Kapitel 1. Einführung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wenn du schon einmal programmieren gelernt hast - sei es in C#, Microsoft Visual Basic, Python oder was auch immer - dann war das, was du gelernt hast, höchstwahrscheinlich und basierte auf dem Programmierparadigma, das derzeit am meisten verbreitet ist: objektorientiert. Die objektorientierte Programmierung (OOP) gibt es schon sehr lange. Das genaue Datum ist umstritten, aber wahrscheinlich wurde sie in den späten 50er oder frühen 60er Jahren erfunden.
Objektorientierter Code basiert auf der Idee, Daten - sogenannte Eigenschaften - undFunktionen in logische Codeblöcke zu packen, die Klassen genannt werden und als eine Art Template dienen, aus dem wir Objekte instanziieren. Das ist aber noch nicht alles: Vererbung, Polymorphismus, virtuelle und abstrakte Methoden - alles Mögliche.
Dies ist jedoch kein OOP-Buch. Wenn du bereits Erfahrung mit OOP hast, wirst du wahrscheinlich mehr von diesem Buch haben, wenn du das, was du bereits weißt, beiseite lässt.
In diesem Buch beschreibe ich einen Programmierstil, der eine Alternative zu OOP darstellt: funktionale Programmierung (FP). Obwohl FP in den letzten Jahren eine gewisse Anerkennung im Mainstream gefunden hat, ist es eigentlich genauso alt, wenn nicht sogar älter als OOP. FP basiert auf mathematischen Prinzipien, die zwischen dem Ende des 19. Jahrhunderts und den 1950er Jahren entwickelt wurden, und ist seit den 1960er Jahren in einigen Programmiersprachen enthalten. Ich zeige dir, wie du FP in C# implementieren kannst, ohne eine neue Programmiersprache lernen zu müssen.
Bevor wir mit dem Code loslegen, möchte ich zuerst über FP selbst sprechen. Was ist das? Warum solltest du dich dafür interessieren? Wann wird es am besten eingesetzt? Das sind alles wichtige Fragen.
Was ist funktionale Programmierung?
FP hat ein paar grundlegende Konzepte, von denen viele ziemlich obskure Namen haben, aber ansonsten nicht sonderlich schwer zu verstehen sind. Ich werde versuchen, sie hier so einfach wie möglich zu erklären.
Ist es eine Sprache, eine API, oder was?
FP ist keine Sprache oder eine Plug-in-Bibliothek eines Drittanbieters in NuGet; es ist ein Paradigma. Was will ich damit sagen? Obwohl es formalere Definitionen für Paradigmen gibt, betrachte ich es als einen Programmierstil. So wie eine Gitarre zum Spielen vieler, oft sehr unterschiedlicher Musikstile verwendet werden kann, bieten einige Programmiersprachen Unterstützung für verschiedene Arbeitsstile.
FP ist genauso alt wie OOP, wenn nicht sogar noch älter. Ich werde in "Woher kommt die funktionale Programmierung?" mehr über ihre Ursprünge erzählen , aber sei dir jetzt schon einmal bewusst, dass sie nicht neu ist und die Theorie dahinter nicht nur OOP, sondern auch der Computerindustrie selbst vorausgeht.
Es ist auch erwähnenswert, dass du Paradigmen kombinieren kannst, wie zum Beispiel Rock und Jazz. Sie lassen sich nicht nur kombinieren, sondern manchmal kannst du auch die besten Eigenschaften von beiden nutzen, um ein besseres Endergebnis zu erzielen.
Programmierparadigmen gibt es in vielen Variationen,1 aber der Einfachheit halber werde ich nur über die beiden gängigsten in der modernen Programmierung sprechen:
- Imperativ
-
Dies war lange Zeit die einzige Art von Programmierparadigma. Die prozedurale Programmierung und OOP gehören zu dieser Kategorie. Diese Arten der Programmierung weisen die ausführende Umgebung direkter an, welche Schritte im Detail ausgeführt werden müssen, d.h. welche Variable welche Zwischenschritte enthält und wie der Prozess Schritt für Schritt bis ins kleinste Detail ausgeführt wird. Das ist Programmieren, wie es normalerweise in der Schule oder am Arbeitsplatz gelehrt wird.
- Deklarativ
-
Bei diesem Programmierparadigma geht es weniger um die genauen Details, wie wir unser Ziel erreichen. Stattdessen ähnelt der Code eher einer Beschreibung dessen, was am Ende des Prozesses erreicht werden soll, und die Details (wie die Reihenfolge der Ausführung der Schritte) werden eher der Ausführungsumgebung überlassen. Dies ist die Kategorie, zu der FP gehört. Die strukturierte Abfragesprache (SQL) gehört ebenfalls in diese Kategorie, sodass FP in mancher Hinsicht eher SQL als OOP ähnelt. Beim Schreiben von SQL-Anweisungen geht es nicht um die Reihenfolge der Operationen (erst
SELECT, dannWHERE, dannORDER BY) oder darum, wie genau die Datenumwandlungen im Detail durchgeführt werden; du schreibst einfach ein Skript, das die gewünschte Ausgabe effektiv beschreibt. Dies sind auch einige der Ziele von funktionalem C#, so dass diejenigen unter euch, die bereits mit Microsoft SQL Server oder anderen relationalen Datenbanken gearbeitet haben, einige der kommenden Ideen vielleicht leichter verstehen werden als diejenigen, die dies nicht getan haben.
Es gibt noch viele weitere Paradigmen, aber sie würden den Rahmen dieses Buches sprengen. Fairerweise muss man sagen, dass die meisten anderen Paradigmen ziemlich obskur sind, so dass du sie wahrscheinlich nicht so bald kennenlernen wirst.
Die Eigenschaften der funktionalen Programmierung
In diesem Abschnitt geht es um die einzelnen Eigenschaften von FP und was sie für einen Entwickler wirklich bedeuten.
Unveränderlichkeit
Wenn sich etwas verändern kann, kann man auch sagen, dass es mutiert, wie eine Teenage Mutant Ninja Turtle.2 Eine andere Art zu sagen, dass etwas sich verändern kann, ist, dass es veränderbar ist. Wenn sich etwas hingegen überhaupt nicht verändern kann, ist es unveränderlich.
In der Programmierung bezieht sich dies auf Variablen, deren Wert bei der Definition festgelegt wird und die danach nie wieder geändert werden können. Wenn ein neuer Wert benötigt wird, sollte eine neue Variable erstellt werden, die auf der alten basiert. So werden alle Variablen in funktionalem Code behandelt.
Es ist eine etwas andere Arbeitsweise als bei imperativem Code, aber sie führt zu Programmen, die eher der schrittweisen Arbeit ähneln, die wir in der Mathematik machen, um eine Lösung zu finden. Dieser Ansatz fördert eine gute Struktur und einen vorhersehbaren - und damit robusteren - Code.
DateTime und String sind beide unveränderliche Datenstrukturen in .NET. Du denkst vielleicht , dass du sie verändert hast, aber hinter den Kulissen erzeugt jede Veränderung ein neues Element auf dem Stack. Das ist der Grund, warum die meisten neuen Entwickler/innen von der Verkettung von Zeichenketten in for Schleifen hören und warum du das niemals tun solltest.
Funktionen höherer Ordnung
Funktionen höherer Ordnung werden als Variablen übergeben - entweder als lokale Variablen, als Parameter für eine Funktion oder als Rückgabewert einer Funktion. Die Delegatentypen Func<T,TResult> oder Action<T> sind perfekte Beispiele dafür.
Falls du mit diesen Delegierten noch nicht vertraut bist, hier eine kurze Erklärung, wie sie funktionieren. Sie sind beide Formen von Funktionen, die als Variablen gespeichert werden. Beide nehmen eine Reihe von generischen Typen an, die ihre Parameter und Rückgabetypen darstellen, falls vorhanden. Der Unterschied zwischen Func und Action ist, dass Action keinen Wert zurückgibt, d.h. es ist eine void Funktion, die kein return Schlüsselwort enthält. Der letzte generische Typ, der in Func aufgeführt ist, ist der Rückgabetyp.
Betrachte diese Funktionen:
// Given parameters 10 and 20, this would output the following string:// "10 + 20 = 30"publicstringComposeMessage(inta,intb){returna+" + "+b+" = "+(a+b);}publicvoidLogMessage(stringa){this.Logger.LogInfo("message received: "+a);}
Sie können wie folgt als Delegatentypen umgeschrieben werden:
Func<int,int,string>ComposeMessage=(a,b)=>a+" + "+b+" = "+(a+b);Action<string>LogMessage=a=>this.Logger.LogInfo($"message received: {a}");
Diese Delegatentypen können genau so aufgerufen werden, als wären sie Standardfunktionen:
varmessage=ComposeMessage(10,20);LogMessage(message);
Der große Vorteil dieser Delegatentypen ist, dass sie in Variablen gespeichert sind, die in der Codebasis weitergegeben werden können. Sie können als Parameter für andere Funktionen oder als Rückgabetypen verwendet werden. Richtig eingesetzt, gehören sie zu den mächtigsten Funktionen von C#.
