Kapitel 1. Warum sollte ich zu Amazon Web Services migrieren?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Ich habe mich gefragt, ob es eine gute Idee war, eine so brisante Frage in das erste Kapitel meines Buches zu stellen. Die eigentliche Liste der Gründe für eine Migration zu AWS könnte so lang sein wie dieses Buch, aber wie Simon Sinek sagt: "Beginne immer mit dem Warum."1 Deshalb hielt ich es für klug. Die größte Hürde, auf die du stoßen wirst, ist die Abneigung der Menschen gegen Veränderungen. Die Umstellung von deiner derzeitigen Plattform auf AWS bedeutet eine Veränderung der Arbeitsweise und der erforderlichen Fähigkeiten. Wenn du die Gründe für die Umstellung gut erklärst, kannst du die Menschen in deinem Umfeld inspirieren und bessere Ergebnisse erzielen, ohne dass sie zögern. In diesem Kapitel werden die vielen technischen und geschäftlichen Vorteile der Migration in die Cloud erläutert. Mit diesen Informationen kannst du den oberen Führungsebenen und den Mitarbeitern das Warum vermitteln.
Während du dieses Kapitel liest, möchte ich dich ermutigen, über die Situationen in deinem Unternehmen nachzudenken und zu überlegen, wie diese Vorteile zusammenhängen.
Eine Methode, die sich in der Vergangenheit bewährt hat, um den Mitarbeitern das Warum zu vermitteln, ist eine Reihe von häufig gestellten Fragen (FAQ). Im weiteren Verlauf dieses Kapitels werden wir die Erstellung von FAQ erläutern, um das Warum der oberen Führungsebene und den Mitarbeitern zu vermitteln. Du kannst dies erreichen, indem du die Fragen, die sie stellen werden, vorwegnimmst und die Antworten auf der Grundlage der Vorteile, die dein Unternehmen erzielen wird, zusammenstellst. Wenn du diese Übung durchführst, gewinnst du an Akzeptanz und verringerst die Zahl der Kritiker/innen. Du erhöhst die Wahrscheinlichkeit des Erfolgs und der Wirksamkeit der Umstellung.
Vorteile der Cloud-Technologie
AWS bietet mit den neuesten Kanten-Technologien viele Vorteile. Allerdings gelten nicht alle diese Technologien und ihre Vorteile für jedes Unternehmen. Anstatt alle Vorteile zu erläutern, gehen wir auf die technischen Vorteile ein, die für jedes Unternehmen gelten. Sie sind vielleicht nicht auffällig, aber sie schaffen eine solide Basis, auf der du deine Infrastruktur aufbauen kannst. Wenn du diese Vorteile bei der Migration zu AWS nutzt, wirst du genug Kapital und Zeit sparen, um die Erprobung fortschrittlicherer Technologien zu finanzieren. Mit diesen Methoden konnte ich Unternehmen Millionen von Dollar sparen, die sie dann wieder in Innovationen investieren können. Ich stimme zu, dass die automatische Transkription von Kundendienstanrufen und die Analyse der Kundenstimmung ein großartiges und leistungsstarkes Werkzeug für dein Unternehmen ist. Ich glaube jedoch, dass die Migration eine der "Kriech-vor-dem-Gehen"-Situationen ist. Als Manager musst du in erster Linie dafür sorgen, dass deine Migration den Anforderungen und Vorschriften deines Unternehmens entspricht. Die Implementierung der neuesten KI ist zweitrangig; schließlich ist die Infrastruktur, die du heute hast, das, was deine Rechnungen bezahlt und deinen aktuellen Kunden einen Mehrwert bietet.
Skalierbarkeit und dynamischer Verbrauch
Wenn du zu AWS migrierst, musst du dich darauf konzentrieren, deine Denkweise von der Art und Weise, wie du deine Infrastruktur vor Ort betrieben hast, abzuweichen. Viele der herkömmlichen Entwurfsmuster und Betriebsprozesse sind in der Cloud kontraproduktiv. Im Hinblick auf die Skalierbarkeit und zeigen sich viele dieser Anti-Muster schon früh in deiner Migration. Es ist am besten, sie schnell zu erkennen und zu überwinden. Wenn du deine bisherige Denkweise in Bezug auf die Skalierbarkeit vor Ort änderst, wirst du im Vergleich zur Skalierbarkeit in der Cloud sofort Kosten sparen und flexibler sein. Bevor wir uns mit diesen neuen Mustern befassen und erklären, warum die lokalen Muster Anti-Muster sind, gehen wir die Skalierbarkeit durch, die AWS dir bietet. Während du liest, solltest du dir ein paar Notizen zu deinen Anwendungen machen und überlegen, wie diese Skalierungsmethoden deine Möglichkeiten verbessern könnten.
Vertikale Skalierung
Vertikale Skalierung ist die Praxis, einem Server Rechenleistung und Arbeitsspeicher hinzuzufügen, um die für die Arbeitslast verfügbare Leistung zu erhöhen. Ich vergleiche das mit einem Amish, der sein Feld pflügt. Ich pflüge eine neue Reihe, aber der Boden wird hart. Um mein Feld fertig zu pflügen, spanne ich mein Pferd ab, gehe in die Scheune und hole ein größeres Zugpferd. Vertikale Skalierung ist keine neue Idee für die Wolke. In deinem Rechenzentrum gibt es sie schon die ganze Zeit, und meiner Erfahrung nach ist sie das Mittel der Wahl, um die Leistung zu verbessern und die Kapazität zu erhöhen. Die Migration zu AWS bringt jedoch einige wichtige Unterschiede mit sich.
Wenn du deine Infrastruktur in AWS laufen lässt, hast du ein dynamisches Verbrauchsmodell mit Umlageverfahren anstelle eines Prepaid-Modells. Ich erkläre es gerne mit den Gezeiten: Die Schwerkraft des Mondes zieht an der Erde und hebt den Wasserspiegel des Ozeans an, wenn er vorbeizieht. Diese Analogie spiegelt die Nutzung deiner Infrastruktur im Laufe des Tages wider - die Anziehungskraft auf deine Ressourcen ebbt und fließt. Genau wie die Gezeiten hast du am Ende eine Hoch- und eine Niedrigwassermarke. Der Unterschied zur Cloud ist, dass du nur für das bezahlst, was du verbrauchst; du musst nur bei der niedrigen Wasserstandsmarke kaufen. Dann zahlst du schrittweise für mehr Verbrauch in den Zeiten hoher Nutzung. Vor Ort musst du bei der hohen Wassermarke im Voraus kaufen. Erschwerend kommt hinzu, dass du deinen Verbrauch für die Lebensdauer der Hardware prognostizieren musst, der über oder unter dem tatsächlichen Verbrauch liegen kann. Zu wenig genutzte Ressourcen belasten die Finanzmittel deines Unternehmens, und zu stark genutzte Ressourcen sorgen für eine schlechte Nutzererfahrung. In meiner Analogie kann man sich den Kauf von Geräten vor Ort wie den Bau eines Docks vorstellen. Wenn du die Anlegestelle zu hoch anlegst, musst du Leitern aufstellen, damit die Leute zu ihren Booten gelangen können. Wenn du den Steg zu niedrig anlegst, schwimmen die Boote im Wasser herum. AWS ist ein Schwimmsteg, der sich hebt und senkt und so optimale Bedingungen schafft. Abbildung 1-1 zeigt, wie der Prepaid-Einkauf und -Verbrauch über die gesamte Lebensdauer aussieht.
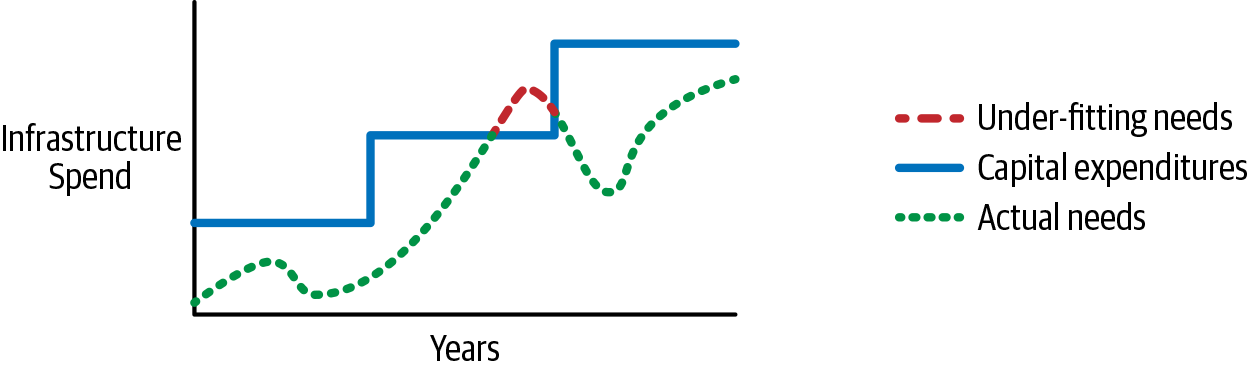
Abbildung 1-1. Infrastrukturkosten im Zeitverlauf
Abbildung 1-1 zeigt sehr gut, wie der Kauf von Geräten vor Ort die Bedürfnisse deines Unternehmens unter- oder übertrifft. Wenn du die gestrichelte Linie, die für deinen Bedarf steht, und die durchgezogene Linie, die deine Investitionsausgaben darstellt, vergleichst, siehst du, wie weit die Lücke zwischen beiden schwankt. An einem Punkt übersteigt die Nachfrage die Kapazität der Infrastruktur, was durch die gestrichelte Linie angezeigt wird, was bedeutet, dass du nicht genug Kapazität hast, um die Kunden zu bedienen. Ich würde sagen, dass es nicht üblich ist, nicht genug Kapazität zu haben. Die meisten Leute, mich eingeschlossen, kaufen mehr, als sie brauchen, sodass eine solche Situation nie eintritt. Wenn deine IT-Ressourcen ständig nicht ausreichen, ist das ein guter Grund für deinen Vorgesetzten, dich zu bitten, deinen Schreibtisch zu räumen. Das Wichtigste, was diese Grafik zeigt, ist, dass du nicht nur für die Hochwassermarke einkaufen musst, sondern auch für weit darüber. Die Überschreitung sorgt für genügend Kapazität, und der ganze Raum zwischen der gestrichelten und der durchgezogenen Linie ist verschwendetes Kapital. Die dynamische Fähigkeit von AWS beseitigt diese Überschreitung und das verlorene Kapital, so dass du diese Mittel für andere Geschäftsanforderungen verwenden kannst.
Wenn du an deine jüngste Vergangenheit zurückdenkst, erinnerst du dich vielleicht an ein Gespräch, das dem folgenden Szenario ähnelt.
Dies ist ein weit verbreitetes Szenario, sowohl vor Ort als auch in der Cloud. Es gibt ein paar Dinge, auf die ich hinweisen möchte, die sich nach der Migration zu AWS ändern werden. Erstens: Instanz ist die AWS-Nomenklatur für einen Server oder eine virtuelle Maschine des Elastic Compute Cloud (EC2) Service, und diese Begriffe können austauschbar verwendet werden. Ich werde jedoch Instanz verwenden, wenn ich über einen Server in AWS spreche, und Server oder virtuelle Maschine, um einen Server vor Ort zu bezeichnen. Die zweite ist die Aussage "Die Speichernutzung liegt innerhalb der Grenzen". Wenn du mit der Instanzgröße in AWS arbeitest, kannst du CPU und Speicher nicht separat einstellen. Du musst die kleinste Instanz finden, die das Speicher- oder CPU-Ziel erfüllt, und das, was nicht dein Ziel ist, bleibt auf der Strecke. In diesem Beispiel ist die CPU-Kapazität dein Ziel. Wenn du die CPU-Kapazität in AWS um zwei weitere CPUs erhöhst, erhöht sich auch dein Arbeitsspeicher. Drittens kann es besser sein, eine horizontale Skalierung vorzunehmen, d.h. bei Bedarf mehr Instanzen aufzusetzen, um die Last zu bewältigen, anstatt eine permanente vertikale Änderung vorzunehmen. Wir werden die horizontale Skalierung im nächsten Abschnitt besprechen.
Hinweis
AWS bietet eine Funktion namens Optimize CPUs für Amazon EC2-Instances. Mit dieser Funktion kannst du die Anzahl der CPUs festlegen, wenn du eine Instanz startest. Diese Einstellung kann später nicht mehr geändert werden und hat keinen Einfluss auf die Ausführungsrate der Instanz. Diese Einschränkungen sind vielleicht nicht sofort ersichtlich, wenn du die Dokumentation liest, und erwecken den Eindruck, dass AWS wie die On-Premises-Funktionen funktioniert. Der Hauptgrund für die Funktion "CPUs optimieren" ist die Softwarelizenzierung auf Basis der CPU-Anzahl und der Kanten-Nutzungsfälle, in denen die CPU niedrig ist und gleichzeitig viel RAM benötigt wird.
Werfen wir einen Blick auf ein anderes mögliches Szenario.
In dieser Situation kann AWS glänzen, indem es deine Betriebskosten senkt. Wie bereits erwähnt, musst du bei einem On-Premises-Betrieb Geräte kaufen, um deine hohen Anforderungen zu erfüllen, du hast also bereits Mittel für den Betrieb deiner Umgebung bereitgestellt. Die Zuweisung von mehr CPU-Leistung für die Stapelverarbeitung ist für die Betriebskosten irrelevant. In AWS hingegen kaufst du zu einem niedrigen Preis ein und bleibst am besten dort.
Du fragst dich vielleicht, wie du das Leistungsproblem lösen kannst. Am besten löst du dieses Szenario mit einer vorübergehenden vertikalen Skalierung. Du weißt, wann diese Arbeitslast anfallen wird und dass sie nur vorübergehend ist. Es würde keinen Sinn machen, die Kapazität zu erhöhen, um den Batch-Prozess dauerhaft zu bewältigen. Mithilfe von geplanten Ereignissen oder Software von Drittanbietern kannst du die Skalierung dieses Servers vor der Arbeitslast einplanen und ihn dann nach Abschluss der Arbeit wieder herunterfahren. Eine temporäre Skalierung würde dir den kostengünstigsten Betrieb ermöglichen.
