Chapter 4. Economical Pipeline Fundamentals
In the preceding chapters, you learned how to design cloud compute and storage solutions that make the right cost–performance trade-offs given your overall product goals. This gives you a strong foundation for cost-effective design.
The next step is to design and implement data pipelines that scale effectively, limit waste by making smart use of engineering and compute resources, and minimize data downtime. The first part of this process involves some fundamental design strategies for data pipelines: idempotency, checkpointing, automatic retries, and data validation.
In this chapter, you’ll see common data pipeline issues and how to mitigate them using these four strategies. Rather than simply defining idempotency, checkpointing, retries, and data validation, I’ll illustrate how to implement these strategies across batch and streaming environments as well as discuss some of the trade-offs you will encounter. You’ll also get to see how these strategies (or lack thereof) contributed to real-world pipeline failures and successes.
Idempotency
The first place to start is designing your pipelines to be idempotent. Idempotency means you can repeatedly run a pipeline against the same source data and the results will be exactly the same. This has benefits on its own and is a prerequisite for implementing retries, as you’ll see later in this chapter.
Preventing Data Duplication
The definition of idempotency can vary based on how the pipeline output is consumed. One way you can think about idempotency is an absence of duplicated data if the pipeline runs multiple times using the same source data.
For example, consider a pipeline that inserts data into a database by looping through the dataset and inserting each line into the database. If an error occurs, such as a networking blip that interrupts the connection to the database, you wouldn’t be able to tell which portion of the data was written to the database and which was not. If you retry from this state, the pipeline could end up creating duplicate data.
To make this process idempotent, you can wrap the database inserts in a transaction, ensuring that if any of the inserts failed, any prior inserts would be rolled back.1 This eliminates the possibility of partial writes.
You can also build data sinks that reject duplicated data. If you can create a unique key for ingested data, you can detect duplicate entries and decide how to handle them. In this case, you want to be absolutely sure the key you come up with is truly unique, such as a natural key. Keep in mind that unique constraints can slow down inserts, as the database needs to validate that the key is unique and update the index. In columnar databases and data lakes, you can enforce uniqueness by hashing, preventing updates and inserts if the hash matches existing data. Some data lakes support merge keys, such as Delta Lake merge, where you can specify a unique key and instructions for how to handle matches.
Tip
Reducing data duplication will reduce costs by limiting your storage footprint. Depending on how data is used, this can also save on compute expenses.
When working with cloud storage, you can use an overwrite approach, also known as delete-write. Consider a pipeline that runs once a day, writing data out to a folder named for the current date. Prior to writing out the data, the pipeline can check whether any data already exists in the current date folder. If so, the data is deleted and then the new data is written. This prevents partial data ingestion as well as duplicated data.
For streaming processes, you can achieve idempotency through unique message identification. You can accomplish this by setting up the data producer to create the same ID when the same data is encountered. On the consumer side, you can keep a record of message IDs that have already been processed to prevent a duplicate message from being ingested.
Especially for streaming or long-running processes, consider maintaining a durable record of the information you need to ensure idempotency. As an example, Kafka persists messages on disk, making sure messages are not lost across deployments or due to unexpected outages.
Idempotency can be hard to ensure, particularly in streaming processes where you have a lot of options for how to handle messages. Keep your message acknowledgment (ack) strategy in mind; do you acknowledge messages when they’re pulled from a queue or only when the consumer is finished? Another consideration is where your consumers read from; is it always the end of the stream or are there conditions where you may reread previously consumed messages?
For example, if you ack a message when the consumer reads it from the queue, a failure in the consumer means the message will go unprocessed, dropping data. If instead the messages are ack’d only when the consumer has finished processing, you can have an opportunity to reprocess the message if a failure occurs.
This opportunity to retry can also create duplicated data. I saw this happen in a pipeline where occasionally the data source would produce a large message that significantly increased processing time. These processes would sometimes fail partway through, creating partial data similar to the database example you saw earlier. Our team remedied the issue by setting a max message to prevent the long-running processes.
Tolerating Data Duplication
Given that idempotency can be difficult to achieve in the sense of preventing data duplication, consider if you need data deduplication. Depending on your pipeline design and data consumers, you may be able to allow duplicate data.
For example, I worked on a pipeline that ingested and evaluated customer data for the presence of specific issues. In this case, it didn’t matter whether the data was duplicated; the question was “Does X exist?” If instead the question was how many times X had occurred, data deduplication would have been necessary.
Another place you may be able to tolerate duplication is time-series data where only the most recent records are used. I worked on a pipeline that, ideally, generated records once a day, but if there were errors, the pipeline had to be rerun. This made it particularly tricky to detect duplicates, as the source data changed throughout the day, meaning the results of an earlier pipeline run could generate different records than a rerun later in the day. To handle this case, I added some metadata that tracked the time the job was run and filtered records to only the most recent runtime. In this case, there was data duplication, but its effects were mitigated by this filtering logic.
If you can tolerate eventual deduplication, you could create a process that periodically cleans up duplicates. Something like this could run as a background process to make use of spare compute cycles, as you learned about in Chapter 1.
