Kapitel 1. Einführung und Überblick
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Datenbankmanagementsysteme können unterschiedlichen Zwecken dienen: Einige werden vor allem für temporäre heiße Daten verwendet, andere dienen als langlebige kalte Speicherung, einige ermöglichen komplexe analytische Abfragen, einige erlauben nur den Zugriff auf Werte nach dem Schlüssel, einige sind für die Speicherung von Zeitreihendaten optimiert und einige speichern große Blobs effizient. Um die Unterschiede zu verstehen und Unterscheidungen zu treffen, beginnen wir mit einer kurzen Klassifizierung und einem Überblick, denn das hilft uns, den Rahmen für die weiteren Diskussionen zu verstehen.
Die Terminologie kann manchmal zweideutig und ohne einen vollständigen Kontext schwer zu verstehen sein. So gibt es z.B. Unterscheidungen zwischen Spalten- und Wide-List-Speichern, die wenig oder gar nichts miteinander zu tun haben, oder wie sich geclusterte und nicht geclusterte Indizes zu indexorganisierten Tabellen verhalten. In diesem Kapitel geht es darum, diese Begriffe zu klären und ihre genauen Definitionen zu finden.
Wir beginnen mit einem Überblick über die Architektur von Datenbankmanagementsystemen (siehe "DBMS-Architektur") und diskutieren die Systemkomponenten und ihre Aufgaben. Danach besprechen wir die Unterschiede zwischen den Datenbankmanagementsystemen in Bezug auf das Speichermedium (siehe "Speicher- versus plattenbasiertes DBMS") und das Layout (siehe "Spalten- versus zeilenorientiertes DBMS").
Diese beiden Gruppen stellen keine vollständige Taxonomie der Datenbankmanagementsysteme dar und es gibt noch viele andere Möglichkeiten, sie zu klassifizieren. Einige Quellen teilen DBMS zum Beispiel in drei Hauptkategorien ein:
- Online-Transaktionsverarbeitung (OLTP) Datenbanken
-
Diese bearbeiten eine große Anzahl von nutzerorientierten Anfragen und Transaktionen. Die Abfragen sind oft vordefiniert und kurzlebig.
- OLAP-Datenbanken (Online Analytical Processing)
-
Diese verarbeiten komplexe Aggregationen. OLAP-Datenbanken werden häufig für Analysen und Data Warehousing verwendet und sind in der Lage, komplexe, langwierige Ad-hoc-Abfragen zu bearbeiten.
- Hybride transaktionale und analytische Verarbeitung (HTAP)
-
Diese Datenbanken vereinen die Eigenschaften von OLTP- und OLAP-Speichern.
Es gibt viele weitere Begriffe und Klassifizierungen: Key-Value-Stores, relationale Datenbanken, dokumentenorientierte Speicher und Graphdatenbanken. Diese Konzepte werden hier nicht definiert, da davon ausgegangen wird, dass der Leser ein hohes Maß an Wissen und Verständnis über ihre Funktionsweise hat. Da die Konzepte, die wir hier erörtern, weithin anwendbar sind und in den meisten der genannten Speichertypen in irgendeiner Form verwendet werden, ist eine vollständige Taxonomie für die weitere Diskussion nicht notwendig oder wichtig.
Da sich Teil I dieses Buches auf die Strukturen der Speicherung und Indizierung konzentriert, müssen wir die Ansätze der Datenorganisation auf hoher Ebene und die Beziehung zwischen den Daten- und Indexdateien verstehen (siehe "Datendateien und Indexdateien").
In "Buffering, Immutability, and Ordering" (Pufferung, Unveränderlichkeit und Ordnung) diskutieren wir schließlich drei Techniken, die häufig zur Entwicklung effizienter Speicherstrukturen verwendet werden, und wie die Anwendung dieser Techniken ihr Design und ihre Implementierung beeinflusst.
DBMS-Architektur
Es gibt keinen gemeinsamen Entwurf für ein Datenbankmanagementsystem. Jede Datenbank ist etwas anders aufgebaut, und die Grenzen zwischen den Komponenten sind schwer zu erkennen und zu definieren. Selbst wenn diese Grenzen auf dem Papier existieren (z. B. in der Projektdokumentation), können im Code scheinbar unabhängige Komponenten aufgrund von Leistungsoptimierungen, der Handhabung von Kanten oder architektonischen Entscheidungen gekoppelt sein.
Quellen, die die Architektur von Datenbankmanagementsystemen beschreiben (zum Beispiel [HELLERSTEIN07], [WEIKUM01], [ELMASRI11] und [GARCIAMOLINA08]), definieren die Komponenten und die Beziehungen zwischen ihnen unterschiedlich. Die in Abbildung 1-1 dargestellte Architektur veranschaulicht einige der gemeinsamen Themen dieser Darstellungen.
Datenbankmanagementsysteme verwenden ein Client/Server-Modell, bei dem die Instanzen des Datenbanksystems(Knoten) die Rolle des Servers und die Anwendungsinstanzen die Rolle des Clients einnehmen.
Kundenanfragen kommen über das Transport-Subsystem an. Die Anfragen kommen in Form von Abfragen, die meist in einer Abfragesprache formuliert sind. Das Transport-Subsystem ist auch für die Kommunikation mit anderen Knoten im Datenbank-Cluster zuständig.
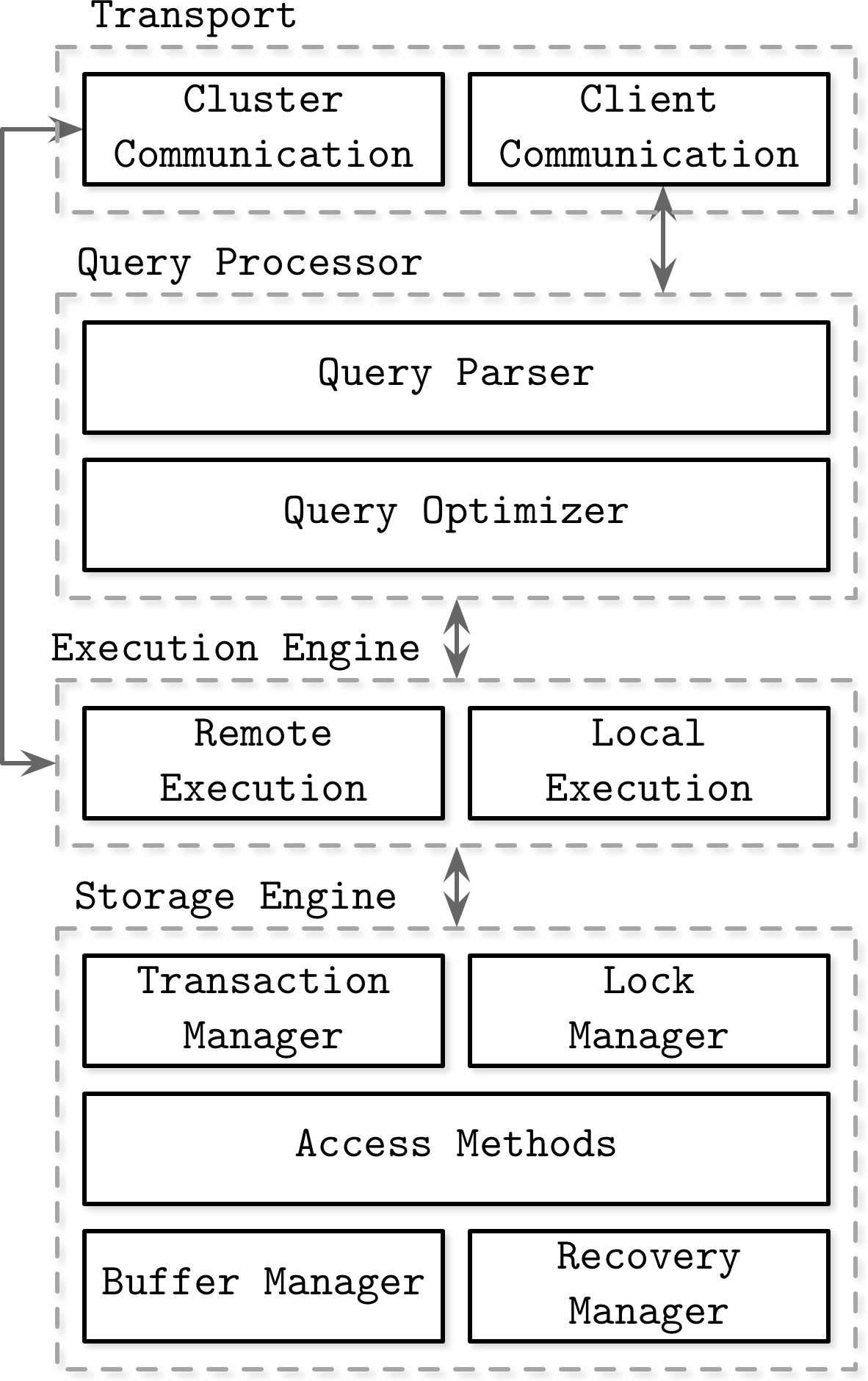
Abbildung 1-1. Architektur eines Datenbankmanagementsystems
Nach dem Empfang von übergibt das Transport-Subsystem die Abfrage an einen Abfrageprozessor, der sie parst, interpretiert und validiert. Später werden die Zugriffskontrollen durchgeführt, da sie erst nach der Interpretation der Abfrage vollständig durchgeführt werden können.
