Kapitel 4. Überwachung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Überwachung kann viele Arten von Daten umfassen, darunter Metriken, Textprotokollierung, strukturierte Ereignisprotokollierung, verteiltes Tracing, und Ereignisintrospektion. Obwohl alle diese Ansätze für sich genommen nützlich sind, befasst sich dieses Kapitel hauptsächlich mit Metriken und strukturierter Protokollierung. Unserer Erfahrung nach sind diese beiden Datenquellen am besten für die grundlegenden Überwachungsanforderungen von SRE geeignet.
Auf der grundlegendsten Ebene ermöglicht dir das Monitoring einen Einblick in ein System, was eine Grundvoraussetzung für die Beurteilung des Zustands deines Dienstes und die Diagnose von Fehlern ist. Kapitel 6 des ersten SRE-Buches enthält einige grundlegende Definitionen zum Thema Monitoring und erklärt, dass SREs ihre Systeme überwachen, um:
-
Informiere dich über Bedingungen, die Aufmerksamkeit erfordern.
-
Untersuche und diagnostiziere diese Probleme.
-
Zeigt Informationen über das System visuell an.
-
Erhalte Einblicke in Trends bei der Ressourcennutzung oder dem Zustand der Dienste für die langfristige Planung.
-
Vergleiche das Verhalten des Systems vor und nach einer Veränderung oder zwischen zwei Gruppen in einem Experiment.
Die relative Bedeutung dieser Anwendungsfälle kann dazu führen, dass du bei der Auswahl oder dem Aufbau eines Überwachungssystems Kompromisse eingehen musst.
In diesem Kapitel erfährst du, wie Google Überwachungssysteme verwaltet und erhältst einige Richtlinien für Fragen, die bei der Auswahl und dem Betrieb eines Überwachungssystems auftreten können.
Wünschenswerte Merkmale einer Überwachungsstrategie
Bei der Auswahl eines Überwachungssystems ist es wichtig, die für dich wichtigen Funktionen zu kennen und zu priorisieren. Wenn du verschiedene Überwachungssysteme in Betracht ziehst, können dir die Eigenschaften in diesem Abschnitt dabei helfen, herauszufinden, welche Lösung(en) deinen Bedürfnissen am besten entsprechen. Wenn du bereits eine Überwachungsstrategie hast, könntest du in Erwägung ziehen, einige zusätzliche Funktionen deiner aktuellen Lösung zu nutzen. Je nach deinen Bedürfnissen kann ein einziges Überwachungssystem alle deine Anwendungsfälle abdecken, oder du möchtest eine Kombination aus verschiedenen Systemen verwenden.
Geschwindigkeit
Verschiedene Organisationen haben unterschiedliche Bedürfnisse, wenn es um die Aktualität der Daten und die Geschwindigkeit des Datenabrufs geht.
Die Daten sollten verfügbar sein, wenn du sie brauchst: Die Aktualität der Daten hat Einfluss darauf, wie lange dein Überwachungssystem braucht, um dich zu informieren, wenn etwas schief läuft. Außerdem können langsame Daten dazu führen, dass du versehentlich auf falsche Daten reagierst. Wenn zum Beispiel bei der Reaktion auf einen Vorfall die Zeit zwischen Ursache (dem Ergreifen einer Maßnahme) und Wirkung (der Anzeige dieser Maßnahme in deiner Überwachung) zu lang ist, könntest du davon ausgehen, dass eine Änderung keine Auswirkungen hatte, oder eine falsche Korrelation zwischen Ursache und Wirkung ableiten. Daten, die mehr als vier bis fünf Minuten veraltet sind, können sich erheblich darauf auswirken, wie schnell du auf einen Vorfall reagieren kannst.
Wenn du ein Überwachungssystem nach diesem Kriterium auswählst, musst du dir im Voraus Gedanken über deine Geschwindigkeitsanforderungen machen. Die Geschwindigkeit des Datenabrufs ist vor allem dann ein Problem, wenn du große Datenmengen abfragst. Es kann einige Zeit dauern, bis ein Diagramm geladen ist, wenn es viele Daten von vielen überwachten Systemen zusammenfassen muss. Um deine langsameren Diagramme zu beschleunigen, ist es hilfreich, wenn das Überwachungssystem auf der Grundlage der eingehenden Daten neue Zeitreihen erstellen und speichern kann; dann kann es Antworten auf häufige Abfragen vorberechnen.
Berechnungen
Die Unterstützung für Berechnungen kann eine Vielzahl von Anwendungsfällen mit unterschiedlicher Komplexität umfassen. Zumindest möchtest du wahrscheinlich, dass dein System Daten über einen mehrmonatigen Zeitraum speichert. Ohne einen langfristigen Überblick über deine Daten kannst du keine langfristigen Trends wie das Wachstum des Systems analysieren. Was die Granularität angeht, so sind zusammengefasste Daten (d.h. aggregierte Daten, die du nicht weiter aufschlüsseln kannst) ausreichend, um die Wachstumsplanung zu erleichtern. Die Aufbewahrung aller detaillierten Einzelkennzahlen kann bei der Beantwortung von Fragen wie "Ist dieses ungewöhnliche Verhalten schon einmal aufgetreten?" helfen. Allerdings könnte die Speicherung der Daten teuer oder die Abfrage unpraktisch sein.
