Capítulo 4. Datos de entrenamiento
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En el Capítulo 3, tratamos cómo manejar los datos desde la perspectiva de los sistemas. En este capítulo, repasaremos cómo manejar los datos desde la perspectiva de la ciencia de los datos. A pesar de la importancia de los datos de entrenamiento para desarrollar y mejorar los modelos de ML, los planes de estudios de ML están muy sesgados hacia el modelado, que muchos profesionales consideran la parte "divertida" del proceso. Construir un modelo de vanguardia es interesante. Pasar días lidiando con una enorme cantidad de datos mal formateados que ni siquiera caben en la memoria de tu máquina es frustrante.
Los datos son desordenados, complejos, impredecibles y potencialmente traicioneros. Si no se manejan adecuadamente, pueden hundir fácilmente toda tu operación de ML. Pero ésta es precisamente la razón por la que los científicos de datos y los ingenieros de ML deben aprender a manejar bien los datos, para ahorrarnos tiempo y dolores de cabeza en el futuro.
En este capítulo, repasaremos las técnicas para obtener o crear buenos datos de entrenamiento. Los datos de entrenamiento, en este capítulo, engloban todos los datos utilizados en la fase de desarrollo de los modelos de ML, incluidas las diferentes divisiones utilizadas para el entrenamiento, la validación y la prueba (las divisiones entrenar, validar, probar). Este capítulo comienza con diferentes técnicas de muestreo para seleccionar los datos para el entrenamiento. A continuación, abordaremos los retos habituales en la creación de datos de entrenamiento, incluyendo el problema de la multiplicidad de etiquetas, el problema de la falta de etiquetas, el problema del desequilibrio de clases y las técnicas de aumento de datos para abordar el problema de la falta de datos.
Utilizamos el término "datos de entrenamiento" en lugar de "conjunto de datos de entrenamiento" porque "conjunto de datos" denota un conjunto que es finito y estacionario. Los datos en producción no son ni finitos ni estacionarios, un fenómeno que trataremos en la sección "Cambios en la distribución de los datos". Al igual que otros pasos en la construcción de sistemas de ML, la creación de datos de entrenamiento es un proceso iterativo. A medida que tu modelo evoluciona a lo largo del ciclo de vida de un proyecto, es probable que tus datos de entrenamiento también evolucionen.
Antes de seguir adelante, quiero hacerme eco de una advertencia que se ha dicho muchas veces, pero que sigue sin ser suficiente. Los datos están llenos de sesgos potenciales. Estos sesgos tienen muchas causas posibles. Hay sesgos causados durante la recogida, el muestreo o el etiquetado. Los datos históricos pueden estar impregnados de sesgos humanos, y los modelos de ML, entrenados con estos datos, pueden perpetuarlos. Utiliza los datos, ¡pero no confíes demasiado en ellos!
Muestreo
El muestreo es una parte integral del flujo de trabajo de ML que, por desgracia, a menudo se pasa por alto en los cursos típicos de ML. El muestreo se produce en muchos pasos del ciclo de vida de un proyecto de ML, como el muestreo de de todos los datos posibles del mundo real para crear datos de entrenamiento; el muestreo de un conjunto de datos determinado para crear divisiones para entrenamiento, validación y prueba; o el muestreo de todos los posibles eventos que ocurren dentro de tu sistema de ML con fines de monitoreo. En esta sección, nos centraremos en los métodos de muestreo para crear datos de entrenamiento, pero estos métodos de muestreo también pueden utilizarse para otros pasos del ciclo de vida de un proyecto de ML.
En muchos casos, el muestreo es necesario. Un caso es cuando no tienes acceso a todos los datos posibles del mundo real, los datos que utilizas para entrenar tu modelo son un subconjunto de datos del mundo real, creados por un método de muestreo u otro. Otro caso es cuando no es factible procesar todos los datos a los que tienes acceso -porque requiere demasiado tiempo o recursos-, así que tienes que muestrear esos datos para crear un subconjunto que sea factible procesar. En muchos otros casos, el muestreo es útil, ya que te permite realizar una tarea de forma más rápida y barata. Por ejemplo, al plantearte un nuevo modelo, quizá quieras hacer un experimento rápido con un pequeño subconjunto de tus datos para ver si el nuevo modelo es prometedor, antes de entrenar este nuevo modelo con todos tus datos.1
Comprender los distintos métodos de muestreo y cómo se utilizan en nuestro flujo de trabajo puede, en primer lugar, ayudarnos a evitar posibles sesgos en el muestreo y, en segundo lugar, ayudarnos a elegir los métodos que mejoren la eficacia de los datos que muestreamos.
Existen dos familias de muestreo: el muestreo no probabilístico y el muestreo aleatorio. Empezaremos con los métodos de muestreo no probabilístico, seguidos de varios métodos comunes de muestreo aleatorio.
Muestreo no probabilístico
El muestreo no probabilístico es cuando la selección de los datos de no se basa en ningún criterio de probabilidad. Éstos son algunos de los criterios del muestreo no probabilístico:
- Muestreo de conveniencia
Las muestras de datos se seleccionan basándose en su disponibilidad. Este método de muestreo es popular porque, bueno, es cómodo.
- Muestreo de bola de nieve
Las muestras futuras se seleccionan a partir de las muestras existentes en . Por ejemplo, para raspar cuentas legítimas de Twitter sin tener acceso a las bases de datos de Twitter, se empieza con un pequeño número de cuentas, luego se raspan todas las cuentas a las que siguen, y así sucesivamente.
- Muestreo de juicio
- Muestreo por cuotas
Seleccionas muestras basadas en cuotas para determinadas porciones de datos sin ningún tipo de aleatorización. Por ejemplo, al hacer una encuesta, puedes querer 100 respuestas de cada uno de los grupos de edad: menores de 30 años, entre 30 y 60 años, y mayores de 60 años, independientemente de la distribución real de edades.
Las muestras seleccionadas mediante criterios no probabilísticos no son representativas de los datos del mundo real y, por tanto, están plagadas de sesgos de selección.2 Debido a estos sesgos , podrías pensar que es una mala idea seleccionar datos para entrenar modelos ML utilizando esta familia de métodos de muestreo. Y tienes razón. Desgraciadamente, en muchos casos, la selección de datos para los modelos ML sigue guiándose por la conveniencia.
Un ejemplo de estos casos es el modelado lingüístico. A menudo, los modelos lingüísticos no se entrenan con datos representativos de todos los textos posibles, sino con datos que se pueden recopilar fácilmente: Wikipedia, Common Crawl, Reddit.
Otro ejemplo son los datos para el análisis de sentimientos de texto general. Muchos de estos datos se recogen de fuentes con etiquetas naturales (valoraciones), como las reseñas de IMDB y las de Amazon. Estos conjuntos de datos se utilizan después para otras tareas de análisis de sentimientos. Las reseñas de IMDB y las de Amazon están sesgadas hacia los usuarios que están dispuestos a dejar reseñas en línea, y no son necesariamente representativas de las personas que no tienen acceso a Internet o de las personas que no están dispuestas a dejar reseñas en línea.
Un tercer ejemplo son los datos para el entrenamiento de coches autoconducidos. Inicialmente, los datos recopilados para los coches autoconducidos procedían en gran medida de dos zonas: Phoenix, Arizona (debido a sus laxas normativas), y la zona de la Bahía de California (porque muchas empresas que construyen coches autónomos están ubicadas aquí). Ambas zonas tienen un clima generalmente soleado. En 2016, Waymo amplió sus operaciones a Kirkland, Washington, especialmente por el clima lluvioso de Kirkland,3 pero sigue habiendo muchos más datos de coches autoconducidos para el tiempo soleado que para el tiempo lluvioso o nevado.
El muestreo no probabilístico puede ser una forma rápida y sencilla de recopilar los datos iniciales para poner en marcha tu proyecto. Sin embargo, para obtener modelos fiables, quizá te convenga utilizar el muestreo probabilístico, que trataremos a continuación en .
Muestreo aleatorio simple
En la forma más sencilla de muestreo aleatorio, das a todas las muestras de la población las mismas probabilidades de ser seleccionadas.4 Por ejemplo, seleccionas al azar el 10% de la población, dando a todos los miembros de esta población una probabilidad igual del 10% de ser seleccionados.
La ventaja de este método es que es fácil de aplicar. El inconveniente es que las categorías raras de datos podrían no aparecer en tu selección. Considera el caso de que una clase sólo aparezca en el 0,01% de tu población de datos. Si seleccionas al azar el 1% de tus datos, es poco probable que se seleccionen muestras de esta clase poco frecuente. Los modelos entrenados en esta selección podrían pensar que esta clase rara no existe.
Muestreo estratificado
Para evitar el inconveniente del muestreo aleatorio simple , puedes dividir primero tu población en los grupos que te interesan y tomar muestras de cada grupo por separado. Por ejemplo, para muestrear el 1% de unos datos que tienen dos clases, A y B, puedes muestrear el 1% de la clase A y el 1% de la clase B. De este modo, por muy rara que sea la clase A o B, te asegurarás de que se incluirán muestras de ella en la selección. Cada grupo se denomina estrato, y este método se llama muestreo estratificado.
Un inconveniente de este método de muestreo es que no siempre es posible, como cuando es imposible dividir todas las muestras en grupos. Esto es especialmente difícil cuando una muestra puede pertenecer a varios grupos, como en el caso de las tareas multietiqueta.5 Por ejemplo, una muestra puede pertenecer tanto a la clase A como a la clase B.
Muestreo ponderado
En el muestreo ponderado, a cada muestra se le asigna un peso, que determina la probabilidad de que sea seleccionada. Por ejemplo, si tienes tres muestras, A, B y C, y quieres que se seleccionen con las probabilidades del 50%, 30% y 20% respectivamente, puedes darles los pesos 0,5, 0,3 y 0,2.
Este método te permite aprovechar la experiencia en el dominio. Por ejemplo, si sabes que una determinada subpoblación de datos, como los datos más recientes, es más valiosa para tu modelo y quieres que tenga más posibilidades de ser seleccionada, puedes darle un peso mayor.
Esto también ayuda en el caso de que los datos que tienes procedan de una distribución distinta a la de los datos reales. Por ejemplo, si en tus datos, las muestras rojas representan el 25% y las azules el 75%, pero sabes que en el mundo real, el rojo y el azul tienen la misma probabilidad de ocurrir, puedes dar a las muestras rojas pesos tres veces mayores que a las azules.
En Python, puedes hacer un muestreo ponderado con random.choices del siguiente modo:
# Choose two items from the list such that 1, 2, 3, 4 each has# 20% chance of being selected, while 100 and 1000 each have only 10% chance.importrandomrandom.choices(population=[1,2,3,4,100,1000],weights=[0.2,0.2,0.2,0.2,0.1,0.1],k=2)# This is equivalent to the followingrandom.choices(population=[1,1,2,2,3,3,4,4,100,1000],k=2)
Un concepto común en ML que está estrechamente relacionado con el muestreo ponderado es el de pesos muestrales. El muestreo ponderado se utiliza para seleccionar muestras con las que entrenar tu modelo, mientras que los pesos de las muestras se utilizan para asignar "pesos" o "importancia" a las muestras de entrenamiento. Las muestras con pesos más altos afectan más a la función de pérdida. Cambiar los pesos de las muestras puede modificar significativamente los límites de decisión de tu modelo, como se muestra en la Figura 4-1.
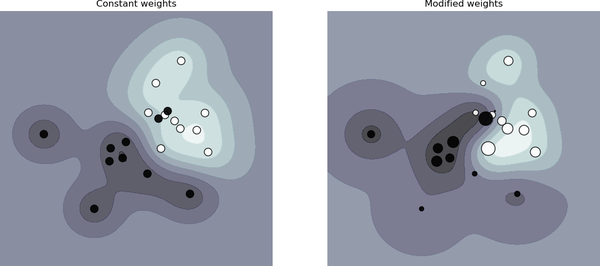
Figura 4-1. Las ponderaciones de las muestras pueden afectar al límite de decisión. A la izquierda, cuando todas las muestras tienen el mismo peso. A la derecha, cuando las muestras tienen pesos diferentes. Fuente: scikit-learn6
Muestreo en embalses
El muestreo de yacimientos es un fascinante algoritmo de que resulta especialmente útil cuando tienes que tratar con datos en flujo, que es lo que sueles tener en producción.