Horizontale Skalierung
Während die vertikale Skalierung die Kapazität eines einzelnen Servers erhöht, kannst du mit der horizontalen Skalierung mehr Server hinzufügen, um die Last für deine Anwendung zu bewältigen. Wenn der Boden zu hart wird, würde ich ein zweites Pferd einspannen, um den Pflug fertigzustellen, anstatt ein größeres Pferd zu kaufen. Auch hier kannst du mit dem AWS Pay-as-you-go-Modell durch horizontale Skalierung erhebliche Kosteneinsparungen erzielen. Um eine horizontale Skalierung zu erreichen, bietet AWS zwei wichtige Dienste an: Elastic Load Balancing und AWS Auto Scaling.
Tipp
Beginne immer mit der horizontalen Skalierung und suche dann nach technischen Gründen, warum sie nicht funktioniert. Erst dann kehrst du zur vertikalen Skalierung zurück.
Warnung
Windows-Server, die mit einer Domäne verbunden sind, müssen besonders berücksichtigt werden. Diese Server benötigen ein spezielles Skript, um sich bei horizontalen Skalierungsereignissen zur Domäne hinzuzufügen und zu entfernen.
Elastischer Lastausgleich
Du erinnerst dich vielleicht daran, dass ich gesagt habe, dass die vertikale Skalierung in der Regel die bevorzugte Methode für die Skalierung vor Ort ist. Um eine horizontale Skalierung vor Ort durchzuführen, müsstest du einen Load Balancer kaufen. Die höheren Investitions-, Wartungs- und Pflegekosten schrecken erheblich davon ab, Load Balancer für Kapazitätsanforderungen einzusetzen. Der Einsatz von Load Balancern vor Ort wird häufiger eingesetzt, wenn es um die Hochverfügbarkeit geht oder die Möglichkeit der vertikalen Skalierung begrenzt ist. Beim Lastausgleich bietet der dynamische Verbrauch in AWS wiederum einen erheblichen Vorteil. Du zahlst nur für den Load Balancing, den du brauchst, es fallen also keine Vorabkosten an. Außerdem profitierst du von einer serverlosen Technologie. Das Elastic Load Balancing in AWS hat keine Server, die du warten oder patchen musst, was deine weichen Kosten reduziert. Wie du siehst, ist der Lastausgleich in AWS attraktiver und macht eine horizontale Skalierung für die Leistung leichter zugänglich.
Hinweis
Der Begriff " serverlos" bedeutet für verschiedene Menschen und Unternehmen eine ganze Menge. In dem Kontext, in dem ich ihn verwende und der in diesem Buch dargestellt wird, bezieht er sich auf jeden Dienst, bei dem du keine Server oder Infrastruktur verwalten musst. Natürlich gibt es irgendwo Server, die die Arbeit erledigen; du musst dich nur nicht um sie kümmern.
AWS Auto Scaling
Während der Elastic Load Balancing Service die Netzwerkverbindung zwischen den Nutzern deiner Anwendung und den Servern herstellt, enthält der AWS Auto Scaling Service die notwendige Logik, um die Erweiterung und Schrumpfung des Serverpools zu steuern. Ohne diese Erweiterung und Schrumpfung wären deine Kosten wiederum statisch und weniger effizient. Auto Scaling verfügt über mehrere Auslöser, um deinem Anwendungsserver-Pool Kapazität hinzuzufügen oder zu entfernen. Du kannst die CPU-Auslastung, die Speichernutzung und die Festplatteneingabe-/Ausgabeoperationen pro Sekunde (IOPS) für eine bedarfsorientierte Option nutzen. Eine weitere Option ist die automatische Skalierung mithilfe eines Zeitplans, wenn du weißt, wann deine Last anfallen wird. Mit dem AWS Auto Scaling Service kannst du auch eine Mindestanzahl von Servern festlegen und als Hochverfügbarkeits-Orchestrator fungieren, der sicherstellt, dass eine Mindestmenge an Rechenleistung für deine Kunden verfügbar ist. Die Art und Weise, wie du Verfügbarkeit und Notfallwiederherstellung (Disaster Recovery, DR) betrachtest, ändert sich ebenfalls, aber darauf werde ich später in "Disaster Recovery/Business Continuity" eingehen .
Erinnern wir uns noch einmal an das Gespräch mit Tom über den Bedarf an CPU-Kapazität für die Meme-Generator-Anwendung in "Szenario 1-1". In diesem Szenario ist es absolut sinnvoll, von einer vertikalen Skalierungslösung vor Ort auf eine horizontale Skalierung in der Cloud umzusteigen. Mit dieser Methode erhältst du das beste Erlebnis für deine Kunden und gleichzeitig den bestmöglichen Kostenverbrauch für dein Unternehmen. Wenn die CPU-Auslastung ansteigt, weil mehr Menschen Memes erstellen, fügt der Auto-Scaling-Dienst einen Server hinzu, um die Last zu bewältigen. Wenn der Server online und verfügbar ist, fügt Auto-Scaling ihn dem Load Balancer hinzu, um die Kundenanfragen zu bedienen. Wenn die Last sinkt, kehrt der Prozess in umgekehrter Reihenfolge zu deinen Grundeinstellungen zurück. Allerdings gibt es bei der horizontalen Skalierung einige Einschränkungen. Deine Server müssen zustandslos sein. Zustandslos bedeutet, dass keine spezifischen Konfigurationen oder Daten auf dem Server gespeichert sind und der Server gelöscht werden kann, ohne dass dies negative Auswirkungen auf den Gesamtbetrieb hat. Ein weiterer Vorbehalt könnte sein, dass du vorkonfigurierte Instance-Images brauchst, um die Startzeit der Instanzen zu verkürzen.
Geografische Vielfalt
Nachdem wir uns nun mit der Skalierbarkeit beschäftigt haben, wollen wir einen weiteren wichtigen AWS-Vorteil ansprechen: die geografische Vielfalt. Denk an dein(e) Rechenzentrum(e). Wo befinden sie sich? Wie weit sind sie voneinander entfernt? Wie viele gibt es? Wenn du einen kleineren Betrieb führst, dann ist die Antwort wahrscheinlich wenige, und wenn du mehr als eines hast, dann sind sie wahrscheinlich nicht weit voneinander entfernt. Aus meiner Erfahrung kann ich dir sagen, dass meine Rechenzentren in einem Unternehmen nur sieben Meilen voneinander entfernt waren. Das ist zwar nicht gerade eine geografische Vielfalt, aber besser als die Lösung mit einem einzigen Rechenzentrum. Wenn du ein großes Unternehmen bist, hast du wahrscheinlich zwei oder mehr Rechenzentren, die wahrscheinlich noch weiter voneinander entfernt sind. Aber wie nah sind sie an deinen Nutzern dran? Wie ist das Außenbüro in Brasilien mit deinem Rechenzentrum in New York verbunden?
Ich habe viele Fortune-500-Unternehmen und ein paar kleinere Firmen zu AWS migriert. Aus meiner Erfahrung heraus kann ich dir sagen, dass du es unabhängig von deiner Konfiguration besser machen kannst, wenn du zu AWS migrierst. AWS verfügt über eine beeindruckende geografische Vielfalt, die du zu deinem Vorteil nutzen kannst, wenn es um Hochverfügbarkeit und Notfallwiederherstellung geht, und du kannst die Dienste näher an deine Kunden bringen, um ein schnelleres Nutzererlebnis zu haben. Um zu zeigen, wie du diese Fähigkeit nutzen kannst, gehen wir durch, wie AWS seine Infrastruktur bereitstellt. Es gibt die Konzepte der Regionen und Verfügbarkeitszonen (AZ), wie in Abbildung 1-2 dargestellt. AWS stellt eine Website mit einem interaktiven Globus zur Verfügung, auf dem die Regionen, Netzwerkverbindungen und Präsenzpunkte dargestellt sind.
Tipp
Versuche nicht, dein Unternehmen in viele Regionen auszudehnen, nur um der Vielfalt willen. Es sollte einen zwingenden geschäftlichen Grund geben, denn das kann mit zusätzlichen Kosten verbunden sein.
Regionen
AWS-Regionen sind eine Sammlung von Verfügbarkeitszonen, die Rechenzentren in einem geografischen Gebiet haben. Das Konzept der Regionen ist im Vergleich zum Betrieb vor Ort sehr fremd. Vor Ort hast du nicht die Möglichkeit, eine vergleichbare Infrastruktur zu schaffen. Du hast nicht die Größenvorteile, um eine so große Infrastruktur aufzubauen.
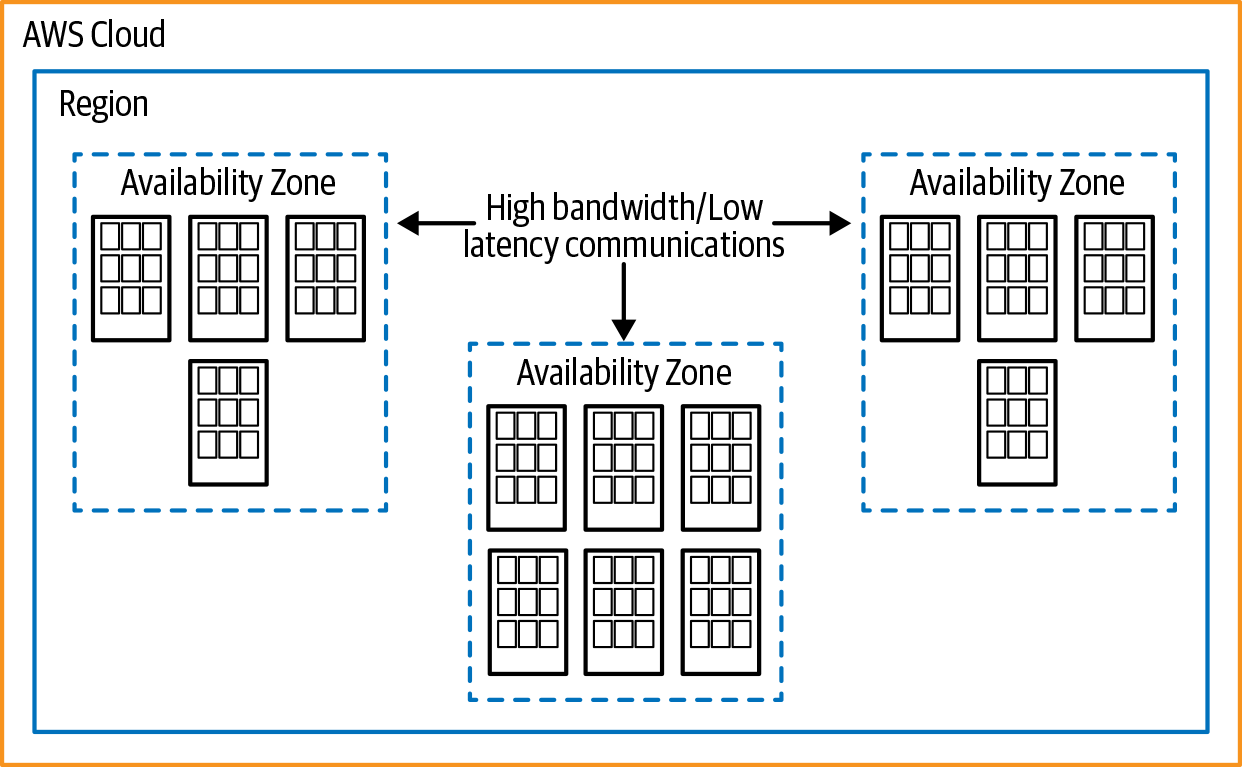
Um das Konzept zu verstehen, können wir eine Parallele zur Unterteilung der Vereinigten Staaten ziehen. Eine Region kann durch einen einzelnen Bundesstaat repräsentiert werden. Innerhalb eines Bundesstaates gibt es Bezirke(Parishes, wenn du in Louisiana lebst, oder Stadtbezirke in Alaska), die Verfügbarkeitszonen darstellen. Der letzte Aspekt einer Region in AWS sind die Rechenzentren; du kannst sie dir als Städte innerhalb eines Bezirks vorstellen. Zum Zeitpunkt der Erstellung dieses Artikels besteht die AWS-Infrastruktur aus den in Tabelle 1-1 dargestellten Regionen.
| Name der Region | Region |
|---|---|
US-Ost (N. Virginia) |
us-ost-1 |
US Ost (Ohio) |
us-ost-2 |
US West (N. California) |
us-west-1 |
US West (Oregon) |
us-west-2 |
Afrika (Kapstadt) |
af-south-1 |
Asien-Pazifik (Hongkong) |
ap-ost-1 |
Asien-Pazifik (Mumbai) |
ap-south-1 |
Asien-Pazifik (Osaka-Lokal) |
ap-nordost-3 |
Asien-Pazifik (Seoul) |
ap-nordost-2 |
Asien-Pazifik (Singapur) |
ap-südost-1 |
Asien-Pazifik (Sydney) |
ap-südost-2 |
Asien-Pazifik (Tokio) |
ap-nordost-1 |
Kanada (Zentral) |
ca-zentral-1 |
China (Peking) |
cn-nord-1 |
China (Ningxia) |
cn-nordwest-1 |
EU (Frankfurt) |
eu-west-1 |
EU (Irland) |
eu-zentral-1 |
EU (London) |
eu-west-2 |
EU (Mailand) |
eu-süd-1 |
EU (Paris) |
eu-west-3 |
EU (Stockholm) |
eu-nord-1 |
Naher Osten (Bahrain) |
me-south-1 |
Südamerika (São Paulo) |
sa-ost-1 |
Warnung
AWS bietet nicht alle Services in jeder Region an. Schau in der AWS-Regionentabelle nach, um sicherzustellen, dass alle von dir benötigten Services vor der Migration verfügbar sind.
