consumir las aplicaciones el producto de streaming de datos, de modo que podamos construir autoservicios para crear sin problemas integraciones entre dominios. Esto, en última instancia, construye la malla en la malla de streaming de datos. El documento AsyncAPI YAML también nos permitirá realizar búsquedas en el catálogo de datos de streaming, que trataremos en el Capítulo 5.
Los documentos YAML de la AsyncAPI son analizados por aplicaciones para generar código cliente consumidor para dominios en cualquier lenguaje de programación. Estas aplicaciones pueden hacer otras cosas, como generar páginas HTML que puedan ser servidas por un catálogo de datos en streaming. Lo demostraremos en el Capítulo 5. En el Capítulo 6, mostraremos cómo un servicio YAML AsyncAPI puede invocar una API REST que aprovisionará un conector Kafka para leer del tema Kafka y escribir en Amazon S3.
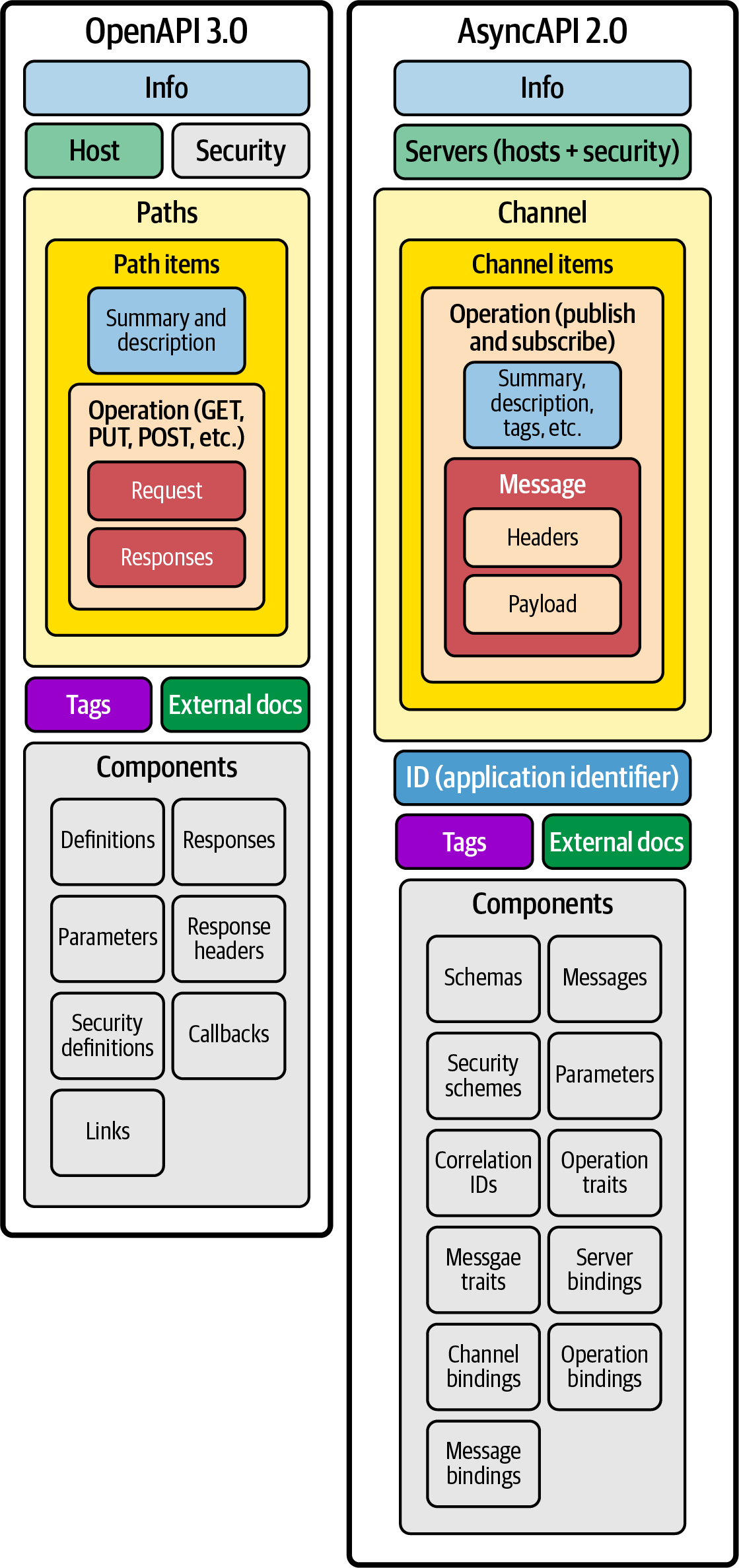
Figura 4-13. Diferencias entre OpenAPI y AsyncAPI
Construir un documento YAML AsyncAPI
Crear el documento YAML de la AsyncAPI es el último paso para publicar un producto de datos en una malla de flujo de datos. El Ejemplo 4-6 muestra un esqueleto de documento YAML AsyncAPI; hemos eliminado los detalles. Rellenaremos este documento YAML con los metadatos necesarios para definir un producto de datos de flujo que se publicará en la malla de datos. En YAML, todos los campos se denominan objetos. Por ejemplo, en el Ejemplo 4-6, asyncapi, externalDocs, info, etc., se consideran todos objetos, al igual que los subobjetos como covid, messages, schemas, etc. Nos referiremos a ellos como objetos cuando hablemos en el contexto de YAML.
Ejemplo 4-6. Un esqueleto de documento YAML AsyncAPI
asyncapi:'2.2.0'externalDocs:info:tags:servers:defaultContentType:channels:covid:components:messages:covidapi:schemas:covidapi:securitySchemes:user-password:type:userPasswordmessageTraits:operationTraits:
Nota
