Kapitel 4. Erstellung deines Business Case
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Nate Gandert, Chief Technology Officer/Chief Product Officer Getty Images
Jetzt, wo du deine Erkundung abgeschlossen und alle manuellen Anpassungen vorgenommen hast, ist es an der Zeit, deinen Business Case zu erstellen. Du fragst dich vielleicht, warum du einen Business Case brauchst. Die wenigsten Unternehmen erhalten von der Geschäftsleitung den Auftrag, in die Cloud zu wechseln. Das kommt zwar vor, aber in der Regel gibt es ein wichtiges Geschäftsziel, das in diesen Fällen erreicht werden muss. Wir anderen müssen zeigen, warum wir in die Cloud wechseln sollten. Leider geht es dabei meist um die Kosten, obwohl der eigentliche Geschäftswert in der Flexibilität liegt.
Wenn es um die Migration geht, sind die Kosten hoch. Du musst für eine gewisse Zeit in zwei Umgebungen arbeiten, was den größten Teil deiner Ausgaben ausmacht. Außerdem fallen Schulungs-, Beratungs- und möglicherweise auch Softwarekosten an. Die Migration bedeutet auch eine erhebliche Störung deiner Geschäftsbereiche und ihrer Zeitpläne. Um es ganz offen zu sagen: Wenn du die Migration ohne die Zustimmung der Unternehmensleitung in Angriff nimmst, ist das ein sicherer Weg, vor die Tür gesetzt zu werden. Der Business Case vermittelt die Informationen, die du über deine Umgebung gesammelt hast, in einem verständlichen Format an das Management.
Der Großteil dieses Kapitels befasst sich mit den harten Kosten von , da es hier am einfachsten ist, die Zustimmung des Unternehmens zur Migration zu erhalten. Es gibt aber auch einige Bereiche, in denen deine Kosten im Vergleich zu On-Premises steigen könnten. In diesen Fällen ist es wichtig, die zusätzlichen Vorteile hervorzuheben, die dein Unternehmen dadurch erhält. Die Geschichte sollte sich mehr um die Agilität und die Möglichkeiten drehen, die dein Unternehmen durch den Wechsel zu AWS erhält. Agilität ist nicht immer quantifizierbar. Das macht es schwierig, sie in deinem Business Case zu verwenden, da du Einsparungen oder Umsatzsteigerungen nicht direkt mit dieser Agilität in Verbindung bringen kannst. Dennoch ist nicht alles verloren: Es gibt einige Vorteile der Agilität, die du quantifizieren kannst und die wir in diesem Kapitel behandeln werden.
Ein unsichtbarer Vorteil des Business Case-Prozesses ist, dass die Unternehmensleitung vielleicht Fragen stellt und Nachforschungen verlangt, an die du vorher nicht gedacht hast. Dieser Prozess garantiert, dass alle Grundlagen abgedeckt sind, und sorgt für einen höheren Grad an langfristigem Erfolg.
Schätze deinen Zeitplan ein
Um einen guten Business Case zu erstellen, musst du wissen, wie lange deine Migration dauern wird. Die Dauer der Umstellung hat einen erheblichen Einfluss auf die Kosten deiner Umstellung. Sie wirkt sich auf die doppelten Ausgaben, die Werkzeuge und eventuelle Beratungskosten aus. Wir haben noch nicht über die Migrationsplanung gesprochen; wir werden sie später in Kapitel 7 behandeln. Für den Moment werden wir die Länge anhand von drei Faktoren abschätzen:
-
Die Anzahl der Server, die du migrieren musst
-
Die Anzahl der Server, die du pro Tag verschieben kannst
-
Ein Puffer für unerwartete Zeitverzögerungen, um den geschätzten Zeitplan zu erstellen.
Anzahl von Servern
Der größte Teil des Aufwands bei der Migration entsteht durch die Anzahl der Server, die du vor Ort hast. Der größte Teil des Aufwands bei der Migration liegt in der Anzahl der Server vor Ort. Du musst Agenten auf den Servern installieren, um sie zu AWS zu migrieren, Netzwerkadapter nach der Migration auf dem Ausgangsserver deaktivieren, einen Smoke-Test durchführen und andere Vorgänge während der Migration ausführen. Selbst mit Automatisierung ist das immer noch der größte Zeitaufwand.
Anzahl der verschobenen Server pro Tag
Die Berechnung der Anzahl der Server, die pro Tag migriert werden können, kann knifflig sein. Sie hängt von der AWS-Erfahrung des Personals ab, das die Migration durchführt. Es hängt auch von der Art der Anwendungen ab und davon, ob die Mitarbeiter/innen bereits in der Vergangenheit Migrationen durchgeführt haben. Als ich Berater war und den Aufwand für Projekte berechnete, habe ich zwei Server pro Tag und Ingenieur eingesetzt. Dabei handelte es sich um erfahrene AWS-Techniker, die bereits mehrere Migrationen durchgeführt hatten. Wenn du Berater oder Auftragnehmer einsetzt, kannst du mit dieser Zahl rechnen. Wenn du dein Personal einsetzt, solltest du einen halben bis einen Server pro Tag anpeilen.
Du fragst dich vielleicht, wie deine Techniker die Migration beginnen und jeden Tag einen Server migrieren können. Das ist eine sehr gute Frage; diese Zahlen sind Durchschnittswerte. Wenn du Server migrierst, tust du das in Wellen und hast normalerweise einen Cutover in der Nacht oder am Wochenende. Du könntest mit 2 Technikern am Samstag 10 Server migrieren, aber die Vorbereitungen würden die ganze Woche in Anspruch nehmen.
Verzögerungspuffer
Verzögerungen kommen vor. Ich glaube nicht, dass ich jemals ein Projekt hatte, das sich nicht verzögert hat. In den Augen meines Managements verfehle ich keine Ziele, weil ich darauf bestehe, einen Puffer einzuplanen. Zu Beginn meiner Karriere habe ich meine Zeitpläne immer sehr eng gehalten, weil ich dachte, es würde gut aussehen, wenn ich ein Projekt mit einem kurzen und optimalen Zeitplan vorschlagen würde. Das erste Mal, als ich ein Projekt verlängern musste, war das keine große Sache. Aber beim dritten, vierten und fünften Mal begann ich jedes Mal zusammenzuzucken, wenn ich dem Management sagen musste, dass ich den Zeitplan verlängern musste. Dieses Versehen war eine schmerzhafte Lektion, die ich lernen musste.
Seitdem bin ich in der Regel eher vorsichtig, oder wie ich es nenne: ich mache es wie Scotty. Wenn du dich an all die Star Trek-Folgen erinnerst, wurde Scotty immer gebeten, etwas Unglaubliches zu tun. Die Zeitvorgabe, die ihm gegeben wurde, war immer zu kurz, um die Aufgabe zu erfüllen, und er gab eine längere vor. Aber irgendwie schaffte Scotty es trotzdem und übertraf die geschätzte Zeitspanne. Für seine Bemühungen sahen sie Scotty immer als Held. Ich bin gerne Scotty, wenn ich Vorhersagen mache. Ich schätze lieber etwas höher und werde gelobt, wenn sich der Staub gelegt hat, als zu niedrig zu schießen und das Ziel zu verfehlen. Es ist besser, ein bisschen mehr Raketenpower zu haben, um die Austrittsgeschwindigkeit zu erreichen, als sie nicht zu brauchen.
Bei Migrationen würde ich in der Regel eine Fehlermarge von 10-20 % als Puffer für den Zeitplan der Migration einplanen. Wenn du mit einem erfahrenen Migrationsteam zusammenarbeitest, würde ich zu 10 % tendieren. Bei einem weniger erfahrenen Team würde ich mich auf 20 % einstellen. Neben den Fähigkeiten des Teams hat auch die Art der Software einen Einfluss auf den Zeitpuffer für die Migration. Wenn du zum Beispiel viele COTS-Anwendungen hast, ist dein Zeitplan weniger risikobehaftet als wenn du viel intern entwickelte Software hast. Der Grund für diese Risikoverschiebung ist, dass COTS-Anwendungen gut dokumentiert sind und bereits von anderen Unternehmen zu AWS verlagert wurden. Blogbeiträge und Antworten in Foren stehen zur Verfügung, um deinem Team bei der Lösung von Problemen zu helfen. Wenn du viele intern entwickelte Anwendungen hast, ist das Gegenteil der Fall. In der Regel ist die Dokumentation nicht so umfangreich, und ein Großteil des Stammeswissens ist im Laufe der Zeit verloren gegangen. Da du das einzige Unternehmen bist, das die Software betreibt, gibt es auch keine Ressourcen im Internet, auf die du zurückgreifen kannst. Aus diesen Gründen schätze ich den Puffer für Unternehmen mit einem großen Bestand an intern entwickelter Software auf 20 %.
Bevor wir uns damit beschäftigen, wie wir den Verzögerungspuffer einbauen können, müssen wir zunächst auf die Ferien und Feiertage der Mitarbeiter eingehen. Sie sind ein wichtiger Bestandteil des Zeitplans für die Migration.
Urlaub und Feiertage der Mitarbeiter
Eine oft übersehene Komponente der Zeitplanung ist der Urlaub der Mitarbeiter. Der Urlaub von Mitarbeitern kann sich erheblich auf deinen Zeitplan auswirken, und ich habe gesehen, dass dies in vielen Schätzungen vergessen wurde. Ebenso können sich Feiertage auf den Zeitplan auswirken, aber möglicherweise nicht so, wie du es erwartest.
Ich möchte nicht, dass du in die Falle tappst, nicht an den Urlaub deiner Mitarbeiter zu denken. Dadurch verzögert sich deine Umstellung. Der Effekt wird umso schlimmer, je größer dein Unternehmen ist, und je größer dein Team ist, desto mehr Urlaubstage musst du berücksichtigen. Je größer das Unternehmen, desto mehr Server und desto länger ist auch der Zeitplan. Je länger die Zeitspanne ist, desto mehr Urlaub nehmen die Mitarbeiter. Bei kleinen Unternehmen, die nicht so viele Server haben, wirkt sich der Urlaub weniger aus, weil der Zeitrahmen viel kürzer ist. Das folgende Szenario verdeutlicht, wie sich der Urlaub auf deinen Zeitplan auswirken kann.
Die Auswirkungen auf den Zeitplan für die Migration sind in Beths Situation beträchtlich. Da sechs Mitarbeiter an der Umstellung beteiligt sind und jeder einen Monat Urlaub hat, hat sie sechs Monate potenziellen Urlaub. Das ist ein halbes Jahr, in dem eine Vollzeitkraft arbeitet. Da ein Monat etwa 20 Arbeitstage hat, multipliziert mit sechs Monaten, sind das 120 Arbeitstage, wenn ihr Team 1,25 Server pro Tag migrieren kann, also 150 Server, die fehlen, wenn Beth keinen Ausgleich schafft.
Auch Feiertage können deinen Zeitplan für die Migration durcheinander bringen. Die meisten Menschen denken sofort an freie Tage und an Leute, die nicht arbeiten können. Um ehrlich zu sein, hat dieser Aspekt kaum Auswirkungen auf deinen Zeitplan. Was wirklich schaden kann, sind die potenziellen Sperrzeiten, die mit den Feiertagen einhergehen. Das trifft vor allem auf den Einzelhandel zu. Es ist üblich, dass eine Einzelhandelskette von Thanksgiving bis nach Neujahr Sperrzeiten hat. Das sind etwa anderthalb Monate, in denen man nicht umziehen kann. In einem Unternehmen, für das ich gearbeitet habe, gab es zu jedem Feiertag Sperrzeiten. Der Valentinstag, der St. Patrick's Day, der vierte Juli und andere Feiertage brachten einwöchige Sperrungen mit sich. Die Auswirkungen der Feiertage sind sehr spezifisch und hängen von den individuellen Bedürfnissen deines Unternehmens ab.
Ich möchte Urlaub und Feiertage ausgleichen, indem ich die Gesamtzahl der Ingenieure, die in die Gleichung einfließen, reduziere. In "Szenario 4-1" würde Beth die Anzahl ihrer Mitarbeiter von sechs auf fünfeinhalb Ingenieure reduzieren. Dadurch wird die Diskrepanz für den Aufwand, der während ihres Urlaubs fehlt, behoben. Jetzt, da wir alle Komponenten kennen, können wir sie in die Gleichung für den Zeitplan einsetzen.
Die Gleichung zusammenstellen
Jetzt, wo du die Anzahl der Server, die Anzahl der Server pro Tag, die Freistellung der Mitarbeiter und den Puffer im Kopf hast, können wir alles zusammenrechnen, um die Gesamtdauer der Migration zu ermitteln. Dazu habe ich eine Gleichung erstellt, mit der du die Gesamtdauer der Migration berechnen kannst. Sie benötigt eine Reihe von Eingaben, die wir gerade besprochen haben.
Gleichung 4-1. Gleichung für die Zeitachse
Schauen wir uns ein anderes Szenario an, um zu sehen, wie eine Zeitleiste mit einigen tatsächlichen Datenpunkten aussehen könnte.
Richard wird am Ende eine Gleichung haben, die ungefähr so aussieht:
Er hat 1.400 Server, die von vier Technikern migriert werden sollen, die eineinviertel Server pro Tag umziehen können. Da die Hälfte seiner Mitarbeiter in AWS geschult ist, geht er davon aus, dass ein Techniker etwas mehr als einen Server pro Tag umziehen kann. Da Richards Unternehmen fast ausschließlich auf COTS setzt und die Hälfte seiner Mitarbeiter schon einmal migriert hat, ist ein Puffer von 13 % sinnvoll. Richards Mitarbeiter arbeiten in einer Standard-Arbeitswoche, also wird alles durch fünf geteilt, um zu ermitteln, wie viele Wochen Gesamtaufwand nötig sind. Richards kompletter Zeitplan für die Migration beträgt 63,28 Wochen, also knapp 14,5 Monate. Gemessen an der Anzahl der Server, die Richard betreibt, sind diese Zahlen branchenüblich.
Jetzt, wo der Zeitplan fertig ist, können wir mit der Arbeit am Business Case beginnen. Du fragst dich vielleicht, warum der Zeitplan für die Migration vor dem Business Case fertiggestellt wurde und nicht Teil des Business Case ist. Tatsache ist, dass er im Vergleich zu den übrigen Informationen, die dem Management übermittelt werden, unwichtig ist. Du kannst ihn einfach in den Annahmen vermerken, die wir später in diesem Kapitel besprechen werden, und angeben, wie du ihn ermittelt hast.
Wie sieht ein Business Case aus?
In der Regel beginne ich einen Business Case mit einem schriftlichen Bericht über die Migration und die Vorteile, die die Umstellung auf die Cloud dem Unternehmen bringen wird. Nach dem Bericht folgt eine fünfjährige Finanzprognose, die die Einsparungen durch die Umstellung auf die Cloud veranschaulicht. Zum Schluss füge ich alle Details und Ergebnisse der Untersuchung in einem Anhang zusammen, den die Teilnehmer auf Wunsch einsehen können. Normalerweise kümmert sich die oberste Leitung nicht um die kleinsten Details. Es kann aber vorkommen, dass die Mitglieder Details für einen Bereich, für den sie verantwortlich sind, überprüfen wollen. In den nächsten Abschnitten werden wir die einzelnen Bestandteile eines Business Case im Detail erläutern.
Die Erzählung
Die Erzählung ist der wichtigste Teil des Business Case. Hier hast du die Möglichkeit, die geschäftlichen Vorteile der Umstellung auf AWS zu vermitteln. Ich mag Erzählungen, weil du damit eine Geschichte über den zukünftigen Erfolg deines Unternehmens erzählen kannst. Eine Geschichte ist für die Menschen interessanter als eine PowerPoint-Präsentation mit einer Reihe von Aufzählungspunkten. Das Lesen einer Erzählung regt die Fantasie der Menschen an und enthält genug Details, damit sie sich die Zukunft vorstellen können. Andere Formen der Kommunikation lassen mehr Fragen als Antworten zurück. Es gibt nur so viele Informationen, wie du in eine Folie packen kannst, bevor sie unverständlich wird.
