Chapter 1. What Is eBPF, and Why Is It Important?
eBPF is a revolutionary kernel technology that allows developers to write custom code that can be loaded into the kernel dynamically, changing the way the kernel behaves. (Don’t worry if you’re not confident about what the kernel is—we’ll come to that shortly in this chapter.)
This enables a new generation of highly performant networking, observability, and security tools. And as you’ll see, if you want to instrument an app with these eBPF-based tools, you don’t need to modify or reconfigure the app in any way, thanks to eBPF’s vantage point within the kernel.
Just a few of the things you can do with eBPF include:
-
Performance tracing of pretty much any aspect of a system
-
High-performance networking, with built-in visibility
-
Detecting and (optionally) preventing malicious activity
Let’s take a brief journey through eBPF’s history, starting with the Berkeley Packet Filter.
eBPF’s Roots: The Berkeley Packet Filter
What we call “eBPF” today has its roots in the BSD Packet Filter, first described in 1993 in a paper1 written by Lawrence Berkeley National Laboratory’s Steven McCanne and Van Jacobson. This paper discusses a pseudomachine that can run filters, which are programs written to determine whether to accept or reject a network packet. These programs were written in the BPF instruction set, a general-purpose set of 32-bit instructions that closely resembles assembly language. Here’s an example taken directly from that paper:
ldh [12] jeq #ETHERTYPE IP, L1, L2 L1: ret #TRUE L2: ret #0
This tiny piece of code filters out packets that aren’t Internet Protocol (IP) packets. The input to this filter
is an Ethernet packet, and the first instruction (ldh) loads a 2-byte value starting at byte 12 in
this packet. In the next instruction (jeq) that value is compared with the value that represents an
IP packet. If it matches, execution jumps to the instruction labeled L1, and the packet is accepted
by returning a nonzero value (identified here as #TRUE). If it doesn’t match, the packet is not an IP
packet and is rejected by returning 0.
You can imagine (or, indeed, refer to the paper to find examples of) more complex filter programs that make decisions based on other aspects of the packet. Importantly, the author of the filter can write their own custom programs to be executed within the kernel, and this is the heart of what eBPF enables.
BPF came to stand for “Berkeley Packet Filter,” and it was first introduced to Linux in 1997, in kernel version 2.1.75,2 where it was used in the tcpdump utility as an efficient way to capture the packets to be traced out.
Fast-forward to 2012, when seccomp-bpf was introduced in version 3.5 of the kernel. This enabled the use of BPF programs to make decisions about whether to allow or deny user space applications from making system calls. We’ll explore this in more detail in Chapter 10. This was the first step in evolving BPF from the narrow scope of packet filtering to the general-purpose platform it is today. From this point on, the words packet filter in the name started to make less sense!
From BPF to eBPF
BPF evolved to what we call “extended BPF” or “eBPF” starting in kernel version 3.18 in 2014. This involved several significant changes:
-
The BPF instruction set was completely overhauled to be more efficient on 64-bit machines, and the interpreter was entirely rewritten.
-
eBPF maps were introduced, which are data structures that can be accessed by BPF programs and by user space applications, allowing information to be shared between them. You’ll learn about maps in Chapter 2.
-
The
bpf()system call was added so that user space programs can interact with eBPF programs in the kernel. You’ll read about this system call in Chapter 4. -
Several BPF helper functions were added. You’ll see a few examples in Chapter 2 and some more details in Chapter 6.
-
The eBPF verifier was added to ensure that eBPF programs are safe to run. This is discussed in Chapter 6.
This put the basis for eBPF in place, but development did not slow down! Since then, eBPF has evolved significantly.
The Evolution of eBPF to Production Systems
A feature called kprobes (kernel probes) had existed in the Linux kernel since 2005, allowing for traps to be set on almost any instruction in the kernel code. Developers could write kernel modules that attached functions to kprobes for debugging or performance measurement purposes.3
The ability to attach eBPF programs to kprobes was added in 2015, and this was the starting point for a revolution in the way tracing is done across Linux systems. At the same time, hooks started to be added within the kernel’s networking stack, allowing eBPF programs to take care of more aspects of networking functionality. We’ll see more of this in Chapter 8.
