Chapter 4. Security
The internet is a hostile environment. Security is not an option but a necessity. When you design your application, security has to be an integral part of the design, not something you add on at a later phase. When it comes to security, the goal of Dapr is to make applications secure by default. That means you should get common security best practices out of the box by default, and you can then fine-tune the system to satisfy your security requirements. Dapr is still a young project and our journey toward this goal is far from finished, but this chapter introduces how we design Dapr components so that we can plug in security features and bring best practices to your applications in the most natural way.
Securing a Distributed Application
To secure a system you need to consider several challenges, including access control, data protection, secured communication, intrusion and abnormality detection, and user privacy. Dapr’s long-term goal is to help you to address these challenges as much as possible so that your applications will be secure by default.
Because Dapr is still in its infancy, we still have a long way to go. This chapter begins by discussing some of our thoughts on security, to give you an idea of the general directions Dapr security is taking. Then the chapter will cover what we’ve implemented in Dapr. Chances are that by the time you read this text, Dapr will have put more security features at your disposal. And of course, if you have any feedback or suggestions, please submit issues to the Dapr repository.
Let’s start with the most obvious area of concern: access control.
Access Control
Securing a central server is relatively easy, as you have full control of the hosting environment. For example, you can set up firewall rules and load balancer policies to limit accesses to specific client IP segments and ports. You also can integrate with central identity providers such as Active Directory to enable centralized authentication and authorization.
Tip
These two terms are often confused. Simply put, authentication answers the question “Who are you?” and authorization answers the question “What are you allowed to do?”
When you host your application in the cloud, you should leverage the security features the cloud platform provides. Modern cloud platforms offer security features that are similar to what you have available on premises, so you can manage access control using familiar technologies and concepts such as network security groups, RBAC, certificate-based authentication, and firewalls.
Things become more complicated when you’re trying to manage the security of a distributed system, because you often need to deal with scattered compute resources, untrusted connections, and heterogeneous technology stacks. You’ll have to rethink your strategies when dealing with common security challenges such as establishing identity, setting access control policies, and communicating over the network.
Identity
An application needs to deal with two types of identity: user identity and service identity. A user identity identifies a specific user, while a service identity represents a service or a process. You can define access control policies (discussed next) for both types of identity. For example, you can grant a user identity read access to a relational database table, and you can constrain a service identity from making any outbound connections.
Services like Microsoft Azure Active Directory (AAD) allow you to establish and manage identities for both users and services. In such cases, AAD is referred as a trusted identity provider (IP), and your application is a relying party (RP) of the IP. The IP issues security tokens to trusted RPs. RPs extract claims from the tokens and make authorization decisions based on the claims. For instance, when you go to rent a car, the car rental company (the RP) requires a security token, which is your driver’s license in this case, issued by a trusted IP—the Department of Motor Vehicles (DMV). A claim is a statement made about a particular property of that token. In the case of a driver’s license, the name on the license is a claim made by the DMV about the name property of the holder. Because the RP trusts the IP and the issued security token, the RP takes every claim made by the token—name, address, age, eye color, etc.—to be true. This design of delegating authentication to a trusted IP is called a claim-based architecture.
From Dapr’s perspective, establishing the user’s identity is an application concern. Dapr can build up utilities, such as the OAuth middleware you saw in Chapter 1, to facilitate authentication and authorization processes under popular protocols such as OAuth 2.0, WS-Federation, and decentralized identifiers (DIDs). But Dapr will not be opinionated about how your applications choose to identify users and impose access control policies.
Dapr has the potential to provide great assistance in establishing service identity. As you saw in theIntroduction, each Dapr instance is identified by a unique string name. If we can harden the name, we can use the Dapr ID as the service identity of the application that the Dapr sidecar represents. For example, one possibility is for Dapr to integrate with AAD Pod Identity, which allows Kubernetes applications to access cloud resources and services securely with AAD.
