Kapitel 4. Effektive Datenpipelines entwerfen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel lernst du, wie du mit Kafka Connect belastbare und effektive Datenpipelines aufbauen kannst. Wir erklären die wichtigsten Konzepte und Entscheidungspunkte, die Dateningenieure und -architekten verstehen müssen, wenn sie die in Kapitel 3 vorgestellten Komponenten zusammenstellen.
In der ersten Hälfte dieses Kapitels geht es darum, wie du Connector-Plug-ins für deine Pipelines auswählst. Du brauchst einen Konnektor, einen Konverter und optional einige Transformationen und Prädikate. Wir besprechen, wie du Konnektoren evaluierst und unter den Hunderten von Konnektoren, die in der Community verfügbar sind, denjenigen findest, der deinen Produktionsanforderungen entspricht. Dann besprechen wir, wie du deine Daten modellierst, während sie durch die Pipeline fließen, und welche Formatierungsoptionen dir zur Verfügung stehen.
Die zweite Hälfte dieses Kapitels befasst sich mit den Ausfallsicherheitsmerkmalen von Kafka Connect. Bevor du deine Pipeline aufbaust, musst du die Semantik festlegen, die du für deine Anwendungsfälle benötigst. Musst du zum Beispiel garantieren, dass alle Daten geliefert werden, oder ist es akzeptabel, dass einige Daten zugunsten eines höheren Durchsatzes verloren gehen? Zunächst gehen wir auf das Innenleben von Kafka Connect ein und erklären, warum es eine robuste Umgebung ist, die mit Ausfällen umgehen kann. Dann schauen wir uns die Semantik an, die Sink- und Source-Pipelines erreichen können, und die verschiedenen Konfigurationsoptionen und Kompromisse, die für deine spezifischen Anwendungsfälle zur Verfügung stehen.
Auswahl eines Verbinders
Wenn du eine Datenpipeline aufbaust, die Kafka Connect nutzt, musst du zunächst entscheiden, welchen Konnektor du installieren möchtest. Da Kafka eine sehr beliebte Technologie ist, gibt es viele bestehende Konnektoren, aus denen du wählen kannst. Anstatt das Rad neu zu erfinden, ist es oft besser, einen bestehenden Konnektor zu verwenden, aber nur, wenn er deine Anforderungen erfüllt. Hier sind einige Dinge, die du beachten solltest, wenn du dich entscheidest, ob du einen bestimmten Konnektor als Teil deiner Pipeline verwenden willst:
-
Richtung der Pipeline (Quelle oder Senke)
-
Lizenzierung und Unterstützung
-
Merkmale des Anschlusses
Richtung der Pipeline
Überprüfe zunächst, ob der Connector Daten in die richtige Richtung fließen lässt. Handelt es sich um einen Quell-Connector, der Daten an Kafka liefert, oder um einen Senken-Connector, der Daten von Kafka abruft? Bei den meisten Konnektoren ist diese Angabe Teil des Namens, und in der Regel geht sie auch aus der Dokumentation hervor. Falls nicht, kannst du den Konnektor in einer Kafka-Connect-Umgebung installieren und die REST-API verwenden, um seinen Typ abzufragen.
$curllocalhost:8083/connector-plugins[{"class":"org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type":"source","version":"3.5.0"},{"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"3.5.0"},{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"3.5.0"}]
Das Feld type gibt den Typ des Anschlusses an.
Einige Projekte bieten einen einzigen Download an, der sowohl einen Source- als auch einen Sink-Connector enthält, aber andere Projekte bieten vielleicht nur das eine oder das andere.
Lizenzierung und Unterstützung
Bevor du einen Connector verwendest, solltest du prüfen, was die Lizenz erlaubt. Nur weil der Quellcode eines Connectors öffentlich ist oder frei heruntergeladen werden kann, heißt das nicht, dass die Lizenz erlaubt ist. Du solltest auch den Umfang der Wartung und des Supports berücksichtigen, den du erwartest. Die Kafka-Gemeinschaft arbeitet hart daran, sicherzustellen, dass ältere Konnektoren mit neueren Versionen der Laufzeitumgebung kompatibel sind; allerdings werden nicht alle Konnektoren mit der gleichen Regelmäßigkeit gewartet oder aktualisiert. Unabhängig davon, für welchen Konnektor du dich entscheidest, ob es sich um einen Open-Source- oder einen proprietären Konnektor handelt, solltest du wissen, wie oft der Konnektor mit den neuesten Kafka-APIs aktualisiert wird und wie die Entwickler Sicherheitslücken beheben.
Der Umfang des Supports, den du für einen bestimmten Connector erhältst, ist sehr unterschiedlich. Viele Unternehmen bieten kostenpflichtigen Support für Konnektoren an, unabhängig davon, ob es sich um proprietäre oder Open-Source-Produkte handelt. Dazu gehört in der Regel ein eigener Kommunikationskanal, wenn du Probleme hast, und der Zugang zu Branchenexperten, die dich bei der Konfiguration beraten. Allerdings reagieren auch viele Open-Source-Communities schnell auf Fehlerberichte und bieten eigene Kommunikationskanäle, die je nach Anwendungsfall eine Alternative zum kostenpflichtigen Support sein können.
Hinweis
Da ein einziger Konnektor oft für viele verschiedene Anwendungsfälle verwendet wird, kann es sein, dass es keinen gibt, der perfekt auf deine Bedürfnisse zugeschnitten ist. Wenn das der Fall ist, empfehlen wir dir, anstatt einen neuen Connector zu schreiben, zu schauen, ob es einen Open-Source-Connector gibt, zu dem du beitragen kannst. Du musst deine Änderungen zwar noch akzeptieren, aber die meisten Open-Source-Projekte nehmen neue Mitwirkende auf.
Stecker Merkmale
Sobald du mögliche Konnektoren für deine Pipelines identifiziert hast, musst du dir die Funktionen dieser Konnektoren genauer ansehen. Zunächst einmal: Unterstützt der Konnektor die Art von Verbindung, die du brauchst? Dein externes System könnte zum Beispiel eine verschlüsselte Verbindung, eine Form der Authentifizierung oder ein bestimmtes Format der Daten erfordern. Du solltest auch prüfen, ob der Konnektor für den Produktionseinsatz geeignet ist. Bietet er z. B. Metriken zur Überwachung des Status und eine Protokollierung, die dir bei der Fehlersuche hilft? Sieh dir die Dokumentation - und bei einem Open-Source-Konnektor auch den Code - an, um zu sehen, wie der Konnektor funktioniert und welche Funktionen er bietet.
In Kapitel 3 haben wir die gemeinsamen Konfigurationsoptionen für alle Anschlüsse vorgestellt: topics für Sink-Anschlüsse und tasks.max für Source- und Sink-Anschlüsse. Die meisten Konnektoren bieten zusätzliche Optionen zur Konfiguration ihrer spezifischen Funktionen. Für einen bestimmten Konnektor kannst du die REST-API verwenden, um alle verfügbaren Konfigurationsoptionen aufzulisten und deine Konfiguration zu überprüfen, bevor du den Konnektor startest.
Die Verwendung der REST-API ist besonders nützlich, wenn der Code nicht verfügbar ist, aber sei dir bewusst, dass dies davon abhängt, dass der Entwickler seine Konfiguration korrekt dokumentiert. Einige Felder könnten fälschlicherweise als optional oder erforderlich gekennzeichnet sein. Ebenso ist die Validierung nützlich, um zu überprüfen, ob die Konfiguration des Konnektors akzeptiert wird, aber eine erfolgreiche Validierungsanfrage ist keine Garantie dafür, dass dein Konnektor funktioniert.
Verwende den Endpunkt GET /connector-plugins/<CONNECTOR_PLUGIN>/config, um die Konfigurationsoptionen aufzulisten, und den Endpunkt PUT /connector-plugins/<CONNECTOR_PLUGIN>/config/validate, um eine bestimmte Konfiguration zu validieren.
Wir beschreiben die REST-API-Endpunkte ausführlich in Kapitel 7.
Datenmodelle definieren
Keine zwei Pipelines sind identisch. Selbst wenn sie einen ähnlichen Anwendungsfall erfüllen oder dieselben Komponenten verwenden, sind die tatsächlichen Daten und die Art und Weise, wie sich diese Daten entwickeln, von Pipeline zu Pipeline unterschiedlich. Wenn du deine Pipeline entwirfst, musst du berücksichtigen, wann und wie sich jeder einzelne Dateneintrag ändern wird und wie die einzelnen Einträge zueinander in Beziehung stehen. Die Art und Weise, wie du deine Daten gruppierst oder aufteilst, wirkt sich darauf aus, wie gut du deine Pipeline skalieren kannst, wenn die Menge der zu verarbeitenden Daten steigt. Um diese Ideen genauer zu untersuchen, erörtern wir zunächst, wann Daten in Kafka Connect mithilfe von Transformationen und Prädikaten umgewandelt werden können, und diskutieren dann Techniken für das Mapping von Daten zwischen Kafka Connect und anderen Systemen.
Datenumwandlung
Es gibt zwei gängige Muster, die verwendet werden, um Daten zu entwickeln, während sie durch eine Pipeline fließen: ETL (Extract-Transform-Load) und ELT (Extract-Load-Transform). Bei diesen Mustern bezieht sich das Wort "Transformation" nicht nur auf die Aktualisierung des Formats. Die Umwandlung kann auch das Bereinigen der Daten umfassen, um sensible Informationen zu entfernen, die Daten mit anderen Datenströmen zusammenzuführen oder weitergehende Analysen durchzuführen.
