Capítulo 1. Introducción a la Malla de Datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Los jóvenes piensan que en algún momento las arquitecturas de datos fueron fáciles, y luego crecieron el volumen, la velocidad y la variedad de los datos y necesitamos nuevas arquitecturas que son difíciles. En realidad, los problemas de datos siempre fueron problemas de organización y, por tanto, nunca se resolvieron.
Gwen (Chen) Shapira, Kafka: La Guía Definitiva (O'Reilly)
Si trabajas en una empresa en crecimiento, te darás cuenta de que existe una correlación positiva entre el crecimiento de la empresa y la escala de entrada de datos. Esto puede deberse a un mayor uso de las aplicaciones existentes o a nuevas aplicaciones y funciones añadidas. Corresponde al ingeniero de datos organizar, optimizar, procesar, gobernar y servir estos datos crecientes a los consumidores, manteniendo al mismo tiempo los acuerdos de nivel de servicio (SLA). Lo más probable es que estos SLA se garantizaran a los consumidores sin la intervención del ingeniero de datos. Lo primero que se aprende cuando se trabaja con una cantidad tan grande de datos es que, cuando el procesamiento de datos empieza a invadir las garantías establecidas por estos SLA, se pone más énfasis en mantenerse dentro de los SLA, y se marginan cosas como la gobernanza de los datos. Esto, a su vez, genera mucha desconfianza en los datos que se sirven y, en última instancia, desconfianza en los análisis, los mismos análisis que pueden utilizarse para mejorar las aplicaciones operativas con el fin de generar más ingresos o evitar la pérdida de ingresos.
Si reproduces este problema en todas las líneas de negocio de la empresa, empiezas a tener ingenieros de datos muy descontentos tratando de acelerar las canalizaciones de datos dentro de la capacidad del lago de datos y los clusters de procesamiento de datos. Esta es la posición en la que me encontraba la mayoría de las veces.
Entonces, ¿qué es una malla de datos? El término "malla" en "malla de datos" se tomó del término "malla de servicios", que es un medio de añadir observabilidad, seguridad, descubrimiento y fiabilidad a nivel de plataforma en lugar de a nivel de aplicación. Una malla de servicios suele implementarse como un conjunto escalable de proxies de red desplegados junto al código de la aplicación (un patrón que a veces se denomina sidecar). Estos proxies gestionanla comunicación entre los microservicios de y también actúan como punto en el que seintroducen las funciones de la malla de servicios.
La arquitectura de microservicios es el núcleo de una arquitectura de malla de streaming de datos, e introduce un cambio fundamental que descompone las aplicaciones monolíticas de creando servicios débilmente acoplados, más pequeños, altamente mantenibles, ágiles y escalables de forma independiente, más allá de la capacidad de cualquier arquitectura monolítica. En la Figura 1-1 puedes ver esta descomposición de la aplicación monolítica para crear una arquitectura de microservicios más escalable sin perder el propósito empresarial de la aplicación.
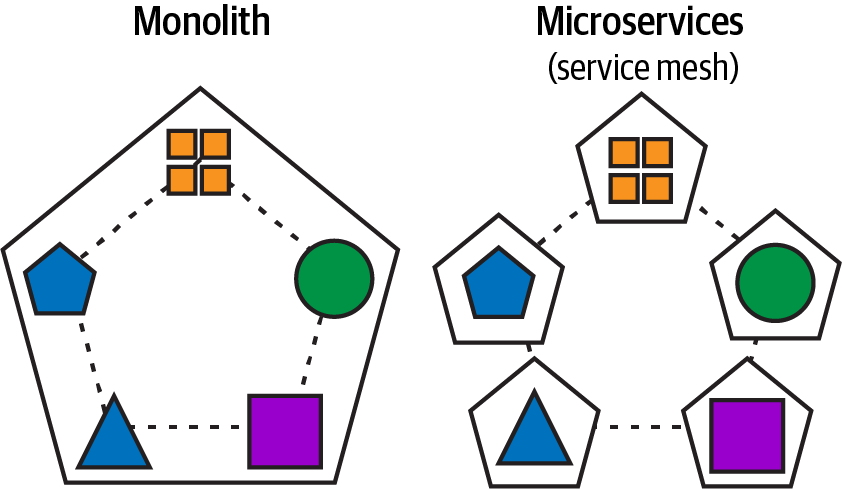
Figura 1-1. Descomponer una aplicación monolítica en microservicios que se comunican entre sí a través de una malla de servicios
Una malla de datos intenta lograr los mismos objetivos que los microservicios lograron para las aplicaciones monolíticas. En la Figura 1-2, una malla de datos trata de crear los mismos productos de datos débilmente acoplados, más pequeños, altamente mantenibles, ágiles y escalables independientemente, más allá de la capacidad de cualquier arquitectura monolítica de lago de datos.