Die Metriken, die du über Ereignisse oder den Ressourcenverbrauch speicherst, sollten idealerweise monoton ansteigende Zähler sein. Mit Hilfe von Zählern kann dein Überwachungssystem zeitlich abgestufte Funktionen berechnen, z. B. um die Rate der Anfragen pro Sekunde von diesem Zähler zu melden. Wenn du diese Raten über ein längeres Zeitfenster (bis zu einem Monat) berechnest, kannst du die Bausteine für SLO-Burn-basierte Warnmeldungen implementieren (siehe Kapitel 5).
Und schließlich kann die Unterstützung einer umfassenderen Palette statistischer Funktionen nützlich sein, da triviale Operationen schlechtes Verhalten verschleiern können. Ein Überwachungssystem, das die Berechnung von Perzentilen (d.h. 50., 95., 99. Perzentile) bei der Aufzeichnung der Latenzzeit unterstützt, zeigt dir, ob 50 %, 5 % oder 1 % deiner Anfragen zu langsam sind, während das arithmetische Mittel dir nur sagen kann, dass die Anfrage langsamer ist - ohne nähere Angaben. Wenn dein System die direkte Berechnung von Perzentilen nicht unterstützt, kannst du dies auch erreichen, indem du:
-
Ermitteln eines Mittelwerts durch Summieren der für Anfragen verbrauchten Sekunden und Dividieren durch die Anzahl der Anfragen
-
Protokollierung jeder Anfrage und Berechnung der Perzentilwerte durch Scannen oder Stichproben der Protokolleinträge
Vielleicht möchtest du deine Rohdaten in einem separaten System aufzeichnen, um sie offline zu analysieren - zum Beispiel für wöchentliche oder monatliche Berichte oder um kompliziertere Berechnungen durchzuführen, die in deinem Überwachungssystem zu schwierig zu berechnen sind.
Schnittstellen
Ein robustes Überwachungssystem sollte es dir ermöglichen, Zeitreihendaten in Diagrammen übersichtlich darzustellen und die Daten in Tabellen oder einer Reihe von Diagrammstilen zu strukturieren. Deine Dashboards werden die wichtigsten Schnittstellen für die Anzeige des Monitorings sein, daher ist es wichtig, dass du Formate wählst, die die Daten, die dir wichtig sind, am deutlichsten darstellen. Einige Optionen sind Heatmaps, Histogramme und logarithmische Diagramme.
Wahrscheinlich musst du je nach Zielgruppe unterschiedliche Ansichten derselben Daten anbieten; die oberste Führungsebene möchte vielleicht ganz andere Informationen sehen als SREs. Achte darauf, Dashboards zu erstellen, die für die Personen, die die Inhalte nutzen, sinnvoll sind. Für jede Gruppe von Dashboards ist es für die Kommunikation wichtig, die gleichen Datentypen einheitlich darzustellen.
Es kann sein, dass du Informationen über verschiedene Aggregationen einer Kennzahl - wie z.B. den Maschinentyp, die Serverversion oder die Art der Anfrage - in Echtzeit grafisch darstellen musst. Es ist eine gute Idee, wenn dein Team in der Lage ist, Ad-hoc-Drilldowns deiner Daten durchzuführen. Wenn du deine Daten nach einer Vielzahl von Kennzahlen aufschlüsselst, kannst du bei Bedarf nach Korrelationen und Mustern in den Daten suchen.
Warnungen
Es ist hilfreich, Alarme zu klassifizieren: Mehrere Kategorien von Alarmen ermöglichen eine angemessene Reaktion. Die Möglichkeit, unterschiedliche Schweregrade für verschiedene Warnungen festzulegen, ist ebenfalls nützlich: Du könntest ein Ticket einreichen, um eine niedrige Fehlerrate zu untersuchen, die mehr als eine Stunde dauert, während eine 100%ige Fehlerrate ein Notfall ist, der eine sofortige Reaktion erfordert.
Mit der Funktion zurUnterdrückung von Alarmen kannst du vermeiden, dass unnötige Geräusche die Techniker im Bereitschaftsdienst ablenken. Zum Beispiel:
-
Wenn alle Knoten dieselbe hohe Fehlerrate aufweisen, kannst du nur einmal für die globale Fehlerrate alarmieren, anstatt für jeden einzelnen Knoten einen Alarm zu senden.
-
Wenn eine deiner Service-Abhängigkeiten einen Alert auslöst (z.B. ein langsames Backend), brauchst du keinen Alert für die Fehlerraten deines Services.
Du musst auch in der Lage sein, sicherzustellen, dass Alarme nicht mehr unterdrückt werden, wenn das Ereignis vorbei ist.
Der Grad der Kontrolle, den du über dein System benötigst, bestimmt, ob du einen Überwachungsdienst eines Drittanbieters nutzt oder dein eigenes Überwachungssystem einsetzt und betreibst. Google hat sein eigenes Überwachungssystem selbst entwickelt, aber es gibt auch viele Open-Source- und kommerzielle Überwachungssysteme.
