Kapitel 4. Suche anwenden: Von einfachen zu fortgeschrittenen Mustern
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Im vorigen Kapitel haben wir besprochen, wie die Suche in einem Datenkatalog funktioniert und wie das Verständnis der Suchmechanismen deine Suche verbessern und damit den Wert deines Datenkatalogs steigern kann. Du musst dich daran erinnern, dass die Suche davon abhängt, wie gut du die Daten in deinem Datenkatalog organisierst. Selbst wenn du die perfekte Abfrage für das, was du brauchst, zusammenstellst, wird die Suche kaum etwas ergeben, wenn der Datenkatalog schlechte Metadaten enthält.
Das bringt uns zu der Frage, wie man die Suche anwendet. Die Anwendung der Suche ist ein Handwerk, das sich vom Verständnis der Technologie selbst unterscheidet. Zunächst einmal musst du bei der Suche nach Daten wie ein Bibliothekar suchen, der für die Suche nach Daten ausgebildet ist, und nicht wie ein Datenwissenschaftler, der für die Suche in Daten ausgebildet ist. Mit der Denkweise eines Bibliothekars wirst du kreative Wege finden, um Suchfunktionen freizuschalten. Die einfache Suche kann auf verschiedene Arten genutzt werden, um die Genauigkeit zu erhöhen oder zu verringern, um breiter zu suchen oder nur wenige Treffer zu finden. Das Browsen ermöglicht es, in den Daten zu navigieren und ihren Kontext zu verstehen - und ein zusätzlicher Vorteil ist, dass dieser Kontext genutzt werden kann, um sowohl die einfache als auch die komplexe Suche zu verfeinern. Und so wie die einfache Suche auf viele verschiedene Arten genutzt werden kann, kann dies auch die komplexe Suche.
Was du in diesem Kapitel lernst, ist nur der Anfang. Du wirst die angewandte Suche weiter anpassen und verfeinern müssen, damit sie zur Sprache und zum Zweck deines Unternehmens passt.
Suchen wie Bibliothekare - nicht wie Datenwissenschaftler
Data Scientists zeichnen sich durch die Analyse von Daten aus - egal, ob es sich um kleine oder riesige Datensätze handelt, sie haben die Werkzeuge und die Denkweise, um die Daten zu durchsuchen und die benötigten Erkenntnisse zu gewinnen. Das ist ihre Superkraft. Die Suche nach den Daten, mit denen sie arbeiten sollen, kann jedoch eine echte Herausforderung sein, denn die Fähigkeiten, die sie bei der Suche in Daten so gut machen, gelten nicht unbedingt für die Suche nach Daten. Wie du dich aus Kapitel 3 erinnerst, gibt es einen großen Unterschied zwischen der Suche nach Daten und der Suche in Daten.
Bibliothekarinnen und Bibliothekare hingegen sind sehr gut darin, alle Arten von Material unter der Sonne zu finden - Bücher, Zeitschriften, Zeitungen, alles! Wenn du danach fragst, können sie wahrscheinlich danach suchen und es finden. Und zu ihren Superkräften gehört auch, dass sie nach Daten suchen und wissen, welche Daten du brauchst.
Im Gegensatz zu den Datenwissenschaften, die erst in den letzten Jahrzehnten an Bedeutung gewonnen haben, gibt es die Bibliotheks- und Informationswissenschaft (LIS) schon seit Hunderten von Jahren und ebenso vielen Jahren, in denen die Kunst, Wissen zu organisieren und zu suchen, perfektioniert wurde.
Als Bibliothekar/in zu recherchieren bedeutet in erster Linie, einen Informationsbedarf gut einschätzen zu können, denn der Informationsbedarf bestimmt, wie du nach Daten suchst. Der Begriff " Informationsbedarf " wurde 1962 von Robert S. Taylor geprägt und beschreibt die Art und Weise, wie wir Fragen an Referenzdatenbanken stellen.1
Dein Informationsbedarf kann groß oder klein sein. Frage dich, ob du auf der Suche bist nach:
-
Alles
-
Ein paar gute Dinge
-
Die einzig richtige Sache
-
Eine Sache, die du wieder brauchst2
Dein Informationsbedarf bestimmt, wie du nach Daten suchst, denn Bedürfnisse drücken unterschiedliche Größen und Absichten aus.
Alles ist mit einer komplexen Suche verbunden - und du strebst eine hohe Trefferquote auf Kosten der Genauigkeit an. Aber du kannst dies auf viele verschiedene Arten tun, wie du später in diesem Kapitel sehen wirst.
Ein paar gute Dinge sind ein Informationsbedarf, der nicht so eindeutig ist. Du kannst entweder nach einem relativ hohen Recall oder einer relativ hohen Präzision suchen, aber nicht nach beidem.
Das einzig Richtige, wie der Name schon sagt, zielt darauf ab, nur einen Vermögenswert oder eine genau definierte Gruppe von Vermögenswerten zu finden. Deshalb streben diese Suchen nach Präzision.
Schließlich verlässt sich eine Sache, die du brauchst, wieder auf Werte, die du bereits kennst. Auch sie strebt nach Präzision, aber sie ist weniger schwierig zu finden als die einzig richtige Sache.
Du musst bedenken, dass die Suche nach Daten in Metadaten-Repositories wie einem Datenkatalog ein langwieriger Prozess sein kann (wie Taylor bereits 1962 betont hat). Werde also nicht ungeduldig. Wir haben uns daran gewöhnt, dass wir alles googeln können, aber das ist eine einfache Suche, die dir Streiche spielt. Die Suche nach Daten ist nicht immer so; es kann viele Schritte dauern, bis du das findest, wonach du suchst, und das ist in Ordnung. Es kann sein, dass du die Suche anpassen musst, und zwar sowohl die Übersetzung dessen, was mit einer Suche beabsichtigt ist, als auch die Art und Weise, wie der spezifische IRQL des Systems funktioniert, und von da an, welche Begriffe eingeschlossen werden, welche davon anschließend ausgeschlossen oder geändert werden, und so weiter, in einer mehrstufigen langen Suche nach den relevantesten und wertvollsten Treffern. Das bedeutet, dass es bei der Suche nicht nur darum geht, einen Informationsbedarf in eine Suche zu übersetzen. Der Prozess ist viel subtiler, und man braucht Erfahrung.