Die geparste Abfrage wird an den Abfrageoptimierer weitergeleitet, der zunächst unmögliche und redundante Teile der Abfrage eliminiert und dann versucht, anhand interner Statistiken (Indexkardinalität, ungefähre Schnittmenge usw.) und der Datenplatzierung (welche Knoten im Cluster die Daten enthalten und welche Kosten mit ihrer Übertragung verbunden sind) den effizientesten Weg zur Ausführung zu finden. Der Optimierer kümmert sich sowohl um die relationalen Operationen, die für die Auflösung der Abfrage erforderlich sind und in der Regel als Abhängigkeitsbaum dargestellt werden, als auch um Optimierungen wie Indexreihenfolge, Kardinalitätsschätzung und die Wahl der Zugriffsmethoden.
Die Abfrage wird normalerweise in Form eines Ausführungsplans (oder Abfrageplans) präsentiert: eine Abfolge von Operationen, die ausgeführt werden müssen, damit die Ergebnisse als vollständig gelten. Da dieselbe Abfrage mit verschiedenen Ausführungsplänen erfüllt werden kann, die sich in ihrer Effizienz unterscheiden, wählt der Optimierer den besten verfügbaren Plan aus.
Der Ausführungsplan wird von der Execution Engine ausgeführt, die die Ergebnisse der lokalen und entfernten Operationen zusammenfasst. Die Remote-Ausführung kann das Schreiben und Lesen von Daten zu und von anderen Knoten im Cluster sowie die Replikation umfassen.
Lokale Abfragen (direkt vom Kunden oder von anderen Knoten) werden von der Speicher-Engine ausgeführt. Die Speicher-Engine besteht aus mehreren Komponenten mit speziellen Aufgaben:
- Transaktionsmanager
-
Dieser Manager plant die Transaktionen und stellt sicher, dass sie die Datenbank nicht in einem logisch inkonsistenten Zustand verlassen.
- Sperre Manager
-
Dieser Manager sperrt die Datenbankobjekte für die laufenden Transaktionen und stellt so sicher, dass die physische Datenintegrität durch gleichzeitige Operationen nicht verletzt wird.
- Zugriffsmethoden (Speicherstrukturen)
-
Diese verwalten den Zugriff und die Organisation von Daten auf der Festplatte. Zu den Zugriffsmethoden gehören Heap-Dateien und Speicherstrukturen wie B-Trees (siehe "Ubiquitäre B-Trees") oder LSM-Trees (siehe "LSM-Trees").
- Puffer-Manager
-
Dieser Manager legt Datenseiten im Speicher zwischen (siehe "Pufferverwaltung").
- Recovery Manager
-
Dieser Manager verwaltet das Betriebsprotokoll und stellt den Systemzustand im Falle eines Ausfalls wieder her (siehe "Wiederherstellung").
Transaktions- und Sperrmanager sind gemeinsam für die Gleichzeitigkeitskontrolle verantwortlich (siehe "Gleichzeitigkeitskontrolle"): Sie garantieren die logische und physische Datenintegrität und sorgen dafür, dass gleichzeitige Operationen so effizient wie möglich ausgeführt werden.
Speicher- versus plattenbasiertes DBMS
Datenbanksysteme speichern Daten im Speicher und auf der Festplatte. In-Memory-Datenbankmanagementsysteme (manchmal auch Hauptspeicher-DBMS genannt) speichern die Daten hauptsächlich im Speicher und nutzen die Festplatte für die Wiederherstellung und Protokollierung. Festplattenbasierte DBMS speichern den Großteil der Daten auf der Festplatte und nutzen den Arbeitsspeicher zum Zwischenspeichern von Festplatteninhalten oder als temporäre Speicherung. Beide Arten von Systemen nutzen die Festplatte bis zu einem gewissen Grad, aber Hauptspeicher-Datenbanken speichern ihre Inhalte fast ausschließlich im Arbeitsspeicher.
Der Zugriff auf den Speicher war und ist immer noch um Größenordnungen schneller als der Zugriff auf die Festplatte,1 Deshalb ist es sinnvoll, den Arbeitsspeicher als primäre Speicherung zu nutzen, und es wird immer wirtschaftlicher, dies zu tun, wenn die Preise für Arbeitsspeicher sinken. Allerdings sind die Preise für Arbeitsspeicher im Vergleich zu dauerhaften Speichergeräten wie SSDs und HDDs immer noch hoch.
Hauptspeicher-Datenbanksysteme unterscheiden sich von ihren plattenbasierten Pendants nicht nur in Bezug auf das primäre Speichermedium, sondern auch in Bezug auf die verwendeten Datenstrukturen, Organisations- und Optimierungstechniken.
Datenbanken, die den Arbeitsspeicher als primären Datenspeicher nutzen, tun dies vor allem wegen der Leistung, der vergleichsweise geringen Zugriffskosten und der Zugriffsgranularität. Die Programmierung für den Hauptspeicher ist auch wesentlich einfacher als die für die Festplatte. Betriebssysteme abstrahieren die Speicherverwaltung und erlauben es uns, über die Zuweisung und Freigabe von beliebig großen Speicherabschnitten nachzudenken. Auf der Festplatte müssen wir Datenreferenzen, Serialisierungsformate, freigegebenen Speicher und Fragmentierung manuell verwalten.