Access control policies
Because Dapr sidecars sit on service invocation paths, Dapr can provide more assistance with fine-grained access control. For example, Dapr can apply an access policy to a /foo route to allow access only from explicitly allowed Dapr IDs through specific HTTP verbs (such as GET). Before this feature is implemented by the Dapr runtime itself, you can author a custom middleware to provide such filtering. The following pseudocode shows how a filter can be defined using Dapr middleware:
func (m *Middleware) GetHandler(metadata middleware.Metadata)
(func(h fasthttp.RequestHandler) fasthttp.RequestHandler, error) {
...
return func(h fasthttp.RequestHandler) fasthttp.RequestHandler {
return func(ctx *fasthttp.RequestCtx) {
if (ctx.IsGet() && ctx.Path == "/foo") {
h(ctx);
} else {
// Deny access
}
}
}, nil
}
What’s even more interesting is that Dapr can reinforce similar access control policies when messaging is used. For example, a Dapr sidecar can reject requests to publish to certain topics or forbid an application to read from certain topics.
Such policies can be captured by middleware configurations or other metadata formats, and reinforcement of the policies is completely separated from the application code. This is exactly the kind of separation of concerns Dapr aims to provide to distributed application developers. Combined with Dapr’s tracing feature, such an access control mechanism also provides full visibility into how access is granted or denied.
Network security
Access controls can also be implemented at the network layer. Many microservice systems use service meshes to manage the dynamic network environment. Dapr is designed to work well with existing service mesh solutions such as Consul and Istio. Figure 4-1 illustrates how Dapr sidecars can be laid on top of service mesh envoys to provide additional access control and filtering on top of network policies that are reinforced by a service mesh.
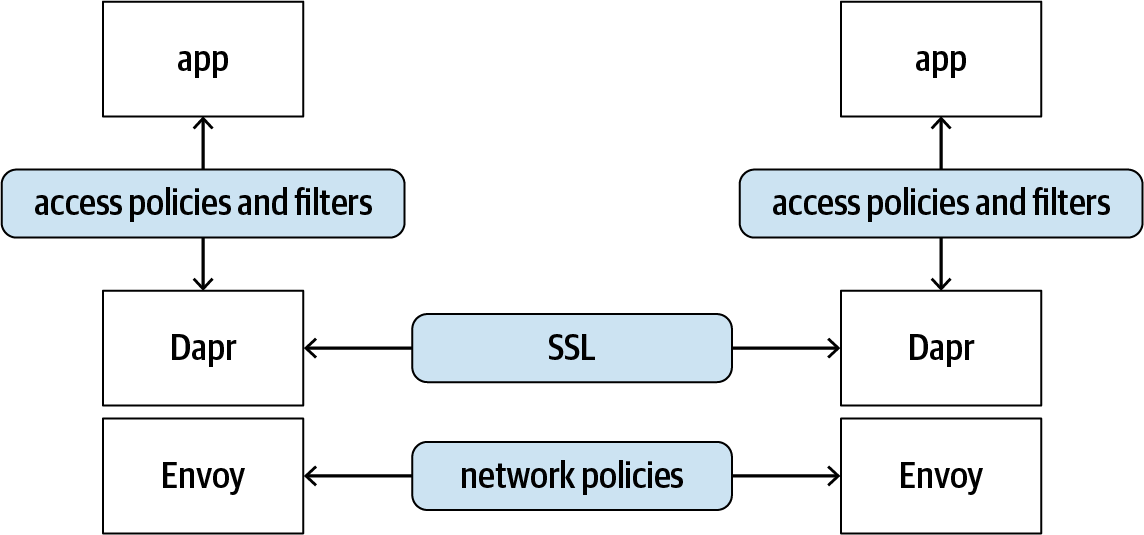
Figure 4-1. Dapr sidecar working with service mesh envoy
For example, the following Consul service rules, written in HashiCorp Configuration Language (HCL), allow read access to any services without prefixes and write access to the “app” services. The rules also deny all access to the “admin” service. These rules are enforced by Consul, and Dapr (and the app) remains oblivious in this case:
service_prefix""{ policy ="read"} service"app"{ policy ="write"} service"admin"{ policy ="deny"}
One thing to be aware of is that Dapr provides mutual TLS, a feature that is common in service meshes. Thus, when you configure Dapr to work with a service mesh, you’ll probably want to disable one of the TLS layers. Please consult the Dapr documentation for instructions and recommendations.
