Capítulo 1. Visión general de los sistemas de aprendizaje automático
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En noviembre de 2016, Google anunció que había incorporado su sistema de traducción automática neuronal multilingüe a Google Translate, marcando uno de los primeros éxitos de las redes neuronales artificiales profundas en producción a escala.1 Según Google, con esta actualización, la calidad de la traducción mejoró más en un solo salto de lo que habían visto en los 10 años anteriores juntos.
Este éxito del aprendizaje profundo renovó el interés de por el aprendizaje automático (AM) en general. Desde entonces, cada vez más empresas han recurrido al ML en busca de soluciones a sus problemas más desafiantes. En sólo cinco años, el ML se ha abierto camino en casi todos los aspectos de nuestras vidas: cómo accedemos a la información, cómo nos comunicamos, cómo trabajamos, cómo encontramos el amor. La difusión del ML ha sido tan rápida que ya resulta difícil imaginar la vida sin él. Sin embargo, aún quedan muchos más casos de uso del ML por explorar en campos como la asistencia sanitaria, el transporte, la agricultura e incluso para ayudarnos a comprender el universo.2
Mucha gente, cuando oye "sistema de aprendizaje automático", piensa sólo en los algoritmos de ML que se utilizan, como la regresión logística o los distintos tipos de redes neuronales. Sin embargo, el algoritmo es sólo una pequeña parte de un sistema de ML en producción. El sistema también incluye los requisitos empresariales que dieron origen al proyecto de ML en primer lugar, la interfaz en la que los usuarios y desarrolladores interactúan con tu sistema, la pila de datos y la lógica para desarrollar, monitorizar y actualizar tus modelos, así como la infraestructura que permite la entrega de esa lógica. La Figura 1-1 muestra los distintos componentes de un sistema de ML y en qué capítulos de este libro se tratarán.
La relación entre los MLOps y el diseño de sistemas ML
Ops en MLOps viene de DevOps, abreviatura de Desarrollos y Operaciones. Operacionalizar algo significa ponerlo en producción, lo que incluye su implementación, monitoreo y mantenimiento. MLOps es un conjunto de herramientas y buenas prácticas para poner el ML en producción.
El diseño de sistemas de ML adopta un enfoque de sistema para los MLOps, lo que significa que considera un sistema de ML de forma holística para garantizar que todos los componentes y sus partes interesadas puedan trabajar juntos para satisfacer los objetivos y requisitos especificados.
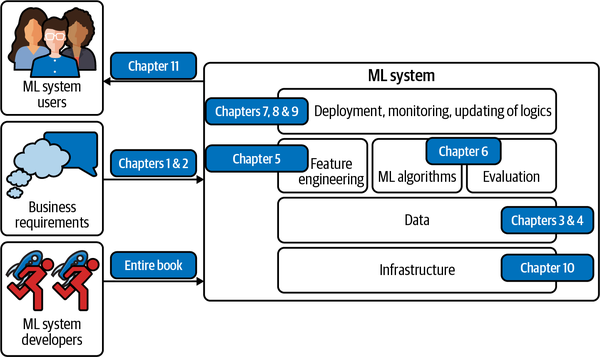
Figura 1-1. Diferentes componentes de un sistema de ML. "Algoritmos de ML" suele ser en lo que piensa la gente cuando dice aprendizaje automático, pero es sólo una pequeña parte de todo el sistema.
Hay muchos libros excelentes sobre diversos algoritmos de ML. Este libro no trata en detalle ningún algoritmo específico, sino que ayuda a los lectores a comprender todo el sistema de ML en su conjunto. En otras palabras, el objetivo de este libro es proporcionarte un marco para desarrollar la solución que mejor se adapte a tu problema, independientemente del algoritmo que acabes utilizando. Los algoritmos pueden quedar obsoletos rápidamente, ya que se desarrollan nuevos algoritmos constantemente, pero el marco propuesto en este libro debería seguir funcionando con los nuevos algoritmos.
El primer capítulo del libro pretende darte una visión general de lo que se necesita para llevar un modelo de ML a la producción. Antes de hablar de cómo desarrollar un sistema de ML, es importante plantearse la pregunta fundamental de cuándo y cuándo no utilizar el ML. Cubriremos algunos de los casos de uso más populares del ML para ilustrar este punto.
Tras los casos de uso, pasaremos a los retos de la implementación de sistemas de ML, y lo haremos comparando el ML en producción con el ML en investigación, así como con el software tradicional. Si has estado en las trincheras del desarrollo de sistemas de ML aplicado, puede que ya estés familiarizado con lo que se ha escrito en este capítulo. Sin embargo, si sólo has tenido experiencia con el ML en un entorno académico, este capítulo te dará una visión honesta del ML en el mundo real de y preparará tu primera aplicación para el éxito.
Cuándo utilizar el aprendizaje automático
A medida que crece rápidamente su adopción en la industria , el ML ha demostrado ser una poderosa herramienta para una amplia gama de problemas. A pesar de la increíble cantidad de entusiasmo y expectación generados por personas tanto de dentro como de fuera del campo, el ML no es una herramienta mágica que pueda resolver todos los problemas. Incluso para los problemas que el ML puede resolver, las soluciones de ML podrían no ser las soluciones óptimas. Antes de iniciar un proyecto de ML, quizá quieras preguntarte si el ML es necesario o rentable.3
Para entender lo que puede hacer el ML, examinemos lo que hacen generalmente las soluciones de ML:
El aprendizaje automático es un enfoque para (1) aprender (2) patrones complejos a partir de (3) datos existentes y utilizar estos patrones para hacer (4) predicciones sobre (5) datos no vistos.
Examinaremos cada una de las frases clave en cursiva del encuadre anterior para comprender sus implicaciones en los problemas que puede resolver el ML:
- 1. Aprender: el sistema tiene la capacidad de aprender
-
Una base de datos relacional no es un sistema ML porque no tiene capacidad de aprendizaje. Puedes establecer explícitamente la relación entre dos columnas en una base de datos relacional, pero es poco probable que tenga la capacidad de averiguar por sí misma la relación entre esas dos columnas.
Para que un sistema ML aprenda, debe haber algo de lo que pueda aprender. En la mayoría de los casos, los sistemas de ML aprenden de los datos. En el aprendizaje supervisado, basado en pares de entrada y salida de ejemplo, los sistemas de ML aprenden a generar salidas para entradas arbitrarias. Por ejemplo, si quieres crear un sistema de ML que aprenda a predecir el precio de alquiler de los anuncios de Airbnb, tienes que proporcionar un conjunto de datos en el que cada entrada sea un anuncio con características relevantes (metros cuadrados, número de habitaciones, barrio, servicios, valoración de ese anuncio, etc.) y la salida asociada sea el precio de alquiler de ese anuncio. Una vez aprendido, este sistema ML debería ser capaz de predecir el precio de un nuevo anuncio dadas sus características.
- 2. Patrones complejos: hay patrones que aprender, y son complejos
-
Las soluciones ML sólo son útiles cuando hay patrones que aprender. La gente sensata no invierte dinero en construir un sistema de ML para predecir el próximo resultado de un dado justo, porque no hay patrones en cómo se generan esos resultados.4 Sin embargo, hay patrones en la forma en que se valoran las acciones, y por ello las empresas han invertido miles de millones de dólares en construir sistemas de ML para aprender esos patrones.
La existencia de un patrón puede no ser obvia, o si existen patrones, tu conjunto de datos o tus algoritmos de ML pueden no ser suficientes para captarlos. Por ejemplo, podría haber un patrón en la forma en que los tweets de Elon Musk afectan a los precios de las criptodivisas. Sin embargo, no lo sabrás hasta que hayas entrenado y evaluado rigurosamente tus modelos de ML con sus tweets. Aunque todos tus modelos no consigan hacer predicciones razonables sobre los precios de las criptomonedas, eso no significa que no haya un patrón.
