Capítulo 4. Sin servidor y seguridad
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Sólo podemos ver una corta distancia por delante, pero podemos ver muchas cosas que hay que hacer.
Alan Turing
Utilizar las tecnologías sin servidor significa que algunas preocupaciones tradicionales de seguridad desaparecen, como parchear los fallos del sistema operativo y asegurar las conexiones de red. Sin embargo, como ocurre con cualquier avance tecnológico, la tecnología sin servidor introduce nuevos retos a la vez que resuelve los problemas existentes. La seguridad sin servidor no es diferente. Este capítulo examina las amenazas a la seguridad de una aplicación sin servidor y profundiza en las principales primitivas de seguridad y cómo se aplican a la ingeniería sin servidor en AWS.
Por desgracia, los desarrolladores de software normalmente sólo tienen en cuenta la seguridad una vez que se ha desarrollado toda la aplicación, normalmente en las semanas o días previos a la puesta en marcha. Incluso entonces, tienden a centrar esos esfuerzos de última hora únicamente en asegurar el perímetro de la aplicación. Hay dos factores que contribuyen a ello: en primer lugar, la seguridad parece intrínsecamente compleja para los ingenieros, y en segundo lugar, los ingenieros suelen pensar que aplicar medidas de seguridad va en contra de la práctica de la iteración basada en el fracaso.
Aunque los equipos de ingeniería de software pueden utilizar herramientas de seguridad y delegar ciertas tareas en ellas, la seguridad debe ser siempre una preocupación operativa y de ingeniería básica.
Los equipos modernos de ingeniería de software tienen un proceso de desarrollo establecido desde hace mucho tiempo. Tradicionalmente, ha sido algo parecido a esto: diseñar, construir, probar, implementar. El movimiento DevOps garantizó que el funcionamiento del software se integrara en el ciclo de vida de desarrollo del software . Ahora la seguridad también debe formar parte de todo el proceso de desarrollo.
La recomendación popular es cambiar a la izquierda en materia de seguridad, introduciéndola en el ciclo de vida del desarrollo mucho antes, y aprovechar la gestión de identidades y accesos para proporcionar defensa en profundidad, no sólo en el perímetro. La ingeniería sin servidor presenta una oportunidad para integrar un enfoque de seguridad por diseño en tu trabajo diario. Mientras diseñas, construyes y operas tu aplicación, ten siempre presentes los vectores de ataque, las vulnerabilidades potenciales y las mitigaciones a tu disposición (ver Figura 4-1).
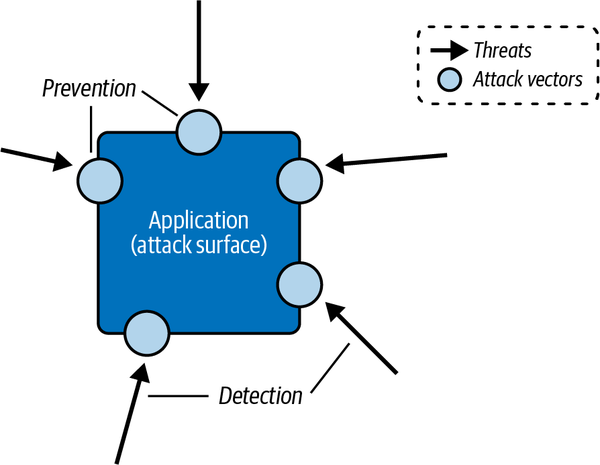
Figura 4-1. La seguridad de las aplicaciones consiste en detectar las amenazas y aplicar medidas preventivas a los vectores de ataque
La práctica del modelado de amenazas se está convirtiendo cada vez más en una herramienta esencial para identificar y protegerse continuamente contra las amenazas. Se añadió al respetado Radar Tecnológico de Thoughtworks en 2015, con la observación de que "a lo largo de la vida útil de cualquier software, surgirán nuevas amenazas y las existentes seguirán evolucionando gracias a los acontecimientos externos y a los continuos cambios en los requisitos y la arquitectura."
Como ingeniero de software, también debes reconocer y aceptar tus limitaciones. Los equipos de ingeniería suelen tener una experiencia práctica o unos conocimientos prácticos limitados sobre la seguridad de las aplicaciones. Consulta a los equipos de seguridad al principio de tus ciclos de diseño y desarrollo de software. Normalmente, los equipos de seguridad pueden ayudar a organizar pruebas de penetración y auditorías de seguridad antes de lanzar nuevas aplicaciones y funciones importantes, así como apoyar los esfuerzos de detección de vulnerabilidades y respuesta a incidentes. Ten siempre presente la estrategia de ciberseguridad de tu organización, que debe incluir orientaciones sobre la seguridad de las cuentas en la nube y la preservación de la privacidad de los datos.
Antes de seguir adelante, tomémonos un momento para establecer un punto importante: ¡la seguridad puede ser sencilla!
La seguridad puede ser sencilla
Dado lo que está en juego, garantizar la seguridad de una aplicación de software puede ser una tarea desalentadora. Las violaciones de los perímetros de las aplicaciones y los almacenes de datos suelen ser dramáticas y devastadoras. Además de las consecuencias inmediatas, como la pérdida de datos y la necesidad de reparación, estos incidentes suelen tener un impacto negativo en la confianza entre los consumidores y la empresa, y entre la empresa y sus tecnólogos.
Retos de seguridad
Asegurar las aplicaciones sin servidor nativas de la nube de puede ser especialmente difícil por varias razones, entre ellas:
- Servicios gestionados
-
A lo largo de , verás que los servicios gestionados son fundamentales para las aplicaciones sin servidor y, cuando se aplican correctamente, pueden respaldar una clara separación de preocupaciones, un rendimiento óptimo y una observabilidad eficaz. Aunque los servicios gestionados proporcionan una base sólida para tu infraestructura, así como varias ventajas de seguridad -principalmente a través del modelo de responsabilidad compartida, que se trata más adelante en este capítulo-, el gran número de ellos disponibles para los equipos que construyen en AWS presenta un problema: para utilizar (o incluso evaluar) un servicio gestionado, primero debes comprender las características disponibles, el modelo de precios y, sobre todo, las implicaciones de seguridad. ¿Cómo funcionan los permisos IAM para este servicio? ¿Cómo se aplica el modelo de responsabilidad compartida a este servicio? ¿Cómo funcionarán el control de acceso y el cifrado?
- Configurabilidad
-
Un aspecto de que comparten todos los servicios gestionados es la configurabilidad. Cada servicio de AWS tiene una serie de opciones que pueden ajustarse para optimizar el rendimiento, la latencia, la resistencia y el coste. La combinación de servicios también puede dar lugar a otras optimizaciones, como el empleo de colas SQS entre funciones Lambda para proporcionar procesamiento por lotes y almacenamiento en búfer. De hecho, una de las principales ventajas de serverless que se destaca en este libro es la granularidad de . Como has visto, tienes la capacidad de configurar cada uno de los servicios gestionados de tus aplicaciones hasta un grado muy fino. En términos de seguridad, esto representa una amplia superficie para la introducción inadvertida de fallos como el exceso de permisos y la escalada de privilegios.
- Normas emergentes
-
AWS ofrece nuevos servicios, nuevas características y mejoras de las características y servicios existentes a un ritmo elevado y constante. Estos nuevos servicios y características pueden estar directamente relacionados con la seguridad de las aplicaciones o las cuentas, o presentar nuevos vectores de ataque que analizar y proteger. Siempre hay nuevas palancas de las que tirar y más cosas que configurar. La comunidad en torno a AWS y, en particular, a serverless también se mueve a un ritmo relativamente rápido, con nuevas publicaciones en blogs, tutoriales en vídeo y charlas en conferencias que aparecen todos los días. El aspecto de seguridad de la ingeniería de software quizás se mueva un poco más despacio que otros elementos, pero sigue habiendo un flujo constante de consejos de profesionales de la ciberseguridad junto con publicaciones periódicas de revelaciones de vulnerabilidades e investigaciones asociadas. Mantenerte al día de todas las actualizaciones de los productos AWS y de las buenas prácticas a la hora de proteger tu aplicación en constante evolución puede convertirse fácilmente en uno de tus mayores retos.
Aunque las aplicaciones sin servidor nativas de la nube presentan retos de seguridad únicos, también hay muchas ventajas inherentes cuando se trata de asegurar este tipo de software. La arquitectura de las aplicaciones sin servidor introduce un marco de seguridad único y ofrece la posibilidad de trabajar de forma novedosa dentro de este marco. Tienes la oportunidad de redefinir tu relación con la seguridad de las aplicaciones. La seguridad puede ser sencilla.
A continuación, vamos a explorar cómo empezar a asegurar tu aplicación sin servidor.
Cómo empezar
Establecer una base sólida para tu práctica de seguridad sin servidor es fundamental. La seguridad puede, y debe, ser una preocupación primordial. Y nunca es demasiado tarde para establecer esta base.
Como ya se ha dicho, la seguridad debe ser un proceso claramente definido. No se trata de completar una lista de comprobación, implantar una herramienta o delegar en otros equipos. La seguridad debe formar parte del diseño, el desarrollo, las pruebas y el funcionamiento de cada parte de tu sistema.
Trabajar con marcos de seguridad sólidos que encajen bien con la tecnología sin servidor y adoptar hábitos de ingeniería sensatos, combinado con todo el apoyo y la experiencia de tu proveedor de la nube, contribuirá en gran medida a garantizar que tus aplicaciones sigan siendo seguras.
Cuando se aplican al software sin servidor, dos tendencias modernas de seguridad pueden proporcionar una base sólida para proteger tu aplicación: la confianza cero y el principio del mínimo privilegio. La siguiente sección examina estos conceptos.
Una vez que hayas establecido un marco de seguridad de confianza cero y mínimo privilegio, el siguiente paso es identificar la superficie de ataque de tus aplicaciones y las amenazas de seguridad a las que son vulnerables. Las secciones siguientes examinan las amenazas sin servidor más comunes y el proceso de modelado de amenazas.
Combinar el Modelo de Seguridad de Confianza Cero con los Permisos de Mínimo Privilegio
Hay dos principios modernos de ciberseguridad que puedes aprovechar como piedras angulares de tu estrategia de seguridad sin servidor: la arquitectura de confianza cero y el principio del mínimo privilegio.
Arquitectura de confianza cero
La premisa básica de la seguridad de confianza cero es asumir que cada conexión a tu sistema es una amenaza. Entonces, cada interfaz debe estar protegida por una capa de autenticación (¿quién eres?) y autorización (¿qué quieres?). Esto se aplica tanto a los puntos finales de las API públicas, o el perímetro en el modelo tradicional castillo-y-muralla, como a las interfaces privadas e internas, como las funciones Lambda o las tablas DynamoDB. La confianza cero controla el acceso a cada recurso distinto de tu aplicación, mientras que un modelo de castillo y ciénaga sólo controla el acceso a los recursos del perímetro de tu aplicación.
Imagínate a un caballero errante galopando hasta las murallas del castillo, presentando a los guardias credenciales que parezcan probables y convenciéndoles de sus honorables intenciones antes de entrar confiadamente en el castillo por el puente levadizo bajado. Si estos guardias del perímetro constituyen el alcance de la seguridad del castillo, el caballero es ahora libre de recorrer las habitaciones, las mazmorras y el almacén de joyas, recopilando información sensible para futuras incursiones o robando bienes valiosos in situ. Sin embargo, si cada puerta o pasillo tuviera guardias sospechosos adicionales o controles de seguridad sofisticados que asumieran una confianza cero por defecto, el caballero estaría totalmente restringido e incluso podría verse disuadido de infiltrarse en este castillo.
Otro escenario a tener en cuenta es el de un castillo que corta una llave única para cada puerta resistente: si el caballero accede a una copia de esta llave, podrá abrir todas las puertas, por gruesas o engorrosas que sean. Con confianza cero, hay una llave única para cada puerta. La Figura 4-2 muestra cómo se compara el modelo de castillo y turba con una arquitectura de confianza cero.
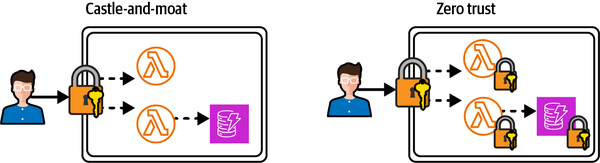
Figura 4-2. Seguridad perimetral de castillo y ciénaga comparada con la arquitectura de confianza cero
Existen varias aplicaciones de la arquitectura de confianza cero, como la informática a distancia y la seguridad de las redes empresariales. La siguiente sección analiza brevemente cómo puede interpretarse y aplicarse el modelo de confianza cero a las aplicaciones sin servidor.
