Kapitel 1. Das Python-Datenmodell
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Guidos Sinn für die Ästhetik des Sprachdesigns ist erstaunlich. Ich habe schon viele gute Sprachdesigner kennengelernt, die theoretisch schöne Sprachen entwickeln konnten, die niemand jemals benutzen würde, aber Guido ist einer der wenigen Menschen, die eine Sprache entwickeln können, die theoretisch nicht ganz so schön ist, mit der es aber trotzdem Spaß macht, Programme zu schreiben.
Jim Hugunin, Schöpfer von Jython, Miterfinder von AspectJ und Architekt des .Net DLR1
Eine der besten Eigenschaften von Python ist seine Beständigkeit. Wenn du eine Weile mit Python gearbeitet hast, kannst du fundierte und korrekte Vermutungen über Funktionen anstellen, die für dich neu sind.
Wenn du jedoch vor Python eine andere objektorientierte Sprache gelernt hast, wirst du es vielleicht seltsam finden, len(collection) statt collection.len() zu verwenden. Diese scheinbare Merkwürdigkeit ist die Spitze eines Eisbergs, der, wenn man ihn richtig versteht, der Schlüssel zu allem ist, was wir Pythonic nennen. Der Eisberg heißt Python Data Model und ist die API, die wir verwenden, damit unsere eigenen Objekte mit den idiomatischstenSprachfunktionen gut zusammenspielen.
Du kannst dir das Datenmodell als eine Beschreibung von Python als Rahmenwerk vorstellen. Es formalisiert die Schnittstellen der Bausteine der Sprache selbst, wie Sequenzen, Funktionen, Iteratoren, Coroutines, Klassen, Kontextmanager und so weiter.
Wenn wir ein Framework verwenden, verbringen wir viel Zeit damit, Methoden zu kodieren, die vom Framework aufgerufen werden. Das Gleiche passiert, wenn wir das Python-Datenmodell nutzen, um neue Klassen zu erstellen. Der Python-Interpreter ruft spezielle Methoden auf, um grundlegende Objektoperationen durchzuführen, die oft durch eine spezielle Syntax ausgelöst werden. Die speziellen Methodennamen werden immer mit führenden und nachgestellten doppelten Unterstrichen geschrieben. Die Syntax obj[key] wird zum Beispiel von der __getitem__ speziellen Methode unterstützt. Um my_collection[key] auszuwerten, ruft der Interpreter my_collection.__getitem__(key) auf.
Wir implementieren spezielle Methoden, wenn wir wollen, dass unsere Objekte grundlegende Sprachkonstrukte unterstützen und mit ihnen interagieren, z. B:
-
Sammlungen
-
Zugriff auf Attribute
-
Iteration (einschließlich asynchroner Iteration mit
async for) -
Operator-Überladung
-
Funktion und Methodenaufruf
-
String-Darstellung und -Formatierung
-
Asynchrone Programmierung mit
await -
Erstellung und Zerstörung von Objekten
-
Verwaltete Kontexte mit den Anweisungen
withoderasync with
Magie und Dunder
Der Begriff magic method ist Slang für spezielle Methode, aber wie spricht man über eine spezielle Methode wie __getitem__? Ich habe von Autor und Lehrer Steve Holden gelernt, "dunder-getitem" zu sagen. "Dunder" ist eine Abkürzung für "doppelter Unterstrich vor und nach". Deshalb werden die speziellen Methoden auch als dunder-Methoden bezeichnet. Das Kapitel "Lexikalische Analyse"der Python-Sprachreferenz warnt davor, dass "jede Verwendung von __*__ Namen in irgendeinem Kontext, die nicht der explizit dokumentierten Verwendung folgt, ohne Vorwarnung zu Bruch geht."
Was ist neu in diesem Kapitel?
In diesem Kapitel gab es nur wenige Änderungen gegenüber der ersten Ausgabe, da es eine Einführung in das Python-Datenmodell ist, das recht stabil ist. Die wichtigsten Änderungen sind:
-
Spezielle Methoden, die asynchrone Programmierung und andere neue Funktionen unterstützen, wurden zu den Tabellen in "Übersicht der speziellen Methoden" hinzugefügt .
-
Abbildung 1-2 zeigt die Verwendung von speziellen Methoden in der "Collection API", einschließlich der abstrakten Basisklasse
collections.abc.Collection, die in Python 3.6 eingeführt wurde.
Außerdem habe ich hier und in der gesamten zweiten Auflage die in Python 3.6 eingeführte f-string-Syntax übernommen, die lesbarer und oft bequemer ist als die älteren Notationen zur String-Formatierung: die str.format() Methode und der % Operator.