Checkpointing
Checkpointing is when state is saved periodically over the course of pipeline operation. This gives you a way to retry data processing from a last known state if a fault occurs in the pipeline.
Checkpointing is particularly important in stream processing. If a failure occurs while processing the stream, you need to know where you were in the stream when the failure happened. This will show you where to restart processing after the pipeline recovers.
You can benefit from checkpointing in batch pipelines as well. For example, if you have to acquire data from several sources and then perform a long, compute-intensive transformation, it can be a good idea to save the source data. If the transformation is interrupted, you can read from the saved source data and reattempt the transformation rather than rerunning the data acquisition step.
Not only does this cut down on the expense of having to rerun pipeline stages prior to the failure, but you also have a cache of the source data. This can be especially helpful if the source data changes frequently. In this case, you may altogether miss ingesting some of the source data if you have to rerun the entire pipeline.
Warning
Clean up checkpointed data as soon as you no longer need it. Not doing so can negatively impact cost and performance. As an example, I worked at a company where a large Airflow DAG checkpointed data after every task, but it didn’t clean up after the job was completed. This created terabytes of extra data that resulted in high latency, made DAG execution excruciatingly slow, and increased storage costs. While I am not familiar with the details, I suspect that checkpointing after every task was overkill, which is a good reminder to be judicious about where you use checkpointing.
Remove checkpointed data after a job has completed successfully, or use a lifecycle policy, as you saw in Chapter 3, if you want to let it persist for a short time for debugging.
Intermediate data can also be helpful for debugging pipeline issues. Consider building in logic to selectively checkpoint, using criteria such as data source, pipeline stage, or customer. You can then use a configuration to toggle checkpointing as needed without deploying new code. This finer granularity will help you reduce the performance impacts of checkpointing while still reaping the benefits of capturing state for debugging.
For even finer granularity, consider enabling checkpointing on a per-run basis. If a job fails, you can rerun with checkpointing enabled to capture the intermediate data for debugging.
As an example, I built checkpointing into a pipeline stage that retrieved data from an API. The checkpointing was enabled only if the pipeline was running in debug mode, allowing me to inspect the retrieved data if there were problems. The state was small, and it was automatically purged after a few days as part of the pipeline metadata cleanup cycle.
Automatic Retries
At best a rite of passage and at worst a daily occurrence, rerunning a failed pipeline job (or many) is something that I think most data engineers are familiar with. Not only are manual job reruns mind-numbing, they are also costly.
One project I worked on had a dedicated on-call engineer whose time was mostly spent rerunning failed jobs. Consider that for a moment: the cost of one full-time engineer and the cost of the resources for rerunning failed jobs. A lot of times this cost isn’t accounted for; as long as SLAs continue to be met, the cost of rerunning failed jobs can remain hidden. The cost of reduced team velocity due to one less engineer is harder to quantify and can lead to burnout. In addition, this manual overhead can reduce your ability to scale.
In my experience, a significant driver of failed pipeline jobs is resource availability. This can be anything from a CSP outage taking down part of your infrastructure, a temporary blip in the availability of a credentials service, or under-provisioned resources, to data source availability, such as getting a 500 error when making a request of a REST API. It can be extremely frustrating to lose an entire job’s worth of computation because of a temporary issue like this, not to mention the wasted cloud costs.
The good news is that a lot of these pipeline killers can be handled with automated processes. You just have to know where these failures occur and implement retry strategies. Recall that retrying jobs can lead to duplicate data, making idempotency a precondition to implementing retries. Checkpointing can also be needed for retries, as you’ll see later in this section.
Retry Considerations
At a high level, a retry involves four steps:
Attempt a process.
Receive a retryable error.
Wait to retry.
Repeat a limited number of times.
Generally, a retryable error is the result of a failed process that you expect to succeed within a short time period after your initial attempt, such that it makes sense to delay pipeline execution.
Tip
Consistent, repeated retries can be a sign of under-resourcing, which can lead to poor pipeline performance and can limit scaling and reliability. Logging retry attempts will give you insight into these issues and help you determine whether additional resources are needed to improve pipeline performance.
As an example, I worked on a pipeline that differentiated the kinds of database errors it received when making queries. An error could be due to either connectivity or an issue with the query, such as running a SELECT statement against a table that didn’t exist. A connectivity error is something that could be temporary, whereas a query error is something that will persist until a code change is made. With separate errors, the pipeline could selectively retry database queries only if the error received was related to connectivity.
Retrying involves waiting a period of time before attempting the process again. Where possible, you want to make this a nonblocking event so that other processes can continue while the retried process is waiting for its next attempt. If instead you allow a waiting process to take up a worker slot or thread, you will be wasting time and resources.
You can prevent blocking at various execution levels, such as by using asynchronous methods or multithreading. Task runners and scheduling systems such as Airflow and Celery support nonblocking retries using queues. If a retryable task fails, these systems place the failed task back onto the queue, allowing other tasks to move forward while the retryable task waits out the retry delay.