Confianza cero y sin servidor
A menudo se habla de la confianza cero como la próxima gran novedad en seguridad de redes. Dejando a un lado las palabras de moda y el bombo publicitario, verás que es un ajuste natural para aplicar la seguridad a los sistemas distribuidos sin servidor. De hecho, la confianza cero es a menudo la metodología de facto para asegurar las aplicaciones sin servidor. Abordar la seguridad de las aplicaciones con una mentalidad de confianza cero favorece el desarrollo de buenos hábitos, como la verificación de mensajes entre servicios y la seguridad de las API accesibles internamente.
No puedes pasar simplemente de un modelo de castillo y ciénaga a la confianza cero. Primero necesitas una arquitectura de aplicación de apoyo. Por ejemplo, si tu API, tu lógica empresarial y tu base de datos se ejecutan en una única aplicación en contenedores, será muy difícil aplicar los permisos granulares basados en recursos necesarios para respaldar la confianza cero. La arquitectura sin servidor proporciona la arquitectura de aplicación óptima para la confianza cero, ya que los recursos están aislados de forma natural entre la API, la informática y el almacenamiento, y cada uno puede tener un control de acceso altamente granular en lugar.
El principio del menor privilegio
La identidad y el control de acceso son esenciales para una arquitectura eficaz de confianza cero. Si ahora el perímetro de seguridad debe estar alrededor de cada recurso y activo de tu sistema, vas a necesitar una capa de autenticación y autorización altamente fiable y granular para implementar este perímetro.
Cuando los recursos de tu aplicación interactúan entre sí, se les deben conceder los permisos mínimos necesarios para completar sus operaciones. Esto es una aplicación del principio del menor privilegio, introducido en el Capítulo 1.
Tomemos un ejemplo relativamente sencillo. Supongamos que tienes una tabla DynamoDB y dos funciones Lambda que interactúan con la tabla (ver Figura 1-11). Una función Lambda de debe ser capaz de leer elementos de la tabla, y la otra función debe ser capaz de escribir elementos en la tabla.
Podrías tener la tentación de aplicar permisos de manta a una política de control de acceso y compartirla entre las dos funciones Lambda, de este modo:
{"Version":"2012-10-17","Statement":[{"Sid":"FullAccessToTable","Effect":"Allow","Action":["dynamodb:*"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Sin embargo, esto daría a cada función más permisos de los que necesita, violando el principio del mínimo privilegio. En su lugar, una política de mínimos privilegios para la función Lambda de sólo lectura tendría el siguiente aspecto:
{"Version":"2012-10-17","Statement":[{"Sid":"ReadItemsFromTable","Effect":"Allow","Action":["dynamodb:GetItem","dynamodb:Query","dynamodb:Scan"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Y una política de mínimos privilegios para la función Lambda de sólo escritura tendría este aspecto:
{"Version":"2012-10-17","Statement":[{"Sid":"WriteItemsToTable","Effect":"Allow","Action":["dynamodb:PutItem","dynamodb:UpdateItem"],"Resource":"arn:aws:dynamodb:eu-west-2:account-id:table/TableName"}]}
Afortunadamente, el motor de permisos subyacente utilizado por todos los recursos de AWS, llamado AWS Identity and Access Management (IAM), aplica una postura de denegación por defecto: debes conceder permisos explícitamente, superponiendo nuevos permisos con el tiempo, según sea necesario. Echemos un vistazo más de cerca al poder de AWS IAM.
El poder de AWS IAM
AWS IAM es el único servicio que utilizarás en todas partes, pero también suele considerarse uno de los más complejos. Por lo tanto, es importante comprender IAM y aprender a aprovechar su poder. (Aunque no tienes por qué convertirte en un experto en IAM, a menos que quieras, claro).
El poder de AWS IAM reside en los roles y las políticas. Las políticas definen en las acciones que pueden realizarse sobre determinados recursos. Por ejemplo, una política podría definir el permiso para colocar eventos en un bus de eventos EventBridge específico. Las funciones son colecciones de una o más políticas. Los roles pueden adjuntarse a usuarios IAM, pero el patrón más común en una aplicación moderna sin servidor es adjuntar un rol a un recurso. De este modo, se puede conceder permiso a una regla EventBridge para invocar una función Lambda, y a su vez se puede permitir a esa función colocar elementos en una tabla DynamoDB.
Las acciones IAM pueden dividirse en dos categorías: acciones del plano de control y acciones del plano de datos. Las acciones del plano de control, como PutEvents y GetItem (por ejemplo, utilizadas por un rol de implementación automatizada) gestionan recursos. Las acciones del plano de datos, como PutEvents y GetItem (por ejemplo, utilizadas por un rol de ejecución Lambda), interactúan con esos recursos.
Veamos una simple declaración de política IAM y los elementos que la componen:
{"Sid":"ListObjectsInBucket",# Statement ID, optional identifier for# policy statement"Action":"s3:ListBucket",# AWS service API action(s) that will be allowed# or denied"Effect":"Allow",# Whether the statement should result in an allow or deny"Resource":"arn:aws:s3:::bucket-name",# Amazon Resource Name (ARN) of the# resource(s) covered by the statement"Condition":{# Conditions for when a policy is in effect"StringLike":{# Condition operator"s3:prefix":[# Condition key"photos/",# Condition value]}}}
Consulta la documentación de AWS IAM para conocer todos los elementos de una política IAM.
Funciones de ejecución lambda
Un uso clave de los roles IAM en las aplicaciones sin servidor son los roles de ejecución de la función Lambda . Un rol de ejecución se adjunta a una función Lambda y concede a la función los permisos necesarios para ejecutarse correctamente, incluido el acceso a cualquier otro recurso de AWS que sea necesario. Por ejemplo, si la función Lambda utiliza el SDK de AWS para realizar una solicitud a DynamoDB que inserte un registro en una tabla, el rol de ejecución debe incluir una política con la acción dynamodb:PutItem para el recurso de la tabla.
La función de ejecución la asume el servicio Lambda cuando realiza operaciones del plano de control y del plano de datos. El servicio AWS Security Token Service (STS) se utiliza para obtener credenciales de seguridad temporales de corta duración, que se ponen a disposición a través de las variables de entorno de la función durante la invocación.
Cada función de tu aplicación debe tener su propio rol de ejecución único, con los permisos mínimos necesarios para cumplir su cometido. De este modo, las funciones de propósito único (introducidas en el Capítulo 6) también son clave para la seguridad: Los permisos de IAM pueden estar estrechamente vinculados a la función y permanecer extremadamente restringidos de acuerdo con la funcionalidad limitada.
Barandillas IAM
Como sin duda estás empezando a notar, la seguridad eficaz sin servidor en la nube tiene que ver con la higiene básica de la seguridad. Establecer barandillas para el uso de AWS IAM es una parte fundamental de la promoción de un enfoque seguro de la actividad diaria de ingeniería. He aquí algunos barandales recomendados:
- Aplica el principio del menor privilegio en las políticas.
-
Las políticas de IAM sólo deben incluir el conjunto mínimo de permisos necesarios para que el recurso asociado realice las operaciones necesarias en el plano de control o de datos. Como norma general, no utilices comodines (*) en las declaraciones de tus políticas. Los comodines son la antítesis del privilegio mínimo, ya que aplican permisos generales para acciones y recursos. A menos que la acción requiera explícitamente un comodín, sé siempre específico.
- Evita utilizar políticas IAM gestionadas.
-
Estas son políticas proporcionadas por AWS, y a menudo son atajos tentadores, especialmente cuando acabas de empezar o utilizas un servicio por primera vez. Puedes utilizar estas políticas al principio de la creación de prototipos o del desarrollo, pero deberías sustituirlas por políticas personalizadas en cuanto entiendas mejor la integración. Dado que estas políticas están diseñadas para aplicarse a escenarios genéricos, simplemente no están lo suficientemente restringidas y normalmente violarán el principio del menor privilegio cuando se apliquen a interacciones dentro de tu aplicación.
- Prefiere las funciones a los usuarios.
-
Los usuarios de IAM reciben credenciales de acceso a AWS estáticas y de larga duración (un ID de clave de acceso y una clave de acceso secreta). Estas credenciales pueden utilizarse para acceder directamente a la cuenta de AWS del proveedor de la aplicación, incluidos todos los recursos y datos de esa cuenta. Dependiendo de los roles y políticas de IAM asociados, el usuario autenticador puede incluso tener la capacidad de crear o destruir recursos. Dado el poder que otorgan al titular, el uso y distribución de las credenciales estáticas debe limitarse para reducir el riesgo de acceso no autorizado. Siempre que sea posible, restringe los usuarios IAM a un mínimo absoluto (o, mejor aún, no tengas ningún usuario IAM).
- Prefiere un rol por recurso.
-
Cada recurso de tu aplicación, como una regla EventBridge, una función Lambda y una cola SQS, debe tener su propio rol único. Los permisos para esos roles deben ser de grano fino y menos privilegiado.
El modelo de responsabilidad compartida de AWS
AWS utiliza unmodelo de responsabilidad compartida para definir las competencias de los consumidores de seguridad de las aplicaciones y del proveedor de la nube (ver Figura 4-3). Lo importante aquí es el traspaso de la responsabilidad de la seguridad a AWS cuando se utilizan servicios en la nube. Esto aumenta cuando se utilizan los servicios sin servidor totalmente gestionados de , como la informática con AWS Lambda: AWS gestiona los parches del tiempo de ejecución de Lambda, el aislamiento de la ejecución de funciones, etc. .
Las aplicaciones sin servidor se componen de lógica empresarial, definiciones de infraestructura y servicios gestionados. La propiedad de estos elementos se divide entre AWS y los consumidores de sus servicios en la nube pública. Como ingeniero de aplicaciones sin servidor y cliente de AWS, eres responsable de la seguridad de:
-
Tu código de función y las bibliotecas de terceros utilizadas en ese código
-
Configuración de los recursos de AWS utilizados en tu aplicación
-
Los roles y políticas IAM que rigen el control de acceso a los recursos y funciones de tu aplicación
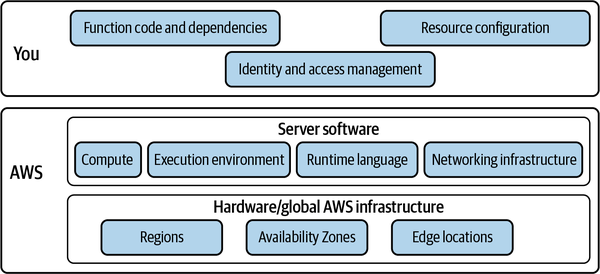
Figura 4-3. El modelo de responsabilidad compartida de la seguridad en la nube: tú eres responsable de la seguridad en la nube, y AWS es responsable de la seguridad de la nube
Piensa como un hacker
Con tu estrategia fundacional de seguridad de confianza cero y mínimo privilegio y una clara delimitación de responsabilidades, el siguiente paso es identificar los posibles vectores de ataque en tu aplicación y ser consciente de las posibles amenazas a la seguridad e integridad de tus sistemas.
Cuando imaginas las amenazas a tus sistemas, es posible que te imagines a malos actores externos a tu organización: piratas informáticos. Aunque ciertamente existen amenazas externas , no deben eclipsar las amenazas internas , contra las que también hay que protegerse. Las amenazas internas podrían, por supuesto, ser deliberadamente maliciosas, pero lo más probable es que las vulnerabilidades se introduzcan involuntariamente. Los ingenieros de una aplicación pueden ser a menudo los artífices de sus propios fallos de seguridad y de la exposición de sus datos, a menudo a través de una configuración de seguridad débil o inexistente de los recursos de la nube.
La popular representación de un hacker realizando un ataque obvio de denegación de servicio en una aplicación web o infiltrándose en el cortafuegos de un servidor sigue siendo una posibilidad muy real, pero los ataques más sutiles en la cadena de suministro de software son ahora igual de probables. Estos ataques insidiosos implican incrustar código malicioso en bibliotecas de terceros y automatizar los exploits de forma remota una vez que el código se implementa en cargas de trabajo de producción.