Die Suche nach Daten ist wie Autofahren. Manchmal bist du nur für eine kurze Fahrt unterwegs, um etwas aufzusammeln. Gelegentlich bist du auf einer langen, mühsamen Straße auf einer geraden Linie unterwegs. Ab und zu überquerst du Berge mit endlosen scharfen Kurven, dem Gefühl von Schwindel, auf und ab, bis du das Ziel erreichst. Oder es kommt vor, dass du an einen Ort gehst, nur um festzustellen, dass du erst an einen zweiten und dann an einen dritten Ort gehen musst, bevor du mit den Dingen, die du besorgen wolltest, nach Hause zurückkehren kannst. Manchmal findest du dich in Gegenden wieder, in denen es keine Regeln gibt, manchmal ist der Verkehr überwältigend, manchmal sind die Straßen alt und voller Löcher. Und manchmal fährst du einfach so schnell, wie du kannst, weil es Spaß macht.
Bibliothekare und Bibliothekarinnen kombinieren alle möglichen Methoden und Techniken, wenn sie suchen - das solltest du auch tun. In den nächsten Abschnitten werden einige der am häufigsten verwendeten Suchmuster vorgestellt. Obwohl sie alle für sich genommen gut funktionieren, sind sie am besten, wenn sie kombiniert werden.
Suchmuster
Ist dir schon mal aufgefallen, dass die Art und Weise, wie du suchst, davon abhängt, wonach du suchst? In diesem Abschnitt werde ich typische Muster der angewandten Suche besprechen. Du wirst sehen, wie Recall, Precision, Serendipity, Exhaustivity, Specificity und andere Konzepte bei der Suche eine Rolle spielen.
Alle Suchmuster sind in Tabelle 4-1 aufgelistet, zusammen mit dem Suchnamen, dem Suchtyp, einer kurzen Beschreibung und dem relativen Präzisions- und Erinnerungsgrad der Suche. Beachte, dass Genauigkeit und Auffindbarkeit nicht für das Browsing gelten.
Tipp
Beachte, wie die Suchart den Unterschied zwischen einfacher und komplexer Suche aufweicht.
| Name suchen | Suchart | Beschreibung | Präzision | Rückruf |
|---|---|---|---|---|
| Grundlegende einfache Suche | Einfache Suche | Ein paar präzise Treffer und eine Menge Lärm | Hoch | Niedrig |
| Detaillierte einfache Suche | Einfache kombinatorische Suche | Langsam formulierte einfache Suche, denn die Suche muss genau formuliert werden | Hoch | Niedrig |
| Flexible einfache Suche | Einfache kombinatorische Suche | Trunkierte Suche, die eine einfache Suche vereinfacht und ausweitet | Niedrig | Hoch |
| Bereichssuche | Komplexe kombinatorische Suche | Bereichssuche, die den Abruf von Assets zwischen zwei Werten ermöglicht | Hoch | Niedrig |
| Blocksuche | Komplexe kombinatorische Suche | Kombination ausgewählter Begriffe, um ein Thema darzustellen | Niedrig | Hoch |
| Statement Suche | Komplexe kombinatorische Suche | Lange Erklärung der genauen Bedingungen, die Vermögenswerte erfüllen müssen | Hoch | Niedrig |
| Glossar durchsuchen | Suche durchsuchen | Die Suche nach einem bestimmten Wort führt zu Wortlisten im Glossar, die durchgeblättert werden können | - | - |
| Domain durchsuchen | Suche durchsuchen | Domänen wie in Kapitel 3 erklärt | - | - |
| Abstammung durchsuchen | Suche durchsuchen | Abstammung wie in Kapitel 3 erklärt | - | - |
| Grafik durchsuchen | Suche durchsuchen | Diagramme wie in Kapitel 3 erklärt | - | - |
Lass uns über jeden einzelnen sprechen.
Grundlegende einfache Suche
Im Allgemeinen sind deine gelegentlichen Suchanfragen an einem typischen Arbeitstag wahrscheinlich einfache Suchen mit ein paar Wörtern in der Suchleiste. Bei dieser Art von Suche geht es dir nicht darum, etwas ganz genau zu wissen - du willst einfach nur etwas Gutes, und zwar schnell. Was bei dieser Art von Suche zählt, ist der Treffer an der Spitze der Suchergebnisse. Dieser Treffer muss, isoliert vom Rest des Suchergebnisses betrachtet, ein perfekter Präzisionstreffer sein. Alles, was darunter liegt, spielt keine Rolle.
Einfache Suchen verwenden Suchbegriffe in einfacher Sprache und keine Abfragesprache. Die einfache Suche ist die am wenigsten komplizierte Art der Suche, da sie nur aus einem oder zwei einfachen Suchbegriffen besteht, wie z. B. "gutes Wetter" oder "Sommer".
Nehmen wir an, ein Vertriebsmitarbeiter von Hugin & Munin, der für Schweden zuständig ist, möchte den neuesten und wichtigsten BI-Bericht für sein Gebiet finden. Er könnte eine einfache Suche nach Verkäufen durchführen, wie in Abbildung 4-1 dargestellt. Als durchschnittlicher Endnutzer erwartet der Vertriebsmitarbeiter, dass das oberste Ergebnis genau das ist, wonach er gesucht hat. Wenn das nicht der Fall ist, geht er zu komplexeren Suchmustern über, um das Gesuchte zu finden. Da die einfache Suche alle in Kapitel 3 erwähnten Technologien wie Vorhersagen, Fuzzy-Logik und die Historie des Suchverhaltens berücksichtigt, kann sie gut herausfinden, was der Durchschnittsnutzer will.

