Chapter 4. Building Blocks for Machine Teaching
My eight-year-old son, Christien, loves to play with LEGO blocks. He can play for hours building cars, jets, and landscapes. I enjoy building things together with him. Sometimes, when we are building, we need just the right piece to complete a section. So, we search through large bins, trolling for just the right piece for the job. When we find a block that performs the right function, the whole structure comes together nicely.
The same is true for AI brains. Autonomous decision-making that works in real life doesnât magically emerge from a monolithic algorithm: it is built from building blocks of machine learning, AI, optimization, control theory, and expert systems.
Hereâs an example. A group of researchers at UC Berkeley, under Pieter Abbeel, taught a robot how to walk. This robot, Cassie, looks a little like a bird with no torso (just legs). The AI brain that they built to control the robot snaps together decision-making modules of multiple different types and orchestrates them in a way that makes sense with what we know about how walking works. It combines math (control theory), manuals (expert systems), and machine-learning AI modules to enable faster learning of more competent walking than any of those decision-making techniques could on their own.
You can see from Figure 4-1 that this brain uses different modules to perform different functions. It uses PD controllers to control the joints. As you learned in Chapter 2, PD controllers are quite good at controlling for a single variable like joint position based on feedback. The gait library contains stored expertise about successful walking patterns (Iâll discuss exactly what a gait is in a minute). This module is an expert system (remember manuals from Chapter 2) that allows lookup of codified and stored expertise. The module labeled âPolicyâ is a DRL module that selects the right gait pattern to use and how to execute that gait pattern. You can read the details of how this brain works in the Cassie teamâs research paper.
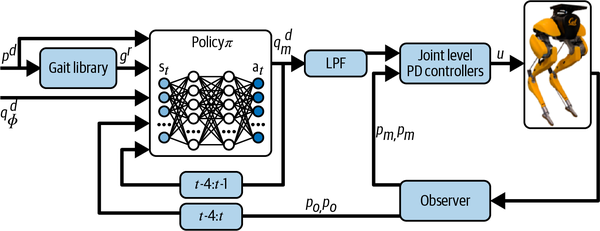
Figure 4-1. Brain design of AI that controls the Cassie walking robot.
Each of these modules works at different time scales and uses different decision-making technology, but neither of these characteristics explain why this brain has multiple modules. The reason for different brain modules is to perform the multiple skills necessary for walking. One quick and easy way to determine that you need multiple modules, though, is to look for decisions that happen at different timescales and assign them to skills. For example, PD controllers operate at a very high frequency (think 10 decisions per second) as they move the joints. But how quickly does body position change during the execution of the walking gait? Not quite as quickly. When weâre walking, we change gaits when the surface or walking conditions change, even less frequently than adjusting to a new body position to execute the gait.
Table 4-1 outlines the skills that the research team explicitly taught the brain through their modular design. The first skill is about understanding what a gait is. A gait is a repeating cycle of phases in a complex walking movement. Simple robots have simpler gaits, but bipeds with ankles and toes (such as humans) use approximately eight gait phases when we walk. Before you get carried away thinking about whether AI has true, human-like understanding, let me explain to you what I mean. Without this gait library expert system, the AI would have no understanding of what a gait is, how a gait relates to walking, or how to use gaits to walk. But this expert system defines and stores gaits that the AI will use to walk the robot. So, in a primitive way, this brain does indeed understand gaits.
| Walking skill | Technique used to perform skill |
|---|---|
Understand gait |
Expert system (menus) |
Select and execute gait |
Deep reinforcement learning |
Translate gait to joint control |
Low pass filter (math) |
Control joints |
PD control (math) |
The second skill is to select which gait to use at any particular time and to make sure that the pose of the robot obeys the gait. A robot pose is much like a human pose: the shape of the robot frame when its joints are set to specific positions. This is a job for DRL! You can think of each gait phase (Figure 4-2) as a strategy to be used at just the right time to complete the task successfully. DRL is great for learning strategy and adapting behavior to changing conditions.
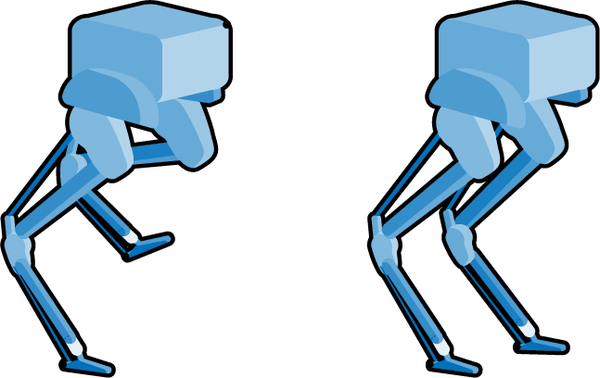
Figure 4-2. Examples of robot poses related to walking.
Next, we need to translate the poses to low-level control of the joints. This third skill is not a decision-making skill. It doesnât take any action on the system. Itâs a translator between the pose and the joint position command to give to the PD controller. The technology that is a perfect fit for performing this skill is a low pass filter. Often used in audio applications, low pass filters are great at blurring or smoothing signals so that the joints move smoothly between poses instead of jerking around. After using low pass filters to articulate the joints, we can finally use our tried and true PD controllers to apply feedback and make sure that the joints execute the motions of successful walking. The brain design captures the fundamental skills required for walking and allows the learning algorithm to acquire walking behavior in a structured way with practice. Figure 4-3 shows what the brain design looks like translated into our visual language for brains.
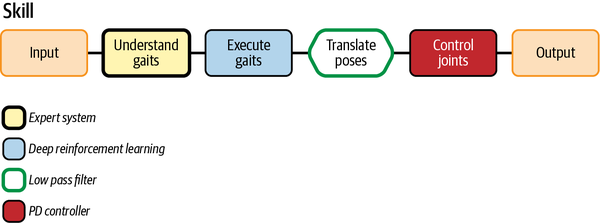
Figure 4-3. Brain design diagram of the Cassie robot brain from Abbeelâs team.
Case Study: Learning to Walk Is Hard to Evolve, Easier to Teach
Walking on two legs is a complex movement that is difficult to describe and execute. Roboticists have done a lot of work to reverse-engineer walking and teach robots to walk. Most of this work uses complex mathematics to calculate control actions, then apply them to each robot joint. A second approach leverages AI algorithms to learn control policies or to search for the right way to control each joint for walking (this includes optimization algorithms like evolutionary algorithms and DRL). Neither of these approaches allow a human to teach even the most well-understood knowledge about walking.
See the funny looking purple robot in Figure 4-4? This is a training gym for teaching AI how to walk on two legs. This environment simulates a two-legged robot with four joints: two upper joints that work like human hips and two lower joints that work like human knees. This robot has no ankles or feet.
Figure 4-4. Simple, simulated two-legged walking robot for AI to practice controlling.
Remember, in DRL, the agent practices the task and receives a reward based on how well it performs the task. The basic reward that comes with this gym environment gives points for how much forward progress you make but penalizes 100 points if you fall over (your purple hull touches the ground). One AI researcher uses the picture in Figure 4-5 to describe four movement strategies that agents will learn on their own with this reward.
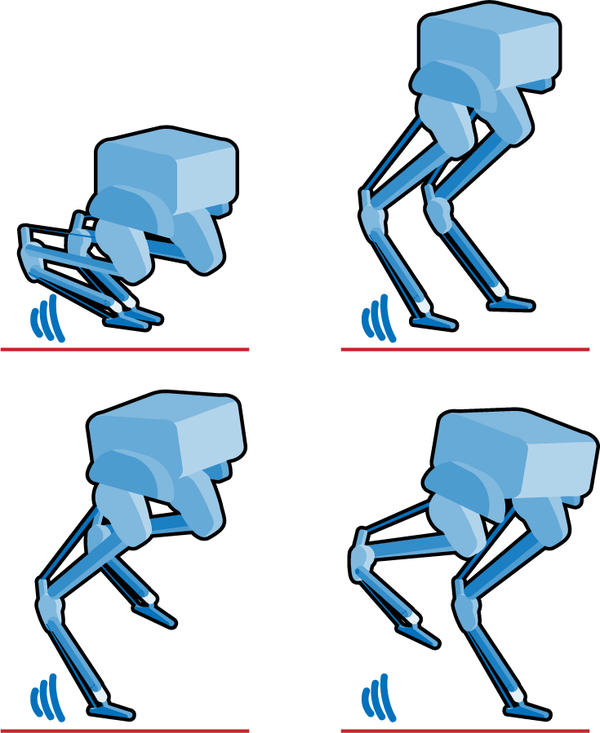
Figure 4-5. Four self-learned movement strategies that do not qualify as walking.
The double balance looks like someone rapidly tapping the ground on their tiptoes. While kneel balancing, the AI kneels on one knee, then uses the front leg to reach out and drag the body forward in a pawing motion. The rear balance strategy puts the weight of the body on the back leg and moves forward by pawing the front leg. This is similar to the kneel balance, but in a standing position. At first glance, this looks a little like walking but the legs never cross in the characteristic scissor motion. Finally, the front balance extends and stiffens the back leg and paws forward with the front leg. Again, the legs never switch.
So, Why Do We Walk?