By 2016, eBPF-based tools were being used in production systems. Brendan Gregg’s work on tracing at Netflix became widely known in infrastructure and operations circles, as did his statement that eBPF “brings superpowers to Linux.” In the same year, the Cilium project was announced, being the first networking project to use eBPF to replace the entire datapath in container environments.
The following year Facebook (now Meta) made Katran an open source project. Katran, a layer 4 load balancer, met Facebook’s need for a highly scalable and fast solution. Every single packet to Facebook.com since 2017 has passed through eBPF/XDP.4 For me personally, this was the year that ignited my excitement about the possibilities enabled by this technology, after seeing Thomas Graf’s talk about eBPF and the Cilium project at DockerCon in Austin, Texas.
In 2018, eBPF became a separate subsystem within the Linux kernel, with Daniel Borkmann from Isovalent and Alexei Starovoitov from Meta as its maintainers (they were later joined by Andrii Nakryiko, also from Meta). The same year saw the introduction of BPF Type Format (BTF), which makes eBPF programs much more portable. We’ll explore this in Chapter 5.
The year 2020 saw the introduction of LSM BPF, allowing eBPF programs to be attached to the Linux Security Module (LSM) kernel interface. This indicated that a third major use case for eBPF had been identified: it became clear that eBPF is a great platform for security tooling, in addition to networking and observability.
Over the years, eBPF’s capabilities have grown substantially, thanks to the work of more than 300 kernel
developers and many contributors to the associated user space tools (such as bpftool, which we’ll
meet in Chapter 3), compilers, and
programming language libraries. Programs were once limited to 4,096
instructions, but that limit has grown to 1 million verified instructions5 and has
effectively been rendered irrelevant by support for tail calls and function calls (which you’ll see in Chapters 2 and 3).
Note
For deeper insight into the history of eBPF, who better to refer to than the maintainers who have been working on it from the beginning?
Alexei Starovoitov gave a fascinating presentation about the history of BPF from its roots in software-defined networking (SDN). In this talk, he discusses the strategies used to get the early eBPF patches accepted into the kernel and reveals that the official birthday of eBPF is September 26, 2014, which marked the acceptance of the first set of patches covering the verifier, BPF system call, and maps.
Daniel Borkmann has also discussed the history of BPF and its evolution to support networking and tracing functionality. I highly recommend his talk “eBPF and Kubernetes: Little Helper Minions for Scaling Microservices”, which is full of interesting nuggets of information.
Naming Is Hard
eBPF’s applications range so far beyond packet filtering that the acronym is
essentially meaningless now, and it has become a standalone term. And since the Linux kernels in widespread use
these days all have support for the “extended” parts, the terms eBPF and BPF are largely used
interchangeably. In the kernel source code and in eBPF programming, the common terminology is BPF. For
example, as we’ll see in Chapter 4, the system call
for interacting with eBPF is bpf(), helper functions start with bpf_, and the different
types of (e)BPF programs are identified with names that start with BPF_PROG_TYPE. Outside the kernel
community, the name “eBPF” seems to have stuck, for example, in the community site ebpf.io and in the name of the eBPF Foundation.
The Linux Kernel
To understand eBPF you’ll need a solid grasp of the difference between the kernel and user space in Linux. I covered this in my report “What Is eBPF?”6 and I’ve adapted some of that content for the next few paragraphs.
The Linux kernel is the software layer between your applications and the hardware they’re running on. Applications run in an unprivileged layer called user space, which can’t access hardware directly. Instead, an application makes requests using the system call (syscall) interface to request the kernel to act on its behalf. That hardware access can involve reading and writing to files, sending or receiving network traffic, or even just accessing memory. The kernel is also responsible for coordinating concurrent processes, enabling many applications to run at once. This is illustrated in Figure 1-1.