El ejemplo de AsyncAPI utiliza Confluent Cloud como plataforma de streaming. Confluent Cloud proporciona un Apache Kafka y un Registro de Esquemas totalmente gestionados, de los que hablaremos más en secciones posteriores de este capítulo.
Objetos asyncapi, externalDocs, info y tags
Construyamos ahora un documento YAML AsyncAPI que defina un producto de datos de flujo que proporcione estadísticas globales COVID-19. En el Ejemplo 4-7 rellenamos toda la información descriptiva del producto de datos. Esto cubre las cuatro secciones superiores del YAML del Ejemplo 4-6.
Ejemplo 4-7. Secciones informativas YAML de AsyncAPI
asyncapi:'2.2.0'externalDocs:description:ThesourceoftheCOVID-19globalstatisticsthatisprovidedasareal-timedatastream.url:https://covid19api.com/info:title:COVID-19GlobalStatisticsAsyncAPISpecversion:'0.0.1'description:|This AsyncAPI provides pub/sub information for clients to pub/sub COVIDdata to Kafkalicense:name:Apache2.0url:https://www.apache.org/licenses/LICENSE-2.0contact:name:APISupporturl:http://www.asyncapi.com/support:info@asyncapi.iox-twitter:'@AsyncAPISpec'tags:-name:root-tag1externalDocs:description:Externaldocsdescription1url:https://www.asyncapi.com/-name:root-tag2description:Description2externalDocs:url:"https://www.asyncapi.com/"-name:root-tag3-name:root-tag4description:Description4-name:root-tag5externalDocs:url:"https://www.asyncapi.com/"
La AsyncAPI versión 2.2.0.
externalDocsproporciona una descripción del producto de datos y una URL donde los usuarios pueden encontrar más información sobre el producto de datos.La sección
infodel YAML proporciona detalles adicionales sobre el producto de datos, incluida la información sobre la versión y la licencia.La sección opcional
tagscoloca hashtags que puedan estar relacionados con el producto de datos.
Observa que en el Ejemplo 4-7 podríamos colocar URL en varios lugares para que los usuarios que compren puedan investigar más sobre los productos de datos, por lo que es beneficioso añadirlas para proporcionar toda la información necesaria para entenderlo.
