Chapter 4. Infrastructure as Code Tools and Languages
Systems administrators have been using scripts, configuration, and tools to automatically provision and configure infrastructure for decades. Infrastructure as Code emerged into the mainstream with the adoption of virtualization and cloud, and has evolved considerably along with those technologies.
This chapter discusses infrastructure code techniques, languages, and tools. Whichever automation tool you currently use, understanding the landscape and evolution of tools gives context helps to make informed decisions about how to design, implement, and deliver infrastructure. And the evolution of infrastructure tools and techniques is far from over, so every team will need to continuously evaluate new tools and adopt new techniques as options emerge.
The first topic is the essentials of Infrastructure as Code, including comparison with alternatives like “ClickOps” and task-focused scripting, discussing the types of things that can be configured as code, and the consequences of a code-based approach to infrastructure configuration.
The next topic is infrastructure code processing models. This topic includes thinking about the differences between editing infrastructure code, assembling it, processing it, applying it, and the resulting deployed infrastructure resources. This is important context for understanding how different infrastructure code tools work, as well as for making decisions about how to design and deliver infrastructure.
The context of these processing models inform the following discussion of different infrastructure tools and their approaches to languages, imperative versus declarative languages and tools, and “real” programming languages versus DSLs. It also helps to understand why some tools use external state files.
The final part of this chapter looks at some emerging models for infrastructure automation, potentially the next stage in the evolution of Infrastructure as Code.
Coding Infrastructure
There are simpler ways to provision infrastructure than writing code and then using a tool to apply it to an IaaS API. You could follow the ClickOps approach by opening the platform’s web-based user interface in a browser and poking and clicking an application server cluster into being. Or you could embrace CLIOps by opening a prompt and using your command-line prowess to wield the IaaS platform’s CLI (command-line interface) tool to forge an unbreakable network boundary.
Earlier chapters listed advantages of defining Infrastructure as Code over alternative approaches, including repeatability, consistency, and visibility. Building infrastructure by hand, whether with a GUI or on the command line, creates systems that are difficult to maintain and keep consistent.
Moving Beyond Task-Based Scripting
Systems administration has always involved automating tasks by writing scripts, and often developing more complex in-house tools using languages like Perl, Python, and Ruby. Task-focused scripting focuses on activities within an overall process, such as “create a server” or “add nodes to a container cluster.” A symptom of task-focused scripting is wiki pages and other documentation that list steps to carry out the overall process, including guidance on what to do before running the script, arguments to use when running it, and then steps to carry out after it finishes.
Task-focused scripting usually needs someone to actively make decisions to carry out a complete process. Infrastructure as Code, on the other hand, pulls decision-making knowledge into the act of writing definitions, specifications, code, and tests. Provisioning, configuring, and deploying systems then become hands-off processes that can be left to the machines. Getting this right creates capabilities like automated scaling, recovery, and self-service platform services.
Capturing decision-making in code and specifications also creates the opportunity for more effective knowledge sharing and governance. Anyone can understand how the system is implemented by reading the code. Compliance can be assured and proven by reviewing the history of code changes. They can use the code and its history to troubleshoot and fix issues.
What You Can Define as Code
The “as code” paradigm works for many different parts of infrastructure as well as things that are infrastructure-adjacent. A partial list of things to consider defining as code includes:
- IaaS resources
-
Collections of infrastructure resources provisioned on an IaaS platform are defined and managed as deployable infrastructure stacks.1.
- Servers
-
Managing the configuration of operating systems and other elements of servers was the focus of the first generation of Infrastructure as Code tools, as discussed in Chapter 11.
- Hardware provisioning
-
Even most physical devices can be provisioned and configured using code. “Creating a Server Using Network Provisioning” describes automating bare-metal server provisioning. Software Defined Networking (SDN) can be used to automate the configuration of networking devices like routers and firewalls.
- Application deployments
-
Application deployment has largely moved away from procedural deployment scripts in favor of immutable containers and declarative descriptors.
- Delivery pipelines
-
Continuous Delivery pipeline stages for building, deploying, and testing software can and should be defined as code (Chapter 16).
- Platform service configuration
-
Other services such as monitoring, log aggregation, and identity management should ideally be configured as code. When using a platform service provided by your cloud vendor, you can provision and configure it using the same infrastructure coding tools you use for lower-level infrastructure. But even when using a platform service from a separate SaaS provider, or through a packaged application deployed on your IaaS platform, you should configure it using APIs and code as well. Many infrastructure deployment tools like Terraform and Pulumi support plugins and extensions to configure third-party software as well as IaaS and SaaS resources. Configuring platform services as code has the added benefit of making it easier to integrate infrastructure with other resources such as monitoring and DNS.
- Tests
-
Tests, monitoring checks, and other validations should all be defined as code. See Chapter 15 for more.
Code or Configuration?
What is the difference between “as code” and configuration? A working definition for this book is that code specifies those aspects of a component that are consistent across multiple deployed instances of the component. Configuration specifies those aspects that are specific to a particular deployed instance of a component. For example, the FoodSpin team uses infrastructure code to define an application server as a virtual machine provisioned with an Ubuntu, Java, JBoss, and various other packages and settings. The team uses configuration to specify a different amount of system memory to allocate to the virtual machine in each environment.