As application developers, we typically don’t use the system call interface directly, because programming
languages give us high-level abstractions and standard libraries that are easier interfaces to program. As a
result, a lot of people are blissfully unaware of how much the kernel is doing while our programs run. If you want
to get a sense of how often the kernel is invoked, you can use the strace utility to show all the
system calls an application makes.
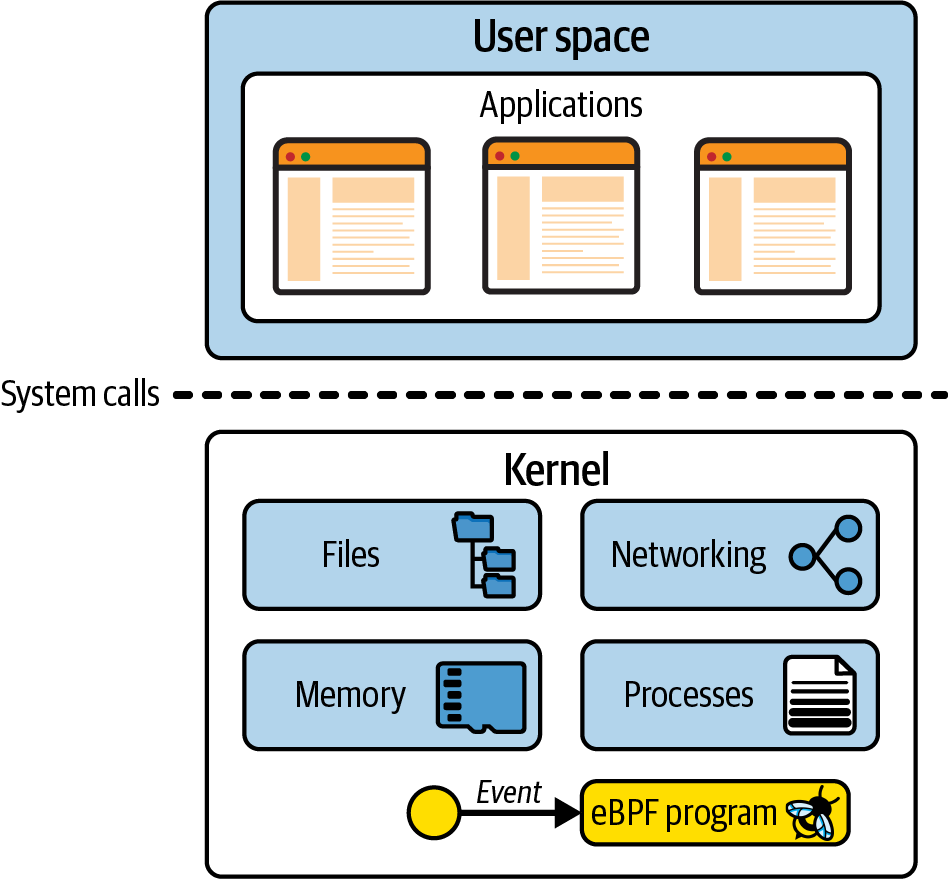
Figure 1-1. Applications in user space use the syscall interface to make requests to the kernel
Here’s an example, where using cat to echo the word hello to the screen involves more than
100 system calls:
$ strace -c echo "hello" hello % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 24.62 0.001693 56 30 12 openat 17.49 0.001203 60 20 mmap 15.92 0.001095 57 19 newfstatat 15.66 0.001077 53 20 close 10.35 0.000712 712 1 execve 3.04 0.000209 52 4 mprotect 2.52 0.000173 57 3 read 2.33 0.000160 53 3 brk 2.09 0.000144 48 3 munmap 1.11 0.000076 76 1 write 0.96 0.000066 66 1 1 faccessat 0.76 0.000052 52 1 getrandom 0.68 0.000047 47 1 rseq 0.65 0.000045 45 1 set_robust_list 0.63 0.000043 43 1 prlimit64 0.61 0.000042 42 1 set_tid_address 0.58 0.000040 40 1 futex ------ ----------- ----------- --------- --------- ---------------- 100.00 0.006877 61 111 13 total
Because applications rely so heavily on the kernel, it means we can learn a lot about how an application behaves if we can observe its interactions with the kernel. With eBPF we can add instrumentation into the kernel to get these insights.