Einführung
Aber wo soll man anfangen? Ein hervorragender und logischer Anfang ist eine Einleitung, die den aktuellen Zustand deiner Infrastruktur beschreibt. Ich mag es, wenn du dich auf die positiven und negativen Aspekte konzentrierst, ohne das Bashing vor Ort zu betreiben. Am besten wäre es, wenn du unparteiisch oder zumindest ausgewogen erscheinst. Wenn du den Eindruck erweckst, dass du den aktuellen Zustand schlecht machst, läufst du Gefahr, die Führungskräfte, die du für deinen Plan gewinnen willst, zu verärgern. Dein Unternehmen ist schon eine Weile im Geschäft, und die Arbeit vor Ort hat sich bewährt. Du versuchst, die gleichen Führungskräfte zu überzeugen, wie du oder dein Vorgänger es zuvor getan haben. Dieselben Führungskräfte haben die Anschaffung der Geräte und Werkzeuge genehmigt, die derzeit im Rechenzentrum laufen. Vielleicht ist dein Vorgänger jetzt sogar der CIO, und du willst sein Baby nicht als hässlich bezeichnen. Wenn du das tust, wird das zwar nicht gut ankommen, aber du gewinnst einen großen Gegner, der die ganze Sache ins Stocken bringen könnte. Wenn du sachlich bleibst und dich auf ein Minimum an Voreingenommenheit beschränkst, wirst du mehr Unterstützung bekommen.
FAQ
Du hast deine Einleitung über den aktuellen Stand geschrieben. Jetzt ist es an der Zeit, sich mit den Vorteilen zu befassen, die die Migration in die Cloud mit sich bringt. Am besten fängst du damit an, indem du dir die FAQs ansiehst, die du in Kapitel 1 erstellt hast. Du hast bereits viel Zeit damit verbracht, die Fragen zu entwickeln, die deiner Meinung nach von den Geschäftsbereichen, den Entwicklungsteams und der Geschäftsführung gestellt werden. Jetzt musst du eine überzeugende Geschichte rund um diese spezifischen Fragen entwickeln. Schauen wir uns dieses FAQ-Beispiel an und überlegen wir, wie du eine überzeugende Geschichte schreiben kannst.
Wie du in "FAQ Frage 1" sehen kannst, haben wir uns nicht strikt gegen die lokale Infrastruktur ausgesprochen. Wir haben erklärt, dass die Migration zu AWS einige Vorteile mit sich bringt. Der Bericht führt sie auch auf einen Weg, der ihnen hoffentlich die Details liefert, die sie brauchen, um sich eine Meinung zu bilden und Fragen einzuschränken. Lass uns einen Blick darauf werfen, wie du einen Bericht nicht schreiben solltest.
Wie du siehst, nimmt diese FAQ eine ganz andere Position ein, was die Art und Weise angeht, wie sie die Geschichte erzählt. Die Erzählung ist sehr einseitig auf die Cloud ausgerichtet. Sie zeichnet auch ein ziemlich düsteres Bild vom aktuellen Zustand der On-Premises. Das Problem dabei ist, dass es deine Aufgabe ist, dafür zu sorgen, dass all diese Unstimmigkeiten beseitigt werden. Wenn du einen Bericht wie diesen schreibst, unterschreibst du vielleicht dein eigenes Todesurteil.
Du kannst dich weiter durch die FAQ arbeiten und die Fragen heraussuchen, zu denen du eine fesselnde und spannende Geschichte schreiben kannst. Einige Punkte, wie die Umstellung auf SSD mit gp2 EBS-Volumes, könnten für einen Techniker eine faszinierende Geschichte sein. Bei den oberen Managementebenen kommt das aber wahrscheinlich nicht so gut an. Wenn du die falschen Fragen stellst, kann das dein Publikum langweilen und die Begeisterung bremsen.
Schließen
Der letzte Teil deines Berichts sollte das Schlusswort sein. Er sollte eine kurze Zusammenfassung der wichtigsten Punkte enthalten, die du besprochen hast. In meinen Abschlüssen stelle ich gerne die Zukunft vor und zeige Möglichkeiten auf, die das Unternehmen noch nicht genutzt hat, aber nach der Umstellung auf AWS nutzen könnte. Im Abschlussgespräch kannst du über den Tellerrand hinausschauen und eine Vision von einer neuen Funktion oder einem zusätzlichen Kundennutzen entwerfen. Sobald die Migration abgeschlossen ist und deine Daten in AWS liegen, gibt es eine ganze Reihe von Möglichkeiten, die du nutzen kannst. Künstliche Intelligenz und Augmented Reality sind zwei weit verbreitete Technologien, die in vielen Branchen auf neue und kreative Weise genutzt werden.
Warnung
Ich tendiere dazu, mich von den "Silver Bullet"-Technologien für meine Zukunftsvisionen fernzuhalten. Das sind Technologien, die sich aus irgendeinem Grund massiv durchsetzen, um jedes Problem auf der Welt zu lösen. Die jüngste davon ist die Blockchain. Vor nicht allzu langer Zeit konnte man keine Tech-Website lesen, ohne dass Blockchain zur Lösung eines Problems erwähnt wurde. Tennisarm? Kein Problem; reibe dich zweimal täglich an der Blockchain. Ein Patentrezept gibt es nicht. Meiner Erfahrung nach wird jede Technologie, die als bedeutende Veränderung angepriesen wird, selten eine. Sie stirbt entweder oder wird zu einem Nischenanbieter. Blockchain, Grid-Computing, Next-Gen-Firewalls und andere sind alle auf den Zug aufgesprungen, der die Probleme der Welt lösen soll, und sie sind alle entgleist. Technologien, die die Welt verändern, brauchen eine lange Zeit, um dies zu tun. Schau dir Virtualisierung, künstliche Intelligenz, virtuelle Realität und sogar AWS an. Diese Technologien haben mindestens ein Jahrzehnt oder länger gebraucht, um einen Reifegrad zu erreichen, der die Welt verändert, und einige fangen gerade erst an, sich durchzusetzen. Du willst, dass dein Bild von der Zukunft realisierbar ist und nicht nur eine Fantasievorstellung.
Die Vorhersage
Du hast jetzt deinen Bericht geschrieben und ein wunderbares Bild von all den Vorteilen und Problemen gezeichnet, die durch den Wechsel in die Cloud gelöst werden. Jetzt ist es an der Zeit, zur Sache zu kommen. Du musst aufzeigen, wie viel die Migration zu AWS kosten wird. Nichts ist umsonst, besonders wenn es um die Migration geht. Die doppelten Ausgaben während der Migration sind ein großes Hindernis. Allerdings werden die Ausgaben nicht genau doppelt so hoch ausfallen. Du solltest einen Kostenunterschied zwischen On-Premises und der Cloud feststellen. Außerdem solltest du bei der Migration einen gewissen "Burn-Down" bei den Kosten für deine Vor-Ort-Ausrüstung feststellen. Das Thema "Burn-Down" ist nicht ganz einfach und wird später im Abschnitt "Cost Burn-Up/Burn-Down" ausführlicher behandelt .
Wichtig ist, dass du in der Prognose festhältst, ab wann du durch die Umstellung auf AWS Geld sparen wirst. Jede gute Führungskraft oder jeder Vorstand wird erkennen, dass die Einsparungen nicht sofort eintreten werden. Man kann davon ausgehen, dass ein typischer Vorstand bei einer großen Investition wie der Umstellung auf AWS eine Rendite von drei bis fünf Jahren anstrebt. In der Regel habe ich gesehen, dass sich die Investition in nur 18 Monaten amortisiert hat, je nach Situation des Unternehmens. Ich würde jedoch sagen, dass zwei bis drei Jahre eher die Regel sind. Es besteht die Möglichkeit, dass Unternehmen durch die Umstellung auf AWS kein Geld sparen. Schauen wir uns ein Szenario an, das zeigt, wie das passieren kann.
Hoffentlich erkennst du, dass die Art und Weise, wie Stefans Firma die Infrastruktur eingerichtet hat, einige erhebliche Probleme mit sich bringt. Das größte Problem ist, dass es keine Redundanz in den Räumlichkeiten des Unternehmens gibt. Das Unternehmen verfügt wahrscheinlich nicht über Feuerlöschanlagen, Generatoren oder physische Sicherheit. Aus technischer Sicht gibt es keine Redundanz für den Server oder seine Speicherung. Stefans Vorgänger hat die Umgebung so dünn wie möglich gehalten. Wenn du diese Art der Bereitstellung vor Ort mit AWS vergleichst, könnte es leicht doppelt so viel kosten, sie in AWS zu betreiben. AWS hat all diese Funktionen bereits eingebaut, und es wäre unmöglich, die Kosten anzugleichen. In diesem Szenario ist es von entscheidender Bedeutung, sich auf die Verfügbarkeitsvorteile zu konzentrieren, die AWS gegenüber einer lokalen Umgebung bietet, und nicht auf die Kosten.
Die Prognose sollte mehrere Punkte über einen Zeitraum von mindestens fünf Jahren enthalten. Eine gute Prognose umfasst:
-
Geschätzte Run Rate
-
Kosten für die Migration, wie z.B. Werkzeuge und Beraterkosten
-
Run Rate Modifier, wie reservierte Instanzen
-
Einsparungen durch Agilität
Einige dieser Posten, wie z. B. die Betriebsrate, stammen aus deiner Entdeckung, und andere, wie z. B. die Einsparungen bei der Agilität, müssen von Hand auf der Grundlage der Situation deines Unternehmens berechnet werden. Du solltest dir ein Bild von den Kosten machen, damit sie leicht zu verstehen sind. Die Prognose sollte auf eine einzige Seite passen und nicht mehr als 10 bis 15 Datenzeilen enthalten. Fügst du mehr hinzu, besteht die Gefahr, dass du dein Publikum verwirrst. Eine Tabellenkalkulation nach der anderen mit Serverlisten hilft niemandem, das Gesamtbild zu verstehen. Diese Informationen kannst du dir für den Detailteil am Ende aufheben. Außerdem werden einige Posten, die ich Run-Rate-Modifikatoren nenne, deine Gesamtzahlen anpassen, um die Kosten anzunähern, wie z. B. reservierte Instanzen.
Abbildung 4-1 zeigt ein Beispiel für eine typische Prognose, die ich erstellen würde. Sie enthält alle wichtigen Details, macht sie aber so verdaulich wie möglich. Du kannst auch sehen, dass ich am Ende eine Liste mit Annahmen einfüge, in der ich genau aufführe, woher diese Annahmen stammen. Du kannst das Format so gestalten, wie du es möchtest, aber Einfachheit ist der Schlüssel. Du willst den Verbraucher nicht mit unnötigen Details überfordern.
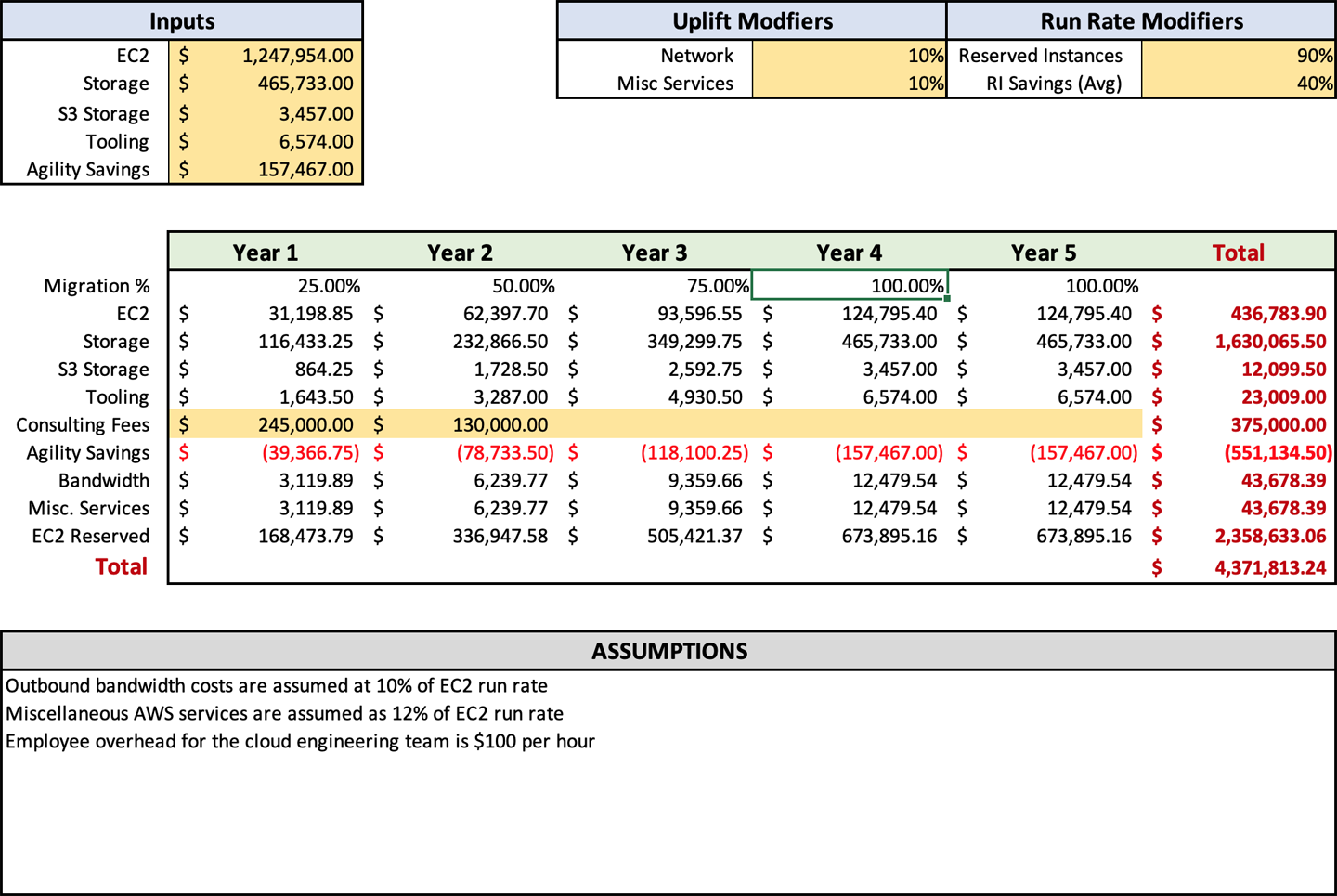
Der letzte Punkt, den wir behandeln müssen, ist das Entfernen der Anwendungen, die du nicht in die Cloud migrieren willst, oder besser gesagt, das Abschneiden des Fettes. Wie bei einem Rib-Eye in einem erstklassigen Steakhaus musst du auch hier das Zeug von den Kanten entfernen, das die Migration unattraktiv macht.
Das Fett abspecken
Bevor wir eine genaue Run-Rate-Modellierung durchführen können, müssen wir etwas Fett abschneiden. Das Fett, von dem ich spreche, sind die Anwendungen, die du nicht nach AWS verlagern wirst. Amazon hat eine Methode mit den sieben R-Faktoren (Refactor, Redeploy, Rehost, Repurchase, Retire, Re-platform, Retain) entwickelt. Ursprünglich waren es sechs, aber Redeploy wurde zu einem neuen R-Faktor, da immer mehr Unternehmen Container oder Deployment-Pipelines vor Ort einsetzen. Die Faktoren sollen dir helfen, deine Anwendungen zu kategorisieren, um zu entscheiden, ob und wie du deine Anwendungen in die Cloud migrieren solltest.
Dein Discovery Tool hat alles gefunden, was du vor Ort hast, und kann dir die Instanzen in der richtigen Größe zur Verfügung stellen. Was das Discovery Tool nicht kann, ist dir zu sagen, ob du eine Anwendung verlagern solltest. Diese Klassifizierung ist ein manueller Prozess, der abgeschlossen werden muss, bevor wir eine genaue Run-Rate-Modellierung durchführen können. Du willst natürlich keine Kosten in AWS berücksichtigen, die nicht verschoben oder stillgelegt werden. Das würde deine Zahlen aufblähen und deinen Business Case unattraktiv und ungenau machen. Wir werden nun auf die sieben R-Faktoren eingehen, was sie bedeuten, wie hoch der geschätzte Prozentsatz deiner Migration für jedes R ist und wie du sie anwenden solltest.