Retry Levels in Data Pipelines
You can think about processes in a data pipeline as falling into three levels: low, task, and pipeline. Low-level processes are where you interact with a resource, such as making an API request or writing to a database. A retryable error in these cases could be a 429 from an API, indicating that too many requests have occurred in a set time period. Another potential retryable error is resource contention, such as waiting for a pool slot to write to a database and exceeding the timeout period.
When working with cloud services, retries can be a bit more involved. For example, I worked on a pipeline where data was written to cloud storage. The data size was small, and the requests were well within the bandwidth and request limitations. Uploads succeeded most of the time, but occasionally an upload would fail, not because of issues with the storage service but because there was an issue with the credentials service that granted access to the storage bucket.
Note
This is an important consideration when working with cloud services: while you may think you’re interacting with a single service, such as cloud storage, several services can be involved in handling your request.
This issue was particularly hard to nail down because the retry mechanism was encapsulated in the CSP client library. I was using the Google Cloud Storage (GCS) client, which had its own retry strategy that applied only to the storage service. Because the credentials service was a different service, the GCS retry didn’t handle cases in which the credentials service was temporarily unavailable. Ultimately, I had to wrap the GCS client retry in a custom retry using the tenacity library to retry on the credentials service issues.
In the next level above low-level processes are task-level processes. You can think of these as different steps in the pipeline, including tasks such as running a data transformation or performing validation. Task-level processes often include low-level processes, such as a task that writes data to cloud storage. In these cases, you have two levels of retry: a low-level retry that may attempt for seconds to a few minutes, and the opportunity to retry at the task level over a greater time period.
As an example, a pipeline I worked on included a task that sent email to customers after data processing was complete. The request to send the email went to an internal API, which prepared a customized email based on the customer data. The pipeline had task-level retries on the “Send email” task and low-level retries on the request to the Internal Email API, as depicted in Figure 4-1.
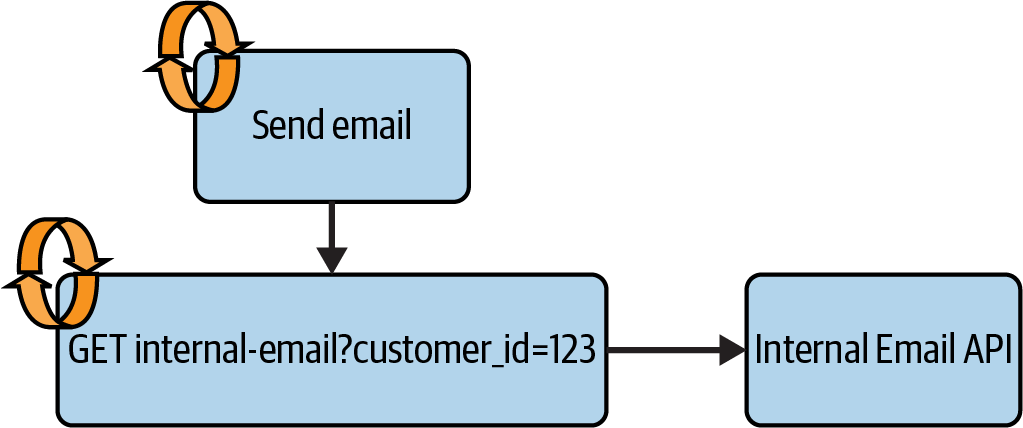
Figure 4-1. Email sending process with retries
The timing of the task and low-level retries is depicted in Figure 4-2. The “Send email” task started at the beginning of the time window, making a low-level request to the Internal Email API. If a retryable error was received, the GET request was retried using an exponential backoff. You can see this as the increasing length of time between the first, second, and third retries on the “Low-level API retries” timeline.
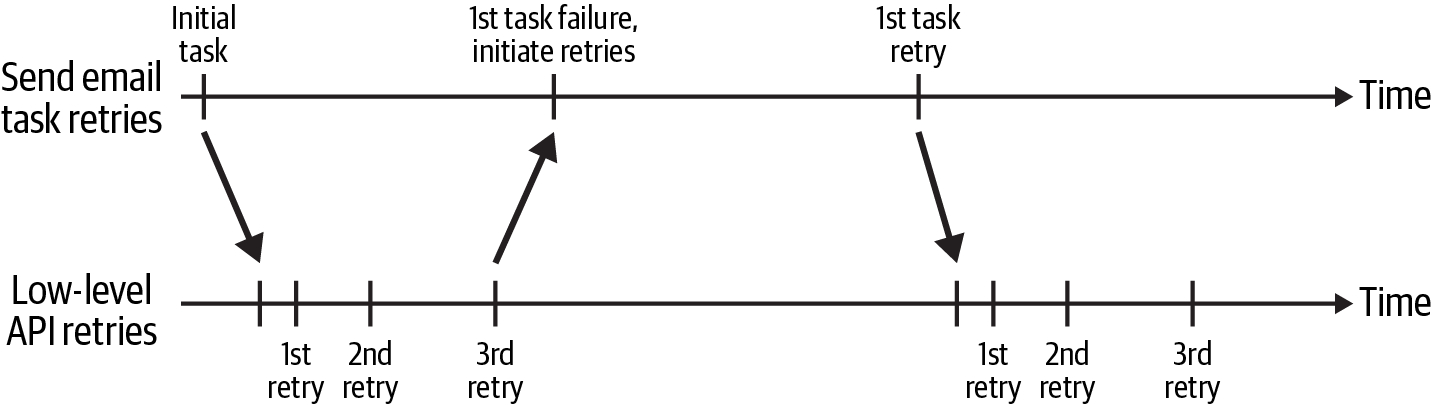
Figure 4-2. Retry timeline for “Send email” task and API request
If the GET request was still failing after three attempts, the “Send email” task would fail. This triggered the task-level retry, which retried over a longer time period. Whereas the low-level process would be retried several times over the course of a few minutes, the task-level process would retry once starting at 10 minutes and would exponentially increase the wait period with every retry. As long as the errors returned from the API were retryable, the task-level retry would continue until a specific time of day, after which the email was no longer relevant.
