Chapter 1. What Is Infrastructure as Code?
If you work in a team that builds and runs IT infrastructure, then cloud and infrastructure automation tools should help you deliver more value in less time, and to do it more reliably. In practice, however, they drive ever-increasing size, complexity, and diversity of things to manage.
These technologies have become especially relevant over the past decade as organizations brought digital technology deeper into the core of what they do. Previously, many leaders had treated the IT function as an unfortunate distraction that should be outsourced and ignored. But digitally sophisticated competitors, users, and staff drove more processes and products online and created entirely new categories of services like streaming media, social media, and machine learning.
Cloud and automation have helped by making it far easier for organizations to add and change digital services. But many teams have struggled to manage the proliferation of cloud-hosted products, applications, services, and platforms. As one of my clients told me, “Moving from the data center, where we were limited to the capacity of our hardware, to the cloud, where capacity is effectively unlimited, knocked down the walls that kept our tire fire contained.”1
Using code to define and build infrastructure creates the opportunity to bring a wide set of tools, practices, and patterns to bear on the problem of how to design and implement systems. This book explores ways of doing this. I describe the problems that Infrastructure as Code can help with, challenges that come from different approaches to using infrastructure code, and patterns and practices that have proven to be useful.
This chapter gives context for the rest of the book. This starts, in the traditional way, with a definition of Infrastructure as Code. Next is a discussion of the trends that are affecting the spread and evolution of managing infrastructure using code, and how the infrastructure architecture fits into the needs of an organization and its technology strategy.
The central theme of this book is the need to build infrastructure that can continuously evolve to meet changing requirements.
In the past few years the term “infrastructure delivery lifecycle” is gaining popularity among vendors, along with “day 2 requirements”. In other words, it’s not enough to build infrastructure, we need to be able to continuously fix, update, upgrade, expand, reshape, and adapt our infrastructure. The second half of this chapter expands on this thesis, including common myths that people believe about infrastructure in general, and cloud infrastructure in particular.
The context provided in this chapter shapes everything else in this book. If you’ve been working with infrastructure code and cloud for a while, you’ll probably skim over it, hopefully nodding your head. If you’re new to it, or new to these approaches, this content may help clarify the approaches advocated throughout the rest of the book.
Infrastructure as Code
A literal definition of Infrastructure as Code is the practice of provisioning and managing infrastructure using code, as opposed to doing it interactively or with non-code automation tools. By “interactively”, I mean using a command-line tool or GUI interface to carry out tasks.
Interactive infrastructure management doesn’t help in doing things consistently or repeatably, since we decide how to implement each change as we work. This leads to inconsistent implementations and mistakes. Chapter 2 talks about some of the principles and goals that using code helps to achieve, most of which are nearly impossible with interactive infrastructure management.
No-code automation tools typically provide a GUI interface to define the infrastructure we want, for example by choosing options from drop-down menus. These tools usually have ways to save configurations that we build, for example creating templates, which means we can build multiple instances consistently. They may also have ways to update existing infrastructure to keep consistency over time.
However, no-code tools store the definitions for infrastructure in closed systems, rather than in open files. With these systems we can’t exploit the vast ecosystem of tools for working with code, such as source control repositories, code scanning tools, automated testing, and automated delivery, to name just a few.
Chapter 4 goes into more detail about different types of infrastructure coding tools and languages.
No-code and low-code infrastructure automation may have a place in building and managing infrastructure, but generally work best at higher levels of abstraction, assembling components. The components themselves, however, are likely to be built using code. Read more about infrastructure componentization in Chapter 6.
The definition of Infrastructure as Code is about more than the mechanics of how infrastructure is defined and provisioned. Infrastructure as Code is about applying the principles, practices, and tools of software engineering to infrastructure.
This book explains how to use modern software development practices such as Test Driven Development (TDD), Continuous Integration (CI), and Continuous Delivery (CD) to make changing infrastructure fast and safe. It also describes how principles of software design help create resilient, well-maintained infrastructure. These practices and design approaches reinforce each other. Well-designed infrastructure is easier to test and deliver. Automated testing and delivery drive simpler and cleaner designs.
From the Iron Age to the Cloud Age
We can use modern technologies like cloud and virtualization, and tools to automate infrastructure, deployment, and testing, to carry out tasks much more quickly than we can by managing physical hardware and manually typing commands or clicking on GUIs. But as many organizations have discovered, simply adopting these tools doesn’t necessarily bring visible benefits.
Iron Age |
Cloud Age |
|
Types of resources |
Physical hardware |
Virtualized resources |
Provisioning |
Takes days or weeks |
Takes minutes or seconds |
Processes |
Manual (runbooks) |
Automated (code) |
The ability to provision new infrastructure in moments, and to set up systems that provision it without direct human involvement, can lead to uncontrolled sprawl. If we don’t have good processes for ensuring systems are well-managed and maintained, then the unbounded nature of cloud technology leads to spiraling technical debt.
Cloud Age Approaches To Change Management
Many organizations try to control the potential chaos by using older, traditional IT governance models. These models focus on throttling the speed of change, requiring implementation details to be decided before work begins, high-effort process gates, and strictly siloed responsibilities between teams.
However, these models were designed for the Iron Age when changes were made to physical infrastructure manually, meaning changes were slow and expensive. This in turn made mistakes difficult and expensive to correct. If a task would take two weeks, and a mistake could take a week or more to fix afterwards, then it seemed reasonable to add an extra week up front in hopes of preventing a mistake from happening. With cloud technology these processes add weeks to tasks that may take less than an hour to implement and a few minutes to correct, destroying the advantages of the technology.