Refactor
Das Refactoring ist die komplexeste Art der Migration zu AWS und sollte den geringsten Anteil an der Gesamtmigration ausmachen. Refactoring bedeutet, eine bestehende monolithische und veraltete Anwendung in eine neue, stark entkoppelte und Cloud-native Architektur umzuwandeln. Das Problem beim Refactoring von Anwendungen ist, dass es oft einen längeren Zeitraum dauert, bis die Arbeit abgeschlossen ist. Diese längere Zeitspanne bedeutet, dass du mehr Geld für die gesamte Migration ausgibst, indem du die Anwendung an zwei Orten laufen lässt oder dein Rechenzentrum für längere Zeiträume ausdehnst. Der größte Vorteil des Refactorings ist jedoch, dass deine Anwendungen reibungsloser laufen, ein höheres Maß an Verfügbarkeit haben, der Verwaltungsaufwand reduziert wird und du Kosten sparst. Das Refactoring wird an dieser Stelle wahrscheinlich nur 5 % oder weniger deiner Migration ausmachen. In Kapitel 8 werden wir einige niedrig hängende Früchte besprechen, die du bei der ersten Migration ernten kannst.
Umgruppieren
Redeploy wird vor allem dann eingesetzt, wenn du bereits eine Deployment-Pipeline oder Container vor Ort hast. Wenn du bereits eine Bereitstellungspipeline hast und migrierst, änderst du im Wesentlichen den Endpunkt dieser Bereitstellung. Die meisten Tools haben bereits Plugins für AWS. Anstatt eine Migration durchzuführen, verweist du die Pipeline auf AWS statt auf VMware oder Hyper-V vor Ort.
Das Gleiche gilt, wenn du Container verwendest. Da es sich bei Containern um in sich geschlossene Arbeitslasten handelt, verschiebst du den Container zu AWS und nicht auf die Hardware vor Ort. Natürlich ist die Migration dieser Art von Arbeitslasten mit etwas mehr Arbeit verbunden, z. B. mit DNS-Änderungen und Ähnlichem, aber der Gesamtaufwand ist geringer als z. B. bei einem Lift and Shift oder einem Rehost. Es ist schwer zu sagen, wie viel von deiner Migration umgestellt werden muss, da dies stark von deinen Anwendungen abhängt.
Rehost
Das Rehosting von wird den größten Teil deiner Migration ausmachen, vor allem wegen der Geschwindigkeit. Beim Rehosting verschiebst du die Arbeitslast in die Cloud. Je schneller sie in der Cloud ankommt, desto schneller kannst du damit beginnen, Ressourcen vor Ort abzuschalten. Die Geschwindigkeit wird durch das CloudEndure-Replikationstool auf Blockebene erhöht. Rehost ist die am wenigsten sexy Migrationsmethode, aber oft die effektivste. Du bekommst eine Block-für-Block-Kopie deines Servers in AWS. Deine Migration wird wahrscheinlich zu 80 % aus Rehost-Arbeitslasten bestehen.
Rückkauf
Manchmal veraltet Software in deiner IT-Infrastruktur. Oft handelt es sich dabei um kleine, vernachlässigte Anwendungen, die einen wichtigen Zweck erfüllen, aber nicht viel Aufmerksamkeit erhalten. Dieser Mangel an Aufmerksamkeit lässt sie alt und veraltet werden, aber sie funktionieren immer noch, sodass sie nie ersetzt werden. Wenn du zu AWS migrierst, ist das ein guter Zeitpunkt, um diese Anwendungen endgültig auslaufen zu lassen und sie durch etwas Neueres zu ersetzen. Ich bin auf einige alte Visual Basic-Programme in dieser Kategorie gestoßen. Wenn möglich, würde ich versuchen, alle Anwendungen durch ein SaaS-Tool zu ersetzen, damit du dich in Zukunft nicht um die Wartung kümmern musst. Meiner Erfahrung nach macht die Neuanschaffung wahrscheinlich etwa 5 % deiner Migration aus.
In Rente gehen
Manchmal brauchst du keine Software mehr, wenn du zu AWS wechselst. In der Regel handelt es sich bei dieser Software um Tools für das Infrastrukturmanagement, die für die Verwaltung der lokalen Arbeitslasten verwendet wurden. Dinge wie Protokollaggregation, SNMP-Überwachung (Simple Network Management Protocol) und andere Überwachungs-Tools werden nicht mehr benötigt, wenn du zu AWS umziehst und native Funktionen nutzt. Dadurch sparst du sowohl harte als auch weiche Verwaltungskosten. Der Rückzugsfaktor R wird nicht sehr häufig genutzt und macht wahrscheinlich weniger als 5 % deiner Migration aus.
Re-platform
Wenn du etwas neu plattest, änderst du nur einen kleinen Aspekt der Anwendung, aber keine größeren Änderungen an der Architektur. Diese Änderung wäre z. B. die Umstellung von einem Datenbankserver auf RDS. Eine andere mögliche Änderung wäre das Upgrade eines älteren Windows-Betriebssystems auf eine neuere, unterstützte Version. Wichtig ist dabei, dass du keine größeren Änderungen vornimmst, wie z.B. den Wechsel von Microsoft SQL zu MySQL. Bei den Migrationen, mit denen ich zu tun hatte, ist die Neuplattformierung in der Regel häufiger als viele andere R-Faktoren. Es gibt eine ganze Reihe älterer Betriebssysteme, bei denen es dich überraschen könnte, dass du sie noch verwendest. Wenn du außerdem aus Sicherheitsgründen und um Verwaltungsaufwand zu sparen RDS nutzen möchtest, kann es leicht passieren, dass 20 % deiner Migration als Re-Platforming eingestuft werden.
Behalte
Der letzte R-Faktor ist Retain. Wenn du einen Workload beibehältst, lässt du ihn so, wie er ist, vor Ort. In der Spalte "Beibehalten" werden mehrere Elemente angezeigt, aber die meisten davon sind Anwendungen, die vor Ort bleiben müssen, damit deine Büros funktionieren. Active Directory wäre eine gute Wahl, um es vor Ort zu belassen, weil du willst, dass sich die Nutzer lokal authentifizieren. Andere Systeme könnten Sicherheitssysteme, DHCP-Server (Dynamic Host Configuration Protocol) und andere Netzwerkverwaltungseinrichtungen sein.
Auch Altsysteme können in diese Kategorie fallen. Du wirst deinen Großrechner nicht zu AWS migrieren, weil AWS die Hardware nicht unterstützt. Da diese Art von Arbeitslasten jedoch nicht durch dein Discovery-Tool erkannt wurde, wird sie sich nicht auf deine Run-Rate auswirken und wahrscheinlich nicht einmal aufgeführt werden.
Du wirst wahrscheinlich weniger als 5% deiner Infrastruktur behalten.
Jetzt, wo du weißt, wie du alle deine Anwendungen klassifizieren kannst, ist es an der Zeit, deine R-Faktoren zu überprüfen und anzuwenden. Wenn du damit fertig bist, musst du die Ausführungsrate für die Entscheidungen Rehosting, Replatform, Redeployment und Refactoring erfassen. Das sind die Run Rates, die in deine Prognose einfließen werden. Du wirst sie nicht einzeln eingeben. Stattdessen solltest du diese Zahlen zu einer Gesamtsumme zusammenfassen.
Nachdem du nun auf breiter Ebene verstanden hast, worauf es bei einer Prognose ankommt, wollen wir uns den einzelnen Posten im Detail widmen. Wir werden erklären, was die einzelnen Posten sind, warum sie wichtig sind, wie man sie berechnet und welche Annahmen man aufstellen muss. Microsoft Excel, Google Sheets oder ein ähnliches Tabellenkalkulationsprogramm wird benötigt, um die Prognose zu erstellen und die notwendigen Berechnungen durchzuführen. Eine Beispieldatei ist als Zusatzinhalt für dieses Buch erhältlich. Du kannst die Datei unter AWS Forecast abrufen.
Run Rate Modellierung
Die Run Rate, die sich aus deinem Discovery-Prozess ergibt, ist einer der wichtigsten Punkte, die in deine Prognose einfließen müssen. Was wir hier verwenden wollen, ist die geänderte Zahl, die von deinem Discovery-Tool ausgegeben wurde und die du dann anhand der manuellen Discovery-Elemente, die dein Team überprüft und mit den R-Faktoren getrimmt hat, angepasst hast. Wenn du mit diesem Prozess beginnst, solltest du die vollständige Run Rate, die du ermittelt hast, in die Eingabezellen für EC2 (C3), Speicherung (C4) und S3 Speicherung (C5) eingeben. Später wirst du Formeln anwenden, um die Zahlen auf der Grundlage deiner Eingaben anzupassen, aber für den Moment solltest du mit der vollen Run Rate beginnen. Ab jetzt sollte deine Prognose in etwa so aussehen wie in Abbildung 4-2.
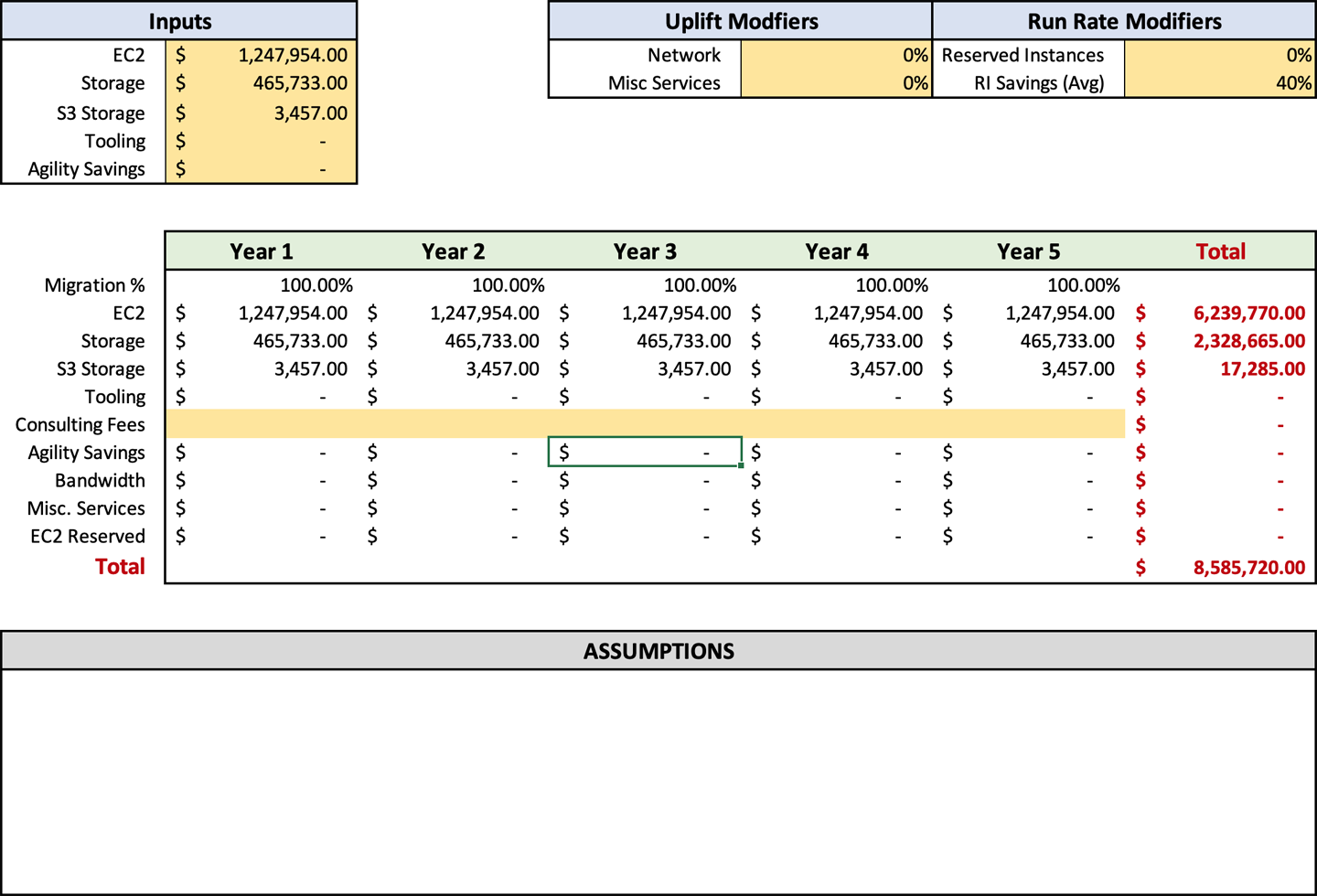
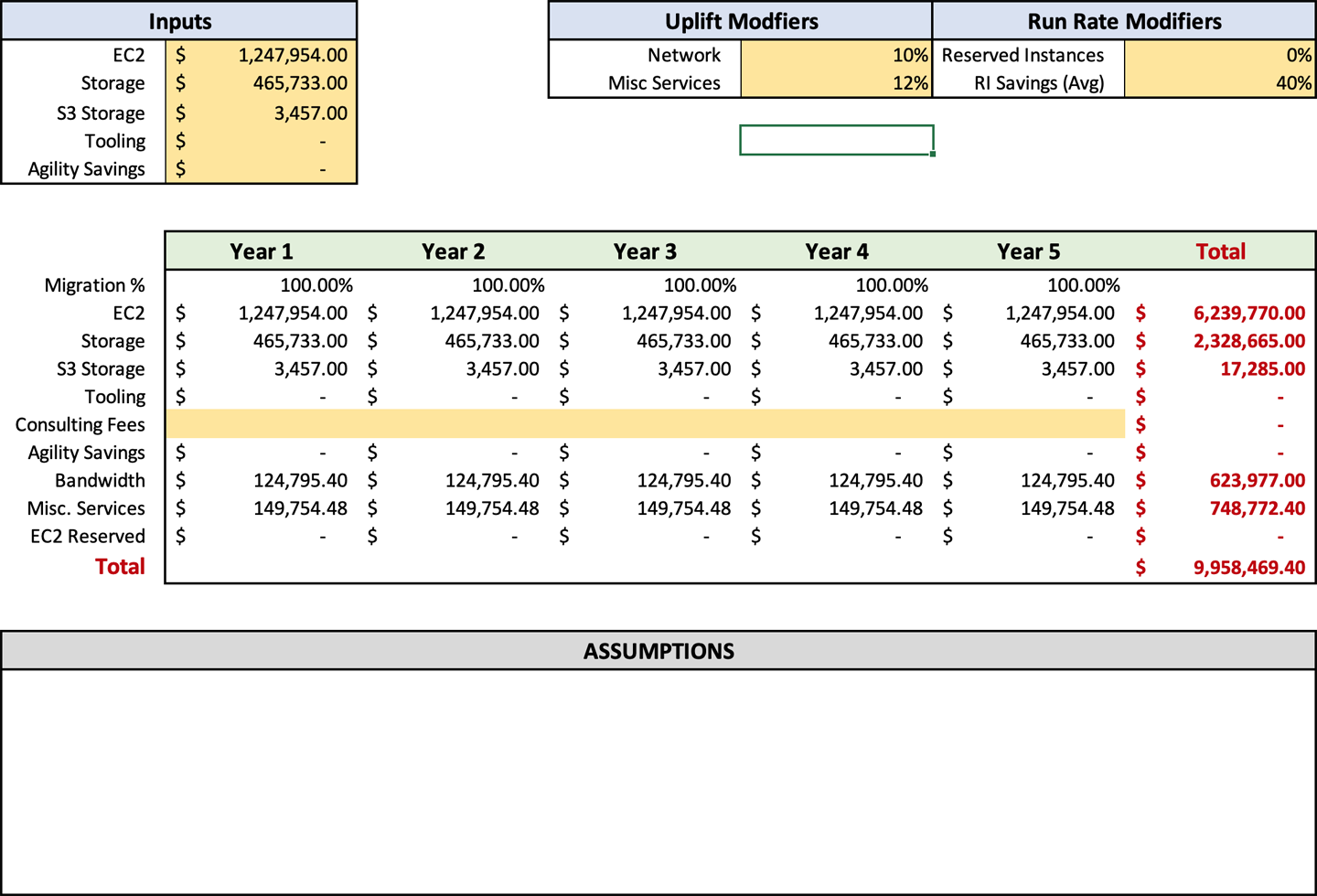
Wenn du die Kosten für Speicherung und Berechnung wie in Abbildung 4-2 dargestellt aufteilst, ist es einfacher, die zusätzlichen Kosten zu berechnen. Du erinnerst dich vielleicht daran, dass ich in den Abschnitten "Ausgehende Gesamtbandbreite" und "Zusätzliche AWS-Servicegebühren" empfohlen habe, einen Aufschlag auf die EC2-Ausgaben für diese Posten zu berechnen. Wenn du die Kosten für Datenverarbeitung und Speicherung aufschlüsselst, kannst du diese Prozentsätze leichter einsehen und anpassen.