Las etiquetas de esta sección podrían utilizarse para relacionar productos de datos entre sí. Esto será más útil cuando empecemos a hablar de los grafos de conocimiento en el Capítulo 5. Los grafos de conocimiento permiten construir relaciones semánticas multidimensionales entre datos y metadatos, haciendo que los datos sean más valiosos para los usuarios.
Sección de servidores y seguridad
En el Ejemplo 4-8 añadimos un bloque importante al YAML que proporciona información sobre conectividad y seguridad. En este caso, el producto de datos se publica en un tema Kafka. AsyncAPI admite cualquier tipo de plataforma de streaming, por lo que es necesario configurarla con un protocol para que los analizadores comprendan cómo construir la integración entre el producto de datos de streaming y el componente que se suscribirá a él.
Ejemplo 4-8. Una AsyncAPI que define un producto de datos para la malla de datos
servers:kafka-aws-useast2:url:https://kafka.us-east-2.aws.confluent.cloud:9092protocol:kafkadescription:KafkaclusterConfluentcloudAWSUS-EAST-2security:-user-password:[]defaultContentType:application/json
Lista de servidores que definen la conexión con el producto de datos.
kafka-aws-useast2es una propiedad personalizada que identifica un servidor Kafka concreto y sus requisitos de conexión y seguridad.La URL a utilizar para conectarse a la plataforma de streaming -en este caso, Apache Kafka-.
protocolidentifica el tipo de plataforma de streaming a la que se sirve el producto de datos. Este campo informa a la aplicación que lea este YAML que incluya bibliotecas específicas para permitir la conectividad con la plataforma de streaming -en este caso, Apache Kafka.user-passwordhace referencia alsecuritySchemaque informa a la aplicación que lee este YAML de que el mecanismo de seguridad a utilizar es SASL_SSL, lo que garantiza que la comunicación está encriptada y autenticada utilizando SASL/PLAIN.La propiedad
defaultContentTypeinforma a la aplicación lectora de que el contenido del producto de datos es JSON. Tipos alternativos podrían ser Apache Avro o protobuf.
En el Ejemplo 4-8, tenemos múltiples opciones de seguridad. Algunas de ellas son las siguientes:
-
Usuario y contraseña
-
Certificados
-
Claves API
-
OAuth 2
-
OpenID
La sección security puede contener varias opciones de seguridad, pero en este caso sólo hay user-password. La mayoría de las configuraciones de seguridad hacen uso de usuario/contraseña o certificados. En AsyncAPI, la seguridad amplía OpenAPI para añadir otros mecanismos de seguridad como OAuth 2 y OpenID, compatibles con las plataformas de streaming. No repasaremos cada implementación en detalle porque está fuera del alcance de este libro (sería otro libro entero). A efectos de este libro, utilizaremos user-password como mecanismo de seguridad. Más adelante en este capítulo mostraremos cómo proporcionamos detalles para esta configuración de seguridad.
Canales y sección temática
El Ejemplo 4-9 muestra en el bloque channels de la AsyncAPI, donde residen muchos de los detalles del producto de streaming de datos. Debajo de channels hay otro nivel etiquetado covid que corresponde al nombre del tema en Apache Kafka, el tema desde el que se sirve el producto de streaming de datos. En este caso, el producto de datos de flujo es de nuevo la estadística global COVID-19.
Ejemplo 4-9. Secciónchannels
channels:covid:# topic namex-confluent-cloud-security:$ref:'#/components/securitySchemes/user-password'description:Publishes/SubscribestotheCOVIDtopicfornewstatistics.subscribe:summary:SubscribetoglobalCOVID-19Statistics.description:|The schema that this service follows the https://api.covid19api.com/operationId:receiveNewCovidInfotags:-name:covid19apiexternalDocs:description:COVID-19APIurl:https://api.covid19api.com/-name:coviddescription:covidservicetraits:-$ref:'#/components/operationTraits/covid'message:$ref:'#/components/messages/covidapi'
El nombre del canal que corresponde al nombre del tema Kafka.
La propiedad implementación de seguridad.