Datennähe
Wenn du dich auf die Migration zu AWS vorbereitest, solltest du über deine Nutzer und deren Standort nachdenken und die Region auswählen, die ihnen am nächsten liegt. Dabei kann es sich um interne oder externe Nutzer handeln, oder um beides. Der Vorteil von AWS gegenüber herkömmlichen Rechenzentren vor Ort ist, dass du dich nicht auf nur eine oder zwei Regionen beschränken musst. Dir steht jede AWS-Region auf der ganzen Welt zur Verfügung. Bei der Einrichtung einer neuen Region fallen keine versunkenen Kosten an wie bei einem Rechenzentrum. Du musst keinen Platz anmieten oder Strom, Feuerschutz, Sicherheit, Racks und all die anderen Dinge kaufen, die für den Start eines Rechenzentrums notwendig sind. AWS hat das alles für dich erledigt. Dank des Multitenant- und des Pay-as-you-go-Modells musst du nur für die Infrastruktur zahlen, die du in der jeweiligen Region nutzt. Schauen wir uns ein paar Szenarien an, damit du eine Vorstellung davon bekommst, wie du Regionen bei deiner Migration nutzen kannst.
Nehmen wir uns einen Moment Zeit, um dieses Szenario durchzugehen, als wären wir Sam. Die meisten Benutzer des Unternehmens befinden sich in Washington, DC. Als Erstes solltest du eine AWS-Region auswählen, die sich in der Nähe deiner Mitarbeiter befindet, um die Latenz zu verringern. Eine naheliegende Wahl wäre die Region us-east-1 in Virginia. Die Wahl von Virginia stellt sicher, dass der Großteil der internen Nutzer die geringstmögliche Latenzzeit hat. Die Lichtgeschwindigkeit ist unveränderlich; es gibt nicht viel, was wir tun können, um die Datenübertragung schneller zu machen. Die Wahl eines nahegelegenen Ortes wie Virginia ist nicht einzigartig für die Cloud; ihr Rechenzentrum ist wahrscheinlich schon ein paar hundert Meilen vom Firmensitz entfernt. Wenn du jedoch über die zweite Aussage nachdenkst, dass der größte Kunde in Seattle sitzt, ändert sich die Planung bei AWS. AWS hat Regionen in den ganzen USA; es wäre sinnvoll, einige Infrastrukturen zur Unterstützung ihres größten Kunden in Seattle zu platzieren. Ich würde die Region us-west-2 in Oregon als zweiten Bereitstellungsort wählen, speziell für ihre Online-Anwendung. Das Schöne daran ist, dass Sam sich nicht um alle Komponenten eines Rechenzentrums kümmern muss. Sie muss sich nur auf die Server konzentrieren, die sie für ihren größten Kunden benötigt, und diese auch bezahlen. Eine solche Bereitstellung in zwei Regionen vor Ort wäre sehr kostspielig.
In Bills Situation würde ich empfehlen, mit der Latenz zu beginnen, um herauszufinden, wie der Basiseinsatz aussehen würde. Da die Server in den Büros nur das lokale Büro bedienen, in dem sie sich befinden, wird nicht viel Datenverkehr über das Land hinweg stattfinden. Ich würde Bill empfehlen, die Region us-east-2 in Ohio für die Server in Chicago und us-east-1 für seine Server in New York zu verwenden. Mit dieser Konfiguration sollten seine Nutzer die geringste Latenz zu den jeweiligen Servern haben. Da sein Unternehmen eine Website hat, die aber keine wesentliche Kundenanwendung ist, würde ich vorschlagen, dass Bill sie in einer einzigen Region in AWS unterbringt. Bill kann seine Website für Kunden schneller machen, indem er Amazon CloudFront nutzt, ein Content Distribution Network (CDN). Die Nutzung von CloudFront erhöht die Leistung ohne die Komplexität weiterer Server in anderen Regionen. Schließlich hat Bill eine intern entwickelte Anwendung, die beide Büros nutzen. Da diese Anwendung privat entwickelt wurde, kann Bill mit einer kleinen Umprogrammierung die Vorteile der beiden Regionen nutzen. Dieses Design bietet eine Multimaster- (du kannst Daten an beiden Orten schreiben) und Multiregionslösung, die die beste Leistung und Verfügbarkeit bietet.
Brittany hat das einfachste Auswahlverfahren. Ihre gesamte Nutzerbasis befindet sich in Columbus, OH. Ich würde ihr vorschlagen, die Region us-east-2 in Ohio für das Hosting ihrer Infrastruktur zu nutzen, da ihre Website von einem Dritten gehostet wird. Der Standort ihrer Website hat keinen Einfluss auf ihre Entscheidung. Es kann sein, dass Brittany ihre Daten für Disaster Recovery-Zwecke in eine zweite Region replizieren möchte, aber darauf gehe ich im Abschnitt "Disaster Recovery/Business Continuity" ein.
Datenlokalisierung und Datenschutzbestimmungen
Es wurde viel über die Allgemeine Datenschutzverordnung (GDPR) in der Europäischen Union (EU) gesprochen. Diese und andere Verordnungen haben beim IT-Management die Frage aufgeworfen, wie die damit verbundenen Anforderungen an die Datenhoheit erfüllt werden können. Da AWS über Regionen rund um den Globus verfügt, ist es einfach, die Souveränität der Datenspeicherung nach dem Land zu kontrollieren, in dem die Vorschriften gelten. Die Datenlokalisierung ist nur ein Teil des Puzzles. Du musst eventuell auch sicherstellen, dass die Daten bei Transaktionen keine Grenzen überschreiten. Allein die Speicherung der Daten im richtigen Land reicht nicht aus, um deine gesamte Infrastruktur und alle Vorgänge zu kontrollieren, wenn du Daten außerhalb der angegebenen Region verarbeitest. Wenn dir alle AWS-Regionen zur Verfügung stehen, hast du jedoch einen erheblichen Vorteil gegenüber dem Einsatz vor Ort, wo du möglicherweise neue Rechenzentren erwerben musst, um die Vorschriften zu erfüllen.
Ein wichtiger Vorbehalt, auf den ich in Bezug auf die Datenhoheit hinweisen möchte, ist, dass es in manchen Ländern nur eine Region gibt. Wenn du zum Beispiel in Kanada Vorschriften hast, die vorschreiben, dass die Daten im Land gespeichert werden müssen, hast du derzeit nur begrenzte Möglichkeiten für eine multiregionale Bereitstellung. Derzeit gibt es bei AWS nur die zentrale Region Kanada (ca-central-1). AWS fügt ständig neue Regionen hinzu, was für Kanada vielleicht nicht immer der Fall ist, aber es ist wichtig, dass du deine DR-Anforderungen für die Souveränität berücksichtigst. AWS hat die USA und die EU ausreichend abgedeckt, aber Gebiete wie Südamerika und Asien-Pazifik müssen möglicherweise zusätzlich berücksichtigt werden. Es ist wichtig zu wissen, dass jede Region mindestens zwei Availability Zones hat. Für die meisten Unternehmen dürfte die Verfügbarkeit ausreichen, um die DR-Anforderungen zu erfüllen und gleichzeitig die Souveränität zu wahren.
Verfügbarkeitszonen
Wenn ich an meine Analogie zu den Bundesstaaten zurückdenke, stehen die Städte für die eigentlichen Rechenzentren und die Landkreise für die Availability Zones (AZs) in einer AWS-Region. AZs spielen eine Schlüsselrolle für die hohe Verfügbarkeit innerhalb einer Region. AWS verbindet die AZs mit einem Glasfasernetzwerk mit niedriger Latenz, so dass die Daten problemlos zwischen den AZs übertragen werden können. Die Zonen sind auch geografisch voneinander getrennt, so dass ein Ereignis wie eine Überschwemmung oder ein Tornado in einer Zone keine Auswirkungen auf die anderen hat. Zur besseren Veranschaulichung kannst du dir eine Verfügbarkeitszone als ein einzelnes Rechenzentrum vorstellen. Die meisten Regionen haben drei Verfügbarkeitszonen, aus denen sie für die Bereitstellung ihrer Infrastruktur wählen können. Um das Konzept zu verdeutlichen, wollen wir eine hypothetische AWS-Region durchgehen.
Die AZs und ihre Trennung sind ein großer Vorteil gegenüber herkömmlichen Rechenzentren. Viele Unternehmen haben das Äquivalent von zwei Regionen in ihrer On-Premises-Implementierung, aber nur ein einziges AZ. Ein Rechenzentrum befindet sich in der Regel in der Nähe des Hauptsitzes und ein zweites an einem weiter entfernten Ort für Disaster Recovery-Zwecke. Das Konzept der Verfügbarkeitszonen gibt es vor Ort nur selten. Ähnlich wie bei der Skalierung und den Regionen muss auch bei der Verfügbarkeit deiner Infrastruktur ein Umdenken stattfinden. Wenn du deine Denkweise änderst, kannst du die Vorteile von AZs nutzen. Schauen wir uns ein Szenario an, damit du eine Vorstellung davon bekommst, wie du AZs bei deiner Migration einsetzen kannst.
Jim hat seine Verfügbarkeit erhöht, aber er hat seine geografische Vielfalt nicht verbessert. Wenn sein primäres Rechenzentrum ausfällt, muss Jim immer noch auf den Disaster-Recovery-Standort in Kalifornien ausweichen. Ich weiß nicht, wie es dir geht, aber wenn ich an DR denke, bekomme ich Sodbrennen. Unsere Notfallwiederherstellung war fertig geplant und verifiziert, und wir hatten Failover-Tests durchgeführt. Allerdings werden die Tests in der Regel nur für einzelne Teile durchgeführt, nicht für das gesamte Rechenzentrum. Würde das alles im Falle einer Katastrophe funktionieren? Das sollte es, lautet die Antwort. Ich mag es nicht , wenn es funktioniert. Ich will sichere Dinge, und der beste Weg, um im Katastrophenfall eine sichere Sache zu haben, ist, von DR auf Business Continuity (BC) umzudenken. Vor Ort wäre es für Jim schwierig, BC in seine Anwendung einzubauen und sie hochverfügbar zu machen. In AWS ist die Geschäftskontinuität dank der AZs viel einfacher zu erreichen. Verfügbarkeitszonen sind innerhalb einer Region geografisch verteilt und verfügen über separate Strom- und Kommunikationsleitungen. Sie sind auch weit genug voneinander entfernt, so dass ein Tornado nur eine AZ betreffen würde. Jim kann seine Anwendung neu konfigurieren, wenn er zu AWS migriert. Er kann zwei AZs für seinen SQL-Server-Spiegel und seine Webserver nutzen. Sein Ziel sollte es sein, einen hochverfügbaren und kontinuierlichen Betrieb zu schaffen, falls eine AZ offline gehen sollte.
AZs und Disaster Recovery
Die AWS AZs sind eine der wichtigsten Änderungen, die Unternehmen helfen, wenn sie zu AWS migrieren. Die Notfallwiederherstellung vor Ort ist ein schwer zu lösendes Problem, das nie die nötige Liebe, Aufmerksamkeit und Finanzierung erhält. Am Ende ist es eine Belastung für die Ressourcen und eine erhebliche Stressquelle für das Management. Ich denke an meine Zeit im Bankwesen zurück, wo die Datenwiederherstellung von entscheidender Bedeutung ist. Es wäre so viel einfacher, das Gespräch auf BC zu lenken und ein paar Jahre meines Lebens zurückzugewinnen. Wenn du auf AWS umsteigst, rate ich dir, besonders darauf zu achten, wie du deine Infrastruktur in mehreren AZs bereitstellen kannst, um Business Continuity zu erreichen.
Ich möchte die Aufmerksamkeit auf ein Entwurfsmuster lenken, das beim AZ-Einsatz immer wieder auftaucht. Du darfst nicht in die gleiche Falle tappen. Viele Unternehmen installieren und konfigurieren zwei AZs in einer Region und denken, sie hätten die nötige Verfügbarkeit. Wer kann ihnen diese Logik verdenken? Sie haben zwei Bereitstellungen; wenn eine fehlschlägt, übernimmt die andere. Ich würde dich ermutigen, langfristig zu denken. Was passiert, wenn eine AZ fehlschlägt, aber es war eine Naturkatastrophe? Die fehlgeschlagene AZ wird nicht so schnell wieder online gehen. In diesem Fall müsstest du die zweite Infrastruktur auf eine andere AZ verlagern. Wenn du nur zwei AZs eingerichtet hast und eine davon nun offline ist, müsstest du eine neue AZ-Bereitstellung aufbauen. Währenddessen spürst du immer noch den Druck, in einem fehlgeschlagenen Zustand zu sein. Ich empfehle, von Anfang an mindestens drei AZs einzurichten, um einem möglichen AZ-Ausfall zu begegnen.
Einfacher Zugang zu neueren Technologien
Mit der Skalierbarkeit und der geografischen Vielfalt haben wir die physischen Vorteile von AWS angesprochen; jetzt werden wir einen logischen Vorteil mit dem einfachen Zugang zu neueren Technologien behandeln. In den Anfängen von AWS gab es nur wenige Dienste wie den Simple Storage Service (S3) für die Speicherung von Objekten und die Elastic Compute Cloud (EC2) für Berechnungen. Heute bietet AWS Dutzende von Diensten an, von verwalteten Datenbankplattformen wie Relational Database Service (RDS) bis hin zu KI-Tools wie SageMaker. Der Zugang zu neuen Technologien ermöglicht es Unternehmen, ihre Fähigkeiten zu übernehmen und zu erweitern und Innovationen für ihre Kunden zu entwickeln. Um zu verdeutlichen, wie der Zugang zu diesen Technologien jedes Unternehmen verbessern kann, möchte ich dies anhand eines sehr drastischen Vergleichs zeigen. Das Hinzufügen dieser fortschrittlichen Dienste in Verbindung mit dem Pay-as-you-go-Modell hat die Fähigkeit kleiner Startups verändert, mit Fortune-500-Unternehmen zu konkurrieren. Stell dir einen Boxkampf vor. In der einen Ecke steht das Startup - klein, aber schnell. In der anderen Ecke steht das etablierte Fortune-Unternehmen - groß, aber langsam. In diesem Boxkampf sind die Gegner nicht gleich stark. Das kleinere, agilere Unternehmen kann das große etablierte Unternehmen ausmanövrieren, aber sein Erfolg hängt davon ab, ob es genug Schläge landen kann, bevor das große Unternehmen es umwirft und niederschlägt.