Piensa en un sitio web como Airbnb con muchos anuncios de casas; cada anuncio viene con un código postal. Si quieres clasificar los listados según los estados en los que se encuentran, no necesitarías un sistema ML. Como el patrón es sencillo -cada código postal corresponde a un estado conocido-, puedes utilizar simplemente una tabla de búsqueda.
La relación entre el precio de un alquiler y todas sus características sigue un patrón mucho más complejo, que sería muy difícil especificar manualmente. ML es una buena solución para esto. En lugar de decirle a tu sistema cómo calcular el precio a partir de una lista de características, puedes proporcionar precios y características, y dejar que tu sistema ML descubra el patrón. En la Figura 1-2 se muestra la diferencia entre las soluciones ML y la solución de tabla de consulta, así como las soluciones generales de software tradicional. Por este motivo, el ML también se denomina Software 2.0.5
El ML ha tenido mucho éxito con tareas con patrones complejos, como la detección de objetos y el reconocimiento del habla. Lo que es complejo para las máquinas es diferente de lo que es complejo para los humanos. Muchas tareas difíciles para los humanos son fáciles para las máquinas, como elevar un número a la potencia de 10. Por otro lado, muchas tareas fáciles para los humanos pueden ser difíciles para las máquinas. Por otra parte, muchas tareas que son fáciles para los humanos pueden ser difíciles para las máquinas -por ejemplo, decidir si hay un gato en una foto.
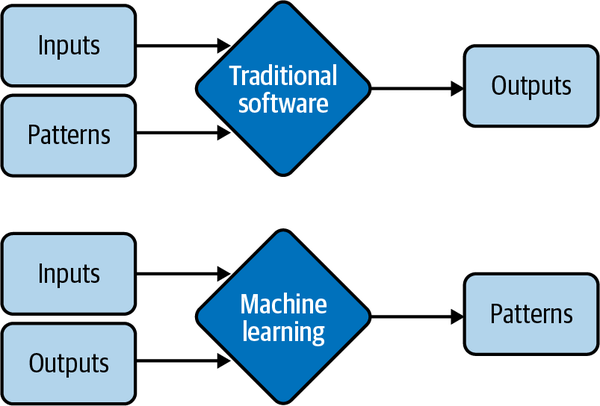
Figura 1-2. En lugar de requerir patrones especificados a mano para calcular las salidas, las soluciones ML aprenden patrones de las entradas y salidas
- 3. Datos existentes: hay datos disponibles, o es posible recopilar datos
-
Como el ML aprende de los datos, debe haber datos de los que pueda aprender. Es divertido pensar en construir un modelo para predecir cuántos impuestos debe pagar una persona al año, pero no es posible a menos que tengas acceso a los datos fiscales y de ingresos de una gran población.
En el contexto del aprendizaje sin datos (a veces conocido como aprendizaje con datos cero), es posible que un sistema de ML haga buenas predicciones para una tarea sin haber sido entrenado con datos para esa tarea. Sin embargo, este sistema ML fue entrenado previamente con datos para otras tareas, a menudo relacionadas con la tarea en cuestión. Por tanto, aunque el sistema no necesite datos de la tarea en cuestión para aprender, sigue necesitando datos para aprender.
También es posible lanzar un sistema de ML sin datos. Por ejemplo, en el contexto del aprendizaje continuo, los modelos ML pueden desplegarse sin haber sido entrenados con ningún dato, pero aprenderán de los datos entrantes en producción.6 Sin embargo, servir modelos insuficientemente entrenados a los usuarios conlleva ciertos riesgos, como una mala experiencia del cliente.
Sin datos y sin aprendizaje continuo, muchas empresas siguen un planteamiento de "fingirlo hasta conseguirlo": lanzar un producto que sirva para predicciones hechas por humanos, en lugar de modelos de ML, con la esperanza de utilizar los datos generados para entrenar modelos de ML más adelante.
- 4. Predicciones: es un problema de predicción
-
Los modelos ML hacen predicciones, por lo que sólo pueden resolver problemas que requieran respuestas predictivas. El ML puede ser especialmente atractivo cuando puedes beneficiarte de una gran cantidad de predicciones baratas pero aproximadas. En inglés, "predecir" significa "estimar un valor en el futuro". Por ejemplo, ¿qué tiempo hará mañana? ¿Quién ganará la Super Bowl este año? ¿Qué película querrá ver un usuario a continuación?
A medida que las máquinas predictivas (por ejemplo, los modelos de ML) se vuelven más eficaces, cada vez más problemas se reformulan como problemas predictivos. Sea cual sea la pregunta que tengas, siempre puedes formularla como "¿Cuál sería la respuesta a esta pregunta?", independientemente de si se trata de algo del futuro, del presente o incluso del pasado.
Los problemas de cálculo intensivo son una clase de problemas que se han replanteado con mucho éxito como predictivos. En lugar de calcular el resultado exacto de un proceso, que podría ser incluso más costoso computacionalmente y llevar más tiempo que el ML, puedes plantear el problema como: "¿Cómo sería el resultado de este proceso?" y aproximarlo utilizando un modelo ML. El resultado será una aproximación del resultado exacto, pero a menudo es suficientemente bueno. Puedes ver mucho de esto en las representaciones gráficas, como la eliminación de ruido de las imágenes y el sombreado del espacio de la pantalla.7
- 5. Datos no vistos: los datos no vistos comparten patrones con los datos de entrenamiento
-
Los patrones que tu modelo aprende de datos existentes sólo son útiles si los datos no vistos también comparten estos patrones. Un modelo para predecir si una aplicación se descargará en Navidad de 2020 no funcionará muy bien si se entrena con datos de 2008, cuando la aplicación más popular de la App Store era Koi Pond. ¿Qué es Estanque Koi? Exacto.
En términos técnicos, significa que tus datos no vistos y tus datos de entrenamiento deben proceder de distribuciones similares. Te preguntarás: "Si los datos no se ven, ¿cómo sabemos de qué distribución proceden?". No lo sabemos, pero podemos hacer suposiciones -como suponer que los comportamientos de los usuarios mañana no serán muy diferentes de los comportamientos de los usuarios hoy- y esperar que nuestras suposiciones se cumplan. Si no es así, tendremos un modelo con un rendimiento deficiente, que podremos averiguar con el monitoreo, como se explica en el Capítulo 8, y probarlo en producción, como se explica en el Capítulo 9.
Debido a la forma en que la mayoría de los algoritmos de ML aprenden hoy en día, las soluciones de ML brillarán especialmente si tu problema tiene estas características adicionales siguientes:
- 6. Es repetitivo
-
A los humanos se nos da muy bien el aprendizaje de pocos ejemplos: en puedes enseñar a los niños unas cuantas fotos de gatos y la mayoría reconocerá un gato la próxima vez que lo vea. A pesar de los emocionantes avances en la investigación del aprendizaje de pocos disparos, la mayoría de los algoritmos de ML siguen necesitando muchos ejemplos para aprender un patrón. Cuando una tarea es repetitiva, cada patrón se repite varias veces, lo que facilita que las máquinas lo aprendan.
- 7. El coste de las predicciones erróneas es barato
-
A menos que el rendimiento de tu modelo ML sea del 100% todo el tiempo, lo que es muy poco probable para cualquier tarea significativa, tu modelo va a cometer errores. El ML es especialmente adecuado cuando el coste de una predicción errónea es bajo. Por ejemplo, uno de los mayores casos de uso del ML en la actualidad es en los sistemas de recomendación, porque en estos sistemas, una mala recomendación suele ser indulgente: el usuario simplemente no hará clic en la recomendación.