Beide Ansätze haben ihre Vor- und Nachteile. In Systemen, in denen die Speicherung begrenzt ist, ist es besser, den ETL-Ansatz zu verwenden und die Daten umzuwandeln, bevor sie in die Speicherung geladen werden. Dies erleichtert die Abfrage der Daten, da sie bereits für die Analyse vorbereitet wurden. Es kann jedoch schwierig sein, die Pipeline zu aktualisieren, wenn ein neuer Anwendungsfall entdeckt wird, der eine andere Umwandlung erfordert. Im Gegensatz dazu bleiben die Daten bei ELT so lange wie möglich generisch, sodass sie für andere Zwecke wiederverwendet werden können. Das ELT-Muster wird immer beliebter und es gibt inzwischen viele spezielle Datenverarbeitungs- und Analysetools, die es unterstützen. Einige Beispiele für diese Tools sind Kafka Streams, Apache Spark, Apache Flink, Apache Druid und Apache Pinot.
Wie passen nun die Kafka Connect Transformationen in diesen Fluss? In Kafka Connect gibt es eine Vielzahl von Transformationen, die du mit deinen Daten durchführen kannst, während sie im Fluss sind, was natürlich in das ETL-Muster passt. Wenn du Kafka Connect für deine Transformationen nutzt, brauchst du kein separates Tool mehr, um die Daten vor dem Laden zu transformieren. Da du die anzuwendenden Transformationen selbst auswählst und Kafka Connect es dir ermöglicht, benutzerdefinierte Transformationen hinzuzufügen, sind die Möglichkeiten endlos. Allerdings haben die Kafka-Connect-Transformationen ihre Grenzen, denn sie werden auf jeden einzelnen Datensatz angewendet. Das bedeutet, dass du keine weitergehenden Verarbeitungen durchführen kannst, wie z. B. das Zusammenführen von zwei Datenströmen oder das Aggregieren von Daten im Zeitverlauf. Stattdessen solltest du für diese Art von Operationen eine der speziellen Stream-Verarbeitungstechnologien verwenden.
Auch wenn du dich dafür entscheidest, eine eigene Technologie für den Großteil deiner Datenverarbeitung und -analyse zu verwenden, kannst du die Kafka Connect-Transformationen nutzen. Einige besondere Transformationen, die du in Betracht ziehen solltest, sind diejenigen, die Felder entfernen oder umbenennen und Datensätze löschen können. Diese sind sehr nützlich, um sicherzustellen, dass sensible Daten nicht weiter in der Pipeline gesendet werden, und um Daten zu entfernen, die später Verarbeitungsprobleme verursachen könnten. Wenn du mehrere unterschiedliche Quellen hast, die in weiteren Schritten aggregiert werden müssen, kannst du auch Kafka Connect-Transformationen verwenden, um die Daten zunächst so auszurichten, dass sie gemeinsame Felder haben. Abbildung 4-1 zeigt diese Art von Fluss.
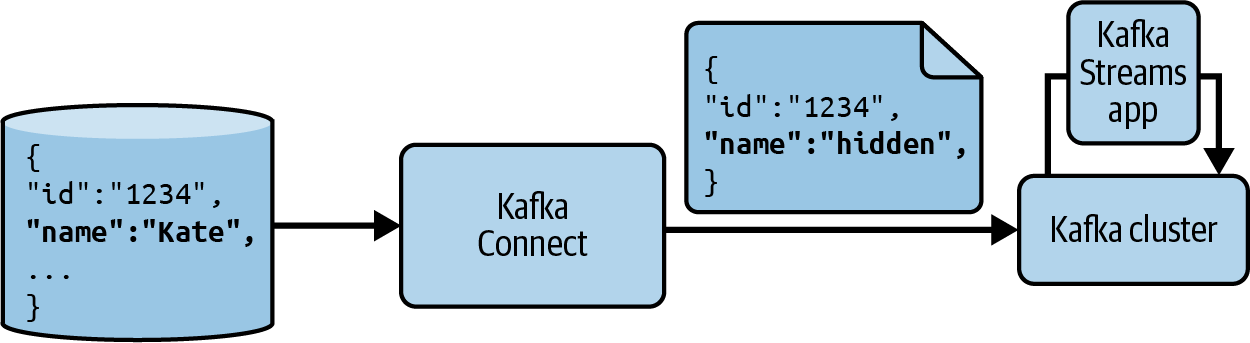
Abbildung 4-1. Datenpipeline mit Kafka Connect-Transformationen zum Entfernen sensibler Daten und Kafka Streams zur weiteren Verarbeitung
Daten zwischen Systemen abbilden
Wir haben besprochen, wie du einzelne Dateneinträge transformieren kannst, aber wie sieht es mit der Gesamtstruktur deiner Daten aus, wenn sie die Pipeline durchlaufen?
Eines der schwierigsten Dinge beim Aufbau einer Datenpipeline ist die Frage, wie die Datenstrukturen zwischen verschiedenen Systemen abgebildet werden können. Dabei geht es nicht nur um das Format der einzelnen Einträge, sondern auch darum, wie die Daten gruppiert und gespeichert werden sollen, welche Reihenfolge erforderlich ist und was passiert, wenn die Pipeline skaliert werden muss - all das sind strukturelle Überlegungen. In Kafka Connect werden viele dieser Entscheidungen von dem Entwickler getroffen, der den Konnektor geschrieben hat. Dennoch solltest du die Mechanismen kennen, die den Konnektoren zur Verfügung stehen, um Daten zwischen Kafka und anderen Systemen abzubilden. Wenn du diese Mechanismen verstehst, bist du besser in der Lage, einen Konnektor, den du verwenden möchtest, zu beurteilen und ihn für deinen Anwendungsfall richtig zu konfigurieren.
Um zu verstehen, wie Konnektoren Daten gruppieren und zuordnen können, musst du die Interaktion zwischen Kafka Connect Tasks und Kafka Partitionen betrachten. In Kapitel 3 haben wir Tasks als den Mechanismus vorgestellt, mit dem Kafka Connect die eigentliche Arbeit der Datenübertragung von einem Ort zum anderen erledigt. In Kapitel 2 haben wir über Partitionen gesprochen und die Tatsache hervorgehoben, dass Kafka Ordnungsgarantien innerhalb einer einzelnen Partition bietet. Beide Mechanismen bieten eine Möglichkeit, Daten zu splitten.
Schauen wir uns zunächst die Auswirkungen von Aufgaben auf Quellkonnektoren an. Wenn ein Quellkonnektor Daten aus einem externen System liest, liest jede Aufgabe die Daten parallel. Der Konnektor muss entscheiden, wie er diese Daten auf die verfügbaren Aufgaben aufteilt, um sicherzustellen, dass es keine Duplikate gibt. Ein einfacher Konnektor könnte eine einzige Aufgabe ausführen und das Problem der Aufteilung der Daten im externen System vermeiden. So funktioniert FileStreamSourceConnector, das mit Kafka ausgeliefert wird, . Siehe Abbildung 4-2 für ein Beispiel.

Abbildung 4-2. Ein einzelner Task in FileStreamSourceConnector liest die Datei Zeile für Zeile
Selbst wenn du die Einstellung tasks.max erhöhst, führt immer noch nur eine einzige Aufgabe aus, weil es keinen sinnvollen Mechanismus zur Aufteilung der Daten hat. Die meisten Konnektoren sind fortschrittlicher als FileStreamSourceConnector und haben eingebaute Mechanismen, um die Daten auf die Aufgaben zu verteilen. Abbildung 4-3 zeigt ein Beispiel für einen solchen Konnektor, der es verschiedenen Aufgaben ermöglicht, verschiedene Zeilen einer Tabelle zu lesen.
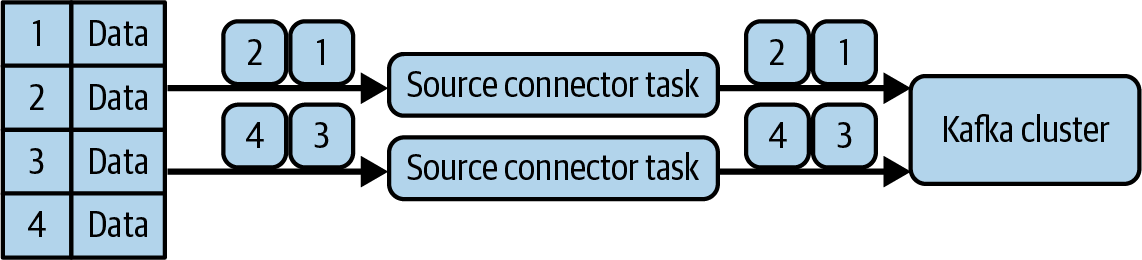
Abbildung 4-3. Mehrere Aufgaben, die jeweils eine Teilmenge der Daten lesen, verhindern Duplikate in Kafka
Betrachten wir die Partitionen. Ein einzelner Quellkonnektor kann entweder auswählen, welche Datensätze an welche Partitionen gehen sollen, oder sich auf die konfigurierte Partitionierungsstrategie verlassen. Viele Connectoren verwenden Schlüssel, um die Daten zu identifizieren, die an dieselben Partitionen gesendet werden müssen. Statusaktualisierungen, die sich auf eine bestimmte Entität beziehen, können zum Beispiel die Entitäts-ID als Schlüssel verwenden. Abbildung 4-4 zeigt ein Beispiel für Aufgaben, die Daten an Partitionen senden.
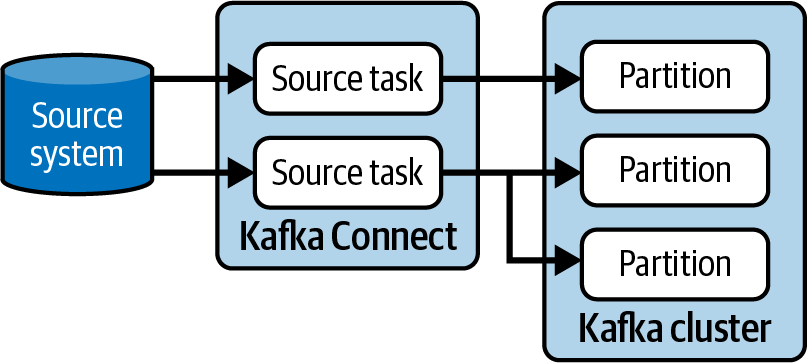
Abbildung 4-4. Quellaufgaben können ihre Daten an eine oder mehrere Partitionen senden
Die Art und Weise, wie ein Quell-Connector seine Daten partitioniert , wirkt sich auf die nächste Stufe der Pipeline aus, unabhängig davon, ob es sich bei dieser nächsten Stufe um einen Sink-Connector oder nur um einen Kafka-Konsumenten handelt, da Kafka die Partitionen sowohl auf Sink-Tasks als auch auf Konsumenten einer Gruppe verteilt. Jede Partition kann nur einer einzigen Sink-Task eines bestimmten Sink-Connectors zugewiesen werden, und ebenso einem einzigen Consumer innerhalb einer bestimmten Gruppe, so dass alle Daten, die von einer einzelnen Task oder einem Consumer gelesen werden müssen, vom Source-Connector an dieselbe Partition gesendet werden müssen.