Um ein Beispiel dafür zu geben, wie das aussehen könnte, schauen wir uns einige Technologien an, die AWS für Start-ups kostengünstig bereitstellen kann. Ein Beispiel für eine kostspielige Technologie, die vor Ort implementiert werden muss, ist Data Warehousing und Analytik. Wenn ein Startup in die Analytik einsteigen will, muss es eine beträchtliche Summe investieren, um die nötige Hardware für die Speicherung und Verarbeitung großer Datenmengen zu kaufen. Ausgaben in dieser Größenordnung nehmen Mittel von wichtigen Unternehmensfunktionen wie der Bezahlung der Mitarbeiter/innen weg. Ein Startup, das Analysen vor Ort durchführt, könnte am ersten Tag Zehn- oder Hunderttausende von Dollar für die anfänglichen Hardware-Ausgaben ausgeben. Die Beschaffung großer Mengen an Hardware durch ein großes, etabliertes Unternehmen ist einfach. Hunderttausende zu bezahlen ist nicht schwer; die Schwierigkeit für ein großes Unternehmen liegt in der Zeit, die für die Umsetzung benötigt wird.
Ein Start bei AWS würde demselben Startup den Zugang zu neuen Technologien wie der Analytik aus zwei Gründen erleichtern. Der erste Grund ist, dass AWS viele fortschrittliche Technologiedienste zur Verfügung stellt, aus denen ein Startup im Bereich der Analytik wählen kann. Mit Amazon S3 Object Storage lassen sich große Datenmengen kostengünstig speichern. Amazon QuickSight bietet Business-Intelligence-Tools, und Dienste wie Amazon Athena und AWS Glue bieten Datenverarbeitungs- und Abfragefunktionen. Das Anbieten dieser Dienste allein ist noch kein besonderer Clou. Wenn du diese fortschrittlichen Technologiedienste mit dem Umlageverfahren kombinierst, hast du die richtigen Zutaten, um den Wettbewerb anzukurbeln, indem du die beträchtlichen Investitionskosten fallen lässt und die Eintrittsbarriere beseitigst.
Der kostengünstige und einfache Zugang zu diesen neuen Technologien ermöglicht es jedem Unternehmen, auf nie dagewesene Weise zu testen, zu experimentieren und zu innovieren. Was Unternehmen von Experimenten und Innovationen abhält, ist vor allem die Angst vor dem Scheitern. Ein Scheitern vor Ort ist ein sehr kostspieliges Unterfangen, bei dem zusätzliche oder spezialisierte Hardware und Software in den Regalen liegen bleibt, anstatt Geld auf der Bank zu haben. Nach der Migration zu AWS kann dein Unternehmen dank der Zugänglichkeit der Technologie und der geringen Kosten für Fehlschläge innovativ sein und bessere Ergebnisse für deine Kunden erzielen. Sehen wir uns an, wie die Zugänglichkeit zu neuen Technologien für dein Unternehmen aussehen könnte.
Vor Ort hätte Amy alle Hände voll zu tun, um diese Anfrage zu erfüllen. Sie müsste einige Server bereitstellen, um das KI-Modell zu trainieren. Je nachdem, welcher Algorithmus für das maschinelle Lernen ausgewählt wird, muss Amy möglicherweise spezielle Hardware kaufen, um die Berechnungen durchzuführen. Amy muss auch das Problem lösen, wer diese KI-Anwendung programmieren und warten soll, was spezielle Fähigkeiten erfordert. All diese Punkte stellen ein großes Hindernis für die Einführung dar. Amy hat keinen einfachen Zugang zu neuer Technologie. Wenn Amys Unternehmen jedoch zu AWS wechselt, wird es für sie viel einfacher sein, diese Anforderung umzusetzen. AWS bietet einen Service namens Amazon Forecast an, der diese KI-Berechnungen durchführt. Amy müsste sich keine Gedanken über Server, Hardware oder spezielle KI-Programmierkenntnisse machen, um diese Technologie zu testen. Amy könnte ihr derzeitiges IT-Personal und ihre Programmierer nutzen, um einen Proof of Concept (POC) durchzuführen, und müsste nur für die Trainingszeit in Stunden, die Speicherung der Daten in Gigabyte (GB) und die erstellten Prognosen (0,238 $, 0,088 $ bzw. 0,60 $ pro 1.000) bezahlen.
Verfügbarkeit
Wir haben bereits über geografische Vielfalt und Skalierung gesprochen und wie sie deine Verfügbarkeit erhöhen können. Das sind jedoch nicht die einzigen Möglichkeiten, die AWS bietet, um deine Verfügbarkeit zu verbessern. Es gibt viele technologische Möglichkeiten, wie AWS die Verfügbarkeit erhöht, aber wir wollen uns auf einige wenige konzentrieren, die für deine Bedürfnisse am ehesten relevant sind.
Wenn du dir die Geschichte von AWS ansiehst, kannst du sehen, dass die Angebote weiterhin serverlos erstellt werden, wie die Elastic Load Balancer, die wir zuvor besprochen haben. Da du keine Server bereitstellst, hast du keine Kontrolle über die Menge oder den Bereitstellungsort. AWS entwirft diese Dienste so, dass sie für dich hochverfügbar sind und dir diese Arbeit und diesen Stress abnehmen. Ich bin mir sicher, dass du dich über weniger Arbeit und Stress freuen wirst. Du wirst nicht am Strand sitzen und Piña Coladas schlürfen, aber es ist eine Sache weniger, um die du dich nach der Migration kümmern musst. AWS erreicht dieses höhere Verfügbarkeitsniveau für diese serverlosen Angebote, indem es das Konzept der Verfügbarkeitszonen voll ausschöpft, um sie bereitzustellen. Hier sind zwei Szenarien, die zeigen, wie du diese Services in deiner Umgebung nutzen kannst, um eine höhere Verfügbarkeit als bei deiner lokalen Konfiguration zu erreichen.
In Keiths Einsatz gibt es eine bessere Möglichkeit, diese Lösung in AWS zu archivieren, um seine Verfügbarkeit zu erhöhen. In dieser Situation würde ich empfehlen, die Berichtsdateien nach Amazon S3 zu verschieben. S3 ist ein Objektspeicher und eignet sich perfekt für die Speicherung von Daten, die aus dem Internet heruntergeladen werden müssen. S3 gehört auch zu den serverlosen Angeboten von AWS und ist für hohe Verfügbarkeit ausgelegt. S3 repliziert deine Dateien automatisch zwischen allen AZs in einer Region und bietet 11 Neunen an Haltbarkeit. Was sind 11 Neunen der Haltbarkeit? Das bedeutet, dass deine Datei mit einer Wahrscheinlichkeit von 99,999999999% noch in der Speicherung vorhanden ist. Ich habe gehört, dass es wahrscheinlich ist, dass S3-Daten die Menschheit überleben werden. Da ich kein Mathematiker bin, kann ich diese Behauptung nicht bestätigen. Aber wenn ich ein paar Berechnungen anstelle, klingt es plausibel. Mit ein paar kleinen Änderungen an der Anwendung kann Keith eine hohe Verfügbarkeit und eine fast unvorstellbare Haltbarkeit erreichen.
Hinweis
AWS bietet 11 Neunen an Haltbarkeit, nicht an Verfügbarkeit. Es ist wichtig, sich an diesen Unterschied zu erinnern. Das AWS Service Level Agreement (SLA) garantiert, dass die Daten in der Speicherung vorhanden sind, nicht, dass sie immer abrufbar sind. Sei versichert, dass die Erfolgsbilanz von AWS verdammt gut ist.
Die Situation von Kathy ist nicht einzigartig. Ich habe dieses Szenario aus meiner Erfahrung mit einem meiner Rechenzentren abgeleitet. Wenn es in einem Rechenzentrum Wasser regnet, ist das keine gute Sache und etwas, woran du nie gedacht hast. Wenn ich es mir recht überlege, ist das dasselbe Rechenzentrum, bei dem ein Teil der Wand eingestürzt ist. Bauarbeiter waren dabei, eine Fußgängerbrücke nebenan zu entfernen. Ein Kran rammte ein massives Stück Beton in die Wand. Das sind die Situationen, in denen das Leben seltsamer ist als die Fiktion. Ich kann mir so etwas nicht ausdenken, und du auch nicht - das ist der Punkt. Du kannst nicht an alles denken, was deinem Rechenzentrum zustoßen kann, und wie Kathy ist es am besten, wenn du dies bei deiner Implementierung berücksichtigst. Für Kathys Implementierung würde es Sinn machen, das Amazon Elastic File System (EFS) zu verwenden, um die Daten für ihren HPC-Cluster zu speichern. EFS unterstützt das NFS-Protokoll, das für den Betrieb ihres Clusters erforderlich ist, und bietet eine redundante Speicherung der Daten über die AZs hinweg. Dieser Service ist ein serverloses Angebot und erfordert keine Eingaben für diese Verfügbarkeit.
Erhöhte Sicherheit
Dem Trend der logischen Vorteile folgend, bietet AWS einen weiteren mit erhöhter Sicherheit. Noch vor ein paar Jahren hatten die Menschen Angst vor der Sicherheit ihrer Daten in der Cloud. Ich kann ihre Zurückhaltung teilweise verstehen. Ich sage teilweise, weil große Software-as-a-Service (SaaS)-Anbieter wie Box ein boomendes Geschäft hatten. Die Leute hatten keine Angst, ihre Geschäftsdaten auf diesen Plattformen zu speichern. Die Ironie ist, dass dieselben Leute Angst davor hatten, den Rest ihrer Daten auf AWS zu stellen. Für die meisten ist die Angst, ihre Daten auf AWS zu verschieben, verflogen. Nach Sicherheitsverstößen haben große Unternehmen erklärt, dass der Sicherheitsverstoß nicht passiert wäre, wenn sie AWS genutzt hätten, oder dass er weniger Auswirkungen gehabt hätte. Zero Trust und Least Privilege sind bewährte Methoden in AWS. Diese beiden Methoden sind sehr effektiv, um deine Umgebung zu schützen. Der Vorteil von AWS ist, dass es die Umsetzung dieser Prinzipien recht einfach macht.
Null Vertrauen
Die Vertrauenssicherheit vor Ort ist in den letzten Jahrzehnten weitgehend unverändert geblieben. Die meisten Netzwerke sind in drei Zonen unterteilt. Eine Internetzone dient der Verbindung zum Internet und beherbergt andere Geräte wie Firewalls und Virtual Private Network (VPN)-Controller. Dahinter befindet sich eine Randzone oder demilitarisierte Zone (DMZ), in der die Webserver und E-Mail-Server untergebracht sind.
Im Inneren deines Netzwerks gibt es eine interne Zone, in der sich deine privaten Server und Daten befinden. Manche Unternehmen richten eine vierte Zone ein, in der sich Drucker und Workstations befinden, die eine weitere Trennung von den privaten Servern ermöglichen. Die Einteilung in Zonen war vor 20 Jahren ein gutes Sicherheitskonzept für Netzwerke. Das Problem bei diesem Konzept ist, dass es für jede Zone einen bestimmten Grad an Vertrauen gibt. Du vertraust dem Internet nicht, der Kante einigermaßen und der privaten Zone voll und ganz. Dieses Konzept klingt auf den ersten Blick gut, aber nach all den jüngsten Sicherheitsverletzungen in Unternehmen wird klar, warum es veraltet ist. Sobald du den Schleier der Kanten oder der internen Zonen durchbrochen hast, kannst du herumhüpfen wie Dorothy auf der gelben Ziegelsteinstraße. Bei diesem Konzept wird die Sicherheit am Rande des Netzwerks hergestellt. Wenn du den Perimeter durchbrichst, hält dich nichts mehr davon ab, in den restlichen Servern herumzustochern, bis du in sie eindringst.
Null Vertrauen bedeutet, dass kein Server einem anderen Server vertraut. Wenn du in einen Server in der Randzone eindringen kannst, kannst du mit keinem anderen Server in dieser Zone kommunizieren, es sei denn, es ist von vornherein erlaubt. Anstatt als glücklicher Dorothy zu enden, landest du wie Al Capone in einer kalten, dunklen Zelle und denkst über deine rapide abnehmende Gesundheit nach. Nullvertrauen schränkt deinen Aktionsradius für Angriffe ein und macht deine Umgebung damit sicherer. Nichts spricht dagegen, dies auch vor Ort zu tun. Ich habe diese Sicherheit für eine Bank, für die ich gearbeitet habe, eingeführt. Die Umsetzung dauerte lange und kostete Zehntausende von Dollar für die Technologie und weitere Zehntausende für die Mitarbeiter.