$refes una referencia a otra parte de la AsyncAPI que define la implementación de seguridad con más detalle, tratada en la "Sección Esquemas de seguridad".Indica cómo se suscribirá el cliente al tema
covid. Esta sección es para los suscriptores, no para los productores.tagspermite construir más relaciones en el grafo de conocimiento del catálogo de datos de flujo. Proporcionamos más metadatos sobre el producto de datos de flujo y mejoramos la capacidad de búsqueda.traitsproporciona más información para que el cliente se configure a sí mismo. En este caso, AsyncAPI está haciendo referencia a otra parte del documento que proporcionará más información sobre cómo tendrá que configurarse el cliente suscriptor/consumidor. Repasaremos estos detalles en la sección "Rasgos".messagees otro$refque hace referencia al esquema del producto de transmisión de datos. La referencia apunta a otra parte del documento AsyncAPI que dará detalles sobre cómo está estructurado el mensaje para que el cliente consumidor pueda analizarlo y procesarlo.
La sección channels de la AsyncAPI puede proporcionar tanto una sección subscribe como una publish. Hemos omitido la sección publish porque, dado que este documento AsyncAPI está pensado para describir productos de streaming de datos, otros dominios no deberían tener la información para producir al tema Apache Kafka. Esta AsyncAPI sólo debe tener suscriptores que sean los otros dominios de la malla de streaming de datos.
Sección de componentes
El objeto components contiene cinco subsecciones que contienen objetos reutilizables para diferentes partes de la especificación AsyncAPI (ver Ejemplo 4-10). Todos los objetos definidos dentro del objeto components no tendrán ningún efecto en la API a menos que se haga referencia a ellos explícitamente desde propiedades fuera del objeto components. En las secciones anteriores, los ejemplos de AsyncAPI hacían referencia a muchas de las subsecciones del objeto components. Repasemos en detalle cada una de las subsecciones.
Ejemplo 4-10. components contiene los detalles de los mensajes y esquemas
components:messages:schemas:securitySchemes:messageTraits:operationTraits:
Sección Mensajes
Tal vez recuerdes del Ejemplo 4-9 que la sección channel/covid/message del documento AsyncAPI hacía referencia a un objeto mensaje que era components/messages/covidapi. Ese esquema se define en la sección components del documento AsyncAPI. La sección components contiene dos subsecciones: messages y schemas. La sección messages describe la envoltura de la carga útil (ver Ejemplo 4-11), y schemas describe la propia carga útil.
Ejemplo 4-11. messages describe el sobre que contiene la carga útil
components:messages:covidapi:name:covidapititle:covidapisummary:covidapifromhttps://api.covid19api.com/correlationId:description:|You can correlate / join with other data using theCountryCode field.location:$message.payload#/CountryCodetags:-name:message-tag1externalDocs:description:Externaldocsdescription1url:https://www.asyncapi.com/-name:message-tag2description:Description2externalDocs:url:"https://www.asyncapi.com/"headers:type:objectproperties:my-custom-app-header:type:stringcorrelationId:type:stringpayload:$ref:"#/components/schemas/covidapi"bindings:kafka:key:type:objectproperties:id:type:stringtype:type:stringbindingVersion:'0.1.0'
El nombre del componente
message. Este es el elemento al que se hace referencia en el Ejemplo 4-9.El
correlationIdhace referencia al(5)para identificar el campo que se utilizará como ID de correlación, un identificador en el seguimiento de mensajes. En Kafka, lo más probable es que sea la clave utilizada para asignar la partición en un tema.De nuevo,
tagspuede utilizarse para establecer relaciones entre otros productos o dominios de datos.La sección
headersproporciona información en la cabecera del mensaje de la plataforma de streaming. También contiene elcorrelationIden caso de que se proporcione en la cabecera.El
payloadhace referencia a otra sección de la AsyncAPI que contiene el esquema del mensaje ubicado encomponents/schemas/covidapien el mismo objetocomponents.Un mapa de forma libre en el que las claves describen el nombre del protocolo (en este caso, el protocolo Kafka), y los valores describen definiciones específicas del protocolo para el servidor (Kafka).