Si un error de predicción puede tener consecuencias catastróficas, el ML podría seguir siendo una solución adecuada si, por término medio, los beneficios de las predicciones correctas superan el coste de las predicciones erróneas. Desarrollar coches autoconducidos es un reto porque un error algorítmico puede provocar la muerte. Sin embargo, muchas empresas siguen queriendo desarrollar coches autoconducidos porque tienen el potencial de salvar muchas vidas una vez que los coches autoconducidos sean estadísticamente más seguros que los conductores humanos.
- 8. Es a escala
-
Las soluciones de ML suelen requerir una inversión inicial no trivial de en datos, computación, infraestructura y talento, por lo que tendría sentido que pudiéramos utilizar mucho estas soluciones.
"A escala" significa cosas diferentes para tareas diferentes, pero, en general, significa hacer muchas predicciones. Por ejemplo, clasificar millones de correos electrónicos al año o predecir a qué departamentos deben dirigirse miles de solicitudes de asistencia al día.
Un problema puede parecer una predicción singular, pero en realidad es una serie de predicciones. Por ejemplo, un modelo que predice quién ganará unas elecciones presidenciales en EE.UU. parece que sólo hace una predicción cada cuatro años, pero en realidad podría estar haciendo una predicción cada hora o incluso con más frecuencia, porque esa predicción tiene que actualizarse continuamente para incorporar nueva información.
Tener un problema a escala también significa que hay muchos datos que recopilar, lo que es útil para entrenar modelos de ML.
- 9. Los patrones cambian constantemente
-
Las culturas cambian. Cambian los gustos. Las tecnologías cambian. Lo que hoy está de moda, mañana puede ser anticuado. Considera la tarea de clasificación del spam de correo electrónico. Hoy un indicio de correo basura es un príncipe nigeriano, pero mañana podría ser un escritor vietnamita angustiado.
Si tu problema implica uno o varios patrones que cambian constantemente, las soluciones codificadas, como las reglas escritas a mano, pueden quedar obsoletas rápidamente. Averiguar cómo ha cambiado tu problema para poder actualizar tus reglas escritas a mano en consecuencia puede ser demasiado caro o imposible. Como el ML aprende de los datos, puedes actualizar tu modelo ML con nuevos datos sin tener que averiguar cómo han cambiado los datos. También es posible configurar tu sistema para que se adapte a las distribuciones cambiantes de los datos, un enfoque que trataremos en la sección "Aprendizaje continuo".
La lista de casos de uso puede seguir y seguir, y crecerá aún más a medida que madure la adopción del ML en la industria. Aunque el ML puede resolver muy bien un subconjunto de problemas, no puede resolver y/o no debe utilizarse para muchos problemas. La mayoría de los algoritmos actuales de ML no deberían utilizarse en ninguna de las siguientes condiciones:
-
No es ético. Repasaremos un caso práctico en el que se puede argumentar que el uso de algoritmos de ML no es ético en la sección "Caso práctico I: Sesgos del calificador automatizado".
-
Las soluciones más sencillas sirven. En el Capítulo 6, trataremos las cuatro fases del desarrollo de modelos ML, en las que la primera fase deben ser las soluciones no ML.
-
No es rentable.
Sin embargo, aunque el ML no pueda resolver tu problema, tal vez sea posible dividirlo en componentes más pequeños y utilizar el ML para resolver algunos de ellos. Por ejemplo, si no puedes construir un chatbot que responda a todas las consultas de tus clientes, podría ser posible construir un modelo de ML para predecir si una consulta coincide con una de las preguntas frecuentes. En caso afirmativo, dirige al cliente a la respuesta. Si no, dirígelo al servicio de atención al cliente.
También me gustaría advertir que no hay que descartar una nueva tecnología porque no sea tan rentable como las tecnologías existentes en este momento. La mayoría de los avances tecnológicos son incrementales. Puede que un tipo de tecnología no sea eficiente ahora, pero puede que lo sea con el tiempo, con más inversiones. Si esperas a que la tecnología demuestre su valía al resto de la industria antes de lanzarte, podrías acabar años o décadas por detrás de tus competidores.
Casos prácticos de aprendizaje automático
El ML se utiliza cada vez más en las aplicaciones empresariales y de consumo de . Desde mediados de la década de 2010, se ha producido una explosión de aplicaciones que aprovechan el ML para ofrecer a los consumidores servicios superiores o antes imposibles.
Con la explosión de información y servicios, nos habría resultado muy difícil encontrar lo que queremos sin la ayuda del ML, manifestada en un motor de búsqueda o en un sistema de recomendación. Cuando visitas un sitio web como Amazon o Netflix, se te recomiendan los artículos que, según las predicciones, mejor se ajustan a tus gustos. Si no te gusta ninguna de las recomendaciones, es posible que quieras buscar artículos concretos, y es probable que los resultados de tu búsqueda estén potenciados por el ML.
Si tienes un smartphone, es probable que el ML ya te esté ayudando en muchas de tus actividades cotidianas. Escribir en tu teléfono es más fácil con la escritura predictiva, un sistema de ML que te da sugerencias sobre lo que podrías querer decir a continuación. Un sistema de ML podría funcionar en tu aplicación de edición de fotos para sugerirte la mejor forma de mejorar tus fotos. Podrías autenticar tu teléfono utilizando tu huella dactilar o tu cara, lo que requiere un sistema de ML para predecir si una huella dactilar o una cara coincide con la tuya.
El caso de uso del ML que me atrajo a este campo fue la traducción automática, que traduce automáticamente de un idioma a otro. Tiene el potencial de permitir que personas de diferentes culturas se comuniquen entre sí, borrando la barrera del idioma. Mis padres no hablan inglés, pero gracias a Google Translate, ahora pueden leer lo que escribo y hablar con mis amigos que no hablan vietnamita.
La ML está cada vez más presente en nuestros hogares con asistentes personales inteligentes como Alexa y Google Assistant. Las cámaras de seguridad inteligentes pueden avisarte cuando tus mascotas salen de casa o si tienes un invitado no deseado. A un amigo mío le preocupaba que su madre anciana viviera sola -si se cae, no hay nadie para ayudarla a levantarse-, así que confió en un sistema de monitoreo de la salud en el hogar que predice si alguien se ha caído en casa.
Aunque el mercado de las aplicaciones de ML para consumidores está en auge, la mayoría de los casos de uso de ML siguen estando en el mundo empresarial. Las aplicaciones empresariales de ML suelen tener requisitos y consideraciones muy diferentes de las aplicaciones de consumo. Hay muchas excepciones, pero en la mayoría de los casos, las aplicaciones empresariales pueden tener requisitos de precisión más estrictos, pero ser más indulgentes con los requisitos de latencia. Por ejemplo, mejorar la precisión de un sistema de reconocimiento de voz del 95% al 95,5% puede no ser perceptible para la mayoría de los consumidores, pero mejorar la eficiencia de un sistema de asignación de recursos en sólo un 0,1% puede ayudar a una empresa como Google o General Motors a ahorrar millones de dólares. Al mismo tiempo, una latencia de un segundo puede hacer que un consumidor se distraiga y abra otra cosa, pero los usuarios empresariales pueden ser más tolerantes con una latencia alta. Para las personas interesadas en crear empresas a partir de aplicaciones ML, las aplicaciones de consumo podrían ser más fáciles de distribuir, pero mucho más difíciles de monetizar. Sin embargo, la mayoría de los casos de uso empresarial no son obvios a menos que te los hayas encontrado tú mismo.