Es esencial adoptar la mentalidad de un hacker y comprender plenamente las amenazas potenciales a tus aplicaciones sin servidor para defenderte adecuadamente contra ellas.
Conoce el Top 10 de OWASP
La ciberseguridad es un área increíblemente bien investigada, con profesionales de la seguridad que evalúan constantemente el siempre cambiante panorama del software, identifican los riesgos emergentes y distribuyen medidas preventivas y consejos. Aunque como ingeniero moderno sin servidor debes aceptar la responsabilidad que tienes en la seguridad de las aplicaciones que construyes, es absolutamente crucial que combines tus propios esfuerzos con la deferencia al asesoramiento profesional y la utilización de la amplia investigación que está disponible públicamente.
Identificar las amenazas a la seguridad de tu software es una tarea que no debes intentar solo. Existen varios marcos de categorización de amenazas que pueden ayudarte en este sentido, pero centrémonos en el Top 10 de OWASP.
El Proyecto Abierto de Seguridad de las Aplicaciones Web, o OWASP para abreviar, es una "fundación sin ánimo de lucro que trabaja para mejorar la seguridad del software". Lo hace principalmente a través de proyectos, herramientas e investigación de código abierto dirigidos por la comunidad. La Fundación OWASP ha publicado repetidamente una lista de los 10 riesgos de seguridad más prevalentes y críticos para las aplicaciones web desde 2003. La última versión, publicada en 2021, proporciona la lista de riesgos de seguridad más actualizada (en el momento de escribir este artículo).
Aunque una aplicación sin servidor diferirá en algunos aspectos de una aplicación web típica, la Tabla 4-1 interpreta el Top 10 de OWASP a través de una lente sin servidor. Observa que la lista está en orden descendente, con el riesgo más crítico para la seguridad de la aplicación, según la clasificación de OWASP, en la primera posición. Hemos añadido la columna "nivel de riesgo sin servidor" como indicador del riesgo asociado específico a las aplicaciones sin servidor.
| Categoría de amenaza | Descripción de la amenaza | Mitigación | Nivel de riesgo sin servidor |
|---|---|---|---|
| Control de acceso roto | El control de acceso es el guardián de tu aplicación y de sus recursos y datos. Controlar el acceso a tus recursos y activos te permite restringir a los usuarios de tu aplicación para que no puedan actuar fuera de los permisos previstos. |
|
Medio |
| Fallos criptográficos | Un cifrado débil o ausente de los datos, tanto en tránsito entre los componentes de tu aplicación como en reposo en colas, cubos y tablas, es un riesgo de seguridad importante. |
|
Medio |
| Inyección | La inyección de código malicioso en una aplicación a través de datos suministrados por el usuario es un vector de ataque popular. Los ataques más comunes incluyen la inyección SQL y NoSQL. |
|
Alta |
| Diseño inseguro | Implantar y poner en funcionamiento una aplicación que no se diseñó con la seguridad como principal preocupación es arriesgado, ya que será susceptible de sufrir lagunas en la postura de seguridad. |
|
Medio |
| Mala configuración de la seguridad |
Los errores de configuración del cifrado, del control de acceso y de las restricciones computacionales representan vulnerabilidades que pueden ser explotadas por los atacantes. El acceso público no intencionado a los buckets de S3 es una causa muy común de filtración de datos en la nube. Las funciones Lambda con tiempos de espera excesivos pueden ser explotadas para provocar un ataque DoS. |
|
Medio |
| Componentes vulnerables y obsoletos | El uso continuado de software vulnerable, no compatible o anticuado (sistemas operativos, servidores web, bases de datos, etc.) hace que tu aplicación sea susceptible a ataques que aprovechan vulnerabilidades conocidas. |
|
Baja |
| Fallos de identificación y autenticación | Estos fallos pueden permitir el uso no autorizado de API y recursos integrados, como funciones Lambda, buckets S3 o tablas DynamoDB. |
|
Medio |
| Fallos en el software y en la integridad de los datos |
La presencia de vulnerabilidades o exploits en código de terceros se está convirtiendo rápidamente en el riesgo más común para las aplicaciones de software. Como las dependencias de la aplicación se agrupan y ejecutan con el código de la función Lambda, se les conceden los mismos permisos que a tu lógica empresarial. |
|
Alta |
| Registro de seguridad y fallos de monitoreo |
Los atacantes confían en la falta de monitoreo y respuesta oportuna para lograr sus objetivos sin ser detectados. Sin registro y monitoreo, las brechas no pueden detectarse ni analizarse. Los registros de aplicaciones y API no se monitorean para detectar actividades sospechosas. |
|
Medio |
| Falsificación de peticiones del lado del servidor (SSRF) | En AWS se trata principalmente de una vulnerabilidad al ejecutar servidores web en instancias EC2. El ejemplo más devastador fue la violación de datos de Capital One en 2019. |
|
Baja |
Hay hay otros dos riesgos de seguridad dignos de mención que son relevantes para las aplicaciones sin servidor :
- Denegación de servicio
-
Este es un ataque habitual en en el que una API es bombardeada constantemente con peticiones falsas para interrumpir el servicio de las peticiones auténticas. Las API públicas siempre se enfrentarán a la posibilidad de ataques DoS. Tu trabajo no consiste siempre en impedirlos por completo, sino en hacerlos tan difíciles de ejecutar que la disuasión por sí sola baste para asegurar los recursos. Los cortafuegos, los límites de velocidad y las alarmas de estrangulamiento de recursos (por ejemplo, Lambda, DynamoDB) son medidas clave para evitar los ataques DoS.
- Denegación de cartera
-
Este tipo de ataque es bastante exclusivo de las aplicaciones sin servidor, debido al modelo de precios de pago por uso y a la gran escalabilidad de los servicios gestionados. Los ataques de denegación de cartera tienen como objetivo la ejecución constante de recursos para acumular una factura de uso tan alta que probablemente causará graves daños financieros a la empresa.
Consejo
Configurar las alertas de presupuesto puede ayudarte a asegurarte de que te avisan de los ataques de denegación de cartera antes de que puedan escalar. Consulta el Capítulo 9 para más detalles.
Ahora que ya conoces las amenazas comunes a una aplicación sin servidor, a continuación explorarás cómo utilizar el proceso de modelado de amenazas para asignar estos riesgos de seguridad a tus aplicaciones .
Modelado de amenazas sin servidor
Antes de diseñar una estrategia de seguridad integral para cualquier aplicación sin servidor, es crucial comprender los vectores de ataque y modelar las amenazas potenciales. Esto puede hacerse definiendo claramente la superficie de la aplicación, los activos que merece la pena proteger y las amenazas, tanto internas como externas, a la seguridad de la aplicación.
Como ya se ha dicho, la seguridad es un proceso continuo: no existe un estado final. Para mantener la seguridad de una aplicación a medida que crece, hay que revisar constantemente las amenazas y evaluar periódicamente los vectores de ataque. Con el tiempo se añaden nuevas funciones, se atiende a más usuarios y se recopilan más datos. Las amenazas cambiarán, su gravedad aumentará y disminuirá, y el comportamiento de la aplicación evolucionará. Las herramientas disponibles y las buenas prácticas del sector también evolucionarán, haciéndose más eficaces y centradas como reacción a estos cambios.
Introducción al modelado de amenazas
Llegados a este punto, deberías tener una comprensión bastante clara de tus responsabilidades en materia de seguridad, un marco de seguridad básico y las principales amenazas para las aplicaciones sin servidor. A continuación, tienes que asignar el marco y las amenazas a tu aplicación y sus servicios.
El modelado de amenazas es un proceso que puede ayudar a tu equipo a identificar vectores de ataque, amenazas y mitigaciones mediante el debate y la colaboración. Puede ayudar a a adoptar un enfoque de la seguridad de desplazamiento a la izquierda (o incluso de inicio a la izquierda) , en el que la seguridad pertenece principalmente al equipo que diseña, construye y opera la aplicación, y se trata como una preocupación primordial durante todo el ciclo de vida de desarrollo del software. A veces también se denomina DevSecOps a .
Para garantizar un endurecimiento continuo de tu postura de seguridad, el modelado de amenazas debe ser un proceso que lleves a cabo con regularidad, por ejemplo en las sesiones de perfeccionamiento de tareas. Las amenazas deben modelarse inicialmente al principio del proceso de diseño de la solución (véase el Capítulo 6) y centrarse en el nivel de característica o servicio.
Consejo
Threat Composer es una herramienta de AWS Labs que puede ayudarte a guiar y visualizar tu proceso de modelado de amenazas.
A continuación se te presentará un marco que añade estructura al proceso de modelado de amenazas: STRIDE.
DESLÍZATE
El acrónimo STRIDE describe seis categorías de amenazas:
- Suplantación de identidad
- Manipulación
-
Cambiando los datos de en el disco, en la memoria, en la red o en cualquier otro lugar.
- Repudio
- Divulgación de información
- Denegación de servicio
- Elevación de privilegios
-
Realizar acciones en recursos protegidos que no deberías estar autorizado a realizar
STRIDE-por-elemento, o STRIDE/elemento para abreviar, es una forma de aplicar las categorías de amenazas STRIDE a los elementos de tu aplicación. Puede ayudar a centrar aún más el proceso de modelado de amenazas.
Los elementos son objetivos de amenazas potenciales y se definen como:
-
Actores humanos/entidades externas
-
Procesos
-
Almacenes de datos
-
Flujos de datos
Es importante no sentirse abrumado por el proceso de modelado de amenazas. Asegurar una aplicación puede ser desalentador, pero recuerda que, como se indica al principio de este capítulo, también puede ser sencillo, especialmente con la tecnología sin servidor. Empieza poco a poco, trabaja en equipo y sigue el proceso etapa por etapa. Identificar una amenaza por cada combinación de elemento/amenaza en la matriz de la Figura 4-4 representaría un gran comienzo.
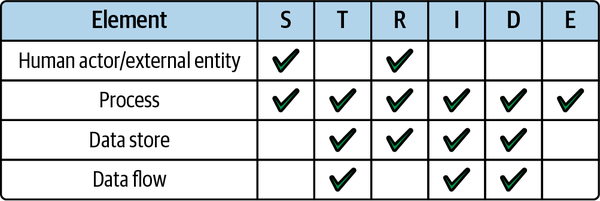
Figura 4-4. Aplicación de las categorías de amenazas STRIDE por elemento en tu aplicación
Un proceso de modelización de amenazas
Como preparación para tus sesiones de modelado de amenazas, puede que te resulte útil para que las reuniones sean productivas tener preparada la siguiente información:
-
Arquitectura de alto nivel de la aplicación
-
Documentos de diseño de la solución
-
Modelos de datos y esquemas
-
Diagramas de flujo de datos
-
Normas de cumplimiento de la industria específicas de cada dominio
Un proceso típico de modelado de amenazas comprenderá los siguientes pasos:
-
Identifica los elementos de tu aplicación que podrían ser objetivos de posibles amenazas, incluidos los activos de datos, los actores externos, los puntos de entrada accesibles desde el exterior y los recursos de infraestructura.
-
Identifica una lista de amenazas para cada elemento identificado en el paso 1. Asegúrate de centrarte en las amenazas y no en las mitigaciones en esta fase.
-
Para cada amenaza identificada en el paso 2, identifica las medidas adecuadas que pueden adoptarse para mitigarla. Esto podría incluir la encriptación de los activos de datos sensibles, la aplicación de un control de acceso a los actores externos y a los puntos de entrada, y la garantía de que a cada recurso sólo se le conceden los permisos mínimos necesarios para realizar sus operaciones.
-
Por último, evalúa si la reparación acordada mitiga adecuadamente la amenaza o si existe algún riesgo residual que deba abordarse.
Para obtener una plantilla de modelado integral de amenazas , consulta el Apéndice C.
Asegurar la cadena de suministro sin servidor
Los componentes vulnerables y obsoletos y los ataques basados en la cadena de suministro se están convirtiendo rápidamente en una preocupación primordial para los ingenieros de software.
Nota
Según la empresa de seguridad de la cadena de suministro Socket, "los ataques a la cadena de suministro aumentaron la friolera de un 700% el año pasado, con más de 15.000 ataques registrados". Un ejemplo que citan ocurrió en enero de 2022, cuando un mantenedor de software de código abierto añadió intencionadamente malware a su propio paquete, que se descargaba una media de 100 millones de veces al mes. Una víctima notable fue el SDK oficial de AWS.