Tipp
Ein Grund, my_fmt.format() immer noch zu verwenden, ist, wenn die Definition von my_fmt an einer anderen Stelle im Code stehen muss als der Ort, an dem die Formatierung stattfinden soll. Zum Beispiel, wenn my_fmt über mehrere Zeilen geht und besser in einer Konstanten definiert wird, oder wenn sie aus einer Konfigurationsdatei oder aus der Datenbank kommen muss. Das sind echte Bedürfnisse, die aber nicht sehr oft vorkommen.
Ein pythonisches Kartendeck
Beispiel 1-1 ist einfach, aber es demonstriert die Macht der Implementierung von nur zwei speziellen Methoden, __getitem__ und __len__.
Beispiel 1-1. Ein Deck als eine Folge von Spielkarten
importcollectionsCard=collections.namedtuple('Card',['rank','suit'])classFrenchDeck:ranks=[str(n)forninrange(2,11)]+list('JQKA')suits='spades diamonds clubs hearts'.split()def__init__(self):self._cards=[Card(rank,suit)forsuitinself.suitsforrankinself.ranks]def__len__(self):returnlen(self._cards)def__getitem__(self,position):returnself._cards[position]
Das erste, was auffällt, ist die Verwendung von collections.namedtuple, um eine einfache Klasse zu erstellen, die einzelne Karten repräsentiert. Wir verwenden namedtuple, um Klassen von Objekten zu erstellen, die nur Bündel von Attributen ohne benutzerdefinierte Methoden sind, wie z. B. ein Datenbankdatensatz. In diesem Beispiel verwenden wir es, um eine schöne Darstellung für die Karten im Deck zu erstellen, wie in der Konsolensitzung gezeigt:
>>>beer_card=Card('7','diamonds')>>>beer_cardCard(rank='7', suit='diamonds')
Aber in diesem Beispiel geht es um die Klasse FrenchDeck. Sie ist kurz, aber sie hat es in sich. Erstens reagiert ein Deck wie jede normale Python-Sammlung auf die Funktion len() , indem es die Anzahl der Karten zurückgibt, die es enthält:
>>>deck=FrenchDeck()>>>len(deck)52
Bestimmte Karten aus dem Deck zu lesen - z.B. die erste oder die letzte - ist dank der __getitem__ Methode ganz einfach:
>>>deck[0]Card(rank='2', suit='spades')>>>deck[-1]Card(rank='A', suit='hearts')
Sollen wir eine Methode erstellen, um eine zufällige Karte auszuwählen? Das ist nicht nötig, denn Python hat bereits eine Funktion, um ein zufälliges Element aus einer Sequenz zu erhalten: random.choice. Wir können sie für eine Deck-Instanz verwenden:
>>>fromrandomimportchoice>>>choice(deck)Card(rank='3', suit='hearts')>>>choice(deck)Card(rank='K', suit='spades')>>>choice(deck)Card(rank='2', suit='clubs')
Wir haben gerade zwei Vorteile der Verwendung spezieller Methoden gesehen, um das Python-Datenmodell zu nutzen:
-
Die Benutzer deiner Klassen müssen sich nicht beliebige Methodennamen für Standardoperationen merken ("Wie bekomme ich die Anzahl der Artikel?
.size(),.length(), oder was?"). -
Es ist einfacher, von der reichhaltigen Python-Standardbibliothek zu profitieren und das Rad nicht neu zu erfinden, wie zum Beispiel die Funktion
random.choice.
Aber es kommt noch besser.
Da unser __getitem__ an den [] Operator von self._cards delegiert, unterstützt unser Deck automatisch das Slicing. So schauen wir uns die obersten drei Karten eines brandneuen Decks an und wählen dann nur die Asse aus, indem wir bei Index 12 beginnen und 13 Karten auf einmal überspringen:
>>>deck[:3][Card(rank='2', suit='spades'), Card(rank='3', suit='spades'),Card(rank='4', suit='spades')]>>>deck[12::13][Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'),Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]
Nur durch die Implementierung der __getitem__ Spezialmethode ist unser Deck auch iterierbar:
>>>forcardindeck:# doctest: +ELLIPSIS...(card)Card(rank='2', suit='spades')Card(rank='3', suit='spades')Card(rank='4', suit='spades')...
Wir können das Deck auch in umgekehrter Reihenfolge durchlaufen:
>>>forcardinreversed(deck):# doctest: +ELLIPSIS...(card)Card(rank='A', suit='hearts')Card(rank='K', suit='hearts')Card(rank='Q', suit='hearts')...
Ellipsen in Doktortests
Wann immer möglich, habe ich die Python-Konsolenauflistungen in diesem Buch vondoctest Wenn die Ausgabe zu lang war, wird der ausgelassene Teil durch eine Ellipse (...) gekennzeichnet, wie in der letzten Zeile des vorangegangenen Codes. In solchen Fällen habe ich die Direktive # doctest: +ELLIPSIS verwendet, um den Doctest zu bestehen. Wenn du diese Beispiele in der interaktiven Konsole ausprobierst, kannst du die Doctest-Kommentare ganz weglassen.