AWS-Sicherheitsgruppen sind ein großer Vorteil für die Zero-Trust-Sicherheit und kosten nicht Zehntausende von Dollar. Sicherheitsgruppen kosten nichts. Sicherheitsgruppen sind die Art und Weise, wie AWS Firewalls in AWS implementiert. Eine Sicherheitsgruppe stellt eine externe Firewall für deine Instanz oder eine Gruppe von Instanzen dar; es handelt sich nicht um eine Software, die auf der Instanz selbst läuft. Wie eine Firewall kontrolliert sie den gesamten Datenverkehr, der in deine Instanz fließt, und blockiert alles, was du nicht ausdrücklich zugelassen hast. Um die Verwaltung noch einfacher zu machen, musst du den Datenverkehr nicht nur anhand von IP-Adressen kontrollieren. Sicherheitsgruppen ermöglichen es dir, auf andere Sicherheitsgruppen zu verweisen. Diese Referenzierbarkeit macht die Verwaltung der Sicherheit noch weniger aufwändig als vor Ort. Wenn du Instanzen einer Sicherheitsgruppe zuordnest oder ihre Zuordnung aufhebst, passt sich die Sicherheitsgruppe automatisch an, ohne dass du manuell eingreifen musst, während die Änderung von Servern und IP-Adressen vor Ort zu einem Problem wird, wenn die Firewall-Regeln nicht aktualisiert werden und veralten. Indem eine Sicherheitsgruppe als Quelle referenziert wird, wenn ein Server hinzugefügt oder entfernt wird, wird er automatisch in die Sicherheitsgruppe eingefügt oder aus ihr entfernt. Diese Automatisierung stellt sicher, dass es keine alten, statischen Verweise gibt.
Tipp
Stelle sicher, dass dein Team mit der Gewohnheit bricht, IP-Adressen für AWS-Ressourcen zu verwenden und zu Sicherheitsgruppenreferenzen wechselt.
Schauen wir uns ein Szenario an, in dem dies vor Ort geschehen würde.
Wenn Johns Server in AWS gewesen wären, wäre der Angriff größtenteils abgewehrt worden. Die Kompromittierung des Webservers hätte trotzdem stattgefunden - John hat die Sicherheit nicht effektiv verwaltet und die Schwachstelle nicht beseitigt. Aber wenn der Angreifer erst einmal in den Webserver eingedrungen war, hätte er nicht so leicht von dem Server auf einen anderen Server wechseln können. Durch die Implementierung von Sicherheitsgruppenregeln mit Nullvertrauen hätte der Hacker nicht zu den anderen Servern in der Randzone wechseln können. Er hätte keine Möglichkeit gehabt, dorthin zu gelangen, und in der Sekunde, in der John den dritten Datenbankserver entfernt hätte, wäre er nicht mehr in der Sicherheitsgruppe gewesen. Somit wäre auch der Zugriff auf den Lohndatenbankserver blockiert worden.
Das geringste Privileg
Least Privilege bedeutet, dass die Berechtigung auf die kleinste Stufe beschränkt wird, um die erforderliche Arbeit zu erledigen. Du kannst dir das wie die Sicherheitskontrolle an einem Flughafen vorstellen. Als Passagier kannst du die Sicherheitskontrolle passieren, aber du kannst nicht in das falsche Flugzeug einsteigen oder eine Speicherung betreten. Die Frau, die bei Starbucks am Schalter arbeitet, kann die Sicherheitskontrolle passieren und die Speicherung betreten, aber sie kann kein Flugzeug oder das Rollfeld betreten. Ein Gepäckabfertiger kann auf die Rollbahn und in die Gepäckabfertigungsräume gelangen, aber er kann weder in ein Flugzeug noch in einen Lagerraum einsteigen. Das ist das geringste Privileg: Jeder bekommt den Zugang, den er braucht, um seine Arbeit zu erledigen, mehr nicht.
AWS betrachtet Sicherheit als Job Zero, was bedeutet, dass sie noch wichtiger ist als Priorität Nummer eins. Es wurde viel darüber nachgedacht, wie die Zugriffskontrollen funktionieren. AWS bietet über einen Service namens Identity and Access Management (IAM) eine sehr fein abgestufte Kontrolle über die Fähigkeiten der einzelnen Services. Mit dieser Kontrolle kannst du, wie der Flughafen, nur den Zugriff gewähren, der für den Betrieb eines bestimmten Dienstes erforderlich ist. Die zahllosen Berechtigungen, die die AWS-Services bieten, sind unterteilt in Listen-, Lese-, Markierungs- und Schreibberechtigungen. Tabelle 1-2 zeigt, welche Funktionen mit diesen Berechtigungen verbunden sind.
Mit diesen individuellen Zugriffskontrollen kannst du den Zugriff auf eine minimale Teilmenge von Aktionen gewähren. Warum solltest du das tun, und warum ist es ein Vorteil für die Sicherheit in AWS? Es geht um den Explosionsradius. Wenn sich ein Angreifer Zugang zu einer Reihe von Anmeldeinformationen verschafft, willst du die Aktionen, die er durchführen kann, begrenzen, um den Schaden zu begrenzen. Schauen wir uns ein Szenario an, in dem die geringsten Rechte nicht eingerichtet sind, um zu sehen, was passieren kann.
Eine Situation wie die von Rob ist nicht nur in der Cloud möglich. Genauso wie die Skalierung vor Ort möglich ist, ist auch das kleinste Privileg möglich. Es ist nur schwieriger, es vor Ort umzusetzen. Wenn du vor Ort arbeitest, gibt es Dutzende von Stellen, an denen du Sicherheit implementieren musst: Firewalls, Switches, Hypervisoren und so weiter. Es ist wie ein Büro voller Schreibtische, bei dem du zu jedem Schreibtisch gehen und die Schubladen abschließen musst. Nach der Migration und der Nutzung der AWS-Dienste wird die Aufgabe der Sicherung viel einfacher. Anstatt dich darauf zu konzentrieren, jeden Schreibtisch im Büro zu sichern, musst du nur noch das Büro sichern. IAM funktioniert wie die Tür zu deiner Infrastruktur. Jeder Nutzer, der durch diese Tür geht, erhält seine Berechtigung, wenn er sie passiert. Mit IAM kannst du die Liste, die Lese-, Markierungs- und Schreibberechtigungen zuweisen, wenn deine Nutzer/innen eintreten, um dir eine granulare Kontrolle zu ermöglichen.
Cloud Business Vorteile
Obwohl die Migration zu AWS erhebliche technische Vorteile mit sich bringt, gibt es auch eine Reihe von geschäftlichen Vorteilen. Ich halte die geschäftlichen Vorteile für wesentlich attraktiver als die technischen. Es ist ein bisschen wie beim Beginn einer Beziehung. Die technischen Vorteile ziehen dich in erster Linie an, während die geschäftlichen Aspekte die mentalen Attraktionen sind, die die Beziehung wachsen und interessant bleiben lassen. Auch wenn die technischen Vorteile zu Beginn der Umstellung auf AWS ein Warum sein mögen, werden sie schnell zu einem Wie, wenn die technischen Hürden überwunden sind. Genau wie in der Welt der Liebe kann die physische Seite der Gleichung schwinden, wenn sie gewöhnlich und erwartet wird. Sicherlich wird AWS mit neuen Diensten und Funktionen aufwarten, um die technische Seite aufzupeppen, aber es kommt immer auf die geschäftliche Seite des Hauses zurück. Man implementiert keine Technologie um der Technologie willen - es gibt immer einen geschäftlichen Grund dafür. Deshalb möchte ich die geschäftlichen Vorteile hervorheben, die dir die Umstellung auf AWS bietet.
Die geschäftlichen Vorteile werden als Motivation für dein Unternehmen viel länger Bestand haben als alle technischen Gründe. Aufgrund der Langlebigkeit dieser Beweggründe ist es sinnvoll, sich mehr Zeit für die Bewertung und Überlegung zu nehmen, wie sie sich direkt auf dein Unternehmen beziehen. Wenn du diese Vorteile gut begründest, kannst du eine überzeugende Geschichte erzählen, die deine Stakeholder und Mitarbeiter für deine Umstellung motiviert.
Reduzierte Ausgaben und Unterstützung
Wir haben uns bereits mit dem Konzept des Pay-as-you-go und dem Kauf deiner Infrastruktur zum Niedrigpreis befasst, also wollen wir nicht noch tiefer in diese Gewässer eintauchen (Wortspiel beabsichtigt). Das sind jedoch nicht die einzigen Möglichkeiten, wie AWS dazu beitragen kann, deine IT-Ausgaben zu senken. Wenn ich über die Vorteile von AWS in Bezug auf die Kosten spreche, unterteile ich sie gerne in zwei Bereiche. Im ersten Bereich haben wir die harten Kosten, die mit dem Betrieb deiner Umgebung verbunden sind. Das sind die Kosten für Ausrüstung, Software, Dienstleistungen, Strom, Brandschutz und dergleichen. Sie sind sehr greifbar und leicht zu messen. Auf der anderen Seite enthält der zweite Bereich die weichen Kosten, die mit deinem Anwesen verbunden sind. Diese Kosten, wie z. B. die Zeit, die das Personal für das Patchen, das Aufstellen von Regalen, das Durchführen von Backups und anderes aufwendet, sind schwer zu messen. Diese weichen Kosten sind der Parasit in deinem IT-Budget, der ihm das Leben aussaugt. Wenn du diese Kosten einsparen könntest, stünden deinem Unternehmen mehr IT-Mittel für Innovationen und die Schaffung von Mehrwert für deine Kunden zur Verfügung.
Harte Kosten
Ich habe gerade gesagt, dass harte Kosten leicht zu messen sind, aber jetzt werde ich das stark einschränken. Sie sind leicht zu messen , wenn du sie misst. Wenn du von Hardware wie Servern und Switches sprichst, bin ich mir sicher, dass du eine genaue Messung hast. Du hast sie gekauft, sie stehen in deinen Büchern als abschreibungsfähiger Vermögenswert, und du kannst mir wahrscheinlich genau sagen, wie viel sie dich kosten. Sobald du über die Hardware hinausgehst, könnte es etwas schwieriger werden. Wenn du zum Beispiel kein externes Rechenzentrum hast, wird es schwierig, die einzelnen Kosten zu erfassen. Ich habe hier zwei Beispiele aufgeführt, die zeigen, wie drastisch der Unterschied in der Kostenzuordnung sein kann.
Andrea hat einen ziemlich einfachen Job. Alles, was Andrea braucht, um ein Rechenzentrum zu betreiben, wird ihr mit einer hübschen kleinen Schleife auf dem Kopf verkauft. Sie weiß genau, was all diese Dinge kosten, und sie muss sich keine Gedanken über die Buchhaltung machen. AWS bietet Andrea keine Vereinfachung in Bezug auf die Kostenabrechnung. Die Kosten für den Betrieb ihrer Systeme in AWS werden ebenfalls in einer einzigen Rechnung mit einer schönen Schleife darauf geliefert. Andrea könnte einige ungenutzte Kapazitäten in ihrem Rack haben, wenn es nicht vollgestopft mit Geräten ist. Sie könnte von AWS profitieren, weil sie für diese zusätzliche Kapazität nicht bezahlen müsste. Wenn sie das Kosten-Nutzen-Verhältnis mit AWS vergleicht, wird es Andrea leicht fallen, die Analyse durchzuführen.
Ob du es glaubst oder nicht, ich treffe Jims Situation immer wieder an. Viele Unternehmen haben keine Ahnung, wie hoch die tatsächlichen Kosten für den Betrieb ihrer Infrastruktur sind. Wie Jim sind die Dinge einfach organisch vor Ort gewachsen, und es gab keine wirkliche Trennung aus buchhalterischer Sicht. Für Jim wird es schwierig sein, einen Kostenvergleich zwischen den Ausgaben vor Ort und AWS anzustellen. Da seine Kosten nicht direkt zugewiesen werden, muss Jim einige Annahmen treffen. Er kann die Quadratmeterzahl der Rechenzentren zugrunde legen oder einen Industriestandard als Basis verwenden. AWS kann ihm dabei helfen, indem er das online verfügbare TCO-Tool (Total Cost of Ownership) verwendet. Ich habe die Erfahrung gemacht, dass die Schätzungen von AWS von einigen Führungskräften nicht gern gesehen werden. Sie haben das Gefühl, dass es sich eher um Marketingmaterial als um qualitative Daten handelt, und würden Daten von einem unvoreingenommenen Dritten vorziehen. Wenn du deine Schätzungen von Hand erstellen möchtest, kannst du den AWS-Preisrechner verwenden.
Hinweis
Der AWS Pricing Calculator unterstützt nicht die Kalkulation aller AWS-Services, aber seine Möglichkeiten werden mit der Zeit immer größer.
Die Größenvorteile, die AWS den Unternehmen bei den harten Kosten bietet, sind ein wesentlicher Vorteil. AWS hat mehr Server, als ein einzelnes Unternehmen haben könnte. AWS nutzt spezialisierte Geräte und kann so die Anschaffungs- und Betriebskosten senken. Diese Einsparungen werden dann an die Kunden weitergegeben. Sogar die größten Unternehmen der Welt, die selbst über große Infrastrukturen verfügen, entscheiden sich dafür, zu AWS zu wechseln und ihre Rechenzentren zu schließen. Der Grund dafür ist ganz einfach: Sie sind nicht im Rechenzentrumsgeschäft tätig. Ihr Geschäft ist es, ihren Kunden einen anderen Service oder ein anderes Produkt anzubieten. Da Rechenzentren nicht zu ihrem Geschäft gehören, können sie nicht die Größenordnung von AWS und damit die Kosteneinsparungen erreichen. Wenn diese großen Unternehmen es nicht so effektiv wie AWS machen können, dann stell dir vor, was die Migration für dein Unternehmen bedeuten kann.