Según la encuesta de Algorithmia sobre el estado del aprendizaje automático empresarial en 2020, las aplicaciones de ML en las empresas son diversas y sirven tanto para casos de uso interno (reducción de costes, generación de información e inteligencia sobre los clientes, automatización del procesamiento interno) como para casos de uso externo (mejora de la experiencia del cliente, retención de clientes, interacción con los clientes), como se muestra en la Figura 1-3.8
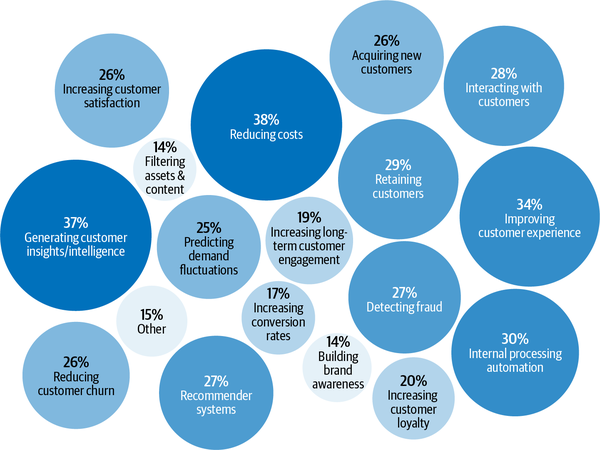
Figura 1-3. Estado del aprendizaje automático empresarial en 2020. Fuente: Adaptado de una imagen de Algorithmia
La detección del fraude es una de las aplicaciones más antiguas del ML en el mundo empresarial. Si tu producto o servicio implica transacciones de algún valor, será susceptible de fraude. Aprovechando las soluciones de ML para la detección de anomalías, puedes tener sistemas que aprendan del historial de transacciones fraudulentas y predigan si una transacción futura es fraudulenta.
Decidir cuánto cobrar por tu producto o servicio es probablemente una de las decisiones empresariales más difíciles; ¿por qué no dejar que ML lo haga por ti? La optimización de precios es el proceso de estimar un precio en un determinado periodo de tiempo para maximizar una función objetivo definida, como el margen, los ingresos o la tasa de crecimiento de la empresa. La optimización de precios basada en ML es más adecuada para casos con un gran número de transacciones en las que la demanda fluctúa y los consumidores están dispuestos a pagar un precio dinámico: por ejemplo, anuncios en Internet, billetes de avión, reservas de alojamiento, viajes compartidos y eventos.
Para dirigir un negocio, es importante ser capaz de prever la demanda de los clientes para poder preparar un presupuesto, almacenar existencias, asignar recursos y actualizar la estrategia de precios. Por ejemplo, si diriges una tienda de comestibles, querrás tener existencias suficientes para que los clientes encuentren lo que buscan, pero no querrás tener un exceso de existencias, porque si lo haces, tus comestibles podrían echarse a perder y perderías dinero.
Adquirir un nuevo usuario es caro. En 2019, el coste medio para que una aplicación adquiera un usuario que hará una compra dentro de la aplicación es de 86,61 $.9 El coste de adquisición para Lyft se estima en 158 $/usuario.10 Este coste es mucho mayor para los clientes empresariales. El coste de adquisición de clientes es aclamado por los inversores como un asesino de startups.11 Reducir los costes de adquisición de clientes en una pequeña cantidad puede suponer un gran aumento de los beneficios. Esto puede hacerse identificando mejor a los clientes potenciales, mostrando anuncios mejor orientados, ofreciendo descuentos en el momento adecuado, etc., todas ellas tareas adecuadas para el ML.
Después de haber gastado tanto dinero en adquirir un cliente, sería una pena que se fuera. Se calcula que el coste de adquirir un nuevo usuario es entre 5 y 25 veces más caro que retener a uno existente.12 La predicción del churn consiste en predecir cuándo un cliente concreto está a punto de dejar de utilizar tus productos o servicios, de modo que puedas tomar las medidas adecuadas para recuperarlo. La predicción del abandono no sólo puede utilizarse para los clientes, sino también para los empleados.
Para evitar que los clientes se vayan, es importante mantenerlos contentos atendiendo sus preocupaciones tan pronto como surjan. La clasificación automatizada de los tickets de soporte puede ayudar a conseguirlo. Antes, cuando un cliente abría un ticket de soporte o enviaba un correo electrónico, primero debía procesarse y luego pasar por distintos departamentos hasta llegar a la bandeja de entrada de alguien que pudiera atenderlo. Un sistema ML puede analizar el contenido del ticket y predecir a dónde debe ir, lo que puede acortar el tiempo de respuesta y mejorar la satisfacción del cliente. También puede utilizarse para clasificar los tickets internos de TI.
Otro caso popular de uso del ML en la empresa es el monitoreo de la marca . La marca es un activo valioso de una empresa.13 Es importante monitorear cómo el público y tus clientes perciben tu marca. Quizá quieras saber cuándo/dónde/cómo se menciona, tanto explícitamente (por ejemplo, cuando alguien menciona "Google") como implícitamente (por ejemplo, cuando alguien dice "el gigante de las búsquedas"), así como el sentimiento asociado a ella. Si de repente se produce un aumento del sentimiento negativo en las menciones de tu marca, quizá quieras abordarlo lo antes posible. El análisis del sentimiento es una tarea típica de ML.
Un conjunto de casos de uso del ML que ha generado mucho entusiasmo recientemente es el de la asistencia sanitaria. Hay sistemas de ML que pueden detectar el cáncer de piel y diagnosticar la diabetes. Aunque muchas aplicaciones de asistencia sanitaria están orientadas a los consumidores, debido a sus estrictos requisitos de precisión y privacidad, suelen proporcionarse a través de un proveedor de asistencia sanitaria, como un hospital, o utilizarse para ayudar a los médicos a proporcionar diagnósticos.
Comprender los sistemas de aprendizaje automático
Comprender los sistemas de ML será útil para diseñarlos y desarrollarlos. En esta sección, repasaremos en qué se diferencian los sistemas de ML tanto del ML en investigación (o como se suele enseñar en la escuela) como del software tradicional, lo que motiva la necesidad de este libro.
El aprendizaje automático en la investigación frente a la producción
Como el uso de ML en la industria es todavía bastante nuevo, la mayoría de las personas con experiencia en ML de la han adquirido a través del mundo académico: haciendo cursos, investigando, leyendo artículos académicos. Si esa es tu experiencia, puede que te resulte difícil comprender los retos de la implementación de sistemas de ML en la naturaleza y navegar por un conjunto abrumador de soluciones a estos retos. El ML en producción es muy diferente del ML en investigación. La Tabla 1-1 muestra cinco de las principales diferencias.
| Investiga | Producción | |
|---|---|---|
| Requisitos | Rendimiento del modelo más avanzado en conjuntos de datos de referencia | Las distintas partes interesadas tienen requisitos diferentes |
| Prioridad computacional | Entrenamiento rápido, alto rendimiento | Inferencia rápida, baja latencia |
| Datos | Estáticaa | Cambiando constantemente |
| Equidad | A menudo no es un objetivo | Debe considerarse |
| Interpretabilidad | A menudo no es un objetivo | Debe considerarse |
a Un subcampo de la investigación se centra en el aprendizaje continuo: desarrollar modelos que funcionen con distribuciones de datos cambiantes. Trataremos el aprendizaje continuo en el Capítulo 9. | ||
Diferentes partes interesadas y requisitos
Las personas que participan en un proyecto de investigación y clasificación suelen alinearse en torno a un único objetivo. El objetivo más común es el rendimiento del modelo: desarrollar un modelo que alcance los resultados más avanzados en conjuntos de datos de referencia. Para conseguir un pequeño perímetro de mejora en el rendimiento, los investigadores suelen recurrir a técnicas que hacen que los modelos sean demasiado complejos para ser útiles.
Hay muchas partes implicadas en la puesta en producción de un sistema de ML. Cada parte interesada tiene sus propios requisitos. Tener requisitos diferentes, a menudo contradictorios, puede dificultar el diseño, el desarrollo y la selección de un modelo de ML que satisfaga todos los requisitos.