Die wichtigsten Faktoren, die das Wachstum von In-Memory-Datenbanken einschränken, sind die Volatilität des Arbeitsspeichers (mit anderen Worten, die fehlende Haltbarkeit) und die Kosten. Da die Inhalte des Arbeitsspeichers nicht beständig sind, können Softwarefehler, Abstürze, Hardwareausfälle und Stromausfälle zu Datenverlusten führen. Es gibt Möglichkeiten, die Dauerhaftigkeit zu gewährleisten, z. B. unterbrechungsfreie Stromversorgungen und batteriegepufferte Arbeitsspeicher, aber sie erfordern zusätzliche Hardwareressourcen und betriebliches Know-how. In der Praxis läuft alles auf die Tatsache hinaus, dass Festplatten einfacher zu warten und deutlich günstiger sind.
Die Situation wird sich wahrscheinlich ändern, wenn die Verfügbarkeit und Popularität von nichtflüchtigen Speichertechnologien (NVM) [ARULRAJ17] zunimmt. Die NVM Speicherung reduziert oder eliminiert (je nach Technologie) die Asymmetrie zwischen Lese- und Schreiblatenzen, verbessert die Lese- und Schreibleistung weiter und ermöglicht den byteadressierbaren Zugriff.
Langlebigkeit in speicherbasierten Lagern
In-Memory-Datenbanksysteme halten Backups auf der Festplatte, um die Haltbarkeit zu gewährleisten und den Verlust der flüchtigen Daten zu verhindern. Einige Datenbanken speichern Daten ausschließlich im Speicher, ohne jegliche Haltbarkeitsgarantien, aber darauf gehen wir im Rahmen dieses Buches nicht ein.
Bevor der Vorgang als abgeschlossen betrachtet werden kann, müssen seine Ergebnisse in eine sequentielle Protokolldatei geschrieben werden. Wir besprechen Write-Ahead-Logs ausführlicher im Abschnitt "Wiederherstellung". Um zu vermeiden, dass der gesamte Log-Inhalt beim Start oder nach einem Absturz erneut abgespielt wird, führen die In-Memory-Speicher eine Sicherungskopie. Die Sicherungskopie wird als sortierte Struktur auf der Festplatte verwaltet, und Änderungen an dieser Struktur werden oft asynchron (entkoppelt von Client-Anfragen) und in Batches durchgeführt, um die Anzahl der E/A-Vorgänge zu reduzieren. Bei der Wiederherstellung kann der Datenbankinhalt aus der Sicherungskopie und den Logs wiederhergestellt werden.
Log-Einträge werden in der Regel in Stapeln auf das Backup angewendet. Nachdem der Stapel von Log-Einträgen verarbeitet wurde, hält das Backup einen Datenbank-Snapshot für einen bestimmten Zeitpunkt fest, und die Log-Inhalte bis zu diesem Zeitpunkt können verworfen werden. Dieser Prozess wird Checkpointing genannt. Er verkürzt die Wiederherstellungszeiten, indem er die plattenresidente Datenbank mit den Log-Einträgen auf dem neuesten Stand hält, ohne dass die Clients blockieren müssen, bis die Sicherung aktualisiert wird.
Hinweis
Es ist unfair zu sagen, dass die In-Memory-Datenbank das Äquivalent einer On-Disk-Datenbank mit einem riesigen Seiten-Cache ist (siehe "Pufferverwaltung"). Auch wenn die Seiten im Speicher zwischengespeichert werden, verursachen das Serialisierungsformat und das Datenlayout zusätzlichen Aufwand und ermöglichen nicht denselben Grad an Optimierung, den In-Memory-Speicher erreichen können.
Festplattenbasierte Datenbanken verwenden spezielle Speicherstrukturen, die für den Festplattenzugriff optimiert sind. Im Speicher können Zeiger vergleichsweise schnell verfolgt werden, und der zufällige Speicherzugriff ist deutlich schneller als der zufällige Festplattenzugriff. Festplattenbasierte Speicherstrukturen haben oft die Form von breiten und kurzen Bäumen (siehe "Bäume für die festplattenbasierte Speicherung"), während speicherbasierte Implementierungen aus einem größeren Pool von Datenstrukturen wählen und Optimierungen durchführen können, die auf der Festplatte sonst nicht oder nur schwer zu realisieren wären [GARCIAMOLINA92]. Ebenso erfordert der Umgang mit Daten variabler Größe auf der Festplatte besondere Aufmerksamkeit, während es im Speicher oft ausreicht, den Wert mit einem Zeiger zu referenzieren.
Bei einigen Anwendungsfällen kann man davon ausgehen, dass ein ganzer Datensatz in den Speicher passt. Einige Datensätze sind durch ihre reale Darstellung begrenzt, wie z. B. Schülerdatensätze für Schulen, Kundendatensätze für Unternehmen oder Inventar in einem Online-Store. Jeder Datensatz benötigt nicht mehr als ein paar Kilobyte, und seine Anzahl ist begrenzt.
Spalten- versus zeilenorientiertes DBMS
Die meisten Datenbanksysteme speichern eine Menge von Datensätzen, die aus Spalten und Zeilen in Tabellen bestehen. Ein Feld ist eine Schnittmenge aus einer Spalte und einer Zeile: ein einzelner Wert eines bestimmten Typs. Felder, die zur gleichen Spalte gehören, haben normalerweise den gleichen Datentyp. Wenn wir zum Beispiel eine Tabelle mit Benutzerdatensätzen definieren, sind alle Namen vom gleichen Typ und gehören zur gleichen Spalte. Eine Sammlung von Werten, die logisch zu demselben Datensatz gehören (normalerweise durch den Schlüssel identifiziert), bildet eine Zeile.
Eine Möglichkeit, Datenbanken zu klassifizieren, besteht darin, wie die Daten auf der Festplatte gespeichert werden: zeilen- oder spaltenweise. Tabellen können entweder horizontal (Werte, die zur selben Zeile gehören, werden zusammen gespeichert) oder vertikal (Werte, die zur selben Spalte gehören, werden zusammen gespeichert) partitioniert werden. Abbildung 1-2 veranschaulicht diese Unterscheidung: (a) zeigt die spaltenweise partitionierten Werte und (b) die zeilenweise partitionierten Werte.
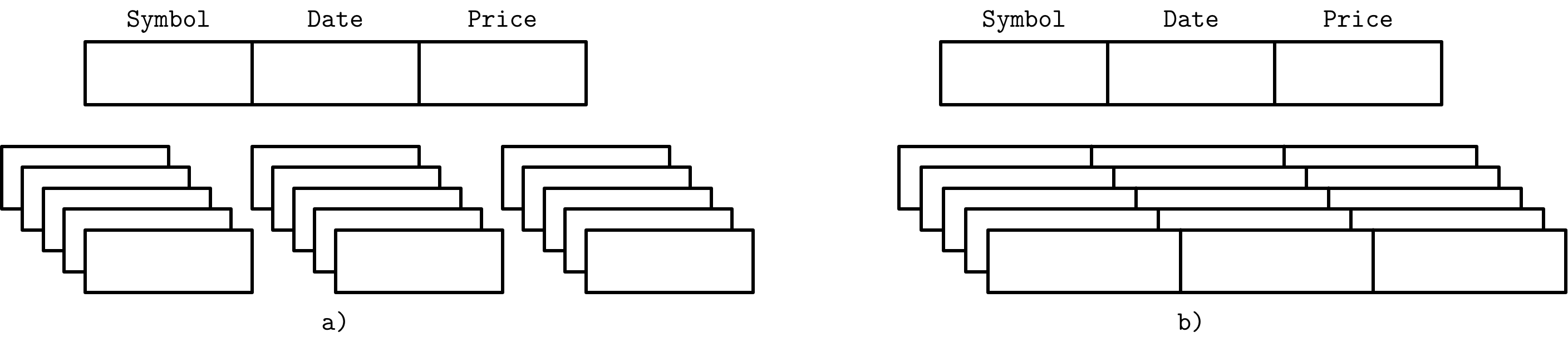
Abbildung 1-2. Datenlayout in spalten- und zeilenorientierten Läden
Beispiele für zeilenorientierte Datenbankmanagementsysteme gibt es zuhauf: MySQL, PostgreSQL und die meisten der traditionellen relationalen Datenbanken. Die beiden wegweisenden Open Source spaltenorientierten Speicher sind MonetDB und C-Store (C-Store ist ein Open Source Vorgänger von Vertica).