Walking is defined by an inverted pendulum gait in which the body vaults over the stiff limb or limbs with each step and where at least one leg remains in contact with the ground at all times. Basically, this means that when you walk, you vault (like a pole vaulter) over your planted leg, lift the opposite leg, then repeat the process. So thatâs a bit of how we walk, but hereâs why: walking is the most energy-efficient way for bipeds (animals with two legs) to move around. Itâs not the fastest way to move around or the easiest way to move around, but walking uses the least amount of energy for each distance that you travel.
So am I telling you that none of the motion strategies above even meet the criteria of walking? Exactly, none of these strategies for moving around on two legs meet the definition of walking. So, while these agents have learned to move by experience alone, they have not learned to walk. If brains can learn by practicing and pursuing reward, why donât these agents learn to walk? It turns out that DRL becomes conservative when you penalize it harshly, much like human learners do. The AI receives severe punishment when it falls over but a much smaller reward to incentivize it to take its first steps. In contrast, the AI has to get a lot of things right to get the full reward of walking, so it settles for things that are more certain ways to get rewards without punishment. These things (which are more like crawling) let the brain get the reward of moving forward with a lot less risk of falling and without having to learn to balance.
The AI training gym comes with a PID controller that is tuned to perform the walking motion. The controller walks successfully, but will only succeed at certain walking speeds. Mathematical calculation provides a very precise definition of which action to take under each condition but results in a jerky mechanical walking motion. When I saw the PID control example, it gave me an idea. The PID controller separates the motion into three walking gait phases. After seeing this, I used my first two fingers (index and middle fingers) as âwalking legsâ to identify and name the three walking skills that I wanted to teach. My goal was to go beyond the motion strategies that emerged from trial and error only and the rigid walking motions of the PID controller: I wanted to teach the AI how to walk.
Table 4-2 shows how each heuristic strategy specifies effective joint motions that comprise the walking gait.
| Gait phase | Heuristic strategy (hips) | Heuristic strategy (knees) |
|---|---|---|
Lift swinging leg |
Flex swinging hip (curl swinging leg), extend planted hip |
Flex swinging knee, extend planted knee (keep planted leg straight) |
Plant swinging leg |
Extend swinging hip, flex planted hip/flex |
Extend swinging knee (curl, then straighten swinging leg) |
Strategy Versus Evolution
The AI research conference NeurIPS (Neural Information Processing Systems), formerly NIPS, hosted a reinforcement learning competition in 2017 and 2018 where the challenge was to train AI to control a human skeleton and 18 lower-body muscles to make it run and walk. A couple freeze-frames of the winning AI are pictured in Figure 4-6.
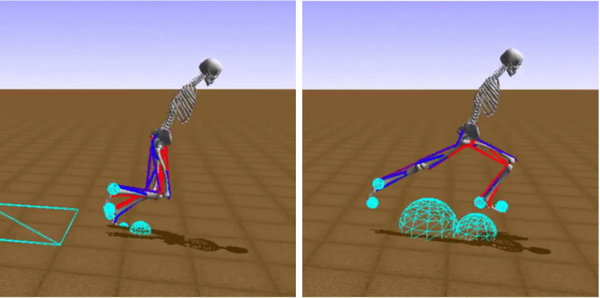
Figure 4-6. The winning entrant of the NIPS â17 competition actually runs!
I designed and trained AI for this competition. It was extremely frustrating to watch my AI brain do things like the movements shown in Figure 4-7, none of which are used in walking, when (being a bipedal walker myself), I already had quite a bit of knowledge about walking that I wanted to teach.
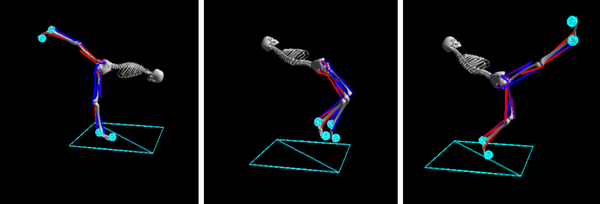
Figure 4-7. My skeleton performing three motions that are not used to walk: leaning forward and extending one leg backward (this is yoga, not walking), jumping up and falling backward, and kicking one leg out (this looks more like bad can-can dancing than walking)
My brains performed horribly at the competition tasks, but what I learned helped me develop the brain design techniques in this book and solve a lot of real-world problems. Table 4-3 shows some other behaviors that my AI brain spent a lot of time exploring, and the corresponding things that I desperately wanted to teach it instead.
| Donât do this | Reason | Do this instead |
|---|---|---|
Hop |
When walking and running, both legs do not operate in unison. |
Move legs in a scissor-like motion. |
Fall forward |
Walking involves vaulting over a planted leg. |
Swing one leg forward, then plant it. |
Stand on one leg, while swinging the other leg around |
Walking requires planting your swinging leg, so that you can vault over it and move forward. |
Swing one leg forward, then plant it. |
Even the 2017 competition winner, NNAISENSE, feels my pain. Hereâs the warning they share on the website with the code they used to create the AI:
[Reproducing] the results using this code is hard due to several reasons. First, the learning process (mostly in Stage I: Global Policy Optimization) was manually supportedâââmultiple runs were executed and visually inspected to select the most promising one for the subsequent stages. Second, the original random seeds were lost. Third, the whole learning process required significant computational resources (at least a couple of weeks of a 128-CPUs machine). You have been warned.
Translation: we had to capture the brain doing things correctly like lightning in a bottle and stitch behaviors together, and even then it took extreme amounts of practice and computing power.
This is not surprising, since it took humans approximately 2 million years to learn to walk fully upright through evolution. In âThe Origin of Strategyâ, a groundbreaking article on business strategy, Harvard Business School professor Bruce D. Henderson asserts that strategy creates intelligent, creative, and planned interruption of incremental evolution. In biology, competition drives natural selection to differentiate, but incrementally and at a very slow pace. This is how the poison dart frog developed bright-colored, toxic skin to deter predators, and how the Roraima bush toad developed the behavior of curling up and jumping off mountain cliffs, which makes it look like a rock rolling downhill.
Strategy disrupts and diverts evolution and its long periods of drift toward equilibrium. Much like the scientific revolutions that we discussed in Chapter 1, strategy punctuates these periods. Stephen Jay Gould and Niles Eldredge describe a very similar phenomenon in their 1977 journal article âPunctuated Equilibriaâ.1 We see this in business all the time. The Blockbuster movie rental chain dominated the home entertainment market by allowing you to browse titles in-store and borrow your selection for a few dollars. Then, Netflix offered to send the movie directly to your home and later enabled you to stream it directly to your TV. You donât have to leave your home, but you donât get access to all the most recent releases either. Then, Redbox offered a new and interesting twist to location-based movie rentals when they created vending machines where you can self-serve and rent the titles you want. Walking gaits are strategies that humans discovered over millions of years. We can shortcut learning to walk by introducing these strategies to the agent. In the next section, Iâll show you how I used strategies to bootstrap learning for my AI brain.
Teaching Walking as Three Skills
So, I decided to teach my brain the same three skills that the PID controller used in the reference example: the skills that I validated by walking my fingers across a table.
Defining skills
To teach each of these three skills, I had to limit the range of motion for the hip and the knee for each skill (strategy). For example, you canât lift one leg (balancing on the other leg) unless you keep the planted leg stiff. You canât keep the planted leg stiff unless you extend the knee and flex the hip. This is where it helps to try it out by walking your fingers on a hard surface. See Table 4-4 for details on the action ranges I used.
| Gait phase | Range of motion (hip) | Range of motion (knee) |
|---|---|---|
Lift leg |
Flex (close) swinging hip, flex then extend (open) planted hip |
Flex (curl) swinging knee, extend (straighten) planted knee |
Plant leg |
Extend (open) swinging hip, flex then extend planted hip |
Extend (straighten) swinging knee, extend (straighten) planted knee |
Swing leg |
Flex (close) swinging hip, flex then extend planted hip |
Flex (curl) swinging knee, extend (straighten) planted knee |
Figure 4-8 illustrates the outcome of these efforts. This is what walking looks like. The AI made a lot of mistakes and took a lot of practice, but it didnât spend any time doing things that donât resemble walking! By the way, this step of defining the actions each skill requires is crucial. I cover it in detail in Chapter 5, âTeaching Your AI Brain What to Doâ. You can find the complete code for teaching this brain on a GitHub fork of OpenAI Baselines.
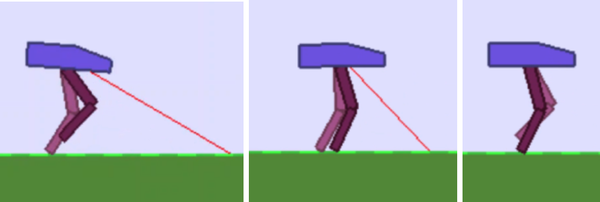
Figure 4-8. My AI brain executed the three skills I taught it: lift leg, plant leg, swing (opposite) leg.
Setting goals for each skill
Next, I set a goal and success criteria for each of the three skills. We will talk more about setting goals for your AI brain in Chapter 6. Each gait phase has distinct goals that facilitate walking.
| Gait phase | Goal |
|---|---|
Lift leg |
Push off with enough velocity to vault over the planted leg. |
Plant leg |
Plant the leg with enough impulse (force at the moment of impact) to support the weight of the robot. |
Swing leg |
This is the gait phase that generates most of the forward motion. |
You can see that each of these gait phases have radically different goals. The first gait phase is about pushing off and picking up enough speed to vault over the other leg when you plant it. In the second phase, velocity doesnât matter nearly as much. Walkers succeed in the second phase when they plant their leg with enough force to support the weight of the body. Otherwise, the walker will collapse to the ground. The final phase has yet another primary objective: forward motion. This phase is the big mover of the three gaits. During the first and second phase, the body doesnât move forward very much even when the phases are very successful. Do you see how each gait phase performs a different functional skill with different goals?