These definitions are imperfect and, honestly, not used consistently. I might mention a JBoss “configuration file” that is copied to every instance of the application server, even if it’s the same for every server. But I would talk about Ansible “code” used to dynamically generate that file on each server.
Some people describe all infrastructure code as configuration, especially code not written in a “real” programming language like Python. However, complex declarative infrastructure codebases are fundamentally different from simple property files. Even if it’s written in a “not-real” language like YAML, a complex codebase needs to be managed with the same discipline and governance as “actual” code written in Java. Later, this chapter offers more useful terminology for describing different types of Infrastructure as Code languages.
Treat Infrastructure Code Like Real Code
Many infrastructure codebases evolve from configuration files and utility scripts into unmanageable messes. Too often, people don’t consider infrastructure code to be “real” code. They don’t give it the same level of engineering discipline as application code. To keep an infrastructure codebase maintainable, you need to treat it as a first-class concern.
Design and manage your infrastructure code so that it is easy to understand and maintain. Follow code quality practices, such as code reviews, pair programming, and automated testing. Your team should be aware of technical debt and strive to minimize it.
Chapter 5 describes how to apply various software design principles to infrastructure, such as improving cohesion and reducing coupling. Chapter 17 explains ways to organize and manage infrastructure codebases to make them easier to work with.
Configuration as Code
Many tools, including some infrastructure automation tools, manage configuration with a “closed-box” model. Users edit and manage configuration using a UI or perhaps an API, but the tool manages all access to the data files where the configuration is stored. The closed-box approach offers some benefits, like checking that configuration follows the correct syntax. However, it sacrifices many benefits of externalizing configuration.
For example, some packaged platform services like CI servers and monitoring servers were originally released as closed-box tools, but later added the capability to define aspects of their configuration as code.2
Externalized configuration can be stored in a standard version control system. The configuration code can be organized in useful ways, such as putting an application’s pipeline configuration with the application code and the code for the tests the pipeline runs. Other examples of things you can do with externalized configuration that you can’t do with closed-box configuration include:
-
Use a software development IDE or text editor with advanced syntax highlighting, refactoring, and AI coding assistance.
-
Edit the configuration together with associated code and configuration, potentially with automated support for ensuring dependencies across them are correct.
-
Automatically trigger CI or pipeline stages to run to test when a configuration change is made, to give fast feedback on errors.
-
Track and record configuration and code changes in version across different but related tools and systems. For example, understand what the configuration options were set to when a particular version of an application’s code was deployed.
For infrastructure in particular, specifying infrastructure components as code enables teams to use Agile engineering practices like TDD, CI, and CD pipelines.
Manage Your Code in a Source Code Repository
Code and configuration for infrastructure and other system elements should be stored in a source code repository (also called a Version Control System (VCS) or Source Code Management (SCM) system). These systems provide loads of useful features, including tracking changes, comparing versions, and recovering and using old revisions when new ones have issues. They can also trigger actions automatically when changes are committed, which is the enabler for CI jobs and CD pipelines.
Secrets in source control
One thing that you should not put into source control is unencrypted secrets, such as passwords and keys. Even if your source code repository is private, its history and revisions of code are too easily leaked. Secrets leaked from source code are one of the most common causes of security breaches. See “Handling Secrets” for better ways to manage secrets.
Infrastructure Code Processing Lifecycle
The ability to treat infrastructure like software opens many possibilities, such as applying well-proven software design principles and patterns to our infrastructure architecture. But differences between how infrastructure code and application code work can confuse things, leading us to force-fit concepts and techniques even when they’re not appropriate. It’s useful to consider the differences between infrastructure code and application code.
For example, refactoring application code is usually straightforward: edit the code, compile, and deploy. However, refactoring infrastructure code in an editor is disconnected from how the changes will be applied to real infrastructure. An IDE gives you control to carefully update references to class when you change it. Controlling the way the code is applied to change an IaaS resource is a different matter.
When Code Executes
An application’s code executes after it’s deployed and running. Figure 4-1 shows a simplified lifecycle for software code.