Sobald du deine Run Rates in die Prognose eingegeben hast, kannst du in den Zellen F3 und F4 deine Uplift-Prozentsätze für die Bandbreite bzw. die Zusatzleistungen eingeben. Diese sind anpassbar, so dass du deine Einstellungen manuell ändern kannst, wenn die Ergebnisse nicht mit deinen Erwartungen übereinstimmen. Manchmal musst du deine Einstellungen um ein paar Prozentpunkte nach oben oder unten korrigieren, um eine Zahl zu erhalten, die deinem geschätzten Verbrauch entspricht. Erinnere dich bei der Anpassung daran, dass du wie Scotty aus Star Trek einen Puffer einplanen solltest. Sobald du diese Daten eingegeben hast, sollte deine Prognose wie in Abbildung 4-3 aussehen.
Migrationskosten
Bei den Migrationskosten geht es nicht nur um die doppelte Rate zwischen den Ausgaben vor Ort und in der Cloud. Die Kosten hängen auch mit der Arbeitszeit der Mitarbeiter, den Werkzeugen, der Beratung und den Kosten für die Datenübertragung zusammen. Wenn du alle diese Kosten zusammenrechnest, erhältst du ein genaues Bild davon, wie viel die Migration kosten wird. Wenn du keine dieser Kosten berücksichtigst, können sich die Migrationskosten deutlich zu Gunsten der Cloud verschieben. Wenn du sie nicht mit einbeziehst, hat die Gegenseite die Möglichkeit, deinen Business Case zu diskreditieren und deine Initiative zum Scheitern zu bringen. Ich bin fest davon überzeugt, dass ich ein möglichst genaues Bild zeichnen sollte. Meistens ist es völlig klar, wie die Cloud dem Unternehmen Vorteile bringt und ein großes Potenzial hat, die Kosten zu senken.
Obwohl ich versuche, ein genaues Bild zu vermitteln, konzentriere ich mich nicht darauf, banale und eintönige Details zu liefern. Ich verschwende auch nicht zu viel Zeit damit, Zahlen für die "Landung auf dem Mond" zu ermitteln, wenn die Zahlen für den "Start ins All" für viele dieser Kategorien ausreichen. In den nächsten Abschnitten werden wir uns mit diesen zusätzlichen Ausgabenkategorien befassen und wie man sie berücksichtigt. Wir werden auch auf die möglichen Fallstricke bei der Berechnung eingehen und wie man Zeitverschwendung vermeiden kann.
Werkzeugkosten
AWS hat eine ganze Reihe von Tools, die dir bei der Migration in die Cloud helfen; einige davon sind kostenlos, andere kostenpflichtig. Obwohl die Tools von AWS großartig sind, verfügen sie nicht immer über die Funktionen, die dein Unternehmen benötigt, um die Arbeit zu erledigen. Wenn das der Fall ist, musst du ein zusätzliches Tool auswählen, das mehr kostet.
Schauen wir uns die Tools an, die AWS anbietet. Diese Tools helfen bei der Migration, und du musst wissen, wie du diese Gebühren abrechnen kannst. Tabelle 4-1 zeigt eine Liste der aktuellen Tools von AWS und ihre Anwendungsfälle.
Wie du siehst, hat AWS ein gutes Portfolio für die Migration deiner Systeme und Daten in die Cloud. Diese speziell entwickelten Tools erfüllen ihre Aufgaben sehr gut, aber leider haben sie alle unterschiedliche Verbrauchs- und Kostenmodelle. Diese unterschiedlichen Verbrauchsmodelle können entmutigend wirken, wenn du zum ersten Mal versuchst, sie auszurechnen. Das ist aber gar nicht so schwer, denn wir werden für viele von ihnen Schätzungen vornehmen:
- CloudEndure
-
das AWS-Tool für die Migration von Servern ist jetzt kostenlos, nachdem Amazon es 2019 gekauft hat. Obwohl die Nutzung des Tools kostenlos ist, fallen Kosten für die Instanzen an, die für die Verwaltung der Replikation benötigt werden. CloudEndure stellt eine Replikationsinstanz für jeweils 15 Quellfestplatten bereit, die du replizierst. Um die Kosten für die Nutzung von CloudEndure abzuschätzen, musst du die maximale Anzahl der Server ermitteln, die du während einer deiner Migrationswellen replizieren wirst. Dazu nimmst du die Anzahl der wöchentlichen Server, die du nach der Lektüre von "Schätze deinen Zeitplan" berechnet hast . In "Szenario 4-1" lag die wöchentliche Schätzung bei fünf Servern. Da 5 deutlich unter den erlaubten 15 liegt, würde Richard nur eine Replikationsinstanz benötigen. Zum Zeitpunkt der Erstellung dieses Artikels kostet eine t3.medium-Instanz in us-east-1 $0,0416 pro Stunde. Multipliziert man diesen Preis mit 730 Stunden, ergeben sich Kosten von 30,368 $ pro Monat. Richards Gesamtkosten für CloudEndure für seine 14,5-monatige Migration betragen 440,336 $.
- Schneeball
-
AWS Snowball ist ein physisches Gerät, das an dein Büro geliefert wird. Du lädst dieses Gerät mit Daten und schickst es zurück an AWS. AWS lädt alle Daten auf dem Gerät in S3. Bei allen Migrationen, die ich durchgeführt habe, habe ich noch nie Snowball verwendet. Das liegt daran, dass die Daten, die du verschieben musst, relativ statisch sein müssen. Es dauert Tage, die Daten zu laden, das Gerät zu versenden und sie später wieder zu laden. Letztendlich haben sich die Unternehmen, mit denen ich gearbeitet habe, dafür entschieden, alles über das Netzwerk zu schicken, anstatt Snowball zu benutzen. Durch die Nutzung des Netzwerks konnten sie die Synchronisierung umgehen, die nach dem Laden der Daten durch AWS erforderlich gewesen wäre. Wenn du Daten hast, die für Snowball geeignet sind, wie z. B. alte Backup-Daten, kostet Snowball 200 US-Dollar für ein 50-TB-Gerät oder 250 US-Dollar für eine 80-TB-Speicherung (zum Zeitpunkt des Schreibens). In dieser Gebühr sind 10 Tage Vor-Ort-Zeit enthalten. Wenn du das Gerät für mehr als 10 Tage brauchst, zahlst du 15 Dollar pro Tag. Wenn du Snowball nutzen willst, empfehle ich dir, deine Daten vorzubereiten und alles bereitzuhalten, bevor du das Gerät über die AWS-Konsole anforderst.
- Server-Migrationsdienst
-
Normalerweise rate ich davon ab, SMS zu verwenden. Es funktioniert nur mit virtuellen Maschinen und ist nicht mit physischen Geräten kompatibel. Für die meisten Unternehmen bedeutet das, dass du zwei Tools statt einem verwenden musst. Da CloudEndure kostenlos ist und sowohl physische als auch virtuelle Maschinen abdeckt, schlage ich vor, stattdessen dieses Tool zu verwenden. SMS lädt Snapshots von VMs auf S3 hoch und erstellt dann EBS-Snapshots. Schließlich erstellt SMS ein Amazon Machine Image (AMI) für die endgültige Nutzung und Bereitstellung in AWS. Ein AMI ist so etwas wie eine Vorlage in der VMware-Terminologie. Der SMS-Service selbst ist kostenlos. Aufgrund des Designs fallen jedoch Gebühren für eine geringe Anzahl von EBS-Snapshots und die S3 Speicherung an. Insgesamt sind diese Gebühren bescheiden und du solltest sie als Teil des Aufschlags für verschiedene AWS-Gebühren betrachten, den wir in "Run Rate Modeling" besprochen haben .
- DataSync
-
DataSync ist ein neuerer Service von AWS, der die Übertragung von Daten von vor Ort zu S3 oder EFS auf Dateiebene statt auf Serverebene erleichtert. Mit diesem Service kannst du Daten von einem SAN- oder Network Attached Storage (NAS)-Gerät mit Windows- oder NFS-Dateifreigaben zu AWS übertragen. DataSync ist als Tool eine willkommene Ergänzung. Vor DataSync wurden die meisten Migrationen dieser Art mit Skripten und der AWS CLI durchgeführt, was nicht die robusteste Lösung war. DataSync selbst kostet zum Zeitpunkt der Erstellung dieses Artikels $0,04 pro GB in der Region us-east-1. Dieser Service ist einfach zu prognostizieren, basierend auf der Menge der Daten, die du übertragen musst. Wenn du zum Beispiel ein NAS-Gerät mit 1 TB auf einer NFS-Freigabe hast, würdest du 1.024 GB mit $0,04 multiplizieren, was insgesamt $40,96 ergibt. Die 40,96 $ decken nicht die Kosten für die Speicherung selbst ab, daher müssen diese ebenfalls berücksichtigt werden. Wenn es sich um eine kleine Datenmenge handelt, decken die von dir angegebenen Uplift-Zahlen diese Kosten wahrscheinlich ab, aber wenn du Dutzende oder Hunderte von Terabytes hast, solltest du diese Kosten in einem separaten Posten berücksichtigen.
- Befehlszeilen-Tools
-
Wenn du nur eine kleine Anzahl von Dateien nach S3 verschieben musst, ist die Verwendung der Befehlszeilen-Tools von AWS die bequemste Option. Keines dieser Tools ist mit Kosten verbunden, aber du zahlst für die Ressourcen, die sie verbrauchen. Da die Verwendung der Befehlszeilen-Tools für die Übertragung großer Datenmengen nicht zu empfehlen ist, sollte der Uplift die Kosten für den Datenverbrauch in der Prognose abdecken.
- Schema-Konvertierungstool
-
Mit dem Schema Conversion Tool kannst du die Datenbank-Engine für deine Datenbank wechseln. Mit diesem Tool kannst du von einer Datenbank-Engine zu einer anderen wechseln, zum Beispiel von Oracle zu MySQL. Das Tool ist jedoch nur ein Teil des Puzzles. Um deine Datenbank-Engine erfolgreich zu wechseln, musst du deine Software aktualisieren, um die notwendigen Änderungen in SQL-Nuancen, Triggern und Stored Procedures zu berücksichtigen. Zum Glück ist das SCT kostenlos und muss in keiner Prognose berücksichtigt werden.
- Datenbank-Migrationsdienst
-
DMS ermöglicht es dir, Daten mit Hilfe von asynchroner Spiegelung von einem lokalen Server in die Cloud zu übertragen. Mit diesem Dienst kannst du Daten von einem Standalone-Server zu AWS RDS übertragen. Der Vorteil von DMS ist, dass sich die Ausfallzeit für den Cutover beim Verschieben von Datenbanken drastisch verkürzt, weil der Dienst Quelle und Ziel im Gleichschritt hält. Wenn du eine Backup- und Wiederherstellungsmethode verwenden würdest, um deine Datenbank nach RDS zu übertragen, wäre das Ausfallfenster viel größer. Der DMS-Service nutzt eine AWS-Instanz, um die schwere Arbeit deiner Datenbank zu erledigen. Sie befindet sich zwischen deiner Quelle und deinem Ziel. Diese Instanz verwaltet die Kommunikation und Synchronisierung der Datenbanken und verursacht die Kosten für DMS. Für DMS würde ich eine Instanzgröße von r4.large oder größer empfehlen. Kleinere Instanzen wie T2/3 sind zwar zulässig, aber ich würde diese nicht für die Übertragung von Produktionsworkloads verwenden. Zum Zeitpunkt der Erstellung dieses Artikels kostet eine r4.large Instanz in us-east-1 $0,21 pro Stunde. Wenn du diese Instanz einen Monat lang laufen lässt, kostet das 153,30 $. Jede Replikationsinstanz ist auf 20 Quellen und Ziele begrenzt. Das bedeutet, dass du pro Instanz nur 10 Serverpaare in der Replikation haben kannst. Wenn du mehr als das brauchst, musst du eine weitere DMS-Replikationsinstanz buchen.
Hinweis
Wenn du nicht die Datenbank-Engine wechselst oder zu RDS umziehst, würde ich CloudEndure verwenden, um den Server statt der Datenbank zu übertragen.
In Abbildung 4-4 siehst du, dass ich die Werkzeuge in Zelle C6 auf dem Prognoseblatt eingetragen habe. Hier sollte die Summe der Werkzeuge eingetragen werden. Das Tabellenblatt füllt die Werkzeuge in Zeile 14 automatisch auf der Grundlage der Migrationsprozentsätze in Zeile 10 aus. Wir werden die "Migrationsprozentsätze" und ihre Verwendung später besprechen. Wenn du planst, für deine Migration AWS-fremde Werkzeuge zu verwenden, musst du die Preise des Anbieters erfragen und sie zu den Kosten der AWS-Werkzeuge addieren.
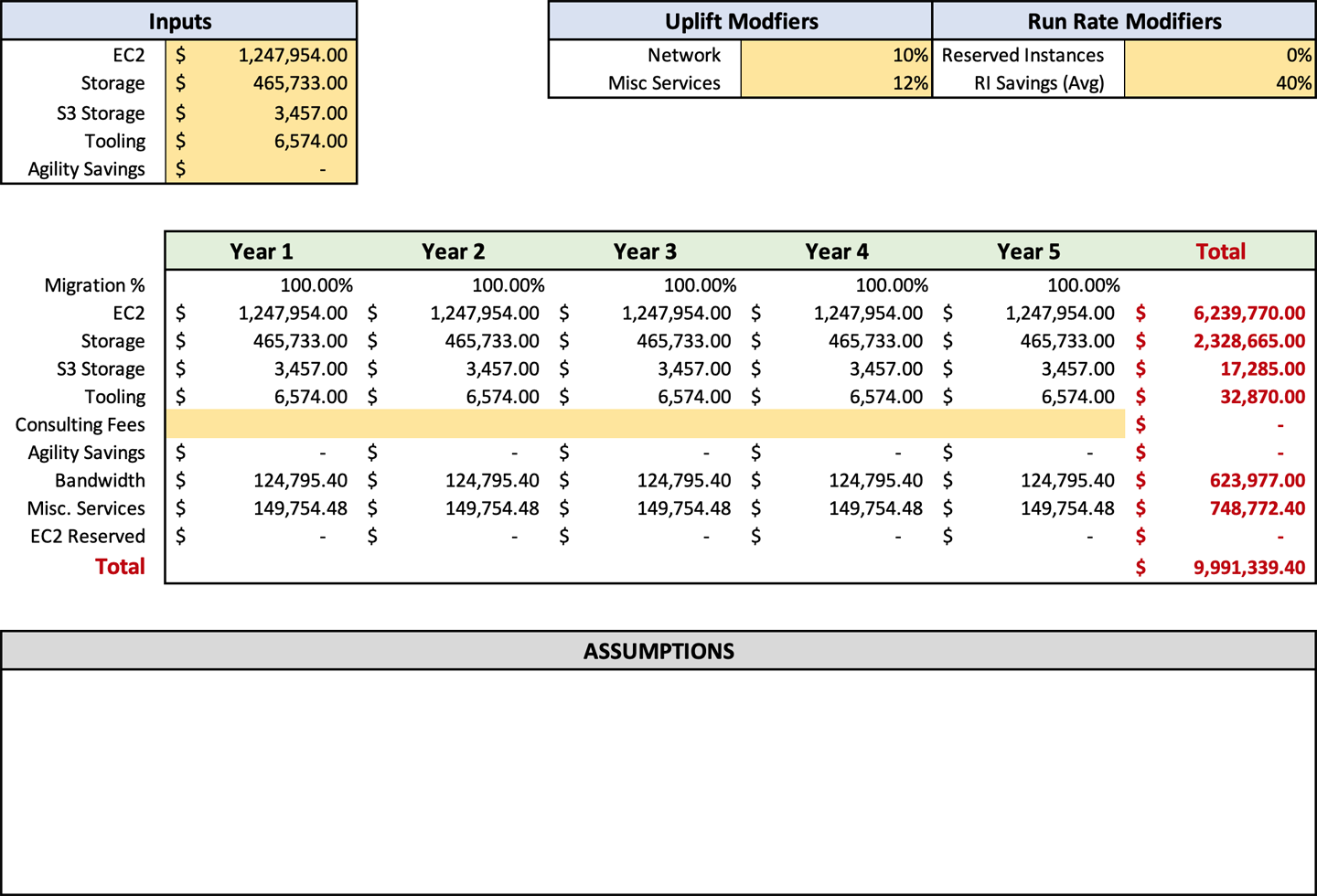
Beratungsgebühren
In Kapitel 2 haben wir über "Auftragnehmer und Beratung" gesprochen und darüber, wie sie durch ihre Erfahrung die Risiken für dein Unternehmen verringern können. Oft werden Berater und Auftragnehmer bei einer Umstellung als Kostenfaktor betrachtet. Es ist jedoch wichtig zu zeigen, dass ihre Erfahrung und ihre Fähigkeiten höchstwahrscheinlich die Zeitspanne verkürzen werden. Sie werden auch das Gesamtrisiko während der Migration verringern. Die Inanspruchnahme von Beratern ist nicht zu vermeiden, sondern eine taktische Entscheidung, um das Unternehmen zu unterstützen und die Dauer der Migration zu verkürzen. Insgesamt ist der Dollarbetrag für Berater nicht gering. Menschen sind in der Regel der größte Kostenfaktor für ein Unternehmen. Wenn du nicht über ein Budget verfügst, das die Beratungskosten abdecken kann, ist es wichtig, sie in die Migrationsprognose aufzunehmen.