Quellen für Überwachungsdaten
Die Wahl deines Überwachungssystems hängt davon ab, welche Quellen du für deine Überwachungsdaten nutzen willst. In diesem Abschnitt geht es um zwei gängige Quellen für Überwachungsdaten: Logs und Metriken. Es gibt noch weitere wertvolle Überwachungsquellen, auf die wir hier nicht eingehen, wie z. B. verteiltes Tracing und Introspektion zur Laufzeit.
Metriken sind numerische Messungen von Attributen und Ereignissen, die in der Regel über viele Datenpunkte in regelmäßigen Zeitabständen erhoben werden. Logs sind eine Aufzeichnung von Ereignissen, die nur als Anhang vorliegt. In diesem Kapitel geht es um strukturierte Protokolle, die im Gegensatz zu reinen Textprotokollen umfangreiche Abfrage- und Aggregationswerkzeuge ermöglichen.
Googles Logs-basierte Systeme verarbeiten große Mengen hochgranularer Daten. Zwischen dem Eintreten eines Ereignisses und seiner Sichtbarkeit in den Protokollen gibt es eine gewisse Verzögerung. Für Analysen, die nicht zeitkritisch sind, können diese Protokolle mit einem Batch-System verarbeitet, mit Ad-hoc-Abfragen abgefragt und mit Dashboards visualisiert werden. Ein Beispiel für diesen Arbeitsablauf wäre die Verwendung von Cloud Dataflow zur Verarbeitung von Protokollen, BigQuery für Ad-hoc-Abfragen und Data Studio für die Dashboards.
Im Gegensatz dazu liefert unser metrikbasiertes Überwachungssystem, das eine große Anzahl von Metriken von jedem Dienst bei Google sammelt, viel weniger granulare Informationen, dafür aber nahezu in Echtzeit. Diese Merkmale sind ziemlich typisch für andere log- und metrikbasierte Überwachungssysteme, obwohl es auch Ausnahmen gibt, wie z. B. Echtzeit-Log-Systeme oder Metriken mit hoher Kardinalität.
Unsere Warnmeldungen und Dashboards verwenden in der Regel Metriken. Da unser metrikbasiertes Überwachungssystem in Echtzeit arbeitet, können Ingenieure sehr schnell über Probleme informiert werden. Wir verwenden in der Regel Protokolle, um die Ursache eines Problems zu finden, da die benötigten Informationen oft nicht in Form von Metriken verfügbar sind.
Wenn die Berichterstattung nicht zeitkritisch ist, erstellen wir oft detaillierte Berichte mit Hilfe von Systemen zur Verarbeitung von Protokollen, da Protokolle fast immer genauere Daten liefern als Metriken.
Wenn du auf der Grundlage von Metriken alarmierst, könnte es verlockend sein, die Alarmierung auf der Grundlage von Protokollen zu erweitern - zum Beispiel, wenn du benachrichtigt werden möchtest, wenn auch nur ein einziges außergewöhnliches Ereignis eintritt. In solchen Fällen empfehlen wir nach wie vor die metrikbasierte Alarmierung: Du kannst eine Zählermetrik erhöhen, wenn ein bestimmtes Ereignis eintritt, und einen Alarm basierend auf dem Wert dieser Metrik konfigurieren. Bei dieser Strategie bleibt die gesamte Alarmkonfiguration an einem Ort und ist somit leichter zu verwalten (siehe "Verwalten deines Überwachungssystems").
Beispiele
Die folgenden Beispiele aus der Praxis veranschaulichen, wie du dich bei der Wahl zwischen verschiedenen Überwachungssystemen entscheiden kannst.
Informationen aus den Protokollen in die Metriken verschieben
Problem
Der HTTP-Statuscode ist ein wichtiges Signal für App Engine Kunden, die ihre Fehler beheben wollen. Diese Information war in den Logs verfügbar, aber nicht in den Metriken. Das Metriken-Dashboard konnte nur eine globale Rate aller Fehler anzeigen und enthielt keine Informationen über den genauen Fehlercode oder die Ursache des Fehlers. Der Arbeitsablauf zur Fehlerbehebung umfasste daher Folgendes:
-
Suche im globalen Fehlerdiagramm nach einem Zeitpunkt, an dem ein Fehler aufgetreten ist.
-
Lesen von Logdateien, um nach Zeilen zu suchen, die einen Fehler enthalten.
-
Versuch, Fehler in der Logdatei mit dem Diagramm zu korrelieren.
Die Protokollierungstools vermittelten kein Gefühl für die Größenordnung, so dass es schwierig war, festzustellen, ob ein Fehler, der in einer Protokollzeile auftrat, häufig auftrat. Außerdem enthielten die Protokolle viele andere irrelevante Zeilen, was es schwierig machte, die Ursache zu finden.
Vorgeschlagene Lösung
Das App-Engine-Entwicklungsteam entschied sich dafür, den HTTP-Statuscode als Kennzeichnung der Metrik zu exportieren (z. B. requests_total{status=404} gegenüber requests_total{status=500}). Da die Anzahl der verschiedenen HTTP-Statuscodes relativ begrenzt ist, hat dies die Menge der Metrikdaten nicht zu einer unpraktischen Größe anwachsen lassen, sondern die relevantesten Daten für die grafische Darstellung und die Warnmeldungen verfügbar gemacht.