Piensa en una aplicación móvil que recomienda restaurantes a los usuarios. La aplicación gana dinero cobrando a los restaurantes una comisión de servicio del 10% por cada pedido. Esto significa que los pedidos caros dan más dinero a la aplicación que los baratos. En el proyecto participan ingenieros de ML, vendedores, jefes de producto, ingenieros de infraestructura y un gerente:
- Ingenieros ML
-
Quieren un modelo que recomiende los restaurantes en los que es más probable que los usuarios pidan, y creen que pueden hacerlo utilizando un modelo más complejo con más datos.
- Equipo de ventas
-
Quiere un modelo que recomiende los restaurantes más caros, ya que estos restaurantes aportan más comisiones de servicio.
- Equipo de productos
-
Observa que cada aumento de la latencia provoca un descenso de los pedidos a través del servicio, por lo que quieren un modelo que pueda devolver los restaurantes recomendados en menos de 100 milisegundos.
- Equipo de la plataforma ML
-
A medida que crece el tráfico, este equipo se ha despertado en mitad de la noche por problemas con el escalado de su sistema actual, por lo que quieren aplazar las actualizaciones de los modelos para dar prioridad a la mejora de la plataforma ML.
- Director
-
Quiere maximizar el margen, y una forma de conseguirlo podría ser prescindir del equipo de ML.14
"Recomendar los restaurantes en los que es más probable que los usuarios hagan clic" y "recomendar los restaurantes que aportarán más dinero a la aplicación" son dos objetivos diferentes, y en la sección "Desacoplar objetivos", hablaremos de cómo desarrollar un sistema ML que satisfaga objetivos diferentes. Spoiler: desarrollaremos un modelo para cada objetivo y combinaremos sus predicciones.
Imaginemos por ahora que tenemos dos modelos diferentes. El modelo A es el que recomienda los restaurantes en los que es más probable que los usuarios hagan clic, y el modelo B es el que recomienda los restaurantes que más dinero reportarán a la aplicación. A y B pueden ser modelos muy diferentes. ¿Qué modelo debe implementarse entre los usuarios? Para hacer más difícil la decisión, ni A ni B satisfacen el requisito establecido por el equipo de producto: no pueden devolver recomendaciones de restaurantes en menos de 100 milisegundos.
Al desarrollar un proyecto de ML, es importante que los ingenieros de ML comprendan los requisitos de todas las partes implicadas y lo estrictos que son. Por ejemplo, si la capacidad de devolver recomendaciones en 100 milisegundos es un requisito imprescindible -la empresa ha descubierto que si tu modelo tarda más de 100 milisegundos en recomendar restaurantes, el 10% de los usuarios perderían la paciencia y cerrarían la aplicación-, entonces ni el modelo A ni el modelo B funcionarán. Sin embargo, si se trata sólo de un requisito "agradable de tener", puede que quieras considerar el modelo A o el modelo B.
El hecho de que la producción tenga requisitos diferentes a los de la investigación es una de las razones por las que los proyectos de investigación de éxito no siempre se utilizan en producción. Por ejemplo, el ensamblaje es una técnica popular entre los ganadores de muchos concursos de ML, incluido el famoso Premio Netflix de 1 millón de dólares, y sin embargo no se utiliza mucho en producción. El ensamblaje combina "múltiples algoritmos de aprendizaje para obtener un rendimiento predictivo mejor que el que podría obtenerse de cualquiera de los algoritmos de aprendizaje constituyentes por sí solos".15 Aunque puede dar a tu sistema de ML una pequeña mejora de rendimiento, el ensamblaje tiende a hacer un sistema demasiado complejo para ser útil en producción, por ejemplo, más lento a la hora de hacer predicciones o más difícil de interpretar los resultados. Hablaremos más sobre el ensamblaje en la sección "Ensamblajes".
Para muchas tareas, una pequeña mejora del rendimiento puede suponer un enorme aumento de los ingresos o un ahorro de costes. Por ejemplo, una mejora del 0,2% en el porcentaje de clics de un sistema de recomendación de productos puede suponer un aumento de millones de dólares en los ingresos de un sitio de comercio electrónico. Sin embargo, para muchas tareas, una pequeña mejora puede no ser perceptible para los usuarios. Para el segundo tipo de tareas, si un modelo simple puede hacer un trabajo razonable, los modelos complejos deben tener un rendimiento significativamente mejor para justificar la complejidad.
Prioridades computacionales
Al diseñar un sistema de ML, las personas que no han implementado un sistema de ML suelen cometer el error de centrarse demasiado en la parte de desarrollo del modelo y no lo suficiente en la parte de implementación y mantenimiento del mismo.
Durante el proceso de desarrollo del modelo, puedes entrenar muchos modelos diferentes, y cada modelo realiza múltiples pasadas sobre los datos de entrenamiento. A continuación, cada modelo entrenado genera predicciones sobre los datos de validación una vez para informar de las puntuaciones. Los datos de validación suelen ser mucho más pequeños que los de entrenamiento. Durante el desarrollo del modelo, el entrenamiento es el cuello de botella. Sin embargo, una vez implementado el modelo, su trabajo consiste en generar predicciones, por lo que la inferencia es el cuello de botella. La investigación suele priorizar el entrenamiento rápido, mientras que la producción suele priorizar la inferencia rápida.
Un corolario de esto es que la investigación prioriza el alto rendimiento, mientras que la producción prioriza la baja latencia. En caso de que necesites un refresco, la latencia se refiere al tiempo que transcurre desde que se recibe una consulta hasta que se devuelve el resultado. El rendimiento se refiere al número de consultas que se procesan en un periodo de tiempo determinado.
Choque terminológico
Algunos libros hacen la distinción entre latencia y tiempo de respuesta. Según Martin Kleppmann en su libro Designing Data-Intensive Applications, "El tiempo de respuesta es lo que ve el cliente: además del tiempo real para procesar la solicitud (el tiempo de servicio), incluye los retrasos de la red y los retrasos en las colas. La latencia es el tiempo que una solicitud está esperando a ser atendida: el tiempo durante el cual está latente, a la espera de ser atendida".19
En este libro, para simplificar el debate y ser coherentes con la terminología utilizada en la comunidad de ML, utilizamos latencia para referirnos al tiempo de respuesta, de modo que la latencia de una solicitud mide el tiempo que transcurre desde que se envía la solicitud hasta que se recibe una respuesta.
Por ejemplo, la latencia media de Google Translate es el tiempo medio que transcurre desde que un usuario hace clic en Traducir hasta que se muestra la traducción, y el rendimiento es cuántas consultas procesa y sirve por segundo.
Si tu sistema siempre procesa una consulta cada vez, una latencia mayor significa un rendimiento menor. Si la latencia media es de 10 ms, lo que significa que tarda 10 ms en procesar una consulta, el rendimiento es de 100 consultas/segundo. Si la latencia media es de 100 ms, el rendimiento es de 10 consultas/segundo.
Sin embargo, como la mayoría de los sistemas distribuidos modernos procesan las consultas por lotes, a menudo simultáneamente, una mayor latencia puede significar también un mayor rendimiento. Si procesas 10 consultas a la vez y tardas 10 ms en ejecutar un lote, la latencia media sigue siendo de 10 ms, pero el rendimiento es ahora 10 veces mayor: 1.000 consultas/segundo. Si procesas 50 consultas a la vez y tardas 20 ms en ejecutar un lote, la latencia media es ahora de 20 ms y el rendimiento es de 2.500 consultas/segundo. ¡Tanto la latencia como el rendimiento han aumentado! En la Figura 1-4 se ilustra la diferencia de latencia y rendimiento entre procesar las consultas de una en una y procesarlas por lotes.