Zeilenorientiertes Datenlayout
Zeilenorientierte Datenbankmanagementsysteme speichern Daten in Datensätzen oder Zeilen. Ihr Layout kommt der tabellarischen Datendarstellung recht nahe, bei der jede Zeile den gleichen Satz von Feldern hat. Eine zeilenorientierte Datenbank kann zum Beispiel effizient Benutzereinträge mit Namen, Geburtsdaten und Telefonnummern speichern:
| ID | Name | Birth Date | Phone Number | | 10 | John | 01 Aug 1981 | +1 111 222 333 | | 20 | Sam | 14 Sep 1988 | +1 555 888 999 | | 30 | Keith | 07 Jan 1984 | +1 333 444 555 |
Dieser Ansatz eignet sich gut für Fälle, in denen der Datensatz aus mehreren Feldern besteht (Name, Geburtsdatum und eine Telefonnummer), die durch den Schlüssel (in diesem Beispiel eine monoton steigende Zahl) eindeutig identifiziert werden. Oft werden alle Felder, die einen einzelnen Datensatz darstellen, zusammen gelesen. Beim Erstellen von Datensätzen (z. B. beim Ausfüllen eines Anmeldeformulars) schreiben wir sie ebenfalls zusammen. Gleichzeitig kann jedes Feld einzeln geändert werden.
Da zeilenorientierte Speicher am nützlichsten in Szenarien sind, in denen wir zeilenweise auf Daten zugreifen müssen, verbessert die gemeinsame Speicherung ganzer Zeilen die räumliche Lokalität2 [DENNING68].
Da auf Daten auf einem dauerhaften Medium wie einer Festplatte in der Regel blockweise zugegriffen wird (mit anderen Worten, die kleinste Einheit des Festplattenzugriffs ist ein Block), enthält ein einzelner Block die Daten für alle Spalten. Das ist gut, wenn wir auf einen ganzen Datensatz zugreifen wollen, macht aber Abfragen, die auf einzelne Felder mehrerer Datensätze zugreifen (z. B. Abfragen, die nur die Telefonnummern abrufen), teurer, da die Daten für die anderen Felder ebenfalls ausgelagert werden.
Spaltenorientiertes Datenlayout
Spaltenorientierte Datenbankmanagementsysteme partitionieren Daten vertikal (d.h. nach Spalten), anstatt sie in Zeilen zu speichern. Hier werden die Werte für dieselbe Spalte zusammenhängend auf der Festplatte gespeichert (im Gegensatz zur zusammenhängenden Speicherung von Zeilen wie im vorherigen Beispiel). Wenn wir zum Beispiel historische Börsenkurse speichern, werden die Kurse zusammen gespeichert. Die Speicherung von Werten für verschiedene Spalten in separaten Dateien oder Dateisegmenten ermöglicht effiziente spaltenweise Abfragen, da sie in einem Durchgang gelesen werden können, anstatt ganze Zeilen zu verbrauchen und Daten für Spalten, die nicht abgefragt wurden, zu verwerfen.
Spaltenorientierte Speicher eignen sich gut für analytische Workloads, die Aggregate berechnen, wie z. B. die Suche nach Trends, die Berechnung von Durchschnittswerten usw. Die Verarbeitung komplexer Aggregate kann in Fällen genutzt werden, in denen logische Datensätze mehrere Felder haben, von denen einige (in diesem Fall Preisnotierungen) jedoch unterschiedlich wichtig sind und oft zusammen konsumiert werden.
Aus logischer Sicht können die Daten, die die Börsenkurse darstellen, immer noch als Tabelle ausgedrückt werden:
| ID | Symbol | Date | Price | | 1 | DOW | 08 Aug 2018 | 24,314.65 | | 2 | DOW | 09 Aug 2018 | 24,136.16 | | 3 | S&P | 08 Aug 2018 | 2,414.45 | | 4 | S&P | 09 Aug 2018 | 2,232.32 |
Das physische spaltenbasierte Datenbanklayout sieht jedoch ganz anders aus. Werte, die zur gleichen Spalte gehören, werden dicht nebeneinander gespeichert:
Symbol: 1:DOW; 2:DOW; 3:S&P; 4:S&P Date: 1:08 Aug 2018; 2:09 Aug 2018; 3:08 Aug 2018; 4:09 Aug 2018 Price: 1:24,314.65; 2:24,136.16; 3:2,414.45; 4:2,232.32
Um Daten-Tupel zu rekonstruieren, die für Joins, Filter und mehrzeilige Aggregate nützlich sein können, müssen wir einige Metadaten auf Spaltenebene erhalten, um zu erkennen, mit welchen Datenpunkten aus anderen Spalten sie verbunden sind. Wenn du dies explizit tust, muss jeder Wert einen Schlüssel enthalten, was zu Doppelungen führt und die Menge der gespeicherten Daten erhöht. Einige Spaltenspeicher verwenden stattdessen implizite Bezeichner(virtuelle IDs) und nutzen die Position des Wertes (mit anderen Worten, seinen Offset), um ihn den zugehörigen Werten zuzuordnen [ABADI13].
In den letzten Jahren hat viele neue spaltenorientierte Dateiformate wie Apache Parquet, Apache ORC, RCFile und spaltenorientierte Speicher wie Apache Kudu, ClickHouse und viele andere entwickelt, wahrscheinlich aufgrund der steigenden Nachfrage nach komplexen analytischen Abfragen auf wachsenden Datensätzen [ROY12].
Unterscheidungen und Optimierungen
Es reicht nicht aus zu sagen, dass die Unterschiede zwischen Zeilen- und Spaltenspeichern nur in der Art und Weise liegen, wie die Daten gespeichert werden. Die Wahl des Datenlayouts ist nur einer der Schritte in einer Reihe von möglichen Optimierungen, auf die Spaltenlager abzielen.
Das Lesen mehrerer Werte für dieselbe Spalte in einem Durchgang verbessert die Cache-Nutzung und die Recheneffizienz erheblich. Auf modernen CPUs können vektorisierte Anweisungen verwendet werden, um mehrere Datenpunkte mit einer einzigen CPU-Anweisung zu verarbeiten3 [DREPPER07].
Die gemeinsame Speicherung von Werten desselben Datentyps (z. B. Zahlen mit anderen Zahlen, Zeichenketten mit anderen Zeichenketten) bietet ein besseres Komprimierungsverhältnis. Wir können je nach Datentyp verschiedene Komprimierungsalgorithmen verwenden und die jeweils effektivste Komprimierungsmethode auswählen.