Even when appropriate service access control policies are in place, we still need to go a level deeper and protect the data on which these services operate. We’ll look at data protection next.
Data Protection
When it comes to protecting data, there are three areas we need to consider: data at rest, data in transit, and data in use.
Protecting data at rest
A common way to protect data at rest is to use encryption. At the time of writing, Dapr doesn’t provide data encryption out of the box, but automatic encryption/decryption features might be added to its state store in the future. Dapr also has a built-in feature to manage secrets, which we’ll introduce later in this chapter. You can use this feature to manage encryption keys for user data.
Dapr doesn’t concern itself with data backup and restore; this is a responsibility we believe should be taken up by the underlying data store or through specialized backup/restore solutions.
Protecting data in transit
Dapr sidecars use SSL tunnels when communicating with each other, so data is exchanged through secured channels. This avoids threats such as eavesdropping and man-in-the-middle attacks.
When Dapr sends and receives messages to and from a messaging backbone, it authenticates against the corresponding service using that service’s required authentication method. Most of these services require secured channels when data is exchanged.
If desired, applications can apply additional data integration protections such as encryption and digital signatures. Those are application concerns and are not covered by Dapr.
You might be wondering whether an encryption/decryption middleware could be developed to provide automatic encryption/decryption before the data is put on the wire. This would work, but with one caveat: Dapr tracing middleware is inserted at the top of the middleware stack. This means data may get logged in plain text (when logging the message body is enabled) before it hits the encryption layer. We think this is a reasonable design, because encrypted logs are harder to use in diagnosis. If you need to scramble some sensitive data before it’s logged, you can write a custom exporter to obfuscate certain data fields, such as personally identifiable information (PII), before writing the log to downstream systems.
Finally, the best way to protect data in transit is to not transfer data at all. The Dapr actor model, which we’ll introduce in Chapter 5, provides state encapsulation so that an actor’s state is maintained only by the actor itself. For instance, instead of sending a procurement order across services, you can encapsulate an order as an actor. All possible actions on the order are conducted through the methods exposed by the actor.
There are established methods and protocols for both protecting data at rest and protecting data in transit. Protecting data in use, which we’ll briefly cover next, is much trickier.
Protecting data in use
No matter how data is encrypted and protected at rest and during transit, it is usually processed in plain text. The probability of a hacker gaining access to a running process is low. However, such attacks often aim at high-value targets, such as financial information or access keys. Some of the worst information leaks have been traced back to rogue insiders, who sometimes had administrative access.
The situation is even more complicated on the edge. For example, one unique challenge with edge computing (compared to the cloud) is that an adversary can join a tampered-with device to the compute plane to capture sensitive user information.
Fortunately, there are a few possible ways to protect data from privileged users. For example, confidential computing uses a trusted execution environment (TEE, a.k.a. enclave). A software- or hardware-based TEE creates an isolated execution environment that can’t be observed from the outside by anyone, even the system administrator. A TEE can request attestation (a mechanism for software to prove its identity) to ensure only approved code is executed.
At the algorithm level, secure multiparty computation (MPC) allows multiple parties to jointly compute a function over their inputs while keeping the inputs private, and homomorphic encryption allows calculations (such as AI trainings and inferences) be performed on encrypted data.
At the time of writing, Dapr doesn’t have a plan to aid in protecting data during use. One possible way for Dapr to help in confidential computing is to integrate with the Open Enclave SDK to encapsulate enclave creation, code deployment, attestation, and communication between trusted components and untrusted components. Dapr can also be extended to support certain MPC scenarios. For example, a custom Dapr middleware may provide homomorphic encryption so that data can be processed while encrypted. Additionally, some machine learning models can be adapted to run inference on encrypted data, and the encrypted results can be decrypted only by the original data owner.