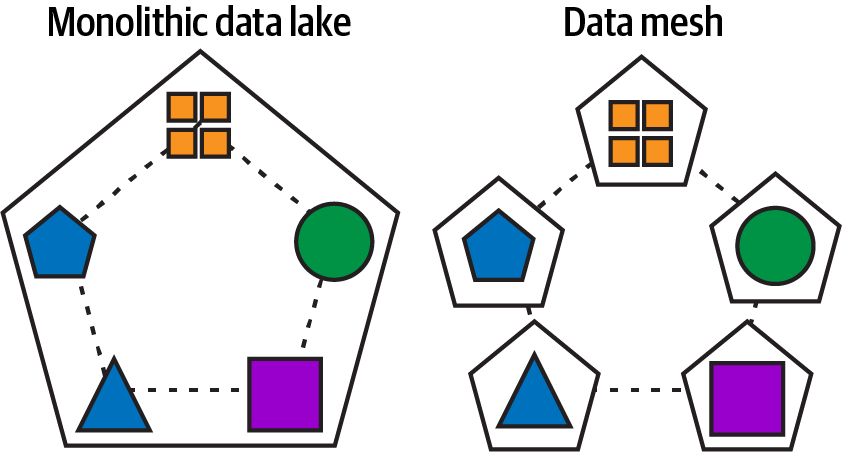
Figura 1-2. Lago de datos/almacén monolítico descompuesto en productos de datos y dominios que se comunican a través de una malla de datos
Zhamak Dehghani (a quien me referiré como ZD en este libro) es el pionero del patrón de malla de datos. Si no conoces a ZD y su blog sobre mallas de datos, te recomiendo encarecidamente que lo leas, así como su popularísimo libro Data Mesh (O'Reilly). Presentaré un sencillo resumen para ayudarte a tener una comprensión básica de los pilares que componen el patrón arquitectónico de malla de datos, de modo que pueda referirme a ellos a lo largo del libro.
En este capítulo estableceremos los fundamentos de lo que es una malla de datos antes de introducir una malla de datos de streaming en el Capítulo 2. Esto ayudará a sentar las bases para una mejor comprensión a medida que superponemos las ideas del streaming. A continuación, hablaremos de otras arquitecturas que comparten similitudes con la malla de datos para ayudar a delimitarlas. Estas otras arquitecturas tienden a confundir a los arquitectos de datos a la hora de diseñar una malla de datos, y es mejor aclararlas antes de que introduzcamos la malla de datos en el streaming.
División de datos
El blog de ZD habla de una división de datos, ilustrada en la Figura 1-3, para ayudar a describir el movimiento de los datos dentro de una empresa. Este concepto fundamental ayudará a comprender cómo los datos impulsan las decisiones empresariales y los problemas monolíticos queconllevan.
Para resumirlo en, el plano de datos operativo contiene almacenes de datos que respaldan las aplicaciones que impulsan una empresa.
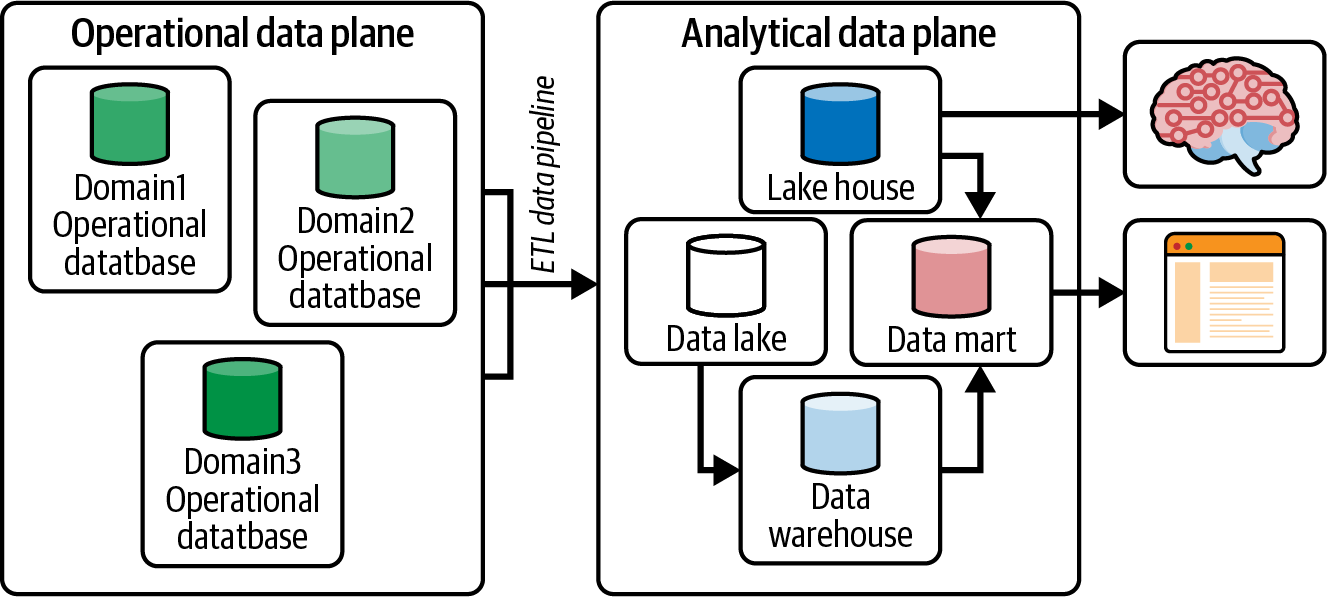
Figura 1-3. La división de datos que separa el plano de datos operativos del plano de datos analíticos
Un proceso de extracción, transformación y carga (ETL) replica los datos operativos en el plano de datos analíticos, ya que no quieres ejecutar consultas analíticas en almacenes de datos operativos, restando recursos de cálculo y almacenamiento necesarios para generar ingresos para tu empresa. El plano analítico contiene lagos/almacenes/lagos de datos para obtener perspectivas. Estas percepciones se retroalimentan al plano de datos operativos para realizar mejoras y hacer crecer el negocio.