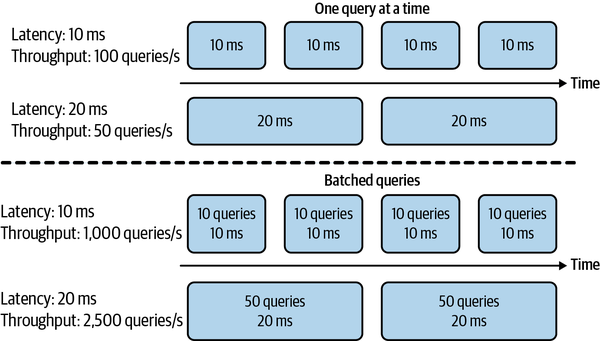
Figura 1-4. Al procesar las consultas de una en una, una mayor latencia implica un menor rendimiento. Sin embargo, al procesar las consultas por lotes, una mayor latencia también puede significar un mayor rendimiento.
Esto es aún más complicado si quieres realizar consultas en línea por lotes. El procesamiento por lotes requiere que tu sistema espere a que lleguen suficientes consultas en un lote antes de procesarlas, lo que aumenta aún más la latencia.
En investigación, te importa más cuántas muestras puedes procesar en un segundo (rendimiento) y menos cuánto tarda en procesarse cada muestra (latencia). Estás dispuesto a aumentar la latencia para aumentar el rendimiento, por ejemplo, con una dosificación agresiva.
Sin embargo, una vez que implementas tu modelo en el mundo real, la latencia importa mucho. En 2017, un estudio de Akamai descubrió que un retraso de 100 ms puede perjudicar las tasas de conversión en un 7%.20 En 2019, Booking.com descubrió que un aumento de alrededor del 30% en la latencia costaba alrededor de un 0,5% en las tasas de conversión: "un coste relevante para nuestro negocio".21 En 2016, Google descubrió que más de la mitad de los usuarios móviles abandonan una página si tarda más de tres segundos en cargarse.22 Los usuarios de hoy son aún menos pacientes.
Para reducir la latencia en producción, puede que tengas que reducir el número de consultas que puedes procesar a la vez en el mismo hardware. Si tu hardware es capaz de procesar muchas más consultas a la vez, utilizarlo para procesar menos consultas significa infrautilizar tu hardware, aumentando el coste de procesar cada consulta.
Al pensar en la latencia, es importante tener en cuenta que la latencia no es un número individual, sino una distribución. Es tentador simplificar esta distribución utilizando un único número como la latencia media (media aritmética) de todas las solicitudes dentro de una ventana de tiempo, pero este número puede ser engañoso. Imagina que tienes 10 solicitudes cuyas latencias son 100 ms, 102 ms, 100 ms, 100 ms, 99 ms, 104 ms, 110 ms, 90 ms, 3.000 ms, 95 ms. La latencia media es de 390 ms, lo que hace que tu sistema parezca más lento de lo que es en realidad. Lo que puede haber ocurrido es que haya habido un error de red que haya hecho que una petición sea mucho más lenta que las demás, y deberías investigar esa petición problemática.
Normalmente es mejor pensar en percentiles, ya que te dicen algo sobre un determinado porcentaje de tus peticiones. El percentil más común es el percentil 50, abreviado como p50. También se conoce como mediana. Si la mediana es 100 ms, la mitad de las solicitudes tardan más de 100 ms, y la mitad de las solicitudes tardan menos de 100 ms.
Los percentiles más altos también te ayudan a descubrir los valores atípicos, que pueden ser síntomas de que algo va mal. Normalmente, los percentiles que querrás mirar son p90, p95 y p99. El percentil 90 (p90) de las 10 solicitudes anteriores es de 3.000 ms, lo que constituye un valor atípico.
Es importante fijarse en los percentiles más altos porque, aunque representen un pequeño porcentaje de tus usuarios, a veces pueden ser los usuarios más importantes. Por ejemplo, en el sitio web de Amazon, los clientes con las solicitudes más lentas suelen ser los que tienen más datos en sus cuentas porque han hecho muchas compras, es decir, son los clientes más valiosos.23
Es una práctica habitual utilizar percentiles altos para especificar los requisitos de rendimiento de tu sistema; por ejemplo, un jefe de producto puede especificar que el percentil 90 o el percentil 99,9 de la latencia de un sistema debe ser inferior a un número determinado.
Datos
Durante la fase de investigación, los conjuntos de datos con los que trabajas suelen estar limpios y bien formateados, lo que te permite centrarte en desarrollando modelos. Son estáticos por naturaleza, para que la comunidad pueda utilizarlos como referencia para nuevas arquitecturas y técnicas. Esto significa que muchas personas pueden haber utilizado y debatido los mismos conjuntos de datos, y se conocen sus peculiaridades. Incluso puedes encontrar scripts de código abierto para procesar e introducir los datos directamente en tus modelos.
En producción, los datos, si están disponibles, son mucho más desordenados. Son ruidosos, posiblemente desestructurados, cambian constantemente. Es probable que estén sesgados, y es probable que no sepas cómo están sesgados. Las etiquetas, si las hay, pueden ser escasas, desequilibradas o incorrectas. Los cambios en los requisitos del proyecto o de la empresa pueden requerir la actualización de algunas o todas las etiquetas existentes. Si trabajas con datos de usuarios, también tendrás que preocuparte por la privacidad y la normativa. Trataremos un caso práctico en el que los datos de los usuarios se manejan inadecuadamente en la sección "Caso práctico II: El peligro de los datos "anonimizados"".
En investigación, trabajas sobre todo con datos históricos, es decir, datos que ya existen y están almacenados en algún sitio. En producción, lo más probable es que también tengas que trabajar con datos que están siendo generados constantemente por usuarios, sistemas y datos de terceros.
La Figura 1-5 ha sido adaptada de un gran gráfico de Andrej Karpathy, director de IA en Tesla, que ilustra los problemas de datos que encontró durante su doctorado en comparación con su época en Tesla.
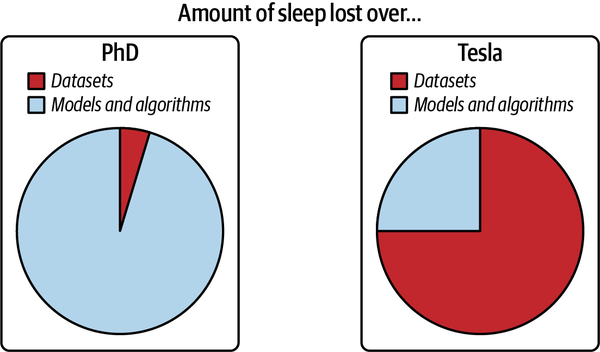
Figura 1-5. Datos en investigación frente a datos en producción. Fuente: Adaptado de una imagen de Andrej Karpathy24
Equidad
Durante la fase de investigación, un modelo es todavía no se ha utilizado en personas, por lo que es fácil que los investigadores dejen la equidad para después: "Intentemos primero conseguir el estado del arte y preocupémonos de la equidad cuando lleguemos a la producción". Cuando se llega a la producción, es demasiado tarde. Si optimizas tus modelos para mejorar la precisión o reducir la latencia, puedes demostrar que tus modelos superan el estado del arte. Pero, en el momento de escribir este libro, no existe un estado del arte equivalente para las métricas de equidad.
Tú o alguien de tu vida podríais ser ya víctimas de algoritmos matemáticos sesgados sin saberlo. Tu solicitud de préstamo puede ser rechazada porque el algoritmo de ML se basa en tu código postal, que contiene prejuicios sobre tu origen socioeconómico. Tu currículum podría ser peor valorado porque el sistema de clasificación que utilizan los empresarios se basa en la ortografía de tu nombre. Tu hipoteca podría tener un tipo de interés más alto porque se basa parcialmente en la puntuación crediticia, que favorece a los ricos y castiga a los pobres. Otros ejemplos de sesgos del ML en el mundo real son los algoritmos de predicción policial, los tests de personalidad administrados por posibles empleadores y las clasificaciones universitarias.