Betrachten wir nun die Sink-Konnektoren. In Sink-Konnektoren laufen die Aufgaben ebenfalls parallel. Das kann sich auf die Reihenfolge auswirken, in der die Daten an das externe System gesendet werden. Du kannst sicher sein, dass jede Aufgabe ihre eigenen Daten in der richtigen Reihenfolge schreibt, aber es gibt keine Koordination der Reihenfolge zwischen den Aufgaben. Die Art und Weise, wie Sink-Tasks mit Partitionen interagieren, hat auch Auswirkungen auf die Anzahl der Sink-Tasks, die du ausführen kannst. Wenn du eine Partition und zwei Aufgaben hast, wird nur eine Aufgabe Daten erhalten. Wenn du also eine Datenpipeline mit einem Sink-Connector erstellst, solltest du die Anzahl der Partitionen in den Themen beachten, aus denen der Connector liest. Abbildung 4-5 zeigt zwei Sink-Tasks, die Daten aus drei Partitionen lesen.
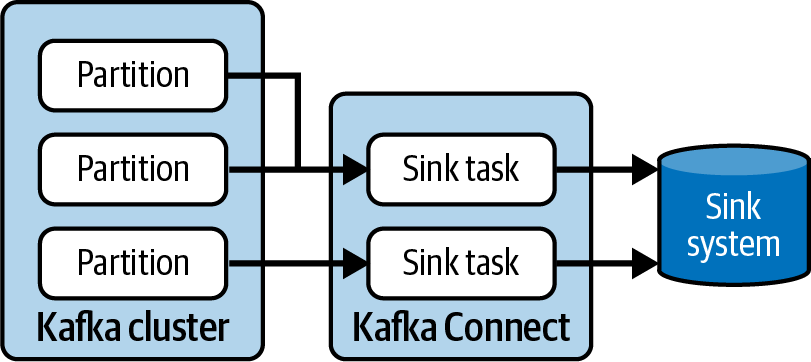
Abbildung 4-5. Jede Partition kann nur von einer Sink-Task für einen bestimmten Anschluss gelesen werden
Wie du dir vorstellen kannst, bedeutet die Kombination aus Tasks und Partitionen, dass es mehrere Möglichkeiten gibt, die Daten zu gruppieren und zu ordnen, während sie durch das System fließen. Wenn du deine Kafka-Connect-Datenpipeline entwirfst, solltest du diese Optionen berücksichtigen und die Konfigurationsoptionen für tasks.max und Partitionen nicht als nachträgliche Überlegung stehen lassen.
Nachdem wir uns nun angesehen haben, wie Daten auf hoher Ebene umgewandelt und zwischen Systemen gemappt werden können, schauen wir uns an, wie du das spezifische Format der Daten in einer Kafka Connect-Pipeline steuern kannst.
Daten formatieren
In Kapitel 3 haben wir über Konverter gesprochen und darüber, wie sie Daten serialisieren und deserialisieren, wenn sie in und aus Kafka gehen. Wir haben auch kurz erläutert, warum du deine Konverter mit den Serialisierern und Deserialisierern der Producer und Consumer abstimmen musst, die ebenfalls mit den Daten interagieren. Hier gehen wir näher auf die Unterschiede zwischen Konvertern, Transformationen und Konnektoren ein und erläutern, wie sie das Datenformat in der gesamten Pipeline beeinflussen. Wir sehen uns auch an, wie du diese Struktur mit Schemas und einer Schemaregistrierung durchsetzen kannst.
Datenformate
In einer Kafka-Connect-Pipeline hängt das Format der Daten und ihre Entwicklung vom Connector, den konfigurierten Transformationen und dem Konverter ab. Schauen wir uns jeden dieser Faktoren an und wie sie das Datenformat beeinflussen.
Betrachten wir zunächst den Konnektor. In einem Quellfluss läuft der Konnektor zuerst; er liest die Daten aus dem externen System und erstellt ein Java-Objekt, das ConnectRecord genannt wird. Der Konnektor entscheidet, welche Teile der Datensatzdaten beibehalten werden sollen und wie sie auf ConnectRecord abgebildet werden. Die Einzelheiten dieser Abbildung können sich zwischen den Konnektoren unterscheiden, selbst wenn sie für dasselbe System sind. Achte also darauf, dass der von dir gewählte Konnektor die Teile der Daten beibehält, die für dich wichtig sind.
In einem Sink-Flow läuft der Konnektor als letztes und nicht als erstes. Er nimmt die Objekte von ConnectRecord und wandelt sie in Datenobjekte um, die er an das externe System senden kann. Das bedeutet, dass ein Sink-Connector das letzte Wort darüber hat, welche Daten an das externe System weitergeleitet werden.
Schauen wir uns nun den Unterschied zwischen Konvertern und Transformationen an, wenn es um ihren Eingang und Ausgang geht:
-
Transformationen haben
ConnectRecordObjekte als Eingang und Ausgang. -
Konverter konvertieren zwischen
ConnectRecordObjekten und den rohen Bytes, die Kafka sendet und empfängt. Sie werden in Quell-Pipelines zuletzt und in Sink-Pipelines zuerst ausgeführt.
Abbildung 4-6 zeigt die verschiedenen Datentypen, die zwischen Konnektoren, Transformationen und Konvertern weitergegeben werden.
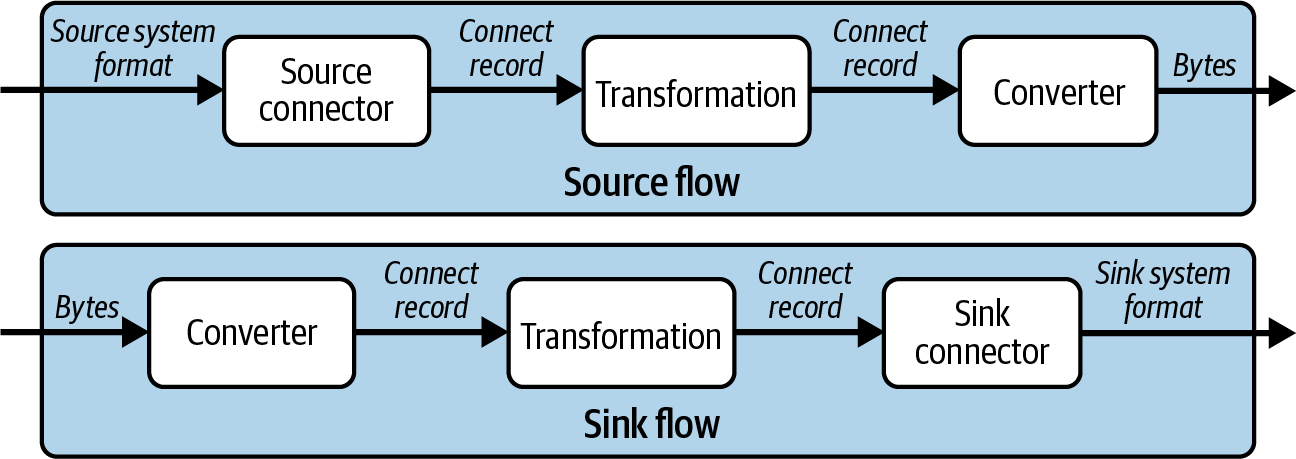
Abbildung 4-6. Datentypen in Quell- und Senkenströmen
Transformationen und Konverter sind separate Schritte, um die Kompositionsfähigkeit zu ermöglichen, die Kafka Connect bietet. Du könntest einen JSON-Konverter schreiben, der den Inhalt des Datensatzes manipuliert, bevor er an Kafka gesendet wird. Wenn du eine Pipeline möchtest, die die Daten auf dieselbe Weise bearbeitet, aber ein Format wie Avro verwendet, brauchst du einen neuen Konverter. Es wäre besser, eine Transformation zu erstellen, die die Daten manipuliert, und dann zwei Konverter zu verwenden, einen für JSON und einen für Avro.
Transformationen können verkettet werden, so dass du nicht erst eine eigene Transformation schreiben musst, sondern mehrere einfache Transformationen ausführen kannst, um deine Anforderungen zu erfüllen. Wenn du keine Transformationen oder Konverter findest, die deinen Anforderungen entsprechen, kannst du deine eigenen schreiben (siehe Kapitel 12).
Jetzt, da du die Rolle von Konnektoren, Transformationen und Konvertern und die Reihenfolge, in der sie ausgeführt werden können, verstehst, kannst du besser entscheiden, welche Bibliotheken du für deine Pipeline verwenden willst, um in jeder Phase genau das Datenformat zu erhalten, das du brauchst. Wie bei der Auswahl der Konnektoren solltest du auch bei der Auswahl der Transformationen und Konverter die Anforderungen an die Lizenzierung und den Support berücksichtigen .
Schemata
Ein Schema liefert einen Entwurf für die Form der Daten. In einem Schema kann zum Beispiel festgelegt werden, welche Felder erforderlich sind und welche Typen vorhanden sein müssen. Die Verwendung von Schemata ist wichtig, wenn du eine Datenpipeline aufbaust, denn die meisten Daten sind komplex und enthalten mehrere Felder unterschiedlicher Typen. Ohne Schemata, die den Daten einen Kontext geben, ist es für Anwendungen sehr schwierig, die Schritte zur Verarbeitung und Analyse der Daten zuverlässig durchzuführen.