Imagina que tienes un flujo entrante de tweets y quieres tomar una muestra de un cierto número, k, de tweets para hacer un análisis o entrenar un modelo. No sabes cuántos tweets hay, pero sabes que no te caben todos en la memoria, lo que significa que no conoces de antemano la probabilidad a la que debe seleccionarse un tweet. Quieres asegurarte de que
Cada tuit tiene la misma probabilidad de ser seleccionado.
Puedes detener el algoritmo en cualquier momento y los tweets se muestrean con la probabilidad correcta.
Una solución a este problema es el muestreo de depósitos. El algoritmo implica un depósito, que puede ser una matriz, y consta de tres pasos:
Coloca los primeros k elementos en el depósito.
Para cada n-ésimo elemento entrante, genera un número aleatorio i tal que 1 ≤ i ≤ n.
Si 1 ≤ i ≤ k: sustituye el elemento i-ésimo del depósito por el elemento n-ésimo. Si no, no hagas nada.
Esto significa que cada n-ésimo elemento entrante tiene probabilidad de estar en el depósito. También puedes demostrar que cada elemento del depósito tiene probabilidad de estar allí. Esto significa que todas las muestras tienen la misma probabilidad de ser seleccionadas. Si detenemos el algoritmo en cualquier momento, todas las muestras del depósito se habrán muestreado con la probabilidad correcta. La Figura 4-2 muestra un ejemplo ilustrativo de de cómo funciona el muestreo de depósitos.
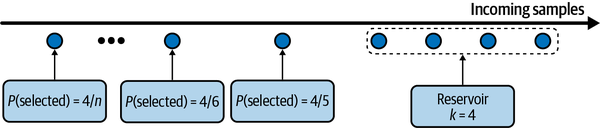
Figura 4-2. Visualización del funcionamiento del muestreo de yacimientos
Muestreo de Importancia
El muestreo de importancia es uno de los métodos de muestreo más importantes de , no sólo en ML. Nos permite muestrear a partir de una distribución cuando sólo tenemos acceso a otra distribución.
Imagina que tienes que muestrear x a partir de una distribución P(x), pero muestrear a partir de P(x ) es realmente caro, lento o inviable. Sin embargo, tienes una distribución Q(x) de la que es mucho más fácil tomar muestras. Así que, en su lugar, muestrea x a partir de Q(x) y pondera esta muestra por . Q(x) se denomina distribución de la propuesta o distribución de importancia. Q(x) puede ser cualquier distribución siempre que Q(x) > 0 siempre que P(x) ≠ 0. La siguiente ecuación muestra que, en la expectativa, x muestreada de P(x) es igual a x muestreada de Q(x) ponderada por :
Un ejemplo en el que se utiliza el muestreo de importancia en ML es el aprendizaje por refuerzo basado en políticas. Considera el caso de que quieras actualizar tu política. Quieres estimar las funciones de valor de la nueva política, pero calcular las recompensas totales de realizar una acción puede ser costoso porque requiere considerar todos los resultados posibles hasta el final del horizonte temporal posterior a esa acción. Sin embargo, si la nueva política es relativamente parecida a la antigua, puedes calcular las recompensas totales basándote en la antigua política y reponderarlas según la nueva política. Las recompensas de la antigua política conforman la distribución de la propuesta.
Etiquetado
A pesar de la promesa del ML no supervisado, la mayoría de los modelos de ML en producción hoy en día son supervisados, lo que significa que necesitan datos etiquetados con los que aprender. El rendimiento de un modelo de ML sigue dependiendo en gran medida de la calidad y cantidad de los datos etiquetados con los que se entrena.
En una charla con mis alumnos, Andrej Karpathy, director de IA en Tesla, compartió una anécdota sobre cómo, cuando decidió tener un equipo interno de etiquetado, su reclutador le preguntó por cuánto tiempo necesitaría este equipo. Él respondió: "¿Para cuánto tiempo necesitamos un equipo de ingenieros?". El etiquetado de datos ha pasado de ser una tarea auxiliar a ser una función básica de muchos equipos de ML en producción.
En esta sección, hablaremos del reto de obtener etiquetas para tus datos. Primero hablaremos del método de etiquetado que suele venir primero a la mente de los científicos de datos cuando hablan de etiquetado: el etiquetado manual. A continuación, hablaremos de las tareas con etiquetas naturales, que son tareas en las que las etiquetas se pueden deducir del sistema sin necesidad de anotaciones humanas, seguidas de qué hacer cuando faltan etiquetas naturales y manuales.
Etiquetas manuales
Cualquiera que haya tenido que trabajar alguna vez con datos en producción probablemente haya sentido esto a un nivel visceral : adquirir etiquetas manuales para tus datos es difícil por muchas, muchas razones. En primer lugar, etiquetar a mano los datos puede ser caro, sobre todo si se requiere experiencia en la materia. Para clasificar si un comentario es spam, podrías encontrar 20 anotadores en una plataforma de crowdsourcing y entrenarlos en 15 minutos para etiquetar tus datos. Sin embargo, si quieres etiquetar radiografías de tórax, necesitarías encontrar radiólogos colegiados, cuyo tiempo es limitado y caro.
En segundo lugar, el etiquetado a mano supone una amenaza para la privacidad de los datos. El etiquetado manual significa que alguien tiene que ver tus datos, lo que no siempre es posible si tus datos tienen requisitos estrictos de privacidad. Por ejemplo, no puedes enviar los historiales médicos de tus pacientes o la información financiera confidencial de tu empresa a un servicio externo para que los etiqueten. En muchos casos, puede que ni siquiera se permita que tus datos salgan de tu organización, y que tengas que contratar o contratar anotadores para etiquetar tus datos in situ.
En tercer lugar, el etiquetado manual es lento. Por ejemplo, la transcripción exacta de un discurso a nivel fonético puede tardar 400 veces más que la duración del discurso.7 Así que si quieres anotar 1 hora de habla, una persona tardará 400 horas o casi 3 meses en hacerlo. En un estudio para utilizar el ML para ayudar a clasificar los cánceres de pulmón a partir de radiografías, mis colegas tuvieron que esperar casi un año para obtener etiquetas suficientes.
Un etiquetado lento conduce a una velocidad de iteración lenta y hace que tu modelo sea menos adaptable a entornos y requisitos cambiantes. Si cambia la tarea o cambian los datos, tendrás que esperar a que se vuelvan a etiquetar antes de actualizar tu modelo. Imagina el escenario en el que tienes un modelo de análisis de sentimiento para analizar el sentimiento de cada tuit que menciona tu marca. Sólo tiene dos clases: NEGATIVO y POSITIVO. Sin embargo, tras la implementación, tu equipo de relaciones públicas se da cuenta de que el mayor daño procede de los tuits enfadados y quieren atender más rápidamente los mensajes enfadados. Así que tienes que actualizar tu modelo de análisis de sentimiento para que tenga tres clases: NEGATIVO, POSITIVO y ENOJADO. Para ello, tendrás que volver a examinar tus datos para ver qué ejemplos de entrenamiento existentes deben ser reetiquetados como ENFADADO. Si no tienes suficientes ejemplos ANGRÍOS, tendrás que recopilar más datos. Cuanto más tiempo lleve el proceso, más se degradará el rendimiento de tu modelo existente.
Multiplicidad de etiquetas
A menudo, para obtener suficientes datos etiquetados, las empresas tienen que utilizar datos de múltiples fuentes y confiar en múltiples anotadores que tienen diferentes niveles de experiencia. Estas diferentes fuentes de datos y anotadores también tienen diferentes niveles de precisión. Esto nos lleva al problema de la ambigüedad o multiplicidad de etiquetas: qué hacer cuando hay varias etiquetas contradictorias para un dato.
Considera esta sencilla tarea de reconocimiento de entidades. Das a tres anotadores la siguiente muestra y les pides que anoten todas las entidades que puedan encontrar:
Darth Sidious, conocido simplemente como el Emperador, fue un Señor Oscuro de los Sith que reinó sobre la galaxia como Emperador Galáctico del Primer Imperio Galáctico.
Recibes de vuelta tres soluciones diferentes, como se muestra en la Tabla 4-1. Tres anotadores han identificado entidades diferentes. ¿Con cuál debe entrenarse tu modelo? Un modelo entrenado en los datos etiquetados por el anotador 1 tendrá un rendimiento muy diferente al de un modelo entrenado en los datos etiquetados por el anotador 2.
| Anotador | # entidades | Anotación |
|---|---|---|
| 1 | 3 | [Darth Sidious], conocido simplemente como el Emperador, fue un[Señor Oscuro de los Sith] que reinó sobre la galaxia como[Emperador Galáctico del Primer Imperio Galáctico]. |
| 2 | 6 | [Darth Sidious], conocido simplemente como el[Emperador], fue un[Señor Oscuro] de los[Sith] que reinó sobre la galaxia como[Emperador Galáctico] del[Primer Imperio Galáctico]. |
| 3 | 4 | [Darth Sidious], conocido simplemente como el[Emperador], fue un[Señor Oscuro de los Sith] que reinó sobre la galaxia como[Emperador Galáctico del Primer Imperio Galáctico]. |
Los desacuerdos entre anotadores son extremadamente frecuentes. Cuanto mayor sea el nivel de experiencia en el dominio requerido, mayor será el potencial de desacuerdo en la anotación.8 Si un experto humano cree que la etiqueta debe ser A, mientras que otro cree que debe ser B, ¿cómo resolvemos este conflicto para obtener una única verdad fundamental? Si los expertos humanos no pueden ponerse de acuerdo sobre una etiqueta, ¿qué significa el rendimiento a nivel humano?
Para minimizar los desacuerdos entre los anotadores, es importante tener primero una definición clara del problema. Por ejemplo, en la tarea anterior de reconocimiento de entidades, se podrían haber eliminado algunos desacuerdos si aclaramos que, en caso de múltiples entidades posibles, hay que elegir la entidad que comprenda la subcadena más larga. Es decir, Emperador Galáctico del Primer Imperio Galáctico en lugar de Emperador Galáctico y Primer Imperio Galáctico. En segundo lugar, tienes que incorporar esa definición a la formación de los anotadores de para asegurarte de que todos los anotadores entienden las reglas.
Linaje de los datos
Utilizar indiscriminadamente datos de múltiples fuentes, generados con diferentes anotadores, sin examinar su calidad puede hacer que tu modelo falle misteriosamente. Considera un caso en el que has entrenado un modelo moderadamente bueno con 100K muestras de datos. Tus ingenieros de ML confían en que más datos mejorarán el rendimiento del modelo, así que gastas mucho dinero en contratar anotadores para etiquetar otro millón de muestras de datos.
Sin embargo, el rendimiento del modelo disminuye después de entrenarlo con los nuevos datos. La razón es que los nuevos millones de muestras se encargaron a anotadores que etiquetaron los datos con mucha menos precisión que los datos originales. Puede ser especialmente difícil remediarlo si ya has mezclado los datos y no puedes diferenciar los datos nuevos de los antiguos.
Es una buena práctica llevar un registro del origen de cada una de tus muestras de datos, así como de sus etiquetas, una técnica conocida como linaje de datos. El linaje de datos te ayuda tanto a señalar posibles sesgos en tus datos como a depurar tus modelos. Por ejemplo, si tu modelo falla sobre todo en las muestras de datos adquiridas recientemente, quizá quieras investigar cómo se adquirieron los nuevos datos. En más de una ocasión, hemos descubierto que el problema no estaba en nuestro modelo, sino en el número inusualmente alto de etiquetas erróneas en los datos que habíamos adquirido recientemente.