Weiche Kosten
Einer der aufregendsten Vorteile von AWS bezieht sich auf die weichen Kosten. Wenn du zu AWS migrierst, stehen dir viele Services zur Verfügung, um die weichen Kosten für den Betrieb deiner Umgebung zu senken. Diese Dienste können nicht nur die Kosten senken, sondern auch das Risiko reduzieren. Einer der besten Services zur Senkung der weichen Kosten nach der Migration ist RDS, ein verwalteter Datenbankservice. Diese Verwaltung bedeutet, dass AWS das Patchen des Betriebssystems, die Sicherung der Datenbanken und das Patchen der Datenbank-Engine übernimmt. Durch diese Automatisierung entfällt ein Großteil des Aufwands, den deine Mitarbeiter/innen für diese Funktionen aufbringen müssen. Viele Stunden pro Jahr würden die Mitarbeiter/innen mit der Installation der Patches und der Überprüfung der Datensicherung verbringen. Solche Vorgänge sind zeitraubend und bringen den Kunden keinen Nutzen. Die Kunden wollen, dass ihre Daten gesichert werden, aber es ist ihnen egal, wie das geschieht, und sie sind auch nicht bereit, dafür zu bezahlen. Sie sehen es als unvermeidlich an und als Teil deines Problems, nicht ihres. Die Kunden wollen Produktfunktionen, Updates und die Behebung von Fehlern. AWS hilft dir bei diesen nicht wertschöpfenden Funktionen, wie z. B. dem Patchen von Datenbanken, und gibt deinen Mitarbeitern die Zeit, sich um die wertschöpfenden Dinge zu kümmern, die die Kunden wollen.
Diese Form der weichen Kosteneinsparungen ist auf der gesamten Plattform zu finden. Wenn du an alle Posten denkst, die für den Betrieb eines Rechenzentrums erforderlich sind, wirst du diese Einsparungen erkennen. Zum Beispiel gehören zum Betrieb eines Rechenzentrums Batteriesicherungssysteme. Diese Systeme müssen gewartet und getestet werden. Wenn du dein eigenes Rechenzentrum betreibst, fallen diese Aufgaben auf deine Schultern. Je nach deinem Risikoprofil könntest du deine Backup-Systeme jedes Jahr, jedes Quartal oder jeden Monat testen. Auch das bietet deinen Kunden keinen Mehrwert, außer dass sie erwarten, dass deine Systeme online sind, wenn sie sie brauchen. Du kannst noch eine Ebene tiefer gehen und an die Zeit denken, die du brauchst, um die Verträge für deine Kommunikationsleitungen und die Verträge für den HLK-Support auszuhandeln. All diese Dinge kosten dich Zeit und Mühe, und die tatsächlichen Kosten dieser Zeit sind schwer zu beziffern. Wenn ich an meine Rechenzentren und den Zeitaufwand für deren Verwaltung zurückdenke, würde ich all das lieber auslagern und mich um den Betrieb meiner Software kümmern. Wenn du ein Colocation-Rechenzentrum nutzt, sind viele dieser Aufgaben bereits für dich ausgelagert, und du musst dich nicht darum kümmern.
Wenn wir einen Schritt über die betrieblichen Anforderungen für ein Rechenzentrum hinausgehen und uns Dinge wie das Netzwerk und die Hypervisoren ansehen, wirst du einen Trend erkennen, bei dem AWS dir noch mehr Zeit ersparen kann. In AWS musst du dich zum Beispiel nicht um die Verwaltung des Hypervisors kümmern. Das Patchen deiner VMware-Umgebung oder von Microsoft Hyper-V wird überflüssig. Der Hypervisor ist Teil des EC2-Produkts, um das du dich nicht mehr kümmern musst. Du verbrauchst die EC2-Instanzen. AWS kümmert sich um die zugrunde liegende Hardware, das Betriebssystem und das Patchen. Das Gleiche gilt für den elastischen Lastausgleich. In deiner lokalen Umgebung müsstest du deinen Load Balancer patchen und dich um die Sicherheit und die Aktualisierung der Hardware kümmern, wenn diese ausläuft. Das Gleiche gilt für dein Speichersubsystem, denn AWS verwaltet das Speichersubsystem für dich. Du nutzt den Elastic Block Store (EBS) Volumes. Du musst dich nicht darum kümmern, wie viel Festplattenkapazität verfügbar ist, wie viel Speicherplatz benötigt wird oder wie viel Wartungsverträge kosten.
Hinweis
Die Senkung der weichen Kosten kann die harten Kosteneinsparungen leicht übertreffen. Die Gehälter der Beschäftigten sind wahrscheinlich die größten Ausgaben deines Unternehmens. Das bedeutet nicht, dass du an Halloween Kündigungen verteilen solltest, aber es bedeutet, dass deine Mitarbeiter mehr Zeit haben, um einen Mehrwert für dein Unternehmen zu schaffen.
Die letzte wichtige Komponente, die wir behandeln werden, um die Betriebskosten zu senken, ist die Firewall. Firewalls sind ein weiteres wichtiges Gerät für die Netzwerkkommunikation, das du verwalten, patchen und aktualisieren musst. Durch den Einsatz von AWS-Sicherheitsgruppen () kannst du einen großen Teil der Kosten für die Wartung deiner Umgebung einsparen. Darüber hinaus bietet AWS einen Netzwerkservice namens Network ACLs an, der durch die Implementierung einer Layer-3-Firewall eine zweite Sicherheitsebene bietet.
Ich könnte noch viele weitere Funktionen von AWS aufzählen, mit denen du diese Kosten sparen kannst. Ich wollte nur ein paar der wichtigsten hervorheben, um dich zum Nachdenken über andere Bereiche anzuregen, in denen deine Mitarbeiter einen Großteil ihrer Zeit für banale Aufgaben verwenden - Aufgaben, die du auslagern und von jemand anderem verwalten lassen kannst. Dein Produkt oder deine Dienstleistung ist das, was dein Unternehmen am besten kann; es ist das, was es einzigartig macht. Das ist der Grund, warum du im Geschäft bist. Das werde ich im Laufe des Buches noch mehrmals wiederholen. Es ist ein grundlegendes Konzept, das du unbedingt verinnerlichen solltest. Es wird dir später helfen, mit Kritikern umzugehen. Manche Mitarbeiter/innen zögern, Veränderungen vorzunehmen, und haben Angst vor Überalterung und zusätzlicher Arbeitsbelastung. Wenn du ihnen zeigen kannst, wie sich ihr Arbeitsleben durch interessantere Aufgaben verbessern wird, wird das ihren Widerwillen verringern. Ich sage es gerne so: Niemand hat eine Ausbildung gemacht, um zu lernen, monotone Aufgaben zu erledigen. Sie haben aus einem anderen Grund gelernt - um ein Produkt zu entwickeln, um großartige Datenbanken zu erstellen oder um gutes Geld zu verdienen. Ich versichere dir, dass keiner von ihnen von einer Arbeit träumte, die ein Roboter erledigen könnte.
In AWS gibt es noch viele weitere Dienste, die dir helfen, deine Arbeit zu erleichtern, ohne dass wir darauf eingehen müssen. Es gibt Tools zum Sichern deiner Daten, Tools zum Einspielen von Patches und sogar Tools zum Verwalten von Lizenzen. Zusammen sind sie eine mächtige Waffe gegen die Verschwendung von Zeit und Aufwand. Du musst herausfinden, wo in deinem Unternehmen viel Zeit verschwendet wird, und herausfinden, ob es einen Dienst oder eine Funktion gibt, mit der diese Verschwendung verringert werden kann. Tabelle 1-3 enthält eine Liste mit einigen zusätzlichen Diensten, die deine weichen Kosten nach der Migration verringern könnten.
Warnung
Verwende keine weichen Kosten in deiner Geschäftsbegründung, wenn du sie nicht absolut quantifizieren kannst. Wenn du das nicht tust, kann das dazu führen, dass sie verworfen werden und deine Migration gefährden. Ich habe schon erlebt, dass Manager in brenzlige Situationen geraten sind, weil das obere Management dachte, dass sie mit der Angabe von "fadenscheinigen" Zahlen eine Agenda vorantreiben würden.
Keine Verpflichtung
Wenn du vor Ort baust, ist es ähnlich wie beim Kauf eines neuen Autos. Du gibst dir viel Mühe bei der Bewertung, um sicherzustellen, dass es gut passt. Ihr werdet für die nächsten drei bis fünf Jahre zusammen sein, und ihr solltet das Beste daraus machen. Es ist die zweitgrößte Ausgabe, die du nach deinem Haus haben wirst. Es ist eine bedeutende Verpflichtung, die einen großen Einfluss auf dein Leben hat. Wie bei deinem Auto ist es die Verpflichtung, die Unternehmen davor zurückschrecken lässt, neue Dinge auszuprobieren. Es ist viel beängstigender, schnell fehlzuschlagen, wenn das Scheitern harte Dollars kostet, die nur schwer wieder hereinzuholen sind. Seien wir ehrlich - Computer-Hardware schreibt sich schneller ab als dein letztes Auto. Bei einem Auto ist der Wert irgendwann am Ende, weil es immer noch die Funktion erfüllt, von A nach B zu fahren. Bei Computerhardware ist das nicht der Fall; der Wert kann bis auf Null sinken, weil die Software, die dafür entwickelt wurde, nicht mehr läuft. Diese Wertminderung führt zu einer großen Angst vor dem schnellen Fehlschlagen. Schnelles Scheitern bedeutet, dass die Hardware, die du heute kaufst, vielleicht nicht wie erwartet mit dem Konzept funktioniert, das du getestet hast, und jetzt hast du diese Hardware herumstehen und Staub sammeln. Wenn du das ein paar Mal machst, hast du Dutzende, Hunderte oder Tausende von Geräten herumliegen. Was passiert dann? Du schlägst nicht schnell fehl. Du willst gar nicht fehlschlagen, also machst du keine Innovationen und dein Unternehmen wird von einem Startup über den Tisch gezogen.
Sag das nicht meiner Frau, mit der ich seit 17 Jahren verheiratet bin, aber Engagement ist schlecht. Zumindest, wenn es um IT geht. Bei AWS gibt es keine Verpflichtungen. Du kannst einen Server in Betrieb nehmen oder ein Geschäftskonzept oder eine Produktverbesserung testen. Wenn es nicht funktioniert, kannst du es zerstören und nicht mehr bezahlen. Die Möglichkeit, zu testen und fehlzuschlagen, nimmt einen viel kleineren Teil deines Budgets in Anspruch. Schnelles Fehlschlagen bedeutet, dass du unbedeutende Geldbeträge mehrmals ausgibst, bis du etwas findest, das funktioniert und das Produkt oder die Funktion liefert, die deine Kunden wollen. Es ist wie bei einem neuen Produkt, das du im Internet siehst und das du ausprobieren möchtest, aber du hast Angst, dass es nicht hält, was es verspricht. Doch dann siehst du, dass es eine Geld-zurück-Garantie gibt, wenn du nicht zufrieden bist. Jetzt ist deine Angst vor dem Scheitern weg und du machst mit dem Kauf weiter. Der unverbindliche Aspekt von AWS ist die gleiche warme Decke, in die du dich gerne einhüllst, bevor du ein neues Produkt ausprobierst.
Einer der Vorteile, den du nutzen kannst, ist das Testen von Mitarbeitern. Im Laufe meiner Karriere hatte ich viele Mitarbeiter, die gerne tüftelten und Dinge ausprobierten. Ich sehe das als einen hervorragenden Geschäftsvorteil. Durch das Experimentieren können Menschen Probleme auf eine Weise lösen, die sie nie erwartet oder an die sie nie gedacht hätten. Am besten wäre es jedoch, wenn du dem Experimentieren einige Leitplanken setzt. Du musst sicherstellen, dass deine Daten sicher sind und deine Kosten nicht aus dem Ruder laufen. In AWS kannst du ein Sandbox-Konto einrichten, das es deinen Mitarbeitern ermöglicht, neue Dinge auszuprobieren, zu lernen und auf kontrollierte Weise zu experimentieren. Du kannst für dieses Konto Ausgabenlimits und Alarme festlegen, um die Kosten niedrig zu halten. Unter Sicherheitsaspekten kannst du den Zugriff auf Produktionsdaten verhindern, um Datenverluste zu vermeiden.
Außerdem kannst du automatisierte Bereinigungsskripte ausführen, um die bereitgestellte Infrastruktur zu bereinigen und so die Kosten niedrig und die Schatten-IT auf ein Minimum zu beschränken. All diese Elemente bieten einen sicheren Ort, an dem deine Mitarbeiter/innen dir dabei helfen können, einen besseren Wert für deine Kunden zu schaffen, während sie sich selbst herausfordern und geistig mit ihrer Arbeit beschäftigt bleiben. Das ist ein Gewinn für alle Beteiligten.
Hinweis
Obwohl AWS in der Regel unverbindlich ist, kann es Situationen geben, in denen du dich verpflichten musst. Sie sind in der Regel an Rabattprogramme gebunden, bei denen du einen bestimmten Betrag garantierst, um einen Rabatt zu erhalten. Dies ist als Enterprise Discount Program (EDP) bekannt.
Business Agility
Ein weiterer Vorteil, den du bei der Migration nutzen kannst, ist die Agilität deines Unternehmens, die für das langfristige Überleben äußerst wichtig ist. Wenn du dir die Unternehmen ansiehst, die in letzter Zeit zu kämpfen hatten und fehlgeschlagen sind - Sears, Kodak, Toys R Us und Blockbuster, um nur einige zu nennen - dann hat ihre Unfähigkeit, sich anzupassen und zu verändern, ihren Untergang beschleunigt. Unterm Strich bedeutet unternehmerische Agilität mehr Wettbewerbsfähigkeit, mehr Anpassungsfähigkeit an veränderte Marktbedingungen und mehr Umsatz.
Tipp
Agilität ist der wichtigste Vorteil der Migration. Achte darauf, dass du dies in deinen Warum-FAQ ansprichst.
Mir ist aufgefallen, dass bei allen Unternehmen, denen ich bei der Migration zu AWS geholfen habe, die Steigerung der geschäftlichen Agilität der schwierigste, aber auch der erfolgreichste Vorteil war. Es ist schwierig, weil viele Menschen beteiligt sind - in der Regel verschiedene Abteilungen und verschiedene Teams innerhalb der Abteilungen. Sie müssen zusammenarbeiten, um die Vorteile der Agilität zu nutzen. Diese Teams sind in einem Unternehmen traditionell sehr abgeschottet. Wenn man mit Menschen und diesen Silos arbeitet, geht der Wandel leider nicht so schnell vonstatten. Oftmals führt der Widerwille gegen Veränderungen zu erheblichen Hindernissen. Ein Grund, warum ich es für wichtig halte, die Gründe für den Wandel zu benennen, ist, dass dies den Prozess vorantreibt und Synergien zwischen den Silos fördert.