Um zu entscheiden, ob du einen spalten- oder einen zeilenorientierten Speicher verwenden sollst, musst du deine Zugriffsmuster kennen. Wenn die gelesenen Daten in Datensätzen verbraucht werden (d.h. die meisten oder alle Spalten werden abgefragt) und die Arbeitslast hauptsächlich aus Punktabfragen und Bereichsscans besteht, wird der zeilenorientierte Ansatz wahrscheinlich bessere Ergebnisse liefern. Wenn sich die Abfragen über viele Zeilen erstrecken oder ein Aggregat über eine Teilmenge von Spalten berechnet wird, lohnt es sich, einen spaltenorientierten Ansatz in Betracht zu ziehen.
Breite Säule Stores
Spaltenorientierte Datenbanken sollten nicht mit breiten Spaltenspeichern wie BigTable oder HBase verwechselt werden, bei denen die Daten als multidimensionale Karte dargestellt werden, die Spalten in Spaltenfamilien gruppiert sind (in denen normalerweise Daten desselben Typs gespeichert werden) und die Daten innerhalb jeder Spaltenfamilie zeilenweise gespeichert werden. Dieses Layout eignet sich am besten für die Speicherung von Daten, die über einen Schlüssel oder eine Reihe von Schlüsseln abgerufen werden.
Ein klassisches Beispiel aus dem Bigtable Paper [CHANG06] ist eine Webtabelle. Eine Webtabelle speichert Schnappschüsse von Webseiteninhalten, ihren Attributen und den Beziehungen zwischen ihnen zu einem bestimmten Zeitstempel. Die Seiten werden durch die umgekehrte URL identifiziert, und alle Attribute (wie Seiteninhalte und Anker, die Links zwischen den Seiten darstellen) werden durch die Zeitstempel identifiziert, zu denen diese Schnappschüsse gemacht wurden. Vereinfacht lässt sich das Ganze als eine verschachtelte Karte darstellen, wie Abbildung 1-3 zeigt.

Abbildung 1-3. Konzeptioneller Aufbau einer Webtabelle
Die Daten werden in einer mehrdimensionalen sortierten Karte mit hierarchischen Indizes gespeichert: Wir können die Daten zu einer bestimmten Webseite anhand ihrer umgekehrten URL und ihre Inhalte oder Anker anhand des Zeitstempels finden. Jede Zeile wird durch ihren Zeilenschlüssel indiziert. Zusammengehörige Spalten werden in Spaltenfamilien zusammengefasst -in diesem Beispielcontents und anchor -, die separat auf der Festplatte gespeichert werden. Jede Spalte innerhalb einer Spaltenfamilie wird durch den Spaltenschlüssel identifiziert, der eine Kombination aus dem Namen der Spaltenfamilie und einem Qualifizierer ist (html, cnnsi.com, my.look.ca in diesem Beispiel). Spaltenfamilien speichern mehrere Versionen von Daten nach Zeitstempel. Dieses Layout ermöglicht es uns, die übergeordneten Einträge (in diesem Fall Webseiten) und ihre Parameter (Versionen des Inhalts und Links zu den anderen Seiten) schnell zu finden.
Während es nützlich ist, die konzeptionelle Darstellung von breiten Spaltenspeichern zu verstehen, ist ihr physisches Layout etwas anders. Eine schematische Darstellung der Datenanordnung in Spaltenfamilien ist in Abbildung 1-4 zu sehen: Spaltenfamilien werden separat gespeichert, aber in jeder Spaltenfamilie werden die Daten, die zum selben Schlüssel gehören, gemeinsam gespeichert.
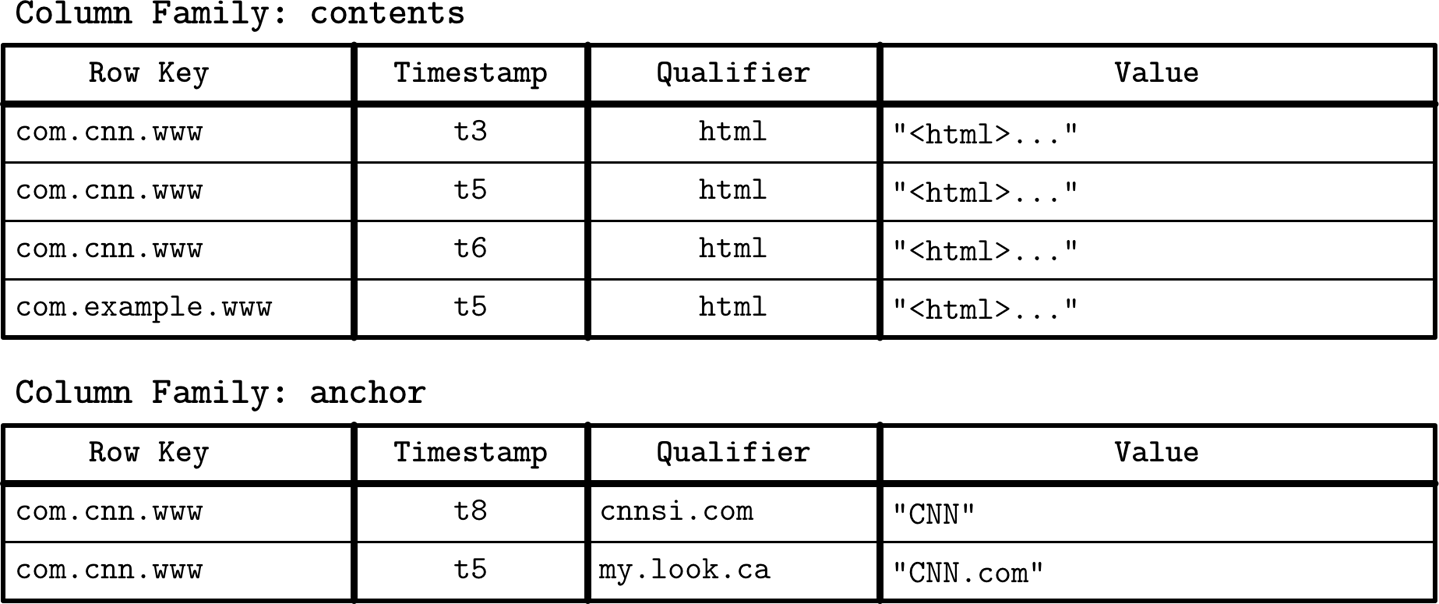
Abbildung 1-4. Physikalische Struktur einer Webtabelle
Datendateien und Indexdateien
Das Hauptziel eines Datenbanksystems ist es, Daten zu speichern und einen schnellen Zugriff darauf zu ermöglichen. Aber wie sind die Daten organisiert? Warum brauchen wir ein Datenbankmanagementsystem und nicht nur einen Haufen von Dateien? Wie verbessert die Dateiorganisation die Effizienz?
Datenbanksysteme verwenden zwar Dateien zum Speichern der Daten, aber anstatt sich auf Dateisystemhierarchien von Verzeichnissen und Dateien zu verlassen, um Datensätze zu finden, setzen sie Dateien mit implementierungsspezifischen Formaten zusammen. Die Hauptgründe für die Verwendung einer speziellen Dateiorganisation anstelle von Flat Files sind:
- Effizienz der Speicherung
-
Die Dateien sind so organisiert, dass der Speicheraufwand pro gespeichertem Datensatz minimiert wird.
- Zugangseffizienz
-
Aufzeichnungen können in der kleinstmöglichen Anzahl von Schritten gefunden werden.