Con la ayuda de Kubernetes en el plano operativo, las aplicaciones han pasado de ser aplicaciones lentas y monolíticas a microservicios ágiles y escalables que se intercomunican, creando una malla de servicios. No puede decirse lo mismo del plano analítico. El objetivo de de la malla de datos es precisamente eso: dividir el plano analítico monolítico en una solución descentralizada que permita datos ágiles, escalables y fáciles de gestionar. Nos referiremos al plano operativo y al plano analítico a lo largo del libro, por lo que es importante establecer esta comprensión desde el principio, cuando empecemos a construir un ejemplo de malla de datos de flujo.
Pilares de la malla de datos
La base de la arquitectura de malla de datos se sustenta en los pilares definidos en la Tabla 1-1. Los resumiremos rápidamente en las secciones siguientes, cubriendo los conceptos más destacados de cada uno, para que podamos centrarnos en la implementación de una malla de datos en flujo en capítulos posteriores.
| Propiedad de los datos | Los datos como producto | Plataforma de datos de autoservicio | Gobernanza federadade datos computacionales |
|---|---|---|---|
Descentralización y distribución de la responsabilidad a las personas que están más cerca de los datos para apoyar el cambio continuoy la escalabilidad. |
Descubrir, comprender, confiar y, en última instancia, utilizardatos de calidad. |
Infraestructura de datos de autoservicio como plataforma para permitir la autonomía de dominio. |
Un modelo de gobernanza que adopte la descentralización, la auto-soberanía de dominio y la interoperabilidad a través de la estandarización global. Una topología dinámica y, lo que es más importante, la ejecución automatizadade las decisiones por parte de la plataforma. |
La propiedad de los datos y los datos como producto constituyen el núcleo de los pilares de la malla de datos. La plataforma de datos de autoservicio y la gobernanza de datos computacionales federados existen para apoyar los dos primeros pilares. Ahora hablaremos brevemente de estos cuatro y dedicaremos un capítulo entero a cada pilar a partir del Capítulo 3.
Propiedad de los datos
Como se ha mencionado anteriormente, el pilar principal de una malla de datos es descentralizar los datos para que su propiedad vuelva al equipo que los produjo originalmente (o al menos que más los conoce y se preocupa por ellos). A los ingenieros de datos de este equipo se les asignará un dominio, uno en el que sean expertos en los propios datos. Algunos ejemplos de dominios son el análisis, el inventario y la(s) aplicación(es). Son los grupos que probablemente antes escribían en el lago de datos monolítico y leían de él.
Dominios se encargan de captar los datos desde su verdadera fuente. Cada dominio transforma, enriquece y, en última instancia, proporciona esos datos a sus consumidores.
En existen tres tipos de dominios:
- Sólo productor
-
Dominios que sólo producen datos y no los consumen de otros dominios
- Sólo para consumidores
- Productor y consumidor
-
Dominios que producen y consumen datos hacia y desde otros dominios, respectivamente
Nota
Siguiendo el enfoque de diseño dirigido por dominios (DDD) de, que modela objetos de dominio definidos por los expertos del dominio empresarial e implementados en software, el dominio conoce los detalles específicos de sus datos, como el esquema y los tipos de datos que se adhieren a estos objetos de dominio. Dado que los datos se definen a nivel de dominio, es el mejor lugar para definir los detalles específicos sobre su definición, transformación y gobierno.
Los datos como producto
Dado que los datos de pertenecen ahora a un dominio, necesitamos una forma de servir datos entre dominios. Como estos datos tienen que ser consumibles y utilizables, hay que tratarlos como cualquier otro producto para que los consumidores tengan una buena experiencia con los datos. A partir de ahora, llamaremos productos de datos a cualquier dato que se sirva a otros dominios.