Mithilfe von FP-Techniken können Delegatentypen zusammengesetzt werden, um größere, komplexere Funktionen aus kleineren, funktionalen Bausteinen zu erstellen - wie LEGO-Steine, die zu einem Modell des Millennium Falken zusammengesetzt werden, oder was auch immer du bevorzugst. Das ist der eigentliche Grund, warum dieses Paradigma funktionale Programmierung genannt wird: weil wir unsere Anwendungen mit Funktionen bauen, und nicht, wie der Name vermuten lässt, weil der in anderen Paradigmen geschriebene Code nicht funktioniert. Warum würde jemand diese Paradigmen verwenden, wenn sie nicht funktionieren würden?
Hier ist eine Faustregel für dich: Wenn es eine Frage gibt, lautet die Antwort von FP mit ziemlicher Sicherheit "Funktionen, Funktionen und nochmals Funktionen".
Hinweis
Es gibt zwei Arten von aufrufbaren Codebausteinen : Funktionen und Methoden. Funktionen geben immer einen Wert zurück, Methoden hingegen nicht. In C# geben Funktionen irgendeine Art von Daten zurück, während Methoden einen Rückgabetyp void haben. Da Methoden fast zwangsläufig Seiteneffekte haben, sollten wir ihre Verwendung in unserem Code vermeiden - es sei denn, es ist unvermeidlich. Die Protokollierung ist ein Beispiel für die Verwendung von Methoden, die nicht nur unvermeidbar, sondern auch für guten Produktionscode unerlässlich ist.
Ausdrücke statt Aussagen
Hier sind ein paar Definitionen erforderlich. Ausdrücke sind diskrete Codeeinheiten, die einen Wert ergeben. Was meine ich damit?
In ihrer einfachsten Form sind das Ausdrücke:
constintexp1=6;constintexp2=6*10;
Wir können auch Werte eingeben, um unsere Ausdrücke zu bilden, also ist das auch einer:
publicintaddTen(intx)=>x+10;
Das nächste Beispiel führt zwar eine Operation aus, d.h. es wird festgestellt, ob eine Bedingung erfüllt ist oder nicht, aber letztendlich gibt es einfach einen Wert des Typs bool zurück, ist also immer noch ein Ausdruck:
publicboolIsTen(intx)=>x==10;
Du kannst auch ternäre Anweisungen (die Kurzform einer if Anweisung) als Ausdrücke betrachten, wenn sie nur zur Bestimmung eines Rückgabewerts verwendet werden:
varrandomNumber=this._rnd.Generate();varmessage=randomNumber==10?"It was ten":"it wasn't ten";
Noch eine kurze Faustregel: Wenn eine Codezeile ein einzelnes Gleichheitszeichen enthält, handelt es sich wahrscheinlich um einen Ausdruck, weil er einen Wert zuweist. Diese Regel hat eine gewisse Grauzone. Der Aufruf anderer Funktionen kann alle möglichen unvorhergesehenen Folgen haben. Es ist aber keine schlechte Regel, die man im Hinterkopf behalten sollte.
Anweisungen hingegen sind Teile des Codes, die nicht als Daten ausgewertet werden. Sie geben in der Regel eine Anweisung, etwas zu tun - entweder eine Anweisung an die ausführende Umgebung, die Reihenfolge der Ausführung über Schlüsselwörter wie if, where, for und foreach zu ändern, oder Aufrufe von Funktionen, die nichts zurückgeben und stattdessen eine Art von Operation ausführen. Hier ist ein Beispiel:
this._thingDoer.GoDoSomething();
Eine letzte Faustregel lautet: Wenn der Code kein Gleichheitszeichen hat, handelt es sich definitiv um eine Anweisung.3
Ausdrucksorientierte Programmierung
Wenn es dir hilft, denke an den Mathematikunterricht aus deiner Schulzeit zurück. Erinnerst du dich an die Zeilen, die du aufschreiben musstest, um deine Arbeit zu zeigen, wenn du deine endgültige Antwort geschrieben hast? Bei der ausdrucksbasierten Programmierung ist es ähnlich.
Jede Zeile ist eine vollständige Berechnung und baut auf einer oder mehreren vorherigen Zeilen auf. Wenn du ausdrucksbasierten Code schreibst, lässt du deine Arbeit hinter dir, während die Funktion ausgeführt wird. Das hat unter anderem den Vorteil, dass der Code leichter zu debuggen ist, weil du dir alle vorherigen Werte ansehen kannst und weißt, dass sie nicht durch eine vorherige Iteration einer Schleife oder Ähnliches verändert wurden.
Diese Herangehensweise mag wie ein Ding der Unmöglichkeit erscheinen, fast so, als würde man von dir verlangen, mit auf dem Rücken gefesselten Armen zu programmieren. Es ist aber durchaus möglich und nicht einmal unbedingt schwierig. Die Werkzeuge dafür gibt es in C# schon seit etwa zehn Jahren, und es gibt viele effektivere Strukturen.
Hier ist ein Beispiel dafür, was ich meine:
publicdecimalCalculateHypotenuse(decimalb,decimalc){varbSquared=b*b;varcSquared=c*c;varaSquared=bSquared+cSquared;vara=Math.Sqrt(aSquared);returna;}
Streng genommen könntest du das auch als eine lange Zeile schreiben, aber das sähe nicht so schön und einfach zu lesen und zu verstehen aus, oder? Du könntest auch dies schreiben, um alle Zwischenvariablen zu speichern:
publicdecimalCalculateHypotenuse(decimalb,decimalc){varreturnValue=b*b;returnValue+=c*c;returnValue=Math.Sqrt(returnValue);returnreturnValue;}
Das Problem dabei ist, dass der Code ohne Variablennamen etwas schwieriger zu lesen ist und alle Zwischenwerte verloren gehen - wenn es einen Fehler gäbe, müssten wir in jeder Phase durchgehen und returnValue überprüfen. Bei der ausdrucksbasierten Lösung bleibt die ganze Arbeit dort, wo sie ist.
Nachdem du ein wenig Erfahrung mit dieser Arbeitsweise gesammelt hast, wird dir die Rückkehr zur alten Arbeitsweise seltsam und sogar ein wenig unbeholfen vorkommen.
Referentielle Transparenz
Referentielle Transparenz ist ein gruselig klingender Name für ein einfaches Konzept. In FP haben reine Funktionen die folgenden Eigenschaften:
-
Sie nehmen keine Änderungen außerhalb der Funktion vor. Es kann kein Zustand aktualisiert werden, es werden keine Dateien gespeichert usw.
-
Mit denselben Parameterwerten werden sie immer genau dasselbe Ergebnis liefern. Das ist egal. Was. Unabhängig davon, in welchem Zustand sich das System befindet.
-
Sie haben keine unerwarteten Nebeneffekte. Dazu gehört auch, dass Ausnahmen ausgelöst werden.
Der Begriff " referenzielle Transparenz" kommt von der Idee, dass bei gleicher Eingabe immer die gleiche Ausgabe resultiert. In einer Berechnung kannst du also im Grunde den Funktionsaufruf mit dem Endwert vertauschen, wenn die Eingaben stimmen. Betrachte dieses Beispiel:
varaddTen=(intx)=>x+10;vartwenty=addTen(10);
Der Aufruf von addTen() mit dem Parameter 10 ergibt immer 20. Es gibt keine Ausnahmen. Bei einer so einfachen Funktion gibt es auch keine möglichen Nebenwirkungen. Folglich kann der Verweis auf addTen(10) im Prinzip ohne Nebeneffekte gegen einen konstanten Wert von 20 ausgetauscht werden. Das ist referenzielle Transparenz.
Hier sind einige reine Funktionen:
publicintAdd(inta,intb)=>a+b;publicstringSayHello(stringname)=>"Hello "+(string.IsNullOrWhitespace(name)?"I don't believe we've met. Would you like a Jelly Baby?":name);
Es kann kein Nebeneffekt auftreten (ich habe sichergestellt, dass der String eine Nullprüfung enthält) und nichts außerhalb der Funktion wird verändert; es wird nur ein neuer Wert erzeugt und zurückgegeben.