Etiquetas naturales
El etiquetado a mano no es la única fuente de etiquetas . Puede que tengas la suerte de trabajar en tareas con etiquetas naturales de verdad. Las tareas con etiquetas naturales son tareas en las que las predicciones del modelo pueden ser evaluadas automáticamente o parcialmente por el sistema. Un ejemplo es el modelo que estima la hora de llegada para una determinada ruta en Google Maps. Si tomas esa ruta, al final de tu viaje, Google Maps sabe cuánto tiempo duró realmente el viaje, y así puede evaluar la exactitud de la hora de llegada predicha. Otro ejemplo es la predicción del precio de las acciones. Si tu modelo predice el precio de una acción en los próximos dos minutos, al cabo de dos minutos puedes comparar el precio predicho con el precio real.
El ejemplo canónico de tareas con etiquetas naturales son los sistemas de recomendación. El objetivo de un sistema recomendador es recomendar a los usuarios artículos relevantes para ellos. El hecho de que un usuario haga clic o no en el elemento recomendado en puede considerarse la respuesta a esa recomendación. Una recomendación sobre la que se hace clic puede considerarse buena (es decir, la etiqueta es POSITIVA) y una recomendación sobre la que no se hace clic tras un periodo de tiempo, digamos 10 minutos, puede considerarse mala (es decir, la etiqueta es NEGATIVA).
Muchas tareas pueden enmarcarse como tareas de recomendación. Por ejemplo, puedes enmarcar la tarea de predecir los porcentajes de clics de los anuncios como una recomendación de los anuncios más relevantes para los usuarios basada en sus historiales de actividad y perfiles. Las etiquetas naturales que se deducen de los comportamientos de los usuarios, como los clics y las valoraciones, también se conocen como etiquetas de comportamiento.
Incluso si tu tarea no tiene intrínsecamente etiquetas naturales, podría ser posible configurar tu sistema de forma que te permita recoger algunas opiniones sobre tu modelo. Por ejemplo, si estás construyendo un sistema de traducción automática como Google Translate, puedes dar a la comunidad la opción de enviar traducciones alternativas para las malas traducciones; estas traducciones alternativas pueden utilizarse para entrenar la siguiente iteración de tus modelos (aunque es posible que quieras revisar primero estas traducciones sugeridas). La clasificación de las noticias no es una tarea con etiquetas inherentes, pero al añadir el botón "Me gusta" y otras reacciones a cada noticia, Facebook puede recoger opiniones sobre su algoritmo de clasificación.
Las tareas con etiquetas naturales son bastante comunes en la industria. En una encuesta realizada a 86 empresas de mi red, descubrí que el 63% de ellas trabajan con tareas con etiquetas naturales, como se muestra en la Figura 4-3. Esto no significa que el 63% de las tareas que pueden beneficiarse de las soluciones de ML tengan etiquetas naturales. Lo que es más probable es que a las empresas les resulte más fácil y barato empezar primero por las tareas que tienen etiquetas naturales.
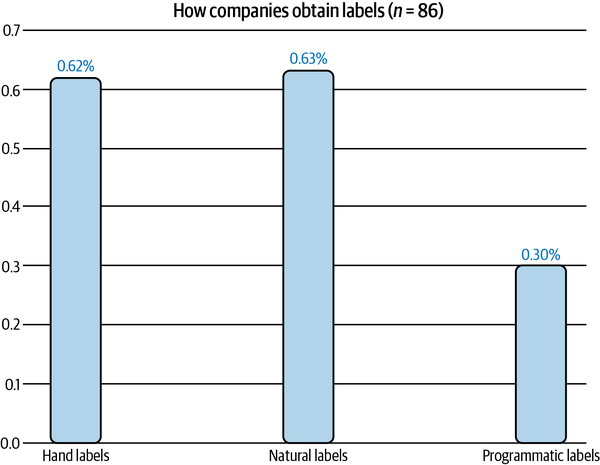
Figura 4-3. El 63% de las empresas de mi red trabajan con tareas con etiquetas naturales. Los porcentajes no suman 1 porque una empresa puede trabajar con tareas con diferentes fuentes de etiquetas.9
En el ejemplo anterior, se puede suponer que una recomendación sobre la que no se hace clic tras un periodo de tiempo es mala. Esto se denomina etiqueta implícita, ya que esta etiqueta negativa se presume a partir de la falta de una etiqueta positiva. Es diferente de las etiquetas explícitas, en las que los usuarios demuestran explícitamente su opinión sobre una recomendación dándole una puntuación baja o votándola a la baja.
Longitud del bucle de realimentación
Para las tareas con etiquetas naturales de verdad básica, el tiempo que transcurre desde que se sirve una predicción hasta que se proporciona la retroalimentación sobre ella es la longitud del bucle de retroalimentación. Las tareas con bucles de retroalimentación cortos son aquellas en las que las etiquetas suelen estar disponibles en cuestión de minutos. Muchos sistemas de recomendación tienen bucles de retroalimentación cortos. Si los elementos recomendados son productos relacionados en Amazon o personas a las que seguir en Twitter, el tiempo que transcurre desde que se recomienda el elemento hasta que se hace clic en él, si es que se hace clic, es corto.
Sin embargo, no todos los sistemas de recomendación tienen bucles de retroalimentación de un minuto de duración. Si trabajas con tipos de contenido más largos, como entradas de blog o artículos o vídeos de YouTube, el bucle de retroalimentación puede durar horas. Si construyes un sistema para recomendar ropa a los usuarios como el que tiene Stitch Fix, no obtendrías retroalimentación hasta que los usuarios hayan recibido los artículos y se los hayan probado, lo que podría ocurrir semanas después.
La elección de la longitud de ventana adecuada requiere una consideración exhaustiva, ya que implica el compromiso entre velocidad y precisión. Una longitud de ventana corta significa que puedes capturar etiquetas más rápidamente, lo que te permite utilizar estas etiquetas para detectar problemas con tu modelo y solucionarlos lo antes posible. Sin embargo, una longitud de ventana corta también significa que podrías etiquetar prematuramente una recomendación como mala antes de que se haga clic en ella.
Por muy larga que establezcas la duración de tu ventana, puede que siga habiendo etiquetas negativas prematuras. A principios de 2021, un estudio del equipo de Anuncios de Twitter descubrió que, aunque la mayoría de los clics en los anuncios se producen en los primeros cinco minutos, algunos clics se producen horas después de que se muestre el anuncio.10 Esto significa que este tipo de etiqueta tiende a dar una subestimación del porcentaje real de clics. Si sólo registras 1.000 etiquetas POSITIVAS, el número real de clics podría ser algo superior a 1.000.
Para las tareas con largos bucles de retroalimentación, las etiquetas naturales podrían no llegar hasta pasadas semanas o incluso meses. La detección del fraude es un ejemplo de tarea con largos bucles de retroalimentación. Durante cierto tiempo después de una transacción, los usuarios pueden discutir si esa transacción es fraudulenta o no. Por ejemplo, cuando un cliente lee el extracto de su tarjeta de crédito y ve una transacción que no reconoce, puede disputarla con su banco, dándole a éste la información necesaria para calificarla de fraudulenta. Una ventana de disputa típica es de uno a tres meses. Una vez transcurrido el plazo de disputa, si no hay disputa por parte del usuario, puedes suponer que la transacción es legítima.
Las etiquetas con largos bucles de retroalimentación son útiles para informar sobre el rendimiento de un modelo en informes comerciales trimestrales o anuales. Sin embargo, no son muy útiles si quieres detectar problemas con tus modelos lo antes posible. Si hay un problema con tu modelo de detección de fraudes y tardas meses en detectarlo, para cuando se solucione el problema, todas las transacciones fraudulentas que tu modelo defectuoso dejó pasar podrían haber provocado la quiebra de una pequeña empresa de .
Manejar la falta de etiquetas
Debido a los retos que supone adquirir etiquetas de alta calidad suficientes, se han desarrollado muchas técnicas para abordar los problemas resultantes. En esta sección trataremos cuatro de ellas: supervisión débil, semisupervisión, aprendizaje por transferencia y aprendizaje activo. En la Tabla 4-2 se muestra un resumen de estos métodos.
| Método | Cómo | ¿Se necesitan verdades sobre el terreno? |
|---|---|---|
| Supervisión deficiente | Aprovecha la heurística (a menudo ruidosa) para generar etiquetas | No, pero se recomienda un pequeño número de etiquetas para orientar el desarrollo de la heurística |
| Semisupervisión | Aprovecha los supuestos estructurales para generar etiquetas | Sí, un pequeño número de etiquetas iniciales como semillas para generar más etiquetas |
| Aprendizaje por transferencia | Aprovecha los modelos preentrenados en otra tarea para tu nueva tarea | No para el aprendizaje sin disparos Sí para el ajuste fino, aunque el número de verdades básicas necesarias suele ser mucho menor que el que se necesitaría si entrenas el modelo desde cero |
| Aprendizaje activo | Etiqueta las muestras de datos más útiles para tu modelo | Sí |
Supervisión deficiente
Si el etiquetado manual es tan problemático, ¿qué pasaría si no utilizáramos etiquetas manuales en absoluto? Un enfoque que ha ganado popularidad es la supervisión débil. Una de las herramientas de código abierto más populares para la supervisión débil es Snorkel, desarrollada en el Stanford AI Lab.11 La idea que subyace a la supervisión débil es que la gente confía en la heurística, que puede desarrollarse con experiencia en la materia, para etiquetar los datos. Por ejemplo, un médico podría utilizar la siguiente heurística para decidir si el caso de un paciente debe priorizarse como emergente:
Si la nota de la enfermera menciona una afección grave como la neumonía, el caso del paciente debe considerarse prioritario.
Las bibliotecas como Snorkel se construyen en torno al concepto de función de etiquetado (LF): una función que codifica la heurística. La heurística anterior puede expresarse mediante la siguiente función:
deflabeling_function(note):if"pneumonia"innote:return"EMERGENT"
Las LF pueden codificar muchos tipos diferentes de heurísticas. He aquí algunos de ellos:
- Palabra clave heurística
Como en el ejemplo anterior
- Expresiones regulares
Por ejemplo, si la nota coincide o no con una determinada expresión regular
- Consulta de la base de datos
Por ejemplo, si la nota contiene la enfermedad que figura en la lista de enfermedades peligrosas
- Los resultados de otros modelos
Por ejemplo, si un sistema existente lo clasifica como
EMERGENT
Después de escribir los LF, puedes aplicarlos a las muestras que quieras etiquetar.
Dado que las LF codifican heurísticas, y las heurísticas son ruidosas, las etiquetas producidas por las LF son ruidosas. Múltiples LF pueden aplicar a los mismos ejemplos de datos, y pueden dar etiquetas contradictorias. Una función podría pensar que la nota de una enfermera es EMERGENT, pero otra podría pensar que no lo es. Una heurística podría ser mucho más precisa que otra heurística, lo que podrías no saber porque no tienes etiquetas de la verdad sobre el terreno con las que compararlas. Es importante combinar, eliminar el ruido y volver a ponderar todos los LF para obtener un conjunto de etiquetas con mayor probabilidad de ser correctas. La Figura 4-4 muestra a alto nivel cómo funcionan los LF.
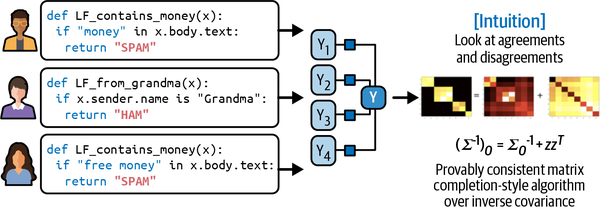
Figura 4-4. Visión general de alto nivel de cómo se combinan las funciones de etiquetado. Fuente: Adaptado de una imagen de Ratner et al.12
En teoría, no necesitas ninguna etiqueta manual para una supervisión débil. Sin embargo, para tener una idea de la precisión de tus LF, se recomienda un pequeño número de etiquetas manuales. Estas etiquetas manuales pueden ayudarte a descubrir patrones en tus datos para escribir mejores LF.