Task-level retries are a place where checkpointing can be especially helpful. Consider the HoD pipeline from Chapter 1, where bird survey data is joined with data from the HoD social media database. Figure 4-3 shows this process with checkpointing added, where the data is saved to the cloud in the Temp Storage bucket after extracting the species information, before the “Enrich with social” step. If “Enrich with social” fails because the HoD database is temporarily busy, the pipeline can retry “Enrich with social” using the data in the Temp Storage bucket, rather than having to reacquire the survey data and rerun “Extract species.”
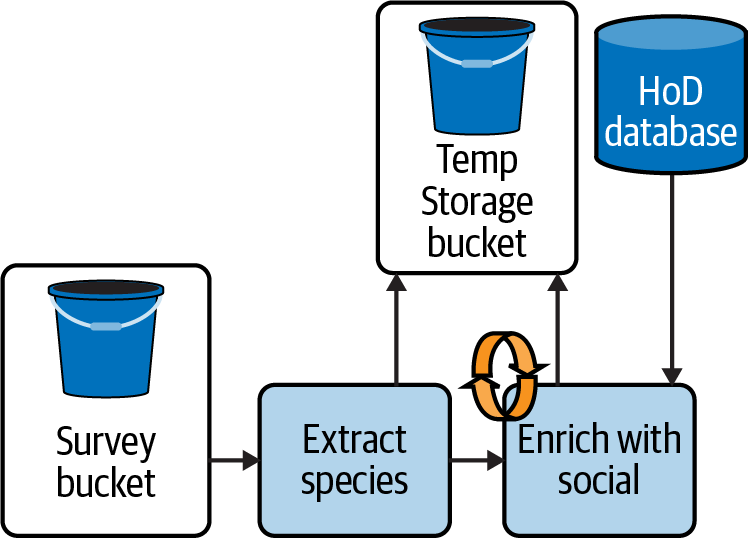
Figure 4-3. HoD batch pipeline with checkpointing and retry
Finally, you can also experience retryable failures at the pipeline level. If you think about the probability of different levels of recoverable failures, with low level being the most common, pipeline level is the least likely level, in part because you’ve already built in low-level and task-level retries to handle most temporary failures.
Largely, retryable errors at a pipeline level result from temporary infrastructure issues. One possible source is the termination of interruptible instances. As you learned in Chapter 1, these are among the cheapest compute options, but they can be terminated before your job completes. In a containerized environment like Kubernetes, temporary resourcing issues could occur if your containers overrun their resource requests.
Building retry strategies for these situations can make it easier to use cheap interruptible instances by building in a self-healing mechanism. It can be tricky to determine whether a pipeline failed due to resourcing shortfalls and whether these shortfalls are due to a temporary service issue or a nonrecoverable problem such as a job that exceeds the provisioned resources and will continue to fail. In some cases, you can get information from the compute infrastructure to help you figure this out.
If you’re using interruptible instances, you can subscribe to termination notifications to help you identify resulting pipeline instability. When I was working on the pipeline that experienced out-of-capacity issues described in Chapter 1, I was able to capture the failure reason when the AWS EMR cluster terminated. If the job failed due to insufficient capacity, a retry mechanism would kick in, alerting the team to a failure only if the job continued to fail after a few hours of waiting for capacity to improve.
There were a few key elements to this solution. First, I knew from experience that these resource issues typically cleared up in a few hours. Second, I accounted for the possibility that the job was simply too large for the capacity that was allocated. I capped retries at two to limit wasting resources in this scenario. Another way a large job could be detected is by comparing the data size to historical values, as you saw in “Autoscaling Example”.
This retry mechanism reduced manual intervention, human errors, and alert fatigue. It also reduced the cost of rerunning jobs and improved pipeline throughput. Previously, every failed job would generate an alert, and an engineer would manually restart the process. If the issue was insufficient capacity, the rerun would also fail, leading to a cascade of failures and wasted resources. Because retries were a manual process, inevitably our team would miss one of the reruns while waiting out the capacity issues, leading to missing data.