Hier sind unsaubere Versionen der gleichen Funktionen:
publicvoidAdd(inta)=>this.total+=a;// Alters statepublicstringSayHello()=>"Hello "+this.Name;// Reads from state instead of a parameter value
In beiden Fällen wird auf Eigenschaften der aktuellen Klasse verwiesen, die nicht in den Aufgabenbereich der Funktion selbst fallen. Die Funktion Add() ändert sogar die Statuseigenschaft. Die Funktion SayHello() hat auch keine Nullprüfung. All diese Faktoren bedeuten, dass wir diese Funktionen nicht als rein betrachten können.
Wie wäre es mit diesen?
publicstringSayHello()=>"Hello "+this.GetName();publicstringSayHello2(Customerc){c.SaidHelloTo=true;return"Hello "+(c?.Name??"Unknown Person");}publicstringSayHello3(stringname)=>DateTime.Now+" - Hello "+(name??"Unknown Person");
Keiner von ihnen wird wahrscheinlich rein sein.
SayHello() verlässt sich auf eine Funktion außerhalb seiner selbst. Ich weiß nicht, was GetName() eigentlich macht.4 Wenn sie einfach eine Konstante zurückgibt, können wir SayHello() als rein betrachten. Wenn sie jedoch in einer Datenbanktabelle nachschlägt, könnten fehlende Daten oder verlorene Netzwerkpakete zu Fehlern führen (alles Beispiele für unerwartete Nebeneffekte). Wenn eine Funktion zum Abrufen des Namens verwendet werden müsste, würde ich in Erwägung ziehen, diese mit einem Func<T,TResult> Delegaten umzuschreiben, um die Funktion sicher in unsere SayHello() Funktion zu integrieren.
SayHello2() verändert das übergebene Objekt - ein klarer Nebeneffekt der Verwendung dieser Funktion. Die Übergabe von Objekten per Referenz und deren Veränderung ist in der OOP nicht ungewöhnlich, aber in der funktionalen Programmierung ist das absolut nicht üblich. Ich würde dies vielleicht vereinfachen, indem ich die Aktualisierung der Objekteigenschaften und die Verarbeitung der Begrüßung in zwei Funktionen aufteile.
SayHello3() verwendet DateTime.Now, das jedes Mal einen anderen Wert zurückgibt, wenn es verwendet wird. Das ist das absolute Gegenteil einer reinen Funktion. Eine einfache Möglichkeit, dies zu beheben, besteht darin, der Funktion einen DateTime Parameter hinzuzufügen und den Wert zu übergeben.
Die referenzielle Transparenz ist eines der Merkmale, die die Testbarkeit von funktionalem Code massiv erhöhen. Das bedeutet allerdings, dass andere Techniken verwendet werden müssen, um denZustand zu verfolgen .
Außerdem ist die "Reinheit" unserer Anwendung begrenzt, vor allem, wenn wir mit der Außenwelt, dem Benutzer oder mit Bibliotheken von Drittanbietern interagieren müssen, die nicht dem funktionalen Paradigma folgen. In C# müssen wir immer hier und da Kompromisse eingehen.
Normalerweise ziehe ich an dieser Stelle gerne eine Metapher heran. Ein Schatten besteht aus zwei Teilen: dem Kernschatten und dem Halbschatten, wie in Abbildung 1-1 dargestellt.5 Der Kernschatten ist der feste, dunkle Teil des Schattens (eigentlich der größte Teil des Schattens). Der Halbschatten ist der graue, unscharfe Kreis an der Außenseite, der Teil, in dem sich Schatten und Nicht-Schatten treffen und der in den anderen übergeht. Bei C#-Anwendungen stelle ich mir vor, dass der reine Bereich der Codebasis der Kernschatten ist und die Bereiche mit Kompromissen der Halbschatten. Meine Aufgabe ist es, den reinen Bereich zu maximieren und den nicht reinen Bereich so weit wie möglich zu minimieren.
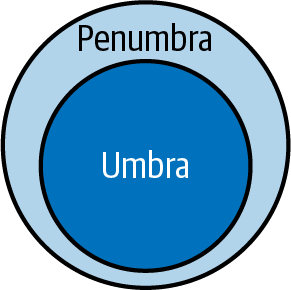
Abbildung 1-1. Die Umbra und Penumbra eines Schattens
Hinweis
Wenn du eine formalere Definition dieses Architekturmusters möchtest, hat Gary Bernhardt Vorträge gehalten, in denen er es Functional Core, Imperative Shell genannt hat.
Rekursion
Wenn du das nicht verstehst, siehe "Rekursion". Ansonsten siehe "Ernsthaft, Rekursion".
Ernsthaft, Rekursion
DieRekursion gibt es schon so lange wie das Programmieren. Es handelt sich um eine Funktion, die sich selbst aufruft, um eine unendliche (aber hoffentlich nicht unendliche) Schleife zu bilden. Jeder, der schon einmal einen Code zum Durchlaufen einer Ordnerstruktur oder einen effizienten Sortieralgorithmus geschrieben hat, sollte damit vertraut sein.
Eine rekursive Funktion besteht normalerweise aus zwei Teilen:
- Eine Bedingung
-
Wird verwendet, um festzustellen, ob die Funktion erneut aufgerufen werden sollte oder ob ein Endzustand erreicht wurde (z. B. der Wert, den wir zu berechnen versuchen, wurde gefunden, es gibt keine Unterordner zu erforschen, usw.)
- Eine Rückgabeanweisung
-
Gibt entweder einen endgültigen Wert zurück oder verweist erneut auf dieselbe Funktion, je nach dem Ergebnis der Endzustandsbedingung
Hier ist eine sehr einfache rekursive Add():
publicintAddUntil(intstartValue,intendValue){if(startValue>=endValue)returnstartValue;elsereturnAddUntil(startValue+1,endValue);}
Warnung
Führe dieses Beispiel niemals im Produktionscode aus. Ich halte es für die Zwecke der Erklärung einfach.
So albern dieses Beispiel auch ist, beachte, dass ich den Wert der beiden Parameter nie ändere. Jeder Aufruf der rekursiven Funktion verwendet Parameterwerte, die auf den Werten basieren, die sie selbst erhält. Dies ist ein weiteres Beispiel für Unveränderlichkeit: Ich ändere keine Werte in einer Variablen, sondern rufe eine Funktion auf, die einen Ausdruck verwendet, der auf den empfangenen Werten basiert.
Rekursion ist eine der Methoden, die FP als Alternative zu Anweisungen wie while und foreach verwendet. In C# treten jedoch einige Leistungsprobleme auf. In Kapitel 9 über unendliche Schleifen wird die Verwendung von Rekursion ausführlicher besprochen, aber für den Moment solltest du sie mit Bedacht einsetzen und dich an mich halten. Es wird alles klar werden...
Musterabgleich
In C# ist der Musterabgleich im Grunde die Verwendung von switch Anweisungen mit "Go-Faster"-Streifen. F# führt das Konzept jedoch weiter. Pattern Matching gibt es in C# schon seit einigen Versionen. Mit den switch Ausdrücken in C# 8 haben wir C#-Entwickler eine eigene Implementierung dieses Konzepts, und das Microsoft-Team hat es regelmäßig verbessert.
Mit dieser Umschaltung kannst du den Ausführungspfad auf den Typ des untersuchten Objekts sowie seine Eigenschaften ändern. Dieses Verfahren kann verwendet werden, um eine große Menge von verschachtelten if Anweisungen wie diese zu reduzieren:
publicintNumberOfDays(intmonth,boolisLeapYear){if(month==2){if(isLeapYear)return29;elsereturn28;}if(month==1||month==3||month==5||month==7||month==8||month==10||month==12)return31;elsereturn30;}
in ein paar prägnante Zeilen zusammenfassen, etwa so:
publicintNumberOfDays(intmonth,boolisLeapYear)=>(month,isLeapYear)switch{{month:2,isLeapYear:true}=>29,{month:2}=>28,{month:1or3or5or7or8or10or12}=>31,_=>30};
Der Musterabgleich ist eine unglaubliche, leistungsstarke Funktion und eine meiner Lieblingsfunktionen.6
In den nächsten Kapiteln findest du viele Beispiele dafür, also lies weiter, wenn du wissen willst, was es damit auf sich hat. Auch für diejenigen, die mit älteren Versionen von C# arbeiten, gibt es Möglichkeiten, dies zu implementieren, und ich zeige ein paar Tipps in "Pattern Matching für alte Versionen von C#".