Organizing the skills
Next, I snapped these skills together into a brain design. The gait pattern for walking cycles the skills in a sequence: lift leg, plant leg, swing leg, lift (the opposite) leg, plant (the opposite leg), swing (the opposite) leg, etc. Figure 4-9 shows what the brain design looks like.
This brain design separates the brain into the skills that it will learn and orchestrates how the learned skills will work together. Each brain design is a miniature AI that will practice and learn how to perform that skill. Three skills execute the gait phases and one skill switches between gait phases. In the next section, I define and categorize the building blocks that you will assemble into your brain designs and provide a framework for organizing those skills together.
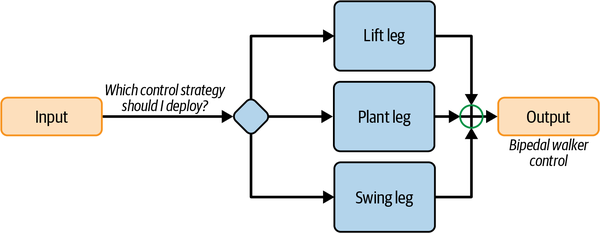
Figure 4-9. A brain design diagram that lists and orchestrates the skills needed to perform the walking task successfully.
Concepts Capture Knowledge
A concept is a notion or an idea that comprises a composable unit of knowledge. There are number of concepts that I wanted my walking AI brain to learn from practicing the skills that I taught it:
- Balance
-
I want the brain to learn how to keep the robot from falling over.
- Symmetry
-
I want the brain to learn that the walking gaits are roughly symmetrical movements.
- Oscillation
-
I want the brain to learn that walking legs oscillate in periodic motion.
These concepts are hard to describe, but as humans we rely on them to walk properly. In my brain design, my teaching plan relies on teaching gait motions explicitly as skills and the AI learning the additional concepts by pursuing rewards as it practices. The AI brain will not succeed consistently unless it learns balance, symmetry, and oscillation even though I havenât explicitly taught any of these concepts.
Skills Are Specialized Concepts
Skills are concepts too, but they are specialized concepts that take action for performing tasks. Skills are units of competence for completing tasks successfully. They are the building blocks for complex tasks. If you perform the right skill at the right time, you succeed. For example, the sequence of skills in our walking AI is important. To walk successfully, you need to lift the robotâs leg, then plant the robotâs leg, then swing the robotâs opposite leg. Otherwise, the robot will not push off with enough velocity (thatâs the goal of the first walking skill), not plant its leg with enough force to support its weight (thatâs the goal of the second walking skill), and not achieve efficient forward motion as it vaults over the planted leg (thatâs the goal of the third walking skill).
This is true for all complex skills, whether itâs Pac-Man, Montezumaâs Revenge, chess, basketball, or the many industrial examples I provide in this book. Let me give you one more example. Remember the AI brain that I designed to control HVAC systems on the Microsoft Headquarters Campus? Figure 4-10 shows some data from controlling the cooling for those seven buildings.
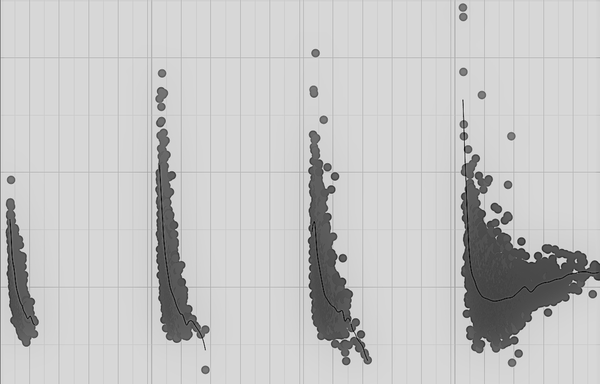
Figure 4-10. Data plot of variables for HVAC chiller system that show different control policies required for each of four temperature ranges.
Can you guess how many skills are required to control this system well?
The data is telling us that the system behaves completely differently in each of four temperature regimes. So, when the experts told us that four skills were required, they were simply reporting on how the system behaved in their experience. This exploratory data analysis told us the exact same thing.
We taught these skills explicitly by creating different modules in the brain that practiced each of these distinct temperature ranges separately. The brain learned by exploring each of these regimes and building more nuanced correlations between input variables and output actions than any single mathematical model could.
Brains Are Built from Skills
The mindset of algorithmic intelligence suggests that brains are built from algorithms. If you need a new brain for a new task, write a new algorithm. But the mindset of teaching intelligence tells us that brains are built from skills. If you need a new brain to accomplish a new task, identify and teach skills. Regardless of which learning paradigm you use to simulate learning, the brain will need to acquire skills to succeed. So how does an AI brain build and acquire skills?
Building Skills
Have you ever tried to articulate a concept that was hard to describe? Hereâs a few examples: love, justice, beauty. Each of these concepts are abstract and best defined by giving many examples and counterexamples (sunsets and roses and smiles can be beautiful, but a sardonic smile is not beautiful, itâs disturbing). Sociologist Herbert Blumer described these kinds of concepts as sensitizing concepts.2 Sensitizing means laying out a set of parameters that we can use to evaluate whether the concept applies. Blumer would define love, justice, and beauty as sensitizing concepts.
The skills that your brain will learn are a lot like sensitizing concepts. We learn sensitizing concepts by receiving feedback on the parameters that evaluate whether the concept applies. For example, one parameter that many use to evaluate beauty is how something makes you feel when you see it. If it makes you feel happy or sad, it might be beautiful. If it makes you feel afraid, angry, or disgusted, it likely isnât beautiful. We then discover the boundaries around these concepts by comparing many examples against the defined sensitizing parameters for the concept. The same is true for skills that your brain will learn.
For example, the skill of an effective (American) football offense is fuzzy. You must be able to score against 3-4, 4-3, player-to-player, and zone (coverage) defenses. Each of those defenses are sensitizing criteria for a teamâs skill at executing American football offense. The same is true for industrial processes and factory automation. One of the most challenging aspects of managing industrial processes is that there are multiple, often competing goals, and many more scenarios to succeed under. One goal in manufacturing is throughput (how much you make) but another competing goal is efficiency. I can make a lot of products but might also spend a lot of energy to do it. I can make products very efficiently (labor and energy) but might sacrifice throughput to gain that efficiency. For this manufacturing skill, throughput and efficiency are both sensitizing criteria.
Expert Rules Inflate into Skills
The process of learning skills fits well into Blumerâs prescription for learning sensitizing concepts: start with a set of examples and then add examples and counterexamples from there.
Tip
You can think of an expert rule as the starting point for learning a skill.
A rule provides a set of examples the same way that the definition of a line provides a set of points. The form y = mx + b (the equation for a straight line) gives us a set of points for the line. So, if a = 1 and b = 0, then the set of points on the line will be (0,0), (1,1), (2,2), etc. The rule provides solid examples that are both true to the concept and easy for the beginner to understand. With practice and experience, the beginner starts to identify exceptions to the rule. These exceptions are also true to the concept and provide a much more nuanced understanding of the concept.
A rule is the starting point of a skill. A skill is developed by identifying exceptions to a rule and aggregating them into a fuller, more nuanced description of the concept. This concept is defined by parameters in two dimensions in Figure 4-11, but concepts can be defined by parameters in any number of dimensions.
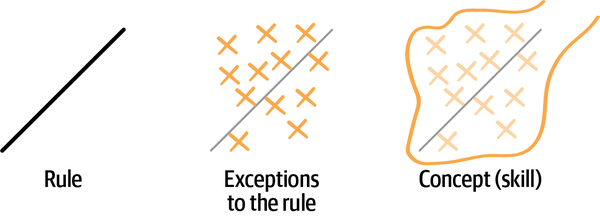
Figure 4-11. A rule as the starting point of a skill.
Table 4-6 shows a few examples of skill concepts that can be expressed as an expert rule but also fleshed out in more detail by discovering exceptions. Most of these examples have already been discussed in the book; weâll look at the naval fleet planning example momentarily.
| Skill | Rule | Example exceptions |
|---|---|---|
Bidding (as in Texas hold âem poker) |
Play âtop 10â hands only, fold everything else. |
Unless you have a lower pair and believe (usually by the bidding) that no one else has a top 10 hand. |
Baggage handling (airport logistics) |
Use the conveyor for bags whose connecting flight is scheduled 45 minutes out or more. |
Unless predictions suggest that some flights will be canceled for weather. In that case, use the conveyor for bags whose connecting flight is likely to be canceled, even if it is scheduled to leave within 45 minutes. |
Basketball scoring |
If you are close to the basket, shoot a layup, not a jump shot. |
Unless you are closely defended by a larger defender. In that case, shoot a jump shot (consider a fadeaway). |
Rock crusher |
Choke the crusher for large, hard rocks, and regulate the crusher for small, soft rocks. |
Unless you have a low customer demand for ore. In that case, produce the required ore as efficiently as possible, which may include choking the crusher for smaller, softer rocks than you otherwise would. |
Naval game fleet planning |
Use a tank (ship with oversized armor and weapons) to attract and sink the enemy fleet. |
Unless, the enemy has a large swarm of ships. In that case, use multiple medium-large ships to split the swarm, then attract and defeat each swarm section. |
As humans and AI practice skills, they identify exceptions to the rule which provide a more accurate and nuanced picture of how to perform the skill, much the same way that we gain a more nuanced understanding of what love, justice, or beauty are after many experiences and of examples counterexamples.