Ergebnis
Diese neue Kennzeichnung bedeutete, dass das Team die Diagramme aktualisieren konnte, um separate Zeilen für verschiedene Fehlerkategorien und -typen anzuzeigen. Die Kunden konnten nun anhand der angezeigten Fehlercodes schnell Vermutungen über mögliche Probleme anstellen. Außerdem konnten wir nun unterschiedliche Schwellenwerte für Client- und Serverfehler festlegen, wodurch die Warnungen genauer ausgelöst wurden.
Verbessere sowohl die Logs als auch die Metriken
Problem
Ein Ads-SRE-Team betreute ~50 Dienste, die in verschiedenen Sprachen und Frameworks geschrieben waren. Das Team nutzte die Logs als kanonische Quelle der Wahrheit für die Einhaltung der SLO. Um das Fehlerbudget zu berechnen, verwendete jeder Dienst ein Skript zur Verarbeitung der Logs mit vielen dienstspezifischen Sonderfällen. Hier ist ein Beispielskript zur Verarbeitung eines Protokolleintrags für einen einzelnen Dienst:
If the HTTP status code was in the range (500, 599) AND the 'SERVER ERROR' field of the log is populated AND DEBUG cookie was not set as part of the request AND the url did not contain '/reports' AND the 'exception' field did not contain 'com.google.ads.PasswordException' THEN increment the error counter by 1
Diese Skripte waren schwer zu pflegen und verwendeten außerdem Daten, die dem metrikbasierten Überwachungssystem nicht zur Verfügung standen. Da Metriken als Grundlage für Warnungen dienten, entsprachen die Warnungen manchmal nicht den Fehlern, die von den Benutzern gemeldet wurden. Jede Warnung erforderte einen expliziten Triage-Schritt, um festzustellen, ob es sich um einen benutzerseitigen Fehler handelte, was die Reaktionszeit verlangsamte.
Vorgeschlagene Lösung
Das Team entwickelte eine Bibliothek, die sich in die Logik der Rahmensprachen jeder Anwendung einklinkte. Die Bibliothek entschied, ob der Fehler zum Zeitpunkt der Anfrage Auswirkungen auf die Nutzer hatte. Die Instrumentierung schrieb diese Entscheidung in die Logs und exportierte sie gleichzeitig als Metrik, um die Konsistenz zu verbessern. Wenn die Metrik zeigte, dass der Dienst einen Fehler zurückgegeben hatte, enthielten die Protokolle den genauen Fehler zusammen mit anfragebezogenen Daten, um das Problem zu reproduzieren und zu beheben. Jeder Fehler, der sich auf die SLO auswirkte und in den Protokollen auftauchte, veränderte auch die SLI-Metriken, so dass das Team darauf reagieren konnte.
Ergebnis
Durch die Einführung einer einheitlichen Steuerungsoberfläche für mehrere Dienste konnte das Team Tools und Alarmierungslogik wiederverwenden, anstatt mehrere individuelle Lösungen zu implementieren. Alle Dienste profitierten davon, dass der komplizierte, dienstspezifische Code zur Verarbeitung von Protokollen wegfiel, was zu einer besseren Skalierbarkeit führte. Sobald die Warnmeldungen direkt mit den SLOs verknüpft waren, konnten sie besser umgesetzt werden, so dass die Falsch-Positiv-Rate deutlich sank.
Behalte Logs als Datenquelle
Problem
Bei der Untersuchung von Produktionsproblemen sah sich ein SRE-Team oft die betroffenen Entity IDs an, um die Auswirkungen auf die Benutzer und die Ursache zu ermitteln. Wie bei dem früheren Beispiel mit der App Engine wurden für diese Untersuchung Daten benötigt, die nur in den Protokollen verfügbar waren. Das Team musste dafür einmalige Log-Abfragen durchführen, während es auf Vorfälle reagierte. Dieser Schritt verlängerte die Wiederherstellung des Vorfalls: ein paar Minuten, um die Abfrage korrekt zu erstellen, plus die Zeit für die Abfrage der Protokolle.
Vorgeschlagene Lösung
Das Team diskutierte zunächst, ob eine Metrik die Log-Tools ersetzen sollte. Anders als im App-Engine-Beispiel könnte die Entity-ID Millionen von verschiedenen Werten annehmen und wäre daher als Metrik-Bezeichnung nicht praktikabel.
Letztendlich entschied sich das Team, ein Skript zu schreiben, um die benötigten einmaligen Protokollabfragen durchzuführen, und dokumentierte das auszuführende Skript in den Warn-E-Mails. Bei Bedarf konnten sie den Befehl dann direkt in ein Terminal kopieren.
Ergebnis
Das Team hatte nicht mehr die kognitive Belastung, die richtige einmalige Protokollabfrage zu verwalten. Dementsprechend konnten sie die benötigten Ergebnisse schneller erhalten (wenn auch nicht so schnell wie bei einem metrikbasierten Ansatz). Außerdem hatten sie einen Backup-Plan: Sie konnten das Skript automatisch ausführen lassen, sobald ein Alarm ausgelöst wurde, und einen kleinen Server nutzen, um die Logs in regelmäßigen Abständen abzufragen, um ständig halbaktuelle Daten zu erhalten.