What’s more, research2 suggests that these heavyweight processes were never very effective in preventing errors in the first place. In fact, they can make things worse by dividing knowledge and accountability across silos and long periods of time.
Fortunately, the emergence of Cloud Age technologies has coincided with the growth of Cloud Age approaches to work, including lean, agile, and DevOps. These approaches encourage close collaboration across roles, short feedback loops with users, and a minimalist, quality-first approach to technical implementation. Automation is leveraged to fundamentally shift thinking about change and risk, which results not only in faster delivery but also higher quality (Table 1-2).
Iron Age |
Cloud Age |
|
Cost of change |
High |
Low |
Changes are |
Risks to be minimized |
Essential to improve quality |
A change of plan means |
Failure of planning |
Success in learning and improving |
Optimize to |
Reduce opportunities to fail |
Maximize speed of improvement |
Delivery approach |
Large batches, test at the end |
Small changes, test continuously |
Architectures |
Monolithic (fewer, larger moving parts) |
Microservices architectures (more, smaller parts) |
This ability to leverage change speed to improve quality starts with cloud technology, which creates the capability to provision and change infrastructure on demand. Automation gives us a way to exploit this capability. Not only can we automate to deploy a change quickly, we can automate to validate the change for correctness, quality, and governance. And by defining changes as code, we create a detailed history that can be used to audit, troubleshoot, and reverse changes.
So another definition of Infrastructure as Code is a Cloud Age approach to automating cloud infrastructure in a way that embraces continuous change to achieve high reliability and quality.
DevOps and Infrastructure as Code
People define DevOps in different ways. The fundamental idea of DevOps is collaboration across all of the people involved in building and running software. This includes not only developers and operations people, but also testers, security specialists, architects, and even managers. There is no one way to implement DevOps.
Many people look at DevOps and only notice the technology that people use to collaborate across software delivery. All too often this leads to reducing “DevOps” to tooling. I’ve seen “DevOps” defined as using an application deployment tool (usually Jenkins), often with a separate “DevOps” team that adds an extra barrier across the software delivery path, which contradicts the meaning of the term.
DevOps is first and foremost about people, culture, and ways of working. Tools and practices like Infrastructure as Code are valuable to the extent that they’re used to bridge gaps and improve collaboration, but they aren’t enough.
The Path To The Cloud Age
DevOps, Infrastructure as Code (the name, at least), and Cloud all emerged between 2005-2010. In the early years, these were largely experimental, dismissed by larger organizations that considered themselves too serious to need to change how they approached IT. The first edition of this book, published in 2016, included arguments for why readers really should consider using cloud even for critical domains like finance and healthcare.
The mid-2010s could be considered the “Shadow Age” of IT. Cloud, DevOps, Continuous Delivery, and Infrastructure as Code were mostly used either by startups or by separate digital departments of larger organizations. These departments were usually set up outside the remit of the existing organization, partly to protect them from the cultural norms and formal policies of the main organization, which people sometimes call “antibodies”. In some cases they were created quietly within existing departments without involving the IT department, as shadow IT.
The mantra of the shadow age was “move fast and break things3.” Casting aside the shackles of Iron Age governance was seen as the key to explosive growth. In the view of digital hipsters, it was time to leave the crusty old-timers to their CAB4 meetings, mainframes, and bankruptcies (“Say hello to Blockbuster and Kodak!”)