La supervisión débil puede ser especialmente útil cuando tus datos tienen requisitos estrictos de privacidad. Sólo necesitas ver un subconjunto pequeño y limpio de datos para escribir LFs, que pueden aplicarse al resto de tus datos sin que nadie los vea.
Con los LF, los conocimientos especializados pueden versionarse, reutilizarse y compartirse. La experiencia de un equipo puede ser codificada y utilizada por otro equipo. Si tus datos cambian o cambian tus requisitos, sólo tienes que volver a aplicar los LF a tus muestras de datos. El enfoque de utilizar LFs para generar etiquetas para tus datos también se conoce como etiquetado programático. La Tabla 4-3 muestra algunas de las ventajas del etiquetado programático sobre el etiquetado manual.
| Etiquetado a mano | Etiquetado programático |
|---|---|
| Caro: Especialmente cuando se requiere experiencia en la materia | Ahorro de costes: Los conocimientos pueden versionarse, compartirse y reutilizarse en toda la organización. |
| Falta de privacidad: Necesidad de enviar datos a anotadores humanos | Privacidad: Crea LFs utilizando una submuestra de datos depurada y luego aplica LFs a otros datos sin mirar las muestras individuales |
| Lento: El tiempo necesario aumenta linealmente con el número de etiquetas necesarias | Rápido: Escala fácilmente de 1K a 1M muestras |
| No adaptable: Cada cambio requiere reetiquetar los datos | Adaptable: Cuando se produzcan cambios, ¡sólo tienes que volver a aplicar los LF! |
He aquí un estudio de caso que demuestra lo bien que funciona en la práctica una supervisión débil. En un estudio con Stanford Medicine13 los modelos entrenados con etiquetas débilmente supervisadas obtenidas por un solo radiólogo tras ocho horas de escribir LF tuvieron un rendimiento comparable al de los modelos entrenados con datos obtenidos durante casi un año de etiquetado manual, como se muestra en la Figura 4-5. Hay dos hechos interesantes sobre los resultados del experimento. En primer lugar, los modelos siguieron mejorando con más datos sin etiquetar, incluso sin más LFs. En segundo lugar, los LF se reutilizaban en distintas tareas. Los investigadores pudieron reutilizar seis LF entre la tarea CXR (radiografías de tórax) y la tarea EXR (radiografías de extremidades).14
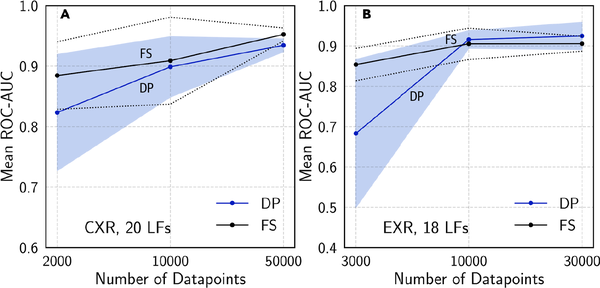
Figura 4-5. Comparación del rendimiento de un modelo entrenado con etiquetas totalmente supervisadas (FS) y un modelo entrenado con etiquetas programáticas (DP) en las tareas CXR y EXR. Fuente: Dunnmon et al.15
Mis alumnos suelen preguntar que si la heurística funciona tan bien para etiquetar datos, ¿por qué necesitamos modelos ML? Una razón es que los LFs pueden no cubrir todas las muestras de datos, por lo que podemos entrenar modelos ML en datos etiquetados programáticamente con LFs y utilizar este modelo entrenado para generar predicciones para muestras que no están cubiertas por ningún LF.
La supervisión débil es un paradigma sencillo pero poderoso. Sin embargo, no es perfecto. En algunos casos, las etiquetas obtenidas mediante supervisión débil pueden ser demasiado ruidosas para ser útiles. Pero incluso en estos casos, la supervisión débil puede ser una buena forma de empezar cuando quieres explorar la eficacia del ML sin querer invertir demasiado en el etiquetado manual por adelantado.
Semisupervisión
Si la supervisión débil aprovecha la heurística para obtener etiquetas ruidosas, la semisupervisión aprovecha los supuestos estructurales para generar nuevas etiquetas basadas en un pequeño conjunto de etiquetas iniciales. A diferencia de la supervisión débil, la semisupervisión requiere un conjunto inicial de etiquetas.
El aprendizaje semisupervisado es una técnica que se utilizó en los años 9016 y desde entonces se han desarrollado muchos métodos de semisupervisión. Una revisión exhaustiva del aprendizaje semisupervisado está fuera del alcance de este libro. Repasaremos un pequeño subconjunto de estos métodos para dar a los lectores una idea de cómo se utilizan. Para una revisión exhaustiva, recomiendo "Semi-Supervised Learning Literature Survey" (Xiaojin Zhu, 2008) y "A Survey on Semi-Supervised Learning" (Engelen y Hoos, 2018).
Un método clásico de semisupervisión es el autoentrenamiento. Empiezas entrenando un modelo en tu conjunto existente de datos etiquetados y utilizas este modelo para hacer predicciones para muestras no etiquetadas. Suponiendo que las predicciones con altas puntuaciones de probabilidad bruta sean correctas, añades las etiquetas predichas con alta probabilidad a tu conjunto de entrenamiento y entrenas un nuevo modelo en este conjunto de entrenamiento ampliado. Así sucesivamente hasta que estés satisfecho con el rendimiento de tu modelo.
Otro método de semisupervisión supone que las muestras de datos que comparten características similares comparten las mismas etiquetas. La similitud puede ser obvia, como en la tarea de clasificar el tema de los hashtags de Twitter. Puedes empezar etiquetando el hashtag "#AI" como Informática. Suponiendo que los hashtags que aparecen en el mismo tweet o perfil probablemente traten del mismo tema, dado el perfil del MIT CSAIL de la Figura 4-6, también puedes etiquetar los hashtags "#ML" y "#BigData" como Ciencias de la Computación.
Figura 4-6. Como #ML y #BigData aparecen en el mismo perfil de Twitter que #AI, podemos suponer que pertenecen al mismo tema
En la mayoría de los casos, la similitud sólo puede descubrirse mediante métodos más complejos. Por ejemplo, puede que necesites utilizar un método de agrupación o un algoritmo de k vecinos más próximos para descubrir las muestras que pertenecen al mismo grupo.
Un método de semisupervisión que ha ganado popularidad en los últimos años es el método basado en perturbaciones. Se basa en la suposición de que pequeñas perturbaciones en una muestra no deberían cambiar su etiqueta. Así que aplicas pequeñas perturbaciones a tus instancias de entrenamiento para obtener nuevas instancias de entrenamiento. Las perturbaciones pueden aplicarse directamente a las muestras (por ejemplo, añadiendo ruido blanco a las imágenes) o a sus representaciones (por ejemplo, añadiendo pequeños valores aleatorios a las incrustaciones de palabras). Las muestras perturbadas tienen las mismas etiquetas que las muestras no perturbadas. Hablaremos más sobre esto en la sección "Perturbación".
En algunos casos, los enfoques de semisupervisión han alcanzado el rendimiento del aprendizaje puramente supervisado, incluso cuando se ha descartado una parte sustancial de las etiquetas de un conjunto de datos determinado.17
La semisupervisión es más útil cuando el número de etiquetas de entrenamiento es limitado. Una cosa que hay que tener en cuenta al hacer semisupervisión con datos limitados es qué cantidad de estos datos limitados debe utilizarse para evaluar múltiples modelos candidatos y seleccionar el mejor. Si utilizas una cantidad pequeña, el modelo con mejor rendimiento en este pequeño conjunto de evaluación podría ser el que más se ajuste a este conjunto. Por otra parte, si utilizas una gran cantidad de datos para la evaluación, el aumento de rendimiento obtenido al seleccionar el mejor modelo basado en este conjunto de evaluación podría ser menor que el aumento obtenido al añadir el conjunto de evaluación al conjunto de entrenamiento limitado. Muchas empresas superan esta disyuntiva utilizando un conjunto de evaluación razonablemente grande para seleccionar el mejor modelo, y luego siguen entrenando el modelo campeón en el conjunto de evaluación.
Aprendizaje por transferencia
El aprendizaje por transferencia se refiere a la familia de métodos en los que un modelo desarrollado para una tarea se reutiliza como punto de partida para un modelo en una segunda tarea. En primer lugar, el modelo base se entrena para una tarea base. La tarea base suele ser una tarea que tiene datos de entrenamiento baratos y abundantes. El modelado del lenguaje es un gran candidato porque no requiere datos etiquetados. Los modelos lingüísticos se pueden entrenar en cualquier cuerpo de texto -libros, artículos de Wikipedia, historiales de chat- y la tarea es: dada una secuencia de tokens,18 predecir el siguiente token. Cuando se da la secuencia "Compré acciones de NVIDIA porque creo en la importancia de", un modelo lingüístico puede dar como resultado "hardware" o "GPU" como siguiente palabra.
El modelo entrenado puede utilizarse para la tarea que te interese -una tarea posterior-, como el análisis de sentimientos, la detección de intenciones o la respuesta a preguntas. En algunos casos, como en escenarios de aprendizaje de disparo cero, podrías utilizar el modelo base en una tarea posterior directamente. En muchos casos, puede que necesites afinar el modelo base. Afinar significa hacer pequeños cambios en el modelo base, como seguir entrenando el modelo base o una parte del modelo base con los datos de una determinada tarea posterior.19
A veces, puede que necesites modificar las entradas utilizando una plantilla para indicar al modelo base que genere las salidas que deseas.20 Por ejemplo, para utilizar un modelo lingüístico como modelo base en una tarea de respuesta a preguntas, puedes utilizar esta instrucción:
P: ¿Cuándo se fundó Estados Unidos?
R: 4 de julio de 1776.
P: ¿Quién escribió la Declaración de Independencia?
R: Thomas Jefferson.
P: ¿En qué año nació Alexander Hamilton?
A:
Si introduces este mensaje en un modelo lingüístico como GPT-3, podría mostrar el año de nacimiento de Alexander Hamilton.
El aprendizaje por transferencia es especialmente atractivo para tareas que no tienen muchos datos etiquetados. Incluso para las tareas que tienen muchos datos etiquetados, utilizar un modelo preentrenado como punto de partida a menudo puede aumentar significativamente el rendimiento en comparación con el entrenamiento desde cero.
El aprendizaje por transferencia ha cobrado mucho interés en los últimos años por las razones adecuadas. Ha permitido muchas aplicaciones que antes eran imposibles debido a la falta de muestras de entrenamiento. Una parte no trivial de los modelos ML que se producen hoy en día son el resultado del aprendizaje por transferencia, incluidos los modelos de detección de objetos que aprovechan los modelos preentrenados en ImageNet y los modelos de clasificación de textos que aprovechan los modelos lingüísticos preentrenados, como BERT o GPT-3.21 El aprendizaje por transferencia también reduce las barreras de entrada al ML, ya que ayuda a reducir el coste inicial necesario para etiquetar los datos con el fin de crear aplicaciones de ML.
Una tendencia que ha surgido en los últimos cinco años es que (normalmente) cuanto mayor es el modelo base preentrenado, mejor es su rendimiento en las tareas posteriores. Los modelos grandes son caros de entrenar. Basándonos en la configuración del GPT-3, se calcula que el coste del entrenamiento de este modelo es de decenas de millones de USD. Muchos han planteado la hipótesis de que en el futuro sólo un puñado de empresas podrán permitirse entrenar grandes modelos preentrenados. El resto de la industria utilizará directamente estos modelos preentrenados o los ajustará a sus necesidades específicas.
Aprendizaje activo
El aprendizaje activo es un método para mejorar la eficacia de las etiquetas de datos. La esperanza es que los modelos de ML puedan lograr una mayor precisión con menos etiquetas de entrenamiento si pueden elegir de qué muestras de datos aprender. El aprendizaje activo se denomina a veces aprendizaje de consultas -aunque este término es cada vez menos popular- porque un modelo (aprendiz activo) envía consultas en forma de muestras sin etiquetar para que las etiqueten los anotadores (normalmente humanos).