Wenn du etwa fünf Jahre zurückgehen würdest, würdest du das Wort Business Agility im Zusammenhang mit der IT nicht hören. Die IT-Abteilung war dafür da, die vom Unternehmen benötigten technischen Dienstleistungen bereitzustellen. In der Regel gab es lange Entwicklungszyklen mit Wasserfallmethoden, oder es wurde kommerzielle Standardsoftware verwendet. In den letzten Jahren haben sich die Dinge jedoch geändert. Die Kombination aus agilen Softwareentwicklungsmethoden und automatisierten Bereitstellungspipelines hat den Blick des Unternehmens auf die IT verändert. Heute ist es nicht ungewöhnlich, dass Unternehmen jeden Tag zehn Produktionsupdates veröffentlichen. Wenn du das mit deinem On-Premises-System vergleichst, wirst du den dramatischen Unterschied sehen, den diese Tools ermöglichen. AWS hat eine Reihe von Produkten für die Automatisierung des Aufbaus und der Bereitstellung von Infrastruktur und Software entwickelt. Allerdings sind diese Dienste für sich allein genommen nicht besonders nützlich. Mit AWS CodePipeline kannst du zum Beispiel die Erstellung und Bereitstellung von Software automatisieren. Wenn die Software nicht automatisch installiert werden kann und ein Benutzereingriff erforderlich ist, ist eine automatisierte Bereitstellungspipeline leider nicht sehr nützlich.
Anders ausgedrückt: Agilität ist die Kombination aus Werkzeugen und Prozessen. Leider bist du als IT-Manager dafür verantwortlich, diese Diskrepanz zu beheben. Die IT-Abteilung ist die zentrale Anlaufstelle für alle anderen Teams, Abteilungen und Geschäftsbereiche in einem Unternehmen. Diese Zentralisierung gibt dem IT-Manager eine einzigartige Perspektive, um eine einheitliche Arbeitsweise im gesamten Unternehmen zu schaffen. Das folgende Szenario zeigt, wie sich Agilität auf ein Unternehmen auswirken kann.
Ich habe einige außergewöhnlich große und erfolgreiche Unternehmen gesehen, die sich in einer ähnlichen Situation wie Judy befanden. Sie haben ihr internes Tooling lange vor der aktuellen Technologiewelle entwickelt. Ihre Konkurrenten sind neuer und wurden in einem Cloud-nativen Zustand entwickelt, was ihnen einige Vorteile verschafft. In Judys Fall nutzt der Konkurrent Analytik und KI und kann mindestens wöchentlich Updates herausbringen. Damit ihr Unternehmen auf gleicher Augenhöhe konkurrieren kann, muss es einige Änderungen vornehmen:
-
Implementiere eine Pipeline für kontinuierliche Integration und kontinuierliche Entwicklung (CI/CD)
-
Regressionstests der Änderungen aus zwei Jahren vor der Aktualisierung der Produktionsumgebung
-
Schulung des Personals und der Kunden über die zweijährigen Veränderungen
Sobald das Update in die Produktion geht, können sie darüber nachdenken, zu einer agilen Entwicklungsmethodik zu wechseln. Währenddessen muss Judy dafür sorgen, dass die Mitarbeiter/innen betreut, geschult und motiviert werden, um ein erfolgreiches Ergebnis zu erzielen.
Disaster Recovery/Business Continuity
Als ich meine berufliche Laufbahn begann, dachten viele Unternehmen nicht an eine Notfallplanung. Viele Jahre lang bestand der Umfang meiner DR-Pläne aus einer Bandsicherung, die in einem feuerfesten Tresor aufbewahrt wurde. Der Begriff " feuerfest" hätte gar nicht verwendet werden dürfen - es war eher eine Feuerverzögerung und garantierte nicht, dass die Temperatur des Feuers meine Bänder nicht schmelzen würde. Mit den Jahren wuchs die Bedeutung von DR. Die IT hat sich von einem reinen Buchhaltungssystem zu einem wichtigen Teil des Unternehmens entwickelt. Heute könnte die IT dein Geschäft sein, und ohne sie würdest du nicht lange im Geschäft bleiben. DR ist ein großer Teil deines Budgets und ein wichtiger Teil deiner Prozesse.
Wenn Unternehmen zu AWS migrieren, sollten sie versuchen, den Schwerpunkt von DR auf BC zu verlagern. Bei der Geschäftskontinuität geht es eher darum, den Betrieb aufrechtzuerhalten, als sich von einem kompletten Ausfall zu erholen. Ich bin sicher, du stimmst mir zu, dass Kontinuität besser ist als Wiederherstellung. Wer will sich schon erholen, wenn es so viel einfacher ist, weiterzumachen? Mit den Möglichkeiten der AWS-Infrastruktur im Rücken ist es einfacher, einen BC-Plan zu erstellen, der deine gewünschten Ziele erfüllt. Diese Ziele sind das Recovery Point Objective (RPO) und das Recovery Time Objective (RTO). Um mich an diese Konzepte zu erinnern, stelle ich mir das RPO-Ziel immer wie das Haltbarkeitsdatum meiner Milch vor. Wie alt darf sie (die Daten) werden, bevor sie für mich unbrauchbar wird? An das RTO-Ziel erinnere ich mich als die Zeit, die ich brauche, um in den Laden zu gehen, um mehr Milch zu holen, oder wie lange ich offline sein kann.
Wenn du AWS AZs in deinem Design verwendest, kannst du einen RTO und einen RPO nahe Null erreichen, indem du deine Anwendungen in einer aktiv/aktiven oder aktiv/passiven Konfiguration bereitstellst. Aktiv/aktiv bedeutet, dass deine Anwendungen auf mindestens zwei Servern gleichzeitig ausgeführt werden. Das kannst du mit einem Load Balancer vor den Servern erreichen. Aktiv/passiv ist ähnlich, aber einer der Server beantwortet zu jeder Zeit die Anfragen. Im Falle eines Ausfalls bei einer aktiv/passiven Bereitstellung übernimmt der zweite Server den primären Server. Herzlichen Glückwunsch, du hast jetzt ein BC-Design mit nahezu Null RPO/RTO in AWS. Mit diesem Konzept kannst du den Ausfall eines AZ überleben und den Betrieb ohne Unterbrechung fortsetzen. Die Frage, die du dir stellen musst, ist, ob dies ein ausreichender Schutz für dein Unternehmen ist. Was ist, wenn eine ganze Region ausfällt? Wenn du diese Frage stellst und die Antwort lautet: Das ist inakzeptabel, dann gibt es noch mehr BC/DR-Arbeit zu tun.
Wenn du die Vorteile von AWS-Regionen nutzt, kannst du deine Infrastruktur so erweitern, dass der Ausfall einer ganzen Region berücksichtigt wird. Abhängig von deiner Implementierung und deinen Anforderungen kann es jedoch zu erheblichen Kostenunterschieden kommen, je nach Implementierung. Du musst entscheiden, ob dein Unternehmen regionsübergreifende DR oder BC wünscht. Regionsübergreifende DR ist kostengünstiger, hat aber eine viel höhere RTO und RPO, während regionenübergreifende BC mehr kostet, weil mehr aktive Infrastruktur betrieben werden muss, um die niedrigere RTO/RPO zu ermöglichen. Gehen wir zwei Szenarien durch, um zu zeigen, wie dein DR/BC nach der Migration zu AWS aussehen könnte.
Die Anforderungen des Distrikts zu erfüllen, wird angesichts der Möglichkeiten von AWS keine schwierige Aufgabe sein. Da die RTO und RPO so hoch sind, macht es wenig Sinn, BC einzusetzen und mit einer DR-Strategie fortzufahren. Kevin wird in der Lage sein, mit einem automatisierten System namens Data Lifecycle Manager (DLM) einen Snapshot der Server zu erstellen (eine Kopie der Daten auf Blockebene). DLM unterstützt ein RPO von nur 2 Stunden, was besser ist als die Anforderung von 168 Stunden. Da Kevin nur 12 Server hat, wäre es für ihn nicht so schwer, die Instanzen innerhalb der geforderten RTO von 24 Stunden manuell auf eine andere AZ zu verlagern. Wenn eine AZ fehlschlägt, könnte Kevin innerhalb von sechs Stunden neue Server in Betrieb nehmen und ihnen die neuesten Snapshots zuweisen, so dass er noch genügend Zeit hätte. Am besten wäre es, wenn Kevin seine 12 Server in drei AZs einsetzen würde. Diese Konfiguration stellt sicher, dass nur 4 statt 12 Server gleichzeitig ausfallen können. Mit dieser Konfiguration würde er vier weitere Stunden für die Neuverteilung der Instanzen einsparen.
Amelia sollte sich überlegen, von einem DR- zu einem BC-Konzept zu wechseln. Sie hat genug geschäftskritische Systeme, die dies erforderlich machen. Indem sie einige der Vorteile von AWS nutzt, kann Amelia ihre Anwendungen auf drei AZs bereitstellen und mit Lastausgleich und automatischer Skalierung für Verfügbarkeit sorgen. Indem sie ihr Datenbank-Backend zu Amazon RDS verschiebt, kann sie von der aktiven/passiven Datenbankverfügbarkeit profitieren. Mit dieser Konfiguration kann Amelia ihr RTO/RPO auf praktisch sofortige Verfügbarkeit reduzieren. Um eine weitere Schutzebene hinzuzufügen, kann sie DLM mit vierstündigen Snapshots implementieren und diese in eine andere Region replizieren, um die DR-Fähigkeit zu gewährleisten. So kann sie ihre Server wiederherstellen, wenn eine ganze Region für längere Zeit ausfällt.
BC ist kein Konzept, das man mit Kosteneinsparungen in Verbindung bringt, aber mit AWS und den Regionen mit drei AZs kannst du 25 % deiner Kosten einsparen und trotzdem das gleiche Maß an Verfügbarkeit bieten. Das hängt von den Fähigkeiten deiner Anwendung ab, aber wenn deine Anwendungen das unterstützen können, kannst du eine beträchtliche Summe einsparen. Diese Einsparungen sind ein weiterer Vorteil von AWS in Bezug auf BC.
Jimmy wird etwas Geld sparen, wenn er seine Anwendung zu AWS verlagert. Nehmen wir an, der Betrieb von Jimmys Produktionsserver kostet 100 US-Dollar pro Monat. Um seine Anforderungen an Verfügbarkeit und BC zu erfüllen, hat Jimmy einen zweiten Server in einem anderen Rechenzentrum. Dieser Server kostet ebenfalls 100 US-Dollar pro Monat, um Datenbank-Updates zu erhalten und für den Datenverkehr bereit zu sein. Jimmy zahlt 200% für seine Anwendung: 100%, um die Anwendung zu bedienen, und 100%, um für den Failover verfügbar zu sein. Da Jimmy in den Vereinigten Staaten lebt, stehen ihm mindestens drei AZs zur Verfügung. Wenn er seine Server migriert, kann er die automatische Skalierung und einen Load Balancer nutzen, um seine Anwendung in einen Aktiv/Aktiv-Cluster umzuwandeln. In dieser Konfiguration kann Jimmy drei Server einsetzen, die 50 % der Last bedienen. Das bedeutet, dass er für jeden Server 50 US-Dollar pro Monat zahlt, so dass er insgesamt 150 US-Dollar statt 200 US-Dollar zahlt. In dieser Konfiguration kann Jimmy einen Server oder AZ fehlschlagen lassen und trotzdem seine gesamte Last bedienen, während er 25 % seiner laufenden Kosten spart.
Geringere Bindung an den Lieferanten
Immer wenn ich im Zusammenhang mit der Migration zu AWS das Wort "Vendor Lock-in" höre, muss ich mich am Kopf kratzen. Wenn überhaupt, eröffnet die Migration zu AWS mehr Optionen, als dass sie sie einschränkt. Als du deine Infrastruktur vor Ort aufgebaut hast, hast du eine Menge Anbieterabhängigkeiten akzeptiert. Du konntest zwar den Anbieter deines SANs (Storage Area Network) oder deiner Serverhardware wechseln, aber nur, wenn du die Hardware erneuern musstest. Wenn du die Hardware kaufst, bist du für drei bis fünf Jahre an sie gebunden. Es war nicht so, dass du ein SAN von Dell EMC kaufen konntest und dann ein Jahr später Festplattenkapazität von Hewlett-Packard kaufen konntest, um es zu erweitern. So funktioniert es einfach nicht, und das Gleiche gilt für deinen Hypervisor. Sicher, du kannst von VMware zu Hyper-V wechseln, aber der Aufwand dafür ist hoch.
Wenn du zu AWS migrierst, tauschst du deine Hardware gegen Bits und Bytes. Wenn du meinen Server zu AWS hochlädst und ihn dort laufen lässt, kannst du ihn am nächsten Tag zu Azure verschieben. Durch den Umzug in die Cloud trennst du die Bindungen zu deiner Hardware. Es gibt zwar einige Kosten für ausgehende Daten von den Cloud-Providern, die geringe Umzugskosten verursachen, aber diese Umzugskosten gibt es überall, auch bei On-Premises, daher halte ich sie für überflüssig. Die Umstellung deiner Systeme auf reine Daten macht sie mobiler als je zuvor. Der Betrieb von Instanzen in AWS bietet dir mehr Mobilitätsvorteile, als du jemals vor Ort haben könntest; das hängt mit dem Pay-as-you-go-Modell und den fehlenden Verpflichtungen zusammen.