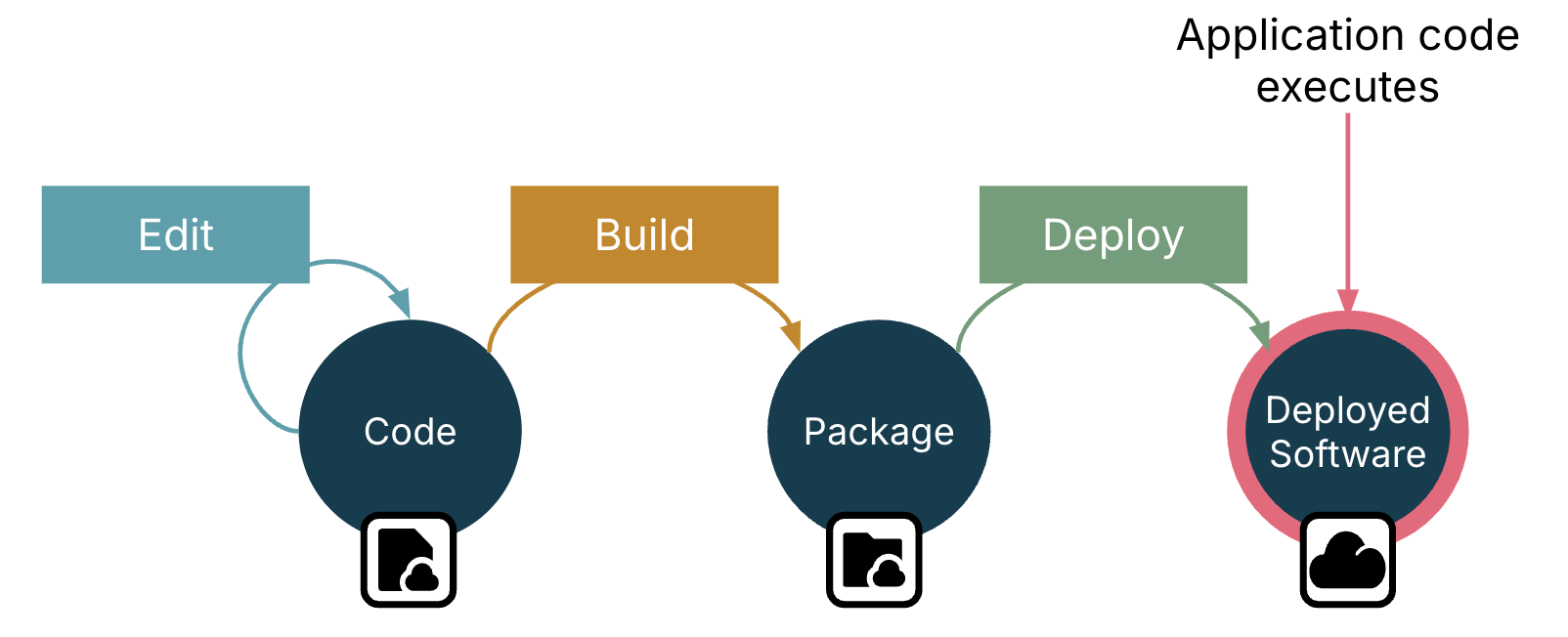
Figure 4-1. Application code executes after it’s deployed
Application code is edited by developers, then compiled and build to create a package, and then deployed to its runtime environment. The code that developers write executes as processes that run after it’s deployed, handling requests and events or doing whatever it is that it does.
The basic workflow for infrastructure code is simpler. Developers write and edit code, then deploy it. As shown in Figure 4-2, the code is executed during deployment, not in the runtime environment.
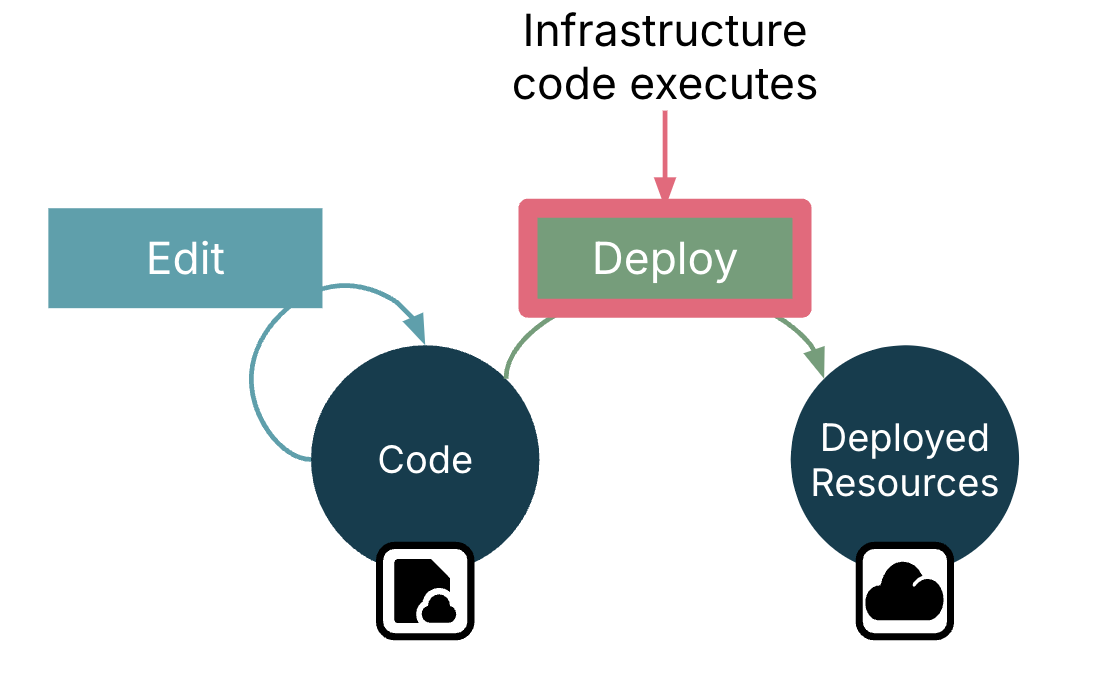
Figure 4-2. Infrastructure code executes in the deployment context
Executing the infrastructure code creates, modifies, or removes infrastructure resources deployed in the IaaS platform. So the outcome is the new state of those resources.