Cavalier attitudes towards governance made it easier for traditionalists to dismiss the newer technologies and related ideas as irresponsible and doomed to failure. At the same time, new technology enthusiasts have often ignored the very real concerns and risks that underpin what may seem like legacy mindsets.
We need to learn how to leverage newer technologies and ways of working to address fundamental issues, rather than either rejecting the new ways or dismissing the issues as legacy.
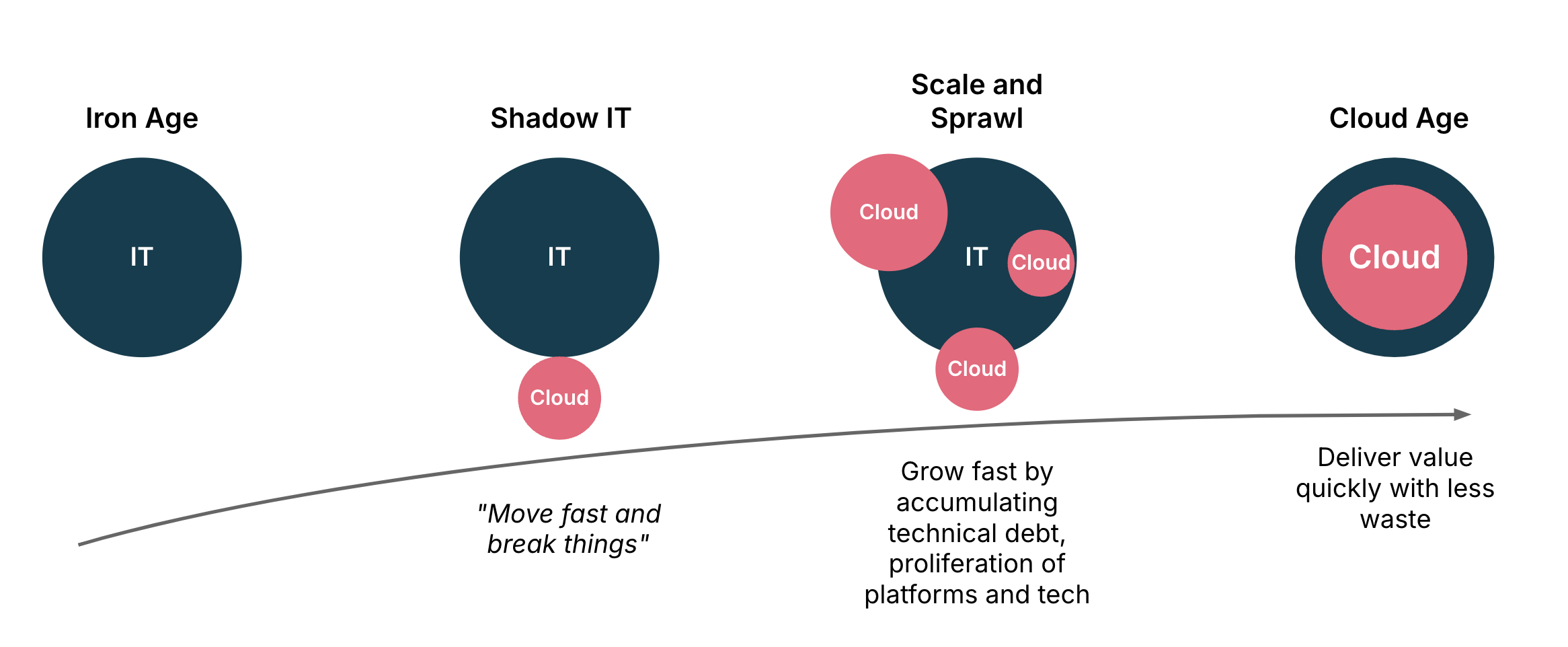
Figure 1-1. The path from the Iron Age to the Cloud Age
As the decade wore on and digital businesses overtook slower businesses in more and more markets, digital technologies and approaches were pulled closer to the center of even older businesses. Digital departments were assimilated, and boards asked to see strategies to migrate core business systems into the cloud. This trend accelerated when the COVID-19 pandemic led to a dramatic rise in consumers and workers moving to online services. Many organizations found that their digital services were not ready for the unexpected level of demand they were faced with. As a result, they increased their investment and efforts in cloud technologies.
This period where cloud technology has been shifting from the periphery of business to the center can be called the “Age of Sprawl”. Although breaking things had gone out of fashion moving fast was still the priority. As a result of the haste to adopt new technologies and practices, larger organizations have seen a proliferation of initiatives. Larger organizations typically have multiple, disconnected teams building “platforms” using various technologies, multiple cloud vendors, and varying levels of maturity and quality.
The variety of options available for building digital infrastructure and platforms5, and the rapid pace of change within them, has made it difficult to keep up to date. Platforms built on the latest technology two years ago may already be legacy.
The drivers that led to this sprawl are real. Organizations have needed to rapidly evolve to survive and prosper in the modern, digital economy. However, as I write this in late 2024, the economic landscape has changed in a way that means most organizations need to be more careful in how they invest. Not only do we need to be choosy about what new systems and initiatives to invest in, but we also need to consider how to manage the cost of running and evolving what we already have in place. The need to grow, improve, and even exploit emerging technologies has not gone away, so the next age is not simply one of cutting back and staying in place. Instead, organizations need to find sustainable ways to grow and evolve. Call it the Age of Sustainable Growth.
What does this have to do with Infrastructure as Code? Those of us involved in designing and building the foundational layers of our organizations’ business systems need to be aware of the strategic drivers those foundations must support. At the moment a key driver is rationalizing systems to sustain growth with less waste. In the years to come our organizations’ needs are likely to shift again.
The future is not evenly distributed
The tidy linear narrative described here as “the path to the Cloud Age” is, as with any tidy linear narrative, simplistic. Many people and organizations have experienced the trends it describes. But none of its “ages” have completely ended, and many of the drivers of different ways of thinking and working are still valid. It’s important to recognize that contexts differ. A Silicon Valley startup has different needs and constraints than a transnational financial institution, and new technologies and methodologies create opportunities to handle old risks and new opportunities in different ways. The path to the Cloud Age is uneven and far from over, understanding how it has unfolded so far can help us navigate what comes next
Strategic Goals and Infrastructure as Code
Figure 1-2 shows the gap between organizational strategy and infrastructure strategy. Customer value should drive the organization’s strategy, which drives strategy to infrastructure via product and technology strategy. Each strategic layer supports the layers above it.