Die Iteration ist oft implizit. Wenn eine Sammlung keine __contains__ Methode hat, führt der in Operator eine sequentielle Suche durch. Ein Beispiel: in funktioniert mit unserer FrenchDeck Klasse, weil sie iterierbar ist. Probiere es aus:
>>>Card('Q','hearts')indeckTrue>>>Card('7','beasts')indeckFalse
Wie wär's mit Sortieren? Ein gängiges System zum Sortieren von Karten ist nach Rang (wobei Asse am höchsten sind), dann nach Farbe in der Reihenfolge Pik (am höchsten), Herz, Karo und Kreuz (am niedrigsten). Hier ist eine Funktion, die Karten nach dieser Regel sortiert und 0 für die Kreuz 2 und 51 für das Pik-Ass zurückgibt:
suit_values=dict(spades=3,hearts=2,diamonds=1,clubs=0)defspades_high(card):rank_value=FrenchDeck.ranks.index(card.rank)returnrank_value*len(suit_values)+suit_values[card.suit]
Mit spades_high können wir nun unser Deck in aufsteigender Reihenfolge auflisten:
>>>forcardinsorted(deck,key=spades_high):# doctest: +ELLIPSIS...(card)Card(rank='2', suit='clubs')Card(rank='2', suit='diamonds')Card(rank='2', suit='hearts')...(46cardsomitted)Card(rank='A', suit='diamonds')Card(rank='A', suit='hearts')Card(rank='A', suit='spades')
Obwohl FrenchDeck implizit von der Klasse object erbt, wird der größte Teil der Funktionalität nicht vererbt, sondern ergibt sich aus der Nutzung des Datenmodells und der Komposition. Durch die Implementierung der speziellen Methoden __len__ und __getitem__ verhält sich unsere FrenchDeck wie eine Standard-Python-Sequenz, so dass sie von den Kernfunktionen der Sprache (z.B. Iteration und Slicing) und von der Standardbibliothek profitieren kann, wie die Beispiele mit random.choice zeigen,reversedsortedDank der Komposition können die Implementierungen von __len__ und __getitem__ die gesamte Arbeit an ein list Objekt,self._cards, delegieren.
Wie wäre es mit Mischen?
So wie es bisher implementiert ist, kann FrenchDeck nicht gemischt werden, weil es unveränderlich ist: Die Karten und ihre Positionen können nicht verändert werden, außer man verletzt die Kapselung und behandelt das _cards Attribut direkt. In Kapitel 13 werden wir das beheben, indem wir eine einzeilige __setitem__ Methode hinzufügen.
Wie besondere Methoden eingesetzt werden
Das erste, was du über spezielle Methoden wissen musst, ist, dass sie vom Python-Interpreter aufgerufen werden sollen und nicht von dir. Du schreibst nicht my_object.__len__(). Du schreibst len(my_object) und wenn my_object eine Instanz einer benutzerdefinierten Klasse ist, dann ruft Python die von dir implementierte Methode __len__ auf.
Aber der Interpreter nimmt eine Abkürzung, wenn es um eingebaute Typen wie list, str, bytearray oder Erweiterungen wie die NumPy-Arrays geht. In C geschriebene Python-Sammlungen mit variabler Größe enthalten eine Struktur2
namens PyVarObject, die ein Feld ob_size hat, das die Anzahl der Elemente in der Sammlung enthält. Wenn my_object also eine Instanz eines dieser Built-Ins ist, ruft len(my_object) den Wert des Feldes ob_size ab, was viel schneller ist als der Aufruf einer Methode.
In den meisten Fällen ist der Aufruf der speziellen Methode implizit. Zum Beispiel bewirkt die Anweisung for i in x: den Aufruf von iter(x), der wiederum x.__iter__() aufrufen kann, wenn diese verfügbar ist, oder x.__getitem__(), wie im Beispiel FrenchDeck.
Normalerweise sollte dein Code nicht viele direkte Aufrufe von speziellen Methoden enthalten. Wenn du nicht gerade viel Metaprogrammierung betreibst, solltest du spezielle Methoden häufiger implementieren als sie explizit aufzurufen. Die einzige spezielle Methode, die häufig direkt vom Benutzercode aufgerufen wird, ist __init__, um den Initialisierer der Oberklasse in deiner eigenen __init__ Implementierung aufzurufen.
Wenn du eine spezielle Methode aufrufen musst, ist es in der Regel besser, die zugehörige eingebaute Funktion aufzurufen (z. B. len, iter, str, usw.). Diese eingebauten Funktionen rufen die entsprechende spezielle Methode auf, bieten aber oft auch andere Dienste und sind - bei eingebauten Typen - schneller als Methodenaufrufe. Siehe z. B. "iter mit einer Callable verwenden" in Kapitel 17.