Verwaltung deines Überwachungssystems
Dein Überwachungssystem ist genauso wichtig wie jeder andere Dienst, den du betreibst. Als solches sollte es mit der entsprechenden Sorgfalt und Aufmerksamkeit behandelt werden.
Behandle deine Konfiguration als Code
Die Behandlung der Systemkonfiguration als Code und ihre Speicherung im Revisionskontrollsystem sind gängige Praxis dass einige offensichtliche Vorteile bietet: Änderungshistorie, Links von bestimmten Änderungen zu deinem Task-Tracking-System, einfachere Rollbacks und Linting-Checks,1 und verstärkte Codeüberprüfungen.
Wir empfehlen nachdrücklich, auch die Überwachungskonfiguration als Code zu behandeln (mehr zur Konfiguration findest du in Kapitel 14). Ein Überwachungssystem, das eine absichtsbasierte Konfiguration unterstützt, ist Systemen vorzuziehen, die nur Web-UIs oder CRUD-ähnliche APIs anbieten. Dieser Konfigurationsansatz ist bei vielen Open-Source-Binärprogrammen, die nur eine Konfigurationsdatei lesen, Standard. Einige Drittanbieterlösungen wie grafanalib ermöglichen diesen Ansatz für Komponenten, die traditionell mit einer Benutzeroberfläche konfiguriert werden.
Ermutige zur Beständigkeit
Große Unternehmen mit mehreren Entwicklungsteams, die das Monitoring nutzen, müssen einen Mittelweg finden: ein zentraler Ansatz sorgt für Konsistenz, aber auf der anderen Seite wollen die einzelnen Teams vielleicht die volle Kontrolle über die Gestaltung ihrer Konfiguration.
Die richtige Lösung hängt von deiner Organisation ab. Der Ansatz von Google hat sich im Laufe der Zeit zu einem einzigen Framework entwickelt, das zentral als Service betrieben wird. Diese Lösung ist für uns aus mehreren Gründen gut geeignet. Ein einziges Framework ermöglicht es den Ingenieuren, schneller mit der Arbeit zu beginnen, wenn sie das Team wechseln, und erleichtert die Zusammenarbeit bei der Fehlersuche. Wir haben auch einen zentralen Dashboarding-Service, bei dem die Dashboards der einzelnen Teams auffindbar und zugänglich sind. Wenn du das Dashboard eines anderen Teams leicht verstehst, kannst du sowohl deine als auch die Probleme des anderen Teams schneller debuggen.
Wenn möglich, solltest du die Grundüberwachung mühelos machen. Wenn alle deine Dienste2 einen einheitlichen Satz von Basiskennzahlen exportieren, kannst du diese Kennzahlen automatisch in deinem gesamten Unternehmen sammeln und einen einheitlichen Satz von Dashboards bereitstellen. Dieser Ansatz bedeutet, dass jede neue Komponente, die du einführst, automatisch mit einer grundlegenden Überwachung ausgestattet ist. Viele Teams in deinem Unternehmen - auch solche, die nicht in der Entwicklung tätig sind - können diese Überwachungsdaten nutzen.
Lose Kupplung bevorzugen
Die Geschäftsanforderungen ändern sich, und dein Produktionssystem wird in einem Jahr anders aussehen. Auch dein Überwachungssystem muss sich im Laufe der Zeit weiterentwickeln, wenn sich die überwachten Dienste durch verschiedene Ausfallmuster verändern.
Wir empfehlen, die Komponenten deines Überwachungssystems lose zu koppeln. Du solltest über stabile Schnittstellen verfügen, um jede Komponente zu konfigurieren und Überwachungsdaten zu übermitteln. Getrennte Komponenten sollten für die Erfassung, Speicherung, Alarmierung und Visualisierung deiner Überwachung zuständig sein. Stabile Schnittstellen machen es einfacher, eine bestimmte Komponente gegen eine bessere Alternative auszutauschen.
Die Aufteilung von Funktionen in einzelne Komponenten wird in der Open-Source-Welt immer beliebter. Vor einem Jahrzehnt haben Überwachungssysteme wie Zabbix alle Funktionen in einer einzigen Komponente zusammengefasst. Das moderne Design beinhaltet in der Regel die Trennung von Sammlung und Regelauswertung (mit einer Lösung wie Prometheus Server), langfristiger Speicherung von Zeitreihen(InfluxDB), Alarmaggregation(Alertmanager) und Dashboarding(Grafana).
Zurzeit gibt es mindestens zwei populäre offene Standards für die Instrumentierung deiner Software und die Veröffentlichung von Metriken:
- statsd
Der Metrik-Aggregations-Daemon, der ursprünglich von Etsy geschrieben wurde und jetzt auf eine Vielzahl von Programmiersprachen portiert wurde.
- Prometheus
Eine Open-Source-Monitoring-Lösung mit einem flexiblen Datenmodell, Unterstützung für metrische Labels und robusten Histogramm-Funktionen. Andere Systeme übernehmen jetzt das Prometheus-Format und es wird als OpenMetrics standardisiert.