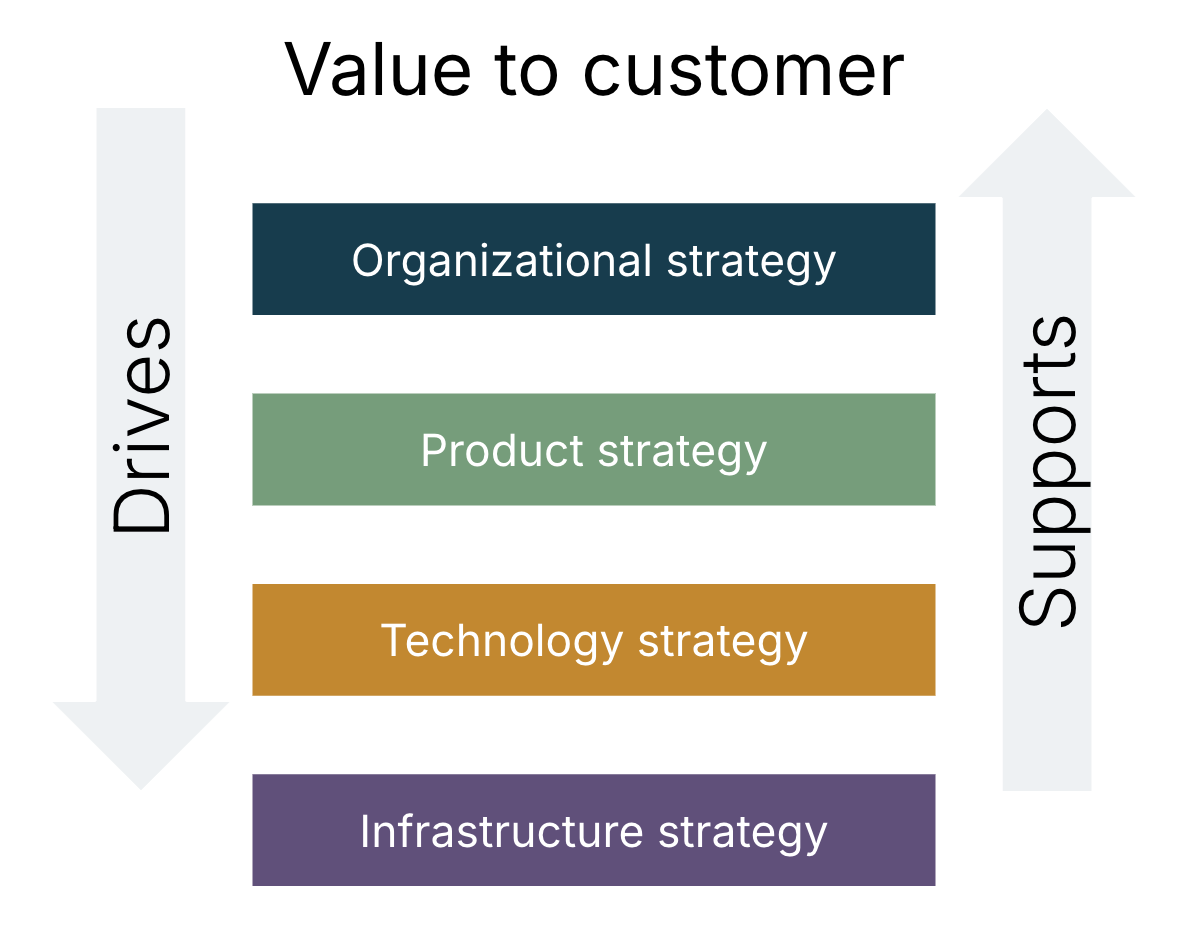
Figure 1-2. Customer value driving strategy down to infrastructure
When talking to organizations about their strategy for cloud infrastructure, I’m often struck by the gap between people responsible for the infrastructure and those responsible for organizational strategy. Engineering people are puzzled when I ask questions about the product and commercial strategy. Organizational leaders are dismissive of the need to spend time planning infrastructure capability, assuming that selecting a cloud vendor is the end of that story. Even when their infrastructure architecture creates problems with growth, stability, or security, the instinct is to demand a quick fix and move on.
The gap is not one-sided. Engineering folks tend to focus on implementing the solutions that seem obvious to them, sometimes assuming that it doesn’t make much difference what will run on it. One example of how this turns out is a company whose engineers built a multi-region cloud hosting solution with iron-clad separation between regions. The team wanted to make sure that user data would be segregated to avoid conflicts with different privacy regulations, so this requirement was baked deep into the architecture of their systems.
However, because neither the product nor engineering teams believed they needed close communication during development, the service was nearly ready for production rollout when it surfaced that the commercial strategy assumed that users would be able to use the service while traveling and working in different countries. It took considerable effort, expense, and delay to rearchitect the system to ensure that privacy laws could be respected between regions while giving users international roaming access.
So although infrastructure can seem distant from strategic goals discussed in the boardroom, it’s essential to make sure everyone from strategic leaders to engineering teams understands how they are related. Table 1-3 describes a few common organizational concerns where infrastructure architecture can make a considerable difference in either enabling success or creating drag.
Business Goal |
Infrastructure Capabilities to Support |
Measures of Success |
Deliver increasing value to customers quickly and reliably through new products and features. |
Provide infrastructure needed to develop, test, and host new and existing digital services. |
High performance on the four key metrics (“The Four Key Metrics”). Low effort and dependency on platform and infrastructure teams for common software delivery use cases. |
Grow revenues by adding new markets, products, and customers. |
Add hosting for new regions, instances of our products, and capacity. |
Time to add new hosting. Incremental cost of ownership for each region, instance, product, and user. |
Provide reliable, performant services to our users. |
Scaling, recovery, monitoring, and performance management services. |
Availability and performance metrics. |
Throughout this book, I use the example of a fictitious company called “FoodSpin”, an online restaurant menu service, to illustrate the concepts I discuss. “Introduction to FoodSpin and their strategy” gives a high-level view of the company’s strategy.
System Architecture Goals and Infrastructure as Code
An organization’s strategic goals typically filter down into goals for services and technology, which can cross teams such as product development, software engineering, platform engineering, and IT operations. These groups will have their own goals, objectives, and initiatives that infrastructure architecture needs to support.
Figure 1-3 shows an example of how organizational goals, such as the ones described in “Introduction to FoodSpin and their strategy”, drive goals for an engineering organization, which in turn drive goals for the infrastructure architecture. Infrastructure as Code can be used to ensure environments are consistent across the path to production as well as across multiple production instances. Read about different types of environments in Chapter 12.
Consistency across environments supports the engineering goal of improving software delivery effectiveness by making sure that test environments accurately reflect production environments. Consistency also reduces the amount of customization needed to provision new environments for adding products or expanding into new regions.