In den nächsten Abschnitten werden wir einige der wichtigsten Verwendungszwecke von speziellen Methoden kennenlernen:
-
Numerische Typen emulieren
-
String-Darstellung von Objekten
-
Boolescher Wert eines Objekts
-
Sammlungen implementieren
Numerische Typen emulieren
Mehrere Spezialmethoden ermöglichen es Benutzerobjekten, auf Operatoren wie + zu reagieren. Wir werden das in Kapitel 16 ausführlicher behandeln, aber hier wollen wir die Verwendung von Spezialmethoden anhand eines anderen einfachen Beispiels weiter veranschaulichen.
Wir werden eine Klasse implementieren, die zweidimensionale Vektoren darstellt, also euklidische Vektoren, wie sie in der Mathematik und Physik verwendet werden (siehe Abbildung 1-1).
Tipp
Der eingebaute Typ complex kann verwendet werden, um zweidimensionale Vektoren darzustellen, aber unsere Klasse kann erweitert werden, um n-dimensionale Vektoren darzustellen. Das werden wir in Kapitel 17 tun.
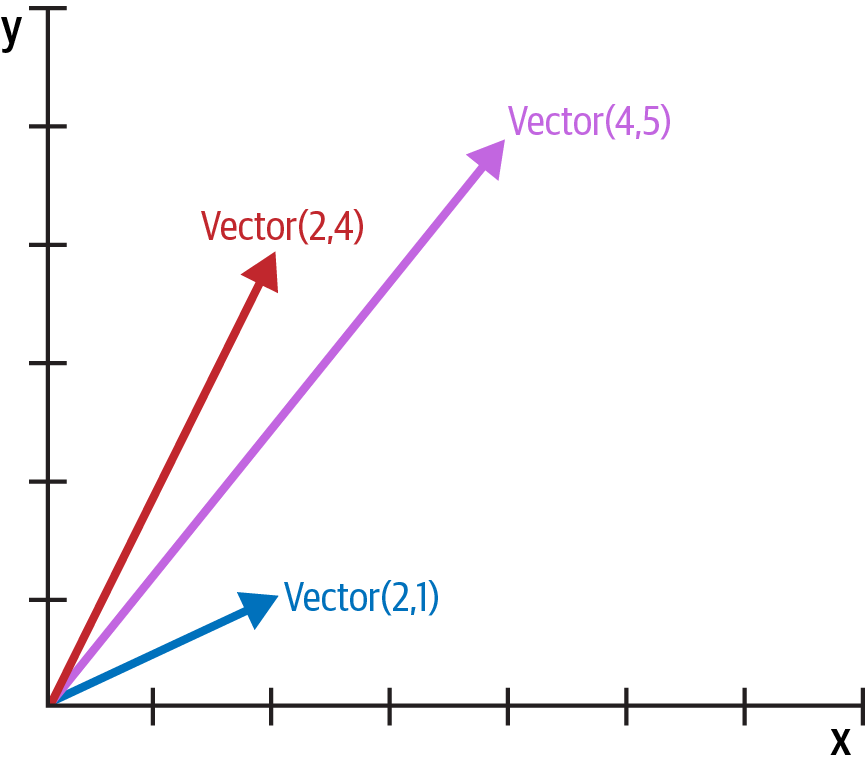
Abbildung 1-1. Beispiel einer zweidimensionalen Vektoraddition; Vektor(2, 4) + Vektor(2, 1) ergibt Vektor(4, 5).
Wir beginnen mit dem Entwurf der API für eine solche Klasse, indem wir eine simulierte Konsolensitzung schreiben, die wir später als Test verwenden können. Das folgende Snippet testet die in Abbildung 1-1 dargestellte Vektoraddition:
>>>v1=Vector(2,4)>>>v2=Vector(2,1)>>>v1+v2Vector(4, 5)
Beachte wie der + Operator zu einem neuen Vector führt, der in einem freundlichen Format auf der Konsole angezeigt wird.
Die eingebaute Funktion abs gibt den Absolutwert von Ganzzahlen und Fließkommazahlen sowie den Betrag von complex Zahlen zurück. Um konsistent zu sein, verwendet unsere API auch abs, um den Betrag eines Vektors zu berechnen:
>>>v=Vector(3,4)>>>abs(v)5.0
Wir können auch den Operator * implementieren, um eine Skalarmultiplikation durchzuführen (d.h. einen Vektor mit einer Zahl zu multiplizieren, um einen neuen Vektor mit der gleichen Richtung und demmultiplizierten Betrag zu erzeugen):
>>>v*3Vector(9, 12)>>>abs(v*3)15.0
Beispiel 1-2 ist eine Vector Klasse, die die gerade beschriebenen Operationen durch die Verwendung der speziellen Methoden __repr__, __abs__, __add__ und __mul__ implementiert.