¿Quién es responsable de la protección contra estas vulnerabilidades y ataques? La informática sin servidor en AWS Lambda te proporciona un claro ejemplo del modelo de responsabilidad compartida presentado anteriormente en este capítulo. Es responsabilidad de AWS mantener actualizado el software en tiempo de ejecución y el entorno de ejecución con los últimos parches de seguridad y mejoras de rendimiento, y es responsabilidad del ingeniero de la aplicación asegurar el propio código de la función. Esto incluye mantener actualizadas las bibliotecas utilizadas por la función.
Dado que es tu responsabilidad como desarrollador de aplicaciones en la nube asegurar el código que entregas a la nube y ejecutas en tus funciones Lambda, ¿cuáles son aquí los vectores de ataque y los niveles de amenaza, y cómo puedes mitigar los problemas de seguridad relacionados?
Asegurar la cadena de suministro de la dependencia
El software de código abierto es un increíble facilitador del desarrollo y la entrega rápidos de software. Como ingeniero de software, puedes confiar en la experiencia y el trabajo de otros miembros de tu comunidad a la hora de componer tus aplicaciones. Sin embargo, esta relación se construye sobre una frágil capa de confianza. Cada vez que instalas una dependencia, implícitamente estás confiando en la miríada de colaboradores de ese paquete y en todo lo que hay en el propio árbol de dependencias de ese paquete. El código de cientos de programadores se convierte en un componente clave de tu software de producción.
Debes ser consciente de los riesgos que conlleva instalar y ejecutar el software de código abierto , y de las medidas que puedes tomar para mitigar dichos riesgos.
Piensa antes de instalar
Puedes empezar a asegurar la cadena de suministro sin servidor examinando los paquetes antes de instalarlos. Se trata de una sugerencia sencilla que puede suponer una diferencia real para asegurar la cadena de suministro de tu aplicación, y para el mantenimiento general a escala.
Utiliza tan pocas dependencias como sea necesario, y sé consciente de las dependencias que ofuscan el flujo de datos y control de tu aplicación, como las bibliotecas de middleware. Si se trata de una tarea trivial, intenta hacerla siempre tú mismo. También se trata de confianza. ¿Confías en el paquete? ¿Confías en los colaboradores?
Antes de instalar el siguiente paquete en tu aplicación sin servidor, adopta las siguientes prácticas:
- Analiza el repositorio de GitHub.
-
Revisión los colaboradores del paquete. Más colaboradores representa más escrutinio y colaboración. Comprueba si el repositorio utiliza confirmaciones verificadas. Evalúa el historial del paquete: ¿Qué antigüedad tiene? ¿Cuántos commits se han hecho? Analiza la actividad del repositorio para saber si la comunidad mantiene y utiliza activamente el paquete: las estrellas de GitHub proporcionan un indicador aproximado de la popularidad, y cosas como la fecha de la confirmación más reciente y el número de incidencias abiertas y pull requests indican el uso. Asegúrate también de que la licencia del paquete cumple las restricciones vigentes en tu organización.
- Utiliza los repositorios de paquetes oficiales.
-
Sólo obtener paquetes de fuentes oficiales, como NPM, PyPI, Maven, NuGet o RubyGems, a través de enlaces seguros (es decir, HTTPS). Prefiere los paquetes firmados por cuya integridad y autenticidad puedan verificarse. Por ejemplo, el gestor de paquetes JavaScript NPM te permite auditar las firmas de los paquetes.
- Revisa el árbol de relaciones.
-
Ten en cuenta las dependencias del paquete y todo el árbol de dependencias. Elige paquetes con cero dependencias en tiempo de ejecución siempre que sea posible.
- Prueba antes de comprar.
-
Prueba nuevos paquetes a una escala lo más aislada posible y retrasa el despliegue en todo el código base el mayor tiempo posible, hasta que te sientas seguro.
- Comprueba si puedes hacerlo tú mismo.
-
No reinventes la rueda porque sí, pero una forma muy sencilla de eliminar el código opaco de terceros es no introducirlo en primer lugar. Examina el código fuente para saber si el paquete hace algo sencillo que sea fácilmente transportable a una utilidad de origen. Las bibliotecas de registro son un ejemplo perfecto: puedes implementar trivialmente tu propio registrador en lugar de distribuir una biblioteca de terceros por toda tu base de código.
- Facilita la marcha atrás.
-
Los patrones de desarrollo como el aislamiento de servicios , las funciones Lambda de responsabilidad única y la limitación del código compartido (para más información sobre estos patrones, consulta el Capítulo 6 ) facilitan la evolución de tu arquitectura y evitan que los antipatrones omnipresentes o el software vulnerable se apoderen de tu código base.
- Bloquea hasta lo último.
-
Utiliza siempre la última versión del paquete, y utiliza siempre una versión explícita en lugar de un rango o una bandera "latest".
- Desinstala los paquetes que no utilices.
-
Siempre desinstala y borra los paquetes no utilizados de tu manifiesto de dependencias. La mayoría de los compiladores y empaquetadores modernos sólo incluirán las dependencias que realmente consuma tu código, pero mantener limpio tu manifiesto añade seguridad y claridad adicionales.
Escanea los paquetes en busca de vulnerabilidades
También debes ejecutar escaneos continuos de vulnerabilidades en en respuesta a nuevos paquetes, actualizaciones de paquetes e informes de nuevas vulnerabilidades. Los escaneos pueden ejecutarse contra un repositorio de código utilizando herramientas como Snyk o el sistema nativo de alertas Dependabot de GitHub.
Automatiza las actualizaciones de dependencias
De todas las sugerencias para asegurar tu cadena de suministro, ésta es la más crucial. Aunque tengas una aplicación sin servidor con abundantes paquetes distribuidos en múltiples servicios, asegúrate de que las actualizaciones de todas las dependencias están automatizadas.
Advertencia
Aunque automatizar las actualizaciones de las dependencias de tu aplicación suele ser una práctica recomendada, siempre debes tener presente la lista de comprobación "piensa antes de instalar" de la sección anterior. Debes prestar especial atención a la integridad de las actualizaciones entrantes, por si un actor malintencionado ha publicado una versión maliciosa de un paquete.
Mantener actualizadas las versiones de los paquetes te garantiza no sólo el acceso a las últimas funciones, sino también, y esto es crucial, a los últimos parches de seguridad. Pueden encontrarse vulnerabilidades en versiones anteriores de software después de que se hayan publicado muchas versiones posteriores. Navegar por una actualización a través de varias versiones menores puede ser bastante difícil, dependiendo de las características del paquete, la adherencia al versionado semántico por parte de los autores y la prevalencia del paquete en tu base de código, pero actualizar de una versión mayor a otra no suele ser trivial, dada la probabilidad de que la siguiente versión contenga cambios de ruptura que afecten a tu uso del paquete.
Actualizaciones en tiempo de ejecución
Además de las actualizaciones de dependencias de , es muy recomendable que te mantengas actualizado con la última versión del tiempo de ejecución de AWS Lambda que estés utilizando. Asegúrate de estar suscrito a las noticias sobre soporte del tiempo de ejecución y actualízate lo antes posible.
Advertencia
Por defecto, AWS actualizará automáticamente el tiempo de ejecución de tus funciones Lambda con cualquier versión de parche de que se publique. Además, tienes la opción de controlar cuándo se actualiza el tiempo de ejecución de tus funciones a través de los controles de gestión del tiempo de ejecución de Lambda.
Estos controles son útiles principalmente para mitigar la rara aparición de fallos causados por una versión de parche en tiempo de ejecución incompatible con el código de tu función. Pero, como es probable que estas versiones de parche incluyan actualizaciones de seguridad, debes utilizar estos controles con precaución. Normalmente, lo más seguro es mantener tus funciones funcionando con la última versión del tiempo de ejecución.
Lo mismo se aplica a cualquier canalización de entrega que mantengas, ya que probablemente se ejecutará en máquinas virtuales y tiempos de ejecución proporcionados por terceros. Y recuerda que no es necesario que utilices la misma versión de tiempo de ejecución en todos los procesos y funciones. Por ejemplo, debes utilizar la última versión de Node.js en tus canalizaciones incluso antes de que sea compatible con el tiempo de ejecución de Lambda.
Ir más lejos con SLSA
El marco de seguridad SLSA (pronunciado salsa, abreviatura de Supply chain Levels for Software Artifacts) es "una lista de normas y controles para evitar la manipulación, mejorar la integridad y asegurar los paquetes y la infraestructura". SLSA trata de pasar de "suficientemente seguro" a la máxima resistencia en toda la cadena de suministro de software.
Si tu nivel de madurez en materia de seguridad es bastante alto, puede resultarte útil utilizar este marco para medir y mejorar la seguridad de tu cadena de suministro de software. Sigue la documentación del SLSA para empezar. El Estándar de Verificación de Componentes de Software (SCVS) de OWASP es otro marco para medir la seguridad de la cadena de suministro.
Firma de código Lambda
La última milla en la cadena de suministro del software es empaquetar e implementar el código de tu función en la nube. En este punto, tu función consistirá normalmente en tu lógica empresarial (código del que eres autor) y cualquier biblioteca de terceros que figure en las dependencias de la función (código del que es autor otra persona).
Lambda ofrece la opción de firmar tu código antes de desplegarlo. Esto permite al servicio Lambda verificar que una fuente de confianza ha iniciado la implementación y que el código no ha sido alterado o manipulado de ninguna manera. Lambda ejecutará varias comprobaciones de validación para verificar la integridad del código, incluyendo que el paquete no ha sido modificado desde que se firmó y que la propia firma es válida.
Para firmar tu código en , primero debes crear uno o varios perfiles de firma. Estos perfiles pueden corresponder a los entornos y cuentas que utiliza tu aplicación; por ejemplo, puedes tener un perfil de firma por cuenta de AWS. Alternativamente, podrías optar por tener un perfil de firma por función para un mayor aislamiento y seguridad. El recurso CloudFormation para un perfil de firma tiene este aspecto, donde PlatformID denota el formato de firma y el algoritmo de firma que utilizará el perfil:
{"Type":"AWS::Signer::SigningProfile","Properties":{"PlatformId":"AWSLambda-SHA384-ECDSA",}}
Una vez que hayas definido un perfil de firma, puedes utilizarlo para configurar la firma de código de tus funciones:
{"Type":"AWS::Lambda::CodeSigningConfig","Properties":{"AllowedPublishers":[{"SigningProfileVersionArns":["arn:aws:signer:us-east-1:123456789123:/signing-profiles/my-profile"]}],"CodeSigningPolicies":{"UntrustedArtifactOnDeployment":"Enforce"}}}
Por último, asigna la configuración de firma de código a tu función:
{"Type":"AWS::Lambda::Function","Properties":{"CodeSigningConfigArn":["arn:aws:lambda:us-east-1:123456789123:code-signing-config:csc-config-id",]}}
Ahora, cuando despliegues esta función, el servicio Lambda verificará que el código fue firmado por una fuente de confianza y que no ha sido manipulado con desde que fue firmado.
Proteger las API sin servidor
Según a la lista OWASP Top 10 que vimos antes en este capítulo, la amenaza número uno para las aplicaciones web es el control de acceso roto. Aunque la tecnología sin servidor ayuda a mitigar algunas de las amenazas que plantea el control de acceso roto, aún tienes trabajo que hacer en este ámbito.
Al aplicar el modelo de seguridad de confianza cero, debes aplicar el control de acceso a cada componente aislado, así como al perímetro de tu sistema. Para la mayoría de las aplicaciones sin servidor, el perímetro de seguridad será un punto final de la Pasarela de la API . Si estás construyendo una aplicación sin servidor que expone una API a la Internet pública, debes diseñar e implementar un mecanismo de control de acceso adecuado para esta API.
En esta sección, exploraremos las estrategias de autorización disponibles para aplicar el control de acceso a las API sin servidor y cuándo utilizar cada una de ellas. Las opciones de control de acceso para API Gateway se resumen en la Tabla 4-2.