Thus far, this chapter has covered design strategies focusing on the mechanics of data pipelines that will help you avoid data corruption and recover from common intermittent failures. The last topic in this chapter, data validation, is a technique to build into pipeline execution to help you catch data issues before they occur.
Data Validation
The 1970s sitcom Laverne and Shirley opens with the duo heading off to their jobs at Shotz Brewery, where they inspect beer bottles coming down an assembly line. As the bottles stream by, Laverne and Shirley look on, pulling out the defective ones to ensure a high-quality product.
Data validation is a bit like the quality control Laverne and Shirley performed at their jobs: inspecting the data as it goes by and getting rid of defects before they make it into the hands of data consumers.
A lack of data validation is what led to the multimillion-dollar mistake I shared in this book’s Preface. The data source our team was ingesting added new columns of data. We were relying on manually updating schemas to capture changes in the source data, a practice I’ll show you how to avoid in this section. The schema had not been maintained and didn’t include the new columns, causing them to be excluded from ingestion.
Before getting into specific data validation techniques, I want to get you thinking about data validation at a high level. This will help you build a data validation plan where you’ll use the techniques in this chapter.
In my experience, data validation has three main goals:
Prevent data downtime.
Prevent wasting cycles processing bad data.
Inform the team of bad data and pipeline bugs.
To meet these goals, think about the source data, how it is being processed, and the expectations for the result data. You can start with these questions:
What constitutes valid source data? For example, are there attributes that must be present for you to be confident the source has provided good data?
Should you ingest all data from a source, including new attributes, or do you only ingest a subset?
Does data need certain formats, data types, or attributes for successful ingestion?
Are there deterministic relationships between pipeline stages, such as data shape, that you can use to identify possible issues?
Thinking through these questions will help you identify areas where data validation would be useful. In addition, consider the overhead of adding validation in the pipeline; this is another process that acts on the data as it moves through ingestion and can impact performance depending on how you approach it.
Finally, think about what you want to do if a data validation failure occurs. Should the bad data be discarded? Should it be set aside for review? Should the job fail?
Validating Data Characteristics
Rather than trying to capture every individual data issue, which is an impossible task, think about validation as identifying patterns in the data. “Know thy data” is the first step to successfully processing and analyzing data. Validation involves codifying what you know and expect to prevent data bugs.
In this section, you’ll see some basic checks that are relatively cheap to compute and easy to implement but pay big dividends in rooting out common data issues. These checks include:
Inspecting data shape and type
Identifying corrupt data
Checking for nulls
Whether you’re cleaning data or analyzing it, checking the shape of data as it moves through different pipeline stages is a good way to check for issues. The issue of missing columns from the book’s Preface could have been prevented by a simple check comparing the number of columns in the input data to the number of columns in the DataFrame that processed the data. In fact, this was one of the first validation checks our team added to mitigate the problem.
While comparing the number of columns can identify missing attributes, additional checks on column names and data types are necessary when attributes are added. For example, the “Extract species” step from Figure 4-3 adds a new column, species, to the raw data. To verify that “Extract species” performed as expected, you could start by validating that there are N + 1 columns in the “Extract species” data. Assuming this checks out, the next step is to ensure that the data produced by “Extract species” has the same column names and types as the input data from the Survey bucket, in addition to the new species field. This verifies that you added the new column and that you didn’t drop any input columns.
Getting the DataFrame shape gives you a second piece of information: the length of the data. This is another helpful characteristic to check as data passes through the pipeline. For example, you would expect “Extract species” to produce the same number of rows as the input data.
In some cases, you might be working with data sources that could provide malformed data. This is especially true if you work with data sources external to your organization where you have limited or no visibility into potential changes. One data pipeline I worked on ingested data from dozens of third-party APIs, which was the backbone of the company’s product. If the pipeline came across malformed data, it would raise an exception, alerting the team that something was amiss.
Let’s take a look at some methods for dealing with malformed data, which you can see in this book’s validation notebook under the heading “Identifying and acting on malformed data.”
Here’s an example of some malformed JSON where the last record was partially written:
bad_data=["{'user': 'pc@cats.xyz', 'location': [26.91756, 82.07842]}","{'user': 'lucy@cats.xyz', 'location': [26.91756, 82.07842]}","{'user': 'scout@cats.xyz', 'location': [26.91756,}"]
If you try to process this with some basic Python, you’ll get an exception on the entire dataset, though only one record is corrupt. Processing each row would let you ingest the good records while allowing you to isolate and respond to the corrupt ones.
PySpark DataFrames give you a few choices for how to handle corrupt data. The mode attribute for reading JSON data can be set to PERMISSIVE, DROPMALFORMED, or FAILFAST, providing different handling options for bad data.
The following sample shows the mode attribute set to PERMISSIVE:
corrupt_df=spark.read.json(sc.parallelize(bad_data),mode="PERMISSIVE",columnNameOfCorruptRecord="_corrupt_record")corrupt_df.show()
PERMISSIVE mode will successfully read the data but will isolate malformed records in a separate column for debug, as you can see in Figure 4-4.