Zustandslos
Objektorientierter Code hat typischerweise eine Reihe von Zustandsobjekten, die einen Prozess darstellen - entweder real oder virtuell. Diese Zustandsobjekte werden regelmäßig aktualisiert, um mit dem, was sie darstellen, synchron zu bleiben. Du könntest zum Beispiel einen Code wie diesen haben, der Daten über meine Lieblingsserie Doctor Who darstellt:
publicclassDoctorWho{publicintNumberOfStories{get;set;}publicintCurrentDoctor{get;set;}publicstringCurrentDoctorActor{get;set;}publicintSeasonNumber{get;set;}}publicclassDoctorWhoRepository{privateDoctorWhoState;publicDoctorWhoRepository(DoctorWhoinitialState){this.State=initialState;}publicvoidAddNewSeason(intstoriesInSeason){this.State.NumberOfStories+=storiesInSeason;this.State.SeasonNumber++;}publicvoidRegenerateDoctor(stringnewActorName){this.State.CurrentDoctor++;this.State.CurrentDoctorActor=newActorName;}}
Nun, vergiss das, wenn du FP machen willst. Es gibt kein Konzept für ein zentrales Zustandsobjekt oder für die Änderung seiner Eigenschaften, wie im vorangegangenen Codebeispiel.
Ernsthaft? Das klingt nach reinstem Wahnsinn, oder? Streng genommen gibt es zwar einen Zustand, aber der ist eher eine entstehende Eigenschaft des Systems.
Jeder, der schon einmal mit React-Redux gearbeitet hat, hat bereits den funktionalen Ansatz für den Zustand kennengelernt (der wiederum von der FP-Sprache Elm inspiriert wurde). In Redux ist der Anwendungsstatus ein unveränderliches Objekt, das nicht aktualisiert wird. Stattdessen definiert der Entwickler eine Funktion, die den alten Status, einen Befehl und alle erforderlichen Parameter entgegennimmt und dann ein neues Statusobjekt auf der Grundlage des alten zurückgibt. Dieser Prozess wurde in C# mit der Einführung von Record-Typen in C# 9 unendlich viel einfacher. Mehr dazu erfährst du unter "Record Types". Im Moment sieht eine einfache Version einer der Repository-Funktionen so aus, dass sie funktional umgestaltet werden kann:
publicDoctorWhoRegenerateDoctor(DoctorWhooldState,stringnewActorName){returnnewDoctorWho{NumberOfStories=oldState.NumberOfStories,CurrentDoctor=oldState.CurrentDoctor+1,CurrentDoctorActor=newActorName,SeasonNumber=oldState.SeasonNumber};}
Der große Vorteil dieses Ansatzes ist die Vorhersagbarkeit. In C# werden Objekte per Referenz übergeben - das heißt, wenn du das Objekt innerhalb der Funktion änderst, wird es auch in der Außenwelt geändert! Wenn du also ein Objekt als Parameter an eine Funktion übergeben hast, kannst du nicht sicher sein, dass es unverändert bleibt, auch wenn du ihm nicht ausdrücklich einen neuen Wert zugewiesen hast.
Alle Änderungen, die an Objekten in FP vorgenommen werden, erfolgen immer über eine bewusste Zuweisung des Wertes, so dass es nie Unklarheiten darüber gibt, ob eine Änderung vorgenommen wurde.
Das ist genug über die Eigenschaften von FP für den Moment. Hoffentlich hast du eine gute Vorstellung davon, was es bedeutet. Jetzt werde ich etwas weniger technisch vorgehen und FP aus einem breiteren Blickwinkel betrachten sowie ein wenig auf die Ursprünge von FP eingehen.
Torten backen
Schauen wir uns den Unterschied zwischen dem imperativen und dem deklarativen Paradigma auf einer etwas höheren Ebene an. Hier siehst du, wie beide Paradigmen Muffins machen würden.7
Ein unerlässlicher Kuchen
Das ist kein echter C#-Code, sondern nur eine Art von Pseudocode im .NET-Stil, um einen Eindruck von der imperativen Lösung dieses imaginären Problems zu vermitteln:
Oven.SetTemperatureInCentigrade(180);for(inti=0;i<3;i++){bowl.AddEgg();boolisEggBeaten=false;while(!isEggBeaten){Bowl.BeatContents();isEggBeaten=Bowl.IsStirred();}}for(inti==0;i<12;i++){OvenTray.Add(paperCase[i]);OvenTray.AddToCase(bowl.TakeSpoonfullOfContents());}Oven.Add(OvenTray);Thread.PauseMinutes(25);Oven.ExtractAll();
Für mich ist das ein typischer verworrener imperativer Code: viele kleine kurzlebige Variablen, um den Status zu verfolgen. Der Code ist auch sehr auf die genaue Reihenfolge der Dinge bedacht. Er ist eher wie Anweisungen für einen Roboter ohne Intelligenz, der alles genau wissen muss.
Eine deklarative Torte
So könnte ein völlig imaginärer deklarativer Code aussehen, der das gleiche Problem löst:
Oven.SetTemperatureInCentigrade(180);varcakeBatter=EggBox.Take(3).Each(e=>Bowl.Add(e).Then(b=>b.While(x=>!x.IsStirred,x.BeatContents()))).DivideInto(12).Each(cb=>OvenTray.Add(PaperCaseBox.Take(1).Add(cb)));
Das mag zunächst seltsam und ungewöhnlich erscheinen, wenn du dich mit FP nicht auskennst, aber im Laufe dieses Buches werde ich dir erklären, wie das alles funktioniert, was die Vorteile sind und wie du das alles selbst in C# implementieren kannst.
Bemerkenswert ist jedoch, dass es keine zustandsverfolgenden Variablen, keine if oder while Anweisungen gibt. Ich bin mir nicht einmal sicher, in welcher Reihenfolge die Vorgänge ablaufen müssen, und das ist auch nicht wichtig, denn das System funktioniert so, dass alle notwendigen Schritte zum richtigen Zeitpunkt ausgeführt werden.
Das sind eher Anweisungen für einen etwas intelligenteren Roboter, der ein wenig selbständig denken kann. Die Anweisungen könnten etwa so klingen: "Tu dies, bis ein bestimmter Zustand erreicht ist", was im prozeduralen Code durch eine Kombination aus einer while Schleife und einigen Codezeilen zur Zustandsverfolgung erreicht würde.
Woher kommt die funktionale Programmierung?
Der erste Punkt, den ich aus dem Weg räumen möchte ist, dass FP alt ist, auch wenn manche Leute das vielleicht denken. Wirklich alt (zumindest nach Computerstandards). Es ist nicht wie das neuste JavaScript-Framework, das dieses Jahr in Mode ist und im nächsten Jahr schon wieder veraltet ist. Es ist älter als alle modernenProgrammiersprachen und bis zu einem gewissen Gradsogar als die Computertechnik selbst. FP gibt es schon länger als wir alle und wird es wahrscheinlich auch noch geben, wenn wir alle längst im Ruhestand sind.
Ich will damit sagen, dass es sich lohnt, Zeit und Energie zu investieren, um FP zu lernen und zu verstehen. Selbst wenn du eines Tages nicht mehr in C# arbeitest, unterstützen die meisten anderen Sprachen mehr oder weniger stark funktionale Konzepte (JavaScript tut dies in einem Ausmaß, von dem die meisten Sprachen nur träumen können), so dass diese Fähigkeiten für den Rest deiner Karriere relevant bleiben werden.
Eine kurze Warnung, bevor ich fortfahre: Ich bin keine Mathematikerin. Ich liebe Mathematik, die während meiner gesamten Schulzeit zu meinen Lieblingsfächern gehörte, aber irgendwann kommt eine Ebene höherer, theoretischer Mathematik, die selbst mich mit glasigen Augen und leichten Kopfschmerzen zurücklässt. Deshalb werde ich mein Bestes tun, um kurz darüber zu sprechen, woher FP kommt, nämlich aus genau dieser Welt der theoretischen Mathematik.
Die erste Figur in der Geschichte der FP, die die meisten Leute kennen, ist Haskell Brooks Curry (1900-1982), ein amerikanischer Mathematiker, nach dem nicht weniger als drei Programmiersprachen und das funktionale Konzept des Currys benannt sind (mehr dazu erfährst du in Kapitel 8). Er arbeitete an der kombinatorischen Logik, einem mathematischen Konzept, bei dem Funktionen in der Form von Lambda- (oder Pfeil-) Ausdrücken geschrieben und dann kombiniert werden, um eine komplexere Logik zu schaffen. Dies ist die grundlegende Basis von FP. Curry war allerdings nicht der Erste, der sich mit diesem Thema befasste, sondern er knüpfte an die Arbeiten und Bücher seiner mathematischen Vorgänger an:
- Alonzo Church (1903-1955, Amerikaner)
-
Church prägte den Begriff Lambda-Ausdruck, den wir bis heute in C# und anderen Sprachen verwenden.