Definir qué es una "buena experiencia" con los productos de datos es una tarea que debe acordarse entre los dominios de la malla de datos. Una definición consensuada ayudará a proporcionar expectativas bien definidas entre los dominios participantes en la malla. La Tabla 1-2 enumera algunas ideas en las que pensar que ayudarán a crear una "buena experiencia" para los consumidores de productos de datos y ayudarán a crear productos de datos en un dominio.
| Consideraciones | Descripción |
|---|---|
Los productos de datos deben ser fácilmente consumibles. |
Algunos ejemplos podrían ser:
|
Los ingenieros deben tener un conjunto de aptitudes generalistas. |
Los ingenieros necesitan construir productos de datos sin necesidad de herramientas que requieran habilidades hiperespecializadas. Estos son un posible conjunto mínimo de habilidades necesarias para construir productos de datos:
|
Los productos de datos deben poder buscarse. |
Al publicar un producto de datos en la malla de datos, se utilizará un catálogo de datos para el descubrimiento, las vistas de metadatos (uso, seguridad, esquema y linaje) y las solicitudes de acceso al producto de datos por parte de los dominios que quieran consumirlo. |
Gobernanza Federada de los Datos Computacionales
Dado que los dominios se utilizan para crear productos de datos, y que compartir productos de datos entre muchos dominios construye en última instancia una malla de datos, tenemos que asegurarnos de que los datos que se sirven siguen algunas directrices. La gobernanza de los datos implica crear y adherirse a un conjunto de reglas, normas y políticas globales aplicadas a todos los productos de datos y sus interfaces para garantizar una comunidad de malla de datos colaborativa e interoperable. Estas directrices deben acordarse entre los dominios de malla de datos participantes.
Nota
La malla de datos no está completamente descentralizada. Los datos están descentralizados en los dominios, pero la parte de malla de la malla de datos no lo está. La gobernanza de los datos es fundamental para construir la malla en una malla de datos. Ejemplos de ello son la creación de autoservicios, la definición de la seguridad y la aplicación de prácticas de interoperabilidad.
He aquí algunas cosas que hay que tener en cuenta al pensar en la gobernanza de datos para una malla de datos: autorización, autenticación, métodos de replicación de datos y metadatos, esquemas, serialización de datos y tokenización/cifrado.
Plataforma de datos de autoservicio
Dado que siguiendo estos pilares requiere un conjunto de habilidades hiperespecializadas, hay que crear un conjunto de servicios para construir una malla de datos y sus productos de datos. Estas herramientas requieren compatibilidad con las habilidades que son accesibles a un ingeniero más generalista. Al construir una malla de datos, es necesario capacitar a los ingenieros existentes en un dominio para realizar las tareas requeridas. Los dominios tienen que capturar datos de sus almacenes operativos, transformarlos (unirlos o enriquecerlos, agregarlos, equilibrarlos) y publicar sus productos de datos en la malla de datos. Los servicios de autoservicio son los "botones fáciles" necesarios para que la malla de datos sea fácil de adoptar con una alta usabilidad. En resumen, los autoservicios permiten a los ingenieros de dominio asumir muchas de las tareas de las que era responsable el ingeniero de datos en todas las líneas de negocio. Una malla de datos no sólo descompone el lago de datos monolítico, sino que también descompone el papel monolítico del ingeniero de datos en tareas sencillas que los ingenieros de dominio pueden realizar.