Nota
Amazon API Gateway proporciona dos tipos de API: API REST y API HTTP. Ofrecen diferentes características a diferentes costes. Una de las diferencias son las opciones de control de acceso disponibles. En la Tabla 4-2 se indica la compatibilidad de cada uno de los métodos de control de acceso que exploraremos en esta sección.
| Estrategia de control de acceso | Descripción | API REST | API HTTP |
|---|---|---|---|
| Autorizadores de Cognito | Integración directa con el servicio de gestión de acceso Amazon Cognito y las API REST de API Gateway. Las credenciales de cliente de Cognito se intercambian por tokens de acceso, que se validan directamente con Cognito. | Sí | No |
| Autorizadores JWT | Puede utilizarse para integrar un servicio de gestión de accesos que utilice Tokens Web JSON (JWTs) para el control de accesos, como Amazon Cognito u Okta, con las API HTTP de API Gateway. | Noa | Sí |
| Autorizadores lambda | Las funciones lambda pueden utilizarse para implementar una lógica de autorización personalizada cuando se utiliza un servicio de gestión de acceso distinto de Cognito o para verificar los mensajes webhook entrantes cuando no se dispone de autenticación basada en el usuario. | Sí | Sí |
a Puedes seguir utilizando los JWT para autorizar y autenticar las solicitudes de la API REST, pero tendrás que escribir un autorizador Lambda personalizado que verifique los tokens entrantes. | |||
Proteger las API REST con Amazon Cognito
Hay son de curso muchos servicios de gestión de acceso y proveedores de identidad disponibles, incluidos Okta y Auth0. Nos centraremos en el uso de Cognito para asegurar una API REST, ya que es nativo de AWS y por esta razón proporciona una sobrecarga mínima.
Amazon Cognito
Antes de sumergirnos en , definamos los componentes básicos que necesitarás. Cognito suele considerarse uno de los servicios de AWS más complejos. Por lo tanto, es importante tener una comprensión básica de los componentes de Cognito y una idea clara de la arquitectura de control de acceso que pretendes. He aquí los componentes clave para implementar el control de acceso mediante Cognito:
- Grupos de usuarios
-
Un grupo de usuarios es un directorio de usuarios en Amazon Cognito. Normalmente tendrás un único grupo de usuarios en tu aplicación. Este grupo de usuarios se puede utilizar para gestionar todos los usuarios de tu aplicación, tanto si tienes un único usuario como varios.
- Clientes de la aplicación
-
Tú puedes estar construyendo una aplicación web cliente/servidor tradicional en la que mantienes una aplicación web frontend y una API backend. O puedes estar operando una plataforma multiinquilino de empresa a empresa, donde los servicios backend del inquilino utilizan una concesión de credenciales de cliente para acceder a tus servicios. En este caso, puedes crear un cliente de aplicación para cada inquilino y compartir el ID y el secreto del cliente con el servicio backend del inquilino para la autenticación de máquina a máquina.
- Visores
-
Ámbitos se utilizan para controlar el acceso de un cliente de aplicación a recursos específicos de la API de tu aplicación.
Cognito y la Pasarela API
Los autorizadores Cognito proporcionan una integración de control de acceso totalmente gestionada con API Gateway, como se ilustra en la Figura 4-5. Los consumidores de la API intercambian sus credenciales (un ID de cliente y un secreto) por tokens de acceso a través de un punto final de Cognito. A continuación, estos tokens de acceso se incluyen en las solicitudes de API y se validan a través del autorizador Cognito.
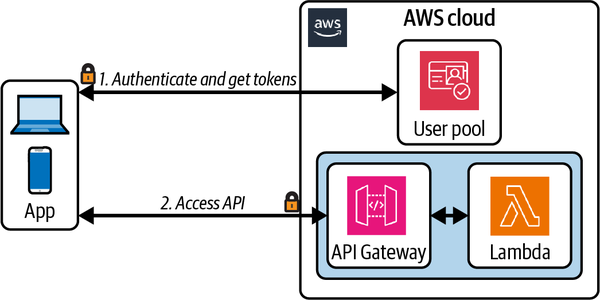
Figura 4-5. Autorizador Cognito de la pasarela de API
Además, a un punto final de la API se le puede asignar un ámbito. Al autorizar una petición al punto final, el autorizador de Cognito comprobará que el ámbito del punto final está incluido en la lista del cliente de ámbitos permitidos .
Proteger las API HTTP
Si estás utilizando una API HTTP de pasarela de API, en lugar de una API REST, no podrás utilizar el autorizador nativo de Cognito. En su lugar, tienes algunas opciones alternativas. Exploraremos ejemplos de las dos más convenientes: Autorizadores Lambda y Autorizadores JWT.
Consejo
Los autorizadores JWT también se pueden utilizar para autenticar solicitudes API con Amazon Cognito cuando se utilizan API HTTP.
Autorizadores JWT
Si tu estrategia de autorización implica simplemente que un cliente envíe un token web JSON para su verificación, utilizar un autorizador JWT será una buena opción. Cuando utilizas un autorizador JWT, todo el proceso de autorización es gestionado por el servicio Pasarela API.
Nota
JWT es un estándar abierto que define una forma compacta y autocontenida de transmitir información de forma segura entre las partes como objetos JSON. Los JWT pueden utilizarse para garantizar la integridad de un mensaje y la autenticación tanto del productor como del consumidor del mensaje.
Los JWT pueden firmarse y cifrarse criptográficamente, lo que permite verificar la integridad de las afirmaciones contenidas en el token y mantenerlas ocultas a otras partes.
Primero configuras el autorizador JWT y luego lo adjuntas a una ruta. El recurso de CloudFormation tendrá este aspecto:
{"Type":"AWS::ApiGatewayV2::Authorizer","Properties":{"ApiId":"ApiGatewayId","AuthorizerType":"JWT","IdentitySource":["$request.header.Authorization"],"JwtConfiguration":{"Audience":["https://my-application.com"],"Issuer":"https://cognito-idp.us-east-1.amazonaws.com/userPoolID"},"Name":"my-authorizer"}}
El IdentitySource debe coincidir con la ubicación del JWT proporcionado por el cliente en la solicitud de la API; por ejemplo, el encabezado HTTP Authorization. El JwtConfiguration debe corresponder a los valores esperados en los tokens que serán enviados por los clientes, donde el Audience es la dirección HTTP para el destinatario del token (normalmente tu dominio API Gateway) y el Issuer es la dirección HTTP para el servicio responsable de emitir tokens, como Cognito u Okta.
Autorizadores lambda
Las funciones Lambda con lógica de autorización personalizada pueden adjuntarse a las rutas API HTTP de API Gateway e invocarse siempre que se realicen solicitudes. Estas funciones se conocen como autorizadores Lambda y pueden utilizarse cuando necesites aplicar estrategias de control de acceso más allá de las que admiten los autorizadores gestionados Cognito o JWT. Las respuestas de las funciones aprobarán o denegarán el acceso a los recursos solicitados (ver Figura 4-6).
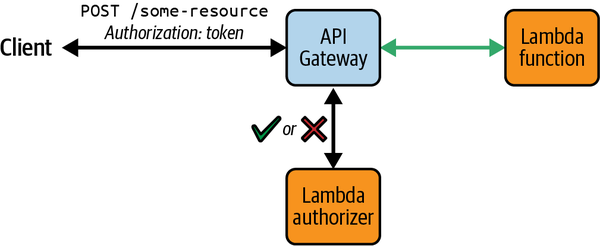
Figura 4-6. Controlar el acceso a los recursos de la pasarela API con un autorizador Lambda
Los autorizadores Lambda admiten varias ubicaciones para proporcionar solicitudes de autorización en las peticiones API. Se conocen como como fuentes de identidad e incluyen cabeceras HTTP y parámetros de cadena de consulta (por ejemplo, la cabecera Authorization ). La fuente de identidad que utilices será necesaria en las solicitudes realizadas a API Gateway; cualquier solicitud sin la propiedad requerida recibirá inmediatamente una respuesta 401 No autorizado y no se invocará al autorizador Lambda.
Las respuestas del autorizador Lambda también pueden almacenarse en caché. Las respuestas se almacenarán en caché según la fuente de identidad proporcionada por los clientes de la API. Si un cliente proporciona los mismos valores para las fuentes de identidad requeridas dentro del periodo de caché, o TTL, configurado, API Gateway utiliza el resultado del autorizador almacenado en caché en lugar de invocar la función del autorizador.
Consejo
El almacenamiento en caché de las respuestas de tus autorizadores Lambda se traducirá en respuestas más rápidas a las solicitudes de API, así como en una reducción de costes, ya que la función Lambda se invocará con mucha menos frecuencia.
La función Lambda utilizada para autorizar solicitudes puede devolver una política IAM o lo que se conoce como una respuesta simple. La respuesta simple de suele ser suficiente, a menos que tu caso de uso requiera una respuesta de política IAM o permisos más granulares. Cuando utilices la respuesta simple, la función autorizadora debe devolver una respuesta que se ajuste al siguiente formato, donde isAuthorized es un valor booleano que denota el resultado de tus comprobaciones de autorización y context es opcional y puede incluir cualquier información adicional para pasar a los registros de acceso a la API y a las funciones Lambda integradas con el recurso de la API :
{"isAuthorized":true/false,"context":{"key":"value"}}
Validar y verificar las solicitudes API
Hay son otras formas de proteger tu API sin servidor más allá de los mecanismos de control de acceso que hemos explorado hasta ahora en esta sección. En particular, las API de acceso público deben estar siempre protegidas contra el uso indebido deliberado o involuntario, y los datos de las solicitudes entrantes a esas API deben estar siempre validados y desinfectados.
Protección de solicitudes de la pasarela de API
La pasarela de API ofrece dos formas de protección contra los ataques de denegación de servicio y de denegación de cartera .
En primer lugar, las solicitudes de clientes API individuales pueden limitarse mediante planes de uso de la pasarela de API . Los planes de uso pueden utilizarse para controlar el acceso a etapas y métodos de la API y para limitar la tasa de solicitudes realizadas a esos métodos. Al limitar la tasa de solicitudes de la API en , puedes evitar que cualquiera de los clientes de tu API abuse de tu servicio deliberada o inadvertidamente. Los planes de uso pueden aplicarse a todos los métodos de una API o a métodos específicos. Los clientes reciben una clave de API generada que deben incluir en cada solicitud a tu API. Si un cliente envía demasiadas solicitudes y, como consecuencia, se le aplica un estrangulamiento, empezará a recibir respuestas de error HTTP 429 Demasiadas solicitudes.
API Gateway también integra con AWS WAF para proporcionar protección granular a nivel de solicitud. Con WAF, puedes especificar un conjunto de reglas para aplicar a cada solicitud entrante, como el estrangulamiento de direcciones IP.
Nota
Las reglas WAF se aplican siempre antes que cualquier otro mecanismo de control de acceso, como los autorizadores Cognito o los autorizadores Lambda.
Validación de solicitudes de la pasarela de API
Las solicitudes a los métodos de la Pasarela de la API pueden validarse antes de seguir procesándose. Digamos que tienes una función Lambda adjunta a una ruta API que acepta la solicitud API como entrada y aplica algunas operaciones al cuerpo de la solicitud. Puedes proporcionar una definición de Esquema JSON de la estructura y formato de entrada esperados, y API Gateway aplicará esas reglas de validación de datos al cuerpo de la solicitud antes de invocar la función. Si la solicitud no supera la validación, no se invocará la función y el cliente recibirá una respuesta HTTP 400 Solicitud incorrecta.
Nota
Implementar la validación de solicitudes a través de API Gateway puede ser especialmente útil cuando se utilizan integraciones directas con servicios de AWS distintos de Lambda. Por ejemplo, puedes tener un recurso de API Gateway que se integre directamente con Amazon EventBridge, respondiendo a las solicitudes de API mediante la colocación de eventos en un bus de eventos. En esta arquitectura, siempre querrás validar y desinfectar la carga útil de la solicitud antes de reenviarla a los consumidores posteriores.
Para más información sobre los modelos de integración sin función, consulta el capítulo 5.
En el siguiente ejemplo de modelo JSON, la propiedad message es obligatoria, y la solicitud será rechazada si falta ese campo en el cuerpo de la solicitud:
{"$schema":"http://json-schema.org/draft-07/schema#","title":"my-request-model","type":"object","properties":{"message":{"type":"string"},"status":{"type":"string"}},"required":["message"]}
En las funciones Lambda en las que se transforman los datos, se almacenan en una base de datos o se entregan a un bus de eventos o cola de mensajes, se debe realizar una validación y sanitización de entrada más profunda. Esto puede proteger tu aplicación de ataques de inyección SQL, la amenaza nº 3 en la lista OWASP Top 10 (ver Tabla 4-1).
