Chapter 1. Machine Learning Roles and the Interview Process
In the first part of this chapter, I’ll walk through the structure of this book. Then, I’ll discuss the various job titles and roles that use ML skills in industry.1 I’ll also clarify the responsibilities of various job titles, such as data scientist, machine learning engineer, and so on, as this is a common point of confusion for job seekers. These will be illustrated with an ML skills matrix and ML lifecycle that will be referenced throughout the book.
The second part of this chapter walks through the interview process, from beginning to end. I’ve mentored candidates who appreciated this overview since online resources often focus on specific pieces of the interview but not how they all connect together and result in an offer. Especially for new graduates2 and readers coming from different industries, this chapter helps get everyone on the same page as well as clarifies the process.
The interconnecting pieces of interviews are complex, with many types of combinations depending on the ML role you’re aiming for. This overview will help set the stage, so you’ll know what to focus your time on. For example, some online resources focus on knowledge specific to “product data scientists,” but will title the course or article “data scientist interview tips” without differentiating. For a newcomer, it’s hard to tell if that is relevant to your own career interests. After this chapter, you’ll be able to tell what skills are required for each job title, and in Chapter 2, you’ll be able to parse out that information yourself from job postings and make your resume as relevant to the job title and job posting as possible.
Overview of This Book
This chapter focuses on helping you differentiate among various ML roles, and walks through the entire interview process, as illustrated in Figure 1-1:
Job applications and resume (Chapter 2)
Technical interviews
Behavioral interviews (Chapter 7)
Your interview roadmap (Chapter 8)
Post-interview and follow-up (Chapter 9)
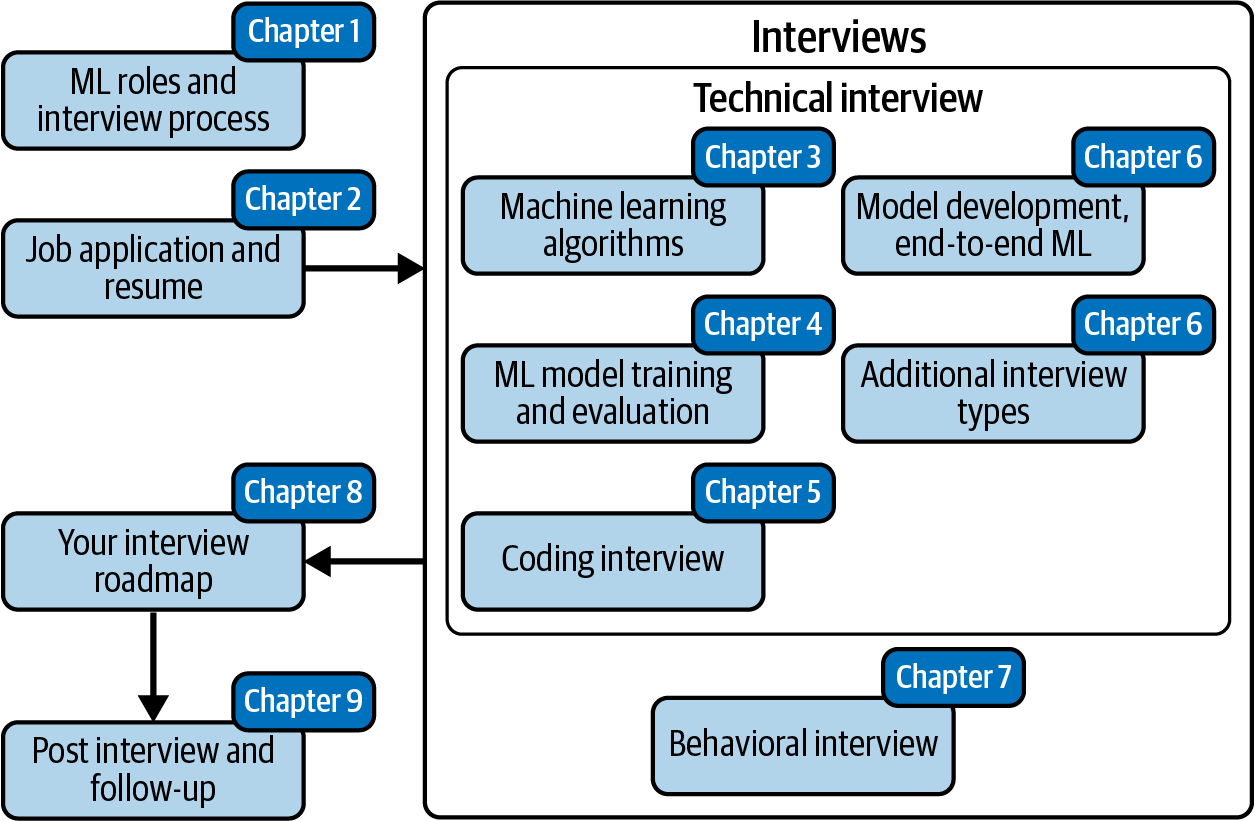
Figure 1-1. Overview of the chapters and how they tie into the ML interview process.
Depending on where you are in your ML interview journey, I encourage you to focus on the chapters and sections that seem relevant to you. I’ve also planned the book to be referenced as you go along; for example, you might iterate on your resume multiple times and then flip back to Chapter 2 when needed. The same applies to the other chapters. With that overview, let’s continue.
Tip
The companion site to this book, https://susanshu.substack.com, features bonus content, helper resources, and more.
A Brief History of Machine Learning and Data Science Job Titles
First, let’s walk through a brief history of job titles. I decided to start with this section to dispel some myths about the “data scientist” job title and shed some light on why there are so many ML-related job titles. After understanding this history, you should be more aware of what job titles to aim for yourself. If you’ve ever been confused about the litany of titles such as machine learning engineer (MLE), product data scientist, MLOps engineer, and more, this section is for you.
ML techniques aren’t a new thing; in 1985, David Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski popularized the Boltzmann Machine algorithm.3 Even before that, regression techniques4 had early developments in the 1800s. There have long been jobs and roles that use modeling techniques to forecast and predict. Econometricians, statisticians, financial modelers, physics modelers, and biochemical modelers have existed as professions for decades. The main difference is that there were much smaller datasets compared to the modern day (barring simulations).
It was only in recent years, just before the 21st century, when compute power started to increase exponentially. In addition, advances in distributed and parallel computing created a cycle in which “big data” became more readily available. This allowed practitioners to apply that advanced compute power to millions or billions of data points.
Larger datasets started being accumulated and distributed for ML research, such as WordNet,5 and, subsequently, ImageNet,6 a project led by Fei-Fei Li. These collective efforts laid the foundation for even more ML breakthroughs. AlexNet7 was released in 2012, achieving high accuracy in the ImageNet challenge,8 which demonstrated that deep learning can be adept at humanlike tasks at a scale that had not been seen before.
Many ML practitioners see this as a time when machine learning, deep learning, and related topics increased by leaps and bounds in terms of recognition from the broader population, not just the AI community. The recent popularity of generative AI (such as ChatGPT) in 2022 and 2023 didn’t come out of nowhere, nor did the deepfakes, self-driving cars, chess bots, and more that came before it; these applications were the results of many advances over recent years.
“Data scientist” as a job title began as an umbrella term, when the ML and data fields were less mature. The term “data scientist” on Google Trends, which measures the popularity of search terms, surged in 2012. That was the year when that article was published by Harvard Business Review: “Data Scientist: The Sexiest Job of the 21st Century.”9 By April 2013, the search popularity of “data scientist” was already tied with “statistician” and subsequently surpassed it by magnitudes, as shown in Figure 1-2. Back in those days, there wasn’t a narrow divide between infrastructure jobs and model training, though. For example, Kubernetes was first released in 2014, but companies have taken some time to adopt it for orchestrating ML jobs. So now there are more specific job titles for ML infrastructure that didn’t exist before.