It’s easier to automate operational capabilities like security, compliance, and recovery when infrastructure is built consistently. And having less variation between environments makes it easier to consolidate and simplify overall system architecture. So this one goal for infrastructure architecture can support multiple higher-level goals for the organization.
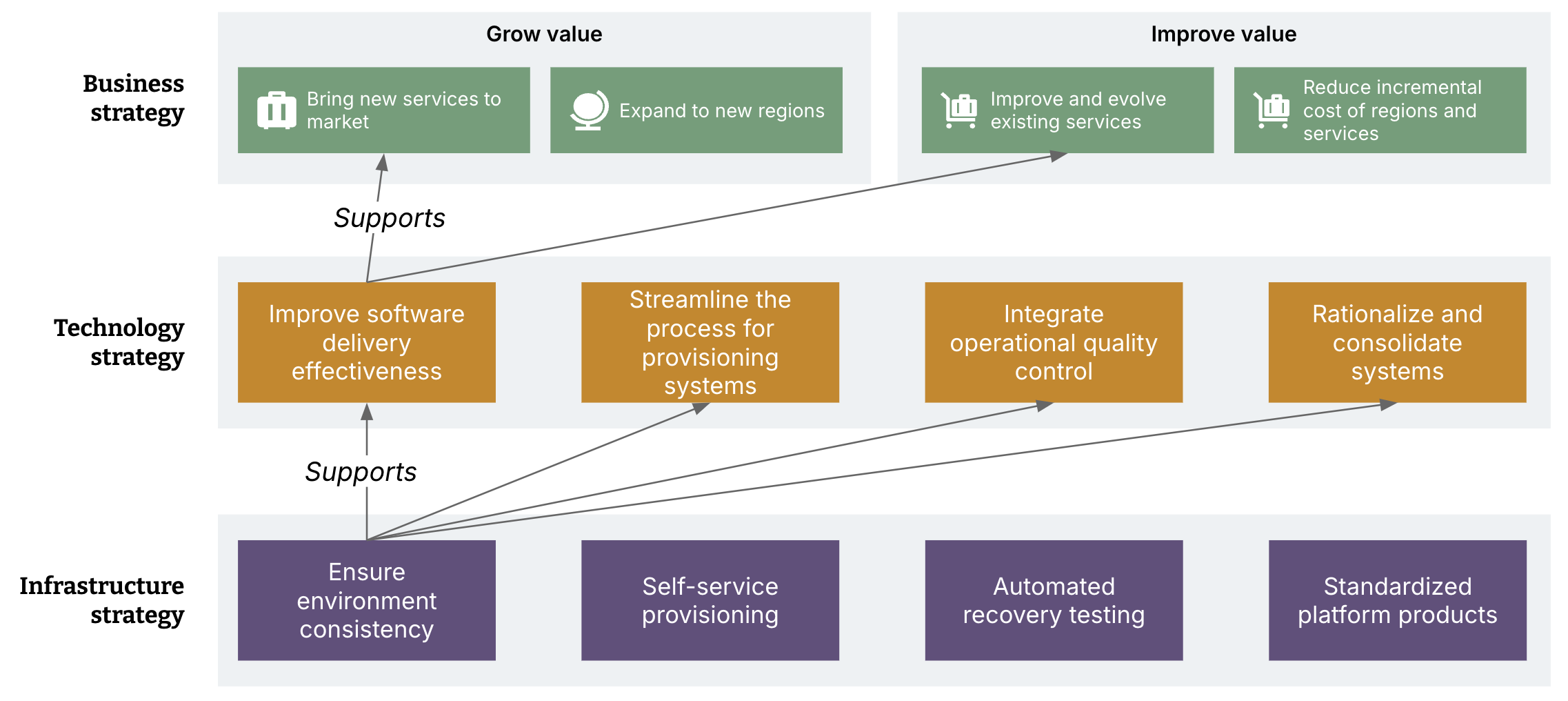
Figure 1-3. Example of infrastructure goals driven by organizational goals
Use Infrastructure as Code to Optimize for Change
One of the most fundamental reasons for adopting Infrastructure as Code, although it’s not universally understood in our industry, is to optimize the process for making changes to IT systems. When an organization finds that they’re failing to see value from their use of cloud and infrastructure automation, it is commonly because they have not approached these technologies as enablers for change.
Operations teams know that the biggest risk to a production system is making a change to it.6 The Iron Age approach to managing this risk, as mentioned earlier, is to add heavyweight processes to make changes more slowly and carefully. However, adding barriers to making changes adds barriers to fixing and improving the quality of a system.
Research from the Accelerate State of DevOps Report backs this up. Making changes frequently and reliably is correlated to organizational success.7
Rather than resisting commercial pressures to make changes frequently and quickly, modern methods of change management, from lean to agile, lean into the idea that this is a good thing. Having the ability to deliver changes both rapidly and reliably is the secret sauce for resilient, highly-available, valuable systems in the digital age.
People raise several common objections when considering change as a goal for automation. These come from misunderstandings of how to use automation.
Myth: Infrastructure Doesn’t Change Very Often
We want to think that we build an environment, and then it’s “done.” In this view, we won’t make many changes, so automating the process to make changes, especially testing, is a waste of time.
In reality, very few systems stop changing before they are retired. Some people assume that a fast pace of change is temporary. Others create heavyweight change request processes in a deliberate effort to discourage people from asking for changes. However, high performing teams handle a continuous stream of changes quickly and effectively.
Consider these common examples of infrastructure changes:
-
An essential new application feature requires a new data processing service.
-
A new application feature needs the messaging service to be upgraded to a newer version.