Secured Communication
We touched upon secured communication when we discussed protecting data in transit in the previous section. However, there’s another transmission channel we need to consider: the communication channel between a Dapr sidecar and the application process it serves. In a sidecar architecture, the sidecar and the application it attaches to are in the same security domain, in which they can communicate with each other in plain text. However, we’ve heard from our customers that they want in-depth protection with secured channels between the Dapr sidecar and the application. This makes sense because the Dapr sidecar also works as an independent process. At the time of writing, this feature has been put on the roadmap; please consult the online documentation for updates.
Intrusion and Abnormality Detection
Although Dapr has no intrusion or abnormality detection capabilities out of the box, integrating with such systems is not a far-fetched goal. For example, a custom Dapr middleware can send data packet duplicates to a machine learning–based abnormality detection system for both training and inference purposes, and this can be done transparently without interfering with the application itself.
Dapr does provide proactive rate limiting to avoid excessive numbers of service calls. This is done through a community-contributed middleware. The implementation uses Tollbooth, a generic middleware for rate-limiting HTTP requests based on the Token Bucket algorithm. The algorithm puts tokens into an imaginary bucket at a fixed rate. Each request consumes a certain number of tokens, proportional to the message size. When a request comes in, if there are enough tokens in the bucket to be “spent” on the request, the request goes through. Otherwise, the request is rejected. When a request is rejected, the response will contain headers such as X-Rate-Limit-Limit holding the maximum request limit and X-Rate-Limit-Duration holding the rate-limiter duration. These are signals to the client to back off with requests.
Rate limiting can be used to defend against some types of attacks. For example, a normal user will not be able to submit login credentials more than a couple of times per second. If you see many rapid consecutive login attempts, your service is likely under attack by a malicious script trying to guess the password; rate limiting can guard against such a brute-force effort. However, rate limiting can be a double-edged sword, because it doesn’t distinguish between legitimate and malicious traffic. When your site is experiencing a denial of service (DoS) or distributed denial of service (DDoS) attack, although you can use rate limiting to avoid your server getting overloaded, you’ll be turning away legitimate traffic as well because a simple rate-limiting system controls only the overall traffic flow.
Some advanced rate-limiting policies, such as constraining only unauthorized requests (by checking for the existence of an authorization header, for instance), can provide better defense against DDoS attacks. We’d be more than happy if security experts in the community can help us to further improve the rate-limiting middleware.
When it comes to security, we want to be open and frank about it. In the preceding discussions, we’ve touched on how Dapr can help with certain aspects of security now, how it likely will be able to help in the future, and some areas where help from the community will be needed to make further improvements. The rest of the chapter covers in more detail what Dapr offers today. Because Dapr is under rapid development, please consult the online documentation for the latest security feature updates.
Dapr Security Features
At the time of writing, Dapr provides a handful of security features, including secret stores, a secret API, and mutual TLS.
Secret Stores
Secret stores are designed to store sensitive information such as certificates and passwords. The difference between a database and a secret store is that a secret store applies additional mechanisms and constraints to further protect the saved information, such as:
- Constrained API surface and access control
- A secret store often requires specific credentials and server roles.
- Encryption at rest
- Some secret stores automatically encrypt secret data at rest with a store-controlled key or a user-supplied key. Note that the Kubernetes secret store saves secrets as base-64 encoded data in the underlying etcd store. The data by default is not encrypted, but you can opt in to encryption at rest. See the Kubernetes documentation for more details.
- Hardware protection
- Security stores like Azure Key Vault use hardware security modules (HSMs) to safeguard secrets using specialized hardware.