Verificación de mensajes en arquitecturas dirigidas por eventos
La mayoría de las técnicas de control de acceso que hemos explorado se aplican generalmente a API síncronas, de petición/respuesta. Pero como aprendiste en el Capítulo 3, es muy probable que, a medida que tú y los equipos o terceros con los que interactúas construyáis aplicaciones basadas en eventos, en algún momento te encuentres con una API asíncrona.
La verificación de mensajes suele ser necesaria en los puntos de integración entre sistemas, por ejemplo, de mensajes entrantes de webhooks de terceros y mensajes enviados por tu aplicación a otros sistemas o cuentas. En una arquitectura de confianza cero , la verificación de mensajes también es importante para la mensajería entre servicios de tu aplicación.
Verificar los mensajes entre consumidores y productores
Normalmente, para desacoplar los servicios, el productor de un evento desconoce deliberadamente cualquier consumidor descendente del evento. Por ejemplo, puedes tener una arquitectura troncal de eventos en toda la organización en la que varios productores envían eventos a un corredor de eventos central y varios consumidores se suscriben a estos eventos, como se muestra en la Figura 4-7.
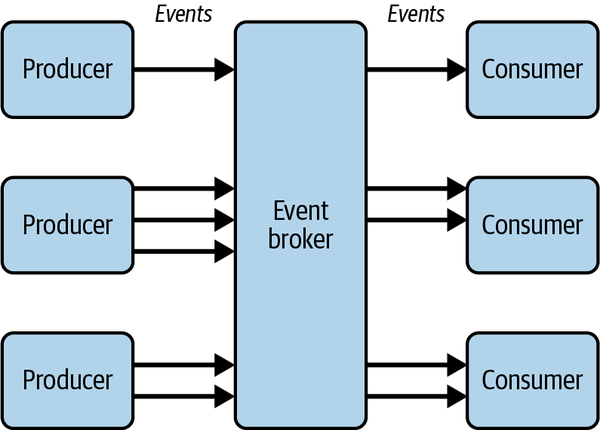
Figura 4-7. Productores y consumidores desacoplados en una arquitectura basada en eventos
La seguridad de los consumidores de API asíncronas se basa en el control de los mensajes entrantes. Los consumidores siempre deben tener el control de la suscripción a una API asíncrona, y ya habrá un cierto nivel de confianza establecido entre los productores de eventos y el agente de eventos, pero los consumidores de eventos también deben protegerse contra la suplantación del remitente y la manipulación de los mensajes. La verificación de los mensajes entrantes es crucial en los sistemas basados en eventos.
Supongamos que el intermediario de eventos de la Figura 4-7 es un bus de eventos de Amazon EventBridge en una cuenta central, parte del dominio principal de tu organización. Los productores son servicios implementados en cuentas de AWS independientes, y lo mismo ocurre con los consumidores. Un consumidor necesita asegurarse de que cada mensaje procede de una fuente de confianza. Un productor necesita asegurarse de que los mensajes sólo pueden ser leídos por consumidores autorizados. Para una arquitectura verdaderamente desacoplada, el propio agente de eventos podría ser responsable del cifrado de mensajes y de la gestión de claves (en lugar del productor), pero para que el ejemplo sea sucinto, haremos que esto sea responsabilidad del productor.
Mensajes encriptados y verificables con Tokens Web JSON
Puedes utilizar JWT como protocolo de transporte de mensajes. Para firmar y cifrar los mensajes puedes utilizar una técnica conocida en como JWT anidados, ilustrada en la Figura 4-8.
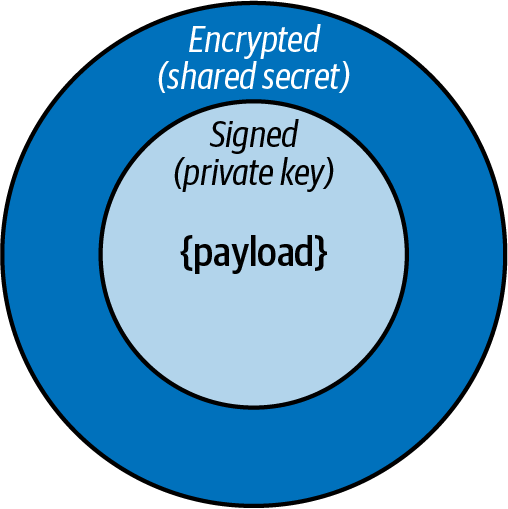
Figura 4-8. Un token web JSON anidado
El productor debe firmar primero la carga útil del mensaje con la clave privada y luego cifrar el mensaje firmado utilizando un secreto compartido:
constpayload={data:{hello:"world"}};constsignedJWT=awaitnewSignJWT(payload).setProtectedHeader({alg:"ES256"}).setIssuer("urn:example:issuer").setAudience("urn:example:audience").setExpirationTime("2h").sign(privateKey);constencryptedJWT=awaitnewEncryptJWT(signedJWT).setProtectedHeader({alg:"dir",cty:"JWT",enc:"A256GCM"}).encrypt(sharedSecret);
Consejo
Los pares de claves de cifrado públicas/privadas y los secretos compartidos deben generarse por separado de la producción del mensaje en tiempo de ejecución y almacenarse en AWS Key Management Service (KMS) o AWS Secrets Manager. Las claves y secretos pueden obtenerse en tiempo de ejecución para firmar y cifrar el mensaje.
Al recibir un mensaje, el consumidor debe verificar primero la firma utilizando la clave pública del productor y luego descifrar la carga útil utilizando el secreto compartido:
constdecryptedJWT=awaitDecryptJWT(encryptedJWT,sharedSecret);constdecodedJWT=awaitVerifyJWT(decryptedJWT,publicKey);// if verified, original payload available at decodedJWT.payload
Advertencia
Sólo la clave pública del productor y el secreto compartido deben distribuirse a los consumidores del mensaje. La clave privada no debe compartirse nunca.
Verificación de mensajes integrada para SNS
Además de a el enfoque descrito en la sección anterior, algunos servicios de AWS, como Amazon Simple Notification Service (SNS), están empezando a admitir las firmas de mensajes de forma nativa. SNS firma los mensajes enviados desde tu tema, permitiendo que los puntos finales HTTP suscritos verifiquen su autenticidad.
Proteger los datos
Los datos son el activo más valioso acumulado por cualquier aplicación de software. Esto incluye datos personales de los usuarios de la aplicación, datos sobre integraciones de terceros con la aplicación y datos sobre la propia aplicación.
El fallo criptográfico es la segunda de las 10 principales amenazas de OWASP para las aplicaciones web, después del control de acceso roto. Esta sección examina el papel crucial del cifrado de datos en la seguridad de una aplicación sin servidor y cómo puedes cifrar tus datos mientras se mueven por tu sistema.
Cifrado de datos en todas partes
A medida que desarrolle y opere tu aplicación sin servidor, descubrirás tanto el poder como los retos que conlleva conectar componentes con eventos. Los eventos te permiten desacoplar componentes e incluir datos enriquecidos en sus mensajes. La computación sin servidor es inherentemente sin estado, lo que significa que los datos que una función Lambda o un flujo de trabajo de Step Functions necesitan para realizar sus operaciones deben consultarse desde un almacén de datos, como DynamoDB o S3, o proporcionarse en la carga útil de la invocación.
En los sistemas basados en eventos, los datos están en todas partes. Esto significa que el cifrado de datos también debe estar en todas partes. Los datos se almacenarán en bases de datos y almacenes de objetos. Se moverán a través de colas de mensajes y buses de eventos. El Dr. Werner Vogels, Director Técnico y Vicepresidente de Amazon, dijo una vez en el escenario de re:Invent: "Baila como si nadie te viera. Cifra como si todo el mundo lo hiciera".
¿Qué es la encriptación?
La encriptación es una técnica para restringir el acceso a los datos haciéndolos ilegibles sin una clave. Los algoritmos criptográficos se utilizan para ocultar datos de texto plano con una clave de encriptación. Los datos cifrados sólo pueden descifrarse con la misma clave.
El cifrado es tu principal herramienta para proteger los datos de tu aplicación. Es especialmente importante en las aplicaciones basadas en eventos, donde los datos fluyen constantemente entre cuentas, servicios, funciones, almacenes de datos, buses y colas. El cifrado puede dividirse en dos categorías: cifrado en reposo y cifrado en tránsito. Cifrando los datos tanto en tránsito como en reposo, te aseguras de que tus datos están protegidos durante todo su ciclo de vida y de extremo a extremo, a medida que pasan por tu sistema y llegan a otros sistemas.
La mayoría de los servicios gestionados de AWS ofrecen soporte nativo para el cifrado, así como integración directa con AWS Secrets Manager y AWS KMS. Esto significa que el proceso de cifrado y descifrado de datos y la gestión de las claves de cifrado asociadas se abstraen en gran medida de ti. Sin embargo, el cifrado no suele estar habilitado por defecto, por lo que tú eres responsable de habilitar y configurar el cifrado a nivel de recurso.
Cifrado en tránsito
Los datos están en tránsito en una aplicación sin servidor mientras se mueven de un servicio a otro. Todos los servicios de AWS proporcionan puntos finales HTTP seguros y cifrados a través de Transport Layer Security (TLS). Siempre que interactúes con la API de un servicio de AWS, debes utilizar el punto final HTTPS. Por defecto, las operaciones que realices con el SDK de AWS utilizarán los puntos finales HTTPS de todos los servicios de AWS. Por ejemplo, esto significa que cuando tu función Lambda es invocada por una solicitud de API Gateway y realizas una llamada a EventBridge PutEvents desde la función, las cargas útiles están totalmente cifradas cuando están en tránsito.
Además de TLS, todas las solicitudes de la API de AWS realizadas mediante el SDK de AWS están protegidas por un proceso de firma de solicitudes, conocido en como Firma Versión 4. Este proceso está diseñado para proteger contra la manipulación de solicitudes y la suplantación del remitente .
Cifrado en reposo
El cifrado en reposo se aplica a los datos de siempre que se almacenan o almacenan en caché. En una aplicación sin servidor, podría tratarse de datos en un bus o archivo de eventos EventBridge, un mensaje en una cola SQS, un objeto en un bucket S3 o un elemento en una tabla DynamoDB.
Como norma general, siempre que un servicio gestionado ofrezca la opción de cifrar los datos en reposo, debes aprovecharla. Sin embargo, esto es especialmente importante cuando hayas clasificado los datos en reposo como sensibles.
Siempre debes limitar el almacenamiento de datos en reposo y en tránsito. Cuantos más datos se almacenen, y durante más tiempo, mayor será la superficie de ataque y el riesgo para la seguridad. Sólo almacena o transporta datos si es absolutamente necesario, y revisa continuamente tus modelos de datos y cargas útiles de eventos para asegurarte de que se eliminan los atributos redundantes .
Consejo
Almacenar menos datos también tiene ventajas desde el punto de vista de la sostenibilidad. Consulta el Capítulo 10 para obtener más información sobre este tema.
AWS KMS
La clave (juego de palabras intencionado) El servicio de AWS cuando se trata de cifrado es AWS Key Management Service. AWS KMS es un servicio totalmente administrado que soporta la generación y administración de las claves criptográficas que se utilizan para proteger tus datos. Siempre que utilices los controles de cifrado nativos de un servicio de AWS como Amazon SQS o S3, como se ha descrito en las secciones anteriores, estarás utilizando KMS para crear y administrar las claves de cifrado necesarias. Siempre que un servicio necesite cifrar o descifrar datos, hará una petición a KMS para acceder a las claves pertinentes. El acceso a las claves se concede a estos servicios a través de sus roles IAM adjuntos.
Hay varios tipos de claves KMS, como las claves HMAC y las claves asimétricas, y generalmente se agrupan en dos categorías: Claves gestionadas por AWS y claves gestionadas por el cliente. Las claves administradas por AWS son claves de cifrado creadas, administradas, rotadas y utilizadas en tu nombre por un servicio de AWS integrado con AWS KMS. Las claves gestionadas por el cliente son claves de cifrado que tú creas, posees y gestionas. Para la mayoría de los casos de uso, deberías elegir claves gestionadas por AWS siempre que estén disponibles. Las claves gestionadas por el cliente pueden utilizarse en casos en los que se te exija auditar el uso o mantener un control adicional sobre las claves .