- Effizienz aktualisieren
-
Datensatzaktualisierungen werden so durchgeführt, dass die Anzahl der Änderungen auf der Festplatte minimiert wird.
Datenbanksysteme speichern Datensätze, die aus mehreren Feldern bestehen, in Tabellen, wobei jede Tabelle normalerweise als separate Datei dargestellt wird. Jeder Datensatz in der Tabelle kann mit Hilfe eines Suchschlüssels nachgeschlagen werden. Um einen Datensatz zu finden, verwenden Datenbanksysteme Indizes: zusätzliche Datenstrukturen, die es ermöglichen, Datensätze effizient zu finden, ohne bei jedem Zugriff die gesamte Tabelle zu durchsuchen. Indizes werden anhand einer Teilmenge von Feldern erstellt, die den Datensatz identifizieren.
Ein Datenbanksystem trennt in der Regel zwischen Datendateien und Indexdateien: Datendateien speichern Datensätze, während Indexdateien Datensatz-Metadaten speichern und diese zum Auffinden von Datensätzen in Datendateien verwenden. Indexdateien sind normalerweise kleiner als die Datendateien. Die Dateien sind in Seiten unterteilt, die in der Regel die Größe eines einzelnen oder mehrerer Festplattenblöcke haben. Seiten können als Sequenzen von Datensätzen oder als Slotted Pages (siehe "Slotted Pages") organisiert werden.
Neue Datensätze (Einfügungen) und Aktualisierungen bestehender Datensätze werden durch Schlüssel/Wertpaare dargestellt. Die meisten modernen Speichersysteme löschen Daten nicht explizit von Seiten. Stattdessen verwenden sie Löschmarkierungen (auch Tombstones genannt), die Metadaten zur Löschung enthalten, z. B. einen Schlüssel und einen Zeitstempel. Der Speicherplatz, der von den Datensätzen belegt wird, die durch ihre Aktualisierungen oder Löschmarkierungen überschattet werden, wird durch die Speicherbereinigung zurückgewonnen.
Daten-Dateien
Datendateien (manchmal auch Primärdateien genannt) können als index-organisierte Tabellen (IOT), heap-organisierte Tabellen (Heap-Dateien) oder hash-organisierte Tabellen (Hash-Dateien) implementiert werden.
Datensätze in Heap-Dateien müssen keiner bestimmten Reihenfolge folgen und werden meistens in einer Schreibreihenfolge abgelegt. Auf diese Weise ist keine zusätzliche Arbeit oder Reorganisation der Datei erforderlich, wenn neue Seiten angehängt werden. Heap-Dateien benötigen zusätzliche Indexstrukturen, die auf die Speicherorte der Datensätze verweisen, um sie durchsuchbar zu machen.
In Hash-Dateien werden die Datensätze in Buckets gespeichert, und der Hash-Wert des Schlüssels bestimmt, zu welchem Bucket ein Datensatz gehört. Die Datensätze im Bucket können in angehängter Reihenfolge oder nach Schlüssel sortiert gespeichert werden, um die Suchgeschwindigkeit zu erhöhen.
Index-organisierte Tabellen (IOTs) speichern Datensätze im Index selbst. Da die Datensätze in Schlüsselreihenfolge gespeichert werden, können Bereichsscans in IOTs durch sequentielles Scannen des Inhalts durchgeführt werden.
Durch die Speicherung von Datensätzen im Index können wir die Anzahl der Festplattenzugriffe um mindestens einen reduzieren, da wir nach dem Durchlaufen des Index und dem Auffinden des gesuchten Schlüssels keine separate Datei ansprechen müssen, um den zugehörigen Datensatz zu finden.
Wenn Datensätze in einer separaten Datei gespeichert werden, enthalten Indexdateien Dateneinträge, die die Datensätze eindeutig identifizieren und genügend Informationen enthalten, um sie in der Datendatei zu finden. Wir können zum Beispiel Datei-Offsets (manchmal auch Zeilenlokatoren genannt), Positionen von Datensätzen in der Datendatei oder Bucket-IDs im Fall von Hash-Dateien speichern. In indexorganisierten Tabellen enthalten die Dateneinträge die eigentlichen Datensätze.
Index Dateien
Ein Index ist eine Struktur, die Datensätze auf der Festplatte so organisiert, dass sie effizient abgerufen werden können. Indexdateien sind als spezialisierte Strukturen organisiert, die Schlüssel auf Orte in Datendateien abbilden, an denen die durch diese Schlüssel (im Falle von Heap-Dateien) oder Primärschlüssel (im Falle von indexorganisierten Tabellen) identifizierten Datensätze gespeichert sind.
Ein Index auf einer Primärdatei (Daten) wird Primärindex genannt. In den meisten Fällen können wir auch davon ausgehen, dass der Primärindex über einen Primärschlüssel oder eine Gruppe von Schlüsseln erstellt wird, die als primär gekennzeichnet sind. Alle anderen Indizes werden als sekundär bezeichnet.
Sekundärindizes können direkt auf den Datensatz verweisen oder einfach den Primärschlüssel speichern. Ein Zeiger auf einen Datensatz kann einen Offset zu einer Heap-Datei oder einer indexorganisierten Tabelle enthalten. Mehrere sekundäre Indizes können auf denselben Datensatz verweisen, so dass ein einzelner Datensatz durch verschiedene Felder identifiziert und über verschiedene Indizes gefunden werden kann. Während primäre Indexdateien einen einzigen Eintrag pro Suchschlüssel enthalten, können sekundäre Indizes mehrere Einträge pro Suchschlüssel enthalten [GARCIAMOLINA08].
Wenn die Reihenfolge der Datensätze der Reihenfolge des Suchschlüssels folgt, wird dieser Index als geclustert bezeichnet (auch als Clustering bekannt). Datensätze im geclusterten Fall werden normalerweise in derselben Datei oder in einer geclusterten Datei gespeichert, in der die Schlüsselreihenfolge beibehalten wird. Wenn die Daten in einer separaten Datei gespeichert sind und ihre Reihenfolge nicht der Schlüsselreihenfolge entspricht, wird der Index als nonclustered (manchmal auch unclustered) bezeichnet.
Abbildung 1-5 zeigt den Unterschied zwischen diesen beiden Ansätzen:
a) Eine indexorganisierte Tabelle, bei der die Datensätze direkt in der Indexdatei gespeichert werden.
b) Eine Indexdatei, in der die Offsets gespeichert werden, und eine separate Datei, in der die Datensätze gespeichert werden.