For example, if you are able to intercept the system call for opening files, you can see exactly which files any application accesses. But how could you do that interception? Let’s consider what would be involved if we wanted to modify the kernel, adding new code to create some kind of output whenever that system call is invoked.
Adding New Functionality to the Kernel
The Linux kernel is complex, with around 30 million lines of code at the time of this writing.7 Making a change to any codebase requires some familiarity with the existing code, so unless you’re a kernel developer already, this is likely to present a challenge.
Additionally, if you want to contribute your change upstream, you’ll be facing a challenge that isn’t purely technical. Linux is a general-purpose operating system, used in all manner of environments and circumstances. This means that if you want your change to become part of an official Linux release, it’s not simply a matter of writing code that works. The code has to be accepted by the community (and more specifically by Linus Torvalds, creator and main developer of Linux) as a change that will be for the greater good of all. This isn’t a given—only one-third of submitted kernel patches are accepted.8
Let’s suppose you’ve figured out a good technical approach for intercepting the system call for opening files. After some months of discussion and some hard development work on your part, let’s imagine the change is accepted into the kernel. Great! But how long will it be until it arrives on everyone’s machines?
There’s a new release of the Linux kernel every two or three months, but even when a change has made it into one of these releases, it’s still some time away from being available in most people’s production environments. This is because most of us don’t just use the Linux kernel directly—we use Linux distributions like Debian, Red Hat, Alpine, and Ubuntu that package up a version of the Linux kernel with various other components. You may well find that your favorite distribution is using a kernel release that’s several years old.
For example, a lot of enterprise users employ Red Hat Enterprise Linux (RHEL). At the time of this writing, the current release is RHEL 8.5, dated November 2021, and it uses version 4.18 of the Linux kernel. This kernel was released in August 2018.
As illustrated in the cartoon in Figure 1-2, it takes literally years to get new functionality from the idea stage into a production environment Linux kernel.9

Figure 1-2. Adding features to the kernel (cartoon by Vadim Shchekoldin, Isovalent)
Kernel Modules
If you don’t want to wait years for your change to make it into the kernel, there is another option. The Linux kernel was designed to accept kernel modules, which can be loaded and unloaded on demand. If you want to change or extend kernel behavior, writing a module is certainly one way to do it. A kernel module can be distributed for others to use independent of the official Linux kernel release, so it doesn’t have to be accepted into the main upstream codebase.
The biggest challenge here is that this is still full-on kernel programming. Users have historically been very cautious about using kernel modules, for one simple reason: if kernel code crashes, it takes down the machine and everything running on it. How can a user be confident that a kernel module is safe to run?
Being “safe to run” doesn’t just mean not crashing—the user wants to know that a kernel module is safe from a security perspective. Does it include vulnerabilities that an attacker could exploit? Do we trust the authors of the module not to put malicious code in it? Because the kernel is privileged code, it has access to everything on the machine, including all the data, so malicious code in the kernel would be a serious cause for concern. This applies to kernel modules too.
The safety of the kernel is one important reason why Linux distributions take so long to incorporate new releases. If other people have been running a kernel version in a variety of circumstances for months or years, this should have flushed out issues. The distribution maintainers can have some confidence that the kernel they ship to their users/customers is hardened—that is, it is safe to run.
eBPF offers a very different approach to safety: the eBPF verifier, which ensures that an eBPF program is loaded only if it’s safe to run—it won’t crash the machine or lock it up in a hard loop, and it won’t allow data to be compromised. We’ll discuss the verification process in more detail in Chapter 6.
Dynamic Loading of eBPF Programs
eBPF programs can be loaded into and removed from the kernel dynamically. Once they are attached to an event, they’ll be triggered by that event regardless of what caused that event to occur. For example, if you attach a program to the syscall for opening files, it will be triggered whenever any process tries to open a file. It doesn’t matter whether that process was already running when the program was loaded. This is a huge advantage compared to upgrading the kernel and then having to reboot the machine to use its new functionality.