En 2019, "los investigadores de Berkeley descubrieron que tanto los prestamistas presenciales como los online rechazaron un total de 1,3 millones de solicitantes negros y latinos solventes entre 2008 y 2015". Cuando los investigadores "utilizaron los ingresos y las puntuaciones crediticias de las solicitudes rechazadas, pero eliminaron los identificadores de raza, la solicitud de hipoteca fue aceptada."25 Para ver ejemplos aún más descarados, recomiendo el libro de Cathy O'Neil Weapons of Math Destruction.26
Los algoritmos de ML no predicen el futuro, sino que codifican el pasado, perpetuando así los sesgos en los datos y más. Cuando los algoritmos de ML se implementan a escala, pueden discriminar a las personas a escala. Si un operador humano sólo puede hacer juicios generales sobre unos pocos individuos a la vez, un algoritmo de ML puede hacer juicios generales sobre millones en fracciones de segundo. Esto puede perjudicar especialmente a los miembros de grupos minoritarios, porque una clasificación errónea sobre ellos sólo podría tener un efecto menor en las métricas de rendimiento general de los modelos.
Si un algoritmo ya puede hacer predicciones correctas sobre el 98% de la población, y mejorar las predicciones sobre el 2% restante supondría un coste multiplicado, algunas empresas podrían, lamentablemente, optar por no hacerlo. Durante un estudio de investigación de McKinsey & Company en 2019, sólo el 13% de las grandes empresas encuestadas afirmaron estar tomando medidas para mitigar los riesgos para la equidad y la justicia, como el sesgo algorítmico y la discriminación.27 Sin embargo, esto está cambiando rápidamente. Trataremos la equidad y otros aspectos de la IA responsable en el Capítulo 11.
Interpretabilidad
A principios de 2020, el profesor Geoffrey Hinton, ganador del Premio Turing, propuso una cuestión muy debatida sobre la importancia de la interpretabilidad en los sistemas de ML. "Supón que tienes cáncer y tienes que elegir entre un cirujano de IA de caja negra que no puede explicar cómo funciona pero tiene un índice de curación del 90% y un cirujano humano con un índice de curación del 80%. ¿Quieres que el cirujano de IA sea ilegal?".28
Un par de semanas después, cuando hice esta pregunta a un grupo de 30 ejecutivos de tecnología de empresas públicas no tecnológicas, sólo la mitad de ellos querrían que les operara el cirujano de IA altamente eficaz pero incapaz de explicarse. La otra mitad quería al cirujano humano.
Mientras que la mayoría de nosotros nos sentimos cómodos utilizando un microondas sin entender cómo funciona, muchos aún no sienten lo mismo respecto a la IA, especialmente si esa IA toma decisiones importantes sobre sus vidas.
Como la mayor parte de la investigación en ML se sigue evaluando en función de un único objetivo, el rendimiento del modelo, los investigadores no están incentivados para trabajar en la interpretabilidad del modelo. Sin embargo, la interpretabilidad no es sólo opcional para la mayoría de los casos de uso de ML en la industria, sino un requisito.
En primer lugar, la interpretabilidad es importante para que los usuarios, tanto los líderes empresariales como los usuarios finales, comprendan por qué se toma una decisión, de modo que puedan confiar en un modelo y detectar los posibles sesgos mencionados anteriormente.29 En segundo lugar, es importante que los desarrolladores puedan depurar y mejorar un modelo.
Que la interpretabilidad sea un requisito no significa que todo el mundo lo esté haciendo. En 2019, sólo el 19% de las grandes empresas trabajan para mejorar la explicabilidad de sus algoritmos.30
Debate
Algunos podrían argumentar que está bien conocer sólo el lado académico del ML porque hay muchos puestos de trabajo en la investigación. La primera parte, es decir, que está bien conocer sólo el lado académico del ML, es cierta. La segunda parte es falsa.
Aunque es importante dedicarse a la investigación pura, la mayoría de las empresas no pueden permitírselo a menos que conduzca a aplicaciones empresariales a corto plazo. Esto es especialmente cierto ahora que la comunidad investigadora ha adoptado el enfoque "más grande, mejor". A menudo, los nuevos modelos requieren una enorme cantidad de datos y decenas de millones de dólares sólo en computación.
A medida que la investigación en ML y los modelos disponibles sean más accesibles, más personas y organizaciones querrán encontrarles aplicaciones, lo que aumenta la demanda de ML en la producción.
La gran mayoría de los trabajos relacionados con el ML estarán, y ya lo están, en la producción del ML.
Sistemas de aprendizaje automático frente al software tradicional
Puesto que el ML forma parte de la ingeniería de software (SWE), y el software se ha utilizado con éxito en la producción durante más de medio siglo, algunos podrían preguntarse por qué no tomamos simplemente las buenas prácticas probadas en ingeniería de software y las aplicamos al ML.
Es una idea excelente. De hecho, la producción de ML sería mucho mejor si los expertos en ML fueran mejores ingenieros de software. Muchas herramientas tradicionales de SWE pueden utilizarse para desarrollar e implementar aplicaciones de ML.
Sin embargo, muchos retos son exclusivos de las aplicaciones de ML y requieren sus propias herramientas. En SWE, existe la suposición subyacente de que el código y los datos están separados. De hecho, en SWE queremos mantener las cosas tan modulares y separadas como sea posible (consulta la página de Wikipedia sobre separación de intereses).
Por el contrario, los sistemas de ML son en parte código, en parte datos y en parte artefactos creados a partir de ambos. La tendencia de la última década muestra que ganan las aplicaciones desarrolladas con los más/mejores datos. En lugar de centrarse en mejorar los algoritmos de ML, la mayoría de las empresas se centrarán en mejorar sus datos. Dado que los datos pueden cambiar rápidamente, las aplicaciones de ML tienen que adaptarse al entorno cambiante, lo que podría requerir ciclos de desarrollo e implementación más rápidos.
En el SWE tradicional, sólo tienes que centrarte en probar y versionar tu código. Con ML, también tenemos que probar y versionar nuestros datos, y eso es lo difícil. ¿Cómo versionar grandes conjuntos de datos? ¿Cómo saber si una muestra de datos es buena o mala para tu sistema? No todas las muestras de datos son iguales: algunas son más valiosas para tu modelo que otras. Por ejemplo, si tu modelo ya se ha entrenado con un millón de exploraciones de pulmones normales y sólo con mil exploraciones de pulmones cancerosos, una exploración de un pulmón canceroso es mucho más valiosa que una exploración de un pulmón normal. Aceptar indiscriminadamente todos los datos disponibles puede perjudicar el rendimiento de tu modelo e incluso hacerlo susceptible a ataques de envenenamiento de datos.31
El tamaño de los modelos ML es otro reto. A partir de 2022, es habitual que los modelos de ML tengan cientos de millones, si no miles de millones, de parámetros, lo que requiere gigabytes de memoria de acceso aleatorio (RAM) para cargarlos en la memoria. Dentro de unos años, mil millones de parámetros podrían parecer pintorescos, como "¿Te puedes creer que el ordenador que envió a los hombres a la Luna sólo tenía 32 MB de RAM?".
Sin embargo, por ahora, poner en producción estos grandes modelos, especialmente en dispositivos de perímetro,32 es un enorme reto de ingeniería. Luego está la cuestión de cómo conseguir que estos modelos funcionen lo suficientemente rápido como para ser útiles. Un modelo de autocompletado es inútil si el tiempo que tarda en sugerir el siguiente carácter es mayor que el tiempo que tardas en escribir.
Monitorear y depurar estos modelos en producción tampoco es trivial. A medida que los modelos ML se hacen más complejos, unido a la falta de visibilidad de su trabajo, es difícil averiguar qué ha ido mal o ser alertado con la suficiente rapidez cuando las cosas van mal.