Beispiel 1-2. Eine einfache zweidimensionale Vektorklasse
"""vector2d.py: a simplistic class demonstrating some special methodsIt is simplistic for didactic reasons. It lacks proper error handling,especially in the ``__add__`` and ``__mul__`` methods.This example is greatly expanded later in the book.Addition::>>> v1 = Vector(2, 4)>>> v2 = Vector(2, 1)>>> v1 + v2Vector(4, 5)Absolute value::>>> v = Vector(3, 4)>>> abs(v)5.0Scalar multiplication::>>> v * 3Vector(9, 12)>>> abs(v * 3)15.0"""importmathclassVector:def__init__(self,x=0,y=0):self.x=xself.y=ydef__repr__(self):returnf'Vector({self.x!r},{self.y!r})'def__abs__(self):returnmath.hypot(self.x,self.y)def__bool__(self):returnbool(abs(self))def__add__(self,other):x=self.x+other.xy=self.y+other.yreturnVector(x,y)def__mul__(self,scalar):returnVector(self.x*scalar,self.y*scalar)
Zusätzlich zu den bekannten Methoden __init__ haben wir fünf spezielle Methoden implementiert. Beachte, dass keine von ihnen direkt innerhalb der Klasse oder bei der typischen Verwendung der Klasse, die durch die Doctests veranschaulicht wird, aufgerufen wird. Wie bereits erwähnt, ist der Python-Interpreter der einzige häufige Aufrufer der meisten speziellen Methoden.
Beispiel 1-2 implementiert zwei Operatoren: + und *, um die grundlegende Verwendung von __add__ und __mul__ zu zeigen. In beiden Fällen erzeugen die Methoden eine neue Instanz von Vector und geben sie zurück, ohne einen der beiden Operanden zu verändern -self oder other werden lediglich gelesen. Das ist das erwartete Verhalten von Infix-Operatoren: Sie erzeugen neue Objekte und berühren ihre Operanden nicht. Darüber werde ich in Kapitel 16 noch viel mehr sagen.
Warnung
So wie es implementiert ist, erlaubt Beispiel 1-2 die Multiplikation einer Vector mit einer Zahl, aber nicht die Multiplikation einer Zahl mit einer Vector, was die kommutative Eigenschaft der Skalarmultiplikation verletzt. Wir werden das mit der speziellen Methode __rmul__ in Kapitel 16 beheben.
In den folgenden Abschnitten gehen wir auf die anderen speziellen Methoden in Vector ein.
String-Darstellung
Die spezielle Methode __repr__ wird von der eingebauten repr aufgerufen, um die String-Repräsentation des Objekts zur Überprüfung zu erhalten. Ohne eine benutzerdefinierte __repr__ würde die Konsole von Python eine Vector Instanz <Vector object at 0x10e100070> anzeigen.
Die interaktive Konsole und der Debugger rufen repr mit den Ergebnissen der ausgewerteten Ausdrücke auf, ebenso wie der %r Platzhalter in der klassischen Formatierung mit dem % Operator und das !r Konvertierungsfeld in der neuen Formatstringsyntax, die in f-strings verwendet wird, die str.format Methode.
Beachte, dass die f-Zeichenkette in unserem __repr__ !r verwendet, um die Standarddarstellung der anzuzeigenden Attribute zu erhalten. Das ist eine gute Praxis, denn sie zeigt den entscheidenden Unterschied zwischen Vector(1, 2) und Vector('1', '2')- letzteres würde im Kontext dieses Beispiels nicht funktionieren, weil die Argumente des Konstruktors Zahlen sein sollten, nicht str.
Die von __repr__ zurückgegebene Zeichenkette sollte eindeutig sein und möglichst mit dem Quellcode übereinstimmen, der notwendig ist, um das dargestellte Objekt neu zu erstellen. Deshalb sieht unsere Vector Darstellung so aus, dass sie den Konstruktor der Klasse aufruft (z.B. Vector(3, 4)).
In dagegen wird __str__ von der eingebauten Funktion str() aufgerufen und implizit von der Funktion print verwendet. Sie sollte eine Zeichenkette zurückgeben, die für die Anzeige für Endbenutzer geeignet ist.
Manchmal ist dieselbe Zeichenkette, die von __repr__ zurückgegeben wird, benutzerfreundlich, und du brauchst __str__ nicht zu codieren, weil die von der Klasse object geerbte Implementierung __repr__ als Fallback aufruft.Beispiel 5-2 ist eines von mehreren Beispielen in diesem Buch mit einer benutzerdefinierten __str__.
Tipp
Programmierer, die bereits Erfahrung mit Sprachen mit einer toString Methode haben, neigen dazu, __str__ und nicht __repr__ zu implementieren. Wenn du nur eine dieser speziellen Methoden in Python implementierst, wähle __repr__.