Ein separates Dashboarding-System, das mehrere Datenquellen nutzen kann, bietet eine zentrale und einheitliche Übersicht über deinen Dienst. Google hat diesen Vorteil kürzlich in der Praxis erlebt: Unser altes Überwachungssystem (Borgmon3) kombinierte Dashboards in derselben Konfiguration wie die Alarmierungsregeln. Bei der Migration auf ein neues System(Monarch) beschlossen wir, das Dashboarding in einen separaten Dienst(Viceroy) auszulagern. Da Viceroy kein Bestandteil von Borgmon oder Monarch war, hatte Monarch weniger funktionale Anforderungen. Da die Nutzerinnen und Nutzer mit Viceroy Diagramme anzeigen konnten, die auf Daten aus beiden Überwachungssystemen basierten, konnten sie schrittweise von Borgmon zu Monarch migrieren.
Metriken mit Zweck
In Kapitel 5 wird beschrieben, wie du mithilfe von SLI-Metriken überwachen und alarmieren kannst, wenn das Fehlerbudget eines Systems gefährdet ist. SLI-Kennzahlen sind die ersten Kennzahlen, die du überprüfen solltest, wenn SLO-basierte Alarme ausgelöst werden. Diese Metriken sollten im Dashboard deines Dienstes an prominenter Stelle erscheinen, am besten auf der Landing Page.
Wenn du die Ursache eines SLO-Verstoßes untersuchst, wirst du höchstwahrscheinlich nicht genügend Informationen aus den SLO-Dashboards erhalten. Diese Dashboards zeigen, dass du gegen die SLO verstößt, aber nicht unbedingt warum. Welche anderen Daten sollten die Monitoring-Dashboards anzeigen?
Wir haben die folgenden Richtlinien als hilfreich für die Implementierung von Metriken empfunden. Diese Metriken sollten eine vernünftige Überwachung ermöglichen, die es dir erlaubt, Produktionsprobleme zu untersuchen und eine breite Palette von Informationen über deinen Dienst zu liefern.
Beabsichtigte Änderungen
Bei der Diagnose eines SLO-basierten Alarms musst du in der Lage sein, von Alarmmetriken, die dich über Probleme informieren, die sich auf die Benutzer auswirken, zu Metriken überzugehen, die dir sagen, was diese Probleme verursacht. Kürzlich geplante Änderungen an deinem Dienst könnten die Ursache sein. Füge eine Überwachung hinzu, die dich über alle Änderungen in der Produktion informiert.4 Um den Auslöser zu bestimmen, empfehlen wir Folgendes:
-
Überprüfe die Version der Binärdatei.
-
Überwache die Befehlszeilenflags, vor allem wenn du diese Flags verwendest, um Funktionen des Dienstes zu aktivieren und zu deaktivieren.
-
Wenn die Konfigurationsdaten dynamisch zu deinem Dienst übertragen werden, musst du die Version dieser dynamischen Konfiguration überwachen.
Wenn einer dieser Teile des Systems nicht versioniert ist, solltest du in der Lage sein, den Zeitstempel zu überwachen, zu dem er zuletzt gebaut oder gepackt wurde.
Wenn du versuchst, einen Ausfall mit einem Rollout in Verbindung zu bringen, ist es viel einfacher, sich ein Diagramm/Dashboard anzusehen, das mit deinem Alert verlinkt ist, als die Logs deines CI/CD-Systems (Continuous Integration/Continuous Delivery) im Nachhinein zu durchforsten.
Abhängigkeiten
Auch wenn sich dein Dienst nicht geändert hat, kann es sein, dass sich seine Abhängigkeiten ändern oder Probleme auftreten. solltest du auch die Antworten von überwachen, die von direkten Abhängigkeiten kommen.
Es ist sinnvoll, die Anfrage- und Antwortgröße in Bytes, die Latenzzeit und die Antwortcodes für jede Abhängigkeit zu exportieren. Bei der Auswahl der Metriken, die du grafisch darstellen willst, solltest du die vier goldenen Signale im Hinterkopf behalten. Du kannst die Metriken mit zusätzlichen Etiketten versehen, um sie nach Antwortcode, RPC (Remote Procedure Call)-Methodenname und Peer-Auftragsname aufzuschlüsseln.
Im Idealfall kannst du die untergeordnete RPC-Client-Bibliothek so instrumentieren, dass sie diese Metriken einmal exportiert, anstatt jede RPC-Client-Bibliothek zu bitten, sie zu exportieren.5 Die Instrumentierung der Client-Bibliothek sorgt für mehr Konsistenz und ermöglicht es dir, neue Abhängigkeiten kostenlos zu überwachen.
Manchmal stößt man auf Abhängigkeiten, die eine sehr enge API anbieten, bei der alle Funktionen über einen einzigen RPC namens Get, Query oder etwas ähnlich wenig Hilfreiches verfügbar sind und der eigentliche Befehl als Argumente für diesen RPC angegeben wird. Ein einziger Instrumentierungspunkt in der Client-Bibliothek reicht bei dieser Art von Abhängigkeit nicht aus: Du wirst eine hohe Varianz bei der Latenz und einen gewissen Prozentsatz an Fehlern feststellen, die darauf hindeuten können, dass ein Teil dieser undurchsichtigen API komplett fehlschlägt. Wenn diese Abhängigkeit kritisch ist, hast du mehrere Möglichkeiten, sie gut zu überwachen:
-
Exportiere separate Metriken, die auf die Abhängigkeit zugeschnitten sind, damit die Metriken die Anfragen, die sie erhalten, auspacken können, um an das eigentliche Signal zu gelangen.