This leads to one of the great strengths of observability or security tooling that uses eBPF—it instantly gets visibility over everything that’s happening on the machine. In environments running containers, that includes visibility over all processes running inside those containers as well as on the host machine. I’ll dig into the consequences of this for cloud native deployments later in this chapter.
Additionally, as illustrated in Figure 1-3, people can create new kernel functionality very quickly through eBPF without requiring every other Linux user to accept the same changes.

Figure 1-3. Adding kernel features with eBPF (cartoon by Vadim Shchekoldin, Isovalent)
High Performance of eBPF Programs
eBPF programs are a very efficient way to add instrumentation. Once loaded and JIT-compiled (which you’ll see in Chapter 3), the program runs as native machine instructions on the CPU. Additionally, there’s no need to incur the cost of transitioning between kernel and user space (which is an expensive operation) to handle each event.
The 2018 paper10 that describes the eXpress Data Path (XDP) includes some illustrations of the kinds of performance improvements eBPF enables in networking. For example, implementing routing in XDP “improves performance with a factor of 2.5” compared to the regular Linux kernel implementation, and “XDP offers a performance gain of 4.3x over IPVS” for load balancing.
For performance tracing and security observability, another advantage of eBPF is that relevant events can be filtered within the kernel before incurring the costs of sending them to user space. Filtering only certain network packets was, after all, the point of the original BPF implementation. Today eBPF programs can collect information about all manner of events across a system, and they can use complex, customized programmatic filters to send only the relevant subset of information to user space.
eBPF in Cloud Native Environments
These days lots of organizations choose not to run applications by executing programs directly on servers. Instead, many use cloud native approaches: containers, orchestrators such as Kubernetes or ECS, or serverless approaches like Lambda, cloud functions, Fargate, and so on. These approaches all use automation to choose the server where each workload will run; in serverless, we’re not even aware what server is running each workload.
Nevertheless, there are servers involved, and each of those servers (whether it’s a virtual machine or bare-metal machine) runs a kernel. Where applications run in a container, if they’re running on the same (virtual) machine, they share the same kernel. In a Kubernetes environment, this means all the containers in all the pods on a given node are using the same kernel. When we instrument that kernel with eBPF programs, all the containerized workloads on that node are visible to those eBPF programs, as illustrated in Figure 1-4.
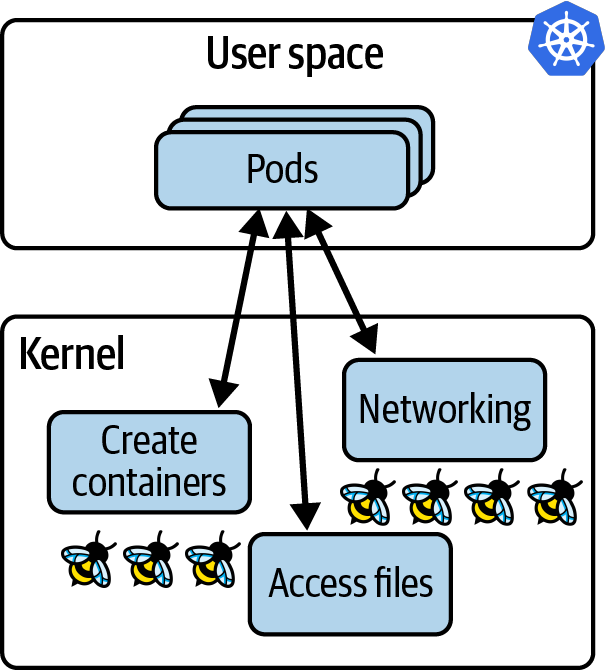
Figure 1-4. eBPF programs in the kernel have visibility of all applications running on a Kubernetes node
Visibility of all the processes on the node, combined with the ability to load eBPF programs dynamically, gives us the real superpowers of eBPF-based tooling in cloud native computing:
-
We don’t need to change our applications, or even the way they are configured, to instrument them with eBPF tooling.