- Moses Schönfinkel (1888-1942, Russe)
-
Schönfinkel schrieb Arbeiten über kombinatorische Logik, die eine Grundlage für Currys Arbeit waren.
- Friedrich Frege (1848-1925, Deutscher)
-
Er war wohl der erste, der das Konzept beschrieben hat, das wir heute als Currying kennen. So wichtig es auch ist, Entdeckungen den richtigen Leuten zuzuschreiben, Freging hat nicht ganz den gleichen Klang.8
Die ersten FP-Sprachen waren die folgenden:
- Informationsverarbeitungssprache (IPL)
-
Entwickelt 1956 von Allen Newell (1927-1992, Amerikaner), Cliff Shaw (1922-1991, Amerikaner) und Herbert Simon (1916-2001, Amerikaner).
- LISt-Prozessor (LISP)
-
Entwickelt 1958 von John McCarthy (1927-2011, Amerikaner). Ich habe gehört, dass LISP auch heute noch seine Fans hat und in einigen Unternehmen immer noch in der Produktion eingesetzt wird. Ich selbst habe allerdings noch nie einen direkten Beweis dafür gesehen.
Interessanterweise ist keine dieser Sprachen das, was man als "rein" funktional bezeichnen würde. Wie C#, Java und zahlreiche andere Sprachen verfolgen sie eine Art hybriden Ansatz, anders als die modernen "rein" funktionalen Sprachen wie Haskell und Elm.
Ich möchte nicht zu lange auf die (zugegebenermaßen faszinierende) Geschichte von FP eingehen, aber aus dem, was ich gezeigt habe, wird hoffentlich deutlich, dass es einen langen und illustren Stammbaum hat.
Wer macht sonst noch funktionale Programmierung?
Wie ich bereits gesagt habe, gibt es FP schon seit einiger Zeit, und nicht nur .NET-Entwickler zeigen Interesse daran. Ganz im Gegenteil: Viele andere Sprachen bieten schon viel länger als .NET Unterstützung für funktionale Paradigmen.
Was meine ich mit Unterstützung? Ich meine damit, dass es die Möglichkeit bietet, Code im funktionalen Paradigma zu implementieren. Dabei gibt es grob zwei Varianten:
- Rein funktionale Sprachen
-
Sie sind für Entwickler gedacht, die ausschließlich funktionalen Code schreiben. Alle Variablen sind unveränderlich, und die Sprachen bieten von Haus aus Currying und Funktionen höherer Ordnung. Einige Funktionen der Objektorientierung sind in diesen Sprachen zwar möglich, aber das ist für die Teams, die hinter ihnen stehen, eher zweitrangig.
- Hybride oder multiparadigmatische Sprachen
-
Diese beiden Begriffe können völlig austauschbar verwendet werden. Sie beschreiben Programmiersprachen, die Funktionen bieten, mit denen Code in zwei oder mehr Paradigmen geschrieben werden kann - oft in zwei oder mehr gleichzeitig. Unterstützte Paradigmen sind in der Regel funktional und objektorientiert. Eine perfekte Implementierung eines der unterstützten Paradigmen ist möglicherweise nicht verfügbar. Es ist nicht ungewöhnlich, dass die Objektorientierung vollständig unterstützt wird, aber nicht unbedingt alle Funktionen des FP-Paradigmas zur Verfügung stehen.
Rein funktionale Sprachen
Es gibt weit über ein Dutzend rein funktionale Sprachen. Hier ist ein kurzer Blick auf die beliebtesten, die heute verwendet werden:
- Haskell
-
Haskell wird im Bankensektor ausgiebig verwendet und wird oft als guter Ausgangspunkt für alle empfohlen, die FP wirklich in den Griff bekommen wollen. Das mag ja sein, aber ehrlich gesagt habe ich weder die Zeit noch den Kopf, eine ganze Programmiersprache zu lernen, die ich in meinem Job nie benutzen werde.
Hinweis
Wenn du wirklich daran interessiert bist, ein Experte für das funktionale Paradigma zu werden, bevor du damit in C# arbeitest, solltest du unbedingt nach Haskell-Inhalten suchen. Eine häufige Empfehlung ist Learn You a Haskell for Great Good! von Miran Lipovača (No Starch Press).9 Ich selbst habe dieses Buch nie gelesen, aber Freunde von mir haben es gelesen und sagen, es sei großartig.
- Ulme
-
Elm scheint in diesen Tagen an Popularität zu gewinnen ( ), und zwar nicht zuletzt deshalb, weil das Elm-System zur Durchführung von Updates in der Benutzeroberfläche von vielen anderen Projekten übernommen und implementiert wurde, darunter auch React.
- Elixier
-
Diese universelle Programmiersprache basiert auf der gleichen virtuellen Maschine, auf der auch Erlang läuft. Sie ist in der Industrie sehr beliebt und hat sogar ihre eigenen jährlichen Konferenzen.
- PureScript
-
PureScript lässt sich zu JavaScript kompilieren ( ), so dass damit sowohl funktionaler Frontend-Code als auch serverseitiger Code und Desktop-Anwendungen in isometrischen Programmierumgebungen erstellt werden können - also in solchen wie Node.js, die es erlauben, dieselbe Sprache auf der Client- und der Serverseite zu verwenden.
Lohnt es sich, zuerst eine reine Funktionssprache zu lernen?
Zumindest im Moment ist OOP das vorherrschende Paradigma für die große Mehrheit der Softwareentwickler und das funktionale Paradigma ist etwas, das man erst noch lernen muss. Ich schließe nicht aus, dass sich das in Zukunft ändern wird, aber zumindest im Moment ist das die Situation, in der wir uns befinden.
Ich habe schon einige Leute argumentieren hören, dass es am besten wäre, FP in seiner reinen Form zu lernen und das Gelernte dann in C# anzuwenden. Wenn es das ist, was du tun willst, dann mach es. Habt Spaß. Ich habe keinen Zweifel daran, dass es ein lohnendes Unterfangen ist.
Diese Sichtweise erinnert mich an die Lehrerinnen und Lehrer, die wir hier in Großbritannien hatten und die darauf bestanden, dass Kinder Latein lernen sollten, weil Lateinkenntnisse als Wurzel vieler europäischer Sprachen leicht auf Französisch, Italienisch, Spanisch usw. übertragen werden können.
Dem kann ich nicht ganz zustimmen.10 Im Gegensatz zu Latein sind rein funktionale Sprachen nicht unbedingt schwierig, obwohl sie der objektorientierten Entwicklung sehr ähnlich sind. Im Vergleich zu OOP gibt es bei FP sogar weniger Konzepte zu lernen. Allerdings wird es denjenigen, die sich in ihrer Karriere intensiv mit OOP beschäftigt haben, wahrscheinlich schwerer fallen, sich umzustellen.
Latein und die reinen Funktionssprachen sind sich jedoch insofern ähnlich, als dass sie eine reinere, ursprüngliche Form darstellen. Sie sind beide nur von begrenztem Wert außerhalb einer kleinen Anzahl von Spezialinteressen.
Latein zu lernen ist auch fast völlig nutzlos, es sei denn, du interessierst dich für Fächer wie Recht, klassische Literatur oder alte Geschichte. Es ist viel sinnvoller, modernes Französisch oder Italienisch zu lernen. Diese Sprachen sind bei weitem einfacher zu lernen und du kannst sie nutzen, um schöne Orte zu besuchen und mit den netten Menschen zu sprechen, die dort leben. Es gibt auch einige tolle französischsprachige Comics aus Belgien. Sieh sie dir an. Ich werde warten.
Genauso werden nur wenige Unternehmen reine funktionale Sprachen in der Produktion einsetzen. Du würdest viel Zeit damit verbringen, deine Arbeitsweise komplett umzustellen und eine Sprache zu lernen, die du wahrscheinlich nie außerhalb deines eigenen Hobby-Codes verwenden wirst. Ich mache diesen Job schon sehr lange und habe noch nie ein Unternehmen getroffen, das in der Produktion etwas Fortschrittlicheres als C# verwendet.
Das Schöne an C# ist, dass sowohl objektorientierten als auch funktionalen Code unterstützt, so dass du nach Belieben zwischen beiden wechseln kannst. Du kannst so viele Funktionen des einen oder des anderen Paradigmas verwenden, wie du willst, ohne dass du dafür Nachteile in Kauf nehmen musst. Die Paradigmen können in der gleichen Codebasis bequem nebeneinander verwendet werden, so dass der Übergang von reinem objektorientiertem zu funktionalem Code ganz einfach ist - und umgekehrt. Eine solche Mischung von Paradigmen ist in einer rein funktionalen Sprache nicht möglich, auch wenn viele funktionale Funktionen in C# nicht möglich sind.