Take a look at the data points in Figure 4-12. I donât know what concept or skill this represents, but it looks quite nuanced and complex. One way to approach this skill is to find a single straight line that seems to best represent this concept. This technique of fitting a line to a set of points is called linear regression. Figure 4-13 shows a linear regression line drawn over the points of data.
There are benefits to this simplifying approach. These simplified representations provide portable replicas of the concept that are easy to manipulate and transfer. In the context of designing autonomous AI, where the concepts are skills that the AI will learn, the simplified representations are expert rules. Humans simplify concepts to expert rules for three main reasons:
-
Expert rules provide a starting point for practicing skills.
-
Expert rules are easy for beginners to understand and follow.
-
Expert rules are easy for teachers to communicate.
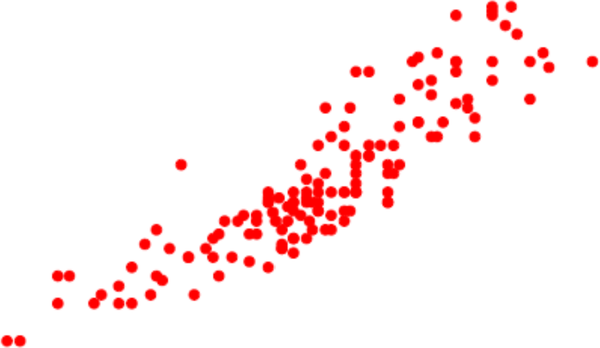
Figure 4-12. A set of examples that might represent a concept. You may be able to approximate this concept with a straight line, but the reality is much more nuanced than the straight line.
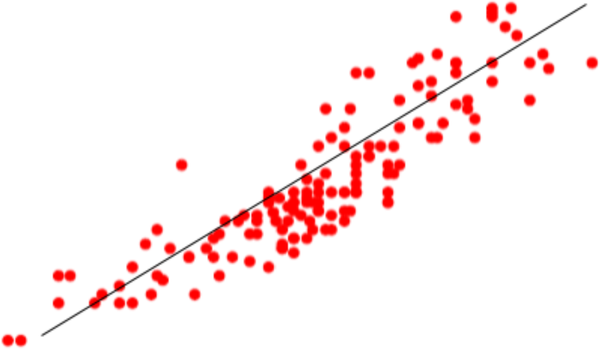
Figure 4-13. A linear regression that describes this complex concept as a line.
This idea of deflating concepts to simplified expert rules is the basis of expert systems. In the same way that vacuum sealing food makes it more portable, deflating concepts into expert rules makes them easier to teach. Promising, but I discussed the drawbacks already in Chapter 2. Is there a way to leverage the simplifying benefits of expert rules and still embrace the full nuance of the concept?
Yes! In the next section, and then in much more detail in Chapter 7, Iâll show you how to use expert rules as abbreviations for the concepts that youâd like to teach. This allows you to define which skills are important for the learner to master (instead of leaving it up to the learner to discover both the skills and how to accomplish them) and allows the learner to discover unique and creative ways to perform these skills by practicing them.
Teach expert rules, and let the learner inflate the concepts through practice
A set of expert rules defines the skills in the AI brain, but instead of writing hundreds of additional expert rules to capture exceptions to describe the nuances of each skill, we allow algorithms like DRL to inflate the skill by practicing: identifying and adapting to the nuances. The structure of the skills provides some of the explainability and predictability of expert systems with the creativity and flexibility of DRL agents. Often human learners also benefit from seeing a few beginning examples of how to inflate a concept; then they can take it further on their own.
Letâs return to the example of the gyratory crusher. The structure of the expert rules, which reflect the two operating modes of the machine, outlines three skills that should be taught and learned. The first skill is the strategy of choking the crusher when the mine produces larger, harder rocks. The second skill is the strategy of regulating the crusher when the mine produces smaller, softer rocks. The third skill decides when to choke the crusher and when to regulate the crusher. This act of using subject matter expertise to define these three skills is itself teaching. Then, if we train each of three separate DRL agents on one of the three skills above, the combined brain will not only tell the engineers which next action to take to control the crusher but also which skill it is using at each decision point to make that decision. Figure 4-14 shows how the skills can be expressed as expert rules (to both people and AI), then practiced to fully inflate the skills in a neural network based on sensitizing feedback.
As the AI learns (in the case of DRL, anyway), it captures the policy in a neural network. The teacher defines the skills to learn. The learning algorithm learns each skill. Machine teaching leverages what you already know about how to perform the skill to structure the AI. Machine learning builds the AI (in this case a set of neural networks).
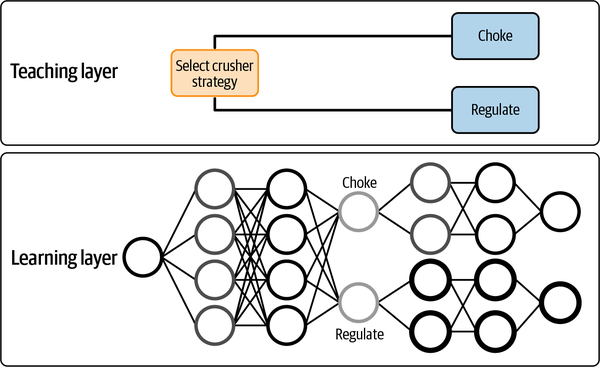
Figure 4-14. Diagram of skills to control a mining crusher.
Tip
As a brain designer, strive to express known skills in the form of expert rules. Then, allow the AI to practice, master, and trade off with other skills.
Next, Iâll outline the three different types of concepts that youâll use in your brain designs. Perceptive concepts help the brain understand what is happening. Directive concepts help the brain decide what to do. Selective concepts assign perception and decision-making work to other brain modules.
Perceptive Concepts Discern or Recognize
Reacting to a changing environment starts with gathering information about whatâs happening in that environment. Machines gather information with mechanical sensors. For example, a thermometer is a type of sensor that measures temperature and a barometer is a type of sensor that measures atmospheric pressure. People that design factories and industrial systems donât use the same thermometers and barometers that we use at home, but they are good examples. We also have sensors on our bodies. Our eyes are complex light sensors, our ears are sophisticated audio sensors (like microphones), etc. See Ravi Tejaâs blog post, âWhat is a Sensor? Different Types of Sensors and their Applicationsâ for a more complete list and description of industrial sensors.
The sensors gather the information, but the information has to be processed and translated into a format that can be used to make decisions. For example, our eyes are more than just sensors that receive light. The rods and cones in our eyes process the light and translate it into electrical signals that our brains can use to make decisions. Our ears perform a similar function after receiving a sound. Machines need more than sensors to make decisions.
Perceptive concepts process information that come in through the sensors and send relevant information through to the decision-making parts of the brain. For example, auditory processing disorder (APD) is a neurodevelopmental disorder impacting sound perception in humans. The ears hear just fine, but difficulty interpreting sounds obscures information. There are five common perceptive skills commonly used in autonomous AI design.
See and hear
Bell Flight designs and builds helicopters and other vertical takeoff and landing (VTOL) vehicles. Have you ever seen the V-22 Osprey? It looks like a plane, but when it takes off, it tilts its rotors up and takes off (straight up) like a helicopter. After it is in the air, it tilts its rotors back and flies like a plane. There is an autonomous version, the V-280 Valor, that flies without a pilot. Bell also makes freight- and passenger-carrying drones.
Autonomous drones and larger rotorcraft like the V-280 use global positioning systems (GPS) to calculate position and control. But if GPS is blocked by buildings, autonomous systems must fly and land by sight, much like human pilots would. Calculating systems like the ones that fly by GPS are based on control theory (math) and cannot process visual information from video feeds and camera images.
So, Bell built an autonomous AI to land by sight. This brain has two modules: the first is a machine learning module that processes the image data and extracts features about the landing zone. Imagine a model that can input an image of the landing zone and output things like coordinates for the center of the landing zone, as well as the pitch, yaw, and roll of the drone in 3D space. This is the perceptive concept and it helps the brain see.
The second module is a DRL module that has practiced landing the drone in simulation many times, on many different landing zones using the visual information that the first module passed to it.
Predict
We make predictions to help us make decisions all the time. When I decide which checkout line to wait in at the grocery store, I look at the number of people in each line (length) and the number of items that various people have in their carts, and make a rough assessment of the speed of each checker. I donât look at every cart in every line and I have no way to measure the actual speed of each checker or the actual number of items that each customer in each line needs to check out. Iâm sampling data from many variables that I have observed before, using my experience to predict which line will get me through the checkout most quickly, then acting on that perception and choosing a line.
I worked with a manufacturing company that wanted to better predict how long their cutting tools would last. Spinning tools cut metal to make all kinds of different parts that we use every day. They wear and break depending on how fast they spin, how much friction they experience, and how much you bend them in each direction. If you retire the tool too early, youâve wasted money, but if the tool breaks while cutting a part, you might have to throw away the part you were working on, wasting even more money.