Beratungshonorare sollten relativ einfach zu bekommen sein. Wenn du Berater/innen in Anspruch nimmst, übergibst du die Verwaltung deiner Migration an eine dritte Partei und auch den Aufwand, deine Ressourcen umzustellen. Diese Abstraktion ermöglicht es dem Beratungsunternehmen, das gesamte Projekt für dich zu kalkulieren. Das Beratungsunternehmen stellt dir einen Arbeitsplan (SOW) zur Verfügung, der auf den Punkten basiert, die du von ihm erledigen lassen möchtest. Der SOW enthält den Gesamtbetrag sowie eine Reihe von Erfolgskriterien und die erwartete Arbeit. Diese Informationen können dann in die Prognose in Zeile 8 eingetragen werden. Leider gibt es keine Standardmethode, um die Beratungskosten auf die gesamte Migration aufzuteilen, also musst du die Kosten nach deinem Ermessen auf die Jahre der Migration aufteilen. Auf dem Blatt sind keine Modifikatoren vorhanden, die dir dabei helfen.
Wenn es um die Honorare der Auftragnehmer geht, sind sie nicht so einfach zu erhalten, weil du sie manuell berechnen musst. Da du das Management bei den Auftragnehmern behältst, musst du die Höhe des Aufwands für deine Migration bestimmen. Zurzeit weiß ich, dass Auftragnehmer in Chicago in der Regel zwischen 100 und 150 Dollar pro Stunde bekommen können. Viele Auftragnehmer arbeiten auch über eine Vermittlungsfirma, also musst du 35% auf diese Gebühren aufschlagen, wenn du eine Vermittlungsfirma nutzt. Wenn du deine Auftragnehmerin oder deinen Auftragnehmer nicht selbst vermittelst, musst du mit 135 bis 195 Dollar pro Stunde rechnen, zuzüglich der Gemeinkosten. Hochwertige Auftragnehmer, die mit großen Unternehmen zusammenarbeiten, können bis zu 300 Dollar pro Stunde verlangen. Die Erfahrung spielt eine große Rolle bei der Preisgestaltung von Auftragnehmern. Ich würde darauf achten, dass du dir die Zertifizierungsnummern für alle behaupteten Zertifizierungen besorgst und dich auf der AWS-Zertifizierungsseite vergewisserst, dass sie tatsächlich vorhanden sind. Je mehr Zertifizierungen ein Auftragnehmer besitzt, desto mehr wird er verlangen. Du willst sichergehen, dass du dein Geld wert bist.
Eine weitere Option für Auftragnehmer ist AWS IQ, ein Service, mit dem sich AWS-zertifizierte Personen registrieren und ihre Dienste Unternehmen anbieten können, die die Plattform nutzen. Der Dienst validiert die Zertifizierungen automatisch, wenn sie ihr Konto registrieren, sodass du dir diesen Schritt sparen kannst. Der Dienst ermöglicht auch die Bezahlung über das bestehende AWS-Marktplatzsystem. Das System ermöglicht es, dass die Gebühren deiner Auftragnehmer als Teil deiner AWS-Rechnung ausgewiesen werden, wodurch deine Finanzabteilung entlastet wird. AWS IQ erhebt eine minimale Gebühr von 3 % zusätzlich zu den Gebühren der Auftragnehmer für die Nutzung des Dienstes.
Wenn du ein Suchunternehmen, AWS IQ oder einen Auftragnehmer direkt beauftragst, musst du trotzdem die Anzahl der Stunden schätzen, die du für diese Dienstleistungen benötigst. Wie lange du die Dienste eines Auftragnehmers benötigst, hängt leider von den Bedürfnissen deines Unternehmens, dem Zeitplan für die Migration und den derzeitigen personellen Möglichkeiten ab. Du musst all diese Faktoren berücksichtigen, um zu bestimmen, wie lange und wie viele Auftragnehmer du brauchst. Sobald du diesen Zeitraum ermittelt hast, kannst du berechnen, wie viel es kosten wird, sie für diesen Zeitraum zu beschäftigen. Das folgende Szenario zeigt dir, wie eine solche Kalkulation aussehen könnte.
Wenn wir rückwärts arbeiten, kann Beccas Team etwa 90 Server pro Monat migrieren. Derzeit ist ihr Zeitplan sechs Monate zu lang. Wenn du 90 mit 5 multiplizierst, kommst du auf 450 Server, die bis zum neunten Monat nicht migriert werden können. Wenn wir die Überschreitung wieder auf neun Monate aufteilen, ihr angestrebtes Ziel, kommen wir auf 50. Becca braucht also genug Vertragspersonal, um weitere 50 Server pro Monat zu migrieren, damit sie ihre neue Frist einhalten kann. Wenn Becca sich an Auftragnehmer wendet, die über AWS-Erfahrung verfügen und bereits Migrationen durchgeführt haben, könnte sie von ihnen eine Migrationsrate von zwei Servern pro Tag erhalten. Bei 20 Arbeitstagen im Monat könnte ein sehr erfahrener Auftragnehmer 40 Server migrieren. Becca braucht zwei, um ihren Mehrbedarf zu decken und ihr Gesamtmigrationsrisiko zu verringern, denn ein zweiter Auftragnehmer erhöht die monatliche Kapazität auf 80 zusätzliche Server pro Monat. Das sind 30 Server mehr als sie braucht, was das Risiko weiter verringert.
Ausgehend von Beccas Bedarf muss sie 2.880 Stunden an Kosten für Auftragnehmer einkalkulieren. Ich würde vorschlagen, einen höheren Stundensatz von 188 $ anzusetzen, um mehr Flexibilität zu gewährleisten. Becca würde für das erste Jahr 541.440 $ in die Zelle C15 eintragen, wie in Abbildung 4-5 dargestellt. Wir wissen, dass es das erste Jahr ist, weil ihr optimaler Zeitplan für die Migration neun Monate beträgt.
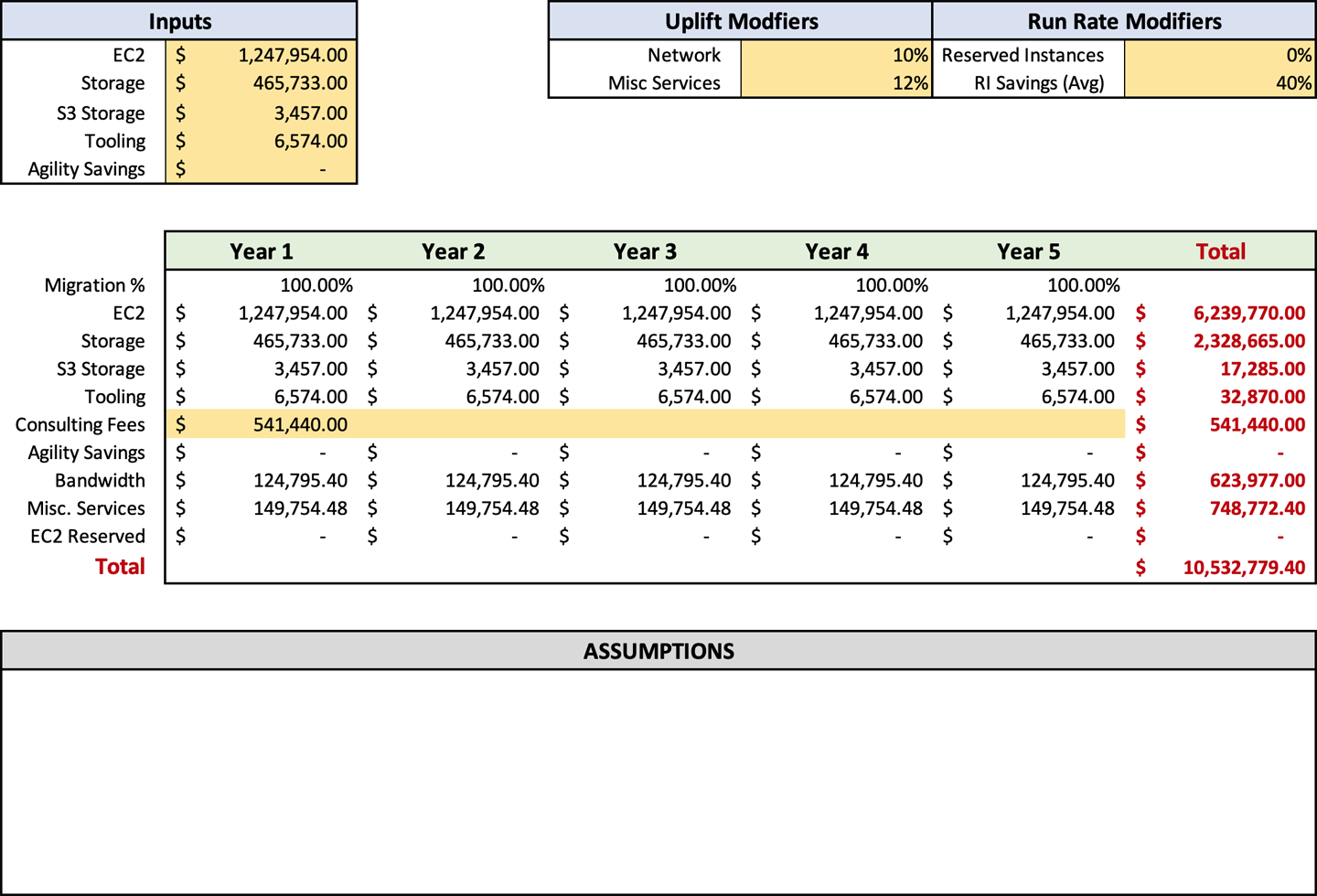
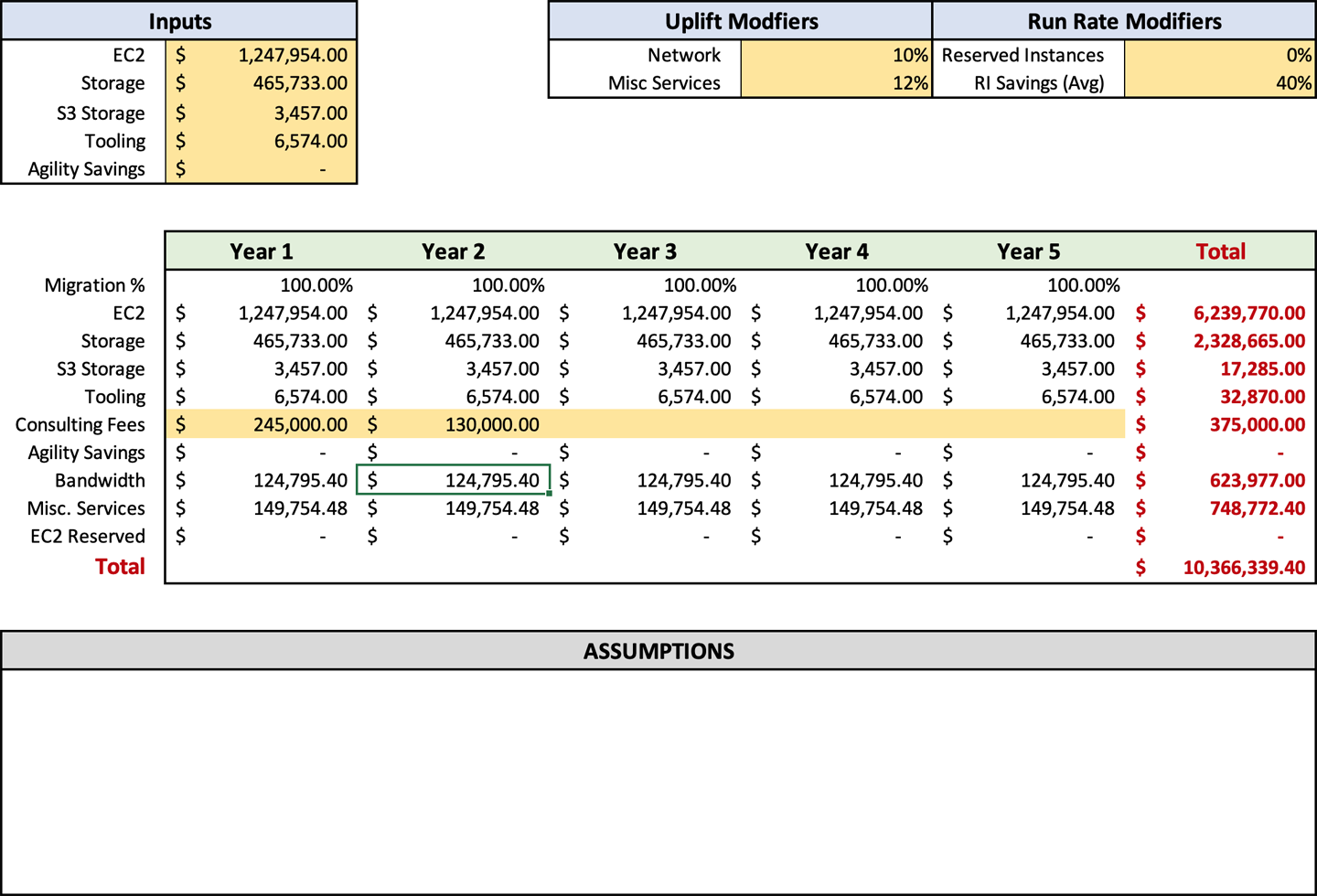
Nachdem du die Kosten für Beratung und Auftragnehmer berechnet hast, kannst du dir ein genaues Bild davon machen, wie viel die Migration kosten wird. Das Prognoseblatt zeigt dir auch, wie hoch deine laufenden Kosten nach der Migration sein werden, die du mit deinen aktuellen Betriebskosten für die Infrastruktur vergleichen kannst. Ich zögere, die Investitionsrendite im Vergleich zu On-Premises zu nennen, weil es oft ein Vergleich von Äpfeln mit Birnen ist. Aber ich würde sagen, dass du bei den meisten Unternehmen eine Kostensenkung feststellen wirst, wenn du die AWS-Betriebskosten mit den Kosten vor Ort vergleichst. Nachdem du deine Beratungs- und Auftragnehmerkosten eingegeben hast, sollte deine Prognose wie in Abbildung 4-6 aussehen.