Diagrama de malla de datos
La Figura 1-4 muestra que hay tres dominios distintos: ciencia de datos, aplicación móvil e inventario.
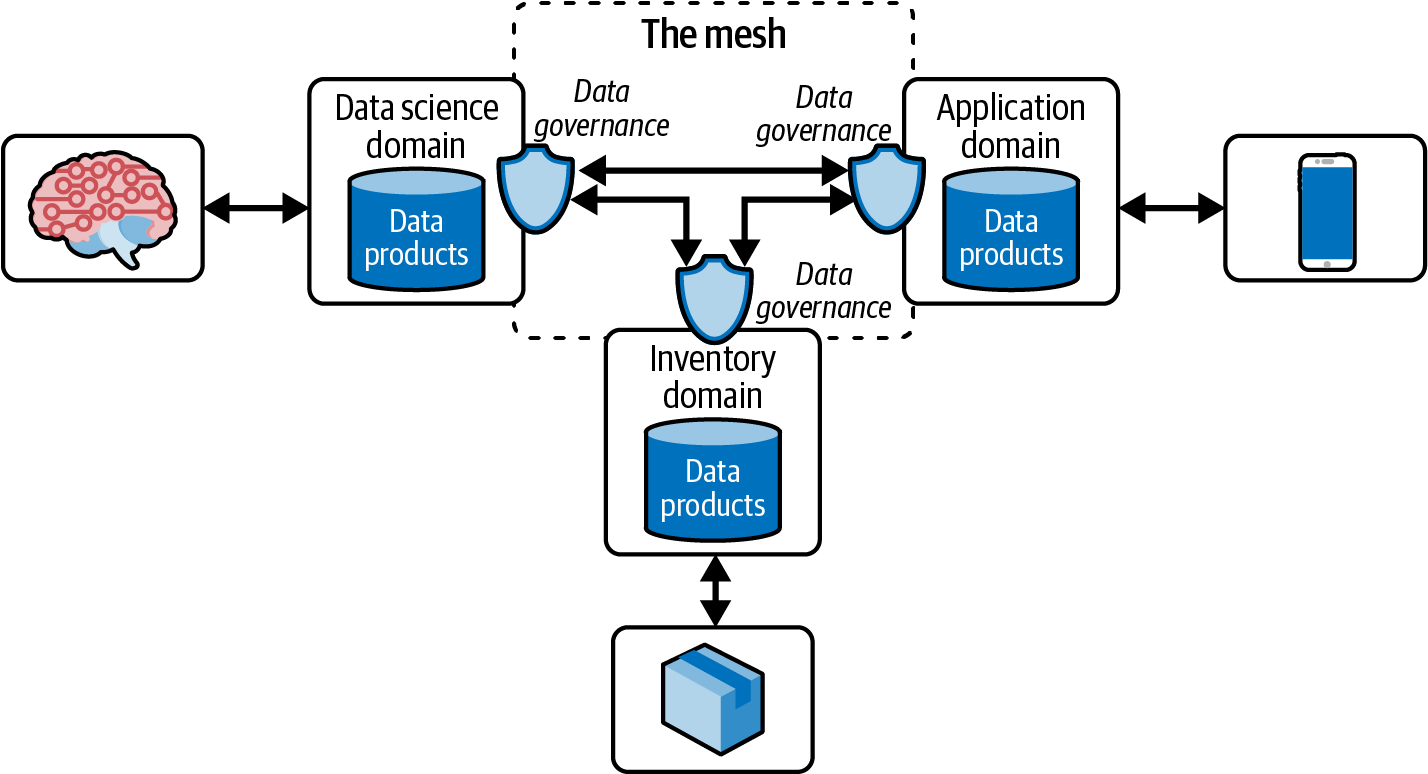
Figura 1-4. Vista de alto nivel de una malla de datos
El dominio de ciencia de datos consume datos del dominio de aplicación, que posee los datos procedentes de las aplicaciones móviles. El dominio de inventario consume datos de la ciencia de datos para la logística de inventario, como reducir la distancia o mover el suministro a lugares con mayor propensión a la compra. Por último, el dominio de aplicación podría estar consumiendo referencias a modelos recién entrenados para cargarlos en sus aplicaciones móviles que crean experiencias personalizadas actualizadas.
La gobernanza de datos crea controles de acceso entre el productor y el consumidor del producto de datos y proporciona metadatos como definiciones de esquemas y linajes. En algunos casos, los datos maestros junto con los datos de referencia pueden ser relevantes para la aplicación. La gobernanza de datos nos permite crear controles de acceso adecuados también para estos recursos.
Los perímetros que conectan los dominios replican los datos entre ellos. Construyen las conexiones entre dominios, creando la "malla". La Figura 1-4 es un gráfico de alto nivel de una malla de datos en la que profundizaremos en los capítulos siguientes.
En capítulos posteriores también hablaremos de cómo identificar y construir un dominio reuniendo un equipo de datos que siga el espíritu de la visión de ZD de una plataforma de datos descentralizada. De nuevo, la Figura 1-4 es una vista de alto nivel de una malla de datos sin streaming. Esta implementación no implica que el streaming sea la solución para publicar datos para su consumo. Otras alternativas pueden mover datos entre y dentro de un dominio. El Capítulo 2 trata específicamente de la malla de datos de streaming y sus ventajas.
Otros patrones arquitectónicos similares
La sección anterior de resumía la arquitectura de malla de datos a un nivel muy alto, tal y como la define la visión de ZD. A muchos arquitectos de datos les gusta señalar las arquitecturas de datos existentes que tienen características similares a una malla de datos. Estas similitudes pueden ser suficientes para que los arquitectos etiqueten sus implementaciones existentes como ya conformes y que cumplen los pilares de la malla de datos. Estos arquitectos pueden estar totalmente en lo cierto o parcialmente. Algunas de estas arquitecturas de datos son los tejidos de datos, las pasarelas de datos, los datos como servicio, la democratización de datos y la virtualización de datos.
Tejido de datos
Un tejido de datos es un patrón muy similar a una malla de datos, en el sentido de que ambos proporcionan soluciones que abarcan la gobernanza y el autoservicio de datos: descubrimiento, acceso, seguridad, integración, transformación y linaje(Figura 1-5).
En el momento de escribir esto, el consenso sobre las diferencias entre malla de datos y tejido de datos no está claro. En términos sencillos, un tejido de datos es un medio metadireccional de conectar conjuntos dispares de datos y herramientas relacionadas para proporcionar una experiencia de datos cohesionada y entregar datos de forma autoservicio.