Abbildung 4-1. Einfache Suche nach Verkäufen
Der Handelsvertreter wird erwarten, dass er den neuesten, relevantesten BI-Bericht für das Gebiet erhält, in dem der Nutzer Handelsvertreter ist. Dies spiegelt den präzisesten, relevantesten Treffer an der Spitze wider, der darauf basiert, wer der Nutzer ist, welche Art von Daten ihn am meisten interessiert und wie der Nutzer zuvor gesucht hat.
Tipp
Wenn dein Datenkatalog auf einem Wissensgraphen basiert, kannst du eine sehr leistungsfähige, einfache Suchfunktion erwarten. Die Suchergebnisse werden dich über die geschäftlichen Zusammenhänge eines bestimmten Assets aufklären und mit hoher Präzision eingeordnet werden. Das ist z. B. beim Knowledge Graph von Google der Fall.
Die einfache Suche wird für viele Endnutzer die einzige Möglichkeit sein, den Datenkatalog zu nutzen. Diese suchmaschinenähnliche Erfahrung erweckt den Eindruck, dass man alles finden kann, aber das ist nicht der Fall. Es ist die einfachste Art der Suche. Sie bietet den Endnutzern Präzision auf Kosten der Wiederauffindbarkeit. Die Nutzer können das einzig Richtige an der Spitze der Suchergebnisse finden.
Warnung
Es ist üblich, dass Anbieter von Datenkatalogen die einfache Suche als die einzige Möglichkeit der Suche in Verkaufsunterlagen darstellen - oft ist es genau diese Art der Suche, die alles abdeckt, wonach die Nutzer/innen suchen. Allerdings kann diese Art der Suche unmöglich alle Informationsbedürfnisse befriedigen. Andere Arten der Suche sind jedoch schwieriger und zeitaufwändiger und werden daher selten beworben.
Detaillierte einfache Suche
Manchmal suchst du nach einer bestimmten Sache und nur danach - und du weißt, wie du sie ausdrücken kannst, wenn du dich konzentrierst. Das ist eine relativ einfache Suche, die nicht schnell geht, weil du deine Suchsyntax richtig hinbekommen musst; sie ist sehr detailliert. Vielleicht musst du sogar ein paar erste Suchen durchführen, um zu testen, ob alles wie gewünscht funktioniert.
Detaillierte einfache Suche ist, wenn du ein wenig Abfragesprache verwenden musst, um deine Suchanweisung zu formulieren. Diese Suche ist langsam, weil sie darauf angewiesen ist, dass die Nutzer/innen genaue Werte eingeben, was Aufmerksamkeit erfordert und den Suchprozess verlangsamt. Der Suchtyp ist eine einfache kombinatorische Suche, denn es handelt sich um eine relativ einfache Suchanweisung, die mit nur einem booleschen Operator kombiniert wird. Wenn du dir das Spektrum der Suche in Abbildung 3-4 ansiehst, bewegen wir uns weg von einfach hin zu schwierig.
In Hugin & Munin, unserem fiktiven Unternehmen für nachhaltige Architektur, nutzen die Endnutzer/innen das gut kuratierte globale Glossar, mit dem sie in fein granulierten Wörtern suchen können, z. B. nach Holzarten: Kernholz, Fichte, Kiefer und so weiter. Die Wörter für Holz im globalen Glossar sind die standardmäßigen englischen Namen für Holzarten in Kombination mit ihrem lateinischen Namen. Nehmen wir an, du möchtest nach Assets mit dem Steward John Miller suchen, die Daten über Eschen aus dem globalen Glossar enthalten, etwa so:
| GlobalGlossary:Ash Fraxinus AND AssetSteward:John Miller |
Es ist möglich, dies in der einfachen Suchansicht einzugeben, ohne den Überblick über die in der einfachen Suchleiste eingegebene Suche zu verlieren, wie in Abbildung 4-2.

Abbildung 4-2. Detaillierte einfache Suche
Diese Suche erfasst alle Bestände mit dem globalen Glossarbegriff "Esche Fraxinus", die "John Miller" als Bestandsverwalter haben. Bei dieser Suche muss der Nutzer vielleicht erst die richtige Art und Weise bestimmen, wie die Holzart im globalen Glossar ausgedrückt wird, bevor er die Suche durchführen kann. Der Aufbau dieser Suche wird einige Zeit in Anspruch nehmen, aber sie wird präzise Ergebnisse liefern, da nur die Assets mit den eindeutigen Merkmalen der Suche zurückgegeben werden. Anders als bei der einfachen Suche sind hier also alle Treffer relevant, die Genauigkeit ist hoch und die Wiederauffindbarkeit niedrig, und die Suche selbst nimmt ein wenig Zeit zum Erstellen in Anspruch.
Du kannst die Syntax auch lockern und von einem detaillierten einfachen Suchmuster zu einem flexiblen Suchmuster übergehen. In diesem Fall ist die einfache Suche zwar nicht ganz präzise, aber relativ schnell.
Flexible einfache Suche
Es kann auch vorkommen, dass du ungenaue Suchen durchführen musst und die Suchergebnisse durchgehen musst, um die gewünschten Vermögenswerte zu finden.
Das ist die flexible einfache Suche, die etwas schneller zu schreiben ist als die detaillierte einfache Suche, weil sie weniger von der genauen Syntax abhängt; du musst die genauen Werte in deiner Abfrage nicht kennen. Die flexible einfache Suche ist auch eine einfache kombinatorische Suche, aber sie ermöglicht eine größere Menge von Suchtreffern und eine höhere Trefferquote, was auf Kosten der Genauigkeit geht.