Figure 4-15 shows three scenarios of part wear. In scenario 1, the tool is run at low speeds but high load for the first part of its life and low speed, high load for the second part of its life. The tool experiences high friction for its entire lifetime. Even though this tool is always run at either high speed or high load, it has the longest lifetime of the three tools. The tool in scenario 2 fails soonest when it is put under very high speed and friction even though it starts its life under low speed, load, and friction. The tool in scenario 3 starts its life at very high speed, and even though it is later used at low speed, load, and friction, it fails soon after the transition. This example isnât intended to model any particular physical scenario, but I want to demonstrate two things to you: predicting wear is difficult, and scenarios determine wear patterns.
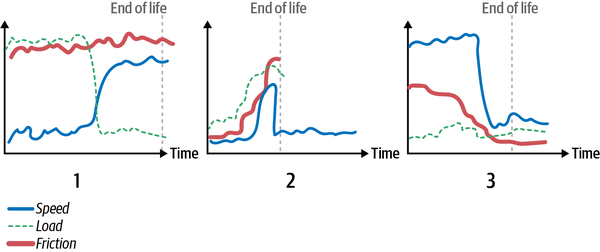
Figure 4-15. Three parts wear in different ways and survive different durations based on what they experience over their lifetime.
The two most common complex predictions I see in industry are wear predictions like the one above and predictions about how much market demand there will be for products. Market demand is complex, seasonal, and depends on different variables for different products. The demand for some products is highly seasonal, for example snowshoes and sunscreen. Crude oil contains gasoline, diesel fuel, and jet fuel, so oil refineries operate differently to make more or less of each depending on the demand. Europe consumes more diesel in the winter to heat homes and more jet fuel during the summer travel season.
Detect
Have you ever played the childhood game âone of these things is not like the other?â In this game, you look at multiple objects (see Figure 4-16 for an example) to determine which one is different (somehow doesnât match the pattern). When you play this game, youâre looking for anomalies.

Figure 4-16. Some of these objects look similar but belong in different categories.
Detecting anomalies is an important perception skill that informs decision-making. One company that I worked with wanted to use AI for cybersecurity to stop cyberattacks like the distributed denial-of-service (DDoS) attack in 2018 that used over 1,000 different autonomous bots to disrupt the GitHub code repository site for over 20 minutes. In a DDoS attack, hackers purposefully generate fake traffic to a websiteâso much traffic, in fact, that the website canât function. The first step in countering a DDoS attack is detecting one. Itâs hard to tell whether a sudden spike in traffic is due to a legitimate spike in customer demand (this would be a very good thing) or the beginning of a DDoS attack (a very bad thing). My prescription was that the AI should have one module that learns to detect anomalies in web traffic and classify them as either a traffic spike or DDoS attack and another module that accepts the first moduleâs conclusions and passes them to the decision-making module, which takes action to stop attacks but lets valuable, legitimate traffic through.
Classify
Sometimes it helps to classify things into categories before making a decision. In the grocery shopping example above, in addition to predicting, I am classifying things that I see: slow lines, quick lines, long lines, short lines, full grocery carts, empty grocery carts, no grocery cart (just a few handheld items), and overstuffed grocery carts. You get the picture. Maintenance technicians often do the same thing after taking a machine offline for repair. They classify the machine into states, then take different actions to bring the machine online based on what state itâs in. This is like what you might do when moving a bicycle from a fixed position. If the bicycle is facing downhill, donât worry about which gear youâre in, just push off. If the bicycle is on flat ground, shift to a lower gear, then push off. If the bicycle is on a hill, stand up and pedal. Youâll need the extra force to get started no matter what gear you are in. Before making this decision, you need to perceive the slope of the path you are headed down.
Filter
There is a fascinating part of the steel-making process called coking where you introduce carbon into molten iron in the presence of limestone. There are hundreds of variables to consider while controlling the blast furnace where this process occurs. Thatâs difficult even for human experts whoâve built decades of experience into their intuition. So, instead of considering the full scope of variables at each decision point, the engineers devised an index that packs a huge amount of information into a single number. This number tells the operators most of what they need to know to control the furnace well. Yes, you lose a lot of information when you process data like this, but thatâs what filters are for: showing you the information that you need to see while weeding out the information that wonât help you decide. This index was likely carefully constructed and tested before using it as feedback on real furnaces. You should take care in how you filter data for decisions as well.
Directive Concepts Decide and Act
Directive concepts make things happen. They decide and act. Whether the decision-making is learned, programmed, or even random, these concepts make the decisions about what the system will do next. I go into a lot of detail on how to use directive concepts in your brains in Chapter 5, âTeaching Your AI Brain What to Doâ.
Selective Concepts Supervise and Assign
Every job needs a supervisor, right? Unless youâre an ant, you need a supervisor to take a high-level view of the work and assign tasks and jobs to team members and crews. Each crew serves a different purpose or needs to be activated in different situations according to their specialty or training. Selective concepts are the supervisors for the brain. They are specialized directive concepts. Their role is to assign the right decisions to the right concept. Once a directive concept is called into service, it makes the decision for the brain.
Figure 4-17 shows an example of an AI that controls heating and cooling in large commercial buildings (such as an office building). The HVAC system uses ice to store energy and water to cool the air in the building. Ducts pass the air across water that cools it. The chiller uses energy to make ice during the times of day when energy is cheaper. The ice stores the energy to cool the building without using energy when energy is more expensive. To control the chiller you switch it into the right mode (make ice, melt ice, pass the water directly through without cooling, etc.).
The most difficult thing about controlling the chiller is the fact that buildings behave differently during the day and during the night. During the day, the flow of people entering and leaving the building drives cooling demand. At night when there are few people in the building, running machines require most of the cooling. These day and night scenarios are so different that youâd train a separate day crew and night crew to control the building at different times. Sometimes itâs easy to determine when to send the day crew home and call in the night crew; other times itâs not.
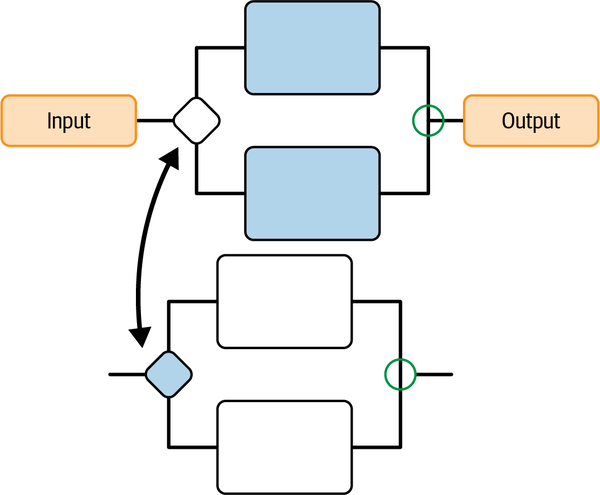
Figure 4-17. AI brain that controls chillers for building heating and cooling. One concept trains on day scenarios, another concept trains on night scenarios; a supervising selective concept assigns control to either the day or the night concept.
We can distinguish two kinds of concepts here: programmed and learned. Design programmed concepts into your brain when itâs clear which concept should make the decision. Use learned concepts when itâs hard to tell which concept should be called to make the decision in a brain.
Programmed concepts
The rule of thumb is that if someone can describe how to assign each crew to the right task as a set of rules, then program the selector. For the buildings with employees that mostly come exactly at 9 a.m. and leave exactly at 5 p.m., you can program the selector like we did. Hereâs what the selector code looks like in Python:
iftime>=9andtime<=5:# Itâs daytime, assign the day crewassign=day_conceptelse:# Itâs nighttime, call in the night crewassign=night_concept
Programming is step-by-step teaching where you specify every decision to make along the way. If you are confident that you know and can simply express instructions for how to supervise the concepts in your brain, design with a programmed selector.
Learned concepts
But when the decision of which crew to assign to a task is fuzzy, itâs better to teach an intelligent supervisor to assign the right crew. A learned selector is a reinforcement learning module that practices assigning tasks to the right concept at the right time. It experiences rewards and penalties based on whether it makes the right assignment. Learned selectors work really well when the policy for which concept to assign tasks is nuanced and depends on a lot of different factors.
So, a learned selector is perfect to supervise the brain that controls chillers for a building where employees arrive and leave at very different times. To decide whether to assign the day crew or the night crew the selector needs to consider lots of factors that affect when people arrive and leave. For example, on Tuesday and Wednesday afternoons employees tend to stay later to beat traffic. On Thursday and Friday afternoons many employees leave early to beat traffic, or even earlier on Fridays before holiday weekends.
Learning allows the brain to explore how best to supervise the concepts in a brain. If you donât know the best way to supervise concepts in a brain under all circumstances, or if you know but writing the instructions would take too much time and effort, design with learned concepts. One of my clients told me that they knew there were two strategies for operating their equipment but that they know how to use only one of the strategies well. I designed a learned selector into the brain. The learned concept figures out how to perform the second strategy, the learned selector figures out when to use the second strategy.
The distinction between programmed and learned concepts applies to directive concepts as well as well as selectors. For example, you can use math, methods, or manuals to perform action skills. If performing a skill (remember, skills are concepts that perform a specific task) is nuanced and requires identifying many exceptions to a rule under different circumstances, learn the directive concept.