La subsección schemas que se muestra en el Ejemplo 4-12 define la carga útil del esquema en línea. Inline significa básicamente que el esquema se define en el documento YAML de la AsyncAPI. También puedes definir el esquema fuera del documento YAML de la AsyncAPI proporcionando un $ref, que no es más que una URL al esquema (véase el Ejemplo 4-13).
Ejemplo 4-12. El esquema describe la carga útil que es el propio producto de flujo de datos
schemas:covidapi:type:objectrequired:-CountryCodeproperties:Country:type:stringCountryCode:type:stringdescription:correlationIdDate:type:stringID:type:stringNewConfirmed:type:integerNewDeaths:type:integerNewRecovered:type:integerPremium:type:objectSlug:type:stringTotalConfirmed:type:integerTotalDeaths:type:integerTotalRecovered:type:integer
Lo mejor es utilizar una herramienta como un registro de esquemas para registrarlos y gestionarlos. El registro de esquemas realiza un seguimiento de las versiones de los esquemas y, a veces, comprueba la compatibilidad con versiones anteriores. Los esquemas son el "contrato" entre el dominio productor y el dominio consumidor de productos de flujo de datos. Esto protege a las aplicaciones de cambios en el esquema que podrían romper el procesamiento de datos en el dominio consumidor. También obliga a los dominios productores a hacer evolucionar sus productos de streaming de datos de forma que no se rompa la compatibilidad con versiones anteriores. Un registro de esquemas entra dentro de la gobernanza federada de datos en la malla de streaming de datos, por lo que entraremos en más detalles en el Capítulo 5. En el documento YAML de la AsyncAPI, es importante saber que en lugar de definir tu esquema en línea, puedes hacerlo a distancia con un registro de esquemas (ver Ejemplo 4-13).
Ejemplo 4-13. messages describe el sobre que contiene la carga útil
messages:covidapi:name:covidapititle:covidapisummary:COVID19globalstatisticscontentType:avro/binaryschemaFormat:application/vnd.apache.avro+json;version=1.9.0payload:$ref:'http://schema-registry:8081/subjects/topic/versions/1/#covidapi'
El esquema
payloades una referencia externa a un registro de esquemas.
Sección de esquemas de seguridad
AsyncAPI proporciona información de seguridad específica en el objeto securitySchemes del documento YAML. El Ejemplo 4-14 muestra cómo conectarse a la plataforma de streaming, que en este caso es Kafka, tal y como se define en la sección servers del YAML de la AsyncAPI. El objeto description tiene una descripción de propiedades que se proporciona a la aplicación consumidora. Esto proporciona información más detallada al cliente del producto de flujo de datos. Los autores del documento AsyncAPI YAML pueden dar formato al contenido del objeto description para proporcionar más información que AsyncAPI YAML no proporciona.
Ejemplo 4-14. Sección de esquemas de seguridad de los componentes que muestra más detalles en el description
securitySchemes:user-password:type:userPassworddescription:|Provide your Confluent KEY as the user and SECRET as the password.```prop# Kafkabootstrap.servers=kafka.us-east-2.aws.confluent.cloud:9092security.protocol=SASL_SSLsasl.mechanisms=PLAINsasl.username={{ CLUSTER_API_KEY }}sasl.password={{ CLUSTER_API_SECRET }}# Best practice for higher availability in librdkafka clients prior to 1.7session.timeout.ms=45000# Confluent Cloud Schema Registryschema.registry.url=https://schema-registry.westus2.azure.confluent.cloudbasic.auth.credentials.source=USER_INFObasic.auth.user.info={{ SR_API_KEY }}:{{ SR_API_SECRET }}```Copy the above YAML replacing the KEY/SECRETS for both the cluster andschema registry and use in your Kafka clients.
{{ CLUSTER_API_KEY }}es la clave o usuario enuser-passworda utilizar para conectarse a Kafka en Confluent Cloud.{{ CLUSTER_API_SECRET }}es el secreto o contraseñauser-passwordque debes utilizar para conectarte a Kafka en Confluent Cloud.{{ SR_API_KEY }}:{{ SR_API_SECRET }}es la clave/secreto ouser-passworda utilizar cuando se soliciten esquemas del Registro de Esquemas en Confluent Cloud.