Fast alle Datenmanagementsysteme verfügen über einen Mechanismus zur Definition von Schemata. Die spezifischen Schemata deiner Systeme werden sich unterscheiden, aber hier ist, wie Kafka Connect Pipelines im Allgemeinen Schemata verwenden. Wie wir im vorherigen Abschnitt gesehen haben, wechseln die Daten beim Durchlaufen von Kafka Connect zwischen zwei verschiedenen Formaten: ConnectRecord und Rohbytes. Jedes Format hat einen anderen Konfigurationsmechanismus.
Kafka Connect Datensatzschemata
Ein ConnectRecord enthält ein optionales Schema Objekt für den Schlüssel und den Wert. Schema ist eine Java-Klasse, die Teil der Kafka-Connect-API ist und von Konnektoren, Transformatoren und Konvertierern verwendet wird, wenn die Daten durch Kafka Connect laufen. Schauen wir uns an, wie Schema in Quell- und Senkenpipelines verwendet wird.
Ein Quell-Connector ist für die Erstellung des anfänglichen ConnectRecord Objekts verantwortlich und hat die Kontrolle über das Schema, das hinzugefügt wird. Wie das Schema definiert wird, hängt vom Connector ab. FileStreamSourceConnector verwendet immer das STRING_SCHEMA, egal welches Format die Datei verwendet. Du kannst das im Quellcode sehen:
privatestaticfinalSchemaVALUE_SCHEMA=Schema.STRING_SCHEMA;@OverridepublicList<SourceRecord>poll()throwsInterruptedException{...records.add(newSourceRecord(offsetKey(filename),offsetValue(streamOffset),topic,null,null,null,VALUE_SCHEMA,line,System.currentTimeMillis()));...}
Die meisten Konnektoren sind komplexer als FileStreamSourceConnector und nutzen die vom System bereitgestellten Schemata, um das Schema Objekt zu erstellen. Die Debezium-Konnektoren, die die Änderungsprotokolle der Datenbank lesen, nehmen beispielsweise Änderungen am Datenbankschema zur Kenntnis und verwenden diese Informationen, um das ConnectRecord-Objekt zu erstellen. ConnectRecord und die darin enthaltenen Schema -Objekte werden dann an alle Transformationen und an den Konverter weitergegeben. Transformationen und Konverter können die Schema nutzen, um die ConnectRecord zu parsen und ihre jeweilige Arbeit zu erledigen.
In einer Sink-Pipeline ist es der Konverter, der die ConnectRecord, und damit die Schema konstruiert; die Transformationen nutzen diese Informationen, um den Inhalt zu parsen. Sink-Connectoren verwenden die ConnectRecord, um das Objekt zu konstruieren, das an das externe System gesendet wird. Das bedeutet, dass sie selbst entscheiden können, wie sie die Schema, die in der ConnectRecord enthalten ist, interpretieren. FileStreamSinkConnector ignoriert zum Beispiel die Schema vollständig, aber nur, weil es in eine Datei schreibt. Die meisten Sink-Connectoren verwenden die Informationen von Schema, um die Daten des externen Systems zu erstellen.
Kafka-Datensatz-Schemata
Kafka Connect-Pipelines können auch Schemas verwenden, um die in Kafka gespeicherten Daten zu beschreiben. Diese Schemata werden von Konvertern verwendet, um zu verstehen, wie die an und von Kafka gesendeten Daten serialisiert und deserialisiert werden können. In einer Sink-Pipeline ist das Schema, das Kafka Connect zur Deserialisierung der Daten verwendet, das gleiche, das auch von den Anwendungen zur Erzeugung dieser Daten verwendet wurde. In einer Source-Pipeline wird das Schema, das Kafka Connect zur Serialisierung der Daten verwendet, auch von den konsumierenden Anwendungen oder Sink-Connectors verwendet, um die Daten weiter unten in der Pipeline zu deserialisieren.
Das ConnectRecord Objekt hat eine eingebaute Unterstützung für Schemata, aber da Datensätze in Kafka rohe Bytes sind, musst du dich für einen Mechanismus entscheiden, um das Schema aufzunehmen. Der naive Ansatz besteht darin, das Schema zusammen mit der Nutzlast in den Wert des Datensatzes aufzunehmen. Das ist die Standardeinstellung von JsonConverter.
Wenn du FileStreamSourceConnector mit JsonConverter gegen eine Datei mit folgendem Inhalt laufen lässt:
This is a string Another string A third string The final string
JsonConverter verwendet das String Schema, das der Konnektor bereitstellt, und erstellt Kafka-Datensätze mit den folgenden Werten:
{"schema":{"type":"string","optional":false},"payload":"This is a string"}{"schema":{"type":"string","optional":false},"payload":"Another string"}{"schema":{"type":"string","optional":false},"payload":"A third string"}{"schema":{"type":"string","optional":false},"payload":"The final string"}
Das macht es zwar einfach, ein Schema an die Verbraucher weiterzugeben, aber es bedeutet, dass jeder einzelne Datensatz das Schema enthalten muss. Das Beispiel hier ist einfach, daher ist das Schema klein, aber je komplexer das Schema ist, desto größer ist der Aufwand für jeden Datensatz.
Ein besserer Ansatz ist es, nur einen kleinen Bezeichner für das Schema in jeden Datensatz aufzunehmen und die Schemata an anderer Stelle zu speichern. Auf diese Weise hast du die Vorteile von Schemas in deiner gesamten Pipeline mit nur geringem Overhead. Die meisten vorhandenen Konverter, Serialisierer und Deserialisierer tun dies und fügen die Schema-ID an einer von zwei Stellen ein: in einem Datensatzkopf oder am Anfang des serialisierten Wertes.
Wenn du einen Quellfluss erstellst, solltest du einen Konverter wählen, der die ID an einer Stelle speichert, die von den nachgelagerten Anwendungen, die den Datensatz verwenden, erwartet wird. Wenn du einen Senkenfluss erstellst, wähle einen Konverter, der weiß, wo im Datensatz die ID zu finden ist. Es ist relativ einfach, ein System zum Speichern von Schemata zu erstellen, das von deinen Anwendungen abgerufen werden kann.
Eine Schema-Registry besteht in der Regel aus zwei Teilen: einem Server, der Schemas speichert und APIs zum Abrufen und Verwalten bereitstellt, und Serializer/Deserializer/Konverter-Bibliotheken, die du in deinen Clients verwenden kannst. Schemaregistraturen enthalten oft zusätzliche Funktionen, die dir bei der Verwaltung deiner Schemas helfen. Viele Registries setzen zum Beispiel die Kompatibilität durch und ermöglichen es dir, den Lebenszyklus deiner Schemas zu kontrollieren. Dies ist für Anwendungen nützlich, da es verhindern kann, dass Änderungen vorgenommen werden, und es ermöglicht Administratoren, Anwendungsentwickler zu informieren, wenn ein Schema veraltet ist.
Die beiden Schema-Registries, die am häufigsten mit Kafka verwendet werden, sind die Confluent Schema Registry und die Apicurio Registry. Beide ermöglichen es dir, Kafka als Backing Store für die Registry zu nutzen, sodass du keine separate Datenbank oder ein anderes Speichersystem benötigst. Außerdem unterstützen beide die gängigsten Schemaformate, die mit Kafka verwendet werden: Avro, JSON Schema und Protobuf.
Ein detaillierter Vergleich der verfügbaren Schemaformate und Schemaregistrierungen für Kafka liegt außerhalb des Rahmens dieses Buches, aber wir können Hinweise geben. Wenn du dich für ein Format entscheidest, solltest du die Tools und Bibliotheken berücksichtigen, die zu jedem Format gehören. Unterstützen sie zum Beispiel die von dir gewünschte Sprache und bieten sie Optionen für die Codegenerierung? Wenn du eine Schemaregistrierung verwendest, musst du sicherstellen, dass der von dir gewählte Konverter und der Serialisierer/Deserialisierer der Anwendung mit der Registrierung kompatibel sind. Die Schemaregistrierung von Confluent funktioniert nur mit Confluent-Bibliotheken, während Apicurio Registry über eine Kompatibilitäts-API verfügt. Das bedeutet, dass du die speziellen Apicurio Registry Bibliotheken oder die von Confluent verwenden kannst.
Die Interna von Kafka Connect erkunden
Um zu verstehen, wie Kafka Connect im verteilten Modus Ausfällen standhalten kann, musst du wissen, wie es seinen Status mit einer Mischung aus internen Topics und Gruppenmitgliedschaft speichert. Zweitens solltest du mit dem Rebalance-Protokoll vertraut sein, das Kafka Connect verwendet, um Aufgaben auf die Worker zu verteilen und Ausfälle von Workern zu erkennen.
Interne Themen
Wie in Kapitel 3 erwähnt, verwendet Kafka Connect im verteilten Modus die Topics , um den Status zu speichern, die sind:
-
Konfigurationsthema, angegeben über
config.storage.topic -
Offset-Thema, angegeben über
offset.storage.topic -
Status-Thema, angegeben über
status.storage.topic
Im Konfigurationsthema speichert Kafka Connect die Konfiguration aller Konnektoren und Aufgaben, die von Nutzern gestartet wurden. Jedes Mal, wenn Nutzer die Konfiguration eines Connectors aktualisieren oder ein Connector eine Neukonfiguration anfordert (z. B. wenn er feststellt, dass er mehr Tasks starten kann), wird ein Datensatz an dieses Topic gesendet. Dieses Topic ist komprimiert, so dass es immer den letzten Status für jede Entität speichert und gleichzeitig sicherstellt, dass es nicht zu viel Speicherung benötigt.