-
As soon as it’s loaded into the kernel and attached to an event, an eBPF program can start observing preexisting application processes.
Contrast this with the sidecar model, which has been used to add functionality like logging, tracing, security, and service mesh functionality into Kubernetes apps. In the sidecar approach, the instrumentation runs as a container that is “injected” into each application pod. This process involves modifying the YAML that defines the application pods, adding in the definition of the sidecar container. This approach is certainly more convenient than adding the instrumentation into the source code of the application (which is what we had to do before the sidecar approach; for example, including a logging library in our application and making calls into that library at appropriate points in the code). Nevertheless, the sidecar approach has a few downsides:
-
The application pod has to be restarted for the sidecar to be added.
-
Something has to modify the application YAML. This is generally an automated process, but if something goes wrong, the sidecar won’t be added, which means the pod doesn’t get instrumented. For example, a deployment might be annotated to indicate that an admission controller should add the sidecar YAML to the pod spec for that deployment. But if the deployment isn’t labeled correctly, the sidecar won’t get added, and it’s therefore not visible to the instrumentation.
-
When there are multiple containers within a pod, they might reach readiness at different times, the ordering of which may not be predictable. Pod start-up time can be significantly slowed by the injection of sidecars, or worse, it can cause race conditions or other instabilities. For example, the Open Service Mesh documentation describes how application containers have to be resilient to all traffic being dropped until the Envoy proxy container is ready.
-
Where networking functionality such as service mesh is implemented as a sidecar, it necessarily means that all traffic to and from the application container has to travel through the network stack in the kernel to reach a network proxy container, adding latency to that traffic; this is illustrated in Figure 1-5. We’ll talk about improving network efficiency with eBPF in Chapter 9.
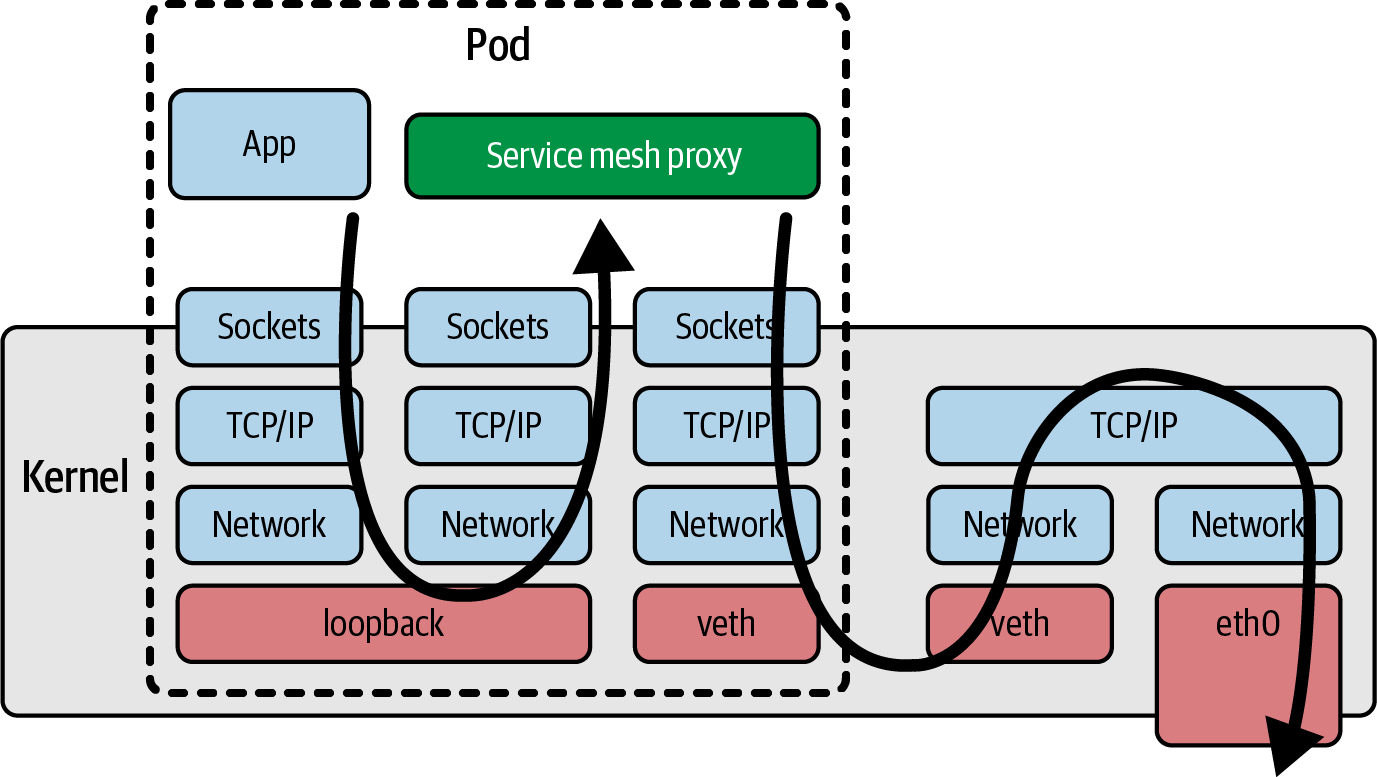
Figure 1-5. Path of a network packet using a service mesh proxy sidecar container