Cuando los consumidores de dominio quieren consumir un producto de datos de streaming, como los datos estadísticos globales COVID-19 descritos en esta AsyncAPI, tienen que solicitar acceso a él. Entonces, el gestor del producto de streaming de datos tiene que aprobar el dominio solicitante. Parte de esta aprobación puede implicar el envío de las credenciales al dominio solicitante para que pueda poner esa información en su configuración para empezar a consumir el producto de streaming de datos. En el Ejemplo 4-14, esto correspondería a los parámetros enumerados en (1), (2) y (3). Estos parámetros deberán ser sustituidos por las credenciales proporcionadas por el dominio productor para acceder a los productos de streaming de datos.
La descripción del Ejemplo 4-14 muestra específicamente cómo configurar un consumidor para que lea de Confluent Cloud. El cliente sólo tendrá que sustituir de nuevo los parámetros por las credenciales, leer esta configuración en la aplicación y pasarla a las bibliotecas del cliente Kafka para configurarlo para leer de Kafka. En capítulos posteriores demostraremos cómo utilizar el documento AsyncAPI YAML para construir conectores Apache Kafka en su lugar, creando aplicaciones que lean de Apache Kafka.
Advertencia
Es importante recordar que este ejemplo utiliza la metodología usuario/contraseña para la seguridad. Como ya se ha mencionado, otras metodologías de seguridad compatibles tienen sus propios tipos de credenciales y puede que no utilicen el enfoque usuario/contraseña. Esas otras metodologías de seguridad quedan fuera del alcance de este libro.
Sección de rasgos
En AsyncAPI, traits proporciona información adicional que podría aplicarse a un objeto del documento YAML. Los rasgos suelen utilizarse sólo cuando la aplicación que analiza el documento YAML de AsyncAPI intenta generar código cliente en un lenguaje específico. El Ejemplo 4-9 tenía un objeto llamado operationId con el valor receiveNewCovidInfo. En el sitio web de AsyncAPI se puede descargar una aplicación que lee un documento YAML AsyncAPI llamada Generador AsyncAPI. Esto generará código cliente Java Spring para que los dominios lo compilen y lo implementen. Esta aplicación puede consumir el producto de streaming de datos de la plataforma de streaming definida en la sección servers del YAML de la AsyncAPI. En este caso, será Apache Kafka. El Generador AsyncAPI utilizará el valor de operationId como nombre del método en el código fuente. Los rasgos de messageTraits y operationTraits en el Ejemplo 4-15 se utilizan para asignar valores a métodos como groupID o clientId para ayudar a generar el código cliente.
Ejemplo 4-15. Los generadores de código utilizan los traits para asignar valores a las propiedades, nombrar clases y métodos en el código generado
messageTraits:commonHeaders:headers:type:objectproperties:my-app-header:type:integerminimum:0maximum:100correlationId:type:stringoperationTraits:covid:bindings:kafka:groupId:my-app-group-id-pubclientId:my-app-client-id-pubbindingVersion:'0.1.0'
Asignar etiquetas de datos
Etiquetas de datos son una forma sencilla de proporcionar a los dominios consumidores más información sobre el producto de datos de flujo: cómo se ha construido y qué se puede esperar al consumirlo. Muchas de las características de los datos de flujo son difíciles de medir, como la calidad y la seguridad, por lo que a veces es difícil proporcionar esa importante información al dominio consumidor. En lugar de proporcionar un número o una puntuación, podemos proporcionar etiquetas que representen niveles de calidad y seguridad. En esta sección intentaremos asignar etiquetas a los datos.
Las etiquetas pueden proporcionar información sobre la calidad o la seguridad del producto de datos de streaming. A veces, los dominios consumidores quieren productos de datos de streaming que no hayan sido modificados (en bruto) desde la fuente original. Otros dominios consumidores pueden querer que ese mismo producto de datos de streaming sea de la máxima calidad que satisfaga las normas de formato y los requisitos de seguridad. Acabarían siendo dos productos de datos de flujo distintos. Las etiquetas nos proporcionan una forma sencilla de presentar los productos de datos de flujo a los dominios consumidores.