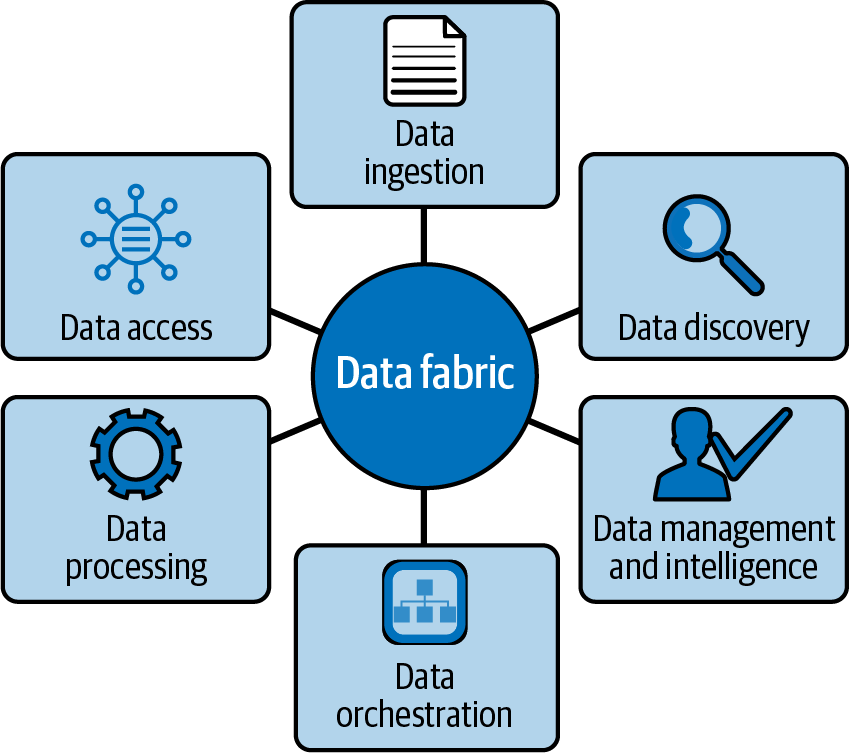
Figura 1-5. Pilares del tejido de datos
Aunque una malla de datos trata de resolver muchos de los mismos problemas que aborda un tejido de datos -a saber, la capacidad de tratar los datos en un entorno de datos único y compuesto-, el enfoque es diferente. Mientras que un tejido de datos permite a los usuarios crear una única capa virtual sobre los datos distribuidos, una malla de datos faculta aún más a los grupos distribuidos de productores de datos para gestionar y publicar los datos como consideren oportuno. Los tejidos de datos permiten una experiencia de virtualización de datos de bajo a ningún código, aplicando la integración de datos dentro de las API que residen en el tejido de datos. La malla de datos, sin embargo, permite a los ingenieros de datos escribir código para las API con las que interactuar más.
Una malla de datos es un enfoque arquitectónico para proporcionar acceso a los datos a través de múltiples tecnologías y plataformas, y se basa en una solución tecnológica. Un contraste clave es que una malla de datos es mucho más que tecnología: es un patrón que implica a personas y procesos. En lugar de asumir la propiedad de toda una plataforma de datos, como en un tejido de datos, la malla de datos permite a los productores de datos centrarse en la producción de datos, permite a los consumidores de datos centrarse en el consumo, y permite a los equipos híbridos consumir otros productos de datos, mezclar otros datos para crear productos de datos aún más interesantes, y publicar estos productos de datos -con algunas consideraciones de gobierno de datos en su lugar.
En una malla de datos, los datos están descentralizados, mientras que en un tejido de datos se permite la centralización de los datos. Y con la centralización de datos como los lagos de datos, se obtienen los problemas monolíticos que conlleva. La malla de datos intenta aplicar un enfoque de microservicios a los datos, descomponiendo los dominios de datos en grupos más pequeños y ágiles.
Afortunadamente, las herramientas que soportan un tejido de datos pueden soportar una malla de datos. También es evidente que una malla de datos necesitará autoservicios adicionales que apoyen a los dominios en la ingeniería de productos de datos y proporcionen la infraestructura para construir y servir productos de datos. En la Figura 1-6 vemos que una malla de datos tiene todos los componentes de un tejido de datos, pero implementados en una malla. En pocas palabras, un tejido de datos es un subconjunto de una malla de datos.
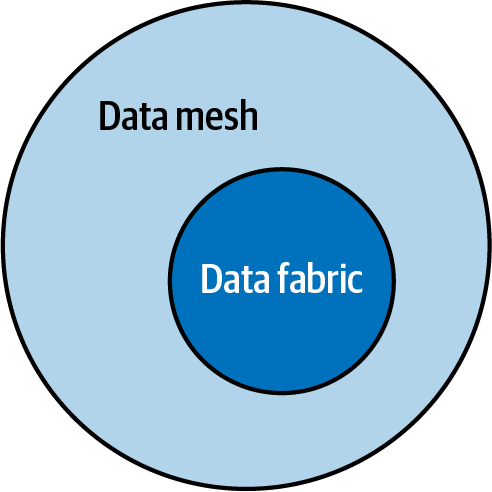
Figura 1-6. El tejido de datos es un subconjunto de la malla de datos
Pasarelas de datos y servicios de datos
Las pasarelas de datos son como las pasarelas API, pero sirven datos:
Las pasarelas de datos actúan como las pasarelas API, pero centrándose en el aspecto de los datos. Una pasarela de datos ofrece abstracciones, seguridad, escalado, federación y funciones de desarrollo basadas en contratos .