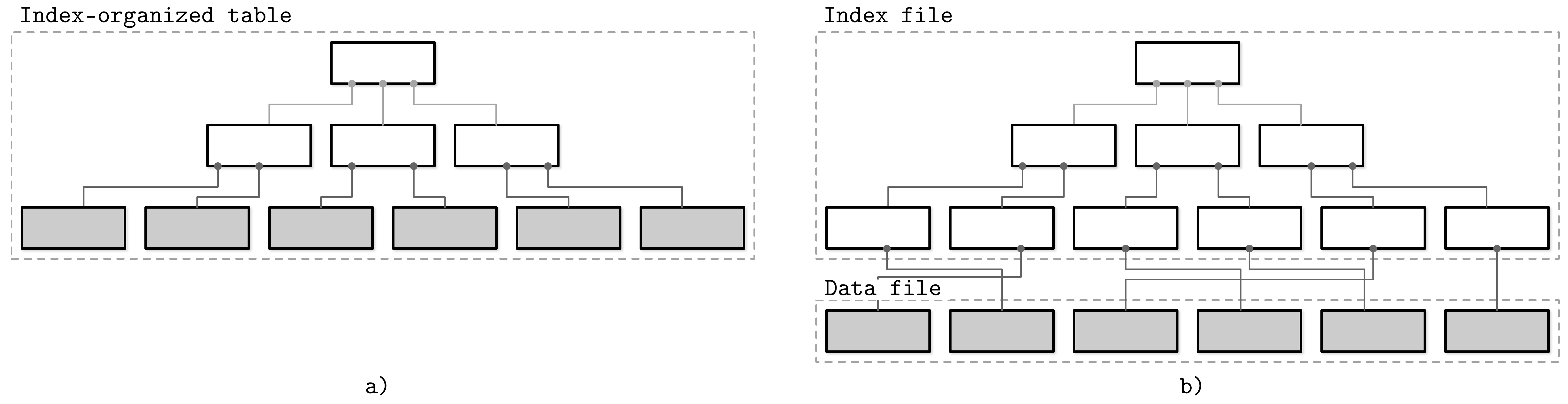
Abbildung 1-5. Speichern von Datensätzen in einer Indexdatei im Vergleich zum Speichern von Offsets in der Datendatei (Indexsegmente sind weiß dargestellt; Segmente mit Datensätzen sind grau dargestellt)
Hinweis
Indexorganisierte Tabellen speichern Informationen in Indexreihenfolge und sind per Definition geclustert. Primärindizes sind am häufigsten geclustert. Sekundäre Indizes sind per Definition nicht geclustert, da sie dazu dienen, den Zugriff über andere Schlüssel als den primären zu erleichtern. Geclusterte Indizes können sowohl indexorganisiert sein als auch separate Index- und Datendateien haben.
Viele Datenbanksysteme haben einen inhärenten und expliziten Primärschlüssel, eine Reihe von Spalten, die den Datenbankdatensatz eindeutig identifizieren. In Fällen, in denen der Primärschlüssel nicht angegeben ist, kann die Speicherung einen impliziten Primärschlüssel erstellen (z. B. fügt MySQL InnoDB eine neue auto-increment-Spalte hinzu und füllt deren Werte automatisch aus).
Diese Terminologie wird in verschiedenen Arten von Datenbanksystemen verwendet: relationale Datenbanksysteme (wie MySQL und PostgreSQL), Dynamo-basierte NoSQL-Speicher (wie Apache Cassandra und Riak) und Dokumentenspeicher (wie MongoDB). Es kann einige projektspezifische Bezeichnungen geben, aber meistens gibt es eine klare Zuordnung zu dieser Terminologie.
Primärindex als Indirektion
In der Datenbankgemeinde gibt es unterschiedliche Meinungen darüber, ob Datensätze direkt (über den Dateiversatz) oder über den Primärschlüsselindex referenziert werden sollten.4
Beide Ansätze haben ihre Vor- und Nachteile und werden besser im Rahmen einer vollständigen Implementierung diskutiert. Wenn wir Daten direkt referenzieren, können wir die Anzahl der Suchvorgänge auf der Festplatte reduzieren, müssen aber die Kosten für die Aktualisierung der Zeiger tragen, wenn der Datensatz während eines Wartungsvorgangs aktualisiert oder verschoben wird. Durch die Verwendung von Indirektion in Form eines primären Indexes können wir die Kosten für Zeigeraktualisierungen reduzieren, haben aber höhere Kosten für den Lesepfad.
Die Aktualisierung von nur ein paar Indizes kann funktionieren, wenn die Arbeitslast hauptsächlich aus Lesevorgängen besteht, aber dieser Ansatz funktioniert nicht gut bei schreiblastigen Arbeitslasten mit mehreren Indizes. Um die Kosten für Zeigeraktualisierungen zu senken, verwenden einige Implementierungen statt Nutzdatenoffsets Primärschlüssel zur Umleitung. MySQL InnoDB zum Beispiel verwendet einen Primärindex und führt zwei Suchvorgänge durch: einen im Sekundärindex und einen im Primärindex, wenn eine Abfrage durchgeführt wird [TARIQ11]. Dadurch entsteht ein zusätzlicher Overhead, da der Primärindex nachgeschlagen wird, anstatt dem Offset direkt aus dem Sekundärindex zu folgen.
Abbildung 1-6 zeigt, wie unterschiedlich die beiden Ansätze sind:
a) Zwei Indizes referenzieren Dateneinträge direkt aus sekundären Indexdateien.
b) Ein Sekundärindex durchläuft die Indirektionsschicht eines Primärindex, um die Dateneinträge zu finden.
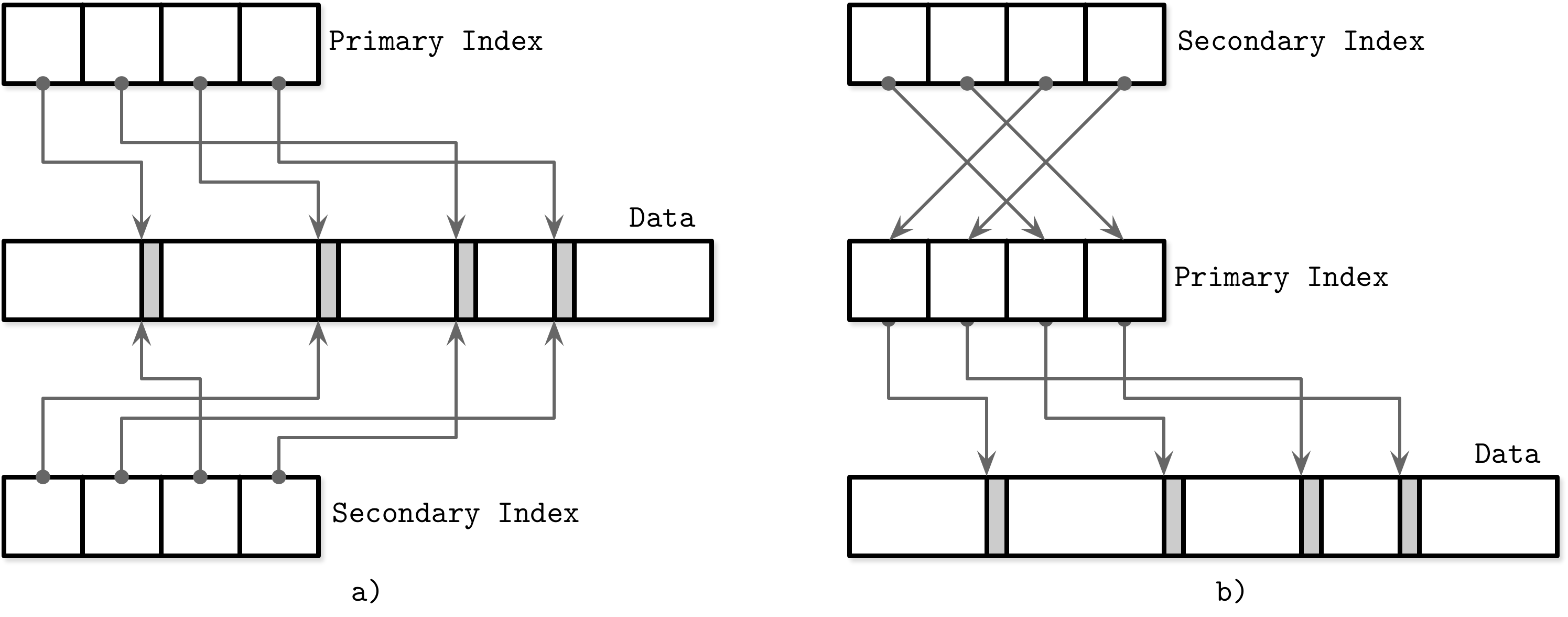
Abbildung 1-6. Direkte Referenzierung von Datentupeln (a) versus Verwendung eines Primärindexes als Indirektion (b)
Es ist auch möglich, einen hybriden Ansatz zu verwenden und sowohl Offsets der Datendatei als auch Primärschlüssel zu speichern. Zuerst überprüfst du, ob der Daten-Offset noch gültig ist, und zahlst die zusätzlichen Kosten für den Primärschlüsselindex, wenn er sich geändert hat, und aktualisierst die Indexdatei, nachdem du einen neuen Offset gefunden hast.