En lugar de etiquetar muestras de datos al azar, etiquetas las muestras que son más útiles para tus modelos según algunas métricas o heurísticas. La métrica más directa es la medición de la incertidumbre: etiqueta los ejemplos sobre los que tu modelo esté menos seguro, con la esperanza de que ayuden a tu modelo a aprender mejor el límite de decisión. Por ejemplo, en el caso de problemas de clasificación en los que tu modelo emite probabilidades brutas para distintas clases, podría elegir las muestras de datos con las probabilidades más bajas para la clase predicha. La Figura 4-7 ilustra lo bien que funciona este método en un ejemplo de juguete.
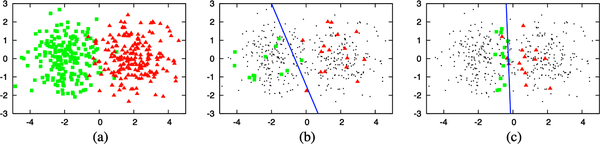
Figura 4-7. Cómo funciona el aprendizaje activo basado en la incertidumbre. (a) Un conjunto de datos de juguete de 400 instancias, muestreadas uniformemente a partir de dos clases gaussianas. (b) Un modelo entrenado en 30 muestras etiquetadas al azar da una precisión del 70%. (c) Un modelo entrenado en 30 muestras elegidas mediante aprendizaje activo da una precisión del 90%. Fuente: Burr Settles22
Otra heurística habitual se basa en el desacuerdo entre varios modelos candidatos. Este método se denomina consulta por comité, un ejemplo de método de conjunto.23 Necesitas un comité de varios modelos candidatos, que suelen ser el mismo modelo entrenado con diferentes conjuntos de hiperparámetros o el mismo modelo entrenado en diferentes porciones de datos. Cada modelo puede emitir un voto sobre qué muestras etiquetar a continuación, y puede votar en función de su grado de incertidumbre sobre la predicción. A continuación, etiqueta las muestras en las que el comité esté más en desacuerdo.
Hay otras heurísticas, como elegir las muestras que, si se entrenan con ellas, darán las mayores actualizaciones de gradiente o reducirán más la pérdida. Para una revisión exhaustiva de los métodos de aprendizaje activo, consulta "Active Learning Literature Survey" (Settles 2010).
Las muestras que hay que etiquetar pueden proceder de distintos regímenes de datos. Pueden ser sintetizadas, donde tu modelo genera muestras en la región del espacio de entrada sobre la que tiene más incertidumbre.24 Pueden proceder de una distribución estacionaria en la que ya has recogido muchos datos sin etiquetar y tu modelo elige muestras de este conjunto para etiquetarlas. Pueden proceder de la distribución del mundo real, en la que recibes un flujo de datos, como en la producción, y tu modelo elige muestras de este flujo de datos para etiquetar.
Me entusiasma más el aprendizaje activo cuando un sistema trabaja con datos en tiempo real. Los datos cambian todo el tiempo, un fenómeno al que nos referimos brevemente en el Capítulo 1 y que detallaremos más en el Capítulo 8. El aprendizaje activo en este régimen de datos permitirá a tu modelo aprender más eficazmente en tiempo real y adaptarse más rápidamente a los entornos cambiantes de .
Desequilibrio de clases
El desequilibrio de clases suele referirse a un problema en las tareas de clasificación en las que hay una diferencia sustancial en el número de muestras en cada clase de los datos de entrenamiento. Por ejemplo, en un conjunto de datos de entrenamiento para la tarea de detectar el cáncer de pulmón a partir de imágenes de rayos X, el 99,99% de las radiografías podrían ser de pulmones normales, y sólo el 0,01% podría contener células cancerosas.
El desequilibrio de clases también puede ocurrir con tareas de regresión en las que las etiquetas son continuas. Considera la tarea de para estimar las facturas sanitarias.25 Las facturas sanitarias están muy sesgadas: la mediana es baja, pero el percentil 95 es astronómico. Al predecir las facturas hospitalarias, puede ser más importante predecir con exactitud las facturas del percentil 95 que las facturas de la mediana. Una diferencia del 100% en una factura de 250$ es aceptable (500$ reales, 250$ previstos), pero una diferencia del 100% en una factura de 10.000$ no lo es (20.000$ reales, 10.000$ previstos). Por lo tanto, puede que tengamos que entrenar al modelo para que sea mejor en la predicción de los billetes del percentil 95, aunque ello reduzca las métricas generales.
Desafíos del desequilibrio de clases
El ML, especialmente el aprendizaje profundo, funciona bien en situaciones en las que la distribución de los datos está más equilibrada, y normalmente no tan bien cuando las clases están muy desequilibradas, como se ilustra en la Figura 4-8. El desequilibrio de clases puede dificultar el aprendizaje por las tres razones siguientes.
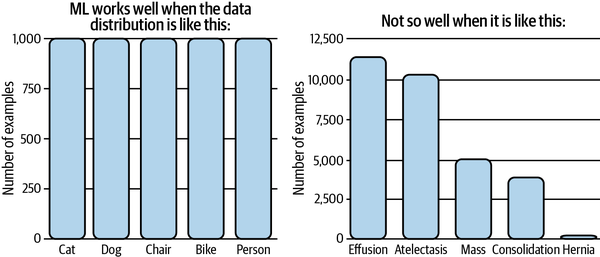
Figura 4-8. El ML funciona bien en situaciones en las que las clases están equilibradas. Fuente: Adaptado de una imagen de Andrew Ng26
La primera razón es que el desequilibrio de clases suele significar que no hay suficiente señal para que tu modelo aprenda a detectar las clases minoritarias. En el caso de que haya un pequeño número de instancias de la clase minoritaria, el problema se convierte en un problema de aprendizaje de pocos disparos en el que tu modelo sólo llega a ver la clase minoritaria unas pocas veces antes de tener que tomar una decisión sobre ella. En el caso de que no haya ninguna instancia de las clases raras en tu conjunto de entrenamiento, tu modelo podría suponer que esas clases raras no existen.
La segunda razón es que el desequilibrio de clases facilita que tu modelo se atasque en una solución no óptima explotando una simple heurística en lugar de aprender algo útil sobre el patrón subyacente de los datos. Considera el ejemplo anterior de detección de cáncer de pulmón. Si tu modelo aprende a dar siempre como resultado la clase mayoritaria, su precisión ya es del 99,99%.27 Esta heurística puede ser muy difícil de superar para los algoritmos de descenso de gradiente, porque una pequeña cantidad de aleatoriedad añadida a esta heurística podría conducir a una precisión peor.
La tercera razón es que el desequilibrio de clases provoca costes de error asimétricos: el coste de una predicción errónea en una muestra de la clase rara puede ser mucho mayor que el de una predicción errónea en una muestra de la clase mayoritaria.
Por ejemplo, una clasificación errónea en una radiografía con células cancerosas es mucho más peligrosa que una clasificación errónea en una radiografía de un pulmón normal. Si tu función de pérdida no está configurada para abordar esta asimetría, tu modelo tratará todas las muestras de la misma manera. Como resultado, puede que obtengas un modelo que funcione igual de bien en las clases mayoritaria y minoritaria, mientras que tú prefieres un modelo que funcione peor en la clase mayoritaria pero mucho mejor en la minoritaria.
Cuando estaba en la escuela, la mayoría de los conjuntos de datos que me daban tenían clases más o menos equilibradas.28 Fue un shock para mí empezar a trabajar y darme cuenta de que el desequilibrio de clases es la norma. En el mundo real, los sucesos raros suelen ser más interesantes (o más peligrosos) que los sucesos regulares, y muchas tareas se centran en detectar esos sucesos raros.
El ejemplo clásico de tareas con desequilibrio de clases es la detección del fraude. La mayoría de las transacciones con tarjeta de crédito no son fraudulentas. En 2018, 6,8¢ de cada 100 $ de gasto del titular de la tarjeta son fraudulentos.29 Otra es la predicción del churn . Es probable que la mayoría de tus clientes no estén pensando en cancelar su suscripción. Si es así, tu empresa tiene más de qué preocuparse que de los algoritmos de predicción de bajas. Otros ejemplos son la detección de enfermedades (la mayoría de la gente, afortunadamente, no tiene una enfermedad terminal) y la detección de currículos (el 98% de los solicitantes de empleo son eliminados en la detección inicial del currículo30).
Un ejemplo menos obvio de tarea con desequilibrio de clases es la detección de objetos. Los algoritmos de detección de objetos funcionan actualmente generando un gran número de cuadros delimitadores sobre una imagen y, a continuación, prediciendo qué cuadros tienen más probabilidades de contener objetos. La mayoría de los recuadros delimitadores no contienen ningún objeto relevante.
Fuera de los casos en que el desequilibrio de clases es inherente al problema, el desequilibrio de clases también puede estar causado por sesgos durante el proceso de muestreo. Considera el caso de que quieras crear datos de entrenamiento para detectar si un correo electrónico es spam o no. Decides utilizar todos los correos electrónicos anonimizados de la base de datos de correo electrónico de tu empresa. Según Talos Intelligence, en mayo de 2021, casi el 85% de todos los correos electrónicos son spam.31 Pero la mayoría de los correos spam se filtraron antes de llegar a la base de datos de tu empresa, por lo que en tu conjunto de datos, sólo un pequeño porcentaje es spam.
Otra causa del desequilibrio de clases, aunque menos frecuente, se debe a errores de etiquetado. Los anotadores pueden haber leído mal las instrucciones o haber seguido instrucciones equivocadas (pensando que sólo hay dos clases, POSITIVA y NEGATIVA, cuando en realidad hay tres), o simplemente haber cometido errores. Siempre que te enfrentes al problema del desequilibrio de clases, es importante que examines tus datos para comprender sus causas.
Manejar el desequilibrio de clases
Debido a su prevalencia en las aplicaciones del mundo real, el desequilibrio de clases se ha estudiado a fondo en las dos últimas décadas.32 El desequilibrio de clases afecta a las tareas de forma diferente según el nivel de desequilibrio. Algunas tareas son más sensibles al desequilibrio de clases que otras. Japkowicz demostró que la sensibilidad al desequilibrio aumenta con la complejidad del problema, y que los problemas no complejos y linealmente separables no se ven afectados por todos los niveles de desequilibrio de clases.33 El desequilibrio de clases en problemas de clasificación binaria es un problema mucho más fácil que el desequilibrio de clases en problemas de clasificación multiclase. Ding et al. demostraron en 2017 que las redes neuronales muy profundas - "muy profundas" significa más de 10 capas- funcionaban mucho mejor con datos desequilibrados que las redes neuronales menos profundas.34
Se han sugerido muchas técnicas para mitigar el efecto del desequilibrio de clases. Sin embargo, como las redes neuronales han llegado a ser mucho más grandes y profundas, con más capacidad de aprendizaje, algunos podrían argumentar que no deberías intentar "arreglar" el desequilibrio de clases si así es como se ven los datos en el mundo real. Un buen modelo debería aprender a modelar ese desequilibrio. Sin embargo, desarrollar un modelo lo suficientemente bueno para eso puede ser todo un reto, por lo que seguimos teniendo que recurrir a técnicas especiales de entrenamiento.
En esta sección, trataremos tres enfoques para tratar el desequilibrio de clases: elegir las métricas adecuadas para tu problema; métodos a nivel de datos, lo que significa cambiar la distribución de los datos para hacerla menos desequilibrada; y métodos a nivel de algoritmo, lo que significa cambiar tu método de aprendizaje para hacerlo más robusto al desequilibrio de clases.
Estas técnicas pueden ser necesarias, pero no suficientes. Para un estudio exhaustivo, recomiendo "Survey on Deep Learning with Class Imbalance" (Johnson y Khoshgoftaar 2019).