La buena noticia es que estos retos de ingeniería se están abordando a un ritmo vertiginoso. En 2018, cuando se publicó por primera vez el documento Representaciones de codificadores bidireccionales a partir de transformadores (BERT), la gente hablaba de que BERT era demasiado grande, demasiado complejo y demasiado lento para ser práctico. El gran modelo BERT preentrenado tiene 340 millones de parámetros y ocupa 1,35 GB.33 Dos años más tarde, BERT y sus variantes ya se utilizaban en casi todas las búsquedas en inglés en Google.34
Resumen
Este capítulo inicial pretendía dar a los lectores una idea de lo que se necesita para llevar el ML al mundo real. Empezamos con un recorrido por la amplia gama de casos de uso de ML en la producción actual. Aunque la mayoría de la gente está familiarizada con el ML en aplicaciones orientadas al consumidor, la mayoría de los casos de uso del ML son para la empresa. También hablamos de cuándo serían apropiadas las soluciones de ML. Aunque el ML puede resolver muy bien muchos problemas, no puede resolver todos los problemas y, desde luego, no es apropiado para todos los problemas. Sin embargo, para los problemas que el ML no puede resolver, es posible que el ML pueda ser una parte de la solución.
Este capítulo también ha puesto de relieve las diferencias entre el ML en la investigación y el ML en la producción. Las diferencias incluyen la participación de las partes interesadas, la prioridad computacional, las propiedades de los datos utilizados, la gravedad de los problemas de imparcialidad y los requisitos de interpretabilidad. Esta sección es la más útil para quienes llegan a la producción de ML desde el mundo académico. También discutimos en qué se diferencian los sistemas de ML de los sistemas de software tradicionales, lo que motivó la necesidad de este libro.
Los sistemas de ML son complejos y constan de muchos componentes diferentes. Los científicos de datos y los ingenieros de ML que trabajan con sistemas de ML en producción probablemente descubrirán que centrarse sólo en la parte de los algoritmos de ML dista mucho de ser suficiente. Es importante conocer otros aspectos del sistema, como la pila de datos, la implementación, el monitoreo, el mantenimiento, la infraestructura, etc. Este libro adopta un enfoque sistémico para desarrollar sistemas de ML, lo que significa que consideraremos todos los componentes de un sistema de forma holística en lugar de fijarnos sólo en los algoritmos de ML. En el próximo capítulo detallaremos lo que significa este enfoque holístico.
1 Mike Schuster, Melvin Johnson y Nikhil Thorat, "Zero-Shot Translation with Google's Multilingual Neural Machine Translation System", Google AI Blog, 22 de noviembre de 2016, https://oreil.ly/2R1CB.
2 Larry Hardesty, "Un método para obtener imágenes de los agujeros negros", MIT News, 6 de junio de 2016, https://oreil.ly/HpL2F.
3 No he preguntado si el ML es suficiente porque la respuesta siempre es no.
4 Los patrones son distintos de las distribuciones. Conocemos la distribución de los resultados de un dado justo, pero no hay patrones en la forma en que se generan los resultados.
5 Andrej Karpathy, "Software 2.0", Medium, 11 de noviembre de 2017, https://oreil.ly/yHZrE.
6 Repasaremos el aprendizaje online en el capítulo 9.
7 Steke Bako, Thijs Vogels, Brian McWilliams, Mark Meyer, Jan Novák, Alex Harvill, Pradeep Sen, Tony Derose y Fabrice Rousselle, "Kernel-Predicting Convolutional Networks for Denoising Monte Carlo Renderings", ACM Transactions on Graphics 36, no. 4 (2017): 97, https://oreil.ly/EeI3j; Oliver Nalbach, Elena Arabadzhiyska, Dushyant Mehta, Hans-Peter Seidel y Tobias Ritschel, "Deep Shading: Convolutional Neural Networks for Screen-Space Shading", arXiv, 2016, https://oreil.ly/dSspz.
8 "2020 State of Enterprise Machine Learning", Algorithmia, 2020, https://oreil.ly/wKMZB.
9 "Average Mobile App User Acquisition Costs Worldwide from September 2018 to August 2019, by User Action and Operating System," Statista, 2019, https://oreil.ly/2pTCH.
10 Jeff Henriksen, "Valuing Lyft Requires a Deep Look into Unit Economics", Forbes, 17 de mayo de 2019, https://oreil.ly/VeSt4.
11 David Skok, "Startup Killer: El coste de adquisición de clientes", Para Emprendedores, 2018, https://oreil.ly/L3tQ7.
12 Amy Gallo, "El valor de conservar a los clientes adecuados", Harvard Business Review, 29 de octubre de 2014, https://oreil.ly/OlNkl.
13 Marty Swant, "Las 20 marcas más valiosas del mundo", Forbes, 2020, https://oreil.ly/4uS5i.
14 No es raro que los equipos de ML y ciencia de datos estén entre los primeros en desaparecer durante el despido masivo de una empresa, como se ha informado en IBM, Uber, Airbnb. Véase también el análisis de Sejuti Das "How Data Scientists Are Also Susceptible to the Layoffs Amid Crisis", Analytics India Magazine, 21 de mayo de 2020, https://oreil.ly/jobmz.
15 Wikipedia, s.v. "Aprendizaje conjunto ", https://oreil.ly/5qkgp.
16 Julia Evans, "El aprendizaje automático no son los concursos de Kaggle", 2014, https://oreil.ly/p8mZq.
17 Lauren Oakden-Rayner, "Los concursos de IA no producen modelos útiles", 19 de septiembre de 2019, https://oreil.ly/X6RlT.
18 Kawin Ethayarajh y Dan Jurafsky, "La utilidad está en el ojo del usuario: una crítica a las tablas de clasificación de la PNL", EMNLP, 2020, https://oreil.ly/4Ud8P.
19 Martin Kleppmann, Designing Data-Intensive Applications (Sebastopol, CA: O'Reilly, 2017).
20 Akamai Technologies, Informe sobre el Rendimiento del Comercio Online de Akamai: Los milisegundos son críticos, 19 de abril de 2017, https://oreil.ly/bEtRu.
21 Lucas Bernardi, Themis Mavridis y Pablo Estévez, "150 modelos de aprendizaje automático exitosos: 6 Lessons Learned at Booking.com", KDD '19, 4-8 de agosto de 2019, Anchorage, AK, https://oreil.ly/G5QNA.
22 "Consumer Insights", Piensa con Google, https://oreil.ly/JCp6Z.
23 Kleppmann, Diseño de aplicaciones intensivas en datos.
24 Andrej Karpathy, "Building the Software 2.0 Stack", Spark+AI Summit 2018, vídeo, 17:54, https://oreil.ly/Z21Oz.
25 Khristopher J. Brooks, "Disparity in Home Lending Costs Minorities Millions, Researchers Find", CBS News, 15 de noviembre de 2019, https://oreil.ly/UiHUB.
26 Cathy O'Neil, Armas de destrucción matemática (Nueva York: Crown Books, 2016).
27 Inteligencia Artificial Centrada en el Ser Humano ( IAH) de la Universidad de Stanford, Informe sobre el Índice de IA 2019, 2019, https://oreil.ly/xs8mG.
28 Tweet de Geoffrey Hinton (@geoffreyhinton), 20 de febrero de 2020, https://oreil.ly/KdfD8.
29 Para determinados casos de uso en determinados países, los usuarios tienen un "derecho a explicación": el derecho a recibir una explicación de un resultado del algoritmo.
30 Stanford HAI, Informe sobre el Índice de IA 2019.
31 Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu y Dawn Song, "Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning", arXiv, 15 de diciembre de 2017, https://oreil.ly/OkAjb.
32 Trataremos los dispositivos de perímetro en el capítulo 7.
33 Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", arXiv, 11 de octubre de 2018, https://oreil.ly/TG3ZW.
34 Búsqueda en Google, 2020, https://oreil.ly/M7YjM.
Get Diseño de sistemas de aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