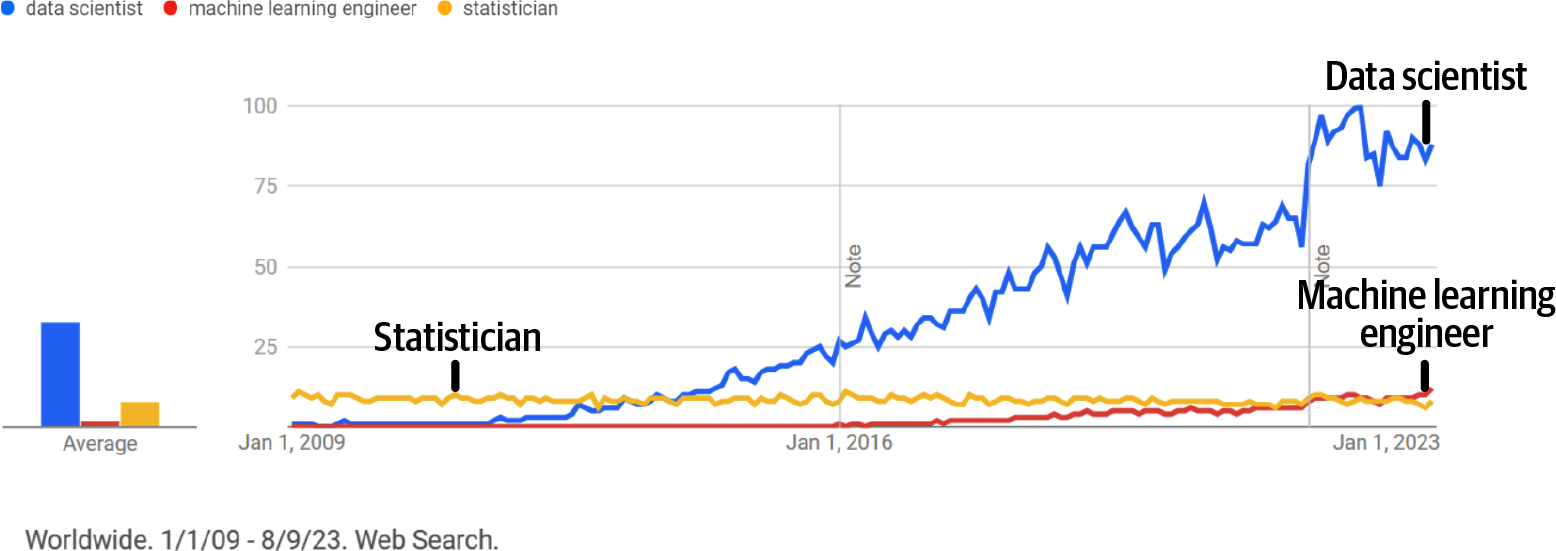
Figure 1-2. Search popularity for the terms “data scientist,” “machine learning engineer,” and “statistician” on Google Trends (retrieved August 9, 2023).
As social media, web recommender systems, and other modern use cases increased, companies started gathering much more granular data, such as clickstream data, which is data collected as a user browses a website or app. Another recent advancement is an average corporation being able to store the sheer amount of telemetry from machines and Internet of Things (IoT) devices. Previously, data scientists may have worked with data that was updated weekly or daily. Now, as many applications update more frequently or in real time, more infrastructure is needed to serve ML functionality in web products and apps, so more jobs have been created around those functions as well.
In short: as the machine learning lifecycle grew more complex, more job titles were created to describe the new skills that a full ML team now requires. I’ll elaborate more on the job titles and ML lifecycle later in this chapter.
All of this happened within the last decade, and companies don’t always change their job titles to reflect how the roles have become more specialized. Regardless, as a candidate, knowing this history can help reduce confusion and frustration from applying for a job and finding the role is different from another company’s job with the exact same title. See Table 1-1 for previous trends in ML-related job titles and Table 1-2 for current trends in ML job titles.
| ML and data job title | Previous trend for the job title |
|---|---|
| Data scientist | Do everything |
| Data analyst | Specifically responsible for data analysis related to business decisions |
| ML and data job titles | Current trends for the job titles |
|---|---|
| Data scientist Machine learning engineer Applied scientist …and so on |
Train ML models |
| Machine learning engineer MLOps engineer, AI engineer Infrastructure software engineer ML software engineer, machine learning …and so on |
MLOps and infrastructure work |
| Data analyst (Product) data scientist …and so on |
Data analysis, A/B testing |
| Data engineer Data scientist in a startup Analytics engineer …and so on |
Data engineering |
With that history to explain why you will encounter different job titles, I’ll elaborate on each of these job titles and their responsibilities.
Job Titles Requiring ML Experience
Here is a nonexhaustive list of job titles for ML (or closely related) roles:
-
Data scientist
-
Machine learning engineer
-
Applied scientist
-
Software engineer, machine learning
-
MLOps engineer
-
Product data scientist
-
Data analyst
-
Decision scientist
-
Data engineer10
-
Research scientist
-
Research engineer11
As I discussed “A Brief History of Machine Learning and Data Science Job Titles”, each role is responsible for a different part of the ML lifecycle. A job title alone does not convey what the job entails. As a job seeker, be warned: in different companies, completely different titles might end up doing similar jobs! As illustrated in Figure 1-3, your ML job title will depend on the company, the team, and which part(s) of the ML lifecycle your role is responsible for.
To give specific examples of how job titles can depend on the company or organization that is hiring for the job—based on real people I’ve spoken to, job descriptions, and job interviews—the person responsible for training ML models but not for building the underlying platform might be called the following:
-
Software engineer (ML) or data scientist (Google)
-
Applied scientist (Amazon)
-
Machine learning engineer (Meta, Pinterest)
-
Data scientist (Elastic, the team where I work)
-
Data scientist (Unity)
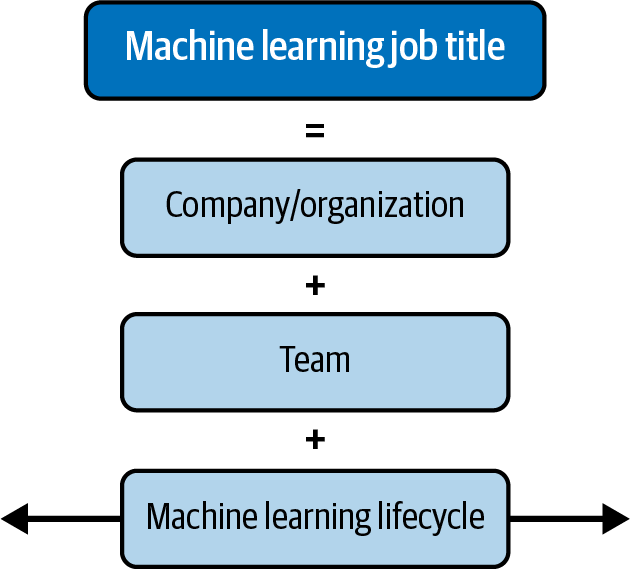
Figure 1-3. What’s in a machine learning job title?
Note
By the time this book is published, any of the job titles within these companies and teams may have changed. Regardless, it demonstrates the point that ML titles may vary between companies and even between different teams in the same company.
The job title also depends on the organization, the department, and so on. Some departments in Google have the data scientist12 job title, and some don’t. At the companies where I’ve worked, my teams had data scientists train ML models while MLEs built the infrastructure (working all day in tools such as Kubernetes, Terraform, Jenkins, and so on). In some other companies, MLEs are the ones who train ML models.