As with other components, Dapr supports pluggable secret stores through a secret store interface. At the time of writing, Dapr supports the following secret stores:
Kubernetes secret store
Azure Key Vault
HashiCorp Vault
AWS Secrets Manager
Google Cloud KMS
Google Secret Manager
Dapr offers built-in support for the Kubernetes secret store, so no specific configuration is needed to set that up. Other secret stores can be described by secret store description manifests. For example, the following manifest describes an Azure Key Vault:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: azurekeyvault
spec:
type: secretstores.azure.keyvault
metadata:
- name: vaultName
value: "<your key vault name>"
- name: spnTenantId
value: "<your service principal tenant ID>"
- name: spnClientId
value: "<your service principal app ID>"
- name: spnCertificateFile
value : "<pfx certificate file local path>"
Once you’ve defined an Azure Key Vault, you can use Azure tools such as the Azure CLI to store secrets in it. The following sample Azure CLI command creates a secret named redisPassword in an Azure Key Vault:
az keyvault secret set --name redisPassword --vault-name<your key vault name>--value "<your Redis password>"
Then when you define other components, you can reference the secrets in your secret store by using a secretKeyRef element. The following sample component manifest defines a Redis state store. The password of the store is saved in Azure Key Vault as a redisPassword secret and is referenced by a secretKeyRef element:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: statestore
spec:
type: state.redis
metadata:
- name: redisHost
value: "redis-master:6379"
- name: redisPassword
secretKeyRef:
name: redisPassword
auth:
secretStore: azurekeyvault
Dapr’s secret store feature was designed for Dapr internal usage only. Later, our customers requested a secret API through which application code can access saved secrets. We’ll introduce this API shortly.
It’s unlikely you’ll need to implement a secret store yourself. But in case you do, the following section provides a brief introduction.
Implementing a Secret Store
Dapr defines a secret store as a simple interface that contains an Init method and a GetSecret method, as shown in the following code snippet:
type SecretStore interface {
Init(metadata Metadata) error
GetSecret(req GetSecretRequest) (GetSecretResponse, error)
}
The GetSecretRequest struct contains a key and a collection of key/value pairs that are attached to the request as metadata:
type GetSecretRequest struct {
Name string `json:"name"`
Metadata map[string]string `json:"metadata"`
}
Dapr doesn’t interpret the metadata in any way. Instead, it simply passes all attached metadata to the secret store implementation. This design is to handle cases in which a secret store requires more information than a secret key name to access a secret. Requesting such metadata makes the code using your security store less portable. Although other stores can choose to ignore the metadata and function as usual, the same metadata keys may be accidentally chosen by multiple secret stores and will be interpreted differently by different stores, causing unpredictable errors. It’s highly recommended that you capture enough information in the Init method so secrets can be retrieved by secret key name only.
The GetSecretResponse struct holds a key/value pair of secret data:
type GetSecretResponse struct {
Data map[string]string `json:"data"`
}
If the requested key is not found, your code should return an error object.
As previously noted, when you define any Dapr manifest you can use the secretKeyRef element to reference secrets. Dapr has also introduced a secret API that allows applications to access secrets through code. We’ll introduce this API in the next section.
The Secret API
Dapr exposes a secret API that an application can use to retrieve a secret from a secret store at the endpoint v1.0/secrets/<secret store name>/<secret key name>.
This convenient API makes it easy for an application to retrieve secrets and use them in its code. The idea is to help developers avoid saving sensitive information, such as passwords and connection strings, in their code. The API is read-only, which means application code can’t create or update any secret keys through it. On the other hand, operations can update the secrets as needed by directly making changes to the secret stores without affecting the code. For example, they can rotate certificates, update passwords, and modify the connection string to a database account with the appropriate access privileges.
Ironically, the downside of this API is exactly its convenience. Once configured, application code can request any secret keys without authentication. As mentioned earlier, under the sidecar architecture, the Dapr sidecar and the application code are considered to be in the same security domain. Hence, allowing direct accesses to the secrets is not necessarily the wrong design. However, there is a potential danger: if application code is compromised, the adversary can gain access to all the secrets in the secret store.
With integration with service identities (see “Identity”), Dapr is able to offer some automatic authentication and authorization mechanisms to constrain access to secrets. For example, it can enforce a policy that grants an application access only to a particular secret store or even specific secret keys. Then, even when an application is compromised, the attacker won’t be able to use the application to gain access to the secrets of other applications sharing the same secret store.