Nota
La documentación de AWS tiene una explicación detallada de los conceptos de KMS si quieres leer más sobre este tema.
Seguridad en la producción
Hacer que la seguridad de forme parte de tu proceso de desarrollo es clave para una estrategia de seguridad integral. Pero, ¿qué ocurre cuando tu aplicación está lista para la producción y, posteriormente, se ejecuta en producción?
Pasar a producción puede ser el momento más desalentador a la hora de plantearse la pregunta: ¿es segura mi aplicación? Para ayudar a facilitar el proceso, hemos creado una lista de comprobación final de seguridad que debes revisar antes de poner tu aplicación a disposición de los usuarios y que también te prepara para monitorear continuamente tu aplicación en busca de vulnerabilidades. Recuerda, la seguridad es un proceso y algo sobre lo que hay que iterar continuamente, como cualquier otro aspecto de tu software.
Lista de comprobación de seguridad para aplicaciones sin servidor
Aquí tienes una lista práctica de cosas que debes comprobar antes de lanzar una aplicación sin servidor. También puede formar parte de una canalización de automatización de la seguridad y de las barandillas de seguridad de tu equipo:
-
Encarga pruebas de penetración y auditorías de seguridad a al principio del desarrollo de tu aplicación.
-
Activa el Acceso Público en Bloque en todos los buckets S3 de .
-
Activa el cifrado del lado del servidor (SSE) en todos los buckets S3 que contengan datos valiosos.
-
Habilita las copias de seguridad entre cuentas o la replicación de objetos en buckets S3 que contengan datos críticos para la empresa.
-
Activa la encriptación en reposo en todas las colas SQS.
-
Habilita WAF en las API REST de API Gateway con reglas gestionadas de base.
-
Utiliza TLS versión 1.2 o superior en las API de pasarela de API.
-
Activa los registros de acceso y ejecución en las API de la pasarela de API .
-
Elimina los datos sensibles de las variables de entorno de la función Lambda.
-
Almacena secretos en AWS Secrets Manager.
-
Encripta Variables de entorno de la función Lambda.
-
Activa las copias de seguridad en todas las tablas de DynamoDB que contengan datos críticos para la empresa.
-
Escanea las dependencias de en busca de vulnerabilidades: resuelve todas las advertencias de seguridad críticas y altas, y minimiza las advertencias medias y bajas.
-
Configura alarmas de presupuesto en CloudWatch para proteger contra ataques de denegación de cartera.
-
Elimina los usuarios IAM cuando sea posible.
-
Elimina los comodines de las políticas IAM siempre que sea posible para preservar el mínimo privilegio.
-
Genera un informe de credenciales IAM para identificar los roles y usuarios no utilizados que se pueden eliminar.
-
Crea un rastro CloudTrail para enviar los registros a S3.
-
Realiza una revisión del Marco Bien Arquitectado centrándote en el pilar Seguridad y en las recomendaciones de seguridad de la Lente Sin Servidor.
Mantener la seguridad en la producción
En una empresa, hay varios servicios de AWS que puedes aprovechar para continuar el proceso de asegurar tu aplicación una vez que esté funcionando en producción.
Monitoreo de seguridad con CloudTrail
AWS CloudTrail registra todas las acciones realizadas por usuarios IAM, roles IAM o un servicio AWS en una cuenta. CloudTrail cubre acciones a través de la consola de AWS, CLI, SDK y APIs de servicio. Este flujo de eventos puede utilizarse para monitorizar tu aplicación sin servidor en busca de accesos inusuales o involuntarios y protegerte contra el ataque nº 9 de la lista OWASP Top 10: seguridad registro y fallos de monitoreo.
Consejo
CloudTrail es una herramienta fundamental para contrarrestar los ataques de repudio, descritos en "STRIDE".
Puedes utilizar Amazon CloudWatch para monitorear los eventos de CloudTrail. Se pueden aplicar filtros de métricas de CloudWatch Logs a los eventos de CloudTrail para que coincidan con determinados términos, como eventos de ConsoleLogin. Estos filtros de métricas pueden asignarse después a métricas de CloudWatch que pueden utilizarse para activar alarmas.
CloudTrail está activado por defecto para tu cuenta de AWS. Esto te permite buscar registros de CloudTrail a través del historial de eventos de la consola de AWS. Sin embargo, para persistir en los registros más allá de 90 días y realizar análisis y auditorías en profundidad de los registros, necesitarás configurar un rastro. Un rastro permite a CloudTrail entregar los registros a un bucket S3.
Una vez que tus logs de CloudTrail estén en S3, tú puedes utilizar Amazon Athena para buscar en los logs y realizar análisis en profundidad y correlaciones. Para obtener más información sobre las buenas prácticas de Cloud Trail, lee el artículo de Chloe Goldstein en el blog de AWS.
Comprobaciones de seguridad continuas con Security Hub
Puedes utilizar AWS Security Hub para apoyar la práctica de seguridad de tu equipo y para agregar hallazgos de seguridad de otros servicios, como Macie, que descubrirás en la siguiente sección.
Security Hub es especialmente útil para identificar posibles errores de configuración, como buckets S3 públicos o falta de cifrado en reposo en una cola SQS, que de otro modo podrían ser difíciles de localizar. Los informes de Security Hub clasificarán los hallazgos por gravedad, proporcionando una descripción completa de cada hallazgo con un enlace a la información de reparación cuando esté disponible y una puntuación global de seguridad.
Exploración de vulnerabilidades con Amazon Inspector
Amazon Inspector puede ser utilizado para escanear continuamente las funciones Lambda en busca de vulnerabilidades conocidas e informar de los hallazgos clasificados por gravedad. Los hallazgos también se pueden ver en Security Hub para proporcionar un panel central de la postura de seguridad.
Advertencia
Las ventajas de seguridad de Amazon Inspector tienen un coste. Debes comprender el modelo de precios antes de activar Inspector.
Inspector puede utilizarse además de las herramientas automatizadas de escaneo de vulnerabilidades que puedas tener en marcha en fases anteriores de tu proceso de desarrollo, como en el propio repositorio de código.
Detectar fugas de datos sensibles
Como has visto en en la sección anterior sobre la protección de datos, mantener a salvo tus datos de producción es fundamental. En particular, los datos clasificados como sensibles deben tratarse con el máximo nivel de seguridad.
El grado en que tu aplicación reciba, procese y almacene datos sensibles, como nombres, direcciones, contraseñas y números de tarjetas de crédito, dependerá de la finalidad de la aplicación. Sin embargo, lo más probable es que todas las aplicaciones, salvo las más sencillas, manejen algún tipo de datos sensibles.
Hay cuatro pasos para gestionar los datos sensibles:
-
Comprender los protocolos, directrices y leyes relacionados con la gestión de datos. Podrían ser directrices organizativas para la privacidad de los datos o normativas de protección de datos como la Ley de Portabilidad y Responsabilidad de los Seguros Sanitarios (HIPAA), el Reglamento General de Privacidad de Datos (GDPR), la Norma de Seguridad de Datos del Sector de las Tarjetas de Pago (PCI-DSS) y el Programa Federal de Gestión de Riesgos y Autorizaciones (FedRAMP).
-
Identifica y clasifica los datos sensibles de en tu sistema. Puede tratarse de datos recibidos en cuerpos de solicitud de API, generados por funciones internas, procesados en flujos de eventos, almacenados en una base de datos o enviados a terceros.
-
Aplica medidas para mitigar la manipulación y el almacenamiento inadecuados de datos sensibles. A menudo existen normativas que impiden almacenar datos más allá de un determinado periodo de tiempo, registrar datos sensibles o trasladar datos entre regiones geográficas.
-
Implanta un sistema para detectar y remediar el almacenamiento inadecuado de datos sensibles.
Mitigar las fugas de datos sensibles
Hay medidas que pueden aplicarse para limitar la posibilidad de que se almacenen datos sensibles en bases de datos, almacenes de objetos o registros, como los registros explícitos y la redacción de registros. Sin embargo, es crucial diseñar los sistemas de forma que toleren el almacenamiento inadvertido de datos sensibles y reaccionar y remediar lo antes posible cuando esto ocurra. La posibilidad de manejar incorrectamente datos sensibles existe en cualquier sistema que maneje dichos datos.
También es aconsejable almacenar únicamente los datos que sean absolutamente necesarios para el funcionamiento de tu aplicación, y sólo almacenarlos durante el tiempo que sean necesarios. La eliminación de datos tras un determinado periodo de tiempo puede automatizarse en varios almacenes de datos de AWS. Por ejemplo, los grupos de registro de CloudWatch deben configurarse con un periodo mínimo de retención, los registros de DynamoDB pueden ser dado un valor TTL, y el ciclo de vida de los objetos de S3 puede controlarse con políticas de caducidad.
Las siguientes secciones describen algunas técnicas para detectar fugas de datos sensibles en los registros de aplicaciones y en el almacenamiento de objetos.
Detección gestionada de datos sensibles
Algunos servicios de AWS ya ofrecen detección gestionada de datos sensibles y otros servicios podrían seguirles en el futuro . Amazon SNS ofrece protección nativa de datos para mensajes enviados a través de temas SNS. Amazon CloudWatch ofrece detección integrada de datos sensibles en registros de aplicaciones, por ejemplo de funciones Lambda.
Amazon Macie
Amazon Macie es un servicio de seguridad de datos totalmente gestionado que utiliza el aprendizaje automático para descubrir datos sensibles en las cargas de trabajo de AWS. Macie es capaz de extraer y analizar datos almacenados en buckets S3 para detectar varios tipos de datos sensibles, como credenciales de AWS, PII, números de tarjetas de crédito, etc.
Los datos pueden enrutarse desde varios componentes de tu aplicación a S3 y Macie puede monitorizarlos continuamente en busca de atributos sensibles. Esto podría incluir eventos enviados a EventBridge, respuestas API generadas por funciones Lambda o mensajes enviados a colas SQS. Los eventos de hallazgos de Macie se envían a EventBridge y pueden enrutarse desde allí para alertarte de los datos sensibles que se almacenan o transmite tu aplicación.
Resumen
La paradoja de la seguridad dicta que, aunque la seguridad del software debería ser de suma importancia para una empresa, a menudo no es una preocupación primordial para los equipos de ingeniería. Esta desconexión suele deberse a la falta de procesos procesables.
La seguridad debe, y puede, ser una parte integral de tu ciclo de vida de entrega de software sin servidor. Puedes conseguirlo adoptando estrategias de seguridad clave como la arquitectura de confianza cero, el principio de mínimo privilegio y el modelado de amenazas; siguiendo los estándares del sector para el cifrado de datos, la protección de API y la seguridad de la cadena de suministro; y aprovechando las herramientas de seguridad que proporciona AWS, como IAM y Security Hub.
Y lo que es más importante, recuerda que la seguridad puede ser sencilla, y estableciendo un marco claro para asegurar tu aplicación sin servidor puedes eliminar gran parte del miedo y la incertidumbre habituales de tus ingenieros.
Entrevista con un experto del sector
Nicole Yip, Ingeniera Principal
Nicole Yip ha pasado muchos años poniendo en marcha equipos de ingeniería en AWS y ayudándoles a alcanzar la madurez operativa en Australia y el Reino Unido. Sus intereses en DevOps (en sus múltiples definiciones), seguridad, fiabilidad, infraestructura y diseño general de sistemas han ayudado a dar forma a los equipos de manera que puedan sacar sus aplicaciones y servicios a producción de forma segura, al tiempo que maduran su comprensión y sus procesos en torno a la propiedad de los sistemas de producción (en particular, un sitio web minorista global muy popular).
Puedes encontrar en Internet algunas charlas en conferencias y entradas de blog sobre sus diversas áreas de interés, pero su principal objetivo ha sido inspirar, desafiar e implementar el crecimiento en los equipos que la rodean en las empresas en las que ha participado.
P: En la industria del software existe la percepción de que la seguridad es difícil y debe dejarse en manos de especialistas en ciberseguridad. ¿Ha cambiado esto con la nube, o los ingenieros deben seguir teniendo miedo a la seguridad?
En la industria del software es cierto que la seguridad se ve como algo difícil e intimidatorio, pero yo lo descompondría diciendo que se ve como "otro requisito más" y una madriguera de conejo, combinados.