As a personal example, my work experience has heavily involved ML model training, so I apply for jobs that have the title “machine learning engineer” or “data scientist.” I’ll provide more examples of skills and roles that could be a good fit for your interests and skills in the following sections.
Machine Learning Lifecycle
In industry, it is an expectation for applied ML projects to eventually improve the customer experience—for example, a better recommender system that shows the user more relevant videos, news, and social media posts. In industry, “customer” can also mean internal customers: people within the same company or organization. For example, your team builds ML models that predict demand, which helps your company’s logistics department better plan its shipment schedules. Regardless of whether the user is external or internal, many components are involved in building a full-fledged, end-to-end ML product. I’ll walk through a simplified example.
First, there needs to be data, as most ML is trained and tested with large amounts of data. Someone needs to make sure the raw data is brought in (ingested) so that it’s easily accessible later on for data analysis, ML, reporting and monitoring, and so on. This is illustrated by step A (data) in Figure 1-4.
Next, with the data in place, someone with knowledge of ML algorithms and tools will use the data to start ML development. This is illustrated by step B (machine learning development) in Figure 1-4. This involves feature engineering, model training, and evaluation. If the results aren’t great, there is a lot of iteration in step B, and this person might enhance their feature engineering or model training, or even go back to step A and request that more data be ingested.
Once there are somewhat satisfactory results, they’ll move on to step C (machine learning deployment), which connects the ML models to customers. Depending on the type of ML project, it could be deployed to a website, app, internal dashboard, and so on. Of course, they’d like to make sure the ML is working properly, so any good team will have a way to monitor the results. In ML there are two main types of potential issues. The first is that something in the software layer doesn’t work, such as bugs in the code. The second is a data or ML model issue—for example, in the model-development phase, the model outputs normal results, but after deployment/release, there is data imbalance, so then the model results become undesirable. From step C onward, there can be more iteration back to step B to improve the models and run more experiments in step C again.
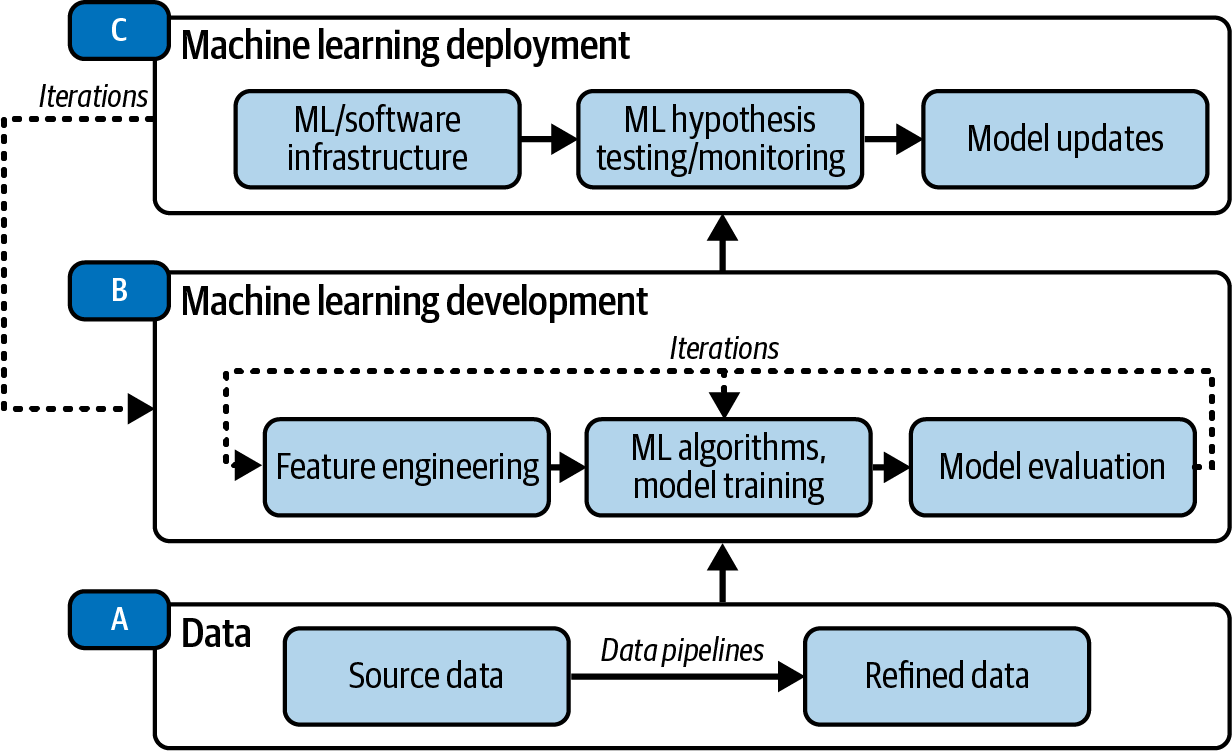
Figure 1-4. Machine learning lifecycle (the graph is simplified for understanding).
In the machine learning lifecycle I just walked through, a lot of skills are required. Data pipelines, model training, maintaining continuous integration and continuous deployment (CI/CD): as a job candidate, what should you be learning to prepare for the interview? Thankfully, as I mentioned in “A Brief History of Machine Learning and Data Science Job Titles” companies nowadays might hire people who have a subset of these skills. For example, they need some people specialized in step A (data engineering), some specialized in step B (ML development), some in step C (ML deployment), and so forth. I emphasize the might since it still differs depending on the company or team; I will walk through some scenarios.
Startups
Startup roles will usually wear more hats, meaning they will need to do the jobs in multiple steps in the machine learning lifecycle as illustrated in Figure 1-4. Here’s an example:
We were a team of 5–25 ML engineers and regularly had to participate in setting up data labeling jobs, QA testing, and performance improvements (on mobile devices), plus setting up demos.
Dominic Monn, CEO of MentorCruise (previous six years in ML startups)
Usually, startup companies have the goal of shipping13 an end-to-end product, but because they have fewer customers they might care less about the scale and stability (at an early stage). Hence, it’s more likely that the person developing and training ML models is the same person doing data analysis and presenting to stakeholders, or even the same person building the platform infrastructure. An ML team in a startup might simply have fewer people. For example, the startup might have 30 software engineers and data people in total, whereas larger corporations could have a team of data analysts alone numbering 30 people to disperse the workload.
Larger ML Teams
If the company and/or team has grown enough, it is more likely the ML roles have become more specialized. Generally, the larger the team, the more specialized the role. If the “machine learning engineer” at a larger company trains models, then it’s likely they don’t wear two or three hats at once, as they might at a startup. Instead, the big company hires more people to fill those roles. That isn’t to say the work is simpler at a larger company. In fact, there’s often more data, more scale, and more downsides if the ML functionality goes down, so each MLE’s time could be completely tied up wearing only one hat.
Note
Larger company size often corresponds to larger ML teams, but it depends. For example, a large company in a traditionally nontech industry, might have its first ML team hires operate in more of a startup-like environment while they figure out how ML best works for the company.
Let’s go one level deeper and add more details of ML or data responsibilities. Figure 1-5 expands on the machine learning lifecycle from Figure 1-4 to reflect teams or companies with more fine-grained roles. (It’s worth repeating that even if this list is a useful and common enough heuristic, it’s still a bit simplified for illustration purposes since there will always be exceptions and outliers.)