Brains Are Organized by Functions and Strategies
So if the building blocks of brains are concepts that perform skills and subtasks, how do you organize these skills as you design a brain? Sequences and hierarchies are the two major paradigms for organizing skills in brains.
Letâs return to the mapping analogy. Remember, a point on a map represents a good outcome in your process where you will arrive if you make good decisions. Brain designs are mental maps with landmarks that help you explore the landmass. Be careful not to confuse the mental map with the landmass (terrain) itself. Even with the mental map and landmarks, youâll need to practice reaching goal destinations from various starting points. Just because you have defined a skill that a task requires, doesnât mean that you are proficient at it. I know that shooting a jump shot is the best way to score in basketball from 18 feet out, but Iâm not a great jump shooter yet. You still need to practice and your brains will need to practice the skills that you teach them, too.
Sequences or Parallel Execution for Functional Skills
Customers often tell me that for their task, you need to perform the skills in a particular sequence. They report that experience and evidence suggest (even demand) that they perform skills in a certain order. Note, Iâm not talking about a sequence of steps here, but a sequence of skills. For these tasks, if you perform the skills in the right sequence, you will reach the goal. If you perform the skills in the wrong sequence, you will get hopelessly lost and never find the location on the map that represents success at the task.
Figure 4-18 gives us a perfect example. The mountain pass provides an obstacle that sequences the skills. One skill: making your way across the mountains, from various starting points on the left side of the island, must be completed first. After you make it through the mountains, the second skill of reaching the target becomes possible. This reminds me of the technology trees in the video game Civilization. You must develop steam power before you invent the locomotive train. This is also related to Vygotzkyâs concept of zones of proximal development that we discussed earlier in Chapter 3. Discovering steam power makes it more likely that youâll invent the locomotive. The skills are related.
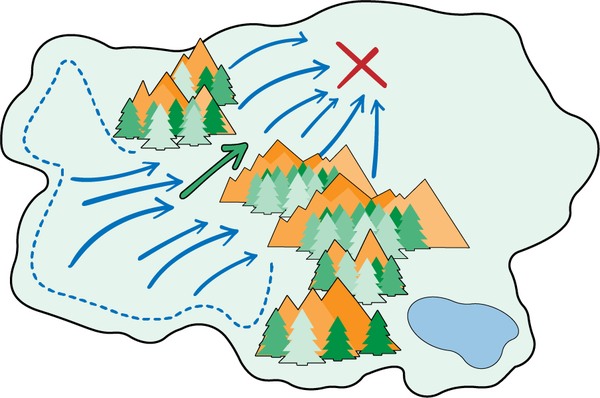
Figure 4-18. A decision landscape where two skills must be executed in sequence to reach the goal. Head through the mountain pass, then explore the flatland to reach the goal.
Thereâs a mathematical term for tasks with decision space landmasses that look like this: they are called funnel states. Funnel states are mathematical bottlenecks like doorways that you must go through in a problem to get to desirable goal states (like the red X marks in each of our landmass diagrams). To navigate these kinds of spaces, you need to use different skills in sequence. Each skill is a function that takes the right navigation action at the right time. Hereâs a real example.
Letâs explore the autonomous AI that Microsoft researchers built to teach a robot to grasp and stack blocks from the People and Process Concerns section of Chapter 1, in more detail. The researchers designed a brain with five directive concepts to execute skills and a learned selector to supervise the concepts:
- Reach
-
This movement extends the hand out from the body.
- Move
-
This movement sweeps the arm back and forth and up and down.
- Orient
-
This movement put the robot hand in the right position to grasp the block.
- Grasp
-
This movement squeezes the fingers to grasp the block.
- Stack
-
This movement picks up the block and places it on top of another block.
Each skill is a function that uses specific joints to perform a subtask. This is important because limiting the actions that each skill takes as it performs its function prevents the brain from having to explore many movements that couldnât possibly accomplish the goal. For example, orienting your hand around a block (putting your hand in position to pick it up) involves rotating your wrist. Now, imagine if your arm is in the perfect position and all you needed to do was turn your wrist to put your hand in position to grab the block, but you jerk your elbow! Now your hand is in a position where you canât grasp the block, no matter how you turn your wrist.
Figure 4-19 illustrates some of these skills for our block-moving robot example. The reach skill extends the robot arm by activating the shoulder, elbow and wrist. The move skill moves the arm laterally back and forth and up and down by activating the shoulder joint only. The grasp skill closes the hand by activating the fingers only.
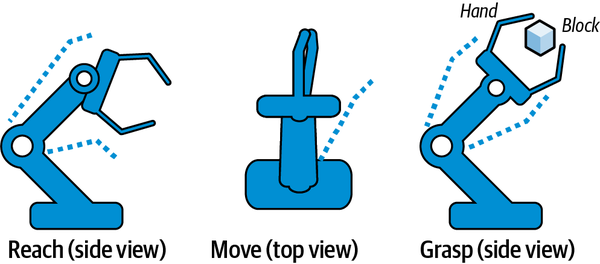
Figure 4-19. Three skills for a robot arm.
| Skill | Actions |
|---|---|
Reach |
Elbow, shoulder, wrist |
Move |
Shoulder |
Orient |
Wrist |
Grasp |
Fingers |
Stack |
Shoulder, fingers |
Try this out for yourself. Identify an object within reach that you can grasp. Reach out your arm (moving mostly your elbow, and also your shoulder and wrist as needed) but only extend your arm straight out from your body. Now use your shoulder only to laterally move your hand toward the object. You might be able to grasp the object at this point, but donât. Youâre so close! Now move your arm around from the elbow. See how frustrating that is! Your elbow movements just moved your hand away from the object that you were previously able to grasp. Now imagine watching your AI brain use joints that ruin the skill sequence over and over in 1,000 different ways instead of turning the wrist and grasping after the arm is in position. This is exactly what will happen to you if you allow an AI to practice a task without teaching functional skills explicitly.
Sequences live in the selector
See the sequence? For the robot arm example above, the skills must be performed in a sequence. Imagine what will happen if you try to grasp the block, then move your hand into the right position or if you try to stack the block before youâve grasped it!
First, before I talk about the different types of functional skills and how to represent them, let me tell you where they live. Sequences live in selective concepts. The selective concepts that supervise the brain and assign which skill to perform next must obey all of the sequence rules that I present in this section. For each example, I include a brain design diagram that outlines the sequence that the selector must obey as it makes its assignments (as shown in Figure 4-20).
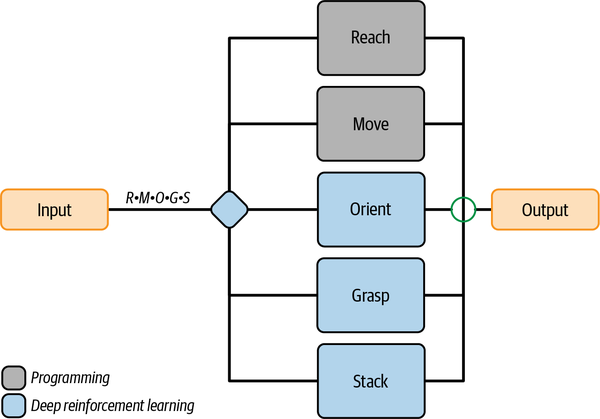
Figure 4-20. Brain design for grasp and stack robotic task with sequence definition living in the selector.
So, how do you make a selector obey a sequence as it assigns tasks? There are two ways to accomplish this. Programmed selectors can accept selection rules that enforce sequences. Alternately, you can enforce sequences in learned selectors using action masking. Action masking is a technique that sets the probability of unwanted actions to zero in the learning algorithm. This is the technique I used to enforce the sequence of the walking gait for the bipedal walker brain.
We borrow some mathematical language symbols from a field called task algebra to describe the rules about how skills relate to each other. These symbols, collected in Table 4-9, represent the landmarks that provide clues to the sequence of skills. Each of the skills in the sequence is a function. When the function has served its purpose, move on to the next task function in the sequence.
| Operator | Name | Example | Description |
|---|---|---|---|
⸠|
Sequencing |
A ⸠B |
Skill A must complete before Skill B can execute. |
â |
Exclusive choice |
A â B |
Both Skill A and Skill B are enabled and can be executed in any order, but not at the same time. |
& |
Conjunction |
A & B |
Both Skill A and Skill B are enabled. |
X[ ] |
Hierarchy |
X[A, B] |
Skill X assigns Skill A or Skill B to execute. The assigned task must be completed (Skill A or B) before Skill X is considered done. |
Note
Some readers will find this kind of mathematical representation refreshingly precise and others will find it intimidating. Donât worry, Iâll provide plenty of examples.
The task algebra for the robotic arm example above is R ⸠M ⸠O ⸠G ⸠S. This means that the brain will always reach first, then move, then orient the robot hand around the block, then grasp the block, then stack the block.
Fixed order sequences
R ⸠M ⸠O ⸠G ⸠S is a fixed order sequence. The sequence doesnât change, regardless of the starting point or the destination on the landmass. Sometimes we know why this is true (physics or chemistry tells us), but sometimes we donât have the science to explain itâyet we know that the sequence holds true because experience over time proves it.