-
Performance profiling shows that the current application deployment architecture is limiting performance. We need to redeploy the applications across multiple clusters globally. Doing this requires changing cloud accounts and network architecture.
-
There is a newly announced security vulnerability in system packages for the container cluster. We need to patch clusters across multiple regions, as well as development and testing systems.
-
The API gateway experiences intermittent failures. We need to make a series of configuration changes to diagnose and resolve the problem.
-
We find a configuration change that improves the performance of the database.
An infrastructure team with heavyweight change processes accumulates a backlog of outdated, unpatched systems, and act as a drag on their organization’s ability to adapt to challenges and opportunities.
Myth: We Can Build the Infrastructure First and Automate It Later
Getting started with infrastructure automation is a steep curve. Setting up the tools, services, and working practices to automate infrastructure delivery is loads of work, especially when also migrating to a new cloud platform or technology stack. The value of this work is hard to demonstrate before starting to build and deploy services with it. Even then, the value may not be apparent to people who don’t work directly with the infrastructure.
Stakeholders often pressure infrastructure teams to build new cloud-hosted systems quickly, by hand, and worry about automating it later. There are several reasons why automating afterward is a bad idea:
-
Automation can enable faster delivery for new systems as well as existing systems. Implementing automation after most of the work has been done sacrifices this opportunity.
-
Automation makes it easier to write automated tests for what we build. And it makes it easier to quickly fix and rebuild when we find problems. Doing this as a part of the build process helps us to build a more robust infrastructure.
-
Automating an existing system is very hard. Automation is part of a system’s design and implementation. To add automation to a system built without it, we need to change the design and implementation of that system significantly. This is also true for automated testing and deployment.
Cloud infrastructure built without automation becomes a write-off sooner than we’d like. The cost of manually maintaining and fixing the system can escalate quickly. If the service it runs is successful, stakeholders will put on pressure to expand and add features rather than go back to add automation.
The same is true when building a system as an experiment. Once a proof of concept is up and running, people want to move on to the next thing, rather than to go back and build it right. And in truth, automation should be a part of the experiment. If we intend to use automation to manage our infrastructure, we need to understand how the automation will work, so it should be part of our proof of concept.
The solution is to build the system incrementally, automating as we go. The trick is to start with the bare minimum of automation needed to deliver the first increment of the system rather than trying to start by building a complete automation system first. It can help to use ready-made solutions to start with, even if we intend to adopt something more sophisticated later.
For example, I worked with a team who wanted to use an advanced, packaged secrets management solution, but they needed a few weeks to implement it properly. We chose to use the cloud platform’s built-in secrets storage service initially, so the development team could start working to get the first increment of business functionality in place. We were able to deploy the packaged solution while the developers were working, rather than making them wait for us.
Myth: Speed And Quality Must Be Traded Off Against Each Other
It’s natural to think that we can only move fast by skimping on quality and that we can only get quality by moving slowly. Many people see this as a continuum, as shown in Figure 1-4.
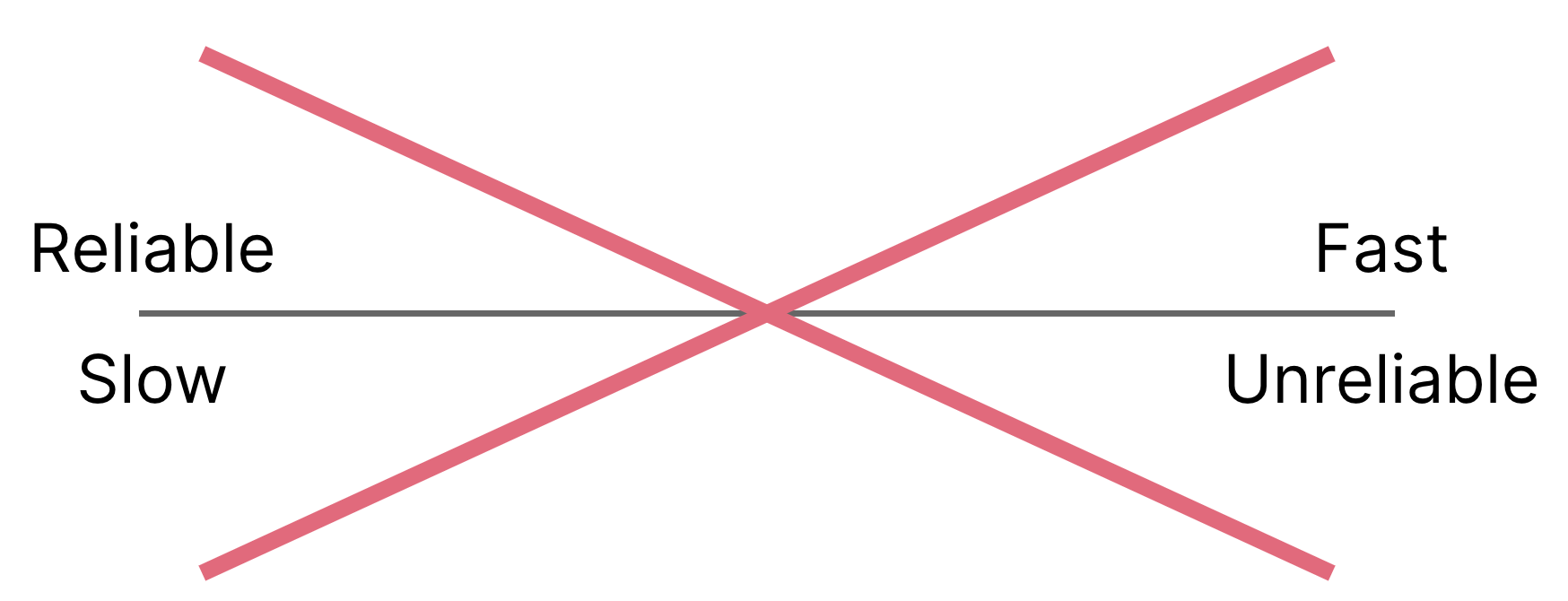
Figure 1-4. The idea that speed and quality are opposite ends of a spectrum is a false dichotomy
However, research shows otherwise:
These results demonstrate that there is no tradeoff between improving performance and achieving higher levels of stability and quality. Rather, high performers do better at all of these measures. This is precisely what the Agile and Lean movements predict, but much dogma in our industry still rests on the false assumption that moving faster means trading off against other performance goals, rather than enabling and reinforcing them.8
Dr. Nicole Forsgren, Accelerate
In short, organizations can’t choose between being good at change or being good at stability. They tend to either be good at both or bad at both.