Figure 4-4. Reading corrupt data with PERMISSIVE mode
PERMISSIVE mode is a good option if you want to inspect the corrupt records. In a medical data management system I worked on, the pipeline isolated records like this for a data steward to inspect. The data management system was used in patient diagnosis, so it was critical that all data was ingested. Debugging the malformed data gave medical staff the opportunity to fix the source data for reingestion.
DROPMALFORMED does what it sounds like: the corrupt records would be dropped from the DataFrame entirely. The result would be records 0–1 in Figure 4-4. Finally, FAILFAST would throw an exception if any records were malformed, rejecting the entire batch.
If certain attributes are required for you to successfully ingest the data, checking for nulls during ingestion can be another validation activity. You can do this by checking for the required attribute in the source data or doing a null check on a DataFrame column. You can also do null checks with schemas.
Schemas
Schemas can help you perform additional validation, such as checking for data type changes or changes in attribute names. You can also define required attributes with a schema, which can be used to check for null values. DoorDash uses schema validation to improve data quality, as described in “Building Scalable Real Time Event Processing with Kafka and Flink”.
Schemas can also limit data to just the attributes you need for ingestion. If you only need a few attributes from a large dataset, using a schema to load only those attributes will cut down on compute and storage costs by not processing and storing extraneous, unused data.
Another use of schemas is as service contracts, setting an expectation for both data producers and consumers as to the required characteristics for ingestion. Schemas can also be used for synthetic data generation, a topic you will see in Chapter 9.
In the following subsections, I cover how to create, maintain, and use schemas for validation. You can find the corresponding code in the validation notebook.
In an ideal world, data sources would publish accurate, up-to-date schemas for the data they provide. In reality, you’re lucky to find documentation on how to access the data, let alone a schema.
That said, when working with data sources developed by teams at your company, you may be able to get schema information. For example, a pipeline I worked on interacted with an API developed by another team. The API team used Swagger annotations and had an automated process that generated JSON schemas when the API changed. The data pipeline could fetch these schemas and use them to both validate the API response and keep the pipeline test data up to date, a topic you’ll learn about in Chapter 9.
Creating schemas
Most of the time you’ll have to create your own schemas. Possibly more important than creating the schemas, you also have to keep the schemas up to date. An inaccurate schema is worse than no schema. Let’s start by looking at ways to create schemas, and in the next section you’ll see ways to keep them up to date with minimal manual intervention.
As an example, let’s look at creating schemas for the survey data pipeline in Figure 4-3. Table 4-1 contains a sample of the raw survey data.
| User | Location | Image files | Description | Count |
|---|---|---|---|---|
| pc@cats.xyz | [“26.91756”, “82.07842”] | Several lesser goldfinches in the yard today. | 5 | |
| sylvia@srlp.org | [“27.9659”, “82.800”] | s3://bird-2345/34541.jpeg | Breezy morning, overcast. Saw a black-crowned night heron on the intercoastal waterway. | 1 |
| birdlover124@email.com | [“26.91756”, “82.07842”] | s3://bird-1243/09731.jpeg, s3://bird-1243/48195.jpeg | Walked over to the heron rookery this afternoon and saw some great blue herons. | 3 |
The survey data contains a row for each sighting recorded by a user of a bird survey app. This includes the user’s email, the user’s location, and a free-form description. Users can attach pictures to each sighting, which are stored by the survey app in a cloud storage bucket, the links to which are listed in the “Image files” column in the table. Users can also provide an approximate count of the number of birds sighted.
In “Validating Data Characteristics”, I mentioned that the location field is used by the “Extract species” step in Figure 4-3. Here’s the code that extracts the species, which you can see in transform.py:
defapply_species_label(species_list,df):species_regex=f".*({'|'.join(species_list)}).*"return(df.withColumn("description_lower",f.lower('description')).withColumn("species",f.regexp_extract('description_lower',species_regex,1)).drop("description_lower"))
The expectation in this code is that description is a string that can be made lowercase and searched for a species match.
Another step in the pipeline extracts the latitude and longitude from the location field and is used to group users into similar geographic regions. This is an important feature of the HoD platform as it helps fellow bird lovers flock together for birding trips. The location is represented as an array of strings, where the underlying code expects a format of [latitude, longitude]:
df.withColumn("latitude",f.element_at(df.location,1)).withColumn("longitude",f.element_at(df.location,2))
So, at a minimum, a schema for the survey data should include constraints that the location field is an array of string values and the description field is a string.
What happens if either of these attributes is null? This is an interesting question. A better question is how should the pipeline process the data if these attributes are null. For example, if the location field is null, the code for extracting the latitude and longitude will throw an exception. This could be a code bug, or it could be that location is a required field within the survey data, meaning a null location value is a sign of a problem with the source data and should fail data validation.
For this example, let’s say location is a required field, and a null location indicates a problem with the data. In addition, user is a required field, and count, if provided, should be coercible to an integer. In terms of which attributes should be ingested, let’s say that just the current five columns in Table 4-1 should be ingested, and if new attributes are added to the survey data they should be ignored.