Eine Gruppe von Hugin & Munin-Mitarbeitern in der Kommunikationsabteilung muss zum Beispiel wissen, welche Arten von Holz das Unternehmen verwendet, um einige Details in eine Pressemitteilung aufnehmen zu können. Sie haben gehört, dass die Informationen in einer CSV-Datei stehen. Sie wissen nicht, wie das Gut im Katalog beschrieben ist, außer dass es Daten über Holz enthält und dass es eine CSV-Datei ist. Sie könnten die folgende Suche durchführen, die in Abbildung 4-3 dargestellt ist:
| FreeGlossary:*Holz* AND FormatDefault:.csv |

Abbildung 4-3. Flexible einfache Suche
Diese Suche ergibt alle Assets, die CSV-Dateien darstellen und die Folksonomy-Begriffe mit dem Wort "Holz" enthalten, aber auf beiden Seiten abgeschnitten, so dass die Ergebnisse für alle Kombinationen mit Holz offen sind. So werden zum Beispiel freie Glossarbegriffe wie "Holzboden", "schönes Holz", "Holz" und so weiter automatisch in die Suche einbezogen.
Diese Art der Suche bietet eine hohe Auffindbarkeit und geht daher auf Kosten der Genauigkeit. Und genau das ist der Punkt: Der Endnutzer weiß nicht, wie er eine Suche durchführen soll, die eine vollständige Präzision liefert, und muss daher einen höheren Recall anstreben, um eine Gruppe von Assets zu finden, in der sich das Asset befindet.
Bereichssuche
Manchmal musst du nach etwas suchen, das zwischen zwei Punkten liegt, z. B. nach einem Datum oder nach etwas, das eine organisatorische Logik in Seriennummern enthält.
Das geht auf mit der Bereichssuche. Dabei handelt es sich um eine verfeinerte komplexe kombinatorische Suche, die einen oder mehrere boolesche Operatoren und mindestens zwei Werte verwendet, die einen Bereich bilden.
Wenn du zum Beispiel nach einer bestimmten Reihe von Hypothesen suchst, die irgendwann in der Zeit, in der bestimmte Projekte durchgeführt wurden, getestet wurden, könntest du nach Forschungsprojekten wie diesen suchen:
| > RES.100.7.1003 UND < RES.100.7.1837 |
Das können auch Raumnummern auf Grundrissen, Ausrüstungsgegenstände und so weiter sein.
Ein Beispiel: Ein Projektteam von Hugin & Munin möchte alle Bilder von Kernholz zwischen November 2012 und Februar 2018 analysieren. Sie suchen so, wie in Abbildung 4-4 dargestellt:
| AssetTypeFree:Bild von Kernholz AND (< 31.01.2018 AND > 31.10.2012) |
Diese Suche liefert alle Treffer, die sich auf Bilder von Kernholz im angegebenen Zeitraum beziehen.

Abbildung 4-4. Bereichssuche
Blocksuche
Angenommen, ein unzufriedener Kunde hat beschlossen, Hugin & Munin zu verklagen. Das Haus, das Hugin & Munin für ihn gebaut haben, hat Risse in der Fassade, und der Kunde behauptet, das Holz, aus dem das Haus gebaut ist, sei nicht stabil genug.
Die Blocksuche ist eine sehr umfassende komplexe kombinatorische Suche, bei der du nach einem ganzen Thema suchst. In der Regel sind bei einer solchen Suche viele verschiedene Dinge und Wörter im Spiel, die du in zusammenhängenden Gruppen als Blöcke anordnest, daher der Name Blocksuche.
Die Anwälte von Hugin & Munin beginnen ihre Due-Diligence-Prüfung mit einer Recherche. Mit ihrer Grundausbildung in DCQL durchsuchen sie den Datenkatalog nach Berichten und Testdaten, die die Widerstandsfähigkeit verschiedener Holzarten in den firmeneigenen Konstruktionen untersuchen. Sie kombinieren eine große Auswahl an Wörtern, um den Recall zu maximieren - sie müssen jedes einzelne potenziell relevante Asset finden, was eine geringe Präzision zur Folge hat, so dass sie davon ausgehen, dass sie ziemlich viel durch die Suchergebnisse blättern werden. Sie suchen folgendermaßen, wie in Abbildung 4-5 dargestellt:
| (DomainTerm:((Kiefer ODER Esche ODER Buche ODER Eiche ODER Holz) NOT Linden) OR FreeTerm:Wood OR GlobalTerm:(Kiefer Pinus ODER Esche Fraxinus ODER Buche Fagus ODER Eiche Quercus) NOT Linden Tilia) AND DomainTerm:(Härte ODER Solidität ODER Ausdauer ODER Widerstandsfähigkeit) |

Abbildung 4-5. Blocksuche
In den Suchergebnissen werden Anlagen angezeigt, die eine oder mehrere Kombinationen von Begriffen für Holz und Begriffe für Widerstandsfähigkeit enthalten.
Die Suche besteht aus Domänen-Glossarbegriffen aus verschiedenen Domänen, die Holzarten in Standard-Englisch beschreiben. Die Assets müssen eines oder mehrere dieser Wörter enthalten, es sei denn, das Asset enthält den nächsten Wert, den freien Glossarbegriff Holz, oder einen oder mehrere der globalen Glossarbegriffe für Holz - denn das Wort "Holz" ist kein Begriff, der im globalen Glossar zu finden ist. Es kann auch eine Mischung aus diesen Begriffen enthalten sein. Wenn eines oder mehrere dieser Kriterien erfüllt sind, müssen diese mit den Begriffen des Bereichsglossars für Widerstandsfähigkeit abgeglichen werden .