Im Offset-Topic speichert Kafka Connect die Offsets der Quellkonnektoren. (Dieses Topic wird aus denselben Gründen komprimiert.) Standardmäßig erstellt Kafka Connect dieses Topic mit mehreren Partitionen, da jede Quell-Task es regelmäßig nutzt, um ihre Position zu schreiben. Offsets für Sink-Connectoren werden in regulären Kafka-Verbrauchergruppen gespeichert.
Im Statusthema speichert Kafka Connect den aktuellen Status von Konnektoren und Aufgaben. Dieses Thema ist der zentrale Ort für die Daten, die von den Nutzern der REST-API abgefragt werden. Es ermöglicht den Nutzern, jeden Worker abzufragen und den Status aller laufenden Plug-ins zu erhalten. Es ist ebenfalls komprimiert und sollte ebenfalls mehrere Partitionen haben.
Beim Start erstellt Kafka Connect diese Themen automatisch, wenn sie noch nicht vorhanden sind. Alle Worker in einem Kafka-Connect-Cluster müssen dieselben Topics verwenden, aber wenn du mehrere Kafka-Connect-Cluster betreibst, braucht jeder Cluster seine eigenen Topics. Die Daten in allen drei Topics werden in JSON gespeichert, sodass sie mit einem normalen Consumer angezeigt werden können.
Mit dem Tool kafka-console-consumer.sh kannst du dir zum Beispiel den Inhalt des Statusthemas ansehen:
$./bin/kafka-console-consumer.sh--bootstrap-serverlocalhost:9092\--topicconnect-status\--from-beginning\--propertyprint.key=truestatus-connector-file-source{"state":"RUNNING","trace":null,"worker_id":"192.168.1.12:8083","generation":5}
In diesem Beispiel ist für die Laufzeit status.storage.topic auf connect-status gesetzt. Die Datensätze in diesem Thema zeigen den Status eines Connectors mit dem Namen file-source. Kafka Connect verwendet diesen Namen, um den Schlüssel status-connector-file-source, für Datensätze abzuleiten, die sich auf den Connector beziehen.
Gruppenmitgliedschaft
Zusätzlich zu den Topics macht Kafka Connect ausgiebigen Gebrauch von Kafkas Gruppenmitgliedschafts-API.
Zunächst führt die Kafka Connect-Laufzeit für jeden Sink-Connector eine reguläre Consumer-Gruppe aus, die Datensätze aus Kafka konsumiert, um sie an den Connector weiterzuleiten. Standardmäßig werden die Gruppen nach dem Namen des Konnektors benannt; für einen Konnektor mit dem Namen file-sink lautet die Gruppe zum Beispiel connect-file-sink. Jeder Konsument in der Gruppe liefert Datensätze an eine einzelne Aufgabe. Diese Gruppen und ihre Offsets können mit den üblichen Tools für Verbrauchergruppen abgerufen werden, z. B. mit kafka-consumer-groups.sh.
Darüber hinaus verwendet Kafka Connect die API für die Gruppenzugehörigkeit, um Workern Konnektoren und Aufgaben zuzuweisen und sicherzustellen, dass jede Benutzerpartition nur von einer einzigen Sink-Task pro Konnektor genutzt wird. Beim Start erstellt Kafka Connect eine Gruppe mit dem Wert group.id aus seiner Konfiguration. Diese Gruppe ist für die Tools für Verbrauchergruppen nicht direkt sichtbar, da es sich nicht um eine Verbrauchergruppe handelt, aber sie funktioniert im Wesentlichen auf die gleiche Weise. Aus diesem Grund werden alle Worker mit demselben group.id Wert Teil desselben Kafka Connect Clusters.
Um Mitglied einer Gruppe zu sein, müssen Arbeiter/innen, genau wie normale Verbraucher/innen, regelmäßig einen Heartbeat senden. Ein Heartbeat ist eine Anfrage, die den Gruppennamen, die Mitglieds-ID und ein paar weitere Felder zur Identifizierung des Absenders enthält. Sie wird in regelmäßigen Abständen (festgelegt durch heartbeat.interval.ms, mit einem Standardwert von drei Sekunden) von allen Arbeitern an den Gruppenkoordinator gesendet. Wenn ein Arbeiter aufhört, Heartbeats zu senden, stellt der Koordinator dies fest, entfernt den Arbeiter aus der Gruppe und löst einen Rebalance aus. Bei einem Rebalance werden die Aufgaben den Arbeitern mithilfe eines Rebalance-Protokolls zugewiesen.
Protokolle zur Wiederherstellung des Gleichgewichts
Die Besonderheiten von Rebalance (oder Rebalancing) Protokollen sind im Allgemeinen schwer zu verstehen. Um Kafka Connect effektiv zu nutzen, reicht es aus, den in diesem Abschnitt beschriebenen Prozess zu verstehen.
Kafka Connect möchte sicherstellen, dass alle Aufgaben ausgeführt werden, dass jede Aufgabe von einem einzigen Arbeiter ausgeführt wird und dass die Aufgaben gleichmäßig auf alle Arbeiter verteilt sind. Die Verteilung der Aufgaben muss immer dann aktualisiert werden, wenn sich die von Kafka Connect verwalteten Ressourcen ändern, z. B. wenn ein Worker der Gruppe beitritt oder sie verlässt oder wenn Aufgaben von einem Connector hinzugefügt oder entfernt werden. Wenn sich die Ressourcen ändern, muss Kafka Connect die Aufgaben neu auf die Worker verteilen.
Der Mechanismus, den Kafka Connect für Rebalances verwendet, hat sich im Laufe der Zeit geändert. Bis Kafka 2.3 hielt Kafka Connect bei einem Rebalance einfach alle Aufgaben an und wies sie den verfügbaren Workern zu. Dies wird als eager Rebalance-Protokoll bezeichnet, auch "stop the world" genannt. Das Hauptproblem bei diesem Protokoll ist, dass Kafka Connect eine Reihe unabhängiger Konnektoren betreiben kann, und jedes Mal, wenn einer dieser Konnektoren beschließt, Aufgaben zu erstellen oder zu löschen, werden alle Konnektoren und Aufgaben gestoppt, dann den Workern neu zugewiesen und dann neu gestartet. In einem ausgelasteten Kafka-Connect-Cluster kann dies zu langen und sich wiederholenden Pausen bei der Datenverarbeitung führen. Außerdem werden rollierende Neustarts dadurch sehr teuer, da jeder Worker zwei Neuzuordnungen verursacht: eine beim Herunterfahren und eine beim Neustart.
In Kafka 2.3 führte Connect ein inkrementelles kooperatives Rebalance-Protokoll namens compatible ein. Die Idee dahinter ist, dass nicht jedes Mal, wenn ein Rebalancing stattfindet, alle Konnektoren und Tasks gestoppt werden, sondern nur die Ressourcen, die rebalanciert werden müssen (wenn möglich inkrementell). Wenn zum Beispiel ein Worker verschwindet, wartet Kafka Connect eine kurze Zeit, bevor es einen Rebalancing-Vorgang durchführt. Das liegt daran, dass Worker in der Regel keine zerstörerischen Ausfälle erleben und sofort wieder starten. Wenn ein Worker schnell wieder einsteigt, behält er die Aufgaben, die ihm vorher gehörten, und es ist kein Rebalancing erforderlich. Wenn der Arbeiter nicht schnell genug wieder einsteigt - die Dauer wird über scheduled.rebalance.max.delay.ms festgelegt, die Standardeinstellung ist fünf Minuten -, werden die Aufgaben, die er zuvor ausgeführt hat, den verfügbaren Arbeitern neu zugewiesen.
Seit Kafka 2.4 ist das Standard-Rebalance-Protokoll sessioned. Was das Rebalancing-Verhalten angeht, funktioniert es genauso wie compatible, stellt aber auch sicher, dass die Kommunikation innerhalb des Clusters gesichert ist. Wie compatible ist auch sessioned nur aktiv, wenn alle Worker es unterstützen; andernfalls wird standardmäßig das gemeinsame Protokoll aller Worker verwendet.
Das von Kafka Connect verwendete Rebalance-Protokoll wird in der Konfiguration connect.protocol festgelegt. Nutzer sollten den Standardwert für die von ihnen verwendete Version beibehalten und nur dann ein Downgrade von auf eager in Erwägung ziehen, wenn sie auf dessen spezifisches Verhalten angewiesen sind.
Umgang mit Fehlern in Kafka Connect
Da du nun weißt, wie Kafka Connect seinen Status verwaltet, schauen wir uns die häufigsten Arten von Fehlern an und wie man sie behandelt.
Um eine widerstandsfähige Pipeline aufzubauen, ist es wichtig zu wissen, wie alle Komponenten deines Systems mit Ausfällen umgehen. In diesem Abschnitt konzentrieren wir uns auf Kafka Connect und wie es mit Ausfällen umgeht. Andere Komponenten wie das Betriebssystem, die Ausführungs- und Bereitstellungsumgebung oder die Hardware werden nicht berücksichtigt.
Wir decken die folgenden Ausfälle ab:
-
Arbeiterausfall
-
Ausfall des Anschlusses/der Aufgabe
-
Ausfall von Kafka/externen Systemen
Wir besprechen auch, wie du Warteschlangen für tote Buchstaben verwenden kannst, um nicht bearbeitbare Datensätze zu behandeln.
Versagen des Arbeiters
Im verteilten Modus kann Kafka Connect über mehrere Worker laufen. Wir empfehlen, mindestens zwei Worker zu verwenden, um gegen Ausfälle von Workern gewappnet zu sein.
Wenn wir zum Beispiel drei Arbeiter haben, die zwei Konnektoren (C1 und C2) betreiben, könnten die verschiedenen Aufgaben wie in Abbildung 4-7 verteilt werden.