This difference may seem obvious, but it has implications for things like testing. If we write a unit test for infrastructure code, does it tell us about the infrastructure our code will create, or does it only tell us about what happens when the infrastructure code is executed? If our code creates networking structures, can we write unit tests that prove that those structures will route traffic the way we expect?
More confusion comes with tools that compile infrastructure code we write in one language into another language. For example, AWS CDK allows developers to write infrastructure code in application development languages like Python and JavaScript, and then compile it to CloudFormation templates. This compiled code is an extra level of abstraction between the code you write and the resources that are provisioned.
Infrastructure Code Lifecycle
The full context of what happens between an engineer writing infrastructure code and having infrastructure resources available for use is more complex than the one-step deploy process shown above. Different Infrastructure as Code tools implement code processing and deployment in different ways. There are four states and five transition steps between them which describe a common model that is useful for comparing different tools and for discussing lifecycle delivery approaches later in this book. Figure 4-3 shows these states and transition steps.
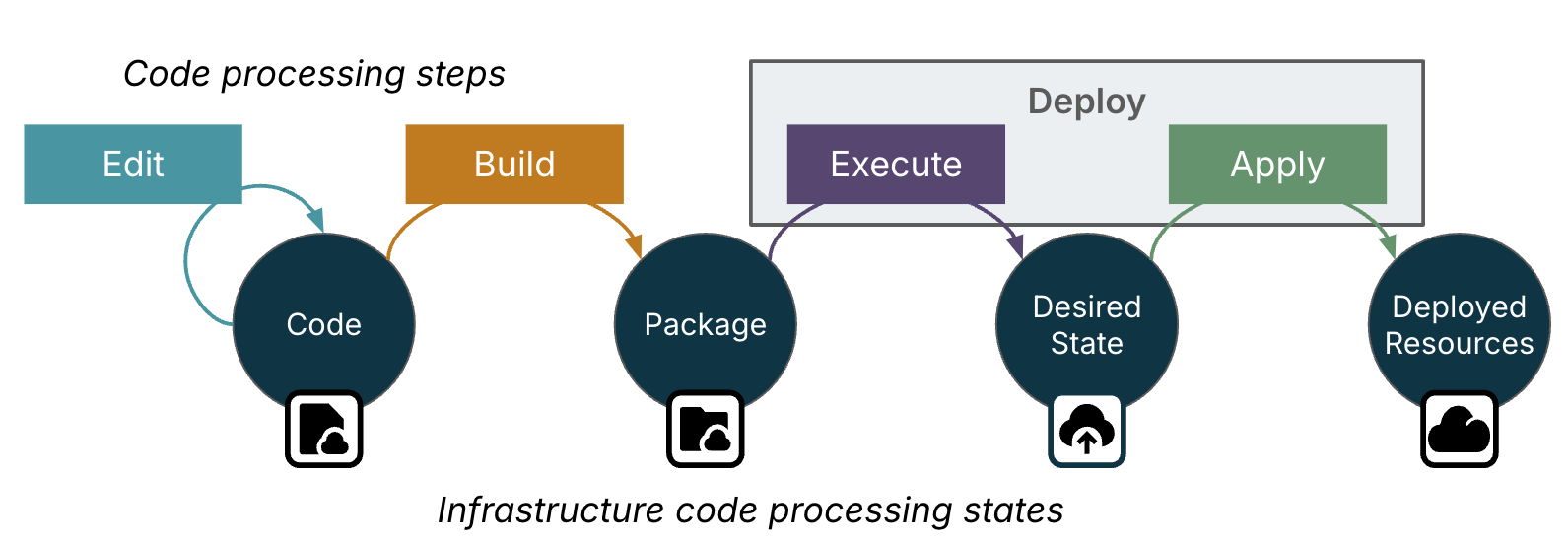
Figure 4-3. An overview of infrastructure code processing
These five steps of infrastructure code processing are:
- Edit
-
Engineers edit infrastructure code files, using development tools like IDEs. This step starts and ends with infrastructure code.
- Build
-
A version of the infrastructure code file are assembled with their dependencies into a package, sometimes also called a build or artifact. The assembled build is not specific to the environment where the infrastructure code will be deployed. The dependencies may include things like code libraries, infrastructure tool plugins and providers, and template files or static resources.
- Execute
-
The infrastructure tool compiles and runs the code from the package to determine the desired state model, a model of what the infrastructure resources should look like. Most often the infrastructure tool builds this model in memory, although in some case it may generate interim files, like CDK generating CloudFormation code. Unlike the resources assembled in the build step, the model is specific to the environment where it will be applied, so the execute step incorporates any configuration parameter values.