Utilizar las métricas de evaluación adecuadas
Lo más importante cuando te enfrentas a una tarea con desequilibrio de clases es elegir la métrica de evaluación adecuada. Unas métricas equivocadas te darán ideas erróneas de cómo van tus modelos y, en consecuencia, no podrán ayudarte a desarrollar o elegir modelos lo suficientemente buenos para tu tarea.
La precisión global y la tasa de error son las métricas más utilizadas para informar del rendimiento de los modelos ML. Sin embargo, son métricas insuficientes para tareas con desequilibrio de clases porque tratan a todas las clases por igual, lo que significa que el rendimiento de tu modelo en la clase mayoritaria dominará estas métricas. Esto es especialmente malo cuando la clase mayoritaria no es la que te interesa.
Considera una tarea con dos etiquetas: CÁNCER (la clase positiva) y NORMAL (la clase negativa), donde el 90% de los datos etiquetados son NORMALES. Considera dos modelos, A y B, con las matrices de confusión que se muestran en las Tablas 4-4 y 4-5.
| Modelo A | CÁNCER real | Actual NORMAL |
|---|---|---|
| Predicción CÁNCER | 10 | 10 |
| Predicción NORMAL | 90 | 890 |
| Modelo B | CÁNCER real | Actual NORMAL |
|---|---|---|
| Predicción CÁNCER | 90 | 90 |
| Predicción NORMAL | 10 | 810 |
Si eres como la mayoría de la gente, probablemente preferirías que el modelo B hiciera predicciones por ti, ya que tiene más posibilidades de decirte si realmente tienes cáncer. Sin embargo, ambos tienen la misma precisión de 0,9.
Las métricas que te ayudan a comprender el rendimiento de tu modelo con respecto a clases específicas serían mejores opciones. La precisión puede seguir siendo una buena métrica si la utilizas para cada clase individualmente. La precisión del modelo A en la clase CÁNCER es del 10% y la precisión del modelo B en la clase CÁNCER es del 90%.
F1, precisión y recuperación son métricas que miden el rendimiento de tu modelo con respecto a la clase positiva en problemas de clasificación binaria, ya que se basan en el verdadero positivo, es decir, un resultado en el que el modelo predice correctamente la clase positiva.35
F1, precisión y recuerdo son métricas asimétricas , lo que significa que sus valores cambian en función de la clase que se considere positiva. En nuestro caso, si consideramos CÁNCER la clase positiva, la F1 del modelo A es 0,17. Sin embargo, si consideramos que la clase positiva es NORMAL, la F1 del modelo A es 0,95. Las puntuaciones de exactitud, precisión, recuperación y F1 del modelo A y del modelo B cuando CÁNCER es la clase positiva se muestran en la Tabla 4-7.
| CÁNCER (1) | NORMAL (0) | Precisión | Precisión | Retirada | F1 | |
|---|---|---|---|---|---|---|
| Modelo A | 10/100 | 890/900 | 0.9 | 0.5 | 0.1 | 0.17 |
| Modelo B | 90/100 | 810/900 | 0.9 | 0.5 | 0.9 | 0.64 |
Muchos problemas de clasificación pueden modelizarse como problemas de regresión. Tu modelo puede dar como resultado una probabilidad, y en función de esa probabilidad, clasificas la muestra. Por ejemplo, si el valor es mayor que 0,5, es una etiqueta positiva, y si es menor o igual que 0,5, es una etiqueta negativa. Esto significa que puedes ajustar el umbral para aumentar la tasa de verdaderos positivos (también conocida como recuerdo) al tiempo que disminuye la tasa de falsos positivos (también conocida como probabilidad de falsa alarma), y viceversa. Podemos representar gráficamente la tasa de verdaderos positivos frente a la tasa de falsos positivos para distintos umbrales. Este gráfico se conoce como curva ROC (características operativas del receptor). Cuando tu modelo es perfecto, el recuerdo es 1,0, y la curva es sólo una línea en la parte superior. Esta curva te muestra cómo cambia el rendimiento de tu modelo en función del umbral, y te ayuda a elegir el umbral que mejor te funcione. Cuanto más se acerque a la línea perfecta, mejor será el rendimiento de tu modelo.
El área bajo la curva (AUC) mide el área bajo la curva ROC. Como cuanto más cerca de la línea perfecta, mejor, cuanto mayor sea esta área, mejor, como se muestra en la Figura 4-9.
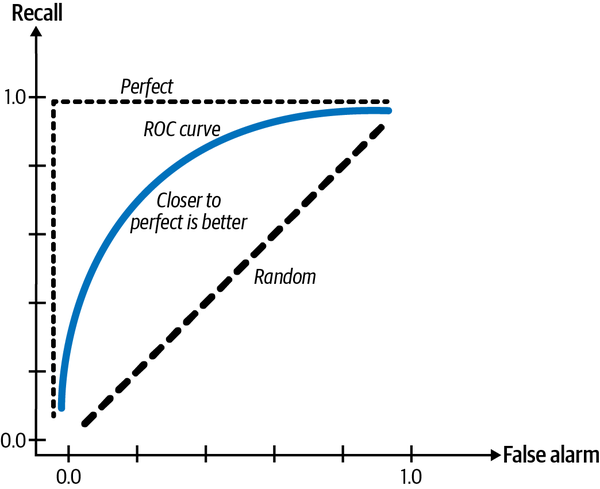
Figura 4-9. Curva ROC
Al igual que F1 y recall, la curva ROC se centra sólo en la clase positiva y no muestra lo bien que funciona tu modelo en la clase negativa. Davis y Goadrich sugirieron que, en su lugar, trazáramos la precisión frente a la recuperación, en lo que denominaron Curva de Precisión-Recuperación. Argumentaron que esta curva ofrece una imagen más informativa del rendimiento de un algoritmo en tareas con un gran desequilibrio de clases.36
Métodos a nivel de datos: Remuestreo
Los métodos a nivel de datos modifican la distribución de los datos de entrenamiento para reducir el nivel de desequilibrio y facilitar el aprendizaje del modelo. Una familia común de técnicas es el remuestreo. El remuestreo incluye el sobremuestreo, añadiendo más casos de las clases minoritarias, y el submuestreo, eliminando casos de las clases mayoritarias. La forma más sencilla de submuestrear es eliminar aleatoriamente casos de la clase mayoritaria, mientras que la forma más sencilla de sobremuestrear es hacer copias aleatorias de la clase minoritaria hasta que obtengas una proporción que te satisfaga. La Figura 4-10 muestra una visualización del sobremuestreo y el submuestreo.

Figura 4-10. Ilustraciones de cómo funcionan el submuestreo y el sobremuestreo. Fuente: Adaptado de una imagen de Rafael Alencar37
Un método popular de submuestreo de datos bidimensionales que se desarrolló en 1976 son los enlaces Tomek.38 Con esta técnica, encuentras pares de muestras de clases opuestas que estén próximas y eliminas la muestra de la clase mayoritaria de cada par.
Aunque esto hace que el límite de decisión sea más claro y podría decirse que ayuda a los modelos a aprender mejor el límite, puede hacer que el modelo sea menos robusto porque no llega a aprender de las sutilezas del verdadero límite de decisión.
Un método popular de sobremuestreo de datos de baja dimensión es SMOTE (técnica de sobremuestreo de minorías sintéticas).39 Sintetiza nuevas muestras de la clase minoritaria mediante muestreo de combinaciones convexas de puntos de datos existentes dentro de la clase minoritaria.40
Tanto los enlaces SMOTE como Tomek sólo han demostrado su eficacia en datos de baja dimensión. Muchas de las técnicas sofisticadas de remuestreo, como Near-Miss y la selección unilateral41 requieren calcular la distancia entre instancias o entre instancias y los límites de decisión, lo que puede resultar caro o inviable para datos de alta dimensión o en un espacio de características de alta dimensión, como es el caso de las grandes redes neuronales.
Cuando vuelvas a muestrear tus datos de entrenamiento, nunca evalúes tu modelo sobre datos remuestreados, ya que provocará que tu modelo se ajuste en exceso a esa distribución remuestreada.
El submuestreo corre el riesgo de perder datos importantes al eliminar datos. El sobremuestreo corre el riesgo de sobreajustar los datos de entrenamiento, sobre todo si las copias añadidas de la clase minoritaria son réplicas de los datos existentes. Se han desarrollado muchas técnicas de muestreo sofisticadas para mitigar estos riesgos.
Una de estas técnicas es el aprendizaje en dos fases.42 Primero entrenas tu modelo con los datos remuestreados. Estos datos remuestreados pueden obtenerse en mediante un submuestreo aleatorio de clases grandes hasta que cada clase tenga sólo N instancias. A continuación, afinas tu modelo con los datos originales.
Otra técnica es muestreo dinámico: sobremuestrea las clases de bajo rendimiento y submuestrea las clases de alto rendimiento durante el proceso de entrenamiento. Introducido por Pouyanfar et al,43 el método pretende mostrar al modelo menos de lo que ya ha aprendido y más de lo que no.
Métodos a nivel de algoritmo
Si los métodos a nivel de datos mitigan el desafío del desequilibrio de clases alterando la distribución de tus datos de entrenamiento, los métodos a nivel de algoritmo mantienen intacta la distribución de los datos de entrenamiento, pero alteran el algoritmo para hacerlo más robusto al desequilibrio de clases.
Dado que la función de pérdida (o la función de coste) guía el proceso de aprendizaje, muchos métodos a nivel de algoritmo implican el ajuste de la función de pérdida. La idea clave es que si hay dos instancias, x1 y x2, y la pérdida resultante de hacer una predicción errónea en x1 es mayor que en x2, el modelo dará prioridad a hacer la predicción correcta en x1 sobre hacer la predicción correcta en x2. Al dar mayor peso a las instancias de entrenamiento que nos importan, podemos hacer que el modelo se centre más en aprender estas instancias.
Sea es la pérdida causada por la instancia x para el modelo con el conjunto de parámetros . La pérdida del modelo suele definirse como la pérdida media causada por todas las instancias. N indica el número total de muestras de entrenamiento.
Esta función de pérdida valora la pérdida causada por todas las instancias por igual, aunque las predicciones erróneas en algunas instancias puedan ser mucho más costosas que las predicciones erróneas en otras instancias. Hay muchas formas de modificar esta función de coste. En esta sección, nos centraremos en tres de ellas, empezando por el aprendizaje sensible a los costes.
Aprendizaje sensible a los costes
Ya en 2001, basándose en la idea de que la clasificación errónea de distintas clases incurre en costes diferentes, Elkan propuso el aprendizaje sensible a los costes, en el que la función de pérdida individual se modifica para tener en cuenta este coste variable.44 El método empezó utilizando una matriz de costes para especificar Cij: el coste si la clase i se clasifica como clase j. Si i = j, es una clasificación correcta, y el coste suele ser 0. Si no, es una clasificación errónea. Si clasificar ejemplos POSITIVOS como NEGATIVOS es el doble de costoso que al revés, puedes hacer que C10 sea el doble que C01.
Por ejemplo, si tienes dos clases, POSITIVA y NEGATIVA, la matriz de costes puede ser como la de la Tabla 4-8.
| Actual NEGATIVO | Real POSITIVO | |
|---|---|---|
| Predicción NEGATIVA | C(0, 0) = C00 | C(1, 0) = C10 |
| Predicción POSITIVA | C(0, 1) = C01 | C(1, 1) = C11 |
La pérdida causada por la instancia x de la clase i se convertirá en la media ponderada de todas las clasificaciones posibles de la instancia x.
El problema de esta función de pérdida es que tienes que definir manualmente la matriz de costes, que es diferente para distintas tareas a distintas escalas.
Pérdida de clase equilibrada
Lo que puede ocurrir con un modelo entrenado en un conjunto de datos desequilibrado es que se incline hacia las clases mayoritarias y haga predicciones erróneas sobre las clases minoritarias. ¿Y si castigamos al modelo por hacer predicciones erróneas sobre las clases minoritarias para corregir este sesgo?