That’s about all Dapr provides in terms of secret management. Next, we’ll shift gears and talk about how Dapr secures Dapr-to-Dapr communications through mutual TLS.
Mutual TLS (mTLS)
Transport Layer Security (TLS), which replaces the deprecated Secure Sockets Layer (SSL) protocol, is a cryptographic protocol used for secure communication between clients and servers. By default, TLS proves the server’s identity to the client using a server X.509 certificate. Optionally, it can also prove the client’s identity to the server using a client X.509 certificate. This is called mutual TLS. Mutual TLS (mTLS) is often used in distributed systems because in such systems it’s hard to identify a server or a client. Instead, components call each other in a mesh, so any component can be both a server and a client. Mutual TLS ensures all service calls among components are authenticated on both sides by cross-checking the certificates.
Before introducing how mTLS works, we need to provide a brief explanation of certificates and related concepts. If you are familiar with these concepts already, you can skip the following subsections.
X.509 certificates
An X.509 certificate is a digital certificate using the international X.509 public key infrastructure (PKI) standard. A certificate is issued by a trusted certificate authority (CA) and contains information about the represented entity such as the verified entity name and validity period of the certificate. A certificate also includes the entity’s public key and a signature that has been encoded with the entity’s private key. The PKI standard guarantees that if you can use the public key to decrypt the data, the information has been encrypted with the data owner’s private key.
When you use your browser to access a site through HTTPS, your browser validates the server’s certificate, checking that the certificate was issued by a trusted CA and that the domain name contained in the certificate matches with the address you are trying to access. If both checks pass, the browser displays some visual hint (such as the green padlock shown in Figure 4-2) to indicate you are securely connected to a legitimate server.
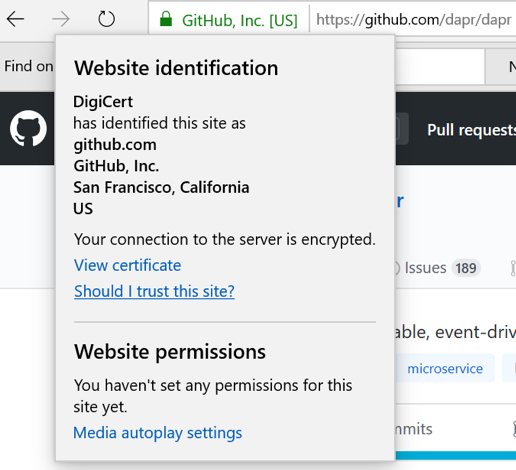
Figure 4-2. A verified HTTPS connection
If the certificate check fails, a modern browser is likely to warn you that your connection to the server is not secure. Figure 4-3 shows an example of a failed certificate check. In this case, the certificate associated with www.test.com has expired (the screenshot was captured on February 29, 2020), and hence the certificate check has failed.
Tip
Always access websites through HTTPS, and always check if their certificates are valid. This will help you to avoid some phishing attacks, in which an adversary uses a decoy website that mimics a legitimate website to try to trick you into providing your personal information (bank account or credit card number, email address, password, etc.) to the attacker. When you access a web service in your application code, make sure your code uses HTTPS as well. Similarly, when you expose a public service, always make sure it exposes an HTTPS endpoint, and keep your certificate up to date.