Calidad
Calidad es una característica difícil de puntuar, pero podríamos utilizar etiquetas como las definidas en la Tabla 4-8.
| Etiquetas | Definición |
|---|---|
RAW |
Datos brutos de la fuente original |
ESTÁNDAR |
Transformación para cumplir las normas de formato |
ENRIQUECIDO |
Transformación a normas de formato y enriquecimiento |
Para los dos productos de flujo de datos que proceden de la misma fuente de datos pero con distinta calidad, podríamos asignar RAW como etiqueta de calidad de datos para el producto de flujo de datos que sirve datos sin procesar. También podríamos asignar ENRICHED como etiqueta de calidad de datos para el segundo producto de flujo de datos, en el que los consumidores esperan un enriquecimiento. Los dominios consumidores identificarían fácilmente a qué producto de datos de flujo deben solicitar acceso.
Estas etiquetas podrían asignarse a tags en la AsyncAPI y los consumidores del dominio podrían hacer clic en ella y obtener las definiciones de las etiquetas, como en el Ejemplo 4-16.
Ejemplo 4-16. Añadir etiquetas de calidad para proporcionar información adicional
covidapi:name:covidapititle:covidapitags:-name:quality.RAWexternalDocs:description:Providesrawsourcedataurl:https://somewhere/quality/raw
quality.RAWcorresponde a los datos brutos. La URL dirigiría al consumidor del dominio a más información sobre cómo se implementó la calidad.
Seguridad
Seguridad en este contexto de etiquetas de datos informativos implicaría proteger la información sensible en el producto de datos de flujo. De forma similar a la calidad, las etiquetas de seguridad también podrían definirse como en la Tabla 4-9.
| Etiquetas | Definición |
|---|---|
FILTRADO |
Los datos sensibles se filtraron o seleccionaron fuera del producto de flujo de datos, o no había información sensible en la carga útil. |
TOKENIZADO |
Los datos sensibles fueron tokenizados y pueden recuperarse mediante un mecanismo de búsqueda. |
ENCRYPTED |
Los datos sensibles, fueron encriptados y desencriptar los datos a su valor original requiere una clave. |
De forma similar a las etiquetas para informar de la calidad, se añaden las etiquetas para la seguridad. Puedes añadir varias etiquetas al documento YAML de la AsyncAPI, tanto para la calidad como para la seguridad(Ejemplo 4-17).
Ejemplo 4-17. Añadir etiquetas de seguridad para proporcionar información adicional
covidapi:name:covidapititle:covidapitags:-name:security.FILTEREDexternalDocs:description:Providesrawsourcedataurl:https://somewhere/security/filtered
security.FILTEREDsignifica que si alguna información era sensible, se filtraba u omitía del producto final de datos de flujo.
El Ejemplo 4-17 muestra cómo podemos proporcionar información al dominio consumidor sobre lo que se hizo con los datos que se van a proteger. El url es un recurso adicional que podría proporcionar más información sobre lo que se filtró y por qué.
Rendimiento
Proporcionar rendimiento al producto de flujo de datos proporcionará una información de escalabilidad muy importante para el dominio consumidor. El rendimiento puede medirse en megabytes por segundo (MBps). Es un indicador de la rapidez con la que los datos llegan al dominio consumidor. Algunos productos de streaming de datos pueden ser lentos, como los datos dimensionales que cambian lentamente, de los que hablamos en "Datos dimensionales frente a datos de hechos en un contexto de streaming". Otros datos de flujo pueden ser realmente rápidos, como los datos de flujo de clics de una aplicación web o un feed de Twitter.
De forma similar a la calidad y la seguridad, en el Ejemplo 4-18 podrías proporcionar el rendimiento como una descripción en una etiqueta de rendimiento y una URL que proporcione información adicional sobre cómo está configurado el tema de Apache Kafka para permitir ese nivel de rendimiento, como el número de particiones.