Bilgin Ibryam, "Pasarelas de datos en la era nativa de la nube" de InfoQ, mayo de 2020
Del mismo modo, data as a service(DaaS) es un patrón que sirve datos desde su fuente original totalmente gestionados y consumibles siguiendo estándares abiertos y es servido por software como servicio(SaaS). Ambos patrones arquitectónicos sirven datos, pero DaaS se centra más en servir los datos desde la nube. Se podría decir que el DaaS habilita pasarelas de datos en la nube, donde antes podían estar sólo en las instalaciones. La Figura 1-7 muestra un ejemplo.
Combinando los conceptos de pasarela de datos y DaaS, es más fácil calificar los datos como procedentes de la fuente original, especialmente si los datos eran inmutables desde el origen. La replicación de datos procedentes de un centro de datos local a un SaaS en la nube sería un requisito.
Todos los requisitos de DaaS los cumple la malla de datos, excepto el de ser habilitada por un SaaS. En la malla de datos, el SaaS es una opción, pero actualmente no hay proveedores de malla de datos SaaS que faciliten la implantación de una malla de datos.
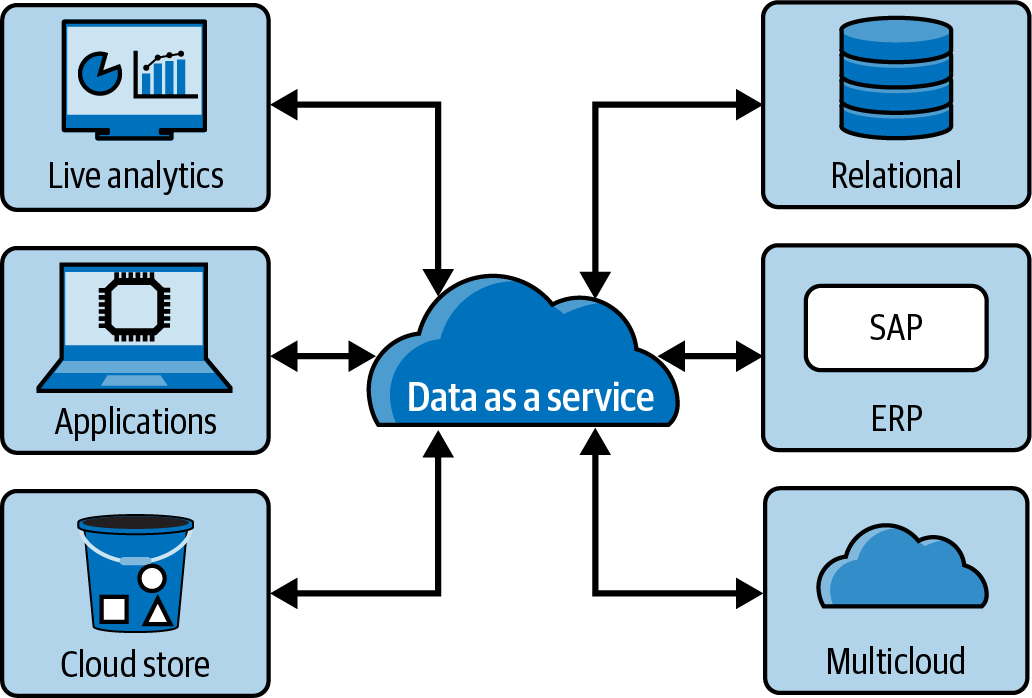
Figura 1-7. Los datos como servicio (DaaS) tienen un objetivo similar al de proporcionar productos de datos en una malla de datos
Democratización de datos
Lademocratización de los datos es el proceso de hacer accesible la información digital al usuario medio no técnico de los sistemas de información sin tener que requerir la participación de las TI:
La democratización de los datos significa que todo el mundo tenga acceso a los datos y que no haya guardianes que creen un cuello de botella en la puerta de acceso a los datos. Requiere que acompañemos el acceso con una forma fácil de que las personas comprendan los datos, de modo que puedan utilizarlos para agilizar la toma de decisiones y descubrir oportunidades para una organización. El objetivo es que cualquiera pueda utilizar los datos en cualquier momento para tomar decisiones sin barreras de acceso o comprensión.
Bernard Marr, "¿Qué es la democratización de datos? A Super Simple Explanation and the Key Pros and Cons," Forbes, julio de 2017
Data mesh satisface esta definición a través de sus productos de datos, autoservicio y enfoque de bajo código para compartir y crear datos. El acceso sencillo a los datos es fundamental para que una empresa siga impulsada por los datos. Obtener un acceso rápido a los datos para crear perspectivas analíticas permitirá una respuesta más rápida a los cambios operativos que podrían salvar a una empresa de costes elevados.
Virtualización de datos
La virtualización de datos es un tipo especial de tecnología de integración de datos que proporciona acceso a datos en tiempo real, a través de múltiples fuentes y volúmenes extremadamente grandes, sin tener que trasladar ningún dato a una nueva ubicación.1
Muchos han considerado la virtualización de datos como una solución para implantar una malla de datos, ya que puede satisfacer todos los pilares de una arquitectura de malla de datos, especialmente la idea de no tener que mover ningún dato a una nueva ubicación, lo que requiere la replicación de los datos mediante un proceso ETL independiente. Cuando empecemos a hablar de la malla de datos en streaming, debemos entender la diferencia entre virtualización de datos y replicación de datos, que es el enfoque que adopta una malla de datos en streaming.