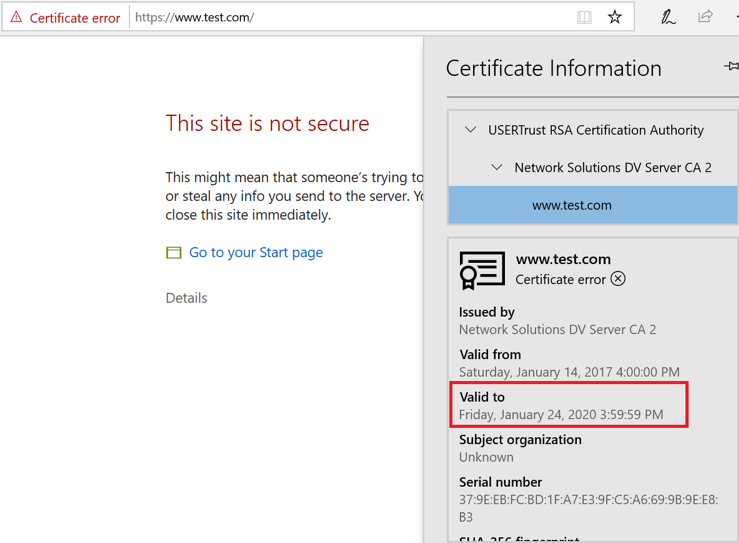
Figure 4-3. An unverified HTTPS connection
A CA is identified by a certificate as well. The certificate is imported into the certificate stores on your computer. There can be multiple levels of CA; an authority without a parent is called a root CA. Certificates representing the root CAs are imported to the Trusted Root Certificate Authorities store. A child CA needs an issuer certificate from its parent CA to issue new certificates. These certificates are chained together, with the root certificate issued by the root CA. When validating a certificate, you need to trace through the certificate chain until you reach a validated root certificate.
Requesting an X.509 certificate
To request a certificate from a CA, the requestor first generates a public/private key pair. Then it creates a certificate signing request (CSR), which contains its public key and requested fields, such as domain name. It signs the CSR with its own private key and sends the CSR to the CA. The CA verifies the CSR using the requestor’s public key. Then it generates a digital certificate that contains the requested fields, the requestor’s public key, and the CA’s public key. The digital certificate is signed with the CA’s private key and sent back to the requestor.
Now that you have an understanding of certificates, we can move on to Dapr mTLS.
Dapr mTLS
Mutual TLS requires each party to identify itself with a certificate, and to obtain a certificate you need to work with a trusted CA. Setting up a CA and completing the certificate application process is not complicated, but it’s something developers don’t often enjoy. This is where Dapr comes in. It hosts a CA service itself, it automates the certificate generation process, and it establishes a secure communication channel between Dapr sidecars. When your application code uses Dapr sidecars to communicate, all traffic is sent through the secured HTTPS channel automatically, without you needing to do anything special in your code.
The Dapr mTLS architecture is designed to work in both Kubernetes mode and standalone mode. The main difference between the two modes is where the root certificate is stored, as explained in the following section.
Dapr mTLS architecture
Dapr ships with a system component named Sentry that acts as a CA. The CA takes a user-supplied root certificate or generates a self-signed certificate as the root certificate. When a new Dapr sidecar launches, the root certificate is injected into the sidecar as the trusted root certificate. Then the Dapr sidecar requests a new workload certificate from Sentry. Finally, two Dapr sidecars authenticate with each other with corresponding workload certificates. Figure 4-4 illustrates how the whole process works, and the steps are described here in a little more detail:
Optionally, an operator loads a root certificate into the Kubernetes secret store (in Kubernetes mode) or a filesystem.
Sentry reads the user-supplied root certificate or, if necessary, generates a self-signed certificate as the root certificate itself. When the root certificate is replaced, Sentry automatically picks up the new certificate and rebuilds the trust chain.
When the sidecar injector injects a Dapr sidecar, it retrieves the root certificate and injects it into the Dapr sidecar.
When the Dapr sidecar initializes, it checks if mutual TLS is enabled. If so, it sends a CSR to Sentry. Sentry issues a workload certificate that is good for 24 hours, with 15 minutes of allowed clock skew by default. The clock skew allowance is to avoid certificate validation errors because of clock drift.
Dapr sidecars use workload certificates to authenticate with each other to establish a secured, encrypted communication channel.