"Was ist der Unterschied zwischen __str__ und __repr__ in Python?" ist eine Stack Overflow-Frage mit ausgezeichneten Beiträgen der Pythonistas Alex Martelli und Martijn Pieters.
Boolescher Wert eines benutzerdefinierten Typs
Obwohl Python einen bool Typ hat, akzeptiert es jedes Objekt in einem booleschen Kontext, wie z.B. den Ausdruck, der eine if oder while Anweisung steuert, oder als Operanden für and, or und not. Um festzustellen, ob ein Wert x wahr oder falsch ist, wendet Python bool(x) an, das entweder True oder False zurückgibt.
Standardmäßig werden Instanzen von benutzerdefinierten Klassen als wahr angesehen, es sei denn, entweder __bool__ oder __len__ ist implementiert. Grundsätzlich ruft bool(x) x.__bool__() auf und verwendet das Ergebnis. Wenn __bool__ nicht implementiert ist, versucht Python, x.__len__() aufzurufen, und wenn dies Null ergibt, gibt bool False zurück. Andernfalls gibt bool True zurück.
Unsere Implementierung von __bool__ ist konzeptionell einfach: Sie gibt False zurück, wenn der Betrag des Vektors Null ist, andernfalls True. Wir wandeln den Betrag mit bool(abs(self)) in einen Booleschen Wert um, da von __bool__ erwartet wird, dass es einen Booleschen Wert zurückgibt. Außerhalb der Methoden von __bool__ ist es selten nötig, bool() explizit aufzurufen, da jedes Objekt in einem booleschen Kontext verwendet werden kann.
Beachte, dass die spezielle Methode __bool__ es deinen Objekten ermöglicht, den Regeln für die Wahrheitswertprüfung zu folgen, die imKapitel "Eingebaute Typen"der Dokumentation The Python Standard Library definiert sind.
Hinweis
Eine schnellere Umsetzung von Vector.__bool__ ist diese:
def__bool__(self):returnbool(self.xorself.y)
Das ist zwar schwieriger zu lesen, erspart aber den Umweg über abs, __abs__, die Quadrate und die Quadratwurzel. Die explizite Umwandlung in bool ist notwendig, weil __bool__ einen Booleschen Wert zurückgeben muss undor einen der beiden Operanden so zurückgibt, wie er ist: x or y wertet x aus, wenn das wahr ist, andernfalls ist das Ergebnis y, was auch immer das ist.
Sammlung API
Abbildung 1-2 dokumentiert die Schnittstellen der wichtigsten Sammlungstypen in der Sprache. Alle Klassen im Diagramm sind ABCs - abstrakteBasisklassen. ABCs und das Modul collections.abc werden in Kapitel 13 behandelt. Das Ziel dieses kurzen Abschnitts ist es, einen Überblick über die wichtigsten Sammlungsschnittstellen in Python zu geben und zu zeigen, wie sie aus speziellen Methoden aufgebaut sind.
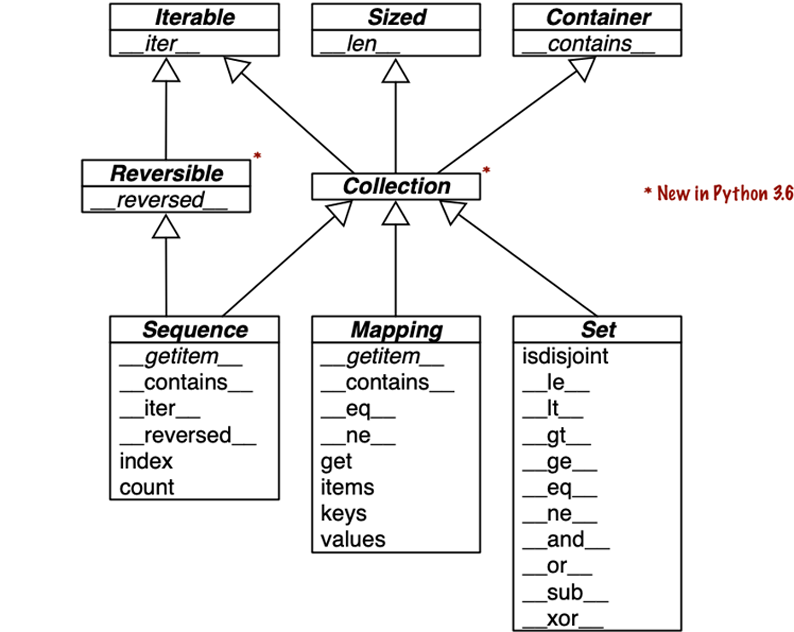
Abbildung 1-2. UML-Klassendiagramm mit grundlegenden Sammlungstypen. Kursiv gedruckte Methodennamen sind abstrakt und müssen daher von konkreten Unterklassen wie list und dict implementiert werden. Die übrigen Methoden haben konkrete Implementierungen, so dass Unterklassen sie erben können.