-
Bitte die Abhängigkeitsverantwortlichen, ein Rewrite durchzuführen, um eine breitere API zu exportieren, die separate Funktionen unterstützt, die auf separate RPC-Dienste und -Methoden verteilt sind.
Sättigung
Versuche, die Nutzung aller Ressourcen, auf die der Dienst angewiesen ist, zu überwachen und zu verfolgen. Für einige Ressourcen gibt es feste Grenzen, die du nicht überschreiten darfst, z. B. das deiner Anwendung zugewiesene RAM-, Festplatten- oder CPU-Kontingent. Andere Ressourcen wie offene Dateideskriptoren, aktive Threads in Thread-Pools, Wartezeiten in Warteschlangen oder die Menge der geschriebenen Logs haben vielleicht keine eindeutige Grenze, müssen aber trotzdem verwaltet werden.
Je nach verwendeter Programmiersprache solltest du zusätzliche Ressourcen überwachen:
-
In Java: Die Heap- und Metaspace-Größe sowie weitere spezifische Metriken, je nachdem, welche Art der Speicherbereinigung du verwendest
-
In Go: Die Anzahl der Goroutinen
Die Sprachen selbst bieten unterschiedliche Unterstützung, um diese Ressourcen zu verfolgen.
Zusätzlich zu den in Kapitel 5 beschriebenen Alarmen bei wichtigen Ereignissen musst du vielleicht auch Alarme einrichten, die ausgelöst werden, wenn du dich der Erschöpfung bestimmter Ressourcen näherst, wie zum Beispiel:
-
Wenn die Ressource eine feste Grenze hat
-
Wenn das Überschreiten eines Nutzungsschwellenwerts zu Leistungseinbußen führt
Du solltest über Überwachungsmetriken verfügen, um alle Ressourcen zu verfolgen - auch die, die der Dienst gut verwaltet. Diese Metriken sind für die Kapazitäts- und Ressourcenplanung unerlässlich.
Status des bedienten Verkehrs
Es ist eine gute Idee, Metriken oder Metrik-Labels hinzuzufügen, die es den Dashboards ermöglichen, den zugestellten Verkehr nach Statuscode aufzuschlüsseln (es sei denn, die Metriken, die dein Dienst für SLI-Zwecke verwendet, enthalten diese Informationen bereits). Hier sind einige Empfehlungen:
-
Überwache beim HTTP-Verkehr alle Antwortcodes, auch wenn sie nicht genug Signale für eine Warnung liefern, denn einige können durch falsches Kundenverhalten ausgelöst werden.
-
Wenn du deinen Nutzern Raten- oder Quotenlimits auferlegst, überprüfe, wie viele Anfragen aufgrund mangelnder Quoten abgelehnt wurden.
Anhand von Diagrammen dieser Daten kannst du erkennen, wenn sich das Fehlervolumen während eines Produktionswechsels merklich verändert.
Zielgerichtete Metriken implementieren
Jede exponierte Kennzahl sollte einen Zweck erfüllen. Widerstehe der Versuchung, eine Handvoll Metriken zu exportieren, nur weil sie leicht zu erstellen sind. Denke stattdessen darüber nach, wie diese Kennzahlen verwendet werden sollen. Das Design der Kennzahlen, oder das Fehlen davon, hat Auswirkungen.
Idealerweise ändern sich die Metrikwerte, die für die Alarmierung verwendet werden, nur dann drastisch, wenn das System in einen Problemzustand gerät, und nicht, wenn das System normal funktioniert. Für die Metriken zur Fehlersuche gelten diese Anforderungen hingegen nicht - sie sollen Aufschluss darüber geben, was passiert, wenn Alarme ausgelöst werden. Gute Debugging-Metriken weisen auf einen Aspekt des Systems hin, der möglicherweise die Probleme verursacht. Wenn du einen Postmortem schreibst, überlege, welche zusätzlichen Metriken es dir ermöglicht hätten, das Problem schneller zu diagnostizieren.
Testen der Alarmierungslogik
In einer idealen Welt sollte der Überwachungs- und Alarmierungscode denselben Teststandards unterliegen wie die Codeentwicklung. Die Prometheus-Entwickler diskutieren zwar über die Entwicklung von Unit-Tests für die Überwachung, aber derzeit gibt es kein allgemein anerkanntes System, das dies ermöglicht.
Bei Google testen wir unsere Überwachung und Alarmierung mit einer domänenspezifischen Sprache, mit der wir synthetische Zeitreihen erstellen können. Dann schreiben wir Assertions, die auf den Werten in einer abgeleiteten Zeitreihe oder auf dem Auslösestatus und dem Vorhandensein bestimmter Alarme basieren.
Die Überwachung und Alarmierung ist oft ein mehrstufiger Prozess, der daher mehrere Familien von Unit-Tests erfordert. Dieser Bereich ist zwar noch weitgehend unterentwickelt, aber wenn du irgendwann Überwachungstests einführen willst, empfehlen wir einen dreistufigen Ansatz, wie in Abbildung 4-1 dargestellt.