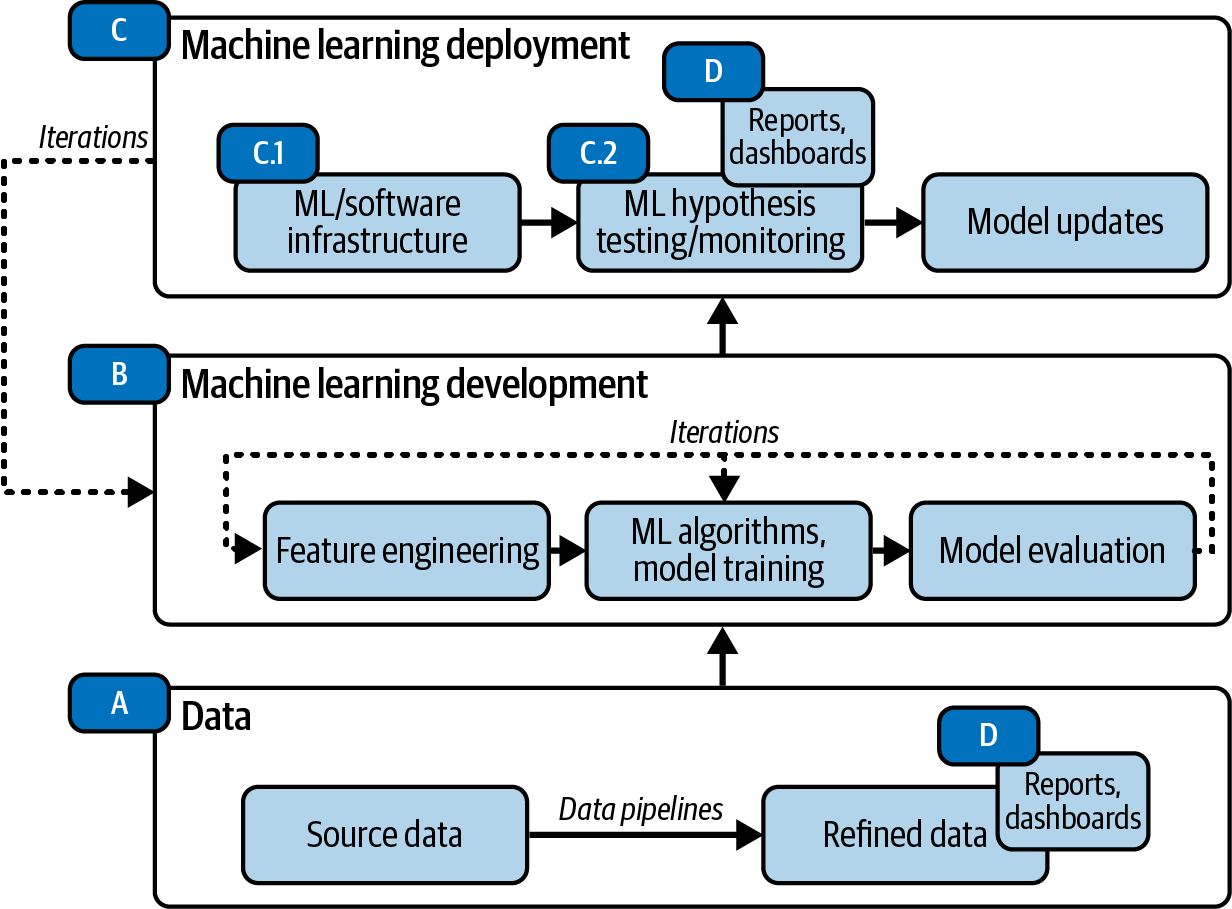
Figure 1-5. Machine learning lifecycle with more fine-grained roles (extended version of Figure 1-4).
Here’s an example of what your role might be responsible for within these more fine-grained roles, as illustrated in Figure 1-5:
-
You build the data pipelines for analytics and ML (step A).
-
You train ML models (step B).
-
You build the infrastructure for ML models to be deployed (step C.1).
-
You design and conduct hypothesis testing, often A/B tests, for new ML product features (step C.2).
-
You do data analysis, build reports and dashboards, and present to stakeholders (step D).
Tip
Figure 1-5 is often referred to in later chapters, so save or bookmark it!
The Three Pillars of Machine Learning Roles
To set the stage for the rest of the book, I’ll go over what I call the three pillars of ML and data science roles:
-
Machine learning algorithms and data intuition
-
Programming and software engineering skills
-
Execution and communication skills
These are the broad categories of skills that you will be evaluated on during ML job interviews. This book focuses a lot on helping you understand these skills and bridge any gaps between your current experiences and skills and those under these three pillars (see Figure 1-6). All these skills will be expanded on in the following chapters.
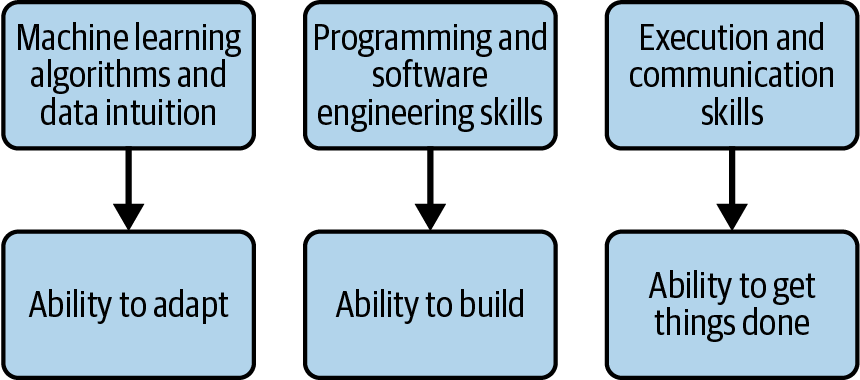
Figure 1-6. Three pillars of machine learning jobs.
Machine Learning Algorithms and Data Intuition: Ability to Adapt
You’re able to understand the underlying workings of ML algorithms and statistics theory and their respective trade-offs—which is essential when you’re faced with an open-ended question in a real-world ML project at work. You’re not just following steps as you would for a school assignment.
Having data intuition means that when you’re faced with a new problem, you know how to use data to solve it; and when you encounter new data or data sources, you know how to dive in to evaluate them. You ask yourself, is this data suitable for ML? What types of ML models might it be suitable for? Are there any issues with the data before you can use it for ML? You know what to ask and how to find the answers.
In the ML job-interview process, various types of interviews and interview questions are aimed at assessing a candidate’s knowledge and readiness in this pillar, which I’ll cover in Chapters 3 and 4.
Programming and Software Engineering: Ability to Build
While working on a project, you have the programming skills required to deliver, such as manipulating data with Python or using an internal deploy process so that another team can use the results from the ML model.
Even if you know the theory well, without the programming or software engineering14 sense, you can’t make ML materialize out of thin air. You need to use code to connect the data with ML algorithms, which are also implemented with code—that is, you must convert theory to practice.
Other programming skills in high demand for ML roles are the (software) engineer’s ability to transition from prototype to production—that is, the ML is integrated and released. Some roles are responsible for end-to-end ML: from researching and training models to deployment and production. Some ML roles, such as MLOps engineers, are responsible for building software infrastructure that can handle the demands of processing large amounts of data to send ML responses to users in seconds or even milliseconds.
In the ML job-interview process, various types of interviews and interview questions assess a candidate’s skills in this pillar, which I’ll walk through in Chapters 5 and 6.
Execution and Communication: Ability to Get Things Done in a Team
You’re able to work with people who aren’t in the same role as you. In ML, we work with software engineers, data engineers, product managers, and many other colleagues. The ability to get things done in a team encompasses a few soft skills such as communication and some project management skills.
For example, being unable to communicate with team members is a real blocker15 for projects and could cause your ML projects to languish or even be deprioritized. Even in cases where you work with only one person (say, your boss), you still need to be able to report on your projects, which requires communication skills. Consequently, in the ML field a highly in-demand skill is being able to communicate technical concepts with nontechnical stakeholders.