Jedes der oberen ABCs hat eine spezielle Methode. Das Collection ABC (neu in Python 3.6) vereint die drei wesentlichen Schnittstellen, die jede Sammlungimplementieren sollte:
-
Iterableunterstütztfor, das Auspacken und andere Formen derIteration
Python verlangt nicht, dass konkrete Klassen tatsächlich von einem dieser ABCs erben. Jede Klasse, die __len__ implementiert, erfüllt die Schnittstelle Sized.
Drei sehr wichtige Spezialisierungen von Collection sind:
-
Sequenceund formalisiert die Schnittstelle von Built-ins wielistundstr -
Mapping, umgesetzt vondict,collections.defaultdict, etc. -
Set, die Schnittstelle der eingebauten Typensetundfrozenset
Nur Sequence ist Reversible, weil Sequenzen eine beliebige Reihenfolge ihrer Inhalte unterstützen, während Mappings und Sets dies nicht tun.
Hinweis
Seit Python 3.7 ist der Typ dict offiziell "geordnet", aber das bedeutet nur, dass die Reihenfolge, in der die Schlüssel eingefügt werden, beibehalten wird. Du kannst die Schlüssel in einem dict nicht nach Beliebenneu anordnen.
Alle Spezialmethoden im Set ABC implementieren Infix-Operatoren. Zum Beispiel,a & b berechnet die Schnittmenge der Mengen a und b und ist in der Spezialmethode __and__ implementiert.
In den nächsten beiden Kapiteln werden Sequenzen, Mappings und Sets der Standardbibliothek im Detail behandelt.
Betrachten wir nun die Hauptkategorien der speziellen Methoden, die im Python-Datenmodell definiert sind.
Überblick über besondere Methoden
Im Kapitel "Datenmodell" von The Python Language Reference ( ) sind mehr als 80 spezielle Methodennamen aufgeführt. Mehr als die Hälfte davon implementieren arithmetische, bitweise und Vergleichsoperatoren. Einen Überblick über die verfügbaren Methoden bieten die folgenden Tabellen.
Tabelle 1-1zeigt die Namen der speziellen Methoden, mit Ausnahme derer, die zur Implementierung von Infix-Operatoren oder mathematischen Kernfunktionen wie abs verwendet werden. Die meisten dieser Methoden werden im Laufe des Buches behandelt, einschließlich der jüngsten Ergänzungen: asynchrone Spezialmethoden wie __anext__ (hinzugefügt in Python 3.5) und der Klassenanpassungshaken __init_subclass__ (ab Python 3.6).
| Kategorie | Methodennamen |
|---|---|
String/Bytes Darstellung |
|
Umrechnung in Zahlen |
|
Sammlungen emulieren |
|
Iteration |
|
Ausführung von Callables oder Coroutines |
|
Context Management |
|
Erstellung und Zerstörung von Instanzen |
|
Attribut-Management |
|
Attribut Deskriptoren |
|
Abstrakte Basisklassen |
|
Klasse Metaprogrammierung |
|
Infix- und numerische Operatoren werden von den inTabelle 1-2 aufgeführten speziellen Methoden unterstützt. Die neuesten Namen sind __matmul__, __rmatmul__ und __imatmul__, die in Python 3.5 hinzugefügt wurden, um die Verwendung von @ als Infix-Operator für die Matrixmultiplikation zu unterstützen, wie wir in Kapitel 16 sehen werden.
| Betreiber-Kategorie | Symbole | Methodennamen |
|---|---|---|
Unary numerisch |
|
|
Reicher Vergleich |
|
|
Arithmetik |
|
|
Umgekehrte Arithmetik |
(arithmetische Operatoren mit vertauschten Operanden) |
|
Erweiterte Zuweisungsarithmetik |
|
|
Bitweise |
|
|
Umgekehrt bitweise |
(bitweise Operatoren mit vertauschten Operanden) |
|
Erweiterte Zuweisung bitweise |
|
|
Hinweis
Python ruft eine spezielle Methode des umgekehrten Operators für den zweiten Operanden auf, wenn die entsprechende spezielle Methode für den ersten Operanden nicht verwendet werden kann. Erweiterte Zuweisungen sind Abkürzungen, die einen Infix-Operator mit einer Variablenzuweisung kombinieren, z. B. a += b.
Kapitel 16 erklärt die umgekehrten Operatoren und die erweiterte Zuweisung im Detail.
Warum len keine Methode ist
Diese Frage habe ich im Jahr 2013 an den Kernentwickler Raymond Hettinger gestellt, und der Schlüssel zu seiner Antwort war ein Zitat aus "The Zen of Python":"In "How Special Methods Are Used" habe ich beschrieben, wie len(x) sehr schnell läuft, wenn x eine Instanz eines eingebauten Typs ist. Für die eingebauten Objekte von CPython wird keine Methode aufgerufen: Die Länge wird einfach aus einem Feld in einer C-Struktur gelesen. Die Anzahl der Elemente in einer Sammlung zu ermitteln, ist eine gängige Operation und muss für so grundlegende und unterschiedliche Typen wie str, list, memoryview usw. effizient funktionieren.