With these criteria in mind, let’s take a look at a few different ways to generate a schema using the data sample in initial_source_data.json. You can find this code under the “Schema validation” heading in the validation notebook.
If you’re working with DataFrames, you can read the data sample and save the schema. You may need to change the nullable information to meet your expectations. Based on the data sample in initial_source_data.json, the inferred schema assumes the nullable value for the description field should be True:
df=(spark.read.option("inferSchema",True).json("initial_source_data.json"))source_schema=df.schemasource_schema>StructType([StructField("count",LongType(),True),StructField("description",StringType(),True),StructField("user",StringType(),False),StructField("img_files",ArrayType(StringType(),True),True),StructField("location",ArrayType(StringType(),True),False)])
If your data transformation logic assumes the description field will always be populated, you will want to modify this value to False for validation.
Another way you could validate the bird survey data is with a JSON schema, which allows for more definition than the Spark schema. You can generate a JSON schema from sample data using some online tools, or by hand if the data attributes are few.
Validating with schemas
These schema generation methods give you a starting point. From here you’ll need to refine the schema to ensure that it will raise validation errors, such as changing the nullable values in the generated Spark schema.
For example, using a JSON schema generator tool for initial_source_data.json provided the schema shown in the “Working with JSON schemas” section of the validation notebook. Notice how the schema generator defined location:
#"location":["26.91756","82.07842"]"location":{"type":"array","items":[{"type":"string"},{"type":"string"}]}
Recall that the code extracting the latitude and longitude expects two elements in location.
Validating this schema against some test data, you can see that this definition isn’t sufficient to ensure that the location field has two elements. For example, the short_location JSON has only one string, but there is no output when executing this line, meaning the validation succeeded:
validate(short_location,initial_json_schema)
To use this JSON schema for data validation, you need to specify the minItems in the location array, as in this updated schema definition for location:
"location":{"type":"array","minItems":2,"items":[{"type":"string"}]},
Now comes the exciting part: check out all the bad data that gets flagged with this new definition.
The following validation errors from the Python jsonschema library tell you exactly what was wrong with the data, giving you a way to both halt execution if bad data is found and provide helpful debug information:
- Not enough elements
validate(short_location,updated_schema)>ValidationError:['26.91756']istooshort- If the
locationdata type changes from an array to a string validate([{"user":"someone","location":"26.91756,82.07842"}],updated_schema)>ValidationError:'26.91756,82.07842'isnotoftype'array'- If the survey data provider decides to change the data type of the latitude and longitude values from string to numerical
validate([{"user":"pc@cats.xyz","location":[26.91756,82.07842]}],updated_schema)>ValidationError:26.91756isnotoftype'string'
These last two errors of the location changing from an array to a string or from an array of strings to an array of floats can also be identified when using a Spark schema. If you’re working with Spark datasets in Scala or Java, you can use the schema to raise an exception if the source data doesn’t match.
In other situations, you can compare the expected schema to the schema that is inferred when reading in the source data, as described in the “Comparing inferred vs explicit schemas” section in the validation notebook.
As an example, let’s say you have an expected schema for the bird survey data, source_schema, where location is an array of strings. To validate a new batch of data against source_schema, read the data into a DataFrame and compare the inferred schema to the expected schema. In this example, the location field in string_location.json is a string:
df=(spark.read.option("inferSchema",True).json('string_location.json'))inferred_schema=df.schema>StructType([...StructField("location",StringType(),True)...])inferred_schema==source_schemaFalse
This check is useful for flagging a validation failure, but it’s not great for reporting the specific differences between the schemas. For more insight, the following code checks for both new fields and mismatches in existing fields:
source_info={f.name:fforfinsource_schema.fields}forfininferred_schema.fields:iff.namenotinsource_info.keys():(f"New field in data source{f}")eliff!=source_info[f.name]:source_field=source_info[f.name](f"Field mismatch for{f.name}Source schema:{source_field},Inferredschema:{f}")>FieldmismatchforlocationSourceschema:StructField(location,ArrayType(StringType,true),true),Inferredschema:StructField(location,StringType,true)
Another useful validation check you could add to this code is to flag fields in source_schema that are missing from inferred_schema.
This kind of schema comparison logic was another validation technique used to fix the missing-columns bug. If the pipeline had a validation check in place like this to begin with, our team would have been alerted to new columns in the source data from the very first batch where the change occurred.
Keeping schemas up to date
As I mentioned at the beginning of this section, it is absolutely essential that schemas are kept up to date. Stale schemas are worse than worthless; they could cause erroneous validation failures or miss real validation failures due to out-of-date data definitions. This section describes a few methods for automating schema upkeep.
For schemas that are generated from source code, such as with the Swagger example I mentioned earlier or by exporting a class to a JSON schema, consider automated builds and centralized schema repositories. This provides a single source of truth for everyone accessing the schemas. As part of the automated build process, you can use the schemas to generate test data for unit tests. With this approach, breaking schema changes will surface as unit-test failures. I promise this is the last time I’ll say “as you will see in Chapter 9.” Schemas are great, and there are more great uses for them in addition to their noble use in data validation.