Was ist mit F#? Sollte ich F# lernen?
Was ist mit F#? Das ist wahrscheinlich die häufigste Frage, die mir gestellt wird. Es ist zwar keine rein funktionale Sprache, aber The Needle ist einer reinen Implementierung des Paradigmas viel näher als C#. Sie verfügt über eine Vielzahl funktionaler Funktionen, ist einfach zu programmieren und ermöglicht es, Anwendungen zu erstellen, die in einer Produktionsumgebung ein hohes Maß an Leistung erbringen - warum sollte man das nicht nutzen?
Bevor ich diese Frage beantworte, schaue ich mir immer erst die verfügbaren Ausgänge im Raum an. F# hat eine leidenschaftliche Nutzerbasis, und sie sind wahrscheinlich alle viel klüger als ich.11 Aber...
Es ist nicht so, dass F# nicht leicht zu lernen ist. Nach dem, was ich gesehen habe, ist es das sehr wohl. Und wahrscheinlich ist es einfacher zu lernen als C#, wenn du ganz neu in der Programmierung bist.
Es geht nicht darum, dass F# keine geschäftlichen Vorteile bringt, denn ich glaube wirklich, dass es das tut.
Es ist nicht so, dass F# nicht absolut alles kann, was jede andere Sprache auch kann. Das kann sie sehr wohl. Ich habe einige beeindruckende Vorträge darüber gesehen, wie man komplette F#-Webanwendungen erstellt.
Ob du F# lernen willst, ist eine berufliche Entscheidung. Es ist nicht schwer, C#-Entwickler zu finden, zumindest in keinem Land, das ich je besucht habe. Wenn ich die Namen aller Teilnehmer einer großen Entwicklerkonferenz in einen Hut stecke und einen zufällig ziehe, ist die Wahrscheinlichkeit, dass es sich um jemanden handelt, der professionell C# schreiben kann, mehr als gleich groß. Wenn ein Team beschließt, in eine C#-Codebasis zu investieren, wird es nicht schwer sein, das Team mit Ingenieuren zu besetzen, die in der Lage sind, den Code gut zu pflegen und das Unternehmen relativ zufrieden zu stellen.
Entwickler, die sich mit F# auskennen, sind auf der anderen Seite relativ selten. Ich kenne nicht viele. Wenn du F# in deine Codebasis aufnimmst, musst du entweder dafür sorgen, dass immer genügend Leute zur Verfügung stehen, die sich damit auskennen, oder du gehst das Risiko ein, dass einige Bereiche des Codes schwer zu warten sind, weil nur wenige Leute das können.
Ich sollte anmerken, dass das Risiko nicht so hoch ist wie bei der Einführung einer völlig neuen Technologie, wie z.B. Node.js. F# ist immer noch eine .NET-Sprache und lässt sich mit der gleichen Intermediate Language (IL) kompilieren. Du kannst sogar problemlos F#-Projekte von C#-Projekten in derselben Lösung referenzieren. Für die meisten .NET-Entwickler/innen ist die F#-Syntax aber immer noch völlig unbekannt.
Ich wünsche mir sehr, dass sich das im Laufe der Zeit ändert. Mir hat sehr gut gefallen, was ich von F# gesehen habe, und ich würde gerne mehr davon machen. Wenn mein Chef mir sagen würde, dass eine geschäftliche Entscheidung zur Einführung von F# getroffen wurde, wäre ich der Erste, der jubeln würde!
Tatsache ist jedoch, dass dieses Szenario derzeit nicht sehr wahrscheinlich ist. Wer weiß, was die Zukunft bringen wird. Vielleicht muss eine künftige Ausgabe dieses Buches stark umgeschrieben werden, um der plötzlich aufkeimenden Liebe zu F# gerecht zu werden, aber im Moment sehe ich das nicht am Horizont.
Meine Empfehlung ist, dieses Buch zuerst auszuprobieren. Wenn dir gefällt, was du siehst, könnte F# der nächste Ort sein, an den du dich auf deiner funktionalen Reise begibst.
Multiparadigma-Sprachen
Man kann wohl sagen, dass alle Sprachen neben den rein funktionalen Sprachen eine Art Hybrid sind. Mit anderen Worten, zumindest einige Aspekte des funktionalen Paradigmas können implementiert werden. Das ist wahrscheinlich wahr, aber ich werde nur kurz auf einige wenige Sprachen eingehen, in denen FP ganz oder größtenteils implementiert werden kann, und zwar als eine Funktion, die vom Team, das dahinter steht, explizit angeboten wird:
- JavaScript
-
JavaScript ist natürlich fast der Wilde Westen der Programmiersprachen, da man mit ihm fast alles machen kann, und es beherrscht FP sehr gut, wahrscheinlich besser als Objektorientierung. Wirf einen Blick auf JavaScript: The Good Parts von Douglas Crockford (O'Reilly) und einige seiner Online-Vorlesungen (z. B."JavaScript: The Good Parts"), wenn du wissen willst, wie man JavaScript funktional und richtig einsetzt.
- Python
-
Python hat sich in den letzten Jahren schnell zu einer beliebten Programmiersprache für die Open-Source-Gemeinde entwickelt. Ich war überrascht, als ich herausfand, dass es diese Sprache schon seit den späten 80er Jahren gibt! Python unterstützt Funktionen höherer Ordnung und verfügt über einige Bibliotheken, wie z. B. itertools und functools, mit denen weitere funktionale Funktionen implementiert werden können.
- Java
-
Die Java-Plattform unterstützt funktionale Funktionen auf demselben Niveau wie .NET. Außerdem bieten Spin-off-Projekte wie Scala, Clojure und Kotlin weitaus mehr funktionale Funktionen als die Sprache Java selbst.
- F#
-
Wie ich bereits ausführlich beschrieben habe, ist F# die rein funktionale Sprache von .NET. Es ist auch möglich, die Interoperabilität zwischen C#- und F#-Bibliotheken herzustellen, so dass du Projekte entwickeln kannst, die die besten Funktionen beider Sprachen nutzen.
- C#
-
Microsoft hat seit den Anfängen von langsam Unterstützung für FP hinzugefügt. Die Einführung der Delegaten-Kovarianz und der anonymen Methoden in C# 2.0 im Jahr 2005 kann wohl als erster Schritt zur Unterstützung des funktionalen Paradigmas angesehen werden. Richtig los ging es aber erst im darauffolgenden Jahr, als mit C# 3.0 das eingeführt wurde, was ich für eines der umwälzendsten Features halte, das jemals zu C# hinzugefügt wurde: LINQ.
LINQ ist tief im funktionalen Paradigma verwurzelt und eines der besten Werkzeuge für den Einstieg in das Schreiben von funktionalem Code in C# (siehe Kapitel 2 für eine ausführlichere Diskussion). Tatsächlich ist es ein erklärtes Ziel des C#-Teams, dass jede neue Version von C# mehr Unterstützung für FP bietet als die vorherige. Diese Entscheidung wird von einer Reihe von Faktoren beeinflusst. Einer davon ist F#, das oft neue funktionale Funktionen von den .NET-Laufzeitentwicklern fordert, von denen auch C# profitiert.
Die Vorteile der funktionalen Programmierung
Ich hoffe, dass du dieses Buch in die Hand genommen hast, weil du bereits von FP überzeugt bist und sofort loslegen willst. Dieser Abschnitt könnte für Teamdiskussionen darüber nützlich sein, ob du es bei der Arbeit einsetzen willst.
Kurz und bündig
Das ist zwar kein Merkmal von FP, aber mein Favorit der vielen Vorteile ist, wie prägnant und elegant er im Vergleich zu objektorientiertem oder imperativem Code aussieht.
Andere Arten von Code beschäftigen sich viel mehr mit den Details auf niedriger Ebene, wie etwas zu tun ist, so dass manchmal eine Menge Code-Gucken nötig ist, nur um herauszufinden, was dieses Etwas überhaupt ist. Bei der funktionalen Programmierung geht es eher darum zu beschreiben , was benötigt wird. Die Details darüber, welche Variablen wie und wann aktualisiert werden, um dieses Ziel zu erreichen, sind weniger wichtig für uns.
Einigen Entwicklern, mit denen ich darüber gesprochen habe, gefiel der Gedanke nicht, weniger mit den unteren Ebenen der Datenverarbeitung zu tun zu haben, aber mir persönlich gefällt es besser, wenn sich die Ausführungsumgebung darum kümmert. Dann habe ich eine Sache weniger, um die ich mich kümmern muss.