Aber nicht alle Anwälte sind in der Abfragesprache des Datenkatalogs geschult und es wird ihnen ein wenig schwindelig, wenn sie versuchen, die Syntax zu beherrschen und sich gleichzeitig auf die Semantik zu konzentrieren. Deshalb benutzen einige Anwälte einfach den Such-Builder. Sie geben den Search Builder über das Feld für die erweiterte Suche auf ein. Der Search Builder ermöglicht es den Endnutzern, ihre Suche mit Point-and-Click-Optionen zu formulieren, so dass sie nicht mehr die Syntax überprüfen müssen und sich nur noch auf die Semantik konzentrieren können. Du kannst den Search Builder in Abbildung 4-6 sehen.
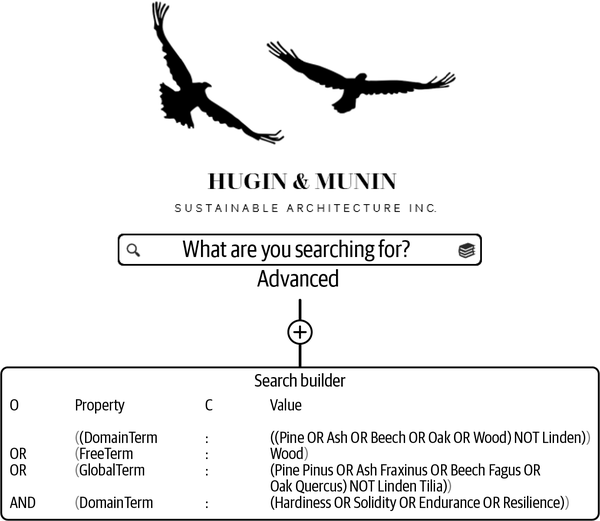
Abbildung 4-6. Search builder
Der Such-Builder in Hugin & Munin erstellt eine visuell navigierbare Übersicht über lange Suchen. O steht für Operator, C für Bedingung. Alle grauen Klammern sind optional; sie werden aktiv, wenn der Endnutzer sie anklickt. Diese Art, die komplexe Suche aufzuschlüsseln, macht es einfacher, den Überblick zu behalten, was die Suche tut, so dass vor allem die Semantik leicht zu überblicken ist.
Hinweis
Suchmasken wie die in Abbildung 4-6 sind Standardkomponenten in Referenzdatenbanken wie PubMed. Viele Datenkataloge, wie data.world, haben auch einen Search Builder.
Diese Art der Suche wird im LIS auch als Blocksuche bezeichnet. Sie wird als Methode eingesetzt, um große Mengen von Suchergebnissen für komplexe Suchen zu erhalten. Normalerweise besteht diese Art der Suche aus mehreren Phasen, in denen Wörter hinzugefügt und andere entfernt werden. Durch eine Reihe von Anpassungen ist der Suchende in der Lage, die benötigten Daten in die Sprache und Struktur des Datenkatalogs zu übersetzen, und zwar auf der Grundlage der Analyse der Treffer aus den vorherigen Suchschritten.
Außerdem ist dies eine Art der Suche, die sich darauf bezieht, wie die Glossare in deinem Datenkatalog angewendet werden. Je höher die Spezifität, d. h. je mehr Begriffe aus den Glossaren tatsächlich auf die Assets im Datenkatalog angewandt werden (unter Ausnutzung der Vollständigkeit der Glossare), desto besser funktioniert dein Abrufmechanismus.
Tipp
Erinnerst du dich an das Zipf'sche Gesetz aus Kapitel 3( )? Wenn du dich nur auf gecrawlte Metadaten verlässt, ist deine Chance auf Erfolg bei der Blocksuche gering. Du brauchst Glossarbegriffe, die von Menschen, nicht von Maschinen, angewendet werden, um deine Assets voneinander zu unterscheiden.
Die Blocksuche ist schwierig zu entwickeln, aber es ist sehr wichtig, sie zu beherrschen. In rechtlichen Fragen, bei der Einhaltung von Vorschriften und bei komplexen Suchvorgängen für innovative Anwendungen ist die Blocksuche die Art von Suche, die über ein positives Ergebnis für dein Unternehmen entscheidet.
Und manchmal musst du eine komplexe Suche durchführen, die nicht wirklich ein klar definiertes Thema mit zugeordneten Glossarbegriffen ist, sondern eine eher zufällige Ansammlung von Dingen, über die jemand zufällig mehr wissen möchte.
Statement Suche
Die meisten komplexen kombinatorischen Suchen sind Statement-Suchen: eine bunte Mischung aus Personen, Systemen, Bereichen und allem anderen, woraus man Suchen erstellen kann. Diese Art von Suche ist in vielen verschiedenen Situationen notwendig, z. B. bei der Verwaltung des Datenkatalogs, beim Sammeln von Daten für ein Projekt oder um sicherzustellen, dass die Assets eines bestimmten Verwalters, der seine Position wechselt, an einen neuen Verwalter weitergegeben werden (zu diesem Anwendungsfall siehe Kapitel 7 über Lebenszyklen).
Abbildung 4-7 zeigt ein Beispiel für eine Suche, die vom Hugin & Munin Data Discovery Team durchgeführt wurde. Sie wollen herausfinden, für wie viele Tableau-Berichte es keinen Eigentümer in der Rechtsabteilung, der Finanzabteilung oder der IT-Abteilung gibt.
Diese Suche liefert alle Tableau-Berichte aus den Abteilungen, die nach dem 1. Januar 2022 erstellt wurden und keinen Eigentümer haben.
Das Datenermittlungsteam nutzt dieses Suchergebnis, um die Datenverwalter für die Assets zu kontaktieren und sie zu bitten, einen Eigentümer des Assets hinzuzufügen.