Como ya se ha dicho, con la virtualización de datos, los datos no se trasladan a una nueva ubicación y, por tanto, no se copian varias veces al realizar consultas, a diferencia de la replicación de datos. Dependiendo de lo dispersos que estén los datos, esto puede ser beneficioso. Sin embargo, si los datos existen en varias regiones globales, realizar consultas a través de grandes distancias afectará significativamente al rendimiento de las consultas. El objetivo de replicar los datos de los planos operativos a los analíticos mediante ETL no es sólo evitar que se ejecuten consultas ad hoc en los almacenes de datos operativos, lo que afectaría a las aplicaciones operativas que impulsan el negocio, sino también acercar los datos a las herramientas que realizan los análisis. Así que la ETL sigue siendo necesaria, y la replicación es inevitable:
La virtualización de datos procede de una visión del mundo en la que el almacenamiento de datos es caro y la conexión en red es barata (es decir, in situ). El problema que resuelve es hacer que los datos sean accesibles independientemente de dónde estén y sin tener que copiarlos. Las copias en las bases de datos son malas por la dificultad de garantizar la coherencia. La replicación de datos se basa en la visión de que las copias no son malas (porque los datos han mutado). Lo que resulta más útil cuando lo caro es la red (la nube).Mic Hussey, ingeniero principal de soluciones de Confluent
Considera una replicación y virtualización híbridas. Cuando los datos empiecen a residir en distintas regiones globales, podría ser mejor replicar los datos en una región y luego aplicar la virtualización de datos dentro de una región.
Centrarse en la aplicación
El streaming no es un requisito en la definición de ZD de una malla de datos. Servir productos de datos en una malla de datos puede implementarse como API de procesamiento por lotes o streaming. ZD también afirma que la malla de datos sólo debe utilizarse para casos de uso analítico. Nosotros llevaremos la malla de datos más allá de la analítica y la aplicaremos a arquitecturas que ofrezcan soluciones para DaaS y tejidos de datos. El Capítulo 2 destaca algunas de las ventajas del streaming sobre la malla de datos por lotes.
Tomar los fundamentos de la malla de datos y aplicarlos a un contexto de streaming requerirá que tomemos decisiones de implementación para que podamos construir una malla de datos de streaming con el ejemplo. Las elecciones de implementación que se hacen en este libro no son necesariamente requisitos para una malla de datos de streaming, sino opciones elegidas para ayudar a coser la solución de streaming al tiempo que se adhieren a los pilares de la malla de datos de ZD. Las dos tecnologías clave necesarias para una implementación de streaming requerirán (1) una tecnología de streaming como Apache Kafka, Redpanda o Amazon Kinesis; y (2) una forma de exponer los datos como recursos asíncronos, utilizando una tecnología como AsyncAPI. A medida que avance este libro, nos centraremos en implementaciones que utilicen Kafka y AsyncAPI.
Apache Kafka
Apache Kafka como implementación para plataformas de streaming de datos. Este libro no requiere que conozcas Apache Kafka, sino que cubrirá sólo las características importantes que permiten una malla de datos en streaming adecuada. Además, Kafka puede sustituirse por una plataforma de streaming similar, como Apache Pulsar o Redpanda, que siguen el marco de productor y consumidor de Apache Kafka. Es importante señalar que las plataformas de streaming que son capaces de mantener sus datos en un registro de commit implementarán mejor el patrón de malla de datos de streaming descrito en este libro. Los registros de confirmación en una plataforma de streaming se describen en el Capítulo 2.
AsyncAPI
AsyncAPI es un proyecto de código abierto que simplifica la arquitectura asíncrona dirigida por eventos (EDA). AsyncAPI es un marco que permite a los implementadores generar código o configuraciones, en cualquier lenguaje o herramienta que les guste, para producir o consumir datos de streaming. Permite describir cualquier dato de streaming en una configuración AsyncAPI de forma sencilla, descriptiva e interoperable. Será uno de los componentes fundacionales que utilizaremos para construir una malla de datos de streaming. La AsyncAPI por sí sola no basta para definir productos de datos en una malla de datos en flujo. Sin embargo, como AsyncAPI es extensible, la ampliaremos para incluir los pilares de la malla de datos definidos anteriormente. Repasaremos los detalles de AsyncAPI en capítulos posteriores.
Con la malla de datos y sus pilares definidos, vamos a profundizar en cómo podemos aplicar los pilares y conceptos tratados en este capítulo a los datos en streaming para crear una malla de datos en streaming.
1 Kriptos; "¿Qué es la Virtualización de Datos? Comprender el concepto y sus ventajas", Virtualización de Datos, febrero de 2022.
Get Malla de transmisión de datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