All these issues are inherent problems with the sidecar model. Fortunately, now that eBPF is available as a platform, we have a new model that can avoid these issues. Additionally, because eBPF-based tools can see everything that’s happening on a (virtual) machine, they are harder for bad actors to sidestep. For example, if an attacker manages to deploy a cryptocurrency mining app on one of your hosts, they probably won’t do you the courtesy of instrumenting it with the sidecars you’re using on your application workloads. If you’re relying on a sidecar-based security tool to prevent apps from making unexpected network connections, that tool isn’t going to spot the mining app connecting to its mining pool if the sidecar isn’t injected. In contrast, network security implemented in eBPF can police all traffic on the host machine, so this cryptocurrency mining operation could easily be stopped. The ability to drop network packets for security reasons is something we’ll come back to in Chapter 8.
Summary
I hope this chapter has given you some insight into why eBPF as a platform is so powerful. It allows us to change the behavior of the kernel, providing us the flexibility to build bespoke tools or customized policies. eBPF-based tools can observe any event across the kernel, and hence across all applications running on a (virtual) machine, whether they are containerized or not. eBPF programs can also be deployed dynamically, allowing behavior to be changed on the fly.
So far we’ve discussed eBPF at a relatively conceptual level. In the next chapter we’ll make it more concrete and explore the constituent parts of an eBPF-based application.
1 “The BSD Packet Filter: A New Architecture for User-level Packet Capture” by Steven McCanne and Van Jacobson.
2 These and other details come from Alexei Starovoitov’s 2015 NetDev presentation, “BPF – in-kernel virtual machine”.
3 There is a good description of how kprobes work in the kernel documentation.
4 This wonderful fact comes from Daniel Borkmann’s KubeCon 2020 talk titled “eBPF and Kubernetes: Little Helper Minions for Scaling Microservices”.
5 For more details on the instruction limit and “complexity limit,” see https://oreil.ly/0iVer.
6 Extract from “What Is eBPF?” by Liz Rice. Copyright © 2022 O’Reilly Media. Used with permission.
7 “Linux 5.12 Coming In At Around 28.8 Million Lines”. Phoronix, March 2021.
8 Jiang Y, Adams B, German DM. 2013. “Will My Patch Make It? And How Fast?” (2013). According to this research paper, 33% of patches are accepted, and most take three to six months.
9 Thankfully, security patches to existing functionality are made available more quickly.
10 Høiland-Jørgensen T, Brouer JD, Borkmann D, et al. “The eXpress data path: fast programmable packet processing in the operating system kernel”. Proceedings of the 14th International Conference on emerging Networking EXperiments and Technologies (CoNEXT ’18). Association for Computing Machinery; 2018:54–66.
Get Learning eBPF now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