In this case the fixed-order sequence of skills is effective but seems a bit too rigid. For example, I can easily imagine many ways that you could move the arm first, before reaching, or alternate between reaching and moving the arm to get the arm into position for orienting the hand. A more flexible brain design allows more options for how the brain sequences the reach and move tasks, for example:
R â M ⸠(O ⸠G ⸠S)
R â M means that you can perform the reach and move skill as many times as you want in any order, which is a more natural movement. Then after reach and move are complete (the hand is in position to grasp the block after the correct wrist movement), the orient, grasp, and stack skills must be executed in exactly that order, as shown in Figure 4-21.
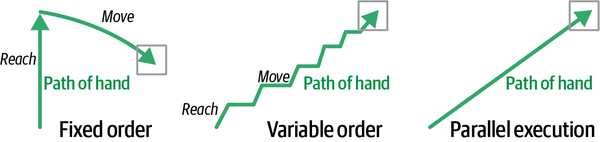
Figure 4-21. The path of the robot hand moving toward the block for fixed order task sequences, variable order task sequences, and parallel execution of the reach and move functions
Parallel execution of functional skills
Sometimes skills can be executed independently but in parallel. The most smooth and natural hand motion for reach and move likely results from parallel execution. See Figure 4-21 for an example. If you reach first, then move R ⸠M, the motion looks very mechanical. The robot reaches the entire distance, then activates the move skill to sweep over to the block. A variable order sequence R â M alternates between reaching and moving, which looks smoother but is still a jerky motion. Activating reaching and moving simultaneously at each time step (R & M) leads to the smoothest path toward the block. The reach skill controls one set of joints and the move skill controls another set of joints, so that each action to control the arm joins the decisions from the independent reach and move skills. I think that the original definition of the reach skill (with the shoulder, elbow, and wrist) is a better brain design.
Not every set of skills can be executed successfully in parallel. We can only teach these skills in parallel (practice them separately, then combine them for parallel execution) if we slightly change the definitions of the skills. Recall how the reach skill uses the shoulder, wrist, and elbow and the move skill uses the shoulder only. To teach and execute these skills in parallel, each skill needs to use a mutually exclusive set of joints. This means that no joints are shared between skills. So, if we changed the reach skill to use the elbow and wrist only, then we can teach and execute reach and move in parallel.
You might look at the resulting paths toward the block and wonder why we should use fixed order or variable order sequences for skills that learn this grasp and stack task. Keep in mind that the research project used fixed order R ⸠M very successfully to complete the tasks and that the motion looks quite smooth as this seven-jointed robot learns and executes the skills. Thatâs one of the great things about brain design: there are multiple (maybe even many) valid brain designs that provide good landmarks for autonomous AI to acquire skills that enable them to complete tasks well, just like there are many teaching strategies that can guide human students to successfully learn the jumpshot.
Variable order sequences
Just like the reach and move skill sequence for R â M, other task sequences can be completed in any order. In the Nintendo game Breath of the Wild that I discussed earlier, the first four puzzles can be solved in any order, but the subsequent skills must be performed in a sequence. You need a paraglider to get off the plateau (completing the first âlevelâ of the game). The task algebra for the opening skills in Breath of the Wild is:
(Gain Spirit Orb from Ja Baij Shrine â Gain Spirit Orb from Keh Namut Shrine â Gain Spirit Orb from Oman Au Shrine â Gain Spirit Orb from Owa Daim Shrine) ⸠Climb Tower ⸠Fly Glider
Figure 4-22 shows a landmass that requires skills to be performed in variable order. Sometimes you will need to travel around the lake first, then through the mountain pass to get to the goal state; other times you will need to travel through the mountain pass first, then travel around the lake. Perform the tasks in any order that helps you succeed.
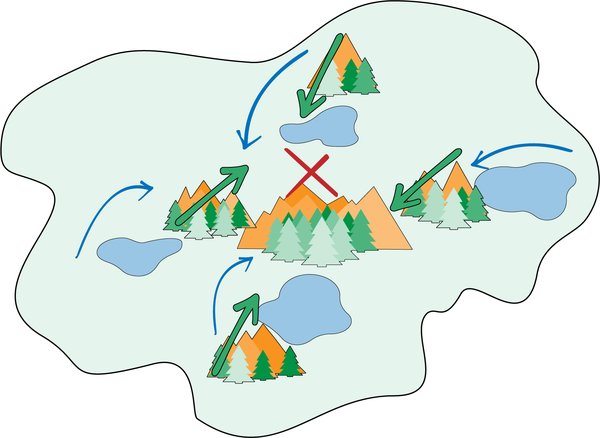
Figure 4-22. Landmass where exploration functions (âtravel through the mountain passâ and âtravel around the lakeâ) should be used in variable sequences.
From any point on the outskirts of the island, you will need to navigate around lakes and through mountain passes in sequence, but the sequence will vary depending on which point you start from. The task algebra looks like this:
Travel through the mountain pass â Travel around the lake
Let me give you another real robot example, this time with variable order sequences. In this example, the brain is controlling the two-armed Baxter robot to lift a table. This brain was also built by researchers at Microsoft. But hereâs the catch: the robot needs to follow a humanâs lead. Most of us have done this before. We team up with another person to lift a table: one person leads and the other follows.

Figure 4-23. Baxter robot lifting a table in simulation. There is a simulated, invisible force standing in for the human on the other side of the table. Baxter is trying to learn to lift the table by following this forceâs lead.
We divide the task and teach it as two separate skills, shown in Table 4-10: lift and level.
| Skill | Goal |
|---|---|
Lift |
Move the tableâs center of mass vertically upward. If you lift one end of the table only, this goal cannot be satisfied. |
Level |
Return the angle of the table to 0 degrees (perfectly level). You need to level the table only if the table is tilted. |
For the lift and level tasks, there is clearly a sequence, but the sequence is variable. If the table is not level, you need to perform the level skill before you can successfully lift the table vertically. But if the table is level, you should start lifting (there is no leveling to do). The task algebra for these skills looks like this: Lift â Level. The tasks must be performed in sequence, but the sequence is variable. A good sequence might look like (Lift ⸠Lift ⸠Level ⸠Lift ⸠Level ⸠Lift) but will vary depending on how the other lifter leads. Note that these skills cannot be taught as parallel execution (taught separately, then combined) because they are not completely independent.
Hierarchies for Strategies
Strategies are different from functions. Functions are skills that must be performed in some sequence or executed in parallel. Strategies are skills that map to a scenario, not a sequence. Use strategies on landscapes that force you to choose the right skills for the right scenario.
Take a look at the landmass in Figure 4-24. Unlike the lift and level skills in the table-lifting example, both strategies are completely valid ways to traverse the island from left to right. But one of the strategies looks significantly more attractive depending on where you start and where the target is. If you start closer to the top or the bottom of the island, going around the bodies of water will require less distance traveled. If you start closer to the center of the island (vertically), then you can reach the goal sooner by traveling between the bodies of water.
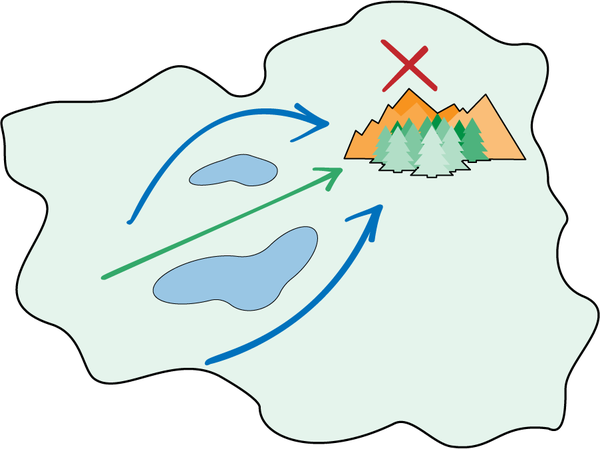
Figure 4-24. This landmass allows you to travel from left to right using either of two strategies: pass between the two bodies of water or around the bodies of water.
Thatâs how strategies work. You need to read the situation correctly to choose the right strategy. In his iconic 1985 talk âCan Machines Thinkâ, Richard Feynman tells the story of how Douglas Lenat used strategy to win a prominent game competition. In this wargame competition, participants designed a navy fleet of miniature ships with different amounts of armor and weapons. Mock naval battles had rules governing the maneuverability, survivability, and destructive output of a variety of vessels, and players use a combination of tactical maneuvering and chance (as many games do) to determine the outcome of ship-to-ship combat, with the last navy standing declared the winner.
During the month of June 1981, the EURISKO program was set the task of exploring the design of naval fleets conforming to a body of (several hundreds of) rules and constraints as set forward in Traveller: The Trillion Credit Squadron. EURISKO designed a fleet of ships suitable for entry in the 1981 Origins national wargame tournament, held at Dunfeyâs Hotel, in San Mateo, Ca., over July 4 weekend. The Traveller tournament, run by Game Designers Workshop (based in Normal, Illinois), was single elimination, six rounds. EURISKOâs fleet won that tournament, thereby becoming the ranking player in the United States (and also an honorary admiral in the Traveller navy). This win is made more significant by the fact that the programâs creator, Professor Douglas Lenat of Stanford Universityâs Heuristic Programming Project, had never played this game before, nor any miniatures battle game of this type.