A fundamental truth of the Cloud Age is: Stablity comes from making changes. The longer it takes to make a change, the slower we are to fix things. The flow of changes needed, like those listed above to rebut the myth that infrastructure doesn’t change often, will outpace the capacity to make them. Systems are left unpatched and with quick-fix workarounds to “known issues”.
If our systems aren’t fully patched, they are not stable, they are vulnerable. If we can’t fix issues as soon as we discover them, the system is not stable. If we can’t recover from failure quickly, the system is not stable. If making changes involves considerable downtime, the system is not stable. If changes frequently fail, the system is not stable.
Quality and speed should be seen as a quadrant rather than a continuum, as shown in Figure 1-5.
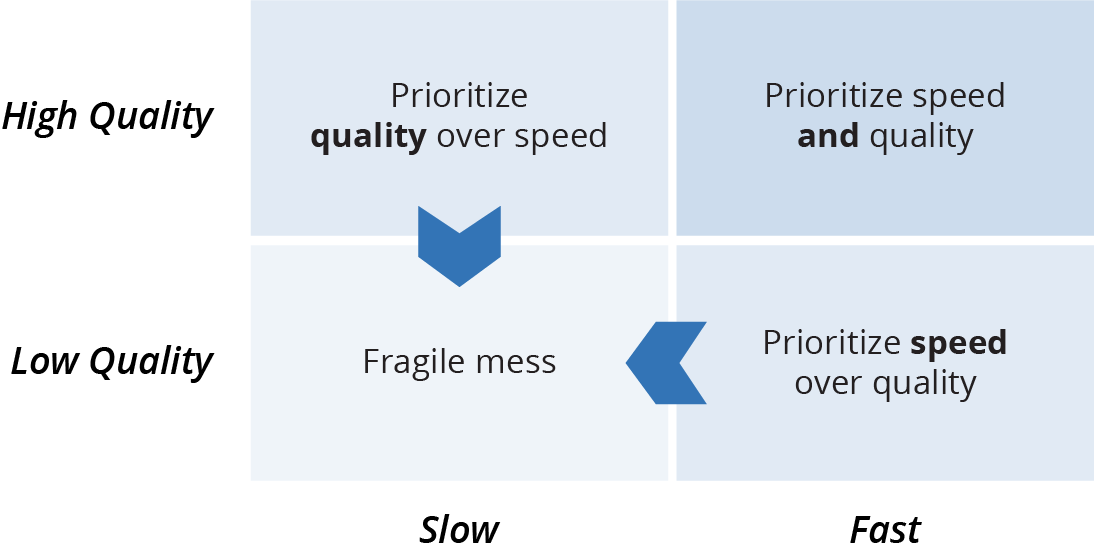
Figure 1-5. Speed and quality are not tradeoffs, they can be combined
This quadrant model shows how trying to choose between speed and quality leads to doing poorly at both:
- Lower-right quadrant: Prioritize speed over quality
-
This is the “move fast and break things” philosophy. Teams that optimize for speed and sacrifice quality build messy, fragile systems. They slide into the lower-left quadrant because their shoddy systems slow them down. A common pattern for startups is seeing development slow down after a year or two, leading founders to despair that their team has lost their “mojo.” Simple changes that they would have whipped out quickly in the old days now take days or weeks because the system is a tangled mess. This is a consequence of a system built in a rush, without treating quality as a priority.
- Upper-left quadrant: Prioritize quality over speed
-
Also known as “We’re doing serious and important things, so we have to do things properly.” Then deadline pressures drive “workarounds.” Heavyweight processes create barriers to improvement, so technical debt grows along with lists of “known issues.” These teams slump into the lower-left quadrant. They end up with low-quality systems because it’s too hard to improve them. They add more processes in response to failures. These processes make it harder to make improvements and increase fragility and risk. This leads to more failures and more process. Many people working in organizations that work this way assume this is normal,9 especially those who work in risk-sensitive industries.10
The upper-right quadrant is the goal of modern approaches like Lean, Agile, and DevOps. Being able to move quickly while also maintaining a high level of quality may seem like a fantasy. However, the Accelerate research proves that many teams do achieve this. So this quadrant is where “high performers” are found.
Antifragility
Nicholas Taleb coined the term “antifragile” in his book of the same title, to describe systems that actually grow stronger when stressed. Taleb’s book is not IT-specific—his main focus is on financial systems—but his ideas are relevant to IT architecture.