Validation checks can also be used to keep schemas up to date. If a pipeline is designed to ingest all data source attributes, you could spawn a process to update the schema when nonbreaking changes occur in the source data. For example, if the pipeline in Figure 4-3 is designed to ingest any fields provided by the bird survey data, so long as the user and location fields are present and valid any new columns could be added to the source schema.
If you adopt a practice of automatically updating schemas to contain more or fewer attributes based on source data, make sure you account for nulls. Particularly with semistructured formats like JSON, it’s possible to get a few batches of data where an attribute value hasn’t been dropped from the source; it just happens to be null.
Another thing to keep in mind is the impact of changing the schema. If new attributes are added, do you need to fill in values for older data? If an attribute is removed, should old data retain this attribute?
Finally, a pseudo-automated approach of schema updates can be effective, in which you get alerted to schema-breaking changes in the source data. This could be from a validation failure, or you could set up a scheduled job to periodically compare the schema against a sample from the data source. You could even work this check into the pipeline, acquiring a data sample, running schema validation, and exiting without any subsequent steps.
I urge you to avoid relying on manual updates to keep schemas up to date. If none of the preceding options work for you, strive to keep your schemas to a minimum to limit what you have to maintain. Additionally, make schema upkeep part of the release process to ensure that they are regularly attended to.
Summary
The combination of cloud infrastructure, third-party services, and the idiosyncrasies of distributed software development pave the way for a cornucopia of potential pipeline failure mechanisms. Changes in source data or pipeline code, bad credentials, resource contention, and blips in cloud service availability are just a few possibilities. These issues can be temporary, as in a few seconds during the exact moment you try to write to cloud storage, or more permanent, such as the data type of an important source data field changing without notice. In the worst cases, they can result in data downtime, as with the multimillion-dollar mistake.
If this landscape sounds grim, don’t despair. You are now well equipped to build pipelines that can prevent and recover from many of these issues with a minimum of engineering overhead, reducing the cost of cloud resources, engineering time, and loss of trust in data quality by data consumers.
Idempotency is an important first step for building atomic pipelines that support retries and limit data duplication.
For batch processes, delete-write and database transactions support idempotency by ensuring that the batch is processed in its entirety or not at all, giving you a clean slate to retry from without the potential of data duplication. You can also prevent duplication at the data sink by enforcing unique constraints, such as with primary keys, which will prevent duplicate data from being recorded.
For stream processing, building producers that guarantee unique IDs based on the source data and consumers that process each unique key only once provides idempotency. When building these systems, make sure you consider how messages are being consumed, acknowledged, and retried. Durable storage for idempotency data will help you ensure idempotency across outages and deployments.
Keep in mind that you may be able to tolerate some data duplication depending on how pipeline data is used. If the data is used to verify the absence or presence of particular features, duplicated data might be OK. Consider deduplicating data post-ingest if you have a time gap between when ingestion completes and when data is accessed. Attaching metadata to filter out duplicates when data is queried is another option, as you saw in the example of using data from only the most recent runtime for analysis.
With idempotency in place, the next foundational design element is checkpointing, providing a known state to retry from if a fault occurs, as well as debug information when investigating issues. You can benefit from this technique without sacrificing performance and cloud spend by automating the deletion of checkpoint data.
Checkpointing and idempotency lay the groundwork for automatic retries, which enable pipelines to recover from temporary issues. This reduces wasted resources and manual intervention and can also help you take advantage of cheap, interruptible compute.
When looking for opportunities to use retries, think about processes that could temporarily fail and recover within a reasonable window of time based on your pipeline throughput needs. Something like database connectivity could be a temporary issue and may recover, whereas an invalid database query would not succeed no matter how many times you try it.
Overcoming temporary issues involves waiting between retry attempts. Nonblocking retries will help you maintain performance and limit wasted cycles. Don’t forget to log retry attempts, as this can help you introspect for performance and scalability issues.
Idempotency, checkpointing, and automatic retries are like the hardware of an assembly line—components that work together to keep things running efficiently. This is necessary but not sufficient to produce a quality product. You also need a keen pair of eyes checking product quality, ejecting bad products before they reach customers, and raising alarms if there is a problem on the assembly line.
Data validation is like Laverne and Shirley, diligently inspecting and, if needed, rejecting data as it moves through the pipeline. If you’ve ever had to debug bad data by hand, combing through logs and datasets to determine what when wrong and when, you can definitely appreciate the automated approaches described in this chapter, from checking data shape and format to using schemas to validate attribute name, type, and existence against expectations.
Schemas can be powerful tools for data validation and other data pipeline activities I’ll describe in later chapters, but they must be kept up to date to be an asset and not a liability.
Just as the strategies covered in this chapter provide a foundation for pipeline design, an effective development environment provides the foundation for pipeline implementation and testing. In the next chapter, I’ll cover techniques to reduce cost and streamline development environments for data pipelines.
1 This assumes that the database is ACID compliant.
Get Cost-Effective Data Pipelines now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