Run Rate Modifier
Jetzt, da du weißt, wie viel alles kosten wird, ist es an der Zeit, Run-Rate-Modifikatoren anzuwenden, damit du die Ausgaben auf der Grundlage von Variablen anpassen kannst, die stark von den Gegebenheiten eines Unternehmens abhängen. Eine Vielzahl von Optionen kann sich auf deine Run Rate auswirken; das ist eine der schönen Seiten von AWS. Ich werde mich jedoch auf die größten und am häufigsten anwendbaren Hebel konzentrieren, die zur Verfügung stehen. Diese Hebel sind reservierte Instanzen, Sparpläne, Migrationsprozentsätze, Einsparungen bei der Agilität und Einsparungen beim Management.
Reservierte Instanzen
Reservierte Instanzen (RIs) sind wahrscheinlich die einfachste Möglichkeit, bei AWS eine Menge Geld zu sparen. Eine reservierte Instanz bedeutet, dass du dich bereit erklärst, eine Instanz eines bestimmten Typs und Betriebssystems für einen Zeitraum von einem oder drei Jahren zu nutzen. Wenn du dich bereit erklärst, die Instanz für einen längeren Zeitraum zu nutzen, erhältst du einen Rabatt auf die Gesamtbetriebskosten für diese Instanz. Der Rabatt, den du erhältst, hängt davon ab, für wie lange du deine RI kaufst und wie viel du im Voraus bezahlst. Es gibt die Möglichkeit, die gesamten Kosten für die Instanz im Voraus zu bezahlen, die so genannte "all up-front RI", bis hin zu "no up-front" (keine Vorauszahlung). Den höchsten Rabatt erhältst du beim Kauf einer RI für drei Jahre ohne Vorauszahlung. Beim Kauf einer RI kannst du im Durchschnitt 40 % für ein Jahr und 60 % für drei Jahre sparen. Ich bin jedoch aus den folgenden vier Gründen kein Fan von dreijährigen RIs:
- Im Gegensatz zu Agilität
-
Der wichtigste Vorteil von AWS ist die geschäftliche Agilität, warum solltest du dich also an eine dreijährige Instanz binden? In drei Jahren könnte ein neuer Service auf den Markt kommen, der serverlos oder on-demand ist und dir Tausende einsparen könnte.
- Instanzen verbessern
-
AWS bringt ständig neue Instanztypen heraus; einige davon sind deutlich schneller als ihre Vorgänger. Du hast dich an einen Ford gebunden, obwohl du einen Tesla haben könntest.
- Barauslagen
-
Um den größten Nutzen zu erzielen, musst du deine Server im Voraus bezahlen, also hast du einen großen Bargeldaufwand wie beim Betrieb vor Ort (allerdings nutzt du die Abschreibung statt der Abschreibungsmethode).
- Gesunkene Preise
-
AWS senkt die Preise für Instances von Zeit zu Zeit. Bei einer dreijährigen Reservierung hast du sie bereits gekauft und kannst die Preissenkung nicht in Anspruch nehmen.
Du kannst reservierte Instanzen auf einem Marktplatz weiterverkaufen und konvertierbare reservierte Instanzen kaufen. Mit diesen beiden Möglichkeiten kannst du entweder deine RI ändern, wie bei den konvertierbaren reservierten Instanzen, oder sie über den Marktplatz verkaufen. Aber du musst dich fragen, ob du wirklich willst, dass deine Mitarbeiter ihre Zeit mit dieser Art der Verwaltung verschwenden. Oder willst du, dass sie einen Mehrwert für dein Unternehmen schaffen?
Es gibt viele Gründe und Methoden, reservierte Instanzen zu kaufen, und ich könnte leicht ein halbes Buch über dieses Thema schreiben. Ich werde mich stattdessen auf eine einfache Möglichkeit konzentrieren, deine Prognose anzupassen, um den Kauf von RI auszugleichen. Die Aufnahme von Instanzinformationen in die Prognose würde ihre Lebensdauer verkürzen und ihre Komplexität erhöhen. Letztendlich brauchen wir dieses Maß an Präzision nicht. Stattdessen werden wir mit generischen Rabatten arbeiten, die auf der Art und Länge der RI basieren.
Um den RI-Fußabdruck in der Prognose anzupassen, änderst du den Prozentsatz in Zelle H3. Der Prozentsatz gibt den Anteil des Grundstücks an, der nicht reserviert ist. Normalerweise empfehle ich, 10-20% als On-Demand-Puffer zu belassen. Dieser On-Demand-Puffer stellt sicher, dass deine RIs immer genutzt werden. Da die RI auf dem Betriebssystem und der Instanzgröße basiert, bleibt die RI ungenutzt, wenn du keine Instanz mit dieser Konfiguration betreibst. Wenn du also einen bestimmten Prozentsatz als On-Demand-Puffer angibst, wird sichergestellt, dass alle deine RIs genutzt werden. Der On-Demand-Prozentsatz ermöglicht es dir auch, deine Umgebung zu ändern. Nach der Migration kannst du zum Beispiel eine Anwendung so aktualisieren, dass sie automatische Skalierung unterstützt. Indem du die Anwendung auf Autoskalierung umstellst, bleiben die reservierten Instanzen, die für die Anwendung gekauft wurden, verfügbar, wenn die Anwendung in Zeiten geringer Nachfrage wieder skaliert.
Wenn deine Infrastruktur über viel automatische Skalierung verfügt, solltest du den Prozentsatz nach oben anpassen. Wenn du viele COTS-Anwendungen ohne automatische Skalierung verwendest und dich nicht oft änderst, solltest du den Prozentsatz der On-Demand-Anwendung niedriger ansetzen. Wenn dein Unternehmen klein ist und du nicht viele Server hast, hast du wahrscheinlich eine gute Vorstellung von deinem Bestand und seinem Wachstum. In diesem Fall solltest du einen sehr niedrigen On-Demand-Anteil wählen.
Sparpläne
2019 hat AWS eine neue Möglichkeit geschaffen, Rechenressourcen zu kaufen: Savings Plans. Savings Plans bieten einen Rabatt, wenn du die Nutzung von Ressourcen garantierst, genau wie reservierte Instances. Der Hauptunterschied zwischen Savings Plans und reservierten Instances besteht darin, dass Savings Plans ein hohes Maß an Flexibilität bieten. Savings Plans werden auf der Grundlage der Rechenleistung gekauft, die du pro Instance-Familie nutzen möchtest. Siehe Tabelle 3-1 zur Erläuterung. Außerdem sind Savings Plans nicht an eine Region gebunden, wie es bei RIs der Fall ist. Das bedeutet, dass du dein Risiko und deinen Verwaltungsaufwand durch den Einsatz von Sparplänen erheblich reduzieren kannst.
Natürlich gibt es auch einen möglichen Nachteil bei der Nutzung von Sparplänen. Die Höhe der Einsparungen in einem Sparplan ist etwa 10 % geringer als beim Kauf von RIs. Wenn du ein mittelgroßes Unternehmen bist, empfehle ich dir, einen Sparplan zu nutzen. Wenn du ein sehr großes Unternehmen bist, könnten die 10 % weniger Einsparungen den erhöhten Personalaufwand für die Verwaltung der RI-Käufe rechtfertigen. Für ein kleines Unternehmen würde ich bei den RIs bleiben, da du die Nutzung deiner Computerinfrastruktur wahrscheinlich sehr gut kennst. In der Prognosevorlage gibt es keine speziellen Zellen für Sparpläne. Wenn du Sparpläne anstelle von RIs verwenden willst, solltest du den Prozentsatz in Zelle H4 von 40%, der durchschnittlichen RI-Einsparung, auf 27% ändern. Du nimmst diese Änderung vor, weil die durchschnittliche Kostenreduzierung eines einjährigen Sparplans 27% beträgt. In diesem Stadium des Prozesses sollte Abbildung 4-7 eine ähnliche Darstellung deiner Eingaben sein.
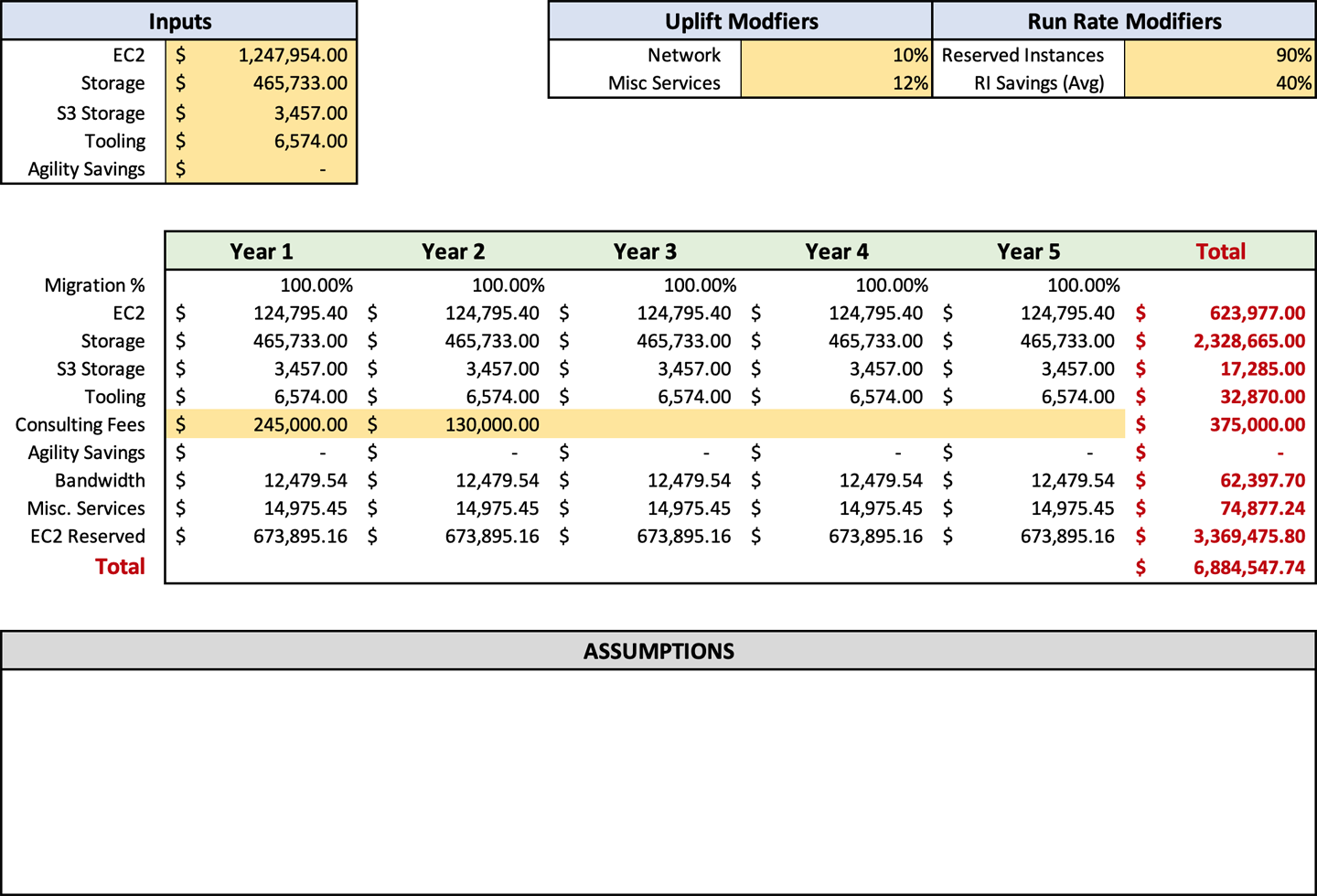
Hinweis
Du kannst eine Kombination aus einem Sparplan und RIs verwenden. Ich würde dir aber davon abraten, wenn du die Auswirkungen beider Möglichkeiten nicht wirklich verstehst.
Prozentsätze der Migration
Die Migration zu AWS ist kein sofortiger Prozess. Keine Form der Migration ist ein sofortiger Prozess. Wenn du an die jüngere Geschichte zurückdenkst, wirst du die gleichen Zeitspannen bei der Migration von physischen Servern zu virtuellen Maschinen sehen, sogar bei der Migration von VMware von einem Rechenzentrum zum anderen. In dieser Hinsicht ist die Migration zu AWS nichts Neues. Es sind nur die Möglichkeiten, die sich geändert haben.
Du hast die Discovery bereits durchlaufen. Du weißt, wie viele Server du hast. Du hast berechnet, wie viel Arbeit dein Team leisten kann, und du hast die Auftragnehmer und Berater berücksichtigt. All diese Werte hast du in die Microsoft Excel-Prognose eingegeben. So wie es jetzt aussieht, hast du Ausgaben für fünf Jahre, und jedes Jahr ist dasselbe, nämlich die volle migrierte Run Rate.
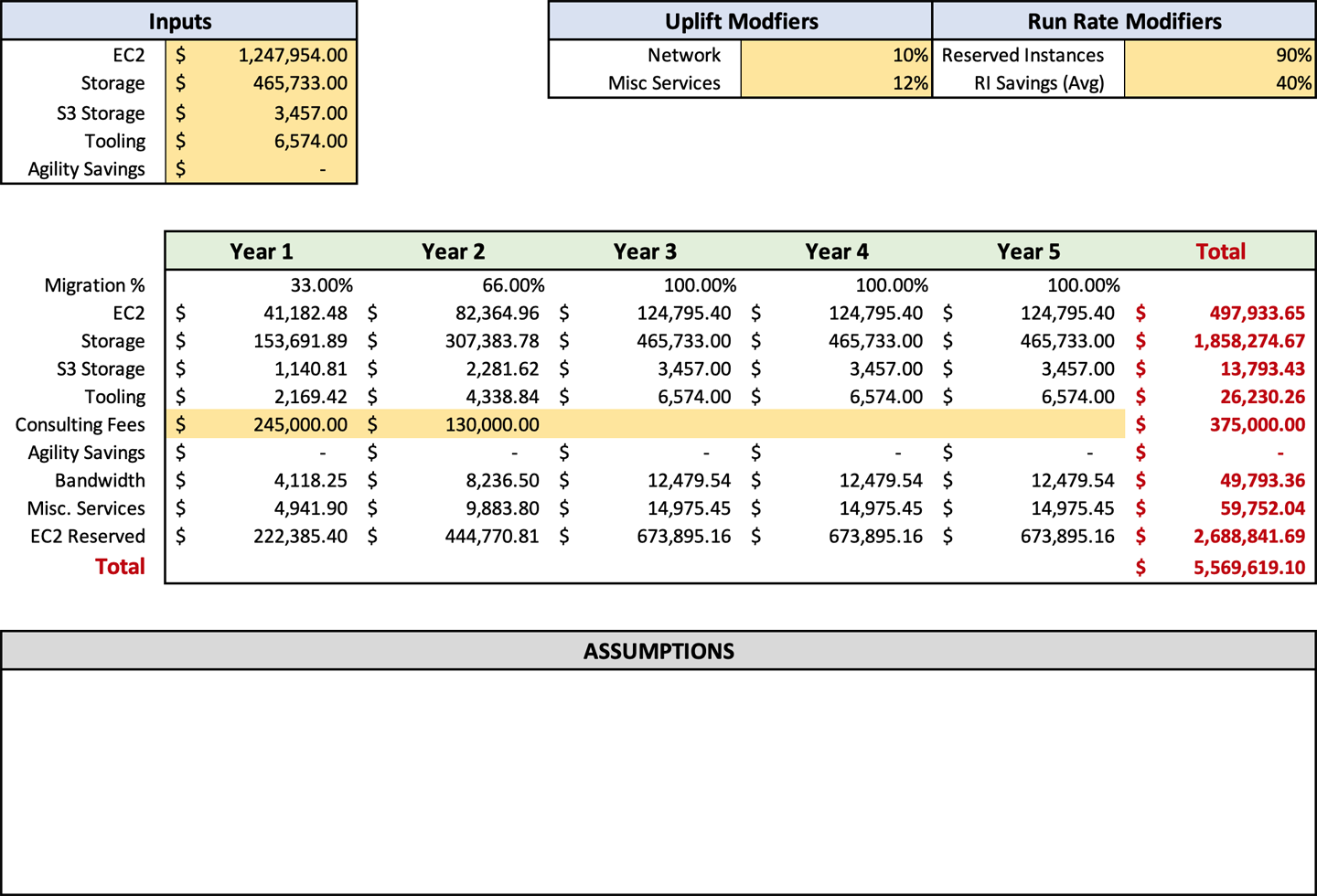
Da es sich um Run-Rate-Modifikatoren handelt, werden wir die Migrationsprozentsätze in Zeile 10 anpassen. Die Tabelle beginnt mit einem Wert von 100% für alle fünf Jahre. Das ist so, als hätte eine magische Fee alle deine Server für dich migriert. Jetzt musst du zurückgehen und die Werte an deinen Zeitplan anpassen. Wenn du zum Beispiel einen Zeitrahmen von zwei Jahren hast, hast du im ersten Jahr ungefähr 50 %, und die Jahre zwei bis fünf bleiben bei 100 %. Bei einer dreijährigen Migration wären es 33% im ersten Jahr, gefolgt von 66% im zweiten Jahr und 100% in den Jahren drei bis fünf.