En su forma vainilla, podemos hacer que el peso de cada clase sea inversamente proporcional al número de muestras de esa clase, de modo que las clases más raras tengan pesos más altos. En la siguiente ecuación, N denota el número total de muestras de entrenamiento:
La pérdida causada por la instancia x de la clase i será la siguiente, siendo Pérdida(x, j) la pérdida cuando x se clasifica como clase j. Puede ser la entropía cruzada o cualquier otra función de pérdida.
Una versión más sofisticada de esta pérdida puede tener en cuenta el solapamiento entre las muestras existentes, como la pérdida por equilibrio de clases basada en el número efectivo de muestras.45
Pérdida focal
En nuestros datos, algunos ejemplos son más fáciles de clasificar que otros, y nuestro modelo podría aprender a clasificarlos rápidamente. Queremos incentivar a nuestro modelo para que se centre en aprender las muestras que aún tiene dificultades para clasificar. ¿Y si ajustamos la pérdida de modo que si una muestra tiene una probabilidad menor de ser correcta, tenga un peso mayor? Esto es exactamente lo que hace la pérdida focal.46 La ecuación de la pérdida focal y su rendimiento en comparación con la pérdida de entropía cruzada se muestra en la Figura 4-11.
En la práctica, se ha demostrado que los ensamblajes ayudan con el problema del desequilibrio de clases.47 Sin embargo, no incluimos el ensamblaje en esta sección porque el desequilibrio de clases no suele ser el motivo por el que se utilizan los ensamblajes. Las técnicas de ensamblaje se tratarán en el Capítulo 6.
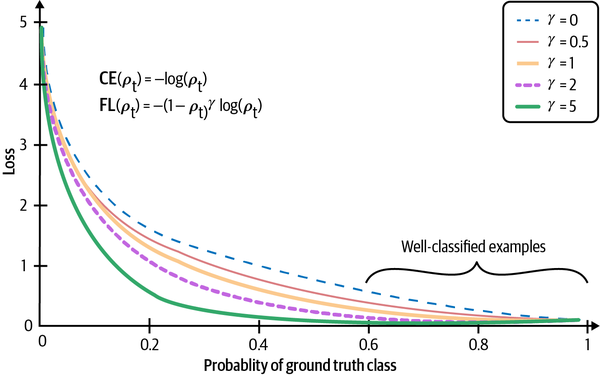
Figura 4-11. El modelo entrenado con pérdida focal (FL) muestra valores de pérdida reducidos en comparación con el modelo entrenado con pérdida de entropía cruzada (CE). Fuente: Adaptado de una imagen de Lin et al.
Aumento de datos
El aumento de datos es una familia de técnicas que se utilizan para aumentar la cantidad de datos de entrenamiento. Tradicionalmente, estas técnicas de se utilizan para tareas que tienen datos de entrenamiento limitados, como en la imagen médica. Sin embargo, en los últimos años, han demostrado ser útiles incluso cuando tenemos muchos datos: los datos aumentados pueden hacer que nuestros modelos sean más robustos al ruido e incluso a los ataques de adversarios.
El aumento de datos se ha convertido en un paso estándar en muchas tareas de visión por ordenador y se está abriendo camino en las tareas de procesamiento del lenguaje natural (PLN) de . Las técnicas dependen en gran medida del formato de los datos, ya que la manipulación de imágenes es diferente de la manipulación de texto. En esta sección, trataremos tres tipos principales de aumento de datos: transformaciones simples que conservan la etiqueta; perturbación, que es un término para "añadir ruidos"; y síntesis de datos. En cada tipo, repasaremos ejemplos tanto de visión por ordenador como de PNL.
Transformaciones simples que conservan la etiqueta
En visión por ordenador, la técnica más sencilla de aumento de datos consiste en modificar aleatoriamente una imagen conservando su etiqueta. Puedes modificar la imagen recortándola, volteándola, rotándola, invirtiéndola (horizontal o verticalmente), borrando parte de la imagen, etc. Esto tiene sentido porque una imagen girada de un perro sigue siendo un perro. Los marcos ML más comunes, como PyTorch, TensorFlow y Keras, admiten el aumento de imágenes. Según Krizhevsky et al. en su legendario artículo sobre AlexNet, "Las imágenes transformadas se generan en código Python en la CPU mientras la GPU se entrena con el lote anterior de imágenes. Así que estos esquemas de aumento de datos son, en efecto, computacionalmente gratuitos".48
En PNL, puedes sustituir aleatoriamente una palabra por otra similar, suponiendo que esta sustitución no cambie el significado o el sentimiento de la frase, como se muestra en la Tabla 4-9. Las palabras similares se pueden encontrar con un diccionario de palabras sinónimas o encontrando palabras cuyas incrustaciones estén próximas entre sí en un espacio de incrustación de palabras.
| Sentencia original | Me alegro mucho de verte. |
| Frases generadas | Me alegro mucho de veros. Me alegro mucho de veros. Me alegro mucho de veros. |
Este tipo de aumento de datos es una forma rápida de duplicar o triplicar tus datos de entrenamiento.
Perturbación
La perturbación también es una operación que preserva la etiqueta , pero como a veces se utiliza para engañar a los modelos para que hagan predicciones erróneas, pensé que merecía su propia sección.
Las redes neuronales, en general, son sensibles al ruido. En el caso de la visión por ordenador, esto significa que añadir una pequeña cantidad de ruido a una imagen puede hacer que una red neuronal la clasifique erróneamente. Su et al. demostraron que el 67,97% de las imágenes naturales del conjunto de datos de prueba Kaggle CIFAR-10 y el 16,04% de las imágenes de prueba ImageNet pueden clasificarse erróneamente cambiando sólo un píxel (véase la Figura 4-12).49

Figura 4-12. Cambiar un píxel puede hacer que una red neuronal haga predicciones erróneas. Los tres modelos utilizados son AllConv, NiN y VGG. Las etiquetas originales hechas por esos modelos están por encima de las etiquetas hechas después de cambiar un píxel. Fuente: Su et al.50
Utilizar datos engañosos para que una red neuronal haga predicciones erróneas se denomina ataque adversario. Añadir ruido a las muestras es una técnica habitual para crear muestras adversarias. El éxito de los ataques adversarios es especialmente exagerado a medida que aumenta la resolución de las imágenes.
Añadir muestras ruidosas a los datos de entrenamiento de puede ayudar a los modelos a reconocer los puntos débiles de su límite de decisión aprendido y mejorar su rendimiento.51 Las muestras ruidosas pueden crearse añadiendo ruido aleatorio o mediante una estrategia de búsqueda. Moosavi-Dezfooli et al. propusieron un algoritmo, llamado DeepFool, que encuentra la mínima inyección de ruido posible necesaria para causar una clasificación errónea con alta confianza.52 Este tipo de aumento se denomina aumento adversarial.53
El aumento adversarial es menos común en la PNL (una imagen de un oso con píxeles añadidos al azar sigue pareciendo un oso, pero añadir caracteres aleatorios a una frase aleatoria probablemente la convertirá en un galimatías), pero la perturbación se ha utilizado para hacer que los modelos sean más robustos. Uno de los ejemplos más notables es el BERT, en el que el modelo elige al azar el 15% de todos los tokens de cada secuencia y opta por sustituir el 10% de los tokens elegidos por palabras aleatorias. Por ejemplo, dada la frase "Mi perro es peludo", y el modelo sustituye aleatoriamente "peludo" por "manzana", la frase se convierte en "Mi perro es manzana". Así que el 1,5% de todos los tokens pueden dar lugar a un significado sin sentido. Sus estudios de ablación muestran que una pequeña fracción de sustitución aleatoria da a su modelo un pequeño aumento de rendimiento.54
En el Capítulo 6, veremos cómo utilizar la perturbación no sólo como forma de mejorar el rendimiento de tu modelo , sino también como forma de evaluar su rendimiento.
Síntesis de datos
Dado que recopilar datos es caro y lento, con muchos posibles problemas de privacidad, sería un sueño si pudiéramos evitarlo por completo y entrenar nuestros modelos con datos sintetizados. Aunque aún estamos lejos de poder sintetizar todos los datos de entrenamiento, es posible sintetizar algunos datos de entrenamiento para aumentar el rendimiento de un modelo.
En PNL, las plantillas pueden ser una forma barata de arrancar tu modelo. Un equipo con el que trabajé utilizó plantillas para crear datos de entrenamiento para su IA conversacional (chatbot). Una plantilla podría tener este aspecto "Encuéntrame un restaurante de [COCINA] en un radio de [NÚMERO] kilómetros de [UBICACIÓN]" (ver Tabla 4-10). Con listas de todas las cocinas posibles, números razonables (probablemente nunca querrías buscar restaurantes a más de 1.000 millas) y ubicaciones (casa, oficina, lugares emblemáticos, direcciones exactas) para cada ciudad, puedes generar miles de consultas de entrenamiento a partir de una plantilla.
| Plantilla | Búscame un restaurante de [COCINA] en un radio de [NÚMERO] kilómetros de [UBICACIÓN]. |
| Consultas generadas | Encuéntrame un restaurante vietnamita a menos de 3 km de mi oficina. Encuéntrame un restaurante tailandés a menos de 5 millas de mi casa. Encuéntrame un restaurante mexicano a menos de 5 km de la sede de Google. |
En visión por ordenador, una forma sencilla de sintetizar datos nuevos es combinar ejemplos existentes con etiquetas discretas para generar etiquetas continuas. Considera una tarea de clasificación de imágenes con dos etiquetas posibles: PERRO (codificada como 0) y GATO (codificada como 1). A partir del ejemplo x1 de la etiqueta PERRO y del ejemplo x2 de la etiqueta CAT, puedes generar x' como
La etiqueta de x' es una combinación de las etiquetas de x1 y x2: . Este método se denomina mixup. Los autores demostraron que la mezcla mejora la generalización de los modelos, reduce su memorización de etiquetas corruptas, aumenta su robustez frente a ejemplos adversos y estabiliza el entrenamiento de las redes generativas adversas.55
El uso de redes neuronales para sintetizar datos de entrenamiento es un enfoque interesante que se está investigando activamente, pero que aún no se ha popularizado en la producción. Sandfort et al. demostraron que añadiendo imágenes generadas mediante CycleGAN a sus datos de entrenamiento originales, podían mejorar significativamente el rendimiento de su modelo en tareas de segmentación de tomografía computarizada (TC).56
Si te interesa saber más sobre el aumento de datos para la visión por ordenador, "A Survey on Image Data Augmentation for Deep Learning" (Shorten y Khoshgoftaar 2019) es una revisión exhaustiva de .
Resumen
Los datos de entrenamiento siguen siendo la base de los algoritmos modernos de ML. Por muy inteligentes que sean tus algoritmos, si tus datos de entrenamiento son malos, tus algoritmos no podrán funcionar bien. Merece la pena invertir tiempo y esfuerzo en curar y crear datos de entrenamiento que permitan a tus algoritmos aprender algo significativo.
En este capítulo, hemos hablado de los múltiples pasos para crear datos de entrenamiento. Primero hemos tratado los distintos métodos de muestreo, tanto el muestreo no probabilístico como el muestreo aleatorio, que pueden ayudarnos a muestrear los datos adecuados para nuestro problema.
La mayoría de los algoritmos de ML que se utilizan hoy en día son algoritmos de ML supervisados, por lo que la obtención de etiquetas es una parte integral de la creación de datos de entrenamiento. Muchas tareas, como la estimación del tiempo de entrega o los sistemas de recomendación, tienen etiquetas naturales. Las etiquetas naturales suelen ser retardadas, y el tiempo que transcurre desde que se sirve una predicción hasta que se proporciona la retroalimentación sobre ella es la longitud del bucle de retroalimentación. Las tareas con etiquetas naturales son bastante comunes en la industria, lo que podría significar que las empresas prefieren empezar con tareas que tienen etiquetas naturales antes que con tareas sin etiquetas naturales.