Abbildung 4-7. Anweisung suchen
Muster durchstöbern
Suchmuster sind eigentlich Suchmuster, aber sie erfordern in der Regel nicht, dass der Endnutzer Suchanweisungen formuliert (außer bei der Suche im Glossar). Stattdessen funktioniert das Browsing durch das Hin- und Herklicken in Listen von Glossarbegriffen, Linien oder Diagrammen. Sieh das Browsing als eine Phase zwischen den anderen Sucharten, in der die Nutzer/innen die Sprache und die Bereiche ihres Unternehmens entdecken und lernen. Wenn sie die Datenlandschaft durchstöbern können, werden sie mit mehr Verstand suchen können.
Glossar durchsuchen
Manchmal möchtest du einfach nur ein Thema erforschen, um einen Bereich besser zu verstehen. Du hast viele Möglichkeiten, aber eine davon ist, in Glossaren zu stöbern.
Ein Beispiel von Hugin & Munin ist ein neuer Mitarbeiter, der besser verstehen möchte, wie Farbe als Oberflächenbehandlung für Holzhäuser verwendet wird. Der Nutzer gibt "Farbe" in die Suchleiste des Glossars ein, wie in Abbildung 4-8 zu sehen ist.
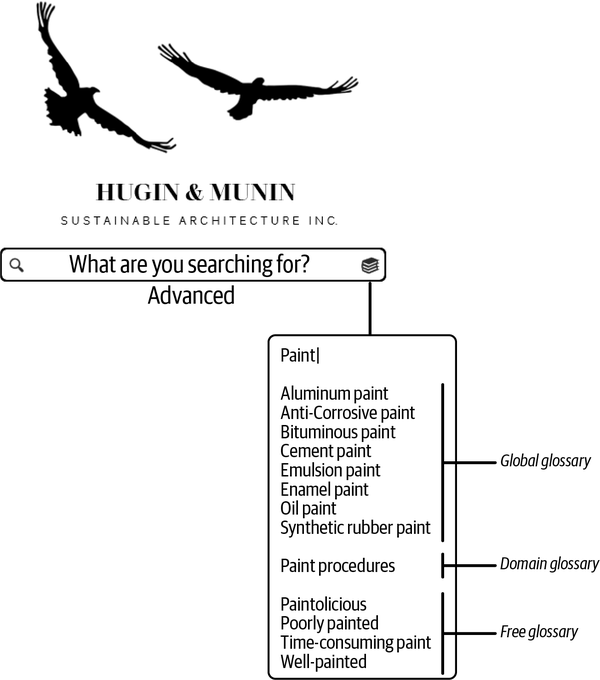
Abbildung 4-8. Glossar browsen nach dem Anstrich
Hier wird der Unterschied zwischen den verschiedenen Glossaren deutlich: Das globale Glossar besteht aus streng kontrollierten Begriffen, die unternehmensweit gelten, das Bereichsglossar bezieht sich auf einen einzigen Bereich und das freie Glossar fügt einfach hinzu, was den Leuten gefällt. Wenn du tiefer in die Glossare klickst, siehst du, wie gut sie organisiert sind (siehe Abbildung 2-11).
Domain Browsing
Beim Domain Browsing gehst du die Fähigkeiten oder Prozesse in deinem Unternehmen durch. Diese Art der Durchsuchung wird oft durch fehlenden Kontext ausgelöst - sie ermöglicht es dir, eine Vorstellung davon zu bekommen, wo sich potenziell relevante Ressourcen befinden könnten. Vielleicht arbeitet jemand an einem Projekt über Kundenprofile und möchte wissen, ob es in den Bereich Kundeninformationsmanagement oder Kundenpräferenzmanagement fällt. Das könnte ihm sagen, mit wem er bei Problemen sprechen muss.
Sie können aber auch aus reiner Neugierde handeln - und diese Art des Browsens ist nie Zeitverschwendung, denn sie ermöglicht es dir, die Datenlandschaft deines Unternehmens besser zu verstehen. Wenn du sehen willst, wie das Domain-Browsing aussieht, gehe zurück zu Abbildung 3-7.
Lineage Browsing
Manchmal möchtest du vielleicht wissen, woher ein bestimmter Vermögenswert stammt (Upstream) oder wohin er gereist ist (Downstream). Durch das Durchsuchen der Lineage kannst du herausfinden, warum ein bestimmter Datenanalysebericht fehlerhaft ist. Durch das Durchsuchen der Lineage kannst du auch testen, welche Folgen es hätte, wenn du ein bestimmtes Asset im Upstream ändern würdest. Du könntest auch nach möglichen Verbesserungen an bestehenden Datenverarbeitungsabläufen suchen oder ungenutzte Assets in der Umgebung entdecken (z. B. eine Tabelle mit eingehenden, aber nicht ausgehenden Datenströmen). Du kannst auch nach Datenströmen suchen, die sich in bestimmten Zeitspannen geändert (oder nicht geändert) haben, um alte Datenpipelines zu identifizieren.
Ein DSB kann auch dokumentieren, wie sensible Daten nachgelagert verarbeitet werden. Ich zeige solche Beispiele für angewandte Abstammungssuche in Kapitel 5.
Hinweis
Erinnere dich daran, dass die Lineage-Funktionalität von Anbieter zu Anbieter variiert und dass dementsprechend auch deine angewandten Suchmöglichkeiten unterschiedlich sind: Denke daran, die Lineage-Funktionalität bei deiner Anbieterauswahl zu bewerten, wenn dieses Kriterium für dich wichtig ist. Diese Bewertung ist komplex und erfordert viel Zeit, um die Vor- und Nachteile einer bestimmten Lineage-Funktionalität herauszufinden. Du kannst z. B. die Lineage-Funktionalität erweitern, um die Lineage aus der Vergangenheit eines bestimmten Assets einzubeziehen, oder eine Lineage-Funktionalität wählen, die die Daten-Lineage mit zusätzlichen Metadaten anreichert, um zu verfolgen, wie hochwertige Daten-Assets reisen, und so weiter.