You’ll also need some project management skills to keep your tasks on track. We all learn to how manage our to-do lists and calendars during the process of education or self-learning, but it’s more chaotic since now your project calendar depends on others’ calendars and priorities. Even if you have a project and/or product manager to keep the team on track, you still need to manage yourself to some extent.
Without soft skills, things don’t get done, full stop. Don’t be that candidate who focuses only on technical skills but neglects building and demonstrating their soft skills in interviews. I’ll delve into the details of how ML interviews evaluate candidates on this pillar in Chapter 7.
Clearing Minimum Requirements in the Three ML Pillars
Growing your skills in all three ML pillars is a tall order, and for entry-level roles you’re usually only expected to have a minimum (such as a 3/10) for each pillar, as illustrated in Figure 1-7. For example, a job candidate who has some exposure to programming, even if they aren’t skilled or experienced, can be taught to improve. Ideally, you’d be stronger on at least one pillar (such as 5/10 for programming) that is most related to the particular ML role in order to stand out from other job candidates.
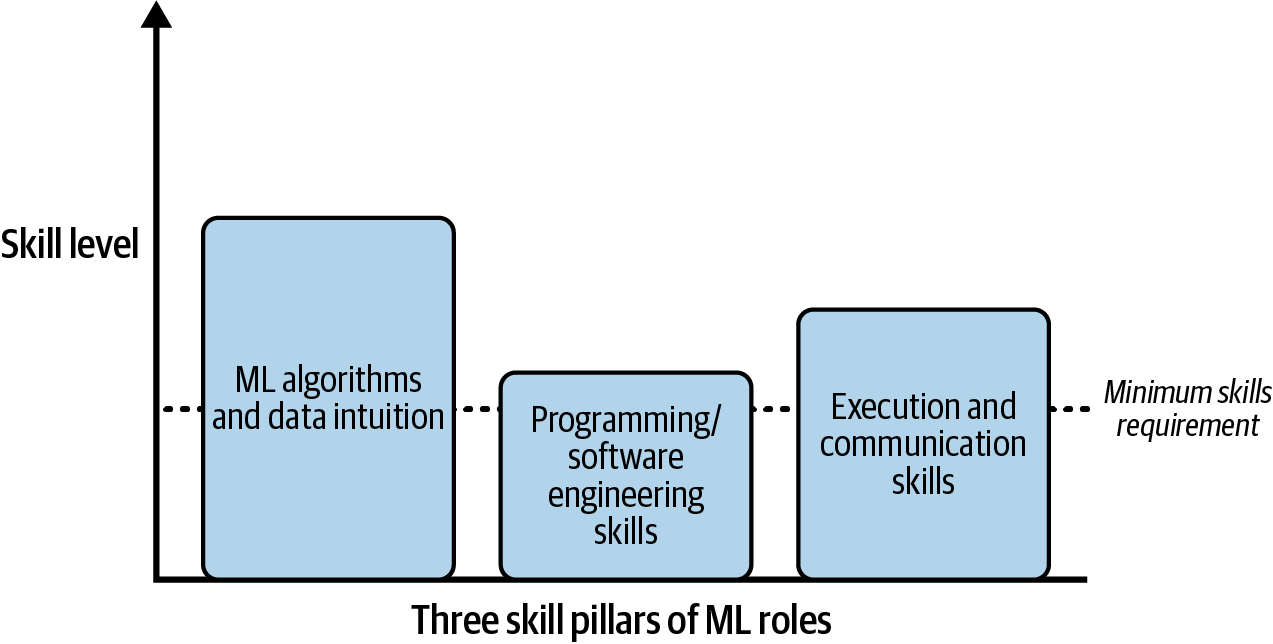
Figure 1-7. Minimum required skill levels for ML jobs (example).
For senior roles, the bare minimum requirements are higher, but a similar rule of thumb applies: clear the minimum skill requirements. From then on, you’ll be compared with other candidates on the skills that you are great in, depending on the role. Data scientists who only train ML models but don’t deploy them might not need to develop their programming skills as much as their ML theory and communication skills.
For entry level roles, I’d argue that the communication pillar has a lower requirement (but not 0/10, please!) because it takes the hard-earned experience of working with a larger group of people, including nontechnical teammates, to raise it higher. This also gives some candidates an edge in this pillar: for those with a nontraditional background, such as candidates who are self-taught or switching from software engineer roles or another field, the ability to adeptly tell a story and showcase a portfolio can set them apart from other candidates.
Now that you’ve had an overview of the three pillars, you can use this mental model to stand out.
Machine Learning Skills Matrix
Congratulations! You’ve made it to the end of a pretty dense section! Now that you’ve gone through the overview of the machine learning lifecycle and three pillars of ML skills, it’s time for you to map your interests and skills to job titles.
Table 1-3 will give you a rough idea of what skills you will need to learn in order to succeed in specific roles. On a scale from one to three stars, one star represents a skill of lower importance, and three stars represents a highly important skill.
Skills |
Job titles | ||||
|---|---|---|---|---|---|
| Data scientist (DS) |
ML engineer (MLE) |
MLOps engineer |
Data engineer |
Data analyst |
|
| Data visualization, communication | ★★★ | ★★ | ★ | ★ | ★★★ |
| Data exploration, cleaning, intuition | ★★★ | ★★★ | ★ | ★★★ | ★★★ |
| ML theory, statistics | ★★★ | ★★★ | ★★ | ★ | ★ |
| Programming tools (Python, SQL) | ★★★ | ★★★ | ★★★ | ★★★ | ★ |
| Software infrastructure (Docker, Kubernetes, CI/CD) | ★ | ★ to ★★★ | ★★★ | ★ | ★ |
Tip
Table 1-3 is often referred to in later chapters, so save or bookmark it!
Taking a look at these skills, you can roughly map them to the three pillars of ML skills in the previous section, as shown in Table 1-4.
| Pillar | ML and data skills |
|---|---|
| Pillar 1 Machine learning algorithms and data intuition: ability to adapt | Data exploration, cleaning, intuition Machine learning theory, statistics Data visualization |
| Pillar 2 Programming and software engineering skills: ability to build | Programming tools (Python, SQL) Software infrastructure |
| Pillar 3 Execution and communication skills: ability to get things done in a team | Communication and so on |
It’s OK if you aren’t completely sure what each type of skill might entail just yet. In Chapter 2, we will revisit this matrix, and there will be details and a checklist for self assessment.
Now, let’s tie all this together. We’ve looked at the machine learning lifecycle (Figure 1-5) and machine learning skills matrix (Table 1-3). What’s left is to see what jobs are best for you to apply to now or to gain the skills for! To do so, let’s connect everything to the current trend of ML and data job titles (Table 1-2). This is illustrated in Figure 1-8.

Figure 1-8. Common ML job titles and how they correspond to the ML lifecycle.
The alphabetical annotations in Figure 1-8 can be mapped to those in Figure 1-5, listed here for convenience:
-
(A) Data
-
(B) Machine learning development
-
(C.1) ML/software infrastructure
-
(C.2) ML hypothesis testing/monitoring
-
(D) Reports and dashboards
Tip
Figure 1-8 is often referred to in later chapters, so save or bookmark it!
When you see a job title and check the details of the job posting, you can map it to what that job is likely responsible for in the day to day. In addition, based on what part of the ML lifecycle you’re interested in, you can better prepare and target your job applications, so you don’t accidentally bark up the wrong tree.
Introduction to ML Job Interviews
Now that I’ve introduced many job titles that might be of interest to you, it’s time to go through all the steps and types of interviews you will encounter during the process! This book is called Machine Learning Interviews, but interviews are so much more than just interview questions. There are job applications and your resume, which are how you get interviews in the first place. If you don’t increase your chances of getting more interviews, then you won’t even get the chance to answer any interview questions! I’ll be covering the process from beginning to end, including how to follow up after the interview (Chapter 9).