- Apply
-
The infrastructure tool uses the infrastructure platform’s IaaS API to examine the current state of the infrastructure, compare it with the desired state generated in the execute step, and change the deployed infrastructure resources to match it.
- Use
-
The resources on the IaaS platform are now in a state where they can support workloads. This is arguably not a step in the infrastructure code lifecycle because the code is no longer involved at this point. However, information about the current state of running infrastructure resources may be used to trigger the execution and apply steps again.3
Splitting the Lifecycle
In many cases multiple steps in the infrastructure code lifecycle are run as a single action. Running an infrastructure tool’s “deploy” or “apply” command might download dependencies and generate intermediary files in a working folder (the build step), run the code to create the desired state in memory (the execute step), and then connect to the cloud platform to update the current infrastructure (the apply step).
However, separating the build and execute steps creates some useful opportunities for better workflows.
The build step is distinguished from the later steps in that its result, the build package, can be deployed to multiple environments. The execute step adds additional information specific to the particular instance of the infrastructure being deployed. For example, if the same infrastructure code is deployed to a test environment, a staging environment, and then a production environment, different configuration parameters may be used each time. This is the basis of the reusable stack pattern (“Pattern: Reusable Stack” in Chapter 7).
Building each version of an infrastructure project’s code once and then deploying the resulting artifact to multiple environments makes those environments more consistent. This consistency improves the reliability of tests run in one environment, not only for testing the infrastructure code, but also for testing software in development and QA environments. Chapter 14 and the rest of the chapters in Part III discuss tradeoffs and techniques for structuring the infrastructure code lifecycle.
Generating Intermediate Code
Some tools generate intermediate code in a different language. For example, AWS CDK can be used to generate CloudFormation or Terraform code, while Bicep generates JSON code. Although in theory intermediate code could be generated in the build stage, and then tested and applied to different environments, in practice most of these tools generates the code for a specific environment. If so, code generation happens in the execute step.
The execute and apply step are normally run together, so may not be obvious as separate steps unless something fails.
Previewing Changes
Some infrastructure tools have a plan command (Terraform and OpenTofu) or preview command (Pulumi) that compares the desired state generated in the execute step with the running infrastructure. These preview commands run part of the apply step in our four-step model, connecting to the infrastructure platform API to examine the current state of the deployed infrastructure and identify what changes would be made if it were to actually apply the desired state.
An engineer can use a preview to see what changes will be made to reassure themselves that they understand what the code will do before they apply it. However, there are some situations where applying code can have effects that aren’t revealed by previewing the change.
Tracing Infrastructure Code Execution
The four-step code processing model helps to understand that tracing, debugging, profiling, and potentially even unit testing infrastructure code may not work the way you expect. Running an infrastructure tool will execute the code to generate the desired state model, and then make a series of API calls to the IaaS platform to implement changes. So a normal code debugger will not necessarily trace the execution of the infrastructure code as you’ve written.
Unit tests, especially for infrastructure code written with general purpose languages like Typescript or Python, often focus on making assertions about the desired state data structures the code generates rather than how the code executes.
It’s especially easy to get muddled when refactoring infrastructure code. When you refactor application code, you build a new executable that you can deploy with only the expected changes to its behavior. Deploying refactored infrastructure code can make unexpected changes to the running infrastructure, such as destroying a storage device with critical data and creating a new, empty device in its place. See [Link to Come] for more on making changes to infrastructure.
Infrastructure State
Infrastructure tools need a way to know which resource defined in code corresponds to which resource instance running on the IaaS platform. This mapping is used to make sure a change to the code is applied to the correct resource. IaaS platforms can handle this internally for their own infrastructure tools. For instance, when you run AWS CloudFormation, you pass an identifier for the stack instance, which the AWS API uses as a reference to an internal data structure that lists the resources that belong to that stack instance.
Tools from third-party vendors, like Terraform, OpenTofu, and Pulumi, need their own data structures to manage these mappings of code to instances. They store these data structures in a state file for each instance. Users of these tools have the option to maintain storage for these state files or to store state data on hosted services.45
Although there are advantages to having instance state handled transparently by the IaaS platform, it can be useful to view and even edit state data structures to debug and fix issues. [Link to Come] discusses techniques for managing changes with state files.
Infrastructure as Code Tools
Systems administrators have always used interpreted languages like shell scripts, Perl, Ruby, and Python to write scripts and tools to manage their infrastructure. In the 1990s CFEngine pioneered the use of a declarative, idempotent, domain-specific languages (DSL) for infrastructure management. Puppet and then Chef emerged alongside mainstream server virtualization and IaaS cloud in the 2000s, both heavily inspired by CFEngine. Ansible, Saltstack, and others followed, also focusing on configuring servers during and after operating system installation.
As IaaS cloud platforms emerged with APIs for managing resources, pioneered by AWS, many people reverted to writing procedural code in languages like Ruby and Python. We used SDKs to interact with the IaaS platform API, perhaps using a library like boto or fog.