Ein echter Vendor Lock-in entsteht, wenn du proprietäre Dienste nutzt, die nur von einem Anbieter angeboten werden. Ich habe viele Manager sagen hören, dass sie nur Dienste nutzen wollen, die in allen Clouds verfügbar sind, damit sie mobil sind und den Anbieter wechseln können. Diese Mentalität ist langfristig nicht förderlich für deine Karriere. Wenn du deine Infrastruktur im Gleichschritt mit dem kleinsten gemeinsamen Nenner hältst, wirst du nie einen Wettbewerbsvorteil auf deinem Markt haben. Deine Konkurrenten werden mit der Übernahme von Lock-in-Technologien vorankommen, um ihren Unternehmen einen Mehrwert zu verschaffen. Das ist so, als würdest du eine Corvette kaufen und dann nie den ersten Gang einlegen. Ein gewisses Maß an Lock-in ist unvermeidlich, und wenn eine Lock-in-Situation eintritt, ist es wichtig, sich zu fragen, ob sie gut für dein Unternehmen ist.
Warnung
Sei misstrauisch, wenn sich die Diskussionen auf Multicloud verlagern. Das ist der sicherste Weg, um deine Kosten in die Höhe schnellen zu lassen. Du musst dann für alles doppelt zahlen. Doppelte Sicherheitstools, doppelte Audits und möglicherweise doppelt so viel Personal, je nach Qualifikation.
Veränderung der operativen Ausgaben
Ein Vorteil der Migration zu AWS und der Einführung eines Umlageverfahrens ist, dass du von einer Investitionsausgabe zu einer Betriebsausgabe wechselst. Oberflächlich betrachtet ist es nicht sofort ersichtlich, warum dies ein Vorteil ist, und manche sehen es als Nachteil an. Wenn du einen Server vor Ort kaufst und ihn abschreibst, d.h. die Abnutzung der Anlage über mehrere Jahre hinweg, hast du am Ende eine feste monatliche Ausgabe für diese Hardware. Nach der Migration tauschst du diese Form der Abrechnung gegen variable Betriebskosten ein. Diese Änderung scheint aus buchhalterischer Sicht keine gute Sache zu sein; du gehst von festen monatlichen Ausgaben zu variablen Ausgaben über. Viele Menschen bevorzugen eine feste, bekannte Variable für die Ausgaben, und die Hinzufügung einer variablen Ausgabe bereitet ihnen Unbehagen.
Auch wenn die Kosten variabel sind, sehe ich darin einen Vorteil gegenüber On-Premises. Um den Vorteil der festen monatlichen Ausgaben für den Server zu haben, musst du ihn kaufen. Der Kauf von Hardware bedeutet, dass du dein Kassenkonto in Anspruch nimmst, für das du dann in meinem Buchhaltungssystem ein Anlagenkonto einrichtest. Sobald du das Anlagenkonto eingerichtet hast, kannst du die Gesamtkosten des Servers durch die Anzahl der Monate teilen, die du ihn behalten willst. Viele Unternehmen verwenden 36 Monate oder 3 Jahre als Abschreibungsplan. Du musst dein Geldkonto ausschöpfen. Das Geld ist weg und steht nicht für andere Dinge zur Verfügung, z. B. um Mitarbeiter zu bezahlen oder mehr Werbung zu kaufen. Das ist bei AWSnicht der Fall - dumusst dein Konto nicht abschreiben, und dein Geld ist immer noch verfügbar, um das Unternehmen voranzubringen.
Du fragst vielleicht noch nach den variablen Kosten und ihrer Unvorhersehbarkeit. Ich sehe das als einen Vorteil an. Es ist nicht immer ganz einfach zu verstehen, warum das ein Vorteil ist, also lass uns das folgende Szenario betrachten, um es besser zu verstehen.
Um zu erklären, warum die Situation bei Duke und die variablen Kosten ein Vorteil sind, lass uns ein paar Zahlen aufschlüsseln. Dukes Plattform läuft in einem stabilen Zustand ohne Nutzer und kostet etwa 850 US-Dollar pro Monat. Diese Kosten entsprechen den Fixkosten von Duke für sein Produkt. Unabhängig davon, wie viele Nutzer/innen auf der Plattform sind, kostet die Herstellung des Produkts für die Nutzer/innen rund 850 US-Dollar pro Monat. Die variablen Kosten sind die Kosten pro Nutzer von 0,55 $. Die Summe der variablen Kosten steigt mit jedem zusätzlichen Nutzer linear an. Und jetzt kommt das Beste: Da die Kosten auf dem Verbrauch - den Nutzern - basieren, steigen auch die Einnahmen linear. Diese Zahlen helfen Dukes Unternehmen, Vorhersagen darüber zu treffen, wie viel es kosten wird und wie viel es einnehmen wird. Sie sagen nichts über die Marktdurchdringung oder darüber aus, wie viele Nutzer die Anwendung nicht mochten und den Dienst abbestellt haben. Der Finanzvorstand von Duke wird sich jedoch viel wohler fühlen, wenn er weiß, dass die variablen Kosten an die Nutzerbasis gebunden sind. Wenn du dieses Szenario damit vergleichst, dass Duke seine Anwendung vor Ort betreibt, müsste er für die erwartete Nachfrage eine große Menge an Hardware kaufen. Die Kosten wären zwar fix, aber sie wären auch teurer und fix, selbst wenn das Unternehmen zum Start nur zehntausend statt hunderttausend Nutzer hätte.
Wenn du mehr Vorhersehbarkeit in deiner Rechnung haben möchtest und einen relativ statischen Verbrauch hast, kannst du reservierte AWS-Instanzen kaufen . Eine reservierte Instanz ist eine im Voraus bezahlte EC2-Instanz anstelle des Pay-as-you-go-Modells und bietet dir einen vergünstigten Preis. Du zahlst für eine reservierte Instanz im Voraus und schreibst die Kosten dann über das Jahr hinweg ab. Diese Funktion ähnelt der Abschreibung, denn du zahlst im Voraus und zahlst dann jeden Monat 1/12 der Kosten zurück. AWS bietet auch reservierte Instanzen mit dreijähriger Laufzeit an, aber die lehne ich aus vielen Gründen ab, auf die ich in "Run Rate Modeling" eingehen werde.
Hinweis
Manchmal funktioniert das Umlageverfahren nicht für alle; es schränkt einige Möglichkeiten für kleine und mittlere Unternehmen ein, um die Abschreibung zu beschleunigen. Dein Buchhalter möchte vielleicht deine Steuerlast reduzieren, indem er die IRS Section 179 nutzt. Bevor du umstellst, solltest du unbedingt mit deinem Buchhalter oder CFO sprechen, um zu klären, was unter diesen Umständen zu tun ist und wie du das Problem lösen kannst.
Dein Warum in eine FAQ umwandeln
In diesem Kapitel haben wir viel darüber erfahren, wie du mit ein paar Änderungen eine ganze Reihe von technischen und geschäftlichen Vorteilen aus der Migration zu AWS ziehen kannst. Ich hoffe, dass du beim Lesen der verschiedenen Szenarien, in denen einige dieser Änderungen erläutert werden, über deine persönlichen Erfahrungen nachdenken und Ähnlichkeiten feststellen konntest. Du solltest eine gute Grundlage haben, um deine FAQ für die Migration zu AWS zu erstellen, indem du deine Notizen als Leitfaden verwendest.
Warum erstellen wir eine FAQ für die Migration? Nun, die Leute werden Fragen stellen, das ist ganz klar. Ich erstelle gerne im Voraus eine FAQ mit Antworten auf Fragen, von denen ich glaube, dass die Leute sie am ehesten stellen werden. Das zeigt zum einen, dass du viel Zeit damit verbracht hast, das Projekt mit ihren Augen zu sehen. Diese Verbindung gibt ihnen das Gefühl, dass du ihren Schmerz nachfühlst und ihre Sichtweise verstehst. Mit Empathie wirst du schnell Unterstützung gewinnen. Tatsache ist, dass du durch diese Übung ihre Perspektive verstehst! Der nächste Punkt, den die FAQ anspricht, ist, dass die allgemeinen Bedenken sofort vom Tisch sind und du dich schneller an die Arbeit machen kannst. Ich bin mir sicher, dass du keine Lust hast, in weiteren Meetings immer wieder über die gleichen Beeinträchtigungen zu diskutieren. Wenn du mit den Teams arbeitest und kommunizierst, wirst du vielleicht feststellen, dass du nicht alle Gedanken und Ideen der Leute erfasst hast. Das ist in Ordnung. Das ist ein Teil des Prozesses. Es ist wichtig, dass du ihre Fragen aufnimmst und sie auch beantwortest. Die Wahrscheinlichkeit ist groß, dass jemand anderes in deiner Organisation sie wieder stellen wird.
Wie man die FAQ erstellt
Der erste Schritt bei der Erstellung deiner FAQ ist es, die Zielgruppe zu bestimmen. Diese Zielgruppe kann die Geschäftsführung, ein Entwicklungsteam, deine Mitarbeiter oder eine Geschäftseinheit sein. Du wirst diese Übung mehrmals mit verschiedenen Zielgruppen durchgehen, um deine FAQ zu erstellen. Für diese Übung werden wir die obere Führungsebene verwenden. Jetzt, wo wir unsere Zielgruppe kennen, musst du dich in ihre Lage versetzen und dir Fragen oder Einwände ausdenken, die sie bei der Migration zu AWS haben könnten. Gehen wir zwei Fragen durch, die dir von der oberen Führungsebene gestellt werden könnten, und überlegen wir, wie wir mit dem Wissen aus diesem Kapitel eine Antwort formulieren würden.
Wie viel mehr wird uns AWS kosten?
CIO
Du kannst darauf wetten, dass du diese Frage gestellt bekommst, und sie ist sehr berechtigt. Das Problem bei dieser Frage ist, dass sie eine vorgefasste Meinung haben, dass AWS mehr und nicht weniger sein wird. Es wäre eine gute Idee, diese Frage mit einer neutraleren Haltung zu formulieren. Du willst, dass die Leute selbst entscheiden und sich nicht von den Fragen in deinen FAQ beeinflussen lassen. "Wie werden sich unsere Infrastrukturkosten nach der Migration verändern?" wäre eine bessere Formulierung für diese Frage.
Um diese Frage zu beantworten, solltest du dich auf die Aspekte deiner Infrastruktur konzentrieren, die mit hohem und niedrigem Wasserstand gekauft werden. Zur zusätzlichen Unterstützung kannst du auch alle Anwendungen einbeziehen, die durch ein aktualisiertes BC-Modell Kosten einsparen können und 25% dieser Kosten einsparen. Es ist wichtig, die Vision so weit wie möglich aus dem Inneren deines Unternehmens zu schöpfen, um sie zu personalisieren und für sie real werden zu lassen.
Wie wird sich diese Umstellung auf unsere Personal- und Betriebskosten auswirken?
CFO
Das ist eine weitere häufige Frage, die vom oberen Management gestellt wird. Sie ist schwieriger zu beantworten. Technisch gesehen steigen deine Betriebskosten aus buchhalterischer Sicht, weil du von einem Capex- zu einem Opex-Modell für deine Infrastruktur übergehst. Es wäre vielleicht eine gute Idee, diese Frage in eine andere Frage und Antwort für die FAQ aufzuteilen. Dann kannst du diese Frage umformulieren in "Wie wird sich die Umstellung auf die Produktivität unserer Mitarbeiter/innen auswirken?" Jetzt kannst du diese Frage mit all den Einsparungen bei den weichen Kosten beantworten, an die du zuvor gedacht hast.
Der nächste Schritt im Prozess besteht darin, die Iteration mit allen Teams und Abteilungen fortzusetzen, die von der Umstellung auf AWS betroffen sind. Das ist zwar ein zeitaufwändiger Prozess, aber er hilft dir, die Reibungsverluste zu verringern. Je mehr Teams du einbeziehst, desto weniger neue Fragen werden auftauchen, weil viele der Gruppen die gleichen Anliegen haben werden. Die Standpunkte und Beweggründe für ihre Fragen werden sich je nach Position ändern. Aufgrund dieser unterschiedlichen Standpunkte fügst du vielleicht keinen weiteren Punkt in die FAQ ein, sondern erweiterst stattdessen die Antwort, um auf das zusätzliche Anliegen einzugehen.
Einpacken
In diesem Kapitel haben wir viel über die technischen und geschäftlichen Vorteile der Migration zu AWS erfahren. Tatsache ist, dass wir nur an der Oberfläche gekratzt haben und dass es noch viele weitere Möglichkeiten gibt, von der Migration zu profitieren. Auch hier handelt es sich um die Vorteile, die universell für alle Migranten gelten und die wir am wichtigsten fanden. Jedes Unternehmen, das ich in die Cloud migriert habe, hat AWS genutzt, um von seinem einzigartigen Aspekt und Szenario zu profitieren. AWS könnte man als den größten Baukasten der Welt betrachten. Er ermöglicht es dir, eine Unzahl möglicher Lösungen zu bauen.
Hinweis
Claude Shannon war ein Mathematiker, der die untere Schranke der Spielbaumkomplexität beim Schach aufgestellt hat, die zu etwa10120 möglichen einzigartigen Spielen führt. Diese Zahl ist als Shannon-Zahl bekannt.
Inzwischen solltest du ein solides Verständnis dafür haben, wie dein Unternehmen die Vorteile von AWS auf einzigartige Weise nutzen kann, indem du die Szenarien und Erklärungen auf deine Erfahrungen beziehst. Du solltest eine solide FAQ erstellt haben, die hilft, die Bedenken der Nutzer zu zerstreuen und das Gespräch voranzubringen. Und schließlich hast du vielleicht auch schon einige Ideen, was die Zukunft für zusätzliche Vorteile nach der Migration bereithält.
1 Simon Sinek, Start with Why: How Great Leaders Inspire Everyone to Take Action (New York: Porfolio, 2011).
Get Die Migration zu AWS: Ein Leitfaden für Manager now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