Para las tareas que no tienen etiquetas naturales, las empresas tienden a confiar en anotadores humanos para anotar sus datos. Sin embargo, el etiquetado manual tiene muchos inconvenientes. Por ejemplo, las etiquetas manuales pueden ser caras y lentas. Para combatir la falta de etiquetas manuales, discutimos alternativas como la supervisión débil, la semisupervisión, el aprendizaje por transferencia y el aprendizaje activo.
Los algoritmos de ML funcionan bien en situaciones en las que la distribución de los datos está más equilibrada, y no tan bien cuando las clases están muy desequilibradas. Por desgracia, los problemas de desequilibrio de clases son la norma en el mundo real. En la sección siguiente, analizamos por qué el desequilibrio de clases dificulta el aprendizaje de los algoritmos de ML. También discutimos distintas técnicas para manejar el desequilibrio de clases, desde elegir la métrica adecuada hasta remuestrear los datos o modificar la función de pérdida para animar al modelo a prestar atención a determinadas muestras.
Terminamos el capítulo con un debate sobre las técnicas de aumento de datos que pueden utilizarse para mejorar el rendimiento y la generalización de un modelo, tanto para tareas de visión por ordenador como de PNL.
Una vez que tengas tus datos de entrenamiento, querrás extraer características de ellos para entrenar tus modelos de ML, lo que trataremos en el próximo capítulo.
1 Algunos lectores podrían argumentar que este enfoque podría no funcionar con modelos grandes, ya que ciertos modelos grandes no funcionan con conjuntos de datos pequeños, pero sí con muchos más datos. En este caso, sigue siendo importante experimentar con conjuntos de datos de distintos tamaños para averiguar el efecto del tamaño del conjunto de datos en tu modelo.
2 James J. Heckman, "Sample Selection Bias as a Specification Error", Econometrica 47, nº 1 (enero de 1979): 153-61, https://oreil.ly/I5AhM.
3 Rachel Lerman, "Google está probando su coche autoconducido en Kirkland", Seattle Times, 3 de febrero de 2016, https://oreil.ly/3IA1V.
4 Población se refiere aquí a una "población estadística", un conjunto (potencialmente infinito) de todas las muestras posibles que se pueden muestrear.
5 Las tareas multietiqueta son tareas en las que un ejemplo puede tener varias etiquetas.
6 "SVM: Muestras ponderadas", scikit-learn, https://oreil.ly/BDqbk.
7 Xiaojin Zhu, "Semi-Supervised Learning with Graphs" (tesis doctoral, Universidad Carnegie Mellon, 2005), https://oreil.ly/VYy4C.
8 Si algo es tan obvio de etiquetar, no necesitarías experiencia en el dominio.
9 Trataremos las etiquetas programáticas en la sección "Supervisión débil".
10 Sofia Ira Ktena, Alykhan Tejani, Lucas Theis, Pranay Kumar Myana, Deepak Dilipkumar, Ferenc Huszar, Steven Yoo y Wenzhe Shi, "Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR Prediction", arXiv, 15 de julio de 2019, https://oreil.ly/5y2WA.
11 Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu y Christopher Ré, "Snorkel: Creación rápida de datos de entrenamiento con supervisión débil", Actas de la Dotación VLDB 11, no. 3 (2017): 269-82, https://oreil.ly/vFPjk.
12 Ratner y otros, "Snorkel: Creación rápida de datos de entrenamiento con supervisión débil".
13 Jared A. Dunnmon, Alexander J. Ratner, Khaled Saab, Matthew P. Lungren, Daniel L. Rubin y Christopher Ré, "Cross-Modal Data Programming Enables Rapid Medical Machine Learning", Patterns 1, nº 2 (2020): 100019, https://oreil.ly/nKt8E.
14 Las dos tareas de este estudio utilizan sólo 18 y 20 LFs respectivamente. En la práctica, he visto equipos que utilizan cientos de LF para cada tarea.
15 Dummon y otros, "Programación de datos multimodal".
16 Avrim Blum y Tom Mitchell, "Combining Labeled and Unlabeled Data with Co-Training", en Proceedings of the Eleventh Annual Conference on Computational Learning Theory (julio de 1998): 92-100, https://oreil.ly/T79AE.
17 Avital Oliver, Augustus Odena, Colin Raffel, Ekin D. Cubuk e Ian J. Goodfellow, "Realistic Evaluation of Deep Semi-Supervised Learning Algorithms", NeurIPS 2018 Proceedings, https://oreil.ly/dRmPV.
18 Una ficha puede ser una palabra, un carácter o parte de una palabra.
19 Jeremy Howard y Sebastian Ruder, "Universal Language Model Fine-tuning for Text Classification", arXiv, 18 de enero de 2018, https://oreil.ly/DBEbw.
20 Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi y Graham Neubig, "Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing", arXiv, 28 de julio de 2021, https://oreil.ly/0lBgn.
21 Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", arXiv, 11 de octubre de 2018, https://oreil.ly/RdIGU; Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan y otros, "Language Models Are Few-Shot Learners", OpenAI, 2020, https://oreil.ly/YVmrr.
22 Burr Settles, Active Learning (Williston, VT: Morgan & Claypool, 2012).
23 Trataremos los conjuntos en el capítulo 6.
24 Dana Angluin, "Consultas y aprendizaje de conceptos", Aprendizaje automático 2 (1988): 319-42, https://oreil.ly/0uKs4.
25 ¡Gracias a Eugene Yan por este maravilloso ejemplo!
26 Andrew Ng, "Bridging AI's Proof-of-Concept to Production Gap" (Seminario HAI, 22 de septiembre de 2020), vídeo, 1:02:07, https://oreil.ly/FSFWS.
27 Y ésta es la razón por la que la precisión es una mala métrica para las tareas con desequilibrio de clases, como exploraremos más a fondo en la sección "Manejar el desequilibrio de clases".
28 Imaginé que sería más fácil aprender la teoría del ML si no tuviera que averiguar cómo tratar el desequilibrio de clases.
29 Informe Nilson, "Las pérdidas por fraude con tarjetas de pago alcanzan los 27.850 millones de dólares", PR Newswire, 21 de noviembre de 2019, https://oreil.ly/NM5zo.
30 "Experto en el mercado de trabajo explica por qué sólo el 2% de los solicitantes de empleo son entrevistados", WebWire, 7 de enero de 2014, https://oreil.ly/UpL8S.
31 "Email and Spam Data", Talos Intelligence, último acceso en mayo de 2021, https://oreil.ly/lI5Jr.
32 Nathalie Japkowciz y Shaju Stephen, "El problema del desequilibrio de clases: un estudio sistemático", 2002, https://oreil.ly/d7lVu.
33 Nathalie Japkowicz, "El problema del desequilibrio de clases: significado y estrategias", 2000, https://oreil.ly/Ma50Z.
34 Wan Ding, Dong-Yan Huang, Zhuo Chen, Xinguo Yu y Weisi Lin, "Facial Action Recognition Using Very Deep Networks for Highly Imbalanced Class Distribution", 2017 Cumbre y Conferencia Anual de la Asociación de Procesamiento de Señales e Información del Asia-Pacífico (APSIPA ASC), 2017, https://oreil.ly/WeW6J.
35 A partir de julio de 2021, cuando utilizas scikit-learn.metrics.f1_score, pos_label se establece en 1 por defecto, pero puedes cambiarlo a 0 si quieres que 0 sea tu etiqueta positiva.
36 Jesse Davis y Mark Goadrich, "The Relationship Between Precision-Recall and ROC Curves", Actas de la 23ª Conferencia Internacional sobre Aprendizaje Automático, 2006, https://oreil.ly/s40F3.
37 Rafael Alencar, "Estrategias de remuestreo para conjuntos de datos desequilibrados", Kaggle, https://oreil.ly/p8Whs.
38 Ivan Tomek, "Un experimento con la regla del vecino más próximo editado", IEEE Transactions on Systems, Man, and Cybernetics (junio de 1976): 448-52, https://oreil.ly/JCxHZ.
39 N.V. Chawla, K.W. Bowyer, L.O. Hall y W.P. Kegelmeyer, "SMOTE: Synthetic Minority Over-sampling Technique, Journal of Artificial Intelligence Research 16 (2002): 341-78, https://oreil.ly/f6y46.
40 "Convexo" aquí significa aproximadamente "lineal".
41 Jianping Zhang e Inderjeet Mani, "kNN Approach to Unbalanced Data Distributions: A Case Study involving Information Extraction" (Taller sobre aprendizaje a partir de conjuntos de datos desequilibrados II, ICML, Washington, DC, 2003), https://oreil.ly/qnpra; Miroslav Kubat y Stan Matwin, "Addressing the Curse of Imbalanced Training Sets: One-Sided Selection", 2000, https://oreil.ly/8pheJ.
42 Hansang Lee, Minseok Park y Junmo Kim, "Plankton Classification on Imbalanced Large Scale Database via Convolutional Neural Networks with Transfer Learning", 2016 IEEE International Conference on Image Processing (ICIP), 2016, https://oreil.ly/YiA8p.
43 Samira Pouyanfar, Yudong Tao, Anup Mohan, Haiman Tian, Ahmed S. Kaseb, Kent Gauen, Ryan Dailey y otros, "Dynamic Sampling in Convolutional Neural Networks for Imbalanced Data Classification", 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), 2018, https://oreil.ly/D3Ak5.
44 Charles Elkan, "The Foundations of Cost-Sensitive Learning", Actas de la Decimoséptima Conferencia Internacional Conjunta sobre Inteligencia Artificial (IJCAI'01), 2001, https://oreil.ly/WGq5M.
45 Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song y Serge Belongie, "Class-Balanced Loss Based on Effective Number of Samples", Actas de la Conferencia sobre Visión por Ordenador y Patrones, 2019, https://oreil.ly/jCzGH.
46 Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He y Piotr Dollár, "Focal Loss for Dense Object Detection", arXiv, 7 de agosto de 2017, https://oreil.ly/Km2dF.
47 Mikel Galar, Alberto Fernández, Edurne Barrenechea, Humberto Bustince y Francisco Herrera, "A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches", IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) 42, no. 4 (julio de 2012): 463-84, https://oreil.ly/1ND4g.
48 Alex Krizhevsky, Ilya Sutskever y Geoffrey E. Hinton, "Clasificación de ImageNet con redes neuronales convolucionales profundas", 2012, https://oreil.ly/aphzA.
49 Jiawei Su, Danilo Vasconcellos Vargas y Sakurai Kouichi, "One Pixel Attack for Fooling Deep Neural Networks", IEEE Transactions on Evolutionary Computation 23, no. 5 (2019): 828-41, https://oreil.ly/LzN9D.
50 Su y otros, "Ataque de un píxel".
51 Ian J. Goodfellow, Jonathon Shlens y Christian Szegedy, "Explaining and Harnessing Adversarial Examples", arXiv, 20 de marzo de 2015, https://oreil.ly/9v2No; Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville y Yoshua Bengio, "Maxout Networks", arXiv, 18 de febrero de 2013, https://oreil.ly/L8mch.
52 Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi y Pascal Frossard, "DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks", en Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, https://oreil.ly/dYVL8.
53 Takeru Miyato, Shin-ichi Maeda, Masanori Koyama y Shin Ishii, "Entrenamiento virtual adversarial: Un método de regularización para el aprendizaje supervisado y semisupervisado", IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, https://oreil.ly/MBQeu.
54 Devlin y otros, "BERT: Preentrenamiento de Transformadores Bidireccionales Profundos para la Comprensión del Lenguaje".
55 Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin y David López-Paz, "Mixup: Más allá de la minimización empírica del riesgo", ICLR 2018, https://oreil.ly/lIM5E.
56 Veit Sandfort, Ke Yan, Perry J. Pickhardt y Ronald M. Summers, "Data Augmentation Using Generative Adversarial Networks (CycleGAN) to Improve Generalizability in CT Segmentation Tasks", Scientific Reports 9, nº 1 (2019): 16884, https://oreil.ly/TDUwm.
Get Diseño de sistemas de aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