Stack-oriented tools like Terraform and AWS CloudFormation emerged in the 2010s, using a declarative DSL model similar to that used by server-oriented tools like Puppet and Chef. OpenTofu is a more recent open-source fork of Terraform. Azure’s Bicep, Google’s Cloud Deployment Manager, and OpenStack’s Heat are stack-oriented tools that use declarative DSLs for working with those specific IaaS platforms. Bosh is an infrastructure tool from CloudFoundry.
Some more recent stack-oriented tools use general-purpose programming languages to define infrastructure rather than a declarative DSL. Pulumi and the AWS CDK (Cloud Development Kit) support languages like Typescript, Python, and Java.
Other tools have experimented with different interfaces for infrastructure code, such as IaSQL and StackQL which, as their names suggest, allow you to query and manage IaaS resources using SQL. As of this writing this type of tool doesn’t seem to have much traction, but they’re interesting experiments if nothing else.
Another genre of infrastructure tools uses an approach called Infrastructure as Data (IaD) for deploying infrastructure code from a Kubernetes cluster. With these tools, infrastructure code is usually written declaratively in YAML and then continuously synchronized using a control loop. Examples of these tools include ACK, Crossplane, GCP Config Connector, and Azure Service Operator. [Link to Come] discusses different approaches for deploying infrastructure code, including infrastructure as data ([Link to Come]).
An emerging class of infrastructure coding is Infrastructure from Code (IfC), which embeds infrastructure code into application code. Examples of Infrastructure from Code tools include ampt, Ballerina, Darklang, Klotho, Winglang, and Nitric.
Different infrastructure tools support different languages, and different types of languages, as discussed in the next section. Tools also differ in what IaaS platforms they support. The tools provided by IaaS platform vendors usually support their own platform, like AWS CloudFormation and CDK, and Azure ARM and Bicep. Many tools, including Terraform, OpenTofu, and Pulumi, support multiple IaaS platforms.
Types of Languages for Coding Infrastructure
Apart from which IaaS platforms they support, Infrastructure as Code tools are distinguished by the types of languages they use for defining infrastructure. Many people who work with infrastructure have strong opinions about what languages are best for working with infrastructure. The reality is that the best language will vary for different systems, for different parts of a system, and for different people. For example, a software developer may prefer to use a general-purpose, imperative language like TypeScript to define run-time infrastructure at a high level of abstraction. Systems administrators often prefer declarative DSLs that allow them to specify infrastructure at a low level.
These four groups of opposing characteristics provide a lot of context for considering which tool is right for your system and your team: procedural versus idempotent; declarative versus imperative; general-purpose versus DSL; and low-level versus high-level. Keep in mind that the right choice may be to use different languages for different parts of your system, rather than trying to force one tool and language to solve all of your use cases.
Procedural and Idempotent Code
Many task-focused scripts are written to be run only when an action needs to be carried out or a specific change made, but can’t be safely run multiple times. For example, this script creates a virtual server using a fictional infrastructure tool called +stack-tool+7:
stack-toolcreate-virtual-server\--name=my-server\--os_image=ubuntu-22.10\--memory=4GB\--disk=80GB
If you run this script once, you get one new server. If you run it three times, you get three new servers8.
We can change the script to check whether the server name exists and refuse to create a new one if so. The following snippet runs the fictional stack-tool find-virtual-server command and only creates a new server if it exits with a value of “1”:
stack-toolfind-virtual-server--name=my-serverif["$?"="1"];thenecho"Creating a new server"stack-toolcreate-virtual-server\--name=my-server\--os_image=ubuntu-22.10\--memory=4GB\--disk=80GBelseecho"Server already exists, not creating a new one"fi
The script is now idempotent. No matter how many times we run it, the result is the same, a single server named my-server. If we configure an automated process to run this script continuously, we can be sure the server exists. If the server doesn’t already exist, the process will create it. If someone destroys the server, or if it crashes, the process will restore it.
But what happens if we decide the server needs more memory? We can edit the script to change the argument --memory=4GB to --memory=8GB. But if the server already exists with 4GB of RAM, the script won’t change it. We could add a new check, taking advantage of some convenient options available in the imaginary stack-tool:
stack-toolfind-virtual-server--name=my-server--print-id>saved-server-idif["$?"="1"];thenecho"Creating a new server"stack-toolcreate-virtual-server\--name=my-server\--os_image=ubuntu-22.10\--memory=8GB\--disk=80GBelseecho"Server already exists, not creating a new one"fiCURRENT_RAM=`stack-toolget-virtual-server-info\--id=$(catsaved-server-id)\--attribute=memory`if["${CURRENT_RAM}"!="8GB"];thenstack-toolmodify-virtual-server\--id=$(catsaved-server-id)\--memory=8GBfi
The modified script now captures the ID of the existing virtual server, if found, into a file. It then passes the ID to stack-tool with a command to change the existing server’s memory allocation to 8GB. I’ve also changed the script so that if the server doesn’t already exist, the command to create a new one creates it with the right memory setting.