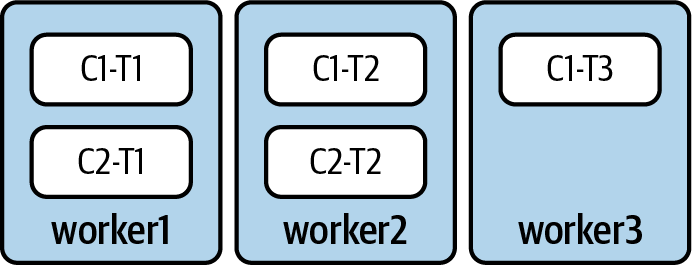
Abbildung 4-7. Beispiel für einen Kafka-Connect-Cluster mit drei Workern. Connector C1 hat drei Tasks (T1, T2, T3) und C2 hat zwei Tasks (T1 und T2).
Wenn worker2 in diesem Fall offline genommen wird - entweder weil er abgestürzt ist oder wegen Wartungsarbeiten - erhält Kafka seinen Heartbeat nicht mehr. Nach einer kurzen Zeitspanne wird Worker2 automatisch aus der Gruppe geworfen, was Kafka Connect dazu zwingt, alle laufenden Aufgaben auf die verbleibenden Worker zu verteilen.
Nach dem Rebalancing kann die Aufgabenzuweisung wie in Abbildung 4-8 aussehen.
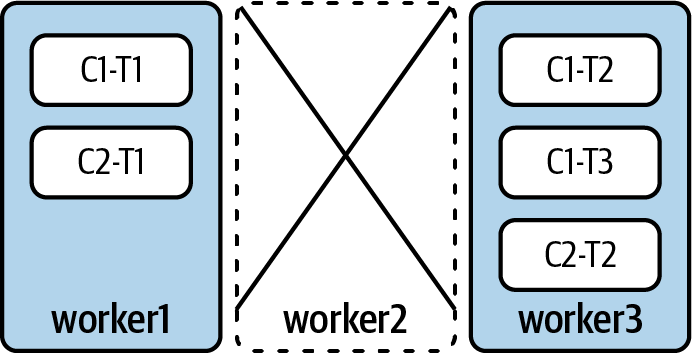
Abbildung 4-8. Kafka Connect hat alle Aufgaben den verbleibenden Workern neu zugewiesen
Während der Ausgleich stattfindet, werden die Aufgaben, die auf Worker2 lagen, nicht ausgeführt. Dieser Mechanismus wird ausgelöst und ist innerhalb von etwa fünf Minuten abgeschlossen. Wie lange es tatsächlich dauert, hängt vor allem von den folgenden Konfigurationen ab:
-
session.timeout.msist die maximale Dauer zwischen zwei aufeinanderfolgenden Herzschlägen von Arbeitern -
rebalance.timeout.msist die maximale Zeitspanne, die Arbeitnehmer brauchen können, um der Gruppe wieder beizutreten, wenn ein Rebalancing stattfindet -
scheduled.rebalance.max.delay.msist die Zeit, die gewartet wird, bevor die Konnektoren und Aufgaben der Arbeiter, die seit dem letzten Rebalancing aus der Gruppe herausgefallen sind, neu zugewiesen werden
Wenn ein Worker nicht sauber gestoppt wird, ist es möglich, dass seine Aufgaben nicht für alle Datensätze, die sie verarbeitet haben, Offsets übertragen haben. Daher kann es sein, dass einige Aufgaben beim Neustart einige Datensätze erneut verarbeiten. Auf dieses Problem gehen wir später in diesem Kapitel ein.
Damit Kafka Connect Ausfälle von Workern verkraften kann, musst du sicherstellen, dass du genügend Kapazität für die Umverteilung von Aufgaben hast. Kafka Connect hat keinen Mechanismus, um die Anzahl der Aufgaben zu begrenzen, die einem Worker während eines Rebalancings zugewiesen werden können. Wenn einem Worker zu viele Aufgaben zugewiesen werden, verschlechtert sich seine Leistung und die Aufgaben kommen schließlich nicht mehr voran. Zumindest solltest du immer genug Kapazität haben, um den Ausfall eines einzelnen Workers zu verkraften, damit rollierende Worker-Neustarts zuverlässig durchführen kann.
Anschluss/Aufgabe Ausfall
Eine weitere häufige Fehlerart ist der Absturz eines der Konnektoren oder einer seiner Aufgaben. Bis jetzt haben wir vereinfacht dargestellt, was genau passiert, wenn Kafka Connect einen Connector ausführt. In Wirklichkeit muss es eine Instanz des Connectors und null oder mehr Task-Instanzen ausführen. Kafka Connect verfolgt den Zustand beider Instanzen und verknüpft sie mit einem Status, der sein kann:
UNASSIGNEDEin Anschluss oder eine Aufgabe wurde noch nicht einem Arbeiter zugewiesen
RUNNINGEin Connector oder eine Aufgabe läuft korrekt auf einem Worker
PAUSEDEin Konnektor oder eine Aufgabe wurde von einem Benutzer über die REST-API pausiert
FAILEDEin Connector oder eine Aufgabe ist auf einen Fehler gestoßen und abgestürzt
RESTARTINGDer Konnektor/die Aufgabe wird entweder aktiv neu gestartet oder soll bald neu gestartet werden
STOPPEDEin Konnektor wurde von einem Benutzer über die REST-API gestoppt
Der Status von Konnektoren und Aufgaben kann über die REST-API abgefragt werden. In Abbildung 4-9 sind die häufigsten Übergänge zwischen den verschiedenen Zuständen dargestellt.
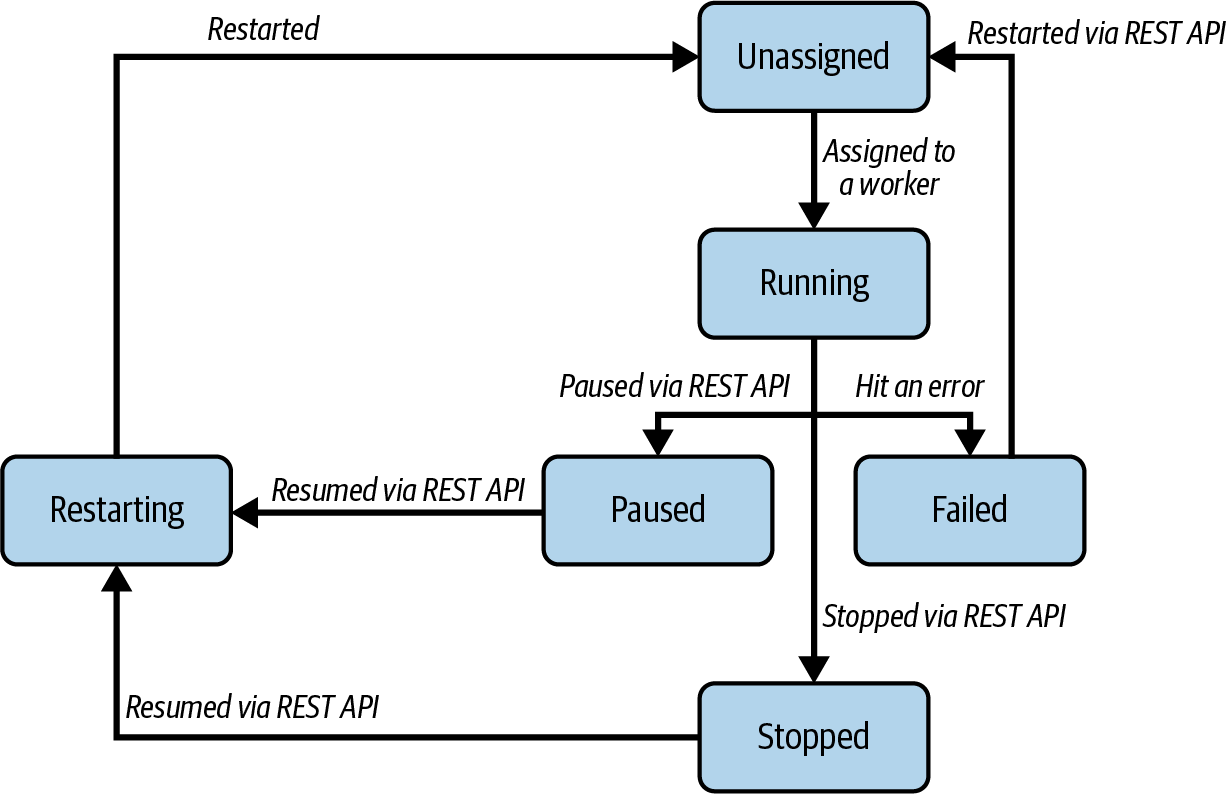
Abbildung 4-9. Die häufigsten Zustandsübergänge für Konnektoren und Aufgaben
Tipp
Kafka Connect gibt detaillierte Metriken aus, die die Zeit aufzeichnen, die jeder Connector in den einzelnen Zuständen verbringt. In Kapitel 9 erfährst du, wie du Metriken abrufen und überwachen kannst.
Der Status des Connectors und der Aufgaben wird unabhängig voneinander bestimmt. Einige Konnektoren können zum Beispiel eine zusätzliche Logik ausführen, wie z. B. eine Verbindung zu ihrem Zielsystem, um Ressourcen zu ermitteln, wenn sie gestartet werden. Während dies geschieht, befindet sich der Konnektor im Status RUNNING, aber es werden keine Aufgaben erstellt.
Jede Aufgabe kann auch unabhängig vom Connector einen Fehler haben (und als FAILED markiert werden). Wenn eine Aufgabe ein Problem hat, lässt Kafka Connect sie standardmäßig abstürzen, markiert sie als FAILED und versucht nicht, sie automatisch neu zu starten. Kafka Connect gibt Metriken für den Zustand von Tasks aus, die Administratoren überwachen müssen, um Ausfälle zu erkennen. Ein Ausfall einer Aufgabe löst keinen Rebalance aus.
Im Falle eines einmaligen Ausfalls können Administratoren Aufgaben über die REST-API neu starten. Über die REST-API können auch die Ausnahme, die die Aufgabe zum Absturz gebracht hat, und ihr Stack-Trace abgerufen werden. Im Falle eines systematischen Fehlers, z. B. eines Datensatzes, der nicht verarbeitet werden kann, bietet Kafka Connect die Möglichkeit, diesen zu überspringen (und optional eine detaillierte Protokollmeldung auszugeben), anstatt die Aufgabe fehlzuschlagen. Dies kann pro Connector über die Konfiguration errors.tolerance konfiguriert werden.