Graph Browsing
Die ultimative Art, deine Daten zu durchsuchen, ist die visuelle Erkundung deines Wissensgraphen - wenn dein Datenkatalog auf einem Wissensgraphen basiert, wie in Kapitel 1 und 2 beschrieben. Der Wissensgraph verbindet alle Teile deines Datenkatalogs auf wunderbare Weise miteinander. Er ist die Manifestation aller tatsächlichen Knoten in deinem Metamodell. Er ist der ideale Weg, um den Zufall bei deiner Suche zu maximieren, denn du kannst dich durch alle Teile des Katalogs klicken und neue Verbindungen entdecken.
Diagramme eignen sich hervorragend, um einen Überblick über soziale Netzwerke zu geben. Grafiken werden zum Beispiel in diesen beiden Bereichen verwendet:
-
Strafverfolgungsbehörden, Militär und Nachrichtendienste
-
Universitäten und akademische Einrichtungen im Allgemeinen
Für Polizei, Militär und Nachrichtendienste sind Netzwerke von Menschen und die Dinge, die sie benutzen und besitzen (z. B. Telefone, Waffen, Dokumente), visuell in einer Grafik dargestellt, ein absolutes Muss. Bei polizeilichen Ermittlungen können Diagramme kriminelle Organisationen wie Mafia-Familien oder Gangs abbilden und bei der Aufklärung der Verbrechen helfen, die diese Organisationen begehen, indem sie zeigen, wie Menschen - und Netzwerke von Menschen - miteinander verbunden sind. Militärische Strategien und Taktiken auf dem Schlachtfeld werden heutzutage von Graphen unterstützt; sie sind Teil der aktiven Kriegsführung, um den Feind zu kartieren und zu besiegen. Für Nachrichtendienste erstellen Graphen Übersichten über Netzwerke von Extremisten, die unter Beobachtung stehen, z. B. politische oder religiöse Extremisten. Der Graph-Überblick hilft den Geheimdiensten, diese Netzwerke zu infiltrieren und aufzulösen, bevor sie handeln. Graph-Lösungen für diese Art von Organisationen werden zum Beispiel von IBM und Palantir angeboten.
An Universitäten und in der Wissenschaft im Allgemeinen werden Diagramme verwendet, um Netzwerke von Forschern oder Forschungsthemen abzubilden und zu visualisieren. Diese sind bibliometrische Karten (manchmal auch Cluster und Netzwerke genannt). Ein schönes Beispiel ist dieses bibliometrische Cluster der Forschung zur psychischen Gesundheit. Bibliometrische Karten werden verwendet, um die Leistung von Forschungsaktivitäten an Universitäten zu bewerten, aber auch für Vorhersagen in der Industrie, denn Patentcluster zeigen an, welche Art von Produkten bestimmte Branchen auf den Markt bringen wollen.
Hinweis
Die Beispiele sollen den Wert des Browsens in Diagrammen verdeutlichen - und möglicherweise auch in Datenkatalogen, wo diese Funktion noch in den Kinderschuhen steckt.
Schauen wir uns ein Beispiel an. In Abbildung 4-9 sucht ein PR-Manager in der Kommunikationsabteilung von Hugin & Munin nach Daten zu Beförderungen; einige der Suchergebnisse scheinen verzerrt, aber es ist schwer zu sagen, warum. Der PR-Manager sucht dann ein weiteres Mal nach "Beförderung". Der erste Treffer ist ein Datensatz mit Details zur Aktionsplanung, und der PR-Manager öffnet diesen Treffer als Diagramm. Das Diagramm visualisiert alle Begriffe, Prozesse und Datenquellen, die mit Promotion zu tun haben. Plötzlich versteht der PR-Manager, warum die Ergebnisse verzerrt sind. Jemand hat "Beförderung" als freien Glossarbegriff hinzugefügt, nicht um Kommunikation, sondern um beruflichen Aufstieg darzustellen. Dieser Begriff wird mit einem Ausrufezeichen (!) gekennzeichnet, weil der Datenkatalog automatisch erkennt, dass es sich um ein Duplikat des Domain-Glossarbegriffs handelt, der PR-Aktivitäten definiert. Daher sollten Assets, die mit dem freien Glossarbegriff gekennzeichnet sind, aus der Suche herausgefiltert werden. Mit diesem Wissen kann die PR-Managerin/der PR-Manager die Suche besser auf das ausrichten, wonach sie/er sucht.
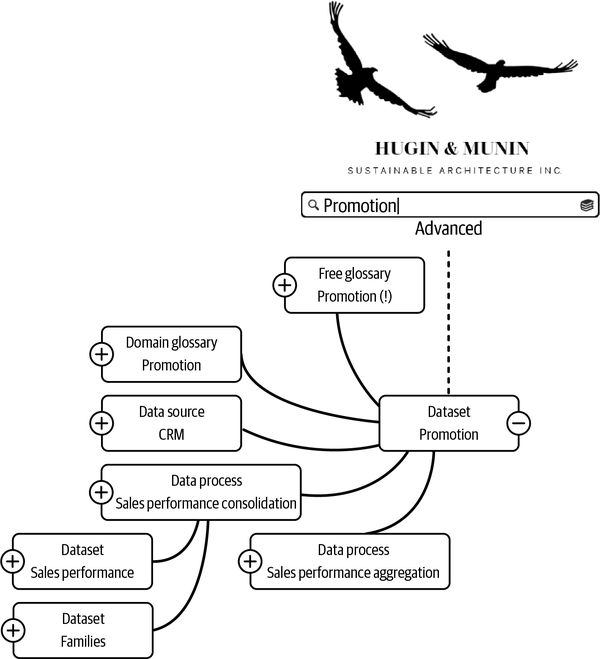
Abbildung 4-9. Grafik durchsuchen
Suche in einem grafikbasierten Datenkatalog
Wie in Abbildung 3-4 dargestellt ist, lässt sich die Suche in ein Spektrum einteilen. Es reicht von leicht ausführbaren einfachen Suchen bis hin zu komplexeren erweiterten Suchen. Im letzteren Fall muss sich der Endnutzer sowohl an die Syntax der IRQL erinnern als auch beurteilen, ob die Semantik der Abfrageanweisung tatsächlich das widerspiegelt, wonach gesucht wird. Das ist anspruchsvoll, aber nützlich. Der IRQL, mit dem der Benutzer sucht, wurde vom Datenkataloganbieter entworfen - ich betrachte DCQL als das Minimum an akzeptablem IRQL. Es ist wahrscheinlich, dass der IRQL im Laufe der Zeit erweitert wird, wenn sich die Technologie mit dem Feedback der Kunden weiterentwickelt. Aber ein IRQL wird dir nie erlauben, nach allem zu suchen.