The Four Key Metrics
Navigating into the high-performing quadrant is challenging. DORA’s Accelerate research team identifies four key metrics for software delivery and operational performance that can help keep a team on track.11 Its research surveys various measures, and has found that these four have the strongest correlation to how well an organization meets its goals:
- Delivery lead time
-
The elapsed time it takes to implement, test, and deliver changes to the production system
- Deployment frequency
-
How often changes are deployed to production systems
- Change fail percentage
-
What percentage of changes either cause an impaired service or need immediate correction, such as a rollback or emergency fix
- Mean Time to Restore (MTTR)
-
How long it takes to restore service when there is an unplanned outage or impairment
The research shows that organizations that perform well against their goals—whether that’s revenue, share price, or other criteria—also perform well against these four metrics. The ideas in this book aim to help teams perform well on these metrics. Three core practices for Infrastructure as Code can help achieve this.
Core Practices for Infrastructure as Code
We can build and maintain highly effective systems by using Infrastructure as Code to deliver changes continuously, quickly, and reliably. The various principles, practices, and techniques described throughout this book can help to achieve this. Underlying all of this are a few core practices:
-
Define everything as code
-
Continuously test and deliver all work in progress
-
Build small, simple pieces that can be changed independently
Core Practice: Define Everything as Code
Defining everything “as code” is a core practice for making changes rapidly and reliably. There are a few reasons why this helps:
- Reusability
-
If we define a thing as code, we can create many instances of it. We can repair and rebuild things quickly, and other people can build identical instances of the thing.
- Consistency
-
Things built from code are built the same way every time. This makes system behavior predictable, makes testing more reliable, and enables continuous testing and delivery.
- Visibility
-
Everyone can see how the thing is built by looking at the code. People can review the code and suggest improvements. They can learn things to use in other code, gain insight to use when troubleshooting, and review and audit for compliance.
Core Practice: Continuously Test and Deliver All Work in Progress
Effective infrastructure teams are rigorous about testing. They use automation to deploy and test each component of their system and integrate all the work everyone has in progress. They test as they work, rather than waiting until they’ve finished.
The idea is to build quality in rather than trying to test quality in.
One part of this that people often overlook is that it involves integrating and testing all work in progress. On many teams, people work on code in separate branches and only integrate when they finish. According to the Accelerate research, however, teams get better results when everyone integrates their work at least daily. CI involves merging and testing everyone’s code throughout development. CD takes this further, keeping the merged code always production-ready.
I go into more detail on how to continuously test and deliver infrastructure code throughout the chapters of Part III.
Core Practice: Build Small, Simple Pieces That Can Change Independently
Teams struggle when their systems are large and tightly coupled. The larger a system is, the harder it is to change, and the easier it is to break.
The codebase of a high-performing team is visibly different from other codebases. The system is composed of small, simple pieces. Each piece is easy to understand and has clearly defined interfaces. The team can easily change each component on its own and can deploy and test each component in isolation.
I dig more deeply into design principles and techniques in the chapters of Part II.
Conclusion
Traditional, Iron Age approaches to software and system design were based on the belief that, if we are sufficiently skilled, knowledgeable, and diligent, we can come up with the correct design for the system’s needs before we start working on it. In reality, we don’t know what the correct design is until the system is already being used. Worse, changes to an organization’s situation, environment, and opportunities mean the system’s needs are a moving target. So even if we do find and implement the correct design, it won’t remain correct for very long.
The only thing we know for sure when designing a system is that it will need to change after it’s in use, not once, but continuously until the system is no longer needed. The essence of Cloud Age, Lean, Agile, DevOps, and similar philosophies is designing and implementing systems so that we can continuously learn and evolve our systems.
With infrastructure, this means exploiting speed to improve quality and building quality in to gain speed. Automating infrastructure takes work, especially when people are learning the tools and techniques. But doing that work helps to ensure the system can be kept relevant and useful throughout its lifespan. The next chapter discusses more specific principles for designing and building cloud infrastructure using code.
1 According to Wikipedia, a tire fire has two forms: “Fast-burning events, leading to almost immediate loss of control, and slow-burning pyrolysis which can continue for over a decade.” Both of these seem relevant to digital infrastructure.
2 The 2019 Accelerate State of DevOps Report specifically researched the effectiveness of governance approaches, and includes a discussion of their findings on pages 48-52.
3 Facebook CEO Mark Zuckerberg said, “Unless you are breaking stuff, you are not moving fast enough.” https://www.businessinsider.com/mark-zuckerberg-2010-10
4 CAB: Change Advisory Board
5 The Cloud Native Landscape diagram is a popular one for illustrating how many products, tools, and projects are available for building platforms. One of my favorite memes extends this into a CNCF conspiracy chart
6 According to Gene Kim, George Spafford, and Kevin Behr in The Visible Ops Handbook (IT Process Institute), changes cause 80% of unplanned outages.
7 Reports from the Accelerate research are available in the annual State of DevOps Report, and in the book, Accelerate, by Dr. Nicole Forsgren, Jez Humble, Gene Kim (IT Revolution Press).
8 Accelerate by Dr. Nicole Forsgren, Jez Humble, Gene Kim (IT Revolution Press). Also see the Accelerate State of DevOps Report.
9 This is an example of “Normalization of Deviance,” which means people get used to working in ways that increase risk. Diane Vaughan defined this term in The Challenger Launch Decision (University Of Chicago Press).
10 It’s ironic (and scary) that so many people in industries like finance, government, and health care consider fragile IT systems—and processes that obstruct improving them—to be normal, and even desirable.
11 DORA, now part of Google, is the team behind the Accelerate State of DevOps Report I cited earlier.
Get Infrastructure as Code, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