Ausfall von Kafka/externen Systemen
Da Kafka Connect Daten zwischen Kafka und externen Systemen fließen lässt, können sich Ausfälle in einem der beiden Systeme auf Kafka Connect auswirken.
Wie in Kapitel 2 beschrieben, kann Kafka sehr widerstandsfähig sein. Für einen stabilen Produktionseinsatz müssen Kafka-Cluster über mehrere Broker verfügen und so konfiguriert sein, dass sie maximale Verfügbarkeit bieten. Außerdem muss Kafka Connect so konfiguriert sein, dass es seine Topics mit mehreren Replikaten erstellt, damit es nicht durch den Ausfall eines einzelnen Brokers beeinträchtigt wird. Dies ist wichtig für Themen, die entweder die Quelle oder Senke für Konnektoren sind, für interne Kafka Connect-Themen sowie für __consumer_offsets und __transaction_state Themen.
Auf der anderen Seite muss ein externer Systemausfall vom Konnektor behandelt werden. Je nach System und Implementierung des Konnektors kann dies automatisch geschehen oder die Aufgaben stürzen ab und erfordern manuelle Eingriffe zur Wiederherstellung.
Bevor du eine Kafka-Connect-Pipeline aufbaust, ist es wichtig, die Dokumentation des Konnektors zu lesen und die Ausfallmodi des externen Systems zu verstehen, um die Ausfallsicherheit der Pipeline zu beurteilen. Manchmal gibt es mehrere Community-Implementierungen für dieselben Konnektoren und du musst diejenige auswählen, die deinen Anforderungen entspricht. Dann musst du Ausfallsicherheitstests durchführen, um festzustellen, ob der Konnektor die erforderliche Ausfallsicherheit für deine Anwendungsfälle bietet. Schließlich ist es wichtig, die entsprechenden Metriken und Protokolle sowohl des externen Systems als auch des Konnektors zu überwachen, die in Kapitel 9 beschrieben werden.
Dead Letter Queues
Wenn ein Datensatz nicht verarbeitet werden kann, kann Kafka Connect für Sink-Konnektoren eine Dead Letter Queue verwenden, anstatt den Datensatz zu überspringen oder fehlzuschlagen. Eine Dead-Letter-Queue, oft abgekürzt als DLQ, ist ein Konzept aus traditionellen Messaging-Systemen - im Grunde ein Ort, an dem Datensätze gespeichert werden, die nicht verarbeitet oder zugestellt werden können. In Kafka Connect ist die Dead Letter Queue ein Topic (das über errors.deadletterqueue.topic.name in der Konfiguration des Connectors angegeben wird), in das nicht verarbeitbare Datensätze geschrieben werden. Kafka Connect bietet jedoch keinen ähnlichen Mechanismus für Quellkonnektoren, da es den nicht zustellbaren Datensatz aus dem externen System nicht in einen Kafka-Datensatz umwandeln kann.
Hinweis
Die Unterstützung für Dead-Letter-Queues für Sink-Connectoren wurde erstmals über KIP-298 eingeführt und in Kafka 2.6 über KIP-610 weiter verbessert.
Schauen wir uns ein Beispiel für die Verwendung einer Dead-Letter-Queue an. Wenn der Confluent S3 Sink Connector ausgeführt wird, liest die Kafka Connect-Laufzeit Datensätze aus einem Kafka-Topic, bevor sie an den Connector übergeben werden. Da erwartet wird, dass das Topic Avro-Datensätze enthält, konfigurieren wir den Connector mit einem Avro-Konverter. Wenn jedoch ein einzelner Datensatz im Topic nicht im Avro-Format ist, kann der Connector diesen Datensatz nicht verarbeiten. Anstatt den Konnektor fehlzuschlagen oder diesen Datensatz zu verlieren, kann Kafka Connect ihn an eine Dead-Letter-Warteschlange weiterleiten und die anderen Datensätze im Topic weiter verarbeiten. Die Konfiguration des Konnektors würde die folgenden Einstellungen enthalten:
{"connector.class":"io.confluent.connect.s3.S3SinkConnector","value.converter":"io.confluent.connect.avro.AvroConverter","errors.tolerance":"all","errors.deadletterqueue.topic.name":"my-dlq"}
So kann der Inhalt der Warteschlange für tote Briefe von einem anderen Mechanismus verarbeitet werden, z. B. von einem anderen Konnektor oder einer Verbraucheranwendung.
Abbildung 4-10 zeigt ein Beispiel für die Verwendung einer Warteschlange für tote Buchstaben.
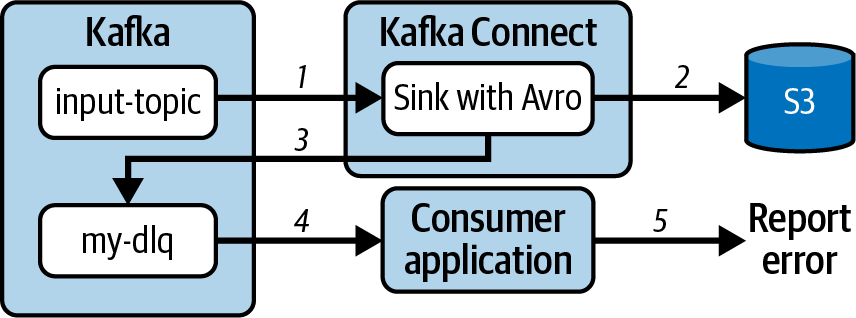
Abbildung 4-10. Nicht verarbeitbare Datensätze werden an eine Warteschlange für tote Buchstaben gesendet, um von einem anderen Mechanismus verarbeitet zu werden
Der Datenfluss beginnt damit, dass der mit Avro konfigurierte S3-Sink-Connector Datensätze aus dem Input-Topic empfängt (1). Avro-Datensätze werden korrekt verarbeitet und an S3 gesendet (2). Wenn ein Datensatz aufgrund von Fehlern in der Konverter-, Transformations- oder Sink-Task-Übermittlungsphase nicht verarbeitet werden kann, wird er an die für den Connector konfigurierte Dead-Letter-Warteschlange gesendet (3). In diesem Beispiel empfängt eine andere Anwendung die Datensätze von in der Warteschlange für tote Briefe (4), verarbeitet sie und meldet Fehler (5).
Semantik der Verarbeitung verstehen
Die Verarbeitungssemantik definiert die Art der Garantien, die gegeben werden, wenn eine Nachricht durch eine Kafka Connect-Pipeline fließt. Es kann sich um eine der drei folgenden Arten handeln:
- Wenigstens einmal
Eine Nachricht, die die Pipeline durchläuft, erreicht das Zielsystem mindestens einmal als eine oder mehrere Kopien. Zusätzliche Kopien einer Nachricht werden als Duplikate bezeichnet.
- Höchstens-einmal
Eine Nachricht, die in die Pipeline gelangt, kommt möglicherweise nicht im Zielsystem an und wird niemals dupliziert.
- Genau-einmal
Eine Nachricht, die in die Pipeline gelangt, wird von den nachgeschalteten Lesern genau einmal verarbeitet.
Die genaue Semantik, die eine Kafka-Connect-Pipeline bietet, hängt von mehreren Aspekten ab, z. B. von dem verwendeten Connector, seiner Konfiguration und der Konfiguration der Laufzeitumgebung.
Schauen wir uns die einzelnen Arten von Konnektoren an und sehen wir uns an, wie die Semantik, die bereitgestellt werden kann, zu verstehen ist.
Senkenanschlüsse
Zusammengefasst sind dies die Schritte, die eine Sink-Pipeline ausmachen:
-
Die Laufzeit konsumiert Datensätze aus dem Kafka-Thema
-
Datensätze werden an den konfigurierten Konverter übergeben
-
Datensätze werden an die konfigurierten Transformationen übergeben
-
Datensätze werden an den Sink-Connector übergeben, der sie in das Sink-System schreibt
Abbildung 4-11 zeigt diesen Fluss.

Abbildung 4-11. Schritte in einer Sink-Pipeline
Um die Semantik einer Sink-Pipeline zu bestimmen, gibt es ein paar verschiedene Elemente zu beachten:
-
Der Wert von
errors.tolerance -
Ob du ein DLQ verwendest
-
Das Verhalten des Verbinders
-
Die Merkmale des Zielsystems
Betrachten wir zunächst errors.tolerance. Diese Konfiguration teilt der Kafka Connect-Laufzeit mit, was zu tun ist, wenn der Konverter, die Transformationen oder der Connector einen Fehler melden. Der Standardwert ist none, was dazu führt, dass die Aufgabe fehlschlägt. In diesem Fall schlägt die Aufgabe fehl, ohne die Offsets für den Datensatz, der den Fehler verursacht hat, zu übermitteln, sodass dieser Datensatz beim Neustart erneut von der Aufgabe verarbeitet wird. Diese Einstellung bietet immer eine Mindesteinmal-Semantik; ob sie eine Exakt-Einmal-Semantik bietet, hängt vom spezifischen Verhalten des Konnektors ab (wir besprechen diese Überlegungen später in diesem Abschnitt).
Manchmal ist es unnötig, dass die Aufgabe fehlschlägt, wenn sie auf einen Fehler stößt. Wenn ein bestimmter Datensatz nicht verarbeitet werden kann (eine so genannte Giftpille), kann er dazu führen, dass die Aufgabe wiederholt fehlschlägt. Stattdessen kannst du errors.tolerance auf all setzen, damit die Laufzeit Datensätze überspringt, die zu Fehlern führen. Das ist gut für deine Aufgaben am Laufen zu halten, aber nicht hilfreich, wenn du eine Exact-once- oder At-least-once-Semantik anstrebst.