Es fühlt sich wie eine Kleinigkeit an, aber ich liebe ehrlich gesagt die Prägnanz von funktionalem Code im Vergleich zu den imperativen Alternativen. Der Job eines Entwicklers ist ein schwieriger Job,12 und wir erben oft komplexe Codebasen, mit denen wir uns schnell zurechtfinden müssen. Je länger und schwieriger es für dich ist, herauszufinden, was eine Funktion eigentlich tut, desto mehr Geld verliert das Unternehmen, wenn es dich dafür bezahlt, anstatt neuen Code zu schreiben. Funktionaler Code liest sich oft so, dass er in einer fast natürlichen Sprache beschreibt, was er tut. Außerdem ist es so einfacher, Fehler zu finden, was wiederum Zeit und Geld für das Unternehmen spart.
Überprüfbar
Eine Sache, die viele Leute als ihr Lieblingsmerkmal von FP beschreiben, ist, wie unglaublich testbar es ist. Das ist es wirklich. Wenn dein Code nicht annähernd zu 100 % testbar ist, besteht die Möglichkeit, dass du das Paradigma nicht richtig befolgt hast.
Testgetriebene Entwicklung (TDD) und verhaltensgetriebene Entwicklung (BDD) sind wichtige professionelle Praktiken. Bei diesen Programmiertechniken werden zuerst automatisierte Einheitstests für den Produktionscode geschrieben und dann der eigentliche Code, der für das Bestehen des Tests erforderlich ist. Dieser Ansatz führt in der Regel zu einem besser konzipierten, robusteren Code. FP ermöglicht diese Praktiken auf elegante Weise. Das wiederum führt zu einer besseren Codebasis und weniger Fehlern in der Produktion.
Robust
Es ist auch nicht nur die Testbarkeit, die zu einer robusteren Codebasis führt. FP besteht aus Strukturen, die aktiv verhindern, dass Fehler überhaupt erst auftreten.
Alternativ verhindern diese Strukturen ein unerwartetes Verhalten und machen es einfacher, das Problem genau zu melden. Das Konzept der Null gibt es in FP nicht. Das allein spart eine unglaubliche Anzahl möglicher Fehler und reduziert die Anzahl der automatisierten Tests, die geschrieben werden müssen.
Vorhersehbar
Funktionaler Code beginnt am Anfang des Codeblocks und arbeitet sich bis zum Ende vor - und zwar ausschließlich der Reihe nach. Das kann man von prozeduralem Code mit seinen Schleifen und Verzweigungen if nicht behaupten. FP hat nur einen einzigen, leicht zu verfolgenden Codefluss.
Wenn es richtig gemacht wird, hat FP nicht einmal irgendwelche try/catch Blöcke, die meiner Erfahrung nach oft zu den schlimmsten Übeltätern gehören, wenn es um Code mit einer unvorhersehbaren Reihenfolge von Operationen geht. Wenn der try nicht klein ist und eng mit dem catch gekoppelt ist, kann der Code manchmal so aussehen, als würde man einen Stein blind in die Luft werfen. Wer weiß, wo er landen wird und wer oder was ihn auffangen könnte? Wer kann sagen, welches unerwartete Verhalten sich aus einer solchen Unterbrechung des Programmflusses ergeben könnte?
Unsachgemäß entworfene try/catch Blöcke waren die Ursache für viele unerwartete Verhaltensweisen in der Produktion, die ich im Laufe meiner Karriere beobachtet habe, und das ist ein Problem, das es im funktionalen Paradigma einfach nicht gibt. Eine unsachgemäße Fehlerbehandlung ist in funktionalem Code zwar immer noch möglich, aber das Wesen von FP schreckt davon ab.
Bessere Unterstützung für Gleichzeitigkeit
In den letzten Jahren haben zwei Entwicklungen in der Welt der Softwareentwicklung an Bedeutung gewonnen:
- Containerisierung
-
Die Containerisierung wird u. a. von Produkten wie Docker und Kubernetes ( ) angeboten. Statt auf einem herkömmlichen Server - ob virtuell oder nicht - läuft die Anwendung auf einer Art virtueller Mini-Maschine (VM), die zum Zeitpunkt der Bereitstellung von einem Skript erzeugt wird. Das ist zwar nicht ganz dasselbe (es findet keine Hardware-Emulation statt), aber aus Sicht des Nutzers fühlt sich das Ergebnis in etwa gleich an. Es löst das Problem, dass "es auf meinem Rechner funktioniert hat", das vielen Entwicklern leider nur allzu bekannt ist. Viele Unternehmen verfügen über eine Software-Infrastruktur, die viele Instanzen derselben Anwendung in einer Reihe von Containern stapelt, die alle dieselbe Eingabequelle verarbeiten - sei es eine Warteschlange, Benutzeranfragen oder was auch immer. Die Umgebung, in der sie gehostet werden, kann sogar so konfiguriert werden, dass die Anzahl der aktiven Container je nach Bedarf erhöht oder verringert wird.
- Serverlos
-
Diese Option ist .NET-Entwicklern vielleicht schon bekannt als Azure Functions oder Amazon Web Services (AWS) Lambda. Dabei handelt es sich um Code, der nicht auf einem herkömmlichen Webserver, wie z. B. Internet Information Services (IIS), bereitgestellt wird, sondern als einzelne Funktion, die isoliert in einer Cloud-Hosting-Umgebung existiert. Dieser Ansatz ermöglicht dieselbe Art von automatischer Skalierung wie bei Containern, aber auch Optimierungen auf Mikroebene: Mehr Geld kann für kritischere Funktionen ausgegeben werden und weniger Geld für Funktionen, die mehr Zeit zum Rendern der Ausgabe benötigen.
Beide Technologien verwenden häufig die gleichzeitige Verarbeitung (d. h. mehrere Instanzen derselben Funktion arbeiten gleichzeitig an derselben Eingabequelle). Das ist so ähnlich wie die asynchronen Funktionen von .NET, nur in einem viel größeren Rahmen.
Das Problem bei jeder Art von asynchronen Operationen ist die gemeinsame Nutzung von Ressourcen, egal ob es sich dabei um einen In-Memory-Status oder eine physische oder softwarebasierte externe Ressource handelt. FP arbeitet ohne Zustand, sodass kein Zustand zwischen Threads, Containern oder serverlosen Funktionen geteilt werden kann.
Wenn das funktionale Paradigma richtig umgesetzt wird, ist es viel einfacher, diese gefragten technischen Funktionen zu implementieren, ohne dass es zu unerwartetem Verhalten in der Produktion kommt.
Reduziertes Code-Rauschen
Bei der Audioverarbeitung wird ein Konzept verwendet, das als Signal-Rausch-Verhältnis bezeichnet wird. Das ist ein Maß für die Klarheit einer Aufnahme, das auf dem Verhältnis zwischen dem Lautstärkepegel des Signals (das, was du hören willst) und dem Rauschen (Zischen, Knistern oder Rumpeln im Hintergrund) basiert.
In der Programmierung ist das Signal die Geschäftslogik eines Codeblocks - das Ziel, das er eigentlich erreichen soll. Das Signal ist das Was des Codes.
Das Rauschen ist all der Boilerplate-Code, der geschrieben werden muss, um das Ziel zu erreichen. Das Rauschen umfasst die for Schleifendefinition, if Anweisungen und dergleichen mehr.
Im Vergleich zu prozeduralem Code hat saubere, prägnante FP deutlich weniger Boilerplate und damit ein viel besseres Signal-Rausch-Verhältnis. Das ist nicht nur ein Vorteil für die Entwickler. Robuste, leichter zu pflegende Codebasen bedeuten, dass das Unternehmen weniger Geld für Wartung und Verbesserungen ausgeben muss.
Die besten Orte, um funktionale Programmierung anzuwenden
FP kann absolut alles, was jedes andere Paradigma auch kann, aber in bestimmten Bereichen ist es am stärksten und am vorteilhaftesten - und in anderen Bereichen kann es notwendig sein, Kompromisse einzugehen und einige objektorientierte Funktionen einzubauen oder die Regeln des funktionalen Paradigmas leicht zu verbiegen. Zumindest in .NET müssen Kompromisse eingegangen werden, weil Basisklassen und Zusatzbibliotheken in der Regel nach dem objektorientierten Paradigma geschrieben werden. Dieser Kompromiss gilt nicht für rein funktionale Sprachen.