Machine Learning Job-Interview Process
Now let’s get into the entire job-interview process. You’ll start by applying to jobs, then interviewing, and then, after some rounds of interviewing, finally receiving offers. This process is detailed in Figure 1-9.
Tip
Figure 1-9 is often referred to in later chapters, so save or bookmark it!
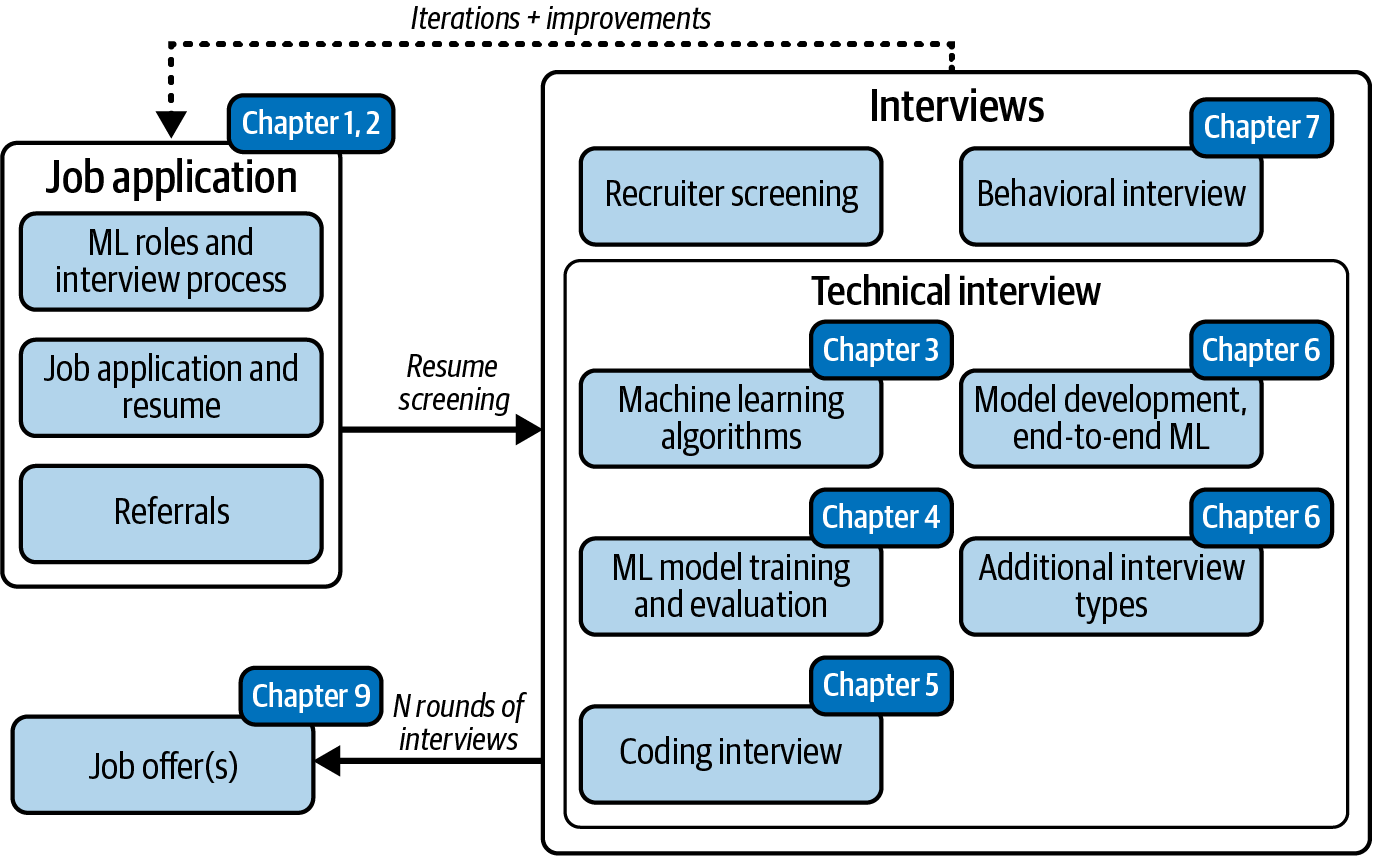
Figure 1-9. ML interview process.
Applying for Jobs Through Websites or Job Boards
Let’s imagine that you’re just starting out and applying for an ML role at a company with an established HR17 and hiring process. You can begin your application in a few ways: by cold applying through the company website or job board (discussed in Chapter 2) or through a referral from someone within the team or company. You can also get interviews through cold messaging on LinkedIn or by emailing recruiters. Usually, at companies that have an HR-tracking software system, even if someone refers you, you’ll still need to upload a standard application into the online portal, which means you’ll need to prepare an updated resume and fill in your information.
Note
You may also choose to supplement your job-search efforts by working with a third-party recruiter, which is different from an in-house recruiter who works or contracts specifically for the hiring company. Third-party recruiters often work with multiple companies at once. Professional peers I know recommend working only with specific trusted third-party recruiters but warned me to beware those who make too many unrealistic promises or aren’t reputable. You can read more about third-party recruiters in this Forbes article.
Resume Screening of Website or Job-Board Applications
Using the first method—cold applying through company websites or third-party job boards—you’ve been browsing job boards like Indeed18 as well as going directly to the career pages of companies you’re interested in working for. In this scenario, you don’t have someone referring you to the team or company (I’ll cover that in “Applying via a Referral”). You’ve seen some ML-related jobs that seem relevant to you, and you clicked the links to apply. After you submit your application and the company has your information and resume, an HR member, recruiter, or whoever is in charge of resume screening, will proceed with the next step.
The reality is that jobs have many applicants, and you should assume the first batch of applicants will be filtered before the hiring manager sees them. The hiring manager is the manager you’ll work with and report to if you join the team. So you can usually assume that a generalized HR partner or internal or external recruiters will be reading your resume first. These recruiters may be somewhat familiar with the roles they are screening resumes for, but they are still predominantly generalists, not as specialized as the engineers and ML professionals you’ll actually be working with. This part of the screening process leads to several hidden criteria for your resume, which is why it might be baffling when your resume doesn’t clear this step even if you have a relevant background.
It’s important to remember that these generalists will likely pass along your resume to the hiring manager if they:
-
See key technologies or experiences on your resume based on the job posting
-
See years of experience in key technologies or experiences or, in the case of entry-level or new-grad jobs, sufficient evidence that you can be easily trained
-
Understand that your skills and accomplishments are relevant, in plain language
To determine whether your resume meets the criteria, the recruiter will likely be searching for keywords and comparing your resume to the job posting. They will not automatically “translate” skills on your resume for you. For example, if the job description says “Python” and your resume says “C++,” at this step they will likely not consider that, since both programming languages are object oriented, you could probably learn Python quickly if you put in the effort.
If you’re able to describe your experiences at a level that HR recruiters can understand is relevant to the job posting, you will increase your chances at the resume-screening step. HR and recruiters, by nature of the role, are aware of higher-level technologies and what’s popular with the roles they’re hiring for but not the details, so it’s important for your resume to be optimized well. (Read more on how to optimize your resume in Chapter 2.)
Applying via a Referral
Now that I’ve walked through cold applications directly via job boards or websites without any referral, I’ll provide some examples of how referrals can help you fast-track the process.
Let’s say you’re interested in an ML job at ARI Corporation.19 You know an alum of your university who works on the ML team. You catch up with them and express your interest in the job. During the chat, you show the alum some of your personal ML projects, which are relevant to the ML job you’re interested in. The school alum agrees to refer you and gives you instructions for how to be referred, something that depends on the way the HR system of the company is set up.