Lenatâs heuristic program (heuristic is just another term for strategy) devised a strategy to build one gigantic ship that contained all of the available armor and weapons. This is a well-used strategy in many battle video games; gamers would call this ship a âtankâ (a large unit that can both inflict and absorb a huge amount of damage). These units are usually very slow, but their firepower and damage absorbing bulk can help them succeed, as Lenatâs gigantic ship did.
Discovering strategies
Well, the next year, the wargameâs rules were changed to prevent a single huge ship from winning the competition. OK, game over, right? Nope. That year, Lenatâs competition entry used a navy of 100,000 tiny ships to overwhelm the competition and win for a second year in a row. Each ship delivered a tiny amount of damage, but there were so many of them that they added up to a victory. Video gamers use this strategy in battle games frequently too. They call this the âswarm.â
Iâm not a video game player (mostly because I donât play them well), but I used to enjoy a strategy game called StarCraft II. In this game, you control a galactic space army. Depending on the race of the space army you control (Terran, Protoss, or Zerg), different strategies become attractive. The Zerg is a âswarmâ race; its military units are collectively stronger by being part of a group. Itâs easy to defeat an individual Zerg unit but, youâll be overwhelmed by a swarm. Thatâs how most Zerg players win the game.
Strategies wax and wane in effectiveness over time
These kinds of strategies arenât just useful in games. Businesses use the swarm strategy as well. Amazon built a reputation as an online shopping giant, a megalith that sells everything from underwear to high-end electronics from its website. It even bought the grocery-store chain Whole Foods. It wins by scale and by controlling a massive, efficient supply chain. Amazonâs global dominion is reminiscent of the Galactic Empire in the Star Wars science fiction series: a huge intergalactic government with massive resources. They even built a space weapon the size of a planet: seemingly unbeatable.
Well, along comes Shopify (and the Rebel Alliance). Shopify provides technology for almost anyone to build and maintain an ecommerce store. OK. Now weâre powering up a swarm of small, nimble ecommerce stores; the Zerg of ecommerce, if you like. Hereâs another thing about the Zerg. The Zerg ecosystem grows in power over time and is almost unbeatable late in the game. You have to beat them early in the game in order to win. In an article titled âShopify: A StarCraft Inspired Business Strategyâ, Mike, an âex-activist investor,â illuminates these very insights and suggests that over time, the Shopify strategy will gain ground over the Amazon strategy.
Strategies capture trade-offs
One ship versus many, tank versus swarm, small and fast versus big and slowâthereâs always a trade-off. Iâve learned some of my most valuable lessons about trade-offs by studying the game of chess. I am not a proficient chess player, but I am fascinated by the strategy of the game. One book in particular that has served as a source of inspiration is Jeremy Silmanâs The Complete Book of Chess Strategy.
In his books, Silman, a teacher and coach of chess masters, evaluates positions according to the âimbalances,â or differences, which exist in every position, and advocates that players plan their play according to these. A good plan according to Silman is one which highlights the positive imbalances in the position. Heâs saying that the differences in chess board scenarios present opportunities for various strategies to have more impact on the game than others.
But there were so many strategies listed in the encyclopedia! I needed a pattern to help me organize and make sense of so much chess strategy. In this context, a trade-off is an organizing pattern for strategies.
Letâs start with the phases of the chess game: the opening, the mid-game, and the endgame. Each of these phases has different objectives and therefore different strategies that map to them. The objective of the opening is to survive. The objective of the mid-game is to gain advantage, and the objective of the endgame is to mate the opponentâs king.
I still needed another scheme to help me better organize all the strategy I saw in the encyclopedia. Another Silman book, The Amateurâs Mind, gave me the organizing pattern I was looking for. It was a trade-off. Looking for strategies that define trade-offs for a task will help you identify patterns among many strategies and design brains that balance important objectives. Weâll talk about how to do this in detail in Chapter 6.
-
One strategy is extremely aggressive. It favors mobility (the ability to move pieces quickly) and therefore favors bishops over knights. Bishops are very mobile and can travel across the board on the long diagonal superhighway (called fiancetto). Bobby Fischer favored this strategy.
-
The opposite strategy is fundamentally defensive. It favors controlling the center of the board and builds edifices of pieces to block and own the center of the board. It favors knights over bishops. Knights can move more easily through crowded center areas of the board. A group of chess masters so preferred this style that they developed the Queenâs Gambit to lure a player into playing the aggressive, offensive strategy and punishes their hubris. The Queenâs Gambit accepted takes up the challenge. The Queenâs Gambit declined sees the danger and takes action to mitigate this strategyâs advantages.
As depicted in Figure 4-25, strategies often come in pairs, but executing strategy usually requires effective navigating of the areas between the extremes.
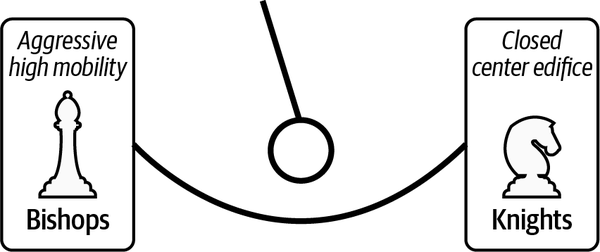
Figure 4-25. Pendulum of strategy
The most important insight is that you canât just play whichever strategy you want. The board scenario (position of your pieces and your opponentâs pieces) tells you when it is most advantageous to use each strategy. There are strategies at almost every point on the continuum that help navigate from most any type of board position.
Hereâs an example from horse racing. The movie Ride Like a Girl tells the story of Michelle Payne, the first woman to win the prestigious Melbourne Cup race. Her father teaches her how to read the competitors during a race to effectively navigate between strategies. The first strategy is to hold the horse back and stay with the pack. Her father then explains that when horses tire during the race, the pack parts and a clear but temporary opening appears. If you wait until the opening appears to make your move, you will charge ahead of the pack. If you try to make your move before the opening appears, you will not be able to break away from the pack.
Selective concepts navigate strategy hierarchies
Strategies live in hierarchies. The selector (remember, selectors are supervisors) decides which strategy to use in each situation, and the strategy decides what to do. The task algebra for the hierarchies above looks like this: Selector[Strategy 1, Strategy 2]. Here are the task algebra representations of each of the strategy examples that I presented earlier in the chapter:
Select Navigation Strategy[Travel Between Lakes, Travel Around Lakes] Select Naval Fleet Strategy[One Huge Ship, 100000 Tiny Ships] Select Chess Strategy[Offensive, Defensive] Select Horse Racing Strategy[Hold Horse Back, Charge Ahead of Pack] Select Crusher Strategy[Choke, Regulate]
As you design brains, you will need to identify hierarchies of strategies and sequences of functional skills so that you can apply AI design patterns that teach skills effectively (that is, they guide the learning algorithm to acquire the skills to succeed). Just like a skilled teacher or coach, you need to be much more concerned with providing landmarks to guide exploration than with figuring out how to prescribe each action (perform the task yourself). In the next chapter, I will describe how to listen to detailed descriptions of tasks and processes for clues that illuminate which building blocks you should use to design a brain that can learn that task. If you practice, you will be able to quickly and easily identify sequences and hierarchies and sketch out effective brain designs. Next, Iâll provide some visual language for expressing brain designs and an example that combines many building blocks that we introduced in this chapter.
Visual Language of Brain Design
You will collaborate with many stakeholders during and after the brain-design process, so it helps to have a common language to describe brain designs. I often whiteboard brain designs together with subject matter experts. I sometimes ask other brain designers to review my preliminary designs and give me feedback. After I am finished designing a brain, I pass the brain design to the group that will build the brain.
Letâs not reinvent the wheel in determining an effective design workflow. Workflow diagrams in the style shown in Figure 4-26 already provide a useful and well known visual language for systems that process information, output decisions, and choose which modules to activate.
Figure 4-26. Stylized workflow diagram example
Perceptive concepts process information, directive concepts output decisions, and selective concepts choose which directive concepts to activate, so I use workflow diagrams as the visual language for brain designs, with the symbols outlined in Table 4-11 used as the building blocks to create diagrams such as the one shown in Figure 4-27.
| Symbol | Meaning in workflow diagram | Function in brain design |
|---|---|---|
Oval |
Terminal (beginning or end of a workflow) |
Input to the brain, output from the brain |
Hexagon |
Processor |
Perceptive concept |
Rectangle |
Action |
Directive concept |
Diamond |
Decision between branches of the workflow |
Selective concept |
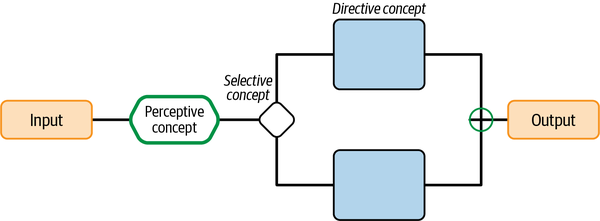
Figure 4-27. Brain design diagram labeling the workflow symbols I use to describe inputs, outputs, perceptive concepts, directive concepts, and selective concepts
1 Gould, Stephen Jay, and Niles Eldredge. âPunctuated Equilibria: The Tempo and Mode of Evolution Reconsidered.â Paleobiology 3, no. 2 (1977): 115â51. http://www.jstor.org/stable/2400177.
2 Herbert Blumer, Symbolic Interactionism: Perspective and Method (University of California Press, 1986).
Get Designing Autonomous AI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