Now we have an idempotent script that ensures the server exists with the right amount of memory. However, scripts like this become messy over time as needs change and more conditionals are added.
An alternative would be to write a new, separate script to change the memory of the existing server. Each script is simpler than the one that combines creating and modifying the server. However you then get a proliferation of scripts.
Writing task-focused scripts comes naturally for systems administrators who maintain systems by carrying out tasks as needed. But the approach depends on humans to make decisions about which scripts to run and when, depending on their knowledge of the current state of the system.
The core premise of Infrastructure as Code is that humans can put their knowledge and the decision making into code ahead of time, so they can stay hands-off and leave it to the machines to make it happen.9 So most modern Infrastructure as Code languages work idempotently, even the imperative ones.
Imperative and Declarative Languages and Tools
Imperative code is a set of instructions that specifies how to make a thing happen. Declarative code specifies what you want, without specifying how to make it happen. Most popular programming languages are imperative, including procedural languages like Python and object-oriented languages like Java. Configuration languages like YAML and XML10 are declarative, as are set-based languages like SQL and functional languages like Clojure.
This example uses declarative code to create the same virtual server instance as the earlier examples:
virtual_server:name:my_serveros_image:ubuntu-22.10memory:8GB
This code doesn’t include any logic to check whether the server already exists or, if it does exist, how much memory it currently has. The infrastructure tool takes care of that when it applies the code to the deployed infrastructure. If you edit the code and change the amount of memory then run it again, the tool will (probably)11 modify the existing instance rather than creating a new one.
The benefit of declarative infrastructure code is its simplicity and clarity. Many infrastructure code tools, including Ansible, Bicep, CloudFormation, Puppet, OpenTofu, and Terraform use declarative languages.
Other tools, including CDK, Pulumi, and most Infrastructure from Code tools, support imperative languages. (Pulumi also supports at least one declarative language, YAML). It’s important to note, however, that most of these tools use a declarative model. The procedural or object-oriented infrastructure logic creates data structures that model the desired state of the infrastructure, which the tool then applies to create or modify the infrastructure resources running in the platform.
This code example creates a virtual server using a conditional statement to set the memory size:
appserverMemory=switch(serverSizeParameter){"S":"1GB""M":"4GB""L":"8GB""XL":"16GB"}VirtualServerappServer=VirtualServer.new(name:"my_server",os_image:"ubuntu-22",memory:appserverMemory)
The code in this example is idempotent, without needing to explicitly implement any checks to see whether the instance already exists and has the specified amount of memory. The code runs in the “execute” step of the infrastructure code processing model described earlier. The tool then executes the “apply” step, interacting with the IaaS API to take whatever actions are needed to create or change the virtual machine.
Although it uses an imperative language, this example is trivial to implement in a declarative language. The HCL language used by Terraform and OpenTofu includes expressions, sets, and other constructs that offer enough flexibility for most situations.12.
Declarative languages get messier when used to write more complex components, and especially when used to create configurable components. On the other hand,using a fully imperative language for straightforward infrastructure definitions often creates code that is unnecessarily verbose. This is why I recommend not trying to use a single language across a large, complex infrastructure estate.
Domain-Specific and General-Purpose Languages
Many infrastructure tools use their own DSL, or Domain-Specific Language.13 A DSL is a language designed to model a specific domain, in our case infrastructure. This makes it easier to write code and makes the code easier to understand because it closely maps the things you’re defining.
Ansible, Chef, and Puppet each have a DSL for configuring servers. Their languages provide constructs for concepts like packages, files, services, and user accounts. A pseudocode example of a server configuration DSL is:
package:jdkpackage:tomcatservice:tomcatport:8443user:tomcatgroup:tomcatfile:/var/lib/tomcat/server.confowner:tomcatgroup:tomcatmode:0644contents:$TEMPLATE(/src/appserver/tomcat/server.conf.template)
This code ensures that two software packages are installed, jdk and tomcat. It defines a service that should be running, including the port it listens to and the user and group it should run as. Finally, the code specifies that a server configuration file should be created using the template file server.conf.template. The example code is pretty easy for someone with systems administration knowledge to understand, even if they don’t know the specific tool or language.
Many IaaS infrastructure tools also use DSLs, including Terraform, OpenTofu, and CloudFormation. These DSLs model the IaaS resources so that you can write code that refers to virtual servers, disk volumes, and network routes.
Many infrastructure DSLs are internal DSLs written as a subset (or superset) of a general-purpose programming language. Chef is an example of an internal DSL written as Ruby code, allowing access to the fully Ruby language and libraries. Others are external DSLs, which are interpreted by code written in a different language. Terraform HCL is an external DSL not related to the Go language its interpreter is written in. Puppet, like Chef, is written in Ruby, but Puppet code isn’t Ruby code and can’t use general-purpose features of Ruby.
Some infrastructure tools, notably AWS CDK and Pulumi, enable you to write infrastructure code using a General-Purpose Language (GPL). A general-purpose language can be used applicable across various domains and problem spaces. Developers can choose a language they’re familiar with from developing software, such as JavaScript, TypeScript, Python, Go, and C#. These languages have a large ecosystem of tools with mature support, including IDEs, linters, and unit testing frameworks.