La seguridad se considera "difícil" porque es otro requisito no funcional que hay que incluir en cada fase, desde el diseño a la implementación e incluso a las operaciones en curso. La seguridad también es difícil porque hay mucho que descubrir cuando entras en el mundo de la seguridad: no es sólo el código que escribes, la arquitectura que diseñas o los controles de acceso en torno a las aplicaciones que utilizas para cumplir determinadas normas y protocolos. También hay categorías enteras de amenazas, como la seguridad física y la ingeniería social, que no te vendrían a la mente cuando sólo miras la seguridad desde el punto de vista de la ingeniería de software, pero que pueden ser igual de dañinas, si no más, como puntos de entrada a tu sistema.
Para los miembros de los equipos de seguridad, las herramientas de InfoSec que solían ser manuales, engorrosas y se programaban mensualmente o con menor frecuencia, han mejorado y se han vuelto mucho más fáciles de usar e integrar con el ciclo de vida de desarrollo del software, facilitando que los problemas se marquen antes de llegar a producción o incluso que se parcheen automáticamente las dependencias vulnerables a medida que se informa de ellas en la comunidad.
Los ingenieros de software suelen ser muy curiosos, así que no creo que deban tener miedo de la seguridad como tema: es una de esas cosas de las que cuanto más consciente eres, más natural es que tomes decisiones más informadas a la hora de elegir cómo alojar esa aplicación o si hacer clic en ese enlace. La seguridad es responsabilidad de todos y no debe "dejarse" en manos de expertos en seguridad: cada línea de código escrita o cada decisión de diseño tomada cambia la postura de seguridad del sistema, así que cuanto más conscientes de la seguridad sean todos los implicados en el ciclo de vida del desarrollo de software, menos probable será que un actor malintencionado pueda encontrar suficientes vulnerabilidades para causar algún daño.
En la nube, la seguridad de partes de tu sistema pasa a ser responsabilidad del proveedor de la nube: la seguridad de tus centros de datos y de los datos en reposo se convierte en un acuerdo contractual con el proveedor de la nube. Para las pequeñas empresas esto es una bendición, ya que es otra cosa más que tendrían que averiguar y hacer cumplir si hubieran optado por autoalojarse y construir una sala de servidores.
Al utilizar un proveedor en la nube, te ves guiado a configurar un sistema más seguro por defecto, sin darte cuenta. La elección de empezar a configurar una aplicación en la nube ya puede hacer que tomes decisiones sobre seguridad, porque se te presentan esas decisiones al configurar los servicios.
Todavía puedes construir un sistema con vulnerabilidades en la nube, así que mantén la curiosidad; aprende todo lo que puedas sobre los vectores de ataque (el modelado de amenazas ayuda a identificarlos) y las implicaciones empresariales reales para tu sistema cuando alguien los descubra y los explote. No se trata de "si", sino de "cuándo".
¿Qué significa "seguridad"?
El objetivo final es permitir que tu sistema se utilice de la forma prevista, y todos los demás posibles abusos y accesos deben mitigarse (limitarse) o no ser posibles desde el principio.
Es una escala de aceptación del riesgo: aseguras un sistema hasta el punto en que tú, como empresa, aceptas la probabilidad y el impacto de los posibles vectores de ataque en tu sistema. ¿Por qué? Porque algunos vectores de ataque no se pueden evitar, como las amenazas internas de un mal actor en tu equipo de desarrollo.
P: La tecnología sin servidor traslada la responsabilidad de la gestión de la infraestructura a AWS, lo que permite a los ingenieros centrarse en el código que se implementa en esa infraestructura. ¿La delegación de la gestión de la infraestructura en serverless facilita o dificulta la seguridad?
Depende del prisma desde el que mires, como ingeniero de infraestructuras/redes o como ingeniero de software. En general, creo que la seguridad sin servidor es un poco más fácil, ya que los entornos están aislados, lo que reduce la capacidad de persistir un punto de entrada. Pero cuando empiezas a introducir casos de uso más complejos que, por ejemplo, introducen redes (si se ejecutan en una VPC), autenticación y autorización de clientes (que llaman a tus API)... entonces el nivel de experiencia en seguridad requerido sigue siendo el mismo. En lugar de que la responsabilidad recaiga en un equipo de operaciones o infraestructura que ya tiene la costumbre de pensar en las amenazas a nivel de red, esa responsabilidad la asume el equipo de ingeniería de software.
Hay que hacer un esfuerzo consciente para elevar el nivel de las expectativas de los ingenieros de software que se aventuran más abajo en la pila de la infraestructura sin servidor: no basta con configurar las bibliotecas que utilizas según sus niveles de seguridad recomendados, ahora también tienes que considerar cuántos permisos necesita realmente el contenedor que ejecuta tu código para funcionar, cuánta conectividad necesita con otros recursos: ¿deberían estar en la misma red o pueden aislarse por su cuenta?
P: Has dirigido equipos de software durante muchos años y has desempeñado un papel activo en la comunidad de la nube y DevOps. ¿Has observado algún cambio en el papel de un ingeniero de software a medida que se hace cada vez más responsable de la seguridad de sus aplicaciones cuando se utiliza la tecnología sin servidor?
Sí, pero no necesariamente porque los ingenieros de software sean cada vez más responsables de la seguridad de sus aplicaciones. Los ingenieros de software suelen empezar en una especialidad -frontend, backend, administrador de bases de datos, etc.- y aprenden los principales marcos, patrones y requisitos no funcionales (incluida la seguridad) para diseñar soluciones fiables dentro de esa especialidad. Entonces empiezan a expandirse y a coleccionar especialidades y aspiran a convertirse en ese mítico ingeniero "full stack". La "pila completa" solía incluir las especialidades de frontend, backend y bases de datos, pero ahora puede incluir fácilmente operaciones, redes e infraestructura con la prevalencia de las plataformas de alojamiento en la nube. Especialmente con la tecnología sin servidor, esto ha reducido la barrera de entrada a nuevas especialidades a las que pueden expandirse, incluidos los datos (migración y gestión), el aprendizaje automático y mucho más.
Como he mencionado antes, la seguridad es uno de esos requisitos no funcionales que existen en todas las partes de la pila, y todas esas áreas especializadas que he mencionado antes necesitan entender la seguridad y la privacidad con diferentes lentes para sus áreas de la pila.
Con la ingeniería de software sin servidor, los ingenieros de software pueden aprender a trabajar en redes e infraestructuras, con una ayuda en seguridad y privacidad integrada en el uso de la plataforma.
Por ejemplo, los ingenieros de redes utilizan cortafuegos para bloquear conexiones de redes no deseadas y en puertos no utilizados; cuando solicitas una VPC de AWS y configuras tus subredes y tablas de rutas, todas ellas están bloqueadas por defecto y tú especificas los puertos y redes a los que necesitas acceder (aunque ignoremos el hecho de que los recursos de red por defecto en las nuevas cuentas de AWS no se adhieren a esto).
Las oportunidades y vías para que un ingeniero de software crezca y evolucione en su función seguirán ampliándose. Cada pocos años surgirán nuevas tecnologías (actualmente GenAI e ingeniería de prompts) que reducirán la barrera de entrada a otras especialidades (por ejemplo, ciencia de datos e industrias creativas) y podrán añadir una nueva línea a la descripción de lo que podría ser un ingeniero full stack.
P: Has desempeñado un papel crucial en la adopción de serverless y DevOps en grandes empresas. Desde tu experiencia, ¿cómo pueden los equipos y las organizaciones fomentar una cultura de seguridad?
Hay dos cosas que he aprovechado para fomentar una cultura en torno a la seguridad. En primer lugar, creando una sólida cultura de equipo de ingeniería y manteniendo los temas de seguridad en la conversación diaria para mantener la concienciación sobre la seguridad.
Las culturas de ingeniería de alto rendimiento suelen tener como principios básicos la transparencia, el fracaso rápido y la no culpabilización. Además de generar confianza, esto también permite a los equipos aprender colectivamente. Ninguna persona podrá revisar una arquitectura y fijarla al 100% sin riesgos que aceptar. Todos tenemos incógnitas desconocidas, y hay algunos vectores de ataque que no puedes bloquear. Así que, cuando ocurra algo, tener una cultura que tenga manuales claros sobre qué hacer cuando se produce una brecha y que no penalice a nadie por identificar e informar de una brecha, hará que la seguridad madure mucho más rápido que un equipo que no fomente activamente estos principios.
La segunda es mantener la seguridad en la conversación y tener suficiente apoyo para el tiempo de holgura/innovación/curiosidad. Las herramientas y los principios de desplazamiento a la izquierda ponen de relieve los problemas de seguridad en una fase temprana del ciclo de vida de desarrollo del software, lo que genera la conversación cuando salen a la luz de forma constructiva. Introducir requisitos para el modelado de amenazas como parte del proceso de diseño lleva la discusión sobre la seguridad aún más a la izquierda. Pero además de eso, lo que realmente necesitas son ingenieros que sean curiosos, que se pregunten constantemente qué pasaría si... y que tengan suficiente tiempo libre para seguir esas líneas de pensamiento. Las sesiones periódicas de almuerzo y aprendizaje sobre la última brecha de la que se ha informado en el sector o sobre un concepto de seguridad pueden desencadenar esos momentos de "¿y si...?". Lo que estás buscando es que un ingeniero piense en lo que está trabajando en ese momento y se dé cuenta de que la vulnerabilidad que permitió esa brecha o ese concepto también podría aplicarse a lo que está escribiendo, y luego asegurarte de que reciben apoyo si van y lo prueban o juegan con el escenario de "¿y si...? De hecho, ¡podrían añadir una mitigación antes de que esa función llegue a producción!
Son esas lentes sobre el código, desde un nivel alto (modelado de amenazas) hasta un nivel bajo (herramientas de análisis estático y de dependencias), las que pueden complementar el diseño y la implementación seguros de un sistema, pero son los ingenieros los que podrán asegurar el sistema teniendo en cuenta la lógica empresarial y las limitaciones a medida que se escribe cada línea de código y se configura cada parte del sistema. ¡Dales el espacio y los conocimientos para que despierten su curiosidad y lo hagan!
P: Existen varias normas y buenas prácticas para la seguridad en AWS, como el principio del mínimo privilegio, el modelo de responsabilidad compartida para la seguridad en la nube y el Marco Bien Arquitectado de AWS. Para una empresa que adopte la tecnología sin servidor, ¿por dónde crees que pueden empezar en términos de concienciación sobre la seguridad?
Lo primero que hay que tener en cuenta es que la seguridad es responsabilidad de todos.
Yo diría que empieces por el nivel de empresa y vayas con la suposición de que te van a violar mañana. ¿Dispones de buenas bases de seguridad en tu empresa? ¿Sabrías si te han violado y cuándo, y sabes cómo reaccionar y remediarlo?
Las medidas de prevención y mitigación son siempre necesarias, pero nunca reducen el riesgo de una brecha al 0%. Como he mencionado antes, hay algunos vectores de ataque que no puedes cerrar y sólo puedes mitigar lo mejor que puedas para reducirlos a un nivel de riesgo aceptable.
Algunas funciones básicas de seguridad a nivel empresarial son:
- Detección
-
Alertas de información de seguridad y gestión de eventos (SIEM) que van a un equipo de respuesta
- Respuesta
-
Sistema de captura de pruebas de integridad asegurada, sandboxes y redes aisladas, experiencia en respuesta de seguridad
- Prevención
-
Barandillas, formación, rutas doradas, auditorías, pruebas de penetración
Desde el punto de vista de la empresa y hacia los equipos de plataforma, los equipos de plataforma deben crear rutas doradas de seguridad para sus productos, que canalicen todo lo que se construye en esa plataforma hacia el SIEM de la empresa, y enviar alertas priorizadas a los equipos. También pueden ayudar a los equipos de aplicaciones integrando herramientas de seguridad en su cadena de herramientas y procesos de implementación, y mostrando los resultados de forma eficaz.
Los equipos de aplicaciones deben participar regularmente en la formación sobre seguridad para estar al día de las últimas amenazas existentes, ya sea participando en presentaciones en las que se describa el último ataque a una capa de aplicación relevante, completando la formación de la empresa, o sintiendo curiosidad y aprendiendo más sobre las buenas prácticas de seguridad a partir de las herramientas en uso (AWS Well-Architected Framework, descubrimientos de GitHub Dependabot, herramientas de análisis estático y/o dinámico, pruebas de penetración , , etc.).
Get Desarrollo sin servidor en AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