Ein großes Unternehmen sollte mit einem dreijährigen Migrationszeitraum rechnen. Ein kleines Unternehmen sollte weniger als ein Jahr für die Umstellung veranschlagen, und ein mittleres Unternehmen etwa zwei Jahre. Sobald du alle Informationen eingegeben hast, wird die Run Rate automatisch auf der Grundlage dieser Prozentsätze berechnet.
Du hast vielleicht bemerkt, dass wir hier nur mit Prozentsätzen arbeiten, und das geht zurück auf meine Analogie mit dem Sprung ins All. Wir haben noch keine Migrationsplanung gemacht und kennen daher nicht die kleinsten Details. Wie bei vielen anderen Prozessen auch, wollen wir jetzt nicht im Teer von mehr Informationen stecken bleiben und damit deinen Migrationsprozess verlangsamen. Wir werden uns später, in Kapitel 7, mit der Migrationsplanung befassen und den Zeitplan genauer erläutern. In diesem Stadium des Prozesses sollte Abbildung 4-8 deinen Eingaben ähneln.
Agilität Ersparnis
Wenn ich Unternehmen bei der Migration zu AWS helfe, betone ich immer, wie wichtig es ist, so viel wie möglich zu verlagern: Server Block für Block zu AWS zu kopieren und sich nicht auf das Refactoring oder wesentliche Änderungen an der Anwendung oder Infrastruktur zu konzentrieren. Ich schlage dies vor, weil du während der Migration doppelt so viel ausgibst. Ich konzentriere mich so weit wie möglich darauf, die Zeitspanne und die Kosten zu verkürzen. Es gibt ein paar Bereiche, in denen ich empfehle, die niedrig hängenden Früchte zu ernten, um Flexibilität und Einsparungen beim Management zu erzielen. Ich würde diese Änderungen nicht als Refactoring, sondern eher als Augmentation bezeichnen. Ich empfehle den Unternehmen, diese Änderungen zu nutzen, denn sie sind leicht zu erreichen.
Schließlich sind Agilität und geringere Arbeitsbelastung die Hauptgründe, warum Menschen zu AWS migrieren wollen. Es ist sinnvoll, einige dieser Funktionen von Anfang an zu nutzen. Ich werde vor allem über Bereitstellungspipelines und den AWS Service Catalog sprechen. Diese Services sind am einfachsten zu nutzen. Sie können sogar mit COTS-Anwendungen genutzt werden, sodass sie für fast alle Arbeitslasten und Unternehmen geeignet sind.
Automatisierter Einsatz
Bereitstellungspipelines werden von vielen mit intern entwickelten Anwendungen in Verbindung gebracht, aber das ist nicht immer der Fall. Pipelines können auch für die Bereitstellung von COTS-Anwendungen verwendet werden. Normalerweise sehe ich Einsatzpipelines für COTS-Anwendungen in hochsicheren Umgebungen. In einer hochsicheren Umgebung würdest du deine Server jede Woche rehydrieren wollen. Bei der Rehydrierung werden die alten Rechner vernichtet und neue Rechner mit den neuesten Patches und Anwendungen installiert. In einer hochsicheren Umgebung solltest du dies tun, weil so sichergestellt wird, dass potenzielle Malware, Viren oder Trojaner entfernt werden. Die Rehydrierung trägt dazu bei, die Angriffsfläche der COTS-Server zu verringern, und kann für Manager in regulierten Umgebungen wie Finanzdienstleistungen ein wichtiges Instrument sein. Für die meisten Menschen ist es jedoch wichtig, eine Deployment-Pipeline für ihre internen Anwendungen zu haben.
Bereitstellungspipelines helfen dabei, den manuellen Aufwand für die Bereitstellung und das Testen erheblich zu reduzieren. Vor Ort gibt es höchstwahrscheinlich eine Person im technischen Team oder im Betriebsteam, die die Anwendung erhält, sobald sie erstellt wurde, und die die Anwendung bereitstellt. Das kostet dein Unternehmen nicht nur viel Geld, sondern ist auch eine langweilige und banale Aufgabe, die die Mitarbeiter/innen demoralisieren kann. Die manuelle Bereitstellung ist außerdem anfällig für menschliche Fehler, was zu Sicherheitsbedenken und Kundenausfällen führt. Durch den Einsatz einer Verteilungspipeline reduzierst du all diese Risiken und die damit verbundenen Kosten.
Der Service, den Amazon für Pipelines anbietet, heißt CodePipeline. Er kann manuell von einer Person oder automatisch auf der Grundlage verschiedener Auslöser ausgelöst werden, z. B. wenn eine neue Datei in S3 bereitgestellt wird oder wenn ein neuer Check-in in deinem Code-Repository erfolgt, oder du kannst ihn mit einem CloudWatch-Ereignis planen. In den meisten Unternehmen wird die Bereitstellung automatisch nach einem Code-Check-in durchgeführt. Du könntest auch eine Pipeline erstellen, die manuell ausgelöst werden muss, obwohl ich das in der Praxis noch nicht gesehen habe. Ich habe jedoch gesehen, dass manuelle Prüfungen in eine automatische Pipeline implementiert werden, z. B. Genehmigungen vor der Produktionsfreigabe.
CodePipeline hat viele Möglichkeiten. Wir werden uns jedoch ein paar wichtige Funktionen ansehen, wie z. B. automatisierte Einheitstests, Lasttests und andere Funktionen, die dazu beitragen, den Personalaufwand weiter zu reduzieren. Die Nutzung von CodePipeline ist kostenpflichtig. Die Kosten sind jedoch sehr gering, es sei denn, du hast einige sehr spezielle Anwendungsfälle. In diesen Fällen kann es vorkommen, dass du viele Unit-Tests oder Lasttests durchführst, was die Kosten in die Höhe treiben würde. Ich würde sagen, dass der Aufschlag für verschiedene AWS-Services, die du bereits in deiner Prognose hast, ausreicht, um CodePipeline zu bezahlen.
Im Moment sprechen wir über Prognosen und wollen mögliche Einsparungen durch den Einsatz von CodePipeline in deiner Umgebung erkennen. Dazu brauchen wir einige Informationen, um diese Einsparungen zu berechnen. Die erste Information sind die durchschnittlichen Kosten pro Stunde für das Personal, das deine Einsätze durchführt. Es ist wichtig, die tatsächliche Auslastung der Mitarbeiter zu berechnen, nicht nur das Grundgehalt. Du musst sicherstellen, dass dein Stundensatz auch Urlaub, Sozialleistungen und Lohnnebenkosten enthält, um eine echte Darstellung zu erhalten. Für diese Übung nehmen wir 100 US-Dollar pro Stunde als Stundensatz an. Die nächste Information, die wir brauchen, ist die Zeit, die für den Einsatz deiner Software benötigt wird. Das ist die Zeit, die ein Techniker braucht, um die Software zu besorgen, sich auf dem Server anzumelden, Backups zu erstellen, die Updates zu installieren und Smoke-Tests und andere Funktionstests durchzuführen. Nehmen wir für unsere Übung vier Stunden pro Umgebung an. Die letzte Information, die wir brauchen, ist, wie oft Aktualisierungen durchgeführt werden. Normalerweise werden Updates am häufigsten in Entwicklungsumgebungen, seltener in Testumgebungen und deutlich seltener in Produktionsumgebungen durchgeführt. Du musst herausfinden, wie oft du in jeder dieser Umgebungen Updates bereitstellst, um genau zu berechnen, wie viel du durch eine automatische Bereitstellung sparen kannst. Für diese Übung nehmen wir eine Implementierung pro Woche für die Entwicklung, eine Implementierung pro Monat für die Tests und eine Implementierung alle drei Monate für die Produktion an. Diese Zahlen sind ein typischer Durchschnitt, den ich in den meisten Unternehmen sehe.
Rechnen wir mal ein bisschen nach. Wir nehmen die 4 mal 4 Stunden, also insgesamt 16 Stunden pro Monat für die Bereitstellung der Entwicklungsumgebung. Das sind 2 Tage Aufwand pro Monat in einem Jahr, was 24 Tagen entspricht, also mehr als einem ganzen Arbeitsmonat. Die 24 Tage gelten nur für die Entwicklungsumgebungen. Als Nächstes wollen wir berechnen, wie viel das genau kostet. Wir haben gesagt, dass wir 100 Dollar pro Stunde nehmen, also multiplizieren wir 100 mit 8 Stunden, was die tägliche Gesamtsumme auf 800 Dollar bringt. Jetzt multiplizieren wir diese 800 Dollar mit den 24 Arbeitstagen des Jahres. Das ergibt eine Gesamtsumme von 19.200 $. Wie du siehst, ist das eine große Ausgabe für dein Unternehmen. Nachdem wir nun die Entwicklungskosten kennen, wollen wir den Prozess für die Test- und Produktionsumgebung wiederholen.
Die Kosten für die Testumgebung betragen ein Viertel der Kosten für die Entwicklung, da sie nur einmal im Monat eingesetzt wird. Der Test wird vier Stunden pro Monat oder einen Tag alle zwei Monate in Anspruch nehmen, was sechs Tage im Jahr ergibt. Wir multiplizieren sechs Tage mit 800 $ und erhalten so die Gesamtkosten für den Test von 4.800 $ pro Jahr.
Die Produktion wird nur einmal pro Quartal eingesetzt. Der Aufwand für die Produktion beträgt zwei Tage pro Jahr oder 1.600 US-Dollar. Du siehst also, dass dieses Unternehmen Zehntausende von Dollar (25.600 $) für die Bereitstellung der Anwendung ausgibt. Die Automatisierung der Anwendungsbereitstellung kann deinem Unternehmen also eine beträchtliche Menge an Geld sparen. Diese Kosten beziehen sich auf nur eine Anwendung. Die meisten Unternehmen setzen mehrere Anwendungen oder mehrere Teile einer großen Anwendung ein. Dieser Anwendungswildwuchs führt zu einer erheblichen Verschwendung von Unternehmensressourcen und möglicherweise zu mehreren Mitarbeitern.
Du möchtest diesen Vorgang für jede Anwendung wiederholen, die du automatisch einsetzen kannst, und deine Gesamteinsparungen in Zelle C7 aktualisieren. Du möchtest dies nicht für eine Anwendung tun, die derzeit eine große Anzahl manueller Änderungen und Konfigurationen erfordert. Diese müssen automatisiert werden. Das dauert länger und verlängert den Zeitrahmen für die Umstellung, wodurch sich die erzielten Einsparungen verringern würden.
Das Wunderbare an der automatisierten Bereitstellung mit CodePipeline ist, dass du die Flexibilität deines Unternehmens erheblich steigern kannst. Wahrscheinlich bringt dein Unternehmen nicht so viele Updates für dein Produkt heraus, wie du es gerne hättest. Das liegt nicht daran, dass die Entwickler keine Änderungen vornehmen. Es liegt daran, dass die Kosten für die Bereitstellung beträchtlich sind und die Risiken, die damit verbunden sind, die Vorteile aufwiegen. Wenn du deine Pipeline erst einmal eingerichtet hast, kannst du die Zahl der Produktionsaktualisierungen deutlich erhöhen und deinen Kunden schneller einen Mehrwert bieten. Es ist nicht ungewöhnlich, dass Unternehmen, die einen agilen und automatisierten Bereitstellungsprozess eingeführt haben, bis zu 10 Produktionsaktualisierungen pro Tag durchführen. Diese Geschwindigkeit ist eine enorme Verbesserung der Markteinführungszeit im Vergleich zu den meisten Unternehmen, die Updates nur vierteljährlich oder länger bereitstellen. Die Entwicklung kann täglich oder mehrmals am Tag erfolgen. Die Test- und Produktionsphase könnte dem Beispiel folgen und mehrere Produktionsaktualisierungen pro Tag erreichen. Um dieses Maß an Flexibilität zu erreichen, muss dein Unternehmen in mehr als nur eine einfache Verteilungspipeline investieren und die automatisierten Tests ausbauen, um eine qualitativ hochwertige Veröffentlichung zu gewährleisten.
Servicekatalog
AWS Service Catalog ist ein Service, mit dem du Produkte mit CloudFormation-Vorlagen erstellen kannst, die AWS-Infrastruktur als Code (IaC) bereitstellen. Mit CloudFormation kannst du den Großteil der Bereitstellung deiner AWS-Infrastruktur automatisieren. Sieh dir zum Beispiel das folgende Code-Snippet an:
InstanceSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Allow http from the internet
VpcId:
Ref: myVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
SecurityGroupEgress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
Dein Betriebsteam kann dann semitechnischen Mitarbeitern den Zugriff auf diese Produkte erlauben, um die für ihre Arbeitslasten erforderliche Infrastruktur bereitzustellen. Service Catalog ist eine hervorragende Möglichkeit, um nach der Migration zu AWS Geld zu sparen. Ich habe gesehen, dass viele Unternehmen ihre Betriebsabteilung durch die Einführung von Service Catalog erheblich entlastet haben.
In vielen Unternehmen ist das Betriebsteam oder das Cloud-Management-Team ein Hemmschuh und ein Single Point of Failure bei der Bereitstellung der Infrastruktur. Durch die Einführung von Service Catalog ermöglichen Sie es Ihren Geschäftseinheiten, ihre Infrastruktur bereitzustellen, und verringern so die Abhängigkeit von Ihrem Betriebsteam. Dadurch wird die Abhängigkeit vom Betriebsteam verringert, Verzögerungen werden reduziert und die Servicequalität insgesamt erhöht.
Wenn du eine Migration zu AWS planst, empfehle ich dir, bei der Suche nach sich wiederholenden Mustern in deinen aktuellen Anwendungen auf Service Catalog zurückzugreifen. Wenn du diese wiederkehrenden Muster identifizierst, kannst du die Wirkung von Service Catalog maximieren. Dein Team kann diese wiederkehrenden Muster dann in Infrastruktur als Code und ein Service Catalog-Produkt umsetzen. Sobald die Produkte fertiggestellt und dem Katalog hinzugefügt sind, können Zugriffsrechte vergeben werden, damit die Mitarbeiter sie einsetzen können.
Herauszufinden, wie viel du durch den Servicekatalog gespart hast, ist für jedes Unternehmen anders. Um deine Einsparungen zu ermitteln, werden wir zwei Szenarien betrachten. Das folgende Szenario konzentriert sich auf die automatisierte Bereitstellung von EC2-Instanzen, und "Szenario 4-6" befasst sich mit S3-Buckets, die für das Unternehmen gehärtet wurden.
Wenn du deine Infrastruktur nach Mustern untersuchst, stößt du oft auf eine Menge Lärm. Wenn dein Unternehmen wie das von Bridget ist, gibt es wahrscheinlich viele Server, Anwendungen und Entwurfsmuster. Manchmal starrt dir die Antwort jedoch direkt ins Gesicht, und du musst sie erst aus dem Weg räumen, um sie zu sehen. Ich habe absichtlich viele irrelevante Informationen in dieses Szenario eingebaut, um diese Tatsache zu demonstrieren. Wir sind auf der Suche nach sich wiederholenden Mustern, um die Wirkung des Servicekatalogs zu optimieren. Es spielt keine Rolle, wie viele Server oder Anwendungen Bridget hat. Du hast dir vielleicht schon Gedanken über die Infrastruktur gemacht: wie die Server, Load Balancer, Auto-Scaling-Gruppen und ähnliche Elemente angeordnet sind. Für deine Infrastruktur sind das vielleicht brauchbare Optionen. In Bridgets Fall ist die Tatsache, dass ihr Unternehmen reguliert ist und sie für jedes System dreieinhalb Stunden Aufwand betreiben muss, eine enorme Energiemenge.