Wenn du errors.tolerance mit der Einstellung all verwendest und eine Exact-once- oder At-least-once-Semantik wünschst, besteht eine Möglichkeit darin, eine Dead Letter Queue zu konfigurieren. Bei einer DLQ stellt die Laufzeitumgebung sicher, dass im Falle eines Fehlers keine Datensätze verloren gehen und leitet die betroffenen Datensätze automatisch an die DLQ weiter. Mit diesem Ansatz erhältst du in den meisten Fällen die "at-least-once"-Semantik. Allerdings ist zu beachten, dass Kafka Connect beim Senden von Datensätzen an die DLQ keinen erneuten Versuch unternimmt.
Schließlich musst du den Connector selbst in Kombination mit den Eigenschaften des Zielsystems betrachten. Der Unterschied zwischen "at-least-once" und "exactly-once" liegt oft darin, wie die Daten an das Zielsystem gesendet werden. Da die Datensätze in Kafka unveränderlich sind, kann der Konnektor, wenn dieselben Datensätze zweimal verarbeitet werden, genau dieselben Datensätze an das Zielsystem senden. In Systemen, die idempotente Schreibvorgänge anbieten - zum Beispiel durch die Speicherung von Datensätzen auf der Grundlage ihres Schlüssels - können sie doppelte Datensätze entfernen und nur eine einzige Kopie aufbewahren, wodurch eine Exact-once-Semantik erreicht wird.
Das Verhalten des Konnektors bestimmt auch, ob du eine at-most-once oder at-least-once Semantik hast. Jedes Mal, wenn eine Aufgabe startet, fängt sie mit dem letzten übertragenen Offset an. Standardmäßig überträgt die Laufzeitumgebung nur Offsets für Datensätze, die erfolgreich an den Konnektor übergeben wurden und nicht zu einem Fehler geführt haben. Wenn der Konnektor also asynchron Daten an das externe System schreibt, muss er die bereitgestellten Hooks nutzen, um zu beeinflussen, welche Offsets die Laufzeit übertragen kann. Wenn die Aufgabe sonst abstürzt, bevor der Konnektor den Datensatz erfolgreich geschrieben hat und nachdem der Offset übertragen wurde, würde dieser Datensatz beim Neustart der Aufgabe übersprungen werden.
Zusammenfassend lässt sich sagen, dass die Konfiguration errors.tolerance wichtig ist, um die Semantik einer Sink-Pipeline zu bestimmen. Wenn sie auf all gesetzt ist, überspringt die Laufzeit nicht verarbeitbare Datensätze. Wenn du den Verlust von Datensätzen vermeiden und die Verfügbarkeit einer Sink-Pipeline maximieren willst, solltest du die Verwendung einer Dead-Letter-Queue in Erwägung ziehen, aber bedenke die damit verbundenen zusätzlichen Betriebskosten. Auch wenn einige Schritte zu Duplikaten führen können, sind einige externe Systeme in der Lage, damit umzugehen, und bietet eine durchgängige Exact-once-Semantik für Sink-Pipelines.
Quelle Steckverbinder
Zur Erinnerung: Dies sind die Schritte, die eine Source-Pipeline ausmachen, wie in Abbildung 4-12 dargestellt:
-
Der Connector konsumiert Datensätze aus dem externen System
-
Datensätze werden an die konfigurierten Transformationen übergeben
-
Datensätze werden an den konfigurierten Konverter übergeben
-
Datensätze werden an die Laufzeitumgebung übergeben, die sie in einem Kafka-Topic erzeugt

Abbildung 4-12. Schritte in einer Source-Pipeline
Um die Semantik für eine Quellpipeline zu bestimmen, musst du Folgendes beachten:
-
Verwendung der Offsets des Quellanschlusses
-
Der Wert von
errors.tolerance -
Das Verhalten des Produzenten
-
Ob die Exact-once-Unterstützung aktiviert ist
Ähnlich wie der Verbraucher, der in einer Sink-Pipeline Datensätze abruft, muss der Konnektor in einer Source-Pipeline entscheiden, welche Daten er aus dem externen System abrufen will. Nicht alle externen Systeme verfügen über einen Mechanismus wie Offsets in Kafka, mit dem sie einen Datensatz direkt identifizieren können. Aus diesem Grund können Quellkonnektoren eine beliebige Zuordnung von Schlüsseln zu Werten - das sourceOffset Feld in SourceRecord Objekten - assoziieren, um ihre aktuelle Position auszudrücken. Dieses beliebige Objekt kann bei Bedarf von Tasks abgerufen werden. Es liegt in der Verantwortung des Konnektors, sicherzustellen, dass dieses Objekt die richtigen Informationen enthält, um die Datensätze korrekt aus dem externen System abzurufen. Die Kafka-Connect-Laufzeit speichert dieses Objekt automatisch im Offset-Topic und bietet außerdem einen Mechanismus, mit dem die Konnektoren wissen, wann sie Offsets übermitteln, falls sie ihre eigene Offset-Verfolgung im Zielsystem durchführen wollen. In den meisten Quell-Connector-Pipelines werden die Offsets nach der Produktion von Datensätzen in Kafka übertragen. Daher ist es möglich, dass ein Worker zwar erfolgreich Datensätze in Kafka produziert, aber fehlschlägt, bevor er die Offsets übertragen kann. Je nach Funktionsweise des Konnektors kann dieser Schritt zu einer erneuten Verarbeitung von Datensätzen führen, was zu einer "at-least-once"-Semantik führt.
Bei Fehlern in den Transformationen, Konvertierungsschritten oder in dem von der Laufzeit verwendeten Producer bestimmt der Wert der Einstellung errors.tolerance, ob die Aufgabe als FAILED markiert oder der fehlschlagende Datensatz übersprungen wird. Quellaufgaben können sich nicht auf Warteschlangen mit toten Buchstaben verlassen, daher sorgt die Fehlertoleranz dafür, dass diese Schritte im Falle von Fehlern eine at-most-once-Semantik bieten.
Datensätze in einer Quellpipeline werden über einen Producer von der Runtime an Kafka gepusht. Seit Kafka 3.1.0 sind Producer standardmäßig so konfiguriert, dass sie at-least-once anbieten, aber das kann in der Konfiguration des Connectors außer Kraft gesetzt werden.
In Kafka 3.3 wurde über KIP-618 die Unterstützung für Exact-once in Source Connectors hinzugefügt. Wenn diese Funktion aktiviert ist, verwendet die Runtime einen transaktionalen Producer, um Offsets und Producer als Teil einer einzigen Transaktion an Kafka zu übertragen. In Kapitel 8 wird erklärt, welche Worker- und Connector-Konfigurationen erforderlich sind, um diese Funktion zu aktivieren. Nicht alle Quellkonnektoren unterstützen Exact-once, also sieh dir unbedingt die Dokumentation des Konnektors an. Außerdem erklären wir in Kapitel 11, wie du einen Konnektor schreibst, der Exact-once unterstützt. Du kannst diese Informationen nutzen, um deinen eigenen Konnektor zu schreiben oder um die Semantik eines bestehenden Konnektors zu bewerten.
Warnung
Die Exactly-once-Semantik für Quellkonnektoren ist im Standalone-Modus nicht verfügbar.
Zusammenfassend lässt sich sagen, dass die Art und Weise, wie Quellkonnektoren mit Offsets umgehen und wie diese an Kafka übergeben werden, Schlüsselfaktoren für die Semantik von Quellpipelines sind. Wie bei Sink-Pipelines spielt auch die Konfiguration von errors.tolerance eine Rolle. Anders als bei Sink-Pipelines kannst du jedoch keine Dead-Letter-Queues verwenden, um übersprungene Datensätze abzufangen.
Zusammenfassung
In diesem Kapitel haben wir uns mit den verschiedenen Aspekten befasst, die beim Aufbau stabiler Datenpipelines mit Kafka Connect berücksichtigt werden müssen.
Zuerst haben wir uns angesehen, wie man aus den Hunderten von Konnektoren, die von der Kafka-Community entwickelt wurden, die richtigen auswählt. Du musst die Richtung der Pipeline berücksichtigen, ob sie deine Anforderungen an die Funktionen erfüllt und ob sie ein angemessenes Maß an Unterstützung bietet.
Dann haben wir uns mit Datenmodellen und -formaten beschäftigt und mit den Optionen, die du hast, um Daten zwischen Systemen abzubilden. Wie auch immer du dich entscheidest, du musst die Struktur deiner Daten in jeder Phase der Pipeline verstehen und bewusste Entscheidungen zur Umwandlung und Formatierung treffen. Diese Entscheidungen beeinflussen die Wahl deiner Konverter, Transformationen und Prädikate. Wir haben auch die Vorteile der Verwendung von Schemas und einer Schemaregistrierung hervorgehoben, um die Struktur der Daten richtig zu definieren, durchzusetzen und zu verwalten.
Anschließend haben wir uns mit den Herausforderungen befasst, die beim Umgang mit den vielen Arten von Fehlern auftreten können, von Worker-Abstürzen bis hin zu Task-Fehlern. Obwohl Kafka Connect im Allgemeinen als widerstandsfähig gilt, kann es sich nicht von allen Ausfällen erholen. Deshalb solltest du die Hebel verstehen, die wir besprochen haben, und wissen, wie du sie im Falle von Ausfällen einsetzen kannst.
Schließlich haben wir erläutert, wie sich alle Entscheidungen in Bezug auf Datenmodelle, Fehlerbehandlung, Laufzeit und Connector-Konfigurationen direkt auf die Verarbeitungssemantik auswirken, die von Kafka Connect-Pipelines erreicht werden kann. Für Sink-Pipelines sind Dead-Letter-Queues eine leistungsstarke Funktion, um Datenverluste zu vermeiden, und es ist möglich, mit leistungsfähigen Downstream-Systemen eine Exact-Once-Semantik zu erreichen. Seit Kafka 3.3 können Quell-Pipelines mit Konnektoren, die diese Funktion unterstützen, auch Exact-once erreichen.
Get Kafka Verbinden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