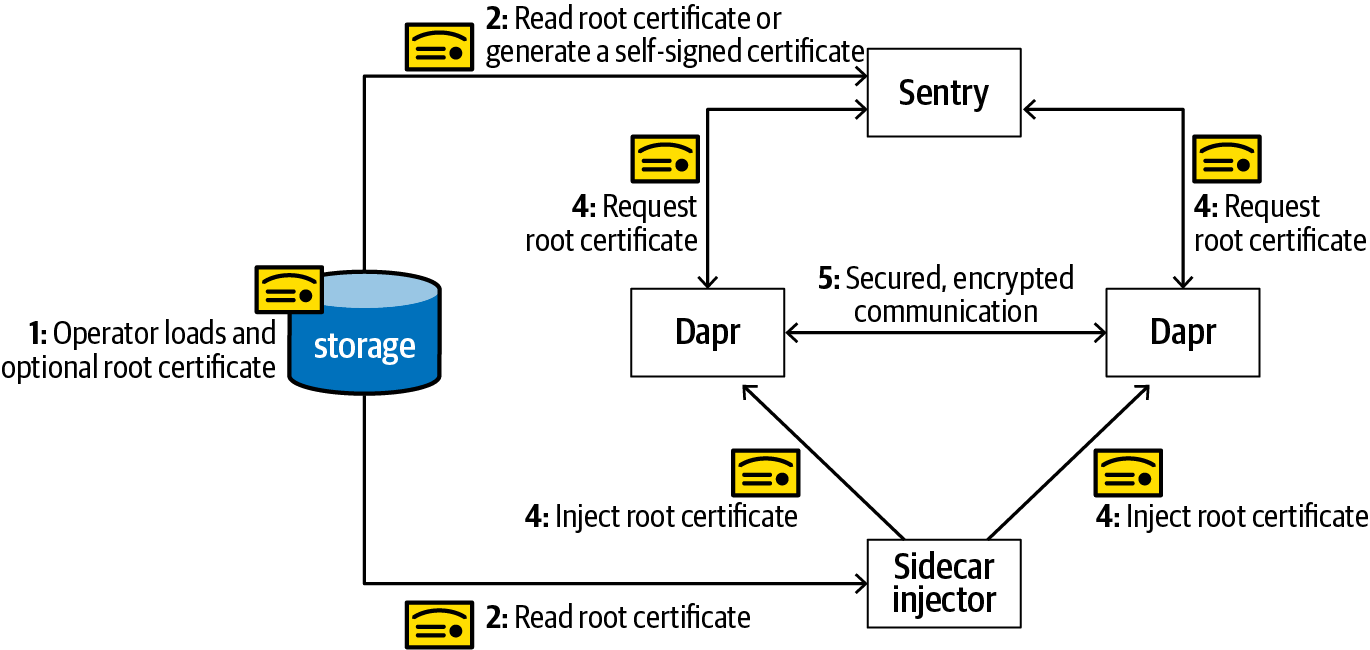
Figure 4-4. Dapr’s mutual TLS architecture
Configuring Sentry
Sentry configuration is described by a Dapr configuration file that looks something like this:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: default
spec:
mtls:
enabled: true
workloadCertTTL: "24h"
allowedClockSkew: "15m"
When running in Kubernetes mode, you can use kubectl to view and update Dapr configurations:
kubectl get configurations/<configuration name>--namespace<Dapr namespace>-o yaml kubectl edit configurations/<configuration name>--namespace<Dapr namespace>
Then delete the Sentry pod so that the replacement pod can pick up the new configuration:
kubectl delete pod --selector=app=dapr-sentry --namespace <Dapr namespace>
When running in standalone mode, you can launch the Sentry process with the --issuer-certificate switch to load a root certificate, and use the --config switch to load a custom configuration file:
./sentry --issuer-credentials $HOME/.dapr/certs --trust-domain cluster.local --config=./my-config.yaml
To launch application code with mTLS enabled, you need to supply a Dapr configuration file with mTLS enabled:
dapr run --app-id myapp --config ./mtls-config.yaml node myapp.js
Dapr mTLS provides secure communication channels between Dapr sidecars. It hides the complexity of certificate management from developers.
Summary
At the time of writing Dapr provides a basic set of security features, including secret management, a secret API, and mutual TLS support. Some additional security features are on the horizon, and we’d be happy to hear your feedback and get contributions.
This concludes our discussion of the fundamentals of Dapr. The rest of the book will focus on various application scenarios and design patterns using Dapr.
Get Learning Dapr now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