Wenn wir der Einfachheit halber 100 Dollar pro Stunde für ihr Betriebsteam ansetzen, sehen wir, dass es das Unternehmen 28.000 Dollar pro Monat kostet, diese Server bereitzustellen,1 oder 336.000 $ im Jahr. Ich weiß nicht, wie es dir geht, aber ich möchte diese Zahl nicht in meinem Budget haben, und ich bin mir sicher, dass meine Mitarbeiter lieber etwas Interessanteres machen würden.
Um zu berechnen, wie viel Bridget letztendlich sparen wird, müssen wir auch die Zeit berechnen, die ihr Team für die Erstellung des Servicekatalogs benötigt. Anhand der Beschreibung ihrer Umgebung kann man mit ziemlicher Sicherheit sagen, dass die Arbeit drei Wochen dauert. Dieser Zeitrahmen würde die Erstellung der erforderlichen CloudFormation- und Automatisierungsskripte sowie das Testen des Produkts nach seiner Fertigstellung beinhalten. Ausgehend von den Kosten pro Stunde wird Bridgets Unternehmen 12.000 $ für die Erstellung des Produkts benötigen.2 Als Nächstes müssen wir wissen, wie viel es kosten wird, das Produkt bereitzustellen. Nehmen wir an, dass es 10 Minuten dauert, sich an der AWS-Konsole anzumelden, das Produkt auszuwählen, die Optionen zu konfigurieren und es bereitzustellen. Das bedeutet, dass es Bridget's Unternehmen 16.000 US-Dollar an Personalaufwand kosten würde, die gleichen Server über einen Zeitraum von einem Jahr bereitzustellen.3 Durch die Einführung dieses Produkts spart Bridgets Unternehmen im ersten Jahr insgesamt 308.000 USD.4 Das ist eine beträchtliche Investitionsrendite und die Einführung würde sich für das Unternehmen sehr lohnen.
Ich würde gerne sagen, dass das ein absurdes Szenario ist, das niemals passieren würde. Aber das ist eine der Situationen, die das Leben seltsamer macht als die Fiktion. Es ist keineswegs ungewöhnlich, dass eine banale technische Aufgabe mit Verwaltungsaufwand überfrachtet wird. Kurt möchte die 354.600 Dollar einsparen, die sein Unternehmen derzeit für eine banale und geringwertige Aufgabe ausgibt. ServiceNow verfügt über einen Konnektor, den Kurts Unternehmen nutzen kann und der es den Mitarbeitern ermöglicht, die AWS-Infrastruktur direkt bereitzustellen, ohne sich bei AWS anzumelden. Mit dem Konnektor kann sein Unternehmen die vorhandenen Workflow- und Genehmigungsfunktionen von ServiceNow nutzen, ohne dass das Cloud-Engineering-Team manuell eingreifen muss. Auch wenn Kurt für die Einrichtung des Konnektors für die Schnittstelle zum AWS Service Catalog Beratungsleistungen in Anspruch nehmen muss, erzielt er bereits im ersten Jahr eine beträchtliche Kapitalrendite (ROI).
Je nach Größe deines Unternehmens kann Service Catalog erhebliche Einsparungen für dein Unternehmen bringen. Wenn dein Unternehmen nur ein paar Dutzend Mitarbeiter hat, würde die Investitionsrendite die Kosten für die Implementierung wahrscheinlich nicht rechtfertigen. Mit dem Servicekatalog kannst du auch dazu beitragen, die finanziellen Ausgaben einzudämmen, indem du nur Infrastrukturgrößen genehmigst, die für dein Unternehmen angemessen sind. Auch für die Nutzerinnen und Nutzer verbessert sich das Nutzererlebnis oft. Mit dem Servicekatalog können sie die Produkte, die sie bereits eingesetzt haben, einfach einsehen und werden automatisch benachrichtigt, wenn ein Update veröffentlicht wird.
Nachdem du nun einige Möglichkeiten gesehen hast, wie der Servicekatalog und die Pipelines deinem Unternehmen beträchtliche Summen einsparen können, ist es an der Zeit, diese in das Arbeitsblatt "Prognose" einzutragen. Diese Einsparungen sollten in Zelle C7, Agilitätseinsparungen, eingetragen werden. An diesem Punkt des Prozesses sollte deine Prognose wie in Abbildung 4-9 aussehen.
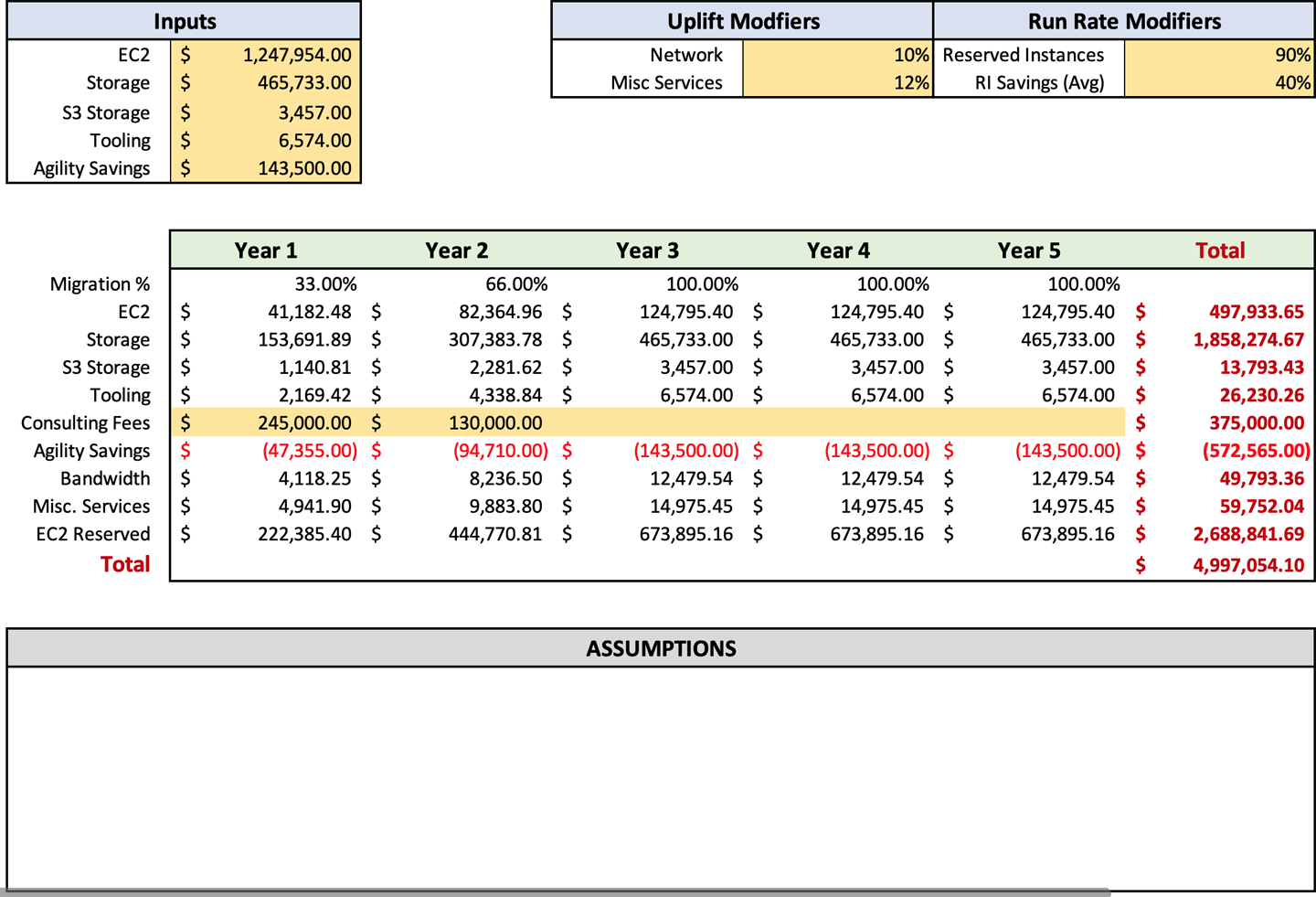
Annahmen
Nachdem wir nun alles in der Prognose abgedeckt haben, ist es wichtig, die Annahmen über die Technologie, die Fähigkeiten und die Kosten zu diskutieren. In diesem Buch haben wir zahlreiche Annahmen getroffen. Wir haben über den Prozentsatz der Migration, die Einsparungen bei der Agilität und die Annäherung an die Bandbreitengebühren gesprochen, um nur einige zu nennen. Insgesamt hast du während des gesamten Prozesses wahrscheinlich Dutzende von Annahmen getroffen. Leider liegt es in der menschlichen Natur, dass du etwas in Stein meißelst, wenn du es aufschreibst. Unweigerlich wird jemand das lesen und erwarten, dass es zu 100 % richtig ist. Deshalb ist es so wichtig, dass du deine Annahmen dokumentierst.
Du fragst dich vielleicht, welche Annahmen du dokumentieren solltest. Es ist nicht ungewöhnlich, dass ich 30 Annahmen aufschreibe, obwohl ich diese Punkte aus einer wesentlich umfangreicheren Liste heraussuche. Normalerweise dokumentiere ich keine offensichtlichen Annahmen. Ich würde zum Beispiel nicht auflisten, dass der Zeitplan für die Migration eine Schätzung ist; das ist eine unbestreitbare Wahrheit, denn du hast keine Kristallkugel. Was ich empfehlen würde, sind Dinge wie die Gemeinkosten pro Stunde für das Cloud-Engineering-Team zu dokumentieren, die du für die Bewertung der Einsparungen bei der Agilität verwendet hast. Um dir bei der Erstellung deiner Annahmen zu helfen und deine Kreativität anzuregen, habe ich in Tabelle 4-2 eine Liste mit möglichen Annahmen zusammengestellt. Diese Annahmen können nicht wortwörtlich übernommen werden, aber sie sollten mit ein paar kleinen Änderungen und Anpassungen verwendbar sein. Sie können dir auch andere Ideen liefern, die für dein Umfeld relevant sind.
Die Excel-Arbeitsmappe hat einen Abschnitt namens "Annahmen" für die Dokumentation deiner Annahmen. So können sie in der Prognose verbleiben und viele Fragen entfallen. Meiner Erfahrung nach ist es am besten, die Annahmen direkt mit der Prognose zu dokumentieren und nicht als Anhang oder zusätzliches Dokument. So kannst du leicht zwischen den Annahmen und der Prognose hin- und herwechseln, um die Analyse zu erleichtern, und ihre Sichtbarkeit zu gewährleisten. Wenn du deine Annahmen dokumentiert hast, sollte deine Prognose jetzt wie in Abbildung 4-10 aussehen.
Kosten Burn-Up/Burn-Down
Die Burn-Down-Rate und die Burn-Up-Rate beziehen sich auf die schrittweise Verringerung bzw. Erhöhung der Ausgaben, wenn du deine Infrastruktur migrierst. Wenn du Server zu AWS migrierst, verbrennst du, d.h. du fügst deiner Run Rate bei Amazon mehr Kosten hinzu. Die andere Hälfte der Gleichung ist der Burn-Down: Wenn du migrierst, holst du einen Teil der Kosten für die vor Ort installierte Ausrüstung zurück. Diese beiden Raten sind jedoch nicht gleich. Die Burn-up-Rate ist in der Regel ein linearer Pfad mit kleinen Schritten, wenn du Anwendungen migrierst. Ein Beispiel für einen Burn-up ist in Abbildung 4-11 zu sehen.
Abbildung 4-11. Abbrand-Beispiel
Abbildung 4-11 zeigt ein Unternehmen, das von On-Premises zu AWS migriert. Wie du siehst, ist der Gesamttrend recht linear, weist aber Stufen auf, wenn die einzelnen wichtigen Migrationswellen abgeschlossen sind. In einigen Wellen gab es Anwendungen mit einer größeren Anzahl von Servern, weshalb einige der Schritte größer sind als andere. In Abbildung 4-12 siehst du ein Burn-down-Diagramm, das sich deutlich vom Burn-up unterscheidet.
Abbildung 4-12. Beispiel für einen Abbrand
Bei der Migration von On-Premises bedeutet die Entfernung eines Servers nicht zwangsläufig, dass auch die gesamte zugrunde liegende Infrastruktur entfernt wird. Diese latente Entfernung gilt nicht für physische Server wie z. B. einen großen Datenbankserver, bei dem die Geräte sofort entfernt werden. Die meisten Unternehmen haben jedoch eine stark virtualisierte Infrastruktur. In einer solchen Infrastruktur werden die meisten Komponenten von Dutzenden bis hin zu Hunderttausenden von Servern gemeinsam genutzt. Im Normalfall musst du viele Server vor Ort entfernen, um die Kosten zu senken. Daher sind die Schritte in Abbildung 4-12 im Vergleich zum Burn-up deutlich länger und kürzer. Der größte Teil der Kostenreduzierung beim Burn-down findet erst ganz am Ende der Migration statt. Dies ist der Zeitpunkt, an dem die wichtigsten Komponenten der lokalen Infrastruktur abgeschaltet werden können, wie z. B. SANs und die Anlagen selbst.
Bei den Migrationen, an denen ich mitgearbeitet habe, wird in der Regel keine Burn-Down-Analyse durchgeführt, vor allem wegen des hohen Aufwands, der für die Berechnung erforderlich wäre. Um den Burndown zu berechnen, musst du wissen, welche Server physisch und welche virtuell sind, und wenn letzteres der Fall ist, an welchen Host und welches SAN sie angeschlossen sind. Am besten wäre es, wenn du dann die entsprechenden Kosten für diese Assets den Servern zuordnest und weißt, wo sie sich in der Migration befinden, um einen Burn-down zu erstellen. Burn-Down-Berechnungen verlängern die Gesamtmigrationszeit um mehrere Wochen und bringen dem Unternehmen nur einen sehr geringen Nutzen. Die Burn-Down-Analyse kann auch erst nach der Migrationsplanungsphase durchgeführt werden und ist nicht in der Prognose enthalten. Der Grund, warum ich sie in dieses Kapitel aufgenommen habe, ist, dass es für viele Leute sinnvoll ist, den Burn-Down als Teil der Finanzprognose zu berücksichtigen. Auf den ersten Blick macht das auch Sinn, aber wenn du erst einmal verstehst, was nötig ist, um einen Burn-Down richtig durchzuführen, wirst du sehen, dass es unpraktisch ist, ihn in die Prognose aufzunehmen.
Einpacken
Im Großen und Ganzen ist die Erstellung deines Business Case wahrscheinlich eine der kleineren Aufgaben im Migrationsprozess. Die meisten Informationen liegen bereits aus den vorherigen Prozessen vor und es geht eher darum, das Material, das für den Business Case wichtig ist, anzupassen und richtig zu vermitteln. Die Erstellung des Berichts ist wahrscheinlich der langwierigste Prozess. Zum Glück hast du aber mit den FAQs, die in Kapitel 1 erstellt wurden, eine gute Informationsquelle.
Der Business Case ist ein zentraler Punkt bei deiner Migration zu AWS; er ist der letzte Teil, der deine Absichten, Kosten und deinen geschäftlichen Nutzen darlegt. An diesem Punkt stehst du an einem Scheideweg: Der eine Weg führt dich weiter zu deiner Migration, der andere lässt dich vor Ort. Ich kann gar nicht genug betonen, wie wichtig der Business Case ist, wenn es darum geht, die Wettbewerbsfähigkeit deines Unternehmens durch die Migration zu verbessern. Er verdient Aufmerksamkeit und sollte nicht als lästig empfunden werden. Hoffentlich zeigt dein Business Case den Wert, den du aufgedeckt hast, und deine Migrationsbemühungen werden genehmigt. Um dich besser auf die Migration vorzubereiten, befasst sich Kapitel 5 damit, wie du die Abläufe in deinem Unternehmen auf die Migration vorbereitest und wie du eine erfolgreiche Geschichte aufbaust, die du an andere Abteilungen weitergeben kannst, um die Akzeptanz zu erhöhen.
Get Die Migration zu AWS: Ein Leitfaden für Manager now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