Bei wissensgraphenbasierten Datenkatalogen ist es jedoch möglich, die Suche noch weiter auszudehnen und tatsächlich nach allem im Datenkatalog zu suchen. Das erfordert Suchfähigkeiten, die über den IRQL des jeweiligen Katalogs hinausgehen: Hier musst du stattdessen den DQL beherrschen, der zur Technologie des jeweiligen Katalogs passt, zum Beispiel SPARQL, Cypher oder Gremlin. Bedenke, dass Data Lineage auch graphenbasiert sein kann und dass, wenn dies der Fall ist, Data Lineage auf ähnliche Weise durchsuchbar ist.
Die Suche mit einer DQL in einem Datenkatalog erfordert technische Fähigkeiten, die nicht für alle Anwendungsfälle von Datenkatalogen erforderlich sind. Aber wenn du deine Daten wirklich so organisieren willst, wie du es möchtest, und sie nach Belieben durchsuchen willst, dann ist das genau das Richtige für dich. Stell dir das so vor: Ein IRQL wird immer vom Anbieter entworfen; er wird einige Elemente enthalten, die für die Suche nützlich sind, und andere weglassen. Mit der Graphen-DQL kannst du jedoch nach allem suchen, was du willst, weil sie so eingerichtet ist, dass sie nach allem sucht, was das Metamodell enthält, egal wie es definiert wurde.
Zusammenfassung
In diesem Kapitel hast du gelernt, wie du die Suche anwenden kannst. Zu den wichtigsten Erkenntnissen gehören:
-
Wenn du nach Daten suchst, musst du die Denkweise eines Bibliothekars anwenden, nicht die eines Datenwissenschaftlers. Die Suche nach Daten ist eine Disziplin, die sich auf Suchmechanismen stützt, aber sie erfordert auch Erfahrung und ein Verständnis für die Daten und die Sprache deines Unternehmens.
-
Die einfache Suche ist die Art der Suche, die die meisten Endnutzer anwenden werden. Ein gut strukturierter Datenkatalog ermöglicht eine präzise, einfache Suche, besonders wenn er auf einem Wissensgraphen basiert. Erwarte aber auch eine Menge Durcheinander in den tieferen Bereichen der Suchergebnisse.
-
Die detaillierte einfache Suche erfordert, dass du die Syntax des IRQL in deinem Datenkatalog kennst. Es braucht also ein bisschen Zeit zum Schreiben oder einfach nur Erfahrung, aber dafür bekommst du superpräzise Treffer.
-
Dieflexible einfache Suche hängt auch davon ab, dass du IRQL verstehst, aber die Suche liefert mehr Ergebnisse, wodurch die Auffindbarkeit (Recall) erhöht und die Genauigkeit (Precision) verringert wird, während sie gleichzeitig eine bessere Möglichkeit ist, ein genau definiertes Thema zu finden als die einfache Suche.
-
Bei derBereichssuche wird in Intervallen gesucht, z. B. in einer Zeitspanne. Diese Art der Suche führt zu einer hohen Genauigkeit und einem niedrigen Recall.
-
DieBlocksuche ist eine strukturierte Methode, um mit IRQL nach einem komplexen Thema zu suchen. Sie funktioniert am besten, wenn deine Glossare erschöpfend sind und sehr spezifisch verwendet werden.
-
DieStatement-Suche ist eine Möglichkeit, nach einem komplexen Thema zu suchen; sie stellt einfach eine Menge Dinge in einer Suche zusammen. Sie ist nicht unstrukturiert, aber sie ist willkürlich.
-
DasDurchsuchen des Glossars ist eine Suche, bei der du dich über die Fachterminologie informierst und aufklärst.
-
Domain Browsing, Lineage Browsing und Graph Browsing sind Möglichkeiten, vertikal, horizontal bzw. relational zu suchen, indem du dich durch die Datenlandschaft klickst.
Im nächsten Kapitel werden wir uns ansehen, wie die Einbindung der Interessengruppen den Unterschied bei der Einführung des Datenkatalogs ausmacht. Wenn jeder den Wert des Datenkatalogs versteht und ihn richtig nutzt, wird die Umsetzung reibungslos verlaufen. Das ist aber nicht immer der Fall. Im nächsten Kapitel erfahren Sie, wie Sie die Beteiligten für einen gut entwickelten Datenkatalog zusammenbringen.
1 Robert S. Taylor, "The Process of Asking Questions", American Documentation 13, no. 4 (Oktober 1962): 391-96.
2 Informationsbedürfnisse können unterschiedlich gruppiert werden; diese Gruppierung stammt aus Louis Rosenfeld et al : For the Web and Beyond (Sebastopol, CA: O'Reilly, 2015), 45.
Get Der Unternehmensdatenkatalog now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