Mit anderen Worten: len wird nicht als Methode aufgerufen, weil es als Teil des Python-Datenmodells eine Sonderbehandlung erfährt, genau wie abs. Aber dank der speziellen Methode __len__ kannst du len auch mit deinen eigenen benutzerdefinierten Objekten arbeiten lassen. Das ist ein fairer Kompromiss zwischen dem Bedarf an effizienten eingebauten Objekten und der Konsistenz der Sprache. Auch aus "The Zen of Python": "Spezialfälle sind nicht speziell genug, um die Regeln zu brechen."
Hinweis
Wenn du dir abs und len als unäre Operatoren vorstellst, wirst du vielleicht eher geneigt sein, ihr funktionales Aussehen zu verzeihen, im Gegensatz zu der Syntax für Methodenaufrufe, die man in einer objektorientierten Sprache erwarten würde.
In der ABC-Sprache - einem direkten Vorläufer von Python, der viele seiner Funktionen entwickelt hat - gab es einen # Operator, der das Äquivalent zu len war (du würdest #s schreiben). Wenn er als Infix-Operator verwendet wurde ( x#s), zählte er die Vorkommen von x in s, was du in Python als s.count(x) für eine beliebige Folge s erhältst.
Kapitel Zusammenfassung
Indem du spezielle Methoden implementierst, können sich deine Objekte wie die eingebauten Typen verhalten und ermöglichen so den ausdrucksstarken Codierungsstil, den die Community als Pythonic bezeichnet.
Eine Grundvoraussetzung für ein Python-Objekt ist, dass es brauchbare String-Repräsentationen von sich selbst bereitstellt, eine für Debugging und Logging, eine andere für die Präsentation für Endbenutzer. Deshalb gibt es im Datenmodell die speziellen Methoden __repr__ und __str__.
Die Emulation von Sequenzen, wie im Beispiel FrenchDeck gezeigt, ist eine der häufigsten Anwendungen der speziellen Methoden. Datenbankbibliotheken geben zum Beispiel oft Abfrageergebnisse zurück, die in sequenzähnliche Sammlungen verpackt sind. Die optimale Nutzung vorhandener Sequenztypen ist Thema von Kapitel 2. Die Implementierung deiner eigenen Sequenzen wird in Kapitel 12 behandelt, wenn wir eine multidimensionale Erweiterung der Klasse Vector erstellen.
Dank der Operatorüberladung bietet Python eine reiche Auswahl an numerischen Typen, von den Built-Ins bis hin zu decimal.Decimal und fractions.Fraction, die alle Infix-Arithmetik-Operatoren unterstützen. Die NumPy Data Science Libraries unterstützen Infix-Operatorenmit Matrizen und Tensoren. Die Implementierung von Operatoren - einschließlich umgekehrter Operatoren und erweiterter Zuweisungen - wird in Kapitel 16 anhand von Erweiterungen desVector Beispiel.
Die Verwendung und Implementierung der meisten anderen speziellen Methoden des Python-Datenmodells werden in diesem Buch behandelt.
Weitere Lektüre
Das Kapitel "Datenmodell" in The Python Language Reference ( ) ist die kanonische Quelle für das Thema dieses Kapitels und eines Großteils dieses Buches.
Python in a Nutshell, 3. Aufl. von Alex Martelli, Anna Ravenscroft und Steve Holden (O'Reilly) behandelt das Datenmodell hervorragend. Ihre Beschreibung der Mechanismen des Attributzugriffs ist die zuverlässigste, die ich bisher gesehen habe, abgesehen vom eigentlichenC-Quellcode von CPython. Martelli ist auch ein fleißiger Mitarbeiter bei Stack Overflow,der mehr als 6.200 Antworten veröffentlicht hat. Siehe sein Benutzerprofil bei Stack Overflow.
David Beazley hat zwei Bücher geschrieben, die das Datenmodell im Kontext von Python 3 ausführlich behandeln: Python Essential Reference, 4. Auflage (Addison-Wesley), und Python Cookbook, 3.
The Art of the Metaobject Protocol (MIT Press) von Gregor Kiczales, Jim des Rivieres und Daniel G. Bobrow erklärt das Konzept eines Metaobjektprotokolls, für das das Python-Datenmodell ein Beispiel ist.
1 "Story of Jython", geschrieben als Vorwort zu Jython Essentials von Samuele Pedroni und Noel Rappin (O'Reilly).
2 Ein C struct ist ein Datensatztyp mit benannten Feldern.
Get Fließendes Python, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