Since this alum knows you and is willing to vouch for your skills after seeing your personal projects, you get your resume to the “top of the pile.” Depending on the strength of the referral/recommendation, you may skip the resume screening altogether and get a highly guaranteed callback from a recruiter or even bypass the recruiter directly and get to the rest of the interview rounds. This is illustrated in Figure 1-11. Note that I say “highly” guaranteed here since it still depends on various factors such as timing. As an example: maybe you got referred, but the job posting has coincidentally just been filled. Thus, you didn’t get to the rest of the interview.
I will cover more on referrals and how to get them via professional networking in Chapter 2.
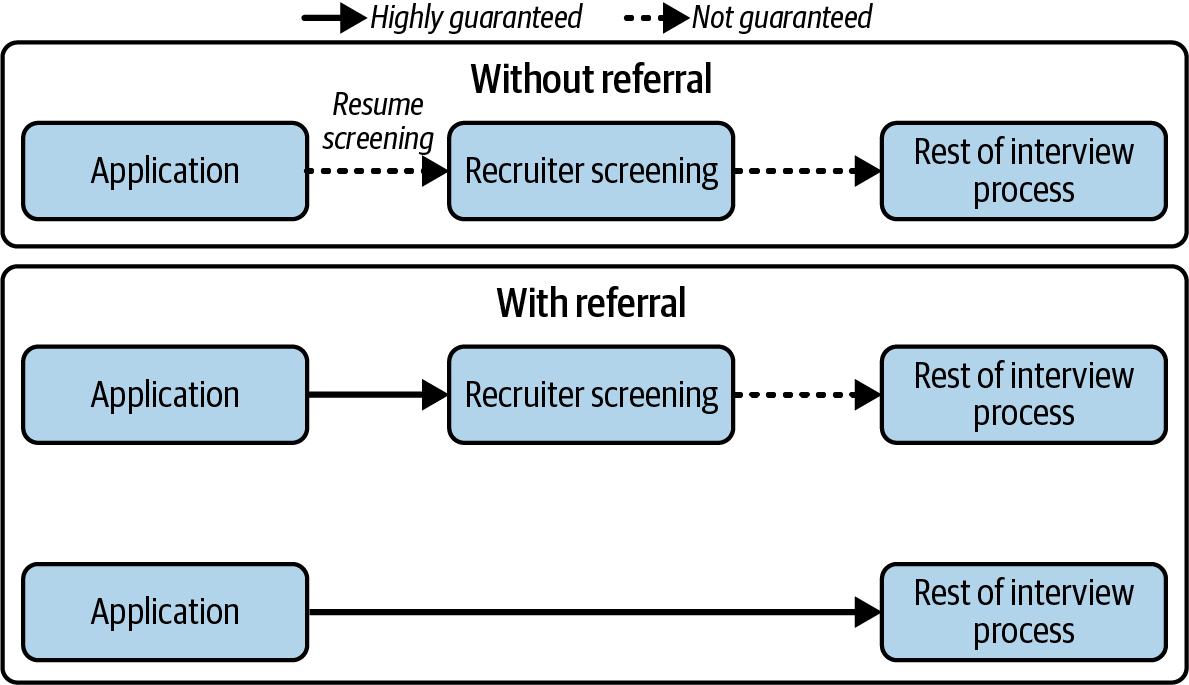
Figure 1-11. The interview process can be shortcut with a strong referral.
Preinterview Checklist
You’ve been invited to an interview! How do you perform your best? Maybe time is limited; what do you do to ensure that you can maximize your outcome?
Review your notes and questions that you fumbled
My personal tactic is to first narrow down the types of questions that might be asked. For example, in the first round of an Amazon interview, the recruiter has outlined the format and it will focus on statistical theory questions. I will read online resources, skim over my notes, and see what topics I’m the weakest on. I will focus less on the questions that I know I can answer confidently and more on those that seem more likely to be asked but that I don’t know well. As to how I “guess” what will likely be asked, that is based mostly on conversations with the recruiter and my follow-up questions to the recruiter or hiring manager. I’m not super accurate at guessing, and this is similar to trying to guess what will come up in a university exam—it could work well, or it could backfire!
Either way, there’s the trade-off between knowing a subset of questions well or knowing all questions roughly but not as well (depth vs. breadth). When reviewing my preparation notes, I personally go for breadth, but your results may vary depending on how well you know the material already.
Scheduling the interview
Depending on your location and your interviewers’ location, there may be time zone differences. I try to find the time when I have the most energy possible. Sometimes the available interview time slots aren’t ideal, so I choose the lesser of the evils (for example, interviewing from GMT+8 and talking to someone in GMT-4 while traveling abroad).
Tip
To make it easy to figure out time zones for candidates invited to an interview, it’s common for HR-scheduling software to have a calendar feature where you can input your preferred times and it will account for your local time zones. However, sometimes the time will be set via back-and-forth emails, and tools such as Calendly or Cal.com can help.
As both an interviewer and interviewee, I am wary of scheduling right at the beginning of a workday. This is so that I have more time to prepare after I wake up. But of course, if no other time slots are available, then I will select the early time.
Preinterview tech prep
As an interviewer, I’ve seen countless candidates’ interviews start late because of connection issues or using a new web-conferencing software—for example, not being able to set up Zoom on time because they hadn’t used it before. As a candidate, I’ve been tripped up and wasted time when needing to use Microsoft Teams because on my personal computers I only had Zoom and Google Meet. In the end, I used the browser version, but there was an issue with my login since my Microsoft student account had expired. We finally got it sorted out, a few minutes later. This could have been avoided if I had tried to sign in a bit earlier or on the day before the interview.
Here are some tips to help your interview go more smoothly:
- Try your best to be in a quiet environment.
- Some software, such as Zoom, has pretty good built-in noise canceling, as do some wireless headphones.
- Check your audio and video beforehand.
- Video-wise, make sure the lighting is good and your camera lens is clean. Sound-wise, make sure your mic sounds clear. On Windows and Mac, there are built-in camera and voice recording apps that I use. You could also start a new Zoom, Google Meet, or Teams session and run a test.
- Keep a mental list of backup options.
- Did the internet at your home suddenly go down before the interview? Is there a nearby cafe with (preferably secure) internet that you could go to? Can you use your phone data? Are there dial-in options via phone on the calendar invite? Knowing these things beforehand can help you a lot. I’ve had to dial in once to an interview, and thankfully, I knew that I had the option to.
Recruiter Screening
Congrats, your resume has made it past the resume screening! Now let’s go through an example to illustrate what might happen next.
Let’s imagine that there were 200 applicants for the role. The recruiter has gone through them and removed 170 that either lacked relevant experience or for some reason didn’t seem to fit the role. Recall that this is based on the impression your resume gave the recruiter; it’s possible that with the same job title and same recruiter team, an improved resume would have passed. If you had a good referral, your resume might have already moved forward. Now that there are 30 applicants, the recruiter will call each of them; this is usually a shorter interview, 15 to 30 minutes long. We refer to this as the “recruiter screening” or “recruiter call.”
Generally, the recruiter wants to see what you’re like as a person and if you’re easy to work with. If someone blatantly claims to have experience that they don’t, the call could reveal fabricated work or school experiences. There are other logistical issues to screen for, such as location, salary expectations, and legal status.
Tip
The recruiter screening is more of a “smell test” instead of an in-depth test of your technical skills and experience.
My tip for success is to optimize for one thing: that the recruiter understands that you are a good candidate, that your experience is relevant (or you can learn fast), and that you can fit well into the team and role they are hiring for. This is different from convincing a hiring manager of the same things, or an interview panel of senior MLEs. Instead, you will succeed here if you make the additional effort to connect your resume to the job description on this call.