Many general-purpose languages are imperative, although, as mentioned earlier, they’re used to build a declarative model to apply to infrastructure. Some infrastructure tools use general-purpose markup languages like YAML (Ansible, CloudFormation, anything related to Kubernetes) and JSON (Packer, CloudFormation). There are many third-party tools for working with these markup languages, although they lack type systems, so arguably the tools aren’t as useful as those for imperative languages which can do things like assist with code refactoring.
Low-Level and High-Level Languages
Most Infrastructure as Code languages directly model the resources they configure. The languages used with tools like Terraform and Pulumi are essentially thin wrappers over IaaS APIs. For example, the Terraform aws_instance provider directly maps to the AWS API run_instances API method.14
Many teams use infrastructure code languages to build their own abstraction layers using libraries or modules. Chapter 10 describes several patterns and anti-patterns for writing libraries or modules to wrap the gritty details of, for example, wiring up network routes.
A few tools support higher-level abstractions for infrastructure, often as components either at the level of libraries, deployable components, or compositions. Chapter 6 discusses components for infrastructure code at different levels.
Infrastructure From Code
Infrastructure from Code, as mentioned earlier, mixes infrastructure code within application code. Some implementations provide support for including infrastructure code with existing general-purpose software development languages, while others introduce a new language, often with dedicated development and testing environments.
I generally recommend separating concerns between applications and infrastructure, which IfC tools may contradict. For example, imagine a developer writing code to save a new customer’s registration information in a database. Code that handles both the registration workflow and details of provisioning and configuring the database to store it would be difficult to understand and maintain.
However, the intent of these languages is not to intermix code at the level normally written in Terraform with business logic. Instead, business logic code can specify the relevant attributes of infrastructure at the right level of detail for the context. The user registration code can specify that the data should be saved to a database that is configured for handling personal customer information. The code calls a separately-written library that handles the details of provisioning and configuring the database appropriately.
So the system can be designed to separate the concerns of business logic and detailed infrastructure configuration, while explicitly managing those concerns that are relevant across those boundaries. The current paradigm of defining and deploying infrastructure separately relies on out-of-band knowledge to know that the database needs to be configured for personal data. It also involves brittle integration points that we need to configure explicitly on both sides, such as connectivity and authentication.
Integrating application and infrastructure development means we can redraw the boundaries of applications vertically, aligning infrastructure with the logic it supports, rather than horizontally.15
Conclusion
The topics in this chapter could be considered “meta” concepts for Infrastructure as Code. However, it’s important to keep in mind the goal of making routine tasks hands-off for team members is what makes Infrastructure as Code more powerful than writing scripts to automate tasks within a hands-on workflow. Considering how different language attributes affect the maintainability of infrastructure code helps to select more useful tools for different jobs in our system.
This chapter wraps up the Foundational chapters of the book (Part I). The following chapters discuss the architecture and design of building infrastructure systems as code (Part II).
1 Infrastructure stacks, as a term, is defined in Chapter 6
2 The Jenkins CI server’s Pipelines as Code feature is a prominent example of configuration as code.
3 See [Link to Come] in [Link to Come] for more.
4 Note that the Terraform license may discourage vendors from providing services such as storing state files to users of its tools.
5 Many of the TACoS services described in [Link to Come] can manage state files. See [Link to Come].
6 Winglang and Nitric are the main examples I know about as of late 2024. I’m sure there are others.
7 I use fictional tools, languages, and platforms throughout this book. Imaginary tools are nice because their features and syntax work exactly the way I need for any example.
8 You might hope that the --name=my-server argument will prevent the tool from creating multiple copies of the server. However, most IaaS platforms don’t treat user-supplied tags or names as unique identifiers. So this example creates three servers with the same name.
9 Other than when things go wrong.
10 Kids today complain about how terrible YAML is, but I remember the days when XML was everywhere. Writing infrastructure definitions in Ansible’s YAML-based syntax is a luxury compared with writing Ant build scripts in XML.
11 Some changes to existing an infrastructure resource will cause it to be destroyed and a new instance built with the changed value, depending on how the IaaS API works for the particular instance.
12 See https://github.com/hashicorp/hcl/blob/main/hclsyntax/spec.md and https://developer.hashicorp.com/terraform/language/expressions
13 Martin Fowler and Rebecca Parsons define a DSL as a “small language, focused on a particular aspect of a software system” in their book Domain-Specific Languages (Addison-Wesley Professional).
14 You can see this in the documentation for the Terraform aws_instance resource and the AWSrun_instances API method.
15 See Gregor Hohpe’s article, IxC: Infrastructure as Code, from Code, with Code, for an exploration of various combinations of infrastructure, architecture, and code and their implications.
16 I recommend reading through Brian Grant’s Infrastructure as Code and Declarative Configuration series of posts for a thorough critique.
17 As of late 2024 System Initiative has released their services as General Availability, while ConfigHub is still in early development.
Get Infrastructure as Code, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