FP ist gut, wenn der Code ein hohes Maß an Vorhersehbarkeit hat - zum Beispiel bei Datenverarbeitungsmodulen oder Funktionen, die Daten von einer Form in eine andere umwandeln. Ein weiteres Beispiel sind Geschäftslogikklassen, die Daten vom Benutzer oder der Datenbank verarbeiten und sie dann weitergeben, damit sie an anderer Stelle wiedergegeben werden können. Solche Dinge.
Die zustandslose Natur von FP macht es zu einem großartigen Enabler für nebenläufige Systeme, wie z. B. stark asynchrone Codebasen oder Situationen, in denen mehrere Prozessoren gleichzeitig auf dieselbe Eingabewarteschlange hören. Wenn es keinen gemeinsamen Status gibt, sind Probleme mit Ressourcenkonflikten so gut wie ausgeschlossen. Wenn dein Team den Einsatz von serverlosen Anwendungen wie Azure Functions in Erwägung zieht, eignet sich FP aus denselben Gründen hervorragend dafür.
FP ist eine Überlegung wert, wenn es um geschäftskritische Systeme geht, denn dieses Paradigma ermöglicht es, Code zu erstellen, der weniger fehleranfällig und robuster ist als Anwendungen, die mit dem objektorientierten Paradigma programmiert wurden. Wenn es unglaublich wichtig ist, dass das System nicht abstürzt (d.h. unerwartet beendet wird), wenn eine unbehandelte Ausnahme oder eine ungültige Eingabe auftritt, dann ist FP vielleicht die beste Wahl.
Wo du den Einsatz anderer Paradigmen in Betracht ziehen solltest
Du musst natürlich nicht in Betracht ziehen, andere Paradigmen zu verwenden. Funktional kann alles, aber in einigen Bereichen kann es sich lohnen, nach anderen Paradigmen Ausschau zu halten - vor allem im Zusammenhang mit C#. Und es ist auch erwähnenswert, dass C# eine hybride Sprache ist, so dass viele Paradigmen gut nebeneinander bestehen können, je nach den Bedürfnissen des Entwicklers. Ich weiß natürlich, was ich bevorzuge!
Die Interaktion mit externen Entitäten ist ein Bereich, der zu berücksichtigen ist: zum Beispiel E/A, Benutzereingaben, Anwendungen von Drittanbietern und Web-APIs. Es gibt keine Möglichkeit, diese zu reinen Funktionen (d.h. ohne Seiteneffekte) zu machen, also sind Kompromisse notwendig. Das Gleiche gilt für Module von Drittanbietern, die aus NuGet-Paketen importiert werden. Sogar einige ältere Microsoft-Bibliotheken sind funktional einfach nicht zu gebrauchen. Das ist auch in .NET Core noch der Fall. Sieh dir die SmtpClient oder MailMessage Klassen in .NET an, wenn du ein konkretes Beispiel sehen willst.
Wenn in der C#-Welt die Leistung das einzige und wichtigste Anliegen deines Projekts ist, das alle anderen Aspekte, selbst die Lesbarkeit und Modularität, übertrumpft, ist es vielleicht nicht die beste Idee, dem funktionalen Paradigma zu folgen. Die Leistung von funktionalem C#-Code ist nicht von Natur aus schlecht, aber es ist auch nicht unbedingt die leistungsstärkste Lösung.
Ich bin der Meinung, dass die Vorteile von FP die geringen Leistungseinbußen bei weitem überwiegen. Heutzutage ist es in der Regel einfach, etwas mehr Hardware (je nach Bedarf virtuell oder physisch) in die App einzubauen, und das ist wahrscheinlich um Größenordnungen billiger als die Kosten für zusätzliche Entwicklerzeit, die sonst für die Entwicklung, das Testen, das Debuggen und die Wartung einer Codebasis im imperativen Stil erforderlich wäre. Das ändert sich, wenn du zum Beispiel an einem Code für ein mobiles Gerät arbeitest, bei dem die Leistung entscheidend ist, weil der Speicher begrenzt ist und nicht aktualisiert werden kann.
Wie weit können wir es treiben?
Leider ist es einfach nicht möglich, das gesamte funktionale Paradigma in C# zu implementieren. Dafür gibt es viele Gründe, darunter die Notwendigkeit der Abwärtskompatibilität der Sprache und die Einschränkungen, die einer stark typisierten Sprache auferlegt sind.
In diesem Buch geht es nicht darum, dir zu zeigen, wie du alles machen kannst, sondern vielmehr darum, die Grenzen zwischen dem, was möglich ist, und dem, was nicht möglich ist, aufzuzeigen. Ich werde auch darauf eingehen, was praktisch ist, vor allem mit Blick auf diejenigen unter euch, die eine produktive Codebasis pflegen. Letztendlich ist dies ein praktischer, pragmatischer Leitfaden für funktionale Kodierungsstile.
Monaden, mach dir noch keine Gedanken darüber
Monaden werden oft als die funktionale Horrorgeschichte angesehen. Wenn du auf Wikipedia nach Definitionen suchst, wirst du mit einer seltsamen Buchstabensuppe konfrontiert, die Fs, Gs, Pfeile und mehr Klammern enthält, als du in den Regalen deiner örtlichen Bibliothek finden kannst. Selbst jetzt finde ich diese formalen Definitionen völlig unleserlich. Schließlich bin ich Ingenieur und kein Mathematiker.
Douglas Crockford sagte einmal, dass der Fluch der Monade darin besteht, dass man in dem Moment, in dem man die Fähigkeit erlangt, sie zu verstehen, auch die Fähigkeit verliert, sie zu erklären. Das werde ich also nicht tun. Monaden könnten aber irgendwo in diesem Buch auftauchen - vor allem zu unwahrscheinlichen Zeiten.
Mach dir keine Sorgen, das wird schon. Wir werden das alles gemeinsam durchstehen. Vertrau mir...
Zusammenfassung
In dieser ersten spannenden Folge von Funktionale Programmierung mit C# hat unser mächtiger, ehrfurchtgebietender Held - du - gelernt, was genau FP ist und warum es sich lohnt, es zu lernen. Du hast eine erste, kurze Einführung in die wichtigen Merkmale des funktionalen Paradigmas erhalten:
-
Unveränderlichkeit
-
Funktionen höherer Ordnung
-
Bevorzugung von Ausdrücken gegenüber Aussagen
-
Referentielle Transparenz
-
Rekursion
-
Musterabgleich
-
Zustandslos
Du hast gelesen, in welchen Bereichen FP am besten eingesetzt werden kann und welche Vorteile die Verwendung des Paradigmas in seiner reinen Form mit sich bringt. Du hast dir auch die vielen Vorteile angesehen, die das funktionale Paradigma beim Schreiben von Anwendungen bietet.
In der nächsten spannenden Folge erfährst du, was du in C# genau hier und jetzt tun kannst. Dazu brauchst du keine neuen Bibliotheken von Drittanbietern oder Microsoft Visual Studio-Erweiterungen, sondern einfach nur C# von der Stange und ein bisschen Einfallsreichtum.
Blättere um und erfahre alles darüber. Dieselbe .NET-Zeit. Derselbe .NET-Kanal.13
1 Mit Vanille und meinem persönlichen Favoriten, der Banane.
2 Als ich in den 90er Jahren im Vereinigten Königreich aufwuchs, hießen sie "Hero Turtles". Ich glaube, die Fernsehleute wollten den gewalttätigen Beigeschmack des Wortes "Ninja" vermeiden. Trotzdem durften wir sehen, wie unsere Helden regelmäßig scharfe Werkzeuge gegen ihre Bösewichte einsetzten.
3 Diese praktischen Regeln verdanke ich dem Oberhaupt der funktionalen Programmierung Mark Seemann.
4 Weil ich es mir für dieses Beispiel ausgedacht habe.
5 Okay, ihr Künstler, ich weiß, dass es eigentlich 12 sind, aber das ist mehr, als ich brauche, damit diese Metapher funktioniert.
6 Aus irgendeinem Grund ruft Julie Andrews nicht zurück, um mit mir über eine aktualisierte .NET-Version ihres berühmten Songs zu sprechen.
7 Mit ein wenig kreativer Freiheit.
8 Zum Beispiel: "Ich kann diesen Freging-Code nicht zum Laufen bringen!"
9 Zum kostenlosen Online-Lesen verfügbar. Sag ihnen, dass ich dich geschickt habe.
10 Obwohl ich gerade Latein lerne. Insipiens sum. Huiusmodi res est ioci facio.
11 Vor allem F#-Guru Ian Russell, der bei den F#-Inhalten in diesem Buch geholfen hat. Danke, Ian!
12 Zumindest sagen wir das unseren Führungskräften.
13 Oder ein Buch, wenn wir wählerisch sein wollen.
Get Funktionale Programmierung mit C# now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