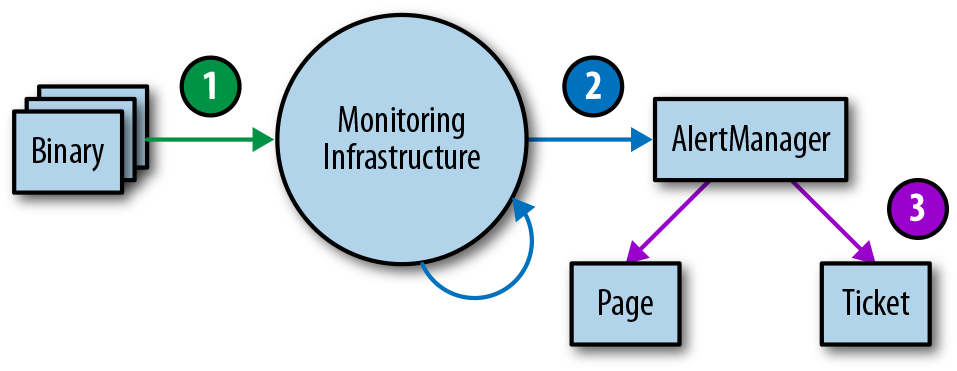
Abbildung 4-1. Überwachung der Testumgebungsebenen
-
Binäres Reporting: Überprüfe, ob die exportierten metrischen Variablen unter bestimmten Bedingungen wie erwartet ihren Wert ändern.
-
Konfigurationen überwachen: Stelle sicher, dass die Regelauswertung zu den erwarteten Ergebnissen führt und dass bestimmte Bedingungen die erwarteten Alarme auslösen.
-
Alerting-Konfigurationen: Teste, ob generierte Alarme an ein vorher festgelegtes Ziel weitergeleitet werden, basierend auf den Werten der Alarmetiketten.
Wenn du deine Überwachung nicht mit synthetischen Mitteln testen kannst oder es eine Phase deiner Überwachung gibt, die du einfach nicht testen kannst, solltest du ein laufendes System erstellen, das bekannte Metriken wie die Anzahl der Anfragen und Fehler exportiert. Mit diesem System kannst du abgeleitete Zeitreihen und Alarme validieren. Es ist sehr wahrscheinlich, dass deine Warnregeln erst Monate oder Jahre nach ihrer Konfiguration ausgelöst werden, und du musst dich darauf verlassen können, dass die richtigen Techniker/innen mit sinnvollen Meldungen benachrichtigt werden, wenn die Kennzahl einen bestimmten Schwellenwert überschreitet.
Fazit
Da die SRE-Rolle für die Zuverlässigkeit der Systeme in der Produktion verantwortlich ist, müssen SREs oft mit dem Überwachungssystem eines Dienstes und seinen Funktionen bestens vertraut sein. Ohne dieses Wissen wissen SREs vielleicht nicht, wo sie suchen müssen, wie sie abnormales Verhalten erkennen können oder wie sie die Informationen finden, die sie in einem Notfall benötigen.
Wir hoffen, dass wir dir dabei helfen können, zu beurteilen, wie gut deine Überwachungsstrategie deinen Bedürfnissen entspricht, und dass wir dir helfen können, zusätzliche Funktionen zu entdecken, die du nutzen kannst, und über Änderungen nachzudenken, die du vielleicht vornehmen möchtest. Wahrscheinlich wirst du es für sinnvoll halten, in deiner Überwachungsstrategie eine Reihe von Kennzahlen und Protokollierungen zu kombinieren; die genaue Mischung ist stark kontextabhängig. Achte darauf, dass du Metriken sammelst, die einem bestimmten Zweck dienen. Dieser Zweck kann darin bestehen, eine bessere Kapazitätsplanung zu ermöglichen, bei der Fehlersuche zu helfen oder dich direkt über Probleme zu informieren.
Sobald du die Überwachung eingerichtet hast, muss sie sichtbar und nützlich sein. Zu diesem Zweck empfehlen wir dir auch, dein Überwachungssystem zu testen. Ein gutes Überwachungssystem zahlt sich aus. Es lohnt sich, gründlich darüber nachzudenken, welche Lösungen deine Bedürfnisse am besten erfüllen, und so lange zu testen, bis du die richtige Lösung gefunden hast.
1 Zum Beispiel kannst du mit promtool überprüfen, ob deine Prometheus-Konfiguration syntaktisch korrekt ist.
2 Du kannst grundlegende Metriken über eine gemeinsame Bibliothek exportieren: ein Instrumentierungs-Framework wie OpenCensus oder ein Service-Mesh wie Istio.
3 Siehe Kapitel 10 von Site Reliability Engineering für die Konzepte und die Struktur von Borgmon.
4 Dies ist ein Fall, in dem die Überwachung anhand von Protokollen interessant ist, vor allem weil Änderungen in der Produktion relativ selten vorkommen. Unabhängig davon, ob du Logs oder Metriken verwendest, sollten diese Änderungen in deinen Dashboards auftauchen, damit sie für die Fehlersuche in der Produktion leicht zugänglich sind.
5 Siehe https://opencensus.io/ für eine Reihe von Bibliotheken, die dies ermöglichen.
Get Das Arbeitsbuch zur Standortzuverlässigkeit now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