Here’s an example of some bullet points in a job description:
-
“The candidate has experience with recommender systems.”
-
“Experience with data processing such as Spark, Snowflake, or Hadoop.”
-
“The candidate has experience with Python.”
A bad example of explaining your experience on the recruiter call for this job is: “For that past project, I used the ALS algorithm, which was implemented with PySpark.”
A better example of explaining your experience on the recruiter call for this job is: “For that past project, I used the alternating least squares (ALS) algorithm, which is a recommender systems algorithm based off of matrix factorization, and I used PySpark, which is Spark that’s wrapped with a Python API.” Note that the italicized phrases also appear in the job description.
The better example allows a recruiter to match up more of your skills to the job description, whereas the bad example doesn’t match up to the posted skills in an obvious manner. When you’re writing your resume, you have limited space; the real-time conversation of an interview is a chance for you to fill in gaps that the recruiter may not have noticed.
It’s also important to expand on acronyms. This is true for interviews conducted with technical people too. I’m relatively specialized in recommender systems and reinforcement learning, but I don’t work with computer vision tasks in my day-to-day work. I appreciated it when a candidate I interviewed was talking about computer vision projects and generally explained the more niche techniques. You can (and should) do this in a way that’s not condescending to your interviewer, whether they are a recruiter or part of your future team.
The recruiter call is a good time for you as the candidate to assess the job as well. You can ask questions that you care about, to see if you should continue to interview. For example, I might ask about the team size and if this job focuses more on ML or data analyst responsibilities. You can also prepare some questions about the company and their products. For example, is the team’s current project focused on improving the click-through rate or long-term engagement? If you’re a user of the product, you might have a lot of ideas and questions to discuss. This is also a chance to show your enthusiasm and knowledge of the company.
Overview of Main Interview Loop
On to the next step. Good news: the recruiter cleared you! You explained your previous experience well, and the recruiter was able to understand your past work and how it connects to the job description they have on hand.
But it’s not over yet. You’re among 15 other candidates who succeeded at the first recruiter screening. The recruiter informs you of upcoming technical interviews which include ML theory, programming, and a case study interview. There are also behavioral interviews sprinkled throughout. If you pass those, you’ll make it to the on-site interview, which is often the final round. These days, there are also virtual on-sites/final rounds. If you pass the final round, you’ll be extended an offer.
Technical interviews
Let’s break down the various types of interviews that take place after the recruiter screening, the first being technical interviews. Technical interviews are typically conducted with technical individual contributors (ICs), such as an MLE or a data scientist.
There may be multiple rounds of technical interviews; there could be one that is a data-focused coding round or one in which the interviewer presents some fictitious example data and asks you to use SQL or Python pandas/NumPy (sometimes there are multiple questions, and you use various programming tools throughout the interview). I’ll expand more on this type of interview structure and interview questions in Chapter 5.
Apart from ML and data-focused programming interviews, you might be asked brainteaser-type questions. For this type of interview, you might use an interview platform such as CoderPad or HackerRank, where the interviewer presents you with a question and you code in the online integrated development environment (IDE) that both you and your interviewer can see in real time. Sometimes you’ll get other formats, such as technical deep dives, systems design, take-home exercises in a private repo or Google Colab, and so on. I’ll elaborate on how to prepare for these types of interviews in Chapters 5 and 6.
These subsequent interview rounds could further reduce the number of candidates before the final round. In our example, fifteen candidates passed the recruiter screen, and eight passed the first round of technical interviews. After the second round of technical interviews, we’re left with three candidates who will proceed to the on-site interview.
Behavioral interviews
Interspersed during the interview process are questions meant to assess how you react in certain situations. The intent often is to use past experience to predict future performance and understand how you react to high-stress or difficult situations. In addition, these questions assess your soft skills, such as communication and teamwork skills. You’ll want to prepare a few past experiences and relay them in a storytelling fashion.
For example, during your first recruiter call, the recruiter might ask about a time when you dealt with a difficult timeline on a project. Once you’ve responded you won’t be out of the woods yet. During the on-site, an hour is often dedicated to behavioral questions. And in some technical interviews, you might be asked a couple of questions that are a mix between a purely technical question and a behavioral question. I’ll help you succeed with behavioral interviews in Chapter 7, which also has tips on company-specific preparation, such as Amazon’s Leadership Principles.
The on-site final round
For many companies there is an “on-site” final round or the virtual equivalent. These are usually back-to-back interviews. For example, starting in the morning, you might meet with a technical director for a case study interview and then a senior data scientist for a programming interview. After a lunch break, you might meet with two data scientists who ask about ML theory, and then the hiring manager asks more behavioral questions and probes about your past experiences. In addition to technical interviewers, you may speak with a stakeholder (e.g., a product manager on an adjacent team that the team you’re interviewing for works closely with). In several final-round interviews I’ve been through, there was a product manager interviewer or someone from another department that the ML team worked closely with, such as marketing or advertising.
Some companies will have an additional mini round after this, such as a quick chat with a skip level (your manager’s manager).
Summary
In this chapter, you’ve learned about various ML roles, the ML lifecycle, and the different responsibilities that map onto the ML lifecycle. You’ve also seen how you make your way from the beginning of the process to the final round of interviews. There’s a lot to prepare for and to learn about, but now you have an overview and hopefully some thoughts on how you can target your preparations.
Now that this chapter has set the foundation, I’ll walk through a detailed job application guide, including a resume guide, to help you greatly increase your chances of getting interviews.
1 This book focuses on industry applications of ML as opposed to jobs with a primary focus on researching the ML algorithms themselves, publishing in conferences, and so on, which mostly require a PhD.
2 Also referred to as “freshers” in some regions. In this book, I will use the term “new graduates” or “new grads.”
3 David H. Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski, “A Learning Algorithm for Boltzmann Machines,” Cognitive Science 9 (1985): 147–169, https://oreil.ly/5bY2p.
4 Jeffrey M. Stanton, “Galton, Pearson, and the Peas: A Brief History of Linear Regression for Statistics Instructors,” Journal of Statistics Education 9, no. 3 (2001), doi:10.1080/10691898.2001.11910537.
5 The official WordNet website provides more information.
6 Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA (2009): 248–255, doi:10.1109/cvpr.2009.5206848.
7 Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems 25 (NIPS 2012), https://oreil.ly/iFMkq.
8 Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Communications of the ACM 60, no. 6 (2017): 84–90, doi:10.1145/3065386.
9 Thomas H. Davenport and DJ Patil, “Data Scientist: The Sexiest Job of the 21st Century,” Harvard Business Review, October 19, 2022, https://oreil.ly/fvroA.
10 ML and data science use data; data engineers are unlikely to use ML techniques themselves, but their work and collaboration are integral to ML workflows.
11 Serena McDonnell (lead data scientist and ex-Shopify) pointed out that in the field of hedge funds, “research scientist” and “research engineer” are used to refer to ML roles.
12 I’ve also seen research scientist job postings at Google, but these roles are specifically for researching ML, are responsible for publishing at large conferences, and require a PhD degree.
13 Ship is a common term in software and, by extension, ML, that refers to releasing something, such as a software product or code update.
14 In the more specialized roles where you deal with on-device or edge ML, some basic knowledge of hardware can also make a difference.
15 Business speak for something that blocks another thing from happening, usually a project or timeline.
16 Wayne Duggan, “What Happened to FAANG Stocks? They Became MAMAA Stocks,” Forbes, September 29, 2023, https://oreil.ly/JzMys.
17 Human resources or equivalent department in the company.
18 I provide a much longer list and overview in Chapter 2.
19 Fictional name, but I wanted to try using something other than ABC Corp. or Acme Corp.
Get Machine Learning Interviews now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