Pufferung, Unveränderlichkeit und Ordnung
Eine Speicher-Engine basiert auf einer Datenstruktur. Diese Strukturen beschreiben jedoch nicht die Semantik der Zwischenspeicherung, Wiederherstellung, Transaktionsfähigkeit und anderer Dinge, die die Speicher-Engines hinzufügen.
In den nächsten Kapiteln beginnen wir die Diskussion mit B-Trees (siehe "Ubiquitäre B-Trees") und versuchen zu verstehen, warum es so viele B-Tree-Varianten gibt und warum immer wieder neue Strukturen für die Speicherung in Datenbanken entstehen.
Speicherstrukturen haben drei gemeinsame Variablen: Sie nutzen Pufferung (oder vermeiden sie), verwenden unveränderliche (oder veränderliche) Dateien und speichern Werte in der Reihenfolge (oder außer der Reihe). Die meisten Unterscheidungen und Optimierungen von Speicherstrukturen, die in diesem Buch behandelt werden, beziehen sich auf eines dieser drei Konzepte.
- Pufferung
-
Damit wird festgelegt, ob die Speicherstruktur eine bestimmte Menge an Daten im Speicher sammelt, bevor sie auf die Festplatte geschrieben wird oder nicht. Natürlich muss jede Struktur auf der Festplatte bis zu einem gewissen Grad gepuffert werden, da die kleinste Einheit der Datenübertragung von und zur Festplatte ein Block ist und es wünschenswert ist, ganze Blöcke zu schreiben. Hier geht es um vermeidbare Pufferung, die von den Implementierern der Speicherung gewählt wird. Eine der ersten Optimierungen, die wir in diesem Buch besprechen, ist das Hinzufügen von In-Memory-Puffern zu B-Tree-Knoten, um die E/A-Kosten zu amortisieren (siehe "Lazy B-Trees"). Das ist jedoch nicht die einzige Möglichkeit, wie wir Puffer einsetzen können. Zweikomponenten-LSM-Bäume (siehe "Zweikomponenten-LSM-Bäume") zum Beispiel nutzen trotz ihrer Ähnlichkeiten mit B-Bäumen die Pufferung auf eine ganz andere Art und Weise und kombinieren Pufferung mit Unveränderlichkeit.
- Veränderlichkeit (oder Unveränderlichkeit)
-
Diese legt fest, ob die Speicherung Teile der Datei liest, sie aktualisiert und die aktualisierten Ergebnisse an dieselbe Stelle in der Datei schreibt oder nicht. Unveränderliche Strukturen sind "append-only": Einmal geschrieben, wird der Inhalt der Datei nicht verändert. Stattdessen werden die Änderungen an das Ende der Datei angehängt. Es gibt noch andere Möglichkeiten, Unveränderlichkeit zu implementieren. Eine davon ist Copy-on-Write (siehe "Copy-on-Write"), bei der die geänderte Seite mit der aktualisierten Version des Datensatzes an die neue Stelle in der Datei geschrieben wird, anstatt an die ursprüngliche Stelle. Oft wird die Unterscheidung zwischen LSM und B-Trees als unveränderlich gegenüber der Speicherung von Aktualisierungen an Ort und Stelle getroffen, aber es gibt auch Strukturen (z. B. "Bw-Trees"), die von B-Trees inspiriert, aber unveränderlich sind.
- Bestellung
-
Diese ist definiert als die Frage, ob die Datensätze in der Schlüsselreihenfolge auf den Seiten auf der Festplatte gespeichert sind oder nicht. Mit anderen Worten: Die Schlüssel, die eng sortiert sind, werden in zusammenhängenden Segmenten auf der Festplatte gespeichert. Die Reihenfolge bestimmt oft, ob wir den Bereich der Datensätze effizient durchsuchen können und nicht nur die einzelnen Datensätze finden. Die Speicherung von Daten in ungeordneter Reihenfolge (meist in Einfügereihenfolge) ermöglicht einige Optimierungen der Schreibzeit. Bitcask (siehe "Bitcask") und WiscKey (siehe "WiscKey") speichern die Datensätze zum Beispiel direkt in reinen Anhangsdateien.
Natürlich reicht eine kurze Erörterung dieser drei Konzepte nicht aus, um ihre Macht zu zeigen, und wir werden diese Diskussion im Rest des Buches fortsetzen.
Zusammenfassung
In diesem Kapitel haben wir die Architektur eines Datenbankmanagementsystems besprochen und seine wichtigsten Komponenten behandelt.
Um die Bedeutung von plattenbasierten Strukturen und ihren Unterschied zu In-Memory-Strukturen zu verdeutlichen, haben wir speicher- und plattenbasierte Speicher diskutiert. Wir sind zu dem Schluss gekommen, dass festplattenbasierte Strukturen für beide Arten von Speichern wichtig sind, aber für unterschiedliche Zwecke verwendet werden.
Um zu verstehen, wie Zugriffsmuster das Design von Datenbanksystemen beeinflussen, haben wir spalten- und zeilenorientierte Datenbankmanagementsysteme und die wichtigsten Faktoren, die sie voneinander unterscheiden, besprochen. Um ein Gespräch darüber zu beginnen, wie die Daten gespeichert werden, haben wir Daten- und Indexdateien besprochen.
Zuletzt haben wir drei zentrale Konzepte vorgestellt: Pufferung, Unveränderlichkeit und Ordnung. Wir werden sie in diesem Buch durchgängig verwenden, um die Eigenschaften der Speicher-Engines hervorzuheben, die sie nutzen.
1 Eine Visualisierung und einen Vergleich von Festplatten- und Speicherzugriffslatenzen und vielen anderen relevanten Zahlen über die Jahre findest du unter https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html.
2 Räumliche Lokalität ist eines der Lokalitätsprinzipien, das besagt, dass bei einem Zugriff auf eine Speicherstelle auch auf die benachbarten Speicherstellen in naher Zukunft zugegriffen wird.
3 Vektorisierte Befehle oder Single Instruction Multiple Data (SIMD) beschreiben eine Klasse von CPU-Befehlen, die dieselbe Operation an mehreren Datenpunkten durchführen.
4 Der ursprüngliche Beitrag, der die Diskussion ausgelöst hat, war kontrovers und einseitig, aber du kannst dich auf die Präsentation beziehen, in der die Index- und Speicherformate von MySQL und PostgreSQL verglichen werden und die auch auf die Originalquelle verweist.
Get Datenbank Interna now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