Ejemplo 4-18. Describir el rendimiento en AsyncAPI
subscribe:summary:SubscribetoglobalCOVID19Statistics.description:|The schema that this service follows the https://api.covid19api.com/operationId:receiveNewCovidInfotags:-name:throughputexternalDocs:description:10/mbpsurl:https://localhost/covid119/throughput
Versionado
En es importante proporcionar la versión del producto de streaming de datos. Esto permite a los dominios consumidores saber si el producto de streaming de datos está listo para sus cargas de trabajo de producción o si se ha producido un cambio de versión importante que podrían aprovechar.
El Ejemplo 4-19 muestra cómo AsyncAPI puede proporcionar información detallada sobre versiones a los dominios consumidores, que podrían utilizarla al gestionarel desarrollo de sus propias aplicaciones.
Ejemplo 4-19. Secciones informativas YAML de AsyncAPI
info:title:COVID 19 Global Statistics AsyncAPI Specversion:'0.0.1'description:|This streaming data product is in preview. DISCLAIMER - this streaming dataproduct could implement breaking changes. Do not use this for your productionapplications in your domain.contact:name:API Supporturl:http://www.asyncapi.com/support
También puede ser beneficioso que el registro de cambios a versiones actualizadas se facilite en la descripción o en una URL. Esto incluye cualquier cambio en la canalización de datos ETL que produce el producto de datos y cualquier cambio en la fuente original.
Los derivados de datos que se originan a partir de otros productos de streaming de datos de otros dominios deben identificarse también en etiquetas o URL, de modo que los dominios consumidores puedan profundizar recursivamente en las fuentes que componen el producto final de streaming de datos. En capítulos posteriores, veremos formas de hacerlo.
Monitoreo
La información de monitoreo sobre el producto de streaming de datos también es fundamental para que la vean los dominios consumidores. Esto también podría proporcionarse como otra URL o etiqueta en el documento YAML de la AsyncAPI. La Tabla 4-10 muestra parte de la información importante que los dominios consumidores querrían conocer.
| Información | Insight |
|---|---|
Número de consumidores |
|
Recuento de errores/SLA |
|
Rendimiento/ancho de banda |
|
Si el dominio consumidor requiere un 99,999% para sus propias aplicaciones y el producto de streaming de datos sólo proporciona un 99,9%, puede que quiera solicitar garantías de SLA más elevadas, lo que puede dar lugar a un producto de streaming de datos distinto.
Los dominios consumidores querrán configurar alertas de estas métricas para poder reaccionar ante posibles problemas. Puedes ofrecer una mejor experiencia de malla de datos si proporcionas monitoreo a todos tus productos de transmisión de datos y haces que sean programáticamente consumibles o alertables para los dominios consumidores.
Resumen
En este capítulo, hemos esbozado todos los pasos necesarios para construir un producto de streaming de datos: cómo definir los requisitos, la ingesta, la transformación y, en última instancia, la publicación de un documento AsyncAPI YAML. Hicimos todo esto con el conjunto de habilidades de los ingenieros generalistas que esperamos de los ingenieros de dominio: JSON, SQL y YAML. Este documento AsyncAPI nos permitirá construir una malla de datos en streaming. En el Capítulo 5, hablaremos de cómo podemos utilizar el documento YAML de AsyncAPI para rellenar un catálogo de datos de flujo. También utilizaremos aplicaciones (herramientas) AsyncAPI que generarán páginas HTML en una aplicación de catálogo de datos de flujo y veremos cómo podemos ampliarla para añadir un flujo de trabajo de malla de datos de flujo. En capítulos posteriores, seguiremos utilizando el documento AsyncAPI para construir autoservicios que puedan crear integraciones y recuperar metadatos recursivamente, como el linaje de datos.
1 Departamento de Salud y Servicios Humanos de EEUU, "Resumen de la Norma de Privacidad de la HIPAA", p. 4.
2 El GDPR de la UE sólo se aplica a los datos personales, que son cualquier información relacionada con una persona identificable. Es crucial que cualquier empresa con consumidores de la UE entienda este concepto para cumplir el GDPR.
Get Malla de transmisión de datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

